cobweb-launcher 3.1.24__py3-none-any.whl → 3.1.26__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- cobweb/base/request.py +446 -57
- cobweb/base/task_queue.py +7 -6
- cobweb/base/test.py +257 -0
- cobweb/constant.py +1 -1
- {cobweb_launcher-3.1.24.dist-info → cobweb_launcher-3.1.26.dist-info}/METADATA +9 -5
- {cobweb_launcher-3.1.24.dist-info → cobweb_launcher-3.1.26.dist-info}/RECORD +9 -8
- {cobweb_launcher-3.1.24.dist-info → cobweb_launcher-3.1.26.dist-info}/LICENSE +0 -0
- {cobweb_launcher-3.1.24.dist-info → cobweb_launcher-3.1.26.dist-info}/WHEEL +0 -0
- {cobweb_launcher-3.1.24.dist-info → cobweb_launcher-3.1.26.dist-info}/top_level.txt +0 -0
cobweb/base/request.py
CHANGED
|
@@ -1,88 +1,477 @@
|
|
|
1
1
|
import random
|
|
2
|
+
import logging
|
|
2
3
|
import requests
|
|
3
|
-
|
|
4
|
+
|
|
5
|
+
from urllib.parse import urlparse
|
|
6
|
+
from typing import Any, Set, Dict, Optional
|
|
7
|
+
from requests.exceptions import RequestException
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
class FileTypeDetector:
|
|
11
|
+
|
|
12
|
+
def __init__(self):
|
|
13
|
+
self.file_signatures = {
|
|
14
|
+
# 图片格式
|
|
15
|
+
b'\x89PNG\r\n\x1a\n': 'PNG',
|
|
16
|
+
b'\xff\xd8\xff': 'JPEG',
|
|
17
|
+
b'GIF87a': 'GIF',
|
|
18
|
+
b'GIF89a': 'GIF',
|
|
19
|
+
b'RIFF': 'WEBP', # 需要进一步检查
|
|
20
|
+
b'BM': 'BMP',
|
|
21
|
+
b'II*\x00': 'TIFF',
|
|
22
|
+
b'MM\x00*': 'TIFF',
|
|
23
|
+
b'\x00\x00\x01\x00': 'ICO',
|
|
24
|
+
b'\x00\x00\x02\x00': 'CUR',
|
|
25
|
+
|
|
26
|
+
# 视频格式
|
|
27
|
+
b'\x00\x00\x00\x18ftypmp4': 'MP4',
|
|
28
|
+
b'\x00\x00\x00\x20ftypM4V': 'M4V',
|
|
29
|
+
b'FLV\x01': 'FLV',
|
|
30
|
+
b'\x1aE\xdf\xa3': 'WEBM',
|
|
31
|
+
b'RIFF': 'AVI', # 需要进一步检查
|
|
32
|
+
b'\x00\x00\x01\xba': 'MPEG',
|
|
33
|
+
b'\x00\x00\x01\xb3': 'MPEG',
|
|
34
|
+
b'OggS': 'OGV',
|
|
35
|
+
|
|
36
|
+
# 音频格式
|
|
37
|
+
b'ID3': 'MP3',
|
|
38
|
+
b'\xff\xfb': 'MP3',
|
|
39
|
+
b'\xff\xf3': 'MP3',
|
|
40
|
+
b'\xff\xf2': 'MP3',
|
|
41
|
+
b'fLaC': 'FLAC',
|
|
42
|
+
b'RIFF': 'WAV', # 需要进一步检查
|
|
43
|
+
b'OggS': 'OGG', # 需要进一步检查
|
|
44
|
+
b'ftypM4A': 'M4A',
|
|
45
|
+
b'MAC ': 'APE',
|
|
46
|
+
|
|
47
|
+
# 其他格式
|
|
48
|
+
b'%PDF': 'PDF',
|
|
49
|
+
b'PK\x03\x04': 'ZIP',
|
|
50
|
+
b'Rar!\x1a\x07\x00': 'RAR',
|
|
51
|
+
b'\x37\x7a\xbc\xaf\x27\x1c': '7Z',
|
|
52
|
+
}
|
|
53
|
+
|
|
54
|
+
# 扩展名映射
|
|
55
|
+
self.extension_map = {
|
|
56
|
+
# 图片
|
|
57
|
+
'.jpg': 'JPEG', '.jpeg': 'JPEG', '.png': 'PNG', '.gif': 'GIF',
|
|
58
|
+
'.webp': 'WEBP', '.bmp': 'BMP', '.tiff': 'TIFF', '.tif': 'TIFF',
|
|
59
|
+
'.ico': 'ICO', '.svg': 'SVG', '.heic': 'HEIC', '.avif': 'AVIF',
|
|
60
|
+
|
|
61
|
+
# 视频
|
|
62
|
+
'.mp4': 'MP4', '.avi': 'AVI', '.mov': 'MOV', '.wmv': 'WMV',
|
|
63
|
+
'.flv': 'FLV', '.webm': 'WEBM', '.mkv': 'MKV', '.m4v': 'M4V',
|
|
64
|
+
'.mpg': 'MPEG', '.mpeg': 'MPEG', '.3gp': '3GP', '.ogv': 'OGV',
|
|
65
|
+
'.ts': 'TS', '.mts': 'MTS', '.vob': 'VOB',
|
|
66
|
+
|
|
67
|
+
# 音频
|
|
68
|
+
'.mp3': 'MP3', '.wav': 'WAV', '.flac': 'FLAC', '.aac': 'AAC',
|
|
69
|
+
'.ogg': 'OGG', '.wma': 'WMA', '.m4a': 'M4A', '.ape': 'APE',
|
|
70
|
+
'.opus': 'OPUS', '.aiff': 'AIFF', '.au': 'AU',
|
|
71
|
+
}
|
|
72
|
+
|
|
73
|
+
# MIME类型映射
|
|
74
|
+
self.mime_type_map = {
|
|
75
|
+
# 图片
|
|
76
|
+
'image/jpeg': 'JPEG', 'image/png': 'PNG', 'image/gif': 'GIF',
|
|
77
|
+
'image/webp': 'WEBP', 'image/bmp': 'BMP', 'image/tiff': 'TIFF',
|
|
78
|
+
'image/svg+xml': 'SVG', 'image/x-icon': 'ICO',
|
|
79
|
+
|
|
80
|
+
# 视频
|
|
81
|
+
'video/mp4': 'MP4', 'video/avi': 'AVI', 'video/quicktime': 'MOV',
|
|
82
|
+
'video/x-msvideo': 'AVI', 'video/webm': 'WEBM', 'video/x-flv': 'FLV',
|
|
83
|
+
'video/3gpp': '3GP', 'video/ogg': 'OGV',
|
|
84
|
+
|
|
85
|
+
# 音频
|
|
86
|
+
'audio/mpeg': 'MP3', 'audio/wav': 'WAV', 'audio/flac': 'FLAC',
|
|
87
|
+
'audio/aac': 'AAC', 'audio/ogg': 'OGG', 'audio/x-ms-wma': 'WMA',
|
|
88
|
+
'audio/mp4': 'M4A', 'audio/opus': 'OPUS',
|
|
89
|
+
}
|
|
90
|
+
|
|
91
|
+
self.session = requests.Session()
|
|
92
|
+
self.session.headers.update({
|
|
93
|
+
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
|
|
94
|
+
})
|
|
95
|
+
|
|
96
|
+
def get_file_extension(self, url: str) -> str:
|
|
97
|
+
"""从URL获取文件扩展名"""
|
|
98
|
+
parsed = urlparse(url)
|
|
99
|
+
path = parsed.path.lower()
|
|
100
|
+
site = parsed.netloc
|
|
101
|
+
|
|
102
|
+
# 移除查询参数
|
|
103
|
+
if '?' in path:
|
|
104
|
+
path = path.split('?')[0]
|
|
105
|
+
|
|
106
|
+
# 获取扩展名
|
|
107
|
+
if '.' in path:
|
|
108
|
+
return '.' + path.split('.')[-1], site
|
|
109
|
+
return '', site
|
|
110
|
+
|
|
111
|
+
def detect_by_extension(self, url: str) -> Optional[str]:
|
|
112
|
+
"""通过文件扩展名检测类型"""
|
|
113
|
+
ext, site = self.get_file_extension(url)
|
|
114
|
+
return self.extension_map.get(ext)
|
|
115
|
+
|
|
116
|
+
def detect_by_mime_type(self, content_type: str) -> Optional[str]:
|
|
117
|
+
"""通过MIME类型检测"""
|
|
118
|
+
if not content_type:
|
|
119
|
+
return None
|
|
120
|
+
|
|
121
|
+
# 清理content-type,移除参数
|
|
122
|
+
mime_type = content_type.split(';')[0].strip().lower()
|
|
123
|
+
return self.mime_type_map.get(mime_type)
|
|
124
|
+
|
|
125
|
+
def get_partial_content(self, url: str, max_bytes: int = 64) -> Optional[bytes]:
|
|
126
|
+
"""获取文件的前几个字节"""
|
|
127
|
+
try:
|
|
128
|
+
headers = {'Range': f'bytes=0-{max_bytes - 1}'}
|
|
129
|
+
response = self.session.get(url, headers=headers, timeout=10)
|
|
130
|
+
|
|
131
|
+
if response.status_code in [200, 206]:
|
|
132
|
+
return response.content
|
|
133
|
+
except Exception as e:
|
|
134
|
+
print(f"获取内容失败: {e}")
|
|
135
|
+
return None
|
|
136
|
+
|
|
137
|
+
def detect_by_signature(self, data: bytes) -> Optional[str]:
|
|
138
|
+
"""通过文件签名检测类型"""
|
|
139
|
+
if not data:
|
|
140
|
+
return None
|
|
141
|
+
|
|
142
|
+
# 检查各种文件签名
|
|
143
|
+
for signature, file_type in self.file_signatures.items():
|
|
144
|
+
if data.startswith(signature):
|
|
145
|
+
# 特殊处理需要进一步检查的格式
|
|
146
|
+
if signature == b'RIFF' and len(data) >= 12:
|
|
147
|
+
# 检查是WEBP、AVI还是WAV
|
|
148
|
+
if data[8:12] == b'WEBP':
|
|
149
|
+
return 'WEBP'
|
|
150
|
+
elif data[8:12] == b'AVI ':
|
|
151
|
+
return 'AVI'
|
|
152
|
+
elif data[8:12] == b'WAVE':
|
|
153
|
+
return 'WAV'
|
|
154
|
+
elif signature == b'OggS' and len(data) >= 32:
|
|
155
|
+
# 检查是OGG音频还是OGV视频
|
|
156
|
+
if b'vorbis' in data[:64].lower():
|
|
157
|
+
return 'OGG'
|
|
158
|
+
elif b'theora' in data[:64].lower():
|
|
159
|
+
return 'OGV'
|
|
160
|
+
else:
|
|
161
|
+
return 'OGG'
|
|
162
|
+
else:
|
|
163
|
+
return file_type
|
|
164
|
+
|
|
165
|
+
# 检查MP4相关格式
|
|
166
|
+
if len(data) >= 12 and data[4:8] == b'ftyp':
|
|
167
|
+
brand = data[8:12]
|
|
168
|
+
if brand in [b'mp41', b'mp42', b'isom', b'avc1']:
|
|
169
|
+
return 'MP4'
|
|
170
|
+
elif brand == b'M4A ':
|
|
171
|
+
return 'M4A'
|
|
172
|
+
elif brand == b'M4V ':
|
|
173
|
+
return 'M4V'
|
|
174
|
+
elif brand == b'qt ':
|
|
175
|
+
return 'MOV'
|
|
176
|
+
|
|
177
|
+
return None
|
|
178
|
+
|
|
179
|
+
def get_detailed_info(self, url, content_type, data) -> Dict:
|
|
180
|
+
"""获取详细的文件信息"""
|
|
181
|
+
result = {
|
|
182
|
+
'url': url,
|
|
183
|
+
'site': None,
|
|
184
|
+
'detected_type': None,
|
|
185
|
+
'confidence': 'unknown',
|
|
186
|
+
'methods_used': [],
|
|
187
|
+
'content_type': content_type,
|
|
188
|
+
'extension': None
|
|
189
|
+
}
|
|
190
|
+
|
|
191
|
+
# 1. 先尝试HEAD请求获取HTTP头信息
|
|
192
|
+
try:
|
|
193
|
+
result['content_type'] = content_type
|
|
194
|
+
# result['file_size'] = content_length
|
|
195
|
+
|
|
196
|
+
# 通过MIME类型检测
|
|
197
|
+
mime_detected = self.detect_by_mime_type(content_type)
|
|
198
|
+
if mime_detected:
|
|
199
|
+
result['detected_type'] = mime_detected
|
|
200
|
+
result['confidence'] = 'high'
|
|
201
|
+
result['methods_used'].append('mime_type')
|
|
202
|
+
except Exception as e:
|
|
203
|
+
print(f"HEAD请求失败: {e}")
|
|
204
|
+
|
|
205
|
+
# 2. 通过扩展名检测
|
|
206
|
+
ext_detected = self.detect_by_extension(url)
|
|
207
|
+
result['extension'], result['site'] = self.get_file_extension(url)
|
|
208
|
+
|
|
209
|
+
if ext_detected:
|
|
210
|
+
if not result['detected_type']:
|
|
211
|
+
result['detected_type'] = ext_detected
|
|
212
|
+
result['confidence'] = 'medium'
|
|
213
|
+
elif result['detected_type'] == ext_detected:
|
|
214
|
+
result['confidence'] = 'very_high' # MIME和扩展名一致
|
|
215
|
+
result['methods_used'].append('extension')
|
|
216
|
+
|
|
217
|
+
# 3. 如果前两种方法不确定,使用文件签名检测
|
|
218
|
+
if result['confidence'] in ['unknown', 'medium']:
|
|
219
|
+
signature_detected = self.detect_by_signature(data)
|
|
220
|
+
if signature_detected:
|
|
221
|
+
if not result['detected_type']:
|
|
222
|
+
result['detected_type'] = signature_detected
|
|
223
|
+
result['confidence'] = 'high'
|
|
224
|
+
elif result['detected_type'] == signature_detected:
|
|
225
|
+
result['confidence'] = 'very_high'
|
|
226
|
+
else:
|
|
227
|
+
# 冲突时,优先相信文件签名
|
|
228
|
+
result['detected_type'] = signature_detected
|
|
229
|
+
result['confidence'] = 'high'
|
|
230
|
+
result['methods_used'].append('file_signature')
|
|
231
|
+
|
|
232
|
+
return result
|
|
233
|
+
|
|
234
|
+
def get_file_category(self, file_type: str) -> str:
|
|
235
|
+
"""获取文件类别"""
|
|
236
|
+
if not file_type or file_type == 'Unknown':
|
|
237
|
+
return 'Unknown'
|
|
238
|
+
|
|
239
|
+
image_types = {'PNG', 'JPEG', 'GIF', 'WEBP', 'BMP', 'TIFF', 'ICO', 'SVG', 'HEIC', 'AVIF'}
|
|
240
|
+
video_types = {'MP4', 'AVI', 'MOV', 'WMV', 'FLV', 'WEBM', 'MKV', 'M4V', 'MPEG', '3GP', 'OGV', 'TS', 'MTS',
|
|
241
|
+
'VOB'}
|
|
242
|
+
audio_types = {'MP3', 'WAV', 'FLAC', 'AAC', 'OGG', 'WMA', 'M4A', 'APE', 'OPUS', 'AIFF', 'AU'}
|
|
243
|
+
|
|
244
|
+
if file_type in image_types:
|
|
245
|
+
return 'Image'
|
|
246
|
+
elif file_type in video_types:
|
|
247
|
+
return 'Video'
|
|
248
|
+
elif file_type in audio_types:
|
|
249
|
+
return 'Audio'
|
|
250
|
+
else:
|
|
251
|
+
return 'Other'
|
|
4
252
|
|
|
5
253
|
|
|
6
254
|
class Request:
|
|
7
255
|
"""
|
|
8
|
-
|
|
256
|
+
HTTP 请求封装类,提供统一的请求接口和相关功能。
|
|
257
|
+
|
|
258
|
+
Features:
|
|
259
|
+
- 自动 User-Agent 生成
|
|
260
|
+
- 灵活的请求参数配置
|
|
261
|
+
- 文件类型检测
|
|
262
|
+
- 错误处理和状态码检查
|
|
9
263
|
"""
|
|
10
264
|
|
|
11
|
-
|
|
12
|
-
|
|
13
|
-
"headers",
|
|
14
|
-
"
|
|
15
|
-
"
|
|
16
|
-
|
|
17
|
-
|
|
18
|
-
|
|
19
|
-
|
|
20
|
-
|
|
21
|
-
|
|
22
|
-
|
|
23
|
-
"
|
|
24
|
-
"
|
|
25
|
-
"
|
|
265
|
+
# 支持的 requests 库参数
|
|
266
|
+
_REQUEST_ATTRS: Set[str] = frozenset({
|
|
267
|
+
"params", "headers", "cookies", "data", "json", "files",
|
|
268
|
+
"auth", "timeout", "proxies", "hooks", "stream", "verify",
|
|
269
|
+
"cert", "allow_redirects"
|
|
270
|
+
})
|
|
271
|
+
|
|
272
|
+
# 默认超时时间
|
|
273
|
+
_DEFAULT_TIMEOUT = 30
|
|
274
|
+
|
|
275
|
+
# User-Agent 模板和版本范围
|
|
276
|
+
_UA_TEMPLATE = (
|
|
277
|
+
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_{v1}_{v2}) "
|
|
278
|
+
"AppleWebKit/{v4}.{v3} (KHTML, like Gecko) "
|
|
279
|
+
"Chrome/105.0.0.0 Safari/{v4}.{v3} Edg/105.0.{v5}.{v6}"
|
|
280
|
+
)
|
|
281
|
+
_UA_VERSION_RANGES = {
|
|
282
|
+
'v1': (4, 15), 'v2': (3, 11), 'v3': (1, 16),
|
|
283
|
+
'v4': (533, 605), 'v5': (1000, 6000), 'v6': (10, 80)
|
|
26
284
|
}
|
|
27
285
|
|
|
28
286
|
def __init__(
|
|
29
|
-
|
|
30
|
-
|
|
31
|
-
|
|
32
|
-
|
|
33
|
-
|
|
34
|
-
|
|
287
|
+
self,
|
|
288
|
+
url: str,
|
|
289
|
+
seed: Any = None,
|
|
290
|
+
method: Optional[str] = None,
|
|
291
|
+
random_ua: bool = True,
|
|
292
|
+
check_status_code: bool = True,
|
|
293
|
+
**kwargs
|
|
35
294
|
):
|
|
36
295
|
"""
|
|
37
296
|
初始化请求对象。
|
|
38
|
-
|
|
39
|
-
:
|
|
40
|
-
|
|
41
|
-
|
|
42
|
-
|
|
297
|
+
|
|
298
|
+
Args:
|
|
299
|
+
url: 请求的 URL
|
|
300
|
+
seed: 种子对象或标识符
|
|
301
|
+
method: HTTP 方法,如果不指定则自动推断
|
|
302
|
+
random_ua: 是否使用随机 User-Agent
|
|
303
|
+
check_status_code: 是否检查响应状态码
|
|
304
|
+
**kwargs: 其他请求参数
|
|
305
|
+
|
|
306
|
+
Raises:
|
|
307
|
+
ValueError: 当 URL 格式无效时
|
|
43
308
|
"""
|
|
309
|
+
self.scheme = None
|
|
310
|
+
self.netloc = None
|
|
311
|
+
self._validate_url(url)
|
|
312
|
+
|
|
44
313
|
self.url = url
|
|
45
314
|
self.seed = seed
|
|
46
315
|
self.check_status_code = check_status_code
|
|
47
|
-
self.
|
|
316
|
+
self.request_settings: Dict[str, Any] = {}
|
|
317
|
+
|
|
318
|
+
# 分离请求参数和实例属性
|
|
319
|
+
self._process_kwargs(kwargs)
|
|
320
|
+
|
|
321
|
+
self.method = self._determine_method(method)
|
|
48
322
|
|
|
323
|
+
# 设置默认超时
|
|
324
|
+
if 'timeout' not in self.request_settings:
|
|
325
|
+
self.request_settings['timeout'] = self._DEFAULT_TIMEOUT
|
|
326
|
+
|
|
327
|
+
# 构建请求头
|
|
328
|
+
if random_ua:
|
|
329
|
+
self._setup_headers()
|
|
330
|
+
|
|
331
|
+
def _validate_url(self, url: str) -> None:
|
|
332
|
+
"""验证 URL 格式"""
|
|
333
|
+
try:
|
|
334
|
+
result = urlparse(url)
|
|
335
|
+
self.scheme = result.scheme
|
|
336
|
+
self.netloc = result.netloc
|
|
337
|
+
if not all([self.scheme, self.netloc]):
|
|
338
|
+
raise ValueError(f"无效的 URL 格式: {url}")
|
|
339
|
+
except Exception as e:
|
|
340
|
+
raise ValueError(f"URL 解析失败: {e}")
|
|
341
|
+
|
|
342
|
+
def _process_kwargs(self, kwargs: Dict[str, Any]) -> None:
|
|
343
|
+
"""处理关键字参数,分离请求参数和实例属性"""
|
|
49
344
|
for key, value in kwargs.items():
|
|
50
|
-
if key in self.
|
|
51
|
-
self.
|
|
345
|
+
if key in self._REQUEST_ATTRS:
|
|
346
|
+
self.request_settings[key] = value
|
|
52
347
|
else:
|
|
53
348
|
setattr(self, key, value)
|
|
54
349
|
|
|
55
|
-
|
|
56
|
-
|
|
350
|
+
def _determine_method(self, method: Optional[str]) -> str:
|
|
351
|
+
if method:
|
|
352
|
+
return method.upper()
|
|
353
|
+
|
|
354
|
+
has_body = bool(
|
|
355
|
+
self.request_settings.get("data") or
|
|
356
|
+
self.request_settings.get("json") or
|
|
357
|
+
self.request_settings.get("files")
|
|
57
358
|
)
|
|
359
|
+
return "POST" if has_body else "GET"
|
|
58
360
|
|
|
59
|
-
|
|
60
|
-
|
|
361
|
+
def _generate_random_ua(self) -> str:
|
|
362
|
+
"""生成随机 User-Agent"""
|
|
363
|
+
versions = {
|
|
364
|
+
key: random.randint(*range_tuple)
|
|
365
|
+
for key, range_tuple in self._UA_VERSION_RANGES.items()
|
|
366
|
+
}
|
|
367
|
+
return self._UA_TEMPLATE.format(**versions)
|
|
61
368
|
|
|
62
|
-
|
|
63
|
-
|
|
64
|
-
|
|
65
|
-
|
|
66
|
-
|
|
67
|
-
|
|
68
|
-
|
|
69
|
-
|
|
70
|
-
|
|
71
|
-
|
|
72
|
-
|
|
73
|
-
|
|
74
|
-
|
|
75
|
-
|
|
76
|
-
|
|
77
|
-
|
|
369
|
+
def _setup_headers(self) -> None:
|
|
370
|
+
"""设置请求头,包括随机 User-Agent"""
|
|
371
|
+
headers = self.request_settings.setdefault("headers", {})
|
|
372
|
+
|
|
373
|
+
# 使用小写键名进行检查,保持一致性
|
|
374
|
+
ua_keys = ['user-agent', 'User-Agent']
|
|
375
|
+
if not any(headers.get(key) for key in ua_keys):
|
|
376
|
+
headers["User-Agent"] = self._generate_random_ua()
|
|
377
|
+
|
|
378
|
+
def execute(self) -> requests.Response:
|
|
379
|
+
"""
|
|
380
|
+
执行 HTTP 请求。
|
|
381
|
+
|
|
382
|
+
Returns:
|
|
383
|
+
requests.Response: 响应对象
|
|
384
|
+
|
|
385
|
+
Raises:
|
|
386
|
+
RequestException: 请求执行失败
|
|
387
|
+
requests.HTTPError: HTTP 状态码错误(当 check_status_code=True 时)
|
|
388
|
+
"""
|
|
389
|
+
try:
|
|
390
|
+
response = requests.request(
|
|
391
|
+
method=self.method,
|
|
392
|
+
url=self.url,
|
|
393
|
+
**self.request_settings
|
|
394
|
+
)
|
|
395
|
+
|
|
396
|
+
if self.check_status_code:
|
|
397
|
+
response.raise_for_status()
|
|
398
|
+
|
|
399
|
+
return response
|
|
78
400
|
|
|
401
|
+
except RequestException as e:
|
|
402
|
+
logging.error(f"请求执行失败 - URL: {self.url}, 错误: {e}")
|
|
403
|
+
raise
|
|
404
|
+
|
|
405
|
+
# 保持向后兼容性
|
|
79
406
|
def download(self) -> requests.Response:
|
|
80
|
-
|
|
81
|
-
|
|
82
|
-
|
|
83
|
-
|
|
407
|
+
"""下载方法,为了向后兼容性保留"""
|
|
408
|
+
return self.execute()
|
|
409
|
+
|
|
410
|
+
def detect_file_type(self) -> Dict[str, Any]:
|
|
411
|
+
"""
|
|
412
|
+
检测文件类型。
|
|
413
|
+
|
|
414
|
+
Returns:
|
|
415
|
+
Dict[str, Any]: 文件类型信息
|
|
416
|
+
|
|
417
|
+
Raises:
|
|
418
|
+
RequestException: 请求执行失败
|
|
419
|
+
ImportError: FileTypeDetector 未找到
|
|
420
|
+
"""
|
|
421
|
+
try:
|
|
422
|
+
# 创建检测请求的配置
|
|
423
|
+
detect_settings = self.request_settings.copy()
|
|
424
|
+
|
|
425
|
+
# 设置 Range 头获取文件前64字节
|
|
426
|
+
headers = detect_settings.setdefault("headers", {}).copy()
|
|
427
|
+
headers['Range'] = "bytes=0-63"
|
|
428
|
+
detect_settings["headers"] = headers
|
|
429
|
+
|
|
430
|
+
# 移除 stream 参数避免冲突
|
|
431
|
+
detect_settings.pop('stream', None)
|
|
432
|
+
|
|
433
|
+
# 执行检测请求
|
|
434
|
+
response = requests.request(
|
|
435
|
+
method=self.method,
|
|
436
|
+
url=self.url,
|
|
437
|
+
**detect_settings
|
|
438
|
+
)
|
|
439
|
+
|
|
440
|
+
content_type = response.headers.get("Content-Type")
|
|
441
|
+
detector = FileTypeDetector()
|
|
442
|
+
|
|
443
|
+
return detector.get_detailed_info(
|
|
444
|
+
url=self.url,
|
|
445
|
+
content_type=content_type,
|
|
446
|
+
data=response.content
|
|
447
|
+
)
|
|
448
|
+
|
|
449
|
+
except RequestException as e:
|
|
450
|
+
logging.error(f"文件类型检测失败 - URL: {self.url}, 错误: {e}")
|
|
84
451
|
|
|
85
452
|
@property
|
|
86
453
|
def to_dict(self) -> Dict[str, Any]:
|
|
87
|
-
|
|
88
|
-
|
|
454
|
+
"""
|
|
455
|
+
将请求对象转换为字典格式。
|
|
456
|
+
|
|
457
|
+
Returns:
|
|
458
|
+
Dict[str, Any]: 包含请求信息的字典
|
|
459
|
+
"""
|
|
460
|
+
excluded_keys = {"request_settings"}
|
|
461
|
+
result = {
|
|
462
|
+
key: value for key, value in self.__dict__.items()
|
|
463
|
+
if not key.startswith('_') and key not in excluded_keys
|
|
464
|
+
}
|
|
465
|
+
|
|
466
|
+
# 添加请求设置信息
|
|
467
|
+
result['request_settings'] = self.request_settings.copy()
|
|
468
|
+
|
|
469
|
+
return result
|
|
470
|
+
|
|
471
|
+
def __repr__(self) -> str:
|
|
472
|
+
"""返回对象的字符串表示"""
|
|
473
|
+
return f"Request(method='{self.method}', url='{self.url}')"
|
|
474
|
+
|
|
475
|
+
def __str__(self) -> str:
|
|
476
|
+
"""返回对象的可读字符串表示"""
|
|
477
|
+
return f"{self.method} {self.url}"
|
cobweb/base/task_queue.py
CHANGED
|
@@ -10,8 +10,8 @@ class Status(Enum):
|
|
|
10
10
|
PENDING = 0 # 待处理
|
|
11
11
|
PROCESSING = 1 # 处理中
|
|
12
12
|
FINISHED = 2 # 已完成
|
|
13
|
-
INSERT = 3 #
|
|
14
|
-
UPLOAD = 4 #
|
|
13
|
+
INSERT = 3 # 新增
|
|
14
|
+
UPLOAD = 4 # 上传
|
|
15
15
|
|
|
16
16
|
|
|
17
17
|
@dataclass
|
|
@@ -138,9 +138,10 @@ class TaskQueue:
|
|
|
138
138
|
if data:
|
|
139
139
|
task_item.data = data
|
|
140
140
|
|
|
141
|
-
|
|
142
|
-
|
|
143
|
-
|
|
141
|
+
if task_item.status != Status.FINISHED:
|
|
142
|
+
for tid in task_item.children_ids:
|
|
143
|
+
if self._tasks[tid].status == Status.INSERT:
|
|
144
|
+
del self._tasks[tid]
|
|
144
145
|
|
|
145
146
|
task_item.children_ids = []
|
|
146
147
|
self._tasks[task_id] = task_item
|
|
@@ -176,4 +177,4 @@ class TaskQueue:
|
|
|
176
177
|
# expired_ids.append(seed_id)
|
|
177
178
|
# for seed_id in expired_ids:
|
|
178
179
|
# self._seeds[seed_id] = self._seeds[seed_id]._replace(status=SeedStatus.EXPIRED)
|
|
179
|
-
# print(f"清理了 {len(expired_ids)} 个过期种子")
|
|
180
|
+
# print(f"清理了 {len(expired_ids)} 个过期种子")
|
cobweb/base/test.py
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
1
|
+
import requests
|
|
2
|
+
from urllib.parse import urlparse
|
|
3
|
+
from typing import Dict, Optional
|
|
4
|
+
|
|
5
|
+
|
|
6
|
+
class FileTypeDetector:
|
|
7
|
+
def __init__(self):
|
|
8
|
+
self.file_signatures = {
|
|
9
|
+
# 图片格式
|
|
10
|
+
b'\x89PNG\r\n\x1a\n': 'PNG',
|
|
11
|
+
b'\xff\xd8\xff': 'JPEG',
|
|
12
|
+
b'GIF87a': 'GIF',
|
|
13
|
+
b'GIF89a': 'GIF',
|
|
14
|
+
b'RIFF': 'WEBP', # 需要进一步检查
|
|
15
|
+
b'BM': 'BMP',
|
|
16
|
+
b'II*\x00': 'TIFF',
|
|
17
|
+
b'MM\x00*': 'TIFF',
|
|
18
|
+
b'\x00\x00\x01\x00': 'ICO',
|
|
19
|
+
b'\x00\x00\x02\x00': 'CUR',
|
|
20
|
+
|
|
21
|
+
# 视频格式
|
|
22
|
+
b'\x00\x00\x00\x18ftypmp4': 'MP4',
|
|
23
|
+
b'\x00\x00\x00\x20ftypM4V': 'M4V',
|
|
24
|
+
b'FLV\x01': 'FLV',
|
|
25
|
+
b'\x1aE\xdf\xa3': 'WEBM',
|
|
26
|
+
b'RIFF': 'AVI', # 需要进一步检查
|
|
27
|
+
b'\x00\x00\x01\xba': 'MPEG',
|
|
28
|
+
b'\x00\x00\x01\xb3': 'MPEG',
|
|
29
|
+
b'OggS': 'OGV',
|
|
30
|
+
|
|
31
|
+
# 音频格式
|
|
32
|
+
b'ID3': 'MP3',
|
|
33
|
+
b'\xff\xfb': 'MP3',
|
|
34
|
+
b'\xff\xf3': 'MP3',
|
|
35
|
+
b'\xff\xf2': 'MP3',
|
|
36
|
+
b'fLaC': 'FLAC',
|
|
37
|
+
b'RIFF': 'WAV', # 需要进一步检查
|
|
38
|
+
b'OggS': 'OGG', # 需要进一步检查
|
|
39
|
+
b'ftypM4A': 'M4A',
|
|
40
|
+
b'MAC ': 'APE',
|
|
41
|
+
|
|
42
|
+
# 其他格式
|
|
43
|
+
b'%PDF': 'PDF',
|
|
44
|
+
b'PK\x03\x04': 'ZIP',
|
|
45
|
+
b'Rar!\x1a\x07\x00': 'RAR',
|
|
46
|
+
b'\x37\x7a\xbc\xaf\x27\x1c': '7Z',
|
|
47
|
+
}
|
|
48
|
+
|
|
49
|
+
# 扩展名映射
|
|
50
|
+
self.extension_map = {
|
|
51
|
+
# 图片
|
|
52
|
+
'.jpg': 'JPEG', '.jpeg': 'JPEG', '.png': 'PNG', '.gif': 'GIF',
|
|
53
|
+
'.webp': 'WEBP', '.bmp': 'BMP', '.tiff': 'TIFF', '.tif': 'TIFF',
|
|
54
|
+
'.ico': 'ICO', '.svg': 'SVG', '.heic': 'HEIC', '.avif': 'AVIF',
|
|
55
|
+
|
|
56
|
+
# 视频
|
|
57
|
+
'.mp4': 'MP4', '.avi': 'AVI', '.mov': 'MOV', '.wmv': 'WMV',
|
|
58
|
+
'.flv': 'FLV', '.webm': 'WEBM', '.mkv': 'MKV', '.m4v': 'M4V',
|
|
59
|
+
'.mpg': 'MPEG', '.mpeg': 'MPEG', '.3gp': '3GP', '.ogv': 'OGV',
|
|
60
|
+
'.ts': 'TS', '.mts': 'MTS', '.vob': 'VOB',
|
|
61
|
+
|
|
62
|
+
# 音频
|
|
63
|
+
'.mp3': 'MP3', '.wav': 'WAV', '.flac': 'FLAC', '.aac': 'AAC',
|
|
64
|
+
'.ogg': 'OGG', '.wma': 'WMA', '.m4a': 'M4A', '.ape': 'APE',
|
|
65
|
+
'.opus': 'OPUS', '.aiff': 'AIFF', '.au': 'AU',
|
|
66
|
+
}
|
|
67
|
+
|
|
68
|
+
# MIME类型映射
|
|
69
|
+
self.mime_type_map = {
|
|
70
|
+
# 图片
|
|
71
|
+
'image/jpeg': 'JPEG', 'image/png': 'PNG', 'image/gif': 'GIF',
|
|
72
|
+
'image/webp': 'WEBP', 'image/bmp': 'BMP', 'image/tiff': 'TIFF',
|
|
73
|
+
'image/svg+xml': 'SVG', 'image/x-icon': 'ICO',
|
|
74
|
+
|
|
75
|
+
# 视频
|
|
76
|
+
'video/mp4': 'MP4', 'video/avi': 'AVI', 'video/quicktime': 'MOV',
|
|
77
|
+
'video/x-msvideo': 'AVI', 'video/webm': 'WEBM', 'video/x-flv': 'FLV',
|
|
78
|
+
'video/3gpp': '3GP', 'video/ogg': 'OGV',
|
|
79
|
+
|
|
80
|
+
# 音频
|
|
81
|
+
'audio/mpeg': 'MP3', 'audio/wav': 'WAV', 'audio/flac': 'FLAC',
|
|
82
|
+
'audio/aac': 'AAC', 'audio/ogg': 'OGG', 'audio/x-ms-wma': 'WMA',
|
|
83
|
+
'audio/mp4': 'M4A', 'audio/opus': 'OPUS',
|
|
84
|
+
}
|
|
85
|
+
|
|
86
|
+
self.session = requests.Session()
|
|
87
|
+
self.session.headers.update({
|
|
88
|
+
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
|
|
89
|
+
})
|
|
90
|
+
|
|
91
|
+
def get_file_extension(self, url: str) -> str:
|
|
92
|
+
"""从URL获取文件扩展名"""
|
|
93
|
+
parsed = urlparse(url)
|
|
94
|
+
path = parsed.path.lower()
|
|
95
|
+
site = parsed.netloc
|
|
96
|
+
|
|
97
|
+
# 移除查询参数
|
|
98
|
+
if '?' in path:
|
|
99
|
+
path = path.split('?')[0]
|
|
100
|
+
|
|
101
|
+
# 获取扩展名
|
|
102
|
+
if '.' in path:
|
|
103
|
+
return '.' + path.split('.')[-1], site
|
|
104
|
+
return '', site
|
|
105
|
+
|
|
106
|
+
def detect_by_extension(self, url: str) -> Optional[str]:
|
|
107
|
+
"""通过文件扩展名检测类型"""
|
|
108
|
+
ext, site = self.get_file_extension(url)
|
|
109
|
+
return self.extension_map.get(ext)
|
|
110
|
+
|
|
111
|
+
def detect_by_mime_type(self, content_type: str) -> Optional[str]:
|
|
112
|
+
"""通过MIME类型检测"""
|
|
113
|
+
if not content_type:
|
|
114
|
+
return None
|
|
115
|
+
|
|
116
|
+
# 清理content-type,移除参数
|
|
117
|
+
mime_type = content_type.split(';')[0].strip().lower()
|
|
118
|
+
return self.mime_type_map.get(mime_type)
|
|
119
|
+
|
|
120
|
+
def get_partial_content(self, url: str, max_bytes: int = 64) -> Optional[bytes]:
|
|
121
|
+
"""获取文件的前几个字节"""
|
|
122
|
+
try:
|
|
123
|
+
headers = {'Range': f'bytes=0-{max_bytes - 1}'}
|
|
124
|
+
response = self.session.get(url, headers=headers, timeout=10)
|
|
125
|
+
|
|
126
|
+
if response.status_code in [200, 206]:
|
|
127
|
+
return response.content
|
|
128
|
+
except Exception as e:
|
|
129
|
+
print(f"获取内容失败: {e}")
|
|
130
|
+
return None
|
|
131
|
+
|
|
132
|
+
def detect_by_signature(self, data: bytes) -> Optional[str]:
|
|
133
|
+
"""通过文件签名检测类型"""
|
|
134
|
+
if not data:
|
|
135
|
+
return None
|
|
136
|
+
|
|
137
|
+
# 检查各种文件签名
|
|
138
|
+
for signature, file_type in self.file_signatures.items():
|
|
139
|
+
if data.startswith(signature):
|
|
140
|
+
# 特殊处理需要进一步检查的格式
|
|
141
|
+
if signature == b'RIFF' and len(data) >= 12:
|
|
142
|
+
# 检查是WEBP、AVI还是WAV
|
|
143
|
+
if data[8:12] == b'WEBP':
|
|
144
|
+
return 'WEBP'
|
|
145
|
+
elif data[8:12] == b'AVI ':
|
|
146
|
+
return 'AVI'
|
|
147
|
+
elif data[8:12] == b'WAVE':
|
|
148
|
+
return 'WAV'
|
|
149
|
+
elif signature == b'OggS' and len(data) >= 32:
|
|
150
|
+
# 检查是OGG音频还是OGV视频
|
|
151
|
+
if b'vorbis' in data[:64].lower():
|
|
152
|
+
return 'OGG'
|
|
153
|
+
elif b'theora' in data[:64].lower():
|
|
154
|
+
return 'OGV'
|
|
155
|
+
else:
|
|
156
|
+
return 'OGG'
|
|
157
|
+
else:
|
|
158
|
+
return file_type
|
|
159
|
+
|
|
160
|
+
# 检查MP4相关格式
|
|
161
|
+
if len(data) >= 12 and data[4:8] == b'ftyp':
|
|
162
|
+
brand = data[8:12]
|
|
163
|
+
if brand in [b'mp41', b'mp42', b'isom', b'avc1']:
|
|
164
|
+
return 'MP4'
|
|
165
|
+
elif brand == b'M4A ':
|
|
166
|
+
return 'M4A'
|
|
167
|
+
elif brand == b'M4V ':
|
|
168
|
+
return 'M4V'
|
|
169
|
+
elif brand == b'qt ':
|
|
170
|
+
return 'MOV'
|
|
171
|
+
|
|
172
|
+
return None
|
|
173
|
+
|
|
174
|
+
def get_detailed_info(self, url, content_type, data) -> Dict:
|
|
175
|
+
"""获取详细的文件信息"""
|
|
176
|
+
result = {
|
|
177
|
+
'url': url,
|
|
178
|
+
'site': None,
|
|
179
|
+
'detected_type': None,
|
|
180
|
+
'confidence': 'unknown',
|
|
181
|
+
'methods_used': [],
|
|
182
|
+
'content_type': content_type,
|
|
183
|
+
'extension': None
|
|
184
|
+
}
|
|
185
|
+
|
|
186
|
+
# 1. 先尝试HEAD请求获取HTTP头信息
|
|
187
|
+
try:
|
|
188
|
+
result['content_type'] = content_type
|
|
189
|
+
# result['file_size'] = content_length
|
|
190
|
+
|
|
191
|
+
# 通过MIME类型检测
|
|
192
|
+
mime_detected = self.detect_by_mime_type(content_type)
|
|
193
|
+
if mime_detected:
|
|
194
|
+
result['detected_type'] = mime_detected
|
|
195
|
+
result['confidence'] = 'high'
|
|
196
|
+
result['methods_used'].append('mime_type')
|
|
197
|
+
except Exception as e:
|
|
198
|
+
print(f"HEAD请求失败: {e}")
|
|
199
|
+
|
|
200
|
+
# 2. 通过扩展名检测
|
|
201
|
+
ext_detected = self.detect_by_extension(url)
|
|
202
|
+
result['extension'], result['site'] = self.get_file_extension(url)
|
|
203
|
+
|
|
204
|
+
if ext_detected:
|
|
205
|
+
if not result['detected_type']:
|
|
206
|
+
result['detected_type'] = ext_detected
|
|
207
|
+
result['confidence'] = 'medium'
|
|
208
|
+
elif result['detected_type'] == ext_detected:
|
|
209
|
+
result['confidence'] = 'very_high' # MIME和扩展名一致
|
|
210
|
+
result['methods_used'].append('extension')
|
|
211
|
+
|
|
212
|
+
# 3. 如果前两种方法不确定,使用文件签名检测
|
|
213
|
+
if result['confidence'] in ['unknown', 'medium']:
|
|
214
|
+
signature_detected = self.detect_by_signature(data)
|
|
215
|
+
if signature_detected:
|
|
216
|
+
if not result['detected_type']:
|
|
217
|
+
result['detected_type'] = signature_detected
|
|
218
|
+
result['confidence'] = 'high'
|
|
219
|
+
elif result['detected_type'] == signature_detected:
|
|
220
|
+
result['confidence'] = 'very_high'
|
|
221
|
+
else:
|
|
222
|
+
# 冲突时,优先相信文件签名
|
|
223
|
+
result['detected_type'] = signature_detected
|
|
224
|
+
result['confidence'] = 'high'
|
|
225
|
+
result['methods_used'].append('file_signature')
|
|
226
|
+
|
|
227
|
+
return result
|
|
228
|
+
|
|
229
|
+
def detect_file_type(self, url: str) -> str:
|
|
230
|
+
"""简单的文件类型检测,返回类型字符串"""
|
|
231
|
+
info = self.get_detailed_info(url)
|
|
232
|
+
return info.get('detected_type', 'Unknown')
|
|
233
|
+
|
|
234
|
+
def get_file_category(self, file_type: str) -> str:
|
|
235
|
+
"""获取文件类别"""
|
|
236
|
+
if not file_type or file_type == 'Unknown':
|
|
237
|
+
return 'Unknown'
|
|
238
|
+
|
|
239
|
+
image_types = {'PNG', 'JPEG', 'GIF', 'WEBP', 'BMP', 'TIFF', 'ICO', 'SVG', 'HEIC', 'AVIF'}
|
|
240
|
+
video_types = {'MP4', 'AVI', 'MOV', 'WMV', 'FLV', 'WEBM', 'MKV', 'M4V', 'MPEG', '3GP', 'OGV', 'TS', 'MTS',
|
|
241
|
+
'VOB'}
|
|
242
|
+
audio_types = {'MP3', 'WAV', 'FLAC', 'AAC', 'OGG', 'WMA', 'M4A', 'APE', 'OPUS', 'AIFF', 'AU'}
|
|
243
|
+
|
|
244
|
+
if file_type in image_types:
|
|
245
|
+
return 'Image'
|
|
246
|
+
elif file_type in video_types:
|
|
247
|
+
return 'Video'
|
|
248
|
+
elif file_type in audio_types:
|
|
249
|
+
return 'Audio'
|
|
250
|
+
else:
|
|
251
|
+
return 'Other'
|
|
252
|
+
|
|
253
|
+
|
|
254
|
+
# if __name__ == "__main__":
|
|
255
|
+
# detector = FileTypeDetector()
|
|
256
|
+
# result = detector.get_detailed_info("https://cdn.pixabay.com/user/2024/12/10/12-18-33-812_96x96.jpeg")
|
|
257
|
+
# print(result)
|
cobweb/constant.py
CHANGED
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.1
|
|
2
2
|
Name: cobweb-launcher
|
|
3
|
-
Version: 3.1.
|
|
3
|
+
Version: 3.1.26
|
|
4
4
|
Summary: spider_hole
|
|
5
5
|
Home-page: https://github.com/Juannie-PP/cobweb
|
|
6
6
|
Author: Juannie-PP
|
|
@@ -177,12 +177,16 @@ app.start()
|
|
|
177
177
|
> upload_item["text"] = item.response.text
|
|
178
178
|
> yield ConsoleItem(item.seed, data=json.dumps(upload_item, ensure_ascii=False))
|
|
179
179
|
## todo
|
|
180
|
-
- 队列优化完善,使用queue的机制wait()同步各模块执行?
|
|
181
|
-
- 日志功能完善,单机模式调度和保存数据写入文件,结构化输出各任务日志
|
|
182
|
-
- 去重过滤(布隆过滤器等)
|
|
183
|
-
-
|
|
180
|
+
- [ ] 队列优化完善,使用queue的机制wait()同步各模块执行?
|
|
181
|
+
- [x] 日志功能完善,单机模式调度和保存数据写入文件,结构化输出各任务日志
|
|
182
|
+
- [ ] 去重过滤(布隆过滤器等)
|
|
183
|
+
- [ ] 请求检验
|
|
184
|
+
- [ ] 异常回调
|
|
185
|
+
- [ ] 失败回调
|
|
184
186
|
|
|
185
187
|
> 未更新流程图!!!
|
|
186
188
|
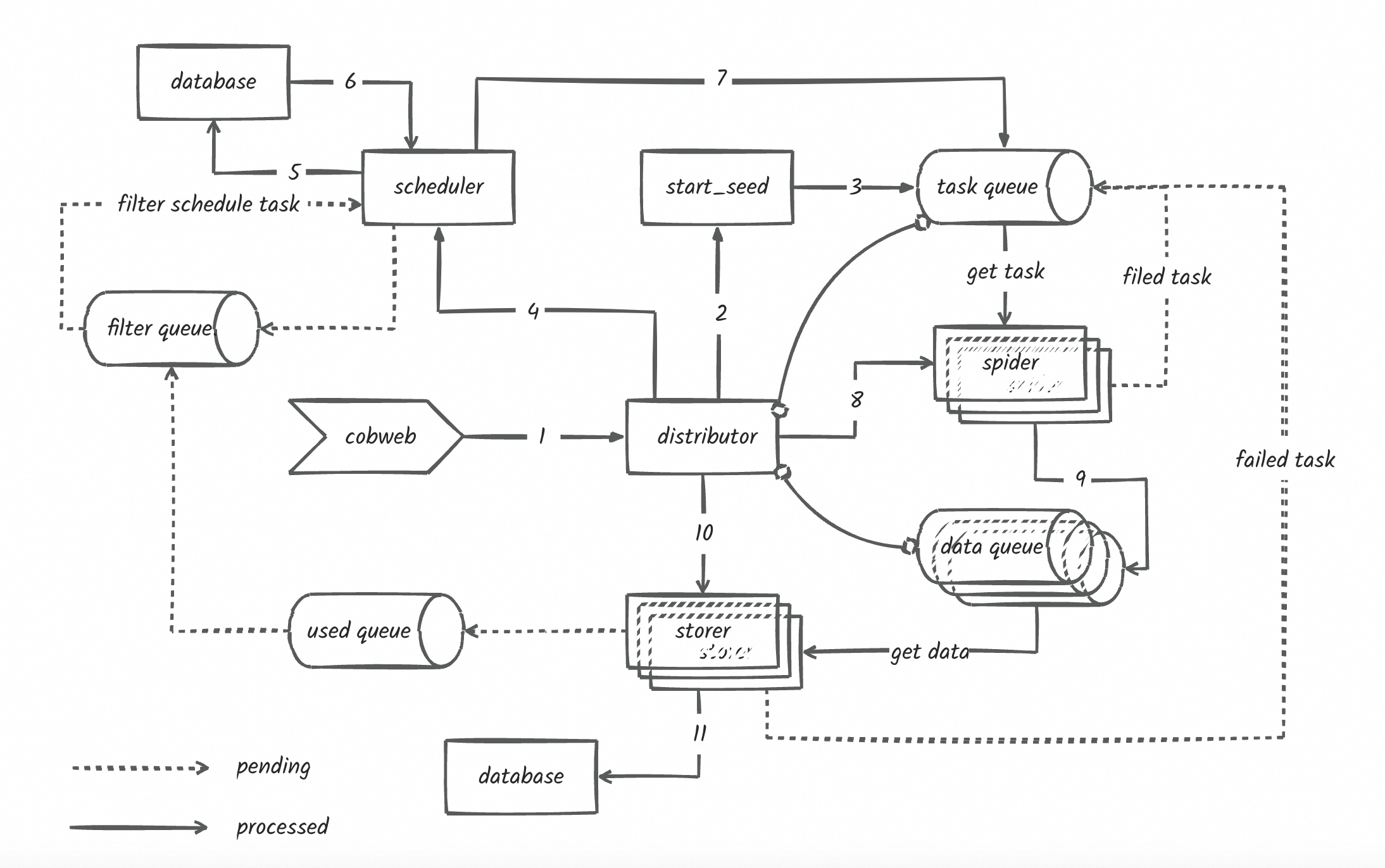
|
|
187
189
|
|
|
188
190
|
|
|
191
|
+
|
|
192
|
+
|
|
@@ -1,14 +1,15 @@
|
|
|
1
1
|
cobweb/__init__.py,sha256=YdBi3uytEFRXan155xU1kKMpiUKUupO2RGeJyXmH0zk,129
|
|
2
|
-
cobweb/constant.py,sha256=
|
|
2
|
+
cobweb/constant.py,sha256=s6W4Fz3DhH-4RutoWnR2bylL8eU44rc-CeOsovj87I0,2839
|
|
3
3
|
cobweb/setting.py,sha256=rHPQfc4a1xMTbkt3_KXBfUomhYcbTXogsz7ew-QsqHw,1670
|
|
4
4
|
cobweb/base/__init__.py,sha256=NanSxJr0WsqjqCNOQAlxlkt-vQEsERHYBzacFC057oI,222
|
|
5
5
|
cobweb/base/common_queue.py,sha256=hYdaM70KrWjvACuLKaGhkI2VqFCnd87NVvWzmnfIg8Q,1423
|
|
6
6
|
cobweb/base/item.py,sha256=1bS4U_3vzI2jzSSeoEbLoLT_5CfgLPopWiEYtaahbvw,1674
|
|
7
7
|
cobweb/base/logger.py,sha256=Vsg1bD4LXW91VgY-ANsmaUu-mD88hU_WS83f7jX3qF8,2011
|
|
8
|
-
cobweb/base/request.py,sha256=
|
|
8
|
+
cobweb/base/request.py,sha256=hBbjGfvmOA-GknfH32BwasUJfHxcDOZlmxh2jH_CJYg,16258
|
|
9
9
|
cobweb/base/response.py,sha256=g8e5H0hEiRfqseh3nD7t6a1rhIJYRMV7nI47kqNOd-U,446
|
|
10
10
|
cobweb/base/seed.py,sha256=ddaWCq_KaWwpmPl1CToJlfCxEEnoJ16kjo6azJs9uls,5000
|
|
11
|
-
cobweb/base/task_queue.py,sha256=
|
|
11
|
+
cobweb/base/task_queue.py,sha256=2MqGpHGNmK5B-kqv7z420RWyihzB9zgDHJUiLsmtzOI,6402
|
|
12
|
+
cobweb/base/test.py,sha256=N8MDGb94KQeI4pC5rCc2QdohE9_5AgcOyGqKjbMsOEs,9588
|
|
12
13
|
cobweb/crawlers/__init__.py,sha256=msvkB9mTpsgyj8JfNMsmwAcpy5kWk_2NrO1Adw2Hkw0,29
|
|
13
14
|
cobweb/crawlers/crawler.py,sha256=ZZVZJ17RWuvzUFGLjqdvyVZpmuq-ynslJwXQzdm_UdQ,709
|
|
14
15
|
cobweb/db/__init__.py,sha256=uZwSkd105EAwYo95oZQXAfofUKHVIAZZIPpNMy-hm2Q,56
|
|
@@ -33,8 +34,8 @@ cobweb/utils/decorators.py,sha256=ZwVQlz-lYHgXgKf9KRCp15EWPzTDdhoikYUNUCIqNeM,11
|
|
|
33
34
|
cobweb/utils/dotting.py,sha256=L-jGSApdnFIP4jUWH6p5qIme0aJ1vyDrxAx8wOJWvcs,1960
|
|
34
35
|
cobweb/utils/oss.py,sha256=wmToIIVNO8nCQVRmreVaZejk01aCWS35e1NV6cr0yGI,4192
|
|
35
36
|
cobweb/utils/tools.py,sha256=14TCedqt07m4z6bCnFAsITOFixeGr8V3aOKk--L7Cr0,879
|
|
36
|
-
cobweb_launcher-3.1.
|
|
37
|
-
cobweb_launcher-3.1.
|
|
38
|
-
cobweb_launcher-3.1.
|
|
39
|
-
cobweb_launcher-3.1.
|
|
40
|
-
cobweb_launcher-3.1.
|
|
37
|
+
cobweb_launcher-3.1.26.dist-info/LICENSE,sha256=z1rxSIGOyzcSb3orZxFPxzx-0C1vTocmswqBNxpKfEk,1063
|
|
38
|
+
cobweb_launcher-3.1.26.dist-info/METADATA,sha256=BVtA2LQ0U9wc7egAKrP4Enf_YEC391eZd-GtkgY_HVA,6051
|
|
39
|
+
cobweb_launcher-3.1.26.dist-info/WHEEL,sha256=ewwEueio1C2XeHTvT17n8dZUJgOvyCWCt0WVNLClP9o,92
|
|
40
|
+
cobweb_launcher-3.1.26.dist-info/top_level.txt,sha256=4GETBGNsKqiCUezmT-mJn7tjhcDlu7nLIV5gGgHBW4I,7
|
|
41
|
+
cobweb_launcher-3.1.26.dist-info/RECORD,,
|
|
File without changes
|
|
File without changes
|
|
File without changes
|