cobweb-launcher 1.0.5__py3-none-any.whl → 3.2.18__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- cobweb/__init__.py +5 -1
- cobweb/base/__init__.py +3 -3
- cobweb/base/common_queue.py +37 -16
- cobweb/base/item.py +40 -14
- cobweb/base/{log.py → logger.py} +3 -3
- cobweb/base/request.py +744 -47
- cobweb/base/response.py +381 -13
- cobweb/base/seed.py +98 -50
- cobweb/base/task_queue.py +180 -0
- cobweb/base/test.py +257 -0
- cobweb/constant.py +39 -2
- cobweb/crawlers/__init__.py +1 -2
- cobweb/crawlers/crawler.py +27 -0
- cobweb/db/__init__.py +1 -0
- cobweb/db/api_db.py +83 -0
- cobweb/db/redis_db.py +118 -27
- cobweb/launchers/__init__.py +3 -1
- cobweb/launchers/distributor.py +141 -0
- cobweb/launchers/launcher.py +103 -130
- cobweb/launchers/uploader.py +68 -0
- cobweb/log_dots/__init__.py +2 -0
- cobweb/log_dots/dot.py +258 -0
- cobweb/log_dots/loghub_dot.py +53 -0
- cobweb/pipelines/__init__.py +3 -2
- cobweb/pipelines/pipeline.py +19 -0
- cobweb/pipelines/pipeline_csv.py +25 -0
- cobweb/pipelines/pipeline_loghub.py +54 -0
- cobweb/schedulers/__init__.py +1 -0
- cobweb/schedulers/scheduler.py +66 -0
- cobweb/schedulers/scheduler_with_redis.py +189 -0
- cobweb/setting.py +37 -38
- cobweb/utils/__init__.py +5 -2
- cobweb/utils/bloom.py +58 -0
- cobweb/{base → utils}/decorators.py +14 -12
- cobweb/utils/dotting.py +300 -0
- cobweb/utils/oss.py +113 -86
- cobweb/utils/tools.py +3 -15
- cobweb_launcher-3.2.18.dist-info/METADATA +193 -0
- cobweb_launcher-3.2.18.dist-info/RECORD +44 -0
- {cobweb_launcher-1.0.5.dist-info → cobweb_launcher-3.2.18.dist-info}/WHEEL +1 -1
- cobweb/crawlers/base_crawler.py +0 -121
- cobweb/crawlers/file_crawler.py +0 -181
- cobweb/launchers/launcher_pro.py +0 -174
- cobweb/pipelines/base_pipeline.py +0 -54
- cobweb/pipelines/loghub_pipeline.py +0 -34
- cobweb_launcher-1.0.5.dist-info/METADATA +0 -48
- cobweb_launcher-1.0.5.dist-info/RECORD +0 -32
- {cobweb_launcher-1.0.5.dist-info → cobweb_launcher-3.2.18.dist-info}/LICENSE +0 -0
- {cobweb_launcher-1.0.5.dist-info → cobweb_launcher-3.2.18.dist-info}/top_level.txt +0 -0
cobweb/crawlers/file_crawler.py
DELETED
|
@@ -1,181 +0,0 @@
|
|
|
1
|
-
|
|
2
|
-
from typing import Union
|
|
3
|
-
from cobweb import setting
|
|
4
|
-
from cobweb.utils import OssUtil
|
|
5
|
-
from cobweb.crawlers import Crawler
|
|
6
|
-
from cobweb.base import Seed, BaseItem, Request, Response
|
|
7
|
-
from cobweb.exceptions import OssDBPutPartError, OssDBMergeError
|
|
8
|
-
|
|
9
|
-
|
|
10
|
-
class CrawlerAir(Crawler):
|
|
11
|
-
|
|
12
|
-
oss_util = OssUtil()
|
|
13
|
-
|
|
14
|
-
@staticmethod
|
|
15
|
-
def download(item: Request) -> Union[Seed, BaseItem, Response, str]:
|
|
16
|
-
seed_dict = item.seed.to_dict
|
|
17
|
-
bucket_name = CrawlerAir.oss_util.bucket
|
|
18
|
-
try:
|
|
19
|
-
key = item.seed.oss_path
|
|
20
|
-
if CrawlerAir.oss_util.exists(key):
|
|
21
|
-
content_length = CrawlerAir.oss_util.head(key).content_length
|
|
22
|
-
yield Response(item.seed, "exists", bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
23
|
-
# data, cols = download_meta(item.seed, bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
24
|
-
# yield DownloadItem(item.seed, sid=item.seed.sid, cols=cols, data=data)
|
|
25
|
-
|
|
26
|
-
end = seed_dict.get("end", "")
|
|
27
|
-
start = seed_dict.get("start", "0")
|
|
28
|
-
|
|
29
|
-
if end or int(start):
|
|
30
|
-
item.request_setting["headers"]['Range'] = f'bytes={start}-{end}'
|
|
31
|
-
|
|
32
|
-
if not item.seed.params.identifier:
|
|
33
|
-
content = b""
|
|
34
|
-
chunk_size = CrawlerAir.oss_util.chunk_size
|
|
35
|
-
min_upload_size = CrawlerAir.oss_util.min_upload_size
|
|
36
|
-
position = seed_dict.get("position", 1)
|
|
37
|
-
|
|
38
|
-
response = item.download()
|
|
39
|
-
|
|
40
|
-
content_length = response.headers.get("content-length") or 0
|
|
41
|
-
content_type = response.headers.get("content-type", "").split(";")[0]
|
|
42
|
-
if content_type and content_type in setting.FILE_FILTER_CONTENT_TYPE:
|
|
43
|
-
yield Response(
|
|
44
|
-
item.seed, response, filter=True, msg=f"response content type is {content_type}",
|
|
45
|
-
bucket_name=bucket_name, data_size=content_length, **seed_dict
|
|
46
|
-
)
|
|
47
|
-
elif position == 1 and min_upload_size >= int(content_length) > 0:
|
|
48
|
-
"""过小文件标识返回"""
|
|
49
|
-
yield Response(
|
|
50
|
-
item.seed, response, filter=True, msg="file size is too small",
|
|
51
|
-
bucket_name=bucket_name, data_size=content_length, **seed_dict
|
|
52
|
-
)
|
|
53
|
-
elif position == 1 and chunk_size > int(content_length) > min_upload_size:
|
|
54
|
-
"""小文件直接下载"""
|
|
55
|
-
for part_data in response.iter_content(chunk_size):
|
|
56
|
-
content += part_data
|
|
57
|
-
CrawlerAir.oss_util.put(key, content)
|
|
58
|
-
yield Response(item.seed, response, bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
59
|
-
response.close()
|
|
60
|
-
else:
|
|
61
|
-
"""中大文件同步分片下载"""
|
|
62
|
-
upload_content_length = 0
|
|
63
|
-
if not seed_dict.get("upload_id"):
|
|
64
|
-
seed_dict["upload_id"] = CrawlerAir.oss_util.init_part(key).upload_id
|
|
65
|
-
upload_id = seed_dict["upload_id"]
|
|
66
|
-
for part_data in response.iter_content(chunk_size):
|
|
67
|
-
content += part_data
|
|
68
|
-
if len(content) >= chunk_size:
|
|
69
|
-
upload_data = content[:chunk_size]
|
|
70
|
-
content = content[chunk_size:]
|
|
71
|
-
CrawlerAir.oss_util.put_part(key, upload_id, position, upload_data)
|
|
72
|
-
upload_content_length += len(upload_data)
|
|
73
|
-
position += 1
|
|
74
|
-
seed_dict['position'] = position
|
|
75
|
-
seed_dict['start'] = upload_content_length
|
|
76
|
-
|
|
77
|
-
response.close()
|
|
78
|
-
if content:
|
|
79
|
-
CrawlerAir.oss_util.put_part(key, upload_id, position, content)
|
|
80
|
-
content_length += len(content)
|
|
81
|
-
CrawlerAir.oss_util.merge(key, upload_id)
|
|
82
|
-
yield Response(item.seed, response, bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
83
|
-
# data, cols = download_meta(item.seed, bucket_name, data_size=content_length, **seed_dict)
|
|
84
|
-
# yield DownloadItem(item.seed, sid=item.seed.sid, cols=cols, data=data)
|
|
85
|
-
|
|
86
|
-
elif item.seed.params.identifier == "merge":
|
|
87
|
-
CrawlerAir.oss_util.merge(key, seed_dict["upload_id"])
|
|
88
|
-
content_length = CrawlerAir.oss_util.head(key).content_length
|
|
89
|
-
yield Response(item.seed, "merge", bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
90
|
-
# data, cols = download_meta(item.seed, bucket_name, data_size=content_length, **seed_dict)
|
|
91
|
-
# yield DownloadItem(item.seed, sid=item.seed.sid, cols=cols, data=data)
|
|
92
|
-
except OssDBPutPartError:
|
|
93
|
-
yield Seed(seed_dict)
|
|
94
|
-
except OssDBMergeError:
|
|
95
|
-
yield Seed(seed_dict, identifier="merge")
|
|
96
|
-
|
|
97
|
-
|
|
98
|
-
class CrawlerPro(Crawler):
|
|
99
|
-
|
|
100
|
-
oss_util = OssUtil()
|
|
101
|
-
|
|
102
|
-
@staticmethod
|
|
103
|
-
def download(item: Request) -> Union[Seed, BaseItem, Response, str]:
|
|
104
|
-
seed_dict = item.seed.to_dict
|
|
105
|
-
bucket_name = CrawlerAir.oss_util.bucket
|
|
106
|
-
try:
|
|
107
|
-
key = item.seed.oss_path
|
|
108
|
-
if CrawlerAir.oss_util.exists(key):
|
|
109
|
-
content_length = CrawlerAir.oss_util.head(key).content_length
|
|
110
|
-
yield Response(item.seed, "exists", bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
111
|
-
|
|
112
|
-
end = seed_dict.get("end", "")
|
|
113
|
-
start = seed_dict.get("start", "0")
|
|
114
|
-
|
|
115
|
-
if end or int(start):
|
|
116
|
-
item.request_setting["headers"]['Range'] = f'bytes={start}-{end}'
|
|
117
|
-
|
|
118
|
-
if not item.seed.params.identifier:
|
|
119
|
-
content = b""
|
|
120
|
-
chunk_size = CrawlerAir.oss_util.chunk_size
|
|
121
|
-
min_upload_size = CrawlerAir.oss_util.min_upload_size
|
|
122
|
-
position = seed_dict.get("position", 1)
|
|
123
|
-
|
|
124
|
-
response = item.download()
|
|
125
|
-
|
|
126
|
-
content_length = response.headers.get("content-length") or 0
|
|
127
|
-
content_type = response.headers.get("content-type", "").split(";")[0]
|
|
128
|
-
if content_type and content_type in setting.FILE_FILTER_CONTENT_TYPE:
|
|
129
|
-
yield Response(
|
|
130
|
-
item.seed, response, filter=True, msg=f"response content type is {content_type}",
|
|
131
|
-
bucket_name=bucket_name, data_size=content_length, **seed_dict
|
|
132
|
-
)
|
|
133
|
-
elif position == 1 and min_upload_size >= int(content_length) > 0:
|
|
134
|
-
"""过小文件标识返回"""
|
|
135
|
-
yield Response(
|
|
136
|
-
item.seed, response, filter=True, msg="file size is too small",
|
|
137
|
-
bucket_name=bucket_name, data_size=content_length, **seed_dict
|
|
138
|
-
)
|
|
139
|
-
elif position == 1 and chunk_size > int(content_length) > min_upload_size:
|
|
140
|
-
"""小文件直接下载"""
|
|
141
|
-
for part_data in response.iter_content(chunk_size):
|
|
142
|
-
content += part_data
|
|
143
|
-
CrawlerAir.oss_util.put(key, content)
|
|
144
|
-
yield Response(item.seed, response, bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
145
|
-
response.close()
|
|
146
|
-
else:
|
|
147
|
-
"""中大文件同步分片下载"""
|
|
148
|
-
upload_content_length = 0
|
|
149
|
-
if not seed_dict.get("upload_id"):
|
|
150
|
-
seed_dict["upload_id"] = CrawlerAir.oss_util.init_part(key).upload_id
|
|
151
|
-
upload_id = seed_dict["upload_id"]
|
|
152
|
-
for part_data in response.iter_content(chunk_size):
|
|
153
|
-
content += part_data
|
|
154
|
-
if len(content) >= chunk_size:
|
|
155
|
-
upload_data = content[:chunk_size]
|
|
156
|
-
content = content[chunk_size:]
|
|
157
|
-
CrawlerAir.oss_util.put_part(key, upload_id, position, upload_data)
|
|
158
|
-
upload_content_length += len(upload_data)
|
|
159
|
-
position += 1
|
|
160
|
-
seed_dict['position'] = position
|
|
161
|
-
seed_dict['start'] = upload_content_length
|
|
162
|
-
|
|
163
|
-
response.close()
|
|
164
|
-
if content:
|
|
165
|
-
CrawlerAir.oss_util.put_part(key, upload_id, position, content)
|
|
166
|
-
content_length += len(content)
|
|
167
|
-
CrawlerAir.oss_util.merge(key, upload_id)
|
|
168
|
-
yield Response(item.seed, response, bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
169
|
-
# data, cols = download_meta(item.seed, bucket_name, data_size=content_length, **seed_dict)
|
|
170
|
-
# yield DownloadItem(item.seed, sid=item.seed.sid, cols=cols, data=data)
|
|
171
|
-
|
|
172
|
-
elif item.seed.params.identifier == "merge":
|
|
173
|
-
CrawlerAir.oss_util.merge(key, seed_dict["upload_id"])
|
|
174
|
-
content_length = CrawlerAir.oss_util.head(key).content_length
|
|
175
|
-
yield Response(item.seed, "merge", bucket_name=bucket_name, data_size=content_length, **seed_dict)
|
|
176
|
-
# data, cols = download_meta(item.seed, bucket_name, data_size=content_length, **seed_dict)
|
|
177
|
-
# yield DownloadItem(item.seed, sid=item.seed.sid, cols=cols, data=data)
|
|
178
|
-
except OssDBPutPartError:
|
|
179
|
-
yield Seed(seed_dict)
|
|
180
|
-
except OssDBMergeError:
|
|
181
|
-
yield Seed(seed_dict, identifier="merge")
|
cobweb/launchers/launcher_pro.py
DELETED
|
@@ -1,174 +0,0 @@
|
|
|
1
|
-
import time
|
|
2
|
-
import threading
|
|
3
|
-
|
|
4
|
-
from cobweb.db import RedisDB
|
|
5
|
-
from cobweb.base import Seed, logger
|
|
6
|
-
from cobweb.launchers import Launcher
|
|
7
|
-
from cobweb.constant import DealModel, LogTemplate
|
|
8
|
-
|
|
9
|
-
|
|
10
|
-
class LauncherPro(Launcher):
|
|
11
|
-
|
|
12
|
-
def __init__(self, task, project, custom_setting=None):
|
|
13
|
-
super().__init__(task, project, custom_setting)
|
|
14
|
-
self._todo = "{%s:%s}:todo" % (project, task)
|
|
15
|
-
self._done = "{%s:%s}:done" % (project, task)
|
|
16
|
-
self._fail = "{%s:%s}:fail" % (project, task)
|
|
17
|
-
self._heartbeat = "heartbeat:%s_%s" % (project, task)
|
|
18
|
-
self._reset_lock = "lock:reset:%s_%s" % (project, task)
|
|
19
|
-
self._heartbeat_lock = "lock:heartbeat:%s_%s" % (project, task)
|
|
20
|
-
self._db = RedisDB()
|
|
21
|
-
|
|
22
|
-
self._heartbeat_start_event = threading.Event()
|
|
23
|
-
self._redis_queue_empty_event = threading.Event()
|
|
24
|
-
|
|
25
|
-
@property
|
|
26
|
-
def heartbeat(self):
|
|
27
|
-
return self._db.exists(self._heartbeat)
|
|
28
|
-
|
|
29
|
-
def _execute_heartbeat(self):
|
|
30
|
-
while not self._stop.is_set():
|
|
31
|
-
if self._heartbeat_start_event.is_set():
|
|
32
|
-
if self._db.lock(self._heartbeat_lock, t=1):
|
|
33
|
-
self._db.setex(self._heartbeat, 3)
|
|
34
|
-
time.sleep(1)
|
|
35
|
-
time.sleep(0.5)
|
|
36
|
-
|
|
37
|
-
def _reset(self):
|
|
38
|
-
"""
|
|
39
|
-
检查过期种子,重新添加到redis缓存中
|
|
40
|
-
"""
|
|
41
|
-
first = True
|
|
42
|
-
while not self._pause.is_set():
|
|
43
|
-
reset_wait_seconds = 15
|
|
44
|
-
if self._db.lock(self._reset_lock, t=120):
|
|
45
|
-
if not self.heartbeat:
|
|
46
|
-
self._heartbeat_start_event.set()
|
|
47
|
-
|
|
48
|
-
_min = -int(time.time()) + self._seed_reset_seconds \
|
|
49
|
-
if self.heartbeat or not first else "-inf"
|
|
50
|
-
|
|
51
|
-
self._db.members(
|
|
52
|
-
self._todo, 0,
|
|
53
|
-
_min=_min, _max="(0"
|
|
54
|
-
)
|
|
55
|
-
self._db.delete(self._reset_lock)
|
|
56
|
-
reset_wait_seconds = 60
|
|
57
|
-
|
|
58
|
-
time.sleep(reset_wait_seconds)
|
|
59
|
-
first = False
|
|
60
|
-
|
|
61
|
-
def _scheduler(self):
|
|
62
|
-
"""
|
|
63
|
-
调度任务,获取redis队列种子,同时添加到doing字典中
|
|
64
|
-
"""
|
|
65
|
-
if self.start_seeds:
|
|
66
|
-
self.__LAUNCHER_QUEUE__['todo'].push(self.start_seeds)
|
|
67
|
-
while not self._pause.is_set():
|
|
68
|
-
if not self._db.zcount(self._todo, 0, "(1000"):
|
|
69
|
-
time.sleep(self._scheduler_wait_seconds)
|
|
70
|
-
continue
|
|
71
|
-
if self.__LAUNCHER_QUEUE__['todo'].length >= self._todo_queue_size:
|
|
72
|
-
time.sleep(self._todo_queue_full_wait_seconds)
|
|
73
|
-
continue
|
|
74
|
-
members = self._db.members(
|
|
75
|
-
self._todo, int(time.time()),
|
|
76
|
-
count=self._todo_queue_size,
|
|
77
|
-
_min=0, _max="(1000"
|
|
78
|
-
)
|
|
79
|
-
for member, priority in members:
|
|
80
|
-
seed = Seed(member, priority=priority)
|
|
81
|
-
self.__LAUNCHER_QUEUE__['todo'].push(seed)
|
|
82
|
-
self.__DOING__[seed.to_string] = seed.params.priority
|
|
83
|
-
|
|
84
|
-
def _insert(self):
|
|
85
|
-
"""
|
|
86
|
-
添加新种子到redis队列中
|
|
87
|
-
"""
|
|
88
|
-
while not self._pause.is_set():
|
|
89
|
-
seeds = {}
|
|
90
|
-
status = self.__LAUNCHER_QUEUE__['new'].length < self._new_queue_max_size
|
|
91
|
-
for _ in range(self._new_queue_max_size):
|
|
92
|
-
seed = self.__LAUNCHER_QUEUE__['new'].pop()
|
|
93
|
-
if not seed:
|
|
94
|
-
break
|
|
95
|
-
seeds[seed.to_string] = seed.params.priority
|
|
96
|
-
if seeds:
|
|
97
|
-
self._db.zadd(self._todo, seeds, nx=True)
|
|
98
|
-
if status:
|
|
99
|
-
time.sleep(self._new_queue_wait_seconds)
|
|
100
|
-
|
|
101
|
-
def _refresh(self):
|
|
102
|
-
"""
|
|
103
|
-
刷新doing种子过期时间,防止reset重新消费
|
|
104
|
-
"""
|
|
105
|
-
while not self._pause.is_set():
|
|
106
|
-
if self.__DOING__:
|
|
107
|
-
refresh_time = int(time.time())
|
|
108
|
-
seeds = {k:-refresh_time - v / 1000 for k, v in self.__DOING__.items()}
|
|
109
|
-
self._db.zadd(self._todo, item=seeds, xx=True)
|
|
110
|
-
time.sleep(30)
|
|
111
|
-
|
|
112
|
-
def _delete(self):
|
|
113
|
-
"""
|
|
114
|
-
删除队列种子,根据状态添加至成功或失败队列,移除doing字典种子索引
|
|
115
|
-
"""
|
|
116
|
-
while not self._pause.is_set():
|
|
117
|
-
seeds, s_seeds, f_seeds = [], [], []
|
|
118
|
-
status = self.__LAUNCHER_QUEUE__['done'].length < self._done_queue_max_size
|
|
119
|
-
|
|
120
|
-
for _ in range(self._done_queue_max_size):
|
|
121
|
-
seed = self.__LAUNCHER_QUEUE__['done'].pop()
|
|
122
|
-
if not seed:
|
|
123
|
-
break
|
|
124
|
-
if seed.params.identifier == DealModel.fail:
|
|
125
|
-
f_seeds.append(seed.to_string)
|
|
126
|
-
elif self._done_model == 1:
|
|
127
|
-
s_seeds.append(seed.to_string)
|
|
128
|
-
else:
|
|
129
|
-
seeds.append(seed.to_string)
|
|
130
|
-
if seeds:
|
|
131
|
-
self._db.zrem(self._todo, *seeds)
|
|
132
|
-
if s_seeds:
|
|
133
|
-
self._db.done([self._todo, self._done], *s_seeds)
|
|
134
|
-
if f_seeds:
|
|
135
|
-
self._db.done([self._todo, self._fail], *f_seeds)
|
|
136
|
-
|
|
137
|
-
self._remove_doing_seeds(seeds)
|
|
138
|
-
|
|
139
|
-
if status:
|
|
140
|
-
time.sleep(self._done_queue_wait_seconds)
|
|
141
|
-
|
|
142
|
-
def _polling(self):
|
|
143
|
-
check_emtpy_times = 0
|
|
144
|
-
while not self._stop.is_set():
|
|
145
|
-
queue_not_empty_count = 0
|
|
146
|
-
pooling_wait_seconds = 30
|
|
147
|
-
if not self._db.zcard(self._todo):
|
|
148
|
-
for q in self.__LAUNCHER_QUEUE__.values():
|
|
149
|
-
if q.length != 0:
|
|
150
|
-
queue_not_empty_count += 1
|
|
151
|
-
if self._pause.is_set() and queue_not_empty_count != 0:
|
|
152
|
-
self._pause.clear()
|
|
153
|
-
self._execute()
|
|
154
|
-
elif queue_not_empty_count == 0:
|
|
155
|
-
pooling_wait_seconds = 3
|
|
156
|
-
check_emtpy_times += 1
|
|
157
|
-
else:
|
|
158
|
-
check_emtpy_times = 0
|
|
159
|
-
if check_emtpy_times > 2:
|
|
160
|
-
check_emtpy_times = 0
|
|
161
|
-
self.__DOING__ = {}
|
|
162
|
-
self._pause.set()
|
|
163
|
-
if not self._pause.is_set():
|
|
164
|
-
logger.info(LogTemplate.launcher_pro_polling.format(
|
|
165
|
-
task=self.task,
|
|
166
|
-
doing_len=len(self.__DOING__.keys()),
|
|
167
|
-
todo_len=self.__LAUNCHER_QUEUE__['todo'].length,
|
|
168
|
-
done_len=self.__LAUNCHER_QUEUE__['done'].length,
|
|
169
|
-
redis_seed_count=self._db.zcount(self._todo, "-inf", "+inf"),
|
|
170
|
-
redis_todo_len=self._db.zcount(self._todo, 0, "(1000"),
|
|
171
|
-
redis_doing_len=self._db.zcount(self._todo, "-inf", "(0"),
|
|
172
|
-
upload_len=self._upload_queue.length
|
|
173
|
-
))
|
|
174
|
-
time.sleep(pooling_wait_seconds)
|
|
@@ -1,54 +0,0 @@
|
|
|
1
|
-
import time
|
|
2
|
-
import threading
|
|
3
|
-
|
|
4
|
-
from abc import ABC, abstractmethod
|
|
5
|
-
from cobweb.base import BaseItem, Queue, logger
|
|
6
|
-
|
|
7
|
-
|
|
8
|
-
class Pipeline(threading.Thread, ABC):
|
|
9
|
-
|
|
10
|
-
def __init__(
|
|
11
|
-
self,
|
|
12
|
-
done_queue: Queue,
|
|
13
|
-
upload_queue: Queue,
|
|
14
|
-
upload_queue_size: int,
|
|
15
|
-
upload_wait_seconds: int
|
|
16
|
-
):
|
|
17
|
-
super().__init__()
|
|
18
|
-
self.done_queue = done_queue
|
|
19
|
-
self.upload_queue = upload_queue
|
|
20
|
-
self.upload_queue_size = upload_queue_size
|
|
21
|
-
self.upload_wait_seconds = upload_wait_seconds
|
|
22
|
-
|
|
23
|
-
@abstractmethod
|
|
24
|
-
def build(self, item: BaseItem) -> dict:
|
|
25
|
-
pass
|
|
26
|
-
|
|
27
|
-
@abstractmethod
|
|
28
|
-
def upload(self, table: str, data: list) -> bool:
|
|
29
|
-
pass
|
|
30
|
-
|
|
31
|
-
def run(self):
|
|
32
|
-
while True:
|
|
33
|
-
status = self.upload_queue.length < self.upload_queue_size
|
|
34
|
-
if status:
|
|
35
|
-
time.sleep(self.upload_wait_seconds)
|
|
36
|
-
data_info, seeds = {}, []
|
|
37
|
-
for _ in range(self.upload_queue_size):
|
|
38
|
-
item = self.upload_queue.pop()
|
|
39
|
-
if not item:
|
|
40
|
-
break
|
|
41
|
-
data = self.build(item)
|
|
42
|
-
seeds.append(item.seed)
|
|
43
|
-
data_info.setdefault(item.table, []).append(data)
|
|
44
|
-
for table, datas in data_info.items():
|
|
45
|
-
try:
|
|
46
|
-
self.upload(table, datas)
|
|
47
|
-
status = True
|
|
48
|
-
except Exception as e:
|
|
49
|
-
logger.info(e)
|
|
50
|
-
status = False
|
|
51
|
-
if status:
|
|
52
|
-
self.done_queue.push(seeds)
|
|
53
|
-
|
|
54
|
-
|
|
@@ -1,34 +0,0 @@
|
|
|
1
|
-
import json
|
|
2
|
-
|
|
3
|
-
from cobweb import setting
|
|
4
|
-
from cobweb.base import BaseItem
|
|
5
|
-
from cobweb.pipelines import Pipeline
|
|
6
|
-
from aliyun.log import LogClient, LogItem, PutLogsRequest
|
|
7
|
-
|
|
8
|
-
|
|
9
|
-
class LoghubPipeline(Pipeline):
|
|
10
|
-
|
|
11
|
-
def __init__(self, *args, **kwargs):
|
|
12
|
-
super().__init__(*args, **kwargs)
|
|
13
|
-
self.client = LogClient(**setting.LOGHUB_CONFIG)
|
|
14
|
-
|
|
15
|
-
def build(self, item: BaseItem):
|
|
16
|
-
log_item = LogItem()
|
|
17
|
-
temp = item.to_dict
|
|
18
|
-
for key, value in temp.items():
|
|
19
|
-
if not isinstance(value, str):
|
|
20
|
-
temp[key] = json.dumps(value, ensure_ascii=False)
|
|
21
|
-
contents = sorted(temp.items())
|
|
22
|
-
log_item.set_contents(contents)
|
|
23
|
-
return log_item
|
|
24
|
-
|
|
25
|
-
def upload(self, table, datas):
|
|
26
|
-
request = PutLogsRequest(
|
|
27
|
-
project=setting.LOGHUB_PROJECT,
|
|
28
|
-
logstore=table,
|
|
29
|
-
topic=setting.LOGHUB_TOPIC,
|
|
30
|
-
source=setting.LOGHUB_SOURCE,
|
|
31
|
-
logitems=datas,
|
|
32
|
-
compress=True
|
|
33
|
-
)
|
|
34
|
-
self.client.put_logs(request=request)
|
|
@@ -1,48 +0,0 @@
|
|
|
1
|
-
Metadata-Version: 2.1
|
|
2
|
-
Name: cobweb-launcher
|
|
3
|
-
Version: 1.0.5
|
|
4
|
-
Summary: spider_hole
|
|
5
|
-
Home-page: https://github.com/Juannie-PP/cobweb
|
|
6
|
-
Author: Juannie-PP
|
|
7
|
-
Author-email: 2604868278@qq.com
|
|
8
|
-
License: MIT
|
|
9
|
-
Keywords: cobweb-launcher, cobweb
|
|
10
|
-
Platform: UNKNOWN
|
|
11
|
-
Classifier: Programming Language :: Python :: 3
|
|
12
|
-
Requires-Python: >=3.7
|
|
13
|
-
Description-Content-Type: text/markdown
|
|
14
|
-
License-File: LICENSE
|
|
15
|
-
Requires-Dist: requests (>=2.19.1)
|
|
16
|
-
Requires-Dist: oss2 (>=2.18.1)
|
|
17
|
-
Requires-Dist: redis (>=4.4.4)
|
|
18
|
-
Requires-Dist: aliyun-log-python-sdk
|
|
19
|
-
|
|
20
|
-
# cobweb
|
|
21
|
-
|
|
22
|
-
> 通用爬虫框架: 1.单机模式采集框架;2.分布式采集框架
|
|
23
|
-
>
|
|
24
|
-
> 5部分
|
|
25
|
-
>
|
|
26
|
-
> 1. starter -- 启动器
|
|
27
|
-
>
|
|
28
|
-
> 2. scheduler -- 调度器
|
|
29
|
-
>
|
|
30
|
-
> 3. distributor -- 分发器
|
|
31
|
-
>
|
|
32
|
-
> 4. storer -- 存储器
|
|
33
|
-
>
|
|
34
|
-
> 5. utils -- 工具函数
|
|
35
|
-
>
|
|
36
|
-
|
|
37
|
-
need deal
|
|
38
|
-
- 队列优化完善,使用queue的机制wait()同步各模块执行?
|
|
39
|
-
- 日志功能完善,单机模式调度和保存数据写入文件,结构化输出各任务日志
|
|
40
|
-
- 去重过滤(布隆过滤器等)
|
|
41
|
-
- 防丢失(单机模式可以通过日志文件进行检查种子)
|
|
42
|
-
- 自定义数据库的功能
|
|
43
|
-
- excel、mysql、redis数据完善
|
|
44
|
-
|
|
45
|
-
|
|
46
|
-
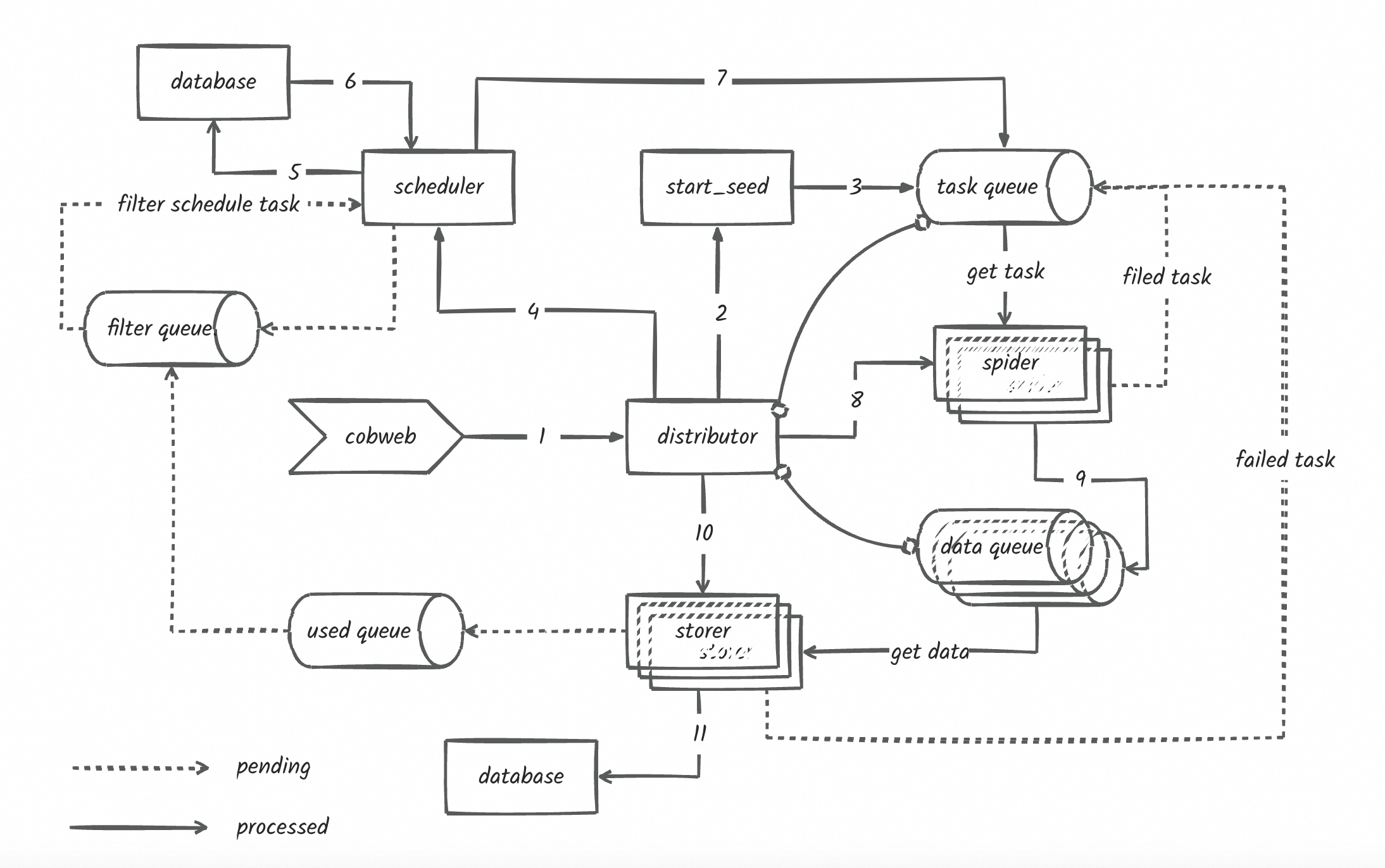
|
|
47
|
-
|
|
48
|
-
|
|
@@ -1,32 +0,0 @@
|
|
|
1
|
-
cobweb/__init__.py,sha256=IkGcdTU6fEBNyzWowcJSSMdErntFM1kmu4WUp1BgImU,45
|
|
2
|
-
cobweb/constant.py,sha256=Aw2ES_nohVRLTWylZp6WMiUAlgyw4kLbae7LpwdZ5y4,1867
|
|
3
|
-
cobweb/setting.py,sha256=T693DAwLFLs9P6ZEvugP99UzXn-8PLeMEgdxRmL6cb4,1955
|
|
4
|
-
cobweb/base/__init__.py,sha256=diiK5MygQaWjlWNLbW6eUIg-93O6glMGC9WLNM5jyOc,209
|
|
5
|
-
cobweb/base/common_queue.py,sha256=W7PPZZFl52j3Mc916T0imHj7oAUelA6aKJwW-FecDPE,872
|
|
6
|
-
cobweb/base/decorators.py,sha256=wDCaQ94aAZGxks9Ljc0aXq6omDXT1_yzFy83ZW6VbVI,930
|
|
7
|
-
cobweb/base/item.py,sha256=pMriHStzUXtSvIf5Z3KXsP-bCvjlG1gM3z33wWeuoH8,966
|
|
8
|
-
cobweb/base/log.py,sha256=L01hXdk3L2qEm9X1FOXQ9VmWIoHSELe0cyZvrdAN61A,2003
|
|
9
|
-
cobweb/base/request.py,sha256=b08AtUSZjlFLEFIEw5uGS__FjU6QSldL20-UjZD0LbI,2128
|
|
10
|
-
cobweb/base/response.py,sha256=7h9TwCNqRlwM_fvNmid9zOoRfHbKB8ABSU0eaVUJdVo,405
|
|
11
|
-
cobweb/base/seed.py,sha256=XswH16eEd6iwIBpt71E2S_AsV5UVCcOEOBFoP0r5QRo,2900
|
|
12
|
-
cobweb/crawlers/__init__.py,sha256=1sMhQ0-NJxiff3IqF2aMCXkSXcJFzzoCKIayQ5go4aI,71
|
|
13
|
-
cobweb/crawlers/base_crawler.py,sha256=-3WQSMrMROensTrTulh-eLK61qBsZDPoK2AM-sQwUHA,4893
|
|
14
|
-
cobweb/crawlers/file_crawler.py,sha256=lOLsWxDKUQy0uJZ1NlXIPFiOJ17ufcveJIJD0Wqsqy8,9696
|
|
15
|
-
cobweb/db/__init__.py,sha256=ut0iEyBLjcJL06WNG_5_d4hO5PJWvDrKWMkDOdmgh2M,30
|
|
16
|
-
cobweb/db/redis_db.py,sha256=XE1ebIi_4e0KBKiyPdKX7l2lSgV5vhMwEhNDlAcsccU,4247
|
|
17
|
-
cobweb/exceptions/__init__.py,sha256=E9SHnJBbhD7fOgPFMswqyOf8SKRDrI_i25L0bSpohvk,32
|
|
18
|
-
cobweb/exceptions/oss_db_exception.py,sha256=iP_AImjNHT3-Iv49zCFQ3rdLnlvuHa3h2BXApgrOYpA,636
|
|
19
|
-
cobweb/launchers/__init__.py,sha256=qwlkEJVri7dvCgi45aX3lqAmQS0HrPicAipDvH75kew,69
|
|
20
|
-
cobweb/launchers/launcher.py,sha256=O6Kkvqk-0kOxJom8YO9zW18e_2eMYrA5RTS9Xy4TW5k,5665
|
|
21
|
-
cobweb/launchers/launcher_pro.py,sha256=GlDpyP1XAY2bX5SuSBn3920D5OKNigQgLnJfu6QOmPw,6760
|
|
22
|
-
cobweb/pipelines/__init__.py,sha256=xanY-Z1d7zRR5JhCdW2htzrAywnKBkigiaUlTFa6of0,80
|
|
23
|
-
cobweb/pipelines/base_pipeline.py,sha256=fYnWf79GmhufXpcnMa3te18SbmnVeYLwxfyo-zLd9CY,1577
|
|
24
|
-
cobweb/pipelines/loghub_pipeline.py,sha256=cjPO6w6UJ0jNw2fVvdX0BCdlm58T7dmYXlxzXOBpvfY,1027
|
|
25
|
-
cobweb/utils/__init__.py,sha256=JTE4sBfHnKHhD6w9Auk0MIT7O9BMOamCeryhlHNx3Zg,47
|
|
26
|
-
cobweb/utils/oss.py,sha256=uD5aN2oVYImit3amE6TjxWMaTAcbAh9dCnpIQhf4M9Q,3238
|
|
27
|
-
cobweb/utils/tools.py,sha256=8oLxkzwaYcDqKXXuLI3A_lNabyLBr7HSPgTF6x4xbnk,1239
|
|
28
|
-
cobweb_launcher-1.0.5.dist-info/LICENSE,sha256=z1rxSIGOyzcSb3orZxFPxzx-0C1vTocmswqBNxpKfEk,1063
|
|
29
|
-
cobweb_launcher-1.0.5.dist-info/METADATA,sha256=qZCm5HEq0VbbPTtZbWoRh6a_Jx7JsUtk_VIXU_-zQAA,1245
|
|
30
|
-
cobweb_launcher-1.0.5.dist-info/WHEEL,sha256=ewwEueio1C2XeHTvT17n8dZUJgOvyCWCt0WVNLClP9o,92
|
|
31
|
-
cobweb_launcher-1.0.5.dist-info/top_level.txt,sha256=4GETBGNsKqiCUezmT-mJn7tjhcDlu7nLIV5gGgHBW4I,7
|
|
32
|
-
cobweb_launcher-1.0.5.dist-info/RECORD,,
|
|
File without changes
|
|
File without changes
|