@huggingface/tasks 0.0.6 → 0.0.7
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +16 -2
- package/dist/index.d.ts +358 -5
- package/dist/index.js +1906 -72
- package/dist/index.mjs +1905 -71
- package/package.json +1 -1
- package/src/default-widget-inputs.ts +718 -0
- package/src/index.ts +35 -4
- package/src/library-to-tasks.ts +47 -0
- package/src/library-ui-elements.ts +765 -0
- package/src/model-data.ts +239 -0
- package/src/pipelines.ts +15 -0
- package/src/snippets/curl.ts +63 -0
- package/src/snippets/index.ts +6 -0
- package/src/snippets/inputs.ts +129 -0
- package/src/snippets/js.ts +150 -0
- package/src/snippets/python.ts +114 -0
- package/src/{audio-classification → tasks/audio-classification}/about.md +2 -1
- package/src/{audio-classification → tasks/audio-classification}/data.ts +3 -3
- package/src/{audio-to-audio → tasks/audio-to-audio}/data.ts +1 -1
- package/src/{automatic-speech-recognition → tasks/automatic-speech-recognition}/about.md +3 -2
- package/src/{automatic-speech-recognition → tasks/automatic-speech-recognition}/data.ts +6 -6
- package/src/{conversational → tasks/conversational}/data.ts +1 -1
- package/src/{depth-estimation → tasks/depth-estimation}/data.ts +1 -1
- package/src/{document-question-answering → tasks/document-question-answering}/data.ts +1 -1
- package/src/{feature-extraction → tasks/feature-extraction}/data.ts +2 -7
- package/src/{fill-mask → tasks/fill-mask}/data.ts +1 -1
- package/src/{image-classification → tasks/image-classification}/data.ts +1 -1
- package/src/{image-segmentation → tasks/image-segmentation}/data.ts +1 -1
- package/src/{image-to-image → tasks/image-to-image}/about.md +8 -7
- package/src/{image-to-image → tasks/image-to-image}/data.ts +1 -1
- package/src/{image-to-text → tasks/image-to-text}/data.ts +1 -1
- package/src/{tasksData.ts → tasks/index.ts} +140 -15
- package/src/{object-detection → tasks/object-detection}/data.ts +1 -1
- package/src/{placeholder → tasks/placeholder}/data.ts +1 -1
- package/src/{question-answering → tasks/question-answering}/data.ts +1 -1
- package/src/{reinforcement-learning → tasks/reinforcement-learning}/data.ts +1 -1
- package/src/{sentence-similarity → tasks/sentence-similarity}/data.ts +1 -1
- package/src/{summarization → tasks/summarization}/data.ts +1 -1
- package/src/{table-question-answering → tasks/table-question-answering}/data.ts +1 -1
- package/src/{tabular-classification → tasks/tabular-classification}/data.ts +1 -1
- package/src/{tabular-regression → tasks/tabular-regression}/data.ts +1 -1
- package/src/{text-classification → tasks/text-classification}/data.ts +1 -1
- package/src/{text-generation → tasks/text-generation}/about.md +3 -3
- package/src/{text-generation → tasks/text-generation}/data.ts +2 -2
- package/src/{text-to-image → tasks/text-to-image}/data.ts +1 -1
- package/src/{text-to-speech → tasks/text-to-speech}/about.md +2 -1
- package/src/{text-to-speech → tasks/text-to-speech}/data.ts +4 -4
- package/src/{text-to-video → tasks/text-to-video}/data.ts +1 -1
- package/src/{token-classification → tasks/token-classification}/data.ts +1 -1
- package/src/{translation → tasks/translation}/data.ts +1 -1
- package/src/{unconditional-image-generation → tasks/unconditional-image-generation}/data.ts +1 -1
- package/src/{video-classification → tasks/video-classification}/about.md +8 -28
- package/src/{video-classification → tasks/video-classification}/data.ts +1 -1
- package/src/{visual-question-answering → tasks/visual-question-answering}/data.ts +1 -1
- package/src/{zero-shot-classification → tasks/zero-shot-classification}/data.ts +1 -1
- package/src/{zero-shot-image-classification → tasks/zero-shot-image-classification}/data.ts +1 -1
- package/src/Types.ts +0 -64
- package/src/const.ts +0 -59
- /package/src/{modelLibraries.ts → model-libraries.ts} +0 -0
- /package/src/{audio-to-audio → tasks/audio-to-audio}/about.md +0 -0
- /package/src/{conversational → tasks/conversational}/about.md +0 -0
- /package/src/{depth-estimation → tasks/depth-estimation}/about.md +0 -0
- /package/src/{document-question-answering → tasks/document-question-answering}/about.md +0 -0
- /package/src/{feature-extraction → tasks/feature-extraction}/about.md +0 -0
- /package/src/{fill-mask → tasks/fill-mask}/about.md +0 -0
- /package/src/{image-classification → tasks/image-classification}/about.md +0 -0
- /package/src/{image-segmentation → tasks/image-segmentation}/about.md +0 -0
- /package/src/{image-to-text → tasks/image-to-text}/about.md +0 -0
- /package/src/{object-detection → tasks/object-detection}/about.md +0 -0
- /package/src/{placeholder → tasks/placeholder}/about.md +0 -0
- /package/src/{question-answering → tasks/question-answering}/about.md +0 -0
- /package/src/{reinforcement-learning → tasks/reinforcement-learning}/about.md +0 -0
- /package/src/{sentence-similarity → tasks/sentence-similarity}/about.md +0 -0
- /package/src/{summarization → tasks/summarization}/about.md +0 -0
- /package/src/{table-question-answering → tasks/table-question-answering}/about.md +0 -0
- /package/src/{tabular-classification → tasks/tabular-classification}/about.md +0 -0
- /package/src/{tabular-regression → tasks/tabular-regression}/about.md +0 -0
- /package/src/{text-classification → tasks/text-classification}/about.md +0 -0
- /package/src/{text-to-image → tasks/text-to-image}/about.md +0 -0
- /package/src/{text-to-video → tasks/text-to-video}/about.md +0 -0
- /package/src/{token-classification → tasks/token-classification}/about.md +0 -0
- /package/src/{translation → tasks/translation}/about.md +0 -0
- /package/src/{unconditional-image-generation → tasks/unconditional-image-generation}/about.md +0 -0
- /package/src/{visual-question-answering → tasks/visual-question-answering}/about.md +0 -0
- /package/src/{zero-shot-classification → tasks/zero-shot-classification}/about.md +0 -0
- /package/src/{zero-shot-image-classification → tasks/zero-shot-image-classification}/about.md +0 -0
|
@@ -0,0 +1,114 @@
|
|
|
1
|
+
import type { ModelData } from "../model-data.js";
|
|
2
|
+
import type { PipelineType } from "../pipelines.js";
|
|
3
|
+
import { getModelInputSnippet } from "./inputs.js";
|
|
4
|
+
|
|
5
|
+
export const snippetZeroShotClassification = (model: ModelData): string =>
|
|
6
|
+
`def query(payload):
|
|
7
|
+
response = requests.post(API_URL, headers=headers, json=payload)
|
|
8
|
+
return response.json()
|
|
9
|
+
|
|
10
|
+
output = query({
|
|
11
|
+
"inputs": ${getModelInputSnippet(model)},
|
|
12
|
+
"parameters": {"candidate_labels": ["refund", "legal", "faq"]},
|
|
13
|
+
})`;
|
|
14
|
+
|
|
15
|
+
export const snippetBasic = (model: ModelData): string =>
|
|
16
|
+
`def query(payload):
|
|
17
|
+
response = requests.post(API_URL, headers=headers, json=payload)
|
|
18
|
+
return response.json()
|
|
19
|
+
|
|
20
|
+
output = query({
|
|
21
|
+
"inputs": ${getModelInputSnippet(model)},
|
|
22
|
+
})`;
|
|
23
|
+
|
|
24
|
+
export const snippetFile = (model: ModelData): string =>
|
|
25
|
+
`def query(filename):
|
|
26
|
+
with open(filename, "rb") as f:
|
|
27
|
+
data = f.read()
|
|
28
|
+
response = requests.post(API_URL, headers=headers, data=data)
|
|
29
|
+
return response.json()
|
|
30
|
+
|
|
31
|
+
output = query(${getModelInputSnippet(model)})`;
|
|
32
|
+
|
|
33
|
+
export const snippetTextToImage = (model: ModelData): string =>
|
|
34
|
+
`def query(payload):
|
|
35
|
+
response = requests.post(API_URL, headers=headers, json=payload)
|
|
36
|
+
return response.content
|
|
37
|
+
image_bytes = query({
|
|
38
|
+
"inputs": ${getModelInputSnippet(model)},
|
|
39
|
+
})
|
|
40
|
+
# You can access the image with PIL.Image for example
|
|
41
|
+
import io
|
|
42
|
+
from PIL import Image
|
|
43
|
+
image = Image.open(io.BytesIO(image_bytes))`;
|
|
44
|
+
|
|
45
|
+
export const snippetTextToAudio = (model: ModelData): string => {
|
|
46
|
+
// Transformers TTS pipeline and api-inference-community (AIC) pipeline outputs are diverged
|
|
47
|
+
// with the latest update to inference-api (IA).
|
|
48
|
+
// Transformers IA returns a byte object (wav file), whereas AIC returns wav and sampling_rate.
|
|
49
|
+
if (model.library_name === "transformers") {
|
|
50
|
+
return `def query(payload):
|
|
51
|
+
response = requests.post(API_URL, headers=headers, json=payload)
|
|
52
|
+
return response.content
|
|
53
|
+
|
|
54
|
+
audio_bytes = query({
|
|
55
|
+
"inputs": ${getModelInputSnippet(model)},
|
|
56
|
+
})
|
|
57
|
+
# You can access the audio with IPython.display for example
|
|
58
|
+
from IPython.display import Audio
|
|
59
|
+
Audio(audio_bytes)`;
|
|
60
|
+
} else {
|
|
61
|
+
return `def query(payload):
|
|
62
|
+
response = requests.post(API_URL, headers=headers, json=payload)
|
|
63
|
+
return response.json()
|
|
64
|
+
|
|
65
|
+
audio, sampling_rate = query({
|
|
66
|
+
"inputs": ${getModelInputSnippet(model)},
|
|
67
|
+
})
|
|
68
|
+
# You can access the audio with IPython.display for example
|
|
69
|
+
from IPython.display import Audio
|
|
70
|
+
Audio(audio, rate=sampling_rate)`;
|
|
71
|
+
}
|
|
72
|
+
};
|
|
73
|
+
export const pythonSnippets: Partial<Record<PipelineType, (model: ModelData) => string>> = {
|
|
74
|
+
// Same order as in js/src/lib/interfaces/Types.ts
|
|
75
|
+
"text-classification": snippetBasic,
|
|
76
|
+
"token-classification": snippetBasic,
|
|
77
|
+
"table-question-answering": snippetBasic,
|
|
78
|
+
"question-answering": snippetBasic,
|
|
79
|
+
"zero-shot-classification": snippetZeroShotClassification,
|
|
80
|
+
translation: snippetBasic,
|
|
81
|
+
summarization: snippetBasic,
|
|
82
|
+
conversational: snippetBasic,
|
|
83
|
+
"feature-extraction": snippetBasic,
|
|
84
|
+
"text-generation": snippetBasic,
|
|
85
|
+
"text2text-generation": snippetBasic,
|
|
86
|
+
"fill-mask": snippetBasic,
|
|
87
|
+
"sentence-similarity": snippetBasic,
|
|
88
|
+
"automatic-speech-recognition": snippetFile,
|
|
89
|
+
"text-to-image": snippetTextToImage,
|
|
90
|
+
"text-to-speech": snippetTextToAudio,
|
|
91
|
+
"text-to-audio": snippetTextToAudio,
|
|
92
|
+
"audio-to-audio": snippetFile,
|
|
93
|
+
"audio-classification": snippetFile,
|
|
94
|
+
"image-classification": snippetFile,
|
|
95
|
+
"image-to-text": snippetFile,
|
|
96
|
+
"object-detection": snippetFile,
|
|
97
|
+
"image-segmentation": snippetFile,
|
|
98
|
+
};
|
|
99
|
+
|
|
100
|
+
export function getPythonInferenceSnippet(model: ModelData, accessToken: string): string {
|
|
101
|
+
const body =
|
|
102
|
+
model.pipeline_tag && model.pipeline_tag in pythonSnippets ? pythonSnippets[model.pipeline_tag]?.(model) ?? "" : "";
|
|
103
|
+
|
|
104
|
+
return `import requests
|
|
105
|
+
|
|
106
|
+
API_URL = "https://api-inference.huggingface.co/models/${model.id}"
|
|
107
|
+
headers = {"Authorization": ${accessToken ? `"Bearer ${accessToken}"` : `f"Bearer {API_TOKEN}"`}}
|
|
108
|
+
|
|
109
|
+
${body}`;
|
|
110
|
+
}
|
|
111
|
+
|
|
112
|
+
export function hasPythonInferenceSnippet(model: ModelData): boolean {
|
|
113
|
+
return !!model.pipeline_tag && model.pipeline_tag in pythonSnippets;
|
|
114
|
+
}
|
|
@@ -66,7 +66,7 @@ Speaker Identification is classifying the audio of the person speaking. Speakers
|
|
|
66
66
|
|
|
67
67
|
## Solving audio classification for your own data
|
|
68
68
|
|
|
69
|
-
We have some great news! You can do fine-tuning (transfer learning) to train a well-performing model without requiring as much data. Pretrained models such as Wav2Vec2 and HuBERT exist. [Facebook's Wav2Vec2 XLS-R model](https://
|
|
69
|
+
We have some great news! You can do fine-tuning (transfer learning) to train a well-performing model without requiring as much data. Pretrained models such as Wav2Vec2 and HuBERT exist. [Facebook's Wav2Vec2 XLS-R model](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2) is a large multilingual model trained on 128 languages and with 436K hours of speech. Similarly, you can also use [OpenAI's Whisper](https://huggingface.co/docs/transformers/model_doc/whisper) trained on up to 4 Million hours of multilingual speech data for this task too!
|
|
70
70
|
|
|
71
71
|
## Useful Resources
|
|
72
72
|
|
|
@@ -82,4 +82,5 @@ Would you like to learn more about the topic? Awesome! Here you can find some cu
|
|
|
82
82
|
|
|
83
83
|
### Documentation
|
|
84
84
|
|
|
85
|
+
- [Hugging Face Audio Course](https://huggingface.co/learn/audio-course/chapter4/introduction)
|
|
85
86
|
- [Audio classification task guide](https://huggingface.co/docs/transformers/tasks/audio_classification)
|
|
@@ -1,4 +1,4 @@
|
|
|
1
|
-
import type { TaskDataCustom } from "
|
|
1
|
+
import type { TaskDataCustom } from "..";
|
|
2
2
|
|
|
3
3
|
const taskData: TaskDataCustom = {
|
|
4
4
|
datasets: [
|
|
@@ -64,8 +64,8 @@ const taskData: TaskDataCustom = {
|
|
|
64
64
|
],
|
|
65
65
|
spaces: [
|
|
66
66
|
{
|
|
67
|
-
description: "An application that can
|
|
68
|
-
id: "
|
|
67
|
+
description: "An application that can classify music into different genre.",
|
|
68
|
+
id: "kurianbenoy/audioclassification",
|
|
69
69
|
},
|
|
70
70
|
],
|
|
71
71
|
summary:
|
|
@@ -25,7 +25,7 @@ import json
|
|
|
25
25
|
import requests
|
|
26
26
|
|
|
27
27
|
headers = {"Authorization": f"Bearer {API_TOKEN}"}
|
|
28
|
-
API_URL = "https://api-inference.huggingface.co/models/openai/whisper-large-
|
|
28
|
+
API_URL = "https://api-inference.huggingface.co/models/openai/whisper-large-v3"
|
|
29
29
|
|
|
30
30
|
def query(filename):
|
|
31
31
|
with open(filename, "rb") as f:
|
|
@@ -63,7 +63,7 @@ await inference.automaticSpeechRecognition({
|
|
|
63
63
|
|
|
64
64
|
## Solving ASR for your own data
|
|
65
65
|
|
|
66
|
-
We have some great news! You can fine-tune (transfer learning) a foundational speech model on a specific language without tonnes of data. Pretrained models such as Whisper, Wav2Vec2-MMS and HuBERT exist. [OpenAI's Whisper model](https://huggingface.co/openai/whisper-large-
|
|
66
|
+
We have some great news! You can fine-tune (transfer learning) a foundational speech model on a specific language without tonnes of data. Pretrained models such as Whisper, Wav2Vec2-MMS and HuBERT exist. [OpenAI's Whisper model](https://huggingface.co/openai/whisper-large-v3) is a large multilingual model trained on 100+ languages and with 4 Million hours of speech.
|
|
67
67
|
|
|
68
68
|
The following detailed [blog post](https://huggingface.co/blog/fine-tune-whisper) shows how to fine-tune a pre-trained Whisper checkpoint on labeled data for ASR. With the right data and strategy you can fine-tune a high-performant model on a free Google Colab instance too. We suggest to read the blog post for more info!
|
|
69
69
|
|
|
@@ -75,6 +75,7 @@ These events help democratize ASR for all languages, including low-resource lang
|
|
|
75
75
|
|
|
76
76
|
## Useful Resources
|
|
77
77
|
|
|
78
|
+
- [Hugging Face Audio Course](https://huggingface.co/learn/audio-course/chapter5/introduction)
|
|
78
79
|
- [Fine-tuning MetaAI's MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters)
|
|
79
80
|
- [Making automatic speech recognition work on large files with Wav2Vec2 in 🤗 Transformers](https://huggingface.co/blog/asr-chunking)
|
|
80
81
|
- [Boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram)
|
|
@@ -1,4 +1,4 @@
|
|
|
1
|
-
import type { TaskDataCustom } from "
|
|
1
|
+
import type { TaskDataCustom } from "..";
|
|
2
2
|
|
|
3
3
|
const taskData: TaskDataCustom = {
|
|
4
4
|
datasets: [
|
|
@@ -44,7 +44,7 @@ const taskData: TaskDataCustom = {
|
|
|
44
44
|
models: [
|
|
45
45
|
{
|
|
46
46
|
description: "A powerful ASR model by OpenAI.",
|
|
47
|
-
id: "openai/whisper-large-
|
|
47
|
+
id: "openai/whisper-large-v3",
|
|
48
48
|
},
|
|
49
49
|
{
|
|
50
50
|
description: "A good generic ASR model by MetaAI.",
|
|
@@ -58,20 +58,20 @@ const taskData: TaskDataCustom = {
|
|
|
58
58
|
spaces: [
|
|
59
59
|
{
|
|
60
60
|
description: "A powerful general-purpose speech recognition application.",
|
|
61
|
-
id: "
|
|
61
|
+
id: "hf-audio/whisper-large-v3",
|
|
62
62
|
},
|
|
63
63
|
{
|
|
64
64
|
description: "Fastest speech recognition application.",
|
|
65
65
|
id: "sanchit-gandhi/whisper-jax",
|
|
66
66
|
},
|
|
67
67
|
{
|
|
68
|
-
description: "
|
|
69
|
-
id: "
|
|
68
|
+
description: "A high quality speech and text translation model by Meta.",
|
|
69
|
+
id: "facebook/seamless_m4t",
|
|
70
70
|
},
|
|
71
71
|
],
|
|
72
72
|
summary:
|
|
73
73
|
"Automatic Speech Recognition (ASR), also known as Speech to Text (STT), is the task of transcribing a given audio to text. It has many applications, such as voice user interfaces.",
|
|
74
|
-
widgetModels: ["openai/whisper-large-
|
|
74
|
+
widgetModels: ["openai/whisper-large-v3"],
|
|
75
75
|
youtubeId: "TksaY_FDgnk",
|
|
76
76
|
};
|
|
77
77
|
|
|
@@ -1,4 +1,4 @@
|
|
|
1
|
-
import type { TaskDataCustom } from "
|
|
1
|
+
import type { TaskDataCustom } from "..";
|
|
2
2
|
|
|
3
3
|
const taskData: TaskDataCustom = {
|
|
4
4
|
datasets: [
|
|
@@ -29,12 +29,7 @@ const taskData: TaskDataCustom = {
|
|
|
29
29
|
},
|
|
30
30
|
],
|
|
31
31
|
},
|
|
32
|
-
metrics: [
|
|
33
|
-
{
|
|
34
|
-
description: "",
|
|
35
|
-
id: "",
|
|
36
|
-
},
|
|
37
|
-
],
|
|
32
|
+
metrics: [],
|
|
38
33
|
models: [
|
|
39
34
|
{
|
|
40
35
|
description: "A powerful feature extraction model for natural language processing tasks.",
|
|
@@ -2,22 +2,22 @@
|
|
|
2
2
|
|
|
3
3
|
### Style transfer
|
|
4
4
|
|
|
5
|
-
One of the most popular use cases of image
|
|
5
|
+
One of the most popular use cases of image-to-image is style transfer. Style transfer models can convert a normal photography into a painting in the style of a famous painter.
|
|
6
6
|
|
|
7
7
|
## Task Variants
|
|
8
8
|
|
|
9
9
|
### Image inpainting
|
|
10
10
|
|
|
11
|
-
Image inpainting is widely used during photography editing to remove unwanted objects, such as poles, wires or sensor
|
|
11
|
+
Image inpainting is widely used during photography editing to remove unwanted objects, such as poles, wires, or sensor
|
|
12
12
|
dust.
|
|
13
13
|
|
|
14
14
|
### Image colorization
|
|
15
15
|
|
|
16
|
-
Old
|
|
16
|
+
Old or black and white images can be brought up to life using an image colorization model.
|
|
17
17
|
|
|
18
18
|
### Super Resolution
|
|
19
19
|
|
|
20
|
-
Super
|
|
20
|
+
Super-resolution models increase the resolution of an image, allowing for higher-quality viewing and printing.
|
|
21
21
|
|
|
22
22
|
## Inference
|
|
23
23
|
|
|
@@ -55,20 +55,21 @@ await inference.imageToImage({
|
|
|
55
55
|
|
|
56
56
|
## ControlNet
|
|
57
57
|
|
|
58
|
-
Controlling outputs of diffusion models only with a text prompt is a challenging problem. ControlNet is a neural network
|
|
58
|
+
Controlling the outputs of diffusion models only with a text prompt is a challenging problem. ControlNet is a neural network model that provides image-based control to diffusion models. Control images can be edges or other landmarks extracted from a source image.
|
|
59
59
|
|
|
60
60
|
Many ControlNet models were trained in our community event, JAX Diffusers sprint. You can see the full list of the ControlNet models available [here](https://huggingface.co/spaces/jax-diffusers-event/leaderboard).
|
|
61
61
|
|
|
62
62
|
## Most Used Model for the Task
|
|
63
63
|
|
|
64
|
-
Pix2Pix is a popular model used for image
|
|
64
|
+
Pix2Pix is a popular model used for image-to-image translation tasks. It is based on a conditional-GAN (generative adversarial network) where instead of a noise vector a 2D image is given as input. More information about Pix2Pix can be retrieved from this [link](https://phillipi.github.io/pix2pix/) where the associated paper and the GitHub repository can be found.
|
|
65
65
|
|
|
66
|
-
|
|
66
|
+
The images below show some examples extracted from the Pix2Pix paper. This model can be applied to various use cases. It is capable of relatively simpler things, e.g., converting a grayscale image to its colored version. But more importantly, it can generate realistic pictures from rough sketches (can be seen in the purse example) or from painting-like images (can be seen in the street and facade examples below).
|
|
67
67
|
|
|
68
68
|
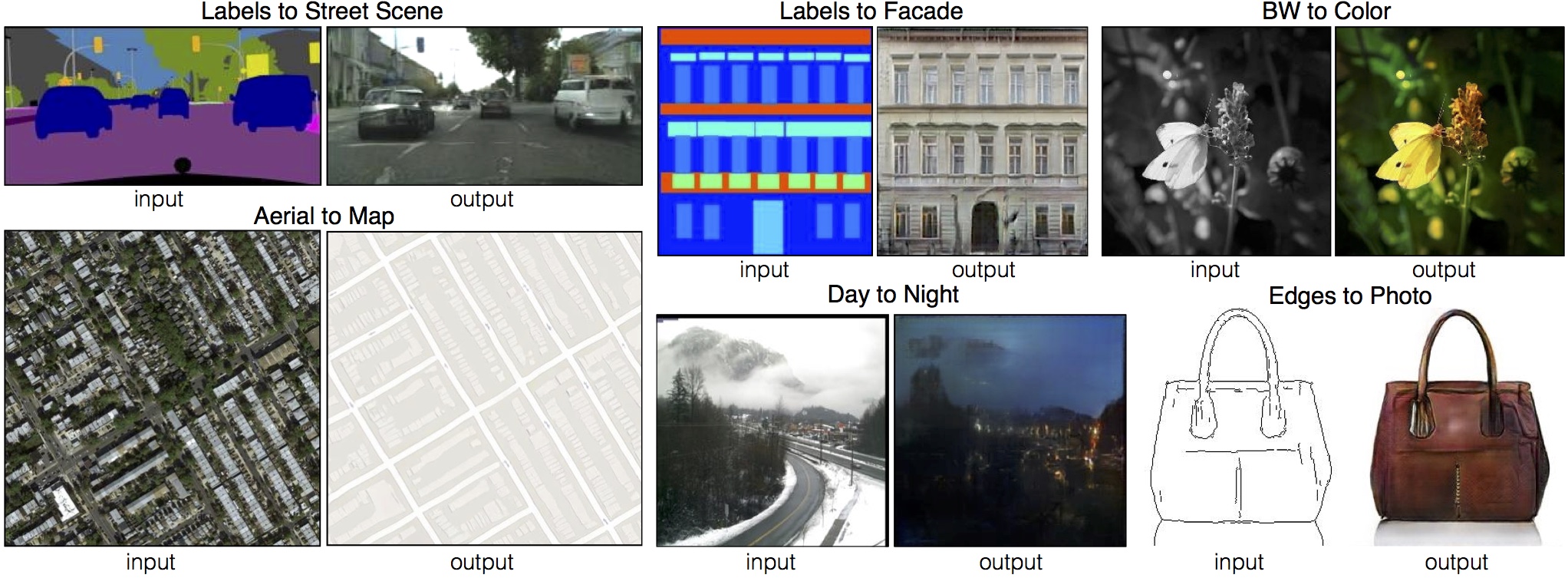
|
|
69
69
|
|
|
70
70
|
## Useful Resources
|
|
71
71
|
|
|
72
|
+
- [Image-to-image guide with diffusers](https://huggingface.co/docs/diffusers/using-diffusers/img2img)
|
|
72
73
|
- [Train your ControlNet with diffusers 🧨](https://huggingface.co/blog/train-your-controlnet)
|
|
73
74
|
- [Ultra fast ControlNet with 🧨 Diffusers](https://huggingface.co/blog/controlnet)
|
|
74
75
|
|
|
@@ -1,5 +1,4 @@
|
|
|
1
|
-
import { type PipelineType, PIPELINE_DATA } from "
|
|
2
|
-
import type { TaskDataCustom, TaskData } from "./Types";
|
|
1
|
+
import { type PipelineType, PIPELINE_DATA } from "../pipelines";
|
|
3
2
|
|
|
4
3
|
import audioClassification from "./audio-classification/data";
|
|
5
4
|
import audioToAudio from "./audio-to-audio/data";
|
|
@@ -34,7 +33,82 @@ import videoClassification from "./video-classification/data";
|
|
|
34
33
|
import visualQuestionAnswering from "./visual-question-answering/data";
|
|
35
34
|
import zeroShotClassification from "./zero-shot-classification/data";
|
|
36
35
|
import zeroShotImageClassification from "./zero-shot-image-classification/data";
|
|
37
|
-
|
|
36
|
+
|
|
37
|
+
import type { ModelLibraryKey } from "../model-libraries";
|
|
38
|
+
|
|
39
|
+
/**
|
|
40
|
+
* Model libraries compatible with each ML task
|
|
41
|
+
*/
|
|
42
|
+
export const TASKS_MODEL_LIBRARIES: Record<PipelineType, ModelLibraryKey[]> = {
|
|
43
|
+
"audio-classification": ["speechbrain", "transformers"],
|
|
44
|
+
"audio-to-audio": ["asteroid", "speechbrain"],
|
|
45
|
+
"automatic-speech-recognition": ["espnet", "nemo", "speechbrain", "transformers", "transformers.js"],
|
|
46
|
+
conversational: ["transformers"],
|
|
47
|
+
"depth-estimation": ["transformers"],
|
|
48
|
+
"document-question-answering": ["transformers"],
|
|
49
|
+
"feature-extraction": ["sentence-transformers", "transformers", "transformers.js"],
|
|
50
|
+
"fill-mask": ["transformers", "transformers.js"],
|
|
51
|
+
"graph-ml": ["transformers"],
|
|
52
|
+
"image-classification": ["keras", "timm", "transformers", "transformers.js"],
|
|
53
|
+
"image-segmentation": ["transformers", "transformers.js"],
|
|
54
|
+
"image-to-image": ["diffusers"],
|
|
55
|
+
"image-to-text": ["transformers.js"],
|
|
56
|
+
"image-to-video": ["diffusers"],
|
|
57
|
+
"video-classification": ["transformers"],
|
|
58
|
+
"mask-generation": ["transformers"],
|
|
59
|
+
"multiple-choice": ["transformers"],
|
|
60
|
+
"object-detection": ["transformers", "transformers.js"],
|
|
61
|
+
other: [],
|
|
62
|
+
"question-answering": ["adapter-transformers", "allennlp", "transformers", "transformers.js"],
|
|
63
|
+
robotics: [],
|
|
64
|
+
"reinforcement-learning": ["transformers", "stable-baselines3", "ml-agents", "sample-factory"],
|
|
65
|
+
"sentence-similarity": ["sentence-transformers", "spacy", "transformers.js"],
|
|
66
|
+
summarization: ["transformers", "transformers.js"],
|
|
67
|
+
"table-question-answering": ["transformers"],
|
|
68
|
+
"table-to-text": ["transformers"],
|
|
69
|
+
"tabular-classification": ["sklearn"],
|
|
70
|
+
"tabular-regression": ["sklearn"],
|
|
71
|
+
"tabular-to-text": ["transformers"],
|
|
72
|
+
"text-classification": ["adapter-transformers", "spacy", "transformers", "transformers.js"],
|
|
73
|
+
"text-generation": ["transformers", "transformers.js"],
|
|
74
|
+
"text-retrieval": [],
|
|
75
|
+
"text-to-image": ["diffusers"],
|
|
76
|
+
"text-to-speech": ["espnet", "tensorflowtts", "transformers"],
|
|
77
|
+
"text-to-audio": ["transformers"],
|
|
78
|
+
"text-to-video": ["diffusers"],
|
|
79
|
+
"text2text-generation": ["transformers", "transformers.js"],
|
|
80
|
+
"time-series-forecasting": [],
|
|
81
|
+
"token-classification": [
|
|
82
|
+
"adapter-transformers",
|
|
83
|
+
"flair",
|
|
84
|
+
"spacy",
|
|
85
|
+
"span-marker",
|
|
86
|
+
"stanza",
|
|
87
|
+
"transformers",
|
|
88
|
+
"transformers.js",
|
|
89
|
+
],
|
|
90
|
+
translation: ["transformers", "transformers.js"],
|
|
91
|
+
"unconditional-image-generation": ["diffusers"],
|
|
92
|
+
"visual-question-answering": ["transformers"],
|
|
93
|
+
"voice-activity-detection": [],
|
|
94
|
+
"zero-shot-classification": ["transformers", "transformers.js"],
|
|
95
|
+
"zero-shot-image-classification": ["transformers", "transformers.js"],
|
|
96
|
+
"zero-shot-object-detection": ["transformers"],
|
|
97
|
+
};
|
|
98
|
+
|
|
99
|
+
/**
|
|
100
|
+
* Return the whole TaskData object for a certain task.
|
|
101
|
+
* If the partialTaskData argument is left undefined,
|
|
102
|
+
* the default placholder data will be used.
|
|
103
|
+
*/
|
|
104
|
+
function getData(type: PipelineType, partialTaskData: TaskDataCustom = placeholder): TaskData {
|
|
105
|
+
return {
|
|
106
|
+
...partialTaskData,
|
|
107
|
+
id: type,
|
|
108
|
+
label: PIPELINE_DATA[type].name,
|
|
109
|
+
libraries: TASKS_MODEL_LIBRARIES[type],
|
|
110
|
+
};
|
|
111
|
+
}
|
|
38
112
|
|
|
39
113
|
// To make comparisons easier, task order is the same as in const.ts
|
|
40
114
|
// Tasks set to undefined won't have an associated task page.
|
|
@@ -54,6 +128,8 @@ export const TASKS_DATA: Record<PipelineType, TaskData | undefined> = {
|
|
|
54
128
|
"image-segmentation": getData("image-segmentation", imageSegmentation),
|
|
55
129
|
"image-to-image": getData("image-to-image", imageToImage),
|
|
56
130
|
"image-to-text": getData("image-to-text", imageToText),
|
|
131
|
+
"image-to-video": undefined,
|
|
132
|
+
"mask-generation": getData("mask-generation", placeholder),
|
|
57
133
|
"multiple-choice": undefined,
|
|
58
134
|
"object-detection": getData("object-detection", objectDetection),
|
|
59
135
|
"video-classification": getData("video-classification", videoClassification),
|
|
@@ -84,18 +160,67 @@ export const TASKS_DATA: Record<PipelineType, TaskData | undefined> = {
|
|
|
84
160
|
"voice-activity-detection": undefined,
|
|
85
161
|
"zero-shot-classification": getData("zero-shot-classification", zeroShotClassification),
|
|
86
162
|
"zero-shot-image-classification": getData("zero-shot-image-classification", zeroShotImageClassification),
|
|
163
|
+
"zero-shot-object-detection": getData("zero-shot-object-detection", placeholder),
|
|
87
164
|
} as const;
|
|
88
165
|
|
|
89
|
-
|
|
90
|
-
|
|
91
|
-
|
|
92
|
-
* the default placholder data will be used.
|
|
93
|
-
*/
|
|
94
|
-
function getData(type: PipelineType, partialTaskData: TaskDataCustom = placeholder): TaskData {
|
|
95
|
-
return {
|
|
96
|
-
...partialTaskData,
|
|
97
|
-
id: type,
|
|
98
|
-
label: PIPELINE_DATA[type].name,
|
|
99
|
-
libraries: TASKS_MODEL_LIBRARIES[type],
|
|
100
|
-
};
|
|
166
|
+
export interface ExampleRepo {
|
|
167
|
+
description: string;
|
|
168
|
+
id: string;
|
|
101
169
|
}
|
|
170
|
+
|
|
171
|
+
export type TaskDemoEntry =
|
|
172
|
+
| {
|
|
173
|
+
filename: string;
|
|
174
|
+
type: "audio";
|
|
175
|
+
}
|
|
176
|
+
| {
|
|
177
|
+
data: Array<{
|
|
178
|
+
label: string;
|
|
179
|
+
score: number;
|
|
180
|
+
}>;
|
|
181
|
+
type: "chart";
|
|
182
|
+
}
|
|
183
|
+
| {
|
|
184
|
+
filename: string;
|
|
185
|
+
type: "img";
|
|
186
|
+
}
|
|
187
|
+
| {
|
|
188
|
+
table: string[][];
|
|
189
|
+
type: "tabular";
|
|
190
|
+
}
|
|
191
|
+
| {
|
|
192
|
+
content: string;
|
|
193
|
+
label: string;
|
|
194
|
+
type: "text";
|
|
195
|
+
}
|
|
196
|
+
| {
|
|
197
|
+
text: string;
|
|
198
|
+
tokens: Array<{
|
|
199
|
+
end: number;
|
|
200
|
+
start: number;
|
|
201
|
+
type: string;
|
|
202
|
+
}>;
|
|
203
|
+
type: "text-with-tokens";
|
|
204
|
+
};
|
|
205
|
+
|
|
206
|
+
export interface TaskDemo {
|
|
207
|
+
inputs: TaskDemoEntry[];
|
|
208
|
+
outputs: TaskDemoEntry[];
|
|
209
|
+
}
|
|
210
|
+
|
|
211
|
+
export interface TaskData {
|
|
212
|
+
datasets: ExampleRepo[];
|
|
213
|
+
demo: TaskDemo;
|
|
214
|
+
id: PipelineType;
|
|
215
|
+
isPlaceholder?: boolean;
|
|
216
|
+
label: string;
|
|
217
|
+
libraries: ModelLibraryKey[];
|
|
218
|
+
metrics: ExampleRepo[];
|
|
219
|
+
models: ExampleRepo[];
|
|
220
|
+
spaces: ExampleRepo[];
|
|
221
|
+
summary: string;
|
|
222
|
+
widgetModels: string[];
|
|
223
|
+
youtubeId?: string;
|
|
224
|
+
}
|
|
225
|
+
|
|
226
|
+
export type TaskDataCustom = Omit<TaskData, "id" | "label" | "libraries">;
|
|
@@ -26,11 +26,11 @@ A popular variant of Text Generation models predicts the next word given a bunch
|
|
|
26
26
|
- Continue a story given the first sentences.
|
|
27
27
|
- Provided a code description, generate the code.
|
|
28
28
|
|
|
29
|
-
The most popular models for this task are GPT-based models or [Llama series](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf). These models are trained on data that has no labels, so you just need plain text to train your own model. You can train text generation models to generate a wide variety of documents, from code to stories.
|
|
29
|
+
The most popular models for this task are GPT-based models, [Mistral](mistralai/Mistral-7B-v0.1) or [Llama series](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf). These models are trained on data that has no labels, so you just need plain text to train your own model. You can train text generation models to generate a wide variety of documents, from code to stories.
|
|
30
30
|
|
|
31
31
|
### Text-to-Text Generation Models
|
|
32
32
|
|
|
33
|
-
These models are trained to learn the mapping between a pair of texts (e.g. translation from one language to another). The most popular variants of these models are [FLAN-T5](https://huggingface.co/google/flan-t5-xxl), and [BART](https://huggingface.co/docs/transformers/model_doc/bart). Text-to-Text models are trained with multi-tasking capabilities, they can accomplish a wide range of tasks, including summarization, translation, and text classification.
|
|
33
|
+
These models are trained to learn the mapping between a pair of texts (e.g. translation from one language to another). The most popular variants of these models are [NLLB](facebook/nllb-200-distilled-600M), [FLAN-T5](https://huggingface.co/google/flan-t5-xxl), and [BART](https://huggingface.co/docs/transformers/model_doc/bart). Text-to-Text models are trained with multi-tasking capabilities, they can accomplish a wide range of tasks, including summarization, translation, and text classification.
|
|
34
34
|
|
|
35
35
|
## Inference
|
|
36
36
|
|
|
@@ -38,7 +38,7 @@ You can use the 🤗 Transformers library `text-generation` pipeline to do infer
|
|
|
38
38
|
|
|
39
39
|
```python
|
|
40
40
|
from transformers import pipeline
|
|
41
|
-
generator = pipeline('text-generation', model = '
|
|
41
|
+
generator = pipeline('text-generation', model = 'HuggingFaceH4/zephyr-7b-beta')
|
|
42
42
|
generator("Hello, I'm a language model", max_length = 30, num_return_sequences=3)
|
|
43
43
|
## [{'generated_text': "Hello, I'm a language modeler. So while writing this, when I went out to meet my wife or come home she told me that my"},
|
|
44
44
|
## {'generated_text': "Hello, I'm a language modeler. I write and maintain software in Python. I love to code, and that includes coding things that require writing"}, ...
|
|
@@ -1,4 +1,4 @@
|
|
|
1
|
-
import type { TaskDataCustom } from "
|
|
1
|
+
import type { TaskDataCustom } from "..";
|
|
2
2
|
|
|
3
3
|
const taskData: TaskDataCustom = {
|
|
4
4
|
datasets: [
|
|
@@ -119,7 +119,7 @@ const taskData: TaskDataCustom = {
|
|
|
119
119
|
],
|
|
120
120
|
summary:
|
|
121
121
|
"Generating text is the task of producing new text. These models can, for example, fill in incomplete text or paraphrase.",
|
|
122
|
-
widgetModels: ["
|
|
122
|
+
widgetModels: ["HuggingFaceH4/zephyr-7b-beta"],
|
|
123
123
|
youtubeId: "Vpjb1lu0MDk",
|
|
124
124
|
};
|
|
125
125
|
|