html-to-adf 0.1.0__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
|
@@ -0,0 +1,145 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: html-to-adf
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: Convert HTML to Atlassian Document Format (ADF) for Jira and Confluence.
|
|
5
|
+
Author-email: Avery Tomlin <actesbusiness@gmail.com>
|
|
6
|
+
License: MIT
|
|
7
|
+
Project-URL: Homepage, https://github.com/actes2/html-to-adf
|
|
8
|
+
Project-URL: Documentation, https://github.com/actes2/html-to-adf#readme
|
|
9
|
+
Project-URL: Issues, https://github.com/actes2/html-to-adf/issues
|
|
10
|
+
Keywords: atlassian,jira,adf,html,converter
|
|
11
|
+
Requires-Python: >=3.9
|
|
12
|
+
Description-Content-Type: text/markdown
|
|
13
|
+
License-File: LICENSE
|
|
14
|
+
Requires-Dist: beautifulsoup4
|
|
15
|
+
Dynamic: license-file
|
|
16
|
+
|
|
17
|
+
# html-to-adf - Convert HTML to ADF (Atlassian Document Format)
|
|
18
|
+
|
|
19
|
+
## What is this?
|
|
20
|
+
This is a rudimentary python helper module, dedicated to producing Jira/Confluence ready ADF out of incoming HTML.
|
|
21
|
+
|
|
22
|
+
The module itself attempts to handle generalized sanitization, while cutting some corners to forcibly marshal 'whatever' text into something tangible and compatible with Jira/Confluence.
|
|
23
|
+
|
|
24
|
+
This module is focused at **front-loading** incoming comments and descriptions for Jira and follows out of the box a relatively strict subset of tags from HTML.
|
|
25
|
+
|
|
26
|
+
|
|
27
|
+
## Dependencies
|
|
28
|
+
Everything here is mostly a painfully hand-rolled parser; we have one dependency which is: `beautifulsoup4` non-version specific.
|
|
29
|
+
|
|
30
|
+
### Supported and Converted tags
|
|
31
|
+
```html
|
|
32
|
+
<html>
|
|
33
|
+
<body>
|
|
34
|
+
|
|
35
|
+
<h1>...<h6>
|
|
36
|
+
<head> -> Converted to a heading type
|
|
37
|
+
<title> -> Converted to a heading type
|
|
38
|
+
|
|
39
|
+
<div> -> Converted to a paragraph type
|
|
40
|
+
<p>
|
|
41
|
+
|
|
42
|
+
<table> -> Represents a tablebase
|
|
43
|
+
<thead> -> Represents a tablehead
|
|
44
|
+
<tbody> -> Represents a tablebody
|
|
45
|
+
|
|
46
|
+
<tr> -> represents a tablerow
|
|
47
|
+
<th> -> represents a tablecell
|
|
48
|
+
<td> -> represents a tablecell
|
|
49
|
+
|
|
50
|
+
Modifiers:
|
|
51
|
+
|
|
52
|
+
<b>
|
|
53
|
+
<strong>
|
|
54
|
+
<i>
|
|
55
|
+
<em>
|
|
56
|
+
<s>
|
|
57
|
+
<u>
|
|
58
|
+
```
|
|
59
|
+
|
|
60
|
+
We also _support links and `<a>` tags_. (The magic under the hood can break; usually defaulting to nothing happening at all or [your entire line being a link](https://example.com/))
|
|
61
|
+
|
|
62
|
+
### Example:
|
|
63
|
+
|
|
64
|
+
We'll convert the following HTML to ADF:
|
|
65
|
+
|
|
66
|
+
```python
|
|
67
|
+
# test.py
|
|
68
|
+
from html_to_adf import import_html_to_str, convert_html_to_adf, export_document
|
|
69
|
+
|
|
70
|
+
html_text = import_html_to_str("test.html")
|
|
71
|
+
|
|
72
|
+
# If you were going to send this in an API request format, you would want to structure the ADF around a 'body {}'
|
|
73
|
+
# adding True to: convert_html_to_adf(html_text, True) will wrap the entire contents of the dict in a body {} for your ease of use.
|
|
74
|
+
resulting_adf_document: dict = convert_html_to_adf(html_text)
|
|
75
|
+
|
|
76
|
+
|
|
77
|
+
print(resulting_adf_document)
|
|
78
|
+
export_document(resulting_adf_document)
|
|
79
|
+
|
|
80
|
+
```
|
|
81
|
+
|
|
82
|
+
```html
|
|
83
|
+
<!--test.html-->
|
|
84
|
+
|
|
85
|
+
<html>
|
|
86
|
+
<head>
|
|
87
|
+
<title>Monthly Sales Report</title>
|
|
88
|
+
</head>
|
|
89
|
+
<body>
|
|
90
|
+
<h1>Monthly Sales Report</h1>
|
|
91
|
+
<p>
|
|
92
|
+
The following table shows <b>sales performance</b> by region for
|
|
93
|
+
<i>September 2025</i>.
|
|
94
|
+
For more info, visit our
|
|
95
|
+
<a href="https://example.com/reports/september">report page</a>.
|
|
96
|
+
</p>
|
|
97
|
+
|
|
98
|
+
<table>
|
|
99
|
+
<thead>
|
|
100
|
+
<tr>
|
|
101
|
+
<th>Region</th>
|
|
102
|
+
<th>Sales ($)</th>
|
|
103
|
+
<th>Growth</th>
|
|
104
|
+
</tr>
|
|
105
|
+
</thead>
|
|
106
|
+
<tbody>
|
|
107
|
+
<tr>
|
|
108
|
+
<td>North America</td>
|
|
109
|
+
<td><b>125,000</b></td>
|
|
110
|
+
<td><span style="color:green">+5%</span></td>
|
|
111
|
+
</tr>
|
|
112
|
+
<tr>
|
|
113
|
+
<td>Europe</td>
|
|
114
|
+
<td>98,500</td>
|
|
115
|
+
<td><span style="color:red">-2%</span></td>
|
|
116
|
+
</tr>
|
|
117
|
+
<tr>
|
|
118
|
+
<td>Asia-Pacific</td>
|
|
119
|
+
<td>142,750</td>
|
|
120
|
+
<td><u>+8%</u></td>
|
|
121
|
+
</tr>
|
|
122
|
+
</tbody>
|
|
123
|
+
</table>
|
|
124
|
+
|
|
125
|
+
<p>
|
|
126
|
+
Summary: <strong>Asia-Pacific</strong> led the month with strong growth.
|
|
127
|
+
<br>
|
|
128
|
+
Keep up the great work!
|
|
129
|
+
</p>
|
|
130
|
+
</body>
|
|
131
|
+
</html>
|
|
132
|
+
```
|
|
133
|
+
|
|
134
|
+
This yields the following ADF:
|
|
135
|
+
[Here's the rather large textblob](https://raw.githubusercontent.com/actes2/html-to-adf/refs/heads/main/tests/output.json)
|
|
136
|
+
_To view in live time, copy that blob and float on over to the Atlassian Live Document Preview: https://developer.atlassian.com/cloud/jira/platform/apis/document/viewer/_
|
|
137
|
+
|
|
138
|
+
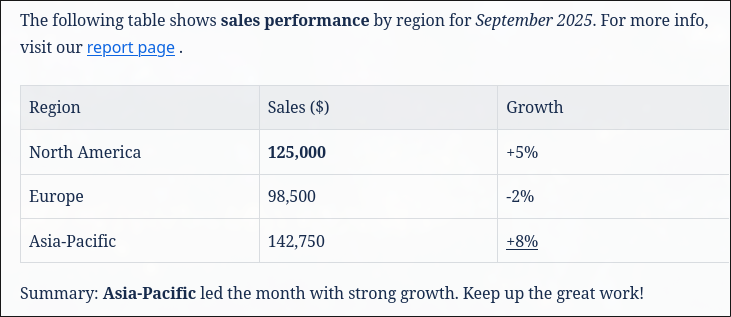
|
|
139
|
+
|
|
140
|
+
|
|
141
|
+
## Further development and support
|
|
142
|
+
|
|
143
|
+
This module is a creation of necessity, not passion; there's a large chance I won't update it very much, but that said if I get inspired you never know!
|
|
144
|
+
|
|
145
|
+
Feel free to drop something in the Issues section as you see them and I may visit those issues!
|
|
@@ -0,0 +1,6 @@
|
|
|
1
|
+
html_to_adf.py,sha256=7Rz_PKZ7cpmp_mVSHA9BKbnA1KMGlbUPYZhD4MsKZR8,35918
|
|
2
|
+
html_to_adf-0.1.0.dist-info/licenses/LICENSE,sha256=OSJv1WKKehiDqWd0UPgP33EZAOaeOB7lptWo01XpMDM,1062
|
|
3
|
+
html_to_adf-0.1.0.dist-info/METADATA,sha256=7alBFqMYmsJnF2zcoEx5gx8xpJL5a1ikROXJHNBbXiA,4313
|
|
4
|
+
html_to_adf-0.1.0.dist-info/WHEEL,sha256=_zCd3N1l69ArxyTb8rzEoP9TpbYXkqRFSNOD5OuxnTs,91
|
|
5
|
+
html_to_adf-0.1.0.dist-info/top_level.txt,sha256=ilQ_43SzwKfruKrWbkxe2bEqdwcMIipixTi6pwdqwyg,12
|
|
6
|
+
html_to_adf-0.1.0.dist-info/RECORD,,
|
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2025 actes2
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
html_to_adf
|
html_to_adf.py
ADDED
|
@@ -0,0 +1,1008 @@
|
|
|
1
|
+
from collections import namedtuple
|
|
2
|
+
import re
|
|
3
|
+
from bs4 import (
|
|
4
|
+
BeautifulSoup,
|
|
5
|
+
Comment,
|
|
6
|
+
Doctype,
|
|
7
|
+
ProcessingInstruction,
|
|
8
|
+
MarkupResemblesLocatorWarning,
|
|
9
|
+
)
|
|
10
|
+
import logging
|
|
11
|
+
import copy
|
|
12
|
+
import json
|
|
13
|
+
import warnings
|
|
14
|
+
|
|
15
|
+
warnings.filterwarnings("ignore", category=MarkupResemblesLocatorWarning)
|
|
16
|
+
|
|
17
|
+
logger = logging.getLogger(__name__)
|
|
18
|
+
logger.setLevel(logging.DEBUG)
|
|
19
|
+
handler = logging.StreamHandler()
|
|
20
|
+
handler.setLevel(logging.DEBUG)
|
|
21
|
+
logger.addHandler(handler)
|
|
22
|
+
|
|
23
|
+
|
|
24
|
+
# All of the valid operations we can perform and translate to ADF
|
|
25
|
+
VALID_PARTS = [
|
|
26
|
+
("<html>", "</html>", "html"),
|
|
27
|
+
("<head>", "</head>", "heading1"),
|
|
28
|
+
("<title>", "</title>", "heading1"),
|
|
29
|
+
("<body>", "</body>", "body"),
|
|
30
|
+
("<div>", "</div>", "paragraph"),
|
|
31
|
+
("<h1>", "</h1>", "heading1"),
|
|
32
|
+
("<h2>", "</h2>", "heading2"),
|
|
33
|
+
("<h3>", "</h3>", "heading3"),
|
|
34
|
+
("<h4>", "</h4>", "heading4"),
|
|
35
|
+
("<h5>", "</h5>", "heading5"),
|
|
36
|
+
("<h6>", "</h6>", "heading6"),
|
|
37
|
+
("<p>", "</p>", "paragraph"),
|
|
38
|
+
("<table>", "</table>", "tablebase"),
|
|
39
|
+
("<thead>", "</thead>", "tablehead"),
|
|
40
|
+
("<tbody>", "</tbody>", "tablebody"),
|
|
41
|
+
("<th>", "</th>", "tablecell"),
|
|
42
|
+
("<tr>", "</tr>", "tablerow"),
|
|
43
|
+
("<td>", "</td>", "tablecell"),
|
|
44
|
+
("<b>", "</b>", "strong"),
|
|
45
|
+
("<strong>", "</strong>", "strong"),
|
|
46
|
+
("<i>", "</i>", "em"),
|
|
47
|
+
("<em>", "</em>", "em"),
|
|
48
|
+
("<s>", "</s>", "strike"),
|
|
49
|
+
("<u>", "</u>", "underline"),
|
|
50
|
+
]
|
|
51
|
+
|
|
52
|
+
# This is aimed at a simple test-for-word-inside
|
|
53
|
+
# We check if the type contains the following to validate if it's a container_type object
|
|
54
|
+
CONTAINER_TYPES = {
|
|
55
|
+
"paragraph",
|
|
56
|
+
"head",
|
|
57
|
+
"table",
|
|
58
|
+
"html",
|
|
59
|
+
"body",
|
|
60
|
+
}
|
|
61
|
+
|
|
62
|
+
# modifier type of nodes
|
|
63
|
+
modifiers = {"strong", "em", "strike", "underline"}
|
|
64
|
+
|
|
65
|
+
# This just wraps up what I define as a container type, by matching if it has head, paragraph, or table in the valid_part
|
|
66
|
+
all_container_types = [
|
|
67
|
+
vpart for cont in CONTAINER_TYPES for vpart in VALID_PARTS if cont in vpart[2]
|
|
68
|
+
]
|
|
69
|
+
|
|
70
|
+
|
|
71
|
+
# Extracts valid tags from valid_parts
|
|
72
|
+
def extract_valid_tags(valid_parts):
|
|
73
|
+
tags = set()
|
|
74
|
+
for part in valid_parts:
|
|
75
|
+
items = part
|
|
76
|
+
for item in items:
|
|
77
|
+
if not isinstance(item, str):
|
|
78
|
+
continue
|
|
79
|
+
|
|
80
|
+
_match = re.search(r"<\s*/?\s*([a-zA-Z0-9:-]+)", item)
|
|
81
|
+
if _match:
|
|
82
|
+
tags.add(_match.group(1).lower())
|
|
83
|
+
else:
|
|
84
|
+
tags.add(item.strip().lower())
|
|
85
|
+
return tags
|
|
86
|
+
|
|
87
|
+
|
|
88
|
+
# Marshals our incoming html to something we can parse
|
|
89
|
+
def sanitize_html(html: str, valid_parts):
|
|
90
|
+
html = html.replace("<br>", "\n")
|
|
91
|
+
allowed = extract_valid_tags(valid_parts)
|
|
92
|
+
sanitizer_special_tags = {"<a>"}
|
|
93
|
+
|
|
94
|
+
allowed |= sanitizer_special_tags
|
|
95
|
+
|
|
96
|
+
soup = BeautifulSoup(html, "html.parser")
|
|
97
|
+
|
|
98
|
+
for link in soup.find_all("a"):
|
|
99
|
+
href = link.get("href", "")
|
|
100
|
+
encoded_text = f'~y~href="{href}"~y~~z~{link.get_text()}~z~'
|
|
101
|
+
link.replace_with(encoded_text)
|
|
102
|
+
|
|
103
|
+
# Throw out comments, docstrings and spans
|
|
104
|
+
for el in soup.find_all(string=True):
|
|
105
|
+
if isinstance(el, (Comment, Doctype, ProcessingInstruction)):
|
|
106
|
+
el.extract()
|
|
107
|
+
|
|
108
|
+
# Delete anything we don't want
|
|
109
|
+
for bad in soup.find_all(["script", "style"]):
|
|
110
|
+
bad.decompose()
|
|
111
|
+
|
|
112
|
+
# Find all of our tags and go through them
|
|
113
|
+
for tag in soup.find_all(True):
|
|
114
|
+
name = tag.name.lower()
|
|
115
|
+
if name not in allowed:
|
|
116
|
+
tag.unwrap() # Instead of decompose, we unwrap to keep the content
|
|
117
|
+
continue
|
|
118
|
+
tag.attrs.clear()
|
|
119
|
+
|
|
120
|
+
# Remove nested empty structures
|
|
121
|
+
def is_effectively_empty(tag):
|
|
122
|
+
if not tag.get_text(strip=True):
|
|
123
|
+
return True
|
|
124
|
+
if tag.find_all(True) and all(
|
|
125
|
+
is_effectively_empty(child) for child in tag.find_all(True)
|
|
126
|
+
):
|
|
127
|
+
return True
|
|
128
|
+
return False
|
|
129
|
+
|
|
130
|
+
# Multiple passes to handle nested structures
|
|
131
|
+
for _ in range(3):
|
|
132
|
+
for tag in soup.find_all(["table", "tbody", "th", "tr", "td", "div"]):
|
|
133
|
+
if is_effectively_empty(tag):
|
|
134
|
+
tag.decompose()
|
|
135
|
+
|
|
136
|
+
# get all lite container types, and remove our < and > to play nice with bs
|
|
137
|
+
all_container_lites = [
|
|
138
|
+
cont[0].replace("<", "").replace(">", "")
|
|
139
|
+
for cont in all_container_types
|
|
140
|
+
if cont[0]
|
|
141
|
+
not in [
|
|
142
|
+
"<thead>",
|
|
143
|
+
"<tbody>",
|
|
144
|
+
"<table>",
|
|
145
|
+
"<tr>",
|
|
146
|
+
"<td>",
|
|
147
|
+
"<th>",
|
|
148
|
+
"<html>",
|
|
149
|
+
"<body>",
|
|
150
|
+
]
|
|
151
|
+
]
|
|
152
|
+
|
|
153
|
+
# Final pass: convert remaining divs to paragraphs and remove empty tags
|
|
154
|
+
for tag in soup.find_all(True):
|
|
155
|
+
if tag.name.lower() == "head":
|
|
156
|
+
if tag.title:
|
|
157
|
+
title_text = tag.title.get_text(strip=True)
|
|
158
|
+
tag.clear()
|
|
159
|
+
tag.append(title_text)
|
|
160
|
+
|
|
161
|
+
if tag.name.lower() == "div":
|
|
162
|
+
if tag.get_text(strip=True):
|
|
163
|
+
uwrapped: bool = False
|
|
164
|
+
for _c_node in tag.children:
|
|
165
|
+
if _c_node.name in all_container_lites:
|
|
166
|
+
tag.unwrap()
|
|
167
|
+
uwrapped: bool = True
|
|
168
|
+
|
|
169
|
+
if not uwrapped:
|
|
170
|
+
tag.name = "p"
|
|
171
|
+
else:
|
|
172
|
+
tag.decompose()
|
|
173
|
+
continue
|
|
174
|
+
elif not tag.contents or (not tag.get_text(strip=True) and not tag.find(True)):
|
|
175
|
+
tag.decompose()
|
|
176
|
+
continue
|
|
177
|
+
|
|
178
|
+
# clean up any nested container_lites
|
|
179
|
+
if any(True for _cont in all_container_lites if tag.name.lower() == _cont):
|
|
180
|
+
for inner in tag.find_all(all_container_lites):
|
|
181
|
+
inner.unwrap()
|
|
182
|
+
sanitized = (
|
|
183
|
+
str(soup).replace("\n", "\n\n").replace(" ", "").replace("\r", "")
|
|
184
|
+
)
|
|
185
|
+
|
|
186
|
+
return sanitized
|
|
187
|
+
|
|
188
|
+
|
|
189
|
+
class Part:
|
|
190
|
+
"""
|
|
191
|
+
Part is a object which contains a 'part' of an adf document
|
|
192
|
+
"""
|
|
193
|
+
|
|
194
|
+
def __init__(self, type_of_node="", text=""):
|
|
195
|
+
self.type_of_node = type_of_node
|
|
196
|
+
self.text = text
|
|
197
|
+
self.inner_parts = []
|
|
198
|
+
self.marks = set()
|
|
199
|
+
# It gets all the existing marks in a set and the cleaned up text without the marks.
|
|
200
|
+
|
|
201
|
+
def propagate_parent_marks_downwards(self):
|
|
202
|
+
"""
|
|
203
|
+
propagate current marks downwards, if we're a text part with children, since html follows a top-down schema
|
|
204
|
+
"""
|
|
205
|
+
if (
|
|
206
|
+
self.type_of_node == "text"
|
|
207
|
+
or self.type_of_node in modifiers
|
|
208
|
+
and self.inner_parts
|
|
209
|
+
):
|
|
210
|
+
for child in self.inner_parts:
|
|
211
|
+
if self.type_of_node in modifiers:
|
|
212
|
+
self.marks.add(self.type_of_node)
|
|
213
|
+
child.marks |= self.marks
|
|
214
|
+
child.propagate_parent_marks_downwards()
|
|
215
|
+
|
|
216
|
+
# If text is just floating around in the text field of a non type_of_node=text we can mutate the Part to follow our schema
|
|
217
|
+
def cleanup_flat_text(self):
|
|
218
|
+
if (
|
|
219
|
+
self.type_of_node != "table"
|
|
220
|
+
and any(True for cont in CONTAINER_TYPES if cont in self.type_of_node)
|
|
221
|
+
or self.type_of_node == "disconnected_text"
|
|
222
|
+
):
|
|
223
|
+
if self.text:
|
|
224
|
+
self.text = self.clear_all_disconnected_marks()
|
|
225
|
+
|
|
226
|
+
_subpart_marks_and_text = self.get_marks_and_text()
|
|
227
|
+
_subpart = Part(type_of_node="text", text=_subpart_marks_and_text[1])
|
|
228
|
+
_subpart.marks = _subpart_marks_and_text[0]
|
|
229
|
+
|
|
230
|
+
self.inner_parts.append(_subpart)
|
|
231
|
+
self.text = ""
|
|
232
|
+
|
|
233
|
+
def get_marks_and_text(self) -> tuple[set, str]:
|
|
234
|
+
text = self.text
|
|
235
|
+
marks = set()
|
|
236
|
+
while any(
|
|
237
|
+
valid_mark[0] in text and valid_mark[1] in text
|
|
238
|
+
for valid_mark in VALID_PARTS
|
|
239
|
+
):
|
|
240
|
+
# filter out marks and make sure they're not container_types
|
|
241
|
+
for mark in (_m for _m in VALID_PARTS if _m[2]):
|
|
242
|
+
if mark[0] in text and mark[1] in text:
|
|
243
|
+
s_index = text.find(mark[0])
|
|
244
|
+
l_index = text.rfind(mark[1])
|
|
245
|
+
marks.add(mark[2])
|
|
246
|
+
text = text[s_index + len(mark[0]) : l_index]
|
|
247
|
+
return (marks, text)
|
|
248
|
+
|
|
249
|
+
def clear_all_disconnected_marks(self) -> str:
|
|
250
|
+
# Clear all disconnected marks from a string and leave our raw text.
|
|
251
|
+
text = self.text
|
|
252
|
+
while any(
|
|
253
|
+
valid_mark[0] in text and valid_mark[1] not in text
|
|
254
|
+
for valid_mark in VALID_PARTS
|
|
255
|
+
):
|
|
256
|
+
# filter out marks and make sure they're not container_types
|
|
257
|
+
for mark in (_m for _m in VALID_PARTS):
|
|
258
|
+
if mark[0] in text and mark[1] not in text:
|
|
259
|
+
s_index = text.find(mark[0])
|
|
260
|
+
text = text[s_index + len(mark[0]) :]
|
|
261
|
+
|
|
262
|
+
if mark[0] in text and mark[1] in text:
|
|
263
|
+
continue
|
|
264
|
+
while any(
|
|
265
|
+
valid_mark[1] in text and valid_mark[0] not in text
|
|
266
|
+
for valid_mark in VALID_PARTS
|
|
267
|
+
):
|
|
268
|
+
# filter out marks and make sure they're not container_types
|
|
269
|
+
for mark in (_m for _m in VALID_PARTS):
|
|
270
|
+
if mark[1] in text and mark[0] not in text:
|
|
271
|
+
s_index = text.find(mark[1])
|
|
272
|
+
text = text[s_index + len(mark[1]) :]
|
|
273
|
+
|
|
274
|
+
if mark[0] in text and mark[1] in text:
|
|
275
|
+
continue
|
|
276
|
+
return text
|
|
277
|
+
|
|
278
|
+
# Drill down all sub-parts and extract their raw text
|
|
279
|
+
def drill_all_text(self):
|
|
280
|
+
txt_result = ""
|
|
281
|
+
if self.inner_parts:
|
|
282
|
+
for i_c in self.inner_parts:
|
|
283
|
+
txt_result += f" {i_c.drill_all_text()}"
|
|
284
|
+
else:
|
|
285
|
+
if self.text:
|
|
286
|
+
txt_result += self.text
|
|
287
|
+
return txt_result.replace(" ", " ")
|
|
288
|
+
|
|
289
|
+
def d(self):
|
|
290
|
+
print(self.__dict__)
|
|
291
|
+
|
|
292
|
+
|
|
293
|
+
def find_next_tag(buffer: str, valid_parts: str):
|
|
294
|
+
"""Searches for for the earliest opening tag in a string relative to our valid_parts
|
|
295
|
+
Parameters:
|
|
296
|
+
buffer (str): A buffer string to scan over
|
|
297
|
+
valid_parts (List[tuple[str, str, str]]): a List of valid_parts (intro_tag, exit_tag, real_name)
|
|
298
|
+
Returns:
|
|
299
|
+
NextValidPart (object): NextValidPart(open_tag, close_tag, type_of, start_index, end_index, is_container)
|
|
300
|
+
If no match None
|
|
301
|
+
"""
|
|
302
|
+
best_match = None
|
|
303
|
+
for open_tag, close_tag, type_of in valid_parts:
|
|
304
|
+
s = buffer.find(open_tag)
|
|
305
|
+
if s == -1:
|
|
306
|
+
continue
|
|
307
|
+
e = buffer.find(close_tag, s + len(open_tag))
|
|
308
|
+
if e == -1:
|
|
309
|
+
continue
|
|
310
|
+
if best_match is None or s < best_match[3]:
|
|
311
|
+
is_container_object = False
|
|
312
|
+
if any([True for ct in CONTAINER_TYPES if ct in type_of]):
|
|
313
|
+
is_container_object = True
|
|
314
|
+
best_match = (open_tag, close_tag, type_of, s, e, is_container_object)
|
|
315
|
+
if best_match:
|
|
316
|
+
NextValidPart = namedtuple(
|
|
317
|
+
"NextValidPart",
|
|
318
|
+
field_names=[
|
|
319
|
+
"open_tag",
|
|
320
|
+
"close_tag",
|
|
321
|
+
"type_of",
|
|
322
|
+
"start_index",
|
|
323
|
+
"end_index",
|
|
324
|
+
"is_container",
|
|
325
|
+
],
|
|
326
|
+
)
|
|
327
|
+
return NextValidPart(
|
|
328
|
+
best_match[0],
|
|
329
|
+
best_match[1],
|
|
330
|
+
best_match[2],
|
|
331
|
+
best_match[3],
|
|
332
|
+
best_match[4],
|
|
333
|
+
best_match[5],
|
|
334
|
+
)
|
|
335
|
+
else:
|
|
336
|
+
return None
|
|
337
|
+
|
|
338
|
+
|
|
339
|
+
def get_parts(html: str, in_container=False, debug=False) -> list:
|
|
340
|
+
"""
|
|
341
|
+
This function is what breaks html off into a structure I can comprehend and translate to ADF
|
|
342
|
+
|
|
343
|
+
Essentially if it's an HTML Node in VALID_PARTS, we break the node into container types, modifier types and text nodes.
|
|
344
|
+
This can then be drilled down, depending on the modifiers that occur, allowing for multi-layered recursion fun
|
|
345
|
+
|
|
346
|
+
My only rule of thumb, is most container-types except container-lites (html, body, tables) cannot have container-types
|
|
347
|
+
We follow this rule because ADF follows this rule.
|
|
348
|
+
|
|
349
|
+
Parameters:
|
|
350
|
+
html (str): Our sanitized HTML
|
|
351
|
+
in_container (bool optional): Used in recursion to decide if we're recursing
|
|
352
|
+
debug (bool optional): Leveraged to help add some output to what's going on internally
|
|
353
|
+
|
|
354
|
+
Returns:
|
|
355
|
+
list of parts we've extracted
|
|
356
|
+
"""
|
|
357
|
+
if debug:
|
|
358
|
+
logger.debug("____________\nIteration:🕒\n____________\n")
|
|
359
|
+
|
|
360
|
+
# Setup our buffer string which we'll carve out
|
|
361
|
+
buffer_str: str = html.strip()
|
|
362
|
+
|
|
363
|
+
# Create our intended object to pull per iteration
|
|
364
|
+
parts = []
|
|
365
|
+
|
|
366
|
+
first_instance = True
|
|
367
|
+
previous_end_position = 0
|
|
368
|
+
|
|
369
|
+
# Loop while we have a buffer_str that hasn't been completely chipped away
|
|
370
|
+
while any(
|
|
371
|
+
_v_part[0] in buffer_str and _v_part[1] in buffer_str for _v_part in VALID_PARTS
|
|
372
|
+
):
|
|
373
|
+
# ? NextValidPart (object): NextValidPart(open_tag, close_tag, type_of, start_index, end_index, is_container)
|
|
374
|
+
next_valid_part = find_next_tag(buffer=buffer_str, valid_parts=VALID_PARTS)
|
|
375
|
+
if next_valid_part:
|
|
376
|
+
part = Part()
|
|
377
|
+
|
|
378
|
+
if first_instance:
|
|
379
|
+
# On first iteration we attempt to catch all of the preamble text, into a paragraph object.
|
|
380
|
+
intro_text = buffer_str[: next_valid_part.start_index]
|
|
381
|
+
if intro_text:
|
|
382
|
+
_intro_part = Part()
|
|
383
|
+
_intro_part.text = buffer_str[: next_valid_part.start_index]
|
|
384
|
+
|
|
385
|
+
_intro_part.type_of_node = (
|
|
386
|
+
"paragraph"
|
|
387
|
+
if not any(
|
|
388
|
+
[
|
|
389
|
+
True
|
|
390
|
+
for cont in CONTAINER_TYPES
|
|
391
|
+
if cont in next_valid_part.type_of
|
|
392
|
+
]
|
|
393
|
+
)
|
|
394
|
+
else next_valid_part.type_of
|
|
395
|
+
)
|
|
396
|
+
|
|
397
|
+
parts.append(_intro_part)
|
|
398
|
+
first_instance = False
|
|
399
|
+
else:
|
|
400
|
+
# Capture interlude text between tags (not just preamble)
|
|
401
|
+
interlude_text = buffer_str[
|
|
402
|
+
previous_end_position : next_valid_part.start_index
|
|
403
|
+
]
|
|
404
|
+
if interlude_text.strip(): # Only create part if there's actual content
|
|
405
|
+
_interlude_part = Part()
|
|
406
|
+
_interlude_part.text = interlude_text
|
|
407
|
+
# Interlude text should always be paragraph type since it wont follow a specific node
|
|
408
|
+
_interlude_part.type_of_node = "paragraph"
|
|
409
|
+
parts.append(_interlude_part)
|
|
410
|
+
|
|
411
|
+
start_index = next_valid_part.start_index + len(next_valid_part.open_tag)
|
|
412
|
+
end_index = next_valid_part.end_index
|
|
413
|
+
|
|
414
|
+
part.type_of_node = (
|
|
415
|
+
next_valid_part.type_of
|
|
416
|
+
) # Define what type of part this is for look-up and transformation
|
|
417
|
+
|
|
418
|
+
part.text = buffer_str[
|
|
419
|
+
start_index:end_index
|
|
420
|
+
] # The substringed text content
|
|
421
|
+
|
|
422
|
+
# This is the voodoo responsible for drilling down recursively, and iterating over descendent: containers / modifier parts.
|
|
423
|
+
def _walk(origin_part: Part):
|
|
424
|
+
next_tag = find_next_tag(origin_part.text, valid_parts=VALID_PARTS)
|
|
425
|
+
if next_tag:
|
|
426
|
+
|
|
427
|
+
# Recurse:
|
|
428
|
+
# Get the 3 parts of the document and combine them.
|
|
429
|
+
_inner_shards = get_document_shards(
|
|
430
|
+
origin_part.text, in_container=True
|
|
431
|
+
)
|
|
432
|
+
for _, _shard_parts in _inner_shards.items():
|
|
433
|
+
origin_part.inner_parts += _shard_parts
|
|
434
|
+
|
|
435
|
+
if next_tag.is_container:
|
|
436
|
+
origin_part.text = "" # ? We do not preserve active start and end text around nodes as our top-level recursion handles that
|
|
437
|
+
else:
|
|
438
|
+
for child in origin_part.inner_parts:
|
|
439
|
+
child.marks.add(origin_part.type_of_node)
|
|
440
|
+
if child.type_of_node in modifiers:
|
|
441
|
+
child.marks.add(child.type_of_node)
|
|
442
|
+
child.marks = child.marks | origin_part.marks
|
|
443
|
+
|
|
444
|
+
# remove non-modifiers from our children
|
|
445
|
+
non_mod_parts = set()
|
|
446
|
+
for i in child.marks:
|
|
447
|
+
if any(
|
|
448
|
+
[True for cont in CONTAINER_TYPES if cont in i]
|
|
449
|
+
):
|
|
450
|
+
non_mod_parts.add(i)
|
|
451
|
+
[child.marks.remove(nmp) for nmp in non_mod_parts]
|
|
452
|
+
|
|
453
|
+
child.type_of_node = "text"
|
|
454
|
+
|
|
455
|
+
origin_part.text = ""
|
|
456
|
+
|
|
457
|
+
return origin_part
|
|
458
|
+
|
|
459
|
+
part = _walk(part)
|
|
460
|
+
|
|
461
|
+
# Update previous_end_position to track where this tag ended
|
|
462
|
+
previous_end_position = 0 # Reset to 0 since we're updating buffer_str
|
|
463
|
+
buffer_str = buffer_str[(end_index + len(next_valid_part.close_tag)) :]
|
|
464
|
+
|
|
465
|
+
parts.append(part)
|
|
466
|
+
if debug:
|
|
467
|
+
logger.debug("top_level_iterated part: {}".format(part.__dict__))
|
|
468
|
+
|
|
469
|
+
if buffer_str:
|
|
470
|
+
buffer_str = buffer_str.strip()
|
|
471
|
+
if debug:
|
|
472
|
+
logger.debug("LAST invoke of buffer string is: {}".format(buffer_str))
|
|
473
|
+
part = Part()
|
|
474
|
+
part.text = buffer_str
|
|
475
|
+
part.cleanup_flat_text()
|
|
476
|
+
# This is a disconnected_node because the last portion of the buffer isn't any html tags - paragraph might work too
|
|
477
|
+
part.type_of_node = "disconnected_text"
|
|
478
|
+
parts.append(part)
|
|
479
|
+
|
|
480
|
+
def clear_standalone_flat_text(part: Part):
|
|
481
|
+
# An optimal structure is any text merged into it's own Part as an inner_part
|
|
482
|
+
# This recurses over the children of our parts, and drills to the bottom.
|
|
483
|
+
_c_part: Part
|
|
484
|
+
for _c_part in part.inner_parts:
|
|
485
|
+
if not _c_part.inner_parts:
|
|
486
|
+
_c_part.cleanup_flat_text()
|
|
487
|
+
clear_standalone_flat_text(_c_part)
|
|
488
|
+
|
|
489
|
+
_part: Part
|
|
490
|
+
for _part in parts:
|
|
491
|
+
clear_standalone_flat_text(_part)
|
|
492
|
+
_part.propagate_parent_marks_downwards()
|
|
493
|
+
|
|
494
|
+
return parts
|
|
495
|
+
|
|
496
|
+
|
|
497
|
+
def get_document_shards(html: str, in_container=False):
|
|
498
|
+
"""
|
|
499
|
+
Hunts through the presented html, and breaks the parts off into what I call document shards.
|
|
500
|
+
|
|
501
|
+
This is because the preamble and epilogue are undetectable if we follow traditional html schema
|
|
502
|
+
But due to the ambigious nature of ADF text, we have to compensate for non-standard schemas
|
|
503
|
+
|
|
504
|
+
Returns:
|
|
505
|
+
document (dict): {
|
|
506
|
+
"preamble": List[Part] if exists,
|
|
507
|
+
"body": List[Part],
|
|
508
|
+
"epilogue": List[Part] if exists
|
|
509
|
+
}
|
|
510
|
+
"""
|
|
511
|
+
doc_start = html.find("<html>")
|
|
512
|
+
|
|
513
|
+
shards = {}
|
|
514
|
+
if doc_start != -1 and doc_start != 0 and html.count("<html>") < 2:
|
|
515
|
+
shards["preamble"] = get_parts(html=html[:doc_start], in_container=in_container)
|
|
516
|
+
|
|
517
|
+
html = html[doc_start:]
|
|
518
|
+
doc_end = html.find("</html>")
|
|
519
|
+
|
|
520
|
+
if doc_end != -1 and doc_end:
|
|
521
|
+
body_html = html[: doc_end + len("</html>")]
|
|
522
|
+
else:
|
|
523
|
+
body_html = html
|
|
524
|
+
|
|
525
|
+
shards["body"] = get_parts(html=body_html, in_container=in_container)
|
|
526
|
+
|
|
527
|
+
if doc_end != -1 and doc_end + len("</html>") != len(html):
|
|
528
|
+
shards["epilogue"] = get_parts(
|
|
529
|
+
html=html[doc_end + len("</html>") :], in_container=in_container
|
|
530
|
+
)
|
|
531
|
+
|
|
532
|
+
else:
|
|
533
|
+
if html.count("<html>") > 2:
|
|
534
|
+
html.replace("<html>", "").replace("</html>", "")
|
|
535
|
+
shards["body"] = get_parts(html=html, in_container=in_container)
|
|
536
|
+
|
|
537
|
+
for shard in shards:
|
|
538
|
+
for stand_alone_part in shards[shard]:
|
|
539
|
+
if stand_alone_part.type_of_node in modifiers:
|
|
540
|
+
stand_alone_part.propagate_parent_marks_downwards()
|
|
541
|
+
child_part = Part(type_of_node="text", text=stand_alone_part.text)
|
|
542
|
+
child_part.marks.add(stand_alone_part.type_of_node)
|
|
543
|
+
|
|
544
|
+
stand_alone_part.inner_parts.append(child_part)
|
|
545
|
+
stand_alone_part.type_of_node = "disconnected_text"
|
|
546
|
+
stand_alone_part.text = ""
|
|
547
|
+
|
|
548
|
+
if not stand_alone_part.inner_parts and stand_alone_part.text:
|
|
549
|
+
stand_alone_part.cleanup_flat_text()
|
|
550
|
+
stand_alone_part.type_of_node = "disconnected_text"
|
|
551
|
+
|
|
552
|
+
return shards
|
|
553
|
+
|
|
554
|
+
|
|
555
|
+
# HTML -> ADF conversion function for most text
|
|
556
|
+
def generate_adf_text_content(part):
|
|
557
|
+
all_text_blobs = []
|
|
558
|
+
|
|
559
|
+
def clearout_link(original_text: str):
|
|
560
|
+
# Clears out text at the detected sanitization strings
|
|
561
|
+
left_most = original_text.find("~y~")
|
|
562
|
+
right_most = original_text.find("~y~", (left_most + 1)) + len("~y~")
|
|
563
|
+
original_text = f"{original_text[:left_most]}{original_text[right_most:]}"
|
|
564
|
+
|
|
565
|
+
left_most = original_text.find("~z~")
|
|
566
|
+
right_most = original_text.find("~z~", (left_most + 1)) + len("~z~")
|
|
567
|
+
original_text = f"{original_text[:left_most]} ~x~ {original_text[right_most:]}"
|
|
568
|
+
return original_text
|
|
569
|
+
|
|
570
|
+
def convert_to_text_obj(text_content: str):
|
|
571
|
+
# Convert whatever text we have into an adf text object.
|
|
572
|
+
adf_obj = {
|
|
573
|
+
"type": "text",
|
|
574
|
+
"text": text_content,
|
|
575
|
+
}
|
|
576
|
+
return adf_obj
|
|
577
|
+
|
|
578
|
+
def get_link_object(href_start, text):
|
|
579
|
+
# Using a link index and text, we create an adf link object out of the text going left to right for our santized delimiters
|
|
580
|
+
if text.find("~z~") == -1 and text.find("~y~") == -1 and href_start == -1:
|
|
581
|
+
link_content = {"type": "text", "text": text, "marks": {}}
|
|
582
|
+
link_type = {
|
|
583
|
+
"type": "link",
|
|
584
|
+
"attrs": {
|
|
585
|
+
"href": text,
|
|
586
|
+
},
|
|
587
|
+
}
|
|
588
|
+
link_content["marks"] = [link_type]
|
|
589
|
+
return link_content
|
|
590
|
+
|
|
591
|
+
link_start = href_start + len('~y~href="')
|
|
592
|
+
link = text[link_start:]
|
|
593
|
+
link = link[: link.find('"~y~')]
|
|
594
|
+
href_end = text.find('"~y~', link_start) + len('"~y~')
|
|
595
|
+
|
|
596
|
+
# Substring out our delimiter
|
|
597
|
+
text = text[:href_start] + text[href_end:]
|
|
598
|
+
|
|
599
|
+
msg_start = text.find("~z~")
|
|
600
|
+
msg = text[(msg_start + len("~z~")) :]
|
|
601
|
+
msg = msg[: msg.find("~z~")]
|
|
602
|
+
|
|
603
|
+
link_content = {"type": "text", "text": msg, "marks": {}}
|
|
604
|
+
|
|
605
|
+
link_type = {
|
|
606
|
+
"type": "link",
|
|
607
|
+
"attrs": {
|
|
608
|
+
"href": link if link else text,
|
|
609
|
+
},
|
|
610
|
+
}
|
|
611
|
+
|
|
612
|
+
link_content["marks"] = [link_type]
|
|
613
|
+
return link_content
|
|
614
|
+
|
|
615
|
+
def recursive_content_generation(child: Part):
|
|
616
|
+
content = {
|
|
617
|
+
"type": "text",
|
|
618
|
+
"text": child.drill_all_text(),
|
|
619
|
+
}
|
|
620
|
+
|
|
621
|
+
# If we encounter a link we have to restructure the entire text to compensate
|
|
622
|
+
independent_link_content = None
|
|
623
|
+
inner_content = []
|
|
624
|
+
|
|
625
|
+
# If a mark is not a container_type, wrap it into an adf style object
|
|
626
|
+
valid_marks = [
|
|
627
|
+
{"type": mark}
|
|
628
|
+
for mark in child.marks
|
|
629
|
+
if not any(mark in cont[2] for cont in all_container_types) and child.marks
|
|
630
|
+
]
|
|
631
|
+
|
|
632
|
+
if "https://" in content["text"] or "http://" in content["text"]:
|
|
633
|
+
# The ~y~ is our custom encoding that the sanitizer sprinkles in replacement for <a> links, so we can leverage the href
|
|
634
|
+
href_start = content["text"].find('~y~href="')
|
|
635
|
+
|
|
636
|
+
# If we didn't sanitize the string with our delimiters, we just treat the whole thing as a link.
|
|
637
|
+
if href_start == -1:
|
|
638
|
+
link_content = get_link_object(
|
|
639
|
+
href_start=href_start, text=content["text"]
|
|
640
|
+
)
|
|
641
|
+
inner_content.append(link_content)
|
|
642
|
+
else:
|
|
643
|
+
while href_start != -1:
|
|
644
|
+
# add the length of our cutter
|
|
645
|
+
independent_link_content = get_link_object(
|
|
646
|
+
href_start=href_start,
|
|
647
|
+
text=content["text"],
|
|
648
|
+
)
|
|
649
|
+
|
|
650
|
+
split_content = clearout_link(content["text"]).split("~x~")
|
|
651
|
+
|
|
652
|
+
inner_content.append(split_content[0])
|
|
653
|
+
inner_content.append(independent_link_content)
|
|
654
|
+
content["text"] = split_content[1]
|
|
655
|
+
href_start = content["text"].find('~y~href="')
|
|
656
|
+
|
|
657
|
+
# Throw the tail remainder on
|
|
658
|
+
if content["text"]:
|
|
659
|
+
inner_content.append(content["text"])
|
|
660
|
+
|
|
661
|
+
if inner_content:
|
|
662
|
+
for cont in inner_content:
|
|
663
|
+
if isinstance(cont, str):
|
|
664
|
+
cont = cont.replace(" ", " ")
|
|
665
|
+
cont = convert_to_text_obj(cont)
|
|
666
|
+
if valid_marks:
|
|
667
|
+
if cont.get("marks"):
|
|
668
|
+
cont["marks"] += valid_marks
|
|
669
|
+
else:
|
|
670
|
+
cont["marks"] = valid_marks
|
|
671
|
+
all_text_blobs.append(cont)
|
|
672
|
+
else:
|
|
673
|
+
if valid_marks:
|
|
674
|
+
content["marks"] = valid_marks
|
|
675
|
+
|
|
676
|
+
all_text_blobs.append(content)
|
|
677
|
+
|
|
678
|
+
for child in part.inner_parts:
|
|
679
|
+
if child.inner_parts:
|
|
680
|
+
for inner_mod_child in child.inner_parts:
|
|
681
|
+
recursive_content_generation(child=inner_mod_child)
|
|
682
|
+
else:
|
|
683
|
+
recursive_content_generation(child=child)
|
|
684
|
+
|
|
685
|
+
for txt in all_text_blobs:
|
|
686
|
+
if txt["text"] == "":
|
|
687
|
+
txt["text"] = " "
|
|
688
|
+
|
|
689
|
+
return all_text_blobs
|
|
690
|
+
|
|
691
|
+
|
|
692
|
+
# HTML -> ADF conversion function for paragraphs
|
|
693
|
+
def construct_paragraph_blob(part: Part) -> dict:
|
|
694
|
+
resulting_type = {
|
|
695
|
+
"type": "paragraph",
|
|
696
|
+
"content": [],
|
|
697
|
+
}
|
|
698
|
+
if part.text and part.type_of_node == "paragraph" and not part.inner_parts:
|
|
699
|
+
part.cleanup_flat_text()
|
|
700
|
+
resulting_type["content"] = generate_adf_text_content(part)
|
|
701
|
+
return resulting_type
|
|
702
|
+
|
|
703
|
+
|
|
704
|
+
# HTML -> ADF conversion function for headers
|
|
705
|
+
def construct_heading_blob(part: Part) -> dict:
|
|
706
|
+
name_index = part.type_of_node.find("heading") + len("heading")
|
|
707
|
+
level = part.type_of_node[name_index:]
|
|
708
|
+
resulting_type = {
|
|
709
|
+
"type": "heading",
|
|
710
|
+
"attrs": {"level": int(level)}, # not required
|
|
711
|
+
"content": [], # not required, applicable only in containers
|
|
712
|
+
}
|
|
713
|
+
|
|
714
|
+
resulting_type["content"] = generate_adf_text_content(part=part)
|
|
715
|
+
|
|
716
|
+
return resulting_type
|
|
717
|
+
|
|
718
|
+
|
|
719
|
+
# HTML -> ADF conversion function for tables
|
|
720
|
+
def construct_table_blob(part: Part) -> dict:
|
|
721
|
+
resulting_type = {
|
|
722
|
+
"type": "table",
|
|
723
|
+
"content": [],
|
|
724
|
+
}
|
|
725
|
+
|
|
726
|
+
table_content = []
|
|
727
|
+
|
|
728
|
+
row_template = {
|
|
729
|
+
"type": "tableRow",
|
|
730
|
+
"content": [],
|
|
731
|
+
}
|
|
732
|
+
|
|
733
|
+
# template for structure marshalling
|
|
734
|
+
inner_template = {
|
|
735
|
+
"type": "",
|
|
736
|
+
"content": [],
|
|
737
|
+
}
|
|
738
|
+
|
|
739
|
+
malformed_structure = False
|
|
740
|
+
|
|
741
|
+
if len(part.inner_parts) == 1 and "tablehead" not in [
|
|
742
|
+
part.inner_parts[0].type_of_node
|
|
743
|
+
]:
|
|
744
|
+
malformed_structure = True
|
|
745
|
+
|
|
746
|
+
known_dimensionsf = False
|
|
747
|
+
row_dimensions = 0
|
|
748
|
+
current_cell = 0
|
|
749
|
+
|
|
750
|
+
if not malformed_structure:
|
|
751
|
+
for table_top in part.inner_parts:
|
|
752
|
+
|
|
753
|
+
row_t = copy.deepcopy(row_template)
|
|
754
|
+
cell_t = copy.deepcopy(inner_template)
|
|
755
|
+
|
|
756
|
+
if table_top.type_of_node == "tablehead":
|
|
757
|
+
cell_t["type"] = "tableHeader"
|
|
758
|
+
else:
|
|
759
|
+
cell_t["type"] = "tableCell"
|
|
760
|
+
|
|
761
|
+
inner_content = []
|
|
762
|
+
# iterate through each 'row' in our table
|
|
763
|
+
for table_row in table_top.inner_parts:
|
|
764
|
+
if table_row.type_of_node == "tablerow":
|
|
765
|
+
for cell in table_row.inner_parts:
|
|
766
|
+
cell_t["content"] = [unwrap_part_to_adf_type(cell)]
|
|
767
|
+
|
|
768
|
+
# dynamically define our dimensions
|
|
769
|
+
if cell_t["type"] == "tableHeader":
|
|
770
|
+
row_dimensions += 1
|
|
771
|
+
known_dimensionsf = True
|
|
772
|
+
# mark each indice
|
|
773
|
+
if cell_t["type"] == "tableCell":
|
|
774
|
+
current_cell += 1
|
|
775
|
+
|
|
776
|
+
# Default supply content to our middle table
|
|
777
|
+
inner_content.append(copy.deepcopy(cell_t))
|
|
778
|
+
if known_dimensionsf and current_cell == row_dimensions:
|
|
779
|
+
new_row = copy.deepcopy(row_template)
|
|
780
|
+
current_row_cells = []
|
|
781
|
+
|
|
782
|
+
for item in inner_content:
|
|
783
|
+
current_row_cells.append(item)
|
|
784
|
+
inner_content.clear()
|
|
785
|
+
|
|
786
|
+
new_row["content"] = current_row_cells
|
|
787
|
+
table_content.append(copy.deepcopy(new_row))
|
|
788
|
+
current_cell = 0
|
|
789
|
+
else:
|
|
790
|
+
logger.error(
|
|
791
|
+
"[html_to_adf] -> error we've bumped into a non_table_row inside a table?? {}".format(
|
|
792
|
+
table_row.type_of_node
|
|
793
|
+
)
|
|
794
|
+
)
|
|
795
|
+
|
|
796
|
+
row_t["content"] = inner_content
|
|
797
|
+
table_content.append(copy.deepcopy(row_t))
|
|
798
|
+
|
|
799
|
+
if malformed_structure:
|
|
800
|
+
for table_row in part.inner_parts[0].inner_parts:
|
|
801
|
+
row_t = copy.deepcopy(row_template)
|
|
802
|
+
row_content = []
|
|
803
|
+
|
|
804
|
+
for cell in table_row.inner_parts:
|
|
805
|
+
cell_t = copy.deepcopy(inner_template)
|
|
806
|
+
cell_t["type"] = "tableCell"
|
|
807
|
+
cell_t["content"] = [unwrap_part_to_adf_type(cell)]
|
|
808
|
+
row_content.append(cell_t)
|
|
809
|
+
|
|
810
|
+
row_t["content"] = [*row_content]
|
|
811
|
+
|
|
812
|
+
table_content.append(copy.deepcopy(row_t))
|
|
813
|
+
else:
|
|
814
|
+
table_content.pop() # Remove our template
|
|
815
|
+
|
|
816
|
+
resulting_type["content"] = [*table_content]
|
|
817
|
+
|
|
818
|
+
return resulting_type
|
|
819
|
+
|
|
820
|
+
|
|
821
|
+
# HTML -> ADF conversion function for bodies
|
|
822
|
+
def construct_body_content(part: Part) -> dict:
|
|
823
|
+
content = []
|
|
824
|
+
for sub_part in part.inner_parts:
|
|
825
|
+
content.append(unwrap_part_to_adf_type(sub_part))
|
|
826
|
+
return content
|
|
827
|
+
|
|
828
|
+
|
|
829
|
+
def unwrap_part_to_adf_type(part: Part) -> dict | list:
|
|
830
|
+
"""
|
|
831
|
+
Takes in a Part, and translates that part into ADF via it's type_of_node property
|
|
832
|
+
```
|
|
833
|
+
Example of output
|
|
834
|
+
resulting_type = {
|
|
835
|
+
"type": "",
|
|
836
|
+
"content": "", # not required, applicable only in containers
|
|
837
|
+
"attrs": "", # not required
|
|
838
|
+
"marks": "", # not required
|
|
839
|
+
}
|
|
840
|
+
```
|
|
841
|
+
|
|
842
|
+
Parameters:
|
|
843
|
+
part (Part): The Part we're looking to translate to ADF.
|
|
844
|
+
|
|
845
|
+
Returns:
|
|
846
|
+
An ADF formatted dict
|
|
847
|
+
or a list of ADF formatted dicts (only if we construct a Major node, like a body or html)
|
|
848
|
+
"""
|
|
849
|
+
try:
|
|
850
|
+
type_comparisons = {
|
|
851
|
+
"paragraph": construct_paragraph_blob,
|
|
852
|
+
"heading": construct_heading_blob,
|
|
853
|
+
"heading1": construct_heading_blob,
|
|
854
|
+
"heading2": construct_heading_blob,
|
|
855
|
+
"heading3": construct_heading_blob,
|
|
856
|
+
"heading4": construct_heading_blob,
|
|
857
|
+
"heading5": construct_heading_blob,
|
|
858
|
+
"heading6": construct_heading_blob,
|
|
859
|
+
"tablecell": construct_paragraph_blob,
|
|
860
|
+
"disconnected_text": construct_paragraph_blob,
|
|
861
|
+
"body": construct_body_content,
|
|
862
|
+
"html": construct_body_content,
|
|
863
|
+
"text": generate_adf_text_content, # shouldn't get hit?
|
|
864
|
+
"tablebase": construct_table_blob,
|
|
865
|
+
}
|
|
866
|
+
adf_content: dict = type_comparisons[part.type_of_node](part)
|
|
867
|
+
except Exception as ex:
|
|
868
|
+
logger.error(
|
|
869
|
+
"[html_to_adf - unwrap_part_to_adf_type] -> error unwrapping: {}\n{}".format(
|
|
870
|
+
part.__dict__,
|
|
871
|
+
ex
|
|
872
|
+
)
|
|
873
|
+
)
|
|
874
|
+
return adf_content
|
|
875
|
+
|
|
876
|
+
|
|
877
|
+
def join_document_shards(shards: list[list]) -> dict:
|
|
878
|
+
"""
|
|
879
|
+
Joins multiple document shards to a combined document
|
|
880
|
+
|
|
881
|
+
Document shards are segmented into 3 possible parts ['preamble'], ['body'], ['epilogue']
|
|
882
|
+
|
|
883
|
+
Parameters:
|
|
884
|
+
shards (list[list]) - Our shards hopefully retrieved from get_document_shards()
|
|
885
|
+
|
|
886
|
+
Returns:
|
|
887
|
+
An ADF document (dict)
|
|
888
|
+
"""
|
|
889
|
+
|
|
890
|
+
def merge_disconnected_parts(_parts):
|
|
891
|
+
# Process right-to-left, since it makes merging easier
|
|
892
|
+
merged_parts = []
|
|
893
|
+
i = len(_parts) - 1
|
|
894
|
+
|
|
895
|
+
while i >= 0:
|
|
896
|
+
current_part = _parts[i]
|
|
897
|
+
|
|
898
|
+
if current_part.type_of_node == "disconnected_text":
|
|
899
|
+
# Start a new merged part - preserve disconnected_text type
|
|
900
|
+
merged_part = Part("disconnected_text", "")
|
|
901
|
+
merged_part.inner_parts.extend(current_part.inner_parts)
|
|
902
|
+
|
|
903
|
+
# Look backwards for more consecutive disconnected_text parts
|
|
904
|
+
j = i - 1
|
|
905
|
+
while j >= 0 and _parts[j].type_of_node == "disconnected_text":
|
|
906
|
+
# Prepend the inner_parts (since we're going backwards)
|
|
907
|
+
merged_part.inner_parts = (
|
|
908
|
+
_parts[j].inner_parts + merged_part.inner_parts
|
|
909
|
+
)
|
|
910
|
+
j -= 1
|
|
911
|
+
|
|
912
|
+
merged_parts.append(merged_part)
|
|
913
|
+
i = j # Skip all the parts we just merged
|
|
914
|
+
else:
|
|
915
|
+
merged_parts.append(current_part)
|
|
916
|
+
i -= 1
|
|
917
|
+
return merged_parts
|
|
918
|
+
|
|
919
|
+
document = {
|
|
920
|
+
"body": {
|
|
921
|
+
"version": 1,
|
|
922
|
+
"type": "doc",
|
|
923
|
+
"content": [],
|
|
924
|
+
},
|
|
925
|
+
}
|
|
926
|
+
|
|
927
|
+
preamble_parts = shards.get("preamble")
|
|
928
|
+
if preamble_parts:
|
|
929
|
+
merged_parts = merge_disconnected_parts(preamble_parts)
|
|
930
|
+
# Reverse the list since we built it backwards
|
|
931
|
+
shards["preamble"] = list(reversed(merged_parts))
|
|
932
|
+
|
|
933
|
+
# repeat the same for epilogue parts
|
|
934
|
+
epilogue_parts = shards.get("epilogue")
|
|
935
|
+
if epilogue_parts:
|
|
936
|
+
merged_parts = merge_disconnected_parts(epilogue_parts)
|
|
937
|
+
shards["epilogue"] = list(reversed(merged_parts))
|
|
938
|
+
|
|
939
|
+
# repeat the same for body
|
|
940
|
+
body_parts = shards.get("body")
|
|
941
|
+
if body_parts:
|
|
942
|
+
merged_parts = merge_disconnected_parts(body_parts)
|
|
943
|
+
shards["body"] = list(reversed(merged_parts))
|
|
944
|
+
|
|
945
|
+
for shard_type in shards:
|
|
946
|
+
for sub_parts in shards[shard_type]:
|
|
947
|
+
resulting_list = []
|
|
948
|
+
adf_sub_doc = unwrap_part_to_adf_type(sub_parts)
|
|
949
|
+
|
|
950
|
+
# Preambles and epilogues follow this
|
|
951
|
+
if isinstance(adf_sub_doc, dict):
|
|
952
|
+
resulting_list.append(adf_sub_doc)
|
|
953
|
+
|
|
954
|
+
if isinstance(adf_sub_doc, list):
|
|
955
|
+
|
|
956
|
+
for item in adf_sub_doc:
|
|
957
|
+
if isinstance(item, list):
|
|
958
|
+
resulting_list += item
|
|
959
|
+
if isinstance(item, dict):
|
|
960
|
+
resulting_list.append(item)
|
|
961
|
+
document["body"]["content"] += resulting_list
|
|
962
|
+
|
|
963
|
+
return document
|
|
964
|
+
|
|
965
|
+
|
|
966
|
+
def convert_html_to_adf(html: str, output_request_structure=False) -> dict | None:
|
|
967
|
+
"""Primary function of this helper, this converts any provided html-to-adf so long as it falls in the confines of `VALID_PARTS`
|
|
968
|
+
|
|
969
|
+
Parameters:
|
|
970
|
+
html (str): Any html formatted text, preferably not malformed or we may just reject it.
|
|
971
|
+
output_request_structure (bool): Do we want the structure to be 'request' payload friendly (keep 'body': {})
|
|
972
|
+
|
|
973
|
+
Returns:
|
|
974
|
+
|
|
975
|
+
"""
|
|
976
|
+
try:
|
|
977
|
+
# Sanitize incoming html
|
|
978
|
+
sanitized_html = sanitize_html(html, VALID_PARTS)
|
|
979
|
+
|
|
980
|
+
# Branch each segment of html into it's own context
|
|
981
|
+
document_shards = get_document_shards(html=sanitized_html)
|
|
982
|
+
|
|
983
|
+
# Join each document segment together and unify into an adf document
|
|
984
|
+
document = join_document_shards(document_shards)
|
|
985
|
+
|
|
986
|
+
if not output_request_structure:
|
|
987
|
+
return document["body"]
|
|
988
|
+
except Exception as ex:
|
|
989
|
+
logger.error(
|
|
990
|
+
"[html_to_adf] -> Error occurred trying to parse html to adf: {}".format(
|
|
991
|
+
ex
|
|
992
|
+
),
|
|
993
|
+
exc_info=True,
|
|
994
|
+
)
|
|
995
|
+
return None
|
|
996
|
+
return document
|
|
997
|
+
|
|
998
|
+
|
|
999
|
+
def export_document(document):
|
|
1000
|
+
with open("output.json", "w") as f:
|
|
1001
|
+
json.dump(document, f, indent=2)
|
|
1002
|
+
|
|
1003
|
+
|
|
1004
|
+
def import_html_to_str(name):
|
|
1005
|
+
html = ""
|
|
1006
|
+
with open(name, "r") as f:
|
|
1007
|
+
html = f.read()
|
|
1008
|
+
return html
|