vexor 0.19.0a1__py3-none-any.whl → 0.21.0__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- vexor/__init__.py +4 -2
- vexor/_bundled_skills/vexor-cli/SKILL.md +1 -0
- vexor/api.py +87 -1
- vexor/cache.py +483 -275
- vexor/cli.py +78 -5
- vexor/config.py +240 -2
- vexor/providers/gemini.py +79 -13
- vexor/providers/openai.py +79 -13
- vexor/services/config_service.py +14 -0
- vexor/services/index_service.py +285 -4
- vexor/services/search_service.py +235 -24
- vexor/text.py +14 -0
- {vexor-0.19.0a1.dist-info → vexor-0.21.0.dist-info}/METADATA +42 -30
- vexor-0.21.0.dist-info/RECORD +33 -0
- vexor-0.19.0a1.dist-info/RECORD +0 -33
- {vexor-0.19.0a1.dist-info → vexor-0.21.0.dist-info}/WHEEL +0 -0
- {vexor-0.19.0a1.dist-info → vexor-0.21.0.dist-info}/entry_points.txt +0 -0
- {vexor-0.19.0a1.dist-info → vexor-0.21.0.dist-info}/licenses/LICENSE +0 -0
vexor/services/search_service.py
CHANGED
|
@@ -7,12 +7,15 @@ from functools import lru_cache
|
|
|
7
7
|
from pathlib import Path
|
|
8
8
|
import json
|
|
9
9
|
import re
|
|
10
|
+
import numpy as np
|
|
10
11
|
from typing import Sequence, TYPE_CHECKING
|
|
11
12
|
from urllib import error as urlerror
|
|
12
13
|
from urllib import request as urlrequest
|
|
13
14
|
|
|
14
15
|
from ..config import (
|
|
15
16
|
DEFAULT_EMBED_CONCURRENCY,
|
|
17
|
+
DEFAULT_EXTRACT_BACKEND,
|
|
18
|
+
DEFAULT_EXTRACT_CONCURRENCY,
|
|
16
19
|
DEFAULT_FLASHRANK_MAX_LENGTH,
|
|
17
20
|
DEFAULT_FLASHRANK_MODEL,
|
|
18
21
|
DEFAULT_RERANK,
|
|
@@ -45,7 +48,11 @@ class SearchRequest:
|
|
|
45
48
|
exclude_patterns: tuple[str, ...]
|
|
46
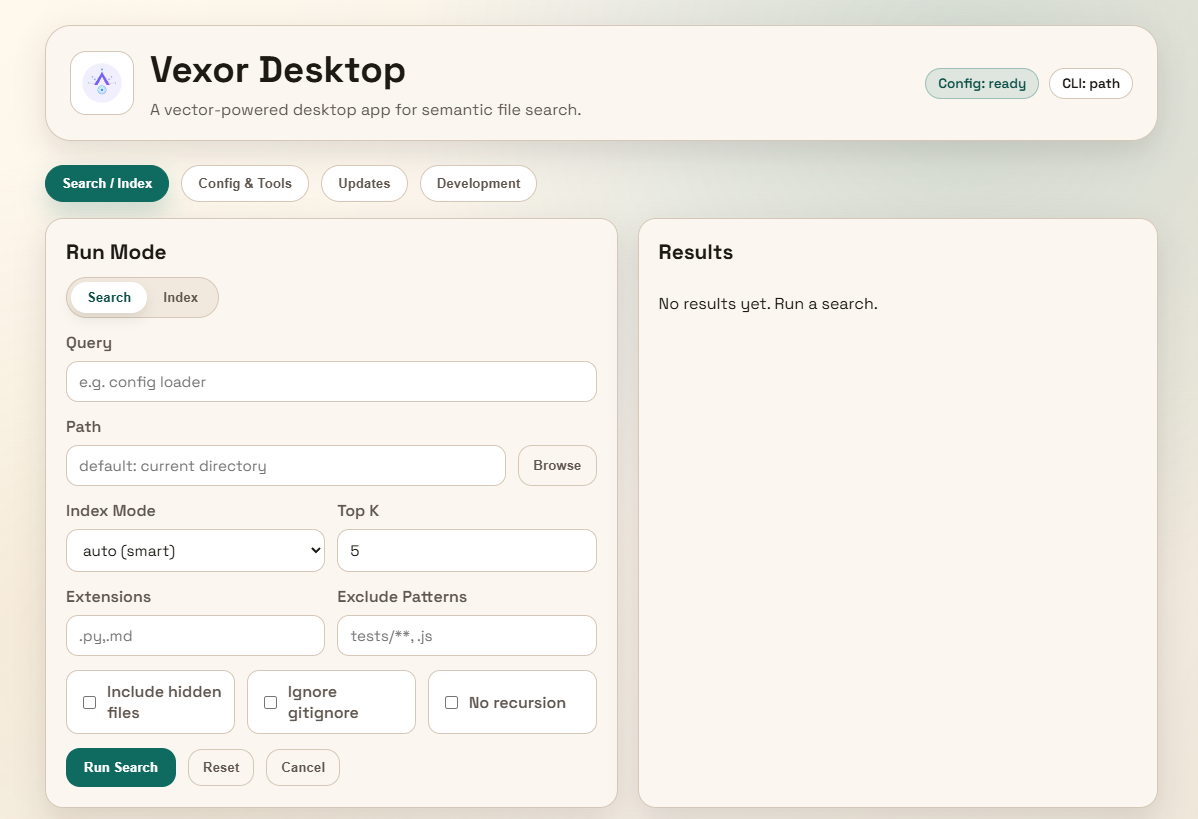
49
|
extensions: tuple[str, ...]
|
|
47
50
|
auto_index: bool = True
|
|
51
|
+
temporary_index: bool = False
|
|
52
|
+
no_cache: bool = False
|
|
48
53
|
embed_concurrency: int = DEFAULT_EMBED_CONCURRENCY
|
|
54
|
+
extract_concurrency: int = DEFAULT_EXTRACT_CONCURRENCY
|
|
55
|
+
extract_backend: str = DEFAULT_EXTRACT_BACKEND
|
|
49
56
|
rerank: str = DEFAULT_RERANK
|
|
50
57
|
flashrank_model: str | None = None
|
|
51
58
|
remote_rerank: RemoteRerankConfig | None = None
|
|
@@ -105,6 +112,20 @@ def _normalize_by_max(scores: Sequence[float]) -> list[float]:
|
|
|
105
112
|
return [score / max_score for score in scores]
|
|
106
113
|
|
|
107
114
|
|
|
115
|
+
def _resolve_rerank_candidates(top_k: int) -> int:
|
|
116
|
+
candidate = int(top_k * 2)
|
|
117
|
+
return max(20, min(candidate, 150))
|
|
118
|
+
|
|
119
|
+
|
|
120
|
+
def _top_indices(scores: np.ndarray, limit: int) -> list[int]:
|
|
121
|
+
if limit <= 0:
|
|
122
|
+
return []
|
|
123
|
+
if limit >= scores.size:
|
|
124
|
+
return sorted(range(scores.size), key=lambda idx: (-scores[idx], idx))
|
|
125
|
+
indices = np.argpartition(-scores, limit - 1)[:limit]
|
|
126
|
+
return sorted(indices.tolist(), key=lambda idx: (-scores[idx], idx))
|
|
127
|
+
|
|
128
|
+
|
|
108
129
|
def _bm25_scores(
|
|
109
130
|
query_tokens: Sequence[str],
|
|
110
131
|
documents: Sequence[Sequence[str]],
|
|
@@ -336,9 +357,13 @@ def _apply_remote_rerank(
|
|
|
336
357
|
def perform_search(request: SearchRequest) -> SearchResponse:
|
|
337
358
|
"""Execute the semantic search flow and return ranked results."""
|
|
338
359
|
|
|
360
|
+
if request.temporary_index or request.no_cache:
|
|
361
|
+
return _perform_search_with_temporary_index(request)
|
|
362
|
+
|
|
339
363
|
from ..cache import ( # local import
|
|
340
364
|
embedding_cache_key,
|
|
341
365
|
list_cache_entries,
|
|
366
|
+
load_chunk_metadata,
|
|
342
367
|
load_embedding_cache,
|
|
343
368
|
load_index_vectors,
|
|
344
369
|
load_query_vector,
|
|
@@ -375,12 +400,15 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
375
400
|
model_name=request.model_name,
|
|
376
401
|
batch_size=request.batch_size,
|
|
377
402
|
embed_concurrency=request.embed_concurrency,
|
|
403
|
+
extract_concurrency=request.extract_concurrency,
|
|
404
|
+
extract_backend=request.extract_backend,
|
|
378
405
|
provider=request.provider,
|
|
379
406
|
base_url=request.base_url,
|
|
380
407
|
api_key=request.api_key,
|
|
381
408
|
local_cuda=request.local_cuda,
|
|
382
409
|
exclude_patterns=request.exclude_patterns,
|
|
383
410
|
extensions=request.extensions,
|
|
411
|
+
no_cache=request.no_cache,
|
|
384
412
|
)
|
|
385
413
|
if result.status == IndexStatus.EMPTY:
|
|
386
414
|
return SearchResponse(
|
|
@@ -435,6 +463,7 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
435
463
|
|
|
436
464
|
file_snapshot = metadata.get("files", [])
|
|
437
465
|
chunk_entries = metadata.get("chunks", [])
|
|
466
|
+
chunk_ids = metadata.get("chunk_ids", [])
|
|
438
467
|
stale = bool(file_snapshot) and not is_cache_current(
|
|
439
468
|
request.directory,
|
|
440
469
|
request.include_hidden,
|
|
@@ -455,12 +484,15 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
455
484
|
model_name=request.model_name,
|
|
456
485
|
batch_size=request.batch_size,
|
|
457
486
|
embed_concurrency=request.embed_concurrency,
|
|
487
|
+
extract_concurrency=request.extract_concurrency,
|
|
488
|
+
extract_backend=request.extract_backend,
|
|
458
489
|
provider=request.provider,
|
|
459
490
|
base_url=request.base_url,
|
|
460
491
|
api_key=request.api_key,
|
|
461
492
|
local_cuda=request.local_cuda,
|
|
462
493
|
exclude_patterns=index_excludes,
|
|
463
494
|
extensions=index_extensions,
|
|
495
|
+
no_cache=request.no_cache,
|
|
464
496
|
)
|
|
465
497
|
if result.status == IndexStatus.EMPTY:
|
|
466
498
|
return SearchResponse(
|
|
@@ -529,7 +561,6 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
529
561
|
index_empty=True,
|
|
530
562
|
)
|
|
531
563
|
|
|
532
|
-
from sklearn.metrics.pairwise import cosine_similarity # local import
|
|
533
564
|
from ..search import SearchResult, VexorSearcher # local import
|
|
534
565
|
searcher = VexorSearcher(
|
|
535
566
|
model_name=request.model_name,
|
|
@@ -542,9 +573,9 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
542
573
|
)
|
|
543
574
|
query_vector = None
|
|
544
575
|
query_hash = None
|
|
545
|
-
query_text_hash =
|
|
576
|
+
query_text_hash = None
|
|
546
577
|
index_id = metadata.get("index_id")
|
|
547
|
-
if index_id is not None:
|
|
578
|
+
if index_id is not None and not request.no_cache:
|
|
548
579
|
query_hash = query_cache_key(request.query, request.model_name)
|
|
549
580
|
try:
|
|
550
581
|
query_vector = load_query_vector(int(index_id), query_hash)
|
|
@@ -554,7 +585,8 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
554
585
|
if query_vector is not None and query_vector.size != file_vectors.shape[1]:
|
|
555
586
|
query_vector = None
|
|
556
587
|
|
|
557
|
-
if query_vector is None:
|
|
588
|
+
if query_vector is None and not request.no_cache:
|
|
589
|
+
query_text_hash = embedding_cache_key(request.query)
|
|
558
590
|
cached = load_embedding_cache(request.model_name, [query_text_hash])
|
|
559
591
|
query_vector = cached.get(query_text_hash)
|
|
560
592
|
if query_vector is not None and query_vector.size != file_vectors.shape[1]:
|
|
@@ -562,25 +594,57 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
562
594
|
|
|
563
595
|
if query_vector is None:
|
|
564
596
|
query_vector = searcher.embed_texts([request.query])[0]
|
|
565
|
-
|
|
566
|
-
|
|
567
|
-
|
|
568
|
-
|
|
569
|
-
|
|
570
|
-
|
|
571
|
-
|
|
572
|
-
|
|
597
|
+
if not request.no_cache:
|
|
598
|
+
if query_text_hash is None:
|
|
599
|
+
query_text_hash = embedding_cache_key(request.query)
|
|
600
|
+
try:
|
|
601
|
+
store_embedding_cache(
|
|
602
|
+
model=request.model_name,
|
|
603
|
+
embeddings={query_text_hash: query_vector},
|
|
604
|
+
)
|
|
605
|
+
except Exception: # pragma: no cover - best-effort cache storage
|
|
606
|
+
pass
|
|
607
|
+
if (
|
|
608
|
+
not request.no_cache
|
|
609
|
+
and query_vector is not None
|
|
610
|
+
and index_id is not None
|
|
611
|
+
and query_hash is not None
|
|
612
|
+
):
|
|
573
613
|
try:
|
|
574
614
|
store_query_vector(int(index_id), query_hash, request.query, query_vector)
|
|
575
615
|
except Exception: # pragma: no cover - best-effort cache storage
|
|
576
616
|
pass
|
|
577
|
-
|
|
578
|
-
|
|
579
|
-
|
|
580
|
-
|
|
581
|
-
|
|
582
|
-
|
|
583
|
-
|
|
617
|
+
reranker = None
|
|
618
|
+
rerank = (request.rerank or DEFAULT_RERANK).strip().lower()
|
|
619
|
+
use_rerank = rerank in {"bm25", "flashrank", "remote"}
|
|
620
|
+
if use_rerank:
|
|
621
|
+
candidate_limit = _resolve_rerank_candidates(request.top_k)
|
|
622
|
+
else:
|
|
623
|
+
candidate_limit = request.top_k
|
|
624
|
+
candidate_count = min(len(paths), candidate_limit)
|
|
625
|
+
|
|
626
|
+
query_vector = np.asarray(query_vector, dtype=np.float32).ravel()
|
|
627
|
+
similarities = np.asarray(file_vectors @ query_vector, dtype=np.float32)
|
|
628
|
+
top_indices = _top_indices(similarities, candidate_count)
|
|
629
|
+
chunk_meta_by_id: dict[int, dict] = {}
|
|
630
|
+
if chunk_ids:
|
|
631
|
+
candidate_ids = [
|
|
632
|
+
chunk_ids[idx] for idx in top_indices if idx < len(chunk_ids)
|
|
633
|
+
]
|
|
634
|
+
if candidate_ids:
|
|
635
|
+
try:
|
|
636
|
+
chunk_meta_by_id = load_chunk_metadata(candidate_ids)
|
|
637
|
+
except Exception: # pragma: no cover - best-effort metadata lookup
|
|
638
|
+
chunk_meta_by_id = {}
|
|
639
|
+
scored: list[SearchResult] = []
|
|
640
|
+
for idx in top_indices:
|
|
641
|
+
path = paths[idx]
|
|
642
|
+
score = similarities[idx]
|
|
643
|
+
chunk_meta = {}
|
|
644
|
+
if chunk_ids and idx < len(chunk_ids):
|
|
645
|
+
chunk_meta = chunk_meta_by_id.get(chunk_ids[idx], {})
|
|
646
|
+
elif idx < len(chunk_entries):
|
|
647
|
+
chunk_meta = chunk_entries[idx]
|
|
584
648
|
start_line = chunk_meta.get("start_line")
|
|
585
649
|
end_line = chunk_meta.get("end_line")
|
|
586
650
|
scored.append(
|
|
@@ -593,12 +657,138 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
593
657
|
end_line=int(end_line) if end_line is not None else None,
|
|
594
658
|
)
|
|
595
659
|
)
|
|
596
|
-
|
|
660
|
+
if use_rerank:
|
|
661
|
+
candidates = scored
|
|
662
|
+
if rerank == "bm25":
|
|
663
|
+
candidates = _apply_bm25_rerank(request.query, candidates)
|
|
664
|
+
reranker = "bm25"
|
|
665
|
+
elif rerank == "flashrank":
|
|
666
|
+
candidates = _apply_flashrank_rerank(
|
|
667
|
+
request.query,
|
|
668
|
+
candidates,
|
|
669
|
+
request.flashrank_model,
|
|
670
|
+
)
|
|
671
|
+
reranker = "flashrank"
|
|
672
|
+
else:
|
|
673
|
+
candidates = _apply_remote_rerank(
|
|
674
|
+
request.query,
|
|
675
|
+
candidates,
|
|
676
|
+
request.remote_rerank,
|
|
677
|
+
)
|
|
678
|
+
reranker = "remote"
|
|
679
|
+
results = candidates[: request.top_k]
|
|
680
|
+
else:
|
|
681
|
+
results = scored[: request.top_k]
|
|
682
|
+
return SearchResponse(
|
|
683
|
+
base_path=request.directory,
|
|
684
|
+
backend=searcher.device,
|
|
685
|
+
results=results,
|
|
686
|
+
is_stale=stale,
|
|
687
|
+
index_empty=False,
|
|
688
|
+
reranker=reranker,
|
|
689
|
+
)
|
|
690
|
+
|
|
691
|
+
|
|
692
|
+
def _perform_search_with_temporary_index(request: SearchRequest) -> SearchResponse:
|
|
693
|
+
from .index_service import build_index_in_memory # local import
|
|
694
|
+
|
|
695
|
+
paths, file_vectors, metadata = build_index_in_memory(
|
|
696
|
+
request.directory,
|
|
697
|
+
include_hidden=request.include_hidden,
|
|
698
|
+
respect_gitignore=request.respect_gitignore,
|
|
699
|
+
mode=request.mode,
|
|
700
|
+
recursive=request.recursive,
|
|
701
|
+
model_name=request.model_name,
|
|
702
|
+
batch_size=request.batch_size,
|
|
703
|
+
embed_concurrency=request.embed_concurrency,
|
|
704
|
+
extract_concurrency=request.extract_concurrency,
|
|
705
|
+
extract_backend=request.extract_backend,
|
|
706
|
+
provider=request.provider,
|
|
707
|
+
base_url=request.base_url,
|
|
708
|
+
api_key=request.api_key,
|
|
709
|
+
local_cuda=request.local_cuda,
|
|
710
|
+
exclude_patterns=request.exclude_patterns,
|
|
711
|
+
extensions=request.extensions,
|
|
712
|
+
no_cache=request.no_cache,
|
|
713
|
+
)
|
|
714
|
+
|
|
715
|
+
if not len(paths):
|
|
716
|
+
return SearchResponse(
|
|
717
|
+
base_path=request.directory,
|
|
718
|
+
backend=None,
|
|
719
|
+
results=[],
|
|
720
|
+
is_stale=False,
|
|
721
|
+
index_empty=True,
|
|
722
|
+
)
|
|
723
|
+
|
|
724
|
+
from ..search import SearchResult, VexorSearcher # local import
|
|
725
|
+
|
|
726
|
+
searcher = VexorSearcher(
|
|
727
|
+
model_name=request.model_name,
|
|
728
|
+
batch_size=request.batch_size,
|
|
729
|
+
embed_concurrency=request.embed_concurrency,
|
|
730
|
+
provider=request.provider,
|
|
731
|
+
base_url=request.base_url,
|
|
732
|
+
api_key=request.api_key,
|
|
733
|
+
local_cuda=request.local_cuda,
|
|
734
|
+
)
|
|
735
|
+
query_vector = None
|
|
736
|
+
query_text_hash = None
|
|
737
|
+
if not request.no_cache:
|
|
738
|
+
from ..cache import embedding_cache_key, load_embedding_cache, store_embedding_cache
|
|
739
|
+
|
|
740
|
+
query_text_hash = embedding_cache_key(request.query)
|
|
741
|
+
cached = load_embedding_cache(request.model_name, [query_text_hash])
|
|
742
|
+
query_vector = cached.get(query_text_hash)
|
|
743
|
+
if query_vector is not None and query_vector.size != file_vectors.shape[1]:
|
|
744
|
+
query_vector = None
|
|
745
|
+
|
|
746
|
+
if query_vector is None:
|
|
747
|
+
query_vector = searcher.embed_texts([request.query])[0]
|
|
748
|
+
if not request.no_cache:
|
|
749
|
+
if query_text_hash is None:
|
|
750
|
+
from ..cache import embedding_cache_key, store_embedding_cache
|
|
751
|
+
|
|
752
|
+
query_text_hash = embedding_cache_key(request.query)
|
|
753
|
+
try:
|
|
754
|
+
store_embedding_cache(
|
|
755
|
+
model=request.model_name,
|
|
756
|
+
embeddings={query_text_hash: query_vector},
|
|
757
|
+
)
|
|
758
|
+
except Exception: # pragma: no cover - best-effort cache storage
|
|
759
|
+
pass
|
|
597
760
|
reranker = None
|
|
598
761
|
rerank = (request.rerank or DEFAULT_RERANK).strip().lower()
|
|
599
|
-
|
|
600
|
-
|
|
601
|
-
|
|
762
|
+
use_rerank = rerank in {"bm25", "flashrank", "remote"}
|
|
763
|
+
if use_rerank:
|
|
764
|
+
candidate_limit = _resolve_rerank_candidates(request.top_k)
|
|
765
|
+
else:
|
|
766
|
+
candidate_limit = request.top_k
|
|
767
|
+
candidate_count = min(len(paths), candidate_limit)
|
|
768
|
+
|
|
769
|
+
query_vector = np.asarray(query_vector, dtype=np.float32).ravel()
|
|
770
|
+
similarities = np.asarray(file_vectors @ query_vector, dtype=np.float32)
|
|
771
|
+
top_indices = _top_indices(similarities, candidate_count)
|
|
772
|
+
chunk_entries = metadata.get("chunks", [])
|
|
773
|
+
scored: list[SearchResult] = []
|
|
774
|
+
for idx in top_indices:
|
|
775
|
+
path = paths[idx]
|
|
776
|
+
score = similarities[idx]
|
|
777
|
+
chunk_meta = chunk_entries[idx] if idx < len(chunk_entries) else {}
|
|
778
|
+
start_line = chunk_meta.get("start_line")
|
|
779
|
+
end_line = chunk_meta.get("end_line")
|
|
780
|
+
scored.append(
|
|
781
|
+
SearchResult(
|
|
782
|
+
path=path,
|
|
783
|
+
score=float(score),
|
|
784
|
+
preview=chunk_meta.get("preview"),
|
|
785
|
+
chunk_index=int(chunk_meta.get("chunk_index", 0)),
|
|
786
|
+
start_line=int(start_line) if start_line is not None else None,
|
|
787
|
+
end_line=int(end_line) if end_line is not None else None,
|
|
788
|
+
)
|
|
789
|
+
)
|
|
790
|
+
if use_rerank:
|
|
791
|
+
candidates = scored
|
|
602
792
|
if rerank == "bm25":
|
|
603
793
|
candidates = _apply_bm25_rerank(request.query, candidates)
|
|
604
794
|
reranker = "bm25"
|
|
@@ -623,7 +813,7 @@ def perform_search(request: SearchRequest) -> SearchResponse:
|
|
|
623
813
|
base_path=request.directory,
|
|
624
814
|
backend=searcher.device,
|
|
625
815
|
results=results,
|
|
626
|
-
is_stale=
|
|
816
|
+
is_stale=False,
|
|
627
817
|
index_empty=False,
|
|
628
818
|
reranker=reranker,
|
|
629
819
|
)
|
|
@@ -764,6 +954,7 @@ def _filter_index_by_extensions(
|
|
|
764
954
|
ext_set = {ext.lower() for ext in extensions if ext}
|
|
765
955
|
if not ext_set:
|
|
766
956
|
return list(paths), file_vectors, metadata
|
|
957
|
+
chunk_ids = metadata.get("chunk_ids")
|
|
767
958
|
keep_indices: list[int] = []
|
|
768
959
|
filtered_paths: list[Path] = []
|
|
769
960
|
for idx, path in enumerate(paths):
|
|
@@ -778,6 +969,8 @@ def _filter_index_by_extensions(
|
|
|
778
969
|
ext_set,
|
|
779
970
|
)
|
|
780
971
|
filtered_metadata["chunks"] = []
|
|
972
|
+
if chunk_ids is not None:
|
|
973
|
+
filtered_metadata["chunk_ids"] = []
|
|
781
974
|
return [], filtered_vectors, filtered_metadata
|
|
782
975
|
filtered_vectors = file_vectors[keep_indices]
|
|
783
976
|
chunk_entries = metadata.get("chunks", [])
|
|
@@ -790,6 +983,10 @@ def _filter_index_by_extensions(
|
|
|
790
983
|
ext_set,
|
|
791
984
|
)
|
|
792
985
|
filtered_metadata["chunks"] = filtered_chunks
|
|
986
|
+
if chunk_ids is not None:
|
|
987
|
+
filtered_metadata["chunk_ids"] = [
|
|
988
|
+
chunk_ids[idx] for idx in keep_indices if idx < len(chunk_ids)
|
|
989
|
+
]
|
|
793
990
|
return filtered_paths, filtered_vectors, filtered_metadata
|
|
794
991
|
|
|
795
992
|
|
|
@@ -802,6 +999,7 @@ def _filter_index_by_exclude_patterns(
|
|
|
802
999
|
) -> tuple[list[Path], Sequence[Sequence[float]], dict]:
|
|
803
1000
|
if exclude_spec is None:
|
|
804
1001
|
return list(paths), file_vectors, metadata
|
|
1002
|
+
chunk_ids = metadata.get("chunk_ids")
|
|
805
1003
|
keep_indices: list[int] = []
|
|
806
1004
|
filtered_paths: list[Path] = []
|
|
807
1005
|
root_resolved = root.resolve()
|
|
@@ -822,6 +1020,8 @@ def _filter_index_by_exclude_patterns(
|
|
|
822
1020
|
exclude_spec,
|
|
823
1021
|
)
|
|
824
1022
|
filtered_metadata["chunks"] = []
|
|
1023
|
+
if chunk_ids is not None:
|
|
1024
|
+
filtered_metadata["chunk_ids"] = []
|
|
825
1025
|
return [], filtered_vectors, filtered_metadata
|
|
826
1026
|
filtered_vectors = file_vectors[keep_indices]
|
|
827
1027
|
chunk_entries = metadata.get("chunks", [])
|
|
@@ -834,6 +1034,10 @@ def _filter_index_by_exclude_patterns(
|
|
|
834
1034
|
exclude_spec,
|
|
835
1035
|
)
|
|
836
1036
|
filtered_metadata["chunks"] = filtered_chunks
|
|
1037
|
+
if chunk_ids is not None:
|
|
1038
|
+
filtered_metadata["chunk_ids"] = [
|
|
1039
|
+
chunk_ids[idx] for idx in keep_indices if idx < len(chunk_ids)
|
|
1040
|
+
]
|
|
837
1041
|
return filtered_paths, filtered_vectors, filtered_metadata
|
|
838
1042
|
|
|
839
1043
|
|
|
@@ -850,6 +1054,7 @@ def _filter_index_by_directory(
|
|
|
850
1054
|
relative_dir = directory.resolve().relative_to(index_root.resolve())
|
|
851
1055
|
except ValueError:
|
|
852
1056
|
return list(paths), file_vectors, metadata
|
|
1057
|
+
chunk_ids = metadata.get("chunk_ids")
|
|
853
1058
|
keep_indices: list[int] = []
|
|
854
1059
|
filtered_paths: list[Path] = []
|
|
855
1060
|
for idx, path in enumerate(paths):
|
|
@@ -870,6 +1075,8 @@ def _filter_index_by_directory(
|
|
|
870
1075
|
recursive=recursive,
|
|
871
1076
|
)
|
|
872
1077
|
filtered_metadata["chunks"] = []
|
|
1078
|
+
if chunk_ids is not None:
|
|
1079
|
+
filtered_metadata["chunk_ids"] = []
|
|
873
1080
|
filtered_metadata["root"] = str(directory)
|
|
874
1081
|
return [], filtered_vectors, filtered_metadata
|
|
875
1082
|
filtered_vectors = file_vectors[keep_indices]
|
|
@@ -884,6 +1091,10 @@ def _filter_index_by_directory(
|
|
|
884
1091
|
recursive=recursive,
|
|
885
1092
|
)
|
|
886
1093
|
filtered_metadata["chunks"] = filtered_chunks
|
|
1094
|
+
if chunk_ids is not None:
|
|
1095
|
+
filtered_metadata["chunk_ids"] = [
|
|
1096
|
+
chunk_ids[idx] for idx in keep_indices if idx < len(chunk_ids)
|
|
1097
|
+
]
|
|
887
1098
|
filtered_metadata["root"] = str(directory)
|
|
888
1099
|
return filtered_paths, filtered_vectors, filtered_metadata
|
|
889
1100
|
|
vexor/text.py
CHANGED
|
@@ -19,6 +19,7 @@ class Messages:
|
|
|
19
19
|
HELP_SEARCH_FORMAT = (
|
|
20
20
|
"Output format (rich=table, porcelain=tab-separated for scripts, porcelain-z=NUL-delimited)."
|
|
21
21
|
)
|
|
22
|
+
HELP_NO_CACHE = "Disable all disk caches (index + embedding/query)."
|
|
22
23
|
HELP_INCLUDE_HIDDEN = "Use the index built with hidden files included."
|
|
23
24
|
HELP_INDEX_PATH = "Root directory to scan for indexing."
|
|
24
25
|
HELP_INDEX_INCLUDE = "Include hidden files and directories when building the index."
|
|
@@ -58,6 +59,8 @@ class Messages:
|
|
|
58
59
|
HELP_SET_MODEL = "Set the default embedding model."
|
|
59
60
|
HELP_SET_BATCH = "Set the default batch size (0 = single request)."
|
|
60
61
|
HELP_SET_EMBED_CONCURRENCY = "Set the number of concurrent embedding requests."
|
|
62
|
+
HELP_SET_EXTRACT_CONCURRENCY = "Set the number of concurrent file extraction workers."
|
|
63
|
+
HELP_SET_EXTRACT_BACKEND = "Set the extraction backend (auto, thread, process)."
|
|
61
64
|
HELP_SET_PROVIDER = "Set the default embedding provider (e.g., gemini, openai, custom, or local)."
|
|
62
65
|
HELP_SET_BASE_URL = "Override the provider's base URL (leave unset for official endpoints)."
|
|
63
66
|
HELP_CLEAR_BASE_URL = "Remove the custom base URL override."
|
|
@@ -116,6 +119,10 @@ class Messages:
|
|
|
116
119
|
ERROR_EMPTY_QUERY = "Query text must not be empty."
|
|
117
120
|
ERROR_BATCH_NEGATIVE = "Batch size must be >= 0"
|
|
118
121
|
ERROR_CONCURRENCY_INVALID = "Embedding concurrency must be >= 1"
|
|
122
|
+
ERROR_EXTRACT_CONCURRENCY_INVALID = "Extraction concurrency must be >= 1"
|
|
123
|
+
ERROR_EXTRACT_BACKEND_INVALID = (
|
|
124
|
+
"Unsupported extraction backend '{value}'. Allowed values: {allowed}."
|
|
125
|
+
)
|
|
119
126
|
ERROR_MODE_INVALID = "Unsupported mode '{value}'. Allowed values: {allowed}."
|
|
120
127
|
ERROR_PROVIDER_INVALID = "Unsupported provider '{value}'. Allowed values: {allowed}."
|
|
121
128
|
ERROR_RERANK_INVALID = "Unsupported rerank value '{value}'. Allowed values: {allowed}."
|
|
@@ -265,6 +272,8 @@ class Messages:
|
|
|
265
272
|
INFO_MODEL_SET = "Default model set to {value}."
|
|
266
273
|
INFO_BATCH_SET = "Default batch size set to {value}."
|
|
267
274
|
INFO_EMBED_CONCURRENCY_SET = "Embedding concurrency set to {value}."
|
|
275
|
+
INFO_EXTRACT_CONCURRENCY_SET = "Extraction concurrency set to {value}."
|
|
276
|
+
INFO_EXTRACT_BACKEND_SET = "Extraction backend set to {value}."
|
|
268
277
|
INFO_PROVIDER_SET = "Default provider set to {value}."
|
|
269
278
|
INFO_BASE_URL_SET = "Base URL override set to {value}."
|
|
270
279
|
INFO_BASE_URL_CLEARED = "Base URL override cleared."
|
|
@@ -299,12 +308,16 @@ class Messages:
|
|
|
299
308
|
ERROR_CONFIG_EDITOR_NOT_FOUND = "Unable to determine a text editor. Set $VISUAL or $EDITOR, or install nano/vi."
|
|
300
309
|
ERROR_CONFIG_EDITOR_FAILED = "Editor exited with status {code}."
|
|
301
310
|
ERROR_CONFIG_EDITOR_LAUNCH = "Failed to launch editor: {reason}."
|
|
311
|
+
ERROR_CONFIG_JSON_INVALID = "Config JSON must be an object."
|
|
312
|
+
ERROR_CONFIG_VALUE_INVALID = "Config JSON has invalid value for {field}."
|
|
302
313
|
INFO_CONFIG_SUMMARY = (
|
|
303
314
|
"API key set: {api}\n"
|
|
304
315
|
"Default provider: {provider}\n"
|
|
305
316
|
"Default model: {model}\n"
|
|
306
317
|
"Default batch size: {batch}\n"
|
|
307
318
|
"Embedding concurrency: {concurrency}\n"
|
|
319
|
+
"Extract concurrency: {extract_concurrency}\n"
|
|
320
|
+
"Extract backend: {extract_backend}\n"
|
|
308
321
|
"Auto index: {auto_index}\n"
|
|
309
322
|
"Rerank: {rerank}\n"
|
|
310
323
|
"{flashrank_line}"
|
|
@@ -315,6 +328,7 @@ class Messages:
|
|
|
315
328
|
INFO_FLASHRANK_MODEL_SUMMARY = "FlashRank model: {value}"
|
|
316
329
|
INFO_REMOTE_RERANK_SUMMARY = "Remote rerank: {value}"
|
|
317
330
|
INFO_SEARCH_RUNNING = "Searching cached index under {path}..."
|
|
331
|
+
INFO_SEARCH_RUNNING_NO_CACHE = "Searching in-memory index under {path}..."
|
|
318
332
|
INFO_DOCTOR_CHECKING = "Checking if `vexor` is on PATH..."
|
|
319
333
|
INFO_DOCTOR_FOUND = "`vexor` command is available at {path}."
|
|
320
334
|
ERROR_DOCTOR_MISSING = (
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: vexor
|
|
3
|
-
Version: 0.
|
|
3
|
+
Version: 0.21.0
|
|
4
4
|
Summary: A vector-powered CLI for semantic search over files.
|
|
5
5
|
Project-URL: Repository, https://github.com/scarletkc/vexor
|
|
6
6
|
Author: scarletkc
|
|
@@ -69,9 +69,8 @@ Description-Content-Type: text/markdown
|
|
|
69
69
|
|
|
70
70
|
---
|
|
71
71
|
|
|
72
|
-
**Vexor** is a
|
|
73
|
-
|
|
74
|
-
|
|
72
|
+
**Vexor** is a semantic search engine that builds reusable indexes over files and code.
|
|
73
|
+
It supports configurable embedding and reranking providers, and exposes the same core through a Python API, a CLI tool, and an optional desktop frontend.
|
|
75
74
|
|
|
76
75
|
<video src="https://github.com/user-attachments/assets/4d53eefd-ab35-4232-98a7-f8dc005983a9" controls="controls" style="max-width: 600px;">
|
|
77
76
|
Vexor Demo Video
|
|
@@ -98,18 +97,13 @@ vexor init
|
|
|
98
97
|
```
|
|
99
98
|
The wizard also runs automatically on first use when no config exists.
|
|
100
99
|
|
|
101
|
-
### 1.
|
|
102
|
-
```bash
|
|
103
|
-
vexor config --set-api-key "YOUR_KEY"
|
|
104
|
-
```
|
|
105
|
-
Or via environment: `VEXOR_API_KEY`, `OPENAI_API_KEY`, or `GOOGLE_GENAI_API_KEY`.
|
|
106
|
-
|
|
107
|
-
### 2. Search
|
|
100
|
+
### 1. Search
|
|
108
101
|
```bash
|
|
109
|
-
vexor "api client config" # defaults to search
|
|
110
|
-
vexor search "api client config" # searches current directory
|
|
102
|
+
vexor "api client config" # defaults to search current directory
|
|
111
103
|
# or explicit path:
|
|
112
104
|
vexor search "api client config" --path ~/projects/demo --top 5
|
|
105
|
+
# in-memory search only:
|
|
106
|
+
vexor search "api client config" --no-cache
|
|
113
107
|
```
|
|
114
108
|
|
|
115
109
|
Vexor auto-indexes on first search. Example output:
|
|
@@ -122,7 +116,7 @@ Vexor semantic file search results
|
|
|
122
116
|
3 0.809 ./tests/test_config_loader.py - tests for config loader
|
|
123
117
|
```
|
|
124
118
|
|
|
125
|
-
###
|
|
119
|
+
### 2. Explicit Index (Optional)
|
|
126
120
|
```bash
|
|
127
121
|
vexor index # indexes current directory
|
|
128
122
|
# or explicit path:
|
|
@@ -130,6 +124,15 @@ vexor index --path ~/projects/demo --mode code
|
|
|
130
124
|
```
|
|
131
125
|
Useful for CI warmup or when `auto_index` is disabled.
|
|
132
126
|
|
|
127
|
+
## Desktop App (Experimental)
|
|
128
|
+
|
|
129
|
+
> The desktop app is experimental and not actively maintained.
|
|
130
|
+
> It may be unstable. For production use, prefer the CLI.
|
|
131
|
+
|
|
132
|
+

|
|
133
|
+
|
|
134
|
+
Download the desktop app from [releases](https://github.com/scarletkc/vexor/releases).
|
|
135
|
+
|
|
133
136
|
## Python API
|
|
134
137
|
|
|
135
138
|
Vexor can also be imported and used directly from Python:
|
|
@@ -144,8 +147,19 @@ for hit in response.results:
|
|
|
144
147
|
print(hit.path, hit.score)
|
|
145
148
|
```
|
|
146
149
|
|
|
147
|
-
By default it reads `~/.vexor/config.json`.
|
|
148
|
-
|
|
150
|
+
By default it reads `~/.vexor/config.json`. For runtime config overrides, cache
|
|
151
|
+
controls, and per-call options, see [`docs/api/python.md`](https://github.com/scarletkc/vexor/tree/main/docs/api/python.md).
|
|
152
|
+
|
|
153
|
+
## AI Agent Skill
|
|
154
|
+
|
|
155
|
+
This repo includes a skill for AI agents to use Vexor effectively:
|
|
156
|
+
|
|
157
|
+
```bash
|
|
158
|
+
vexor install --skills claude # Claude Code
|
|
159
|
+
vexor install --skills codex # Codex
|
|
160
|
+
```
|
|
161
|
+
|
|
162
|
+
Skill source: [`plugins/vexor/skills/vexor-cli`](https://github.com/scarletkc/vexor/raw/refs/heads/main/plugins/vexor/skills/vexor-cli/SKILL.md)
|
|
149
163
|
|
|
150
164
|
## Configuration
|
|
151
165
|
|
|
@@ -153,7 +167,9 @@ set `use_config=False`.
|
|
|
153
167
|
vexor config --set-provider openai # default; also supports gemini/custom/local
|
|
154
168
|
vexor config --set-model text-embedding-3-small
|
|
155
169
|
vexor config --set-batch-size 0 # 0 = single request
|
|
156
|
-
vexor config --set-embed-concurrency
|
|
170
|
+
vexor config --set-embed-concurrency 4 # parallel embedding requests
|
|
171
|
+
vexor config --set-extract-concurrency 4 # parallel file extraction workers
|
|
172
|
+
vexor config --set-extract-backend auto # auto|thread|process (default: auto)
|
|
157
173
|
vexor config --set-auto-index true # auto-index before search (default)
|
|
158
174
|
vexor config --rerank bm25 # optional BM25 rerank for top-k results
|
|
159
175
|
vexor config --rerank flashrank # FlashRank rerank (requires optional extra)
|
|
@@ -175,10 +191,16 @@ FlashRank requires `pip install "vexor[flashrank]"` and caches models under `~/.
|
|
|
175
191
|
|
|
176
192
|
Config stored in `~/.vexor/config.json`.
|
|
177
193
|
|
|
194
|
+
### Configure API Key
|
|
195
|
+
```bash
|
|
196
|
+
vexor config --set-api-key "YOUR_KEY"
|
|
197
|
+
```
|
|
198
|
+
Or via environment: `VEXOR_API_KEY`, `OPENAI_API_KEY`, or `GOOGLE_GENAI_API_KEY`.
|
|
199
|
+
|
|
178
200
|
### Rerank
|
|
179
201
|
|
|
180
|
-
Rerank reorders the semantic results with a secondary ranker.
|
|
181
|
-
|
|
202
|
+
Rerank reorders the semantic results with a secondary ranker. Candidate sizing uses
|
|
203
|
+
`clamp(int(--top * 2), 20, 150)`.
|
|
182
204
|
|
|
183
205
|
Recommended defaults:
|
|
184
206
|
- Keep `off` unless you want extra precision.
|
|
@@ -285,20 +307,10 @@ Re-running `vexor index` only re-embeds changed files; >50% changes trigger full
|
|
|
285
307
|
| `--no-respect-gitignore` | Include gitignored files |
|
|
286
308
|
| `--format porcelain` | Script-friendly TSV output |
|
|
287
309
|
| `--format porcelain-z` | NUL-delimited output |
|
|
310
|
+
| `--no-cache` | In-memory only; do not read/write index cache |
|
|
288
311
|
|
|
289
312
|
Porcelain output fields: `rank`, `similarity`, `path`, `chunk_index`, `start_line`, `end_line`, `preview` (line fields are `-` when unavailable).
|
|
290
313
|
|
|
291
|
-
## AI Agent Skill
|
|
292
|
-
|
|
293
|
-
This repo includes a skill for AI agents to use Vexor effectively:
|
|
294
|
-
|
|
295
|
-
```bash
|
|
296
|
-
vexor install --skills claude # Claude Code
|
|
297
|
-
vexor install --skills codex # Codex
|
|
298
|
-
```
|
|
299
|
-
|
|
300
|
-
Skill source: [`plugins/vexor/skills/vexor-cli`](https://github.com/scarletkc/vexor/raw/refs/heads/main/plugins/vexor/skills/vexor-cli/SKILL.md)
|
|
301
|
-
|
|
302
314
|
## Documentation
|
|
303
315
|
|
|
304
316
|
See [docs](https://github.com/scarletkc/vexor/tree/main/docs) for more details.
|
|
@@ -0,0 +1,33 @@
|
|
|
1
|
+
vexor/__init__.py,sha256=i0ly8cFA4N_PEQ_rhYgoLp2NPRQc3_ln8Gfi8QWjXSQ,441
|
|
2
|
+
vexor/__main__.py,sha256=ZFzom1wCfP6TPXe3aoDFpNcUgjbCZ7Quy_vfzNsH5Fw,426
|
|
3
|
+
vexor/api.py,sha256=YCHpiydbPbRJUqdQYrpwe1JrRI-w_7LRuyZDGBP1_d4,11506
|
|
4
|
+
vexor/cache.py,sha256=3i9FKFLSyZ1kx-w1apc12umPaQxWqMP-P8_lvo67hBw,52832
|
|
5
|
+
vexor/cli.py,sha256=M9GKdD_mJ068Zpm62znTp0KhhKp1dkh_WHmfJHR9hwU,68094
|
|
6
|
+
vexor/config.py,sha256=CiPfEH7Ilt6XepEx4p02qfW5HfkpNDBjhEMyckbSWaA,17413
|
|
7
|
+
vexor/modes.py,sha256=N_wAWoqbxmCfko-v520p59tpAYvUwraCSSQRtMaF4ac,11549
|
|
8
|
+
vexor/output.py,sha256=iooZgLlK8dh7ajJ4XMHUNNx0qyTVtD_OAAwrBx5MeqE,864
|
|
9
|
+
vexor/search.py,sha256=MSU4RmH6waFYOofkIdo8_ElTiz1oNaKuvr-3umif7Bs,6826
|
|
10
|
+
vexor/text.py,sha256=2aK5nJHkosmbmyzp9o_Tzb3YlmVnju_IX8BcEPUdhTA,24794
|
|
11
|
+
vexor/utils.py,sha256=GzfYW2rz1-EuJjkevqZVe8flLRtrQ60OWMmFNbMh62k,12472
|
|
12
|
+
vexor/providers/__init__.py,sha256=kCEoV03TSLKcxDUYVNjXnrVoLU5NpfNXjp1w1Ak2imE,92
|
|
13
|
+
vexor/providers/gemini.py,sha256=IWHHjCMJC0hUHQPhuaJ_L_97c_mnOXkPkCVdrIR6z-g,5705
|
|
14
|
+
vexor/providers/local.py,sha256=5X_WYCXgyBGIVvvVLgMnDjTkPR4GBF0ksNPyviBlB7w,4838
|
|
15
|
+
vexor/providers/openai.py,sha256=YnJDY9gJW7RfGGdkgswVHvmOKNvgLRQUsbpA1MUuLPg,5356
|
|
16
|
+
vexor/services/__init__.py,sha256=dA_i2N03vlYmbZbEK2knzJLWviunkNWbzN2LWPNvMk0,160
|
|
17
|
+
vexor/services/cache_service.py,sha256=ywt6AgupCJ7_wC3je4znCMw5_VBouw3skbDTAt8xw6o,1639
|
|
18
|
+
vexor/services/config_service.py,sha256=PojolfbSKh9pW8slF4qxCOs9hz5L6xvjf_nB7vfVlsU,5039
|
|
19
|
+
vexor/services/content_extract_service.py,sha256=zdhLxpNv70BU7irLf3Uc0ou9rKSvdjtrDcHkgRKlMn4,26421
|
|
20
|
+
vexor/services/index_service.py,sha256=FXf1bBoqj4-K1l38ItxHf6Oh7QHVIdNAdVY2kg_Zoq8,32265
|
|
21
|
+
vexor/services/init_service.py,sha256=3D04hylGA9FRQhLHCfR95nMko3vb5MNBcRb9nWWaUE8,26863
|
|
22
|
+
vexor/services/js_parser.py,sha256=eRtW6KlK4JBYDGbyoecHVqLZ0hcx-Cc0kx6bOujHPAQ,16254
|
|
23
|
+
vexor/services/keyword_service.py,sha256=vmke8tII9kTwRDdBaLHBc6Hpy_B3p98L65iGkCQgtMU,2211
|
|
24
|
+
vexor/services/search_service.py,sha256=K7SiAuMA7bGeyPWOHPMKpFFvzzkj5kHWwa3p94NakJs,38663
|
|
25
|
+
vexor/services/skill_service.py,sha256=Rrgt3OMsKPPiXOiRhSNAWjBM9UNz9qmSWQe3uYGzq4M,4863
|
|
26
|
+
vexor/services/system_service.py,sha256=KPlv83v3rTvBiNiH7vrp6tDmt_AqHxuUd-5RI0TfvWs,24638
|
|
27
|
+
vexor/_bundled_skills/vexor-cli/SKILL.md,sha256=m3FlyqgHBdRwyGPEp8PrUS21K0G2jEl88tRvhSPta08,2798
|
|
28
|
+
vexor/_bundled_skills/vexor-cli/references/install-vexor.md,sha256=IUBShLI1mAxugwUIMAJQ5_j6KcaPWfobe0gSd6MWU7w,1245
|
|
29
|
+
vexor-0.21.0.dist-info/METADATA,sha256=Lc5PHY_Ir3F56ILYe6IBlkwhN6gMQGZvf48f7x_uVDg,13494
|
|
30
|
+
vexor-0.21.0.dist-info/WHEEL,sha256=WLgqFyCfm_KASv4WHyYy0P3pM_m7J5L9k2skdKLirC8,87
|
|
31
|
+
vexor-0.21.0.dist-info/entry_points.txt,sha256=dvxp6Q1R1d6bozR7TwmpdJ0X_v83MkzsLPagGY_lfr0,40
|
|
32
|
+
vexor-0.21.0.dist-info/licenses/LICENSE,sha256=wP7TAKRll1t9LoYGxWS9NikPM_0hCc00LmlLyvQBsL8,1066
|
|
33
|
+
vexor-0.21.0.dist-info/RECORD,,
|