arize-phoenix 0.0.36__py3-none-any.whl → 0.0.38__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of arize-phoenix might be problematic. Click here for more details.
- arize_phoenix-0.0.38.dist-info/METADATA +445 -0
- {arize_phoenix-0.0.36.dist-info → arize_phoenix-0.0.38.dist-info}/RECORD +23 -22
- phoenix/__init__.py +1 -1
- phoenix/server/api/schema.py +4 -6
- phoenix/server/api/types/DataQualityMetric.py +1 -10
- phoenix/server/api/types/ExportEventsMutation.py +1 -4
- phoenix/server/api/types/Segments.py +6 -5
- phoenix/server/api/types/Span.py +20 -2
- phoenix/server/api/types/TimeSeries.py +1 -8
- phoenix/server/static/index.js +498 -471
- phoenix/session/session.py +5 -2
- phoenix/trace/fixtures.py +22 -1
- phoenix/trace/langchain/__init__.py +3 -0
- phoenix/{experimental/callbacks/langchain_tracer.py → trace/langchain/tracer.py} +102 -2
- phoenix/trace/llama_index/__init__.py +3 -0
- phoenix/{experimental/callbacks/llama_index_trace_callback_handler.py → trace/llama_index/callback.py} +35 -16
- phoenix/trace/semantic_conventions.py +2 -2
- phoenix/trace/span_json_decoder.py +0 -12
- phoenix/trace/trace_dataset.py +6 -1
- phoenix/trace/utils.py +1 -1
- arize_phoenix-0.0.36.dist-info/METADATA +0 -219
- phoenix/experimental/callbacks/__init__.py +0 -0
- {arize_phoenix-0.0.36.dist-info → arize_phoenix-0.0.38.dist-info}/WHEEL +0 -0
- {arize_phoenix-0.0.36.dist-info → arize_phoenix-0.0.38.dist-info}/licenses/IP_NOTICE +0 -0
- {arize_phoenix-0.0.36.dist-info → arize_phoenix-0.0.38.dist-info}/licenses/LICENSE +0 -0
phoenix/session/session.py
CHANGED
|
@@ -159,9 +159,9 @@ class Session(ABC):
|
|
|
159
159
|
)
|
|
160
160
|
if predicate:
|
|
161
161
|
spans = filter(predicate, spans)
|
|
162
|
-
if not (data :=
|
|
162
|
+
if not (data := [json.loads(span_to_json(span)) for span in spans]):
|
|
163
163
|
return None
|
|
164
|
-
return pd.json_normalize(data).set_index("context.span_id", drop=False)
|
|
164
|
+
return pd.json_normalize(data, max_level=1).set_index("context.span_id", drop=False)
|
|
165
165
|
|
|
166
166
|
|
|
167
167
|
_session: Optional[Session] = None
|
|
@@ -319,6 +319,9 @@ def launch_app(
|
|
|
319
319
|
)
|
|
320
320
|
_session.end()
|
|
321
321
|
|
|
322
|
+
host = host or get_env_host()
|
|
323
|
+
port = port or get_env_port()
|
|
324
|
+
|
|
322
325
|
if run_in_thread:
|
|
323
326
|
_session = ThreadSession(primary, reference, corpus, trace, host=host, port=port)
|
|
324
327
|
# TODO: catch exceptions from thread
|
phoenix/trace/fixtures.py
CHANGED
|
@@ -16,7 +16,19 @@ class TracesFixture:
|
|
|
16
16
|
llama_index_rag_fixture = TracesFixture(
|
|
17
17
|
name="llama_index_rag",
|
|
18
18
|
description="Traces from running the llama_index on a RAG use case.",
|
|
19
|
-
file_name="
|
|
19
|
+
file_name="llama_index_rag_v6.jsonl",
|
|
20
|
+
)
|
|
21
|
+
|
|
22
|
+
llama_index_calculator_agent = TracesFixture(
|
|
23
|
+
name="llama_index_calculator_agent",
|
|
24
|
+
description="Traces from running the llama_index with calculator tools.",
|
|
25
|
+
file_name="llama_index_calculator_agent_v2.jsonl",
|
|
26
|
+
)
|
|
27
|
+
|
|
28
|
+
llama_index_rag_fixture_with_davinci = TracesFixture(
|
|
29
|
+
name="llama_index_rag_with_davinci",
|
|
30
|
+
description="Traces from running llama_index on a RAG use case with the completions API.",
|
|
31
|
+
file_name="llama_index_rag_with_davinci_v0.jsonl",
|
|
20
32
|
)
|
|
21
33
|
|
|
22
34
|
langchain_rag_stuff_document_chain_fixture = TracesFixture(
|
|
@@ -25,6 +37,12 @@ langchain_rag_stuff_document_chain_fixture = TracesFixture(
|
|
|
25
37
|
file_name="langchain_rag.jsonl",
|
|
26
38
|
)
|
|
27
39
|
|
|
40
|
+
langchain_titanic_csv_agent_evaluator_fixture = TracesFixture(
|
|
41
|
+
name="lc_titanic",
|
|
42
|
+
description="LangChain titanic.csv Agent Evaluator",
|
|
43
|
+
file_name="lc_titanic.jsonl",
|
|
44
|
+
)
|
|
45
|
+
|
|
28
46
|
random_fixture = TracesFixture(
|
|
29
47
|
name="random",
|
|
30
48
|
description="Randomly generated traces",
|
|
@@ -33,8 +51,11 @@ random_fixture = TracesFixture(
|
|
|
33
51
|
|
|
34
52
|
TRACES_FIXTURES: List[TracesFixture] = [
|
|
35
53
|
llama_index_rag_fixture,
|
|
54
|
+
llama_index_rag_fixture_with_davinci,
|
|
36
55
|
langchain_rag_stuff_document_chain_fixture,
|
|
56
|
+
langchain_titanic_csv_agent_evaluator_fixture,
|
|
37
57
|
random_fixture,
|
|
58
|
+
llama_index_calculator_agent,
|
|
38
59
|
]
|
|
39
60
|
|
|
40
61
|
NAME_TO_TRACES_FIXTURE = {fixture.name: fixture for fixture in TRACES_FIXTURES}
|
|
@@ -2,10 +2,20 @@ import json
|
|
|
2
2
|
import logging
|
|
3
3
|
from copy import deepcopy
|
|
4
4
|
from datetime import datetime
|
|
5
|
-
from typing import
|
|
5
|
+
from typing import (
|
|
6
|
+
Any,
|
|
7
|
+
Dict,
|
|
8
|
+
Iterator,
|
|
9
|
+
List,
|
|
10
|
+
Optional,
|
|
11
|
+
Tuple,
|
|
12
|
+
)
|
|
13
|
+
from uuid import UUID
|
|
6
14
|
|
|
7
15
|
from langchain.callbacks.tracers.base import BaseTracer
|
|
8
16
|
from langchain.callbacks.tracers.schemas import Run
|
|
17
|
+
from langchain.load.dump import dumpd
|
|
18
|
+
from langchain.schema.messages import BaseMessage
|
|
9
19
|
|
|
10
20
|
from phoenix.trace.exporter import HttpExporter
|
|
11
21
|
from phoenix.trace.schemas import (
|
|
@@ -22,13 +32,17 @@ from phoenix.trace.semantic_conventions import (
|
|
|
22
32
|
INPUT_VALUE,
|
|
23
33
|
LLM_FUNCTION_CALL,
|
|
24
34
|
LLM_INVOCATION_PARAMETERS,
|
|
35
|
+
LLM_MESSAGES,
|
|
25
36
|
LLM_MODEL_NAME,
|
|
26
37
|
LLM_PROMPT_TEMPLATE,
|
|
27
38
|
LLM_PROMPT_TEMPLATE_VARIABLES,
|
|
28
39
|
LLM_PROMPT_TEMPLATE_VERSION,
|
|
40
|
+
LLM_PROMPTS,
|
|
29
41
|
LLM_TOKEN_COUNT_COMPLETION,
|
|
30
42
|
LLM_TOKEN_COUNT_PROMPT,
|
|
31
43
|
LLM_TOKEN_COUNT_TOTAL,
|
|
44
|
+
MESSAGE_CONTENT,
|
|
45
|
+
MESSAGE_ROLE,
|
|
32
46
|
OUTPUT_MIME_TYPE,
|
|
33
47
|
OUTPUT_VALUE,
|
|
34
48
|
RETRIEVAL_DOCUMENTS,
|
|
@@ -41,6 +55,9 @@ from phoenix.trace.tracer import Tracer
|
|
|
41
55
|
logger = logging.getLogger(__name__)
|
|
42
56
|
|
|
43
57
|
|
|
58
|
+
Message = Dict[str, Any]
|
|
59
|
+
|
|
60
|
+
|
|
44
61
|
def _langchain_run_type_to_span_kind(run_type: str) -> SpanKind:
|
|
45
62
|
# TODO: LangChain is moving away from enums and to arbitrary strings
|
|
46
63
|
# for the run_type variable, so we may need to do the same
|
|
@@ -68,6 +85,42 @@ def _convert_io(obj: Optional[Dict[str, Any]]) -> Iterator[Any]:
|
|
|
68
85
|
yield MimeType.JSON
|
|
69
86
|
|
|
70
87
|
|
|
88
|
+
def _prompts(run_inputs: Dict[str, Any]) -> Iterator[Tuple[str, List[str]]]:
|
|
89
|
+
"""Yields prompts if present."""
|
|
90
|
+
if "prompts" in run_inputs:
|
|
91
|
+
yield LLM_PROMPTS, run_inputs["prompts"]
|
|
92
|
+
|
|
93
|
+
|
|
94
|
+
def _messages(run_inputs: Dict[str, Any]) -> Iterator[Tuple[str, List[Message]]]:
|
|
95
|
+
"""Yields chat messages if present."""
|
|
96
|
+
if "messages" in run_inputs:
|
|
97
|
+
yield LLM_MESSAGES, [
|
|
98
|
+
_parse_message_data(message_data) for message_data in run_inputs["messages"][0]
|
|
99
|
+
]
|
|
100
|
+
|
|
101
|
+
|
|
102
|
+
def _parse_message_data(message_data: Dict[str, Any]) -> Message:
|
|
103
|
+
"""Parses message data to grab message role, content, etc."""
|
|
104
|
+
message_class_name = message_data["id"][-1]
|
|
105
|
+
if message_class_name == "HumanMessage":
|
|
106
|
+
role = "user"
|
|
107
|
+
elif message_class_name == "AIMessage":
|
|
108
|
+
role = "assistant"
|
|
109
|
+
elif message_class_name == "SystemMessage":
|
|
110
|
+
role = "system"
|
|
111
|
+
elif message_class_name == "FunctionMessage":
|
|
112
|
+
role = "function"
|
|
113
|
+
elif message_class_name == "ChatMessage":
|
|
114
|
+
role = message_data["kwargs"]["role"]
|
|
115
|
+
else:
|
|
116
|
+
raise ValueError(f"Cannot parse message of type: {message_class_name}")
|
|
117
|
+
parsed_message_data = {
|
|
118
|
+
MESSAGE_ROLE: role,
|
|
119
|
+
MESSAGE_CONTENT: message_data["kwargs"]["content"],
|
|
120
|
+
}
|
|
121
|
+
return parsed_message_data
|
|
122
|
+
|
|
123
|
+
|
|
71
124
|
def _prompt_template(run_serialized: Dict[str, Any]) -> Iterator[Tuple[str, Any]]:
|
|
72
125
|
"""
|
|
73
126
|
A best-effort attempt to locate the PromptTemplate object among the
|
|
@@ -179,6 +232,8 @@ class OpenInferenceTracer(Tracer, BaseTracer):
|
|
|
179
232
|
"outputs": (OUTPUT_VALUE, OUTPUT_MIME_TYPE),
|
|
180
233
|
}.items():
|
|
181
234
|
attributes.update(zip(io_attributes, _convert_io(run.get(io_key))))
|
|
235
|
+
attributes.update(_prompts(run["inputs"]))
|
|
236
|
+
attributes.update(_messages(run["inputs"]))
|
|
182
237
|
attributes.update(_prompt_template(run["serialized"]))
|
|
183
238
|
attributes.update(_invocation_parameters(run))
|
|
184
239
|
attributes.update(_model_name(run["extra"]))
|
|
@@ -205,9 +260,14 @@ class OpenInferenceTracer(Tracer, BaseTracer):
|
|
|
205
260
|
timestamp=error_event["time"],
|
|
206
261
|
)
|
|
207
262
|
)
|
|
263
|
+
span_kind = (
|
|
264
|
+
SpanKind.AGENT
|
|
265
|
+
if "agent" in run["name"].lower()
|
|
266
|
+
else _langchain_run_type_to_span_kind(run["run_type"])
|
|
267
|
+
)
|
|
208
268
|
span = self.create_span(
|
|
209
269
|
name=run["name"],
|
|
210
|
-
span_kind=
|
|
270
|
+
span_kind=span_kind,
|
|
211
271
|
parent_id=None if parent is None else parent.context.span_id,
|
|
212
272
|
trace_id=None if parent is None else parent.context.trace_id,
|
|
213
273
|
start_time=run["start_time"],
|
|
@@ -226,3 +286,43 @@ class OpenInferenceTracer(Tracer, BaseTracer):
|
|
|
226
286
|
self._convert_run_to_spans(run.dict())
|
|
227
287
|
except Exception:
|
|
228
288
|
logger.exception("Failed to convert run to spans")
|
|
289
|
+
|
|
290
|
+
def on_chat_model_start(
|
|
291
|
+
self,
|
|
292
|
+
serialized: Dict[str, Any],
|
|
293
|
+
messages: List[List[BaseMessage]],
|
|
294
|
+
*,
|
|
295
|
+
run_id: UUID,
|
|
296
|
+
tags: Optional[List[str]] = None,
|
|
297
|
+
parent_run_id: Optional[UUID] = None,
|
|
298
|
+
metadata: Optional[Dict[str, Any]] = None,
|
|
299
|
+
**kwargs: Any,
|
|
300
|
+
) -> None:
|
|
301
|
+
"""
|
|
302
|
+
Adds chat messages to the run inputs.
|
|
303
|
+
|
|
304
|
+
LangChain's BaseTracer class does not implement hooks for chat models and hence does not
|
|
305
|
+
record data such as the list of messages that were passed to the chat model.
|
|
306
|
+
|
|
307
|
+
For reference, see https://github.com/langchain-ai/langchain/pull/4499.
|
|
308
|
+
"""
|
|
309
|
+
|
|
310
|
+
parent_run_id_ = str(parent_run_id) if parent_run_id else None
|
|
311
|
+
execution_order = self._get_execution_order(parent_run_id_)
|
|
312
|
+
start_time = datetime.utcnow()
|
|
313
|
+
if metadata:
|
|
314
|
+
kwargs.update({"metadata": metadata})
|
|
315
|
+
run = Run(
|
|
316
|
+
id=run_id,
|
|
317
|
+
parent_run_id=parent_run_id,
|
|
318
|
+
serialized=serialized,
|
|
319
|
+
inputs={"messages": [[dumpd(message) for message in batch] for batch in messages]},
|
|
320
|
+
extra=kwargs,
|
|
321
|
+
events=[{"name": "start", "time": start_time}],
|
|
322
|
+
start_time=start_time,
|
|
323
|
+
execution_order=execution_order,
|
|
324
|
+
child_execution_order=execution_order,
|
|
325
|
+
run_type="llm",
|
|
326
|
+
tags=tags,
|
|
327
|
+
)
|
|
328
|
+
self._start_trace(run)
|
|
@@ -25,7 +25,6 @@ from llama_index.callbacks.schema import (
|
|
|
25
25
|
)
|
|
26
26
|
from llama_index.llms.base import ChatMessage, ChatResponse
|
|
27
27
|
from llama_index.tools import ToolMetadata
|
|
28
|
-
from openai.openai_object import OpenAIObject
|
|
29
28
|
|
|
30
29
|
from phoenix.trace.exporter import HttpExporter
|
|
31
30
|
from phoenix.trace.schemas import Span, SpanID, SpanKind, SpanStatusCode
|
|
@@ -43,7 +42,9 @@ from phoenix.trace.semantic_conventions import (
|
|
|
43
42
|
LLM_INVOCATION_PARAMETERS,
|
|
44
43
|
LLM_MESSAGES,
|
|
45
44
|
LLM_MODEL_NAME,
|
|
46
|
-
|
|
45
|
+
LLM_PROMPT_TEMPLATE,
|
|
46
|
+
LLM_PROMPT_TEMPLATE_VARIABLES,
|
|
47
|
+
LLM_PROMPTS,
|
|
47
48
|
LLM_TOKEN_COUNT_COMPLETION,
|
|
48
49
|
LLM_TOKEN_COUNT_PROMPT,
|
|
49
50
|
LLM_TOKEN_COUNT_TOTAL,
|
|
@@ -88,6 +89,14 @@ def payload_to_semantic_attributes(
|
|
|
88
89
|
if event_type in (CBEventType.NODE_PARSING, CBEventType.CHUNKING):
|
|
89
90
|
# TODO(maybe): handle these events
|
|
90
91
|
return attributes
|
|
92
|
+
if event_type == CBEventType.TEMPLATING:
|
|
93
|
+
if template := payload.get(EventPayload.TEMPLATE):
|
|
94
|
+
attributes[LLM_PROMPT_TEMPLATE] = template
|
|
95
|
+
if template_vars := payload.get(EventPayload.TEMPLATE_VARS):
|
|
96
|
+
attributes[LLM_PROMPT_TEMPLATE_VARIABLES] = template_vars
|
|
97
|
+
# TODO(maybe): other keys in the same payload
|
|
98
|
+
# EventPayload.SYSTEM_PROMPT
|
|
99
|
+
# EventPayload.QUERY_WRAPPER_PROMPT
|
|
91
100
|
if EventPayload.CHUNKS in payload and EventPayload.EMBEDDINGS in payload:
|
|
92
101
|
attributes[EMBEDDING_EMBEDDINGS] = [
|
|
93
102
|
{EMBEDDING_TEXT: text, EMBEDDING_VECTOR: vector}
|
|
@@ -107,7 +116,7 @@ def payload_to_semantic_attributes(
|
|
|
107
116
|
for node_with_score in payload[EventPayload.NODES]
|
|
108
117
|
]
|
|
109
118
|
if EventPayload.PROMPT in payload:
|
|
110
|
-
attributes[
|
|
119
|
+
attributes[LLM_PROMPTS] = [payload[EventPayload.PROMPT]]
|
|
111
120
|
if EventPayload.MESSAGES in payload:
|
|
112
121
|
messages = payload[EventPayload.MESSAGES]
|
|
113
122
|
# Messages is only relevant to the LLM invocation
|
|
@@ -120,14 +129,14 @@ def payload_to_semantic_attributes(
|
|
|
120
129
|
# akin to the query_str
|
|
121
130
|
attributes[INPUT_VALUE] = _message_payload_to_str(messages[0])
|
|
122
131
|
if response := (payload.get(EventPayload.RESPONSE) or payload.get(EventPayload.COMPLETION)):
|
|
123
|
-
attributes
|
|
124
|
-
|
|
125
|
-
|
|
126
|
-
|
|
127
|
-
|
|
128
|
-
attributes[
|
|
129
|
-
|
|
130
|
-
attributes[LLM_TOKEN_COUNT_TOTAL] =
|
|
132
|
+
attributes.update(_get_response_output(response))
|
|
133
|
+
if (raw := getattr(response, "raw", None)) and (usage := getattr(raw, "usage", None)):
|
|
134
|
+
if prompt_tokens := getattr(usage, "prompt_tokens", None):
|
|
135
|
+
attributes[LLM_TOKEN_COUNT_PROMPT] = prompt_tokens
|
|
136
|
+
if completion_tokens := getattr(usage, "completion_tokens", None):
|
|
137
|
+
attributes[LLM_TOKEN_COUNT_COMPLETION] = completion_tokens
|
|
138
|
+
if total_tokens := getattr(usage, "total_tokens", None):
|
|
139
|
+
attributes[LLM_TOKEN_COUNT_TOTAL] = total_tokens
|
|
131
140
|
if EventPayload.TEMPLATE in payload:
|
|
132
141
|
...
|
|
133
142
|
if event_type is CBEventType.RERANKING:
|
|
@@ -354,11 +363,21 @@ def _message_payload_to_str(message: Any) -> Optional[str]:
|
|
|
354
363
|
return str(message)
|
|
355
364
|
|
|
356
365
|
|
|
357
|
-
def
|
|
366
|
+
def _get_response_output(response: Any) -> Iterator[Tuple[str, Any]]:
|
|
358
367
|
"""
|
|
359
|
-
Gets
|
|
360
|
-
response objects includes extra information in addition to the content itself.
|
|
368
|
+
Gets output from response objects. This is needed since the string representation of some
|
|
369
|
+
response objects includes extra information in addition to the content itself. In the
|
|
370
|
+
case of an agent's ChatResponse the output may be a `function_call` object specifying
|
|
371
|
+
the name of the function to call and the arguments to call it with.
|
|
361
372
|
"""
|
|
362
373
|
if isinstance(response, ChatResponse):
|
|
363
|
-
|
|
364
|
-
|
|
374
|
+
message = response.message
|
|
375
|
+
if content := message.content:
|
|
376
|
+
yield OUTPUT_VALUE, content
|
|
377
|
+
yield OUTPUT_MIME_TYPE, MimeType.TEXT
|
|
378
|
+
else:
|
|
379
|
+
yield OUTPUT_VALUE, json.dumps(message.additional_kwargs)
|
|
380
|
+
yield OUTPUT_MIME_TYPE, MimeType.JSON
|
|
381
|
+
else:
|
|
382
|
+
yield OUTPUT_VALUE, str(response)
|
|
383
|
+
yield OUTPUT_MIME_TYPE, MimeType.TEXT
|
|
@@ -125,9 +125,9 @@ LLM_MODEL_NAME = "llm.model_name"
|
|
|
125
125
|
"""
|
|
126
126
|
The name of the model being used.
|
|
127
127
|
"""
|
|
128
|
-
|
|
128
|
+
LLM_PROMPTS = "llm.prompts"
|
|
129
129
|
"""
|
|
130
|
-
|
|
130
|
+
Prompts provided to a completions API.
|
|
131
131
|
"""
|
|
132
132
|
LLM_PROMPT_TEMPLATE = "llm.prompt_template.template"
|
|
133
133
|
"""
|
|
@@ -13,23 +13,13 @@ from phoenix.trace.schemas import (
|
|
|
13
13
|
SpanStatusCode,
|
|
14
14
|
)
|
|
15
15
|
from phoenix.trace.semantic_conventions import (
|
|
16
|
-
DOCUMENT_METADATA,
|
|
17
16
|
EXCEPTION_MESSAGE,
|
|
18
17
|
INPUT_MIME_TYPE,
|
|
19
18
|
OUTPUT_MIME_TYPE,
|
|
20
|
-
RETRIEVAL_DOCUMENTS,
|
|
21
19
|
MimeType,
|
|
22
20
|
)
|
|
23
21
|
|
|
24
22
|
|
|
25
|
-
def json_to_document(obj: Optional[Dict[str, Any]]) -> Dict[str, Any]:
|
|
26
|
-
if obj is None:
|
|
27
|
-
return {}
|
|
28
|
-
if document_metadata := obj.get(DOCUMENT_METADATA):
|
|
29
|
-
obj[DOCUMENT_METADATA] = json.loads(document_metadata)
|
|
30
|
-
return obj
|
|
31
|
-
|
|
32
|
-
|
|
33
23
|
def json_to_attributes(obj: Optional[Dict[str, Any]]) -> Dict[str, Any]:
|
|
34
24
|
if obj is None:
|
|
35
25
|
return {}
|
|
@@ -39,8 +29,6 @@ def json_to_attributes(obj: Optional[Dict[str, Any]]) -> Dict[str, Any]:
|
|
|
39
29
|
obj[INPUT_MIME_TYPE] = MimeType(mime_type)
|
|
40
30
|
if mime_type := obj.get(OUTPUT_MIME_TYPE):
|
|
41
31
|
obj[OUTPUT_MIME_TYPE] = MimeType(mime_type)
|
|
42
|
-
if documents := obj.get(RETRIEVAL_DOCUMENTS):
|
|
43
|
-
obj[RETRIEVAL_DOCUMENTS] = [json_to_document(document) for document in documents]
|
|
44
32
|
return obj
|
|
45
33
|
|
|
46
34
|
|
phoenix/trace/trace_dataset.py
CHANGED
|
@@ -70,7 +70,12 @@ class TraceDataset:
|
|
|
70
70
|
Returns:
|
|
71
71
|
TraceDataset: A TraceDataset containing the spans.
|
|
72
72
|
"""
|
|
73
|
-
return cls(
|
|
73
|
+
return cls(
|
|
74
|
+
pd.json_normalize(
|
|
75
|
+
(json.loads(span_to_json(span)) for span in spans), # type: ignore
|
|
76
|
+
max_level=1,
|
|
77
|
+
)
|
|
78
|
+
)
|
|
74
79
|
|
|
75
80
|
def to_spans(self) -> Iterator[Span]:
|
|
76
81
|
for _, row in self.dataframe.iterrows():
|
phoenix/trace/utils.py
CHANGED
|
@@ -15,5 +15,5 @@ def json_lines_to_df(lines: List[str]) -> pd.DataFrame:
|
|
|
15
15
|
data.append(json.loads(line))
|
|
16
16
|
|
|
17
17
|
# Normalize data to a flat structure
|
|
18
|
-
df = pd.concat([pd.json_normalize(item) for item in data], ignore_index=True)
|
|
18
|
+
df = pd.concat([pd.json_normalize(item, max_level=1) for item in data], ignore_index=True)
|
|
19
19
|
return df
|
|
@@ -1,219 +0,0 @@
|
|
|
1
|
-
Metadata-Version: 2.1
|
|
2
|
-
Name: arize-phoenix
|
|
3
|
-
Version: 0.0.36
|
|
4
|
-
Summary: ML Observability in your notebook
|
|
5
|
-
Project-URL: Documentation, https://docs.arize.com/phoenix/
|
|
6
|
-
Project-URL: Issues, https://github.com/Arize-ai/phoenix/issues
|
|
7
|
-
Project-URL: Source, https://github.com/Arize-ai/phoenix
|
|
8
|
-
Author-email: Arize AI <phoenix-devs@arize.com>
|
|
9
|
-
License-Expression: Elastic-2.0
|
|
10
|
-
License-File: IP_NOTICE
|
|
11
|
-
License-File: LICENSE
|
|
12
|
-
Keywords: Explainability,Monitoring,Observability
|
|
13
|
-
Classifier: Programming Language :: Python
|
|
14
|
-
Classifier: Programming Language :: Python :: 3.8
|
|
15
|
-
Classifier: Programming Language :: Python :: 3.9
|
|
16
|
-
Classifier: Programming Language :: Python :: 3.10
|
|
17
|
-
Classifier: Programming Language :: Python :: 3.11
|
|
18
|
-
Requires-Python: <3.12,>=3.8
|
|
19
|
-
Requires-Dist: hdbscan<1.0.0,>=0.8.33
|
|
20
|
-
Requires-Dist: numpy
|
|
21
|
-
Requires-Dist: pandas
|
|
22
|
-
Requires-Dist: protobuf<5.0,>=3.20
|
|
23
|
-
Requires-Dist: psutil
|
|
24
|
-
Requires-Dist: pyarrow
|
|
25
|
-
Requires-Dist: scikit-learn<1.3.0
|
|
26
|
-
Requires-Dist: scipy
|
|
27
|
-
Requires-Dist: sortedcontainers
|
|
28
|
-
Requires-Dist: starlette
|
|
29
|
-
Requires-Dist: strawberry-graphql==0.205.0
|
|
30
|
-
Requires-Dist: typing-extensions
|
|
31
|
-
Requires-Dist: umap-learn
|
|
32
|
-
Requires-Dist: uvicorn
|
|
33
|
-
Requires-Dist: wrapt
|
|
34
|
-
Provides-Extra: dev
|
|
35
|
-
Requires-Dist: arize[autoembeddings,llm-evaluation]; extra == 'dev'
|
|
36
|
-
Requires-Dist: black[jupyter]; extra == 'dev'
|
|
37
|
-
Requires-Dist: gcsfs; extra == 'dev'
|
|
38
|
-
Requires-Dist: hatch; extra == 'dev'
|
|
39
|
-
Requires-Dist: jupyter; extra == 'dev'
|
|
40
|
-
Requires-Dist: nbqa; extra == 'dev'
|
|
41
|
-
Requires-Dist: pandas-stubs<=2.0.2.230605; extra == 'dev'
|
|
42
|
-
Requires-Dist: pre-commit; extra == 'dev'
|
|
43
|
-
Requires-Dist: pytest; extra == 'dev'
|
|
44
|
-
Requires-Dist: pytest-cov; extra == 'dev'
|
|
45
|
-
Requires-Dist: pytest-lazy-fixture; extra == 'dev'
|
|
46
|
-
Requires-Dist: ruff==0.0.289; extra == 'dev'
|
|
47
|
-
Requires-Dist: strawberry-graphql[debug-server]==0.205.0; extra == 'dev'
|
|
48
|
-
Provides-Extra: experimental
|
|
49
|
-
Requires-Dist: langchain>=0.0.257; extra == 'experimental'
|
|
50
|
-
Requires-Dist: llama-index>=0.8.25; extra == 'experimental'
|
|
51
|
-
Requires-Dist: openai; extra == 'experimental'
|
|
52
|
-
Requires-Dist: tenacity; extra == 'experimental'
|
|
53
|
-
Description-Content-Type: text/markdown
|
|
54
|
-
|
|
55
|
-
<p align="center">
|
|
56
|
-
<a target="_blank" href="https://phoenix.arize.com" style="background:none">
|
|
57
|
-
<img alt="phoenix logo" src="https://storage.googleapis.com/arize-assets/phoenix/assets/phoenix-logo-light.svg" width="auto" height="200"></img>
|
|
58
|
-
</a>
|
|
59
|
-
<br/>
|
|
60
|
-
<br/>
|
|
61
|
-
<a href="https://docs.arize.com/phoenix/">
|
|
62
|
-
<img src="https://img.shields.io/static/v1?message=Docs&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAIAAAACACAYAAADDPmHLAAAG4ElEQVR4nO2d4XHjNhCFcTf+b3ZgdWCmgmMqOKUC0xXYrsBOBVEqsFRB7ApCVRCygrMriFQBM7h5mNlwKBECARLg7jeDscamSQj7sFgsQfBL27ZK4MtXsT1vRADMEQEwRwTAHBEAc0QAzBEBMEcEwBwRAHNEAMwRATBnjAByFGE+MqVUMcYOY24GVUqpb/h8VErVKAf87QNFcEcbd4WSw+D6803njHscO5sATmGEURGBiCj6yUlv1uX2gv91FsDViArbcA2RUKF8QhAV8RQc0b15DcOt0VaTE1oAfWj3dYdCBfGGsmSM0XX5HsP3nEMAXbqCeCdiOERQPx9og5exGJ0S4zRQN9KrUupfpdQWjZciure/YIj7K0bjqwTyAHdovA805iqCOg2xgnB1nZ97IvaoSCURdIPG/IHGjTH/YAz/A8KdJai7lBQzgbpx/0Hg6DT18UzWMXxSjMkDrElPNEmKfAbl6znwI3IMU/OCa0/1nfckwWaSbvWYYDnEsvCMJDNckhqu7GCMKWYOBXp9yPGd5kvqUAKf6rkAk7M2SY9QDXdEr9wEOr9x96EiejMFnixBNteDISsyNw7hHRqc22evWcP4vt39O85bzZH30AKg4+eo8cQRI4bHAJ7hyYM3CNHrG9RrimSXuZmUkZjN/O6nAPpcwCcJNmipAle2QM/1GU3vITCXhvY91u9geN/jOY27VuTnYL1PCeAcRhwh7/Bl8Ai+IuxPiOCShtfX/sPDtY8w+sZjby86dw6dBeoigD7obd/Ko6fI4BF8DA9HnGdrcU0fLt+n4dfE6H5jpjYcVdu2L23b5lpjHoo+18FDbcszddF1rUee/4C6ZiO+80rHZmjDoIQUQLdRtm3brkcKIUPjjqVPBIUHgW1GGN4YfawAL2IqAVB8iEE31tvIelARlCPPVaFOLoIupzY6xVcM4MoRUyHXyHhslH6PaPl5RP1Lh4UsOeKR2e8dzC0Aiuvc2Nx3fwhfxf/hknouUYbWUk5GTAIwmOh5e+H0cor8vEL91hfOdEqINLq1AV+RKImJ6869f9tFIBVc6y7gd3lHfWyNX0LEr7EuDElhRdAlQjig0e/RU31xxDltM4pF7IY3pLIgxAhhgzF/iC2M0Hi4dkOGlyGMd/g7dsMbUlsR9ICe9WhxbA3DjRkSdjiHzQzlBSKNJsCzIcUlYdfI0dcWS8LMkPDkcJ0n/O+Qyy/IAtDkSPnp4Fu4WpthQR/zm2VcoI/51fI28iYld9/HEh4Pf7D0Bm845pwIPnHMUJSf45pT5x68s5T9AW6INzhHDeP1BYcNMew5SghkinWOwVnaBhHGG5ybMn70zBDe8buh8X6DqV0Sa/5tWOIOIbcWQ8KBiGBnMb/P0OuTd/lddCrY5jn/VLm3nL+fY4X4YREuv8vS9wh6HSkAExMs0viKySZRd44iyOH2FzPe98Fll7A7GNMmjay4GF9BAKGXesfCN0sRsDG+YrhP4O2ACFgZXzHdKPL2RMJoxc34ivFOod3AMMNUj5XxFfOtYrUIXvB5MandS+G+V/AzZ+MrEcBPlpoFtUIEwBwRAG+OIgDe1CIA5ogAmCMCYI4IgDkiAOaIAJgjAmCOCIA5IgDmiACYIwJgjgiAOSIA5ogAmCMCYI4IgDkiAOaIAJgjAmCOCIA5IgDmiACYIwJgjgiAOSIA5ogAmCMCYI4IgDkiAOaIAJgjAmDOVYBXvwvxQV8NWJOd0esvJ94babZaz7B5ovldxnlDpYhp0JFr/KTlLKcEMMQKpcDPXIQxGXsYmhZnXAXQh/EWBQrr3bc80mATyyrEvs4+BdBHgbdxFOIhrDkSg1/6Iu2LCS0AyoqI4ftUF00EY/Q3h1fRj2JKAVCMGErmnsH1lfnemEsAlByvgl0z2qx5B8OPCuB8EIMADBlEEOV79j1whNE3c/X2PmISAGUNr7CEmUSUhjfEKgBDAY+QohCiNrwhdgEYzPv7UxkadvBg0RrekMrNoAozh3vLN4DPhc7S/WL52vkoSO1u4BZC+DOCulC0KJ/gqWaP7C8hlSGgjxyCmDuPsEePT/KuasrrAcyr4H+f6fq01yd7Sz1lD0CZ2hs06PVJufs+lrIiyLwufjfBtXYpjvWnWIoHoJSYe4dIK/t4HX1ULFEACkPCm8e8wXFJvZ6y1EWhJkDcWxw7RINzLc74auGrgg8e4oIm9Sh/CA7LwkvHqaIJ9pLI6Lmy1BigDy2EV8tjdzh+8XB6MGSLKH4INsZXDJ8MGhIBK+Mrpo+GnRIBO+MrZjFAFxoTNBwCvj6u4qvSZJiM3iNX4yvmHoA9Sh4PF0QAzBEBMEcEwBwRAHNEAMwRAXBGKfUfr5hKvglRfO4AAAAASUVORK5CYII=&labelColor=grey&color=blue&logoColor=white&label=%20"/>
|
|
63
|
-
</a>
|
|
64
|
-
<a target="_blank" href="https://join.slack.com/t/arize-ai/shared_invite/zt-1px8dcmlf-fmThhDFD_V_48oU7ALan4Q">
|
|
65
|
-
<img src="https://img.shields.io/static/v1?message=Community&logo=slack&labelColor=grey&color=blue&logoColor=white&label=%20"/>
|
|
66
|
-
</a>
|
|
67
|
-
<a target="_blank" href="https://twitter.com/ArizePhoenix">
|
|
68
|
-
<img src="https://img.shields.io/badge/-ArizePhoenix-blue.svg?color=blue&labelColor=gray&logo=twitter">
|
|
69
|
-
</a>
|
|
70
|
-
<a target="_blank" href="https://pypi.org/project/arize-phoenix/">
|
|
71
|
-
<img src="https://img.shields.io/pypi/v/arize-phoenix?color=blue">
|
|
72
|
-
</a>
|
|
73
|
-
<a target="_blank" href="https://anaconda.org/conda-forge/arize-phoenix">
|
|
74
|
-
<img src="https://img.shields.io/conda/vn/conda-forge/arize-phoenix.svg?color=blue">
|
|
75
|
-
</a>
|
|
76
|
-
<a target="_blank" href="https://pypi.org/project/arize-phoenix/">
|
|
77
|
-
<img src="https://img.shields.io/pypi/pyversions/arize-phoenix">
|
|
78
|
-
</a>
|
|
79
|
-
</p>
|
|
80
|
-
|
|
81
|
-
Phoenix provides MLOps insights at lightning speed with zero-config observability for model drift, performance, and data quality. Phoenix is notebook-first python library that leverages embeddings to uncover problematic cohorts of your LLM, CV, NLP and tabular models.
|
|
82
|
-
|
|
83
|
-
<!-- EXCLUDE -->
|
|
84
|
-
|
|
85
|
-
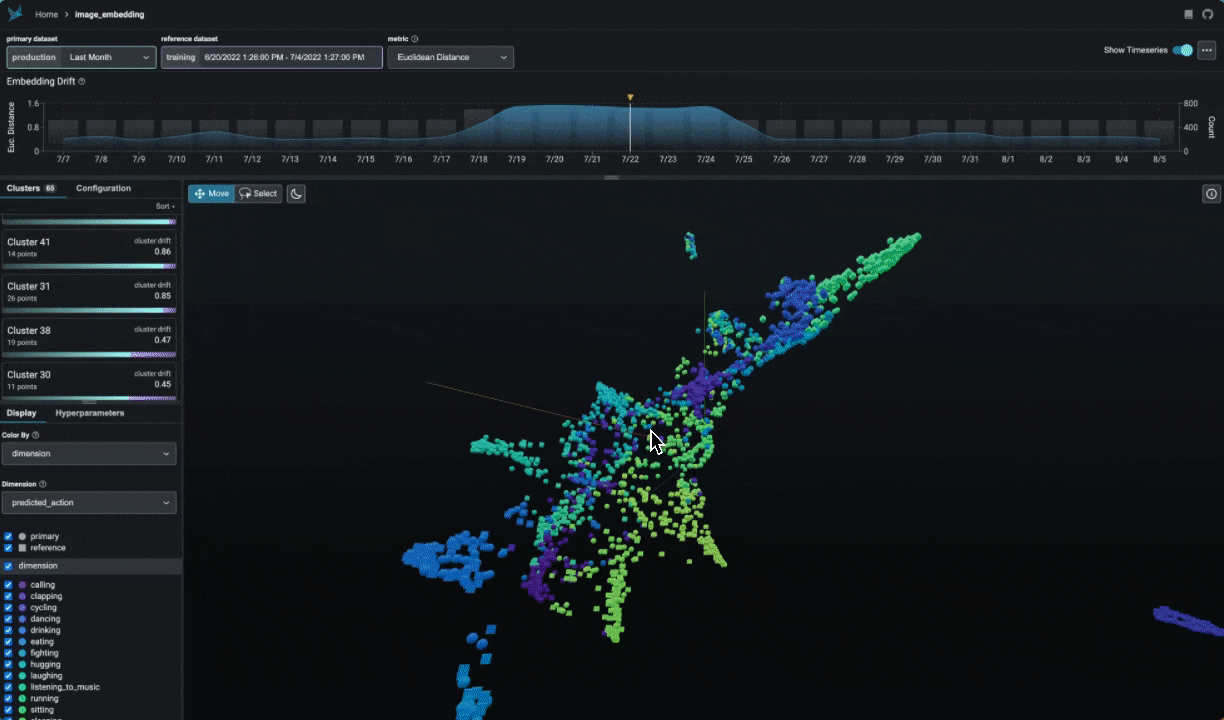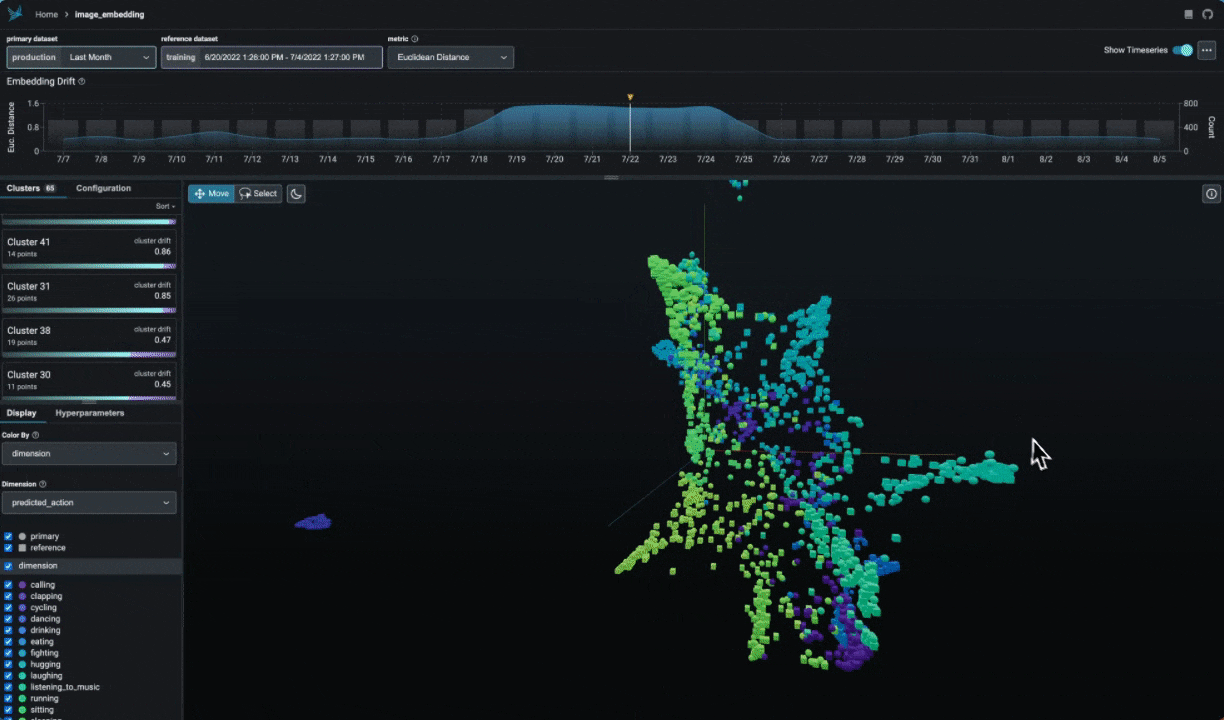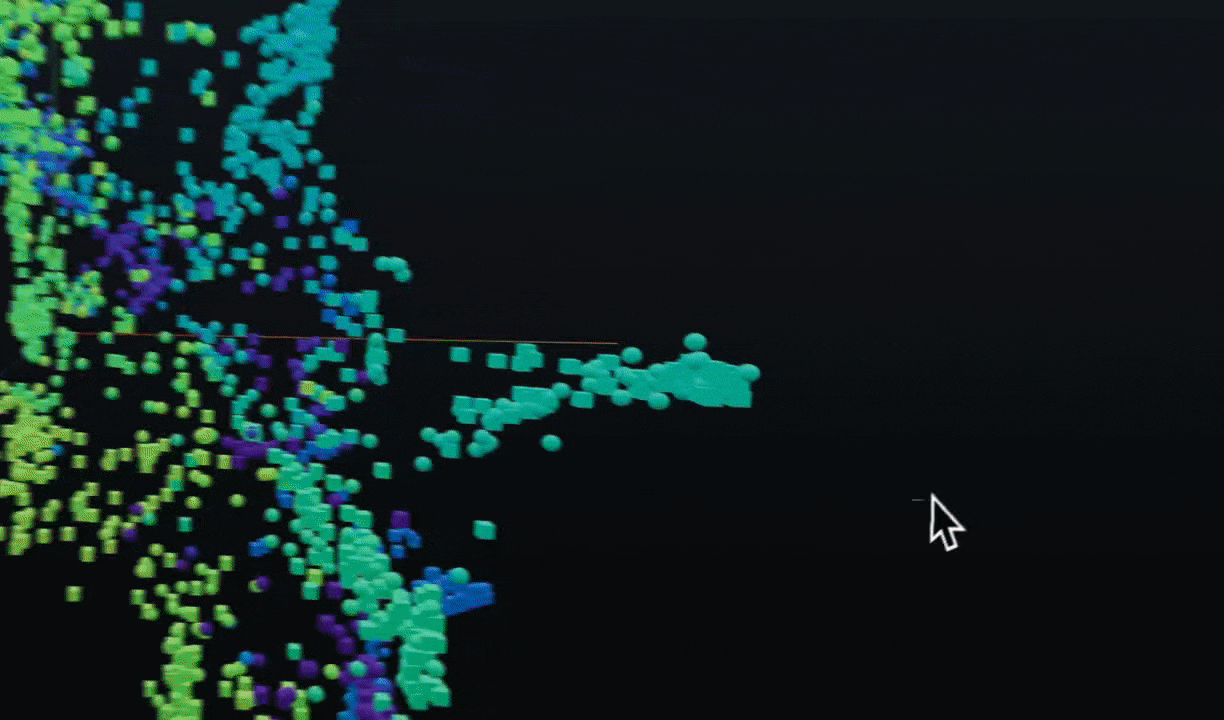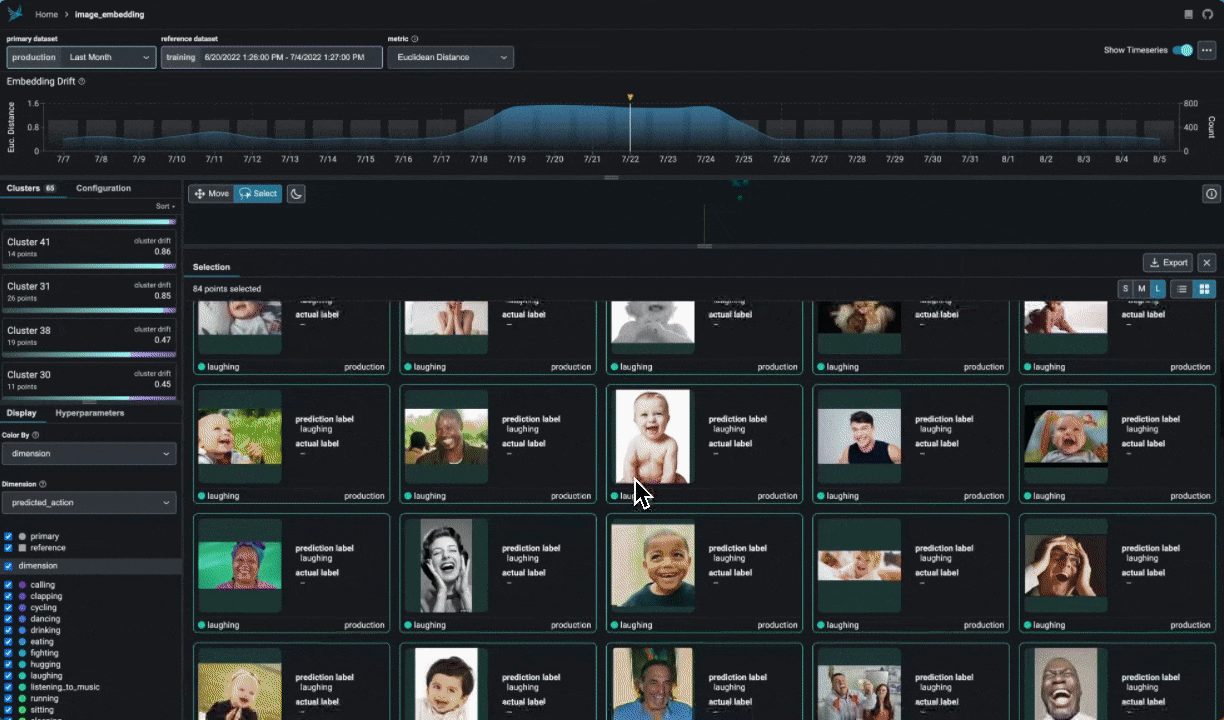
|
|
86
|
-
|
|
87
|
-
<!-- /EXCLUDE -->
|
|
88
|
-
|
|
89
|
-
## Installation
|
|
90
|
-
|
|
91
|
-
```shell
|
|
92
|
-
pip install arize-phoenix
|
|
93
|
-
```
|
|
94
|
-
|
|
95
|
-
## Quickstart
|
|
96
|
-
|
|
97
|
-
[](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/image_classification_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/image_classification_tutorial.ipynb)
|
|
98
|
-
|
|
99
|
-
Import libraries.
|
|
100
|
-
|
|
101
|
-
```python
|
|
102
|
-
from dataclasses import replace
|
|
103
|
-
import pandas as pd
|
|
104
|
-
import phoenix as px
|
|
105
|
-
```
|
|
106
|
-
|
|
107
|
-
Download curated datasets and load them into pandas DataFrames.
|
|
108
|
-
|
|
109
|
-
```python
|
|
110
|
-
train_df = pd.read_parquet(
|
|
111
|
-
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_training.parquet"
|
|
112
|
-
)
|
|
113
|
-
prod_df = pd.read_parquet(
|
|
114
|
-
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_production.parquet"
|
|
115
|
-
)
|
|
116
|
-
```
|
|
117
|
-
|
|
118
|
-
Define schemas that tell Phoenix which columns of your DataFrames correspond to features, predictions, actuals (i.e., ground truth), embeddings, etc.
|
|
119
|
-
|
|
120
|
-
```python
|
|
121
|
-
train_schema = px.Schema(
|
|
122
|
-
prediction_id_column_name="prediction_id",
|
|
123
|
-
timestamp_column_name="prediction_ts",
|
|
124
|
-
prediction_label_column_name="predicted_action",
|
|
125
|
-
actual_label_column_name="actual_action",
|
|
126
|
-
embedding_feature_column_names={
|
|
127
|
-
"image_embedding": px.EmbeddingColumnNames(
|
|
128
|
-
vector_column_name="image_vector",
|
|
129
|
-
link_to_data_column_name="url",
|
|
130
|
-
),
|
|
131
|
-
},
|
|
132
|
-
)
|
|
133
|
-
prod_schema = replace(train_schema, actual_label_column_name=None)
|
|
134
|
-
```
|
|
135
|
-
|
|
136
|
-
Define your production and training datasets.
|
|
137
|
-
|
|
138
|
-
```python
|
|
139
|
-
prod_ds = px.Dataset(prod_df, prod_schema)
|
|
140
|
-
train_ds = px.Dataset(train_df, train_schema)
|
|
141
|
-
```
|
|
142
|
-
|
|
143
|
-
Launch the app.
|
|
144
|
-
|
|
145
|
-
```python
|
|
146
|
-
session = px.launch_app(prod_ds, train_ds)
|
|
147
|
-
```
|
|
148
|
-
|
|
149
|
-
You can open Phoenix by copying and pasting the output of `session.url` into a new browser tab.
|
|
150
|
-
|
|
151
|
-
```python
|
|
152
|
-
session.url
|
|
153
|
-
```
|
|
154
|
-
|
|
155
|
-
Alternatively, you can open the Phoenix UI in your notebook with
|
|
156
|
-
|
|
157
|
-
```python
|
|
158
|
-
session.view()
|
|
159
|
-
```
|
|
160
|
-
|
|
161
|
-
When you're done, don't forget to close the app.
|
|
162
|
-
|
|
163
|
-
```python
|
|
164
|
-
px.close_app()
|
|
165
|
-
```
|
|
166
|
-
|
|
167
|
-
## Features
|
|
168
|
-
|
|
169
|
-
### Embedding Drift Analysis
|
|
170
|
-
|
|
171
|
-
Explore UMAP point-clouds at times of high euclidean distance and identify clusters of drift.
|
|
172
|
-
|
|
173
|
-
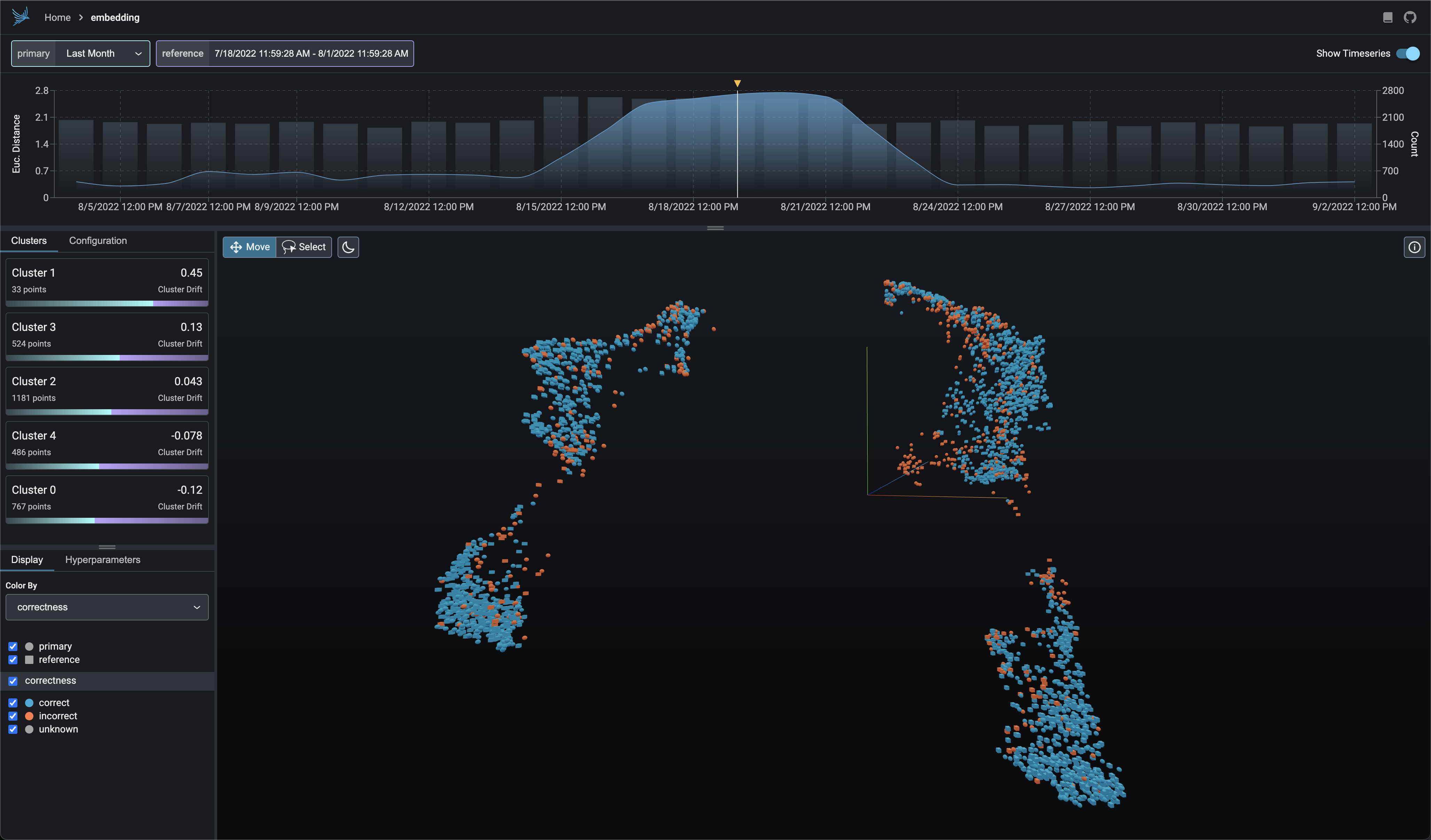
|
|
174
|
-
|
|
175
|
-
### UMAP-based Exploratory Data Analysis
|
|
176
|
-
|
|
177
|
-
Color your UMAP point-clouds by your model's dimensions, drift, and performance to identify problematic cohorts.
|
|
178
|
-
|
|
179
|
-
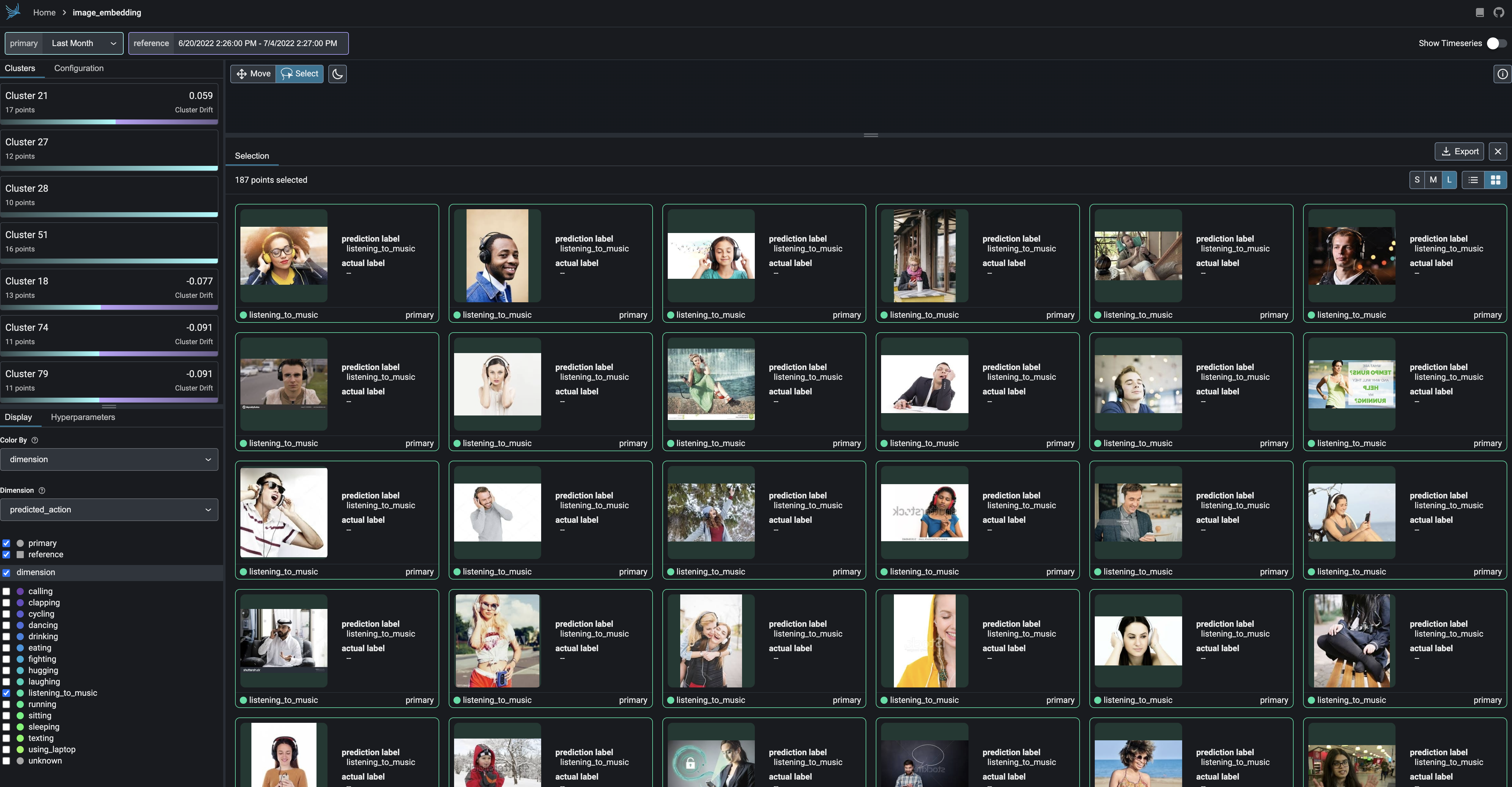
|
|
180
|
-
|
|
181
|
-
### Cluster-driven Drift and Performance Analysis
|
|
182
|
-
|
|
183
|
-
Break-apart your data into clusters of high drift or bad performance using HDBSCAN
|
|
184
|
-
|
|
185
|
-
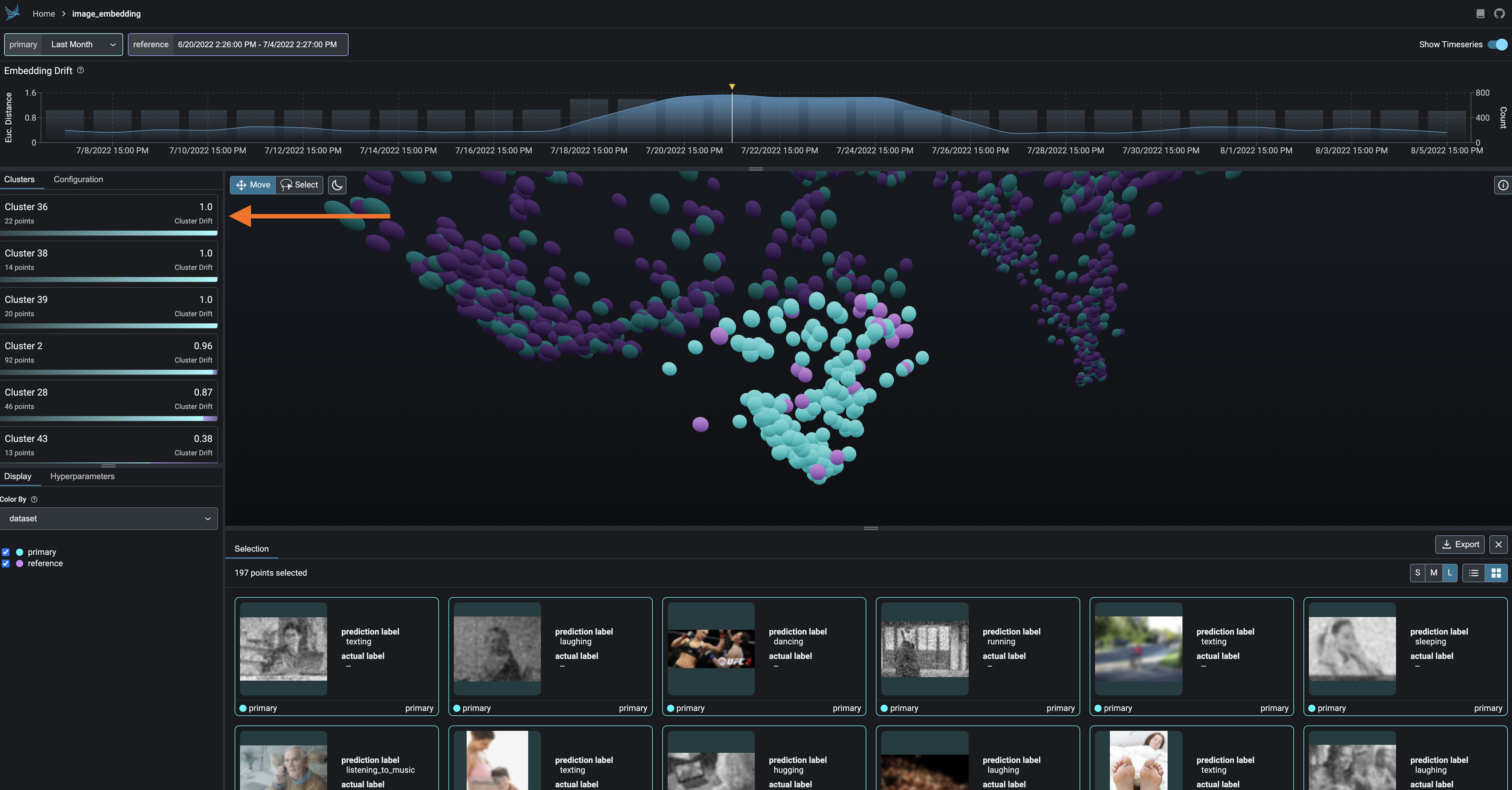
|
|
186
|
-
|
|
187
|
-
### Exportable Clusters
|
|
188
|
-
|
|
189
|
-
Export your clusters to `parquet` files or dataframes for further analysis and fine-tuning.
|
|
190
|
-
|
|
191
|
-
## Documentation
|
|
192
|
-
|
|
193
|
-
For in-depth examples and explanations, read the [docs](https://docs.arize.com/phoenix).
|
|
194
|
-
|
|
195
|
-
## Community
|
|
196
|
-
|
|
197
|
-
Join our community to connect with thousands of machine learning practitioners and ML observability enthusiasts.
|
|
198
|
-
|
|
199
|
-
- 🌍 Join our [Slack community](https://join.slack.com/t/arize-ai/shared_invite/zt-1px8dcmlf-fmThhDFD_V_48oU7ALan4Q).
|
|
200
|
-
- 💡 Ask questions and provide feedback in the _#phoenix-support_ channel.
|
|
201
|
-
- 🌟 Leave a star on our [GitHub](https://github.com/Arize-ai/phoenix).
|
|
202
|
-
- 🐞 Report bugs with [GitHub Issues](https://github.com/Arize-ai/phoenix/issues).
|
|
203
|
-
- 🐣 Follow us on [twitter](https://twitter.com/ArizePhoenix).
|
|
204
|
-
- 💌️ Sign up for our [mailing list](https://phoenix.arize.com/#updates).
|
|
205
|
-
- 🗺️ Check out our [roadmap](https://github.com/orgs/Arize-ai/projects/45) to see where we're heading next.
|
|
206
|
-
- 🎓 Learn the fundamentals of ML observability with our [introductory](https://arize.com/ml-observability-fundamentals/) and [advanced](https://arize.com/blog-course/) courses.
|
|
207
|
-
|
|
208
|
-
## Thanks
|
|
209
|
-
|
|
210
|
-
- [UMAP](https://github.com/lmcinnes/umap) For unlocking the ability to visualize and reason about embeddings
|
|
211
|
-
- [HDBSCAN](https://github.com/scikit-learn-contrib/hdbscan) For providing a clustering algorithm to aid in the discovery of drift and performance degradation
|
|
212
|
-
|
|
213
|
-
## Copyright, Patent, and License
|
|
214
|
-
|
|
215
|
-
Copyright 2023 Arize AI, Inc. All Rights Reserved.
|
|
216
|
-
|
|
217
|
-
Portions of this code are patent protected by one or more U.S. Patents. See [IP_NOTICE](https://github.com/Arize-ai/phoenix/blob/main/IP_NOTICE).
|
|
218
|
-
|
|
219
|
-
This software is licensed under the terms of the Elastic License 2.0 (ELv2). See [LICENSE](https://github.com/Arize-ai/phoenix/blob/main/LICENSE).
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|