@huggingface/tasks 0.13.1-test → 0.13.1-test2
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/package.json +4 -2
- package/src/dataset-libraries.ts +89 -0
- package/src/default-widget-inputs.ts +718 -0
- package/src/gguf.ts +40 -0
- package/src/hardware.ts +482 -0
- package/src/index.ts +59 -0
- package/src/library-to-tasks.ts +76 -0
- package/src/local-apps.ts +412 -0
- package/src/model-data.ts +149 -0
- package/src/model-libraries-downloads.ts +18 -0
- package/src/model-libraries-snippets.ts +1128 -0
- package/src/model-libraries.ts +820 -0
- package/src/pipelines.ts +698 -0
- package/src/snippets/common.ts +39 -0
- package/src/snippets/curl.spec.ts +94 -0
- package/src/snippets/curl.ts +120 -0
- package/src/snippets/index.ts +7 -0
- package/src/snippets/inputs.ts +167 -0
- package/src/snippets/js.spec.ts +148 -0
- package/src/snippets/js.ts +305 -0
- package/src/snippets/python.spec.ts +144 -0
- package/src/snippets/python.ts +321 -0
- package/src/snippets/types.ts +16 -0
- package/src/tasks/audio-classification/about.md +86 -0
- package/src/tasks/audio-classification/data.ts +81 -0
- package/src/tasks/audio-classification/inference.ts +52 -0
- package/src/tasks/audio-classification/spec/input.json +35 -0
- package/src/tasks/audio-classification/spec/output.json +11 -0
- package/src/tasks/audio-to-audio/about.md +56 -0
- package/src/tasks/audio-to-audio/data.ts +70 -0
- package/src/tasks/automatic-speech-recognition/about.md +90 -0
- package/src/tasks/automatic-speech-recognition/data.ts +82 -0
- package/src/tasks/automatic-speech-recognition/inference.ts +160 -0
- package/src/tasks/automatic-speech-recognition/spec/input.json +35 -0
- package/src/tasks/automatic-speech-recognition/spec/output.json +38 -0
- package/src/tasks/chat-completion/inference.ts +322 -0
- package/src/tasks/chat-completion/spec/input.json +350 -0
- package/src/tasks/chat-completion/spec/output.json +206 -0
- package/src/tasks/chat-completion/spec/stream_output.json +213 -0
- package/src/tasks/common-definitions.json +100 -0
- package/src/tasks/depth-estimation/about.md +45 -0
- package/src/tasks/depth-estimation/data.ts +70 -0
- package/src/tasks/depth-estimation/inference.ts +35 -0
- package/src/tasks/depth-estimation/spec/input.json +25 -0
- package/src/tasks/depth-estimation/spec/output.json +16 -0
- package/src/tasks/document-question-answering/about.md +53 -0
- package/src/tasks/document-question-answering/data.ts +85 -0
- package/src/tasks/document-question-answering/inference.ts +110 -0
- package/src/tasks/document-question-answering/spec/input.json +85 -0
- package/src/tasks/document-question-answering/spec/output.json +36 -0
- package/src/tasks/feature-extraction/about.md +72 -0
- package/src/tasks/feature-extraction/data.ts +57 -0
- package/src/tasks/feature-extraction/inference.ts +40 -0
- package/src/tasks/feature-extraction/spec/input.json +47 -0
- package/src/tasks/feature-extraction/spec/output.json +15 -0
- package/src/tasks/fill-mask/about.md +51 -0
- package/src/tasks/fill-mask/data.ts +79 -0
- package/src/tasks/fill-mask/inference.ts +62 -0
- package/src/tasks/fill-mask/spec/input.json +38 -0
- package/src/tasks/fill-mask/spec/output.json +29 -0
- package/src/tasks/image-classification/about.md +50 -0
- package/src/tasks/image-classification/data.ts +88 -0
- package/src/tasks/image-classification/inference.ts +52 -0
- package/src/tasks/image-classification/spec/input.json +35 -0
- package/src/tasks/image-classification/spec/output.json +11 -0
- package/src/tasks/image-feature-extraction/about.md +23 -0
- package/src/tasks/image-feature-extraction/data.ts +59 -0
- package/src/tasks/image-segmentation/about.md +63 -0
- package/src/tasks/image-segmentation/data.ts +99 -0
- package/src/tasks/image-segmentation/inference.ts +69 -0
- package/src/tasks/image-segmentation/spec/input.json +45 -0
- package/src/tasks/image-segmentation/spec/output.json +26 -0
- package/src/tasks/image-text-to-text/about.md +76 -0
- package/src/tasks/image-text-to-text/data.ts +102 -0
- package/src/tasks/image-to-3d/about.md +62 -0
- package/src/tasks/image-to-3d/data.ts +75 -0
- package/src/tasks/image-to-image/about.md +129 -0
- package/src/tasks/image-to-image/data.ts +101 -0
- package/src/tasks/image-to-image/inference.ts +68 -0
- package/src/tasks/image-to-image/spec/input.json +55 -0
- package/src/tasks/image-to-image/spec/output.json +12 -0
- package/src/tasks/image-to-text/about.md +61 -0
- package/src/tasks/image-to-text/data.ts +82 -0
- package/src/tasks/image-to-text/inference.ts +143 -0
- package/src/tasks/image-to-text/spec/input.json +34 -0
- package/src/tasks/image-to-text/spec/output.json +14 -0
- package/src/tasks/index.ts +312 -0
- package/src/tasks/keypoint-detection/about.md +57 -0
- package/src/tasks/keypoint-detection/data.ts +50 -0
- package/src/tasks/mask-generation/about.md +65 -0
- package/src/tasks/mask-generation/data.ts +55 -0
- package/src/tasks/object-detection/about.md +37 -0
- package/src/tasks/object-detection/data.ts +86 -0
- package/src/tasks/object-detection/inference.ts +75 -0
- package/src/tasks/object-detection/spec/input.json +31 -0
- package/src/tasks/object-detection/spec/output.json +50 -0
- package/src/tasks/placeholder/about.md +15 -0
- package/src/tasks/placeholder/data.ts +21 -0
- package/src/tasks/placeholder/spec/input.json +35 -0
- package/src/tasks/placeholder/spec/output.json +17 -0
- package/src/tasks/question-answering/about.md +56 -0
- package/src/tasks/question-answering/data.ts +75 -0
- package/src/tasks/question-answering/inference.ts +99 -0
- package/src/tasks/question-answering/spec/input.json +67 -0
- package/src/tasks/question-answering/spec/output.json +29 -0
- package/src/tasks/reinforcement-learning/about.md +167 -0
- package/src/tasks/reinforcement-learning/data.ts +75 -0
- package/src/tasks/sentence-similarity/about.md +97 -0
- package/src/tasks/sentence-similarity/data.ts +101 -0
- package/src/tasks/sentence-similarity/inference.ts +32 -0
- package/src/tasks/sentence-similarity/spec/input.json +40 -0
- package/src/tasks/sentence-similarity/spec/output.json +12 -0
- package/src/tasks/summarization/about.md +58 -0
- package/src/tasks/summarization/data.ts +76 -0
- package/src/tasks/summarization/inference.ts +57 -0
- package/src/tasks/summarization/spec/input.json +42 -0
- package/src/tasks/summarization/spec/output.json +14 -0
- package/src/tasks/table-question-answering/about.md +43 -0
- package/src/tasks/table-question-answering/data.ts +59 -0
- package/src/tasks/table-question-answering/inference.ts +61 -0
- package/src/tasks/table-question-answering/spec/input.json +44 -0
- package/src/tasks/table-question-answering/spec/output.json +40 -0
- package/src/tasks/tabular-classification/about.md +65 -0
- package/src/tasks/tabular-classification/data.ts +68 -0
- package/src/tasks/tabular-regression/about.md +87 -0
- package/src/tasks/tabular-regression/data.ts +57 -0
- package/src/tasks/text-classification/about.md +173 -0
- package/src/tasks/text-classification/data.ts +103 -0
- package/src/tasks/text-classification/inference.ts +51 -0
- package/src/tasks/text-classification/spec/input.json +35 -0
- package/src/tasks/text-classification/spec/output.json +11 -0
- package/src/tasks/text-generation/about.md +154 -0
- package/src/tasks/text-generation/data.ts +114 -0
- package/src/tasks/text-generation/inference.ts +200 -0
- package/src/tasks/text-generation/spec/input.json +219 -0
- package/src/tasks/text-generation/spec/output.json +179 -0
- package/src/tasks/text-generation/spec/stream_output.json +103 -0
- package/src/tasks/text-to-3d/about.md +62 -0
- package/src/tasks/text-to-3d/data.ts +56 -0
- package/src/tasks/text-to-audio/inference.ts +143 -0
- package/src/tasks/text-to-audio/spec/input.json +31 -0
- package/src/tasks/text-to-audio/spec/output.json +17 -0
- package/src/tasks/text-to-image/about.md +96 -0
- package/src/tasks/text-to-image/data.ts +100 -0
- package/src/tasks/text-to-image/inference.ts +75 -0
- package/src/tasks/text-to-image/spec/input.json +63 -0
- package/src/tasks/text-to-image/spec/output.json +13 -0
- package/src/tasks/text-to-speech/about.md +63 -0
- package/src/tasks/text-to-speech/data.ts +79 -0
- package/src/tasks/text-to-speech/inference.ts +145 -0
- package/src/tasks/text-to-speech/spec/input.json +31 -0
- package/src/tasks/text-to-speech/spec/output.json +7 -0
- package/src/tasks/text-to-video/about.md +41 -0
- package/src/tasks/text-to-video/data.ts +102 -0
- package/src/tasks/text2text-generation/inference.ts +55 -0
- package/src/tasks/text2text-generation/spec/input.json +55 -0
- package/src/tasks/text2text-generation/spec/output.json +14 -0
- package/src/tasks/token-classification/about.md +76 -0
- package/src/tasks/token-classification/data.ts +92 -0
- package/src/tasks/token-classification/inference.ts +85 -0
- package/src/tasks/token-classification/spec/input.json +65 -0
- package/src/tasks/token-classification/spec/output.json +37 -0
- package/src/tasks/translation/about.md +65 -0
- package/src/tasks/translation/data.ts +70 -0
- package/src/tasks/translation/inference.ts +67 -0
- package/src/tasks/translation/spec/input.json +50 -0
- package/src/tasks/translation/spec/output.json +14 -0
- package/src/tasks/unconditional-image-generation/about.md +50 -0
- package/src/tasks/unconditional-image-generation/data.ts +72 -0
- package/src/tasks/video-classification/about.md +37 -0
- package/src/tasks/video-classification/data.ts +84 -0
- package/src/tasks/video-classification/inference.ts +59 -0
- package/src/tasks/video-classification/spec/input.json +42 -0
- package/src/tasks/video-classification/spec/output.json +10 -0
- package/src/tasks/video-text-to-text/about.md +98 -0
- package/src/tasks/video-text-to-text/data.ts +66 -0
- package/src/tasks/visual-question-answering/about.md +48 -0
- package/src/tasks/visual-question-answering/data.ts +97 -0
- package/src/tasks/visual-question-answering/inference.ts +62 -0
- package/src/tasks/visual-question-answering/spec/input.json +41 -0
- package/src/tasks/visual-question-answering/spec/output.json +21 -0
- package/src/tasks/zero-shot-classification/about.md +40 -0
- package/src/tasks/zero-shot-classification/data.ts +70 -0
- package/src/tasks/zero-shot-classification/inference.ts +67 -0
- package/src/tasks/zero-shot-classification/spec/input.json +50 -0
- package/src/tasks/zero-shot-classification/spec/output.json +11 -0
- package/src/tasks/zero-shot-image-classification/about.md +75 -0
- package/src/tasks/zero-shot-image-classification/data.ts +84 -0
- package/src/tasks/zero-shot-image-classification/inference.ts +61 -0
- package/src/tasks/zero-shot-image-classification/spec/input.json +45 -0
- package/src/tasks/zero-shot-image-classification/spec/output.json +10 -0
- package/src/tasks/zero-shot-object-detection/about.md +45 -0
- package/src/tasks/zero-shot-object-detection/data.ts +67 -0
- package/src/tasks/zero-shot-object-detection/inference.ts +66 -0
- package/src/tasks/zero-shot-object-detection/spec/input.json +40 -0
- package/src/tasks/zero-shot-object-detection/spec/output.json +47 -0
- package/src/tokenizer-data.ts +32 -0
- package/src/widget-example.ts +125 -0
|
@@ -0,0 +1,99 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../index.js";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "Scene segmentation dataset.",
|
|
7
|
+
id: "scene_parse_150",
|
|
8
|
+
},
|
|
9
|
+
],
|
|
10
|
+
demo: {
|
|
11
|
+
inputs: [
|
|
12
|
+
{
|
|
13
|
+
filename: "image-segmentation-input.jpeg",
|
|
14
|
+
type: "img",
|
|
15
|
+
},
|
|
16
|
+
],
|
|
17
|
+
outputs: [
|
|
18
|
+
{
|
|
19
|
+
filename: "image-segmentation-output.png",
|
|
20
|
+
type: "img",
|
|
21
|
+
},
|
|
22
|
+
],
|
|
23
|
+
},
|
|
24
|
+
metrics: [
|
|
25
|
+
{
|
|
26
|
+
description:
|
|
27
|
+
"Average Precision (AP) is the Area Under the PR Curve (AUC-PR). It is calculated for each semantic class separately",
|
|
28
|
+
id: "Average Precision",
|
|
29
|
+
},
|
|
30
|
+
{
|
|
31
|
+
description: "Mean Average Precision (mAP) is the overall average of the AP values",
|
|
32
|
+
id: "Mean Average Precision",
|
|
33
|
+
},
|
|
34
|
+
{
|
|
35
|
+
description:
|
|
36
|
+
"Intersection over Union (IoU) is the overlap of segmentation masks. Mean IoU is the average of the IoU of all semantic classes",
|
|
37
|
+
id: "Mean Intersection over Union",
|
|
38
|
+
},
|
|
39
|
+
{
|
|
40
|
+
description: "APα is the Average Precision at the IoU threshold of a α value, for example, AP50 and AP75",
|
|
41
|
+
id: "APα",
|
|
42
|
+
},
|
|
43
|
+
],
|
|
44
|
+
models: [
|
|
45
|
+
{
|
|
46
|
+
// TO DO: write description
|
|
47
|
+
description: "Solid semantic segmentation model trained on ADE20k.",
|
|
48
|
+
id: "openmmlab/upernet-convnext-small",
|
|
49
|
+
},
|
|
50
|
+
{
|
|
51
|
+
description: "Background removal model.",
|
|
52
|
+
id: "briaai/RMBG-1.4",
|
|
53
|
+
},
|
|
54
|
+
{
|
|
55
|
+
description: "A multipurpose image segmentation model for high resolution images.",
|
|
56
|
+
id: "ZhengPeng7/BiRefNet",
|
|
57
|
+
},
|
|
58
|
+
{
|
|
59
|
+
description: "Powerful human-centric image segmentation model.",
|
|
60
|
+
id: "facebook/sapiens-seg-1b",
|
|
61
|
+
},
|
|
62
|
+
{
|
|
63
|
+
description: "Panoptic segmentation model trained on the COCO (common objects) dataset.",
|
|
64
|
+
id: "facebook/mask2former-swin-large-coco-panoptic",
|
|
65
|
+
},
|
|
66
|
+
],
|
|
67
|
+
spaces: [
|
|
68
|
+
{
|
|
69
|
+
description: "A semantic segmentation application that can predict unseen instances out of the box.",
|
|
70
|
+
id: "facebook/ov-seg",
|
|
71
|
+
},
|
|
72
|
+
{
|
|
73
|
+
description: "One of the strongest segmentation applications.",
|
|
74
|
+
id: "jbrinkma/segment-anything",
|
|
75
|
+
},
|
|
76
|
+
{
|
|
77
|
+
description: "A human-centric segmentation model.",
|
|
78
|
+
id: "facebook/sapiens-pose",
|
|
79
|
+
},
|
|
80
|
+
{
|
|
81
|
+
description: "An instance segmentation application to predict neuronal cell types from microscopy images.",
|
|
82
|
+
id: "rashmi/sartorius-cell-instance-segmentation",
|
|
83
|
+
},
|
|
84
|
+
{
|
|
85
|
+
description: "An application that segments videos.",
|
|
86
|
+
id: "ArtGAN/Segment-Anything-Video",
|
|
87
|
+
},
|
|
88
|
+
{
|
|
89
|
+
description: "An panoptic segmentation application built for outdoor environments.",
|
|
90
|
+
id: "segments/panoptic-segment-anything",
|
|
91
|
+
},
|
|
92
|
+
],
|
|
93
|
+
summary:
|
|
94
|
+
"Image Segmentation divides an image into segments where each pixel in the image is mapped to an object. This task has multiple variants such as instance segmentation, panoptic segmentation and semantic segmentation.",
|
|
95
|
+
widgetModels: ["nvidia/segformer-b0-finetuned-ade-512-512"],
|
|
96
|
+
youtubeId: "dKE8SIt9C-w",
|
|
97
|
+
};
|
|
98
|
+
|
|
99
|
+
export default taskData;
|
|
@@ -0,0 +1,69 @@
|
|
|
1
|
+
/**
|
|
2
|
+
* Inference code generated from the JSON schema spec in ./spec
|
|
3
|
+
*
|
|
4
|
+
* Using src/scripts/inference-codegen
|
|
5
|
+
*/
|
|
6
|
+
/**
|
|
7
|
+
* Inputs for Image Segmentation inference
|
|
8
|
+
*/
|
|
9
|
+
export interface ImageSegmentationInput {
|
|
10
|
+
/**
|
|
11
|
+
* The input image data as a base64-encoded string. If no `parameters` are provided, you can
|
|
12
|
+
* also provide the image data as a raw bytes payload.
|
|
13
|
+
*/
|
|
14
|
+
inputs: string;
|
|
15
|
+
/**
|
|
16
|
+
* Additional inference parameters
|
|
17
|
+
*/
|
|
18
|
+
parameters?: ImageSegmentationParameters;
|
|
19
|
+
[property: string]: unknown;
|
|
20
|
+
}
|
|
21
|
+
/**
|
|
22
|
+
* Additional inference parameters
|
|
23
|
+
*
|
|
24
|
+
* Additional inference parameters for Image Segmentation
|
|
25
|
+
*/
|
|
26
|
+
export interface ImageSegmentationParameters {
|
|
27
|
+
/**
|
|
28
|
+
* Threshold to use when turning the predicted masks into binary values.
|
|
29
|
+
*/
|
|
30
|
+
mask_threshold?: number;
|
|
31
|
+
/**
|
|
32
|
+
* Mask overlap threshold to eliminate small, disconnected segments.
|
|
33
|
+
*/
|
|
34
|
+
overlap_mask_area_threshold?: number;
|
|
35
|
+
/**
|
|
36
|
+
* Segmentation task to be performed, depending on model capabilities.
|
|
37
|
+
*/
|
|
38
|
+
subtask?: ImageSegmentationSubtask;
|
|
39
|
+
/**
|
|
40
|
+
* Probability threshold to filter out predicted masks.
|
|
41
|
+
*/
|
|
42
|
+
threshold?: number;
|
|
43
|
+
[property: string]: unknown;
|
|
44
|
+
}
|
|
45
|
+
/**
|
|
46
|
+
* Segmentation task to be performed, depending on model capabilities.
|
|
47
|
+
*/
|
|
48
|
+
export type ImageSegmentationSubtask = "instance" | "panoptic" | "semantic";
|
|
49
|
+
export type ImageSegmentationOutput = ImageSegmentationOutputElement[];
|
|
50
|
+
/**
|
|
51
|
+
* Outputs of inference for the Image Segmentation task
|
|
52
|
+
*
|
|
53
|
+
* A predicted mask / segment
|
|
54
|
+
*/
|
|
55
|
+
export interface ImageSegmentationOutputElement {
|
|
56
|
+
/**
|
|
57
|
+
* The label of the predicted segment.
|
|
58
|
+
*/
|
|
59
|
+
label: string;
|
|
60
|
+
/**
|
|
61
|
+
* The corresponding mask as a black-and-white image (base64-encoded).
|
|
62
|
+
*/
|
|
63
|
+
mask: string;
|
|
64
|
+
/**
|
|
65
|
+
* The score or confidence degree the model has.
|
|
66
|
+
*/
|
|
67
|
+
score?: number;
|
|
68
|
+
[property: string]: unknown;
|
|
69
|
+
}
|
|
@@ -0,0 +1,45 @@
|
|
|
1
|
+
{
|
|
2
|
+
"$id": "/inference/schemas/image-segmentation/input.json",
|
|
3
|
+
"$schema": "http://json-schema.org/draft-06/schema#",
|
|
4
|
+
"description": "Inputs for Image Segmentation inference",
|
|
5
|
+
"title": "ImageSegmentationInput",
|
|
6
|
+
"type": "object",
|
|
7
|
+
"properties": {
|
|
8
|
+
"inputs": {
|
|
9
|
+
"type": "string",
|
|
10
|
+
"description": "The input image data as a base64-encoded string. If no `parameters` are provided, you can also provide the image data as a raw bytes payload."
|
|
11
|
+
},
|
|
12
|
+
"parameters": {
|
|
13
|
+
"description": "Additional inference parameters",
|
|
14
|
+
"$ref": "#/$defs/ImageSegmentationParameters"
|
|
15
|
+
}
|
|
16
|
+
},
|
|
17
|
+
"$defs": {
|
|
18
|
+
"ImageSegmentationParameters": {
|
|
19
|
+
"title": "ImageSegmentationParameters",
|
|
20
|
+
"description": "Additional inference parameters for Image Segmentation",
|
|
21
|
+
"type": "object",
|
|
22
|
+
"properties": {
|
|
23
|
+
"mask_threshold": {
|
|
24
|
+
"type": "number",
|
|
25
|
+
"description": "Threshold to use when turning the predicted masks into binary values."
|
|
26
|
+
},
|
|
27
|
+
"overlap_mask_area_threshold": {
|
|
28
|
+
"type": "number",
|
|
29
|
+
"description": "Mask overlap threshold to eliminate small, disconnected segments."
|
|
30
|
+
},
|
|
31
|
+
"subtask": {
|
|
32
|
+
"title": "ImageSegmentationSubtask",
|
|
33
|
+
"type": "string",
|
|
34
|
+
"description": "Segmentation task to be performed, depending on model capabilities.",
|
|
35
|
+
"enum": ["instance", "panoptic", "semantic"]
|
|
36
|
+
},
|
|
37
|
+
"threshold": {
|
|
38
|
+
"type": "number",
|
|
39
|
+
"description": "Probability threshold to filter out predicted masks."
|
|
40
|
+
}
|
|
41
|
+
}
|
|
42
|
+
}
|
|
43
|
+
},
|
|
44
|
+
"required": ["inputs"]
|
|
45
|
+
}
|
|
@@ -0,0 +1,26 @@
|
|
|
1
|
+
{
|
|
2
|
+
"$id": "/inference/schemas/image-segmentation/output.json",
|
|
3
|
+
"$schema": "http://json-schema.org/draft-06/schema#",
|
|
4
|
+
"description": "Outputs of inference for the Image Segmentation task",
|
|
5
|
+
"title": "ImageSegmentationOutput",
|
|
6
|
+
"type": "array",
|
|
7
|
+
"items": {
|
|
8
|
+
"description": "A predicted mask / segment",
|
|
9
|
+
"type": "object",
|
|
10
|
+
"properties": {
|
|
11
|
+
"label": {
|
|
12
|
+
"type": "string",
|
|
13
|
+
"description": "The label of the predicted segment."
|
|
14
|
+
},
|
|
15
|
+
"mask": {
|
|
16
|
+
"type": "string",
|
|
17
|
+
"description": "The corresponding mask as a black-and-white image (base64-encoded)."
|
|
18
|
+
},
|
|
19
|
+
"score": {
|
|
20
|
+
"type": "number",
|
|
21
|
+
"description": "The score or confidence degree the model has."
|
|
22
|
+
}
|
|
23
|
+
},
|
|
24
|
+
"required": ["label", "mask"]
|
|
25
|
+
}
|
|
26
|
+
}
|
|
@@ -0,0 +1,76 @@
|
|
|
1
|
+
## Different Types of Vision Language Models
|
|
2
|
+
|
|
3
|
+
Vision language models come in three types:
|
|
4
|
+
|
|
5
|
+
- **Base:** Pre-trained models that can be fine-tuned. A good example of base models is the [PaliGemma models family](https://huggingface.co/models?sort=trending&search=google%2Fpaligemma-3b-pt) by Google.
|
|
6
|
+
- **Instruction:** Base models fine-tuned on instruction datasets. A good example of instruction fine-tuned models is [idefics2-8b](https://huggingface.co/HuggingFaceM4/idefics2-8b).
|
|
7
|
+
- **Chatty/Conversational:** Base models fine-tuned on conversation datasets. A good example of chatty models is [deepseek-vl-7b-chat](https://huggingface.co/deepseek-ai/deepseek-vl-7b-chat).
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
|
|
11
|
+
## Use Cases
|
|
12
|
+
|
|
13
|
+
### Multimodal Dialogue
|
|
14
|
+
|
|
15
|
+
Vision language models can be used as multimodal assistants, keeping context about the conversation and keeping the image to have multiple-turn dialogues.
|
|
16
|
+
|
|
17
|
+
### Zero-shot Object Detection, Image Segmentation and Localization
|
|
18
|
+
|
|
19
|
+
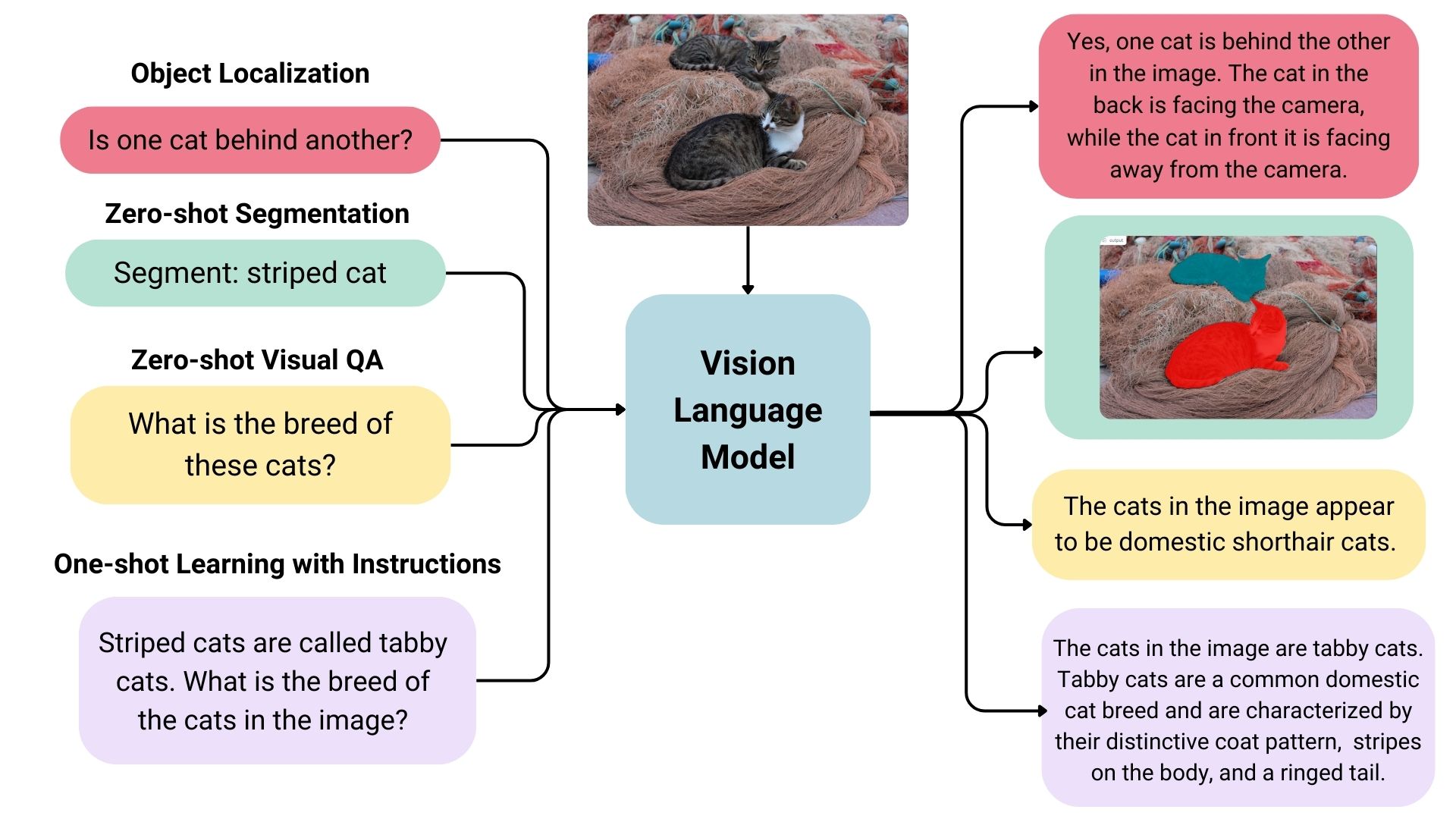
Some vision language models can detect or segment a set of objects or describe the positions or relative positions of the objects. For example, one could prompt such a model to ask if one object is behind another. Such a model can also output bounding box coordination or segmentation masks directly in the text output, unlike the traditional models explicitly trained on only object detection or image segmentation.
|
|
20
|
+
|
|
21
|
+
### Visual Question Answering
|
|
22
|
+
|
|
23
|
+
Vision language models trained on image-text pairs can be used for visual question answering and generating captions for images.
|
|
24
|
+
|
|
25
|
+
### Document Question Answering and Retrieval
|
|
26
|
+
|
|
27
|
+
Documents often consist of different layouts, charts, tables, images, and more. Vision language models trained on formatted documents can extract information from them. This is an OCR-free approach; the inputs skip OCR, and documents are directly fed to vision language models.
|
|
28
|
+
|
|
29
|
+
### Image Recognition with Instructions
|
|
30
|
+
|
|
31
|
+
Vision language models can recognize images through descriptions. When given detailed descriptions of specific entities, it can classify the entities in an image.
|
|
32
|
+
|
|
33
|
+
## Inference
|
|
34
|
+
|
|
35
|
+
You can use the Transformers library to interact with vision-language models. You can load the model like below.
|
|
36
|
+
|
|
37
|
+
```python
|
|
38
|
+
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
|
|
39
|
+
import torch
|
|
40
|
+
|
|
41
|
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
|
42
|
+
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
|
|
43
|
+
model = LlavaNextForConditionalGeneration.from_pretrained(
|
|
44
|
+
"llava-hf/llava-v1.6-mistral-7b-hf",
|
|
45
|
+
torch_dtype=torch.float16
|
|
46
|
+
)
|
|
47
|
+
model.to(device)
|
|
48
|
+
```
|
|
49
|
+
|
|
50
|
+
We can infer by passing image and text dialogues.
|
|
51
|
+
|
|
52
|
+
```python
|
|
53
|
+
from PIL import Image
|
|
54
|
+
import requests
|
|
55
|
+
|
|
56
|
+
# image of a radar chart
|
|
57
|
+
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
|
|
58
|
+
image = Image.open(requests.get(url, stream=True).raw)
|
|
59
|
+
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
|
|
60
|
+
|
|
61
|
+
inputs = processor(prompt, image, return_tensors="pt").to(device)
|
|
62
|
+
output = model.generate(**inputs, max_new_tokens=100)
|
|
63
|
+
|
|
64
|
+
print(processor.decode(output[0], skip_special_tokens=True))
|
|
65
|
+
# The image appears to be a radar chart, which is a type of multivariate chart that displays values for multiple variables represented on axes
|
|
66
|
+
# starting from the same point. This particular radar chart is showing the performance of different models or systems across various metrics.
|
|
67
|
+
# The axes represent different metrics or benchmarks, such as MM-Vet, MM-Vet, MM-Vet, MM-Vet, MM-Vet, MM-V
|
|
68
|
+
```
|
|
69
|
+
|
|
70
|
+
## Useful Resources
|
|
71
|
+
|
|
72
|
+
- [Vision Language Models Explained](https://huggingface.co/blog/vlms)
|
|
73
|
+
- [Open-source Multimodality and How to Achieve it using Hugging Face](https://www.youtube.com/watch?v=IoGaGfU1CIg&t=601s)
|
|
74
|
+
- [Introducing Idefics2: A Powerful 8B Vision-Language Model for the community](https://huggingface.co/blog/idefics2)
|
|
75
|
+
- [Image-text-to-text task guide](https://huggingface.co/tasks/image-text-to-text)
|
|
76
|
+
- [Preference Optimization for Vision Language Models with TRL](https://huggingface.co/blog/dpo_vlm)
|
|
@@ -0,0 +1,102 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../index.js";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "Instructions composed of image and text.",
|
|
7
|
+
id: "liuhaotian/LLaVA-Instruct-150K",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "Conversation turns where questions involve image and text.",
|
|
11
|
+
id: "liuhaotian/LLaVA-Pretrain",
|
|
12
|
+
},
|
|
13
|
+
{
|
|
14
|
+
description: "A collection of datasets made for model fine-tuning.",
|
|
15
|
+
id: "HuggingFaceM4/the_cauldron",
|
|
16
|
+
},
|
|
17
|
+
{
|
|
18
|
+
description: "Screenshots of websites with their HTML/CSS codes.",
|
|
19
|
+
id: "HuggingFaceM4/WebSight",
|
|
20
|
+
},
|
|
21
|
+
],
|
|
22
|
+
demo: {
|
|
23
|
+
inputs: [
|
|
24
|
+
{
|
|
25
|
+
filename: "image-text-to-text-input.png",
|
|
26
|
+
type: "img",
|
|
27
|
+
},
|
|
28
|
+
{
|
|
29
|
+
label: "Text Prompt",
|
|
30
|
+
content: "Describe the position of the bee in detail.",
|
|
31
|
+
type: "text",
|
|
32
|
+
},
|
|
33
|
+
],
|
|
34
|
+
outputs: [
|
|
35
|
+
{
|
|
36
|
+
label: "Answer",
|
|
37
|
+
content:
|
|
38
|
+
"The bee is sitting on a pink flower, surrounded by other flowers. The bee is positioned in the center of the flower, with its head and front legs sticking out.",
|
|
39
|
+
type: "text",
|
|
40
|
+
},
|
|
41
|
+
],
|
|
42
|
+
},
|
|
43
|
+
metrics: [],
|
|
44
|
+
models: [
|
|
45
|
+
{
|
|
46
|
+
description: "Powerful vision language model with great visual understanding and reasoning capabilities.",
|
|
47
|
+
id: "meta-llama/Llama-3.2-11B-Vision-Instruct",
|
|
48
|
+
},
|
|
49
|
+
{
|
|
50
|
+
description: "Cutting-edge vision language models.",
|
|
51
|
+
id: "allenai/Molmo-7B-D-0924",
|
|
52
|
+
},
|
|
53
|
+
{
|
|
54
|
+
description: "Small yet powerful model.",
|
|
55
|
+
id: "vikhyatk/moondream2",
|
|
56
|
+
},
|
|
57
|
+
{
|
|
58
|
+
description: "Strong image-text-to-text model.",
|
|
59
|
+
id: "Qwen/Qwen2-VL-7B-Instruct",
|
|
60
|
+
},
|
|
61
|
+
{
|
|
62
|
+
description: "Strong image-text-to-text model.",
|
|
63
|
+
id: "mistralai/Pixtral-12B-2409",
|
|
64
|
+
},
|
|
65
|
+
{
|
|
66
|
+
description: "Strong image-text-to-text model focused on documents.",
|
|
67
|
+
id: "stepfun-ai/GOT-OCR2_0",
|
|
68
|
+
},
|
|
69
|
+
],
|
|
70
|
+
spaces: [
|
|
71
|
+
{
|
|
72
|
+
description: "Leaderboard to evaluate vision language models.",
|
|
73
|
+
id: "opencompass/open_vlm_leaderboard",
|
|
74
|
+
},
|
|
75
|
+
{
|
|
76
|
+
description: "Vision language models arena, where models are ranked by votes of users.",
|
|
77
|
+
id: "WildVision/vision-arena",
|
|
78
|
+
},
|
|
79
|
+
{
|
|
80
|
+
description: "Powerful vision-language model assistant.",
|
|
81
|
+
id: "akhaliq/Molmo-7B-D-0924",
|
|
82
|
+
},
|
|
83
|
+
{
|
|
84
|
+
description: "An image-text-to-text application focused on documents.",
|
|
85
|
+
id: "stepfun-ai/GOT_official_online_demo",
|
|
86
|
+
},
|
|
87
|
+
{
|
|
88
|
+
description: "An application to compare outputs of different vision language models.",
|
|
89
|
+
id: "merve/compare_VLMs",
|
|
90
|
+
},
|
|
91
|
+
{
|
|
92
|
+
description: "An application for chatting with an image-text-to-text model.",
|
|
93
|
+
id: "GanymedeNil/Qwen2-VL-7B",
|
|
94
|
+
},
|
|
95
|
+
],
|
|
96
|
+
summary:
|
|
97
|
+
"Image-text-to-text models take in an image and text prompt and output text. These models are also called vision-language models, or VLMs. The difference from image-to-text models is that these models take an additional text input, not restricting the model to certain use cases like image captioning, and may also be trained to accept a conversation as input.",
|
|
98
|
+
widgetModels: ["meta-llama/Llama-3.2-11B-Vision-Instruct"],
|
|
99
|
+
youtubeId: "IoGaGfU1CIg",
|
|
100
|
+
};
|
|
101
|
+
|
|
102
|
+
export default taskData;
|
|
@@ -0,0 +1,62 @@
|
|
|
1
|
+
## Use Cases
|
|
2
|
+
|
|
3
|
+
Image-to-3D models can be used in a wide variety of applications that require 3D, such as games, animation, design, architecture, engineering, marketing, and more.
|
|
4
|
+
|
|
5
|
+

|
|
6
|
+
|
|
7
|
+
### Generating Meshes
|
|
8
|
+
|
|
9
|
+
Meshes are the standard representation of 3D in industry.
|
|
10
|
+
|
|
11
|
+
### Generating Gaussian Splats
|
|
12
|
+
|
|
13
|
+
[Gaussian Splatting](https://huggingface.co/blog/gaussian-splatting) is a rendering technique that represents scenes as fuzzy points.
|
|
14
|
+
|
|
15
|
+
### Inference
|
|
16
|
+
|
|
17
|
+
Inference for this task typically leverages the [Diffusers](https://huggingface.co/docs/diffusers/index) library for inference, using [Custom Pipelines](https://huggingface.co/docs/diffusers/v0.6.0/en/using-diffusers/custom_pipelines).
|
|
18
|
+
|
|
19
|
+
These are unstandardized and depend on the model. More details can be found in each model repository.
|
|
20
|
+
|
|
21
|
+
```python
|
|
22
|
+
import torch
|
|
23
|
+
import requests
|
|
24
|
+
import numpy as np
|
|
25
|
+
from io import BytesIO
|
|
26
|
+
from diffusers import DiffusionPipeline
|
|
27
|
+
from PIL import Image
|
|
28
|
+
|
|
29
|
+
pipeline = DiffusionPipeline.from_pretrained(
|
|
30
|
+
"dylanebert/LGM-full",
|
|
31
|
+
custom_pipeline="dylanebert/LGM-full",
|
|
32
|
+
torch_dtype=torch.float16,
|
|
33
|
+
trust_remote_code=True,
|
|
34
|
+
).to("cuda")
|
|
35
|
+
|
|
36
|
+
input_url = "https://huggingface.co/datasets/dylanebert/iso3d/resolve/main/jpg@512/a_cat_statue.jpg"
|
|
37
|
+
input_image = Image.open(BytesIO(requests.get(input_url).content))
|
|
38
|
+
input_image = np.array(input_image, dtype=np.float32) / 255.0
|
|
39
|
+
result = pipeline("", input_image)
|
|
40
|
+
result_path = "/tmp/output.ply"
|
|
41
|
+
pipeline.save_ply(result, result_path)
|
|
42
|
+
```
|
|
43
|
+
|
|
44
|
+
In the code above, we:
|
|
45
|
+
|
|
46
|
+
1. Import the necessary libraries
|
|
47
|
+
2. Load the `LGM-full` model and custom pipeline
|
|
48
|
+
3. Load and preprocess the input image
|
|
49
|
+
4. Run the pipeline on the input image
|
|
50
|
+
5. Save the output to a file
|
|
51
|
+
|
|
52
|
+
### Output Formats
|
|
53
|
+
|
|
54
|
+
Meshes can be in `.obj`, `.glb`, `.stl`, or `.gltf` format. Other formats are allowed, but won't be rendered in the gradio [Model3D](https://www.gradio.app/docs/gradio/model3d) component.
|
|
55
|
+
|
|
56
|
+
Splats can be in `.ply` or `.splat` format. They can be rendered in the gradio [Model3D](https://www.gradio.app/docs/gradio/model3d) component using the [gsplat.js](https://github.com/huggingface/gsplat.js) library.
|
|
57
|
+
|
|
58
|
+
## Useful Resources
|
|
59
|
+
|
|
60
|
+
- [ML for 3D Course](https://huggingface.co/learn/ml-for-3d-course)
|
|
61
|
+
- [3D Arena Leaderboard](https://huggingface.co/spaces/dylanebert/3d-arena)
|
|
62
|
+
- [gsplat.js](https://github.com/huggingface/gsplat.js)
|
|
@@ -0,0 +1,75 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../index.js";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "A large dataset of over 10 million 3D objects.",
|
|
7
|
+
id: "allenai/objaverse-xl",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "A dataset of isolated object images for evaluating image-to-3D models.",
|
|
11
|
+
id: "dylanebert/iso3d",
|
|
12
|
+
},
|
|
13
|
+
],
|
|
14
|
+
demo: {
|
|
15
|
+
inputs: [
|
|
16
|
+
{
|
|
17
|
+
filename: "image-to-3d-image-input.png",
|
|
18
|
+
type: "img",
|
|
19
|
+
},
|
|
20
|
+
],
|
|
21
|
+
outputs: [
|
|
22
|
+
{
|
|
23
|
+
label: "Result",
|
|
24
|
+
content: "image-to-3d-3d-output-filename.glb",
|
|
25
|
+
type: "text",
|
|
26
|
+
},
|
|
27
|
+
],
|
|
28
|
+
},
|
|
29
|
+
metrics: [],
|
|
30
|
+
models: [
|
|
31
|
+
{
|
|
32
|
+
description: "Fast image-to-3D mesh model by Tencent.",
|
|
33
|
+
id: "TencentARC/InstantMesh",
|
|
34
|
+
},
|
|
35
|
+
{
|
|
36
|
+
description: "Fast image-to-3D mesh model by StabilityAI",
|
|
37
|
+
id: "stabilityai/TripoSR",
|
|
38
|
+
},
|
|
39
|
+
{
|
|
40
|
+
description: "A scaled up image-to-3D mesh model derived from TripoSR.",
|
|
41
|
+
id: "hwjiang/Real3D",
|
|
42
|
+
},
|
|
43
|
+
{
|
|
44
|
+
description: "Generative 3D gaussian splatting model.",
|
|
45
|
+
id: "ashawkey/LGM",
|
|
46
|
+
},
|
|
47
|
+
],
|
|
48
|
+
spaces: [
|
|
49
|
+
{
|
|
50
|
+
description: "Leaderboard to evaluate image-to-3D models.",
|
|
51
|
+
id: "dylanebert/3d-arena",
|
|
52
|
+
},
|
|
53
|
+
{
|
|
54
|
+
description: "Image-to-3D demo with mesh outputs.",
|
|
55
|
+
id: "TencentARC/InstantMesh",
|
|
56
|
+
},
|
|
57
|
+
{
|
|
58
|
+
description: "Image-to-3D demo with mesh outputs.",
|
|
59
|
+
id: "stabilityai/TripoSR",
|
|
60
|
+
},
|
|
61
|
+
{
|
|
62
|
+
description: "Image-to-3D demo with mesh outputs.",
|
|
63
|
+
id: "hwjiang/Real3D",
|
|
64
|
+
},
|
|
65
|
+
{
|
|
66
|
+
description: "Image-to-3D demo with splat outputs.",
|
|
67
|
+
id: "dylanebert/LGM-mini",
|
|
68
|
+
},
|
|
69
|
+
],
|
|
70
|
+
summary: "Image-to-3D models take in image input and produce 3D output.",
|
|
71
|
+
widgetModels: [],
|
|
72
|
+
youtubeId: "",
|
|
73
|
+
};
|
|
74
|
+
|
|
75
|
+
export default taskData;
|