mlxmc 0.1.0__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- mlxmc/__init__.py +26 -0
- mlxmc/diagnostics.py +49 -0
- mlxmc/ensemble.py +60 -0
- mlxmc/hmc.py +59 -0
- mlxmc/nuts.py +211 -0
- mlxmc/preconditioned.py +56 -0
- mlxmc/targets.py +70 -0
- mlxmc/warmup.py +178 -0
- mlxmc-0.1.0.dist-info/METADATA +200 -0
- mlxmc-0.1.0.dist-info/RECORD +12 -0
- mlxmc-0.1.0.dist-info/WHEEL +4 -0
- mlxmc-0.1.0.dist-info/licenses/LICENSE +28 -0
mlxmc/__init__.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
1
|
+
"""mlxmc — MCMC samplers in Apple MLX.
|
|
2
|
+
|
|
3
|
+
Affine-invariant ensemble, HMC (identity / preconditioned), Stan-style warmup
|
|
4
|
+
adaptation, and NUTS, plus ESS diagnostics and a set of example targets. Every
|
|
5
|
+
sampler takes a single-point log-density `logp(x) -> scalar` for `x` of shape
|
|
6
|
+
`(D,)`; batching over chains/walkers is handled internally with `vmap`.
|
|
7
|
+
"""
|
|
8
|
+
from mlxmc import targets
|
|
9
|
+
from mlxmc.diagnostics import autocorr_1d, integrated_time, report
|
|
10
|
+
from mlxmc.ensemble import make_sampler, run_ensemble
|
|
11
|
+
from mlxmc.hmc import make_hmc, run_hmc
|
|
12
|
+
from mlxmc.nuts import make_nuts, nuts_warmup, run_nuts
|
|
13
|
+
from mlxmc.preconditioned import make_phmc, run_phmc
|
|
14
|
+
from mlxmc.warmup import DualAveraging, make_warmup_step, run_chain, warmup
|
|
15
|
+
|
|
16
|
+
__version__ = "0.1.0"
|
|
17
|
+
|
|
18
|
+
__all__ = [
|
|
19
|
+
"make_sampler", "run_ensemble",
|
|
20
|
+
"make_hmc", "run_hmc",
|
|
21
|
+
"make_phmc", "run_phmc",
|
|
22
|
+
"DualAveraging", "make_warmup_step", "warmup", "run_chain",
|
|
23
|
+
"make_nuts", "run_nuts", "nuts_warmup",
|
|
24
|
+
"autocorr_1d", "integrated_time", "report",
|
|
25
|
+
"targets",
|
|
26
|
+
]
|
mlxmc/diagnostics.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
1
|
+
"""Effective sample size: how many *independent* draws the chains are worth.
|
|
2
|
+
|
|
3
|
+
ESS = N / tau, with tau the integrated autocorrelation time (emcee-style:
|
|
4
|
+
FFT autocorrelation averaged over walkers, Sokal automatic windowing). The
|
|
5
|
+
fair cross-sampler metric is ESS/sec, since it folds in per-step cost.
|
|
6
|
+
|
|
7
|
+
Pure numpy on a structured (T, N, D) chain -- no sampler or MLX dependency, so
|
|
8
|
+
it's a leaf module the samplers don't pull in.
|
|
9
|
+
"""
|
|
10
|
+
import numpy as np
|
|
11
|
+
|
|
12
|
+
|
|
13
|
+
def autocorr_1d(x):
|
|
14
|
+
x = x - x.mean()
|
|
15
|
+
n = len(x)
|
|
16
|
+
f = np.fft.fft(x, n=2 * n)
|
|
17
|
+
acf = np.fft.ifft(f * np.conj(f))[:n].real
|
|
18
|
+
if acf[0] == 0: # constant (stuck) walker: autocorrelation undefined
|
|
19
|
+
return None
|
|
20
|
+
return acf / acf[0]
|
|
21
|
+
|
|
22
|
+
|
|
23
|
+
def auto_window(taus, c=5.0):
|
|
24
|
+
m = np.arange(len(taus)) < c * taus
|
|
25
|
+
return np.argmin(m) if np.any(~m) else len(taus) - 1
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def integrated_time(y): # y: (T, N) for one dimension
|
|
29
|
+
# Skip stuck (zero-variance) walkers, which would make acf/acf[0] a 0/0 = nan and
|
|
30
|
+
# poison the walker average. A large skipped fraction is itself a mixing-failure tell.
|
|
31
|
+
acfs = [a for a in (autocorr_1d(y[:, w]) for w in range(y.shape[1])) if a is not None]
|
|
32
|
+
if not acfs:
|
|
33
|
+
return np.nan
|
|
34
|
+
f = np.mean(acfs, axis=0)
|
|
35
|
+
taus = 2.0 * np.cumsum(f) - 1.0
|
|
36
|
+
return taus[auto_window(taus)]
|
|
37
|
+
|
|
38
|
+
|
|
39
|
+
def report(chain_mx, label, dt):
|
|
40
|
+
c = np.array(chain_mx) # (T, N, D)
|
|
41
|
+
T, N, D = c.shape
|
|
42
|
+
total = T * N
|
|
43
|
+
tau = max(integrated_time(c[:, :, d]) for d in range(D))
|
|
44
|
+
ess = total / tau
|
|
45
|
+
print(f"\n[{label}]")
|
|
46
|
+
print(f" raw samples {total:,} ({T} steps x {N}) wall {dt:.2f}s")
|
|
47
|
+
print(f" tau (worst dim): {tau:.1f} steps -> ESS {ess:,.0f} ({100 * ess / total:.1f}% independent)")
|
|
48
|
+
print(f" ESS/sec: {ess / dt:,.0f}")
|
|
49
|
+
return ess, dt
|
mlxmc/ensemble.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
1
|
+
"""Affine-invariant ensemble sampler (Goodman & Weare 2010) in MLX.
|
|
2
|
+
|
|
3
|
+
This is the algorithm behind `emcee`. It's gradient-free and invariant to
|
|
4
|
+
affine transforms of parameter space, so a badly-conditioned (elongated,
|
|
5
|
+
correlated) target is sampled as easily as an isotropic one -- no tuning.
|
|
6
|
+
|
|
7
|
+
MLX transforms on display:
|
|
8
|
+
- mx.vmap : batch a single-point log-density over all walkers
|
|
9
|
+
- mx.compile : fuse the stretch-move sweep into one graph
|
|
10
|
+
- mx.random : JAX-style functional keys (split per step), so the
|
|
11
|
+
compiled step is pure
|
|
12
|
+
"""
|
|
13
|
+
import mlx.core as mx
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
def make_sampler(logp_single, n_dim, a=2.0):
|
|
17
|
+
"""Return a compiled half-ensemble update for the G&W stretch move."""
|
|
18
|
+
logp = mx.vmap(logp_single) # (m, D) -> (m,)
|
|
19
|
+
|
|
20
|
+
@mx.compile
|
|
21
|
+
def update_half(active, complement, key):
|
|
22
|
+
m = active.shape[0]
|
|
23
|
+
k_part, k_z, k_acc = mx.random.split(key, 3)
|
|
24
|
+
# Each active walker picks a partner from the *complementary* half.
|
|
25
|
+
j = mx.random.randint(0, complement.shape[0], (m,), key=k_part)
|
|
26
|
+
partners = mx.take(complement, j, axis=0)
|
|
27
|
+
# Stretch factor z ~ g(z) ∝ 1/sqrt(z) on [1/a, a].
|
|
28
|
+
u = mx.random.uniform(shape=(m,), key=k_z)
|
|
29
|
+
z = ((a - 1.0) * u + 1.0) ** 2 / a
|
|
30
|
+
proposal = partners + z[:, None] * (active - partners)
|
|
31
|
+
# Metropolis accept with the (D-1) stretch Jacobian.
|
|
32
|
+
log_ratio = (n_dim - 1) * mx.log(z) + logp(proposal) - logp(active)
|
|
33
|
+
accept = mx.log(mx.random.uniform(shape=(m,), key=k_acc)) < log_ratio
|
|
34
|
+
new_active = mx.where(accept[:, None], proposal, active)
|
|
35
|
+
return new_active, accept.sum()
|
|
36
|
+
|
|
37
|
+
return update_half
|
|
38
|
+
|
|
39
|
+
|
|
40
|
+
def run_ensemble(logp_single, ensemble, n_steps, burn, key, a=2.0):
|
|
41
|
+
"""Sample with the affine-invariant ensemble. Returns (flat samples, accept_frac)."""
|
|
42
|
+
n_walkers, n_dim = ensemble.shape
|
|
43
|
+
half = n_walkers // 2
|
|
44
|
+
update_half = make_sampler(logp_single, n_dim, a)
|
|
45
|
+
|
|
46
|
+
chain, accepted = [], mx.array(0)
|
|
47
|
+
e = ensemble
|
|
48
|
+
for t in range(n_steps):
|
|
49
|
+
key, k0, k1 = mx.random.split(key, 3)
|
|
50
|
+
h0, h1 = e[:half], e[half:]
|
|
51
|
+
h0, n0 = update_half(h0, h1, k0) # update half 0 against half 1
|
|
52
|
+
h1, n1 = update_half(h1, h0, k1) # update half 1 against new half 0
|
|
53
|
+
e = mx.concatenate([h0, h1], axis=0)
|
|
54
|
+
accepted = accepted + n0 + n1
|
|
55
|
+
mx.eval(e, accepted) # keep the lazy graph shallow
|
|
56
|
+
if t >= burn:
|
|
57
|
+
chain.append(e)
|
|
58
|
+
samples = mx.stack(chain, axis=0).reshape(-1, n_dim)
|
|
59
|
+
accept_frac = float(accepted) / (n_steps * n_walkers)
|
|
60
|
+
return samples, accept_frac
|
mlxmc/hmc.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
1
|
+
"""Hamiltonian Monte Carlo in MLX, with an identity mass matrix.
|
|
2
|
+
|
|
3
|
+
MLX transforms on display:
|
|
4
|
+
- mx.grad : gradient of the single-point log-density (the thing HMC needs
|
|
5
|
+
and the ensemble sampler didn't)
|
|
6
|
+
- mx.vmap : compose grad ∘ vmap to batch the gradient over all chains
|
|
7
|
+
- mx.compile : fuse the L-step leapfrog + Metropolis accept into one graph
|
|
8
|
+
|
|
9
|
+
Identity mass (no preconditioning), so the contrast with the affine-invariant
|
|
10
|
+
ensemble on an ill-conditioned target is visible. See `preconditioned` and
|
|
11
|
+
`warmup` for the mass-matrix versions.
|
|
12
|
+
"""
|
|
13
|
+
import mlx.core as mx
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
def make_hmc(logp_single, eps, n_leap):
|
|
17
|
+
grad_logp = mx.vmap(mx.grad(logp_single)) # (n, D) -> (n, D)
|
|
18
|
+
logp = mx.vmap(logp_single) # (n, D) -> (n,)
|
|
19
|
+
|
|
20
|
+
@mx.compile
|
|
21
|
+
def step(q, key):
|
|
22
|
+
n, _ = q.shape
|
|
23
|
+
k_p, k_acc = mx.random.split(key, 2)
|
|
24
|
+
p0 = mx.random.normal(shape=q.shape, key=k_p) # resample momentum ~ N(0, I)
|
|
25
|
+
logp_q = logp(q)
|
|
26
|
+
|
|
27
|
+
# Leapfrog: half-kick, then L drifts with full-kicks between, final half-kick.
|
|
28
|
+
qq = q
|
|
29
|
+
p = p0 + 0.5 * eps * grad_logp(qq)
|
|
30
|
+
for i in range(n_leap):
|
|
31
|
+
qq = qq + eps * p
|
|
32
|
+
if i != n_leap - 1:
|
|
33
|
+
p = p + eps * grad_logp(qq)
|
|
34
|
+
p = p + 0.5 * eps * grad_logp(qq)
|
|
35
|
+
|
|
36
|
+
# Metropolis on the Hamiltonian H = -logp + 0.5 |p|^2.
|
|
37
|
+
logp_new = logp(qq)
|
|
38
|
+
log_accept = (logp_new - logp_q) + 0.5 * ((p0 * p0).sum(1) - (p * p).sum(1))
|
|
39
|
+
accept = mx.log(mx.random.uniform(shape=(n,), key=k_acc)) < log_accept
|
|
40
|
+
q_new = mx.where(accept[:, None], qq, q)
|
|
41
|
+
return q_new, accept.sum()
|
|
42
|
+
|
|
43
|
+
return step
|
|
44
|
+
|
|
45
|
+
|
|
46
|
+
def run_hmc(logp_single, q0, n_steps, burn, eps, n_leap, key):
|
|
47
|
+
"""Sample with fixed-step, fixed-L HMC. Returns (flat samples, accept_frac)."""
|
|
48
|
+
step = make_hmc(logp_single, eps, n_leap)
|
|
49
|
+
chain, accepted = [], mx.array(0)
|
|
50
|
+
q = q0
|
|
51
|
+
for t in range(n_steps):
|
|
52
|
+
key, k = mx.random.split(key, 2)
|
|
53
|
+
q, na = step(q, k)
|
|
54
|
+
accepted = accepted + na
|
|
55
|
+
mx.eval(q, accepted)
|
|
56
|
+
if t >= burn:
|
|
57
|
+
chain.append(q)
|
|
58
|
+
samples = mx.stack(chain, axis=0).reshape(-1, q0.shape[1])
|
|
59
|
+
return samples, float(accepted) / (n_steps * q0.shape[0])
|
mlxmc/nuts.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
1
|
+
"""NUTS (No-U-Turn Sampler), multinomial variant (Hoffman & Gelman 2014 + Betancourt 2017),
|
|
2
|
+
vectorized over chains in MLX.
|
|
3
|
+
|
|
4
|
+
The MLX story (Phase 2): MLX has no `while_loop`/`scan` (see the README's "Why MLX"), so the tree-doubling
|
|
5
|
+
recursion runs in **host Python** while each leapfrog leaf is `vmap`'d over all chains and
|
|
6
|
+
`mx.compile`'d. Chains U-turn at different depths; a finished chain still rides along in the
|
|
7
|
+
batched leapfrog but is **masked out** (`mx.where` on a per-chain `cont` flag), so it's frozen
|
|
8
|
+
correctly. The doubling loop stops at `max_tree_depth` or when no chain is still going. The gap
|
|
9
|
+
vs JAX's traced `while_loop` is the wasted leapfrogs on already-stopped chains (mean tree depth
|
|
10
|
+
<< max is the tell). Trajectory length is adaptive, which removes the fixed-L resonance that
|
|
11
|
+
eps-jitter papers over for fixed-L HMC.
|
|
12
|
+
|
|
13
|
+
`eps` is a per-step argument to the returned step (not closed over) so dual-averaging in
|
|
14
|
+
`nuts_warmup` can vary it every iteration without rebuilding or recompiling the leapfrog leaf.
|
|
15
|
+
`Minv` is closed over for the compile, so changing M (at window boundaries during warmup)
|
|
16
|
+
means rebuilding the closure -- a few recompile events over a warmup, not per step.
|
|
17
|
+
"""
|
|
18
|
+
import mlx.core as mx
|
|
19
|
+
import numpy as np
|
|
20
|
+
|
|
21
|
+
from mlxmc.warmup import DualAveraging, regularize_cov, stan_windows
|
|
22
|
+
|
|
23
|
+
DMAX = 1000.0 # divergence threshold on the Hamiltonian error
|
|
24
|
+
NEG = -1e30 # stand-in for log-weight 0 (divergent leaf); finite to keep logaddexp NaN-free
|
|
25
|
+
|
|
26
|
+
|
|
27
|
+
def expit(x): # logistic; finite NEG keeps this NaN-free
|
|
28
|
+
return 1.0 / (1.0 + mx.exp(-x))
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
def logaddexp(a, b):
|
|
32
|
+
m = mx.maximum(a, b)
|
|
33
|
+
return m + mx.log(mx.exp(a - m) + mx.exp(b - m))
|
|
34
|
+
|
|
35
|
+
|
|
36
|
+
def wsel(mask, a, b): # per-chain select; broadcasts (N,) over (N,D)
|
|
37
|
+
return mx.where(mask[:, None] if a.ndim == 2 else mask, a, b)
|
|
38
|
+
|
|
39
|
+
|
|
40
|
+
def make_nuts(logp_single, Minv_np, max_tree_depth=10):
|
|
41
|
+
"""Build a NUTS step `step(theta, key, eps)` that returns (sample, depths, mean_accept).
|
|
42
|
+
|
|
43
|
+
`mean_accept` is the H&G Alg 6 dual-averaging statistic -- the per-leaf Metropolis
|
|
44
|
+
acceptance min(1, exp(-Delta_H)) averaged over all leapfrog leaves in the iteration's
|
|
45
|
+
tree (per chain), then averaged over chains. Zeroed on divergent leaves. Returned for
|
|
46
|
+
use by `nuts_warmup`; `run_nuts` discards it.
|
|
47
|
+
"""
|
|
48
|
+
grad_logp = mx.vmap(mx.grad(logp_single))
|
|
49
|
+
logp = mx.vmap(logp_single)
|
|
50
|
+
Minv = mx.array(Minv_np.astype(np.float32))
|
|
51
|
+
Mhalf_T = mx.array(np.linalg.cholesky(np.linalg.inv(Minv_np)).T.astype(np.float32))
|
|
52
|
+
|
|
53
|
+
@mx.compile
|
|
54
|
+
def leap(theta, r, se): # one leapfrog; se = signed step, (N,1)
|
|
55
|
+
r = r + 0.5 * se * grad_logp(theta)
|
|
56
|
+
theta = theta + se * (r @ Minv)
|
|
57
|
+
r = r + 0.5 * se * grad_logp(theta)
|
|
58
|
+
return theta, r
|
|
59
|
+
|
|
60
|
+
def joint(theta, r): # -H = logp - 0.5 r^T M^-1 r (the log-weight)
|
|
61
|
+
return logp(theta) - 0.5 * ((r @ Minv) * r).sum(1)
|
|
62
|
+
|
|
63
|
+
def no_uturn(tm, rm, tp, rp): # True = keep going (no U-turn), generalized metric
|
|
64
|
+
d = tp - tm
|
|
65
|
+
return ((d * (rm @ Minv)).sum(1) >= 0) & ((d * (rp @ Minv)).sum(1) >= 0)
|
|
66
|
+
|
|
67
|
+
def build(theta, r, lw0, depth, dirn, eps, key):
|
|
68
|
+
"""Recursive subtree builder. Returns the two endpoints, the multinomial proposal from
|
|
69
|
+
this subtree, its total log-weight, a per-chain continue flag, and the leaf-accept
|
|
70
|
+
(sum, count) used by the dual-averaging statistic."""
|
|
71
|
+
if depth == 0: # base: a single leapfrog in `dirn`
|
|
72
|
+
th1, r1 = leap(theta, r, (dirn * eps)[:, None])
|
|
73
|
+
lw1 = joint(th1, r1)
|
|
74
|
+
div = (lw0 - lw1 > DMAX) | mx.isnan(lw1)
|
|
75
|
+
# H&G Alg 6 leaf statistic: min(1, exp(lw1 - lw0)) = min(1, exp(-Delta_H)); zeroed
|
|
76
|
+
# on divergence/NaN. exp(min(0, ...)) keeps the value <= 1 without an explicit clamp.
|
|
77
|
+
leaf_a = mx.where(div, mx.zeros_like(lw1),
|
|
78
|
+
mx.exp(mx.minimum(mx.zeros_like(lw1), lw1 - lw0)))
|
|
79
|
+
ones = mx.ones_like(lw1)
|
|
80
|
+
return th1, r1, th1, r1, th1, mx.where(div, NEG, lw1), ~div, leaf_a, ones
|
|
81
|
+
|
|
82
|
+
kL, kR, ks = mx.random.split(key, 3)
|
|
83
|
+
tm, rm, tp, rp, p1, lw1, s1, a1, c1 = build(theta, r, lw0, depth - 1, dirn, eps, kL)
|
|
84
|
+
lt, lr = wsel(dirn < 0, tm, tp), wsel(dirn < 0, rm, rp) # extend the leading edge
|
|
85
|
+
tm2, rm2, tp2, rp2, p2, lw2, s2, a2, c2 = build(lt, lr, lw0, depth - 1, dirn, eps, kR)
|
|
86
|
+
|
|
87
|
+
ftm, frm = wsel(dirn < 0, tm2, tm), wsel(dirn < 0, rm2, rm) # stitched full endpoints
|
|
88
|
+
ftp, frp = wsel(dirn < 0, tp, tp2), wsel(dirn < 0, rp, rp2)
|
|
89
|
+
pick2 = mx.random.uniform(shape=(theta.shape[0],), key=ks) < expit(lw2 - lw1)
|
|
90
|
+
prop = wsel(pick2, p2, p1)
|
|
91
|
+
lw = logaddexp(lw1, lw2)
|
|
92
|
+
s = s1 & s2 & no_uturn(ftm, frm, ftp, frp)
|
|
93
|
+
# Accept stat sums all leaves traversed (H&G: n_alpha counts every leapfrog leaf,
|
|
94
|
+
# not just the ones in valid subtrees). State propagation still gates on s1 as before.
|
|
95
|
+
return (wsel(s1, ftm, tm), wsel(s1, frm, rm), wsel(s1, ftp, tp), wsel(s1, frp, rp),
|
|
96
|
+
wsel(s1, prop, p1), mx.where(s1, lw, lw1), s1 & s, a1 + a2, c1 + c2)
|
|
97
|
+
|
|
98
|
+
def step(theta, key, eps):
|
|
99
|
+
N = theta.shape[0]
|
|
100
|
+
km, k = mx.random.split(key, 2)
|
|
101
|
+
r0 = mx.random.normal(shape=theta.shape, key=km) @ Mhalf_T # ~ N(0, M)
|
|
102
|
+
lw0 = joint(theta, r0)
|
|
103
|
+
tm = tp = theta
|
|
104
|
+
rm = rp = r0
|
|
105
|
+
sample, lw_tree = theta, lw0
|
|
106
|
+
cont = mx.array(np.ones(N, dtype=bool))
|
|
107
|
+
depths = mx.zeros((N,), dtype=mx.int32)
|
|
108
|
+
accept_sum = mx.zeros((N,))
|
|
109
|
+
accept_cnt = mx.zeros((N,))
|
|
110
|
+
|
|
111
|
+
for depth in range(max_tree_depth):
|
|
112
|
+
cont_was = cont # gate accept-stat accumulation on entering state
|
|
113
|
+
k, kdir, ksub, ksel = mx.random.split(k, 4)
|
|
114
|
+
dirn = mx.where(mx.random.uniform(shape=(N,), key=kdir) < 0.5, -1.0, 1.0)
|
|
115
|
+
depths = depths + cont.astype(mx.int32)
|
|
116
|
+
lt, lr = wsel(dirn < 0, tm, tp), wsel(dirn < 0, rm, rp)
|
|
117
|
+
ntm, nrm, ntp, nrp, prop, lw_sub, s_sub, a_sub, c_sub = build(
|
|
118
|
+
lt, lr, lw0, depth, dirn, eps, ksub)
|
|
119
|
+
|
|
120
|
+
new_tm, new_rm = wsel(dirn < 0, ntm, tm), wsel(dirn < 0, nrm, rm)
|
|
121
|
+
new_tp, new_rp = wsel(dirn < 0, tp, ntp), wsel(dirn < 0, rp, nrp)
|
|
122
|
+
# multinomial: adopt the new subtree's proposal with prob W_sub / (W_tree + W_sub),
|
|
123
|
+
# but ONLY if the subtree is valid (H&G Alg 3: gate on s'). Adopting proposals from
|
|
124
|
+
# a subtree that internally U-turned/diverged over-samples its returned far points.
|
|
125
|
+
pick = (mx.random.uniform(shape=(N,), key=ksel) < expit(lw_sub - lw_tree)) & cont & s_sub
|
|
126
|
+
sample = wsel(pick, prop, sample)
|
|
127
|
+
lw_tree = mx.where(cont, logaddexp(lw_tree, lw_sub), lw_tree)
|
|
128
|
+
tm, rm = wsel(cont, new_tm, tm), wsel(cont, new_rm, rm)
|
|
129
|
+
tp, rp = wsel(cont, new_tp, tp), wsel(cont, new_rp, rp)
|
|
130
|
+
# Chains that had already stopped contribute no new leaves this iteration.
|
|
131
|
+
accept_sum = accept_sum + mx.where(cont_was, a_sub, mx.zeros_like(a_sub))
|
|
132
|
+
accept_cnt = accept_cnt + mx.where(cont_was, c_sub, mx.zeros_like(c_sub))
|
|
133
|
+
cont = cont & s_sub & no_uturn(new_tm, new_rm, new_tp, new_rp)
|
|
134
|
+
mx.eval(cont, sample, tm, tp, rm, rp, lw_tree, depths, accept_sum, accept_cnt)
|
|
135
|
+
if cont.sum().item() == 0: # host-side early stop once all chains U-turned
|
|
136
|
+
break
|
|
137
|
+
|
|
138
|
+
# Per-chain leaf-mean accept, then mean over chains. Empty count -> 1 to avoid 0/0.
|
|
139
|
+
per_chain = accept_sum / mx.maximum(accept_cnt, mx.ones_like(accept_cnt))
|
|
140
|
+
return sample, depths, per_chain.mean()
|
|
141
|
+
|
|
142
|
+
return step
|
|
143
|
+
|
|
144
|
+
|
|
145
|
+
def run_nuts(logp_single, theta0, n_samples, eps, Minv_np, key, max_tree_depth=10):
|
|
146
|
+
"""Returns (chain (T,N,D), mean_tree_depth, max_tree_depth_seen). theta0 already warmed.
|
|
147
|
+
max-vs-mean depth is the masking-overhead tell: the batch pays the deepest chain's cost."""
|
|
148
|
+
step = make_nuts(logp_single, Minv_np, max_tree_depth)
|
|
149
|
+
chain, depth_sum, depth_max, theta = [], 0.0, 0, theta0
|
|
150
|
+
for _ in range(n_samples):
|
|
151
|
+
key, k = mx.random.split(key, 2)
|
|
152
|
+
theta, depths, _ = step(theta, k, eps) # discard the leaf-accept stat for sampling
|
|
153
|
+
mx.eval(theta, depths)
|
|
154
|
+
chain.append(theta)
|
|
155
|
+
depth_sum += float(depths.mean())
|
|
156
|
+
depth_max = max(depth_max, int(depths.max()))
|
|
157
|
+
return mx.stack(chain, axis=0), depth_sum / n_samples, depth_max
|
|
158
|
+
|
|
159
|
+
|
|
160
|
+
def nuts_warmup(logp_single, q0, n_warmup, key, eps0=0.25, target_accept=0.8,
|
|
161
|
+
init_buffer=75, term_buffer=50, base_window=25, max_tree_depth=10):
|
|
162
|
+
"""NUTS-specific warmup: dual-averaging on NUTS's tree-averaged leaf-acceptance statistic,
|
|
163
|
+
Stan-style windowed dense-M estimation. Returns (q_last, eps_bar, Minv_np) ready for
|
|
164
|
+
`run_nuts` -- the same interface as `mlxmc.warmup.warmup`, but the tuned eps reflects
|
|
165
|
+
NUTS's adaptive trajectory length rather than borrowing fixed-L HMC's optimum.
|
|
166
|
+
|
|
167
|
+
The leaf-accept stat (H&G 2014 Alg 6): per leapfrog leaf, alpha_leaf = min(1, exp(-Delta_H)),
|
|
168
|
+
zeroed on divergence; alpha for the iteration is the mean over leaves per chain, then over
|
|
169
|
+
chains. Stan defaults target this at 0.8 (the same number used here -- the statistic differs,
|
|
170
|
+
so the resulting eps does too).
|
|
171
|
+
|
|
172
|
+
Implementation notes:
|
|
173
|
+
- `eps` is a per-step argument to the NUTS step, so dual-averaging changes it every
|
|
174
|
+
iteration without recompiling the leapfrog leaf.
|
|
175
|
+
- `Minv` is closed over the compiled leaf, so when the windowed estimator produces a
|
|
176
|
+
new M, the NUTS step is rebuilt (one recompile per window boundary, not per step).
|
|
177
|
+
- Covariance + Cholesky are done host-side in fp64; only the leapfrog runs fp32.
|
|
178
|
+
- A NaN accept stat (e.g. all leaves diverged in a single iteration) is treated as 0
|
|
179
|
+
so dual-averaging stays finite.
|
|
180
|
+
"""
|
|
181
|
+
n_chains, d = q0.shape
|
|
182
|
+
init_buffer, term_buffer, window_ends = stan_windows(
|
|
183
|
+
n_warmup, init_buffer, term_buffer, base_window)
|
|
184
|
+
boundaries = set(window_ends)
|
|
185
|
+
|
|
186
|
+
da = DualAveraging(eps0, target_accept)
|
|
187
|
+
Minv_np = np.eye(d)
|
|
188
|
+
step = make_nuts(logp_single, Minv_np, max_tree_depth)
|
|
189
|
+
eps = eps0
|
|
190
|
+
|
|
191
|
+
q, window_samples = q0, []
|
|
192
|
+
for t in range(n_warmup):
|
|
193
|
+
key, k = mx.random.split(key, 2)
|
|
194
|
+
q, _depths, accept_prob = step(q, k, eps)
|
|
195
|
+
mx.eval(q, accept_prob)
|
|
196
|
+
a = float(accept_prob)
|
|
197
|
+
if not np.isfinite(a):
|
|
198
|
+
a = 0.0 # treat all-divergent batch as reject
|
|
199
|
+
eps = da.update(a)
|
|
200
|
+
|
|
201
|
+
if init_buffer <= t < (n_warmup - term_buffer):
|
|
202
|
+
window_samples.append(np.array(q)) # collect cov samples in slow windows
|
|
203
|
+
if (t + 1) in boundaries and window_samples:
|
|
204
|
+
X = np.concatenate(window_samples, axis=0) # (steps * n_chains, d)
|
|
205
|
+
Minv_np = regularize_cov(np.cov(X, rowvar=False), X.shape[0])
|
|
206
|
+
step = make_nuts(logp_single, Minv_np, max_tree_depth) # rebuild for the new M
|
|
207
|
+
window_samples = []
|
|
208
|
+
da.restart(da.eps_bar) # re-anchor eps to the new metric
|
|
209
|
+
eps = da.eps_bar
|
|
210
|
+
|
|
211
|
+
return q, da.eps_bar, Minv_np
|
mlxmc/preconditioned.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
1
|
+
"""Preconditioned HMC: mass matrix M = Sigma^{-1} makes the dynamics isotropic.
|
|
2
|
+
|
|
3
|
+
This closes the loop from the affine-invariance discussion: the mass matrix is
|
|
4
|
+
HMC's version of affine invariance -- but you must *supply* it (here you'd pass
|
|
5
|
+
the true Sigma; in practice you'd estimate it during warmup, as NUTS/Stan do).
|
|
6
|
+
With the right M, HMC mixes with far fewer, cheaper leapfrog steps.
|
|
7
|
+
"""
|
|
8
|
+
import mlx.core as mx
|
|
9
|
+
|
|
10
|
+
|
|
11
|
+
def make_phmc(logp_single, eps, n_leap, Minv, Mhalf):
|
|
12
|
+
grad_logp = mx.vmap(mx.grad(logp_single))
|
|
13
|
+
logp = mx.vmap(logp_single)
|
|
14
|
+
Minv = mx.array(Minv) # M^{-1} = Sigma (drift + kinetic energy)
|
|
15
|
+
Mhalf_T = mx.transpose(mx.array(Mhalf)) # chol(Sigma^{-1})^T (momentum draw)
|
|
16
|
+
|
|
17
|
+
def kinetic(p): # 0.5 p^T M^{-1} p
|
|
18
|
+
return 0.5 * ((p @ Minv) * p).sum(1)
|
|
19
|
+
|
|
20
|
+
@mx.compile
|
|
21
|
+
def step(q, key):
|
|
22
|
+
n, _ = q.shape
|
|
23
|
+
k_p, k_acc = mx.random.split(key, 2)
|
|
24
|
+
z = mx.random.normal(shape=q.shape, key=k_p)
|
|
25
|
+
p0 = z @ Mhalf_T # ~ N(0, M)
|
|
26
|
+
logp_q, K0 = logp(q), kinetic(p0)
|
|
27
|
+
|
|
28
|
+
qq = q
|
|
29
|
+
p = p0 + 0.5 * eps * grad_logp(qq)
|
|
30
|
+
for i in range(n_leap):
|
|
31
|
+
qq = qq + eps * (p @ Minv) # drift uses M^{-1} = Sigma
|
|
32
|
+
if i != n_leap - 1:
|
|
33
|
+
p = p + eps * grad_logp(qq)
|
|
34
|
+
p = p + 0.5 * eps * grad_logp(qq)
|
|
35
|
+
|
|
36
|
+
log_accept = (logp(qq) - logp_q) + (K0 - kinetic(p))
|
|
37
|
+
accept = mx.log(mx.random.uniform(shape=(n,), key=k_acc)) < log_accept
|
|
38
|
+
return mx.where(accept[:, None], qq, q), accept.sum()
|
|
39
|
+
|
|
40
|
+
return step
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
def run_phmc(logp_single, q0, n_steps, burn, eps, n_leap, key, Minv, Mhalf):
|
|
44
|
+
"""Sample with preconditioned (mass-matrix) HMC. Returns the structured (T, N, D) chain.
|
|
45
|
+
|
|
46
|
+
`Minv` is M^{-1} (= the covariance you precondition with) and `Mhalf` is chol(M).
|
|
47
|
+
"""
|
|
48
|
+
step = make_phmc(logp_single, eps, n_leap, Minv, Mhalf)
|
|
49
|
+
chain, q = [], q0
|
|
50
|
+
for t in range(n_steps):
|
|
51
|
+
key, k = mx.random.split(key, 2)
|
|
52
|
+
q, _ = step(q, k)
|
|
53
|
+
mx.eval(q)
|
|
54
|
+
if t >= burn:
|
|
55
|
+
chain.append(q)
|
|
56
|
+
return mx.stack(chain, axis=0)
|
mlxmc/targets.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
1
|
+
"""Example / benchmark target distributions, each a single-point log-density
|
|
2
|
+
`logp(x) -> scalar` suitable for any sampler in mlxmc.
|
|
3
|
+
|
|
4
|
+
- Gaussian: strongly correlated, ill-conditioned -- easy for the affine-invariant
|
|
5
|
+
ensemble, hard for identity-mass HMC. The canonical correctness target.
|
|
6
|
+
- Banana (Haario twisted Gaussian): a curved ridge; local covariance rotates along it,
|
|
7
|
+
so no single linear preconditioner (constant M) or affine map is right everywhere.
|
|
8
|
+
- Funnel (Neal): v ~ N(0, 3^2), x_i | v ~ N(0, exp(v)). The scale of x spans orders of
|
|
9
|
+
magnitude with v, so a constant M is wrong everywhere at once and the neck (v << 0)
|
|
10
|
+
has stiff gradients that diverge in fp32. The honest fix is geometry-aware coordinates.
|
|
11
|
+
- Non-centered funnel: sample (v, x̃) with x = x̃·exp(v/2); the v-dependent scale drops
|
|
12
|
+
out, leaving a product of independent Gaussians -- the reparametrization that fixes HMC.
|
|
13
|
+
|
|
14
|
+
The TRUTH dicts give (dim index, true mean, true std) for the cleanest diagnostics.
|
|
15
|
+
"""
|
|
16
|
+
import mlx.core as mx
|
|
17
|
+
import numpy as np
|
|
18
|
+
|
|
19
|
+
# --------------------------------------------------------------- correlated Gaussian
|
|
20
|
+
GAUSSIAN_MU = np.array([1.0, -2.0])
|
|
21
|
+
GAUSSIAN_SIGMA = np.array([[25.0, 4.5], [4.5, 1.0]]) # corr 0.9, 25:1 variance ratio
|
|
22
|
+
_gauss_mu = mx.array(GAUSSIAN_MU)
|
|
23
|
+
_gauss_sig_inv = mx.array(np.linalg.inv(GAUSSIAN_SIGMA))
|
|
24
|
+
|
|
25
|
+
|
|
26
|
+
def gaussian_logp(x): # x: (D,) -> scalar
|
|
27
|
+
d = x - _gauss_mu
|
|
28
|
+
return -0.5 * (d @ _gauss_sig_inv @ d)
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
# --------------------------------------------------------------- banana (Haario)
|
|
32
|
+
B_BANANA = 0.05 # curvature; Var[x2] = 1 + 2 B^2 * 100^2
|
|
33
|
+
|
|
34
|
+
|
|
35
|
+
def banana_logp(x):
|
|
36
|
+
"""phi(x) = (x1, x2 + B x1^2 - 100 B, x3, ...) ~ N(0, diag(100, 1, 1, ...))."""
|
|
37
|
+
x1, x2 = x[0], x[1]
|
|
38
|
+
twisted = x2 + B_BANANA * x1 * x1 - 100.0 * B_BANANA
|
|
39
|
+
rest = 0.5 * (x[2:] * x[2:]).sum() if x.shape[0] > 2 else 0.0
|
|
40
|
+
return -(x1 * x1) / 200.0 - 0.5 * twisted * twisted - rest
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
BANANA_TRUTH = {
|
|
44
|
+
"x1": (0, 0.0, 10.0), # N(0, 100)
|
|
45
|
+
"x2": (1, 0.0, np.sqrt(1.0 + 2.0 * B_BANANA**2 * 100.0**2)),
|
|
46
|
+
}
|
|
47
|
+
|
|
48
|
+
|
|
49
|
+
# --------------------------------------------------------------- funnel (Neal)
|
|
50
|
+
def funnel_logp(z):
|
|
51
|
+
"""v = z[0] ~ N(0, 9); x = z[1:] | v ~ N(0, exp(v)). The -0.5*(D-1)*v term is the
|
|
52
|
+
v-dependent normalization -- it's what makes this a funnel, not a free-floating v."""
|
|
53
|
+
v, x = z[0], z[1:]
|
|
54
|
+
n_x = z.shape[0] - 1
|
|
55
|
+
return -(v * v) / 18.0 - 0.5 * n_x * v - 0.5 * mx.exp(-v) * (x * x).sum()
|
|
56
|
+
|
|
57
|
+
|
|
58
|
+
def funnel_nc_logp(z):
|
|
59
|
+
"""Non-centered funnel: sample (v, x̃) with x̃ ~ N(0,1), and x = x̃·exp(v/2). In these
|
|
60
|
+
coordinates the v-dependent scale vanishes from the density, leaving a *product of
|
|
61
|
+
independent Gaussians* (v ~ N(0,9), x̃ ~ N(0,1)) -- no funnel geometry, so HMC's global
|
|
62
|
+
metric is now correct everywhere. v's marginal is unchanged (N(0,9)), so the same
|
|
63
|
+
truth/diagnostics apply, and this should flip the centered-funnel result."""
|
|
64
|
+
v, xt = z[0], z[1:]
|
|
65
|
+
return -(v * v) / 18.0 - 0.5 * (xt * xt).sum()
|
|
66
|
+
|
|
67
|
+
|
|
68
|
+
FUNNEL_TRUTH = {
|
|
69
|
+
"v": (0, 0.0, 3.0), # N(0, 9): the honest mixing test
|
|
70
|
+
}
|
mlxmc/warmup.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
1
|
+
"""Warmup adaptation for HMC: dual-averaging step size + windowed dense mass-matrix
|
|
2
|
+
estimation (Stan-style). This makes the preconditioned-HMC result *honest* -- rather
|
|
3
|
+
than being handed the true Sigma, we estimate M^{-1} = Cov(q) during warmup and adapt
|
|
4
|
+
eps to a target acceptance, then sample. The mass matrix is HMC's affine invariance, and
|
|
5
|
+
this is how you earn it instead of supplying it.
|
|
6
|
+
|
|
7
|
+
MLX notes:
|
|
8
|
+
- eps, M^{-1}, and chol(M)^T are passed as *array arguments* to the compiled step, not
|
|
9
|
+
closed-over constants (as make_hmc/make_phmc do). mx.compile recompiles on shape/dtype
|
|
10
|
+
or baked-constant changes, NOT on array-value changes -- so we can vary eps/M every
|
|
11
|
+
warmup iteration and reuse the one compiled graph.
|
|
12
|
+
- n_leap stays a Python int: it's the unrolled leapfrog length, structural to the graph.
|
|
13
|
+
Phase 1 adapts eps + M with L fixed; dynamic trajectory length is NUTS (Phase 2), which
|
|
14
|
+
this MLX has no control-flow primitive (while_loop/scan) for.
|
|
15
|
+
- Covariance + Cholesky run host-side in numpy fp64, so the ill-conditioned linear algebra
|
|
16
|
+
(the real fp32 limit) never touches the GPU; only the leapfrog runs fp32.
|
|
17
|
+
- Covariance is pooled across chains AND steps within a window (many chains => fast
|
|
18
|
+
estimate). Early overdispersion is discarded by the windowed schedule; the final, longest
|
|
19
|
+
slow window estimates M near stationarity.
|
|
20
|
+
"""
|
|
21
|
+
import math
|
|
22
|
+
|
|
23
|
+
import mlx.core as mx
|
|
24
|
+
import numpy as np
|
|
25
|
+
|
|
26
|
+
|
|
27
|
+
class DualAveraging:
|
|
28
|
+
"""Nesterov dual averaging for step-size adaptation (Hoffman & Gelman 2014, Alg. 5).
|
|
29
|
+
|
|
30
|
+
The chain runs on the raw `exp(log_eps)` (keeps exploring); the *averaged* `eps_bar`
|
|
31
|
+
is what we freeze for sampling. `restart` re-anchors at a window boundary, since the
|
|
32
|
+
stable step size changes when the mass matrix does.
|
|
33
|
+
"""
|
|
34
|
+
|
|
35
|
+
def __init__(self, eps0, target_accept=0.8, gamma=0.05, t0=10.0, kappa=0.75):
|
|
36
|
+
self.target, self.gamma, self.t0, self.kappa = target_accept, gamma, t0, kappa
|
|
37
|
+
self.restart(eps0)
|
|
38
|
+
|
|
39
|
+
def restart(self, eps0):
|
|
40
|
+
self.mu = math.log(10.0 * eps0) # shrink toward 10x the anchor
|
|
41
|
+
self.Hbar = 0.0
|
|
42
|
+
self.log_eps = math.log(eps0)
|
|
43
|
+
self.log_eps_bar = math.log(eps0)
|
|
44
|
+
self.m = 0
|
|
45
|
+
|
|
46
|
+
def update(self, accept_prob):
|
|
47
|
+
self.m += 1
|
|
48
|
+
m = self.m
|
|
49
|
+
w = 1.0 / (m + self.t0)
|
|
50
|
+
self.Hbar = (1.0 - w) * self.Hbar + w * (self.target - accept_prob)
|
|
51
|
+
self.log_eps = self.mu - math.sqrt(m) / self.gamma * self.Hbar
|
|
52
|
+
eta = m ** (-self.kappa)
|
|
53
|
+
self.log_eps_bar = eta * self.log_eps + (1.0 - eta) * self.log_eps_bar
|
|
54
|
+
return math.exp(self.log_eps)
|
|
55
|
+
|
|
56
|
+
@property
|
|
57
|
+
def eps_bar(self):
|
|
58
|
+
return math.exp(self.log_eps_bar)
|
|
59
|
+
|
|
60
|
+
|
|
61
|
+
def stan_windows(n_warmup, init_buffer=75, term_buffer=50, base_window=25):
|
|
62
|
+
"""Stan-style warmup schedule. Returns (init_buffer, term_buffer, window_ends), where
|
|
63
|
+
window_ends are iteration counts (1-based, inclusive) at which to re-estimate M and
|
|
64
|
+
restart step-size adaptation. M is held fixed during the init buffer (find the mode)
|
|
65
|
+
and term buffer (final eps polish); the slow windows between double in length, and the
|
|
66
|
+
last absorbs any remainder. Not bit-identical to Stan, but the same structure."""
|
|
67
|
+
if init_buffer + term_buffer + base_window > n_warmup:
|
|
68
|
+
# Too short for the default buffers: fall back to Stan's 15/75/10 proportions.
|
|
69
|
+
init_buffer = max(1, int(round(0.15 * n_warmup)))
|
|
70
|
+
term_buffer = max(1, int(round(0.10 * n_warmup)))
|
|
71
|
+
base_window = max(1, n_warmup - init_buffer - term_buffer)
|
|
72
|
+
last = n_warmup - term_buffer
|
|
73
|
+
ends, start, window = [], init_buffer, base_window
|
|
74
|
+
while start + window < last:
|
|
75
|
+
nxt = start + window
|
|
76
|
+
if nxt + 2 * window > last: # next doubled window would overrun -> absorb now
|
|
77
|
+
nxt = last
|
|
78
|
+
ends.append(nxt)
|
|
79
|
+
start, window = nxt, window * 2
|
|
80
|
+
if not ends or ends[-1] != last:
|
|
81
|
+
ends.append(last)
|
|
82
|
+
return init_buffer, term_buffer, ends
|
|
83
|
+
|
|
84
|
+
|
|
85
|
+
def regularize_cov(cov, n):
|
|
86
|
+
"""Stan's dense-metric shrinkage toward a small diagonal (stabilizes small-n windows)."""
|
|
87
|
+
d = cov.shape[0]
|
|
88
|
+
return (n / (n + 5.0)) * cov + 1e-3 * (5.0 / (n + 5.0)) * np.eye(d)
|
|
89
|
+
|
|
90
|
+
|
|
91
|
+
def make_warmup_step(logp_single, n_leap):
|
|
92
|
+
"""Leapfrog + Metropolis step with eps, M^{-1}, chol(M)^T as array arguments.
|
|
93
|
+
Returns (q_new, mean_accept_prob); the continuous accept prob feeds dual averaging."""
|
|
94
|
+
grad_logp = mx.vmap(mx.grad(logp_single))
|
|
95
|
+
logp = mx.vmap(logp_single)
|
|
96
|
+
|
|
97
|
+
@mx.compile
|
|
98
|
+
def step(q, key, eps, Minv, Mhalf_T):
|
|
99
|
+
n, _ = q.shape
|
|
100
|
+
k_p, k_acc = mx.random.split(key, 2)
|
|
101
|
+
z = mx.random.normal(shape=q.shape, key=k_p)
|
|
102
|
+
p0 = z @ Mhalf_T # ~ N(0, M)
|
|
103
|
+
K0 = 0.5 * ((p0 @ Minv) * p0).sum(1) # 0.5 p^T M^{-1} p
|
|
104
|
+
logp_q = logp(q)
|
|
105
|
+
|
|
106
|
+
qq = q
|
|
107
|
+
p = p0 + 0.5 * eps * grad_logp(qq)
|
|
108
|
+
for i in range(n_leap):
|
|
109
|
+
qq = qq + eps * (p @ Minv) # drift uses M^{-1}
|
|
110
|
+
if i != n_leap - 1:
|
|
111
|
+
p = p + eps * grad_logp(qq)
|
|
112
|
+
p = p + 0.5 * eps * grad_logp(qq)
|
|
113
|
+
|
|
114
|
+
K = 0.5 * ((p @ Minv) * p).sum(1)
|
|
115
|
+
log_accept = (logp(qq) - logp_q) + (K0 - K)
|
|
116
|
+
accept_prob = mx.minimum(1.0, mx.exp(log_accept)) # continuous, for dual avg
|
|
117
|
+
# A divergent leapfrog (NaN energy, e.g. the funnel neck in fp32) must REJECT, not
|
|
118
|
+
# poison the dual-averaging mean with NaN. Treat NaN accept prob as 0.
|
|
119
|
+
accept_prob = mx.where(mx.isnan(accept_prob), mx.zeros_like(accept_prob), accept_prob)
|
|
120
|
+
accept = mx.random.uniform(shape=(n,), key=k_acc) < accept_prob
|
|
121
|
+
q_new = mx.where(accept[:, None], qq, q)
|
|
122
|
+
return q_new, accept_prob.mean()
|
|
123
|
+
|
|
124
|
+
return step
|
|
125
|
+
|
|
126
|
+
|
|
127
|
+
def warmup(logp_single, q0, n_warmup, n_leap, key, eps0=0.25, target_accept=0.8,
|
|
128
|
+
init_buffer=75, term_buffer=50, base_window=25):
|
|
129
|
+
"""Run Stan-style warmup. Returns (q_last, eps_bar, Minv_np) -- the tuned step size and
|
|
130
|
+
estimated M^{-1} = Cov(q), ready to hand to run_chain."""
|
|
131
|
+
n_chains, d = q0.shape
|
|
132
|
+
init_buffer, term_buffer, window_ends = stan_windows(
|
|
133
|
+
n_warmup, init_buffer, term_buffer, base_window)
|
|
134
|
+
boundaries = set(window_ends)
|
|
135
|
+
|
|
136
|
+
da = DualAveraging(eps0, target_accept)
|
|
137
|
+
step = make_warmup_step(logp_single, n_leap)
|
|
138
|
+
|
|
139
|
+
Minv_np = np.eye(d) # start from the identity metric
|
|
140
|
+
eps = mx.array(eps0, dtype=mx.float32)
|
|
141
|
+
Minv = mx.array(Minv_np.astype(np.float32))
|
|
142
|
+
Mhalf_T = mx.array(np.linalg.cholesky(np.linalg.inv(Minv_np)).T.astype(np.float32))
|
|
143
|
+
|
|
144
|
+
q, window_samples = q0, []
|
|
145
|
+
for t in range(n_warmup):
|
|
146
|
+
key, k = mx.random.split(key, 2)
|
|
147
|
+
q, acc_prob = step(q, k, eps, Minv, Mhalf_T)
|
|
148
|
+
mx.eval(q, acc_prob)
|
|
149
|
+
eps = mx.array(da.update(float(acc_prob)), dtype=mx.float32) # adapt eps every step
|
|
150
|
+
|
|
151
|
+
if init_buffer <= t < (n_warmup - term_buffer):
|
|
152
|
+
window_samples.append(np.array(q)) # collect cov samples in slow windows
|
|
153
|
+
if (t + 1) in boundaries and window_samples:
|
|
154
|
+
X = np.concatenate(window_samples, axis=0) # (steps * n_chains, d)
|
|
155
|
+
Minv_np = regularize_cov(np.cov(X, rowvar=False), X.shape[0])
|
|
156
|
+
Minv = mx.array(Minv_np.astype(np.float32))
|
|
157
|
+
Mhalf_T = mx.array(np.linalg.cholesky(np.linalg.inv(Minv_np)).T.astype(np.float32))
|
|
158
|
+
window_samples = []
|
|
159
|
+
da.restart(da.eps_bar) # re-anchor eps to the new metric
|
|
160
|
+
eps = mx.array(da.eps_bar, dtype=mx.float32)
|
|
161
|
+
|
|
162
|
+
return q, da.eps_bar, Minv_np
|
|
163
|
+
|
|
164
|
+
|
|
165
|
+
def run_chain(logp_single, q0, n_steps, burn, eps, Minv_np, key, n_leap):
|
|
166
|
+
"""Sample with fixed tuned (eps, M). Returns the structured (T, N, D) chain for ESS."""
|
|
167
|
+
step = make_warmup_step(logp_single, n_leap)
|
|
168
|
+
eps_a = mx.array(eps, dtype=mx.float32)
|
|
169
|
+
Minv_a = mx.array(Minv_np.astype(np.float32))
|
|
170
|
+
Mhalf_T = mx.array(np.linalg.cholesky(np.linalg.inv(Minv_np)).T.astype(np.float32))
|
|
171
|
+
chain, q = [], q0
|
|
172
|
+
for t in range(n_steps):
|
|
173
|
+
key, k = mx.random.split(key, 2)
|
|
174
|
+
q, _ = step(q, k, eps_a, Minv_a, Mhalf_T)
|
|
175
|
+
mx.eval(q)
|
|
176
|
+
if t >= burn:
|
|
177
|
+
chain.append(q)
|
|
178
|
+
return mx.stack(chain, axis=0)
|
|
@@ -0,0 +1,200 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: mlxmc
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: MCMC samplers in Apple MLX
|
|
5
|
+
Project-URL: Homepage, https://github.com/jrcheshire/mlxmc
|
|
6
|
+
Project-URL: Repository, https://github.com/jrcheshire/mlxmc
|
|
7
|
+
Project-URL: Issues, https://github.com/jrcheshire/mlxmc/issues
|
|
8
|
+
Author-email: Jamie Cheshire <cheshire@caltech.edu>
|
|
9
|
+
License-Expression: BSD-3-Clause
|
|
10
|
+
License-File: LICENSE
|
|
11
|
+
Keywords: apple-silicon,bayesian,ensemble-sampler,hmc,mcmc,mlx,nuts,sampling
|
|
12
|
+
Classifier: Development Status :: 3 - Alpha
|
|
13
|
+
Classifier: Intended Audience :: Science/Research
|
|
14
|
+
Classifier: Operating System :: MacOS
|
|
15
|
+
Classifier: Programming Language :: Python :: 3
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
17
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
18
|
+
Classifier: Topic :: Scientific/Engineering
|
|
19
|
+
Classifier: Topic :: Scientific/Engineering :: Mathematics
|
|
20
|
+
Requires-Python: >=3.11
|
|
21
|
+
Requires-Dist: mlx<0.30,>=0.29.3
|
|
22
|
+
Requires-Dist: numpy<3,>=2
|
|
23
|
+
Provides-Extra: viz
|
|
24
|
+
Requires-Dist: matplotlib<4,>=3.10; extra == 'viz'
|
|
25
|
+
Description-Content-Type: text/markdown
|
|
26
|
+
|
|
27
|
+
# mlxmc
|
|
28
|
+
|
|
29
|
+
MCMC samplers written in Apple [MLX](https://github.com/ml-explore/mlx), using its
|
|
30
|
+
`grad` / `vmap` / `compile` transforms. MLX has no probabilistic-programming library
|
|
31
|
+
yet (nothing like BlackJAX or NumPyro), so this is a first pass at one.
|
|
32
|
+
|
|
33
|
+
> **Status: research code.** The samplers are tested (moment recovery, Σ-estimation,
|
|
34
|
+
> affine invariance, and the autocorrelation diagnostics, on both the CPU and Metal
|
|
35
|
+
> backends), but the API is young and likely to change.
|
|
36
|
+
|
|
37
|
+
## What's here
|
|
38
|
+
|
|
39
|
+
The package lives under `src/mlxmc/`; runnable demos and the benchmark study are in
|
|
40
|
+
`examples/`.
|
|
41
|
+
|
|
42
|
+
| Module (`mlxmc.`) | Sampler / tool |
|
|
43
|
+
|---|---|
|
|
44
|
+
| `ensemble` | Affine-invariant ensemble (Goodman & Weare 2010 — the `emcee` stretch move). Gradient-free, tuning-free. `make_sampler`, `run_ensemble`. |
|
|
45
|
+
| `hmc` | Hamiltonian Monte Carlo, identity mass. `grad ∘ vmap` batched over chains. `make_hmc`, `run_hmc`. |
|
|
46
|
+
| `preconditioned` | Mass-matrix HMC (M = Σ⁻¹). `make_phmc`, `run_phmc`. |
|
|
47
|
+
| `warmup` | Stan-style warmup: dual-averaging step size + windowed **dense** mass-matrix estimation. `warmup`, `run_chain`. |
|
|
48
|
+
| `nuts` | NUTS (multinomial; Hoffman & Gelman 2014), vectorized over chains. `make_nuts`, `run_nuts`. |
|
|
49
|
+
| `diagnostics` | Effective sample size / integrated autocorrelation time (FFT + Sokal window); the cross-sampler **ESS/sec** metric. |
|
|
50
|
+
| `targets` | Example log-densities: correlated Gaussian, banana, centered / non-centered funnel, with known moments. |
|
|
51
|
+
|
|
52
|
+
| Example (`examples/`) | What it shows |
|
|
53
|
+
|---|---|
|
|
54
|
+
| `gaussian_ess.py` | Ensemble vs identity-mass HMC vs preconditioned HMC by ESS/sec on the Gaussian. |
|
|
55
|
+
| `warmup_validation.py` | Warmup recovers the true Σ and matches oracle ESS/sec. |
|
|
56
|
+
| `hard_targets.py` | Banana + funnel benchmark (`lscan` / `dscan` modes). |
|
|
57
|
+
| `nuts_funnel.py` | NUTS correctness on the Gaussian; `funnel` mode for the masking-overhead study. |
|
|
58
|
+
| `affine_invariance.py` | Empirical proof of affine invariance (same RNG → bit-identical acceptance under an affine map). |
|
|
59
|
+
| `plot_hard_targets.py` | Renders `hard_targets_figure.png` (needs the optional `viz` env). |
|
|
60
|
+
|
|
61
|
+
## Why MLX
|
|
62
|
+
|
|
63
|
+
`grad`, `vmap`, `jvp`/`vjp`, and `compile` transfer almost directly from JAX,
|
|
64
|
+
with JAX-style functional RNG keys (`mx.random.split`). The wrinkles that shape
|
|
65
|
+
this code:
|
|
66
|
+
|
|
67
|
+
- **No traced control-flow primitives** (no `while_loop` / `scan` / `cond`). MLX
|
|
68
|
+
is eager execution plus `compile` of *static* graphs. Fixed-length unrolled
|
|
69
|
+
loops (leapfrog, fixed-`L` HMC) compile fine; data-dependent trajectory length
|
|
70
|
+
(NUTS) is the hard case — `mlxmc.nuts` runs every chain to a fixed `max_tree_depth`
|
|
71
|
+
and **masks** finished chains.
|
|
72
|
+
- **fp32 on the GPU.** Apple Metal has no fp64 in hardware (MLX has fp64 only on
|
|
73
|
+
the CPU backend). This is fine for sampling — Monte Carlo error (~1/√ESS) swamps
|
|
74
|
+
fp32 roundoff (~1e-6) — but ill-conditioned linear algebra (covariance, Cholesky
|
|
75
|
+
in warmup) is kept host-side in numpy fp64; only the leapfrog runs on the GPU.
|
|
76
|
+
|
|
77
|
+
## Install
|
|
78
|
+
|
|
79
|
+
This is a [pixi](https://pixi.sh) project (installs the package editable):
|
|
80
|
+
|
|
81
|
+
```bash
|
|
82
|
+
pixi install
|
|
83
|
+
pixi run python examples/gaussian_ess.py # ensemble vs HMC vs preconditioned
|
|
84
|
+
pixi run python examples/nuts_funnel.py funnel # several examples have demo modes
|
|
85
|
+
pixi run -e viz python examples/plot_hard_targets.py # plotting needs the optional viz env
|
|
86
|
+
```
|
|
87
|
+
|
|
88
|
+
Or install into any environment with pip: `pip install -e .` (needs `mlx`, so arm64
|
|
89
|
+
macOS). Add the plotting extra with `pip install -e ".[viz]"` (matplotlib).
|
|
90
|
+
|
|
91
|
+
## Usage
|
|
92
|
+
|
|
93
|
+
Every sampler takes a single-point log-density `logp(x) -> scalar` for `x` of
|
|
94
|
+
shape `(D,)`; batching over walkers/chains is handled internally with `vmap`.
|
|
95
|
+
Positions are MLX arrays of shape `(n_chains, D)`.
|
|
96
|
+
|
|
97
|
+
```python
|
|
98
|
+
import mlx.core as mx
|
|
99
|
+
import numpy as np
|
|
100
|
+
|
|
101
|
+
# Target: a strongly correlated 2-D Gaussian (corr 0.9, 25:1 variance ratio).
|
|
102
|
+
# mlxmc.targets ships this one (as `gaussian_logp`) plus banana / funnel.
|
|
103
|
+
mu = mx.array([1.0, -2.0])
|
|
104
|
+
Sig_inv = mx.array(np.linalg.inv([[25.0, 4.5], [4.5, 1.0]]))
|
|
105
|
+
|
|
106
|
+
def logp(x): # x: (D,) -> scalar
|
|
107
|
+
d = x - mu
|
|
108
|
+
return -0.5 * (d @ Sig_inv @ d)
|
|
109
|
+
|
|
110
|
+
key = mx.random.key(0)
|
|
111
|
+
```
|
|
112
|
+
|
|
113
|
+
**Gradient-free ensemble** — no tuning, handles the ill-conditioning for free:
|
|
114
|
+
|
|
115
|
+
```python
|
|
116
|
+
from mlxmc import run_ensemble
|
|
117
|
+
|
|
118
|
+
key, k = mx.random.split(key)
|
|
119
|
+
ensemble = mx.random.normal(shape=(2000, 2), key=k) * 5.0 # (n_walkers, D)
|
|
120
|
+
samples, accept_frac = run_ensemble(logp, ensemble, n_steps=3000, burn=1000, key=key)
|
|
121
|
+
```
|
|
122
|
+
|
|
123
|
+
**HMC, hand-tuned**, and **NUTS after Stan-style warmup** (same `logp`):
|
|
124
|
+
|
|
125
|
+
```python
|
|
126
|
+
from mlxmc import run_hmc, warmup, run_nuts
|
|
127
|
+
|
|
128
|
+
key, k = mx.random.split(key)
|
|
129
|
+
q0 = mx.random.normal(shape=(1000, 2), key=k) * 5.0 # (n_chains, D)
|
|
130
|
+
|
|
131
|
+
samples, acc = run_hmc(logp, q0, n_steps=1500, burn=500,
|
|
132
|
+
eps=0.15, n_leap=40, key=key)
|
|
133
|
+
|
|
134
|
+
# Warmup adapts (eps, dense M); NUTS then adapts trajectory length itself.
|
|
135
|
+
q_last, eps, Minv = warmup(logp, q0, n_warmup=600, n_leap=8, key=key)
|
|
136
|
+
chain, mean_depth, max_depth = run_nuts(logp, q_last, n_samples=1500,
|
|
137
|
+
eps=eps, Minv_np=Minv, key=key)
|
|
138
|
+
```
|
|
139
|
+
|
|
140
|
+
> **Return shapes differ by sampler.** `run_ensemble` and `run_hmc` return
|
|
141
|
+
> `(samples, accept_frac)` with `samples` flattened to `(n_draws, D)`.
|
|
142
|
+
> `run_phmc`, `run_chain` (post-warmup HMC), and `run_nuts` return a structured
|
|
143
|
+
> `(steps, chains, D)` chain — the layout `mlxmc.diagnostics` expects for ESS —
|
|
144
|
+
> and `run_nuts` additionally returns the mean/max tree depth.
|
|
145
|
+
|
|
146
|
+
## Findings
|
|
147
|
+
|
|
148
|
+
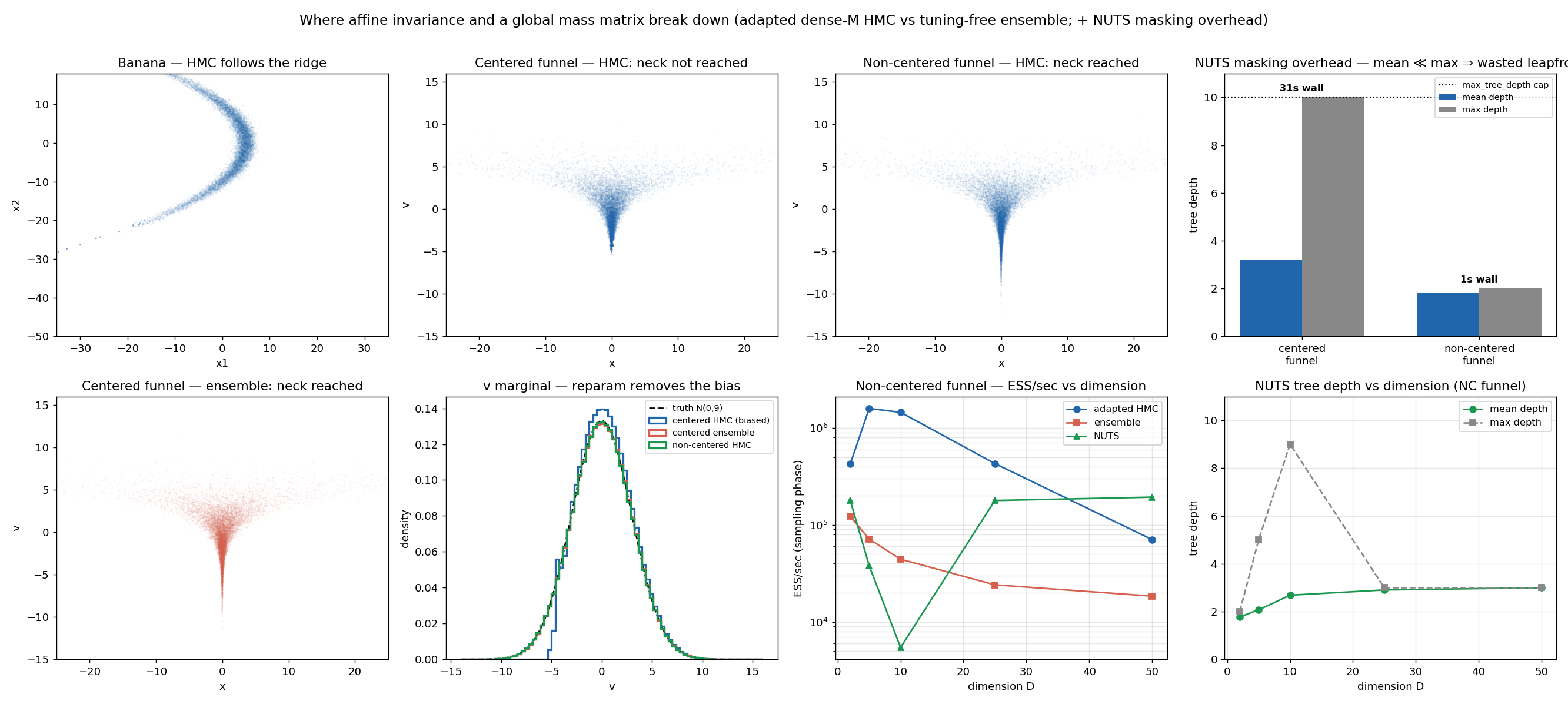
|
|
149
|
+
|
|
150
|
+
Validated on a corr-0.9, 25:1-variance Gaussian and on banana / funnel targets;
|
|
151
|
+
every number below is reproducible with the scripts in
|
|
152
|
+
[`examples/`](https://github.com/jrcheshire/mlxmc/tree/main/examples):
|
|
153
|
+
|
|
154
|
+
- **Affine-invariant ensemble** is the robust low-D default: gradient-free,
|
|
155
|
+
tuning-free, handles ill-conditioning for free (acceptance is bit-identical
|
|
156
|
+
under an affine map). But weaker per-step mixing and it degrades with dimension.
|
|
157
|
+
- **HMC** needs gradients and a tuned `eps`/`L`, but mixes far better
|
|
158
|
+
(τ≈2 vs ≈26). A **warmup-adapted dense mass matrix** recovers the true Σ to
|
|
159
|
+
<1% Frobenius error and buys ~7–11× the ESS/sec — HMC's version of affine
|
|
160
|
+
invariance, earned rather than supplied.
|
|
161
|
+
- **Fixed-`L` HMC has a trajectory resonance:** on near-Gaussian targets, when
|
|
162
|
+
`eps·L` lands near a multiple of 2π the trajectory returns to its start and
|
|
163
|
+
mixing collapses. Jittering `eps` per trajectory cures it; NUTS's adaptive
|
|
164
|
+
trajectory length is the principled fix.
|
|
165
|
+
- **NUTS** is validated exact on the Gaussian (recovered covariance 24.97 vs 25)
|
|
166
|
+
and auto-tunes trajectory length, but vectorized NUTS pays a real masking cost
|
|
167
|
+
when trajectory lengths are heterogeneous — with no `while_loop`, every chain
|
|
168
|
+
runs to the deepest chain's tree depth, up to a ~30× wall-time penalty at the
|
|
169
|
+
funnel mouth versus the same target reparametrized.
|
|
170
|
+
- **Geometry matters more than the sampler:** on the *centered* funnel the
|
|
171
|
+
gradient-free ensemble beats a global-metric HMC, because a constant mass matrix
|
|
172
|
+
is wrong everywhere when the scale is position-dependent; a **non-centered
|
|
173
|
+
reparametrization** removes the geometry and makes HMC unbiased again.
|
|
174
|
+
- **ESS/sec is the honest efficiency metric** — acceptance fraction is a
|
|
175
|
+
misleading proxy.
|
|
176
|
+
|
|
177
|
+
## Development
|
|
178
|
+
|
|
179
|
+
```bash
|
|
180
|
+
pixi run test # full suite on the default device
|
|
181
|
+
MLXMC_TEST_DEVICE=cpu pixi run test # force the CPU backend
|
|
182
|
+
MLXMC_TEST_DEVICE=gpu pixi run test # force the Metal GPU
|
|
183
|
+
```
|
|
184
|
+
|
|
185
|
+
The suite (`tests/`) checks moment recovery for every sampler, warmup's Σ
|
|
186
|
+
estimate, the affine-invariance identity, and the autocorrelation-time
|
|
187
|
+
diagnostics. A GitHub Actions workflow (`.github/workflows/tests.yml`) runs the
|
|
188
|
+
CPU + GPU matrix on an Apple-silicon runner for pull requests to `main` (and on
|
|
189
|
+
manual dispatch from the Actions tab). Direct pushes to `main` don't trigger it,
|
|
190
|
+
which keeps the (10x-billed) macOS runner minutes down.
|
|
191
|
+
|
|
192
|
+
## References
|
|
193
|
+
|
|
194
|
+
- Goodman & Weare (2010), *Ensemble samplers with affine invariance.*
|
|
195
|
+
- Hoffman & Gelman (2014), *The No-U-Turn Sampler.*
|
|
196
|
+
- Betancourt (2017), *A Conceptual Introduction to Hamiltonian Monte Carlo.*
|
|
197
|
+
|
|
198
|
+
## License
|
|
199
|
+
|
|
200
|
+
[BSD-3-Clause](https://github.com/jrcheshire/mlxmc/blob/main/LICENSE).
|
|
@@ -0,0 +1,12 @@
|
|
|
1
|
+
mlxmc/__init__.py,sha256=hRv4Sm6NAklNuG43DnCsaz5KhRh-zRxP_oZ7XDp1FxI,1026
|
|
2
|
+
mlxmc/diagnostics.py,sha256=vET8WYBdP5HK_pr2WGjbrMZbPbA5XV9iCcj7RzzQR2E,1816
|
|
3
|
+
mlxmc/ensemble.py,sha256=t04msVDGj3B_-Z8_Ifyw8fVJ_MWlnoPrpfBqtr2dVfU,2617
|
|
4
|
+
mlxmc/hmc.py,sha256=Vjmop3-X7FeAVqZVnKjPC7PG6UwXk_puhG5W-wju0X0,2242
|
|
5
|
+
mlxmc/nuts.py,sha256=I-TYCDl-vj8BNr0sDZfGxBu1IUGvjRAShLcLJEtGvKY,11342
|
|
6
|
+
mlxmc/preconditioned.py,sha256=hTQkmmNgMW5rgQ4ajlok1dQLc8a5dcBqg5Be-9oehow,2113
|
|
7
|
+
mlxmc/targets.py,sha256=JD95uJJ3oZzYo1vAGB20aHCtGEBR1TYZGrID215FiUo,3165
|
|
8
|
+
mlxmc/warmup.py,sha256=MPAM9otpmNT8PelOARLr_bMI3qbKwhaEnFKnf7uLPu0,8235
|
|
9
|
+
mlxmc-0.1.0.dist-info/METADATA,sha256=hwytPlj-kBRqcEhQ10Wlmo4Mg730XlazKdPPrXaYgns,9499
|
|
10
|
+
mlxmc-0.1.0.dist-info/WHEEL,sha256=mffPy8wBnZQn2VnJUU5jE99KsxaSfiyMHV9Yt0aLVxs,87
|
|
11
|
+
mlxmc-0.1.0.dist-info/licenses/LICENSE,sha256=k4YNKXQbOe0QvMkczCNPA_bck_92SZ5gNsnRbpA23ko,1501
|
|
12
|
+
mlxmc-0.1.0.dist-info/RECORD,,
|
|
@@ -0,0 +1,28 @@
|
|
|
1
|
+
BSD 3-Clause License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026, Jamie Cheshire
|
|
4
|
+
|
|
5
|
+
Redistribution and use in source and binary forms, with or without
|
|
6
|
+
modification, are permitted provided that the following conditions are met:
|
|
7
|
+
|
|
8
|
+
1. Redistributions of source code must retain the above copyright notice, this
|
|
9
|
+
list of conditions and the following disclaimer.
|
|
10
|
+
|
|
11
|
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
|
12
|
+
this list of conditions and the following disclaimer in the documentation
|
|
13
|
+
and/or other materials provided with the distribution.
|
|
14
|
+
|
|
15
|
+
3. Neither the name of the copyright holder nor the names of its
|
|
16
|
+
contributors may be used to endorse or promote products derived from
|
|
17
|
+
this software without specific prior written permission.
|
|
18
|
+
|
|
19
|
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
|
20
|
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
|
21
|
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
|
22
|
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
|
23
|
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
|
24
|
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
|
25
|
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
|
26
|
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
|
27
|
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
|
28
|
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|