txt2detection 0.0.2rc12__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of txt2detection might be problematic. Click here for more details.
- txt2detection/__init__.py +2 -0
- txt2detection/__main__.py +189 -0
- txt2detection/ai_extractor/__init__.py +16 -0
- txt2detection/ai_extractor/anthropic.py +12 -0
- txt2detection/ai_extractor/base.py +57 -0
- txt2detection/ai_extractor/deepseek.py +19 -0
- txt2detection/ai_extractor/gemini.py +18 -0
- txt2detection/ai_extractor/openai.py +20 -0
- txt2detection/ai_extractor/openrouter.py +20 -0
- txt2detection/ai_extractor/prompts.py +116 -0
- txt2detection/ai_extractor/utils.py +19 -0
- txt2detection/bundler.py +283 -0
- txt2detection/config/detection_languages.yaml +14 -0
- txt2detection/models.py +391 -0
- txt2detection/observables.py +186 -0
- txt2detection/utils.py +81 -0
- txt2detection-0.0.2rc12.dist-info/METADATA +199 -0
- txt2detection-0.0.2rc12.dist-info/RECORD +21 -0
- txt2detection-0.0.2rc12.dist-info/WHEEL +4 -0
- txt2detection-0.0.2rc12.dist-info/entry_points.txt +2 -0
- txt2detection-0.0.2rc12.dist-info/licenses/LICENSE +202 -0
|
@@ -0,0 +1,186 @@
|
|
|
1
|
+
import re, validators
|
|
2
|
+
from typing import Any, Dict, List
|
|
3
|
+
from stix2 import parse as parse_stix, parse_observable
|
|
4
|
+
|
|
5
|
+
# Mapping of key regex patterns to STIX observable types
|
|
6
|
+
STIX_PATTERNS_KEYS = {
|
|
7
|
+
"ipv4-addr": r"(?i)\b(ip|ipv4)\b",
|
|
8
|
+
"ipv6-addr": r"(?i)\bipv6\b",
|
|
9
|
+
"email-addr": r"(?i)\bemail\b",
|
|
10
|
+
"url": r"(?i)\b(url|uri)\b",
|
|
11
|
+
"directory": r"(?i)\b(directory|path)\b",
|
|
12
|
+
"domain-name": r"(?i)\bdomain\b",
|
|
13
|
+
"hostname": r"(?i)\bhost\b",
|
|
14
|
+
"file.hashes.MD5": r"(?i)\bmd5\b",
|
|
15
|
+
"file.hashes.SHA-1": r"(?i)\bsha1\b",
|
|
16
|
+
"file.hashes.SHA-256": r"(?i)\bsha256\b",
|
|
17
|
+
"file.hashes.SHA-512": r"(?i)\bsha512\b",
|
|
18
|
+
"file.hashes.SSDEEP": r"(?i)\bssdeep\b",
|
|
19
|
+
"mac-addr": r"(?i)\bmac\b",
|
|
20
|
+
"user-account": r"(?i)\buser\b",
|
|
21
|
+
"windows-registry-key": r"(?i)\bregistry\b",
|
|
22
|
+
"x509-certificate": r"(?i)\bx509\b",
|
|
23
|
+
}
|
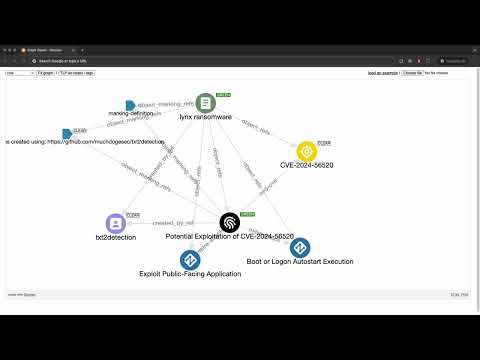
|
24
|
+
|
|
25
|
+
# Mapping of value regex patterns to STIX observable types
|
|
26
|
+
STIX_PATTERNS_VALUES = {
|
|
27
|
+
"ipv4-addr": [r"\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(?:\.|$)){4}\b"],
|
|
28
|
+
"ipv6-addr": [r"\b(?:[A-F0-9]{1,4}:){7}[A-F0-9]{1,4}\b"],
|
|
29
|
+
"email-addr": [r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"],
|
|
30
|
+
"url": [r"\bhttps?://[^\s/$.?#].[^\x00\s]*\b"],
|
|
31
|
+
"directory": [r"(?:[A-Za-z]:)?(?:\\\\[^\\\\:*?\"<>|\r\n]+)+\\\\?"],
|
|
32
|
+
"domain-name": [r"\b(?:[a-zA-Z0-9-]+\.)+[a-zA-Z]{2,}\b"],
|
|
33
|
+
"hostname": [r"\b[a-zA-Z0-9-]{1,63}(\.[a-zA-Z0-9-]{1,63})*\b"],
|
|
34
|
+
"file.hashes.MD5": [r"\b[a-fA-F0-9]{32}\b"],
|
|
35
|
+
"file.hashes.SHA-1": [r"\b[a-fA-F0-9]{40}\b"],
|
|
36
|
+
"file.hashes.SHA-256": [r"\b[a-fA-F0-9]{64}\b"],
|
|
37
|
+
"file.hashes.SHA-512": [r"\b[a-fA-F0-9]{128}\b"],
|
|
38
|
+
"file.hashes.SSDEEP": [r"\b\d{1,}:[A-Za-z0-9/+]{10,}:[A-Za-z0-9/+]{10,}\b"],
|
|
39
|
+
"mac-addr": [r"\b([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})\b"],
|
|
40
|
+
"user-account": [r"\b[A-Za-z0-9._%-]{3,}\\\\?[A-Za-z0-9._%-]{3,}\b"],
|
|
41
|
+
"windows-registry-key": [r"HK\w{0,2}_[A-Z_]+\\.*"],
|
|
42
|
+
"x509-certificate": [r"-----BEGIN CERTIFICATE-----.+?-----END CERTIFICATE-----"],
|
|
43
|
+
}
|
|
44
|
+
|
|
45
|
+
|
|
46
|
+
def filter_out(type, value: str):
|
|
47
|
+
match type:
|
|
48
|
+
case "ipv4-addr":
|
|
49
|
+
return validators.ipv4(value)
|
|
50
|
+
case "ipv6-addr":
|
|
51
|
+
return validators.ipv6(value)
|
|
52
|
+
case "email-addr":
|
|
53
|
+
return validators.email(value)
|
|
54
|
+
case "url":
|
|
55
|
+
return validators.url(value)
|
|
56
|
+
case "domain-name":
|
|
57
|
+
return validators.domain(value, consider_tld=True)
|
|
58
|
+
case "file.hashes.MD5":
|
|
59
|
+
return validators.hashes.md5(value)
|
|
60
|
+
case "file.hashes.SHA-1":
|
|
61
|
+
return validators.hashes.sha1(value)
|
|
62
|
+
case "file.hashes.SHA-256":
|
|
63
|
+
return validators.hashes.sha256(value)
|
|
64
|
+
case "file.hashes.SHA-512":
|
|
65
|
+
return validators.hashes.sha512(value)
|
|
66
|
+
case "file.hashes.SSDEEP":
|
|
67
|
+
pass
|
|
68
|
+
case "mac-addr":
|
|
69
|
+
return validators.mac_address(value)
|
|
70
|
+
case "user-account":
|
|
71
|
+
pass
|
|
72
|
+
|
|
73
|
+
case "windows-registry-key":
|
|
74
|
+
print(value)
|
|
75
|
+
ns, _, _ = value.partition("\\")
|
|
76
|
+
return ns in [
|
|
77
|
+
"HKEY_CLASSES_ROOT",
|
|
78
|
+
"HKCR",
|
|
79
|
+
"HKEY_CURRENT_USER",
|
|
80
|
+
"HKCU",
|
|
81
|
+
"HKEY_LOCAL_MACHINE",
|
|
82
|
+
"HKLM",
|
|
83
|
+
"HKEY_USERS",
|
|
84
|
+
"HKU",
|
|
85
|
+
"HKEY_CURRENT_CONFIG",
|
|
86
|
+
"HKCC",
|
|
87
|
+
"HKEY_PERFORMANCE_DATA",
|
|
88
|
+
"HKEY_DYN_DATA",
|
|
89
|
+
]
|
|
90
|
+
case _:
|
|
91
|
+
return False
|
|
92
|
+
return False
|
|
93
|
+
|
|
94
|
+
|
|
95
|
+
def find_stix_observables(detection: Any, matches: List[str] = None) -> List[str]:
|
|
96
|
+
if matches is None:
|
|
97
|
+
matches = []
|
|
98
|
+
|
|
99
|
+
if isinstance(detection, dict):
|
|
100
|
+
for key, value in detection.items():
|
|
101
|
+
for stix_type, key_pattern in STIX_PATTERNS_KEYS.items():
|
|
102
|
+
value_patterns = STIX_PATTERNS_VALUES.get(stix_type, [])
|
|
103
|
+
if re.search(key_pattern, key, re.IGNORECASE):
|
|
104
|
+
for pattern in value_patterns:
|
|
105
|
+
if isinstance(value, str) and re.search(
|
|
106
|
+
pattern, value, re.IGNORECASE
|
|
107
|
+
):
|
|
108
|
+
if filter_out(stix_type, value):
|
|
109
|
+
matches.append((stix_type, value))
|
|
110
|
+
find_stix_observables(value, matches)
|
|
111
|
+
find_stix_observables(value, matches)
|
|
112
|
+
elif isinstance(detection, list):
|
|
113
|
+
for item in detection:
|
|
114
|
+
find_stix_observables(item, matches)
|
|
115
|
+
elif isinstance(detection, str):
|
|
116
|
+
for stix_type, value_patterns in STIX_PATTERNS_VALUES.items():
|
|
117
|
+
for pattern in value_patterns:
|
|
118
|
+
if re.search(pattern, detection, re.IGNORECASE):
|
|
119
|
+
if filter_out(stix_type, detection):
|
|
120
|
+
matches.append((stix_type, detection))
|
|
121
|
+
return matches
|
|
122
|
+
|
|
123
|
+
|
|
124
|
+
def to_stix_object(observable_type: str, value):
|
|
125
|
+
match observable_type:
|
|
126
|
+
case (
|
|
127
|
+
"ipv4-addr"
|
|
128
|
+
| "ipv6-addr"
|
|
129
|
+
| "email-addr"
|
|
130
|
+
| "url"
|
|
131
|
+
| "domain-name"
|
|
132
|
+
| "mac-addr"
|
|
133
|
+
):
|
|
134
|
+
return parse_observable(
|
|
135
|
+
dict(
|
|
136
|
+
type=observable_type,
|
|
137
|
+
value=value,
|
|
138
|
+
spec_version="2.1",
|
|
139
|
+
)
|
|
140
|
+
)
|
|
141
|
+
case (
|
|
142
|
+
"file.hashes.MD5"
|
|
143
|
+
| "file.hashes.SHA-1"
|
|
144
|
+
| "file.hashes.SHA-256"
|
|
145
|
+
| "file.hashes.SHA-512"
|
|
146
|
+
| "file.hashes.SSDEEP"
|
|
147
|
+
):
|
|
148
|
+
_, _, hash_type = observable_type.rpartition(".")
|
|
149
|
+
return parse_observable(
|
|
150
|
+
dict(type="file", spec_version="2.1", hashes={hash_type: value})
|
|
151
|
+
)
|
|
152
|
+
|
|
153
|
+
case "windows-registry-key":
|
|
154
|
+
return parse_observable(
|
|
155
|
+
dict(
|
|
156
|
+
type=observable_type,
|
|
157
|
+
spec_version="2.1",
|
|
158
|
+
key=value,
|
|
159
|
+
)
|
|
160
|
+
)
|
|
161
|
+
return None
|
|
162
|
+
|
|
163
|
+
|
|
164
|
+
# example_detection = {
|
|
165
|
+
# "selection": {
|
|
166
|
+
# "source_ip": "192.168.1.10",
|
|
167
|
+
# "destination_email": "attacker@example.com",
|
|
168
|
+
# "url_path": "http://malicious.example.com/payload.exe",
|
|
169
|
+
# "file_hash_md5": "44d88612fea8a8f36de82e1278abb02f",
|
|
170
|
+
# "mac_address": "00:1A:2B:3C:4D:5E",
|
|
171
|
+
# "username": "CORP\\jdoe",
|
|
172
|
+
# "registry_key": "HKEY_LOCAL_MACHINE\\Software\\Microsoft\\Windows\\CurrentVersion\\Run",
|
|
173
|
+
# "registry_key2": "HK_LOCAL_MACHINE\\Software\\Microsoft\\Windows\\CurrentVersion\\Run",
|
|
174
|
+
# "certificate": "-----BEGIN CERTIFICATE-----FAKECERT-----END CERTIFICATE-----",
|
|
175
|
+
# "ip": " 192.167.1.1",
|
|
176
|
+
# },
|
|
177
|
+
# "condition": "selection",
|
|
178
|
+
# }
|
|
179
|
+
|
|
180
|
+
# # Usage
|
|
181
|
+
# observables = find_stix_observables(example_detection)
|
|
182
|
+
# print(observables)
|
|
183
|
+
|
|
184
|
+
# for a, b in observables:
|
|
185
|
+
# print(to_stix_object(a, b))
|
|
186
|
+
|
txt2detection/utils.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
1
|
+
from datetime import date, datetime
|
|
2
|
+
from functools import lru_cache
|
|
3
|
+
from types import SimpleNamespace
|
|
4
|
+
import uuid
|
|
5
|
+
import requests
|
|
6
|
+
from .ai_extractor import ALL_AI_EXTRACTORS, BaseAIExtractor, ModelError
|
|
7
|
+
import logging
|
|
8
|
+
|
|
9
|
+
import enum
|
|
10
|
+
import logging
|
|
11
|
+
import requests
|
|
12
|
+
from stix2 import Identity
|
|
13
|
+
|
|
14
|
+
from .models import UUID_NAMESPACE
|
|
15
|
+
|
|
16
|
+
|
|
17
|
+
class DetectionLanguage(SimpleNamespace):
|
|
18
|
+
pass
|
|
19
|
+
|
|
20
|
+
def parse_model(value: str):
|
|
21
|
+
splits = value.split(':', 1)
|
|
22
|
+
provider = splits[0]
|
|
23
|
+
if provider not in ALL_AI_EXTRACTORS:
|
|
24
|
+
raise NotImplementedError(f"invalid AI provider in `{value}`, must be one of {list(ALL_AI_EXTRACTORS)}")
|
|
25
|
+
provider = ALL_AI_EXTRACTORS[provider]
|
|
26
|
+
try:
|
|
27
|
+
if len(splits) == 2:
|
|
28
|
+
return provider(model=splits[1])
|
|
29
|
+
return provider()
|
|
30
|
+
except Exception as e:
|
|
31
|
+
raise ModelError(f"Unable to initialize model `{value}`") from e
|
|
32
|
+
|
|
33
|
+
def make_identity(name, namespace=None, created_by_ref=None, object_marking_refs=None):
|
|
34
|
+
from .bundler import Bundler
|
|
35
|
+
if isinstance(namespace, str):
|
|
36
|
+
namespace = uuid.UUID(namespace)
|
|
37
|
+
namespace = namespace or UUID_NAMESPACE
|
|
38
|
+
return Identity(
|
|
39
|
+
id="identity--" + str(uuid.uuid5(namespace, f"{name}")),
|
|
40
|
+
name=name,
|
|
41
|
+
created_by_ref=created_by_ref or Bundler.default_identity.id,
|
|
42
|
+
created=datetime(2020, 1, 1),
|
|
43
|
+
modified=datetime(2020, 1, 1),
|
|
44
|
+
object_marking_refs=object_marking_refs or [
|
|
45
|
+
"marking-definition--94868c89-83c2-464b-929b-a1a8aa3c8487",
|
|
46
|
+
"marking-definition--a4d70b75-6f4a-5d19-9137-da863edd33d7"
|
|
47
|
+
],
|
|
48
|
+
)
|
|
49
|
+
|
|
50
|
+
|
|
51
|
+
def validate_token_count(max_tokens, input, extractor: BaseAIExtractor):
|
|
52
|
+
logging.info('INPUT_TOKEN_LIMIT = %d', max_tokens)
|
|
53
|
+
token_count = extractor.count_tokens(input)
|
|
54
|
+
logging.info('TOKEN COUNT FOR %s: %d', extractor.extractor_name, token_count)
|
|
55
|
+
if token_count > max_tokens:
|
|
56
|
+
raise Exception(f"{extractor.extractor_name}: input_file token count ({token_count}) exceeds INPUT_TOKEN_LIMIT ({max_tokens})")
|
|
57
|
+
|
|
58
|
+
def valid_licenses():
|
|
59
|
+
@lru_cache(maxsize=5)
|
|
60
|
+
def get_licenses(date):
|
|
61
|
+
resp = requests.get("https://github.com/spdx/license-list-data/raw/refs/heads/main/json/licenses.json")
|
|
62
|
+
return {l['licenseId']: l['name'] for l in resp.json()['licenses']}
|
|
63
|
+
return get_licenses(datetime.now().date().isoformat())
|
|
64
|
+
|
|
65
|
+
|
|
66
|
+
def remove_rule_specific_tags(tags):
|
|
67
|
+
labels = []
|
|
68
|
+
for tag in tags:
|
|
69
|
+
namespace, _, label = tag.partition(".")
|
|
70
|
+
if namespace in ["attack", "cve", "tlp"]:
|
|
71
|
+
continue
|
|
72
|
+
labels.append(tag)
|
|
73
|
+
return labels
|
|
74
|
+
|
|
75
|
+
|
|
76
|
+
def as_date(d: 'date|datetime'):
|
|
77
|
+
if isinstance(d, datetime):
|
|
78
|
+
return d.date()
|
|
79
|
+
return d
|
|
80
|
+
|
|
81
|
+
STATUSES = ['stable', 'test', 'experimental', 'deprecated', 'unsupported']
|
|
@@ -0,0 +1,199 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: txt2detection
|
|
3
|
+
Version: 0.0.2rc12
|
|
4
|
+
Summary: txt2detection is a tool
|
|
5
|
+
Project-URL: Homepage, https://github.com/muchdogesec/txt2detection
|
|
6
|
+
Project-URL: Issues, https://github.com/muchdogesec/txt2detection/issues
|
|
7
|
+
Author-email: DOGESEC <support@dogesec.com>
|
|
8
|
+
License-File: LICENSE
|
|
9
|
+
Classifier: License :: OSI Approved :: Apache Software License
|
|
10
|
+
Classifier: Operating System :: OS Independent
|
|
11
|
+
Classifier: Programming Language :: Python :: 3
|
|
12
|
+
Requires-Python: >=3.11
|
|
13
|
+
Requires-Dist: jsonschema>=4.22.0; python_version >= '3.8'
|
|
14
|
+
Requires-Dist: python-arango>=8.1.3; python_version >= '3.8'
|
|
15
|
+
Requires-Dist: python-dotenv>=1.0.1
|
|
16
|
+
Requires-Dist: python-slugify
|
|
17
|
+
Requires-Dist: pyyaml
|
|
18
|
+
Requires-Dist: requests>=2.31.0; python_version >= '3.7'
|
|
19
|
+
Requires-Dist: stix2
|
|
20
|
+
Requires-Dist: tqdm>=4.66.4; python_version >= '3.7'
|
|
21
|
+
Requires-Dist: validators>=0.34.0
|
|
22
|
+
Provides-Extra: llms
|
|
23
|
+
Requires-Dist: llama-index-core==0.12.7; extra == 'llms'
|
|
24
|
+
Requires-Dist: llama-index-llms-anthropic==0.6.3; extra == 'llms'
|
|
25
|
+
Requires-Dist: llama-index-llms-deepseek==0.1.1; extra == 'llms'
|
|
26
|
+
Requires-Dist: llama-index-llms-gemini==0.4.2; extra == 'llms'
|
|
27
|
+
Requires-Dist: llama-index-llms-openai-like==0.3.3; extra == 'llms'
|
|
28
|
+
Requires-Dist: llama-index-llms-openai==0.3.11; extra == 'llms'
|
|
29
|
+
Requires-Dist: llama-index-llms-openrouter==0.3.1; extra == 'llms'
|
|
30
|
+
Description-Content-Type: text/markdown
|
|
31
|
+
|
|
32
|
+
# txt2detection
|
|
33
|
+
|
|
34
|
+
[](https://codecov.io/gh/muchdogesec/txt2detection)
|
|
35
|
+
|
|
36
|
+
## Overview
|
|
37
|
+
|
|
38
|
+

|
|
39
|
+
|
|
40
|
+
A command line tool that takes a txt file containing threat intelligence and turns it into a detection rule.
|
|
41
|
+
|
|
42
|
+
## The problems
|
|
43
|
+
|
|
44
|
+
To illustrate the problem, lets walk through the current status quo process a human goes through when going from idea (threat TTP) to detection rule:
|
|
45
|
+
|
|
46
|
+
1. read and understand threat using their own research, aided by external sources (blogs, intel feed, etc.)
|
|
47
|
+
* problems: lots of reports, threats described in a range of ways, reports contain differing data
|
|
48
|
+
2. understand what logs or security data can be used to detect this threat
|
|
49
|
+
* problems: log schemas are unknown to analyst, TTPs often span many logs making it hard to ensure your detection rule has full coverage
|
|
50
|
+
3. convert the logic created in step 1 into a Sigma detection rule to search logs identified at step 2
|
|
51
|
+
* problems: hard to convert what has been understood into a logical detection rule (in a detection language an analyst might not be familiar with)
|
|
52
|
+
4. modify the detection rule based on new intelligence as it is discovered
|
|
53
|
+
* problems: this is typically overlooked as people create and forget about rules in their detection tools
|
|
54
|
+
|
|
55
|
+
## The solution
|
|
56
|
+
|
|
57
|
+
Use AI to process threat intelligence, create and keep them updated.
|
|
58
|
+
|
|
59
|
+
txt2detection allows a user to enter some threat intelligence as a file to considered be turned into a detection.
|
|
60
|
+
|
|
61
|
+
1. User uploads intel report
|
|
62
|
+
2. Based on the user input, AI prompts structured and sent to produce an intelligence rule
|
|
63
|
+
3. Rules converted into STIX objects
|
|
64
|
+
|
|
65
|
+
## tl;dr
|
|
66
|
+
|
|
67
|
+
[](https://www.youtube.com/watch?v=uJWXYKyu3Xg)
|
|
68
|
+
|
|
69
|
+
[Watch the demo](https://www.youtube.com/watch?v=uJWXYKyu3Xg).
|
|
70
|
+
|
|
71
|
+
## Usage
|
|
72
|
+
|
|
73
|
+
### Setup
|
|
74
|
+
|
|
75
|
+
Install the required dependencies using:
|
|
76
|
+
|
|
77
|
+
```shell
|
|
78
|
+
# clone the latest code
|
|
79
|
+
git clone https://github.com/muchdogesec/txt2detection
|
|
80
|
+
cd txt2detection
|
|
81
|
+
# create a venv
|
|
82
|
+
python3 -m venv txt2detection-venv
|
|
83
|
+
source txt2detection-venv/bin/activate
|
|
84
|
+
# install requirements
|
|
85
|
+
pip3 install -r requirements.txt
|
|
86
|
+
pip3 install .
|
|
87
|
+
```
|
|
88
|
+
|
|
89
|
+
### Set variables
|
|
90
|
+
|
|
91
|
+
txt2detection has various settings that are defined in an `.env` file.
|
|
92
|
+
|
|
93
|
+
To create a template for the file:
|
|
94
|
+
|
|
95
|
+
```shell
|
|
96
|
+
cp .env.example .env
|
|
97
|
+
```
|
|
98
|
+
|
|
99
|
+
To see more information about how to set the variables, and what they do, read the `.env.markdown` file.
|
|
100
|
+
|
|
101
|
+
### Run
|
|
102
|
+
|
|
103
|
+
```shell
|
|
104
|
+
python3 txt2detection.py MODE \
|
|
105
|
+
ARGUEMENTS
|
|
106
|
+
```
|
|
107
|
+
|
|
108
|
+
There are 3 modes in which you can use txt2detection:
|
|
109
|
+
|
|
110
|
+
* `file`: A text file, usually a threat report you want to create rules from the intel held within
|
|
111
|
+
* `text`: A text prompt that describes the rule you want to create
|
|
112
|
+
* `sigma`: An existing Sigma Rule you want to convert into a STIX bundle
|
|
113
|
+
|
|
114
|
+
#### File (`file`) / Text Input (`text`)
|
|
115
|
+
|
|
116
|
+
Use this mode to generate a set of rules from an input text file;
|
|
117
|
+
|
|
118
|
+
* `--input_file` (required, if not using `--input_text`, file path): the file to be converted. Must be `.txt`
|
|
119
|
+
* `--input_text` (required, if not using `--input_file`, string): a text string that will be analysed to create a rule by the AI if you don't want to use a file.
|
|
120
|
+
* `--name` (required): name of file, max 72 chars. Will be used in the STIX Report Object created. Note, the Indicator object names/titles are generated by AI
|
|
121
|
+
* `--report_id` (optional, default random uuidv4): Sometimes it is required to control the id of the `report` object generated. You can therefore pass a valid UUIDv4 in this field to be assigned to the report. e.g. passing `2611965-930e-43db-8b95-30a1e119d7e2` would create a STIX object id `report--2611965-930e-43db-8b95-30a1e119d7e2`. If this argument is not passed, the UUID will be randomly generated.
|
|
122
|
+
* `--tlp_level` (optional, default `clear`): Options are `clear`, `green`, `amber`, `amber_strict`, `red`.
|
|
123
|
+
* `--labels` (optional): whitspace separated list of labels. Case-insensitive (will all be converted to lower-case). Allowed `a-z`, `0-9`. Must use a namespaces (`NAMESPACE.TAG_VALUE`). e.g.`"namespace.label1" "namespace.label_2"` would create 2 labels. Added to both report and indicator objects created and the rule `tags`.
|
|
124
|
+
* note: you can use reserved namespaces `cve.` and `attack.` when creating labels to perform external enrichment using Vulmatch and CTI Butler. All Indicators will be linked to these objects (AI enrichments link individual rules). Created tags will be appended to the list of AI generated tags.
|
|
125
|
+
* note: you cannot use the namespace `tlp.` Use the `--tlp_level` flag instead.
|
|
126
|
+
* `--created` (optional, `YYYY-MM-DDTHH:MM:SS`): by default all object `created` times will take the time the script was run. If you want to explicitly set these times you can do so using this flag. Pass the value in the format `YYYY-MM-DDTHH:MM:SS` e.g. `2020-01-01T00:00:00`
|
|
127
|
+
* `--use_identity` (optional, default txt2detection identity): can pass a full STIX 2.1 identity object (make sure to properly escape). Will be validated by the STIX2 library. The ID is used to create the Indicator and Report STIX objects, and is used as the `author` property in the Sigma Rule.
|
|
128
|
+
* `--license` (optional): [License of the rule according the SPDX ID specification](https://spdx.org/licenses/). Will be added to the rule.
|
|
129
|
+
* `--reference_urls` (optional): A list of URLs to be added as `references` in the Sigma Rule property and in the `external_references` property of the Indicator and Report STIX object created. e.g `"https://www.google.com/" "https://www.facebook.com/"`
|
|
130
|
+
* `--external_refs` (optional): txt2detection will automatically populate the `external_references` of the report object it creates for the input. You can use this value to add additional objects to `external_references`. Note, you can only add `source_name` and `external_id` values currently. Pass as `source_name=external_id`. e.g. `--external_refs txt2stix=demo1 source=id` would create the following objects under the `external_references` property: `{"source_name":"txt2stix","external_id":"demo1"},{"source_name":"source","external_id":"id"}`
|
|
131
|
+
* `ai_provider` (required): defines the `provider:model` to be used to generate the rule. Select one option. Currently supports:
|
|
132
|
+
* Provider (env var required `OPENROUTER_API_KEY`): `openrouter:`, providers/models `openai/gpt-4o`, `deepseek/deepseek-chat` ([More here](https://openrouter.ai/models))
|
|
133
|
+
* Provider (env var required `OPENAI_API_KEY`): `openai:`, models e.g.: `gpt-4o`, `gpt-4o-mini`, `gpt-4-turbo`, `gpt-4` ([More here](https://platform.openai.com/docs/models))
|
|
134
|
+
* Provider (env var required `ANTHROPIC_API_KEY`): `anthropic:`, models e.g.: `claude-3-5-sonnet-latest`, `claude-3-5-haiku-latest`, `claude-3-opus-latest` ([More here](https://docs.anthropic.com/en/docs/about-claude/models))
|
|
135
|
+
* Provider (env var required `GOOGLE_API_KEY`): `gemini:models/`, models: `gemini-1.5-pro-latest`, `gemini-1.5-flash-latest` ([More here](https://ai.google.dev/gemini-api/docs/models/gemini))
|
|
136
|
+
* Provider (env var required `DEEPSEEK_API_KEY`): `deepseek:`, models `deepseek-chat` ([More here](https://api-docs.deepseek.com/quick_start/pricing))
|
|
137
|
+
|
|
138
|
+
Note, in this mode, the following values will be automatically assigned to the rule
|
|
139
|
+
|
|
140
|
+
* `level`: the AI will be prompted to assign, either `informational`, `low`, `medium`, `high`, `critical`
|
|
141
|
+
* `status`: will always be `experimental` in this mode
|
|
142
|
+
|
|
143
|
+
#### Sigma rule input (`sigma`)
|
|
144
|
+
|
|
145
|
+
Use this mode to turn a Sigma Rule into a STIX bundle and get it enriched with ATT&CK and Vulmatch.
|
|
146
|
+
|
|
147
|
+
Note, in this mode you should be aware of a few things;
|
|
148
|
+
|
|
149
|
+
* `--sigma_file` (required, file path): the sigma rule .yml you want to be processed. Must be a `.yml` or `.yaml` file. Does not currently support correlation rules.
|
|
150
|
+
* `--report_id`: will overwrite any `id` value found in the rule, also used for both Indicator and Report
|
|
151
|
+
* `--name`: will be assigned as `title` of the rule. Will overwrite existing title
|
|
152
|
+
* `--tlp_level` (optional): the `tlp.` tag in the report will be turned into a TLP level. If not TLP tag in rule, default is that is will be assigned TLP `clear` and tag added. You can pass `clear`, `green`, `amber`, `amber_strict`, `red` using this property to overwrite default behaviour. If TLP exist in rule, setting a value for this property will overwrite the existing value
|
|
153
|
+
* `--labels` (optional): whitespace separated list of labels. Case-insensitive (will all be converted to lower-case). Allowed `a-z`, `0-9`. e.g.`"namespace.label1" "namespace.label2"` would create 2 labels. Added to both report and indicator objects created and the rule `tags`. Note, if any existing `tags` in the rule, these values will be appended to the list.
|
|
154
|
+
* note: you can use reserved namespaces `cve.` and `attack.` when creating labels to perform external enrichment using Vulmatch and CTI Butler. Created tags will be appended to the list of existing tags.
|
|
155
|
+
* note: you cannot use the namespace `tlp.` Use the `--tlp_level` flag instead.
|
|
156
|
+
* `--created` (optional, `YYYY-MM-DDTHH:MM:SS`): by default the `data` and `modified` values in the rule will be used. If no values exist for these, the default behaviour is to use script run time. You can pass `created` time here which will overwrite `date` and `modified` date in the rule
|
|
157
|
+
* `--use_identity` (optional): can pass a full STIX 2.1 identity object (make sure to properly escape). Will be validated by the STIX2 library. The ID is used to create the Indicator and Report STIX objects, and is used as the `author` property in the Sigma Rule. Will overwrite any existing `author` value. If `author` value in rule, will be converted into a STIX Identity
|
|
158
|
+
* `--license` (optional): [License of the rule according the SPDX ID specification](https://spdx.org/licenses/). Will be added to the rule as `license`. Will overwrite any existing `license` value in rule.
|
|
159
|
+
* `--reference_urls` (optional): A list of URLs to be added as `references` in the Sigma Rule property and in the `external_references` property of the Indicator and Report STIX object created. e.g `"https://www.google.com/" "https://www.facebook.com/"`. Will appended to any existing `references` in the rule.
|
|
160
|
+
* `--external_refs` (optional): txt2detection will automatically populate the `external_references` of the report object it creates for the input. You can use this value to add additional objects to `external_references`. Note, you can only add `source_name` and `external_id` values currently. Pass as `source_name=external_id`. e.g. `--external_refs txt2stix=demo1 source=id` would create the following objects under the `external_references` property: `{"source_name":"txt2stix","external_id":"demo1"},{"source_name":"source","external_id":"id"}`
|
|
161
|
+
* `status` (optional): either `stable`, `test`, `experimental`, `deprecated`, `unsupported`. If passed, will overwrite any existing `status` recorded in the rule
|
|
162
|
+
* `level` (optional): either `informational`, `low`, `medium`, `high`, `critical`. If passed, will overwrite any existing `level` recorded in the rule
|
|
163
|
+
|
|
164
|
+
### A note on observable extraction
|
|
165
|
+
|
|
166
|
+
txt2detection will automatically attempt to extract any observables (aka indicators of compromise) that are found in the created or imported rules to turn them into STIX objects joined to the STIX Indicator object of the Rule.
|
|
167
|
+
|
|
168
|
+
In `txt2detection/observables.py` you will find the observable types (and regexs used detection) currently supported.
|
|
169
|
+
|
|
170
|
+
### Output
|
|
171
|
+
|
|
172
|
+
The output of each run is structured as follows;
|
|
173
|
+
|
|
174
|
+
```txt
|
|
175
|
+
.
|
|
176
|
+
├── logs
|
|
177
|
+
│ ├── log-<REPORT UUID>.log
|
|
178
|
+
│ ├── log-<REPORT UUID>.log
|
|
179
|
+
│ └── log-<REPORT UUID>.log
|
|
180
|
+
└── output
|
|
181
|
+
└── bundle--<REPORT UUID>
|
|
182
|
+
├── rules
|
|
183
|
+
│ ├── rule--<UUID>.yml
|
|
184
|
+
│ └── rule--<UUID>.yml
|
|
185
|
+
├── data.json # AI output, useful for debugging
|
|
186
|
+
└── bundle.json # final STIX bundle with all objects
|
|
187
|
+
```
|
|
188
|
+
|
|
189
|
+
## Examples
|
|
190
|
+
|
|
191
|
+
See `tests/manual-tests/README.md` for some example commands.
|
|
192
|
+
|
|
193
|
+
## Support
|
|
194
|
+
|
|
195
|
+
[Minimal support provided via the DOGESEC community](https://community.dogesec.com/).
|
|
196
|
+
|
|
197
|
+
## License
|
|
198
|
+
|
|
199
|
+
[Apache 2.0](/LICENSE).
|
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
txt2detection/__init__.py,sha256=Fc460P0q_eb2u3Xc89z-fwl-4ai3jrPqPNVwJQYNkNQ,89
|
|
2
|
+
txt2detection/__main__.py,sha256=Zvz1hZRSsdPONUnMPCpbImM3bXB2Qeq3d95dgztxLSA,8993
|
|
3
|
+
txt2detection/bundler.py,sha256=l3MerTfDkcbiJg_GiovytlvGyY9ZunABuus-PngJB4g,10858
|
|
4
|
+
txt2detection/models.py,sha256=wDRL-Thme8XXuX1b850v_egTjL3mNYpdVmDvYwfzKI8,12000
|
|
5
|
+
txt2detection/observables.py,sha256=NNnwF_gOsPmAbfgk5fj1rcluMsShZOHssAGy2VJgvmo,6763
|
|
6
|
+
txt2detection/utils.py,sha256=wCol8_DBlvzJOV8VvjqvVR6FWWDQjmz8ItbxG8qbvnw,2755
|
|
7
|
+
txt2detection/ai_extractor/__init__.py,sha256=itcwTF0-S80mx-SuSvfrKazvcwsojR-QsBN-UvnSDwE,418
|
|
8
|
+
txt2detection/ai_extractor/anthropic.py,sha256=YOi2rHUeeoRMS4CFG6mX7xUU4q4rw9qNl72R74UN6ZM,420
|
|
9
|
+
txt2detection/ai_extractor/base.py,sha256=2wskkhKaiGe2Lc1nJK1k3WMyGIIiP5DlFAkcui07h9s,2061
|
|
10
|
+
txt2detection/ai_extractor/deepseek.py,sha256=2XehIYbWXG6Odq68nQX4CNtl5GdmBlAmjLP_lG2eEFo,660
|
|
11
|
+
txt2detection/ai_extractor/gemini.py,sha256=hlcKkiHGzQJ0dQECfIhjx2LfdhZoquAF9POwz61RAhw,557
|
|
12
|
+
txt2detection/ai_extractor/openai.py,sha256=e5Of3i-T2CvUSx1T_v7wHOuewHK2IoImxZXfXeZc3Ds,625
|
|
13
|
+
txt2detection/ai_extractor/openrouter.py,sha256=-KcdcyKPpaeiGfvqJB4L7vMmcXTDhml3Mr0T6kwANZA,645
|
|
14
|
+
txt2detection/ai_extractor/prompts.py,sha256=ACYFWUafdHXHBXz7fq_RSooA4PJ-mBdaBzqsOOSFpVg,5918
|
|
15
|
+
txt2detection/ai_extractor/utils.py,sha256=SUxyPhkGp5yDbX_H_E018i93R8IbyLsQ00PIBDecfuc,540
|
|
16
|
+
txt2detection/config/detection_languages.yaml,sha256=dgQUJPxhDRJ_IiFEFOiH0yhEer3SkFSIhY4pS3BsX2c,287
|
|
17
|
+
txt2detection-0.0.2rc12.dist-info/METADATA,sha256=29-gUt5hiBAiCp_1EpnDawuEmcxKcPYgwMGWLS-Tk94,13531
|
|
18
|
+
txt2detection-0.0.2rc12.dist-info/WHEEL,sha256=qtCwoSJWgHk21S1Kb4ihdzI2rlJ1ZKaIurTj_ngOhyQ,87
|
|
19
|
+
txt2detection-0.0.2rc12.dist-info/entry_points.txt,sha256=ep_rLlS2r1-kKE7S3iKf3SVwbCU9-FZhU9zUebitw7A,62
|
|
20
|
+
txt2detection-0.0.2rc12.dist-info/licenses/LICENSE,sha256=BK8Ppqlc4pdgnNzIxnxde0taoQ1BgicdyqmBvMiNYgY,11364
|
|
21
|
+
txt2detection-0.0.2rc12.dist-info/RECORD,,
|