active-vision 0.3.0__py3-none-any.whl → 0.4.1__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- active_vision/__init__.py +1 -1
- active_vision/core.py +364 -74
- {active_vision-0.3.0.dist-info → active_vision-0.4.1.dist-info}/METADATA +78 -30
- active_vision-0.4.1.dist-info/RECORD +6 -0
- {active_vision-0.3.0.dist-info → active_vision-0.4.1.dist-info}/WHEEL +1 -2
- active_vision-0.3.0.dist-info/RECORD +0 -7
- active_vision-0.3.0.dist-info/top_level.txt +0 -1
- {active_vision-0.3.0.dist-info → active_vision-0.4.1.dist-info/licenses}/LICENSE +0 -0
active_vision/__init__.py
CHANGED
active_vision/core.py
CHANGED
|
@@ -1,14 +1,29 @@
|
|
|
1
|
-
import pandas as pd
|
|
2
|
-
from loguru import logger
|
|
3
|
-
from fastai.vision.all import *
|
|
4
|
-
import torch
|
|
5
|
-
import numpy as np
|
|
6
1
|
import bisect
|
|
7
|
-
|
|
2
|
+
import os
|
|
8
3
|
import warnings
|
|
9
4
|
from typing import Callable
|
|
10
5
|
|
|
6
|
+
import numpy as np
|
|
7
|
+
import pandas as pd
|
|
8
|
+
import torch
|
|
9
|
+
import torch.nn.functional as F
|
|
10
|
+
from fastai.vision.all import (
|
|
11
|
+
CrossEntropyLossFlat,
|
|
12
|
+
ImageDataLoaders,
|
|
13
|
+
Resize,
|
|
14
|
+
ShowGraphCallback,
|
|
15
|
+
accuracy,
|
|
16
|
+
load_learner,
|
|
17
|
+
minimum,
|
|
18
|
+
slide,
|
|
19
|
+
steep,
|
|
20
|
+
valley,
|
|
21
|
+
vision_learner,
|
|
22
|
+
)
|
|
23
|
+
from loguru import logger
|
|
24
|
+
|
|
11
25
|
warnings.filterwarnings("ignore", category=FutureWarning)
|
|
26
|
+
pd.set_option("display.max_colwidth", 50)
|
|
12
27
|
|
|
13
28
|
|
|
14
29
|
class ActiveLearner:
|
|
@@ -33,17 +48,61 @@ class ActiveLearner:
|
|
|
33
48
|
eval_df (pd.DataFrame): Predictions on evaluation data
|
|
34
49
|
"""
|
|
35
50
|
|
|
36
|
-
def __init__(self,
|
|
37
|
-
self.
|
|
51
|
+
def __init__(self, name: str):
|
|
52
|
+
self.name = name
|
|
53
|
+
self.model = None
|
|
54
|
+
self.callbacks = [ShowGraphCallback()]
|
|
55
|
+
self.loss_fn = CrossEntropyLossFlat()
|
|
38
56
|
|
|
39
|
-
def load_model(
|
|
40
|
-
|
|
41
|
-
|
|
42
|
-
|
|
57
|
+
def load_model(
|
|
58
|
+
self, model: str | Callable, pretrained: bool = True, device: str = None
|
|
59
|
+
):
|
|
60
|
+
self.model = model
|
|
61
|
+
self.device = self._detect_optimal_device() if device is None else device
|
|
62
|
+
self.pretrained = pretrained
|
|
43
63
|
|
|
44
|
-
if isinstance(
|
|
45
|
-
logger.info(
|
|
46
|
-
|
|
64
|
+
if isinstance(model, Callable):
|
|
65
|
+
logger.info(
|
|
66
|
+
f"Loading a {'pretrained ' if pretrained else 'non-pretrained '}fastai model `{model.__name__}` on `{self.device}`"
|
|
67
|
+
)
|
|
68
|
+
|
|
69
|
+
if isinstance(model, str):
|
|
70
|
+
logger.info(
|
|
71
|
+
f"Loading a {'pretrained ' if pretrained else 'non-pretrained '}timm model `{model}` on `{self.device}`"
|
|
72
|
+
)
|
|
73
|
+
|
|
74
|
+
def _detect_optimal_device(self):
|
|
75
|
+
"""Determine the appropriate device and return device type."""
|
|
76
|
+
cuda_available = torch.cuda.is_available()
|
|
77
|
+
mps_available = (
|
|
78
|
+
hasattr(torch.backends, "mps") and torch.backends.mps.is_available()
|
|
79
|
+
)
|
|
80
|
+
|
|
81
|
+
device = "cpu"
|
|
82
|
+
if cuda_available:
|
|
83
|
+
device = "cuda"
|
|
84
|
+
logger.info("CUDA GPU detected - will load model on GPU")
|
|
85
|
+
elif mps_available:
|
|
86
|
+
device = "mps"
|
|
87
|
+
logger.info("Apple Silicon GPU detected - will load model on MPS")
|
|
88
|
+
else:
|
|
89
|
+
logger.info("No GPU detected - will load model on CPU")
|
|
90
|
+
|
|
91
|
+
return device
|
|
92
|
+
|
|
93
|
+
def _optimize_learner(self, device):
|
|
94
|
+
"""Apply optimization settings to learner based on device."""
|
|
95
|
+
if device != "cpu":
|
|
96
|
+
self.learn.to_fp16()
|
|
97
|
+
logger.info("Enabled mixed precision training")
|
|
98
|
+
|
|
99
|
+
def _finalize_setup(self):
|
|
100
|
+
"""Set common attributes after learner creation."""
|
|
101
|
+
self.train_set = self.learn.dls.train_ds.items
|
|
102
|
+
self.valid_set = self.learn.dls.valid_ds.items
|
|
103
|
+
self.class_names = self.dls.vocab
|
|
104
|
+
self.num_classes = self.dls.c
|
|
105
|
+
logger.info("Done. Ready to train.")
|
|
47
106
|
|
|
48
107
|
def load_dataset(
|
|
49
108
|
self,
|
|
@@ -54,14 +113,23 @@ class ActiveLearner:
|
|
|
54
113
|
batch_size: int = 16,
|
|
55
114
|
image_size: int = 224,
|
|
56
115
|
batch_tfms: Callable = None,
|
|
116
|
+
seed: int = None,
|
|
57
117
|
learner_path: str = None,
|
|
58
118
|
):
|
|
59
|
-
logger.info(f"Loading dataset from {filepath_col} and {label_col}")
|
|
119
|
+
logger.info(f"Loading dataset from `{filepath_col}` and `{label_col}` columns")
|
|
120
|
+
self.image_size = image_size
|
|
121
|
+
self.batch_size = batch_size
|
|
122
|
+
self.seed = seed
|
|
123
|
+
self.eval_accuracy = None
|
|
124
|
+
self.train_accuracy = None
|
|
125
|
+
self.valid_accuracy = None
|
|
126
|
+
|
|
127
|
+
self.dataset = df
|
|
60
128
|
|
|
61
|
-
logger.info("Creating dataloaders")
|
|
62
129
|
self.dls = ImageDataLoaders.from_df(
|
|
63
130
|
df,
|
|
64
131
|
path=".",
|
|
132
|
+
seed=seed,
|
|
65
133
|
valid_pct=valid_pct,
|
|
66
134
|
fn_col=filepath_col,
|
|
67
135
|
label_col=label_col,
|
|
@@ -70,26 +138,37 @@ class ActiveLearner:
|
|
|
70
138
|
batch_tfms=batch_tfms,
|
|
71
139
|
)
|
|
72
140
|
|
|
73
|
-
if
|
|
74
|
-
logger.info(
|
|
75
|
-
|
|
76
|
-
|
|
77
|
-
|
|
141
|
+
if self.model is None:
|
|
142
|
+
logger.info(
|
|
143
|
+
"No model loaded, using a pretrained timm `resnet18`. Load a model by calling `load_model(model_name)`"
|
|
144
|
+
)
|
|
145
|
+
self.load_model("resnet18")
|
|
146
|
+
|
|
147
|
+
try:
|
|
148
|
+
if learner_path:
|
|
149
|
+
logger.info(f"Loading learner from {learner_path}")
|
|
150
|
+
self.learn = load_learner(learner_path, cpu=(self.device == "cpu"))
|
|
151
|
+
self.learn.dls = self.dls
|
|
78
152
|
else:
|
|
79
|
-
logger.info(
|
|
153
|
+
logger.info("Creating new learner")
|
|
154
|
+
self.learn = vision_learner(
|
|
155
|
+
self.dls,
|
|
156
|
+
self.model,
|
|
157
|
+
metrics=accuracy,
|
|
158
|
+
pretrained=self.pretrained,
|
|
159
|
+
cbs=self.callbacks,
|
|
160
|
+
loss_func=self.loss_fn,
|
|
161
|
+
)
|
|
80
162
|
|
|
81
|
-
self.
|
|
82
|
-
else:
|
|
83
|
-
logger.info("Creating learner")
|
|
84
|
-
self.learn = vision_learner(
|
|
85
|
-
self.dls, self.model, metrics=accuracy
|
|
86
|
-
).to_fp16()
|
|
163
|
+
self._optimize_learner(self.device)
|
|
87
164
|
|
|
88
|
-
|
|
89
|
-
|
|
90
|
-
|
|
91
|
-
|
|
92
|
-
|
|
165
|
+
except Exception as e:
|
|
166
|
+
action = "load" if learner_path else "create"
|
|
167
|
+
logger.error(f"Failed to {action} learner")
|
|
168
|
+
logger.exception(e)
|
|
169
|
+
raise RuntimeError(f"Failed to {action} learner: {str(e)}")
|
|
170
|
+
|
|
171
|
+
self._finalize_setup()
|
|
93
172
|
|
|
94
173
|
def show_batch(
|
|
95
174
|
self,
|
|
@@ -128,17 +207,24 @@ class ActiveLearner:
|
|
|
128
207
|
logger.info(f"Training head for {head_tuning_epochs} epochs")
|
|
129
208
|
logger.info(f"Training model end-to-end for {epochs} epochs")
|
|
130
209
|
logger.info(f"Learning rate: {lr} with one-cycle learning rate scheduler")
|
|
131
|
-
self.learn.fine_tune(
|
|
132
|
-
epochs, lr, freeze_epochs=head_tuning_epochs, cbs=[ShowGraphCallback()]
|
|
133
|
-
)
|
|
210
|
+
self.learn.fine_tune(epochs, lr, freeze_epochs=head_tuning_epochs)
|
|
134
211
|
|
|
135
212
|
def predict(self, filepaths: list[str], batch_size: int = 16):
|
|
136
213
|
"""
|
|
137
214
|
Run inference on an unlabeled dataset. Returns a df with filepaths and predicted labels, and confidence scores.
|
|
138
215
|
"""
|
|
139
216
|
logger.info(f"Running inference on {len(filepaths)} samples")
|
|
217
|
+
|
|
140
218
|
test_dl = self.dls.test_dl(filepaths, bs=batch_size)
|
|
141
219
|
|
|
220
|
+
all_features = []
|
|
221
|
+
|
|
222
|
+
def hook_fn(module, input, output):
|
|
223
|
+
all_features.append(output.detach().cpu())
|
|
224
|
+
|
|
225
|
+
penultimate_layer = self.learn.model[1][4]
|
|
226
|
+
handle = penultimate_layer.register_forward_hook(hook_fn)
|
|
227
|
+
|
|
142
228
|
def identity(x):
|
|
143
229
|
return x
|
|
144
230
|
|
|
@@ -146,6 +232,9 @@ class ActiveLearner:
|
|
|
146
232
|
dl=test_dl, with_decoded=True, act=identity
|
|
147
233
|
)
|
|
148
234
|
|
|
235
|
+
handle.remove()
|
|
236
|
+
features = torch.cat(all_features)
|
|
237
|
+
|
|
149
238
|
self.pred_df = pd.DataFrame(
|
|
150
239
|
{
|
|
151
240
|
"filepath": filepaths,
|
|
@@ -153,9 +242,21 @@ class ActiveLearner:
|
|
|
153
242
|
"pred_conf": torch.max(F.softmax(logits, dim=1), dim=1)[0].numpy(),
|
|
154
243
|
"probs": F.softmax(logits, dim=1).numpy().tolist(),
|
|
155
244
|
"logits": logits.numpy().tolist(),
|
|
245
|
+
"embeddings": features.numpy().tolist(),
|
|
156
246
|
}
|
|
157
247
|
)
|
|
158
248
|
|
|
249
|
+
self.pred_df["pred_conf"] = self.pred_df["pred_conf"].round(4)
|
|
250
|
+
self.pred_df["probs"] = self.pred_df["probs"].apply(
|
|
251
|
+
lambda x: [round(p, 4) for p in x]
|
|
252
|
+
)
|
|
253
|
+
self.pred_df["logits"] = self.pred_df["logits"].apply(
|
|
254
|
+
lambda x: [round(l, 4) for l in x]
|
|
255
|
+
)
|
|
256
|
+
self.pred_df["embeddings"] = self.pred_df["embeddings"].apply(
|
|
257
|
+
lambda x: [round(e, 4) for e in x]
|
|
258
|
+
)
|
|
259
|
+
|
|
159
260
|
return self.pred_df
|
|
160
261
|
|
|
161
262
|
def evaluate(
|
|
@@ -180,6 +281,7 @@ class ActiveLearner:
|
|
|
180
281
|
)
|
|
181
282
|
|
|
182
283
|
accuracy = float((self.eval_df["label"] == self.eval_df["pred_label"]).mean())
|
|
284
|
+
self.eval_accuracy = accuracy
|
|
183
285
|
logger.info(f"Accuracy: {accuracy:.2%}")
|
|
184
286
|
return accuracy
|
|
185
287
|
|
|
@@ -197,7 +299,7 @@ class ActiveLearner:
|
|
|
197
299
|
"""
|
|
198
300
|
|
|
199
301
|
# Remove samples that is already in the training set
|
|
200
|
-
df = df[~df["filepath"].isin(self.
|
|
302
|
+
df = df[~df["filepath"].isin(self.dataset["filepath"])].copy()
|
|
201
303
|
|
|
202
304
|
if strategy == "least-confidence":
|
|
203
305
|
logger.info(
|
|
@@ -206,6 +308,7 @@ class ActiveLearner:
|
|
|
206
308
|
df.loc[:, "score"] = 1 - (df["pred_conf"]) / (
|
|
207
309
|
self.num_classes - (self.num_classes - 1)
|
|
208
310
|
)
|
|
311
|
+
df.loc[:, "strategy"] = "least-confidence"
|
|
209
312
|
|
|
210
313
|
elif strategy == "margin-of-confidence":
|
|
211
314
|
logger.info(
|
|
@@ -219,6 +322,7 @@ class ActiveLearner:
|
|
|
219
322
|
df.loc[:, "score"] = df["probs"].apply(
|
|
220
323
|
lambda x: 1 - (np.sort(x)[-1] - np.sort(x)[-2])
|
|
221
324
|
)
|
|
325
|
+
df.loc[:, "strategy"] = "margin-of-confidence"
|
|
222
326
|
|
|
223
327
|
elif strategy == "ratio-of-confidence":
|
|
224
328
|
logger.info(
|
|
@@ -232,6 +336,7 @@ class ActiveLearner:
|
|
|
232
336
|
df.loc[:, "score"] = df["probs"].apply(
|
|
233
337
|
lambda x: np.sort(x)[-2] / np.sort(x)[-1]
|
|
234
338
|
)
|
|
339
|
+
df.loc[:, "strategy"] = "ratio-of-confidence"
|
|
235
340
|
|
|
236
341
|
elif strategy == "entropy":
|
|
237
342
|
logger.info(f"Using entropy strategy to get top {num_samples} samples")
|
|
@@ -241,15 +346,26 @@ class ActiveLearner:
|
|
|
241
346
|
|
|
242
347
|
# Normalize the uncertainty score to be between 0 and 1 by dividing by log2 of the number of classes
|
|
243
348
|
df.loc[:, "score"] = df["score"] / np.log2(self.num_classes)
|
|
349
|
+
df.loc[:, "strategy"] = "entropy"
|
|
244
350
|
|
|
245
351
|
else:
|
|
246
352
|
logger.error(f"Unknown strategy: {strategy}")
|
|
247
353
|
raise ValueError(f"Unknown strategy: {strategy}")
|
|
248
354
|
|
|
249
|
-
df = df[
|
|
355
|
+
df = df[
|
|
356
|
+
[
|
|
357
|
+
"filepath",
|
|
358
|
+
"strategy",
|
|
359
|
+
"score",
|
|
360
|
+
"pred_label",
|
|
361
|
+
"pred_conf",
|
|
362
|
+
"probs",
|
|
363
|
+
"logits",
|
|
364
|
+
"embeddings",
|
|
365
|
+
]
|
|
366
|
+
]
|
|
250
367
|
|
|
251
|
-
df["score"] = df["score"].
|
|
252
|
-
df["pred_conf"] = df["pred_conf"].map("{:.4f}".format)
|
|
368
|
+
df["score"] = df["score"].round(4)
|
|
253
369
|
|
|
254
370
|
return df.sort_values(by="score", ascending=False).head(num_samples)
|
|
255
371
|
|
|
@@ -266,7 +382,7 @@ class ActiveLearner:
|
|
|
266
382
|
|
|
267
383
|
"""
|
|
268
384
|
# Remove samples that is already in the training set
|
|
269
|
-
df = df[~df["filepath"].isin(self.
|
|
385
|
+
df = df[~df["filepath"].isin(self.dataset["filepath"])].copy()
|
|
270
386
|
|
|
271
387
|
if strategy == "model-based-outlier":
|
|
272
388
|
logger.info(
|
|
@@ -286,7 +402,8 @@ class ActiveLearner:
|
|
|
286
402
|
]
|
|
287
403
|
|
|
288
404
|
# Get the logits for the unlabeled set
|
|
289
|
-
unlabeled_set_preds = self.predict(df["filepath"].tolist())
|
|
405
|
+
# unlabeled_set_preds = self.predict(df["filepath"].tolist())
|
|
406
|
+
unlabeled_set_preds = df
|
|
290
407
|
|
|
291
408
|
# For each element in the unlabeled set logits, compare it to the validation set ranked logits and get the position in the ranked logits
|
|
292
409
|
unlabeled_set_logits = []
|
|
@@ -312,26 +429,159 @@ class ActiveLearner:
|
|
|
312
429
|
|
|
313
430
|
# Add outlier scores to dataframe
|
|
314
431
|
df.loc[:, "score"] = unlabeled_set_logits
|
|
432
|
+
df.loc[:, "strategy"] = "model-based-outlier"
|
|
433
|
+
df = df[
|
|
434
|
+
[
|
|
435
|
+
"filepath",
|
|
436
|
+
"strategy",
|
|
437
|
+
"score",
|
|
438
|
+
"pred_label",
|
|
439
|
+
"pred_conf",
|
|
440
|
+
"probs",
|
|
441
|
+
"logits",
|
|
442
|
+
"embeddings",
|
|
443
|
+
]
|
|
444
|
+
]
|
|
315
445
|
|
|
316
|
-
df = df[
|
|
317
|
-
|
|
318
|
-
df["score"] = df["score"].map("{:.4f}".format)
|
|
319
|
-
df["pred_conf"] = df["pred_conf"].map("{:.4f}".format)
|
|
446
|
+
df["score"] = df["score"].round(4)
|
|
320
447
|
|
|
321
448
|
# Sort by score ascending higher rank = more outlier-like compared to the validation set
|
|
322
449
|
return df.sort_values(by="score", ascending=False).head(num_samples)
|
|
323
450
|
|
|
451
|
+
else:
|
|
452
|
+
logger.error(f"Unknown strategy: {strategy}")
|
|
453
|
+
raise ValueError(f"Unknown strategy: {strategy}")
|
|
454
|
+
|
|
324
455
|
def sample_random(self, df: pd.DataFrame, num_samples: int, seed: int = None):
|
|
325
456
|
"""
|
|
326
457
|
Sample `num_samples` random samples. Returns a df with filepaths and predicted labels, and confidence scores.
|
|
327
458
|
"""
|
|
328
459
|
|
|
329
460
|
logger.info(f"Sampling {num_samples} random samples")
|
|
461
|
+
df = df[~df["filepath"].isin(self.dataset["filepath"])].copy()
|
|
462
|
+
df["strategy"] = "random"
|
|
463
|
+
df["score"] = 0.0
|
|
464
|
+
|
|
330
465
|
if seed is not None:
|
|
331
466
|
logger.info(f"Using seed: {seed}")
|
|
332
467
|
return df.sample(n=num_samples, random_state=seed)
|
|
333
468
|
|
|
334
|
-
def
|
|
469
|
+
def sample_combination(self, df: pd.DataFrame, num_samples: int, combination: dict):
|
|
470
|
+
"""
|
|
471
|
+
Sample samples based on a combination of strategies.
|
|
472
|
+
|
|
473
|
+
Args:
|
|
474
|
+
df: DataFrame with filepaths and predicted labels, and confidence scores
|
|
475
|
+
num_samples: Total number of samples to select
|
|
476
|
+
combination: Dictionary mapping strategy names to proportions, e.g.:
|
|
477
|
+
{
|
|
478
|
+
"least-confidence": 0.4,
|
|
479
|
+
"model-based-outlier": 0.6
|
|
480
|
+
}
|
|
481
|
+
|
|
482
|
+
Supported strategies:
|
|
483
|
+
Uncertainty-based:
|
|
484
|
+
- least-confidence
|
|
485
|
+
- margin-of-confidence
|
|
486
|
+
- ratio-of-confidence
|
|
487
|
+
- entropy
|
|
488
|
+
Diversity-based:
|
|
489
|
+
- model-based-outlier
|
|
490
|
+
- cluster-based
|
|
491
|
+
- representative
|
|
492
|
+
Other:
|
|
493
|
+
- random
|
|
494
|
+
|
|
495
|
+
Returns:
|
|
496
|
+
DataFrame containing the combined samples
|
|
497
|
+
"""
|
|
498
|
+
logger.info(f"Using combination sampling to get {num_samples} samples")
|
|
499
|
+
|
|
500
|
+
# Validate total proportions sum to 1
|
|
501
|
+
if not np.isclose(sum(combination.values()), 1.0):
|
|
502
|
+
raise ValueError(
|
|
503
|
+
f"Proportions must sum to 1, got {sum(combination.values())}"
|
|
504
|
+
)
|
|
505
|
+
|
|
506
|
+
# Calculate samples per strategy and handle rounding
|
|
507
|
+
samples_per_strategy = {
|
|
508
|
+
strategy: int(proportion * num_samples)
|
|
509
|
+
for strategy, proportion in combination.items()
|
|
510
|
+
}
|
|
511
|
+
|
|
512
|
+
# Add any remaining samples to the first strategy
|
|
513
|
+
remaining = num_samples - sum(samples_per_strategy.values())
|
|
514
|
+
if remaining > 0:
|
|
515
|
+
first_strategy = list(combination.keys())[0]
|
|
516
|
+
samples_per_strategy[first_strategy] += remaining
|
|
517
|
+
|
|
518
|
+
# Get samples for each strategy
|
|
519
|
+
sampled_dfs = []
|
|
520
|
+
for strategy, n_samples in samples_per_strategy.items():
|
|
521
|
+
if n_samples == 0:
|
|
522
|
+
continue
|
|
523
|
+
|
|
524
|
+
if strategy in [
|
|
525
|
+
"least-confidence",
|
|
526
|
+
"margin-of-confidence",
|
|
527
|
+
"ratio-of-confidence",
|
|
528
|
+
"entropy",
|
|
529
|
+
]:
|
|
530
|
+
strategy_df = self.sample_uncertain(
|
|
531
|
+
df=df, num_samples=n_samples, strategy=strategy
|
|
532
|
+
)
|
|
533
|
+
elif strategy in ["model-based-outlier", "cluster-based", "representative"]:
|
|
534
|
+
strategy_df = self.sample_diverse(
|
|
535
|
+
df=df, num_samples=n_samples, strategy=strategy
|
|
536
|
+
)
|
|
537
|
+
elif strategy == "random":
|
|
538
|
+
strategy_df = self.sample_random(df=df, num_samples=n_samples)
|
|
539
|
+
else:
|
|
540
|
+
raise ValueError(f"Unknown strategy: {strategy}")
|
|
541
|
+
|
|
542
|
+
sampled_dfs.append(strategy_df)
|
|
543
|
+
# Remove selected samples from the pool to avoid duplicates
|
|
544
|
+
df = df[~df["filepath"].isin(strategy_df["filepath"])]
|
|
545
|
+
|
|
546
|
+
return pd.concat(sampled_dfs, ignore_index=True)
|
|
547
|
+
|
|
548
|
+
def summary(self, filename: str = None, show: bool = True):
|
|
549
|
+
results_df = pd.DataFrame(
|
|
550
|
+
{
|
|
551
|
+
"name": [self.name],
|
|
552
|
+
"accuracy": [self.eval_accuracy],
|
|
553
|
+
"train_set_size": [len(self.train_set)],
|
|
554
|
+
"valid_set_size": [len(self.valid_set)],
|
|
555
|
+
"dataset_size": [len(self.train_set) + len(self.valid_set)],
|
|
556
|
+
"num_classes": [self.num_classes],
|
|
557
|
+
"model": [self.model],
|
|
558
|
+
"pretrained": [self.pretrained],
|
|
559
|
+
"loss_fn": [str(self.loss_fn)],
|
|
560
|
+
"device": [self.device],
|
|
561
|
+
"seed": [self.seed],
|
|
562
|
+
"batch_size": [self.batch_size],
|
|
563
|
+
"image_size": [self.image_size],
|
|
564
|
+
}
|
|
565
|
+
)
|
|
566
|
+
|
|
567
|
+
if filename is None:
|
|
568
|
+
# Generate filename with timestamp, accuracy and dataset size
|
|
569
|
+
from datetime import datetime
|
|
570
|
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
|
571
|
+
accuracy_str = f"{self.eval_accuracy:.2%}" if self.eval_accuracy is not None else "no_eval"
|
|
572
|
+
dataset_size = len(self.train_set) + len(self.valid_set)
|
|
573
|
+
filename = f"{self.name}_{timestamp}_acc_{accuracy_str}_n_{dataset_size}.parquet"
|
|
574
|
+
elif not filename.endswith(".parquet"):
|
|
575
|
+
filename = f"{filename}.parquet"
|
|
576
|
+
|
|
577
|
+
results_df.to_parquet(filename)
|
|
578
|
+
logger.info(f"Saved results to {filename}")
|
|
579
|
+
if show:
|
|
580
|
+
return results_df
|
|
581
|
+
else:
|
|
582
|
+
return None
|
|
583
|
+
|
|
584
|
+
def label(self, df: pd.DataFrame, output_filename: str):
|
|
335
585
|
"""
|
|
336
586
|
Launch a labeling interface for the user to label the samples.
|
|
337
587
|
Input is a df with filepaths listing the files to be labeled. Output is a df with filepaths and labels.
|
|
@@ -378,6 +628,10 @@ class ActiveLearner:
|
|
|
378
628
|
|
|
379
629
|
# Add bar plot with top 5 predictions
|
|
380
630
|
with gr.Column():
|
|
631
|
+
filename = gr.Textbox(
|
|
632
|
+
label="Filename", value=filepaths[0], interactive=False
|
|
633
|
+
)
|
|
634
|
+
|
|
381
635
|
pred_plot = gr.BarPlot(
|
|
382
636
|
x="probability",
|
|
383
637
|
y="class",
|
|
@@ -393,9 +647,6 @@ class ActiveLearner:
|
|
|
393
647
|
).nlargest(5, "probability"),
|
|
394
648
|
)
|
|
395
649
|
|
|
396
|
-
filename = gr.Textbox(
|
|
397
|
-
label="Filename", value=filepaths[0], interactive=False
|
|
398
|
-
)
|
|
399
650
|
with gr.Row():
|
|
400
651
|
pred_label = gr.Textbox(
|
|
401
652
|
label="Predicted Label",
|
|
@@ -405,21 +656,33 @@ class ActiveLearner:
|
|
|
405
656
|
interactive=False,
|
|
406
657
|
)
|
|
407
658
|
|
|
659
|
+
def format_for_display(value):
|
|
660
|
+
return f"{value:.4f}" if pd.notnull(value) else ""
|
|
661
|
+
|
|
408
662
|
pred_conf = gr.Textbox(
|
|
409
663
|
label="Confidence",
|
|
410
|
-
value=df["pred_conf"].iloc[0]
|
|
664
|
+
value=format_for_display(df["pred_conf"].iloc[0])
|
|
411
665
|
if "pred_conf" in df.columns
|
|
412
666
|
else "",
|
|
413
667
|
interactive=False,
|
|
414
668
|
)
|
|
415
669
|
|
|
416
|
-
|
|
417
|
-
|
|
418
|
-
|
|
419
|
-
|
|
420
|
-
|
|
421
|
-
|
|
422
|
-
|
|
670
|
+
with gr.Row():
|
|
671
|
+
strategy = gr.Textbox(
|
|
672
|
+
label="Sampling Strategy",
|
|
673
|
+
value=df["strategy"].iloc[0]
|
|
674
|
+
if "strategy" in df.columns
|
|
675
|
+
else "",
|
|
676
|
+
interactive=False,
|
|
677
|
+
)
|
|
678
|
+
|
|
679
|
+
sample_score = gr.Textbox(
|
|
680
|
+
label="Score",
|
|
681
|
+
value=format_for_display(df["score"].iloc[0])
|
|
682
|
+
if "score" in df.columns
|
|
683
|
+
else "",
|
|
684
|
+
interactive=False,
|
|
685
|
+
)
|
|
423
686
|
|
|
424
687
|
category = gr.Radio(
|
|
425
688
|
choices=self.class_names,
|
|
@@ -461,6 +724,7 @@ class ActiveLearner:
|
|
|
461
724
|
progress,
|
|
462
725
|
pred_plot,
|
|
463
726
|
sample_score,
|
|
727
|
+
strategy,
|
|
464
728
|
],
|
|
465
729
|
)
|
|
466
730
|
|
|
@@ -574,6 +838,9 @@ class ActiveLearner:
|
|
|
574
838
|
next_idx,
|
|
575
839
|
plot_data,
|
|
576
840
|
df["score"].iloc[next_idx] if "score" in df.columns else "",
|
|
841
|
+
df["strategy"].iloc[next_idx]
|
|
842
|
+
if "strategy" in df.columns
|
|
843
|
+
else "",
|
|
577
844
|
)
|
|
578
845
|
plot_data = (
|
|
579
846
|
None
|
|
@@ -601,6 +868,9 @@ class ActiveLearner:
|
|
|
601
868
|
current_idx,
|
|
602
869
|
plot_data,
|
|
603
870
|
df["score"].iloc[current_idx] if "score" in df.columns else "",
|
|
871
|
+
df["strategy"].iloc[current_idx]
|
|
872
|
+
if "strategy" in df.columns
|
|
873
|
+
else "",
|
|
604
874
|
)
|
|
605
875
|
|
|
606
876
|
def save_and_next(current_idx, selected_category):
|
|
@@ -634,6 +904,9 @@ class ActiveLearner:
|
|
|
634
904
|
current_idx,
|
|
635
905
|
plot_data,
|
|
636
906
|
df["score"].iloc[current_idx] if "score" in df.columns else "",
|
|
907
|
+
df["strategy"].iloc[current_idx]
|
|
908
|
+
if "strategy" in df.columns
|
|
909
|
+
else "",
|
|
637
910
|
)
|
|
638
911
|
|
|
639
912
|
# Save the current annotation
|
|
@@ -669,6 +942,9 @@ class ActiveLearner:
|
|
|
669
942
|
current_idx,
|
|
670
943
|
plot_data,
|
|
671
944
|
df["score"].iloc[current_idx] if "score" in df.columns else "",
|
|
945
|
+
df["strategy"].iloc[current_idx]
|
|
946
|
+
if "strategy" in df.columns
|
|
947
|
+
else "",
|
|
672
948
|
)
|
|
673
949
|
|
|
674
950
|
plot_data = (
|
|
@@ -695,15 +971,27 @@ class ActiveLearner:
|
|
|
695
971
|
next_idx,
|
|
696
972
|
plot_data,
|
|
697
973
|
df["score"].iloc[next_idx] if "score" in df.columns else "",
|
|
974
|
+
df["strategy"].iloc[next_idx] if "strategy" in df.columns else "",
|
|
698
975
|
)
|
|
699
976
|
|
|
700
977
|
def convert_csv_to_parquet():
|
|
701
978
|
try:
|
|
702
|
-
|
|
979
|
+
csv_path = f"{output_filename}.csv"
|
|
980
|
+
parquet_path = (
|
|
981
|
+
f"{output_filename}.parquet"
|
|
982
|
+
if not output_filename.endswith(".parquet")
|
|
983
|
+
else output_filename
|
|
984
|
+
)
|
|
985
|
+
|
|
986
|
+
df = pd.read_csv(csv_path, header=None)
|
|
703
987
|
df.columns = ["filepath", "label"]
|
|
704
988
|
df = df.drop_duplicates(subset=["filepath"], keep="last")
|
|
705
|
-
df.
|
|
706
|
-
|
|
989
|
+
df.reset_index(drop=True, inplace=True)
|
|
990
|
+
df.to_parquet(parquet_path)
|
|
991
|
+
gr.Info(f"Annotation saved to {parquet_path}")
|
|
992
|
+
|
|
993
|
+
# remove csv file
|
|
994
|
+
os.remove(csv_path)
|
|
707
995
|
except Exception as e:
|
|
708
996
|
logger.error(e)
|
|
709
997
|
return
|
|
@@ -721,6 +1009,7 @@ class ActiveLearner:
|
|
|
721
1009
|
progress,
|
|
722
1010
|
pred_plot,
|
|
723
1011
|
sample_score,
|
|
1012
|
+
strategy,
|
|
724
1013
|
],
|
|
725
1014
|
)
|
|
726
1015
|
|
|
@@ -737,6 +1026,7 @@ class ActiveLearner:
|
|
|
737
1026
|
progress,
|
|
738
1027
|
pred_plot,
|
|
739
1028
|
sample_score,
|
|
1029
|
+
strategy,
|
|
740
1030
|
],
|
|
741
1031
|
)
|
|
742
1032
|
|
|
@@ -753,6 +1043,7 @@ class ActiveLearner:
|
|
|
753
1043
|
progress,
|
|
754
1044
|
pred_plot,
|
|
755
1045
|
sample_score,
|
|
1046
|
+
strategy,
|
|
756
1047
|
],
|
|
757
1048
|
)
|
|
758
1049
|
|
|
@@ -760,19 +1051,18 @@ class ActiveLearner:
|
|
|
760
1051
|
|
|
761
1052
|
demo.launch(height=1000)
|
|
762
1053
|
|
|
763
|
-
def
|
|
1054
|
+
def add_to_dataset(self, labeled_df: pd.DataFrame, output_filename: str):
|
|
764
1055
|
"""
|
|
765
|
-
Add samples to the training
|
|
1056
|
+
Add samples to the dataset used for training - include train and validation sets.
|
|
766
1057
|
"""
|
|
767
|
-
|
|
768
|
-
|
|
769
|
-
logger.info(f"Adding {len(new_train_set)} samples to training set")
|
|
770
|
-
self.train_set = pd.concat([self.train_set, new_train_set])
|
|
1058
|
+
labeled_df = labeled_df.copy()
|
|
771
1059
|
|
|
772
|
-
|
|
773
|
-
|
|
774
|
-
)
|
|
775
|
-
self.
|
|
1060
|
+
logger.info(f"Adding {len(labeled_df)} samples to dataset")
|
|
1061
|
+
self.dataset = pd.concat([self.dataset, labeled_df])
|
|
1062
|
+
self.dataset = self.dataset.drop_duplicates(subset=["filepath"], keep="last")
|
|
1063
|
+
self.dataset.reset_index(drop=True, inplace=True)
|
|
776
1064
|
|
|
777
|
-
|
|
778
|
-
|
|
1065
|
+
if not output_filename.endswith(".parquet"):
|
|
1066
|
+
output_filename = f"{output_filename}.parquet"
|
|
1067
|
+
self.dataset.to_parquet(output_filename)
|
|
1068
|
+
logger.info(f"Saved dataset to {output_filename}")
|
|
@@ -1,10 +1,11 @@
|
|
|
1
|
-
Metadata-Version: 2.
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
2
|
Name: active-vision
|
|
3
|
-
Version: 0.
|
|
3
|
+
Version: 0.4.1
|
|
4
4
|
Summary: Active learning for computer vision.
|
|
5
|
-
|
|
6
|
-
|
|
5
|
+
Project-URL: Homepage, https://github.com/dnth/active-vision
|
|
6
|
+
Project-URL: Bug Tracker, https://github.com/dnth/active-vision/issues
|
|
7
7
|
License-File: LICENSE
|
|
8
|
+
Requires-Python: >=3.10
|
|
8
9
|
Requires-Dist: accelerate>=1.2.1
|
|
9
10
|
Requires-Dist: datasets>=3.2.0
|
|
10
11
|
Requires-Dist: fastai>=2.7.18
|
|
@@ -16,14 +17,57 @@ Requires-Dist: seaborn>=0.13.2
|
|
|
16
17
|
Requires-Dist: timm>=1.0.13
|
|
17
18
|
Requires-Dist: transformers>=4.48.0
|
|
18
19
|
Requires-Dist: xinfer>=0.3.2
|
|
20
|
+
Provides-Extra: dev
|
|
21
|
+
Requires-Dist: black>=22.0; extra == 'dev'
|
|
22
|
+
Requires-Dist: flake8>=4.0; extra == 'dev'
|
|
23
|
+
Requires-Dist: isort>=5.0; extra == 'dev'
|
|
24
|
+
Requires-Dist: pytest>=7.0; extra == 'dev'
|
|
25
|
+
Provides-Extra: docs
|
|
26
|
+
Requires-Dist: ansi2html; extra == 'docs'
|
|
27
|
+
Requires-Dist: ipykernel; extra == 'docs'
|
|
28
|
+
Requires-Dist: jupyter; extra == 'docs'
|
|
29
|
+
Requires-Dist: livereload; extra == 'docs'
|
|
30
|
+
Requires-Dist: mkdocs; extra == 'docs'
|
|
31
|
+
Requires-Dist: mkdocs-git-revision-date-localized-plugin; extra == 'docs'
|
|
32
|
+
Requires-Dist: mkdocs-git-revision-date-plugin; extra == 'docs'
|
|
33
|
+
Requires-Dist: mkdocs-jupyter>=0.24.0; extra == 'docs'
|
|
34
|
+
Requires-Dist: mkdocs-material>=9.1.3; extra == 'docs'
|
|
35
|
+
Requires-Dist: mkdocs-mermaid2-plugin; extra == 'docs'
|
|
36
|
+
Requires-Dist: mkdocs-pdf-export-plugin; extra == 'docs'
|
|
37
|
+
Requires-Dist: mkdocstrings; extra == 'docs'
|
|
38
|
+
Requires-Dist: mkdocstrings-crystal; extra == 'docs'
|
|
39
|
+
Requires-Dist: mkdocstrings-python-legacy; extra == 'docs'
|
|
40
|
+
Requires-Dist: nbconvert; extra == 'docs'
|
|
41
|
+
Requires-Dist: nbformat; extra == 'docs'
|
|
42
|
+
Requires-Dist: pygments; extra == 'docs'
|
|
43
|
+
Requires-Dist: pymdown-extensions; extra == 'docs'
|
|
44
|
+
Requires-Dist: sphinx; extra == 'docs'
|
|
45
|
+
Requires-Dist: watchdog; extra == 'docs'
|
|
46
|
+
Description-Content-Type: text/markdown
|
|
19
47
|
|
|
20
48
|
[](https://pypi.org/project/active-vision/)
|
|
21
49
|
[](https://pypi.org/project/active-vision/)
|
|
22
50
|
[](https://pypi.org/project/active-vision/)
|
|
23
51
|
[](https://github.com/dnth/active-vision/blob/main/LICENSE)
|
|
24
52
|
|
|
53
|
+
[colab_badge]: https://img.shields.io/badge/Open%20In-Colab-blue?style=for-the-badge&logo=google-colab
|
|
54
|
+
[kaggle_badge]: https://img.shields.io/badge/Open%20In-Kaggle-blue?style=for-the-badge&logo=kaggle
|
|
55
|
+
|
|
25
56
|
<p align="center">
|
|
26
57
|
<img src="https://raw.githubusercontent.com/dnth/active-vision/main/assets/logo.png" alt="active-vision">
|
|
58
|
+
<br />
|
|
59
|
+
<br />
|
|
60
|
+
<a href="https://dnth.github.io/active-vision" target="_blank" rel="noopener noreferrer"><strong>Explore the docs »</strong></a>
|
|
61
|
+
<br />
|
|
62
|
+
<a href="#️-quickstart" target="_blank" rel="noopener noreferrer">Quickstart</a>
|
|
63
|
+
·
|
|
64
|
+
<a href="https://github.com/dnth/active-vision/issues/new?assignees=&labels=Feature+Request&projects=&template=feature_request.md" target="_blank" rel="noopener noreferrer">Feature Request</a>
|
|
65
|
+
·
|
|
66
|
+
<a href="https://github.com/dnth/active-vision/issues/new?assignees=&labels=bug&projects=&template=bug_report.md" target="_blank" rel="noopener noreferrer">Report Bug</a>
|
|
67
|
+
·
|
|
68
|
+
<a href="https://github.com/dnth/active-vision/discussions" target="_blank" rel="noopener noreferrer">Discussions</a>
|
|
69
|
+
·
|
|
70
|
+
<a href="https://dicksonneoh.com/" target="_blank" rel="noopener noreferrer">About</a>
|
|
27
71
|
</p>
|
|
28
72
|
|
|
29
73
|
The goal of this project is to create a framework for the active learning loop for computer vision. The diagram below shows a general workflow of how the active learning loop works.
|
|
@@ -89,41 +133,52 @@ pip install -e .
|
|
|
89
133
|
> uv pip install active-vision
|
|
90
134
|
> ```
|
|
91
135
|
|
|
92
|
-
##
|
|
93
|
-
See the [notebook](./nbs/04_relabel_loop.ipynb) for a complete example.
|
|
136
|
+
## 🚀 Quickstart
|
|
94
137
|
|
|
95
|
-
|
|
96
|
-
|
|
97
|
-
- [Unlabeled samples](./nbs/unlabeled_samples.parquet): A dataframe of *unlabeled* images. We will continuously sample from this set using active learning strategies.
|
|
98
|
-
- [Evaluation samples](./nbs/evaluation_samples.parquet): A dataframe of *labeled* images. We will use this set to evaluate the performance of the model. This is the test set, DO NOT use it for active learning. Split this out in the beginning.
|
|
138
|
+
[![Open In Colab][colab_badge]](https://colab.research.google.com/github/dnth/active-vision/blob/main/nbs/imagenette/quickstart.ipynb)
|
|
139
|
+
[![Open In Kaggle][kaggle_badge]](https://kaggle.com/kernels/welcome?src=https://github.com/dnth/active-vision/blob/main/nbs/imagenette/quickstart.ipynb)
|
|
99
140
|
|
|
100
|
-
|
|
141
|
+
The following are code snippets for the active learning loop in active-vision. I recommend running the quickstart notebook in Colab or Kaggle to see the full workflow.
|
|
101
142
|
|
|
102
143
|
```python
|
|
103
144
|
from active_vision import ActiveLearner
|
|
104
|
-
import pandas as pd
|
|
105
145
|
|
|
106
|
-
# Create an active learner instance
|
|
107
|
-
al = ActiveLearner("
|
|
146
|
+
# Create an active learner instance
|
|
147
|
+
al = ActiveLearner(name="cycle-1")
|
|
148
|
+
|
|
149
|
+
# Load model
|
|
150
|
+
al.load_model(model="resnet18", pretrained=True)
|
|
108
151
|
|
|
109
152
|
# Load dataset
|
|
110
|
-
train_df =
|
|
111
|
-
al.load_dataset(df, filepath_col="filepath", label_col="label")
|
|
153
|
+
al.load_dataset(train_df, filepath_col="filepath", label_col="label", batch_size=8)
|
|
112
154
|
|
|
113
155
|
# Train model
|
|
114
|
-
al.train(epochs=
|
|
156
|
+
al.train(epochs=10, lr=5e-3)
|
|
115
157
|
|
|
116
158
|
# Evaluate the model on a *labeled* evaluation set
|
|
117
159
|
accuracy = al.evaluate(eval_df, filepath_col="filepath", label_col="label")
|
|
118
160
|
|
|
161
|
+
# Get summary of the active learning cycle
|
|
162
|
+
al.summary()
|
|
163
|
+
|
|
119
164
|
# Get predictions from an *unlabeled* set
|
|
120
165
|
pred_df = al.predict(filepaths)
|
|
121
166
|
|
|
122
|
-
# Sample
|
|
123
|
-
|
|
124
|
-
|
|
125
|
-
|
|
126
|
-
|
|
167
|
+
# Sample images using a combination of active learning strategies
|
|
168
|
+
samples = al.sample_combination(
|
|
169
|
+
pred_df,
|
|
170
|
+
num_samples=50,
|
|
171
|
+
combination={
|
|
172
|
+
"least-confidence": 0.4,
|
|
173
|
+
"ratio-of-confidence": 0.2,
|
|
174
|
+
"entropy": 0.2,
|
|
175
|
+
"model-based-outlier": 0.1,
|
|
176
|
+
"random": 0.1,
|
|
177
|
+
},
|
|
178
|
+
)
|
|
179
|
+
|
|
180
|
+
# Launch a Gradio UI to label the samples, save the labeled samples to a file
|
|
181
|
+
al.label(samples, output_filename="samples.parquet")
|
|
127
182
|
```
|
|
128
183
|
|
|
129
184
|
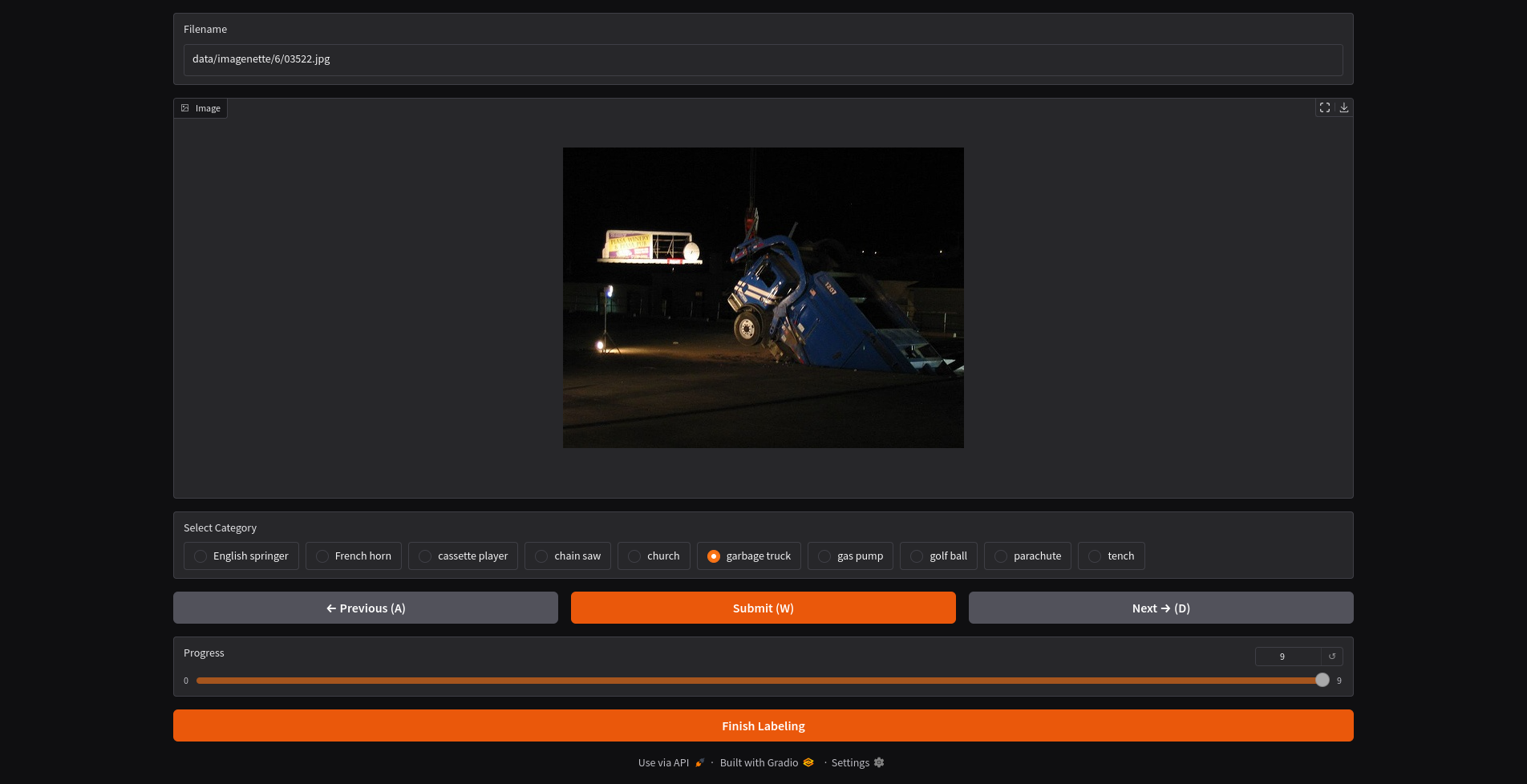
|
|
@@ -136,18 +191,11 @@ Once complete, the labeled samples will be save into a new df.
|
|
|
136
191
|
We can now add the newly labeled data to the training set.
|
|
137
192
|
|
|
138
193
|
```python
|
|
139
|
-
|
|
140
|
-
al.add_to_train_set(labeled_df, output_filename="active_labeled")
|
|
194
|
+
al.add_to_dataset(labeled_df, output_filename="active_labeled.parquet")
|
|
141
195
|
```
|
|
142
196
|
|
|
143
197
|
Repeat the process until the model is good enough. Use the dataset to train a larger model and deploy.
|
|
144
198
|
|
|
145
|
-
> [!TIP]
|
|
146
|
-
> For the toy dataset, I got to about 93% accuracy on the evaluation set with 200+ labeled images. The best performing model on the [leaderboard](https://github.com/fastai/imagenette) got 95.11% accuracy training on all 9469 labeled images.
|
|
147
|
-
>
|
|
148
|
-
> This took me about 6 iterations of relabeling. Each iteration took about 5 minutes to complete including labeling and model training (resnet18). See the [notebook](./nbs/04_relabel_loop.ipynb) for more details.
|
|
149
|
-
>
|
|
150
|
-
> But using the dataset of 200+ images, I trained a more capable model (convnext_small_in22k) and got 99.3% accuracy on the evaluation set. See the [notebook](./nbs/05_retrain_larger.ipynb) for more details.
|
|
151
199
|
|
|
152
200
|
|
|
153
201
|
## 📊 Benchmarks
|
|
@@ -0,0 +1,6 @@
|
|
|
1
|
+
active_vision/__init__.py,sha256=vauWDAlrr6fiIylIKSzErXOEopRtTsBk8G4hC9418M0,43
|
|
2
|
+
active_vision/core.py,sha256=ZDRylM3KsoLxy9qA9bld4WxzcKcyCwH8IJ1cFxtz5mE,41607
|
|
3
|
+
active_vision-0.4.1.dist-info/METADATA,sha256=LpgLc_E7jJVXxUHrIPv-1RZq_CEE3enyb0O2PDZMrJM,17262
|
|
4
|
+
active_vision-0.4.1.dist-info/WHEEL,sha256=qtCwoSJWgHk21S1Kb4ihdzI2rlJ1ZKaIurTj_ngOhyQ,87
|
|
5
|
+
active_vision-0.4.1.dist-info/licenses/LICENSE,sha256=xx0jnfkXJvxRnG63LTGOxlggYnIysveWIZ6H3PNdCrQ,11357
|
|
6
|
+
active_vision-0.4.1.dist-info/RECORD,,
|
|
@@ -1,7 +0,0 @@
|
|
|
1
|
-
active_vision/__init__.py,sha256=hbFzCBVh_5qm0XuZh_I07cRmmDZ_cDx5n-6mf-tFB6s,43
|
|
2
|
-
active_vision/core.py,sha256=8kYsA0cHNty1oOXg0yvvlT2Tau7m_AS9DJ7Sc0RB30k,31096
|
|
3
|
-
active_vision-0.3.0.dist-info/LICENSE,sha256=xx0jnfkXJvxRnG63LTGOxlggYnIysveWIZ6H3PNdCrQ,11357
|
|
4
|
-
active_vision-0.3.0.dist-info/METADATA,sha256=B8t28CcxeXFLAonjFV6zoVwAAOOR1mSn_YtJVEzKqcg,15710
|
|
5
|
-
active_vision-0.3.0.dist-info/WHEEL,sha256=In9FTNxeP60KnTkGw7wk6mJPYd_dQSjEZmXdBdMCI-8,91
|
|
6
|
-
active_vision-0.3.0.dist-info/top_level.txt,sha256=7qUQvccN2UU63z5S9vrgJmqK-8sFGrtpf1e9Z86nihE,14
|
|
7
|
-
active_vision-0.3.0.dist-info/RECORD,,
|
|
@@ -1 +0,0 @@
|
|
|
1
|
-
active_vision
|
|
File without changes
|