llms-py 2.0.32__py3-none-any.whl → 2.0.34__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- llms/llms.json +792 -699
- llms/main.py +2 -2
- llms/ui/ProviderIcon.mjs +1 -0
- llms/ui/ai.mjs +1 -1
- llms/ui/lib/servicestack-vue.mjs +25 -25
- llms/ui/threadStore.mjs +1 -1
- llms_py-2.0.34.dist-info/METADATA +49 -0
- {llms_py-2.0.32.dist-info → llms_py-2.0.34.dist-info}/RECORD +12 -12
- llms_py-2.0.32.dist-info/METADATA +0 -1278
- {llms_py-2.0.32.dist-info → llms_py-2.0.34.dist-info}/WHEEL +0 -0
- {llms_py-2.0.32.dist-info → llms_py-2.0.34.dist-info}/entry_points.txt +0 -0
- {llms_py-2.0.32.dist-info → llms_py-2.0.34.dist-info}/licenses/LICENSE +0 -0
- {llms_py-2.0.32.dist-info → llms_py-2.0.34.dist-info}/top_level.txt +0 -0
|
@@ -1,1278 +0,0 @@
|
|
|
1
|
-
Metadata-Version: 2.4
|
|
2
|
-
Name: llms-py
|
|
3
|
-
Version: 2.0.32
|
|
4
|
-
Summary: A lightweight CLI tool and OpenAI-compatible server for querying multiple Large Language Model (LLM) providers
|
|
5
|
-
Home-page: https://github.com/ServiceStack/llms
|
|
6
|
-
Author: ServiceStack
|
|
7
|
-
Author-email: ServiceStack <team@servicestack.net>
|
|
8
|
-
Maintainer-email: ServiceStack <team@servicestack.net>
|
|
9
|
-
License-Expression: BSD-3-Clause
|
|
10
|
-
Project-URL: Homepage, https://github.com/ServiceStack/llms
|
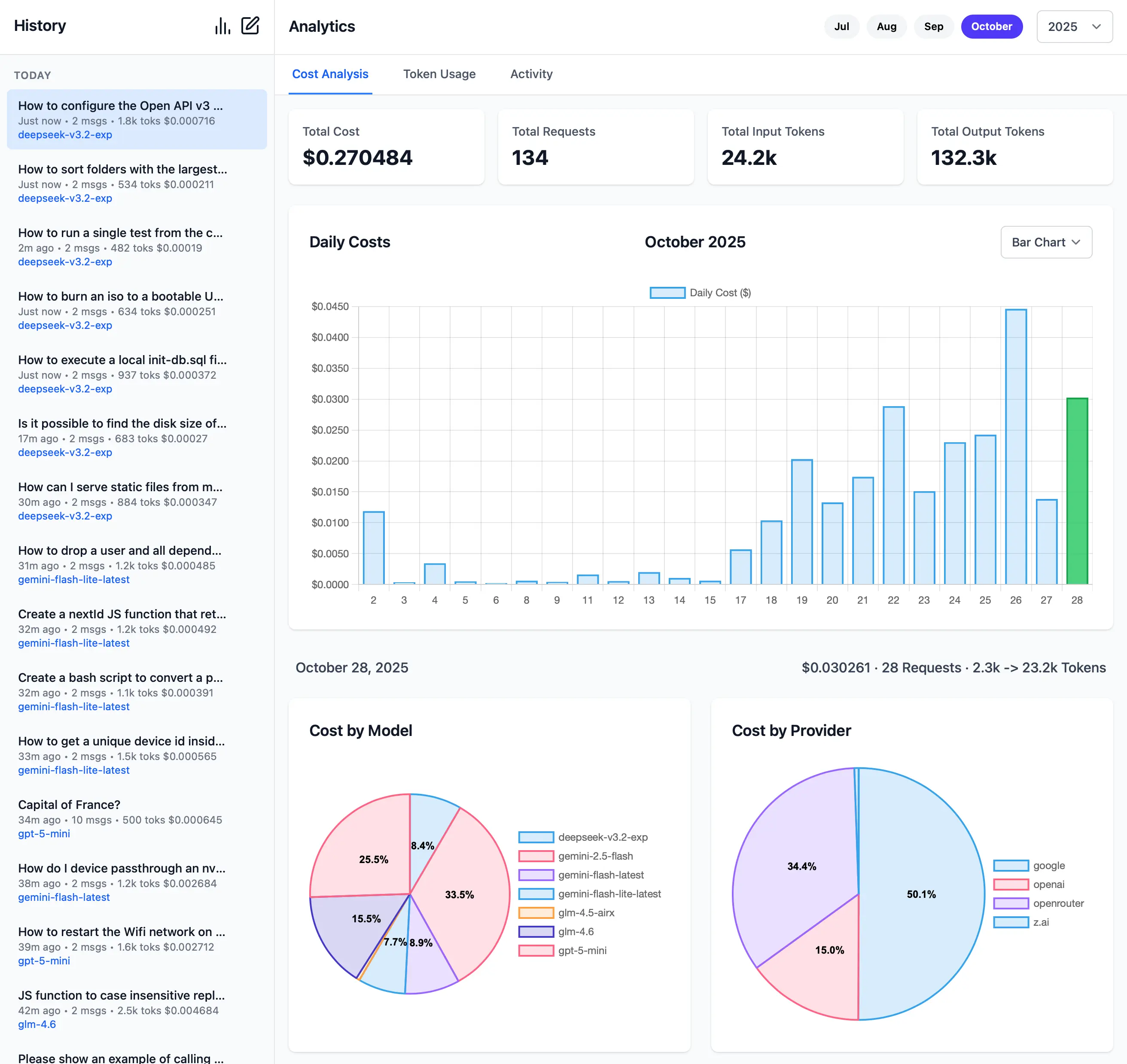
|
11
|
-
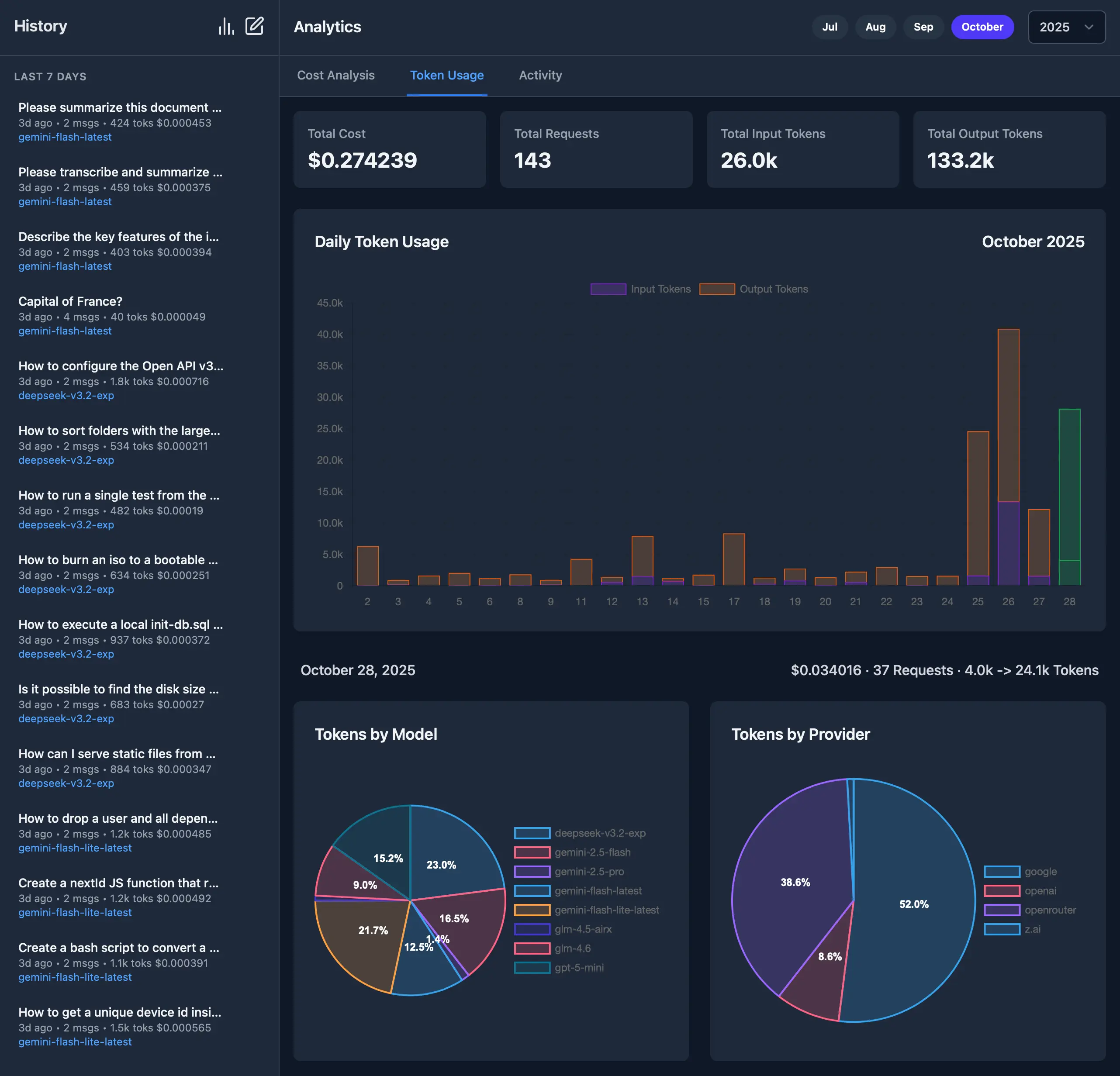
Project-URL: Documentation, https://github.com/ServiceStack/llms#readme
|
|
12
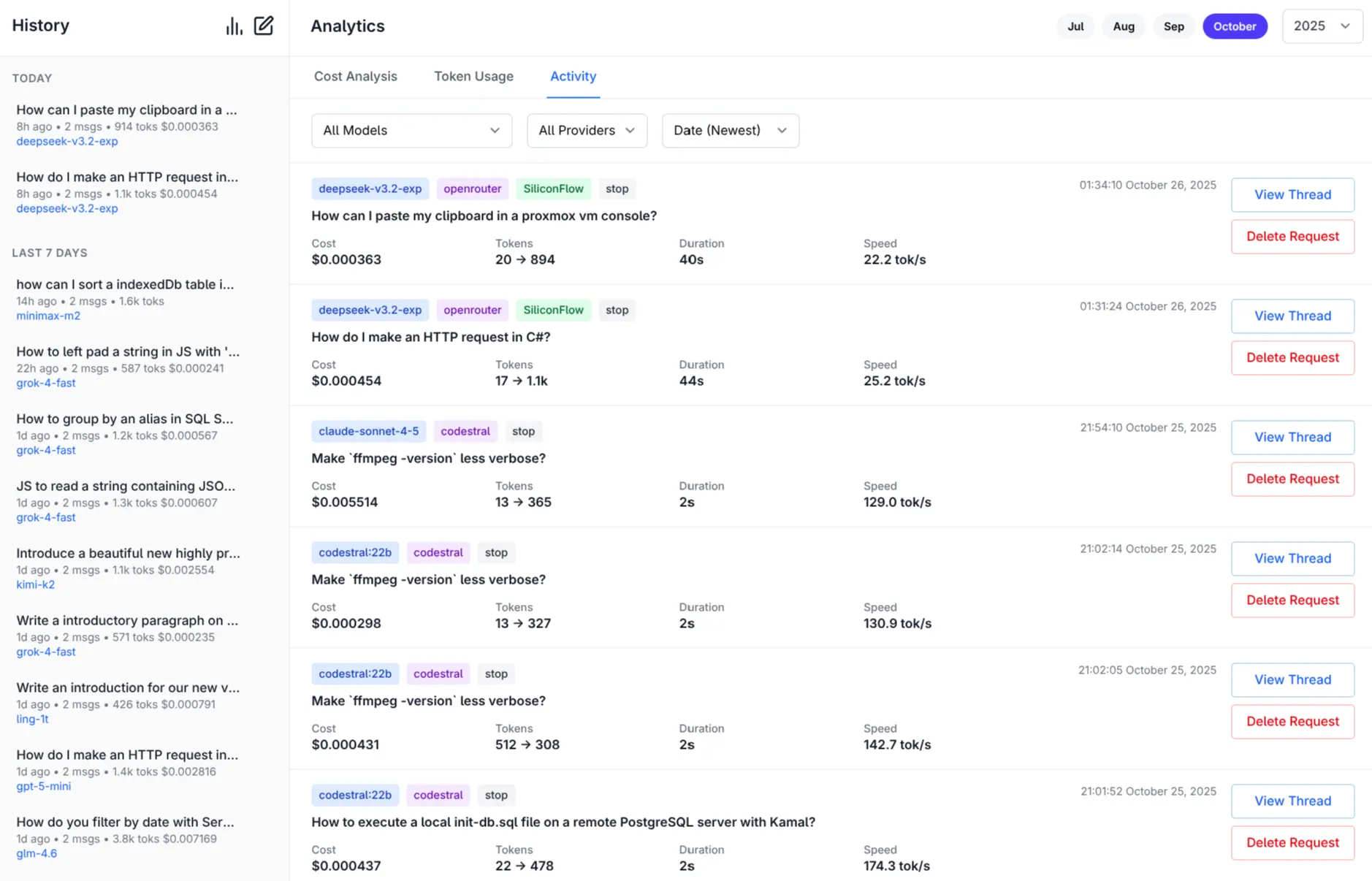
|
-
Project-URL: Repository, https://github.com/ServiceStack/llms
|
|
13
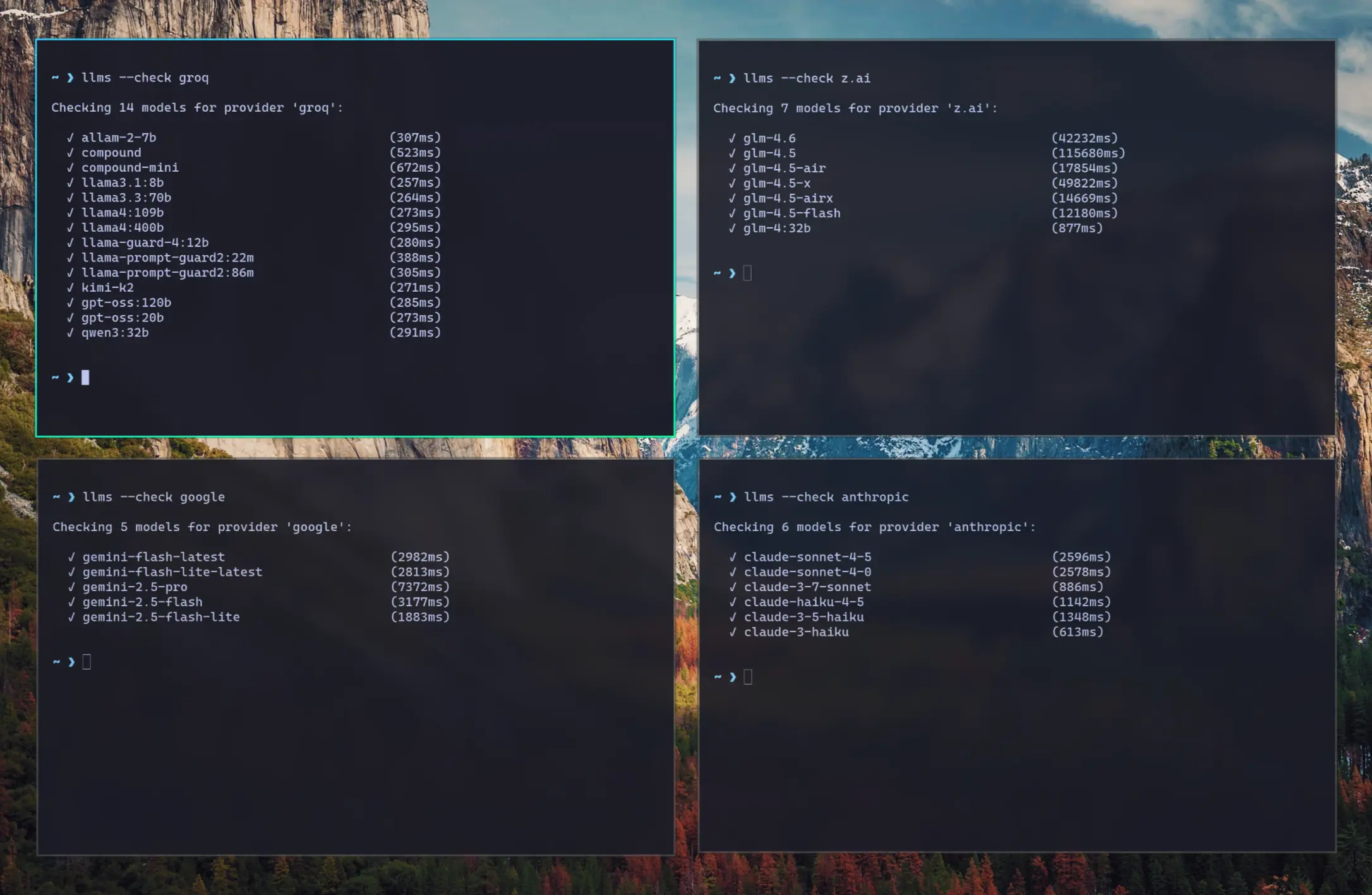
|
-
Project-URL: Bug Reports, https://github.com/ServiceStack/llms/issues
|
|
14
|
-
Keywords: llm,ai,openai,anthropic,google,gemini,groq,mistral,ollama,cli,server,chat,completion
|
|
15
|
-
Classifier: Development Status :: 5 - Production/Stable
|
|
16
|
-
Classifier: Intended Audience :: Developers
|
|
17
|
-
Classifier: Intended Audience :: System Administrators
|
|
18
|
-
Classifier: Operating System :: OS Independent
|
|
19
|
-
Classifier: Programming Language :: Python :: 3
|
|
20
|
-
Classifier: Programming Language :: Python :: 3.7
|
|
21
|
-
Classifier: Programming Language :: Python :: 3.8
|
|
22
|
-
Classifier: Programming Language :: Python :: 3.9
|
|
23
|
-
Classifier: Programming Language :: Python :: 3.10
|
|
24
|
-
Classifier: Programming Language :: Python :: 3.11
|
|
25
|
-
Classifier: Programming Language :: Python :: 3.12
|
|
26
|
-
Classifier: Topic :: Software Development :: Libraries :: Python Modules
|
|
27
|
-
Classifier: Topic :: Internet :: WWW/HTTP :: HTTP Servers
|
|
28
|
-
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
|
|
29
|
-
Classifier: Topic :: System :: Systems Administration
|
|
30
|
-
Classifier: Topic :: Utilities
|
|
31
|
-
Classifier: Environment :: Console
|
|
32
|
-
Requires-Python: >=3.7
|
|
33
|
-
Description-Content-Type: text/markdown
|
|
34
|
-
License-File: LICENSE
|
|
35
|
-
Requires-Dist: aiohttp
|
|
36
|
-
Dynamic: author
|
|
37
|
-
Dynamic: home-page
|
|
38
|
-
Dynamic: license-file
|
|
39
|
-
Dynamic: requires-python
|
|
40
|
-
|
|
41
|
-
# llms.py
|
|
42
|
-
|
|
43
|
-
Lightweight CLI, API and ChatGPT-like alternative to Open WebUI for accessing multiple LLMs, entirely offline, with all data kept private in browser storage.
|
|
44
|
-
|
|
45
|
-
Configure additional providers and models in [llms.json](llms/llms.json)
|
|
46
|
-
- Mix and match local models with models from different API providers
|
|
47
|
-
- Requests automatically routed to available providers that supports the requested model (in defined order)
|
|
48
|
-
- Define free/cheapest/local providers first to save on costs
|
|
49
|
-
- Any failures are automatically retried on the next available provider
|
|
50
|
-
|
|
51
|
-
## Features
|
|
52
|
-
|
|
53
|
-
- **Lightweight**: Single [llms.py](https://github.com/ServiceStack/llms/blob/main/llms/main.py) Python file with single `aiohttp` dependency (Pillow optional)
|
|
54
|
-
- **Multi-Provider Support**: OpenRouter, Ollama, Anthropic, Google, OpenAI, Grok, Groq, Qwen, Z.ai, Mistral
|
|
55
|
-
- **OpenAI-Compatible API**: Works with any client that supports OpenAI's chat completion API
|
|
56
|
-
- **Built-in Analytics**: Built-in analytics UI to visualize costs, requests, and token usage
|
|
57
|
-
- **GitHub OAuth**: Optionally Secure your web UI and restrict access to specified GitHub Users
|
|
58
|
-
- **Configuration Management**: Easy provider enable/disable and configuration management
|
|
59
|
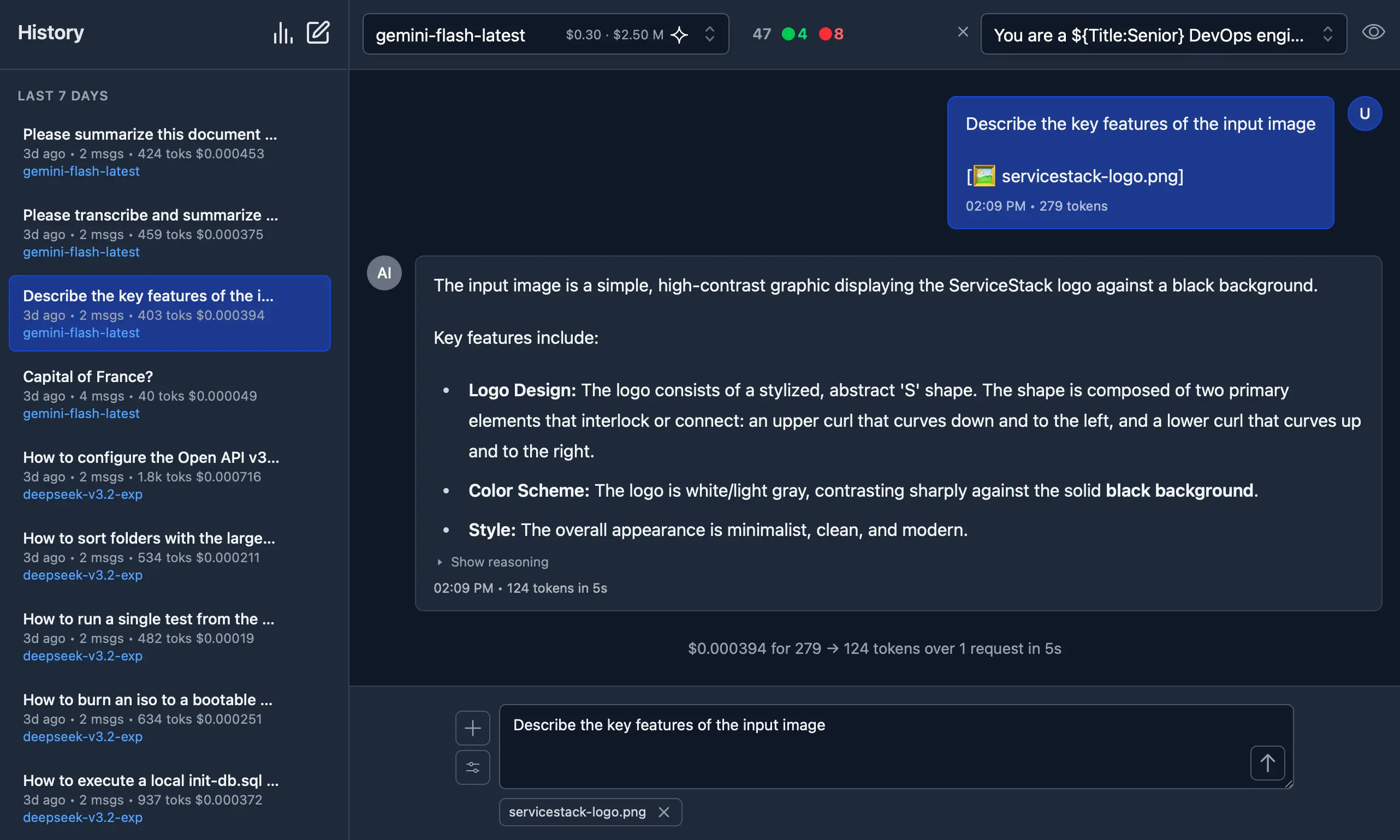
-
- **CLI Interface**: Simple command-line interface for quick interactions
|
|
60
|
-
- **Server Mode**: Run an OpenAI-compatible HTTP server at `http://localhost:{PORT}/v1/chat/completions`
|
|
61
|
-
- **Image Support**: Process images through vision-capable models
|
|
62
|
-
- Auto resizes and converts to webp if exceeds configured limits
|
|
63
|
-
- **Audio Support**: Process audio through audio-capable models
|
|
64
|
-
- **Custom Chat Templates**: Configurable chat completion request templates for different modalities
|
|
65
|
-
- **Auto-Discovery**: Automatically discover available Ollama models
|
|
66
|
-
- **Unified Models**: Define custom model names that map to different provider-specific names
|
|
67
|
-
- **Multi-Model Support**: Support for over 160+ different LLMs
|
|
68
|
-
|
|
69
|
-
## llms.py UI
|
|
70
|
-
|
|
71
|
-
Access all your local all remote LLMs with a single ChatGPT-like UI:
|
|
72
|
-
|
|
73
|
-
[](https://servicestack.net/posts/llms-py-ui)
|
|
74
|
-
|
|
75
|
-
#### Dark Mode Support
|
|
76
|
-
|
|
77
|
-
[](https://servicestack.net/posts/llms-py-ui)
|
|
78
|
-
|
|
79
|
-
#### Monthly Costs Analysis
|
|
80
|
-
|
|
81
|
-
[](https://servicestack.net/posts/llms-py-ui)
|
|
82
|
-
|
|
83
|
-
#### Monthly Token Usage (Dark Mode)
|
|
84
|
-
|
|
85
|
-
[](https://servicestack.net/posts/llms-py-ui)
|
|
86
|
-
|
|
87
|
-
#### Monthly Activity Log
|
|
88
|
-
|
|
89
|
-
[](https://servicestack.net/posts/llms-py-ui)
|
|
90
|
-
|
|
91
|
-
[More Features and Screenshots](https://servicestack.net/posts/llms-py-ui).
|
|
92
|
-
|
|
93
|
-
#### Check Provider Reliability and Response Times
|
|
94
|
-
|
|
95
|
-
Check the status of configured providers to test if they're configured correctly, reachable and what their response times is for the simplest `1+1=` request:
|
|
96
|
-
|
|
97
|
-
```bash
|
|
98
|
-
# Check all models for a provider:
|
|
99
|
-
llms --check groq
|
|
100
|
-
|
|
101
|
-
# Check specific models for a provider:
|
|
102
|
-
llms --check groq kimi-k2 llama4:400b gpt-oss:120b
|
|
103
|
-
```
|
|
104
|
-
|
|
105
|
-
[](https://servicestack.net/img/posts/llms-py-ui/llms-check.webp)
|
|
106
|
-
|
|
107
|
-
As they're a good indicator for the reliability and speed you can expect from different providers we've created a
|
|
108
|
-
[test-providers.yml](https://github.com/ServiceStack/llms/actions/workflows/test-providers.yml) GitHub Action to
|
|
109
|
-
test the response times for all configured providers and models, the results of which will be frequently published to
|
|
110
|
-
[/checks/latest.txt](https://github.com/ServiceStack/llms/blob/main/docs/checks/latest.txt)
|
|
111
|
-
|
|
112
|
-
## Change Log
|
|
113
|
-
|
|
114
|
-
#### v2.0.30 (2025-11-01)
|
|
115
|
-
- Improved Responsive Layout with collapsible Sidebar
|
|
116
|
-
- Watching config files for changes and auto-reloading
|
|
117
|
-
- Add cancel button to cancel pending request
|
|
118
|
-
- Return focus to textarea after request completes
|
|
119
|
-
- Clicking outside model or system prompt selector will collapse it
|
|
120
|
-
- Clicking on selected item no longer deselects it
|
|
121
|
-
- Support `VERBOSE=1` for enabling `--verbose` mode (useful in Docker)
|
|
122
|
-
|
|
123
|
-
#### v2.0.28 (2025-10-31)
|
|
124
|
-
- Dark Mode
|
|
125
|
-
- Drag n' Drop files in Message prompt
|
|
126
|
-
- Copy & Paste files in Message prompt
|
|
127
|
-
- Support for GitHub OAuth and optional restrict access to specified Users
|
|
128
|
-
- Support for Docker and Docker Compose
|
|
129
|
-
|
|
130
|
-
[llms.py Releases](https://github.com/ServiceStack/llms/releases)
|
|
131
|
-
|
|
132
|
-
## Installation
|
|
133
|
-
|
|
134
|
-
### Using pip
|
|
135
|
-
|
|
136
|
-
```bash
|
|
137
|
-
pip install llms-py
|
|
138
|
-
```
|
|
139
|
-
|
|
140
|
-
- [Using Docker](#using-docker)
|
|
141
|
-
|
|
142
|
-
## Quick Start
|
|
143
|
-
|
|
144
|
-
### 1. Set API Keys
|
|
145
|
-
|
|
146
|
-
Set environment variables for the providers you want to use:
|
|
147
|
-
|
|
148
|
-
```bash
|
|
149
|
-
export OPENROUTER_API_KEY="..."
|
|
150
|
-
```
|
|
151
|
-
|
|
152
|
-
| Provider | Variable | Description | Example |
|
|
153
|
-
|-----------------|---------------------------|---------------------|---------|
|
|
154
|
-
| openrouter_free | `OPENROUTER_API_KEY` | OpenRouter FREE models API key | `sk-or-...` |
|
|
155
|
-
| groq | `GROQ_API_KEY` | Groq API key | `gsk_...` |
|
|
156
|
-
| google_free | `GOOGLE_FREE_API_KEY` | Google FREE API key | `AIza...` |
|
|
157
|
-
| codestral | `CODESTRAL_API_KEY` | Codestral API key | `...` |
|
|
158
|
-
| ollama | N/A | No API key required | |
|
|
159
|
-
| openrouter | `OPENROUTER_API_KEY` | OpenRouter API key | `sk-or-...` |
|
|
160
|
-
| google | `GOOGLE_API_KEY` | Google API key | `AIza...` |
|
|
161
|
-
| anthropic | `ANTHROPIC_API_KEY` | Anthropic API key | `sk-ant-...` |
|
|
162
|
-
| openai | `OPENAI_API_KEY` | OpenAI API key | `sk-...` |
|
|
163
|
-
| grok | `GROK_API_KEY` | Grok (X.AI) API key | `xai-...` |
|
|
164
|
-
| qwen | `DASHSCOPE_API_KEY` | Qwen (Alibaba) API key | `sk-...` |
|
|
165
|
-
| z.ai | `ZAI_API_KEY` | Z.ai API key | `sk-...` |
|
|
166
|
-
| mistral | `MISTRAL_API_KEY` | Mistral API key | `...` |
|
|
167
|
-
|
|
168
|
-
### 2. Run Server
|
|
169
|
-
|
|
170
|
-
Start the UI and an OpenAI compatible API on port **8000**:
|
|
171
|
-
|
|
172
|
-
```bash
|
|
173
|
-
llms --serve 8000
|
|
174
|
-
```
|
|
175
|
-
|
|
176
|
-
Launches UI at `http://localhost:8000` and OpenAI Endpoint at `http://localhost:8000/v1/chat/completions`.
|
|
177
|
-
|
|
178
|
-
To see detailed request/response logging, add `--verbose`:
|
|
179
|
-
|
|
180
|
-
```bash
|
|
181
|
-
llms --serve 8000 --verbose
|
|
182
|
-
```
|
|
183
|
-
|
|
184
|
-
### Use llms.py CLI
|
|
185
|
-
|
|
186
|
-
```bash
|
|
187
|
-
llms "What is the capital of France?"
|
|
188
|
-
```
|
|
189
|
-
|
|
190
|
-
### Enable Providers
|
|
191
|
-
|
|
192
|
-
Any providers that have their API Keys set and enabled in `llms.json` are automatically made available.
|
|
193
|
-
|
|
194
|
-
Providers can be enabled or disabled in the UI at runtime next to the model selector, or on the command line:
|
|
195
|
-
|
|
196
|
-
```bash
|
|
197
|
-
# Disable free providers with free models and free tiers
|
|
198
|
-
llms --disable openrouter_free codestral google_free groq
|
|
199
|
-
|
|
200
|
-
# Enable paid providers
|
|
201
|
-
llms --enable openrouter anthropic google openai grok z.ai qwen mistral
|
|
202
|
-
```
|
|
203
|
-
|
|
204
|
-
## Using Docker
|
|
205
|
-
|
|
206
|
-
#### a) Simple - Run in a Docker container:
|
|
207
|
-
|
|
208
|
-
Run the server on port `8000`:
|
|
209
|
-
|
|
210
|
-
```bash
|
|
211
|
-
docker run -p 8000:8000 -e GROQ_API_KEY=$GROQ_API_KEY ghcr.io/servicestack/llms:latest
|
|
212
|
-
```
|
|
213
|
-
|
|
214
|
-
Get the latest version:
|
|
215
|
-
|
|
216
|
-
```bash
|
|
217
|
-
docker pull ghcr.io/servicestack/llms:latest
|
|
218
|
-
```
|
|
219
|
-
|
|
220
|
-
Use custom `llms.json` and `ui.json` config files outside of the container (auto created if they don't exist):
|
|
221
|
-
|
|
222
|
-
```bash
|
|
223
|
-
docker run -p 8000:8000 -e GROQ_API_KEY=$GROQ_API_KEY \
|
|
224
|
-
-v ~/.llms:/home/llms/.llms \
|
|
225
|
-
ghcr.io/servicestack/llms:latest
|
|
226
|
-
```
|
|
227
|
-
|
|
228
|
-
#### b) Recommended - Use Docker Compose:
|
|
229
|
-
|
|
230
|
-
Download and use [docker-compose.yml](https://raw.githubusercontent.com/ServiceStack/llms/refs/heads/main/docker-compose.yml):
|
|
231
|
-
|
|
232
|
-
```bash
|
|
233
|
-
curl -O https://raw.githubusercontent.com/ServiceStack/llms/refs/heads/main/docker-compose.yml
|
|
234
|
-
```
|
|
235
|
-
|
|
236
|
-
Update API Keys in `docker-compose.yml` then start the server:
|
|
237
|
-
|
|
238
|
-
```bash
|
|
239
|
-
docker-compose up -d
|
|
240
|
-
```
|
|
241
|
-
|
|
242
|
-
#### c) Build and run local Docker image from source:
|
|
243
|
-
|
|
244
|
-
```bash
|
|
245
|
-
git clone https://github.com/ServiceStack/llms
|
|
246
|
-
|
|
247
|
-
docker-compose -f docker-compose.local.yml up -d --build
|
|
248
|
-
```
|
|
249
|
-
|
|
250
|
-
After the container starts, you can access the UI and API at `http://localhost:8000`.
|
|
251
|
-
|
|
252
|
-
|
|
253
|
-
See [DOCKER.md](DOCKER.md) for detailed instructions on customizing configuration files.
|
|
254
|
-
|
|
255
|
-
## GitHub OAuth Authentication
|
|
256
|
-
|
|
257
|
-
llms.py supports optional GitHub OAuth authentication to secure your web UI and API endpoints. When enabled, users must sign in with their GitHub account before accessing the application.
|
|
258
|
-
|
|
259
|
-
```json
|
|
260
|
-
{
|
|
261
|
-
"auth": {
|
|
262
|
-
"enabled": true,
|
|
263
|
-
"github": {
|
|
264
|
-
"client_id": "$GITHUB_CLIENT_ID",
|
|
265
|
-
"client_secret": "$GITHUB_CLIENT_SECRET",
|
|
266
|
-
"redirect_uri": "http://localhost:8000/auth/github/callback",
|
|
267
|
-
"restrict_to": "$GITHUB_USERS"
|
|
268
|
-
}
|
|
269
|
-
}
|
|
270
|
-
}
|
|
271
|
-
```
|
|
272
|
-
|
|
273
|
-
`GITHUB_USERS` is optional but if set will only allow access to the specified users.
|
|
274
|
-
|
|
275
|
-
See [GITHUB_OAUTH_SETUP.md](GITHUB_OAUTH_SETUP.md) for detailed setup instructions.
|
|
276
|
-
|
|
277
|
-
## Configuration
|
|
278
|
-
|
|
279
|
-
The configuration file [llms.json](llms/llms.json) is saved to `~/.llms/llms.json` and defines available providers, models, and default settings. If it doesn't exist, `llms.json` is auto created with the latest
|
|
280
|
-
configuration, so you can re-create it by deleting your local config (e.g. `rm -rf ~/.llms`).
|
|
281
|
-
|
|
282
|
-
Key sections:
|
|
283
|
-
|
|
284
|
-
### Defaults
|
|
285
|
-
- `headers`: Common HTTP headers for all requests
|
|
286
|
-
- `text`: Default chat completion request template for text prompts
|
|
287
|
-
- `image`: Default chat completion request template for image prompts
|
|
288
|
-
- `audio`: Default chat completion request template for audio prompts
|
|
289
|
-
- `file`: Default chat completion request template for file prompts
|
|
290
|
-
- `check`: Check request template for testing provider connectivity
|
|
291
|
-
- `limits`: Override Request size limits
|
|
292
|
-
- `convert`: Max image size and length limits and auto conversion settings
|
|
293
|
-
|
|
294
|
-
### Providers
|
|
295
|
-
Each provider configuration includes:
|
|
296
|
-
- `enabled`: Whether the provider is active
|
|
297
|
-
- `type`: Provider class (OpenAiProvider, GoogleProvider, etc.)
|
|
298
|
-
- `api_key`: API key (supports environment variables with `$VAR_NAME`)
|
|
299
|
-
- `base_url`: API endpoint URL
|
|
300
|
-
- `models`: Model name mappings (local name → provider name)
|
|
301
|
-
- `pricing`: Pricing per token (input/output) for each model
|
|
302
|
-
- `default_pricing`: Default pricing if not specified in `pricing`
|
|
303
|
-
- `check`: Check request template for testing provider connectivity
|
|
304
|
-
|
|
305
|
-
## Command Line Usage
|
|
306
|
-
|
|
307
|
-
### Basic Chat
|
|
308
|
-
|
|
309
|
-
```bash
|
|
310
|
-
# Simple question
|
|
311
|
-
llms "Explain quantum computing"
|
|
312
|
-
|
|
313
|
-
# With specific model
|
|
314
|
-
llms -m gemini-2.5-pro "Write a Python function to sort a list"
|
|
315
|
-
llms -m grok-4 "Explain this code with humor"
|
|
316
|
-
llms -m qwen3-max "Translate this to Chinese"
|
|
317
|
-
|
|
318
|
-
# With system prompt
|
|
319
|
-
llms -s "You are a helpful coding assistant" "How do I reverse a string in Python?"
|
|
320
|
-
|
|
321
|
-
# With image (vision models)
|
|
322
|
-
llms --image image.jpg "What's in this image?"
|
|
323
|
-
llms --image https://example.com/photo.png "Describe this photo"
|
|
324
|
-
|
|
325
|
-
# Display full JSON Response
|
|
326
|
-
llms "Explain quantum computing" --raw
|
|
327
|
-
```
|
|
328
|
-
|
|
329
|
-
### Using a Chat Template
|
|
330
|
-
|
|
331
|
-
By default llms uses the `defaults/text` chat completion request defined in [llms.json](llms/llms.json).
|
|
332
|
-
|
|
333
|
-
You can instead use a custom chat completion request with `--chat`, e.g:
|
|
334
|
-
|
|
335
|
-
```bash
|
|
336
|
-
# Load chat completion request from JSON file
|
|
337
|
-
llms --chat request.json
|
|
338
|
-
|
|
339
|
-
# Override user message
|
|
340
|
-
llms --chat request.json "New user message"
|
|
341
|
-
|
|
342
|
-
# Override model
|
|
343
|
-
llms -m kimi-k2 --chat request.json
|
|
344
|
-
```
|
|
345
|
-
|
|
346
|
-
Example `request.json`:
|
|
347
|
-
|
|
348
|
-
```json
|
|
349
|
-
{
|
|
350
|
-
"model": "kimi-k2",
|
|
351
|
-
"messages": [
|
|
352
|
-
{"role": "system", "content": "You are a helpful assistant."},
|
|
353
|
-
{"role": "user", "content": ""}
|
|
354
|
-
],
|
|
355
|
-
"temperature": 0.7,
|
|
356
|
-
"max_tokens": 150
|
|
357
|
-
}
|
|
358
|
-
```
|
|
359
|
-
|
|
360
|
-
### Image Requests
|
|
361
|
-
|
|
362
|
-
Send images to vision-capable models using the `--image` option:
|
|
363
|
-
|
|
364
|
-
```bash
|
|
365
|
-
# Use defaults/image Chat Template (Describe the key features of the input image)
|
|
366
|
-
llms --image ./screenshot.png
|
|
367
|
-
|
|
368
|
-
# Local image file
|
|
369
|
-
llms --image ./screenshot.png "What's in this image?"
|
|
370
|
-
|
|
371
|
-
# Remote image URL
|
|
372
|
-
llms --image https://example.org/photo.jpg "Describe this photo"
|
|
373
|
-
|
|
374
|
-
# Data URI
|
|
375
|
-
llms --image "data:image/png;base64,$(base64 -w 0 image.png)" "Describe this image"
|
|
376
|
-
|
|
377
|
-
# With a specific vision model
|
|
378
|
-
llms -m gemini-2.5-flash --image chart.png "Analyze this chart"
|
|
379
|
-
llms -m qwen2.5vl --image document.jpg "Extract text from this document"
|
|
380
|
-
|
|
381
|
-
# Combined with system prompt
|
|
382
|
-
llms -s "You are a data analyst" --image graph.png "What trends do you see?"
|
|
383
|
-
|
|
384
|
-
# With custom chat template
|
|
385
|
-
llms --chat image-request.json --image photo.jpg
|
|
386
|
-
```
|
|
387
|
-
|
|
388
|
-
Example of `image-request.json`:
|
|
389
|
-
|
|
390
|
-
```json
|
|
391
|
-
{
|
|
392
|
-
"model": "qwen2.5vl",
|
|
393
|
-
"messages": [
|
|
394
|
-
{
|
|
395
|
-
"role": "user",
|
|
396
|
-
"content": [
|
|
397
|
-
{
|
|
398
|
-
"type": "image_url",
|
|
399
|
-
"image_url": {
|
|
400
|
-
"url": ""
|
|
401
|
-
}
|
|
402
|
-
},
|
|
403
|
-
{
|
|
404
|
-
"type": "text",
|
|
405
|
-
"text": "Caption this image"
|
|
406
|
-
}
|
|
407
|
-
]
|
|
408
|
-
}
|
|
409
|
-
]
|
|
410
|
-
}
|
|
411
|
-
```
|
|
412
|
-
|
|
413
|
-
**Supported image formats**: PNG, WEBP, JPG, JPEG, GIF, BMP, TIFF, ICO
|
|
414
|
-
|
|
415
|
-
**Image sources**:
|
|
416
|
-
- **Local files**: Absolute paths (`/path/to/image.jpg`) or relative paths (`./image.png`, `../image.jpg`)
|
|
417
|
-
- **Remote URLs**: HTTP/HTTPS URLs are automatically downloaded
|
|
418
|
-
- **Data URIs**: Base64-encoded images (`data:image/png;base64,...`)
|
|
419
|
-
|
|
420
|
-
Images are automatically processed and converted to base64 data URIs before being sent to the model.
|
|
421
|
-
|
|
422
|
-
### Vision-Capable Models
|
|
423
|
-
|
|
424
|
-
Popular models that support image analysis:
|
|
425
|
-
- **OpenAI**: GPT-4o, GPT-4o-mini, GPT-4.1
|
|
426
|
-
- **Anthropic**: Claude Sonnet 4.0, Claude Opus 4.1
|
|
427
|
-
- **Google**: Gemini 2.5 Pro, Gemini Flash
|
|
428
|
-
- **Qwen**: Qwen2.5-VL, Qwen3-VL, QVQ-max
|
|
429
|
-
- **Ollama**: qwen2.5vl, llava
|
|
430
|
-
|
|
431
|
-
Images are automatically downloaded and converted to base64 data URIs.
|
|
432
|
-
|
|
433
|
-
### Audio Requests
|
|
434
|
-
|
|
435
|
-
Send audio files to audio-capable models using the `--audio` option:
|
|
436
|
-
|
|
437
|
-
```bash
|
|
438
|
-
# Use defaults/audio Chat Template (Transcribe the audio)
|
|
439
|
-
llms --audio ./recording.mp3
|
|
440
|
-
|
|
441
|
-
# Local audio file
|
|
442
|
-
llms --audio ./meeting.wav "Summarize this meeting recording"
|
|
443
|
-
|
|
444
|
-
# Remote audio URL
|
|
445
|
-
llms --audio https://example.org/podcast.mp3 "What are the key points discussed?"
|
|
446
|
-
|
|
447
|
-
# With a specific audio model
|
|
448
|
-
llms -m gpt-4o-audio-preview --audio interview.mp3 "Extract the main topics"
|
|
449
|
-
llms -m gemini-2.5-flash --audio interview.mp3 "Extract the main topics"
|
|
450
|
-
|
|
451
|
-
# Combined with system prompt
|
|
452
|
-
llms -s "You're a transcription specialist" --audio talk.mp3 "Provide a detailed transcript"
|
|
453
|
-
|
|
454
|
-
# With custom chat template
|
|
455
|
-
llms --chat audio-request.json --audio speech.wav
|
|
456
|
-
```
|
|
457
|
-
|
|
458
|
-
Example of `audio-request.json`:
|
|
459
|
-
|
|
460
|
-
```json
|
|
461
|
-
{
|
|
462
|
-
"model": "gpt-4o-audio-preview",
|
|
463
|
-
"messages": [
|
|
464
|
-
{
|
|
465
|
-
"role": "user",
|
|
466
|
-
"content": [
|
|
467
|
-
{
|
|
468
|
-
"type": "input_audio",
|
|
469
|
-
"input_audio": {
|
|
470
|
-
"data": "",
|
|
471
|
-
"format": "mp3"
|
|
472
|
-
}
|
|
473
|
-
},
|
|
474
|
-
{
|
|
475
|
-
"type": "text",
|
|
476
|
-
"text": "Please transcribe this audio"
|
|
477
|
-
}
|
|
478
|
-
]
|
|
479
|
-
}
|
|
480
|
-
]
|
|
481
|
-
}
|
|
482
|
-
```
|
|
483
|
-
|
|
484
|
-
**Supported audio formats**: MP3, WAV
|
|
485
|
-
|
|
486
|
-
**Audio sources**:
|
|
487
|
-
- **Local files**: Absolute paths (`/path/to/audio.mp3`) or relative paths (`./audio.wav`, `../recording.m4a`)
|
|
488
|
-
- **Remote URLs**: HTTP/HTTPS URLs are automatically downloaded
|
|
489
|
-
- **Base64 Data**: Base64-encoded audio
|
|
490
|
-
|
|
491
|
-
Audio files are automatically processed and converted to base64 data before being sent to the model.
|
|
492
|
-
|
|
493
|
-
### Audio-Capable Models
|
|
494
|
-
|
|
495
|
-
Popular models that support audio processing:
|
|
496
|
-
- **OpenAI**: gpt-4o-audio-preview
|
|
497
|
-
- **Google**: gemini-2.5-pro, gemini-2.5-flash, gemini-2.5-flash-lite
|
|
498
|
-
|
|
499
|
-
Audio files are automatically downloaded and converted to base64 data URIs with appropriate format detection.
|
|
500
|
-
|
|
501
|
-
### File Requests
|
|
502
|
-
|
|
503
|
-
Send documents (e.g. PDFs) to file-capable models using the `--file` option:
|
|
504
|
-
|
|
505
|
-
```bash
|
|
506
|
-
# Use defaults/file Chat Template (Summarize the document)
|
|
507
|
-
llms --file ./docs/handbook.pdf
|
|
508
|
-
|
|
509
|
-
# Local PDF file
|
|
510
|
-
llms --file ./docs/policy.pdf "Summarize the key changes"
|
|
511
|
-
|
|
512
|
-
# Remote PDF URL
|
|
513
|
-
llms --file https://example.org/whitepaper.pdf "What are the main findings?"
|
|
514
|
-
|
|
515
|
-
# With specific file-capable models
|
|
516
|
-
llms -m gpt-5 --file ./policy.pdf "Summarize the key changes"
|
|
517
|
-
llms -m gemini-flash-latest --file ./report.pdf "Extract action items"
|
|
518
|
-
llms -m qwen2.5vl --file ./manual.pdf "List key sections and their purpose"
|
|
519
|
-
|
|
520
|
-
# Combined with system prompt
|
|
521
|
-
llms -s "You're a compliance analyst" --file ./policy.pdf "Identify compliance risks"
|
|
522
|
-
|
|
523
|
-
# With custom chat template
|
|
524
|
-
llms --chat file-request.json --file ./docs/handbook.pdf
|
|
525
|
-
```
|
|
526
|
-
|
|
527
|
-
Example of `file-request.json`:
|
|
528
|
-
|
|
529
|
-
```json
|
|
530
|
-
{
|
|
531
|
-
"model": "gpt-5",
|
|
532
|
-
"messages": [
|
|
533
|
-
{
|
|
534
|
-
"role": "user",
|
|
535
|
-
"content": [
|
|
536
|
-
{
|
|
537
|
-
"type": "file",
|
|
538
|
-
"file": {
|
|
539
|
-
"filename": "",
|
|
540
|
-
"file_data": ""
|
|
541
|
-
}
|
|
542
|
-
},
|
|
543
|
-
{
|
|
544
|
-
"type": "text",
|
|
545
|
-
"text": "Please summarize this document"
|
|
546
|
-
}
|
|
547
|
-
]
|
|
548
|
-
}
|
|
549
|
-
]
|
|
550
|
-
}
|
|
551
|
-
```
|
|
552
|
-
|
|
553
|
-
**Supported file formats**: PDF
|
|
554
|
-
|
|
555
|
-
Other document types may work depending on the model/provider.
|
|
556
|
-
|
|
557
|
-
**File sources**:
|
|
558
|
-
- **Local files**: Absolute paths (`/path/to/file.pdf`) or relative paths (`./file.pdf`, `../file.pdf`)
|
|
559
|
-
- **Remote URLs**: HTTP/HTTPS URLs are automatically downloaded
|
|
560
|
-
- **Base64/Data URIs**: Inline `data:application/pdf;base64,...` is supported
|
|
561
|
-
|
|
562
|
-
Files are automatically downloaded (for URLs) and converted to base64 data URIs before being sent to the model.
|
|
563
|
-
|
|
564
|
-
### File-Capable Models
|
|
565
|
-
|
|
566
|
-
Popular multi-modal models that support file (PDF) inputs:
|
|
567
|
-
- OpenAI: gpt-5, gpt-5-mini, gpt-4o, gpt-4o-mini
|
|
568
|
-
- Google: gemini-flash-latest, gemini-2.5-flash-lite
|
|
569
|
-
- Grok: grok-4-fast (OpenRouter)
|
|
570
|
-
- Qwen: qwen2.5vl, qwen3-max, qwen3-vl:235b, qwen3-coder, qwen3-coder-flash (OpenRouter)
|
|
571
|
-
- Others: kimi-k2, glm-4.5-air, deepseek-v3.1:671b, llama4:400b, llama3.3:70b, mai-ds-r1, nemotron-nano:9b
|
|
572
|
-
|
|
573
|
-
## Server Mode
|
|
574
|
-
|
|
575
|
-
Run as an OpenAI-compatible HTTP server:
|
|
576
|
-
|
|
577
|
-
```bash
|
|
578
|
-
# Start server on port 8000
|
|
579
|
-
llms --serve 8000
|
|
580
|
-
```
|
|
581
|
-
|
|
582
|
-
The server exposes a single endpoint:
|
|
583
|
-
- `POST /v1/chat/completions` - OpenAI-compatible chat completions
|
|
584
|
-
|
|
585
|
-
Example client usage:
|
|
586
|
-
|
|
587
|
-
```bash
|
|
588
|
-
curl -X POST http://localhost:8000/v1/chat/completions \
|
|
589
|
-
-H "Content-Type: application/json" \
|
|
590
|
-
-d '{
|
|
591
|
-
"model": "kimi-k2",
|
|
592
|
-
"messages": [
|
|
593
|
-
{"role": "user", "content": "Hello!"}
|
|
594
|
-
]
|
|
595
|
-
}'
|
|
596
|
-
```
|
|
597
|
-
|
|
598
|
-
### Configuration Management
|
|
599
|
-
|
|
600
|
-
```bash
|
|
601
|
-
# List enabled providers and models
|
|
602
|
-
llms --list
|
|
603
|
-
llms ls
|
|
604
|
-
|
|
605
|
-
# List specific providers
|
|
606
|
-
llms ls ollama
|
|
607
|
-
llms ls google anthropic
|
|
608
|
-
|
|
609
|
-
# Enable providers
|
|
610
|
-
llms --enable openrouter
|
|
611
|
-
llms --enable anthropic google_free groq
|
|
612
|
-
|
|
613
|
-
# Disable providers
|
|
614
|
-
llms --disable ollama
|
|
615
|
-
llms --disable openai anthropic
|
|
616
|
-
|
|
617
|
-
# Set default model
|
|
618
|
-
llms --default grok-4
|
|
619
|
-
```
|
|
620
|
-
|
|
621
|
-
### Update
|
|
622
|
-
|
|
623
|
-
```bash
|
|
624
|
-
pip install llms-py --upgrade
|
|
625
|
-
```
|
|
626
|
-
|
|
627
|
-
### Advanced Options
|
|
628
|
-
|
|
629
|
-
```bash
|
|
630
|
-
# Use custom config file
|
|
631
|
-
llms --config /path/to/config.json "Hello"
|
|
632
|
-
|
|
633
|
-
# Get raw JSON response
|
|
634
|
-
llms --raw "What is 2+2?"
|
|
635
|
-
|
|
636
|
-
# Enable verbose logging
|
|
637
|
-
llms --verbose "Tell me a joke"
|
|
638
|
-
|
|
639
|
-
# Custom log prefix
|
|
640
|
-
llms --verbose --logprefix "[DEBUG] " "Hello world"
|
|
641
|
-
|
|
642
|
-
# Set default model (updates config file)
|
|
643
|
-
llms --default grok-4
|
|
644
|
-
|
|
645
|
-
# Pass custom parameters to chat request (URL-encoded)
|
|
646
|
-
llms --args "temperature=0.7&seed=111" "What is 2+2?"
|
|
647
|
-
|
|
648
|
-
# Multiple parameters with different types
|
|
649
|
-
llms --args "temperature=0.5&max_completion_tokens=50" "Tell me a joke"
|
|
650
|
-
|
|
651
|
-
# URL-encoded special characters (stop sequences)
|
|
652
|
-
llms --args "stop=Two,Words" "Count to 5"
|
|
653
|
-
|
|
654
|
-
# Combine with other options
|
|
655
|
-
llms --system "You are helpful" --args "temperature=0.3" --raw "Hello"
|
|
656
|
-
```
|
|
657
|
-
|
|
658
|
-
#### Custom Parameters with `--args`
|
|
659
|
-
|
|
660
|
-
The `--args` option allows you to pass URL-encoded parameters to customize the chat request sent to LLM providers:
|
|
661
|
-
|
|
662
|
-
**Parameter Types:**
|
|
663
|
-
- **Floats**: `temperature=0.7`, `frequency_penalty=0.2`
|
|
664
|
-
- **Integers**: `max_completion_tokens=100`
|
|
665
|
-
- **Booleans**: `store=true`, `verbose=false`, `logprobs=true`
|
|
666
|
-
- **Strings**: `stop=one`
|
|
667
|
-
- **Lists**: `stop=two,words`
|
|
668
|
-
|
|
669
|
-
**Common Parameters:**
|
|
670
|
-
- `temperature`: Controls randomness (0.0 to 2.0)
|
|
671
|
-
- `max_completion_tokens`: Maximum tokens in response
|
|
672
|
-
- `seed`: For reproducible outputs
|
|
673
|
-
- `top_p`: Nucleus sampling parameter
|
|
674
|
-
- `stop`: Stop sequences (URL-encode special chars)
|
|
675
|
-
- `store`: Whether or not to store the output
|
|
676
|
-
- `frequency_penalty`: Penalize new tokens based on frequency
|
|
677
|
-
- `presence_penalty`: Penalize new tokens based on presence
|
|
678
|
-
- `logprobs`: Include log probabilities in response
|
|
679
|
-
- `parallel_tool_calls`: Enable parallel tool calls
|
|
680
|
-
- `prompt_cache_key`: Cache key for prompt
|
|
681
|
-
- `reasoning_effort`: Reasoning effort (low, medium, high, *minimal, *none, *default)
|
|
682
|
-
- `safety_identifier`: A string that uniquely identifies each user
|
|
683
|
-
- `seed`: For reproducible outputs
|
|
684
|
-
- `service_tier`: Service tier (free, standard, premium, *default)
|
|
685
|
-
- `top_logprobs`: Number of top logprobs to return
|
|
686
|
-
- `top_p`: Nucleus sampling parameter
|
|
687
|
-
- `verbosity`: Verbosity level (0, 1, 2, 3, *default)
|
|
688
|
-
- `enable_thinking`: Enable thinking mode (Qwen)
|
|
689
|
-
- `stream`: Enable streaming responses
|
|
690
|
-
|
|
691
|
-
### Default Model Configuration
|
|
692
|
-
|
|
693
|
-
The `--default MODEL` option allows you to set the default model used for all chat completions. This updates the `defaults.text.model` field in your configuration file:
|
|
694
|
-
|
|
695
|
-
```bash
|
|
696
|
-
# Set default model to gpt-oss
|
|
697
|
-
llms --default gpt-oss:120b
|
|
698
|
-
|
|
699
|
-
# Set default model to Claude Sonnet
|
|
700
|
-
llms --default claude-sonnet-4-0
|
|
701
|
-
|
|
702
|
-
# The model must be available in your enabled providers
|
|
703
|
-
llms --default gemini-2.5-pro
|
|
704
|
-
```
|
|
705
|
-
|
|
706
|
-
When you set a default model:
|
|
707
|
-
- The configuration file (`~/.llms/llms.json`) is automatically updated
|
|
708
|
-
- The specified model becomes the default for all future chat requests
|
|
709
|
-
- The model must exist in your currently enabled providers
|
|
710
|
-
- You can still override the default using `-m MODEL` for individual requests
|
|
711
|
-
|
|
712
|
-
### Updating llms.py
|
|
713
|
-
|
|
714
|
-
```bash
|
|
715
|
-
pip install llms-py --upgrade
|
|
716
|
-
```
|
|
717
|
-
|
|
718
|
-
### Beautiful rendered Markdown
|
|
719
|
-
|
|
720
|
-
Pipe Markdown output to [glow](https://github.com/charmbracelet/glow) to beautifully render it in the terminal:
|
|
721
|
-
|
|
722
|
-
```bash
|
|
723
|
-
llms "Explain quantum computing" | glow
|
|
724
|
-
```
|
|
725
|
-
|
|
726
|
-
## Supported Providers
|
|
727
|
-
|
|
728
|
-
Any OpenAI-compatible providers and their models can be added by configuring them in [llms.json](./llms.json). By default only AI Providers with free tiers are enabled which will only be "available" if their API Key is set.
|
|
729
|
-
|
|
730
|
-
You can list the available providers, their models and which are enabled or disabled with:
|
|
731
|
-
|
|
732
|
-
```bash
|
|
733
|
-
llms ls
|
|
734
|
-
```
|
|
735
|
-
|
|
736
|
-
They can be enabled/disabled in your `llms.json` file or with:
|
|
737
|
-
|
|
738
|
-
```bash
|
|
739
|
-
llms --enable <provider>
|
|
740
|
-
llms --disable <provider>
|
|
741
|
-
```
|
|
742
|
-
|
|
743
|
-
For a provider to be available, they also require their API Key configured in either your Environment Variables
|
|
744
|
-
or directly in your `llms.json`.
|
|
745
|
-
|
|
746
|
-
### Environment Variables
|
|
747
|
-
|
|
748
|
-
| Provider | Variable | Description | Example |
|
|
749
|
-
|-----------------|---------------------------|---------------------|---------|
|
|
750
|
-
| openrouter_free | `OPENROUTER_API_KEY` | OpenRouter FREE models API key | `sk-or-...` |
|
|
751
|
-
| groq | `GROQ_API_KEY` | Groq API key | `gsk_...` |
|
|
752
|
-
| google_free | `GOOGLE_FREE_API_KEY` | Google FREE API key | `AIza...` |
|
|
753
|
-
| codestral | `CODESTRAL_API_KEY` | Codestral API key | `...` |
|
|
754
|
-
| ollama | N/A | No API key required | |
|
|
755
|
-
| openrouter | `OPENROUTER_API_KEY` | OpenRouter API key | `sk-or-...` |
|
|
756
|
-
| google | `GOOGLE_API_KEY` | Google API key | `AIza...` |
|
|
757
|
-
| anthropic | `ANTHROPIC_API_KEY` | Anthropic API key | `sk-ant-...` |
|
|
758
|
-
| openai | `OPENAI_API_KEY` | OpenAI API key | `sk-...` |
|
|
759
|
-
| grok | `GROK_API_KEY` | Grok (X.AI) API key | `xai-...` |
|
|
760
|
-
| qwen | `DASHSCOPE_API_KEY` | Qwen (Alibaba) API key | `sk-...` |
|
|
761
|
-
| z.ai | `ZAI_API_KEY` | Z.ai API key | `sk-...` |
|
|
762
|
-
| mistral | `MISTRAL_API_KEY` | Mistral API key | `...` |
|
|
763
|
-
|
|
764
|
-
### OpenAI
|
|
765
|
-
- **Type**: `OpenAiProvider`
|
|
766
|
-
- **Models**: GPT-5, GPT-5 Codex, GPT-4o, GPT-4o-mini, o3, etc.
|
|
767
|
-
- **Features**: Text, images, function calling
|
|
768
|
-
|
|
769
|
-
```bash
|
|
770
|
-
export OPENAI_API_KEY="your-key"
|
|
771
|
-
llms --enable openai
|
|
772
|
-
```
|
|
773
|
-
|
|
774
|
-
### Anthropic (Claude)
|
|
775
|
-
- **Type**: `OpenAiProvider`
|
|
776
|
-
- **Models**: Claude Opus 4.1, Sonnet 4.0, Haiku 3.5, etc.
|
|
777
|
-
- **Features**: Text, images, large context windows
|
|
778
|
-
|
|
779
|
-
```bash
|
|
780
|
-
export ANTHROPIC_API_KEY="your-key"
|
|
781
|
-
llms --enable anthropic
|
|
782
|
-
```
|
|
783
|
-
|
|
784
|
-
### Google Gemini
|
|
785
|
-
- **Type**: `GoogleProvider`
|
|
786
|
-
- **Models**: Gemini 2.5 Pro, Flash, Flash-Lite
|
|
787
|
-
- **Features**: Text, images, safety settings
|
|
788
|
-
|
|
789
|
-
```bash
|
|
790
|
-
export GOOGLE_API_KEY="your-key"
|
|
791
|
-
llms --enable google_free
|
|
792
|
-
```
|
|
793
|
-
|
|
794
|
-
### OpenRouter
|
|
795
|
-
- **Type**: `OpenAiProvider`
|
|
796
|
-
- **Models**: 100+ models from various providers
|
|
797
|
-
- **Features**: Access to latest models, free tier available
|
|
798
|
-
|
|
799
|
-
```bash
|
|
800
|
-
export OPENROUTER_API_KEY="your-key"
|
|
801
|
-
llms --enable openrouter
|
|
802
|
-
```
|
|
803
|
-
|
|
804
|
-
### Grok (X.AI)
|
|
805
|
-
- **Type**: `OpenAiProvider`
|
|
806
|
-
- **Models**: Grok-4, Grok-3, Grok-3-mini, Grok-code-fast-1, etc.
|
|
807
|
-
- **Features**: Real-time information, humor, uncensored responses
|
|
808
|
-
|
|
809
|
-
```bash
|
|
810
|
-
export GROK_API_KEY="your-key"
|
|
811
|
-
llms --enable grok
|
|
812
|
-
```
|
|
813
|
-
|
|
814
|
-
### Groq
|
|
815
|
-
- **Type**: `OpenAiProvider`
|
|
816
|
-
- **Models**: Llama 3.3, Gemma 2, Kimi K2, etc.
|
|
817
|
-
- **Features**: Fast inference, competitive pricing
|
|
818
|
-
|
|
819
|
-
```bash
|
|
820
|
-
export GROQ_API_KEY="your-key"
|
|
821
|
-
llms --enable groq
|
|
822
|
-
```
|
|
823
|
-
|
|
824
|
-
### Ollama (Local)
|
|
825
|
-
- **Type**: `OllamaProvider`
|
|
826
|
-
- **Models**: Auto-discovered from local Ollama installation
|
|
827
|
-
- **Features**: Local inference, privacy, no API costs
|
|
828
|
-
|
|
829
|
-
```bash
|
|
830
|
-
# Ollama must be running locally
|
|
831
|
-
llms --enable ollama
|
|
832
|
-
```
|
|
833
|
-
|
|
834
|
-
### Qwen (Alibaba Cloud)
|
|
835
|
-
- **Type**: `OpenAiProvider`
|
|
836
|
-
- **Models**: Qwen3-max, Qwen-max, Qwen-plus, Qwen2.5-VL, QwQ-plus, etc.
|
|
837
|
-
- **Features**: Multilingual, vision models, coding, reasoning, audio processing
|
|
838
|
-
|
|
839
|
-
```bash
|
|
840
|
-
export DASHSCOPE_API_KEY="your-key"
|
|
841
|
-
llms --enable qwen
|
|
842
|
-
```
|
|
843
|
-
|
|
844
|
-
### Z.ai
|
|
845
|
-
- **Type**: `OpenAiProvider`
|
|
846
|
-
- **Models**: GLM-4.6, GLM-4.5, GLM-4.5-air, GLM-4.5-x, GLM-4.5-airx, GLM-4.5-flash, GLM-4:32b
|
|
847
|
-
- **Features**: Advanced language models with strong reasoning capabilities
|
|
848
|
-
|
|
849
|
-
```bash
|
|
850
|
-
export ZAI_API_KEY="your-key"
|
|
851
|
-
llms --enable z.ai
|
|
852
|
-
```
|
|
853
|
-
|
|
854
|
-
### Mistral
|
|
855
|
-
- **Type**: `OpenAiProvider`
|
|
856
|
-
- **Models**: Mistral Large, Codestral, Pixtral, etc.
|
|
857
|
-
- **Features**: Code generation, multilingual
|
|
858
|
-
|
|
859
|
-
```bash
|
|
860
|
-
export MISTRAL_API_KEY="your-key"
|
|
861
|
-
llms --enable mistral
|
|
862
|
-
```
|
|
863
|
-
|
|
864
|
-
### Codestral
|
|
865
|
-
- **Type**: `OpenAiProvider`
|
|
866
|
-
- **Models**: Codestral
|
|
867
|
-
- **Features**: Code generation
|
|
868
|
-
|
|
869
|
-
```bash
|
|
870
|
-
export CODESTRAL_API_KEY="your-key"
|
|
871
|
-
llms --enable codestral
|
|
872
|
-
```
|
|
873
|
-
|
|
874
|
-
## Model Routing
|
|
875
|
-
|
|
876
|
-
The tool automatically routes requests to the first available provider that supports the requested model. If a provider fails, it tries the next available provider with that model.
|
|
877
|
-
|
|
878
|
-
Example: If both OpenAI and OpenRouter support `kimi-k2`, the request will first try OpenRouter (free), then fall back to Groq than OpenRouter (Paid) if requests fails.
|
|
879
|
-
|
|
880
|
-
## Configuration Examples
|
|
881
|
-
|
|
882
|
-
### Minimal Configuration
|
|
883
|
-
|
|
884
|
-
```json
|
|
885
|
-
{
|
|
886
|
-
"defaults": {
|
|
887
|
-
"headers": {"Content-Type": "application/json"},
|
|
888
|
-
"text": {
|
|
889
|
-
"model": "kimi-k2",
|
|
890
|
-
"messages": [{"role": "user", "content": ""}]
|
|
891
|
-
}
|
|
892
|
-
},
|
|
893
|
-
"providers": {
|
|
894
|
-
"groq": {
|
|
895
|
-
"enabled": true,
|
|
896
|
-
"type": "OpenAiProvider",
|
|
897
|
-
"base_url": "https://api.groq.com/openai",
|
|
898
|
-
"api_key": "$GROQ_API_KEY",
|
|
899
|
-
"models": {
|
|
900
|
-
"llama3.3:70b": "llama-3.3-70b-versatile",
|
|
901
|
-
"llama4:109b": "meta-llama/llama-4-scout-17b-16e-instruct",
|
|
902
|
-
"llama4:400b": "meta-llama/llama-4-maverick-17b-128e-instruct",
|
|
903
|
-
"kimi-k2": "moonshotai/kimi-k2-instruct-0905",
|
|
904
|
-
"gpt-oss:120b": "openai/gpt-oss-120b",
|
|
905
|
-
"gpt-oss:20b": "openai/gpt-oss-20b",
|
|
906
|
-
"qwen3:32b": "qwen/qwen3-32b"
|
|
907
|
-
}
|
|
908
|
-
}
|
|
909
|
-
}
|
|
910
|
-
}
|
|
911
|
-
```
|
|
912
|
-
|
|
913
|
-
### Multi-Provider Setup
|
|
914
|
-
|
|
915
|
-
```json
|
|
916
|
-
{
|
|
917
|
-
"providers": {
|
|
918
|
-
"openrouter": {
|
|
919
|
-
"enabled": false,
|
|
920
|
-
"type": "OpenAiProvider",
|
|
921
|
-
"base_url": "https://openrouter.ai/api",
|
|
922
|
-
"api_key": "$OPENROUTER_API_KEY",
|
|
923
|
-
"models": {
|
|
924
|
-
"grok-4": "x-ai/grok-4",
|
|
925
|
-
"glm-4.5-air": "z-ai/glm-4.5-air",
|
|
926
|
-
"kimi-k2": "moonshotai/kimi-k2",
|
|
927
|
-
"deepseek-v3.1:671b": "deepseek/deepseek-chat",
|
|
928
|
-
"llama4:400b": "meta-llama/llama-4-maverick"
|
|
929
|
-
}
|
|
930
|
-
},
|
|
931
|
-
"anthropic": {
|
|
932
|
-
"enabled": false,
|
|
933
|
-
"type": "OpenAiProvider",
|
|
934
|
-
"base_url": "https://api.anthropic.com",
|
|
935
|
-
"api_key": "$ANTHROPIC_API_KEY",
|
|
936
|
-
"models": {
|
|
937
|
-
"claude-sonnet-4-0": "claude-sonnet-4-0"
|
|
938
|
-
}
|
|
939
|
-
},
|
|
940
|
-
"ollama": {
|
|
941
|
-
"enabled": false,
|
|
942
|
-
"type": "OllamaProvider",
|
|
943
|
-
"base_url": "http://localhost:11434",
|
|
944
|
-
"models": {},
|
|
945
|
-
"all_models": true
|
|
946
|
-
}
|
|
947
|
-
}
|
|
948
|
-
}
|
|
949
|
-
```
|
|
950
|
-
|
|
951
|
-
## Usage
|
|
952
|
-
|
|
953
|
-
usage: llms [-h] [--config FILE] [-m MODEL] [--chat REQUEST] [-s PROMPT] [--image IMAGE] [--audio AUDIO] [--file FILE]
|
|
954
|
-
[--args PARAMS] [--raw] [--list] [--check PROVIDER] [--serve PORT] [--enable PROVIDER] [--disable PROVIDER]
|
|
955
|
-
[--default MODEL] [--init] [--root PATH] [--logprefix PREFIX] [--verbose]
|
|
956
|
-
|
|
957
|
-
llms v2.0.24
|
|
958
|
-
|
|
959
|
-
options:
|
|
960
|
-
-h, --help show this help message and exit
|
|
961
|
-
--config FILE Path to config file
|
|
962
|
-
-m, --model MODEL Model to use
|
|
963
|
-
--chat REQUEST OpenAI Chat Completion Request to send
|
|
964
|
-
-s, --system PROMPT System prompt to use for chat completion
|
|
965
|
-
--image IMAGE Image input to use in chat completion
|
|
966
|
-
--audio AUDIO Audio input to use in chat completion
|
|
967
|
-
--file FILE File input to use in chat completion
|
|
968
|
-
--args PARAMS URL-encoded parameters to add to chat request (e.g. "temperature=0.7&seed=111")
|
|
969
|
-
--raw Return raw AI JSON response
|
|
970
|
-
--list Show list of enabled providers and their models (alias ls provider?)
|
|
971
|
-
--check PROVIDER Check validity of models for a provider
|
|
972
|
-
--serve PORT Port to start an OpenAI Chat compatible server on
|
|
973
|
-
--enable PROVIDER Enable a provider
|
|
974
|
-
--disable PROVIDER Disable a provider
|
|
975
|
-
--default MODEL Configure the default model to use
|
|
976
|
-
--init Create a default llms.json
|
|
977
|
-
--root PATH Change root directory for UI files
|
|
978
|
-
--logprefix PREFIX Prefix used in log messages
|
|
979
|
-
--verbose Verbose output
|
|
980
|
-
|
|
981
|
-
## Docker Deployment
|
|
982
|
-
|
|
983
|
-
### Quick Start with Docker
|
|
984
|
-
|
|
985
|
-
The easiest way to run llms-py is using Docker:
|
|
986
|
-
|
|
987
|
-
```bash
|
|
988
|
-
# Using docker-compose (recommended)
|
|
989
|
-
docker-compose up -d
|
|
990
|
-
|
|
991
|
-
# Or pull and run directly
|
|
992
|
-
docker run -p 8000:8000 \
|
|
993
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
994
|
-
ghcr.io/servicestack/llms:latest
|
|
995
|
-
```
|
|
996
|
-
|
|
997
|
-
### Docker Images
|
|
998
|
-
|
|
999
|
-
Pre-built Docker images are automatically published to GitHub Container Registry:
|
|
1000
|
-
|
|
1001
|
-
- **Latest stable**: `ghcr.io/servicestack/llms:latest`
|
|
1002
|
-
- **Specific version**: `ghcr.io/servicestack/llms:v2.0.24`
|
|
1003
|
-
- **Main branch**: `ghcr.io/servicestack/llms:main`
|
|
1004
|
-
|
|
1005
|
-
### Environment Variables
|
|
1006
|
-
|
|
1007
|
-
Pass API keys as environment variables:
|
|
1008
|
-
|
|
1009
|
-
```bash
|
|
1010
|
-
docker run -p 8000:8000 \
|
|
1011
|
-
-e OPENROUTER_API_KEY="sk-or-..." \
|
|
1012
|
-
-e GROQ_API_KEY="gsk_..." \
|
|
1013
|
-
-e GOOGLE_FREE_API_KEY="AIza..." \
|
|
1014
|
-
-e ANTHROPIC_API_KEY="sk-ant-..." \
|
|
1015
|
-
-e OPENAI_API_KEY="sk-..." \
|
|
1016
|
-
ghcr.io/servicestack/llms:latest
|
|
1017
|
-
```
|
|
1018
|
-
|
|
1019
|
-
### Using docker-compose
|
|
1020
|
-
|
|
1021
|
-
Create a `docker-compose.yml` file (or use the one in the repository):
|
|
1022
|
-
|
|
1023
|
-
```yaml
|
|
1024
|
-
version: '3.8'
|
|
1025
|
-
|
|
1026
|
-
services:
|
|
1027
|
-
llms:
|
|
1028
|
-
image: ghcr.io/servicestack/llms:latest
|
|
1029
|
-
ports:
|
|
1030
|
-
- "8000:8000"
|
|
1031
|
-
environment:
|
|
1032
|
-
- OPENROUTER_API_KEY=${OPENROUTER_API_KEY}
|
|
1033
|
-
- GROQ_API_KEY=${GROQ_API_KEY}
|
|
1034
|
-
- GOOGLE_FREE_API_KEY=${GOOGLE_FREE_API_KEY}
|
|
1035
|
-
volumes:
|
|
1036
|
-
- llms-data:/home/llms/.llms
|
|
1037
|
-
restart: unless-stopped
|
|
1038
|
-
|
|
1039
|
-
volumes:
|
|
1040
|
-
llms-data:
|
|
1041
|
-
```
|
|
1042
|
-
|
|
1043
|
-
Create a `.env` file with your API keys:
|
|
1044
|
-
|
|
1045
|
-
```bash
|
|
1046
|
-
OPENROUTER_API_KEY=sk-or-...
|
|
1047
|
-
GROQ_API_KEY=gsk_...
|
|
1048
|
-
GOOGLE_FREE_API_KEY=AIza...
|
|
1049
|
-
```
|
|
1050
|
-
|
|
1051
|
-
Start the service:
|
|
1052
|
-
|
|
1053
|
-
```bash
|
|
1054
|
-
docker-compose up -d
|
|
1055
|
-
```
|
|
1056
|
-
|
|
1057
|
-
### Building Locally
|
|
1058
|
-
|
|
1059
|
-
Build the Docker image from source:
|
|
1060
|
-
|
|
1061
|
-
```bash
|
|
1062
|
-
# Using the build script
|
|
1063
|
-
./docker-build.sh
|
|
1064
|
-
|
|
1065
|
-
# Or manually
|
|
1066
|
-
docker build -t llms-py:latest .
|
|
1067
|
-
|
|
1068
|
-
# Run your local build
|
|
1069
|
-
docker run -p 8000:8000 \
|
|
1070
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1071
|
-
llms-py:latest
|
|
1072
|
-
```
|
|
1073
|
-
|
|
1074
|
-
### Volume Mounting
|
|
1075
|
-
|
|
1076
|
-
To persist configuration and analytics data between container restarts:
|
|
1077
|
-
|
|
1078
|
-
```bash
|
|
1079
|
-
# Using a named volume (recommended)
|
|
1080
|
-
docker run -p 8000:8000 \
|
|
1081
|
-
-v llms-data:/home/llms/.llms \
|
|
1082
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1083
|
-
ghcr.io/servicestack/llms:latest
|
|
1084
|
-
|
|
1085
|
-
# Or mount a local directory
|
|
1086
|
-
docker run -p 8000:8000 \
|
|
1087
|
-
-v $(pwd)/llms-config:/home/llms/.llms \
|
|
1088
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1089
|
-
ghcr.io/servicestack/llms:latest
|
|
1090
|
-
```
|
|
1091
|
-
|
|
1092
|
-
### Custom Configuration Files
|
|
1093
|
-
|
|
1094
|
-
Customize llms-py behavior by providing your own `llms.json` and `ui.json` files:
|
|
1095
|
-
|
|
1096
|
-
**Option 1: Mount a directory with custom configs**
|
|
1097
|
-
|
|
1098
|
-
```bash
|
|
1099
|
-
# Create config directory with your custom files
|
|
1100
|
-
mkdir -p config
|
|
1101
|
-
# Add your custom llms.json and ui.json to config/
|
|
1102
|
-
|
|
1103
|
-
# Mount the directory
|
|
1104
|
-
docker run -p 8000:8000 \
|
|
1105
|
-
-v $(pwd)/config:/home/llms/.llms \
|
|
1106
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1107
|
-
ghcr.io/servicestack/llms:latest
|
|
1108
|
-
```
|
|
1109
|
-
|
|
1110
|
-
**Option 2: Mount individual config files**
|
|
1111
|
-
|
|
1112
|
-
```bash
|
|
1113
|
-
docker run -p 8000:8000 \
|
|
1114
|
-
-v $(pwd)/my-llms.json:/home/llms/.llms/llms.json:ro \
|
|
1115
|
-
-v $(pwd)/my-ui.json:/home/llms/.llms/ui.json:ro \
|
|
1116
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1117
|
-
ghcr.io/servicestack/llms:latest
|
|
1118
|
-
```
|
|
1119
|
-
|
|
1120
|
-
**With docker-compose:**
|
|
1121
|
-
|
|
1122
|
-
```yaml
|
|
1123
|
-
volumes:
|
|
1124
|
-
# Use local directory
|
|
1125
|
-
- ./config:/home/llms/.llms
|
|
1126
|
-
|
|
1127
|
-
# Or mount individual files
|
|
1128
|
-
# - ./my-llms.json:/home/llms/.llms/llms.json:ro
|
|
1129
|
-
# - ./my-ui.json:/home/llms/.llms/ui.json:ro
|
|
1130
|
-
```
|
|
1131
|
-
|
|
1132
|
-
The container will auto-create default config files on first run if they don't exist. You can customize these to:
|
|
1133
|
-
- Enable/disable specific providers
|
|
1134
|
-
- Add or remove models
|
|
1135
|
-
- Configure API endpoints
|
|
1136
|
-
- Set custom pricing
|
|
1137
|
-
- Customize chat templates
|
|
1138
|
-
- Configure UI settings
|
|
1139
|
-
|
|
1140
|
-
See [DOCKER.md](DOCKER.md) for detailed configuration examples.
|
|
1141
|
-
|
|
1142
|
-
### Custom Port
|
|
1143
|
-
|
|
1144
|
-
Change the port mapping to run on a different port:
|
|
1145
|
-
|
|
1146
|
-
```bash
|
|
1147
|
-
# Run on port 3000 instead of 8000
|
|
1148
|
-
docker run -p 3000:8000 \
|
|
1149
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1150
|
-
ghcr.io/servicestack/llms:latest
|
|
1151
|
-
```
|
|
1152
|
-
|
|
1153
|
-
### Docker CLI Usage
|
|
1154
|
-
|
|
1155
|
-
You can also use the Docker container for CLI commands:
|
|
1156
|
-
|
|
1157
|
-
```bash
|
|
1158
|
-
# Run a single query
|
|
1159
|
-
docker run --rm \
|
|
1160
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1161
|
-
ghcr.io/servicestack/llms:latest \
|
|
1162
|
-
llms "What is the capital of France?"
|
|
1163
|
-
|
|
1164
|
-
# List available models
|
|
1165
|
-
docker run --rm \
|
|
1166
|
-
-e OPENROUTER_API_KEY="your-key" \
|
|
1167
|
-
ghcr.io/servicestack/llms:latest \
|
|
1168
|
-
llms --list
|
|
1169
|
-
|
|
1170
|
-
# Check provider status
|
|
1171
|
-
docker run --rm \
|
|
1172
|
-
-e GROQ_API_KEY="your-key" \
|
|
1173
|
-
ghcr.io/servicestack/llms:latest \
|
|
1174
|
-
llms --check groq
|
|
1175
|
-
```
|
|
1176
|
-
|
|
1177
|
-
### Health Checks
|
|
1178
|
-
|
|
1179
|
-
The Docker image includes a health check that verifies the server is responding:
|
|
1180
|
-
|
|
1181
|
-
```bash
|
|
1182
|
-
# Check container health
|
|
1183
|
-
docker ps
|
|
1184
|
-
|
|
1185
|
-
# View health check logs
|
|
1186
|
-
docker inspect --format='{{json .State.Health}}' llms-server
|
|
1187
|
-
```
|
|
1188
|
-
|
|
1189
|
-
### Multi-Architecture Support
|
|
1190
|
-
|
|
1191
|
-
The Docker images support multiple architectures:
|
|
1192
|
-
- `linux/amd64` (x86_64)
|
|
1193
|
-
- `linux/arm64` (ARM64/Apple Silicon)
|
|
1194
|
-
|
|
1195
|
-
Docker will automatically pull the correct image for your platform.
|
|
1196
|
-
|
|
1197
|
-
## Troubleshooting
|
|
1198
|
-
|
|
1199
|
-
### Common Issues
|
|
1200
|
-
|
|
1201
|
-
**Config file not found**
|
|
1202
|
-
```bash
|
|
1203
|
-
# Initialize default config
|
|
1204
|
-
llms --init
|
|
1205
|
-
|
|
1206
|
-
# Or specify custom path
|
|
1207
|
-
llms --config ./my-config.json
|
|
1208
|
-
```
|
|
1209
|
-
|
|
1210
|
-
**No providers enabled**
|
|
1211
|
-
|
|
1212
|
-
```bash
|
|
1213
|
-
# Check status
|
|
1214
|
-
llms --list
|
|
1215
|
-
|
|
1216
|
-
# Enable providers
|
|
1217
|
-
llms --enable google anthropic
|
|
1218
|
-
```
|
|
1219
|
-
|
|
1220
|
-
**API key issues**
|
|
1221
|
-
```bash
|
|
1222
|
-
# Check environment variables
|
|
1223
|
-
echo $ANTHROPIC_API_KEY
|
|
1224
|
-
|
|
1225
|
-
# Enable verbose logging
|
|
1226
|
-
llms --verbose "test"
|
|
1227
|
-
```
|
|
1228
|
-
|
|
1229
|
-
**Model not found**
|
|
1230
|
-
|
|
1231
|
-
```bash
|
|
1232
|
-
# List available models
|
|
1233
|
-
llms --list
|
|
1234
|
-
|
|
1235
|
-
# Check provider configuration
|
|
1236
|
-
llms ls openrouter
|
|
1237
|
-
```
|
|
1238
|
-
|
|
1239
|
-
### Debug Mode
|
|
1240
|
-
|
|
1241
|
-
Enable verbose logging to see detailed request/response information:
|
|
1242
|
-
|
|
1243
|
-
```bash
|
|
1244
|
-
llms --verbose --logprefix "[DEBUG] " "Hello"
|
|
1245
|
-
```
|
|
1246
|
-
|
|
1247
|
-
This shows:
|
|
1248
|
-
- Enabled providers
|
|
1249
|
-
- Model routing decisions
|
|
1250
|
-
- HTTP request details
|
|
1251
|
-
- Error messages with stack traces
|
|
1252
|
-
|
|
1253
|
-
## Development
|
|
1254
|
-
|
|
1255
|
-
### Project Structure
|
|
1256
|
-
|
|
1257
|
-
- `llms/main.py` - Main script with CLI and server functionality
|
|
1258
|
-
- `llms/llms.json` - Default configuration file
|
|
1259
|
-
- `llms/ui.json` - UI configuration file
|
|
1260
|
-
- `requirements.txt` - Python dependencies, required: `aiohttp`, optional: `Pillow`
|
|
1261
|
-
|
|
1262
|
-
### Provider Classes
|
|
1263
|
-
|
|
1264
|
-
- `OpenAiProvider` - Generic OpenAI-compatible provider
|
|
1265
|
-
- `OllamaProvider` - Ollama-specific provider with model auto-discovery
|
|
1266
|
-
- `GoogleProvider` - Google Gemini with native API format
|
|
1267
|
-
- `GoogleOpenAiProvider` - Google Gemini via OpenAI-compatible endpoint
|
|
1268
|
-
|
|
1269
|
-
### Adding New Providers
|
|
1270
|
-
|
|
1271
|
-
1. Create a provider class inheriting from `OpenAiProvider`
|
|
1272
|
-
2. Implement provider-specific authentication and formatting
|
|
1273
|
-
3. Add provider configuration to `llms.json`
|
|
1274
|
-
4. Update initialization logic in `init_llms()`
|
|
1275
|
-
|
|
1276
|
-
## Contributing
|
|
1277
|
-
|
|
1278
|
-
Contributions are welcome! Please submit a PR to add support for any missing OpenAI-compatible providers.
|