biopipen 0.27.3__py3-none-any.whl → 0.27.4__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of biopipen might be problematic. Click here for more details.
- biopipen/__init__.py +1 -1
- biopipen/ns/delim.py +1 -1
- biopipen/ns/plot.py +36 -0
- biopipen/ns/scrna.py +9 -9
- biopipen/ns/scrna_metabolic_landscape.py +3 -3
- biopipen/ns/snp.py +65 -0
- biopipen/ns/tcr.py +6 -6
- biopipen/scripts/delim/SampleInfo.R +6 -6
- biopipen/scripts/plot/ROC.R +88 -0
- biopipen/scripts/snp/MatrixEQTL.R +157 -0
- {biopipen-0.27.3.dist-info → biopipen-0.27.4.dist-info}/METADATA +1 -2
- {biopipen-0.27.3.dist-info → biopipen-0.27.4.dist-info}/RECORD +14 -12
- {biopipen-0.27.3.dist-info → biopipen-0.27.4.dist-info}/WHEEL +0 -0
- {biopipen-0.27.3.dist-info → biopipen-0.27.4.dist-info}/entry_points.txt +0 -0
biopipen/__init__.py
CHANGED
|
@@ -1 +1 @@
|
|
|
1
|
-
__version__ = "0.27.
|
|
1
|
+
__version__ = "0.27.4"
|
biopipen/ns/delim.py
CHANGED
biopipen/ns/plot.py
CHANGED
|
@@ -114,3 +114,39 @@ class Heatmap(Proc):
|
|
|
114
114
|
"globals": "",
|
|
115
115
|
}
|
|
116
116
|
script = "file://../scripts/plot/Heatmap.R"
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
class ROC(Proc):
|
|
120
|
+
"""Plot ROC curve using [`plotROC`](https://cran.r-project.org/web/packages/plotROC/vignettes/examples.html).
|
|
121
|
+
|
|
122
|
+
Input:
|
|
123
|
+
infile: The input file for data, tab-separated.
|
|
124
|
+
The first column should be ids of the records (this is optional if `envs.noids` is True).
|
|
125
|
+
The second column should be the labels of the records (1 for positive, 0 for negative).
|
|
126
|
+
If they are not binary, you can specify the positive label by `envs.pos_label`.
|
|
127
|
+
From the third column, it should be the scores of the different models.
|
|
128
|
+
|
|
129
|
+
Output:
|
|
130
|
+
outfile: The output figure file
|
|
131
|
+
|
|
132
|
+
Envs:
|
|
133
|
+
noids: Whether the input file has ids (first column) or not.
|
|
134
|
+
pos_label: The positive label.
|
|
135
|
+
ci: Whether to use `geom_rocci()` instead of `geom_roc()`.
|
|
136
|
+
devpars: The parameters for `png()`
|
|
137
|
+
args: Additional arguments for `geom_roc()` or `geom_rocci()` if `envs.ci` is True.
|
|
138
|
+
style_roc: Arguments for `style_roc()`
|
|
139
|
+
""" # noqa: E501
|
|
140
|
+
input = "infile:file"
|
|
141
|
+
output = "outfile:file:{{in.infile | stem}}.roc.png"
|
|
142
|
+
lang = config.lang.rscript
|
|
143
|
+
envs = {
|
|
144
|
+
"noids": False,
|
|
145
|
+
"pos_label": 1,
|
|
146
|
+
"ci": False,
|
|
147
|
+
"devpars": {"res": 100, "width": 750, "height": 600},
|
|
148
|
+
"args": {"labels": False},
|
|
149
|
+
"style_roc": {},
|
|
150
|
+
"show_auc": True,
|
|
151
|
+
}
|
|
152
|
+
script = "file://../scripts/plot/ROC.R"
|
biopipen/ns/scrna.py
CHANGED
|
@@ -413,7 +413,7 @@ class SeuratClusterStats(Proc):
|
|
|
413
413
|
nCells_All = { }
|
|
414
414
|
```
|
|
415
415
|
|
|
416
|
-
{: width="80%" }
|
|
416
|
+
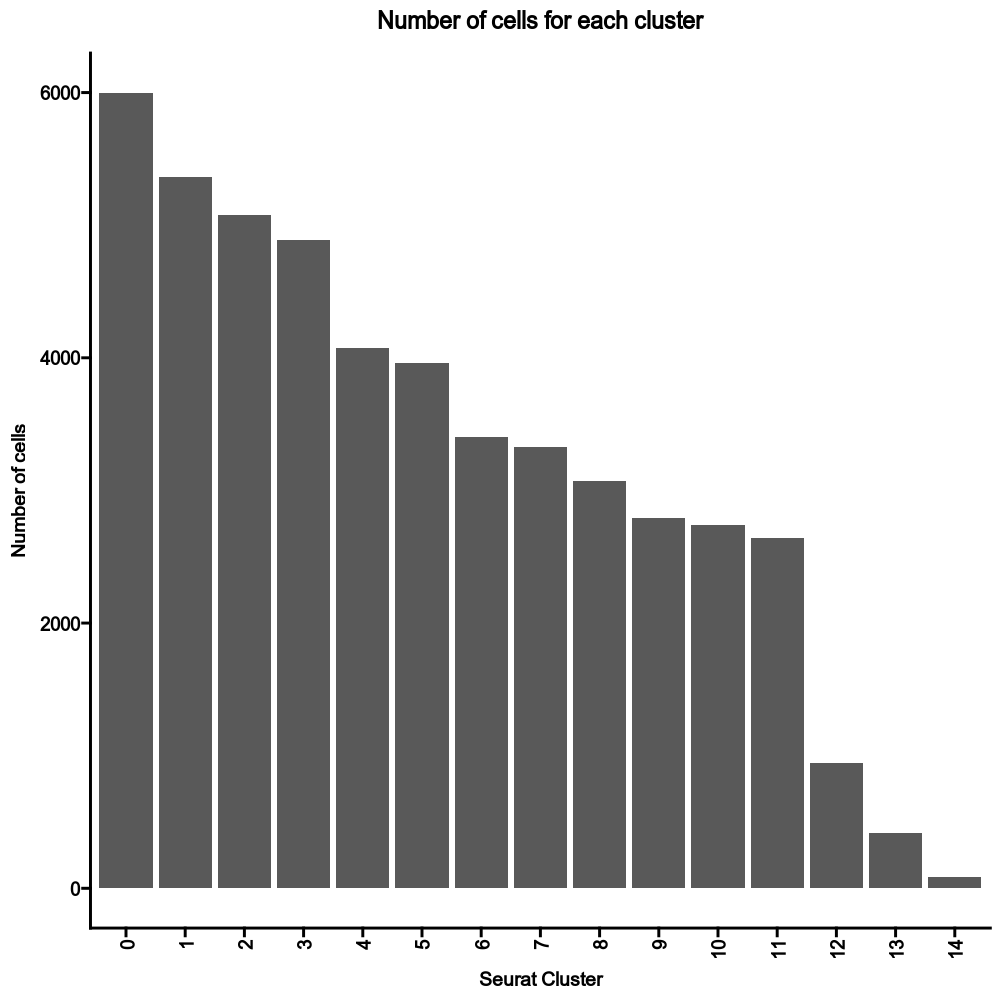{: width="80%" }
|
|
417
417
|
|
|
418
418
|
### Number of cells in each cluster by groups
|
|
419
419
|
|
|
@@ -422,7 +422,7 @@ class SeuratClusterStats(Proc):
|
|
|
422
422
|
nCells_Sample = { group-by = "Sample" }
|
|
423
423
|
```
|
|
424
424
|
|
|
425
|
-
{: width="80%" }
|
|
425
|
+
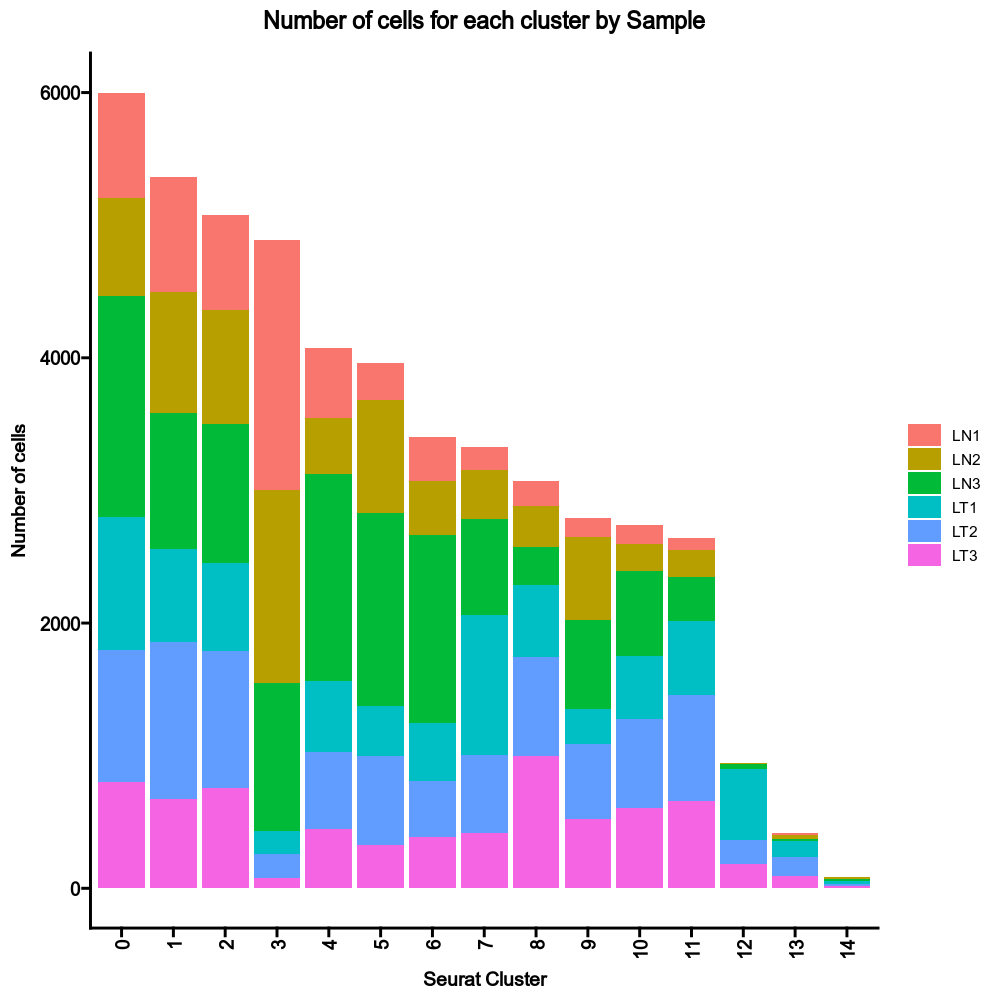{: width="80%" }
|
|
426
426
|
|
|
427
427
|
### Violin plots for the gene expressions
|
|
428
428
|
|
|
@@ -435,8 +435,8 @@ class SeuratClusterStats(Proc):
|
|
|
435
435
|
vlnplots_1 = { features = ["FOXP3", "IL2RA"], pt-size = 0, kind = "vln" }
|
|
436
436
|
```
|
|
437
437
|
|
|
438
|
-
{: width="80%" }
|
|
439
|
-
{: width="80%" }
|
|
438
|
+
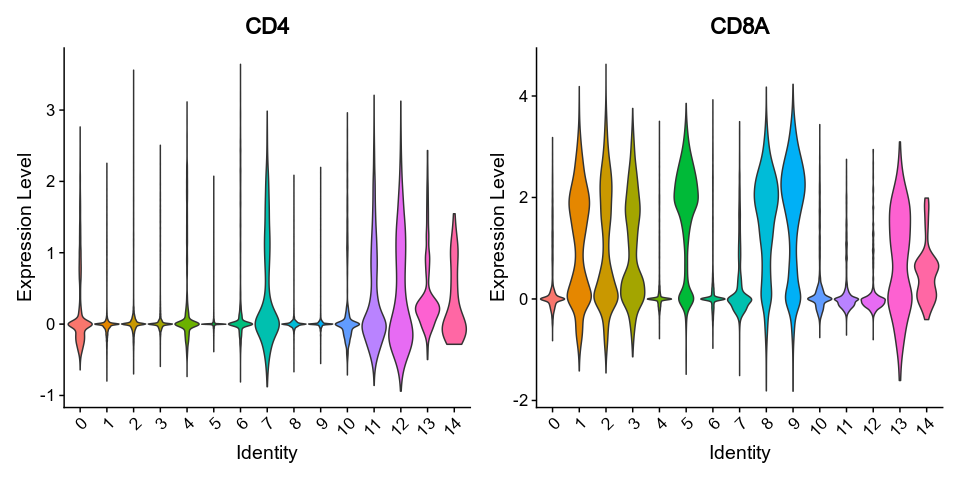{: width="80%" }
|
|
439
|
+
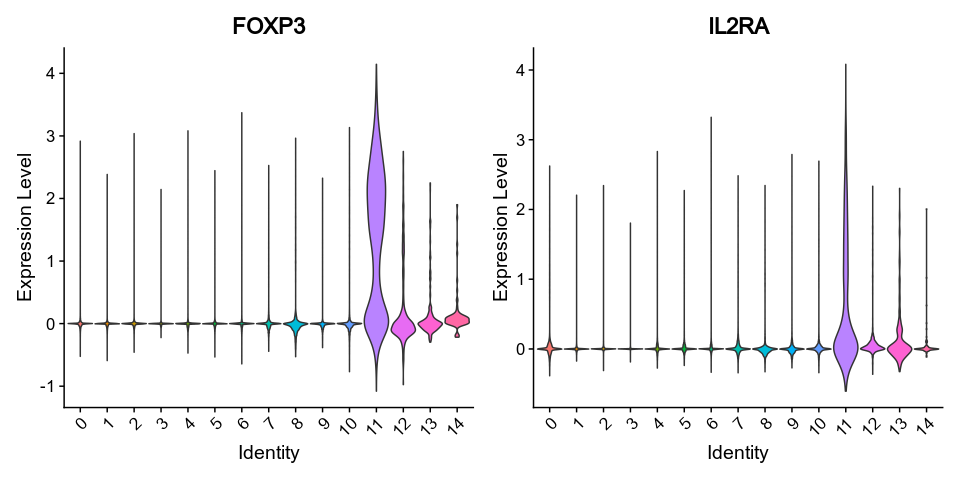{: width="80%" }
|
|
440
440
|
|
|
441
441
|
### Dimension reduction plot with labels
|
|
442
442
|
|
|
@@ -447,7 +447,7 @@ class SeuratClusterStats(Proc):
|
|
|
447
447
|
repel = true
|
|
448
448
|
```
|
|
449
449
|
|
|
450
|
-
{: width="80%" }
|
|
450
|
+
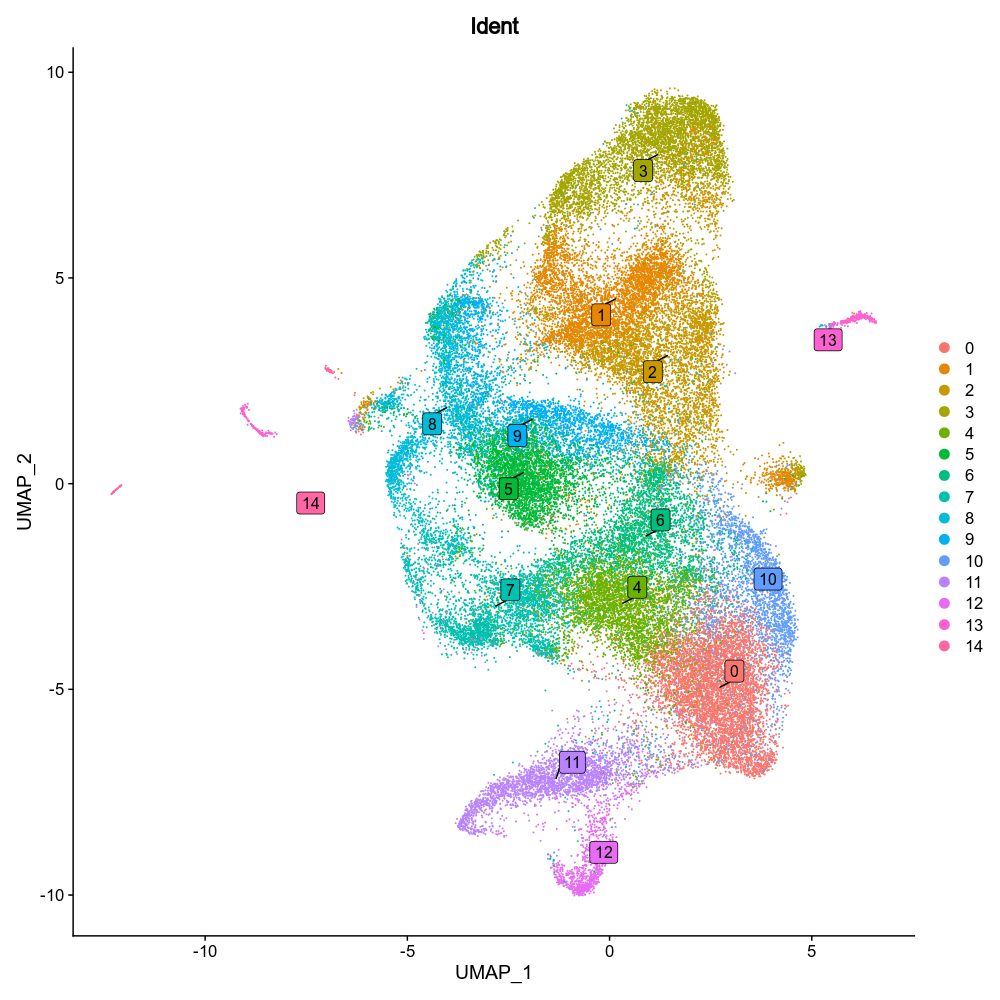{: width="80%" }
|
|
451
451
|
|
|
452
452
|
Input:
|
|
453
453
|
srtobj: The seurat object loaded by `SeuratClustering`
|
|
@@ -857,7 +857,7 @@ class CellsDistribution(Proc):
|
|
|
857
857
|
group_order = [ "Tumor", "Normal" ]
|
|
858
858
|
```
|
|
859
859
|
|
|
860
|
-

|
|
860
|
+
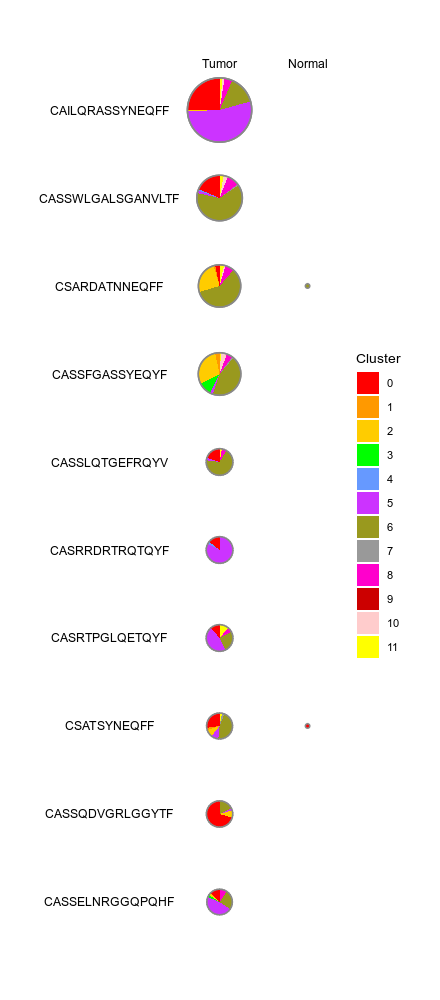
|
|
861
861
|
|
|
862
862
|
Input:
|
|
863
863
|
srtobj: The seurat object in RDS format
|
|
@@ -1870,7 +1870,7 @@ class RadarPlots(Proc):
|
|
|
1870
1870
|
|
|
1871
1871
|
Then we will have a radar plots like this:
|
|
1872
1872
|
|
|
1873
|
-

|
|
1873
|
+
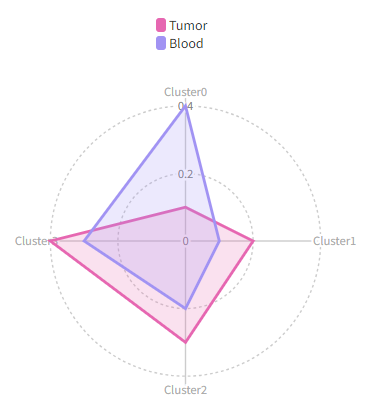
|
|
1874
1874
|
|
|
1875
1875
|
We can use `each` to separate the cells into different cases:
|
|
1876
1876
|
|
|
@@ -1882,7 +1882,7 @@ class RadarPlots(Proc):
|
|
|
1882
1882
|
|
|
1883
1883
|
Then we will have two radar plots, one for `Pre` and one for `Post`:
|
|
1884
1884
|
|
|
1885
|
-

|
|
1885
|
+
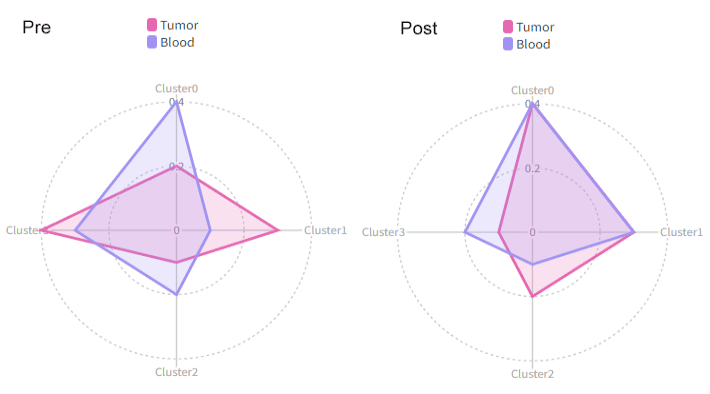
|
|
1886
1886
|
|
|
1887
1887
|
Using `cluster_order` to change the order of the clusters and show only the first 3 clusters:
|
|
1888
1888
|
|
|
@@ -1893,7 +1893,7 @@ class RadarPlots(Proc):
|
|
|
1893
1893
|
breaks = [0, 50, 100] # also change the breaks
|
|
1894
1894
|
```
|
|
1895
1895
|
|
|
1896
|
-

|
|
1896
|
+
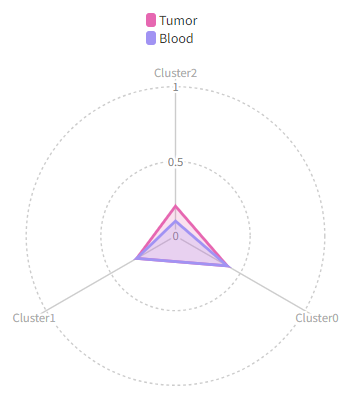
|
|
1897
1897
|
|
|
1898
1898
|
|
|
1899
1899
|
/// Attention
|
|
@@ -22,11 +22,11 @@ class MetabolicPathwayActivity(Proc):
|
|
|
22
22
|
For each subset, a heatmap and a violin plot will be generated.
|
|
23
23
|
The heatmap shows the pathway activities for each group and each metabolic pathway
|
|
24
24
|
|
|
25
|
-
{: width="80%"}
|
|
25
|
+
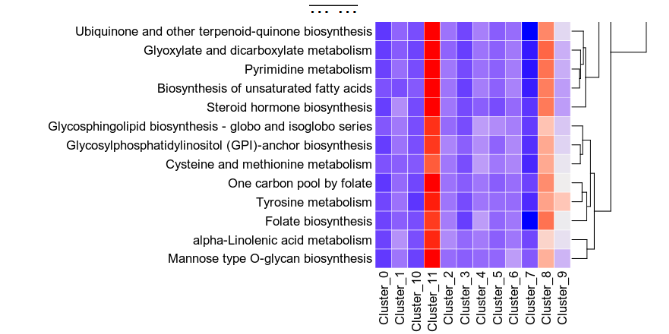{: width="80%"}
|
|
26
26
|
|
|
27
27
|
The violin plot shows the distribution of the pathway activities for each group
|
|
28
28
|
|
|
29
|
-
{: width="45%"}
|
|
29
|
+
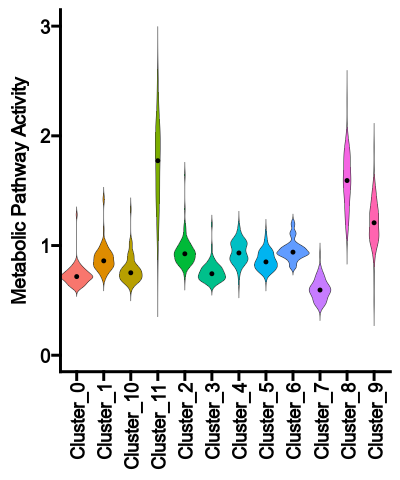{: width="45%"}
|
|
30
30
|
|
|
31
31
|
Envs:
|
|
32
32
|
ntimes (type=int): Number of times to do the permutation
|
|
@@ -294,7 +294,7 @@ class MetabolicPathwayHeterogeneity(Proc):
|
|
|
294
294
|
The heterogeneity can be reflected by the NES values and the p-values in
|
|
295
295
|
different groups for the metabolic pathways.
|
|
296
296
|
|
|
297
|
-

|
|
297
|
+
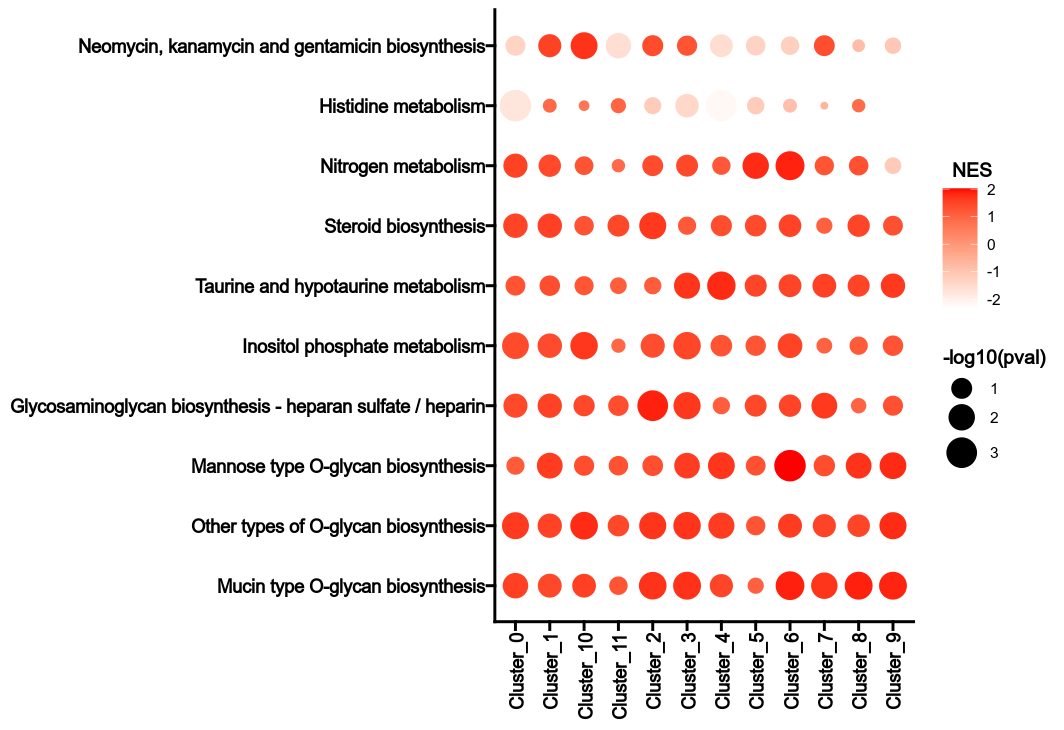
|
|
298
298
|
|
|
299
299
|
|
|
300
300
|
Envs:
|
biopipen/ns/snp.py
CHANGED
|
@@ -71,3 +71,68 @@ class PlinkSimulation(Proc):
|
|
|
71
71
|
"sample_prefix": None,
|
|
72
72
|
}
|
|
73
73
|
script = "file://../scripts/snp/PlinkSimulation.py"
|
|
74
|
+
|
|
75
|
+
|
|
76
|
+
class MatrixEQTL(Proc):
|
|
77
|
+
"""Run Matrix eQTL
|
|
78
|
+
|
|
79
|
+
See also <https://www.bios.unc.edu/research/genomic_software/Matrix_eQTL/>
|
|
80
|
+
|
|
81
|
+
Input:
|
|
82
|
+
geno: Genotype matrix file with rows representing SNPs and columns
|
|
83
|
+
representing samples.
|
|
84
|
+
expr: Expression matrix file with rows representing genes and columns
|
|
85
|
+
representing samples.
|
|
86
|
+
cov: Covariate matrix file with rows representing covariates and columns
|
|
87
|
+
representing samples.
|
|
88
|
+
|
|
89
|
+
Output:
|
|
90
|
+
alleqtls: Matrix eQTL output file
|
|
91
|
+
cisqtls: The cis-eQTL file if `snppos` and `genepos` are provided.
|
|
92
|
+
Otherwise it'll be empty.
|
|
93
|
+
|
|
94
|
+
Envs:
|
|
95
|
+
model (choice): The model to use.
|
|
96
|
+
- `linear`: Linear model
|
|
97
|
+
- `modelLINEAR`: Same as `linear`
|
|
98
|
+
- `anova`: ANOVA model
|
|
99
|
+
- `modelANOVA`: Same as `anova`
|
|
100
|
+
pval (type=float): P-value threshold for eQTLs
|
|
101
|
+
transp (type=float): P-value threshold for trans-eQTLs.
|
|
102
|
+
If cis-eQTLs are not enabled (`snppos` and `genepos` are not set),
|
|
103
|
+
this defaults to 1e-5.
|
|
104
|
+
If cis-eQTLs are enabled, this defaults to `None`, which will disable
|
|
105
|
+
trans-eQTL analysis.
|
|
106
|
+
fdr (flag): Do FDR calculation or not (save memory if not).
|
|
107
|
+
snppos: The path of the SNP position file.
|
|
108
|
+
It could be a BED, GFF, VCF or a tab-delimited file with
|
|
109
|
+
`snp`, `chr`, `pos` as the first 3 columns.
|
|
110
|
+
genepos: The path of the gene position file.
|
|
111
|
+
It could be a BED or GFF file.
|
|
112
|
+
dist (type=int): Distance threshold for cis-eQTLs.
|
|
113
|
+
transpose_geno (flag): If set, the genotype matrix (`in.geno`)
|
|
114
|
+
will be transposed.
|
|
115
|
+
transpose_expr (flag): If set, the expression matrix (`in.expr`)
|
|
116
|
+
will be transposed.
|
|
117
|
+
transpose_cov (flag): If set, the covariate matrix (`in.cov`)
|
|
118
|
+
will be transposed.
|
|
119
|
+
"""
|
|
120
|
+
input = "geno:file, expr:file, cov:file"
|
|
121
|
+
output = [
|
|
122
|
+
"alleqtls:file:{{in.geno | stem}}.alleqtls.txt",
|
|
123
|
+
"cisqtls:file:{{in.geno | stem}}.cisqtls.txt",
|
|
124
|
+
]
|
|
125
|
+
lang = config.lang.rscript
|
|
126
|
+
envs = {
|
|
127
|
+
"model": "linear",
|
|
128
|
+
"pval": 1e-3,
|
|
129
|
+
"transp": None,
|
|
130
|
+
"fdr": False,
|
|
131
|
+
"snppos": None,
|
|
132
|
+
"genepos": config.ref.refgene,
|
|
133
|
+
"dist": 250000,
|
|
134
|
+
"transpose_geno": False,
|
|
135
|
+
"transpose_expr": False,
|
|
136
|
+
"transpose_cov": False,
|
|
137
|
+
}
|
|
138
|
+
script = "file://../scripts/snp/MatrixEQTL.R"
|
biopipen/ns/tcr.py
CHANGED
|
@@ -923,7 +923,7 @@ class CloneResidency(Proc):
|
|
|
923
923
|
|
|
924
924
|
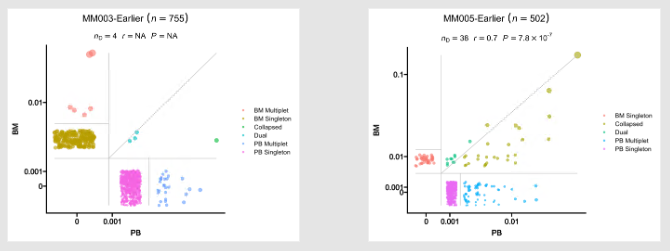
- Residency plots showing the residency of clones in the two groups
|
|
925
925
|
|
|
926
|
-

|
|
926
|
+
|
|
927
927
|
|
|
928
928
|
The points in the plot are jittered to avoid overplotting. The x-axis is the residency in the first group and
|
|
929
929
|
the y-axis is the residency in the second group. The size of the points are relative to the normalized size of
|
|
@@ -943,7 +943,7 @@ class CloneResidency(Proc):
|
|
|
943
943
|
|
|
944
944
|
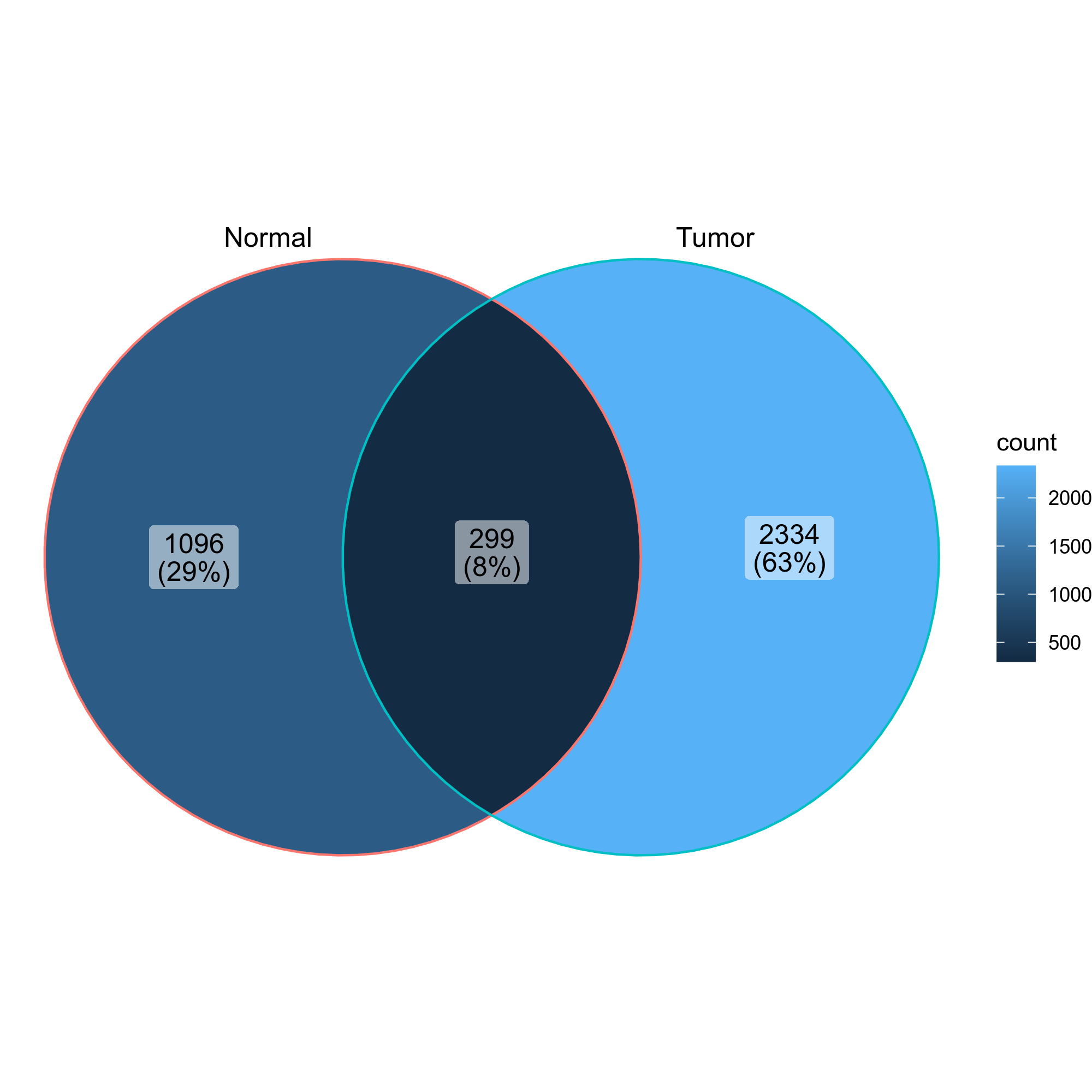
- Venn diagrams showing the overlap of the clones in the two groups
|
|
945
945
|
|
|
946
|
-
{: width="60%"}
|
|
946
|
+
{: width="60%"}
|
|
947
947
|
|
|
948
948
|
Input:
|
|
949
949
|
immdata: The data loaded by `immunarch::repLoad()`
|
|
@@ -1259,7 +1259,7 @@ class TCRClusterStats(Proc):
|
|
|
1259
1259
|
by = "Sample"
|
|
1260
1260
|
```
|
|
1261
1261
|
|
|
1262
|
-
{: width="80%"}
|
|
1262
|
+
{: width="80%"}
|
|
1263
1263
|
|
|
1264
1264
|
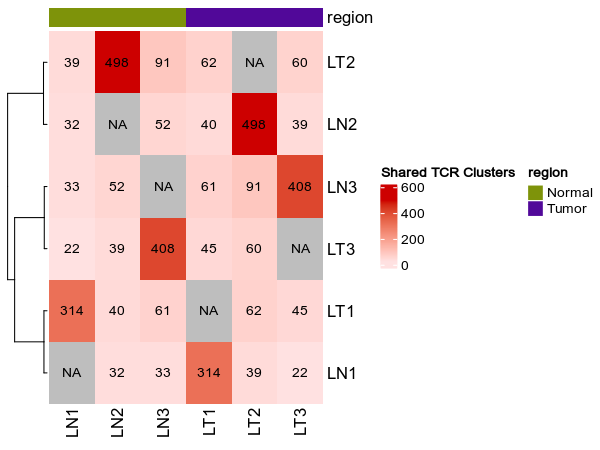
### Shared clusters
|
|
1265
1265
|
|
|
@@ -1269,7 +1269,7 @@ class TCRClusterStats(Proc):
|
|
|
1269
1269
|
heatmap_meta = ["region"]
|
|
1270
1270
|
```
|
|
1271
1271
|
|
|
1272
|
-
{: width="80%"}
|
|
1272
|
+
{: width="80%"}
|
|
1273
1273
|
|
|
1274
1274
|
### Sample diversity
|
|
1275
1275
|
|
|
@@ -1278,11 +1278,11 @@ class TCRClusterStats(Proc):
|
|
|
1278
1278
|
method = "gini"
|
|
1279
1279
|
```
|
|
1280
1280
|
|
|
1281
|
-
{: width="80%"}
|
|
1281
|
+
{: width="80%"}
|
|
1282
1282
|
|
|
1283
1283
|
Compared to the sample diversity using TCR clones:
|
|
1284
1284
|
|
|
1285
|
-
{: width="80%"}
|
|
1285
|
+
{: width="80%"}
|
|
1286
1286
|
|
|
1287
1287
|
Input:
|
|
1288
1288
|
immfile: The immunarch object with TCR clusters attached
|
|
@@ -113,14 +113,14 @@ for (name in names(stats)) {
|
|
|
113
113
|
if (stat$plot == "boxplot" || stat$plot == "box") {
|
|
114
114
|
p <- ggplot(data, aes(x=!!group, y=!!sym(stat$on), fill=!!group)) +
|
|
115
115
|
geom_boxplot(position = "dodge") +
|
|
116
|
-
scale_fill_biopipen() +
|
|
116
|
+
scale_fill_biopipen(alpha = .6) +
|
|
117
117
|
xlab("")
|
|
118
118
|
} else if (stat$plot == "violin" ||
|
|
119
119
|
stat$plot == "violinplot" ||
|
|
120
120
|
stat$plot == "vlnplot") {
|
|
121
121
|
p <- ggplot(data, aes(x = !!group, y = !!sym(stat$on), fill=!!group)) +
|
|
122
122
|
geom_violin(position = "dodge") +
|
|
123
|
-
scale_fill_biopipen() +
|
|
123
|
+
scale_fill_biopipen(alpha = .6) +
|
|
124
124
|
xlab("")
|
|
125
125
|
} else if (
|
|
126
126
|
(grepl("violin", stat$plot) || grepl("vln", stat$plot)) &&
|
|
@@ -129,12 +129,12 @@ for (name in names(stats)) {
|
|
|
129
129
|
p <- ggplot(data, aes(x = !!group, y = !!sym(stat$on), fill = !!group)) +
|
|
130
130
|
geom_violin(position = "dodge") +
|
|
131
131
|
geom_boxplot(width = 0.1, position = position_dodge(0.9), fill="white") +
|
|
132
|
-
scale_fill_biopipen() +
|
|
132
|
+
scale_fill_biopipen(alpha = .6) +
|
|
133
133
|
xlab("")
|
|
134
134
|
} else if (stat$plot == "histogram" || stat$plot == "hist") {
|
|
135
135
|
p <- ggplot(data, aes(x = !!sym(stat$on), fill = !!group)) +
|
|
136
136
|
geom_histogram(bins = 10, position = "dodge", alpha = 0.8, color = "white") +
|
|
137
|
-
scale_fill_biopipen()
|
|
137
|
+
scale_fill_biopipen(alpha = .6)
|
|
138
138
|
} else if (stat$plot == "pie" || stat$plot == "piechart") {
|
|
139
139
|
if (is.null(stat$each)) {
|
|
140
140
|
data <- data %>% distinct(!!group, .keep_all = TRUE)
|
|
@@ -157,7 +157,7 @@ for (name in names(stats)) {
|
|
|
157
157
|
fill="#EEEEEE",
|
|
158
158
|
size=4
|
|
159
159
|
) +
|
|
160
|
-
scale_fill_biopipen(name = group) +
|
|
160
|
+
scale_fill_biopipen(alpha = .6, name = group) +
|
|
161
161
|
ggtitle(paste0("# ", stat$on))
|
|
162
162
|
} else if (stat$plot == "bar" || stat$plot == "barplot") {
|
|
163
163
|
if (is.null(stat$each)) {
|
|
@@ -169,7 +169,7 @@ for (name in names(stats)) {
|
|
|
169
169
|
data,
|
|
170
170
|
aes(x = !!group, y = !!sym(count_on), fill = !!group)) +
|
|
171
171
|
geom_bar(stat = "identity") +
|
|
172
|
-
scale_fill_biopipen() +
|
|
172
|
+
scale_fill_biopipen(alpha = .6) +
|
|
173
173
|
ylab(paste0("# ", stat$on))
|
|
174
174
|
} else {
|
|
175
175
|
stop("Unknown plot type: ", stat$plot)
|
|
@@ -0,0 +1,88 @@
|
|
|
1
|
+
|
|
2
|
+
source("{{biopipen_dir}}/utils/misc.R")
|
|
3
|
+
|
|
4
|
+
library(rlang)
|
|
5
|
+
library(ggplot2)
|
|
6
|
+
library(plotROC)
|
|
7
|
+
|
|
8
|
+
infile <- {{in.infile | r}}
|
|
9
|
+
outfile <- {{out.outfile | r}}
|
|
10
|
+
joboutdir <- {{job.outdir | r}}
|
|
11
|
+
noids <- {{envs.noids | r}}
|
|
12
|
+
pos_label <- {{envs.pos_label | r}}
|
|
13
|
+
ci <- {{envs.ci | r}}
|
|
14
|
+
devpars <- {{envs.devpars | r}}
|
|
15
|
+
show_auc <- {{envs.show_auc | r}}
|
|
16
|
+
args <- {{envs.args | r: todot="-"}}
|
|
17
|
+
style_roc_args <- {{envs.style_roc | r: todot="-"}}
|
|
18
|
+
if (!is.null(style_roc_args$theme)) {
|
|
19
|
+
style_roc_args$theme <- eval(parse(text=style_roc_args$theme))
|
|
20
|
+
}
|
|
21
|
+
|
|
22
|
+
data <- read.table(infile, header=TRUE, sep="\t", row.names = NULL, check.names = FALSE, stringsAsFactors=FALSE)
|
|
23
|
+
if (!noids) {
|
|
24
|
+
data <- data[, -1]
|
|
25
|
+
}
|
|
26
|
+
|
|
27
|
+
# Normalize the first column (labels) into 0 and 1.
|
|
28
|
+
# If they are not 0/1, use pos_label to determine the positive class.
|
|
29
|
+
label_col <- colnames(data)[1]
|
|
30
|
+
if (is.character(data[[label_col]])) {
|
|
31
|
+
data[[label_col]] <- as.numeric(data[[label_col]] == pos_label)
|
|
32
|
+
}
|
|
33
|
+
|
|
34
|
+
models <- colnames(data)[2:ncol(data)]
|
|
35
|
+
|
|
36
|
+
if (length(models) > 1) {
|
|
37
|
+
# pivot longer the models, and put the model names into the column 'model'
|
|
38
|
+
data <- melt_roc(data, label_col, colnames(data)[2:ncol(data)])
|
|
39
|
+
} else {
|
|
40
|
+
data <- data.frame(
|
|
41
|
+
D = data[[label_col]],
|
|
42
|
+
M = data[[models]],
|
|
43
|
+
name = rep(models, nrow(data))
|
|
44
|
+
)
|
|
45
|
+
}
|
|
46
|
+
|
|
47
|
+
# Plot the ROC curve
|
|
48
|
+
p <- ggplot(data, aes(d = D, m = M, color = name))
|
|
49
|
+
|
|
50
|
+
if (isTRUE(ci)) {
|
|
51
|
+
p <- p + do.call(geom_rocci, args)
|
|
52
|
+
} else {
|
|
53
|
+
p <- p + do.call(geom_roc, args)
|
|
54
|
+
}
|
|
55
|
+
|
|
56
|
+
p <- p + do.call(style_roc, style_roc_args)
|
|
57
|
+
p <- p + scale_color_biopipen()
|
|
58
|
+
|
|
59
|
+
if (length(models) > 1) {
|
|
60
|
+
p <- p + theme(legend.title = element_blank())
|
|
61
|
+
} else {
|
|
62
|
+
p <- p + theme(legend.position = "none")
|
|
63
|
+
}
|
|
64
|
+
|
|
65
|
+
aucs = calc_auc(p)
|
|
66
|
+
write.table(aucs, file=file.path(joboutdir, "aucs.tsv"), sep="\t", quote=FALSE, row.names=FALSE)
|
|
67
|
+
|
|
68
|
+
if (show_auc) {
|
|
69
|
+
aucs = split(aucs$AUC, aucs$name)
|
|
70
|
+
if (length(aucs) > 1) {
|
|
71
|
+
# Add AUC values to the legend items
|
|
72
|
+
p <- p +
|
|
73
|
+
scale_color_manual(
|
|
74
|
+
values = pal_biopipen()(length(models)),
|
|
75
|
+
labels = sapply(models, function(m) paste(m, " (AUC =", round(aucs[[m]], 2), ")")),
|
|
76
|
+
breaks = models)
|
|
77
|
+
} else {
|
|
78
|
+
p <- p +
|
|
79
|
+
geom_text(
|
|
80
|
+
x = 0.8, y = 0.2, label = paste("AUC =", round(unlist(aucs), 2)),
|
|
81
|
+
color = "black", size = 4)
|
|
82
|
+
}
|
|
83
|
+
}
|
|
84
|
+
|
|
85
|
+
devpars$filename <- outfile
|
|
86
|
+
do.call(png, devpars)
|
|
87
|
+
print(p)
|
|
88
|
+
dev.off()
|
|
@@ -0,0 +1,157 @@
|
|
|
1
|
+
source("{{biopipen_dir}}/utils/misc.R")
|
|
2
|
+
library(rlang)
|
|
3
|
+
library(MatrixEQTL)
|
|
4
|
+
|
|
5
|
+
snpfile = {{in.geno | r}}
|
|
6
|
+
expfile = {{in.expr | r}}
|
|
7
|
+
covfile = {{in.cov | r}}
|
|
8
|
+
joboutdir = {{job.outdir | r}}
|
|
9
|
+
alleqtl = {{out.alleqtls | r}}
|
|
10
|
+
outfile = {{out.cisqtls | r}}
|
|
11
|
+
|
|
12
|
+
model = {{envs.model | r}}
|
|
13
|
+
pval = {{envs.pval | r}}
|
|
14
|
+
transp = {{envs.transp | r}}
|
|
15
|
+
fdr = {{envs.fdr | r}}
|
|
16
|
+
snppos = {{envs.snppos | r}}
|
|
17
|
+
genepos = {{envs.genepos | r}}
|
|
18
|
+
dist = {{envs.dist | r}}
|
|
19
|
+
|
|
20
|
+
transpose_geno = {{envs.transpose_geno | r}}
|
|
21
|
+
transpose_expr = {{envs.transpose_expr | r}}
|
|
22
|
+
transpose_cov = {{envs.transpose_cov | r}}
|
|
23
|
+
|
|
24
|
+
arg_match(model, c("modelANOVA", "modelLINEAR", "linear", "anova"))
|
|
25
|
+
if (model == "linear") model = "modelLINEAR"
|
|
26
|
+
if (model == "anova") model = "modelANOVA"
|
|
27
|
+
model = get(model)
|
|
28
|
+
|
|
29
|
+
trans_enabled = !is.null(transp)
|
|
30
|
+
cis_enabled = !is.null(snppos) && !is.null(genepos) && dist > 0
|
|
31
|
+
|
|
32
|
+
# if trans is disabled, all files needed for cis should be provided
|
|
33
|
+
if (!trans_enabled && !cis_enabled) {
|
|
34
|
+
log_warn("Using `envs.transp = 1e-5` since cis-eQTL is disabled.")
|
|
35
|
+
trans_enabled <- TRUE
|
|
36
|
+
transp <- 1e-5
|
|
37
|
+
}
|
|
38
|
+
|
|
39
|
+
transpose_file <- function(file) {
|
|
40
|
+
out <- file.path(joboutdir, paste0(
|
|
41
|
+
tools::file_path_sans_ext(basename(file)),
|
|
42
|
+
".transposed.",
|
|
43
|
+
tools::file_ext(file))
|
|
44
|
+
)
|
|
45
|
+
data <- read.table(file, header=TRUE, stringsAsFactors=FALSE, row.names=1, sep="\t", quote="", check.names=FALSE)
|
|
46
|
+
write.table(t(data), file=out, sep="\t", quote=FALSE, row.names=TRUE, col.names=TRUE)
|
|
47
|
+
out
|
|
48
|
+
}
|
|
49
|
+
|
|
50
|
+
if (transpose_geno) snpfile = transpose_file(snpfile)
|
|
51
|
+
if (transpose_expr) expfile = transpose_file(expfile)
|
|
52
|
+
if (transpose_cov) covfile = transpose_file(covfile)
|
|
53
|
+
|
|
54
|
+
snps = SlicedData$new();
|
|
55
|
+
snps$fileDelimiter = "\t"; # the TAB character
|
|
56
|
+
snps$fileOmitCharacters = "NA"; # denote missing values;
|
|
57
|
+
snps$fileSkipRows = 1; # one row of column labels
|
|
58
|
+
snps$fileSkipColumns = 1; # one column of row labels
|
|
59
|
+
snps$fileSliceSize = 10000; # read file in pieces of 2,000 rows
|
|
60
|
+
snps$LoadFile( snpfile );
|
|
61
|
+
|
|
62
|
+
gene = SlicedData$new();
|
|
63
|
+
gene$fileDelimiter = "\t"; # the TAB character
|
|
64
|
+
gene$fileOmitCharacters = "NA"; # denote missing values;
|
|
65
|
+
gene$fileSkipRows = 1; # one row of column labels
|
|
66
|
+
gene$fileSkipColumns = 1; # one column of row labels
|
|
67
|
+
gene$fileSliceSize = 10000; # read file in pieces of 2,000 rows
|
|
68
|
+
gene$LoadFile( expfile );
|
|
69
|
+
|
|
70
|
+
cvrt = SlicedData$new();
|
|
71
|
+
if (!is.null(covfile) && file.exists(covfile)) {
|
|
72
|
+
covmatrix = t(read.table.inopts(covfile, list(cnames=TRUE, rnames=TRUE)))
|
|
73
|
+
cvrt$CreateFromMatrix( as.matrix(covmatrix) )
|
|
74
|
+
}
|
|
75
|
+
|
|
76
|
+
engine_params = list()
|
|
77
|
+
engine_params$snps = snps
|
|
78
|
+
engine_params$gene = gene
|
|
79
|
+
engine_params$cvrt = cvrt
|
|
80
|
+
engine_params$output_file_name = ifelse(trans_enabled, alleqtl, NULL)
|
|
81
|
+
engine_params$pvOutputThreshold = ifelse(trans_enabled, transp, 0)
|
|
82
|
+
engine_params$useModel = model
|
|
83
|
+
engine_params$errorCovariance = numeric()
|
|
84
|
+
engine_params$verbose = TRUE
|
|
85
|
+
engine_params$noFDRsaveMemory = !fdr
|
|
86
|
+
|
|
87
|
+
noq = function(s) {
|
|
88
|
+
gsub('^\"|\"$', "", s)
|
|
89
|
+
}
|
|
90
|
+
|
|
91
|
+
if (cis_enabled) {
|
|
92
|
+
if (endsWith(snppos, ".bed")) {
|
|
93
|
+
snppos_data = read.table.inopts(snppos,
|
|
94
|
+
list(cnames=FALSE, rnames=FALSE))
|
|
95
|
+
snppos_data = snppos_data[, c(4, 1, 2)]
|
|
96
|
+
colnames(snppos_data) = c("snp", "chr", "pos")
|
|
97
|
+
} else if (endsWith(snppos, ".gff") || endsWith(snppos, ".gtf")) {
|
|
98
|
+
snppos_data = read.table.inopts(snppos,
|
|
99
|
+
list(cnames=FALSE, rnames=FALSE));
|
|
100
|
+
snppos_data = snppos_data[, c(9, 1, 4)]
|
|
101
|
+
colnames(snppos_data) = c("snp", "chr", "pos")
|
|
102
|
+
snppos_data$snp = unlist(lapply(snppos_data$snp, function(x) {
|
|
103
|
+
for (s in unlist(strsplit(x, '; ', fixed=T))) {
|
|
104
|
+
if (startsWith(s, "snp_id "))
|
|
105
|
+
return(noq(substring(s, 8)))
|
|
106
|
+
else if (startsWith(s, "rs_id "))
|
|
107
|
+
return(noq(substring(s, 7)))
|
|
108
|
+
else if (startsWith(s, "rs "))
|
|
109
|
+
return(noq(substring(s, 4)))
|
|
110
|
+
}
|
|
111
|
+
}))
|
|
112
|
+
} else if (endsWith(snppos, ".vcf") || endsWith(snppos, ".vcf.gz")) {
|
|
113
|
+
snppos_data = read.table.inopts(snppos,
|
|
114
|
+
list(cnames=FALSE, rnames=FALSE))
|
|
115
|
+
snppos_data = snppos_data[, c(3, 1, 2)]
|
|
116
|
+
colnames(snppos_data) = c("snp", "chr", "pos")
|
|
117
|
+
} else {
|
|
118
|
+
snppos_data = read.table.inopts(snppos, list(cnames=TRUE))
|
|
119
|
+
colnames(snppos_data) = c("snp", "chr", "pos")
|
|
120
|
+
}
|
|
121
|
+
|
|
122
|
+
if (endsWith(genepos, ".bed")) {
|
|
123
|
+
genepos_data = read.table.inopts(genepos,
|
|
124
|
+
list(cnames=FALSE, rnames=FALSE))
|
|
125
|
+
genepos_data = genepos_data[, c(4, 1:3)]
|
|
126
|
+
colnames(genepos_data) = c("geneid", "chr", "s1", "s2")
|
|
127
|
+
} else if (endsWith(genepos, ".gff") || endsWith(genepos, ".gtf")) {
|
|
128
|
+
genepos_data = read.table.inopts(genepos,
|
|
129
|
+
list(cnames=FALSE, rnames=FALSE))
|
|
130
|
+
genepos_data = genepos_data[, c(9, 1, 4, 5)]
|
|
131
|
+
colnames(genepos_data) = c("geneid", "chr", "s1", "s2")
|
|
132
|
+
genepos_data$geneid = noquote(unlist(lapply(genepos_data$geneid, function(x) {
|
|
133
|
+
for (s in unlist(strsplit(x, '; ', fixed=T))) {
|
|
134
|
+
if (startsWith(s, "gene_id "))
|
|
135
|
+
return(noq(substring(s, 9)))
|
|
136
|
+
}
|
|
137
|
+
})))
|
|
138
|
+
} else {
|
|
139
|
+
genepos_data = read.table(genepos, header = TRUE, stringsAsFactors = FALSE);
|
|
140
|
+
colnames(genepos_data) = c("geneid", "chr", "s1", "s2")
|
|
141
|
+
}
|
|
142
|
+
|
|
143
|
+
engine_params$output_file_name.cis = outfile
|
|
144
|
+
engine_params$pvOutputThreshold.cis = pval
|
|
145
|
+
engine_params$cisDist = dist
|
|
146
|
+
engine_params$snpspos = snppos_data
|
|
147
|
+
engine_params$genepos = genepos_data
|
|
148
|
+
do_call(Matrix_eQTL_main, engine_params)
|
|
149
|
+
} else {
|
|
150
|
+
do_call(Matrix_eQTL_engine, engine_params)
|
|
151
|
+
file.create(outfile)
|
|
152
|
+
}
|
|
153
|
+
|
|
154
|
+
if (pval == 0) {
|
|
155
|
+
if (!file.exists(outfile)) file.create(outfile)
|
|
156
|
+
if (!file.exists(alleqtl)) file.create(alleqtl)
|
|
157
|
+
}
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.1
|
|
2
2
|
Name: biopipen
|
|
3
|
-
Version: 0.27.
|
|
3
|
+
Version: 0.27.4
|
|
4
4
|
Summary: Bioinformatics processes/pipelines that can be run from `pipen run`
|
|
5
5
|
License: MIT
|
|
6
6
|
Author: pwwang
|
|
@@ -20,4 +20,3 @@ Requires-Dist: pipen-filters (>=0.12,<0.13)
|
|
|
20
20
|
Requires-Dist: pipen-poplog (>=0.1.2,<0.2.0)
|
|
21
21
|
Requires-Dist: pipen-runinfo (>=0.6,<0.7) ; extra == "runinfo"
|
|
22
22
|
Requires-Dist: pipen-verbose (>=0.11,<0.12)
|
|
23
|
-
Requires-Dist: pyyaml-include (==1.*)
|
|
@@ -1,4 +1,4 @@
|
|
|
1
|
-
biopipen/__init__.py,sha256=
|
|
1
|
+
biopipen/__init__.py,sha256=FRehirBY8kLByuBXp81U_RUAg8WYLFropNPtg2RpV2w,23
|
|
2
2
|
biopipen/core/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
3
3
|
biopipen/core/config.py,sha256=edK5xnDhM8j27srDzsxubi934NMrglLoKrdcC8qsEPk,1069
|
|
4
4
|
biopipen/core/config.toml,sha256=20RCI30Peee1EQdfb_UbV3Hf74XUPndJnYZlUThytsw,1781
|
|
@@ -15,18 +15,18 @@ biopipen/ns/cellranger_pipeline.py,sha256=D6gvIeasHjDCdro7f4wjomxRYTtsJT77Ld47Xz
|
|
|
15
15
|
biopipen/ns/cnv.py,sha256=vq6dZfEOyuVuqg3nP6FQtNmQ-JocpBJMX9IYlZ0OPD0,6803
|
|
16
16
|
biopipen/ns/cnvkit.py,sha256=5mA2Q8-YDs4g1HoxtpB_NWnyZYwEThNr3s3wlubLQrQ,31130
|
|
17
17
|
biopipen/ns/cnvkit_pipeline.py,sha256=2fJLn70L2jJ81ZMNdnU84Sf3HoKA2CSnHuDzLGR8jmw,36854
|
|
18
|
-
biopipen/ns/delim.py,sha256=
|
|
18
|
+
biopipen/ns/delim.py,sha256=fejsh4KW1TG5oMZzAC238LvQhBz7brXkfl3BHfnLK5M,5612
|
|
19
19
|
biopipen/ns/gene.py,sha256=Q5FzRByfnRITXRNRZR65ApG09FRyiihRC3TcIXxufzE,2228
|
|
20
20
|
biopipen/ns/gsea.py,sha256=EsNRAPYsagaV2KYgr4Jv0KCnZGqayM209v4yOGGTIOI,7423
|
|
21
21
|
biopipen/ns/misc.py,sha256=fzn0pXvdghMkQhu-e3MMapPNMyO6IAJbtTzVU3GbFa0,3246
|
|
22
|
-
biopipen/ns/plot.py,sha256=
|
|
22
|
+
biopipen/ns/plot.py,sha256=fzJAKKl4a_tsVkLREGCQTFVHP049m33LdWgeYRb6v7M,5483
|
|
23
23
|
biopipen/ns/rnaseq.py,sha256=bKAa6friFWof4yDTWZQahm1MS-lrdetO1GqDKdfxXYc,7708
|
|
24
|
-
biopipen/ns/scrna.py,sha256=
|
|
25
|
-
biopipen/ns/scrna_metabolic_landscape.py,sha256=
|
|
26
|
-
biopipen/ns/snp.py,sha256=
|
|
24
|
+
biopipen/ns/scrna.py,sha256=u0p2eVqB2T7vpg-19NN0277QKChTsv9yxM6xQA6pJHg,103464
|
|
25
|
+
biopipen/ns/scrna_metabolic_landscape.py,sha256=EhOtHQyoH-jRpzDoOI_06UbjEg6mhvbDEHKhek01bPk,28334
|
|
26
|
+
biopipen/ns/snp.py,sha256=EQ2FS0trQ7YThPmBVTpS66lc2OSfgQ6lCh6WnyP-C2g,5499
|
|
27
27
|
biopipen/ns/stats.py,sha256=yJ6C1CXF84T7DDs9mgufqUOr89Rl6kybE5ji8Vnx6cw,13693
|
|
28
28
|
biopipen/ns/tcgamaf.py,sha256=AFbUJIxiMSvsVY3RcHgjRFuMnNh2DG3Mr5slLNEyz6o,1455
|
|
29
|
-
biopipen/ns/tcr.py,sha256=
|
|
29
|
+
biopipen/ns/tcr.py,sha256=7F_FulZ3UGouuvgH_ylZwJybr_310f9BTz_kouO1SjY,87905
|
|
30
30
|
biopipen/ns/vcf.py,sha256=cdkKroii0_nl_bSP2cnO09qESUAhHqu6btOiTSKS79Y,15314
|
|
31
31
|
biopipen/ns/web.py,sha256=3zucrDo-IVsSnIvlw-deoScuxqWa6OMTm8Vo-R4E44Q,2224
|
|
32
32
|
biopipen/reports/bam/CNAClinic.svelte,sha256=D4IxQcgDCPQZMbXog-aZP5iJEQTK2N4i0C60e_iXyfs,213
|
|
@@ -102,7 +102,7 @@ biopipen/scripts/cnvkit/CNVkitScatter.py,sha256=7DhTiXPHEHbdXn0VFcDOR-wTP6sks08N
|
|
|
102
102
|
biopipen/scripts/cnvkit/CNVkitSegment.py,sha256=q5iGAjY6-yIehPcJpi3hX6EuGre0YgWTPkG_d5LEV48,1629
|
|
103
103
|
biopipen/scripts/cnvkit/guess_baits.py,sha256=7OCMtSMHIJWWZv9qEYVXnB0N4hU_JaGEesKdkr6tvJc,10586
|
|
104
104
|
biopipen/scripts/delim/RowsBinder.R,sha256=yp960u7Ui_jFCL8WDvODa-0vhJvyLo64ll35PzXYUbI,1444
|
|
105
|
-
biopipen/scripts/delim/SampleInfo.R,sha256=
|
|
105
|
+
biopipen/scripts/delim/SampleInfo.R,sha256=1EYlqoVpIEl9l2eBaCLETuI_Ma3HjihS9tRbGmOPiBk,6397
|
|
106
106
|
biopipen/scripts/gene/GeneNameConversion.py,sha256=2RveardTsLv2K1XSj3G0ERYLiln9bcR74bjkRdKcChc,1880
|
|
107
107
|
biopipen/scripts/gsea/Enrichr.R,sha256=tr4vInlVIeiGXumh22ARuTQmy0-Qq869RiX7d7ERqCg,661
|
|
108
108
|
biopipen/scripts/gsea/FGSEA.R,sha256=RLqDgrqnYEacHfzEEuZ3d29lxNqWehigOnGuu248SRg,1483
|
|
@@ -111,6 +111,7 @@ biopipen/scripts/gsea/PreRank.R,sha256=onZK1FQa6yDO0Fz4juy56XQjpzyw3zBdZv7edY9ac
|
|
|
111
111
|
biopipen/scripts/misc/Config2File.py,sha256=NUio0uOEuZtUBpuByDSItYu9Kwu5mosb4pdPq5-QAmE,440
|
|
112
112
|
biopipen/scripts/misc/Str2File.py,sha256=99oQNxChxChNJ9vmD77b48cu-r_P_heSpx7A5wi3qTE,212
|
|
113
113
|
biopipen/scripts/plot/Heatmap.R,sha256=4v_oRME8ZiwczIlBIp-OP_YPWLAvBKzbHiwNBCZ0Xog,1982
|
|
114
|
+
biopipen/scripts/plot/ROC.R,sha256=Cr-mHQx6c748fQYkOWO2xIKWwiVAUxGuxn6lYEhNH78,2430
|
|
114
115
|
biopipen/scripts/plot/VennDiagram.R,sha256=GVc-kyHqnXrbXZvy-evcxI1XGtlLSChBiVnMjPywNMA,731
|
|
115
116
|
biopipen/scripts/rnaseq/Simulation-ESCO.R,sha256=68cEHDdJclX8P8Q7ey9yBOfK09M_kxlL6zgYXsEL2Rs,6378
|
|
116
117
|
biopipen/scripts/rnaseq/Simulation-RUVcorr.R,sha256=6C6Ke5RLF0fC2V9WQPoFEdqoDabCnhslZBIyB6zhIxc,1155
|
|
@@ -160,6 +161,7 @@ biopipen/scripts/scrna_metabolic_landscape/MetabolicFeatures.R,sha256=b77yG5FeRs
|
|
|
160
161
|
biopipen/scripts/scrna_metabolic_landscape/MetabolicFeaturesIntraSubset.R,sha256=ic8Fy8QqYDGh_izmvZVJ3KL66podg_CSF5ITL3FZsvo,5196
|
|
161
162
|
biopipen/scripts/scrna_metabolic_landscape/MetabolicPathwayActivity.R,sha256=95DLX1Rz0tobOuDZ8V9YdGgO0KiNthhccoeeOK21tno,16216
|
|
162
163
|
biopipen/scripts/scrna_metabolic_landscape/MetabolicPathwayHeterogeneity.R,sha256=rQ9iwGh9FNRZlJJzM4QItdyXmebfzLAq05ZAjb1kGUw,9831
|
|
164
|
+
biopipen/scripts/snp/MatrixEQTL.R,sha256=zOR_mhn_sUXuxqgV82TPvDp-E1i5aJVA45QixyRP8no,5930
|
|
163
165
|
biopipen/scripts/snp/PlinkSimulation.py,sha256=mSSoGGG6sbEPBcUGdHgbebUrg4DiHeyNyc7jLPjV5pY,4169
|
|
164
166
|
biopipen/scripts/stats/ChowTest.R,sha256=4p7NULmfOZSfeBSQ04els0h3cXOK5yeCJJ4-gEBPOGk,3617
|
|
165
167
|
biopipen/scripts/stats/DiffCoexpr.R,sha256=5hQDV2_7bKdKUsOGMZUa0GS5rc7kFspxonNyFEPmtbc,4516
|
|
@@ -238,7 +240,7 @@ biopipen/utils/reference.py,sha256=6bPSwQa-GiDfr7xLR9a5T64Ey40y24yn3QfQ5wDFZkU,4
|
|
|
238
240
|
biopipen/utils/rnaseq.R,sha256=Ro2B2dG-Z2oVaT5tkwp9RHBz4dp_RF-JcizlM5GYXFs,1298
|
|
239
241
|
biopipen/utils/single_cell.R,sha256=pJjYP8bIZpNAtTQ32rOXhZxaM1Y-6D-xUcK3pql9tbk,4316
|
|
240
242
|
biopipen/utils/vcf.py,sha256=ajXs0M_QghEctlvUlSRjWQIABVF02wPdYd-0LP4mIsU,9377
|
|
241
|
-
biopipen-0.27.
|
|
242
|
-
biopipen-0.27.
|
|
243
|
-
biopipen-0.27.
|
|
244
|
-
biopipen-0.27.
|
|
243
|
+
biopipen-0.27.4.dist-info/METADATA,sha256=jBHr-0G03oeihg4W1XgeY5gVb4rI-4chXNOt6wWhbJE,882
|
|
244
|
+
biopipen-0.27.4.dist-info/WHEEL,sha256=sP946D7jFCHeNz5Iq4fL4Lu-PrWrFsgfLXbbkciIZwg,88
|
|
245
|
+
biopipen-0.27.4.dist-info/entry_points.txt,sha256=wu70aoBcv1UahVbB_5237MY-9M9_mzqmWjDD-oi3yz0,621
|
|
246
|
+
biopipen-0.27.4.dist-info/RECORD,,
|
|
File without changes
|
|
File without changes
|