arize-phoenix 2.7.0__py3-none-any.whl → 2.8.0__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of arize-phoenix might be problematic. Click here for more details.
- {arize_phoenix-2.7.0.dist-info → arize_phoenix-2.8.0.dist-info}/METADATA +5 -2
- {arize_phoenix-2.7.0.dist-info → arize_phoenix-2.8.0.dist-info}/RECORD +26 -26
- {arize_phoenix-2.7.0.dist-info → arize_phoenix-2.8.0.dist-info}/WHEEL +1 -1
- phoenix/exceptions.py +4 -0
- phoenix/experimental/evals/functions/classify.py +1 -1
- phoenix/experimental/evals/models/anthropic.py +27 -22
- phoenix/experimental/evals/models/base.py +1 -56
- phoenix/experimental/evals/models/bedrock.py +23 -13
- phoenix/experimental/evals/models/litellm.py +10 -17
- phoenix/experimental/evals/models/openai.py +46 -53
- phoenix/experimental/evals/models/vertex.py +19 -29
- phoenix/experimental/evals/models/vertexai.py +1 -20
- phoenix/server/api/schema.py +2 -3
- phoenix/server/static/index.js +557 -517
- phoenix/session/session.py +2 -1
- phoenix/trace/exporter.py +15 -11
- phoenix/trace/fixtures.py +10 -0
- phoenix/trace/llama_index/callback.py +5 -5
- phoenix/trace/llama_index/streaming.py +3 -4
- phoenix/trace/otel.py +49 -21
- phoenix/trace/schemas.py +2 -2
- phoenix/trace/span_json_decoder.py +5 -4
- phoenix/trace/tracer.py +6 -5
- phoenix/version.py +1 -1
- {arize_phoenix-2.7.0.dist-info → arize_phoenix-2.8.0.dist-info}/licenses/IP_NOTICE +0 -0
- {arize_phoenix-2.7.0.dist-info → arize_phoenix-2.8.0.dist-info}/licenses/LICENSE +0 -0
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.1
|
|
2
2
|
Name: arize-phoenix
|
|
3
|
-
Version: 2.
|
|
3
|
+
Version: 2.8.0
|
|
4
4
|
Summary: ML Observability in your notebook
|
|
5
5
|
Project-URL: Documentation, https://docs.arize.com/phoenix/
|
|
6
6
|
Project-URL: Issues, https://github.com/Arize-ai/phoenix/issues
|
|
@@ -86,6 +86,9 @@ Description-Content-Type: text/markdown
|
|
|
86
86
|
<a target="_blank" href="https://pypi.org/project/arize-phoenix/">
|
|
87
87
|
<img src="https://img.shields.io/pypi/pyversions/arize-phoenix">
|
|
88
88
|
</a>
|
|
89
|
+
<a target="_blank" href="https://hub.docker.com/repository/docker/arizephoenix/phoenix/general">
|
|
90
|
+
<img src="https://img.shields.io/docker/v/arizephoenix/phoenix?sort=semver&logo=docker&label=image&color=blue">
|
|
91
|
+
</a>
|
|
89
92
|
</p>
|
|
90
93
|
|
|
91
94
|
|
|
@@ -134,7 +137,7 @@ pip install arize-phoenix[experimental]
|
|
|
134
137
|
|
|
135
138
|
|
|
136
139
|
|
|
137
|
-
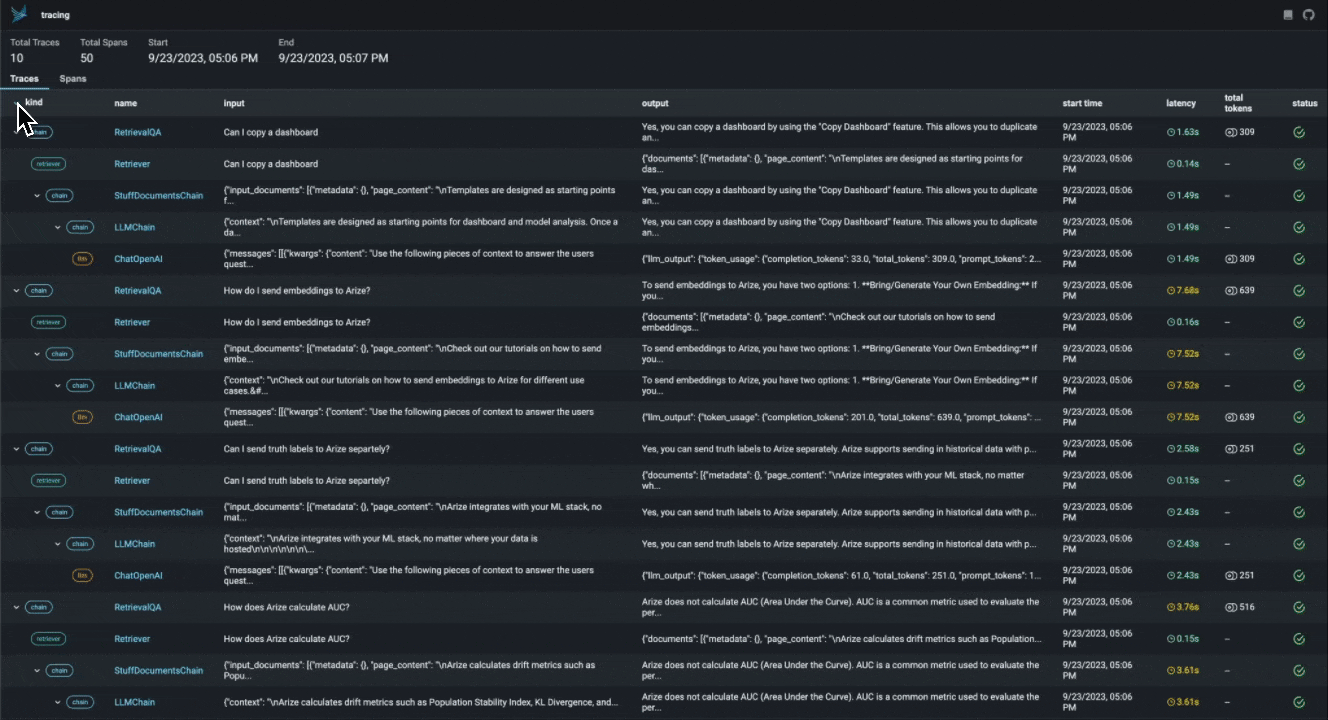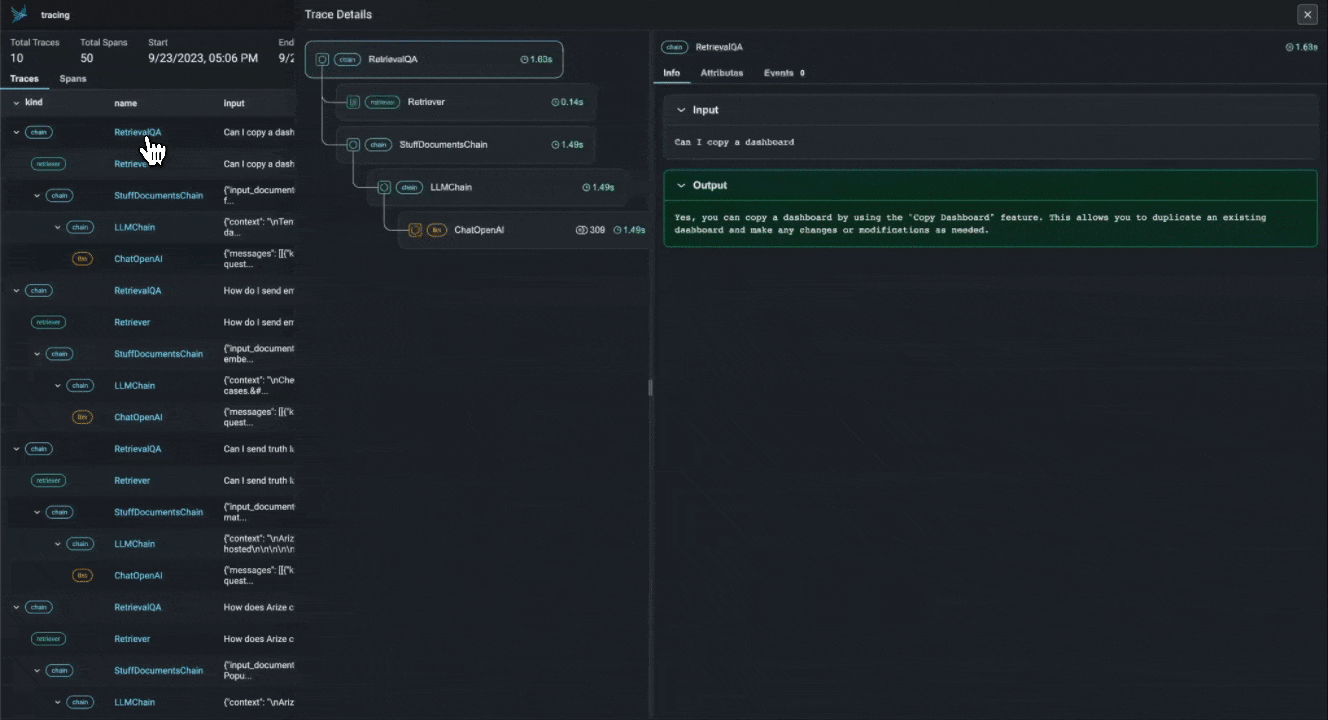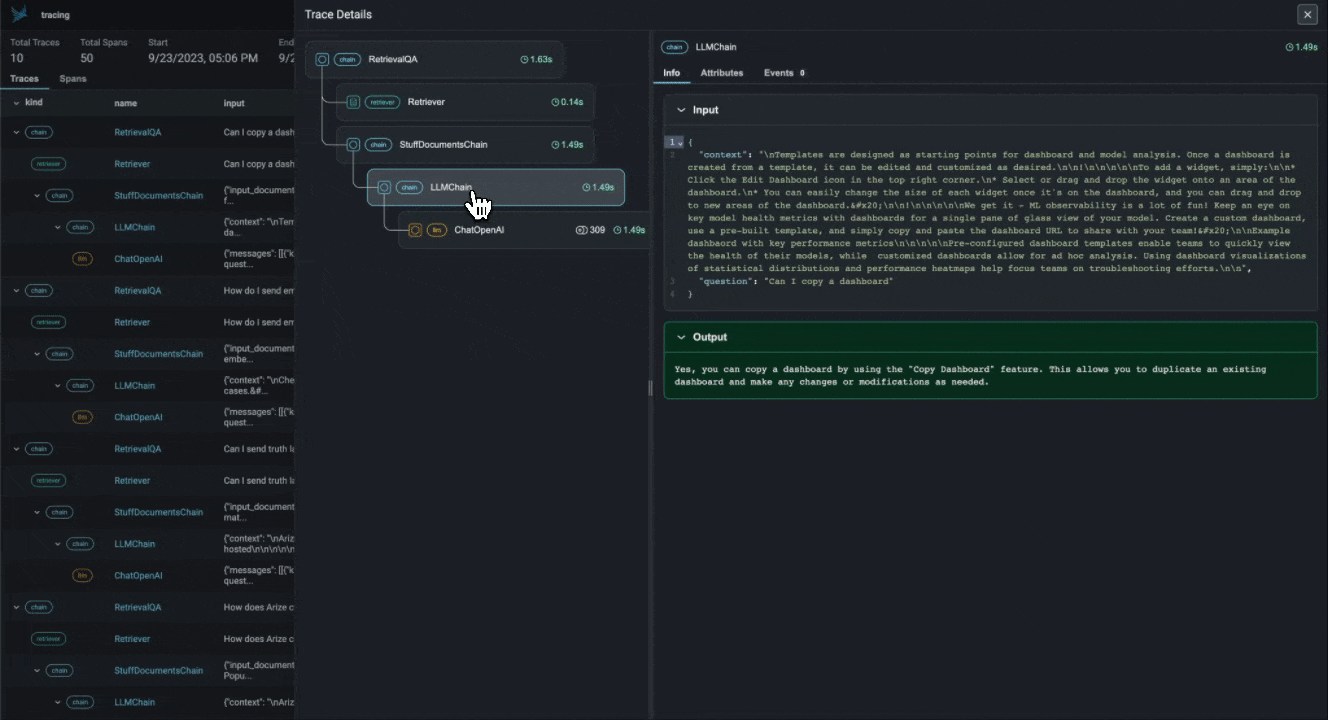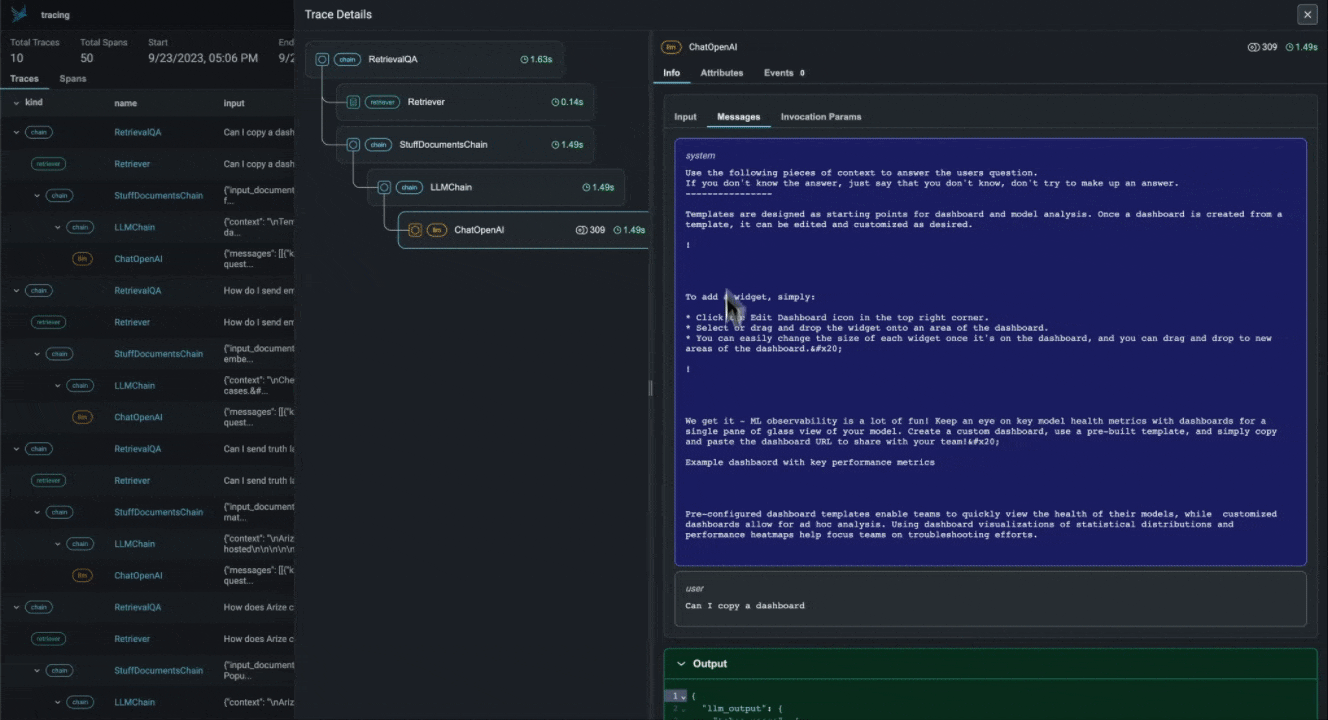
With the advent of powerful LLMs, it is now possible to build LLM Applications that can perform complex tasks like summarization, translation, question and answering, and more. However, these applications are often difficult to debug and troubleshoot as they have an extensive surface area: search and retrieval via vector stores, embedding generation, usage of external tools and so on. Phoenix provides a tracing framework that allows you to trace through the execution of your LLM Application hierarchically. This allows you to understand the internals of your LLM Application and to troubleshoot the complex components of your applicaition. Phoenix is built on top of the OpenInference tracing standard and uses it to trace, export, and collect critical information about your LLM Application in the form of `spans`. For more details on the OpenInference tracing standard, see the [OpenInference Specification](https://github.com/Arize-ai/
|
|
140
|
+
With the advent of powerful LLMs, it is now possible to build LLM Applications that can perform complex tasks like summarization, translation, question and answering, and more. However, these applications are often difficult to debug and troubleshoot as they have an extensive surface area: search and retrieval via vector stores, embedding generation, usage of external tools and so on. Phoenix provides a tracing framework that allows you to trace through the execution of your LLM Application hierarchically. This allows you to understand the internals of your LLM Application and to troubleshoot the complex components of your applicaition. Phoenix is built on top of the OpenInference tracing standard and uses it to trace, export, and collect critical information about your LLM Application in the form of `spans`. For more details on the OpenInference tracing standard, see the [OpenInference Specification](https://github.com/Arize-ai/openinference)
|
|
138
141
|
|
|
139
142
|
### Tracing with LlamaIndex
|
|
140
143
|
|
|
@@ -1,10 +1,10 @@
|
|
|
1
1
|
phoenix/__init__.py,sha256=EEh0vZGRQS8686h34GQ64OjQoZ7neKYO_iO5j6Oa9Jw,1402
|
|
2
2
|
phoenix/config.py,sha256=RbQw8AkVyI4SSo5CD520AjUNcwkDNOGZA6_ErE48R7A,3454
|
|
3
3
|
phoenix/datetime_utils.py,sha256=D955QLrkgrrSdUM6NyqbCeAu2SMsjhR5rHVQEsVUdng,2773
|
|
4
|
-
phoenix/exceptions.py,sha256=
|
|
4
|
+
phoenix/exceptions.py,sha256=X5k9ipUDfwSCwZB-H5zFJLas86Gf9tAx0W4l5TZxp5k,108
|
|
5
5
|
phoenix/py.typed,sha256=AbpHGcgLb-kRsJGnwFEktk7uzpZOCcBY74-YBdrKVGs,1
|
|
6
6
|
phoenix/services.py,sha256=f6AeyKTuOpy9RCcTCjVH3gx5nYZhbTMFOuv1WSUOB5o,4992
|
|
7
|
-
phoenix/version.py,sha256=
|
|
7
|
+
phoenix/version.py,sha256=z6im3C9Qb6qiQIpaJdE4f9WQiCnFGSUQnQXDPw_dvDg,22
|
|
8
8
|
phoenix/core/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
9
9
|
phoenix/core/embedding_dimension.py,sha256=zKGbcvwOXgLf-yrJBpQyKtd-LEOPRKHnUToyAU8Owis,87
|
|
10
10
|
phoenix/core/evals.py,sha256=gJyqQzpud5YjtoY8h4pgXvHDsdubGfqmEewLuZHPPmQ,10224
|
|
@@ -23,19 +23,19 @@ phoenix/experimental/evals/__init__.py,sha256=q96YKLMt2GJD9zL8sjugvWx1INfw40Wa7E
|
|
|
23
23
|
phoenix/experimental/evals/evaluators.py,sha256=r7fXrS-l4gn58SUhLAZSfY3P8lxysouSVJwHddrZJ_Q,15956
|
|
24
24
|
phoenix/experimental/evals/retrievals.py,sha256=o3fqrsYbYZjyGj_jWkN_9VQVyXjLkDKDw5Ws7l8bwdI,3828
|
|
25
25
|
phoenix/experimental/evals/functions/__init__.py,sha256=NNd0-_cmIopdV7vm3rspjfgM726qoQJ4DPq_vqbnaxQ,180
|
|
26
|
-
phoenix/experimental/evals/functions/classify.py,sha256=
|
|
26
|
+
phoenix/experimental/evals/functions/classify.py,sha256=6yCajPT9i98b4_2qYn9ZxGhdI3CLhfUSrEyUUcqQqmQ,19517
|
|
27
27
|
phoenix/experimental/evals/functions/executor.py,sha256=bM7PI2rcPukQQzZ2rWqN_-Kfo_a935YJj0bh1Red8Ps,13406
|
|
28
28
|
phoenix/experimental/evals/functions/generate.py,sha256=8LnnPAjBM9yxitdkaGZ67OabuDTOWBF3fvinJ_uCFRg,5584
|
|
29
29
|
phoenix/experimental/evals/functions/processing.py,sha256=F4xtLsulLV4a8CkuLldRddsCim75dSTIShEJUYN6I6w,1823
|
|
30
30
|
phoenix/experimental/evals/models/__init__.py,sha256=j1N7DhiOPbcaemtVBONcQ0miNnGQwEXz4u3P3Vwe6-4,320
|
|
31
|
-
phoenix/experimental/evals/models/anthropic.py,sha256=
|
|
32
|
-
phoenix/experimental/evals/models/base.py,sha256=
|
|
33
|
-
phoenix/experimental/evals/models/bedrock.py,sha256=
|
|
34
|
-
phoenix/experimental/evals/models/litellm.py,sha256=
|
|
35
|
-
phoenix/experimental/evals/models/openai.py,sha256=
|
|
31
|
+
phoenix/experimental/evals/models/anthropic.py,sha256=BZmLvepkSMj_opCWsZoL34a3yAwRdl7qbJB86DFR84E,6688
|
|
32
|
+
phoenix/experimental/evals/models/base.py,sha256=RWz_Jzj3Z1fENl2WUXIz-4eMsk6HfYXc0K8IZ-BJss4,6306
|
|
33
|
+
phoenix/experimental/evals/models/bedrock.py,sha256=nVOXRZr-iDwHEINozpO2bqZR2KEeDHNyj6jgQPONQYs,8565
|
|
34
|
+
phoenix/experimental/evals/models/litellm.py,sha256=0c-eJFsx41W0MsqeUd4UPquLBKSZp3BRNhKhX2uFCAs,4123
|
|
35
|
+
phoenix/experimental/evals/models/openai.py,sha256=NUWywf2PmHi9IbQ0MK6_An1hZYE5Sr8ngKoLD3MGrjU,17298
|
|
36
36
|
phoenix/experimental/evals/models/rate_limiters.py,sha256=5GVN0RQKt36Przg3-9jLgocRmyg-tbeO-cdbuLIx89w,10160
|
|
37
|
-
phoenix/experimental/evals/models/vertex.py,sha256=
|
|
38
|
-
phoenix/experimental/evals/models/vertexai.py,sha256=
|
|
37
|
+
phoenix/experimental/evals/models/vertex.py,sha256=1VAGJNoiUm56pP8G9Qvnf-4_Rl9u9NI7ToOKbWFNtpk,6226
|
|
38
|
+
phoenix/experimental/evals/models/vertexai.py,sha256=_txsOP2RHyR3AnugeJRFUNvYm3xXvfMbWpULxTko4OA,4821
|
|
39
39
|
phoenix/experimental/evals/templates/__init__.py,sha256=GSJSoWJ4jwyoUANniidmWMUtXQhNQYbTJbfFqCvuYuo,1470
|
|
40
40
|
phoenix/experimental/evals/templates/default_templates.py,sha256=dVKmoLwqgAyGcRuezz9WKnXSHhw7-qk1R8j6wSmqh0s,20722
|
|
41
41
|
phoenix/experimental/evals/templates/template.py,sha256=ImFSaTPo9oalPNwq7cNdOCndrvuwLuIyIFKsgDVcoJE,6715
|
|
@@ -65,7 +65,7 @@ phoenix/server/api/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuF
|
|
|
65
65
|
phoenix/server/api/context.py,sha256=02vRgyLFpDCmh97QwsjWD5cdNZkoCUtDPPs1YItbdbI,583
|
|
66
66
|
phoenix/server/api/helpers.py,sha256=_V1eVkchZmTkhOfRC4QqR1sUB2xtIxdsMJkDouZq_IE,251
|
|
67
67
|
phoenix/server/api/interceptor.py,sha256=do_J4HjPPQ_C7bMmqe1YpTmt_hoxcwC2I8P3n5sZBo4,1302
|
|
68
|
-
phoenix/server/api/schema.py,sha256=
|
|
68
|
+
phoenix/server/api/schema.py,sha256=lEahYCASRgRTw6nOme7zQtyKaVbHqK5CQUbg5XTT5nU,15293
|
|
69
69
|
phoenix/server/api/input_types/ClusterInput.py,sha256=EL4ftvZxQ8mVdruUPcdhMhByORmSmM8S-X6RPqU6GX0,179
|
|
70
70
|
phoenix/server/api/input_types/Coordinates.py,sha256=meTwbIjwTfqx5DGD2DBlH9wQzdQVNM5a8x9dp1FfIgA,173
|
|
71
71
|
phoenix/server/api/input_types/DataQualityMetricInput.py,sha256=LazvmQCCM5m9SDZTpyxQXO1rYF4cmsc3lsR2S9S65X4,1292
|
|
@@ -125,26 +125,26 @@ phoenix/server/static/apple-touch-icon-76x76.png,sha256=CT_xT12I0u2i0WU8JzBZBuOQ
|
|
|
125
125
|
phoenix/server/static/apple-touch-icon.png,sha256=fOfpjqGpWYbJ0eAurKsyoZP1EAs6ZVooBJ_SGk2ZkDs,3801
|
|
126
126
|
phoenix/server/static/favicon.ico,sha256=bY0vvCKRftemZfPShwZtE93DiiQdaYaozkPGwNFr6H8,34494
|
|
127
127
|
phoenix/server/static/index.css,sha256=KKGpx4iwF91VGRm0YN-4cn8oC-oIqC6HecoPf0x3ZM8,1885
|
|
128
|
-
phoenix/server/static/index.js,sha256=
|
|
128
|
+
phoenix/server/static/index.js,sha256=tbeJsyK4L19pFLbl2H4eBCk1JpTQWa8f5m_YJoRXOG4,3140434
|
|
129
129
|
phoenix/server/static/modernizr.js,sha256=mvK-XtkNqjOral-QvzoqsyOMECXIMu5BQwSVN_wcU9c,2564
|
|
130
130
|
phoenix/server/templates/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
131
131
|
phoenix/server/templates/index.html,sha256=DlfcGoq1V5C2QkJWqP1j4Nu6_kPfsOzOrtzYF3ogghE,1900
|
|
132
132
|
phoenix/session/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
133
133
|
phoenix/session/evaluation.py,sha256=DaAtA0XYJbXRJO_StGywa-9APlz2ORSmCXzxrtn3rvI,4997
|
|
134
|
-
phoenix/session/session.py,sha256=
|
|
134
|
+
phoenix/session/session.py,sha256=1kwqPHPyzdlsAsyQ4ZKlvdE0rnt1K8TWtB3KzbtOyP4,20862
|
|
135
135
|
phoenix/trace/__init__.py,sha256=4d_MqzUIFmlY9WWcFeTONJ4xL5mPGoWZaPM2TJ0ZDBQ,266
|
|
136
136
|
phoenix/trace/errors.py,sha256=DbXSJnNErV7305tKv7pUWLD6jcVHJ6EBdSu4mZJ6IM4,112
|
|
137
137
|
phoenix/trace/evaluation_conventions.py,sha256=t8jydM3U0-T5YpiQKRJ3tWdWGlHtzKyttYdw-ddvPOk,1048
|
|
138
|
-
phoenix/trace/exporter.py,sha256=
|
|
139
|
-
phoenix/trace/fixtures.py,sha256=
|
|
140
|
-
phoenix/trace/otel.py,sha256=
|
|
141
|
-
phoenix/trace/schemas.py,sha256=
|
|
138
|
+
phoenix/trace/exporter.py,sha256=jH8jp1Ikt6BmZGElpTG1F3b0yYDm9WSWLFpxHnKiMtY,4409
|
|
139
|
+
phoenix/trace/fixtures.py,sha256=LokNedhbGYxpzXznteO4m5QehvNYjzvoh231-CMJQeY,7113
|
|
140
|
+
phoenix/trace/otel.py,sha256=9oum5RPCsEZvKg41mEy8aKDcXHBwtR-P9eeqEXp-ts4,14642
|
|
141
|
+
phoenix/trace/schemas.py,sha256=fYrhC0sTlw6vilsQexSmyhvifnT7SajMxWLMAQTxv4E,5398
|
|
142
142
|
phoenix/trace/semantic_conventions.py,sha256=u6NG85ZhbreriZr8cqJaddldM_jUcew7JilszY7JUk8,4652
|
|
143
143
|
phoenix/trace/span_evaluations.py,sha256=asGug9lUHUufBwK1nL_PnHIDKsOc5X4ws7cur9lfoyI,12421
|
|
144
|
-
phoenix/trace/span_json_decoder.py,sha256=
|
|
144
|
+
phoenix/trace/span_json_decoder.py,sha256=nrIPkcgbCcNML-0OSjWC6fxIfBEMiP0n67yM_m-vegg,3068
|
|
145
145
|
phoenix/trace/span_json_encoder.py,sha256=C5y7rkyOcV08oJC5t8TZqVxsKCZMJKad7bBQzAgLoDs,1763
|
|
146
146
|
phoenix/trace/trace_dataset.py,sha256=KW0TzmhlKuX8PUPLV172iTK08myYE0QXUC75KiIqJ7k,13204
|
|
147
|
-
phoenix/trace/tracer.py,sha256=
|
|
147
|
+
phoenix/trace/tracer.py,sha256=AoYyWRco-EcvK7TASmZO0z-nJEm3cXlG9lhTWDTz4VU,3691
|
|
148
148
|
phoenix/trace/utils.py,sha256=7LurVGXn245cjj4MJsc7v6jq4DSJkpK6YGBfIaSywuw,1307
|
|
149
149
|
phoenix/trace/dsl/__init__.py,sha256=WIQIjJg362XD3s50OsPJJ0xbDsGp41bSv7vDllLrPuA,144
|
|
150
150
|
phoenix/trace/dsl/filter.py,sha256=2vHtKAvq8OAFlXNDE4qxPEEUpda39tC8xy0gDK9SN4I,12696
|
|
@@ -155,9 +155,9 @@ phoenix/trace/langchain/__init__.py,sha256=vAjrmrreetV7L5IL8VH_9efG9VJunJTgT0iKy
|
|
|
155
155
|
phoenix/trace/langchain/instrumentor.py,sha256=HkNKbFNclTYjRXBM8qU4qvZHdyw06J9bhwgE7JnqbNI,1323
|
|
156
156
|
phoenix/trace/langchain/tracer.py,sha256=1Oz3orSDpZX1pZKwtZbeM_f9tiAhQb7Of8ARjRlKVQY,16827
|
|
157
157
|
phoenix/trace/llama_index/__init__.py,sha256=wCcQgD9CG5TA8i-1XsSed4ZzwHTUmqZwegQAV_FqEng,178
|
|
158
|
-
phoenix/trace/llama_index/callback.py,sha256=
|
|
158
|
+
phoenix/trace/llama_index/callback.py,sha256=cSa5whoaMDdBc7W2QSWWatMoNL-wKU2fozkP8prpUMQ,27563
|
|
159
159
|
phoenix/trace/llama_index/debug_callback.py,sha256=SKToD9q_QADSGTJ5lhilqRVKaUnUSRXUvURCzN4by2U,1367
|
|
160
|
-
phoenix/trace/llama_index/streaming.py,sha256=
|
|
160
|
+
phoenix/trace/llama_index/streaming.py,sha256=yt_kB0LJK6lGdARtivmEmkZgbnzFUqIHfSN0hjYbTpM,3248
|
|
161
161
|
phoenix/trace/openai/__init__.py,sha256=J3G0uqCxGdksUpaQVHds_Egv2drvh8UEqoLjiQAOveg,79
|
|
162
162
|
phoenix/trace/openai/instrumentor.py,sha256=H1T2_1uqeH2lKCKeMmirEUl6PRtHQlQTXfsLR_hwDFM,24948
|
|
163
163
|
phoenix/trace/v1/__init__.py,sha256=-IbAD0ruESMjvQLvGAg9CTfjBUATFDx1OXseDPis6-0,88
|
|
@@ -166,8 +166,8 @@ phoenix/trace/v1/evaluation_pb2.pyi,sha256=cCbbx06gwQmaH14s3J1X25TtaARh-k1abbxQd
|
|
|
166
166
|
phoenix/utilities/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
|
167
167
|
phoenix/utilities/error_handling.py,sha256=7b5rpGFj9EWZ8yrZK1IHvxB89suWk3lggDayUQcvZds,1946
|
|
168
168
|
phoenix/utilities/logging.py,sha256=lDXd6EGaamBNcQxL4vP1au9-i_SXe0OraUDiJOcszSw,222
|
|
169
|
-
arize_phoenix-2.
|
|
170
|
-
arize_phoenix-2.
|
|
171
|
-
arize_phoenix-2.
|
|
172
|
-
arize_phoenix-2.
|
|
173
|
-
arize_phoenix-2.
|
|
169
|
+
arize_phoenix-2.8.0.dist-info/METADATA,sha256=-anApFNW1PtrZU7EHCCg8JD-LDLfFQJZv9mUQfobfnE,26703
|
|
170
|
+
arize_phoenix-2.8.0.dist-info/WHEEL,sha256=TJPnKdtrSue7xZ_AVGkp9YXcvDrobsjBds1du3Nx6dc,87
|
|
171
|
+
arize_phoenix-2.8.0.dist-info/licenses/IP_NOTICE,sha256=JBqyyCYYxGDfzQ0TtsQgjts41IJoa-hiwDrBjCb9gHM,469
|
|
172
|
+
arize_phoenix-2.8.0.dist-info/licenses/LICENSE,sha256=HFkW9REuMOkvKRACuwLPT0hRydHb3zNg-fdFt94td18,3794
|
|
173
|
+
arize_phoenix-2.8.0.dist-info/RECORD,,
|
phoenix/exceptions.py
CHANGED
|
@@ -249,7 +249,7 @@ def run_relevance_eval(
|
|
|
249
249
|
|
|
250
250
|
This latter format is intended for running evaluations on exported OpenInference trace
|
|
251
251
|
dataframes. For more information on the OpenInference tracing specification, see
|
|
252
|
-
https://github.com/Arize-ai/
|
|
252
|
+
https://github.com/Arize-ai/openinference/.
|
|
253
253
|
|
|
254
254
|
model (BaseEvalModel): The model used for evaluation.
|
|
255
255
|
|
|
@@ -1,6 +1,7 @@
|
|
|
1
1
|
from dataclasses import dataclass, field
|
|
2
2
|
from typing import TYPE_CHECKING, Any, Dict, List, Optional
|
|
3
3
|
|
|
4
|
+
from phoenix.exceptions import PhoenixContextLimitExceeded
|
|
4
5
|
from phoenix.experimental.evals.models.base import BaseEvalModel
|
|
5
6
|
from phoenix.experimental.evals.models.rate_limiters import RateLimiter
|
|
6
7
|
|
|
@@ -44,12 +45,6 @@ class AnthropicModel(BaseEvalModel):
|
|
|
44
45
|
self._init_client()
|
|
45
46
|
self._init_tiktoken()
|
|
46
47
|
self._init_rate_limiter()
|
|
47
|
-
self.retry = self._retry(
|
|
48
|
-
error_types=[], # default to catching all errors
|
|
49
|
-
min_seconds=self.retry_min_seconds,
|
|
50
|
-
max_seconds=self.retry_max_seconds,
|
|
51
|
-
max_retries=self.max_retries,
|
|
52
|
-
)
|
|
53
48
|
|
|
54
49
|
def _init_environment(self) -> None:
|
|
55
50
|
try:
|
|
@@ -127,7 +122,7 @@ class AnthropicModel(BaseEvalModel):
|
|
|
127
122
|
kwargs.pop("instruction", None)
|
|
128
123
|
invocation_parameters = self.invocation_parameters()
|
|
129
124
|
invocation_parameters.update(kwargs)
|
|
130
|
-
response = self.
|
|
125
|
+
response = self._rate_limited_completion(
|
|
131
126
|
model=self.model,
|
|
132
127
|
prompt=self._format_prompt_for_claude(prompt),
|
|
133
128
|
**invocation_parameters,
|
|
@@ -135,14 +130,19 @@ class AnthropicModel(BaseEvalModel):
|
|
|
135
130
|
|
|
136
131
|
return str(response)
|
|
137
132
|
|
|
138
|
-
def
|
|
139
|
-
@self.retry
|
|
133
|
+
def _rate_limited_completion(self, **kwargs: Any) -> Any:
|
|
140
134
|
@self._rate_limiter.limit
|
|
141
|
-
def
|
|
142
|
-
|
|
143
|
-
|
|
144
|
-
|
|
145
|
-
|
|
135
|
+
def _completion(**kwargs: Any) -> Any:
|
|
136
|
+
try:
|
|
137
|
+
response = self.client.completions.create(**kwargs)
|
|
138
|
+
return response.completion
|
|
139
|
+
except self._anthropic.BadRequestError as e:
|
|
140
|
+
exception_message = e.args[0]
|
|
141
|
+
if exception_message and "prompt is too long" in exception_message:
|
|
142
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
143
|
+
raise e
|
|
144
|
+
|
|
145
|
+
return _completion(**kwargs)
|
|
146
146
|
|
|
147
147
|
async def _async_generate(self, prompt: str, **kwargs: Dict[str, Any]) -> str:
|
|
148
148
|
# instruction is an invalid input to Anthropic models, it is passed in by
|
|
@@ -150,20 +150,25 @@ class AnthropicModel(BaseEvalModel):
|
|
|
150
150
|
kwargs.pop("instruction", None)
|
|
151
151
|
invocation_parameters = self.invocation_parameters()
|
|
152
152
|
invocation_parameters.update(kwargs)
|
|
153
|
-
response = await self.
|
|
153
|
+
response = await self._async_rate_limited_completion(
|
|
154
154
|
model=self.model, prompt=self._format_prompt_for_claude(prompt), **invocation_parameters
|
|
155
155
|
)
|
|
156
156
|
|
|
157
157
|
return str(response)
|
|
158
158
|
|
|
159
|
-
async def
|
|
160
|
-
@self.retry
|
|
159
|
+
async def _async_rate_limited_completion(self, **kwargs: Any) -> Any:
|
|
161
160
|
@self._rate_limiter.alimit
|
|
162
|
-
async def
|
|
163
|
-
|
|
164
|
-
|
|
165
|
-
|
|
166
|
-
|
|
161
|
+
async def _async_completion(**kwargs: Any) -> Any:
|
|
162
|
+
try:
|
|
163
|
+
response = await self.async_client.completions.create(**kwargs)
|
|
164
|
+
return response.completion
|
|
165
|
+
except self._anthropic.BadRequestError as e:
|
|
166
|
+
exception_message = e.args[0]
|
|
167
|
+
if exception_message and "prompt is too long" in exception_message:
|
|
168
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
169
|
+
raise e
|
|
170
|
+
|
|
171
|
+
return await _async_completion(**kwargs)
|
|
167
172
|
|
|
168
173
|
def _format_prompt_for_claude(self, prompt: str) -> str:
|
|
169
174
|
# Claude requires prompt in the format of Human: ... Assistant:
|
|
@@ -2,22 +2,13 @@ import logging
|
|
|
2
2
|
from abc import ABC, abstractmethod, abstractproperty
|
|
3
3
|
from contextlib import contextmanager
|
|
4
4
|
from dataclasses import dataclass, field
|
|
5
|
-
from typing import TYPE_CHECKING, Any,
|
|
5
|
+
from typing import TYPE_CHECKING, Any, Generator, List, Optional, Sequence
|
|
6
6
|
|
|
7
7
|
from phoenix.experimental.evals.models.rate_limiters import RateLimiter
|
|
8
8
|
|
|
9
9
|
if TYPE_CHECKING:
|
|
10
10
|
from tiktoken import Encoding
|
|
11
11
|
|
|
12
|
-
|
|
13
|
-
from tenacity import (
|
|
14
|
-
RetryCallState,
|
|
15
|
-
retry,
|
|
16
|
-
retry_base,
|
|
17
|
-
retry_if_exception_type,
|
|
18
|
-
stop_after_attempt,
|
|
19
|
-
wait_random_exponential,
|
|
20
|
-
)
|
|
21
12
|
from tqdm.asyncio import tqdm_asyncio
|
|
22
13
|
from tqdm.auto import tqdm
|
|
23
14
|
from typing_extensions import TypeVar
|
|
@@ -65,52 +56,6 @@ class BaseEvalModel(ABC):
|
|
|
65
56
|
def reload_client(self) -> None:
|
|
66
57
|
pass
|
|
67
58
|
|
|
68
|
-
def _retry(
|
|
69
|
-
self,
|
|
70
|
-
error_types: List[Type[BaseException]],
|
|
71
|
-
min_seconds: int,
|
|
72
|
-
max_seconds: int,
|
|
73
|
-
max_retries: int,
|
|
74
|
-
) -> Callable[[Any], Any]:
|
|
75
|
-
"""Create a retry decorator for a given LLM and provided list of error types."""
|
|
76
|
-
|
|
77
|
-
def log_retry(retry_state: RetryCallState) -> None:
|
|
78
|
-
if fut := retry_state.outcome:
|
|
79
|
-
exc = fut.exception()
|
|
80
|
-
else:
|
|
81
|
-
exc = None
|
|
82
|
-
|
|
83
|
-
if exc:
|
|
84
|
-
printif(
|
|
85
|
-
self._verbose,
|
|
86
|
-
(
|
|
87
|
-
f"Failed attempt {retry_state.attempt_number}: "
|
|
88
|
-
f"{type(exc).__module__}.{type(exc).__name__}"
|
|
89
|
-
),
|
|
90
|
-
)
|
|
91
|
-
printif(
|
|
92
|
-
True,
|
|
93
|
-
f"Failed attempt {retry_state.attempt_number}: raised {repr(exc)}",
|
|
94
|
-
)
|
|
95
|
-
else:
|
|
96
|
-
printif(True, f"Failed attempt {retry_state.attempt_number}")
|
|
97
|
-
return None
|
|
98
|
-
|
|
99
|
-
if not error_types:
|
|
100
|
-
# default to retrying on all exceptions
|
|
101
|
-
error_types = [Exception]
|
|
102
|
-
|
|
103
|
-
retry_instance: retry_base = retry_if_exception_type(error_types[0])
|
|
104
|
-
for error in error_types[1:]:
|
|
105
|
-
retry_instance = retry_instance | retry_if_exception_type(error)
|
|
106
|
-
return retry(
|
|
107
|
-
reraise=True,
|
|
108
|
-
stop=stop_after_attempt(max_retries),
|
|
109
|
-
wait=wait_random_exponential(multiplier=1, min=min_seconds, max=max_seconds),
|
|
110
|
-
retry=retry_instance,
|
|
111
|
-
before_sleep=log_retry,
|
|
112
|
-
)
|
|
113
|
-
|
|
114
59
|
def __call__(self, prompt: str, instruction: Optional[str] = None, **kwargs: Any) -> str:
|
|
115
60
|
"""Run the LLM on the given prompt."""
|
|
116
61
|
if not isinstance(prompt, str):
|
|
@@ -3,6 +3,7 @@ import logging
|
|
|
3
3
|
from dataclasses import dataclass, field
|
|
4
4
|
from typing import TYPE_CHECKING, Any, Dict, List, Optional
|
|
5
5
|
|
|
6
|
+
from phoenix.exceptions import PhoenixContextLimitExceeded
|
|
6
7
|
from phoenix.experimental.evals.models.base import BaseEvalModel
|
|
7
8
|
from phoenix.experimental.evals.models.rate_limiters import RateLimiter
|
|
8
9
|
|
|
@@ -54,12 +55,6 @@ class BedrockModel(BaseEvalModel):
|
|
|
54
55
|
self._init_client()
|
|
55
56
|
self._init_tiktoken()
|
|
56
57
|
self._init_rate_limiter()
|
|
57
|
-
self.retry = self._retry(
|
|
58
|
-
error_types=[], # default to catching all errors
|
|
59
|
-
min_seconds=self.retry_min_seconds,
|
|
60
|
-
max_seconds=self.retry_max_seconds,
|
|
61
|
-
max_retries=self.max_retries,
|
|
62
|
-
)
|
|
63
58
|
|
|
64
59
|
def _init_environment(self) -> None:
|
|
65
60
|
try:
|
|
@@ -130,21 +125,36 @@ class BedrockModel(BaseEvalModel):
|
|
|
130
125
|
accept = "application/json"
|
|
131
126
|
contentType = "application/json"
|
|
132
127
|
|
|
133
|
-
response = self.
|
|
128
|
+
response = self._rate_limited_completion(
|
|
134
129
|
body=body, modelId=self.model_id, accept=accept, contentType=contentType
|
|
135
130
|
)
|
|
136
131
|
|
|
137
132
|
return self._parse_output(response) or ""
|
|
138
133
|
|
|
139
|
-
def
|
|
134
|
+
def _rate_limited_completion(self, **kwargs: Any) -> Any:
|
|
140
135
|
"""Use tenacity to retry the completion call."""
|
|
141
136
|
|
|
142
|
-
@self.retry
|
|
143
137
|
@self._rate_limiter.limit
|
|
144
|
-
def
|
|
145
|
-
|
|
146
|
-
|
|
147
|
-
|
|
138
|
+
def _completion(**kwargs: Any) -> Any:
|
|
139
|
+
try:
|
|
140
|
+
return self.client.invoke_model(**kwargs)
|
|
141
|
+
except Exception as e:
|
|
142
|
+
exception_message = e.args[0]
|
|
143
|
+
if not exception_message:
|
|
144
|
+
raise e
|
|
145
|
+
|
|
146
|
+
if "Input is too long" in exception_message:
|
|
147
|
+
# Error from Anthropic models
|
|
148
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
149
|
+
elif "expected maxLength" in exception_message:
|
|
150
|
+
# Error from Titan models
|
|
151
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
152
|
+
elif "Prompt has too many tokens" in exception_message:
|
|
153
|
+
# Error from AI21 models
|
|
154
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
155
|
+
raise e
|
|
156
|
+
|
|
157
|
+
return _completion(**kwargs)
|
|
148
158
|
|
|
149
159
|
def _format_prompt_for_claude(self, prompt: str) -> str:
|
|
150
160
|
# Claude requires prompt in the format of Human: ... Assisatnt:
|
|
@@ -95,24 +95,17 @@ class LiteLLMModel(BaseEvalModel):
|
|
|
95
95
|
|
|
96
96
|
def _generate(self, prompt: str, **kwargs: Dict[str, Any]) -> str:
|
|
97
97
|
messages = self._get_messages_from_prompt(prompt)
|
|
98
|
-
|
|
99
|
-
self.
|
|
100
|
-
|
|
101
|
-
|
|
102
|
-
|
|
103
|
-
|
|
104
|
-
|
|
105
|
-
|
|
106
|
-
|
|
107
|
-
**self.model_kwargs,
|
|
108
|
-
)
|
|
98
|
+
response = self._litellm.completion(
|
|
99
|
+
model=self.model_name,
|
|
100
|
+
messages=messages,
|
|
101
|
+
temperature=self.temperature,
|
|
102
|
+
max_tokens=self.max_tokens,
|
|
103
|
+
top_p=self.top_p,
|
|
104
|
+
num_retries=self.num_retries,
|
|
105
|
+
request_timeout=self.request_timeout,
|
|
106
|
+
**self.model_kwargs,
|
|
109
107
|
)
|
|
110
|
-
|
|
111
|
-
def _generate_with_retry(self, **kwargs: Any) -> Any:
|
|
112
|
-
# Using default LiteLLM completion with retries = self.num_retries.
|
|
113
|
-
|
|
114
|
-
response = self._litellm.completion(**kwargs)
|
|
115
|
-
return response.choices[0].message.content
|
|
108
|
+
return str(response.choices[0].message.content)
|
|
116
109
|
|
|
117
110
|
def _get_messages_from_prompt(self, prompt: str) -> List[Dict[str, str]]:
|
|
118
111
|
# LiteLLM requires prompts in the format of messages
|
|
@@ -14,6 +14,7 @@ from typing import (
|
|
|
14
14
|
get_origin,
|
|
15
15
|
)
|
|
16
16
|
|
|
17
|
+
from phoenix.exceptions import PhoenixContextLimitExceeded
|
|
17
18
|
from phoenix.experimental.evals.models.base import BaseEvalModel
|
|
18
19
|
from phoenix.experimental.evals.models.rate_limiters import RateLimiter
|
|
19
20
|
|
|
@@ -114,25 +115,11 @@ class OpenAIModel(BaseEvalModel):
|
|
|
114
115
|
|
|
115
116
|
def _init_environment(self) -> None:
|
|
116
117
|
try:
|
|
117
|
-
import httpx
|
|
118
118
|
import openai
|
|
119
119
|
import openai._utils as openai_util
|
|
120
120
|
|
|
121
121
|
self._openai = openai
|
|
122
122
|
self._openai_util = openai_util
|
|
123
|
-
self._openai_retry_errors = [
|
|
124
|
-
self._openai.APITimeoutError,
|
|
125
|
-
self._openai.APIError,
|
|
126
|
-
self._openai.APIConnectionError,
|
|
127
|
-
self._openai.InternalServerError,
|
|
128
|
-
httpx.ReadTimeout,
|
|
129
|
-
]
|
|
130
|
-
self.retry = self._retry(
|
|
131
|
-
error_types=self._openai_retry_errors,
|
|
132
|
-
min_seconds=self.retry_min_seconds,
|
|
133
|
-
max_seconds=self.retry_max_seconds,
|
|
134
|
-
max_retries=self.max_retries,
|
|
135
|
-
)
|
|
136
123
|
except ImportError:
|
|
137
124
|
self._raise_import_error(
|
|
138
125
|
package_display_name="OpenAI",
|
|
@@ -265,7 +252,7 @@ class OpenAIModel(BaseEvalModel):
|
|
|
265
252
|
invoke_params["functions"] = functions
|
|
266
253
|
if function_call := kwargs.get("function_call"):
|
|
267
254
|
invoke_params["function_call"] = function_call
|
|
268
|
-
response = await self.
|
|
255
|
+
response = await self._async_rate_limited_completion(
|
|
269
256
|
messages=messages,
|
|
270
257
|
**invoke_params,
|
|
271
258
|
)
|
|
@@ -284,7 +271,7 @@ class OpenAIModel(BaseEvalModel):
|
|
|
284
271
|
invoke_params["functions"] = functions
|
|
285
272
|
if function_call := kwargs.get("function_call"):
|
|
286
273
|
invoke_params["function_call"] = function_call
|
|
287
|
-
response = self.
|
|
274
|
+
response = self._rate_limited_completion(
|
|
288
275
|
messages=messages,
|
|
289
276
|
**invoke_params,
|
|
290
277
|
)
|
|
@@ -296,45 +283,51 @@ class OpenAIModel(BaseEvalModel):
|
|
|
296
283
|
return str(function_call.get("arguments") or "")
|
|
297
284
|
return str(message["content"])
|
|
298
285
|
|
|
299
|
-
async def
|
|
300
|
-
"""Use tenacity to retry the completion call."""
|
|
301
|
-
|
|
302
|
-
@self.retry
|
|
286
|
+
async def _async_rate_limited_completion(self, **kwargs: Any) -> Any:
|
|
303
287
|
@self._rate_limiter.alimit
|
|
304
|
-
async def
|
|
305
|
-
|
|
306
|
-
if
|
|
307
|
-
|
|
308
|
-
|
|
309
|
-
|
|
310
|
-
|
|
311
|
-
|
|
312
|
-
|
|
313
|
-
|
|
314
|
-
|
|
315
|
-
|
|
316
|
-
|
|
317
|
-
|
|
318
|
-
|
|
319
|
-
|
|
320
|
-
|
|
321
|
-
|
|
322
|
-
|
|
323
|
-
|
|
288
|
+
async def _async_completion(**kwargs: Any) -> Any:
|
|
289
|
+
try:
|
|
290
|
+
if self._model_uses_legacy_completion_api:
|
|
291
|
+
if "prompt" not in kwargs:
|
|
292
|
+
kwargs["prompt"] = "\n\n".join(
|
|
293
|
+
(message.get("content") or "")
|
|
294
|
+
for message in (kwargs.pop("messages", None) or ())
|
|
295
|
+
)
|
|
296
|
+
# OpenAI 1.0.0 API responses are pydantic objects, not dicts
|
|
297
|
+
# We must dump the model to get the dict
|
|
298
|
+
res = await self._async_client.completions.create(**kwargs)
|
|
299
|
+
else:
|
|
300
|
+
res = await self._async_client.chat.completions.create(**kwargs)
|
|
301
|
+
return res.model_dump()
|
|
302
|
+
except self._openai._exceptions.BadRequestError as e:
|
|
303
|
+
exception_message = e.args[0]
|
|
304
|
+
if exception_message and "maximum context length" in exception_message:
|
|
305
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
306
|
+
raise e
|
|
307
|
+
|
|
308
|
+
return await _async_completion(**kwargs)
|
|
309
|
+
|
|
310
|
+
def _rate_limited_completion(self, **kwargs: Any) -> Any:
|
|
324
311
|
@self._rate_limiter.limit
|
|
325
|
-
def
|
|
326
|
-
|
|
327
|
-
if
|
|
328
|
-
|
|
329
|
-
|
|
330
|
-
|
|
331
|
-
|
|
332
|
-
|
|
333
|
-
|
|
334
|
-
|
|
335
|
-
|
|
336
|
-
|
|
337
|
-
|
|
312
|
+
def _completion(**kwargs: Any) -> Any:
|
|
313
|
+
try:
|
|
314
|
+
if self._model_uses_legacy_completion_api:
|
|
315
|
+
if "prompt" not in kwargs:
|
|
316
|
+
kwargs["prompt"] = "\n\n".join(
|
|
317
|
+
(message.get("content") or "")
|
|
318
|
+
for message in (kwargs.pop("messages", None) or ())
|
|
319
|
+
)
|
|
320
|
+
# OpenAI 1.0.0 API responses are pydantic objects, not dicts
|
|
321
|
+
# We must dump the model to get the dict
|
|
322
|
+
return self._client.completions.create(**kwargs).model_dump()
|
|
323
|
+
return self._client.chat.completions.create(**kwargs).model_dump()
|
|
324
|
+
except self._openai._exceptions.BadRequestError as e:
|
|
325
|
+
exception_message = e.args[0]
|
|
326
|
+
if exception_message and "maximum context length" in exception_message:
|
|
327
|
+
raise PhoenixContextLimitExceeded(exception_message) from e
|
|
328
|
+
raise e
|
|
329
|
+
|
|
330
|
+
return _completion(**kwargs)
|
|
338
331
|
|
|
339
332
|
@property
|
|
340
333
|
def max_context_size(self) -> int:
|