@huggingface/tasks 0.13.1-test → 0.13.1-test2
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/package.json +4 -2
- package/src/dataset-libraries.ts +89 -0
- package/src/default-widget-inputs.ts +718 -0
- package/src/gguf.ts +40 -0
- package/src/hardware.ts +482 -0
- package/src/index.ts +59 -0
- package/src/library-to-tasks.ts +76 -0
- package/src/local-apps.ts +412 -0
- package/src/model-data.ts +149 -0
- package/src/model-libraries-downloads.ts +18 -0
- package/src/model-libraries-snippets.ts +1128 -0
- package/src/model-libraries.ts +820 -0
- package/src/pipelines.ts +698 -0
- package/src/snippets/common.ts +39 -0
- package/src/snippets/curl.spec.ts +94 -0
- package/src/snippets/curl.ts +120 -0
- package/src/snippets/index.ts +7 -0
- package/src/snippets/inputs.ts +167 -0
- package/src/snippets/js.spec.ts +148 -0
- package/src/snippets/js.ts +305 -0
- package/src/snippets/python.spec.ts +144 -0
- package/src/snippets/python.ts +321 -0
- package/src/snippets/types.ts +16 -0
- package/src/tasks/audio-classification/about.md +86 -0
- package/src/tasks/audio-classification/data.ts +81 -0
- package/src/tasks/audio-classification/inference.ts +52 -0
- package/src/tasks/audio-classification/spec/input.json +35 -0
- package/src/tasks/audio-classification/spec/output.json +11 -0
- package/src/tasks/audio-to-audio/about.md +56 -0
- package/src/tasks/audio-to-audio/data.ts +70 -0
- package/src/tasks/automatic-speech-recognition/about.md +90 -0
- package/src/tasks/automatic-speech-recognition/data.ts +82 -0
- package/src/tasks/automatic-speech-recognition/inference.ts +160 -0
- package/src/tasks/automatic-speech-recognition/spec/input.json +35 -0
- package/src/tasks/automatic-speech-recognition/spec/output.json +38 -0
- package/src/tasks/chat-completion/inference.ts +322 -0
- package/src/tasks/chat-completion/spec/input.json +350 -0
- package/src/tasks/chat-completion/spec/output.json +206 -0
- package/src/tasks/chat-completion/spec/stream_output.json +213 -0
- package/src/tasks/common-definitions.json +100 -0
- package/src/tasks/depth-estimation/about.md +45 -0
- package/src/tasks/depth-estimation/data.ts +70 -0
- package/src/tasks/depth-estimation/inference.ts +35 -0
- package/src/tasks/depth-estimation/spec/input.json +25 -0
- package/src/tasks/depth-estimation/spec/output.json +16 -0
- package/src/tasks/document-question-answering/about.md +53 -0
- package/src/tasks/document-question-answering/data.ts +85 -0
- package/src/tasks/document-question-answering/inference.ts +110 -0
- package/src/tasks/document-question-answering/spec/input.json +85 -0
- package/src/tasks/document-question-answering/spec/output.json +36 -0
- package/src/tasks/feature-extraction/about.md +72 -0
- package/src/tasks/feature-extraction/data.ts +57 -0
- package/src/tasks/feature-extraction/inference.ts +40 -0
- package/src/tasks/feature-extraction/spec/input.json +47 -0
- package/src/tasks/feature-extraction/spec/output.json +15 -0
- package/src/tasks/fill-mask/about.md +51 -0
- package/src/tasks/fill-mask/data.ts +79 -0
- package/src/tasks/fill-mask/inference.ts +62 -0
- package/src/tasks/fill-mask/spec/input.json +38 -0
- package/src/tasks/fill-mask/spec/output.json +29 -0
- package/src/tasks/image-classification/about.md +50 -0
- package/src/tasks/image-classification/data.ts +88 -0
- package/src/tasks/image-classification/inference.ts +52 -0
- package/src/tasks/image-classification/spec/input.json +35 -0
- package/src/tasks/image-classification/spec/output.json +11 -0
- package/src/tasks/image-feature-extraction/about.md +23 -0
- package/src/tasks/image-feature-extraction/data.ts +59 -0
- package/src/tasks/image-segmentation/about.md +63 -0
- package/src/tasks/image-segmentation/data.ts +99 -0
- package/src/tasks/image-segmentation/inference.ts +69 -0
- package/src/tasks/image-segmentation/spec/input.json +45 -0
- package/src/tasks/image-segmentation/spec/output.json +26 -0
- package/src/tasks/image-text-to-text/about.md +76 -0
- package/src/tasks/image-text-to-text/data.ts +102 -0
- package/src/tasks/image-to-3d/about.md +62 -0
- package/src/tasks/image-to-3d/data.ts +75 -0
- package/src/tasks/image-to-image/about.md +129 -0
- package/src/tasks/image-to-image/data.ts +101 -0
- package/src/tasks/image-to-image/inference.ts +68 -0
- package/src/tasks/image-to-image/spec/input.json +55 -0
- package/src/tasks/image-to-image/spec/output.json +12 -0
- package/src/tasks/image-to-text/about.md +61 -0
- package/src/tasks/image-to-text/data.ts +82 -0
- package/src/tasks/image-to-text/inference.ts +143 -0
- package/src/tasks/image-to-text/spec/input.json +34 -0
- package/src/tasks/image-to-text/spec/output.json +14 -0
- package/src/tasks/index.ts +312 -0
- package/src/tasks/keypoint-detection/about.md +57 -0
- package/src/tasks/keypoint-detection/data.ts +50 -0
- package/src/tasks/mask-generation/about.md +65 -0
- package/src/tasks/mask-generation/data.ts +55 -0
- package/src/tasks/object-detection/about.md +37 -0
- package/src/tasks/object-detection/data.ts +86 -0
- package/src/tasks/object-detection/inference.ts +75 -0
- package/src/tasks/object-detection/spec/input.json +31 -0
- package/src/tasks/object-detection/spec/output.json +50 -0
- package/src/tasks/placeholder/about.md +15 -0
- package/src/tasks/placeholder/data.ts +21 -0
- package/src/tasks/placeholder/spec/input.json +35 -0
- package/src/tasks/placeholder/spec/output.json +17 -0
- package/src/tasks/question-answering/about.md +56 -0
- package/src/tasks/question-answering/data.ts +75 -0
- package/src/tasks/question-answering/inference.ts +99 -0
- package/src/tasks/question-answering/spec/input.json +67 -0
- package/src/tasks/question-answering/spec/output.json +29 -0
- package/src/tasks/reinforcement-learning/about.md +167 -0
- package/src/tasks/reinforcement-learning/data.ts +75 -0
- package/src/tasks/sentence-similarity/about.md +97 -0
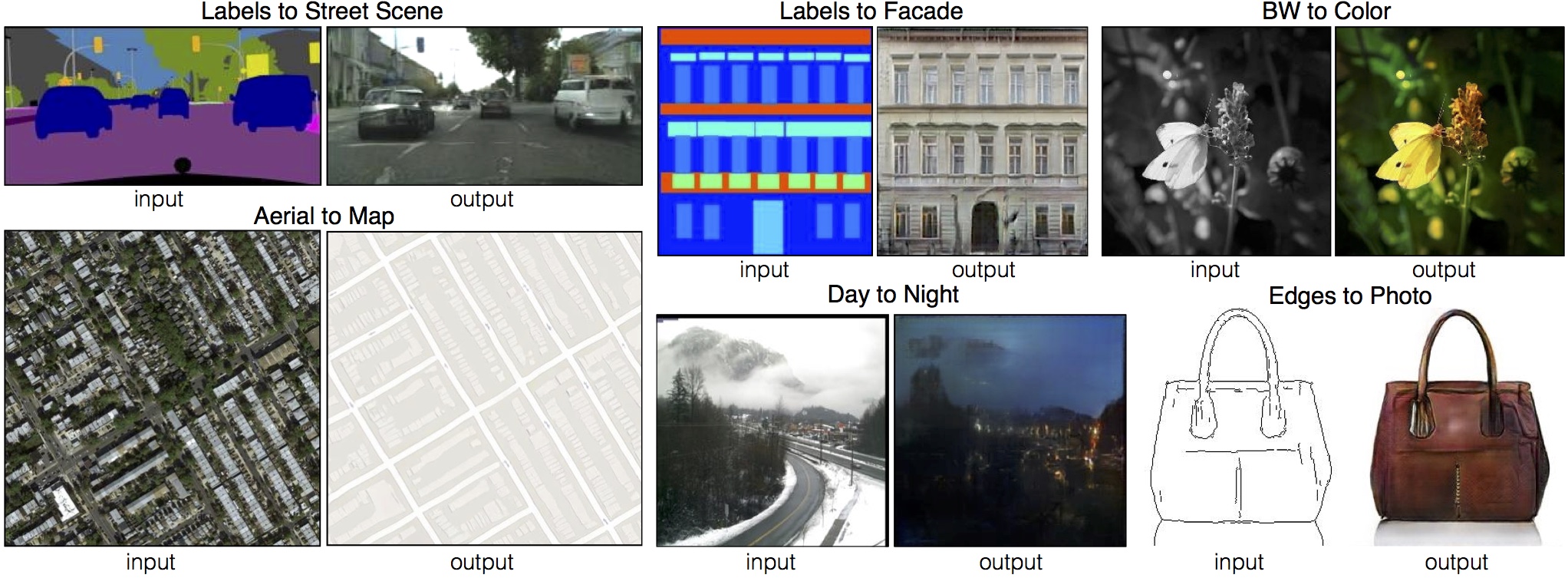
- package/src/tasks/sentence-similarity/data.ts +101 -0
- package/src/tasks/sentence-similarity/inference.ts +32 -0
- package/src/tasks/sentence-similarity/spec/input.json +40 -0
- package/src/tasks/sentence-similarity/spec/output.json +12 -0
- package/src/tasks/summarization/about.md +58 -0
- package/src/tasks/summarization/data.ts +76 -0
- package/src/tasks/summarization/inference.ts +57 -0
- package/src/tasks/summarization/spec/input.json +42 -0
- package/src/tasks/summarization/spec/output.json +14 -0
- package/src/tasks/table-question-answering/about.md +43 -0
- package/src/tasks/table-question-answering/data.ts +59 -0
- package/src/tasks/table-question-answering/inference.ts +61 -0
- package/src/tasks/table-question-answering/spec/input.json +44 -0
- package/src/tasks/table-question-answering/spec/output.json +40 -0
- package/src/tasks/tabular-classification/about.md +65 -0
- package/src/tasks/tabular-classification/data.ts +68 -0
- package/src/tasks/tabular-regression/about.md +87 -0
- package/src/tasks/tabular-regression/data.ts +57 -0
- package/src/tasks/text-classification/about.md +173 -0
- package/src/tasks/text-classification/data.ts +103 -0
- package/src/tasks/text-classification/inference.ts +51 -0
- package/src/tasks/text-classification/spec/input.json +35 -0
- package/src/tasks/text-classification/spec/output.json +11 -0
- package/src/tasks/text-generation/about.md +154 -0
- package/src/tasks/text-generation/data.ts +114 -0
- package/src/tasks/text-generation/inference.ts +200 -0
- package/src/tasks/text-generation/spec/input.json +219 -0
- package/src/tasks/text-generation/spec/output.json +179 -0
- package/src/tasks/text-generation/spec/stream_output.json +103 -0
- package/src/tasks/text-to-3d/about.md +62 -0
- package/src/tasks/text-to-3d/data.ts +56 -0
- package/src/tasks/text-to-audio/inference.ts +143 -0
- package/src/tasks/text-to-audio/spec/input.json +31 -0
- package/src/tasks/text-to-audio/spec/output.json +17 -0
- package/src/tasks/text-to-image/about.md +96 -0
- package/src/tasks/text-to-image/data.ts +100 -0
- package/src/tasks/text-to-image/inference.ts +75 -0
- package/src/tasks/text-to-image/spec/input.json +63 -0
- package/src/tasks/text-to-image/spec/output.json +13 -0
- package/src/tasks/text-to-speech/about.md +63 -0
- package/src/tasks/text-to-speech/data.ts +79 -0
- package/src/tasks/text-to-speech/inference.ts +145 -0
- package/src/tasks/text-to-speech/spec/input.json +31 -0
- package/src/tasks/text-to-speech/spec/output.json +7 -0
- package/src/tasks/text-to-video/about.md +41 -0
- package/src/tasks/text-to-video/data.ts +102 -0
- package/src/tasks/text2text-generation/inference.ts +55 -0
- package/src/tasks/text2text-generation/spec/input.json +55 -0
- package/src/tasks/text2text-generation/spec/output.json +14 -0
- package/src/tasks/token-classification/about.md +76 -0
- package/src/tasks/token-classification/data.ts +92 -0
- package/src/tasks/token-classification/inference.ts +85 -0
- package/src/tasks/token-classification/spec/input.json +65 -0
- package/src/tasks/token-classification/spec/output.json +37 -0
- package/src/tasks/translation/about.md +65 -0
- package/src/tasks/translation/data.ts +70 -0
- package/src/tasks/translation/inference.ts +67 -0
- package/src/tasks/translation/spec/input.json +50 -0
- package/src/tasks/translation/spec/output.json +14 -0
- package/src/tasks/unconditional-image-generation/about.md +50 -0
- package/src/tasks/unconditional-image-generation/data.ts +72 -0
- package/src/tasks/video-classification/about.md +37 -0
- package/src/tasks/video-classification/data.ts +84 -0
- package/src/tasks/video-classification/inference.ts +59 -0
- package/src/tasks/video-classification/spec/input.json +42 -0
- package/src/tasks/video-classification/spec/output.json +10 -0
- package/src/tasks/video-text-to-text/about.md +98 -0
- package/src/tasks/video-text-to-text/data.ts +66 -0
- package/src/tasks/visual-question-answering/about.md +48 -0
- package/src/tasks/visual-question-answering/data.ts +97 -0
- package/src/tasks/visual-question-answering/inference.ts +62 -0
- package/src/tasks/visual-question-answering/spec/input.json +41 -0
- package/src/tasks/visual-question-answering/spec/output.json +21 -0
- package/src/tasks/zero-shot-classification/about.md +40 -0
- package/src/tasks/zero-shot-classification/data.ts +70 -0
- package/src/tasks/zero-shot-classification/inference.ts +67 -0
- package/src/tasks/zero-shot-classification/spec/input.json +50 -0
- package/src/tasks/zero-shot-classification/spec/output.json +11 -0
- package/src/tasks/zero-shot-image-classification/about.md +75 -0
- package/src/tasks/zero-shot-image-classification/data.ts +84 -0
- package/src/tasks/zero-shot-image-classification/inference.ts +61 -0
- package/src/tasks/zero-shot-image-classification/spec/input.json +45 -0
- package/src/tasks/zero-shot-image-classification/spec/output.json +10 -0
- package/src/tasks/zero-shot-object-detection/about.md +45 -0
- package/src/tasks/zero-shot-object-detection/data.ts +67 -0
- package/src/tasks/zero-shot-object-detection/inference.ts +66 -0
- package/src/tasks/zero-shot-object-detection/spec/input.json +40 -0
- package/src/tasks/zero-shot-object-detection/spec/output.json +47 -0
- package/src/tokenizer-data.ts +32 -0
- package/src/widget-example.ts +125 -0
|
@@ -0,0 +1,129 @@
|
|
|
1
|
+
Image-to-image pipelines can also be used in text-to-image tasks, to provide visual guidance to the text-guided generation process.
|
|
2
|
+
|
|
3
|
+
## Use Cases
|
|
4
|
+
|
|
5
|
+
### Image inpainting
|
|
6
|
+
|
|
7
|
+
Image inpainting is widely used during photography editing to remove unwanted objects, such as poles, wires, or sensor dust.
|
|
8
|
+
|
|
9
|
+
### Image colorization
|
|
10
|
+
|
|
11
|
+
Old or black and white images can be brought up to life using an image colorization model.
|
|
12
|
+
|
|
13
|
+
### Super Resolution
|
|
14
|
+
|
|
15
|
+
Super-resolution models increase the resolution of an image, allowing for higher-quality viewing and printing.
|
|
16
|
+
|
|
17
|
+
## Inference
|
|
18
|
+
|
|
19
|
+
You can use pipelines for image-to-image in 🧨diffusers library to easily use image-to-image models. See an example for `StableDiffusionImg2ImgPipeline` below.
|
|
20
|
+
|
|
21
|
+
```python
|
|
22
|
+
import torch
|
|
23
|
+
from diffusers import AutoPipelineForImage2Image
|
|
24
|
+
from diffusers.utils import make_image_grid, load_image
|
|
25
|
+
|
|
26
|
+
pipeline = AutoPipelineForImage2Image.from_pretrained(
|
|
27
|
+
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
|
|
28
|
+
)
|
|
29
|
+
|
|
30
|
+
# this helps us to reduce memory usage- since SDXL is a bit heavy, this could help by
|
|
31
|
+
# offloading the model to CPU w/o hurting performance.
|
|
32
|
+
pipeline.enable_model_cpu_offload()
|
|
33
|
+
|
|
34
|
+
# prepare image
|
|
35
|
+
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdxl-init.png"
|
|
36
|
+
init_image = load_image(url)
|
|
37
|
+
|
|
38
|
+
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
|
39
|
+
|
|
40
|
+
# pass prompt and image to pipeline
|
|
41
|
+
image = pipeline(prompt, image=init_image, strength=0.5).images[0]
|
|
42
|
+
make_image_grid([init_image, image], rows=1, cols=2)
|
|
43
|
+
```
|
|
44
|
+
|
|
45
|
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer image-to-image models on Hugging Face Hub.
|
|
46
|
+
|
|
47
|
+
```javascript
|
|
48
|
+
import { HfInference } from "@huggingface/inference";
|
|
49
|
+
|
|
50
|
+
const inference = new HfInference(HF_TOKEN);
|
|
51
|
+
await inference.imageToImage({
|
|
52
|
+
data: await (await fetch("image")).blob(),
|
|
53
|
+
model: "timbrooks/instruct-pix2pix",
|
|
54
|
+
parameters: {
|
|
55
|
+
prompt: "Deblur this image",
|
|
56
|
+
},
|
|
57
|
+
});
|
|
58
|
+
```
|
|
59
|
+
|
|
60
|
+
## Uses Cases for Text Guided Image Generation
|
|
61
|
+
|
|
62
|
+
### Style Transfer
|
|
63
|
+
|
|
64
|
+
One of the most popular use cases of image-to-image is style transfer. With style transfer models:
|
|
65
|
+
|
|
66
|
+
- a regular photo can be transformed into a variety of artistic styles or genres, such as a watercolor painting, a comic book illustration and more.
|
|
67
|
+
- new images can be generated using a text prompt, in the style of a reference input image.
|
|
68
|
+
|
|
69
|
+
See 🧨diffusers example for style transfer with `AutoPipelineForText2Image` below.
|
|
70
|
+
|
|
71
|
+
```python
|
|
72
|
+
from diffusers import AutoPipelineForText2Image
|
|
73
|
+
from diffusers.utils import load_image
|
|
74
|
+
import torch
|
|
75
|
+
|
|
76
|
+
# load pipeline
|
|
77
|
+
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
|
78
|
+
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
|
79
|
+
|
|
80
|
+
# set the adapter and scales - this is a component that lets us add the style control from an image to the text-to-image model
|
|
81
|
+
scale = {
|
|
82
|
+
"down": {"block_2": [0.0, 1.0]},
|
|
83
|
+
"up": {"block_0": [0.0, 1.0, 0.0]},
|
|
84
|
+
}
|
|
85
|
+
pipeline.set_ip_adapter_scale(scale)
|
|
86
|
+
|
|
87
|
+
style_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg")
|
|
88
|
+
|
|
89
|
+
generator = torch.Generator(device="cpu").manual_seed(26)
|
|
90
|
+
image = pipeline(
|
|
91
|
+
prompt="a cat, masterpiece, best quality, high quality",
|
|
92
|
+
ip_adapter_image=style_image,
|
|
93
|
+
negative_prompt="text, watermark, lowres, low quality, worst quality, deformed, glitch, low contrast, noisy, saturation, blurry",
|
|
94
|
+
guidance_scale=5,
|
|
95
|
+
num_inference_steps=30,
|
|
96
|
+
generator=generator,
|
|
97
|
+
).images[0]
|
|
98
|
+
image
|
|
99
|
+
```
|
|
100
|
+
|
|
101
|
+
### ControlNet
|
|
102
|
+
|
|
103
|
+
Controlling the outputs of diffusion models only with a text prompt is a challenging problem. ControlNet is a neural network model that provides image-based control to diffusion models. Control images can be edges or other landmarks extracted from a source image.
|
|
104
|
+

|
|
105
|
+
|
|
106
|
+
## Pix2Pix
|
|
107
|
+
|
|
108
|
+
Pix2Pix is a popular model used for image-to-image translation tasks. It is based on a conditional-GAN (generative adversarial network) where instead of a noise vector a 2D image is given as input. More information about Pix2Pix can be retrieved from this [link](https://phillipi.github.io/pix2pix/) where the associated paper and the GitHub repository can be found.
|
|
109
|
+
|
|
110
|
+
The images below show some examples extracted from the Pix2Pix paper. This model can be applied to various use cases. It is capable of relatively simpler things, e.g., converting a grayscale image to its colored version. But more importantly, it can generate realistic pictures from rough sketches (can be seen in the purse example) or from painting-like images (can be seen in the street and facade examples below).
|
|
111
|
+
|
|
112
|
+
|
|
113
|
+
|
|
114
|
+
## Useful Resources
|
|
115
|
+
|
|
116
|
+
- [Image-to-image guide with diffusers](https://huggingface.co/docs/diffusers/using-diffusers/img2img)
|
|
117
|
+
- Image inpainting: [inpainting with 🧨diffusers](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/inpaint), [demo](https://huggingface.co/spaces/diffusers/stable-diffusion-xl-inpainting)
|
|
118
|
+
- Colorization: [demo](https://huggingface.co/spaces/modelscope/old_photo_restoration)
|
|
119
|
+
- Super resolution: [image upscaling with 🧨diffusers](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/upscale#super-resolution), [demo](https://huggingface.co/spaces/radames/Enhance-This-HiDiffusion-SDXL)
|
|
120
|
+
- [Style transfer and layout control with diffusers 🧨](https://huggingface.co/docs/diffusers/main/en/using-diffusers/ip_adapter#style--layout-control)
|
|
121
|
+
- [Train your ControlNet with diffusers 🧨](https://huggingface.co/blog/train-your-controlnet)
|
|
122
|
+
- [Ultra fast ControlNet with 🧨 Diffusers](https://huggingface.co/blog/controlnet)
|
|
123
|
+
- [List of ControlNets trained in the community JAX Diffusers sprint](https://huggingface.co/spaces/jax-diffusers-event/leaderboard)
|
|
124
|
+
|
|
125
|
+
## References
|
|
126
|
+
|
|
127
|
+
[1] P. Isola, J. -Y. Zhu, T. Zhou and A. A. Efros, "Image-to-Image Translation with Conditional Adversarial Networks," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5967-5976, doi: 10.1109/CVPR.2017.632.
|
|
128
|
+
|
|
129
|
+
This page was made possible thanks to the efforts of [Paul Gafton](https://github.com/Paul92) and [Osman Alenbey](https://huggingface.co/osman93).
|
|
@@ -0,0 +1,101 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../index.js";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "Synthetic dataset, for image relighting",
|
|
7
|
+
id: "VIDIT",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "Multiple images of celebrities, used for facial expression translation",
|
|
11
|
+
id: "huggan/CelebA-faces",
|
|
12
|
+
},
|
|
13
|
+
],
|
|
14
|
+
demo: {
|
|
15
|
+
inputs: [
|
|
16
|
+
{
|
|
17
|
+
filename: "image-to-image-input.jpeg",
|
|
18
|
+
type: "img",
|
|
19
|
+
},
|
|
20
|
+
],
|
|
21
|
+
outputs: [
|
|
22
|
+
{
|
|
23
|
+
filename: "image-to-image-output.png",
|
|
24
|
+
type: "img",
|
|
25
|
+
},
|
|
26
|
+
],
|
|
27
|
+
},
|
|
28
|
+
isPlaceholder: false,
|
|
29
|
+
metrics: [
|
|
30
|
+
{
|
|
31
|
+
description:
|
|
32
|
+
"Peak Signal to Noise Ratio (PSNR) is an approximation of the human perception, considering the ratio of the absolute intensity with respect to the variations. Measured in dB, a high value indicates a high fidelity.",
|
|
33
|
+
id: "PSNR",
|
|
34
|
+
},
|
|
35
|
+
{
|
|
36
|
+
description:
|
|
37
|
+
"Structural Similarity Index (SSIM) is a perceptual metric which compares the luminance, contrast and structure of two images. The values of SSIM range between -1 and 1, and higher values indicate closer resemblance to the original image.",
|
|
38
|
+
id: "SSIM",
|
|
39
|
+
},
|
|
40
|
+
{
|
|
41
|
+
description:
|
|
42
|
+
"Inception Score (IS) is an analysis of the labels predicted by an image classification model when presented with a sample of the generated images.",
|
|
43
|
+
id: "IS",
|
|
44
|
+
},
|
|
45
|
+
],
|
|
46
|
+
models: [
|
|
47
|
+
{
|
|
48
|
+
description: "An image-to-image model to improve image resolution.",
|
|
49
|
+
id: "fal/AuraSR-v2",
|
|
50
|
+
},
|
|
51
|
+
{
|
|
52
|
+
description: "A model that increases the resolution of an image.",
|
|
53
|
+
id: "keras-io/super-resolution",
|
|
54
|
+
},
|
|
55
|
+
{
|
|
56
|
+
description:
|
|
57
|
+
"A model that creates a set of variations of the input image in the style of DALL-E using Stable Diffusion.",
|
|
58
|
+
id: "lambdalabs/sd-image-variations-diffusers",
|
|
59
|
+
},
|
|
60
|
+
{
|
|
61
|
+
description: "A model that generates images based on segments in the input image and the text prompt.",
|
|
62
|
+
id: "mfidabel/controlnet-segment-anything",
|
|
63
|
+
},
|
|
64
|
+
{
|
|
65
|
+
description: "A model that takes an image and an instruction to edit the image.",
|
|
66
|
+
id: "timbrooks/instruct-pix2pix",
|
|
67
|
+
},
|
|
68
|
+
],
|
|
69
|
+
spaces: [
|
|
70
|
+
{
|
|
71
|
+
description: "Image enhancer application for low light.",
|
|
72
|
+
id: "keras-io/low-light-image-enhancement",
|
|
73
|
+
},
|
|
74
|
+
{
|
|
75
|
+
description: "Style transfer application.",
|
|
76
|
+
id: "keras-io/neural-style-transfer",
|
|
77
|
+
},
|
|
78
|
+
{
|
|
79
|
+
description: "An application that generates images based on segment control.",
|
|
80
|
+
id: "mfidabel/controlnet-segment-anything",
|
|
81
|
+
},
|
|
82
|
+
{
|
|
83
|
+
description: "Image generation application that takes image control and text prompt.",
|
|
84
|
+
id: "hysts/ControlNet",
|
|
85
|
+
},
|
|
86
|
+
{
|
|
87
|
+
description: "Colorize any image using this app.",
|
|
88
|
+
id: "ioclab/brightness-controlnet",
|
|
89
|
+
},
|
|
90
|
+
{
|
|
91
|
+
description: "Edit images with instructions.",
|
|
92
|
+
id: "timbrooks/instruct-pix2pix",
|
|
93
|
+
},
|
|
94
|
+
],
|
|
95
|
+
summary:
|
|
96
|
+
"Image-to-image is the task of transforming an input image through a variety of possible manipulations and enhancements, such as super-resolution, image inpainting, colorization, and more.",
|
|
97
|
+
widgetModels: ["stabilityai/stable-diffusion-2-inpainting"],
|
|
98
|
+
youtubeId: "",
|
|
99
|
+
};
|
|
100
|
+
|
|
101
|
+
export default taskData;
|
|
@@ -0,0 +1,68 @@
|
|
|
1
|
+
/**
|
|
2
|
+
* Inference code generated from the JSON schema spec in ./spec
|
|
3
|
+
*
|
|
4
|
+
* Using src/scripts/inference-codegen
|
|
5
|
+
*/
|
|
6
|
+
|
|
7
|
+
/**
|
|
8
|
+
* Inputs for Image To Image inference
|
|
9
|
+
*/
|
|
10
|
+
export interface ImageToImageInput {
|
|
11
|
+
/**
|
|
12
|
+
* The input image data as a base64-encoded string. If no `parameters` are provided, you can
|
|
13
|
+
* also provide the image data as a raw bytes payload.
|
|
14
|
+
*/
|
|
15
|
+
inputs: string;
|
|
16
|
+
/**
|
|
17
|
+
* Additional inference parameters
|
|
18
|
+
*/
|
|
19
|
+
parameters?: ImageToImageParameters;
|
|
20
|
+
[property: string]: unknown;
|
|
21
|
+
}
|
|
22
|
+
|
|
23
|
+
/**
|
|
24
|
+
* Additional inference parameters
|
|
25
|
+
*
|
|
26
|
+
* Additional inference parameters for Image To Image
|
|
27
|
+
*/
|
|
28
|
+
export interface ImageToImageParameters {
|
|
29
|
+
/**
|
|
30
|
+
* For diffusion models. A higher guidance scale value encourages the model to generate
|
|
31
|
+
* images closely linked to the text prompt at the expense of lower image quality.
|
|
32
|
+
*/
|
|
33
|
+
guidance_scale?: number;
|
|
34
|
+
/**
|
|
35
|
+
* One or several prompt to guide what NOT to include in image generation.
|
|
36
|
+
*/
|
|
37
|
+
negative_prompt?: string[];
|
|
38
|
+
/**
|
|
39
|
+
* For diffusion models. The number of denoising steps. More denoising steps usually lead to
|
|
40
|
+
* a higher quality image at the expense of slower inference.
|
|
41
|
+
*/
|
|
42
|
+
num_inference_steps?: number;
|
|
43
|
+
/**
|
|
44
|
+
* The size in pixel of the output image.
|
|
45
|
+
*/
|
|
46
|
+
target_size?: TargetSize;
|
|
47
|
+
[property: string]: unknown;
|
|
48
|
+
}
|
|
49
|
+
|
|
50
|
+
/**
|
|
51
|
+
* The size in pixel of the output image.
|
|
52
|
+
*/
|
|
53
|
+
export interface TargetSize {
|
|
54
|
+
height: number;
|
|
55
|
+
width: number;
|
|
56
|
+
[property: string]: unknown;
|
|
57
|
+
}
|
|
58
|
+
|
|
59
|
+
/**
|
|
60
|
+
* Outputs of inference for the Image To Image task
|
|
61
|
+
*/
|
|
62
|
+
export interface ImageToImageOutput {
|
|
63
|
+
/**
|
|
64
|
+
* The output image returned as raw bytes in the payload.
|
|
65
|
+
*/
|
|
66
|
+
image?: unknown;
|
|
67
|
+
[property: string]: unknown;
|
|
68
|
+
}
|
|
@@ -0,0 +1,55 @@
|
|
|
1
|
+
{
|
|
2
|
+
"$id": "/inference/schemas/image-to-image/input.json",
|
|
3
|
+
"$schema": "http://json-schema.org/draft-06/schema#",
|
|
4
|
+
"description": "Inputs for Image To Image inference",
|
|
5
|
+
"title": "ImageToImageInput",
|
|
6
|
+
"type": "object",
|
|
7
|
+
"properties": {
|
|
8
|
+
"inputs": {
|
|
9
|
+
"type": "string",
|
|
10
|
+
"description": "The input image data as a base64-encoded string. If no `parameters` are provided, you can also provide the image data as a raw bytes payload."
|
|
11
|
+
},
|
|
12
|
+
"parameters": {
|
|
13
|
+
"description": "Additional inference parameters",
|
|
14
|
+
"$ref": "#/$defs/ImageToImageParameters"
|
|
15
|
+
}
|
|
16
|
+
},
|
|
17
|
+
"$defs": {
|
|
18
|
+
"ImageToImageParameters": {
|
|
19
|
+
"title": "ImageToImageParameters",
|
|
20
|
+
"description": "Additional inference parameters for Image To Image",
|
|
21
|
+
"type": "object",
|
|
22
|
+
"properties": {
|
|
23
|
+
"guidance_scale": {
|
|
24
|
+
"type": "number",
|
|
25
|
+
"description": "For diffusion models. A higher guidance scale value encourages the model to generate images closely linked to the text prompt at the expense of lower image quality."
|
|
26
|
+
},
|
|
27
|
+
"negative_prompt": {
|
|
28
|
+
"type": "array",
|
|
29
|
+
"items": {
|
|
30
|
+
"type": "string"
|
|
31
|
+
},
|
|
32
|
+
"description": "One or several prompt to guide what NOT to include in image generation."
|
|
33
|
+
},
|
|
34
|
+
"num_inference_steps": {
|
|
35
|
+
"type": "integer",
|
|
36
|
+
"description": "For diffusion models. The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference."
|
|
37
|
+
},
|
|
38
|
+
"target_size": {
|
|
39
|
+
"type": "object",
|
|
40
|
+
"description": "The size in pixel of the output image.",
|
|
41
|
+
"properties": {
|
|
42
|
+
"width": {
|
|
43
|
+
"type": "integer"
|
|
44
|
+
},
|
|
45
|
+
"height": {
|
|
46
|
+
"type": "integer"
|
|
47
|
+
}
|
|
48
|
+
},
|
|
49
|
+
"required": ["width", "height"]
|
|
50
|
+
}
|
|
51
|
+
}
|
|
52
|
+
}
|
|
53
|
+
},
|
|
54
|
+
"required": ["inputs"]
|
|
55
|
+
}
|
|
@@ -0,0 +1,12 @@
|
|
|
1
|
+
{
|
|
2
|
+
"$id": "/inference/schemas/image-to-image/output.json",
|
|
3
|
+
"$schema": "http://json-schema.org/draft-06/schema#",
|
|
4
|
+
"description": "Outputs of inference for the Image To Image task",
|
|
5
|
+
"title": "ImageToImageOutput",
|
|
6
|
+
"type": "object",
|
|
7
|
+
"properties": {
|
|
8
|
+
"image": {
|
|
9
|
+
"description": "The output image returned as raw bytes in the payload."
|
|
10
|
+
}
|
|
11
|
+
}
|
|
12
|
+
}
|
|
@@ -0,0 +1,61 @@
|
|
|
1
|
+
## Use Cases
|
|
2
|
+
|
|
3
|
+
### Image Captioning
|
|
4
|
+
|
|
5
|
+
Image Captioning is the process of generating textual description of an image.
|
|
6
|
+
This can help the visually impaired people to understand what's happening in their surroundings.
|
|
7
|
+
|
|
8
|
+
### Optical Character Recognition (OCR)
|
|
9
|
+
|
|
10
|
+
OCR models convert the text present in an image, e.g. a scanned document, to text.
|
|
11
|
+
|
|
12
|
+
## Inference
|
|
13
|
+
|
|
14
|
+
### Image Captioning
|
|
15
|
+
|
|
16
|
+
You can use the 🤗 Transformers library's `image-to-text` pipeline to generate caption for the Image input.
|
|
17
|
+
|
|
18
|
+
```python
|
|
19
|
+
from transformers import pipeline
|
|
20
|
+
|
|
21
|
+
captioner = pipeline("image-to-text", model="Salesforce/blip-image-captioning-base")
|
|
22
|
+
captioner("https://huggingface.co/datasets/Narsil/image_dummy/resolve/main/parrots.png")
|
|
23
|
+
## [{'generated_text': 'two birds are standing next to each other '}]
|
|
24
|
+
```
|
|
25
|
+
|
|
26
|
+
### OCR
|
|
27
|
+
|
|
28
|
+
This code snippet uses Microsoft’s TrOCR, an encoder-decoder model consisting of an image Transformer encoder and a text Transformer decoder for state-of-the-art optical character recognition (OCR) on single-text line images.
|
|
29
|
+
|
|
30
|
+
```python
|
|
31
|
+
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
|
|
32
|
+
|
|
33
|
+
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')
|
|
34
|
+
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten')
|
|
35
|
+
pixel_values = processor(images="image.jpeg", return_tensors="pt").pixel_values
|
|
36
|
+
|
|
37
|
+
generated_ids = model.generate(pixel_values)
|
|
38
|
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
|
39
|
+
|
|
40
|
+
```
|
|
41
|
+
|
|
42
|
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer image-to-text models on Hugging Face Hub.
|
|
43
|
+
|
|
44
|
+
```javascript
|
|
45
|
+
import { HfInference } from "@huggingface/inference";
|
|
46
|
+
|
|
47
|
+
const inference = new HfInference(HF_TOKEN);
|
|
48
|
+
await inference.imageToText({
|
|
49
|
+
data: await (await fetch("https://picsum.photos/300/300")).blob(),
|
|
50
|
+
model: "Salesforce/blip-image-captioning-base",
|
|
51
|
+
});
|
|
52
|
+
```
|
|
53
|
+
|
|
54
|
+
## Useful Resources
|
|
55
|
+
|
|
56
|
+
- [Image Captioning](https://huggingface.co/docs/transformers/main/en/tasks/image_captioning)
|
|
57
|
+
- [Image Captioning Use Case](https://blog.google/outreach-initiatives/accessibility/get-image-descriptions/)
|
|
58
|
+
- [Train Image Captioning model on your dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb)
|
|
59
|
+
- [Train OCR model on your dataset ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR)
|
|
60
|
+
|
|
61
|
+
This page was made possible thanks to efforts of [Sukesh Perla](https://huggingface.co/hitchhiker3010) and [Johannes Kolbe](https://huggingface.co/johko).
|
|
@@ -0,0 +1,82 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../index.js";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
// TODO write proper description
|
|
7
|
+
description: "Dataset from 12M image-text of Reddit",
|
|
8
|
+
id: "red_caps",
|
|
9
|
+
},
|
|
10
|
+
{
|
|
11
|
+
// TODO write proper description
|
|
12
|
+
description: "Dataset from 3.3M images of Google",
|
|
13
|
+
id: "datasets/conceptual_captions",
|
|
14
|
+
},
|
|
15
|
+
],
|
|
16
|
+
demo: {
|
|
17
|
+
inputs: [
|
|
18
|
+
{
|
|
19
|
+
filename: "savanna.jpg",
|
|
20
|
+
type: "img",
|
|
21
|
+
},
|
|
22
|
+
],
|
|
23
|
+
outputs: [
|
|
24
|
+
{
|
|
25
|
+
label: "Detailed description",
|
|
26
|
+
content: "a herd of giraffes and zebras grazing in a field",
|
|
27
|
+
type: "text",
|
|
28
|
+
},
|
|
29
|
+
],
|
|
30
|
+
},
|
|
31
|
+
metrics: [],
|
|
32
|
+
models: [
|
|
33
|
+
{
|
|
34
|
+
description: "A robust image captioning model.",
|
|
35
|
+
id: "Salesforce/blip2-opt-2.7b",
|
|
36
|
+
},
|
|
37
|
+
{
|
|
38
|
+
description: "A powerful and accurate image-to-text model that can also localize concepts in images.",
|
|
39
|
+
id: "microsoft/kosmos-2-patch14-224",
|
|
40
|
+
},
|
|
41
|
+
{
|
|
42
|
+
description: "A strong optical character recognition model.",
|
|
43
|
+
id: "facebook/nougat-base",
|
|
44
|
+
},
|
|
45
|
+
{
|
|
46
|
+
description: "A powerful model that lets you have a conversation with the image.",
|
|
47
|
+
id: "llava-hf/llava-1.5-7b-hf",
|
|
48
|
+
},
|
|
49
|
+
],
|
|
50
|
+
spaces: [
|
|
51
|
+
{
|
|
52
|
+
description: "An application that compares various image captioning models.",
|
|
53
|
+
id: "nielsr/comparing-captioning-models",
|
|
54
|
+
},
|
|
55
|
+
{
|
|
56
|
+
description: "A robust image captioning application.",
|
|
57
|
+
id: "flax-community/image-captioning",
|
|
58
|
+
},
|
|
59
|
+
{
|
|
60
|
+
description: "An application that transcribes handwritings into text.",
|
|
61
|
+
id: "nielsr/TrOCR-handwritten",
|
|
62
|
+
},
|
|
63
|
+
{
|
|
64
|
+
description: "An application that can caption images and answer questions about a given image.",
|
|
65
|
+
id: "Salesforce/BLIP",
|
|
66
|
+
},
|
|
67
|
+
{
|
|
68
|
+
description: "An application that can caption images and answer questions with a conversational agent.",
|
|
69
|
+
id: "Salesforce/BLIP2",
|
|
70
|
+
},
|
|
71
|
+
{
|
|
72
|
+
description: "An image captioning application that demonstrates the effect of noise on captions.",
|
|
73
|
+
id: "johko/capdec-image-captioning",
|
|
74
|
+
},
|
|
75
|
+
],
|
|
76
|
+
summary:
|
|
77
|
+
"Image to text models output a text from a given image. Image captioning or optical character recognition can be considered as the most common applications of image to text.",
|
|
78
|
+
widgetModels: ["Salesforce/blip-image-captioning-large"],
|
|
79
|
+
youtubeId: "",
|
|
80
|
+
};
|
|
81
|
+
|
|
82
|
+
export default taskData;
|
|
@@ -0,0 +1,143 @@
|
|
|
1
|
+
/**
|
|
2
|
+
* Inference code generated from the JSON schema spec in ./spec
|
|
3
|
+
*
|
|
4
|
+
* Using src/scripts/inference-codegen
|
|
5
|
+
*/
|
|
6
|
+
|
|
7
|
+
/**
|
|
8
|
+
* Inputs for Image To Text inference
|
|
9
|
+
*/
|
|
10
|
+
export interface ImageToTextInput {
|
|
11
|
+
/**
|
|
12
|
+
* The input image data
|
|
13
|
+
*/
|
|
14
|
+
inputs: unknown;
|
|
15
|
+
/**
|
|
16
|
+
* Additional inference parameters
|
|
17
|
+
*/
|
|
18
|
+
parameters?: ImageToTextParameters;
|
|
19
|
+
[property: string]: unknown;
|
|
20
|
+
}
|
|
21
|
+
|
|
22
|
+
/**
|
|
23
|
+
* Additional inference parameters
|
|
24
|
+
*
|
|
25
|
+
* Additional inference parameters for Image To Text
|
|
26
|
+
*/
|
|
27
|
+
export interface ImageToTextParameters {
|
|
28
|
+
/**
|
|
29
|
+
* Parametrization of the text generation process
|
|
30
|
+
*/
|
|
31
|
+
generation_parameters?: GenerationParameters;
|
|
32
|
+
/**
|
|
33
|
+
* The amount of maximum tokens to generate.
|
|
34
|
+
*/
|
|
35
|
+
max_new_tokens?: number;
|
|
36
|
+
[property: string]: unknown;
|
|
37
|
+
}
|
|
38
|
+
|
|
39
|
+
/**
|
|
40
|
+
* Parametrization of the text generation process
|
|
41
|
+
*
|
|
42
|
+
* Ad-hoc parametrization of the text generation process
|
|
43
|
+
*/
|
|
44
|
+
export interface GenerationParameters {
|
|
45
|
+
/**
|
|
46
|
+
* Whether to use sampling instead of greedy decoding when generating new tokens.
|
|
47
|
+
*/
|
|
48
|
+
do_sample?: boolean;
|
|
49
|
+
/**
|
|
50
|
+
* Controls the stopping condition for beam-based methods.
|
|
51
|
+
*/
|
|
52
|
+
early_stopping?: EarlyStoppingUnion;
|
|
53
|
+
/**
|
|
54
|
+
* If set to float strictly between 0 and 1, only tokens with a conditional probability
|
|
55
|
+
* greater than epsilon_cutoff will be sampled. In the paper, suggested values range from
|
|
56
|
+
* 3e-4 to 9e-4, depending on the size of the model. See [Truncation Sampling as Language
|
|
57
|
+
* Model Desmoothing](https://hf.co/papers/2210.15191) for more details.
|
|
58
|
+
*/
|
|
59
|
+
epsilon_cutoff?: number;
|
|
60
|
+
/**
|
|
61
|
+
* Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to
|
|
62
|
+
* float strictly between 0 and 1, a token is only considered if it is greater than either
|
|
63
|
+
* eta_cutoff or sqrt(eta_cutoff) * exp(-entropy(softmax(next_token_logits))). The latter
|
|
64
|
+
* term is intuitively the expected next token probability, scaled by sqrt(eta_cutoff). In
|
|
65
|
+
* the paper, suggested values range from 3e-4 to 2e-3, depending on the size of the model.
|
|
66
|
+
* See [Truncation Sampling as Language Model Desmoothing](https://hf.co/papers/2210.15191)
|
|
67
|
+
* for more details.
|
|
68
|
+
*/
|
|
69
|
+
eta_cutoff?: number;
|
|
70
|
+
/**
|
|
71
|
+
* The maximum length (in tokens) of the generated text, including the input.
|
|
72
|
+
*/
|
|
73
|
+
max_length?: number;
|
|
74
|
+
/**
|
|
75
|
+
* The maximum number of tokens to generate. Takes precedence over max_length.
|
|
76
|
+
*/
|
|
77
|
+
max_new_tokens?: number;
|
|
78
|
+
/**
|
|
79
|
+
* The minimum length (in tokens) of the generated text, including the input.
|
|
80
|
+
*/
|
|
81
|
+
min_length?: number;
|
|
82
|
+
/**
|
|
83
|
+
* The minimum number of tokens to generate. Takes precedence over min_length.
|
|
84
|
+
*/
|
|
85
|
+
min_new_tokens?: number;
|
|
86
|
+
/**
|
|
87
|
+
* Number of groups to divide num_beams into in order to ensure diversity among different
|
|
88
|
+
* groups of beams. See [this paper](https://hf.co/papers/1610.02424) for more details.
|
|
89
|
+
*/
|
|
90
|
+
num_beam_groups?: number;
|
|
91
|
+
/**
|
|
92
|
+
* Number of beams to use for beam search.
|
|
93
|
+
*/
|
|
94
|
+
num_beams?: number;
|
|
95
|
+
/**
|
|
96
|
+
* The value balances the model confidence and the degeneration penalty in contrastive
|
|
97
|
+
* search decoding.
|
|
98
|
+
*/
|
|
99
|
+
penalty_alpha?: number;
|
|
100
|
+
/**
|
|
101
|
+
* The value used to modulate the next token probabilities.
|
|
102
|
+
*/
|
|
103
|
+
temperature?: number;
|
|
104
|
+
/**
|
|
105
|
+
* The number of highest probability vocabulary tokens to keep for top-k-filtering.
|
|
106
|
+
*/
|
|
107
|
+
top_k?: number;
|
|
108
|
+
/**
|
|
109
|
+
* If set to float < 1, only the smallest set of most probable tokens with probabilities
|
|
110
|
+
* that add up to top_p or higher are kept for generation.
|
|
111
|
+
*/
|
|
112
|
+
top_p?: number;
|
|
113
|
+
/**
|
|
114
|
+
* Local typicality measures how similar the conditional probability of predicting a target
|
|
115
|
+
* token next is to the expected conditional probability of predicting a random token next,
|
|
116
|
+
* given the partial text already generated. If set to float < 1, the smallest set of the
|
|
117
|
+
* most locally typical tokens with probabilities that add up to typical_p or higher are
|
|
118
|
+
* kept for generation. See [this paper](https://hf.co/papers/2202.00666) for more details.
|
|
119
|
+
*/
|
|
120
|
+
typical_p?: number;
|
|
121
|
+
/**
|
|
122
|
+
* Whether the model should use the past last key/values attentions to speed up decoding
|
|
123
|
+
*/
|
|
124
|
+
use_cache?: boolean;
|
|
125
|
+
[property: string]: unknown;
|
|
126
|
+
}
|
|
127
|
+
|
|
128
|
+
/**
|
|
129
|
+
* Controls the stopping condition for beam-based methods.
|
|
130
|
+
*/
|
|
131
|
+
export type EarlyStoppingUnion = boolean | "never";
|
|
132
|
+
|
|
133
|
+
/**
|
|
134
|
+
* Outputs of inference for the Image To Text task
|
|
135
|
+
*/
|
|
136
|
+
export interface ImageToTextOutput {
|
|
137
|
+
generatedText: unknown;
|
|
138
|
+
/**
|
|
139
|
+
* The generated text.
|
|
140
|
+
*/
|
|
141
|
+
generated_text?: string;
|
|
142
|
+
[property: string]: unknown;
|
|
143
|
+
}
|
|
@@ -0,0 +1,34 @@
|
|
|
1
|
+
{
|
|
2
|
+
"$id": "/inference/schemas/image-to-text/input.json",
|
|
3
|
+
"$schema": "http://json-schema.org/draft-06/schema#",
|
|
4
|
+
"description": "Inputs for Image To Text inference",
|
|
5
|
+
"title": "ImageToTextInput",
|
|
6
|
+
"type": "object",
|
|
7
|
+
"properties": {
|
|
8
|
+
"inputs": {
|
|
9
|
+
"description": "The input image data"
|
|
10
|
+
},
|
|
11
|
+
"parameters": {
|
|
12
|
+
"description": "Additional inference parameters",
|
|
13
|
+
"$ref": "#/$defs/ImageToTextParameters"
|
|
14
|
+
}
|
|
15
|
+
},
|
|
16
|
+
"$defs": {
|
|
17
|
+
"ImageToTextParameters": {
|
|
18
|
+
"title": "ImageToTextParameters",
|
|
19
|
+
"description": "Additional inference parameters for Image To Text",
|
|
20
|
+
"type": "object",
|
|
21
|
+
"properties": {
|
|
22
|
+
"max_new_tokens": {
|
|
23
|
+
"type": "integer",
|
|
24
|
+
"description": "The amount of maximum tokens to generate."
|
|
25
|
+
},
|
|
26
|
+
"generation_parameters": {
|
|
27
|
+
"description": "Parametrization of the text generation process",
|
|
28
|
+
"$ref": "/inference/schemas/common-definitions.json#/definitions/GenerationParameters"
|
|
29
|
+
}
|
|
30
|
+
}
|
|
31
|
+
}
|
|
32
|
+
},
|
|
33
|
+
"required": ["inputs"]
|
|
34
|
+
}
|