zrb 1.8.10__py3-none-any.whl → 1.21.29__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of zrb might be problematic. Click here for more details.
- zrb/__init__.py +126 -113
- zrb/__main__.py +1 -1
- zrb/attr/type.py +10 -7
- zrb/builtin/__init__.py +2 -50
- zrb/builtin/git.py +12 -1
- zrb/builtin/group.py +31 -15
- zrb/builtin/http.py +7 -8
- zrb/builtin/llm/attachment.py +40 -0
- zrb/builtin/llm/chat_completion.py +274 -0
- zrb/builtin/llm/chat_session.py +152 -85
- zrb/builtin/llm/chat_session_cmd.py +288 -0
- zrb/builtin/llm/chat_trigger.py +79 -0
- zrb/builtin/llm/history.py +7 -9
- zrb/builtin/llm/llm_ask.py +221 -98
- zrb/builtin/llm/tool/api.py +74 -52
- zrb/builtin/llm/tool/cli.py +46 -17
- zrb/builtin/llm/tool/code.py +71 -90
- zrb/builtin/llm/tool/file.py +301 -241
- zrb/builtin/llm/tool/note.py +84 -0
- zrb/builtin/llm/tool/rag.py +38 -8
- zrb/builtin/llm/tool/sub_agent.py +67 -50
- zrb/builtin/llm/tool/web.py +146 -122
- zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/_zrb/entity/add_entity_util.py +7 -7
- zrb/builtin/project/add/fastapp/fastapp_template/my_app_name/_zrb/module/add_module_util.py +5 -5
- zrb/builtin/project/add/fastapp/fastapp_util.py +1 -1
- zrb/builtin/searxng/config/settings.yml +5671 -0
- zrb/builtin/searxng/start.py +21 -0
- zrb/builtin/setup/latex/ubuntu.py +1 -0
- zrb/builtin/setup/ubuntu.py +1 -1
- zrb/builtin/shell/autocomplete/bash.py +4 -3
- zrb/builtin/shell/autocomplete/zsh.py +4 -3
- zrb/builtin/todo.py +13 -2
- zrb/config/config.py +614 -0
- zrb/config/default_prompt/file_extractor_system_prompt.md +112 -0
- zrb/config/default_prompt/interactive_system_prompt.md +29 -0
- zrb/config/default_prompt/persona.md +1 -0
- zrb/config/default_prompt/repo_extractor_system_prompt.md +112 -0
- zrb/config/default_prompt/repo_summarizer_system_prompt.md +29 -0
- zrb/config/default_prompt/summarization_prompt.md +57 -0
- zrb/config/default_prompt/system_prompt.md +38 -0
- zrb/config/llm_config.py +339 -0
- zrb/config/llm_context/config.py +166 -0
- zrb/config/llm_context/config_parser.py +40 -0
- zrb/config/llm_context/workflow.py +81 -0
- zrb/config/llm_rate_limitter.py +190 -0
- zrb/{runner → config}/web_auth_config.py +17 -22
- zrb/context/any_shared_context.py +17 -1
- zrb/context/context.py +16 -2
- zrb/context/shared_context.py +18 -8
- zrb/group/any_group.py +12 -5
- zrb/group/group.py +67 -3
- zrb/input/any_input.py +5 -1
- zrb/input/base_input.py +18 -6
- zrb/input/option_input.py +13 -1
- zrb/input/text_input.py +8 -25
- zrb/runner/cli.py +25 -23
- zrb/runner/common_util.py +24 -19
- zrb/runner/web_app.py +3 -3
- zrb/runner/web_route/docs_route.py +1 -1
- zrb/runner/web_route/error_page/serve_default_404.py +1 -1
- zrb/runner/web_route/error_page/show_error_page.py +1 -1
- zrb/runner/web_route/home_page/home_page_route.py +2 -2
- zrb/runner/web_route/login_api_route.py +1 -1
- zrb/runner/web_route/login_page/login_page_route.py +2 -2
- zrb/runner/web_route/logout_api_route.py +1 -1
- zrb/runner/web_route/logout_page/logout_page_route.py +2 -2
- zrb/runner/web_route/node_page/group/show_group_page.py +1 -1
- zrb/runner/web_route/node_page/node_page_route.py +1 -1
- zrb/runner/web_route/node_page/task/show_task_page.py +1 -1
- zrb/runner/web_route/refresh_token_api_route.py +1 -1
- zrb/runner/web_route/static/static_route.py +1 -1
- zrb/runner/web_route/task_input_api_route.py +6 -6
- zrb/runner/web_route/task_session_api_route.py +20 -12
- zrb/runner/web_util/cookie.py +1 -1
- zrb/runner/web_util/token.py +1 -1
- zrb/runner/web_util/user.py +8 -4
- zrb/session/any_session.py +24 -17
- zrb/session/session.py +50 -25
- zrb/session_state_logger/any_session_state_logger.py +9 -4
- zrb/session_state_logger/file_session_state_logger.py +16 -6
- zrb/session_state_logger/session_state_logger_factory.py +1 -1
- zrb/task/any_task.py +30 -9
- zrb/task/base/context.py +17 -9
- zrb/task/base/execution.py +15 -8
- zrb/task/base/lifecycle.py +8 -4
- zrb/task/base/monitoring.py +12 -7
- zrb/task/base_task.py +69 -5
- zrb/task/base_trigger.py +12 -5
- zrb/task/cmd_task.py +1 -1
- zrb/task/llm/agent.py +154 -161
- zrb/task/llm/agent_runner.py +152 -0
- zrb/task/llm/config.py +47 -18
- zrb/task/llm/conversation_history.py +209 -0
- zrb/task/llm/conversation_history_model.py +67 -0
- zrb/task/llm/default_workflow/coding/workflow.md +41 -0
- zrb/task/llm/default_workflow/copywriting/workflow.md +68 -0
- zrb/task/llm/default_workflow/git/workflow.md +118 -0
- zrb/task/llm/default_workflow/golang/workflow.md +128 -0
- zrb/task/llm/default_workflow/html-css/workflow.md +135 -0
- zrb/task/llm/default_workflow/java/workflow.md +146 -0
- zrb/task/llm/default_workflow/javascript/workflow.md +158 -0
- zrb/task/llm/default_workflow/python/workflow.md +160 -0
- zrb/task/llm/default_workflow/researching/workflow.md +153 -0
- zrb/task/llm/default_workflow/rust/workflow.md +162 -0
- zrb/task/llm/default_workflow/shell/workflow.md +299 -0
- zrb/task/llm/error.py +24 -10
- zrb/task/llm/file_replacement.py +206 -0
- zrb/task/llm/file_tool_model.py +57 -0
- zrb/task/llm/history_processor.py +206 -0
- zrb/task/llm/history_summarization.py +11 -166
- zrb/task/llm/print_node.py +193 -69
- zrb/task/llm/prompt.py +242 -45
- zrb/task/llm/subagent_conversation_history.py +41 -0
- zrb/task/llm/tool_wrapper.py +260 -57
- zrb/task/llm/workflow.py +76 -0
- zrb/task/llm_task.py +182 -171
- zrb/task/make_task.py +2 -3
- zrb/task/rsync_task.py +26 -11
- zrb/task/scheduler.py +4 -4
- zrb/util/attr.py +54 -39
- zrb/util/callable.py +23 -0
- zrb/util/cli/markdown.py +12 -0
- zrb/util/cli/text.py +30 -0
- zrb/util/file.py +29 -11
- zrb/util/git.py +8 -11
- zrb/util/git_diff_model.py +10 -0
- zrb/util/git_subtree.py +9 -14
- zrb/util/git_subtree_model.py +32 -0
- zrb/util/init_path.py +1 -1
- zrb/util/markdown.py +62 -0
- zrb/util/string/conversion.py +2 -2
- zrb/util/todo.py +17 -50
- zrb/util/todo_model.py +46 -0
- zrb/util/truncate.py +23 -0
- zrb/util/yaml.py +204 -0
- zrb/xcom/xcom.py +10 -0
- zrb-1.21.29.dist-info/METADATA +270 -0
- {zrb-1.8.10.dist-info → zrb-1.21.29.dist-info}/RECORD +140 -98
- {zrb-1.8.10.dist-info → zrb-1.21.29.dist-info}/WHEEL +1 -1
- zrb/config.py +0 -335
- zrb/llm_config.py +0 -411
- zrb/llm_rate_limitter.py +0 -125
- zrb/task/llm/context.py +0 -102
- zrb/task/llm/context_enrichment.py +0 -199
- zrb/task/llm/history.py +0 -211
- zrb-1.8.10.dist-info/METADATA +0 -264
- {zrb-1.8.10.dist-info → zrb-1.21.29.dist-info}/entry_points.txt +0 -0
|
@@ -1,199 +0,0 @@
|
|
|
1
|
-
import json
|
|
2
|
-
import traceback
|
|
3
|
-
from typing import TYPE_CHECKING, Any
|
|
4
|
-
|
|
5
|
-
from pydantic import BaseModel
|
|
6
|
-
|
|
7
|
-
from zrb.attr.type import BoolAttr, IntAttr
|
|
8
|
-
from zrb.context.any_context import AnyContext
|
|
9
|
-
from zrb.llm_config import llm_config
|
|
10
|
-
from zrb.llm_rate_limitter import LLMRateLimiter
|
|
11
|
-
from zrb.task.llm.agent import run_agent_iteration
|
|
12
|
-
from zrb.task.llm.history import (
|
|
13
|
-
count_part_in_history_list,
|
|
14
|
-
replace_system_prompt_in_history_list,
|
|
15
|
-
)
|
|
16
|
-
from zrb.task.llm.typing import ListOfDict
|
|
17
|
-
from zrb.util.attr import get_bool_attr, get_int_attr
|
|
18
|
-
from zrb.util.cli.style import stylize_faint
|
|
19
|
-
|
|
20
|
-
if TYPE_CHECKING:
|
|
21
|
-
from pydantic_ai.models import Model
|
|
22
|
-
from pydantic_ai.settings import ModelSettings
|
|
23
|
-
else:
|
|
24
|
-
Model = Any
|
|
25
|
-
ModelSettings = Any
|
|
26
|
-
|
|
27
|
-
|
|
28
|
-
class EnrichmentConfig(BaseModel):
|
|
29
|
-
model_config = {"arbitrary_types_allowed": True}
|
|
30
|
-
model: Model | str | None = None
|
|
31
|
-
settings: ModelSettings | None = None
|
|
32
|
-
prompt: str
|
|
33
|
-
retries: int = 3
|
|
34
|
-
|
|
35
|
-
|
|
36
|
-
class EnrichmentResult(BaseModel):
|
|
37
|
-
response: dict[str, Any] # or further decompose as needed
|
|
38
|
-
|
|
39
|
-
|
|
40
|
-
async def enrich_context(
|
|
41
|
-
ctx: AnyContext,
|
|
42
|
-
config: EnrichmentConfig,
|
|
43
|
-
conversation_context: dict[str, Any],
|
|
44
|
-
history_list: ListOfDict,
|
|
45
|
-
rate_limitter: LLMRateLimiter | None = None,
|
|
46
|
-
) -> dict[str, Any]:
|
|
47
|
-
"""Runs an LLM call to extract key info and merge it into the context."""
|
|
48
|
-
from pydantic_ai import Agent
|
|
49
|
-
|
|
50
|
-
ctx.log_info("Attempting to enrich conversation context...")
|
|
51
|
-
# Prepare context and history for the enrichment prompt
|
|
52
|
-
history_summary = conversation_context.get("history_summary")
|
|
53
|
-
try:
|
|
54
|
-
context_json = json.dumps(conversation_context)
|
|
55
|
-
history_json = json.dumps(history_list)
|
|
56
|
-
# The user prompt will now contain the dynamic data
|
|
57
|
-
user_prompt_data = "\n".join(
|
|
58
|
-
[
|
|
59
|
-
"Extract context from the following conversation info.",
|
|
60
|
-
"Extract only contexts that will be relevant across multiple conversations, like", # noqa
|
|
61
|
-
"- user name",
|
|
62
|
-
"- user hobby",
|
|
63
|
-
"- user's long life goal",
|
|
64
|
-
"- standard/SOP",
|
|
65
|
-
"- etc.",
|
|
66
|
-
"Always maintain the relevant context and remove the irrelevant ones.",
|
|
67
|
-
"Restructure the context in a helpful way",
|
|
68
|
-
"Keep the context small",
|
|
69
|
-
f"Existing Context: {context_json}",
|
|
70
|
-
f"Conversation History: {history_json}",
|
|
71
|
-
]
|
|
72
|
-
)
|
|
73
|
-
except Exception as e:
|
|
74
|
-
ctx.log_warning(f"Error formatting context/history for enrichment: {e}")
|
|
75
|
-
return conversation_context # Return original context if formatting fails
|
|
76
|
-
|
|
77
|
-
enrichment_agent = Agent(
|
|
78
|
-
model=config.model,
|
|
79
|
-
system_prompt=config.prompt, # Use the main prompt as system prompt
|
|
80
|
-
model_settings=config.settings,
|
|
81
|
-
retries=config.retries,
|
|
82
|
-
output_type=EnrichmentResult,
|
|
83
|
-
)
|
|
84
|
-
|
|
85
|
-
try:
|
|
86
|
-
ctx.print(stylize_faint("[Context Enrichment Triggered]"), plain=True)
|
|
87
|
-
enrichment_run = await run_agent_iteration(
|
|
88
|
-
ctx=ctx,
|
|
89
|
-
agent=enrichment_agent,
|
|
90
|
-
user_prompt=user_prompt_data, # Pass the formatted data as user prompt
|
|
91
|
-
history_list=[], # Enrichment agent doesn't need prior history itself
|
|
92
|
-
rate_limitter=rate_limitter,
|
|
93
|
-
)
|
|
94
|
-
if enrichment_run and enrichment_run.result.output:
|
|
95
|
-
response = enrichment_run.result.output.response
|
|
96
|
-
usage = enrichment_run.result.usage()
|
|
97
|
-
ctx.print(stylize_faint(f"[Token Usage] {usage}"), plain=True)
|
|
98
|
-
if response:
|
|
99
|
-
conversation_context = response
|
|
100
|
-
# Re inject history summary
|
|
101
|
-
conversation_context["history_summary"] = history_summary
|
|
102
|
-
ctx.log_info("Context enriched based on history.")
|
|
103
|
-
ctx.log_info(
|
|
104
|
-
f"Updated conversation context: {json.dumps(conversation_context)}"
|
|
105
|
-
)
|
|
106
|
-
else:
|
|
107
|
-
ctx.log_warning("Context enrichment returned no data")
|
|
108
|
-
except Exception as e:
|
|
109
|
-
ctx.log_warning(f"Error during context enrichment LLM call: {e}")
|
|
110
|
-
traceback.print_exc()
|
|
111
|
-
return conversation_context
|
|
112
|
-
|
|
113
|
-
|
|
114
|
-
def get_context_enrichment_threshold(
|
|
115
|
-
ctx: AnyContext,
|
|
116
|
-
context_enrichment_threshold_attr: IntAttr | None,
|
|
117
|
-
render_context_enrichment_threshold: bool,
|
|
118
|
-
) -> int:
|
|
119
|
-
"""Gets the context enrichment threshold, handling defaults and errors."""
|
|
120
|
-
try:
|
|
121
|
-
return get_int_attr(
|
|
122
|
-
ctx,
|
|
123
|
-
context_enrichment_threshold_attr,
|
|
124
|
-
# Use llm_config default if attribute is None
|
|
125
|
-
llm_config.default_context_enrichment_threshold,
|
|
126
|
-
auto_render=render_context_enrichment_threshold,
|
|
127
|
-
)
|
|
128
|
-
except ValueError as e:
|
|
129
|
-
ctx.log_warning(
|
|
130
|
-
f"Could not convert context_enrichment_threshold to int: {e}. "
|
|
131
|
-
"Defaulting to -1 (no threshold)."
|
|
132
|
-
)
|
|
133
|
-
return -1
|
|
134
|
-
|
|
135
|
-
|
|
136
|
-
def should_enrich_context(
|
|
137
|
-
ctx: AnyContext,
|
|
138
|
-
history_list: ListOfDict,
|
|
139
|
-
should_enrich_context_attr: BoolAttr | None, # Allow None
|
|
140
|
-
render_enrich_context: bool,
|
|
141
|
-
context_enrichment_threshold_attr: IntAttr | None,
|
|
142
|
-
render_context_enrichment_threshold: bool,
|
|
143
|
-
) -> bool:
|
|
144
|
-
"""
|
|
145
|
-
Determines if context enrichment should occur based on history, threshold, and config.
|
|
146
|
-
"""
|
|
147
|
-
history_part_count = count_part_in_history_list(history_list)
|
|
148
|
-
if history_part_count == 0:
|
|
149
|
-
return False
|
|
150
|
-
enrichment_threshold = get_context_enrichment_threshold(
|
|
151
|
-
ctx,
|
|
152
|
-
context_enrichment_threshold_attr,
|
|
153
|
-
render_context_enrichment_threshold,
|
|
154
|
-
)
|
|
155
|
-
if enrichment_threshold == -1 or enrichment_threshold > history_part_count:
|
|
156
|
-
return False
|
|
157
|
-
return get_bool_attr(
|
|
158
|
-
ctx,
|
|
159
|
-
should_enrich_context_attr,
|
|
160
|
-
llm_config.default_enrich_context,
|
|
161
|
-
auto_render=render_enrich_context,
|
|
162
|
-
)
|
|
163
|
-
|
|
164
|
-
|
|
165
|
-
async def maybe_enrich_context(
|
|
166
|
-
ctx: AnyContext,
|
|
167
|
-
history_list: ListOfDict,
|
|
168
|
-
conversation_context: dict[str, Any],
|
|
169
|
-
should_enrich_context_attr: BoolAttr | None,
|
|
170
|
-
render_enrich_context: bool,
|
|
171
|
-
context_enrichment_threshold_attr: IntAttr | None,
|
|
172
|
-
render_context_enrichment_threshold: bool,
|
|
173
|
-
model: str | Model | None,
|
|
174
|
-
model_settings: ModelSettings | None,
|
|
175
|
-
context_enrichment_prompt: str,
|
|
176
|
-
rate_limitter: LLMRateLimiter | None = None,
|
|
177
|
-
) -> dict[str, Any]:
|
|
178
|
-
"""Enriches context based on history if enabled and threshold met."""
|
|
179
|
-
shorten_history_list = replace_system_prompt_in_history_list(history_list)
|
|
180
|
-
if should_enrich_context(
|
|
181
|
-
ctx,
|
|
182
|
-
shorten_history_list,
|
|
183
|
-
should_enrich_context_attr,
|
|
184
|
-
render_enrich_context,
|
|
185
|
-
context_enrichment_threshold_attr,
|
|
186
|
-
render_context_enrichment_threshold,
|
|
187
|
-
):
|
|
188
|
-
return await enrich_context(
|
|
189
|
-
ctx=ctx,
|
|
190
|
-
config=EnrichmentConfig(
|
|
191
|
-
model=model,
|
|
192
|
-
settings=model_settings,
|
|
193
|
-
prompt=context_enrichment_prompt,
|
|
194
|
-
),
|
|
195
|
-
conversation_context=conversation_context,
|
|
196
|
-
history_list=shorten_history_list,
|
|
197
|
-
rate_limitter=rate_limitter,
|
|
198
|
-
)
|
|
199
|
-
return conversation_context
|
zrb/task/llm/history.py
DELETED
|
@@ -1,211 +0,0 @@
|
|
|
1
|
-
import json
|
|
2
|
-
import os
|
|
3
|
-
from collections.abc import Callable
|
|
4
|
-
from copy import deepcopy
|
|
5
|
-
from typing import Any, Optional
|
|
6
|
-
|
|
7
|
-
from pydantic import BaseModel
|
|
8
|
-
|
|
9
|
-
from zrb.attr.type import StrAttr
|
|
10
|
-
from zrb.context.any_context import AnyContext
|
|
11
|
-
from zrb.context.any_shared_context import AnySharedContext
|
|
12
|
-
from zrb.task.llm.typing import ListOfDict
|
|
13
|
-
from zrb.util.attr import get_str_attr
|
|
14
|
-
from zrb.util.file import read_file, write_file
|
|
15
|
-
from zrb.util.run import run_async
|
|
16
|
-
|
|
17
|
-
|
|
18
|
-
# Define the new ConversationHistoryData model
|
|
19
|
-
class ConversationHistoryData(BaseModel):
|
|
20
|
-
context: dict[str, Any] = {}
|
|
21
|
-
history: ListOfDict = []
|
|
22
|
-
|
|
23
|
-
@classmethod
|
|
24
|
-
async def read_from_sources(
|
|
25
|
-
cls,
|
|
26
|
-
ctx: AnyContext,
|
|
27
|
-
reader: Callable[[AnyContext], dict[str, Any] | list | None] | None,
|
|
28
|
-
file_path: str | None,
|
|
29
|
-
) -> Optional["ConversationHistoryData"]:
|
|
30
|
-
"""Reads conversation history from various sources with priority."""
|
|
31
|
-
# Priority 1: Reader function
|
|
32
|
-
if reader:
|
|
33
|
-
try:
|
|
34
|
-
raw_data = await run_async(reader(ctx))
|
|
35
|
-
if raw_data:
|
|
36
|
-
instance = cls.parse_and_validate(ctx, raw_data, "reader")
|
|
37
|
-
if instance:
|
|
38
|
-
return instance
|
|
39
|
-
except Exception as e:
|
|
40
|
-
ctx.log_warning(
|
|
41
|
-
f"Error executing conversation history reader: {e}. Ignoring."
|
|
42
|
-
)
|
|
43
|
-
# Priority 2: History file
|
|
44
|
-
if file_path and os.path.isfile(file_path):
|
|
45
|
-
try:
|
|
46
|
-
content = read_file(file_path)
|
|
47
|
-
raw_data = json.loads(content)
|
|
48
|
-
instance = cls.parse_and_validate(ctx, raw_data, f"file '{file_path}'")
|
|
49
|
-
if instance:
|
|
50
|
-
return instance
|
|
51
|
-
except json.JSONDecodeError:
|
|
52
|
-
ctx.log_warning(
|
|
53
|
-
f"Could not decode JSON from history file '{file_path}'. "
|
|
54
|
-
"Ignoring file content."
|
|
55
|
-
)
|
|
56
|
-
except Exception as e:
|
|
57
|
-
ctx.log_warning(
|
|
58
|
-
f"Error reading history file '{file_path}': {e}. "
|
|
59
|
-
"Ignoring file content."
|
|
60
|
-
)
|
|
61
|
-
# If neither reader nor file provided valid data
|
|
62
|
-
return None
|
|
63
|
-
|
|
64
|
-
@classmethod
|
|
65
|
-
def parse_and_validate(
|
|
66
|
-
cls, ctx: AnyContext, data: Any, source: str
|
|
67
|
-
) -> Optional["ConversationHistoryData"]:
|
|
68
|
-
"""Parses raw data into ConversationHistoryData, handling validation & old formats."""
|
|
69
|
-
try:
|
|
70
|
-
if isinstance(data, cls):
|
|
71
|
-
return data # Already a valid instance
|
|
72
|
-
if isinstance(data, dict) and "history" in data:
|
|
73
|
-
# Standard format {'context': ..., 'history': ...}
|
|
74
|
-
# Ensure context exists, even if empty
|
|
75
|
-
data.setdefault("context", {})
|
|
76
|
-
return cls.model_validate(data)
|
|
77
|
-
elif isinstance(data, list):
|
|
78
|
-
# Handle old format (just a list) - wrap it
|
|
79
|
-
ctx.log_warning(
|
|
80
|
-
f"History from {source} contains old list format. "
|
|
81
|
-
"Wrapping it into the new structure {'context': {}, 'history': [...]}. "
|
|
82
|
-
"Consider updating the source format."
|
|
83
|
-
)
|
|
84
|
-
return cls(history=data, context={})
|
|
85
|
-
else:
|
|
86
|
-
ctx.log_warning(
|
|
87
|
-
f"History data from {source} has unexpected format "
|
|
88
|
-
f"(type: {type(data)}). Ignoring."
|
|
89
|
-
)
|
|
90
|
-
return None
|
|
91
|
-
except Exception as e: # Catch validation errors too
|
|
92
|
-
ctx.log_warning(
|
|
93
|
-
f"Error validating/parsing history data from {source}: {e}. Ignoring."
|
|
94
|
-
)
|
|
95
|
-
return None
|
|
96
|
-
|
|
97
|
-
|
|
98
|
-
def get_history_file(
|
|
99
|
-
ctx: AnyContext,
|
|
100
|
-
conversation_history_file_attr: StrAttr | None,
|
|
101
|
-
render_history_file: bool,
|
|
102
|
-
) -> str:
|
|
103
|
-
"""Gets the path to the conversation history file, rendering if configured."""
|
|
104
|
-
return get_str_attr(
|
|
105
|
-
ctx,
|
|
106
|
-
conversation_history_file_attr,
|
|
107
|
-
"",
|
|
108
|
-
auto_render=render_history_file,
|
|
109
|
-
)
|
|
110
|
-
|
|
111
|
-
|
|
112
|
-
async def read_conversation_history(
|
|
113
|
-
ctx: AnyContext,
|
|
114
|
-
conversation_history_reader: (
|
|
115
|
-
Callable[[AnySharedContext], ConversationHistoryData | dict | list | None]
|
|
116
|
-
| None
|
|
117
|
-
),
|
|
118
|
-
conversation_history_file_attr: StrAttr | None,
|
|
119
|
-
render_history_file: bool,
|
|
120
|
-
conversation_history_attr: (
|
|
121
|
-
ConversationHistoryData
|
|
122
|
-
| Callable[[AnySharedContext], ConversationHistoryData | dict | list]
|
|
123
|
-
| dict
|
|
124
|
-
| list
|
|
125
|
-
),
|
|
126
|
-
) -> ConversationHistoryData:
|
|
127
|
-
"""Reads conversation history from reader, file, or attribute, with validation."""
|
|
128
|
-
history_file = get_history_file(
|
|
129
|
-
ctx, conversation_history_file_attr, render_history_file
|
|
130
|
-
)
|
|
131
|
-
# Use the class method defined above
|
|
132
|
-
history_data = await ConversationHistoryData.read_from_sources(
|
|
133
|
-
ctx=ctx,
|
|
134
|
-
reader=conversation_history_reader,
|
|
135
|
-
file_path=history_file,
|
|
136
|
-
)
|
|
137
|
-
if history_data:
|
|
138
|
-
return history_data
|
|
139
|
-
# Priority 3: Callable or direct conversation_history attribute
|
|
140
|
-
raw_data_attr: Any = None
|
|
141
|
-
if callable(conversation_history_attr):
|
|
142
|
-
try:
|
|
143
|
-
raw_data_attr = await run_async(conversation_history_attr(ctx))
|
|
144
|
-
except Exception as e:
|
|
145
|
-
ctx.log_warning(
|
|
146
|
-
f"Error executing callable conversation_history attribute: {e}. "
|
|
147
|
-
"Ignoring."
|
|
148
|
-
)
|
|
149
|
-
if raw_data_attr is None:
|
|
150
|
-
raw_data_attr = conversation_history_attr
|
|
151
|
-
if raw_data_attr:
|
|
152
|
-
# Use the class method defined above
|
|
153
|
-
history_data = ConversationHistoryData.parse_and_validate(
|
|
154
|
-
ctx, raw_data_attr, "attribute"
|
|
155
|
-
)
|
|
156
|
-
if history_data:
|
|
157
|
-
return history_data
|
|
158
|
-
# Fallback: Return default value
|
|
159
|
-
return ConversationHistoryData()
|
|
160
|
-
|
|
161
|
-
|
|
162
|
-
async def write_conversation_history(
|
|
163
|
-
ctx: AnyContext,
|
|
164
|
-
history_data: ConversationHistoryData,
|
|
165
|
-
conversation_history_writer: (
|
|
166
|
-
Callable[[AnySharedContext, ConversationHistoryData], None] | None
|
|
167
|
-
),
|
|
168
|
-
conversation_history_file_attr: StrAttr | None,
|
|
169
|
-
render_history_file: bool,
|
|
170
|
-
):
|
|
171
|
-
"""Writes conversation history using the writer or to a file."""
|
|
172
|
-
if conversation_history_writer is not None:
|
|
173
|
-
await run_async(conversation_history_writer(ctx, history_data))
|
|
174
|
-
history_file = get_history_file(
|
|
175
|
-
ctx, conversation_history_file_attr, render_history_file
|
|
176
|
-
)
|
|
177
|
-
if history_file != "":
|
|
178
|
-
write_file(history_file, history_data.model_dump_json(indent=2))
|
|
179
|
-
|
|
180
|
-
|
|
181
|
-
def replace_system_prompt_in_history_list(
|
|
182
|
-
history_list: ListOfDict, replacement: str = "<main LLM system prompt>"
|
|
183
|
-
) -> ListOfDict:
|
|
184
|
-
"""
|
|
185
|
-
Returns a new history list where any part with part_kind 'system-prompt'
|
|
186
|
-
has its 'content' replaced with the given replacement string.
|
|
187
|
-
Args:
|
|
188
|
-
history: List of history items (each item is a dict with a 'parts' list).
|
|
189
|
-
replacement: The string to use in place of system-prompt content.
|
|
190
|
-
|
|
191
|
-
Returns:
|
|
192
|
-
A deep-copied list of history items with system-prompt content replaced.
|
|
193
|
-
"""
|
|
194
|
-
new_history = deepcopy(history_list)
|
|
195
|
-
for item in new_history:
|
|
196
|
-
parts = item.get("parts", [])
|
|
197
|
-
for part in parts:
|
|
198
|
-
if part.get("part_kind") == "system-prompt":
|
|
199
|
-
part["content"] = replacement
|
|
200
|
-
return new_history
|
|
201
|
-
|
|
202
|
-
|
|
203
|
-
def count_part_in_history_list(history_list: ListOfDict) -> int:
|
|
204
|
-
"""Calculates the total number of 'parts' in a history list."""
|
|
205
|
-
history_part_len = 0
|
|
206
|
-
for history in history_list:
|
|
207
|
-
if "parts" in history:
|
|
208
|
-
history_part_len += len(history["parts"])
|
|
209
|
-
else:
|
|
210
|
-
history_part_len += 1
|
|
211
|
-
return history_part_len
|
zrb-1.8.10.dist-info/METADATA
DELETED
|
@@ -1,264 +0,0 @@
|
|
|
1
|
-
Metadata-Version: 2.1
|
|
2
|
-
Name: zrb
|
|
3
|
-
Version: 1.8.10
|
|
4
|
-
Summary: Your Automation Powerhouse
|
|
5
|
-
Home-page: https://github.com/state-alchemists/zrb
|
|
6
|
-
License: AGPL-3.0-or-later
|
|
7
|
-
Keywords: Automation,Task Runner,Code Generator,Monorepo,Low Code
|
|
8
|
-
Author: Go Frendi Gunawan
|
|
9
|
-
Author-email: gofrendiasgard@gmail.com
|
|
10
|
-
Requires-Python: >=3.10.0,<4.0.0
|
|
11
|
-
Classifier: License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)
|
|
12
|
-
Classifier: Programming Language :: Python :: 3
|
|
13
|
-
Classifier: Programming Language :: Python :: 3.10
|
|
14
|
-
Classifier: Programming Language :: Python :: 3.11
|
|
15
|
-
Classifier: Programming Language :: Python :: 3.12
|
|
16
|
-
Provides-Extra: all
|
|
17
|
-
Provides-Extra: playwright
|
|
18
|
-
Provides-Extra: rag
|
|
19
|
-
Requires-Dist: beautifulsoup4 (>=4.13.3,<5.0.0)
|
|
20
|
-
Requires-Dist: black (>=25.1.0,<25.2.0)
|
|
21
|
-
Requires-Dist: chromadb (>=0.6.3,<0.7.0) ; extra == "rag" or extra == "all"
|
|
22
|
-
Requires-Dist: fastapi[standard] (>=0.115.14,<0.116.0)
|
|
23
|
-
Requires-Dist: isort (>=6.0.1,<6.1.0)
|
|
24
|
-
Requires-Dist: libcst (>=1.7.0,<2.0.0)
|
|
25
|
-
Requires-Dist: openai (>=1.86.0,<2.0.0) ; extra == "rag" or extra == "all"
|
|
26
|
-
Requires-Dist: pdfplumber (>=0.11.6,<0.12.0) ; extra == "rag" or extra == "all"
|
|
27
|
-
Requires-Dist: playwright (>=1.53.0,<2.0.0) ; extra == "playwright" or extra == "all"
|
|
28
|
-
Requires-Dist: psutil (>=7.0.0,<8.0.0)
|
|
29
|
-
Requires-Dist: pydantic-ai (>=0.3.4,<0.4.0)
|
|
30
|
-
Requires-Dist: pyjwt (>=2.10.1,<3.0.0)
|
|
31
|
-
Requires-Dist: python-dotenv (>=1.1.1,<2.0.0)
|
|
32
|
-
Requires-Dist: python-jose[cryptography] (>=3.4.0,<4.0.0)
|
|
33
|
-
Requires-Dist: requests (>=2.32.4,<3.0.0)
|
|
34
|
-
Requires-Dist: tiktoken (>=0.8.0,<0.9.0)
|
|
35
|
-
Requires-Dist: ulid-py (>=1.1.0,<2.0.0)
|
|
36
|
-
Project-URL: Documentation, https://github.com/state-alchemists/zrb
|
|
37
|
-
Project-URL: Repository, https://github.com/state-alchemists/zrb
|
|
38
|
-
Description-Content-Type: text/markdown
|
|
39
|
-
|
|
40
|
-

|
|
41
|
-
|
|
42
|
-
[Documentation](https://github.com/state-alchemists/zrb/blob/main/docs/README.md)
|
|
43
|
-
|
|
44
|
-
# 🤖 Zrb: Your Automation Powerhouse
|
|
45
|
-
|
|
46
|
-
|
|
47
|
-
**Unlock the full potential of automation in your projects!**
|
|
48
|
-
|
|
49
|
-
Zrb streamlines repetitive tasks, integrates with powerful LLMs, and lets you create custom automation workflows effortlessly. Whether you’re building CI/CD pipelines, code generators, or unique automation scripts, Zrb is designed to simplify and supercharge your workflow.
|
|
50
|
-
|
|
51
|
-
|
|
52
|
-
## 🚀 Why Zrb?
|
|
53
|
-
|
|
54
|
-
- **Easy Automation with Python:** Write your tasks in Python and let Zrb handle the rest.
|
|
55
|
-
- **Seamless Integration:** Utilize built-in support for LLM tasks, command execution, and more.
|
|
56
|
-
- **Custom Workflows:** Chain tasks, set dependencies, and build robust automation pipelines.
|
|
57
|
-
- **Developer-Friendly:** Quick to install and get started, with clear documentation and examples.
|
|
58
|
-
- **Web Interface:** Run Zrb as a server to make tasks accessible even to non-technical team members.
|
|
59
|
-
|
|
60
|
-
|
|
61
|
-
## 🔥 Key Features
|
|
62
|
-
|
|
63
|
-
- **LLM Integration:** Leverage state-of-the-art language models to generate code, diagrams, and documentation.
|
|
64
|
-
- **Task Chaining:** Easily define dependencies between tasks to create complex workflows.
|
|
65
|
-
- **CLI & Server Mode:** Run tasks directly from the command line or through a user-friendly web UI.
|
|
66
|
-
- **Flexible Input Handling:** Defaults, prompts, and command-line parameters to suit any workflow.
|
|
67
|
-
- **Extensible & Open Source:** Contribute, customize, or extend Zrb to fit your unique needs.
|
|
68
|
-
|
|
69
|
-
|
|
70
|
-
# 🛠️ Installation
|
|
71
|
-
|
|
72
|
-
Install Zrb via pip:
|
|
73
|
-
|
|
74
|
-
```bash
|
|
75
|
-
pip install zrb
|
|
76
|
-
# pip install --pre zrb
|
|
77
|
-
```
|
|
78
|
-
|
|
79
|
-
Or run our installation script to set up Zrb along with all prerequisites:
|
|
80
|
-
|
|
81
|
-
```bash
|
|
82
|
-
bash -c "$(curl -fsSL https://raw.githubusercontent.com/state-alchemists/zrb/main/install.sh)"
|
|
83
|
-
```
|
|
84
|
-
|
|
85
|
-
You can also [run Zrb as container](https://github.com/state-alchemists/zrb?tab=readme-ov-file#-run-zrb-as-a-container)
|
|
86
|
-
|
|
87
|
-
# 🍲 Quick Start: Build Your First Automation Workflow
|
|
88
|
-
|
|
89
|
-
Zrb empowers you to create custom automation tasks using Python. This guide shows you how to define two simple tasks: one to generate a Mermaid script from your source code and another to convert that script into a PNG image.
|
|
90
|
-
|
|
91
|
-
## 1. Create Your Task Definition File
|
|
92
|
-
|
|
93
|
-
Place a file named `zrb_init.py` in a directory that's accessible from your projects. Zrb will automatically search for this file by starting in your current directory and then moving upward (i.e., checking parent directories) until it finds one. This means if you place your `zrb_init.py` in your home directory (e.g., `/home/<your-user-name>/zrb_init.py`), the tasks defined there will be available for any project.
|
|
94
|
-
|
|
95
|
-
Add the following content to your zrb_init.py:
|
|
96
|
-
|
|
97
|
-
```python
|
|
98
|
-
from zrb import cli, LLMTask, CmdTask, StrInput, Group
|
|
99
|
-
from zrb.builtin.llm.tool.code import analyze_repo
|
|
100
|
-
from zrb.builtin.llm.tool.file import write_to_file
|
|
101
|
-
|
|
102
|
-
|
|
103
|
-
# Create a group for Mermaid-related tasks
|
|
104
|
-
mermaid_group = cli.add_group(Group(name="mermaid", description="🧜 Mermaid diagram related tasks"))
|
|
105
|
-
|
|
106
|
-
# Task 1: Generate a Mermaid script from your source code
|
|
107
|
-
make_mermaid_script = mermaid_group.add_task(
|
|
108
|
-
LLMTask(
|
|
109
|
-
name="make-script",
|
|
110
|
-
description="Creating mermaid diagram based on source code in current directory",
|
|
111
|
-
input=[
|
|
112
|
-
StrInput(name="dir", default="./"),
|
|
113
|
-
StrInput(name="diagram", default="state-diagram"),
|
|
114
|
-
],
|
|
115
|
-
message=(
|
|
116
|
-
"Read all necessary files in {ctx.input.dir}, "
|
|
117
|
-
"make a {ctx.input.diagram} in mermaid format. "
|
|
118
|
-
"Write the script into `{ctx.input.dir}/{ctx.input.diagram}.mmd`"
|
|
119
|
-
),
|
|
120
|
-
tools=[
|
|
121
|
-
analyze_repo, write_to_file
|
|
122
|
-
],
|
|
123
|
-
)
|
|
124
|
-
)
|
|
125
|
-
|
|
126
|
-
# Task 2: Convert the Mermaid script into a PNG image
|
|
127
|
-
make_mermaid_image = mermaid_group.add_task(
|
|
128
|
-
CmdTask(
|
|
129
|
-
name="make-image",
|
|
130
|
-
description="Creating png based on source code in current directory",
|
|
131
|
-
input=[
|
|
132
|
-
StrInput(name="dir", default="./"),
|
|
133
|
-
StrInput(name="diagram", default="state-diagram"),
|
|
134
|
-
],
|
|
135
|
-
cmd="mmdc -i '{ctx.input.diagram}.mmd' -o '{ctx.input.diagram}.png'",
|
|
136
|
-
cwd="{ctx.input.dir}",
|
|
137
|
-
)
|
|
138
|
-
)
|
|
139
|
-
|
|
140
|
-
# Set up the dependency: the image task runs after the script is created
|
|
141
|
-
make_mermaid_script >> make_mermaid_image
|
|
142
|
-
```
|
|
143
|
-
|
|
144
|
-
**What This Does**
|
|
145
|
-
|
|
146
|
-
- **Task 1 – make-script**:
|
|
147
|
-
|
|
148
|
-
Uses an LLM to read all files in your current directory and generate a Mermaid script (e.g., `state diagram.mmd`).
|
|
149
|
-
|
|
150
|
-
- **Task 2 – make-image**:
|
|
151
|
-
|
|
152
|
-
Executes a command that converts the Mermaid script into a PNG image (e.g., `state diagram.png`). This task will run only after the script has been generated.
|
|
153
|
-
|
|
154
|
-
|
|
155
|
-
## 2. Run Your Tasks
|
|
156
|
-
|
|
157
|
-
After setting up your tasks, you can execute them from any project. For example:
|
|
158
|
-
|
|
159
|
-
- Clone/Create a Project:
|
|
160
|
-
|
|
161
|
-
```bash
|
|
162
|
-
git clone git@github.com:jjinux/gotetris.git
|
|
163
|
-
cd gotetris
|
|
164
|
-
```
|
|
165
|
-
|
|
166
|
-
- Create a state diagram:
|
|
167
|
-
|
|
168
|
-
```bash
|
|
169
|
-
zrb mermaid make-image --diagram "state diagram" --dir ./
|
|
170
|
-
```
|
|
171
|
-
|
|
172
|
-
- Or use the interactive mode:
|
|
173
|
-
|
|
174
|
-
```bash
|
|
175
|
-
zrb mermaid make-image
|
|
176
|
-
```
|
|
177
|
-
|
|
178
|
-
Zrb will prompt:
|
|
179
|
-
|
|
180
|
-
```bash
|
|
181
|
-
dir [./]:
|
|
182
|
-
diagram [state diagram]:
|
|
183
|
-
```
|
|
184
|
-
|
|
185
|
-
Press **Enter** to use the default value
|
|
186
|
-
|
|
187
|
-
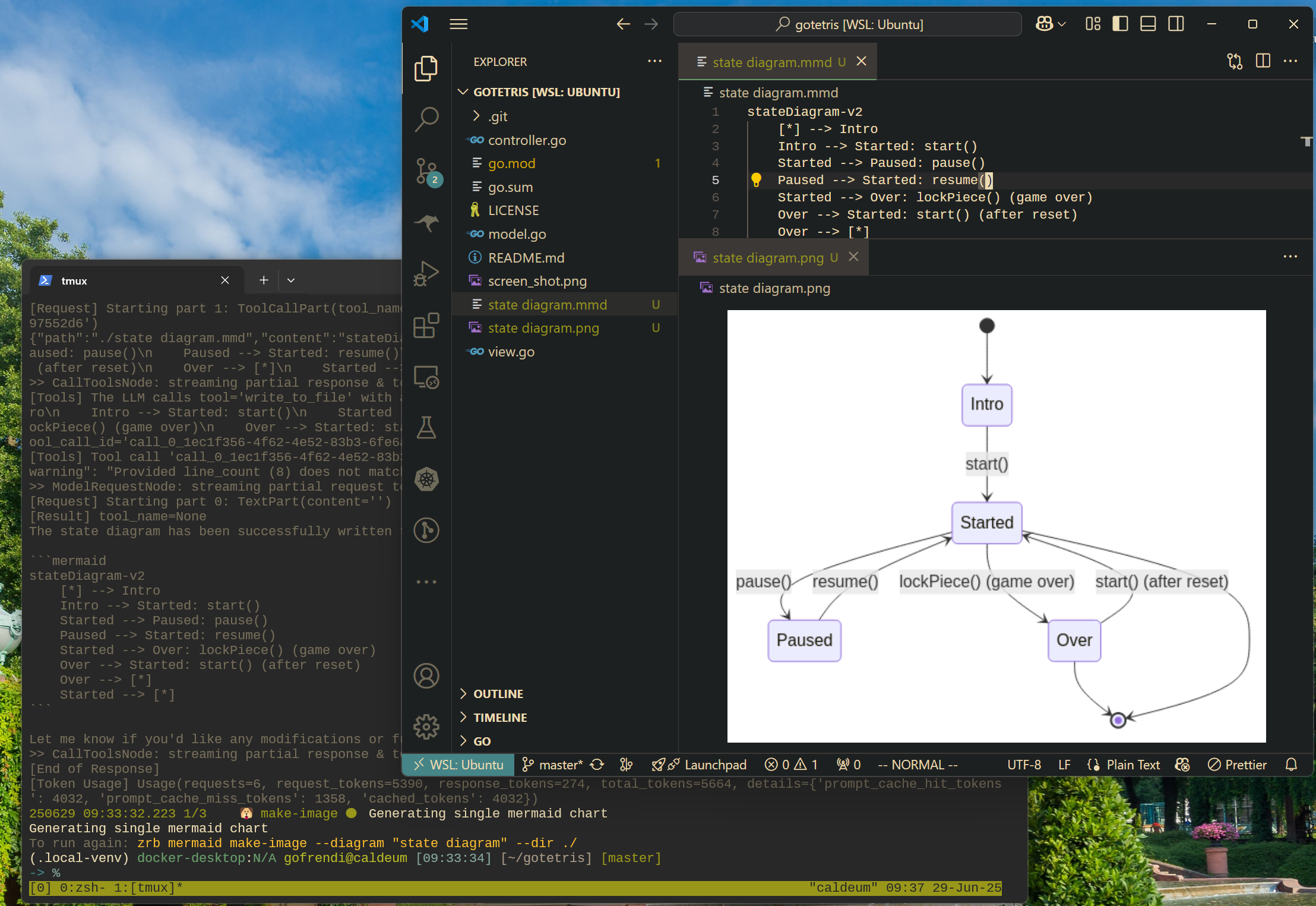
|
|
188
|
-
|
|
189
|
-
|
|
190
|
-
## 3. Try Out the Web UI
|
|
191
|
-
|
|
192
|
-
You can also serve your tasks through a user-friendly web interface:
|
|
193
|
-
|
|
194
|
-
```bash
|
|
195
|
-
zrb server start
|
|
196
|
-
```
|
|
197
|
-
|
|
198
|
-
Then open your browser and visit `http://localhost:21213`
|
|
199
|
-
|
|
200
|
-
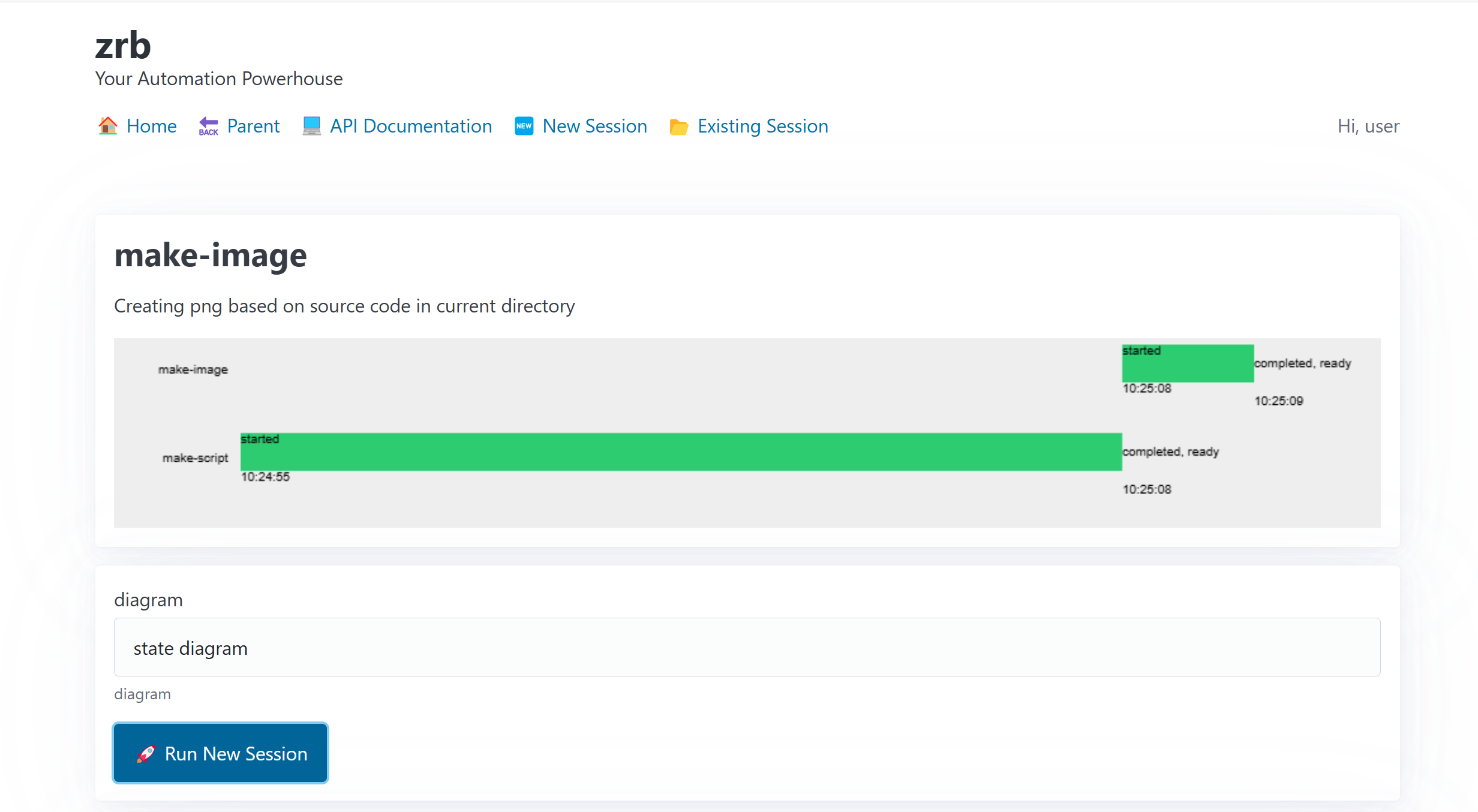
|
|
201
|
-
|
|
202
|
-
|
|
203
|
-
# 🐋 Run Zrb as a Container
|
|
204
|
-
|
|
205
|
-
Zrb can be run in a containerized environment, offering two distinct versions to suit different needs:
|
|
206
|
-
|
|
207
|
-
- **Standard Version**: Ideal for general use cases where Docker CLI access is not required.
|
|
208
|
-
- **Dind (Docker in Docker) Version**: Includes built-in Docker commands, perfect for scenarios where you need to access the host's Docker CLI.
|
|
209
|
-
|
|
210
|
-
### Standard Version
|
|
211
|
-
|
|
212
|
-
The standard version of the Zrb container is suitable for most automation tasks. To run this version, execute the following command:
|
|
213
|
-
|
|
214
|
-
```bash
|
|
215
|
-
# Replace <host-path> and <container-path> with your desired paths
|
|
216
|
-
docker run -v ${HOME}:/zrb-home -it --rm stalchmst/zrb:1.8.1 zrb
|
|
217
|
-
```
|
|
218
|
-
|
|
219
|
-
### Dind Version
|
|
220
|
-
|
|
221
|
-
The Dind version is tailored for advanced use cases where Docker commands need to be executed within the container. This version allows the container to interact with the host's Docker daemon. To run the Dind version, use the command below:
|
|
222
|
-
|
|
223
|
-
```bash
|
|
224
|
-
# Replace <host-path> and <container-path> with your desired paths
|
|
225
|
-
docker run \
|
|
226
|
-
-v ${HOME}:/zrb-home \
|
|
227
|
-
-v /var/run/docker.sock:/var/run/docker.sock \
|
|
228
|
-
-it --rm stalchmst/zrb:1.8.1-dind docker ps
|
|
229
|
-
```
|
|
230
|
-
|
|
231
|
-
> **Note:** The Dind (Docker in Docker) version of the container is larger in size compared to the standard version due to the inclusion of Docker CLI tools. Consider this when choosing the appropriate version for your needs.
|
|
232
|
-
|
|
233
|
-
# 🎥 Demo & Documentation
|
|
234
|
-
|
|
235
|
-
- **Full documentation:** [Zrb Documentation](https://github.com/state-alchemists/zrb/blob/main/docs/README.md)
|
|
236
|
-
- **Video demo:**
|
|
237
|
-
|
|
238
|
-
[](https://www.youtube.com/watch?v=W7dgk96l__o)
|
|
239
|
-
|
|
240
|
-
|
|
241
|
-
# 🤝 Join the Community
|
|
242
|
-
|
|
243
|
-
- **Bug Reports & Feature Requests:** Create an [issue](https://github.com/state-alchemists/zrb/issues) on Zrb's GitHub Repositories and include:
|
|
244
|
-
- Your Zrb version (i.e., `zrb version`).
|
|
245
|
-
- Steps you’ve taken and what you expected versus what happened
|
|
246
|
-
- **Contributions:** We welcome pull requests! Check out our [contribution guidelines](https://github.com/state-alchemists/zrb/pulls).
|
|
247
|
-
|
|
248
|
-
|
|
249
|
-
# ☕ Support The Project
|
|
250
|
-
|
|
251
|
-
If you find Zrb valuable, please consider donating:
|
|
252
|
-
|
|
253
|
-
[](https://stalchmst.com)
|
|
254
|
-
|
|
255
|
-
# 🎉 Fun Fact
|
|
256
|
-
|
|
257
|
-
Did you know?
|
|
258
|
-
|
|
259
|
-
Zrb is named after `Zaruba`, a powerful support tool from the Garo universe!
|
|
260
|
-
|
|
261
|
-
> Madou Ring Zaruba (魔導輪ザルバ, Madōrin Zaruba) is a Madougu which supports bearers of the Garo Armor. [(Garo Wiki | Fandom)](https://garo.fandom.com/wiki/Zaruba)
|
|
262
|
-
|
|
263
|
-

|
|
264
|
-
|
|
File without changes
|