cotengrust 0.2.1__cp313-cp313-win_arm64.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- cotengrust/__init__.py +5 -0
- cotengrust/__init__.pyi +260 -0
- cotengrust/cotengrust.cp313-win_arm64.pyd +0 -0
- cotengrust/py.typed +0 -0
- cotengrust-0.2.1.dist-info/METADATA +371 -0
- cotengrust-0.2.1.dist-info/RECORD +9 -0
- cotengrust-0.2.1.dist-info/WHEEL +4 -0
- cotengrust-0.2.1.dist-info/licenses/LICENSE +661 -0
- cotengrust-0.2.1.dist-info/sboms/cotengrust.cyclonedx.json +906 -0
cotengrust/__init__.py
ADDED
cotengrust/__init__.pyi
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
1
|
+
# This file is automatically generated by pyo3_stub_gen
|
|
2
|
+
# ruff: noqa: E501, F401
|
|
3
|
+
|
|
4
|
+
import typing
|
|
5
|
+
|
|
6
|
+
def find_subgraphs(
|
|
7
|
+
inputs: typing.Sequence[typing.Sequence[str]],
|
|
8
|
+
output: typing.Sequence[str],
|
|
9
|
+
size_dict: typing.Mapping[str, float],
|
|
10
|
+
) -> list[list[int]]:
|
|
11
|
+
r"""
|
|
12
|
+
Find all disconnected subgraphs of a specified contraction.
|
|
13
|
+
"""
|
|
14
|
+
...
|
|
15
|
+
|
|
16
|
+
def optimize_greedy(
|
|
17
|
+
inputs: typing.Sequence[typing.Sequence[str]],
|
|
18
|
+
output: typing.Sequence[str],
|
|
19
|
+
size_dict: typing.Mapping[str, float],
|
|
20
|
+
costmod: typing.Optional[float] = None,
|
|
21
|
+
temperature: typing.Optional[float] = None,
|
|
22
|
+
seed: typing.Optional[int] = None,
|
|
23
|
+
simplify: typing.Optional[bool] = None,
|
|
24
|
+
use_ssa: typing.Optional[bool] = None,
|
|
25
|
+
) -> list[list[int]]:
|
|
26
|
+
r"""
|
|
27
|
+
Find a contraction path using a (randomizable) greedy algorithm.
|
|
28
|
+
|
|
29
|
+
Parameters
|
|
30
|
+
----------
|
|
31
|
+
inputs : Sequence[Sequence[str]]
|
|
32
|
+
The indices of each input tensor.
|
|
33
|
+
output : Sequence[str]
|
|
34
|
+
The indices of the output tensor.
|
|
35
|
+
size_dict : dict[str, int]
|
|
36
|
+
A dictionary mapping indices to their dimension.
|
|
37
|
+
costmod : float, optional
|
|
38
|
+
When assessing local greedy scores how much to weight the size of the
|
|
39
|
+
tensors removed compared to the size of the tensor added::
|
|
40
|
+
|
|
41
|
+
score = size_ab / costmod - (size_a + size_b) * costmod
|
|
42
|
+
|
|
43
|
+
This can be a useful hyper-parameter to tune.
|
|
44
|
+
temperature : float, optional
|
|
45
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
46
|
+
score. This is implemented as::
|
|
47
|
+
|
|
48
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
49
|
+
|
|
50
|
+
which implements boltzmann sampling.
|
|
51
|
+
simplify : bool, optional
|
|
52
|
+
Whether to perform simplifications before optimizing. These are:
|
|
53
|
+
|
|
54
|
+
- ignore any indices that appear in all terms
|
|
55
|
+
- combine any repeated indices within a single term
|
|
56
|
+
- reduce any non-output indices that only appear on a single term
|
|
57
|
+
- combine any scalar terms
|
|
58
|
+
- combine any tensors with matching indices (hadamard products)
|
|
59
|
+
|
|
60
|
+
Such simpifications may be required in the general case for the proper
|
|
61
|
+
functioning of the core optimization, but may be skipped if the input
|
|
62
|
+
indices are already in a simplified form.
|
|
63
|
+
use_ssa : bool, optional
|
|
64
|
+
Whether to return the contraction path in 'single static assignment'
|
|
65
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
66
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
67
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
68
|
+
|
|
69
|
+
Returns
|
|
70
|
+
-------
|
|
71
|
+
path : list[list[int]]
|
|
72
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
73
|
+
may also have single term contractions if `simplify=True`.
|
|
74
|
+
"""
|
|
75
|
+
...
|
|
76
|
+
|
|
77
|
+
def optimize_optimal(
|
|
78
|
+
inputs: typing.Sequence[typing.Sequence[str]],
|
|
79
|
+
output: typing.Sequence[str],
|
|
80
|
+
size_dict: typing.Mapping[str, float],
|
|
81
|
+
minimize: typing.Optional[str] = None,
|
|
82
|
+
cost_cap: typing.Optional[float] = None,
|
|
83
|
+
search_outer: typing.Optional[bool] = None,
|
|
84
|
+
simplify: typing.Optional[bool] = None,
|
|
85
|
+
use_ssa: typing.Optional[bool] = None,
|
|
86
|
+
) -> list[list[int]]:
|
|
87
|
+
r"""
|
|
88
|
+
Find an optimal contraction ordering.
|
|
89
|
+
|
|
90
|
+
Parameters
|
|
91
|
+
----------
|
|
92
|
+
inputs : Sequence[Sequence[str]]
|
|
93
|
+
The indices of each input tensor.
|
|
94
|
+
output : Sequence[str]
|
|
95
|
+
The indices of the output tensor.
|
|
96
|
+
size_dict : dict[str, int]
|
|
97
|
+
The size of each index.
|
|
98
|
+
minimize : str, optional
|
|
99
|
+
The cost function to minimize. The options are:
|
|
100
|
+
|
|
101
|
+
- "flops": minimize with respect to total operation count only
|
|
102
|
+
(also known as contraction cost)
|
|
103
|
+
- "size": minimize with respect to maximum intermediate size only
|
|
104
|
+
(also known as contraction width)
|
|
105
|
+
- 'max': minimize the single most expensive contraction, i.e. the
|
|
106
|
+
asymptotic (in index size) scaling of the contraction
|
|
107
|
+
- 'write' : minimize the sum of all tensor sizes, i.e. memory written
|
|
108
|
+
- 'combo' or 'combo={factor}` : minimize the sum of
|
|
109
|
+
FLOPS + factor * WRITE, with a default factor of 64.
|
|
110
|
+
- 'limit' or 'limit={factor}` : minimize the sum of
|
|
111
|
+
MAX(FLOPS, alpha * WRITE) for each individual contraction, with a
|
|
112
|
+
default factor of 64.
|
|
113
|
+
|
|
114
|
+
'combo' is generally a good default in term of practical hardware
|
|
115
|
+
performance, where both memory bandwidth and compute are limited.
|
|
116
|
+
cost_cap : float, optional
|
|
117
|
+
The maximum cost of a contraction to initially consider. This acts like
|
|
118
|
+
a sieve and is doubled at each iteration until the optimal path can
|
|
119
|
+
be found, but supplying an accurate guess can speed up the algorithm.
|
|
120
|
+
search_outer : bool, optional
|
|
121
|
+
If True, consider outer product contractions. This is much slower but
|
|
122
|
+
theoretically might be required to find the true optimal 'flops'
|
|
123
|
+
ordering. In practical settings (i.e. with minimize='combo'), outer
|
|
124
|
+
products should not be required.
|
|
125
|
+
simplify : bool, optional
|
|
126
|
+
Whether to perform simplifications before optimizing. These are:
|
|
127
|
+
|
|
128
|
+
- ignore any indices that appear in all terms
|
|
129
|
+
- combine any repeated indices within a single term
|
|
130
|
+
- reduce any non-output indices that only appear on a single term
|
|
131
|
+
- combine any scalar terms
|
|
132
|
+
- combine any tensors with matching indices (hadamard products)
|
|
133
|
+
|
|
134
|
+
Such simpifications may be required in the general case for the proper
|
|
135
|
+
functioning of the core optimization, but may be skipped if the input
|
|
136
|
+
indices are already in a simplified form.
|
|
137
|
+
use_ssa : bool, optional
|
|
138
|
+
Whether to return the contraction path in 'single static assignment'
|
|
139
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
140
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
141
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
142
|
+
|
|
143
|
+
Returns
|
|
144
|
+
-------
|
|
145
|
+
path : list[list[int]]
|
|
146
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
147
|
+
may also have single term contractions if `simplify=True`.
|
|
148
|
+
"""
|
|
149
|
+
...
|
|
150
|
+
|
|
151
|
+
def optimize_random_greedy_track_flops(
|
|
152
|
+
inputs: typing.Sequence[typing.Sequence[str]],
|
|
153
|
+
output: typing.Sequence[str],
|
|
154
|
+
size_dict: typing.Mapping[str, float],
|
|
155
|
+
ntrials: int,
|
|
156
|
+
costmod: typing.Optional[tuple[float, float]] = None,
|
|
157
|
+
temperature: typing.Optional[tuple[float, float]] = None,
|
|
158
|
+
seed: typing.Optional[int] = None,
|
|
159
|
+
simplify: typing.Optional[bool] = None,
|
|
160
|
+
use_ssa: typing.Optional[bool] = None,
|
|
161
|
+
) -> tuple[list[list[int]], float]:
|
|
162
|
+
r"""
|
|
163
|
+
Perform a batch of random greedy optimizations, simulteneously tracking
|
|
164
|
+
the best contraction path in terms of flops, so as to avoid constructing a
|
|
165
|
+
separate contraction tree.
|
|
166
|
+
|
|
167
|
+
Parameters
|
|
168
|
+
----------
|
|
169
|
+
inputs : tuple[tuple[str]]
|
|
170
|
+
The indices of each input tensor.
|
|
171
|
+
output : tuple[str]
|
|
172
|
+
The indices of the output tensor.
|
|
173
|
+
size_dict : dict[str, int]
|
|
174
|
+
A dictionary mapping indices to their dimension.
|
|
175
|
+
ntrials : int, optional
|
|
176
|
+
The number of random greedy trials to perform. The default is 1.
|
|
177
|
+
costmod : (float, float), optional
|
|
178
|
+
When assessing local greedy scores how much to weight the size of the
|
|
179
|
+
tensors removed compared to the size of the tensor added::
|
|
180
|
+
|
|
181
|
+
score = size_ab / costmod - (size_a + size_b) * costmod
|
|
182
|
+
|
|
183
|
+
It is sampled uniformly from the given range.
|
|
184
|
+
temperature : (float, float), optional
|
|
185
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
186
|
+
score. This is implemented as::
|
|
187
|
+
|
|
188
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
189
|
+
|
|
190
|
+
which implements boltzmann sampling. It is sampled log-uniformly from
|
|
191
|
+
the given range.
|
|
192
|
+
seed : int, optional
|
|
193
|
+
The seed for the random number generator.
|
|
194
|
+
simplify : bool, optional
|
|
195
|
+
Whether to perform simplifications before optimizing. These are:
|
|
196
|
+
|
|
197
|
+
- ignore any indices that appear in all terms
|
|
198
|
+
- combine any repeated indices within a single term
|
|
199
|
+
- reduce any non-output indices that only appear on a single term
|
|
200
|
+
- combine any scalar terms
|
|
201
|
+
- combine any tensors with matching indices (hadamard products)
|
|
202
|
+
|
|
203
|
+
Such simpifications may be required in the general case for the proper
|
|
204
|
+
functioning of the core optimization, but may be skipped if the input
|
|
205
|
+
indices are already in a simplified form.
|
|
206
|
+
use_ssa : bool, optional
|
|
207
|
+
Whether to return the contraction path in 'single static assignment'
|
|
208
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
209
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
210
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
211
|
+
|
|
212
|
+
Returns
|
|
213
|
+
-------
|
|
214
|
+
path : list[list[int]]
|
|
215
|
+
The best contraction path, given as a sequence of pairs of node
|
|
216
|
+
indices.
|
|
217
|
+
flops : float
|
|
218
|
+
The flops (/ contraction cost / number of multiplications), of the best
|
|
219
|
+
contraction path, given log10.
|
|
220
|
+
"""
|
|
221
|
+
...
|
|
222
|
+
|
|
223
|
+
def optimize_simplify(
|
|
224
|
+
inputs: typing.Sequence[typing.Sequence[str]],
|
|
225
|
+
output: typing.Sequence[str],
|
|
226
|
+
size_dict: typing.Mapping[str, float],
|
|
227
|
+
use_ssa: typing.Optional[bool] = None,
|
|
228
|
+
) -> list[list[int]]:
|
|
229
|
+
r"""
|
|
230
|
+
Find the (partial) contracton path for simplifiactions only.
|
|
231
|
+
|
|
232
|
+
Parameters
|
|
233
|
+
----------
|
|
234
|
+
inputs : Sequence[Sequence[str]]
|
|
235
|
+
The indices of each input tensor.
|
|
236
|
+
output : Sequence[str]
|
|
237
|
+
The indices of the output tensor.
|
|
238
|
+
size_dict : dict[str, int]
|
|
239
|
+
A dictionary mapping indices to their dimension.
|
|
240
|
+
use_ssa : bool, optional
|
|
241
|
+
Whether to return the contraction path in 'single static assignment'
|
|
242
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
243
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
244
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
245
|
+
|
|
246
|
+
Returns
|
|
247
|
+
-------
|
|
248
|
+
path : list[list[int]]
|
|
249
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
250
|
+
may also have single term contractions.
|
|
251
|
+
"""
|
|
252
|
+
...
|
|
253
|
+
|
|
254
|
+
def ssa_to_linear(
|
|
255
|
+
ssa_path: typing.Sequence[typing.Sequence[int]], n: typing.Optional[int] = None
|
|
256
|
+
) -> list[list[int]]:
|
|
257
|
+
r"""
|
|
258
|
+
Convert a SSA path to linear format.
|
|
259
|
+
"""
|
|
260
|
+
...
|
|
Binary file
|
cotengrust/py.typed
ADDED
|
File without changes
|
|
@@ -0,0 +1,371 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: cotengrust
|
|
3
|
+
Version: 0.2.1
|
|
4
|
+
Classifier: Programming Language :: Rust
|
|
5
|
+
Classifier: Programming Language :: Python :: Implementation :: CPython
|
|
6
|
+
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
|
7
|
+
License-File: LICENSE
|
|
8
|
+
Summary: Fast contraction ordering primitives for tensor networks.
|
|
9
|
+
Author-email: Johnnie Gray <johnniemcgray@gmail.com>
|
|
10
|
+
Requires-Python: >=3.9
|
|
11
|
+
Description-Content-Type: text/markdown; charset=UTF-8; variant=GFM
|
|
12
|
+
|
|
13
|
+
# cotengrust
|
|
14
|
+
|
|
15
|
+
`cotengrust` provides fast rust implementations of contraction ordering
|
|
16
|
+
primitives for tensor networks or einsum expressions. The two main functions
|
|
17
|
+
are:
|
|
18
|
+
|
|
19
|
+
- `optimize_optimal(inputs, output, size_dict, **kwargs)`
|
|
20
|
+
- `optimize_greedy(inputs, output, size_dict, **kwargs)`
|
|
21
|
+
|
|
22
|
+
The optimal algorithm is an optimized version of the `opt_einsum` 'dp'
|
|
23
|
+
path - itself an implementation of https://arxiv.org/abs/1304.6112.
|
|
24
|
+
|
|
25
|
+
There is also a variant of the greedy algorithm, which runs `ntrials` of greedy,
|
|
26
|
+
randomized paths and computes and reports the flops cost (log10) simultaneously:
|
|
27
|
+
|
|
28
|
+
- `optimize_random_greedy_track_flops(inputs, output, size_dict, **kwargs)`
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
## Installation
|
|
32
|
+
|
|
33
|
+
`cotengrust` is available for most platforms from
|
|
34
|
+
[PyPI](https://pypi.org/project/cotengrust/):
|
|
35
|
+
|
|
36
|
+
```bash
|
|
37
|
+
pip install cotengrust
|
|
38
|
+
```
|
|
39
|
+
|
|
40
|
+
or if you want to develop locally (which requires [pyo3](https://github.com/PyO3/pyo3)
|
|
41
|
+
and [maturin](https://github.com/PyO3/maturin)):
|
|
42
|
+
|
|
43
|
+
```bash
|
|
44
|
+
git clone https://github.com/jcmgray/cotengrust.git
|
|
45
|
+
cd cotengrust
|
|
46
|
+
maturin develop --release
|
|
47
|
+
```
|
|
48
|
+
(the release flag is very important for assessing performance!).
|
|
49
|
+
|
|
50
|
+
|
|
51
|
+
## Usage
|
|
52
|
+
|
|
53
|
+
If `cotengrust` is installed, then by default `cotengra` will use it for its
|
|
54
|
+
greedy, random-greedy, and optimal subroutines, notably subtree
|
|
55
|
+
reconfiguration. You can also call the routines directly:
|
|
56
|
+
|
|
57
|
+
```python
|
|
58
|
+
import cotengra as ctg
|
|
59
|
+
import cotengrust as ctgr
|
|
60
|
+
|
|
61
|
+
# specify an 8x8 square lattice contraction
|
|
62
|
+
inputs, output, shapes, size_dict = ctg.utils.lattice_equation([8, 8])
|
|
63
|
+
|
|
64
|
+
# find the optimal 'combo' contraction path
|
|
65
|
+
%%time
|
|
66
|
+
path = ctgr.optimize_optimal(inputs, output, size_dict, minimize='combo')
|
|
67
|
+
# CPU times: user 13.7 s, sys: 83.4 ms, total: 13.7 s
|
|
68
|
+
# Wall time: 13.7 s
|
|
69
|
+
|
|
70
|
+
# construct a contraction tree for further introspection
|
|
71
|
+
tree = ctg.ContractionTree.from_path(
|
|
72
|
+
inputs, output, size_dict, path=path
|
|
73
|
+
)
|
|
74
|
+
tree.plot_rubberband()
|
|
75
|
+
```
|
|
76
|
+
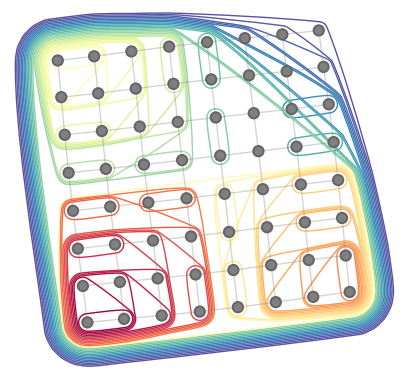
|
|
77
|
+
|
|
78
|
+
|
|
79
|
+
## Benchmarks
|
|
80
|
+
|
|
81
|
+
The following benchmarks illustrate performance and may be a useful comparison point for other implementations.
|
|
82
|
+
|
|
83
|
+
---
|
|
84
|
+
|
|
85
|
+
First, the runtime of the optimal algorithm on random 3-regular graphs,
|
|
86
|
+
with all bond sizes set to 2, for different `mimimize` targets:
|
|
87
|
+
|
|
88
|
+
<img src="https://github.com/user-attachments/assets/e1b906a8-e234-4558-b183-7141c41beb24" width="400">
|
|
89
|
+
|
|
90
|
+
Taken over 20 instances, lines show mean and bands show standard error on mean. Note how much easier it is
|
|
91
|
+
to find optimal paths for the *maximum* intermediate size or cost only (vs. *total* for all contractions).
|
|
92
|
+
While the runtime generally scales exponentially, for some specific geometries it might reduce to
|
|
93
|
+
polynomial.
|
|
94
|
+
|
|
95
|
+
---
|
|
96
|
+
|
|
97
|
+
For very large graphs, the `random_greedy` optimizer is appropriate, and there is a tradeoff between how
|
|
98
|
+
long one lets it run (`ntrials`) and the best cost it achieves. Here we plot these for various
|
|
99
|
+
$N=L\times L$ square grid graphs, with all bond sizes set to 2, for different `ntrials`
|
|
100
|
+
(labelled on each marker):
|
|
101
|
+
|
|
102
|
+
<img src="https://github.com/user-attachments/assets/e319b5cf-25ea-4273-aa0f-4f3acb3beaa6" width="400">
|
|
103
|
+
|
|
104
|
+
Again, data is taken over 20 runs, with lines and bands showing mean and standard error on the mean.
|
|
105
|
+
In most cases 32-64 trials is sufficient to achieve close to convergence, but for larger or harder
|
|
106
|
+
graphs you may need more. The empirical scaling of the random-greedy algorithm is very roughly
|
|
107
|
+
$\mathcal{O}(N^{1.5})$ here.
|
|
108
|
+
|
|
109
|
+
---
|
|
110
|
+
|
|
111
|
+
The depth 20 sycamore quantum circuit amplitude is a standard benchmark nowadays, it is generally
|
|
112
|
+
a harder graph than the 2d lattice. Still, the random-greedy approach can do quite well due to its
|
|
113
|
+
sampling of both temperature and `costmod`:
|
|
114
|
+
|
|
115
|
+
<img src="https://github.com/user-attachments/assets/17b34e11-a755-4ed7-b88b-39b9e5424cfc" width="400">
|
|
116
|
+
|
|
117
|
+
Again, each point is a `ntrials` setting, and the lines and bands show the mean and error on the mean
|
|
118
|
+
respectively, across 20 repeats. The dashed line shows the roughly best known line from other more
|
|
119
|
+
advanced methods.
|
|
120
|
+
|
|
121
|
+
---
|
|
122
|
+
|
|
123
|
+
|
|
124
|
+
## API
|
|
125
|
+
|
|
126
|
+
The optimize functions follow the api of the python implementations in `cotengra.pathfinders.path_basic.py`.
|
|
127
|
+
|
|
128
|
+
```python
|
|
129
|
+
def optimize_optimal(
|
|
130
|
+
inputs,
|
|
131
|
+
output,
|
|
132
|
+
size_dict,
|
|
133
|
+
minimize='flops',
|
|
134
|
+
cost_cap=2,
|
|
135
|
+
search_outer=False,
|
|
136
|
+
simplify=True,
|
|
137
|
+
use_ssa=False,
|
|
138
|
+
):
|
|
139
|
+
"""Find an optimal contraction ordering.
|
|
140
|
+
|
|
141
|
+
Parameters
|
|
142
|
+
----------
|
|
143
|
+
inputs : Sequence[Sequence[str]]
|
|
144
|
+
The indices of each input tensor.
|
|
145
|
+
output : Sequence[str]
|
|
146
|
+
The indices of the output tensor.
|
|
147
|
+
size_dict : dict[str, int]
|
|
148
|
+
The size of each index.
|
|
149
|
+
minimize : str, optional
|
|
150
|
+
The cost function to minimize. The options are:
|
|
151
|
+
|
|
152
|
+
- "flops": minimize with respect to total operation count only
|
|
153
|
+
(also known as contraction cost)
|
|
154
|
+
- "size": minimize with respect to maximum intermediate size only
|
|
155
|
+
(also known as contraction width)
|
|
156
|
+
- 'max': minimize the single most expensive contraction, i.e. the
|
|
157
|
+
asymptotic (in index size) scaling of the contraction
|
|
158
|
+
- 'write' : minimize the sum of all tensor sizes, i.e. memory written
|
|
159
|
+
- 'combo' or 'combo={factor}` : minimize the sum of
|
|
160
|
+
FLOPS + factor * WRITE, with a default factor of 64.
|
|
161
|
+
- 'limit' or 'limit={factor}` : minimize the sum of
|
|
162
|
+
MAX(FLOPS, alpha * WRITE) for each individual contraction, with a
|
|
163
|
+
default factor of 64.
|
|
164
|
+
|
|
165
|
+
'combo' is generally a good default in term of practical hardware
|
|
166
|
+
performance, where both memory bandwidth and compute are limited.
|
|
167
|
+
cost_cap : float, optional
|
|
168
|
+
The maximum cost of a contraction to initially consider. This acts like
|
|
169
|
+
a sieve and is doubled at each iteration until the optimal path can
|
|
170
|
+
be found, but supplying an accurate guess can speed up the algorithm.
|
|
171
|
+
search_outer : bool, optional
|
|
172
|
+
If True, consider outer product contractions. This is much slower but
|
|
173
|
+
theoretically might be required to find the true optimal 'flops'
|
|
174
|
+
ordering. In practical settings (i.e. with minimize='combo'), outer
|
|
175
|
+
products should not be required.
|
|
176
|
+
simplify : bool, optional
|
|
177
|
+
Whether to perform simplifications before optimizing. These are:
|
|
178
|
+
|
|
179
|
+
- ignore any indices that appear in all terms
|
|
180
|
+
- combine any repeated indices within a single term
|
|
181
|
+
- reduce any non-output indices that only appear on a single term
|
|
182
|
+
- combine any scalar terms
|
|
183
|
+
- combine any tensors with matching indices (hadamard products)
|
|
184
|
+
|
|
185
|
+
Such simpifications may be required in the general case for the proper
|
|
186
|
+
functioning of the core optimization, but may be skipped if the input
|
|
187
|
+
indices are already in a simplified form.
|
|
188
|
+
use_ssa : bool, optional
|
|
189
|
+
Whether to return the contraction path in 'single static assignment'
|
|
190
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
191
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
192
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
193
|
+
|
|
194
|
+
Returns
|
|
195
|
+
-------
|
|
196
|
+
path : list[list[int]]
|
|
197
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
198
|
+
may also have single term contractions if `simplify=True`.
|
|
199
|
+
"""
|
|
200
|
+
...
|
|
201
|
+
|
|
202
|
+
|
|
203
|
+
def optimize_greedy(
|
|
204
|
+
inputs,
|
|
205
|
+
output,
|
|
206
|
+
size_dict,
|
|
207
|
+
costmod=1.0,
|
|
208
|
+
temperature=0.0,
|
|
209
|
+
simplify=True,
|
|
210
|
+
use_ssa=False,
|
|
211
|
+
):
|
|
212
|
+
"""Find a contraction path using a (randomizable) greedy algorithm.
|
|
213
|
+
|
|
214
|
+
Parameters
|
|
215
|
+
----------
|
|
216
|
+
inputs : Sequence[Sequence[str]]
|
|
217
|
+
The indices of each input tensor.
|
|
218
|
+
output : Sequence[str]
|
|
219
|
+
The indices of the output tensor.
|
|
220
|
+
size_dict : dict[str, int]
|
|
221
|
+
A dictionary mapping indices to their dimension.
|
|
222
|
+
costmod : float, optional
|
|
223
|
+
When assessing local greedy scores how much to weight the size of the
|
|
224
|
+
tensors removed compared to the size of the tensor added::
|
|
225
|
+
|
|
226
|
+
score = size_ab / costmod - (size_a + size_b) * costmod
|
|
227
|
+
|
|
228
|
+
This can be a useful hyper-parameter to tune.
|
|
229
|
+
temperature : float, optional
|
|
230
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
231
|
+
score. This is implemented as::
|
|
232
|
+
|
|
233
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
234
|
+
|
|
235
|
+
which implements boltzmann sampling.
|
|
236
|
+
simplify : bool, optional
|
|
237
|
+
Whether to perform simplifications before optimizing. These are:
|
|
238
|
+
|
|
239
|
+
- ignore any indices that appear in all terms
|
|
240
|
+
- combine any repeated indices within a single term
|
|
241
|
+
- reduce any non-output indices that only appear on a single term
|
|
242
|
+
- combine any scalar terms
|
|
243
|
+
- combine any tensors with matching indices (hadamard products)
|
|
244
|
+
|
|
245
|
+
Such simpifications may be required in the general case for the proper
|
|
246
|
+
functioning of the core optimization, but may be skipped if the input
|
|
247
|
+
indices are already in a simplified form.
|
|
248
|
+
use_ssa : bool, optional
|
|
249
|
+
Whether to return the contraction path in 'single static assignment'
|
|
250
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
251
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
252
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
253
|
+
|
|
254
|
+
Returns
|
|
255
|
+
-------
|
|
256
|
+
path : list[list[int]]
|
|
257
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
258
|
+
may also have single term contractions if `simplify=True`.
|
|
259
|
+
"""
|
|
260
|
+
|
|
261
|
+
def optimize_simplify(
|
|
262
|
+
inputs,
|
|
263
|
+
output,
|
|
264
|
+
size_dict,
|
|
265
|
+
use_ssa=False,
|
|
266
|
+
):
|
|
267
|
+
"""Find the (partial) contracton path for simplifiactions only.
|
|
268
|
+
|
|
269
|
+
Parameters
|
|
270
|
+
----------
|
|
271
|
+
inputs : Sequence[Sequence[str]]
|
|
272
|
+
The indices of each input tensor.
|
|
273
|
+
output : Sequence[str]
|
|
274
|
+
The indices of the output tensor.
|
|
275
|
+
size_dict : dict[str, int]
|
|
276
|
+
A dictionary mapping indices to their dimension.
|
|
277
|
+
use_ssa : bool, optional
|
|
278
|
+
Whether to return the contraction path in 'single static assignment'
|
|
279
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
280
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
281
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
282
|
+
|
|
283
|
+
Returns
|
|
284
|
+
-------
|
|
285
|
+
path : list[list[int]]
|
|
286
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
287
|
+
may also have single term contractions.
|
|
288
|
+
"""
|
|
289
|
+
...
|
|
290
|
+
|
|
291
|
+
def optimize_random_greedy_track_flops(
|
|
292
|
+
inputs,
|
|
293
|
+
output,
|
|
294
|
+
size_dict,
|
|
295
|
+
ntrials=1,
|
|
296
|
+
costmod=(0.1, 4.0),
|
|
297
|
+
temperature=(0.001, 1.0),
|
|
298
|
+
seed=None,
|
|
299
|
+
simplify=True,
|
|
300
|
+
use_ssa=False,
|
|
301
|
+
):
|
|
302
|
+
"""Perform a batch of random greedy optimizations, simulteneously tracking
|
|
303
|
+
the best contraction path in terms of flops, so as to avoid constructing a
|
|
304
|
+
separate contraction tree.
|
|
305
|
+
|
|
306
|
+
Parameters
|
|
307
|
+
----------
|
|
308
|
+
inputs : tuple[tuple[str]]
|
|
309
|
+
The indices of each input tensor.
|
|
310
|
+
output : tuple[str]
|
|
311
|
+
The indices of the output tensor.
|
|
312
|
+
size_dict : dict[str, int]
|
|
313
|
+
A dictionary mapping indices to their dimension.
|
|
314
|
+
ntrials : int, optional
|
|
315
|
+
The number of random greedy trials to perform. The default is 1.
|
|
316
|
+
costmod : (float, float), optional
|
|
317
|
+
When assessing local greedy scores how much to weight the size of the
|
|
318
|
+
tensors removed compared to the size of the tensor added::
|
|
319
|
+
|
|
320
|
+
score = size_ab / costmod - (size_a + size_b) * costmod
|
|
321
|
+
|
|
322
|
+
It is sampled uniformly from the given range.
|
|
323
|
+
temperature : (float, float), optional
|
|
324
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
325
|
+
score. This is implemented as::
|
|
326
|
+
|
|
327
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
328
|
+
|
|
329
|
+
which implements boltzmann sampling. It is sampled log-uniformly from
|
|
330
|
+
the given range.
|
|
331
|
+
seed : int, optional
|
|
332
|
+
The seed for the random number generator.
|
|
333
|
+
simplify : bool, optional
|
|
334
|
+
Whether to perform simplifications before optimizing. These are:
|
|
335
|
+
|
|
336
|
+
- ignore any indices that appear in all terms
|
|
337
|
+
- combine any repeated indices within a single term
|
|
338
|
+
- reduce any non-output indices that only appear on a single term
|
|
339
|
+
- combine any scalar terms
|
|
340
|
+
- combine any tensors with matching indices (hadamard products)
|
|
341
|
+
|
|
342
|
+
Such simpifications may be required in the general case for the proper
|
|
343
|
+
functioning of the core optimization, but may be skipped if the input
|
|
344
|
+
indices are already in a simplified form.
|
|
345
|
+
use_ssa : bool, optional
|
|
346
|
+
Whether to return the contraction path in 'single static assignment'
|
|
347
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
348
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
349
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
350
|
+
|
|
351
|
+
Returns
|
|
352
|
+
-------
|
|
353
|
+
path : list[list[int]]
|
|
354
|
+
The best contraction path, given as a sequence of pairs of node
|
|
355
|
+
indices.
|
|
356
|
+
flops : float
|
|
357
|
+
The flops (/ contraction cost / number of multiplications), of the best
|
|
358
|
+
contraction path, given log10.
|
|
359
|
+
"""
|
|
360
|
+
...
|
|
361
|
+
|
|
362
|
+
def ssa_to_linear(ssa_path, n=None):
|
|
363
|
+
"""Convert a SSA path to linear format."""
|
|
364
|
+
...
|
|
365
|
+
|
|
366
|
+
def find_subgraphs(inputs, output, size_dict,):
|
|
367
|
+
"""Find all disconnected subgraphs of a specified contraction."""
|
|
368
|
+
...
|
|
369
|
+
```
|
|
370
|
+
|
|
371
|
+
|
|
@@ -0,0 +1,9 @@
|
|
|
1
|
+
cotengrust/__init__.py,sha256=_vTkDe90YaOGQ5XPZUqpSYKfXEi1Wut_TEukOhsiqCE,123
|
|
2
|
+
cotengrust/__init__.pyi,sha256=fujD6TNExfUe7DDd5wAk5n5heimYMG2_icboLH6H1hA,10743
|
|
3
|
+
cotengrust/cotengrust.cp313-win_arm64.pyd,sha256=xzDt4iXD8BzLCnHMEkfXHX-BkaNWmzDfuIIN6sjgsqE,596480
|
|
4
|
+
cotengrust/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
5
|
+
cotengrust-0.2.1.dist-info/METADATA,sha256=j0sxq2eyeF7jHA0PPJD_RsugT7pHYkS-wgcy0-z_tXo,14224
|
|
6
|
+
cotengrust-0.2.1.dist-info/WHEEL,sha256=xuYWMQsToK02EF7CyvobYethXqdmnSx-vHPknFc0cdQ,97
|
|
7
|
+
cotengrust-0.2.1.dist-info/licenses/LICENSE,sha256=bx5iLIKjgAdYQ7sISn7DsfHRKkoCUm1154sJJKhgqnU,35184
|
|
8
|
+
cotengrust-0.2.1.dist-info/sboms/cotengrust.cyclonedx.json,sha256=bU94LF4toUgXOMQJy57BBIdI5Brwm27uslVZrvgrAYQ,27522
|
|
9
|
+
cotengrust-0.2.1.dist-info/RECORD,,
|