foamToPython 0.0.1__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- PODopenFOAM/__init__.py +7 -0
- PODopenFOAM/ofmodes.py +1228 -0
- foamToPython/__init__.py +11 -0
- foamToPython/headerEnd.py +22 -0
- foamToPython/readOFField.py +1275 -0
- foamToPython/readOFList.py +205 -0
- foamtopython-0.0.1.dist-info/METADATA +111 -0
- foamtopython-0.0.1.dist-info/RECORD +10 -0
- foamtopython-0.0.1.dist-info/WHEEL +5 -0
- foamtopython-0.0.1.dist-info/top_level.txt +2 -0
|
@@ -0,0 +1,205 @@
|
|
|
1
|
+
import numpy as np
|
|
2
|
+
import sys
|
|
3
|
+
import re
|
|
4
|
+
from typing import List, Tuple, Optional
|
|
5
|
+
from .headerEnd import *
|
|
6
|
+
|
|
7
|
+
|
|
8
|
+
def _num_list(subcontent: List[bytes]) -> Tuple[int, int]:
|
|
9
|
+
for idx, line in enumerate(subcontent):
|
|
10
|
+
try:
|
|
11
|
+
return int(line), idx
|
|
12
|
+
except ValueError:
|
|
13
|
+
continue
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
def _check_data_type(data: bytes) -> str:
|
|
17
|
+
data = data.decode("utf-8").strip()
|
|
18
|
+
if re.match(r"^\(\s*-?\d+(\.\d+)?\s+-?\d+(\.\d+)?\s+-?\d+(\.\d+)?\s*\)$", data):
|
|
19
|
+
return "vector"
|
|
20
|
+
elif re.match(r"^-?\d+(\.\d+)?([eE][-+]?\d+)?$", data):
|
|
21
|
+
return "scalar"
|
|
22
|
+
elif re.match(r"^\d+$", data):
|
|
23
|
+
return "label"
|
|
24
|
+
else:
|
|
25
|
+
sys.exit("Unknown data_type. please use 'label', 'scalar' or 'vector'.")
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def _extractList(content: List[bytes], data_type: Optional[str]) -> np.ndarray:
|
|
29
|
+
num_data_, data_idx = _num_list(content)
|
|
30
|
+
data_start_idx = data_idx + 2
|
|
31
|
+
# Extract relevant lines containing coordinates
|
|
32
|
+
string_coords = content[data_start_idx : data_start_idx + num_data_]
|
|
33
|
+
|
|
34
|
+
if data_type is None:
|
|
35
|
+
data_type = _check_data_type(string_coords[0])
|
|
36
|
+
|
|
37
|
+
if data_type == "label":
|
|
38
|
+
# Join all lines and replace unwanted characters once
|
|
39
|
+
joined_coords = b" ".join(string_coords).replace(b"\n", b"")
|
|
40
|
+
# Convert to a numpy array in one go
|
|
41
|
+
data_array = np.fromstring(joined_coords, sep=" ", dtype=int)
|
|
42
|
+
|
|
43
|
+
elif data_type == "scalar":
|
|
44
|
+
# Join all lines and replace unwanted characters once
|
|
45
|
+
joined_coords = b" ".join(string_coords).replace(b"\n", b"")
|
|
46
|
+
# Convert to a numpy array in one go
|
|
47
|
+
data_array = np.fromstring(joined_coords, sep=" ", dtype=float)
|
|
48
|
+
|
|
49
|
+
elif data_type == "vector":
|
|
50
|
+
# Join all lines and replace unwanted characters once
|
|
51
|
+
joined_coords = (
|
|
52
|
+
b" ".join(string_coords)
|
|
53
|
+
.replace(b")", b"")
|
|
54
|
+
.replace(b"(", b"")
|
|
55
|
+
.replace(b"\n", b"")
|
|
56
|
+
)
|
|
57
|
+
# Convert to a numpy array in one go
|
|
58
|
+
data_array = np.fromstring(joined_coords, sep=" ", dtype=float).reshape(
|
|
59
|
+
num_data_, 3
|
|
60
|
+
)
|
|
61
|
+
|
|
62
|
+
else:
|
|
63
|
+
sys.exit("Unknown data_type. please use 'label', 'scalar' or 'vector'.")
|
|
64
|
+
|
|
65
|
+
return data_array
|
|
66
|
+
|
|
67
|
+
|
|
68
|
+
def _extractListList(content: List[bytes], data_type: str) -> np.ndarray:
|
|
69
|
+
num_list_, start_idx = _num_list(content)
|
|
70
|
+
# print(f"The number of list is: {num_list_}")
|
|
71
|
+
subcontent = content[start_idx + 1 :]
|
|
72
|
+
data_list = []
|
|
73
|
+
for i in range(num_list_):
|
|
74
|
+
num_data_, data_idx = _num_list(subcontent)
|
|
75
|
+
data_start_idx = data_idx + 2
|
|
76
|
+
# Extract relevant lines containing coordinates
|
|
77
|
+
string_coords = subcontent[data_start_idx : data_start_idx + num_data_]
|
|
78
|
+
|
|
79
|
+
if data_type == "label":
|
|
80
|
+
# Join all lines and replace unwanted characters once
|
|
81
|
+
joined_coords = b" ".join(string_coords).replace(b"\n", b"")
|
|
82
|
+
# Convert to a numpy array in one go
|
|
83
|
+
data_list.append(np.fromstring(joined_coords, sep=" ", dtype=int))
|
|
84
|
+
|
|
85
|
+
elif data_type == "scalar":
|
|
86
|
+
# Join all lines and replace unwanted characters once
|
|
87
|
+
joined_coords = b" ".join(string_coords).replace(b"\n", b"")
|
|
88
|
+
# Convert to a numpy array in one go
|
|
89
|
+
data_list.append(np.fromstring(joined_coords, sep=" ", dtype=float))
|
|
90
|
+
|
|
91
|
+
elif data_type == "vector":
|
|
92
|
+
# Join all lines and replace unwanted characters once
|
|
93
|
+
joined_coords = (
|
|
94
|
+
b" ".join(string_coords)
|
|
95
|
+
.replace(b")", b"")
|
|
96
|
+
.replace(b"(", b"")
|
|
97
|
+
.replace(b"\n", b"")
|
|
98
|
+
)
|
|
99
|
+
# Convert to a numpy array in one go
|
|
100
|
+
data_list.append(
|
|
101
|
+
np.fromstring(joined_coords, sep=" ", dtype=float).reshape(num_data_, 3)
|
|
102
|
+
)
|
|
103
|
+
else:
|
|
104
|
+
sys.exit("Unknown data_type. please use 'label', 'scalar' or 'vector'.")
|
|
105
|
+
|
|
106
|
+
subcontent = subcontent[data_start_idx + num_data_ + 1 :]
|
|
107
|
+
|
|
108
|
+
return np.array(data_list)
|
|
109
|
+
|
|
110
|
+
|
|
111
|
+
def readListList(fileName: str, data_type: str) -> np.ndarray:
|
|
112
|
+
try:
|
|
113
|
+
with open(fileName, "rb") as f:
|
|
114
|
+
pass
|
|
115
|
+
except FileNotFoundError:
|
|
116
|
+
sys.exit(f"File {fileName} not found. Please check the file path.")
|
|
117
|
+
with open(f"{fileName}", "rb") as f:
|
|
118
|
+
return _extractListList(f.readlines(), data_type)
|
|
119
|
+
|
|
120
|
+
|
|
121
|
+
def _extractUniformList(file: List[bytes], data_type: str) -> Tuple[int, np.ndarray]:
|
|
122
|
+
for line in file:
|
|
123
|
+
line = line.decode("utf-8").strip()
|
|
124
|
+
if "{" in line and "}" in line:
|
|
125
|
+
length, data = line.split("{")
|
|
126
|
+
length = int(length.strip())
|
|
127
|
+
data = data.replace("}", "").strip()
|
|
128
|
+
if data_type == "label":
|
|
129
|
+
return length, np.array(int(data))
|
|
130
|
+
elif data_type == "scalar":
|
|
131
|
+
return length, np.array(float(data))
|
|
132
|
+
elif data_type == "vector":
|
|
133
|
+
vector_values = data.strip("()").split()
|
|
134
|
+
return length, np.array(
|
|
135
|
+
[
|
|
136
|
+
float(vector_values[0]),
|
|
137
|
+
float(vector_values[1]),
|
|
138
|
+
float(vector_values[2]),
|
|
139
|
+
]
|
|
140
|
+
)
|
|
141
|
+
else:
|
|
142
|
+
sys.exit("Unknown data_type. please use 'label', 'scalar' or 'vector'.")
|
|
143
|
+
|
|
144
|
+
|
|
145
|
+
def readList(fileName: str, data_type: str, fullLength: bool = True) -> np.ndarray:
|
|
146
|
+
try:
|
|
147
|
+
with open(fileName, "rb") as f:
|
|
148
|
+
pass
|
|
149
|
+
except FileNotFoundError:
|
|
150
|
+
sys.exit(f"File {fileName} not found. Please check the file path.")
|
|
151
|
+
with open(f"{fileName}", "rb") as f:
|
|
152
|
+
file_content = f.readlines()
|
|
153
|
+
file_length = len(file_content)
|
|
154
|
+
if file_length == 1:
|
|
155
|
+
length, data = _extractUniformList(file_content, data_type)
|
|
156
|
+
if fullLength:
|
|
157
|
+
if data_type == "vector":
|
|
158
|
+
return np.tile(data, (length, 1))
|
|
159
|
+
else:
|
|
160
|
+
return np.repeat(data, length, axis=0)
|
|
161
|
+
else:
|
|
162
|
+
return data
|
|
163
|
+
else:
|
|
164
|
+
return _extractList(file_content, data_type)
|
|
165
|
+
|
|
166
|
+
|
|
167
|
+
def writeList(
|
|
168
|
+
data: np.ndarray, data_type: str, fileName: str, object_name: str = "None"
|
|
169
|
+
) -> None:
|
|
170
|
+
"""
|
|
171
|
+
Write data to a file
|
|
172
|
+
:param data: data to write
|
|
173
|
+
:param data_type: data type
|
|
174
|
+
:param fileName: file name
|
|
175
|
+
:return: None
|
|
176
|
+
"""
|
|
177
|
+
|
|
178
|
+
with open(fileName, "w") as f:
|
|
179
|
+
output = []
|
|
180
|
+
|
|
181
|
+
thisHeader = header.replace("className;", f"{data_type}List;")
|
|
182
|
+
if object_name != "None":
|
|
183
|
+
thisHeader = thisHeader.replace(
|
|
184
|
+
"object data;", f"object {object_name};"
|
|
185
|
+
)
|
|
186
|
+
output.append(thisHeader + "\n\n")
|
|
187
|
+
else:
|
|
188
|
+
output.append(thisHeader + "\n\n")
|
|
189
|
+
|
|
190
|
+
output.append(f"{data.shape[0]}\n")
|
|
191
|
+
output.append("(\n")
|
|
192
|
+
if data_type == "label":
|
|
193
|
+
for point in data:
|
|
194
|
+
output.append(f"{point:d}\n")
|
|
195
|
+
elif data_type == "scalar":
|
|
196
|
+
for point in data:
|
|
197
|
+
output.append(f"{point:.8e}\n")
|
|
198
|
+
elif data_type == "vector":
|
|
199
|
+
for point in data:
|
|
200
|
+
output.append(f"({point[0]:.8e} {point[1]:.8e} {point[2]:.8e})\n")
|
|
201
|
+
else:
|
|
202
|
+
sys.exit("Unknown data_type. please use 'label', 'scalar' or 'vector'.")
|
|
203
|
+
output.append(")\n")
|
|
204
|
+
output.append(ender)
|
|
205
|
+
f.write("".join(output))
|
|
@@ -0,0 +1,111 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: foamToPython
|
|
3
|
+
Version: 0.0.1
|
|
4
|
+
Summary: A py package to read and write OpenFOAM data
|
|
5
|
+
Author-email: Shenhui_Ruan <shenhui.ruan@kit.edu>
|
|
6
|
+
Requires-Python: >=3.8
|
|
7
|
+
Description-Content-Type: text/markdown
|
|
8
|
+
Requires-Dist: numpy
|
|
9
|
+
|
|
10
|
+
[foamToPython](https://github.com/Ruansh233/foamToPython.git) is an ongoing repository to read and write the OpenFOAM field and numpy array. You can also perform Proper Orthogonal Decomposition (POD) to OpenFOAM fields with this package. It can handle both serial and parallel OpenFOAM case. The package is developed in Python 3.8+ and depends on numpy.
|
|
11
|
+
|
|
12
|
+
## Features
|
|
13
|
+
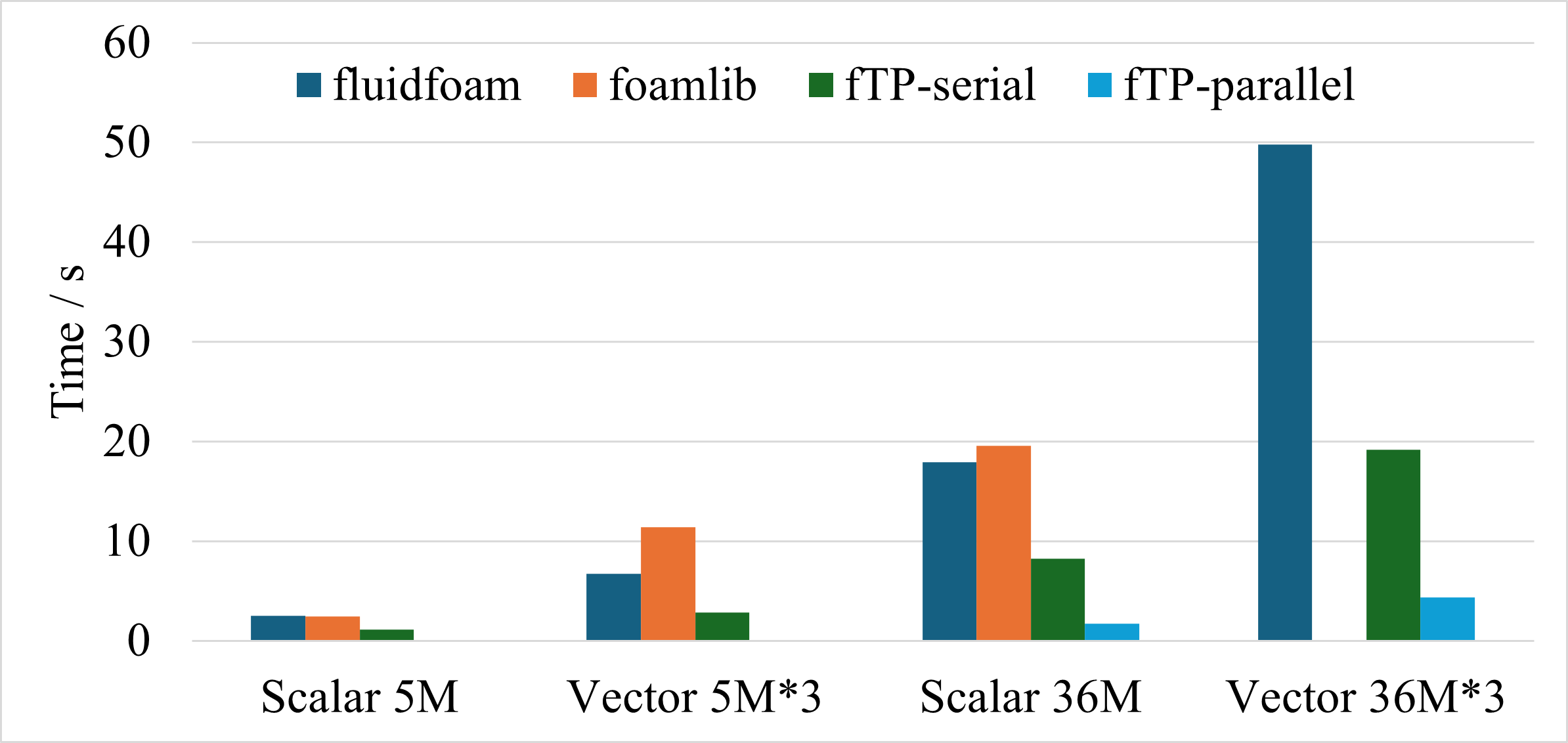
It is about __10 times faster__ than two widely used packages, [FluidFoam](https://github.com/fluiddyn/fluidfoam) and [foamlib](https://github.com/gerlero/foamlib), in reading fields. Moreover, it is capable to read and write parallel OpenFOAM case. The comparison of the performance is shown in the following figure.
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
|
|
17
|
+
The comparsion is performed for 4 conditions.
|
|
18
|
+
1. Scalar fields with 5 million cells.
|
|
19
|
+
2. Vector fields with 5 million cells.
|
|
20
|
+
3. Scalar fields with 36 million cells.
|
|
21
|
+
4. Vector fields with 36 million cells.
|
|
22
|
+
|
|
23
|
+
This test is performed on a cluster node with Intel Xeon Platinum 8358 CPU 64 cores @ 2.60GHz, 256GB RAM, and Red Hat Enterprise Linux.
|
|
24
|
+
|
|
25
|
+
foamToPython is ten times faster than FluidFoam and foamlib when reading parallel case with 36 million cells. Note that the aforementioned packages have more functions compared to the current library. [PyFoam](https://pypi.org/project/PyFoam/) is not involved in the comparsion due to the problem of version compatibility.
|
|
26
|
+
|
|
27
|
+
## Installation
|
|
28
|
+
You can install the package via pip:
|
|
29
|
+
```bash
|
|
30
|
+
pip install foamToPython
|
|
31
|
+
```
|
|
32
|
+
Or you can clone the repository and install it manually:
|
|
33
|
+
```bash
|
|
34
|
+
pip install git+https://github.com/Ruansh233/foamToPython.git
|
|
35
|
+
```
|
|
36
|
+
|
|
37
|
+
## Usage and Examples
|
|
38
|
+
|
|
39
|
+
### <span style="color:blue;">OFField</span> class
|
|
40
|
+
The class could read OpenFOAM fields.
|
|
41
|
+
It can process volScalarField or volVectorField, either uniform or non-uniform internalField.
|
|
42
|
+
|
|
43
|
+
#### read field, e.g., U
|
|
44
|
+
`U = readOFData.OFField('case/1/U', 'vector', read_data=True)`
|
|
45
|
+
|
|
46
|
+
The arguments are:
|
|
47
|
+
1. _filename_: the path of the field file.
|
|
48
|
+
2. _data_type_: the type of the field, e.g., "scalar", "vector", "label".
|
|
49
|
+
3. _read_data_: whether to read the field when initializing the class.
|
|
50
|
+
4. _parallel_: whether the case is run in parallel.
|
|
51
|
+
|
|
52
|
+
If read_data is False, the field will not be read when initializing the class. You can use `U._readField()` to read it later, or access `U.internalField` or `U.boundaryField`, which will trigger the reading of the field.
|
|
53
|
+
|
|
54
|
+
The package can read parallel case, e.g., `U = readOFData.OFField('case/1/U', 'vector', parallel=True)`.
|
|
55
|
+
|
|
56
|
+
#### load <span style="color:blue;">internalField</span> and <span style="color:blue;">boundaryField</span>
|
|
57
|
+
|
|
58
|
+
`U_cell = U.internalField`
|
|
59
|
+
`U_boundary = U.boundaryField`
|
|
60
|
+
|
|
61
|
+
1. _U_cell_ is a numpy array, store the fields values. The length is 1 for the uniform internal field.
|
|
62
|
+
2. _U_boundary_ is a dict store each patches. For each patch, it contain _type_ for the type of boundary. If the _type_ is _fixedValue_, the numpy array can be accessed by the key _value_. For example: `U.boundaryField['velocityInlet']['value']`
|
|
63
|
+
|
|
64
|
+
For parallel case, both internalField and boundaryField are read from all processors and stored as lists. For example, `U.internalField[0]` is the internalField from processor 0.
|
|
65
|
+
|
|
66
|
+
#### <span style="color:blue;">writeField</span>
|
|
67
|
+
You can modify the data of _U_ and then write it as OF field.
|
|
68
|
+
|
|
69
|
+
The arguments are:
|
|
70
|
+
1. _path_: the path to write the field. It can contain `<timeDir>` and `<fieldName>`, which will be replaced by the arguments `timeDir` and `fieldName` if provided.
|
|
71
|
+
2. _timeDir_: the time directory to write the field. Default is `None`.
|
|
72
|
+
3. _fieldName_: the name of the field to write. Default is `None`.
|
|
73
|
+
|
|
74
|
+
Same function can be used to write parallel case, e.g., `U.writeField('case/<timeDir>/<fieldName>')`.
|
|
75
|
+
|
|
76
|
+
Therefore, you can use two types of inputs, e.g.,
|
|
77
|
+
1. `U.writeField('case/<timeDir>/<fieldName>')`.
|
|
78
|
+
2. `U.writeField('case/test', timeDir=<timeDir>, fieldName=<fieldName>)`. Note that `timeDir` and `fieldName` are needed when using **Paraview** to read the fields.
|
|
79
|
+
|
|
80
|
+
### <span style="color:blue;">readList</span> function
|
|
81
|
+
The function could read field value like velocity and pressure.
|
|
82
|
+
The data type are: "lable", "scalar", "vector".
|
|
83
|
+
|
|
84
|
+
For example: `U = readList("1/U", "vector").`
|
|
85
|
+
|
|
86
|
+
### <span style="color:blue;">readListList</span> function
|
|
87
|
+
The function could read ListList, like the cellZones file.
|
|
88
|
+
The data type are: "lable", "scalar", "vector".
|
|
89
|
+
|
|
90
|
+
For example: `cellZones = readList("constant/polyMesh/cellZones", "label")`.
|
|
91
|
+
|
|
92
|
+
### Perform <span style="color:blue;">POD</span> to openfoam fields.
|
|
93
|
+
Please check the submodule _PODopenFOAM_ and the class under it _PODmodes_, which can be called `foamToPython.PODmodes`. It can be created as,
|
|
94
|
+
|
|
95
|
+
`pod = PODmodes(U, POD_algo=<POD_algo>, rank=<rank>)`.
|
|
96
|
+
|
|
97
|
+
The arguments are:
|
|
98
|
+
1. _U_: the OFField class instance, which contains the data to perform POD.
|
|
99
|
+
2. _POD_algo_: the algorithm to perform POD, can be "svd" or "eigen". Default is "eigen".
|
|
100
|
+
3. _rank_: the number of modes to compute. Default is 10, which means 10 modes are computed.
|
|
101
|
+
|
|
102
|
+
The modes can be exported with OpenFOAM format using
|
|
103
|
+
`pod.writeModes(outputDir, fieldName=<fieldName>)`.
|
|
104
|
+
|
|
105
|
+
The arguments are:
|
|
106
|
+
1. _outputDir_: the directory to write the modes. The modes will be written in folders `outputDir/1`, `outputDir/2`, ..., `outputDir/rank`.
|
|
107
|
+
2. _fieldName_: the name of the field to write. Default is `None`.
|
|
108
|
+
|
|
109
|
+
### Parallel case
|
|
110
|
+
The package can read and write parallel case.
|
|
111
|
+
However, the speed is slower than the serial case, and it will be improved in the future.
|
|
@@ -0,0 +1,10 @@
|
|
|
1
|
+
PODopenFOAM/__init__.py,sha256=b69xkbdteJB1NKD0pzbvpZlv5XecgG6rMWqCufjWtvc,88
|
|
2
|
+
PODopenFOAM/ofmodes.py,sha256=ijbToWofpoAS1IH6NZ-ukcIIS2NzJPzexSi7tgha9BI,45123
|
|
3
|
+
foamToPython/__init__.py,sha256=gkxoBFtrheK7_4ypMfvNpzTtuxODXgC14O59nUrtRo8,202
|
|
4
|
+
foamToPython/headerEnd.py,sha256=71YKtxBeTVvNVqwesjTPyN9UUFdLRVnaQrdme5RFp2I,931
|
|
5
|
+
foamToPython/readOFField.py,sha256=YVn40Z7p305rPVhohs7vIuuOb2ee6o_Vh6rI8roiPVA,47006
|
|
6
|
+
foamToPython/readOFList.py,sha256=Vj5viT3NFnCOhKY_rDbohrvgxu2Trt81rR_K1zMmU5w,7384
|
|
7
|
+
foamtopython-0.0.1.dist-info/METADATA,sha256=ufh0PkLQyKfHDvRZX9M_MqudqwhsxM2e0bszFcHF-SM,5823
|
|
8
|
+
foamtopython-0.0.1.dist-info/WHEEL,sha256=wUyA8OaulRlbfwMtmQsvNngGrxQHAvkKcvRmdizlJi0,92
|
|
9
|
+
foamtopython-0.0.1.dist-info/top_level.txt,sha256=MK_8dURMuIU0_VSaR3Z0upsnsFKlfvgeAd2gqXURjRM,25
|
|
10
|
+
foamtopython-0.0.1.dist-info/RECORD,,
|