hud-python 0.4.52__py3-none-any.whl → 0.4.53__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of hud-python might be problematic. Click here for more details.
- hud/agents/base.py +9 -2
- hud/agents/openai_chat_generic.py +15 -3
- hud/agents/tests/test_base.py +15 -0
- hud/agents/tests/test_base_runtime.py +164 -0
- hud/cli/__init__.py +6 -3
- hud/cli/build.py +35 -27
- hud/cli/dev.py +11 -29
- hud/cli/eval.py +61 -61
- hud/cli/tests/test_analyze_module.py +120 -0
- hud/cli/tests/test_build.py +24 -2
- hud/cli/tests/test_build_failure.py +41 -0
- hud/cli/tests/test_build_module.py +50 -0
- hud/cli/tests/test_cli_more_wrappers.py +30 -0
- hud/cli/tests/test_cli_root.py +134 -0
- hud/cli/tests/test_mcp_server.py +8 -7
- hud/cli/tests/test_push_happy.py +74 -0
- hud/cli/tests/test_push_wrapper.py +23 -0
- hud/cli/utils/docker.py +120 -1
- hud/cli/utils/runner.py +1 -1
- hud/cli/utils/tests/__init__.py +0 -0
- hud/cli/utils/tests/test_config.py +58 -0
- hud/cli/utils/tests/test_docker.py +93 -0
- hud/cli/utils/tests/test_docker_hints.py +71 -0
- hud/cli/utils/tests/test_env_check.py +74 -0
- hud/cli/utils/tests/test_environment.py +42 -0
- hud/cli/utils/tests/test_interactive_module.py +60 -0
- hud/cli/utils/tests/test_local_runner.py +50 -0
- hud/cli/utils/tests/test_logging_utils.py +23 -0
- hud/cli/utils/tests/test_metadata.py +49 -0
- hud/cli/utils/tests/test_package_runner.py +35 -0
- hud/cli/utils/tests/test_registry_utils.py +49 -0
- hud/cli/utils/tests/test_remote_runner.py +25 -0
- hud/cli/utils/tests/test_runner_modules.py +52 -0
- hud/cli/utils/tests/test_source_hash.py +36 -0
- hud/cli/utils/tests/test_tasks.py +80 -0
- hud/cli/utils/version_check.py +2 -2
- hud/datasets/tests/__init__.py +0 -0
- hud/datasets/tests/test_runner.py +106 -0
- hud/datasets/tests/test_utils.py +228 -0
- hud/otel/tests/__init__.py +0 -1
- hud/otel/tests/test_instrumentation.py +207 -0
- hud/server/tests/test_server_extra.py +2 -0
- hud/shared/exceptions.py +35 -4
- hud/shared/hints.py +25 -0
- hud/shared/requests.py +15 -3
- hud/shared/tests/test_exceptions.py +31 -23
- hud/shared/tests/test_hints.py +167 -0
- hud/telemetry/tests/test_async_context.py +242 -0
- hud/telemetry/tests/test_instrument.py +414 -0
- hud/telemetry/tests/test_job.py +609 -0
- hud/telemetry/tests/test_trace.py +183 -5
- hud/tools/computer/settings.py +2 -2
- hud/tools/tests/test_submit.py +85 -0
- hud/tools/tests/test_types.py +193 -0
- hud/types.py +7 -1
- hud/utils/agent_factories.py +1 -3
- hud/utils/mcp.py +1 -1
- hud/utils/tests/test_agent_factories.py +60 -0
- hud/utils/tests/test_mcp.py +4 -6
- hud/utils/tests/test_pretty_errors.py +186 -0
- hud/utils/tests/test_tasks.py +187 -0
- hud/utils/tests/test_tool_shorthand.py +154 -0
- hud/utils/tests/test_version.py +1 -1
- hud/version.py +1 -1
- {hud_python-0.4.52.dist-info → hud_python-0.4.53.dist-info}/METADATA +47 -48
- {hud_python-0.4.52.dist-info → hud_python-0.4.53.dist-info}/RECORD +69 -31
- {hud_python-0.4.52.dist-info → hud_python-0.4.53.dist-info}/WHEEL +0 -0
- {hud_python-0.4.52.dist-info → hud_python-0.4.53.dist-info}/entry_points.txt +0 -0
- {hud_python-0.4.52.dist-info → hud_python-0.4.53.dist-info}/licenses/LICENSE +0 -0
|
@@ -0,0 +1,186 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
import sys
|
|
4
|
+
from unittest.mock import MagicMock, patch
|
|
5
|
+
|
|
6
|
+
from hud.utils.pretty_errors import (
|
|
7
|
+
_async_exception_handler,
|
|
8
|
+
_render_and_fallback,
|
|
9
|
+
install_pretty_errors,
|
|
10
|
+
)
|
|
11
|
+
|
|
12
|
+
|
|
13
|
+
def test_render_and_fallback_hud_exception():
|
|
14
|
+
"""Test _render_and_fallback with HudException."""
|
|
15
|
+
from hud.shared.exceptions import HudException
|
|
16
|
+
|
|
17
|
+
exc = HudException("Test error")
|
|
18
|
+
|
|
19
|
+
with (
|
|
20
|
+
patch("sys.__excepthook__") as mock_excepthook,
|
|
21
|
+
patch("hud.utils.pretty_errors.hud_console") as mock_console,
|
|
22
|
+
patch("sys.stderr.flush"),
|
|
23
|
+
):
|
|
24
|
+
_render_and_fallback(HudException, exc, None)
|
|
25
|
+
|
|
26
|
+
mock_excepthook.assert_called_once()
|
|
27
|
+
mock_console.render_exception.assert_called_once_with(exc)
|
|
28
|
+
|
|
29
|
+
|
|
30
|
+
def test_render_and_fallback_non_hud_exception():
|
|
31
|
+
"""Test _render_and_fallback with non-HudException."""
|
|
32
|
+
exc = ValueError("Test error")
|
|
33
|
+
|
|
34
|
+
with (
|
|
35
|
+
patch("sys.__excepthook__") as mock_excepthook,
|
|
36
|
+
patch("hud.utils.pretty_errors.hud_console") as mock_console,
|
|
37
|
+
):
|
|
38
|
+
_render_and_fallback(ValueError, exc, None)
|
|
39
|
+
|
|
40
|
+
mock_excepthook.assert_called_once()
|
|
41
|
+
# Should not render for non-HudException
|
|
42
|
+
mock_console.render_exception.assert_not_called()
|
|
43
|
+
|
|
44
|
+
|
|
45
|
+
def test_render_and_fallback_rendering_error():
|
|
46
|
+
"""Test _render_and_fallback handles rendering errors gracefully."""
|
|
47
|
+
from hud.shared.exceptions import HudException
|
|
48
|
+
|
|
49
|
+
exc = HudException("Test error")
|
|
50
|
+
|
|
51
|
+
with (
|
|
52
|
+
patch("sys.__excepthook__") as mock_excepthook,
|
|
53
|
+
patch("hud.utils.pretty_errors.hud_console") as mock_console,
|
|
54
|
+
):
|
|
55
|
+
mock_console.render_exception.side_effect = Exception("Render failed")
|
|
56
|
+
|
|
57
|
+
# Should not raise
|
|
58
|
+
_render_and_fallback(HudException, exc, None)
|
|
59
|
+
|
|
60
|
+
mock_excepthook.assert_called_once()
|
|
61
|
+
|
|
62
|
+
|
|
63
|
+
def test_async_exception_handler_with_exception():
|
|
64
|
+
"""Test _async_exception_handler with exception in context."""
|
|
65
|
+
mock_loop = MagicMock()
|
|
66
|
+
context = {"exception": ValueError("Test error")}
|
|
67
|
+
|
|
68
|
+
with patch("hud.utils.pretty_errors.hud_console") as mock_console:
|
|
69
|
+
_async_exception_handler(mock_loop, context)
|
|
70
|
+
|
|
71
|
+
mock_console.render_exception.assert_called_once()
|
|
72
|
+
mock_loop.default_exception_handler.assert_called_once_with(context)
|
|
73
|
+
|
|
74
|
+
|
|
75
|
+
def test_async_exception_handler_with_message():
|
|
76
|
+
"""Test _async_exception_handler with message only."""
|
|
77
|
+
mock_loop = MagicMock()
|
|
78
|
+
context = {"message": "Error message"}
|
|
79
|
+
|
|
80
|
+
with patch("hud.utils.pretty_errors.hud_console") as mock_console:
|
|
81
|
+
_async_exception_handler(mock_loop, context)
|
|
82
|
+
|
|
83
|
+
mock_console.error.assert_called_once_with("Error message")
|
|
84
|
+
mock_console.render_support_hint.assert_called_once()
|
|
85
|
+
mock_loop.default_exception_handler.assert_called_once()
|
|
86
|
+
|
|
87
|
+
|
|
88
|
+
def test_async_exception_handler_rendering_error():
|
|
89
|
+
"""Test _async_exception_handler handles rendering errors."""
|
|
90
|
+
mock_loop = MagicMock()
|
|
91
|
+
context = {"exception": ValueError("Test")}
|
|
92
|
+
|
|
93
|
+
with patch("hud.utils.pretty_errors.hud_console") as mock_console:
|
|
94
|
+
mock_console.render_exception.side_effect = Exception("Render failed")
|
|
95
|
+
|
|
96
|
+
# Should not raise, should call default handler
|
|
97
|
+
_async_exception_handler(mock_loop, context)
|
|
98
|
+
|
|
99
|
+
mock_loop.default_exception_handler.assert_called_once()
|
|
100
|
+
|
|
101
|
+
|
|
102
|
+
def test_install_pretty_errors_with_running_loop():
|
|
103
|
+
"""Test install_pretty_errors with a running event loop."""
|
|
104
|
+
mock_loop = MagicMock()
|
|
105
|
+
|
|
106
|
+
with patch("asyncio.get_running_loop", return_value=mock_loop):
|
|
107
|
+
install_pretty_errors()
|
|
108
|
+
|
|
109
|
+
assert sys.excepthook == _render_and_fallback
|
|
110
|
+
mock_loop.set_exception_handler.assert_called_once_with(_async_exception_handler)
|
|
111
|
+
|
|
112
|
+
|
|
113
|
+
def test_install_pretty_errors_no_running_loop():
|
|
114
|
+
"""Test install_pretty_errors without a running loop."""
|
|
115
|
+
with (
|
|
116
|
+
patch("asyncio.get_running_loop", side_effect=RuntimeError("No running loop")),
|
|
117
|
+
patch("asyncio.new_event_loop") as mock_new_loop,
|
|
118
|
+
):
|
|
119
|
+
mock_loop = MagicMock()
|
|
120
|
+
mock_new_loop.return_value = mock_loop
|
|
121
|
+
|
|
122
|
+
install_pretty_errors()
|
|
123
|
+
|
|
124
|
+
assert sys.excepthook == _render_and_fallback
|
|
125
|
+
mock_loop.set_exception_handler.assert_called_once()
|
|
126
|
+
|
|
127
|
+
|
|
128
|
+
def test_install_pretty_errors_new_loop_fails():
|
|
129
|
+
"""Test install_pretty_errors when creating new loop fails."""
|
|
130
|
+
with (
|
|
131
|
+
patch("asyncio.get_running_loop", side_effect=RuntimeError("No running loop")),
|
|
132
|
+
patch("asyncio.new_event_loop", side_effect=Exception("Can't create loop")),
|
|
133
|
+
):
|
|
134
|
+
# Should not raise
|
|
135
|
+
install_pretty_errors()
|
|
136
|
+
|
|
137
|
+
assert sys.excepthook == _render_and_fallback
|
|
138
|
+
|
|
139
|
+
|
|
140
|
+
def test_install_pretty_errors_set_handler_fails():
|
|
141
|
+
"""Test install_pretty_errors when set_exception_handler fails."""
|
|
142
|
+
mock_loop = MagicMock()
|
|
143
|
+
mock_loop.set_exception_handler.side_effect = Exception("Can't set handler")
|
|
144
|
+
|
|
145
|
+
with patch("asyncio.get_running_loop", return_value=mock_loop):
|
|
146
|
+
# Should not raise
|
|
147
|
+
install_pretty_errors()
|
|
148
|
+
|
|
149
|
+
assert sys.excepthook == _render_and_fallback
|
|
150
|
+
|
|
151
|
+
|
|
152
|
+
def test_async_exception_handler_no_exception_or_message():
|
|
153
|
+
"""Test _async_exception_handler with empty context."""
|
|
154
|
+
mock_loop = MagicMock()
|
|
155
|
+
context = {}
|
|
156
|
+
|
|
157
|
+
with patch("hud.utils.pretty_errors.hud_console") as mock_console:
|
|
158
|
+
_async_exception_handler(mock_loop, context)
|
|
159
|
+
|
|
160
|
+
mock_console.render_exception.assert_not_called()
|
|
161
|
+
mock_console.error.assert_not_called()
|
|
162
|
+
mock_loop.default_exception_handler.assert_called_once()
|
|
163
|
+
|
|
164
|
+
|
|
165
|
+
def test_render_and_fallback_with_traceback():
|
|
166
|
+
"""Test _render_and_fallback includes traceback."""
|
|
167
|
+
from hud.shared.exceptions import HudException
|
|
168
|
+
|
|
169
|
+
exc = HudException("Test error")
|
|
170
|
+
|
|
171
|
+
# Create a fake traceback
|
|
172
|
+
try:
|
|
173
|
+
raise exc
|
|
174
|
+
except HudException as e:
|
|
175
|
+
tb = e.__traceback__
|
|
176
|
+
|
|
177
|
+
with (
|
|
178
|
+
patch("sys.__excepthook__") as mock_excepthook,
|
|
179
|
+
patch("hud.utils.pretty_errors.hud_console"),
|
|
180
|
+
patch("sys.stderr.flush"),
|
|
181
|
+
):
|
|
182
|
+
_render_and_fallback(HudException, exc, tb)
|
|
183
|
+
|
|
184
|
+
# Should call excepthook with traceback
|
|
185
|
+
call_args = mock_excepthook.call_args[0]
|
|
186
|
+
assert call_args[2] == tb
|
|
@@ -0,0 +1,187 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
import json
|
|
4
|
+
import tempfile
|
|
5
|
+
from pathlib import Path
|
|
6
|
+
|
|
7
|
+
import pytest
|
|
8
|
+
|
|
9
|
+
from hud.types import Task
|
|
10
|
+
from hud.utils.tasks import load_tasks
|
|
11
|
+
|
|
12
|
+
|
|
13
|
+
def test_load_tasks_from_list():
|
|
14
|
+
"""Test loading tasks from a list of dictionaries."""
|
|
15
|
+
task_dicts = [
|
|
16
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
17
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
18
|
+
]
|
|
19
|
+
|
|
20
|
+
tasks = load_tasks(task_dicts)
|
|
21
|
+
|
|
22
|
+
assert len(tasks) == 2
|
|
23
|
+
assert all(isinstance(t, Task) for t in tasks)
|
|
24
|
+
assert tasks[0].prompt == "Test task 1" # type: ignore
|
|
25
|
+
assert tasks[1].prompt == "Test task 2" # type: ignore
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def test_load_tasks_from_list_raw():
|
|
29
|
+
"""Test loading tasks from a list in raw mode."""
|
|
30
|
+
task_dicts = [
|
|
31
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
32
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
33
|
+
]
|
|
34
|
+
|
|
35
|
+
tasks = load_tasks(task_dicts, raw=True)
|
|
36
|
+
|
|
37
|
+
assert len(tasks) == 2
|
|
38
|
+
assert all(isinstance(t, dict) for t in tasks)
|
|
39
|
+
assert tasks[0]["prompt"] == "Test task 1" # type: ignore
|
|
40
|
+
|
|
41
|
+
|
|
42
|
+
def test_load_tasks_from_json_file():
|
|
43
|
+
"""Test loading tasks from a JSON file."""
|
|
44
|
+
task_dicts = [
|
|
45
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
46
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
47
|
+
]
|
|
48
|
+
|
|
49
|
+
with tempfile.NamedTemporaryFile(mode="w", suffix=".json", delete=False, encoding="utf-8") as f:
|
|
50
|
+
json.dump(task_dicts, f)
|
|
51
|
+
temp_path = f.name
|
|
52
|
+
|
|
53
|
+
try:
|
|
54
|
+
tasks = load_tasks(temp_path)
|
|
55
|
+
|
|
56
|
+
assert len(tasks) == 2
|
|
57
|
+
assert all(isinstance(t, Task) for t in tasks)
|
|
58
|
+
assert tasks[0].prompt == "Test task 1" # type: ignore
|
|
59
|
+
finally:
|
|
60
|
+
Path(temp_path).unlink()
|
|
61
|
+
|
|
62
|
+
|
|
63
|
+
def test_load_tasks_from_json_file_raw():
|
|
64
|
+
"""Test loading tasks from a JSON file in raw mode."""
|
|
65
|
+
task_dicts = [
|
|
66
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
67
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
68
|
+
]
|
|
69
|
+
|
|
70
|
+
with tempfile.NamedTemporaryFile(mode="w", suffix=".json", delete=False, encoding="utf-8") as f:
|
|
71
|
+
json.dump(task_dicts, f)
|
|
72
|
+
temp_path = f.name
|
|
73
|
+
|
|
74
|
+
try:
|
|
75
|
+
tasks = load_tasks(temp_path, raw=True)
|
|
76
|
+
|
|
77
|
+
assert len(tasks) == 2
|
|
78
|
+
assert all(isinstance(t, dict) for t in tasks)
|
|
79
|
+
finally:
|
|
80
|
+
Path(temp_path).unlink()
|
|
81
|
+
|
|
82
|
+
|
|
83
|
+
def test_load_tasks_from_jsonl_file():
|
|
84
|
+
"""Test loading tasks from a JSONL file."""
|
|
85
|
+
task_dicts = [
|
|
86
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
87
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
88
|
+
]
|
|
89
|
+
|
|
90
|
+
with tempfile.NamedTemporaryFile(
|
|
91
|
+
mode="w", suffix=".jsonl", delete=False, encoding="utf-8"
|
|
92
|
+
) as f:
|
|
93
|
+
for task_dict in task_dicts:
|
|
94
|
+
f.write(json.dumps(task_dict) + "\n")
|
|
95
|
+
temp_path = f.name
|
|
96
|
+
|
|
97
|
+
try:
|
|
98
|
+
tasks = load_tasks(temp_path)
|
|
99
|
+
|
|
100
|
+
assert len(tasks) == 2
|
|
101
|
+
assert all(isinstance(t, Task) for t in tasks)
|
|
102
|
+
assert tasks[0].prompt == "Test task 1" # type: ignore
|
|
103
|
+
finally:
|
|
104
|
+
Path(temp_path).unlink()
|
|
105
|
+
|
|
106
|
+
|
|
107
|
+
def test_load_tasks_from_jsonl_file_with_empty_lines():
|
|
108
|
+
"""Test loading tasks from a JSONL file with empty lines."""
|
|
109
|
+
task_dicts = [
|
|
110
|
+
{"id": "1", "prompt": "Test task 1", "mcp_config": {}},
|
|
111
|
+
{"id": "2", "prompt": "Test task 2", "mcp_config": {}},
|
|
112
|
+
]
|
|
113
|
+
|
|
114
|
+
with tempfile.NamedTemporaryFile(
|
|
115
|
+
mode="w", suffix=".jsonl", delete=False, encoding="utf-8"
|
|
116
|
+
) as f:
|
|
117
|
+
f.write(json.dumps(task_dicts[0]) + "\n")
|
|
118
|
+
f.write("\n") # Empty line
|
|
119
|
+
f.write(json.dumps(task_dicts[1]) + "\n")
|
|
120
|
+
temp_path = f.name
|
|
121
|
+
|
|
122
|
+
try:
|
|
123
|
+
tasks = load_tasks(temp_path)
|
|
124
|
+
|
|
125
|
+
assert len(tasks) == 2
|
|
126
|
+
assert all(isinstance(t, Task) for t in tasks)
|
|
127
|
+
finally:
|
|
128
|
+
Path(temp_path).unlink()
|
|
129
|
+
|
|
130
|
+
|
|
131
|
+
def test_load_tasks_from_jsonl_file_with_list():
|
|
132
|
+
"""Test loading tasks from a JSONL file where a line contains a list."""
|
|
133
|
+
task_dict = {"id": "1", "prompt": "Test task 1", "mcp_config": {}}
|
|
134
|
+
|
|
135
|
+
with tempfile.NamedTemporaryFile(
|
|
136
|
+
mode="w", suffix=".jsonl", delete=False, encoding="utf-8"
|
|
137
|
+
) as f:
|
|
138
|
+
f.write(json.dumps([task_dict, task_dict]) + "\n")
|
|
139
|
+
temp_path = f.name
|
|
140
|
+
|
|
141
|
+
try:
|
|
142
|
+
tasks = load_tasks(temp_path)
|
|
143
|
+
|
|
144
|
+
assert len(tasks) == 2
|
|
145
|
+
assert all(isinstance(t, Task) for t in tasks)
|
|
146
|
+
finally:
|
|
147
|
+
Path(temp_path).unlink()
|
|
148
|
+
|
|
149
|
+
|
|
150
|
+
def test_load_tasks_json_not_array_error():
|
|
151
|
+
"""Test that loading from JSON file with non-array raises error."""
|
|
152
|
+
with tempfile.NamedTemporaryFile(mode="w", suffix=".json", delete=False, encoding="utf-8") as f:
|
|
153
|
+
json.dump({"not": "an array"}, f)
|
|
154
|
+
temp_path = f.name
|
|
155
|
+
|
|
156
|
+
try:
|
|
157
|
+
with pytest.raises(ValueError, match="JSON file must contain an array"):
|
|
158
|
+
load_tasks(temp_path)
|
|
159
|
+
finally:
|
|
160
|
+
Path(temp_path).unlink()
|
|
161
|
+
|
|
162
|
+
|
|
163
|
+
def test_load_tasks_invalid_jsonl_format():
|
|
164
|
+
"""Test that loading from JSONL with invalid format raises error."""
|
|
165
|
+
with tempfile.NamedTemporaryFile(
|
|
166
|
+
mode="w", suffix=".jsonl", delete=False, encoding="utf-8"
|
|
167
|
+
) as f:
|
|
168
|
+
f.write(json.dumps("invalid") + "\n")
|
|
169
|
+
temp_path = f.name
|
|
170
|
+
|
|
171
|
+
try:
|
|
172
|
+
with pytest.raises(ValueError, match="Invalid JSONL format"):
|
|
173
|
+
load_tasks(temp_path)
|
|
174
|
+
finally:
|
|
175
|
+
Path(temp_path).unlink()
|
|
176
|
+
|
|
177
|
+
|
|
178
|
+
def test_load_tasks_invalid_input_type():
|
|
179
|
+
"""Test that invalid input type raises TypeError."""
|
|
180
|
+
with pytest.raises(TypeError, match="tasks_input must be str or list"):
|
|
181
|
+
load_tasks(123) # type: ignore
|
|
182
|
+
|
|
183
|
+
|
|
184
|
+
def test_load_tasks_nonexistent_file():
|
|
185
|
+
"""Test that loading from nonexistent file raises error."""
|
|
186
|
+
with pytest.raises(ValueError, match="neither a file path nor a HuggingFace dataset"):
|
|
187
|
+
load_tasks("nonexistent_file_without_slash")
|
|
@@ -0,0 +1,154 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
from hud.utils.tool_shorthand import (
|
|
4
|
+
_is_call_like,
|
|
5
|
+
_to_call_dict,
|
|
6
|
+
normalize_to_tool_call_dict,
|
|
7
|
+
)
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
def test_is_call_like_with_name_and_arguments():
|
|
11
|
+
"""Test _is_call_like with name and arguments keys."""
|
|
12
|
+
obj = {"name": "test_tool", "arguments": {"key": "value"}}
|
|
13
|
+
assert _is_call_like(obj) is True
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
def test_is_call_like_with_single_key_dict_value():
|
|
17
|
+
"""Test _is_call_like with single key dict containing dict value."""
|
|
18
|
+
obj = {"tool": {"name": "test"}}
|
|
19
|
+
assert _is_call_like(obj) is True
|
|
20
|
+
|
|
21
|
+
|
|
22
|
+
def test_is_call_like_with_nested_single_key():
|
|
23
|
+
"""Test _is_call_like with nested single key dict."""
|
|
24
|
+
obj = {"tool": {"inner": {"key": "value"}}}
|
|
25
|
+
assert _is_call_like(obj) is True
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def test_is_call_like_not_dict():
|
|
29
|
+
"""Test _is_call_like returns False for non-dict."""
|
|
30
|
+
assert _is_call_like("string") is False
|
|
31
|
+
assert _is_call_like(123) is False
|
|
32
|
+
assert _is_call_like(None) is False
|
|
33
|
+
assert _is_call_like([]) is False
|
|
34
|
+
|
|
35
|
+
|
|
36
|
+
def test_is_call_like_empty_dict():
|
|
37
|
+
"""Test _is_call_like returns False for empty dict."""
|
|
38
|
+
assert _is_call_like({}) is False
|
|
39
|
+
|
|
40
|
+
|
|
41
|
+
def test_is_call_like_multi_key_dict():
|
|
42
|
+
"""Test _is_call_like returns False for multi-key dict without name/arguments."""
|
|
43
|
+
obj = {"key1": "value1", "key2": "value2"}
|
|
44
|
+
assert _is_call_like(obj) is False
|
|
45
|
+
|
|
46
|
+
|
|
47
|
+
def test_to_call_dict_with_name_arguments():
|
|
48
|
+
"""Test _to_call_dict preserves name and arguments."""
|
|
49
|
+
obj = {"name": "test_tool", "arguments": {"param": "value"}}
|
|
50
|
+
result = _to_call_dict(obj)
|
|
51
|
+
assert result == {"name": "test_tool", "arguments": {"param": "value"}}
|
|
52
|
+
|
|
53
|
+
|
|
54
|
+
def test_to_call_dict_with_nested_call():
|
|
55
|
+
"""Test _to_call_dict with nested call-like arguments."""
|
|
56
|
+
obj = {"name": "outer", "arguments": {"name": "inner", "arguments": {"x": 1}}}
|
|
57
|
+
result = _to_call_dict(obj)
|
|
58
|
+
assert result == {"name": "outer", "arguments": {"name": "inner", "arguments": {"x": 1}}}
|
|
59
|
+
|
|
60
|
+
|
|
61
|
+
def test_to_call_dict_shorthand_single_key():
|
|
62
|
+
"""Test _to_call_dict converts shorthand single-key dict."""
|
|
63
|
+
obj = {"tool_name": {"name": "inner", "arguments": {}}}
|
|
64
|
+
result = _to_call_dict(obj)
|
|
65
|
+
assert result == {"name": "tool_name", "arguments": {"name": "inner", "arguments": {}}}
|
|
66
|
+
|
|
67
|
+
|
|
68
|
+
def test_to_call_dict_non_call_arguments():
|
|
69
|
+
"""Test _to_call_dict with non-call-like arguments."""
|
|
70
|
+
obj = {"name": "test", "arguments": {"simple": "value"}}
|
|
71
|
+
result = _to_call_dict(obj)
|
|
72
|
+
assert result == {"name": "test", "arguments": {"simple": "value"}}
|
|
73
|
+
|
|
74
|
+
|
|
75
|
+
def test_to_call_dict_non_dict():
|
|
76
|
+
"""Test _to_call_dict returns non-dict unchanged."""
|
|
77
|
+
assert _to_call_dict("string") == "string"
|
|
78
|
+
assert _to_call_dict(123) == 123
|
|
79
|
+
assert _to_call_dict(None) is None
|
|
80
|
+
|
|
81
|
+
|
|
82
|
+
def test_to_call_dict_single_key_non_call():
|
|
83
|
+
"""Test _to_call_dict with single key but non-call value."""
|
|
84
|
+
obj = {"key": "simple_value"}
|
|
85
|
+
result = _to_call_dict(obj)
|
|
86
|
+
assert result == {"key": "simple_value"}
|
|
87
|
+
|
|
88
|
+
|
|
89
|
+
def test_normalize_to_tool_call_dict_none():
|
|
90
|
+
"""Test normalize_to_tool_call_dict with None."""
|
|
91
|
+
assert normalize_to_tool_call_dict(None) is None
|
|
92
|
+
|
|
93
|
+
|
|
94
|
+
def test_normalize_to_tool_call_dict_simple_dict():
|
|
95
|
+
"""Test normalize_to_tool_call_dict with simple dict."""
|
|
96
|
+
obj = {"name": "tool", "arguments": {"x": 1}}
|
|
97
|
+
result = normalize_to_tool_call_dict(obj)
|
|
98
|
+
assert result == {"name": "tool", "arguments": {"x": 1}}
|
|
99
|
+
|
|
100
|
+
|
|
101
|
+
def test_normalize_to_tool_call_dict_shorthand():
|
|
102
|
+
"""Test normalize_to_tool_call_dict with shorthand notation."""
|
|
103
|
+
obj = {"tool_name": {"name": "inner", "arguments": {}}}
|
|
104
|
+
result = normalize_to_tool_call_dict(obj)
|
|
105
|
+
assert result == {"name": "tool_name", "arguments": {"name": "inner", "arguments": {}}}
|
|
106
|
+
|
|
107
|
+
|
|
108
|
+
def test_normalize_to_tool_call_dict_list():
|
|
109
|
+
"""Test normalize_to_tool_call_dict with list of dicts."""
|
|
110
|
+
obj = [
|
|
111
|
+
{"name": "tool1", "arguments": {"a": 1}},
|
|
112
|
+
{"name": "tool2", "arguments": {"b": 2}},
|
|
113
|
+
]
|
|
114
|
+
result = normalize_to_tool_call_dict(obj)
|
|
115
|
+
assert len(result) == 2
|
|
116
|
+
assert result[0] == {"name": "tool1", "arguments": {"a": 1}}
|
|
117
|
+
assert result[1] == {"name": "tool2", "arguments": {"b": 2}}
|
|
118
|
+
|
|
119
|
+
|
|
120
|
+
def test_normalize_to_tool_call_dict_list_shorthand():
|
|
121
|
+
"""Test normalize_to_tool_call_dict with list of shorthand dicts."""
|
|
122
|
+
obj = [
|
|
123
|
+
{"tool1": {"name": "inner1", "arguments": {}}},
|
|
124
|
+
{"tool2": {"name": "inner2", "arguments": {}}},
|
|
125
|
+
]
|
|
126
|
+
result = normalize_to_tool_call_dict(obj)
|
|
127
|
+
assert len(result) == 2
|
|
128
|
+
assert result[0]["name"] == "tool1"
|
|
129
|
+
assert result[1]["name"] == "tool2"
|
|
130
|
+
|
|
131
|
+
|
|
132
|
+
def test_normalize_to_tool_call_dict_non_dict_non_list():
|
|
133
|
+
"""Test normalize_to_tool_call_dict with non-dict, non-list value."""
|
|
134
|
+
assert normalize_to_tool_call_dict("string") == "string"
|
|
135
|
+
assert normalize_to_tool_call_dict(123) == 123
|
|
136
|
+
|
|
137
|
+
|
|
138
|
+
def test_normalize_to_tool_call_dict_empty_list():
|
|
139
|
+
"""Test normalize_to_tool_call_dict with empty list."""
|
|
140
|
+
assert normalize_to_tool_call_dict([]) == []
|
|
141
|
+
|
|
142
|
+
|
|
143
|
+
def test_normalize_to_tool_call_dict_complex_nested():
|
|
144
|
+
"""Test normalize_to_tool_call_dict with complex nested structure."""
|
|
145
|
+
obj = {
|
|
146
|
+
"outer_tool": {
|
|
147
|
+
"name": "middle_tool",
|
|
148
|
+
"arguments": {"name": "inner_tool", "arguments": {"x": 1}},
|
|
149
|
+
}
|
|
150
|
+
}
|
|
151
|
+
result = normalize_to_tool_call_dict(obj)
|
|
152
|
+
assert result["name"] == "outer_tool"
|
|
153
|
+
assert result["arguments"]["name"] == "middle_tool"
|
|
154
|
+
assert result["arguments"]["arguments"]["name"] == "inner_tool"
|
hud/utils/tests/test_version.py
CHANGED
hud/version.py
CHANGED
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: hud-python
|
|
3
|
-
Version: 0.4.
|
|
3
|
+
Version: 0.4.53
|
|
4
4
|
Summary: SDK for the HUD platform.
|
|
5
5
|
Project-URL: Homepage, https://github.com/hud-evals/hud-python
|
|
6
6
|
Project-URL: Bug Tracker, https://github.com/hud-evals/hud-python/issues
|
|
@@ -160,12 +160,12 @@ OSS RL environment + evals toolkit. Wrap software as environments, run benchmark
|
|
|
160
160
|
|
|
161
161
|
## Highlights
|
|
162
162
|
|
|
163
|
-
- 🎓 **[One-click RL](https://hud.so/models)** – Run `hud rl` to get a trained model on any environment.
|
|
164
163
|
- 🚀 **[MCP environment skeleton](https://docs.hud.so/core-concepts/mcp-protocol)** – any agent can call any environment.
|
|
165
164
|
- ⚡️ **[Live telemetry](https://hud.so)** – inspect every tool call, observation, and reward in real time.
|
|
166
165
|
- 🗂️ **[Public benchmarks](https://hud.so/leaderboards)** – OSWorld-Verified, SheetBench-50, and more.
|
|
167
166
|
- 🌐 **[Cloud browsers](environments/remote_browser/)** – AnchorBrowser, Steel, BrowserBase integrations for browser automation.
|
|
168
167
|
- 🛠️ **[Hot-reload dev loop](environments/README.md#phase-5-hot-reload-development-with-cursor-agent)** – `hud dev` for iterating on environments without rebuilds.
|
|
168
|
+
- 🎓 **[One-click RL](https://hud.so/models)** – Run `hud rl` to get a trained model on any environment.
|
|
169
169
|
|
|
170
170
|
> We welcome contributors and feature requests – open an issue or hop on a call to discuss improvements!
|
|
171
171
|
|
|
@@ -186,29 +186,6 @@ uv tool install hud-python
|
|
|
186
186
|
Before starting, get your HUD_API_KEY at [hud.so](https://hud.so).
|
|
187
187
|
|
|
188
188
|
|
|
189
|
-
## Quickstart: Training
|
|
190
|
-
|
|
191
|
-
RL using GRPO a Qwen2.5-VL model on any hud dataset:
|
|
192
|
-
|
|
193
|
-
```bash
|
|
194
|
-
hud get hud-evals/basic-2048 # from HF
|
|
195
|
-
hud rl basic-2048.json
|
|
196
|
-
```
|
|
197
|
-
|
|
198
|
-
> See [agent training docs](https://docs.hud.so/train-agents/quickstart)
|
|
199
|
-
|
|
200
|
-
Or make your own environment and dataset:
|
|
201
|
-
|
|
202
|
-
```bash
|
|
203
|
-
hud init my-env && cd my-env
|
|
204
|
-
hud dev --interactive
|
|
205
|
-
# When ready to run:
|
|
206
|
-
hud rl
|
|
207
|
-
```
|
|
208
|
-
|
|
209
|
-
> See [environment design docs](https://docs.hud.so/build-environments)
|
|
210
|
-
|
|
211
|
-
|
|
212
189
|
## Quickstart: Evals
|
|
213
190
|
|
|
214
191
|
For a tutorial that explains the agent and evaluation design, run:
|
|
@@ -265,38 +242,27 @@ The above example let's the agent play 2048 ([See replay](https://hud.so/trace/6
|
|
|
265
242
|
|
|
266
243
|

|
|
267
244
|
|
|
268
|
-
##
|
|
269
|
-
|
|
270
|
-
This is a Qwen‑2.5‑VL‑3B agent training a policy on the 2048-basic browser environment:
|
|
271
|
-
|
|
272
|
-
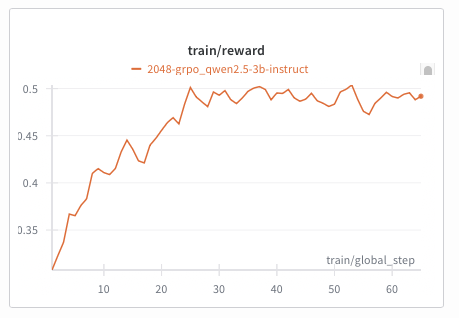
|
|
245
|
+
## Quickstart: Training
|
|
273
246
|
|
|
274
|
-
|
|
247
|
+
RL using GRPO a Qwen2.5-VL model on any hud dataset:
|
|
275
248
|
|
|
276
249
|
```bash
|
|
277
|
-
#
|
|
278
|
-
uv tool install hud-python
|
|
279
|
-
|
|
280
|
-
# Option A: Run directly from a HuggingFace dataset
|
|
281
|
-
hud rl hud-evals/basic-2048
|
|
282
|
-
|
|
283
|
-
# Option B: Download first, modify, then train
|
|
284
|
-
hud get hud-evals/basic-2048
|
|
250
|
+
hud get hud-evals/basic-2048 # from HF
|
|
285
251
|
hud rl basic-2048.json
|
|
286
|
-
|
|
287
|
-
# Optional: baseline evaluation
|
|
288
|
-
hud eval basic-2048.json
|
|
289
252
|
```
|
|
290
253
|
|
|
291
|
-
|
|
292
|
-
- Language‑only models (e.g., `Qwen/Qwen2.5-7B-Instruct`)
|
|
293
|
-
- Vision‑Language models (e.g., `Qwen/Qwen2.5-VL-3B-Instruct`)
|
|
254
|
+
> See [agent training docs](https://docs.hud.so/train-agents/quickstart)
|
|
294
255
|
|
|
295
|
-
|
|
256
|
+
Or make your own environment and dataset:
|
|
296
257
|
|
|
297
|
-
|
|
258
|
+
```bash
|
|
259
|
+
hud init my-env && cd my-env
|
|
260
|
+
hud dev --interactive
|
|
261
|
+
# When ready to run:
|
|
262
|
+
hud rl
|
|
263
|
+
```
|
|
298
264
|
|
|
299
|
-
|
|
265
|
+
> See [environment design docs](https://docs.hud.so/build-environments)
|
|
300
266
|
|
|
301
267
|
## Benchmarking Agents
|
|
302
268
|
|
|
@@ -460,6 +426,39 @@ We highly suggest running 3-5 evaluations per dataset for the most consistent re
|
|
|
460
426
|
|
|
461
427
|
Using the [`run_dataset`](https://docs.hud.so/reference/tasks#run_dataset) function with a HuggingFace dataset automatically assigns your job to that leaderboard page, and allows you to create a scorecard out of it:
|
|
462
428
|
|
|
429
|
+
## Reinforcement Learning with GRPO
|
|
430
|
+
|
|
431
|
+
This is a Qwen‑2.5‑VL‑3B agent training a policy on the 2048-basic browser environment:
|
|
432
|
+
|
|
433
|
+

|
|
434
|
+
|
|
435
|
+
Train with the new interactive `hud rl` flow:
|
|
436
|
+
|
|
437
|
+
```bash
|
|
438
|
+
# Install CLI
|
|
439
|
+
uv tool install hud-python
|
|
440
|
+
|
|
441
|
+
# Option A: Run directly from a HuggingFace dataset
|
|
442
|
+
hud rl hud-evals/basic-2048
|
|
443
|
+
|
|
444
|
+
# Option B: Download first, modify, then train
|
|
445
|
+
hud get hud-evals/basic-2048
|
|
446
|
+
hud rl basic-2048.json
|
|
447
|
+
|
|
448
|
+
# Optional: baseline evaluation
|
|
449
|
+
hud eval basic-2048.json
|
|
450
|
+
```
|
|
451
|
+
|
|
452
|
+
Supports multi‑turn RL for both:
|
|
453
|
+
- Language‑only models (e.g., `Qwen/Qwen2.5-7B-Instruct`)
|
|
454
|
+
- Vision‑Language models (e.g., `Qwen/Qwen2.5-VL-3B-Instruct`)
|
|
455
|
+
|
|
456
|
+
By default, `hud rl` provisions a persistent server and trainer in the cloud, streams telemetry to `hud.so`, and lets you monitor/manage models at `hud.so/models`. Use `--local` to run entirely on your machines (typically 2+ GPUs: one for vLLM, the rest for training).
|
|
457
|
+
|
|
458
|
+
Any HUD MCP environment and evaluation works with our RL pipeline (including remote configurations). See the guided docs: `https://docs.hud.so/train-agents/quickstart`.
|
|
459
|
+
|
|
460
|
+
Pricing: Hosted vLLM and training GPU rates are listed in the [Training Quickstart → Pricing](https://docs.hud.so/train-agents/quickstart#pricing). Manage billing at the [HUD billing dashboard](https://hud.so/project/billing).
|
|
461
|
+
|
|
463
462
|
## Architecture
|
|
464
463
|
|
|
465
464
|
```mermaid
|