zrb 1.8.9__py3-none-any.whl → 1.8.11__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- zrb/builtin/llm/llm_ask.py +4 -4
- zrb/builtin/llm/tool/code.py +31 -25
- zrb/builtin/llm/tool/file.py +9 -6
- zrb/builtin/llm/tool/sub_agent.py +4 -2
- zrb/builtin/llm/tool/web.py +1 -1
- zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/requirements.txt +2 -2
- zrb/config.py +2 -2
- zrb/llm_config.py +2 -8
- zrb/llm_rate_limitter.py +24 -3
- zrb/task/llm/agent.py +45 -2
- zrb/task/llm_task.py +1 -1
- {zrb-1.8.9.dist-info → zrb-1.8.11.dist-info}/METADATA +40 -34
- {zrb-1.8.9.dist-info → zrb-1.8.11.dist-info}/RECORD +15 -15
- {zrb-1.8.9.dist-info → zrb-1.8.11.dist-info}/WHEEL +0 -0
- {zrb-1.8.9.dist-info → zrb-1.8.11.dist-info}/entry_points.txt +0 -0
zrb/builtin/llm/llm_ask.py
CHANGED
|
@@ -127,13 +127,13 @@ llm_group.add_task(
|
|
|
127
127
|
|
|
128
128
|
if CFG.LLM_ALLOW_ACCESS_LOCAL_FILE:
|
|
129
129
|
llm_ask.append_tool(
|
|
130
|
+
analyze_repo,
|
|
131
|
+
analyze_file,
|
|
132
|
+
search_files,
|
|
130
133
|
list_files,
|
|
131
134
|
read_from_file,
|
|
132
|
-
write_to_file,
|
|
133
|
-
search_files,
|
|
134
135
|
apply_diff,
|
|
135
|
-
|
|
136
|
-
analyze_repo,
|
|
136
|
+
write_to_file,
|
|
137
137
|
)
|
|
138
138
|
|
|
139
139
|
if CFG.LLM_ALLOW_ACCESS_SHELL:
|
zrb/builtin/llm/tool/code.py
CHANGED
|
@@ -4,6 +4,7 @@ import os
|
|
|
4
4
|
from zrb.builtin.llm.tool.file import DEFAULT_EXCLUDED_PATTERNS, is_excluded
|
|
5
5
|
from zrb.builtin.llm.tool.sub_agent import create_sub_agent_tool
|
|
6
6
|
from zrb.context.any_context import AnyContext
|
|
7
|
+
from zrb.llm_rate_limitter import llm_rate_limitter
|
|
7
8
|
|
|
8
9
|
_EXTRACT_INFO_FROM_REPO_SYSTEM_PROMPT = """
|
|
9
10
|
You are an extraction info agent.
|
|
@@ -81,12 +82,11 @@ async def analyze_repo(
|
|
|
81
82
|
goal: str,
|
|
82
83
|
extensions: list[str] = _DEFAULT_EXTENSIONS,
|
|
83
84
|
exclude_patterns: list[str] = DEFAULT_EXCLUDED_PATTERNS,
|
|
84
|
-
|
|
85
|
-
|
|
85
|
+
extraction_token_limit: int = 30000,
|
|
86
|
+
summarization_token_limit: int = 30000,
|
|
86
87
|
) -> str:
|
|
87
88
|
"""
|
|
88
|
-
Extract and summarize information from
|
|
89
|
-
contains a large resources.
|
|
89
|
+
Extract and summarize information from any directory.
|
|
90
90
|
You should state the goal specifically so that the tool can return relevant informations.
|
|
91
91
|
Use this tool for:
|
|
92
92
|
- summarization
|
|
@@ -101,9 +101,9 @@ async def analyze_repo(
|
|
|
101
101
|
while reading resources. Defaults to common programming languages and config files.
|
|
102
102
|
exclude_patterns(Optional[list[str]]): List of patterns to exclude from analysis.
|
|
103
103
|
Common patterns like '.venv', 'node_modules' should be excluded by default.
|
|
104
|
-
|
|
104
|
+
extraction_token_limit(Optional[int]): Max resource content char length
|
|
105
105
|
the extraction assistant able to handle. Defaults to 150000
|
|
106
|
-
|
|
106
|
+
summarization_token_limit(Optional[int]): Max resource content char length
|
|
107
107
|
the summarization assistant able to handle. Defaults to 150000
|
|
108
108
|
Returns:
|
|
109
109
|
str: The analysis result
|
|
@@ -117,22 +117,19 @@ async def analyze_repo(
|
|
|
117
117
|
ctx,
|
|
118
118
|
file_metadatas=file_metadatas,
|
|
119
119
|
goal=goal,
|
|
120
|
-
|
|
120
|
+
token_limit=extraction_token_limit,
|
|
121
121
|
)
|
|
122
|
+
if len(extracted_infos) == 1:
|
|
123
|
+
return extracted_infos[0]
|
|
122
124
|
ctx.print("Summarization")
|
|
123
|
-
summarized_infos =
|
|
124
|
-
ctx,
|
|
125
|
-
extracted_infos=extracted_infos,
|
|
126
|
-
goal=goal,
|
|
127
|
-
char_limit=summarization_char_limit,
|
|
128
|
-
)
|
|
125
|
+
summarized_infos = extracted_infos
|
|
129
126
|
while len(summarized_infos) > 1:
|
|
130
127
|
ctx.print("Summarization")
|
|
131
128
|
summarized_infos = await _summarize_info(
|
|
132
129
|
ctx,
|
|
133
130
|
extracted_infos=summarized_infos,
|
|
134
131
|
goal=goal,
|
|
135
|
-
|
|
132
|
+
token_limit=summarization_token_limit,
|
|
136
133
|
)
|
|
137
134
|
return summarized_infos[0]
|
|
138
135
|
|
|
@@ -165,7 +162,7 @@ async def _extract_info(
|
|
|
165
162
|
ctx: AnyContext,
|
|
166
163
|
file_metadatas: list[dict[str, str]],
|
|
167
164
|
goal: str,
|
|
168
|
-
|
|
165
|
+
token_limit: int,
|
|
169
166
|
) -> list[str]:
|
|
170
167
|
extract = create_sub_agent_tool(
|
|
171
168
|
tool_name="extract",
|
|
@@ -174,27 +171,31 @@ async def _extract_info(
|
|
|
174
171
|
)
|
|
175
172
|
extracted_infos = []
|
|
176
173
|
content_buffer = []
|
|
177
|
-
|
|
174
|
+
current_token_count = 0
|
|
178
175
|
for metadata in file_metadatas:
|
|
179
176
|
path = metadata.get("path", "")
|
|
180
177
|
content = metadata.get("content", "")
|
|
181
178
|
file_obj = {"path": path, "content": content}
|
|
182
179
|
file_str = json.dumps(file_obj)
|
|
183
|
-
if
|
|
180
|
+
if current_token_count + llm_rate_limitter.count_token(file_str) > token_limit:
|
|
184
181
|
if content_buffer:
|
|
185
182
|
prompt = _create_extract_info_prompt(goal, content_buffer)
|
|
186
|
-
extracted_info = await extract(
|
|
183
|
+
extracted_info = await extract(
|
|
184
|
+
ctx, llm_rate_limitter.clip_prompt(prompt, token_limit)
|
|
185
|
+
)
|
|
187
186
|
extracted_infos.append(extracted_info)
|
|
188
187
|
content_buffer = [file_obj]
|
|
189
|
-
|
|
188
|
+
current_token_count = llm_rate_limitter.count_token(file_str)
|
|
190
189
|
else:
|
|
191
190
|
content_buffer.append(file_obj)
|
|
192
|
-
|
|
191
|
+
current_token_count += llm_rate_limitter.count_token(file_str)
|
|
193
192
|
|
|
194
193
|
# Process any remaining content in the buffer
|
|
195
194
|
if content_buffer:
|
|
196
195
|
prompt = _create_extract_info_prompt(goal, content_buffer)
|
|
197
|
-
extracted_info = await extract(
|
|
196
|
+
extracted_info = await extract(
|
|
197
|
+
ctx, llm_rate_limitter.clip_prompt(prompt, token_limit)
|
|
198
|
+
)
|
|
198
199
|
extracted_infos.append(extracted_info)
|
|
199
200
|
return extracted_infos
|
|
200
201
|
|
|
@@ -212,7 +213,7 @@ async def _summarize_info(
|
|
|
212
213
|
ctx: AnyContext,
|
|
213
214
|
extracted_infos: list[str],
|
|
214
215
|
goal: str,
|
|
215
|
-
|
|
216
|
+
token_limit: int,
|
|
216
217
|
) -> list[str]:
|
|
217
218
|
summarize = create_sub_agent_tool(
|
|
218
219
|
tool_name="extract",
|
|
@@ -222,10 +223,13 @@ async def _summarize_info(
|
|
|
222
223
|
summarized_infos = []
|
|
223
224
|
content_buffer = ""
|
|
224
225
|
for extracted_info in extracted_infos:
|
|
225
|
-
|
|
226
|
+
new_prompt = content_buffer + extracted_info
|
|
227
|
+
if llm_rate_limitter.count_token(new_prompt) > token_limit:
|
|
226
228
|
if content_buffer:
|
|
227
229
|
prompt = _create_summarize_info_prompt(goal, content_buffer)
|
|
228
|
-
summarized_info = await summarize(
|
|
230
|
+
summarized_info = await summarize(
|
|
231
|
+
ctx, llm_rate_limitter.clip_prompt(prompt, token_limit)
|
|
232
|
+
)
|
|
229
233
|
summarized_infos.append(summarized_info)
|
|
230
234
|
content_buffer = extracted_info
|
|
231
235
|
else:
|
|
@@ -234,7 +238,9 @@ async def _summarize_info(
|
|
|
234
238
|
# Process any remaining content in the buffer
|
|
235
239
|
if content_buffer:
|
|
236
240
|
prompt = _create_summarize_info_prompt(goal, content_buffer)
|
|
237
|
-
summarized_info = await summarize(
|
|
241
|
+
summarized_info = await summarize(
|
|
242
|
+
ctx, llm_rate_limitter.clip_prompt(prompt, token_limit)
|
|
243
|
+
)
|
|
238
244
|
summarized_infos.append(summarized_info)
|
|
239
245
|
return summarized_infos
|
|
240
246
|
|
zrb/builtin/llm/tool/file.py
CHANGED
|
@@ -6,6 +6,7 @@ from typing import Any, Optional
|
|
|
6
6
|
|
|
7
7
|
from zrb.builtin.llm.tool.sub_agent import create_sub_agent_tool
|
|
8
8
|
from zrb.context.any_context import AnyContext
|
|
9
|
+
from zrb.llm_rate_limitter import llm_rate_limitter
|
|
9
10
|
from zrb.util.file import read_file, read_file_with_line_numbers, write_file
|
|
10
11
|
|
|
11
12
|
_EXTRACT_INFO_FROM_FILE_SYSTEM_PROMPT = """
|
|
@@ -464,7 +465,9 @@ def apply_diff(
|
|
|
464
465
|
raise RuntimeError(f"Unexpected error applying diff to {path}: {e}")
|
|
465
466
|
|
|
466
467
|
|
|
467
|
-
async def analyze_file(
|
|
468
|
+
async def analyze_file(
|
|
469
|
+
ctx: AnyContext, path: str, query: str, token_limit: int = 30000
|
|
470
|
+
) -> str:
|
|
468
471
|
"""Analyze file using LLM capability to reduce context usage.
|
|
469
472
|
Use this tool for:
|
|
470
473
|
- summarization
|
|
@@ -474,6 +477,7 @@ async def analyze_file(ctx: AnyContext, path: str, query: str) -> str:
|
|
|
474
477
|
Args:
|
|
475
478
|
path (str): File path to be analyze. Pass exactly as provided, including '~'.
|
|
476
479
|
query(str): Instruction to analyze the file
|
|
480
|
+
token_limit(Optional[int]): Max token length to be taken from file
|
|
477
481
|
Returns:
|
|
478
482
|
str: The analysis result
|
|
479
483
|
Raises:
|
|
@@ -489,9 +493,8 @@ async def analyze_file(ctx: AnyContext, path: str, query: str) -> str:
|
|
|
489
493
|
system_prompt=_EXTRACT_INFO_FROM_FILE_SYSTEM_PROMPT,
|
|
490
494
|
tools=[read_from_file, search_files],
|
|
491
495
|
)
|
|
492
|
-
|
|
493
|
-
|
|
494
|
-
json.dumps(
|
|
495
|
-
{"instruction": query, "file_path": abs_path, "file_content": file_content}
|
|
496
|
-
),
|
|
496
|
+
payload = json.dumps(
|
|
497
|
+
{"instruction": query, "file_path": abs_path, "file_content": file_content}
|
|
497
498
|
)
|
|
499
|
+
clipped_payload = llm_rate_limitter.clip_prompt(payload, token_limit)
|
|
500
|
+
return await _analyze_file(ctx, clipped_payload)
|
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
import json
|
|
2
2
|
from collections.abc import Callable
|
|
3
3
|
from textwrap import dedent
|
|
4
|
-
from typing import TYPE_CHECKING, Any
|
|
4
|
+
from typing import TYPE_CHECKING, Any, Coroutine
|
|
5
5
|
|
|
6
6
|
if TYPE_CHECKING:
|
|
7
7
|
from pydantic_ai import Tool
|
|
@@ -33,7 +33,7 @@ def create_sub_agent_tool(
|
|
|
33
33
|
model_settings: ModelSettings | None = None,
|
|
34
34
|
tools: list[ToolOrCallable] = [],
|
|
35
35
|
mcp_servers: list[MCPServer] = [],
|
|
36
|
-
) -> Callable[[AnyContext, str], str]:
|
|
36
|
+
) -> Callable[[AnyContext, str], Coroutine[Any, Any, str]]:
|
|
37
37
|
"""
|
|
38
38
|
Create an LLM "sub-agent" tool function for use by a main LLM agent.
|
|
39
39
|
|
|
@@ -97,6 +97,8 @@ def create_sub_agent_tool(
|
|
|
97
97
|
tools=tools,
|
|
98
98
|
mcp_servers=mcp_servers,
|
|
99
99
|
)
|
|
100
|
+
|
|
101
|
+
sub_agent_run = None
|
|
100
102
|
# Run the sub-agent iteration
|
|
101
103
|
# Start with an empty history for the sub-agent
|
|
102
104
|
sub_agent_run = await run_agent_iteration(
|
zrb/builtin/llm/tool/web.py
CHANGED
|
@@ -42,7 +42,7 @@ async def open_web_page(url: str) -> str:
|
|
|
42
42
|
return {"content": content, "links_on_page": links}
|
|
43
43
|
finally:
|
|
44
44
|
await browser.close()
|
|
45
|
-
except
|
|
45
|
+
except BaseException:
|
|
46
46
|
import requests
|
|
47
47
|
|
|
48
48
|
response = requests.get(url, headers={"User-Agent": user_agent})
|
zrb/config.py
CHANGED
|
@@ -245,12 +245,12 @@ class Config:
|
|
|
245
245
|
@property
|
|
246
246
|
def LLM_MAX_TOKENS_PER_MINUTE(self) -> int:
|
|
247
247
|
"""Maximum number of LLM tokens allowed per minute."""
|
|
248
|
-
return int(os.getenv("ZRB_LLM_MAX_TOKENS_PER_MINUTE", "
|
|
248
|
+
return int(os.getenv("ZRB_LLM_MAX_TOKENS_PER_MINUTE", "200000"))
|
|
249
249
|
|
|
250
250
|
@property
|
|
251
251
|
def LLM_MAX_TOKENS_PER_REQUEST(self) -> int:
|
|
252
252
|
"""Maximum number of tokens allowed per individual LLM request."""
|
|
253
|
-
return int(os.getenv("ZRB_LLM_MAX_TOKENS_PER_REQUEST", "
|
|
253
|
+
return int(os.getenv("ZRB_LLM_MAX_TOKENS_PER_REQUEST", "50000"))
|
|
254
254
|
|
|
255
255
|
@property
|
|
256
256
|
def LLM_THROTTLE_SLEEP(self) -> float:
|
zrb/llm_config.py
CHANGED
|
@@ -69,14 +69,8 @@ DEFAULT_SPECIAL_INSTRUCTION_PROMPT = (
|
|
|
69
69
|
"is clean.\n"
|
|
70
70
|
"2. **Halt if Dirty:** If the directory is not clean, STOP. Inform the "
|
|
71
71
|
"user and wait for their instructions.\n"
|
|
72
|
-
"3. **
|
|
73
|
-
"
|
|
74
|
-
"name.\n"
|
|
75
|
-
" - Example: 'I will create a branch named `feature/add-user-login`. "
|
|
76
|
-
"Is this okay?'\n"
|
|
77
|
-
" - **Wait for the user to say 'yes' or approve.**\n"
|
|
78
|
-
"4. **Execute on Branch:** Once the user confirms, create the branch and "
|
|
79
|
-
"perform all your work and commits there.\n\n"
|
|
72
|
+
"3. **Create a New Branch:** Create a new branch and inform the user.\n"
|
|
73
|
+
"4. **Execute on Branch:** Perform all your work and commits there.\n\n"
|
|
80
74
|
"**4. Debugging Protocol**\n"
|
|
81
75
|
"1. **Hypothesize:** State the most likely cause of the bug in one "
|
|
82
76
|
"sentence.\n"
|
zrb/llm_rate_limitter.py
CHANGED
|
@@ -3,9 +3,16 @@ import time
|
|
|
3
3
|
from collections import deque
|
|
4
4
|
from typing import Callable
|
|
5
5
|
|
|
6
|
+
import tiktoken
|
|
7
|
+
|
|
6
8
|
from zrb.config import CFG
|
|
7
9
|
|
|
8
10
|
|
|
11
|
+
def _estimate_token(text: str) -> int:
|
|
12
|
+
enc = tiktoken.encoding_for_model("gpt-4o")
|
|
13
|
+
return len(enc.encode(text))
|
|
14
|
+
|
|
15
|
+
|
|
9
16
|
class LLMRateLimiter:
|
|
10
17
|
"""
|
|
11
18
|
Helper class to enforce LLM API rate limits and throttling.
|
|
@@ -53,10 +60,10 @@ class LLMRateLimiter:
|
|
|
53
60
|
return CFG.LLM_THROTTLE_SLEEP
|
|
54
61
|
|
|
55
62
|
@property
|
|
56
|
-
def
|
|
63
|
+
def count_token(self) -> Callable[[str], int]:
|
|
57
64
|
if self._token_counter_fn is not None:
|
|
58
65
|
return self._token_counter_fn
|
|
59
|
-
return
|
|
66
|
+
return _estimate_token
|
|
60
67
|
|
|
61
68
|
def set_max_requests_per_minute(self, value: int):
|
|
62
69
|
self._max_requests_per_minute = value
|
|
@@ -73,9 +80,23 @@ class LLMRateLimiter:
|
|
|
73
80
|
def set_token_counter_fn(self, fn: Callable[[str], int]):
|
|
74
81
|
self._token_counter_fn = fn
|
|
75
82
|
|
|
83
|
+
def clip_prompt(self, prompt: str, limit: int) -> str:
|
|
84
|
+
token_count = self.count_token(prompt)
|
|
85
|
+
if token_count <= limit:
|
|
86
|
+
return prompt
|
|
87
|
+
while token_count > limit:
|
|
88
|
+
prompt_parts = prompt.split(" ")
|
|
89
|
+
last_part_index = len(prompt_parts) - 2
|
|
90
|
+
clipped_prompt = " ".join(prompt_parts[:last_part_index])
|
|
91
|
+
clipped_prompt += "(Content clipped...)"
|
|
92
|
+
token_count = self.count_token(clipped_prompt)
|
|
93
|
+
if token_count < limit:
|
|
94
|
+
return clipped_prompt
|
|
95
|
+
return prompt[:limit]
|
|
96
|
+
|
|
76
97
|
async def throttle(self, prompt: str):
|
|
77
98
|
now = time.time()
|
|
78
|
-
tokens = self.
|
|
99
|
+
tokens = self.count_token(prompt)
|
|
79
100
|
# Clean up old entries
|
|
80
101
|
while self.request_times and now - self.request_times[0] > 60:
|
|
81
102
|
self.request_times.popleft()
|
zrb/task/llm/agent.py
CHANGED
|
@@ -16,6 +16,8 @@ else:
|
|
|
16
16
|
Model = Any
|
|
17
17
|
ModelSettings = Any
|
|
18
18
|
|
|
19
|
+
import json
|
|
20
|
+
|
|
19
21
|
from zrb.context.any_context import AnyContext
|
|
20
22
|
from zrb.context.any_shared_context import AnySharedContext
|
|
21
23
|
from zrb.llm_rate_limitter import LLMRateLimiter, llm_rate_limitter
|
|
@@ -113,6 +115,7 @@ async def run_agent_iteration(
|
|
|
113
115
|
user_prompt: str,
|
|
114
116
|
history_list: ListOfDict,
|
|
115
117
|
rate_limitter: LLMRateLimiter | None = None,
|
|
118
|
+
max_retry: int = 2,
|
|
116
119
|
) -> AgentRun:
|
|
117
120
|
"""
|
|
118
121
|
Runs a single iteration of the agent execution loop.
|
|
@@ -129,13 +132,40 @@ async def run_agent_iteration(
|
|
|
129
132
|
Raises:
|
|
130
133
|
Exception: If any error occurs during agent execution.
|
|
131
134
|
"""
|
|
135
|
+
if max_retry < 0:
|
|
136
|
+
raise ValueError("Max retry cannot be less than 0")
|
|
137
|
+
attempt = 0
|
|
138
|
+
while attempt < max_retry:
|
|
139
|
+
try:
|
|
140
|
+
return await _run_single_agent_iteration(
|
|
141
|
+
ctx=ctx,
|
|
142
|
+
agent=agent,
|
|
143
|
+
user_prompt=user_prompt,
|
|
144
|
+
history_list=history_list,
|
|
145
|
+
rate_limitter=rate_limitter,
|
|
146
|
+
)
|
|
147
|
+
except BaseException:
|
|
148
|
+
attempt += 1
|
|
149
|
+
if attempt == max_retry:
|
|
150
|
+
raise
|
|
151
|
+
raise Exception("Max retry exceeded")
|
|
152
|
+
|
|
153
|
+
|
|
154
|
+
async def _run_single_agent_iteration(
|
|
155
|
+
ctx: AnyContext,
|
|
156
|
+
agent: Agent,
|
|
157
|
+
user_prompt: str,
|
|
158
|
+
history_list: ListOfDict,
|
|
159
|
+
rate_limitter: LLMRateLimiter | None = None,
|
|
160
|
+
) -> AgentRun:
|
|
132
161
|
from openai import APIError
|
|
133
162
|
from pydantic_ai.messages import ModelMessagesTypeAdapter
|
|
134
163
|
|
|
164
|
+
agent_payload = estimate_request_payload(agent, user_prompt, history_list)
|
|
135
165
|
if rate_limitter:
|
|
136
|
-
await rate_limitter.throttle(
|
|
166
|
+
await rate_limitter.throttle(agent_payload)
|
|
137
167
|
else:
|
|
138
|
-
await llm_rate_limitter.throttle(
|
|
168
|
+
await llm_rate_limitter.throttle(agent_payload)
|
|
139
169
|
|
|
140
170
|
async with agent.run_mcp_servers():
|
|
141
171
|
async with agent.iter(
|
|
@@ -159,6 +189,19 @@ async def run_agent_iteration(
|
|
|
159
189
|
return agent_run
|
|
160
190
|
|
|
161
191
|
|
|
192
|
+
def estimate_request_payload(
|
|
193
|
+
agent: Agent, user_prompt: str, history_list: ListOfDict
|
|
194
|
+
) -> str:
|
|
195
|
+
system_prompts = agent._system_prompts if hasattr(agent, "_system_prompts") else ()
|
|
196
|
+
return json.dumps(
|
|
197
|
+
[
|
|
198
|
+
{"role": "system", "content": "\n".join(system_prompts)},
|
|
199
|
+
*history_list,
|
|
200
|
+
{"role": "user", "content": user_prompt},
|
|
201
|
+
]
|
|
202
|
+
)
|
|
203
|
+
|
|
204
|
+
|
|
162
205
|
def _get_plain_printer(ctx: AnyContext):
|
|
163
206
|
def printer(*args, **kwargs):
|
|
164
207
|
if "plain" not in kwargs:
|
zrb/task/llm_task.py
CHANGED
|
@@ -357,7 +357,7 @@ class LLMTask(BaseTask):
|
|
|
357
357
|
if xcom_usage_key not in ctx.xcom:
|
|
358
358
|
ctx.xcom[xcom_usage_key] = Xcom([])
|
|
359
359
|
usage = agent_run.result.usage()
|
|
360
|
-
ctx.xcom
|
|
360
|
+
ctx.xcom[xcom_usage_key].push(usage)
|
|
361
361
|
ctx.print(stylize_faint(f"[Token Usage] {usage}"), plain=True)
|
|
362
362
|
return agent_run.result.output
|
|
363
363
|
else:
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.1
|
|
2
2
|
Name: zrb
|
|
3
|
-
Version: 1.8.
|
|
3
|
+
Version: 1.8.11
|
|
4
4
|
Summary: Your Automation Powerhouse
|
|
5
5
|
Home-page: https://github.com/state-alchemists/zrb
|
|
6
6
|
License: AGPL-3.0-or-later
|
|
@@ -19,18 +19,19 @@ Provides-Extra: rag
|
|
|
19
19
|
Requires-Dist: beautifulsoup4 (>=4.13.3,<5.0.0)
|
|
20
20
|
Requires-Dist: black (>=25.1.0,<25.2.0)
|
|
21
21
|
Requires-Dist: chromadb (>=0.6.3,<0.7.0) ; extra == "rag" or extra == "all"
|
|
22
|
-
Requires-Dist: fastapi[standard] (>=0.115.
|
|
22
|
+
Requires-Dist: fastapi[standard] (>=0.115.14,<0.116.0)
|
|
23
23
|
Requires-Dist: isort (>=6.0.1,<6.1.0)
|
|
24
24
|
Requires-Dist: libcst (>=1.7.0,<2.0.0)
|
|
25
|
-
Requires-Dist: openai (>=1.
|
|
25
|
+
Requires-Dist: openai (>=1.86.0,<2.0.0) ; extra == "rag" or extra == "all"
|
|
26
26
|
Requires-Dist: pdfplumber (>=0.11.6,<0.12.0) ; extra == "rag" or extra == "all"
|
|
27
|
-
Requires-Dist: playwright (>=1.
|
|
27
|
+
Requires-Dist: playwright (>=1.53.0,<2.0.0) ; extra == "playwright" or extra == "all"
|
|
28
28
|
Requires-Dist: psutil (>=7.0.0,<8.0.0)
|
|
29
|
-
Requires-Dist: pydantic-ai (>=0.
|
|
29
|
+
Requires-Dist: pydantic-ai (>=0.3.4,<0.4.0)
|
|
30
30
|
Requires-Dist: pyjwt (>=2.10.1,<3.0.0)
|
|
31
|
-
Requires-Dist: python-dotenv (>=1.1.
|
|
31
|
+
Requires-Dist: python-dotenv (>=1.1.1,<2.0.0)
|
|
32
32
|
Requires-Dist: python-jose[cryptography] (>=3.4.0,<4.0.0)
|
|
33
33
|
Requires-Dist: requests (>=2.32.4,<3.0.0)
|
|
34
|
+
Requires-Dist: tiktoken (>=0.8.0,<0.9.0)
|
|
34
35
|
Requires-Dist: ulid-py (>=1.1.0,<2.0.0)
|
|
35
36
|
Project-URL: Documentation, https://github.com/state-alchemists/zrb
|
|
36
37
|
Project-URL: Repository, https://github.com/state-alchemists/zrb
|
|
@@ -81,9 +82,11 @@ Or run our installation script to set up Zrb along with all prerequisites:
|
|
|
81
82
|
bash -c "$(curl -fsSL https://raw.githubusercontent.com/state-alchemists/zrb/main/install.sh)"
|
|
82
83
|
```
|
|
83
84
|
|
|
85
|
+
You can also [run Zrb as container](https://github.com/state-alchemists/zrb?tab=readme-ov-file#-run-zrb-as-a-container)
|
|
86
|
+
|
|
84
87
|
# 🍲 Quick Start: Build Your First Automation Workflow
|
|
85
88
|
|
|
86
|
-
Zrb empowers you to create custom automation tasks using Python. This guide shows you how to define two simple tasks: one to generate a
|
|
89
|
+
Zrb empowers you to create custom automation tasks using Python. This guide shows you how to define two simple tasks: one to generate a Mermaid script from your source code and another to convert that script into a PNG image.
|
|
87
90
|
|
|
88
91
|
## 1. Create Your Task Definition File
|
|
89
92
|
|
|
@@ -92,59 +95,61 @@ Place a file named `zrb_init.py` in a directory that's accessible from your proj
|
|
|
92
95
|
Add the following content to your zrb_init.py:
|
|
93
96
|
|
|
94
97
|
```python
|
|
95
|
-
import os
|
|
96
98
|
from zrb import cli, LLMTask, CmdTask, StrInput, Group
|
|
97
|
-
from zrb.builtin.llm.tool.
|
|
98
|
-
|
|
99
|
-
)
|
|
100
|
-
|
|
99
|
+
from zrb.builtin.llm.tool.code import analyze_repo
|
|
100
|
+
from zrb.builtin.llm.tool.file import write_to_file
|
|
101
101
|
|
|
102
|
-
CURRENT_DIR = os.getcwd()
|
|
103
102
|
|
|
104
|
-
# Create a group for
|
|
105
|
-
|
|
103
|
+
# Create a group for Mermaid-related tasks
|
|
104
|
+
mermaid_group = cli.add_group(Group(name="mermaid", description="🧜 Mermaid diagram related tasks"))
|
|
106
105
|
|
|
107
|
-
# Task 1: Generate a
|
|
108
|
-
|
|
106
|
+
# Task 1: Generate a Mermaid script from your source code
|
|
107
|
+
make_mermaid_script = mermaid_group.add_task(
|
|
109
108
|
LLMTask(
|
|
110
109
|
name="make-script",
|
|
111
|
-
description="Creating
|
|
112
|
-
input=
|
|
110
|
+
description="Creating mermaid diagram based on source code in current directory",
|
|
111
|
+
input=[
|
|
112
|
+
StrInput(name="dir", default="./"),
|
|
113
|
+
StrInput(name="diagram", default="state-diagram"),
|
|
114
|
+
],
|
|
113
115
|
message=(
|
|
114
|
-
|
|
115
|
-
"make a {ctx.input.diagram} in
|
|
116
|
-
|
|
116
|
+
"Read all necessary files in {ctx.input.dir}, "
|
|
117
|
+
"make a {ctx.input.diagram} in mermaid format. "
|
|
118
|
+
"Write the script into `{ctx.input.dir}/{ctx.input.diagram}.mmd`"
|
|
117
119
|
),
|
|
118
120
|
tools=[
|
|
119
|
-
|
|
121
|
+
analyze_repo, write_to_file
|
|
120
122
|
],
|
|
121
123
|
)
|
|
122
124
|
)
|
|
123
125
|
|
|
124
|
-
# Task 2: Convert the
|
|
125
|
-
|
|
126
|
+
# Task 2: Convert the Mermaid script into a PNG image
|
|
127
|
+
make_mermaid_image = mermaid_group.add_task(
|
|
126
128
|
CmdTask(
|
|
127
129
|
name="make-image",
|
|
128
130
|
description="Creating png based on source code in current directory",
|
|
129
|
-
input=
|
|
130
|
-
|
|
131
|
-
|
|
131
|
+
input=[
|
|
132
|
+
StrInput(name="dir", default="./"),
|
|
133
|
+
StrInput(name="diagram", default="state-diagram"),
|
|
134
|
+
],
|
|
135
|
+
cmd="mmdc -i '{ctx.input.diagram}.mmd' -o '{ctx.input.diagram}.png'",
|
|
136
|
+
cwd="{ctx.input.dir}",
|
|
132
137
|
)
|
|
133
138
|
)
|
|
134
139
|
|
|
135
140
|
# Set up the dependency: the image task runs after the script is created
|
|
136
|
-
|
|
141
|
+
make_mermaid_script >> make_mermaid_image
|
|
137
142
|
```
|
|
138
143
|
|
|
139
144
|
**What This Does**
|
|
140
145
|
|
|
141
146
|
- **Task 1 – make-script**:
|
|
142
147
|
|
|
143
|
-
Uses an LLM to read all files in your current directory and generate a
|
|
148
|
+
Uses an LLM to read all files in your current directory and generate a Mermaid script (e.g., `state diagram.mmd`).
|
|
144
149
|
|
|
145
150
|
- **Task 2 – make-image**:
|
|
146
151
|
|
|
147
|
-
Executes a command that converts the
|
|
152
|
+
Executes a command that converts the Mermaid script into a PNG image (e.g., `state diagram.png`). This task will run only after the script has been generated.
|
|
148
153
|
|
|
149
154
|
|
|
150
155
|
## 2. Run Your Tasks
|
|
@@ -161,18 +166,19 @@ After setting up your tasks, you can execute them from any project. For example:
|
|
|
161
166
|
- Create a state diagram:
|
|
162
167
|
|
|
163
168
|
```bash
|
|
164
|
-
zrb
|
|
169
|
+
zrb mermaid make-image --diagram "state diagram" --dir ./
|
|
165
170
|
```
|
|
166
171
|
|
|
167
172
|
- Or use the interactive mode:
|
|
168
173
|
|
|
169
174
|
```bash
|
|
170
|
-
zrb
|
|
175
|
+
zrb mermaid make-image
|
|
171
176
|
```
|
|
172
177
|
|
|
173
178
|
Zrb will prompt:
|
|
174
179
|
|
|
175
180
|
```bash
|
|
181
|
+
dir [./]:
|
|
176
182
|
diagram [state diagram]:
|
|
177
183
|
```
|
|
178
184
|
|
|
@@ -194,7 +200,7 @@ Then open your browser and visit `http://localhost:21213`
|
|
|
194
200
|
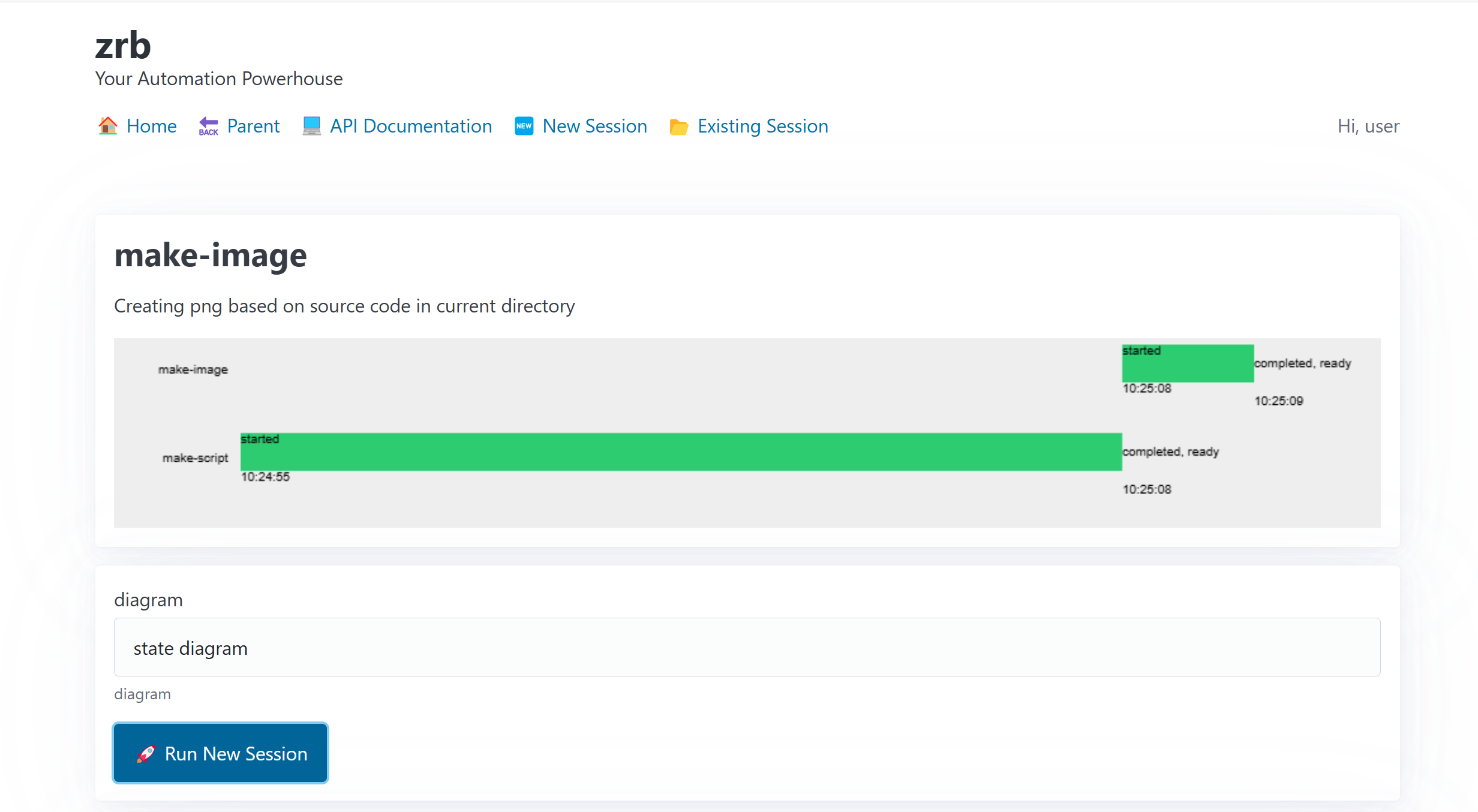
|
|
195
201
|
|
|
196
202
|
|
|
197
|
-
# 🐋
|
|
203
|
+
# 🐋 Run Zrb as a Container
|
|
198
204
|
|
|
199
205
|
Zrb can be run in a containerized environment, offering two distinct versions to suit different needs:
|
|
200
206
|
|
|
@@ -12,16 +12,16 @@ zrb/builtin/jwt.py,sha256=3M5uaQhJZbKQLjTUft1OwPz_JxtmK-xtkjxWjciOQho,2859
|
|
|
12
12
|
zrb/builtin/llm/chat_session.py,sha256=ot2ss6yA4qIINg0nl3KJYnLag8H0eB9ggAgRGEUkZdE,6639
|
|
13
13
|
zrb/builtin/llm/history.py,sha256=cnkOyO43uiMQ9cEvmqk-pPoCk1zCAH_fwAqSgBtsjzY,3079
|
|
14
14
|
zrb/builtin/llm/input.py,sha256=Nw-26uTWp2QhUgKJcP_IMHmtk-b542CCSQ_vCOjhvhM,877
|
|
15
|
-
zrb/builtin/llm/llm_ask.py,sha256=
|
|
15
|
+
zrb/builtin/llm/llm_ask.py,sha256=QUV29gOAFKiMfJlAKbY9YfGPoxYv-4RPv6p7cWogK4U,4438
|
|
16
16
|
zrb/builtin/llm/previous-session.js,sha256=xMKZvJoAbrwiyHS0OoPrWuaKxWYLoyR5sguePIoCjTY,816
|
|
17
17
|
zrb/builtin/llm/tool/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
18
18
|
zrb/builtin/llm/tool/api.py,sha256=yR9I0ZsI96OeQl9pgwORMASVuXsAL0a89D_iPS4C8Dc,1699
|
|
19
19
|
zrb/builtin/llm/tool/cli.py,sha256=_CNEmEc6K2Z0i9ppYeM7jGpqaEdT3uxaWQatmxP3jKE,858
|
|
20
|
-
zrb/builtin/llm/tool/code.py,sha256=
|
|
21
|
-
zrb/builtin/llm/tool/file.py,sha256=
|
|
20
|
+
zrb/builtin/llm/tool/code.py,sha256=q6YrVJkRJg4AQpnK2KHE6AEMo8nMbRN4XUZ3QtMI_Og,8090
|
|
21
|
+
zrb/builtin/llm/tool/file.py,sha256=ufLCAaHB0JkEAqQS4fbM9OaTfLluqlCuSyMmnYhI0rY,18491
|
|
22
22
|
zrb/builtin/llm/tool/rag.py,sha256=yqx7vXXyrOCJjhQJl4s0TnLL-2uQUTuKRnkWlSQBW0M,7883
|
|
23
|
-
zrb/builtin/llm/tool/sub_agent.py,sha256=
|
|
24
|
-
zrb/builtin/llm/tool/web.py,sha256=
|
|
23
|
+
zrb/builtin/llm/tool/sub_agent.py,sha256=GPHD8hLlIfme0h1Q0zzMUuAc2HiKl8CRqWGNcgE_H1Q,4764
|
|
24
|
+
zrb/builtin/llm/tool/web.py,sha256=GYp6e_eaw-dj7MDpB4CP1fplUbfguuJawem9lPJM9TY,5481
|
|
25
25
|
zrb/builtin/md5.py,sha256=690RV2LbW7wQeTFxY-lmmqTSVEEZv3XZbjEUW1Q3XpE,1480
|
|
26
26
|
zrb/builtin/project/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
27
27
|
zrb/builtin/project/add/fastapp/fastapp_input.py,sha256=MKlWR_LxWhM_DcULCtLfL_IjTxpDnDBkn9KIqNmajFs,310
|
|
@@ -170,7 +170,7 @@ zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/module/gateway/view
|
|
|
170
170
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/module/gateway/view/static/pico-css/pico.yellow.min.css,sha256=_UXLKrhEsXonQ-VthBNB7zHUEcV67KDAE-SiDR1SrlU,83371
|
|
171
171
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/module/gateway/view/static/pico-css/pico.zinc.min.css,sha256=C9KHUa2PomYXZg2-rbpDPDYkuL_ZZTwFS-uj1Zo7azE,83337
|
|
172
172
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/module/gateway/view/template/default.html,sha256=Lg4vONCLOx8PSORFitg8JZa-4dp-pyUvKSVzCJEFsB8,4048
|
|
173
|
-
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/requirements.txt,sha256=
|
|
173
|
+
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/requirements.txt,sha256=cV16jm4MpHK020eLm9ityrVBEZgJw0WvwrphOA-2lAE,195
|
|
174
174
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/schema/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
175
175
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/schema/permission.py,sha256=q66LXdZ-QTb30F1VTXNLnjyYBlK_ThVLiHgavtJy4LY,1424
|
|
176
176
|
zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/schema/role.py,sha256=7USbuhHhPc3xXkmwiqTVKsN8-eFWS8Q7emKxCGNGPw0,3244
|
|
@@ -217,7 +217,7 @@ zrb/callback/callback.py,sha256=PFhCqzfxdk6IAthmXcZ13DokT62xtBzJr_ciLw6I8Zg,4030
|
|
|
217
217
|
zrb/cmd/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
218
218
|
zrb/cmd/cmd_result.py,sha256=L8bQJzWCpcYexIxHBNsXj2pT3BtLmWex0iJSMkvimOA,597
|
|
219
219
|
zrb/cmd/cmd_val.py,sha256=7Doowyg6BK3ISSGBLt-PmlhzaEkBjWWm51cED6fAUOQ,1014
|
|
220
|
-
zrb/config.py,sha256=
|
|
220
|
+
zrb/config.py,sha256=qFtVVme30fMyi5x_mgvvULczNbORqK8ZEN8agXokXO4,10222
|
|
221
221
|
zrb/content_transformer/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
222
222
|
zrb/content_transformer/any_content_transformer.py,sha256=v8ZUbcix1GGeDQwB6OKX_1TjpY__ksxWVeqibwa_iZA,850
|
|
223
223
|
zrb/content_transformer/content_transformer.py,sha256=STl77wW-I69QaGzCXjvkppngYFLufow8ybPLSyAvlHs,2404
|
|
@@ -246,8 +246,8 @@ zrb/input/option_input.py,sha256=TQB82ko5odgzkULEizBZi0e9TIHEbIgvdP0AR3RhA74,213
|
|
|
246
246
|
zrb/input/password_input.py,sha256=szBojWxSP9QJecgsgA87OIYwQrY2AQ3USIKdDZY6snU,1465
|
|
247
247
|
zrb/input/str_input.py,sha256=NevZHX9rf1g8eMatPyy-kUX3DglrVAQpzvVpKAzf7bA,81
|
|
248
248
|
zrb/input/text_input.py,sha256=6T3MngWdUs0u0ZVs5Dl11w5KS7nN1RkgrIR_zKumzPM,3695
|
|
249
|
-
zrb/llm_config.py,sha256=
|
|
250
|
-
zrb/llm_rate_limitter.py,sha256=
|
|
249
|
+
zrb/llm_config.py,sha256=pXWHp-7WcAF3s5Gec8IBqoC_l3aRvU3aGt2Yr96SxGo,16607
|
|
250
|
+
zrb/llm_rate_limitter.py,sha256=uM9zmSgV10fQq1dlaDGLDrv72uLj6ldBxMoGjO2Az14,4429
|
|
251
251
|
zrb/runner/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
252
252
|
zrb/runner/cli.py,sha256=AbLTNqFy5FuyGQOWOjHZGaBC8e2yuE_Dx1sBdnisR18,6984
|
|
253
253
|
zrb/runner/common_util.py,sha256=JDMcwvQ8cxnv9kQrAoKVLA40Q1omfv-u5_d5MvvwHeE,1373
|
|
@@ -337,7 +337,7 @@ zrb/task/base_trigger.py,sha256=WSGcmBcGAZw8EzUXfmCjqJQkz8GEmi1RzogpF6A1V4s,6902
|
|
|
337
337
|
zrb/task/cmd_task.py,sha256=irGi0txTcsvGhxjfem4_radR4csNXhgtfcxruSF1LFI,10853
|
|
338
338
|
zrb/task/http_check.py,sha256=Gf5rOB2Se2EdizuN9rp65HpGmfZkGc-clIAlHmPVehs,2565
|
|
339
339
|
zrb/task/llm/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
340
|
-
zrb/task/llm/agent.py,sha256=
|
|
340
|
+
zrb/task/llm/agent.py,sha256=pwGFkRSQ-maH92QaJr2dgfQhEiwFVK5XnyK4OYBJm4c,6782
|
|
341
341
|
zrb/task/llm/config.py,sha256=Gb0lSHCgGXOAr7igkU7k_Ew5Yp_wOTpNQyZrLrtA7oc,3521
|
|
342
342
|
zrb/task/llm/context.py,sha256=U9a8lxa2ikz6my0Sd5vpO763legHrMHyvBjbrqNmv0Y,3838
|
|
343
343
|
zrb/task/llm/context_enrichment.py,sha256=BlW2CjSUsKJT8EZBXYxOE4MEBbRCoO34PlQQdzA-zBM,7201
|
|
@@ -348,7 +348,7 @@ zrb/task/llm/print_node.py,sha256=bpISOUxSH_JBLR-4Nq6-iLrzNWFagrKFX6u8ogYYMw8,43
|
|
|
348
348
|
zrb/task/llm/prompt.py,sha256=zBo3xT3YPX_A4_t8Cd-QjNqQZl9dsoWMTt-NdytI2f4,3827
|
|
349
349
|
zrb/task/llm/tool_wrapper.py,sha256=Xygd4VCY3ykjVv63pqlTI16ZG41ySkp683_5VTnL-Zo,6481
|
|
350
350
|
zrb/task/llm/typing.py,sha256=c8VAuPBw_4A3DxfYdydkgedaP-LU61W9_wj3m3CAX1E,58
|
|
351
|
-
zrb/task/llm_task.py,sha256=
|
|
351
|
+
zrb/task/llm_task.py,sha256=fRzvyso0OpDlwVVwRdib2Cq3dppEszOc9DIm50dDdhk,15930
|
|
352
352
|
zrb/task/make_task.py,sha256=PD3b_aYazthS8LHeJsLAhwKDEgdurQZpymJDKeN60u0,2265
|
|
353
353
|
zrb/task/rsync_task.py,sha256=GSL9144bmp6F0EckT6m-2a1xG25AzrrWYzH4k3SVUKM,6370
|
|
354
354
|
zrb/task/scaffolder.py,sha256=rME18w1HJUHXgi9eTYXx_T2G4JdqDYzBoNOkdOOo5-o,6806
|
|
@@ -390,7 +390,7 @@ zrb/util/string/name.py,sha256=SXEfxJ1-tDOzHqmSV8kvepRVyMqs2XdV_vyoh_9XUu0,1584
|
|
|
390
390
|
zrb/util/todo.py,sha256=VGISej2KQZERpornK-8X7bysp4JydMrMUTnG8B0-liI,20708
|
|
391
391
|
zrb/xcom/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
392
392
|
zrb/xcom/xcom.py,sha256=o79rxR9wphnShrcIushA0Qt71d_p3ZTxjNf7x9hJB78,1571
|
|
393
|
-
zrb-1.8.
|
|
394
|
-
zrb-1.8.
|
|
395
|
-
zrb-1.8.
|
|
396
|
-
zrb-1.8.
|
|
393
|
+
zrb-1.8.11.dist-info/METADATA,sha256=BxzTycMW2mrqcOCsi4k9Z_672xnzwp4IkYPpGrKrkn8,10108
|
|
394
|
+
zrb-1.8.11.dist-info/WHEEL,sha256=sP946D7jFCHeNz5Iq4fL4Lu-PrWrFsgfLXbbkciIZwg,88
|
|
395
|
+
zrb-1.8.11.dist-info/entry_points.txt,sha256=-Pg3ElWPfnaSM-XvXqCxEAa-wfVI6BEgcs386s8C8v8,46
|
|
396
|
+
zrb-1.8.11.dist-info/RECORD,,
|
|
File without changes
|
|
File without changes
|