active-vision 0.1.0__py3-none-any.whl → 0.2.0__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- active_vision/__init__.py +1 -1
- active_vision/core.py +235 -109
- {active_vision-0.1.0.dist-info → active_vision-0.2.0.dist-info}/METADATA +65 -80
- active_vision-0.2.0.dist-info/RECORD +7 -0
- active_vision-0.1.0.dist-info/RECORD +0 -7
- {active_vision-0.1.0.dist-info → active_vision-0.2.0.dist-info}/LICENSE +0 -0
- {active_vision-0.1.0.dist-info → active_vision-0.2.0.dist-info}/WHEEL +0 -0
- {active_vision-0.1.0.dist-info → active_vision-0.2.0.dist-info}/top_level.txt +0 -0
active_vision/__init__.py
CHANGED
active_vision/core.py
CHANGED
|
@@ -2,7 +2,7 @@ import pandas as pd
|
|
|
2
2
|
from loguru import logger
|
|
3
3
|
from fastai.vision.all import *
|
|
4
4
|
import torch
|
|
5
|
-
import
|
|
5
|
+
import numpy as np
|
|
6
6
|
|
|
7
7
|
import warnings
|
|
8
8
|
from typing import Callable
|
|
@@ -142,7 +142,8 @@ class ActiveLearner:
|
|
|
142
142
|
{
|
|
143
143
|
"filepath": filepaths,
|
|
144
144
|
"pred_label": [self.learn.dls.vocab[i] for i in cls_preds.numpy()],
|
|
145
|
-
"pred_conf": torch.max(
|
|
145
|
+
"pred_conf": torch.max(preds, dim=1)[0].numpy(),
|
|
146
|
+
"pred_raw": preds.numpy().tolist(),
|
|
146
147
|
}
|
|
147
148
|
)
|
|
148
149
|
return self.pred_df
|
|
@@ -189,37 +190,61 @@ class ActiveLearner:
|
|
|
189
190
|
df = df[~df["filepath"].isin(self.train_set["filepath"])].copy()
|
|
190
191
|
|
|
191
192
|
if strategy == "least-confidence":
|
|
192
|
-
logger.info(
|
|
193
|
-
|
|
193
|
+
logger.info(
|
|
194
|
+
f"Using least confidence strategy to get top {num_samples} samples"
|
|
195
|
+
)
|
|
194
196
|
df.loc[:, "uncertainty_score"] = 1 - (df["pred_conf"]) / (
|
|
195
197
|
self.num_classes - (self.num_classes - 1)
|
|
196
198
|
)
|
|
197
199
|
|
|
198
|
-
|
|
199
|
-
|
|
200
|
-
num_samples
|
|
200
|
+
elif strategy == "margin-of-confidence":
|
|
201
|
+
logger.info(
|
|
202
|
+
f"Using margin of confidence strategy to get top {num_samples} samples"
|
|
201
203
|
)
|
|
202
|
-
|
|
204
|
+
if len(df["pred_raw"].iloc[0]) < 2:
|
|
205
|
+
logger.error("pred_raw has less than 2 elements")
|
|
206
|
+
raise ValueError("pred_raw has less than 2 elements")
|
|
203
207
|
|
|
204
|
-
|
|
205
|
-
|
|
206
|
-
|
|
207
|
-
|
|
208
|
+
# Calculate uncertainty score as 1 - (difference between top two predictions)
|
|
209
|
+
df.loc[:, "uncertainty_score"] = df["pred_raw"].apply(
|
|
210
|
+
lambda x: 1 - (np.sort(x)[-1] - np.sort(x)[-2])
|
|
211
|
+
)
|
|
208
212
|
|
|
209
|
-
# TODO: Implement ratio of confidence strategy
|
|
210
213
|
elif strategy == "ratio-of-confidence":
|
|
211
|
-
logger.
|
|
212
|
-
|
|
214
|
+
logger.info(
|
|
215
|
+
f"Using ratio of confidence strategy to get top {num_samples} samples"
|
|
216
|
+
)
|
|
217
|
+
if len(df["pred_raw"].iloc[0]) < 2:
|
|
218
|
+
logger.error("pred_raw has less than 2 elements")
|
|
219
|
+
raise ValueError("pred_raw has less than 2 elements")
|
|
220
|
+
|
|
221
|
+
# Calculate uncertainty score as ratio of top two predictions
|
|
222
|
+
df.loc[:, "uncertainty_score"] = df["pred_raw"].apply(
|
|
223
|
+
lambda x: np.sort(x)[-2] / np.sort(x)[-1]
|
|
224
|
+
)
|
|
213
225
|
|
|
214
|
-
# TODO: Implement entropy strategy
|
|
215
226
|
elif strategy == "entropy":
|
|
216
|
-
logger.
|
|
217
|
-
|
|
227
|
+
logger.info(f"Using entropy strategy to get top {num_samples} samples")
|
|
228
|
+
|
|
229
|
+
# Calculate uncertainty score as entropy of the prediction
|
|
230
|
+
df.loc[:, "uncertainty_score"] = df["pred_raw"].apply(
|
|
231
|
+
lambda x: -np.sum(x * np.log2(x))
|
|
232
|
+
)
|
|
233
|
+
|
|
234
|
+
# Normalize the uncertainty score to be between 0 and 1 by dividing by log2 of the number of classes
|
|
235
|
+
df.loc[:, "uncertainty_score"] = df["uncertainty_score"] / np.log2(
|
|
236
|
+
self.num_classes
|
|
237
|
+
)
|
|
218
238
|
|
|
219
239
|
else:
|
|
220
240
|
logger.error(f"Unknown strategy: {strategy}")
|
|
221
241
|
raise ValueError(f"Unknown strategy: {strategy}")
|
|
222
242
|
|
|
243
|
+
df = df[
|
|
244
|
+
["filepath", "pred_label", "pred_conf", "uncertainty_score", "pred_raw"]
|
|
245
|
+
]
|
|
246
|
+
return df.sort_values(by="uncertainty_score", ascending=False).head(num_samples)
|
|
247
|
+
|
|
223
248
|
def sample_diverse(self, df: pd.DataFrame, num_samples: int):
|
|
224
249
|
"""
|
|
225
250
|
Sample top `num_samples` diverse samples. Returns a df with filepaths and predicted labels, and confidence scores.
|
|
@@ -258,7 +283,7 @@ class ActiveLearner:
|
|
|
258
283
|
return;
|
|
259
284
|
}
|
|
260
285
|
|
|
261
|
-
if (e.key === "ArrowUp"
|
|
286
|
+
if (e.key === "ArrowUp") {
|
|
262
287
|
document.getElementById("submit_btn").click();
|
|
263
288
|
} else if (e.key === "ArrowRight") {
|
|
264
289
|
document.getElementById("next_btn").click();
|
|
@@ -275,107 +300,149 @@ class ActiveLearner:
|
|
|
275
300
|
filepaths = df["filepath"].tolist()
|
|
276
301
|
|
|
277
302
|
with gr.Blocks(head=shortcut_js) as demo:
|
|
278
|
-
|
|
279
|
-
|
|
280
|
-
|
|
281
|
-
|
|
282
|
-
|
|
283
|
-
|
|
284
|
-
|
|
285
|
-
|
|
286
|
-
|
|
287
|
-
|
|
303
|
+
with gr.Tabs():
|
|
304
|
+
with gr.Tab("Labeling"):
|
|
305
|
+
current_index = gr.State(value=0)
|
|
306
|
+
|
|
307
|
+
with gr.Row(min_height=500):
|
|
308
|
+
image = gr.Image(
|
|
309
|
+
type="filepath",
|
|
310
|
+
label="Image",
|
|
311
|
+
value=filepaths[0],
|
|
312
|
+
height=500,
|
|
313
|
+
)
|
|
288
314
|
|
|
289
|
-
|
|
290
|
-
|
|
291
|
-
|
|
292
|
-
|
|
293
|
-
|
|
294
|
-
|
|
295
|
-
|
|
296
|
-
|
|
297
|
-
|
|
298
|
-
|
|
299
|
-
|
|
300
|
-
|
|
301
|
-
|
|
302
|
-
|
|
315
|
+
# Add bar plot with top 5 predictions
|
|
316
|
+
with gr.Column():
|
|
317
|
+
pred_plot = gr.BarPlot(
|
|
318
|
+
x="probability",
|
|
319
|
+
y="class",
|
|
320
|
+
title="Top 5 Predictions",
|
|
321
|
+
x_lim=[0, 1],
|
|
322
|
+
value=None
|
|
323
|
+
if "pred_raw" not in df.columns
|
|
324
|
+
else pd.DataFrame(
|
|
325
|
+
{
|
|
326
|
+
"class": self.class_names,
|
|
327
|
+
"probability": df["pred_raw"].iloc[0],
|
|
328
|
+
}
|
|
329
|
+
).nlargest(5, "probability"),
|
|
330
|
+
)
|
|
331
|
+
|
|
332
|
+
filename = gr.Textbox(
|
|
333
|
+
label="Filename", value=filepaths[0], interactive=False
|
|
334
|
+
)
|
|
335
|
+
|
|
336
|
+
pred_label = gr.Textbox(
|
|
337
|
+
label="Predicted Label",
|
|
338
|
+
value=df["pred_label"].iloc[0]
|
|
339
|
+
if "pred_label" in df.columns
|
|
340
|
+
else "",
|
|
341
|
+
interactive=False,
|
|
342
|
+
)
|
|
343
|
+
pred_conf = gr.Textbox(
|
|
344
|
+
label="Confidence",
|
|
345
|
+
value=f"{df['pred_conf'].iloc[0]:.2%}"
|
|
346
|
+
if "pred_conf" in df.columns
|
|
347
|
+
else "",
|
|
348
|
+
interactive=False,
|
|
349
|
+
)
|
|
350
|
+
|
|
351
|
+
category = gr.Radio(
|
|
352
|
+
choices=self.class_names,
|
|
353
|
+
label="Select Category",
|
|
354
|
+
value=df["pred_label"].iloc[0]
|
|
355
|
+
if "pred_label" in df.columns
|
|
356
|
+
else None,
|
|
357
|
+
)
|
|
303
358
|
|
|
304
|
-
|
|
305
|
-
|
|
306
|
-
|
|
307
|
-
|
|
308
|
-
|
|
359
|
+
with gr.Row():
|
|
360
|
+
back_btn = gr.Button("← Previous", elem_id="back_btn")
|
|
361
|
+
submit_btn = gr.Button(
|
|
362
|
+
"Submit ↑",
|
|
363
|
+
variant="primary",
|
|
364
|
+
elem_id="submit_btn",
|
|
365
|
+
)
|
|
366
|
+
next_btn = gr.Button("Next →", elem_id="next_btn")
|
|
367
|
+
|
|
368
|
+
progress = gr.Slider(
|
|
369
|
+
minimum=0,
|
|
370
|
+
maximum=len(filepaths) - 1,
|
|
371
|
+
value=0,
|
|
372
|
+
step=1,
|
|
373
|
+
label="Progress",
|
|
374
|
+
interactive=True,
|
|
375
|
+
)
|
|
309
376
|
|
|
310
|
-
|
|
311
|
-
|
|
312
|
-
|
|
313
|
-
|
|
314
|
-
|
|
315
|
-
|
|
316
|
-
|
|
317
|
-
|
|
318
|
-
|
|
319
|
-
|
|
320
|
-
|
|
321
|
-
|
|
322
|
-
|
|
323
|
-
|
|
324
|
-
|
|
325
|
-
interactive=False,
|
|
326
|
-
)
|
|
377
|
+
# Add event handler for slider changes
|
|
378
|
+
progress.change(
|
|
379
|
+
fn=lambda idx: navigate(idx, 0),
|
|
380
|
+
inputs=[progress],
|
|
381
|
+
outputs=[
|
|
382
|
+
filename,
|
|
383
|
+
image,
|
|
384
|
+
pred_label,
|
|
385
|
+
pred_conf,
|
|
386
|
+
category,
|
|
387
|
+
current_index,
|
|
388
|
+
progress,
|
|
389
|
+
pred_plot,
|
|
390
|
+
],
|
|
391
|
+
)
|
|
327
392
|
|
|
328
|
-
|
|
393
|
+
finish_btn = gr.Button("Finish Labeling", variant="primary")
|
|
329
394
|
|
|
330
|
-
|
|
331
|
-
|
|
332
|
-
|
|
333
|
-
|
|
395
|
+
with gr.Tab("Zero-Shot Inference"):
|
|
396
|
+
gr.Markdown("""
|
|
397
|
+
Uses a VLM to predict the label of the image.
|
|
398
|
+
""")
|
|
334
399
|
|
|
335
|
-
|
|
336
|
-
|
|
337
|
-
|
|
400
|
+
import xinfer
|
|
401
|
+
from xinfer.model_registry import model_registry
|
|
402
|
+
from xinfer.types import ModelInputOutput
|
|
338
403
|
|
|
339
|
-
|
|
340
|
-
|
|
341
|
-
|
|
342
|
-
|
|
343
|
-
|
|
344
|
-
|
|
345
|
-
|
|
404
|
+
# Get models and filter for image-to-text models
|
|
405
|
+
all_models = model_registry.list_models()
|
|
406
|
+
model_list = [
|
|
407
|
+
model.id
|
|
408
|
+
for model in all_models
|
|
409
|
+
if model.input_output == ModelInputOutput.IMAGE_TEXT_TO_TEXT
|
|
410
|
+
]
|
|
346
411
|
|
|
347
|
-
with gr.Row():
|
|
348
412
|
with gr.Row():
|
|
349
|
-
|
|
350
|
-
|
|
351
|
-
|
|
352
|
-
|
|
353
|
-
|
|
354
|
-
|
|
355
|
-
|
|
356
|
-
|
|
357
|
-
|
|
413
|
+
with gr.Row():
|
|
414
|
+
model_dropdown = gr.Dropdown(
|
|
415
|
+
choices=model_list,
|
|
416
|
+
label="Select a model",
|
|
417
|
+
value="vikhyatk/moondream2",
|
|
418
|
+
)
|
|
419
|
+
device_dropdown = gr.Dropdown(
|
|
420
|
+
choices=["cuda", "cpu"],
|
|
421
|
+
label="Device",
|
|
422
|
+
value="cuda" if torch.cuda.is_available() else "cpu",
|
|
423
|
+
)
|
|
424
|
+
dtype_dropdown = gr.Dropdown(
|
|
425
|
+
choices=["float32", "float16", "bfloat16"],
|
|
426
|
+
label="Data Type",
|
|
427
|
+
value="float16"
|
|
428
|
+
if torch.cuda.is_available()
|
|
429
|
+
else "float32",
|
|
430
|
+
)
|
|
431
|
+
|
|
432
|
+
with gr.Column():
|
|
433
|
+
prompt_textbox = gr.Textbox(
|
|
434
|
+
label="Prompt",
|
|
435
|
+
lines=5,
|
|
436
|
+
value=f"Classify the image into one of the following categories: {self.class_names}. Answer with the category name only.",
|
|
437
|
+
interactive=True,
|
|
358
438
|
)
|
|
359
|
-
|
|
360
|
-
choices=["float32", "float16", "bfloat16"],
|
|
361
|
-
label="Data Type",
|
|
362
|
-
value="float16" if torch.cuda.is_available() else "float32",
|
|
363
|
-
)
|
|
364
|
-
|
|
365
|
-
with gr.Column():
|
|
366
|
-
prompt_textbox = gr.Textbox(
|
|
367
|
-
label="Prompt",
|
|
368
|
-
lines=3,
|
|
369
|
-
value=f"Classify the image into one of the following categories: {self.class_names}",
|
|
370
|
-
interactive=True,
|
|
371
|
-
)
|
|
372
|
-
inference_btn = gr.Button("Run Inference", variant="primary")
|
|
439
|
+
inference_btn = gr.Button("Run Inference", variant="primary")
|
|
373
440
|
|
|
374
|
-
|
|
375
|
-
|
|
376
|
-
|
|
377
|
-
|
|
378
|
-
|
|
441
|
+
result_textbox = gr.Textbox(
|
|
442
|
+
label="Result",
|
|
443
|
+
lines=3,
|
|
444
|
+
interactive=False,
|
|
445
|
+
)
|
|
379
446
|
|
|
380
447
|
def run_zero_shot_inference(prompt, model, device, dtype, current_filename):
|
|
381
448
|
model = xinfer.create_model(model, device=device, dtype=dtype)
|
|
@@ -407,6 +474,16 @@ class ActiveLearner:
|
|
|
407
474
|
next_idx = current_idx + direction
|
|
408
475
|
|
|
409
476
|
if 0 <= next_idx < len(filepaths):
|
|
477
|
+
plot_data = (
|
|
478
|
+
None
|
|
479
|
+
if "pred_raw" not in df.columns
|
|
480
|
+
else pd.DataFrame(
|
|
481
|
+
{
|
|
482
|
+
"class": self.class_names,
|
|
483
|
+
"probability": df["pred_raw"].iloc[next_idx],
|
|
484
|
+
}
|
|
485
|
+
).nlargest(5, "probability")
|
|
486
|
+
)
|
|
410
487
|
return (
|
|
411
488
|
filepaths[next_idx],
|
|
412
489
|
filepaths[next_idx],
|
|
@@ -421,7 +498,18 @@ class ActiveLearner:
|
|
|
421
498
|
else None,
|
|
422
499
|
next_idx,
|
|
423
500
|
next_idx,
|
|
501
|
+
plot_data,
|
|
424
502
|
)
|
|
503
|
+
plot_data = (
|
|
504
|
+
None
|
|
505
|
+
if "pred_raw" not in df.columns
|
|
506
|
+
else pd.DataFrame(
|
|
507
|
+
{
|
|
508
|
+
"class": self.class_names,
|
|
509
|
+
"probability": df["pred_raw"].iloc[current_idx],
|
|
510
|
+
}
|
|
511
|
+
).nlargest(5, "probability")
|
|
512
|
+
)
|
|
425
513
|
return (
|
|
426
514
|
filepaths[current_idx],
|
|
427
515
|
filepaths[current_idx],
|
|
@@ -436,6 +524,7 @@ class ActiveLearner:
|
|
|
436
524
|
else None,
|
|
437
525
|
current_idx,
|
|
438
526
|
current_idx,
|
|
527
|
+
plot_data,
|
|
439
528
|
)
|
|
440
529
|
|
|
441
530
|
def save_and_next(current_idx, selected_category):
|
|
@@ -443,6 +532,16 @@ class ActiveLearner:
|
|
|
443
532
|
current_idx = int(current_idx)
|
|
444
533
|
|
|
445
534
|
if selected_category is None:
|
|
535
|
+
plot_data = (
|
|
536
|
+
None
|
|
537
|
+
if "pred_raw" not in df.columns
|
|
538
|
+
else pd.DataFrame(
|
|
539
|
+
{
|
|
540
|
+
"class": self.class_names,
|
|
541
|
+
"probability": df["pred_raw"].iloc[current_idx],
|
|
542
|
+
}
|
|
543
|
+
).nlargest(5, "probability")
|
|
544
|
+
)
|
|
446
545
|
return (
|
|
447
546
|
filepaths[current_idx],
|
|
448
547
|
filepaths[current_idx],
|
|
@@ -457,6 +556,7 @@ class ActiveLearner:
|
|
|
457
556
|
else None,
|
|
458
557
|
current_idx,
|
|
459
558
|
current_idx,
|
|
559
|
+
plot_data,
|
|
460
560
|
)
|
|
461
561
|
|
|
462
562
|
# Save the current annotation
|
|
@@ -466,6 +566,16 @@ class ActiveLearner:
|
|
|
466
566
|
# Move to next image if not at the end
|
|
467
567
|
next_idx = current_idx + 1
|
|
468
568
|
if next_idx >= len(filepaths):
|
|
569
|
+
plot_data = (
|
|
570
|
+
None
|
|
571
|
+
if "pred_raw" not in df.columns
|
|
572
|
+
else pd.DataFrame(
|
|
573
|
+
{
|
|
574
|
+
"class": self.class_names,
|
|
575
|
+
"probability": df["pred_raw"].iloc[current_idx],
|
|
576
|
+
}
|
|
577
|
+
).nlargest(5, "probability")
|
|
578
|
+
)
|
|
469
579
|
return (
|
|
470
580
|
filepaths[current_idx],
|
|
471
581
|
filepaths[current_idx],
|
|
@@ -480,7 +590,19 @@ class ActiveLearner:
|
|
|
480
590
|
else None,
|
|
481
591
|
current_idx,
|
|
482
592
|
current_idx,
|
|
593
|
+
plot_data,
|
|
483
594
|
)
|
|
595
|
+
|
|
596
|
+
plot_data = (
|
|
597
|
+
None
|
|
598
|
+
if "pred_raw" not in df.columns
|
|
599
|
+
else pd.DataFrame(
|
|
600
|
+
{
|
|
601
|
+
"class": self.class_names,
|
|
602
|
+
"probability": df["pred_raw"].iloc[next_idx],
|
|
603
|
+
}
|
|
604
|
+
).nlargest(5, "probability")
|
|
605
|
+
)
|
|
484
606
|
return (
|
|
485
607
|
filepaths[next_idx],
|
|
486
608
|
filepaths[next_idx],
|
|
@@ -495,6 +617,7 @@ class ActiveLearner:
|
|
|
495
617
|
else None,
|
|
496
618
|
next_idx,
|
|
497
619
|
next_idx,
|
|
620
|
+
plot_data,
|
|
498
621
|
)
|
|
499
622
|
|
|
500
623
|
def convert_csv_to_parquet():
|
|
@@ -519,6 +642,7 @@ class ActiveLearner:
|
|
|
519
642
|
category,
|
|
520
643
|
current_index,
|
|
521
644
|
progress,
|
|
645
|
+
pred_plot,
|
|
522
646
|
],
|
|
523
647
|
)
|
|
524
648
|
|
|
@@ -533,6 +657,7 @@ class ActiveLearner:
|
|
|
533
657
|
category,
|
|
534
658
|
current_index,
|
|
535
659
|
progress,
|
|
660
|
+
pred_plot,
|
|
536
661
|
],
|
|
537
662
|
)
|
|
538
663
|
|
|
@@ -547,6 +672,7 @@ class ActiveLearner:
|
|
|
547
672
|
category,
|
|
548
673
|
current_index,
|
|
549
674
|
progress,
|
|
675
|
+
pred_plot,
|
|
550
676
|
],
|
|
551
677
|
)
|
|
552
678
|
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.2
|
|
2
2
|
Name: active-vision
|
|
3
|
-
Version: 0.
|
|
3
|
+
Version: 0.2.0
|
|
4
4
|
Summary: Active learning for edge vision.
|
|
5
5
|
Requires-Python: >=3.10
|
|
6
6
|
Description-Content-Type: text/markdown
|
|
@@ -17,10 +17,10 @@ Requires-Dist: timm>=1.0.13
|
|
|
17
17
|
Requires-Dist: transformers>=4.48.0
|
|
18
18
|
Requires-Dist: xinfer>=0.3.2
|
|
19
19
|
|
|
20
|
-

|
|
21
|
-
](https://pypi.org/project/active-vision/)
|
|
21
|
+
[](https://pypi.org/project/active-vision/)
|
|
22
|
+
[](https://pypi.org/project/active-vision/)
|
|
23
|
+
[](https://github.com/dnth/active-vision/blob/main/LICENSE)
|
|
24
24
|
|
|
25
25
|
<p align="center">
|
|
26
26
|
<img src="https://raw.githubusercontent.com/dnth/active-vision/main/assets/logo.png" alt="active-vision">
|
|
@@ -47,9 +47,9 @@ The goal of this project is to create a framework for the active learning loop f
|
|
|
47
47
|
|
|
48
48
|
Uncertainty Sampling:
|
|
49
49
|
- [X] Least confidence
|
|
50
|
-
- [
|
|
51
|
-
- [
|
|
52
|
-
- [
|
|
50
|
+
- [X] Margin of confidence
|
|
51
|
+
- [X] Ratio of confidence
|
|
52
|
+
- [X] Entropy
|
|
53
53
|
|
|
54
54
|
Diverse Sampling:
|
|
55
55
|
- [X] Random sampling
|
|
@@ -71,17 +71,18 @@ cd active-vision
|
|
|
71
71
|
pip install -e .
|
|
72
72
|
```
|
|
73
73
|
|
|
74
|
-
I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
75
|
-
|
|
76
|
-
If you're using uv:
|
|
77
|
-
|
|
78
|
-
```bash
|
|
79
|
-
uv venv
|
|
80
|
-
uv sync
|
|
81
|
-
```
|
|
82
|
-
Once the virtual environment is created, you can install the package using pip.
|
|
83
74
|
|
|
84
75
|
> [!TIP]
|
|
76
|
+
> I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
77
|
+
>
|
|
78
|
+
> If you're using uv:
|
|
79
|
+
>
|
|
80
|
+
> ```bash
|
|
81
|
+
> uv venv
|
|
82
|
+
> uv sync
|
|
83
|
+
> ```
|
|
84
|
+
> Once the virtual environment is created, you can install the package using pip.
|
|
85
|
+
>
|
|
85
86
|
> If you're using uv add a `uv` before the pip install command to install into your virtual environment. Eg:
|
|
86
87
|
> ```bash
|
|
87
88
|
> uv pip install active-vision
|
|
@@ -120,12 +121,16 @@ pred_df = al.predict(filepaths)
|
|
|
120
121
|
# Sample low confidence predictions from unlabeled set
|
|
121
122
|
uncertain_df = al.sample_uncertain(pred_df, num_samples=10)
|
|
122
123
|
|
|
123
|
-
# Launch a Gradio UI to label the low confidence samples
|
|
124
|
+
# Launch a Gradio UI to label the low confidence samples, save the labeled samples to a file
|
|
124
125
|
al.label(uncertain_df, output_filename="uncertain")
|
|
125
126
|
```
|
|
126
127
|
|
|
127
128
|
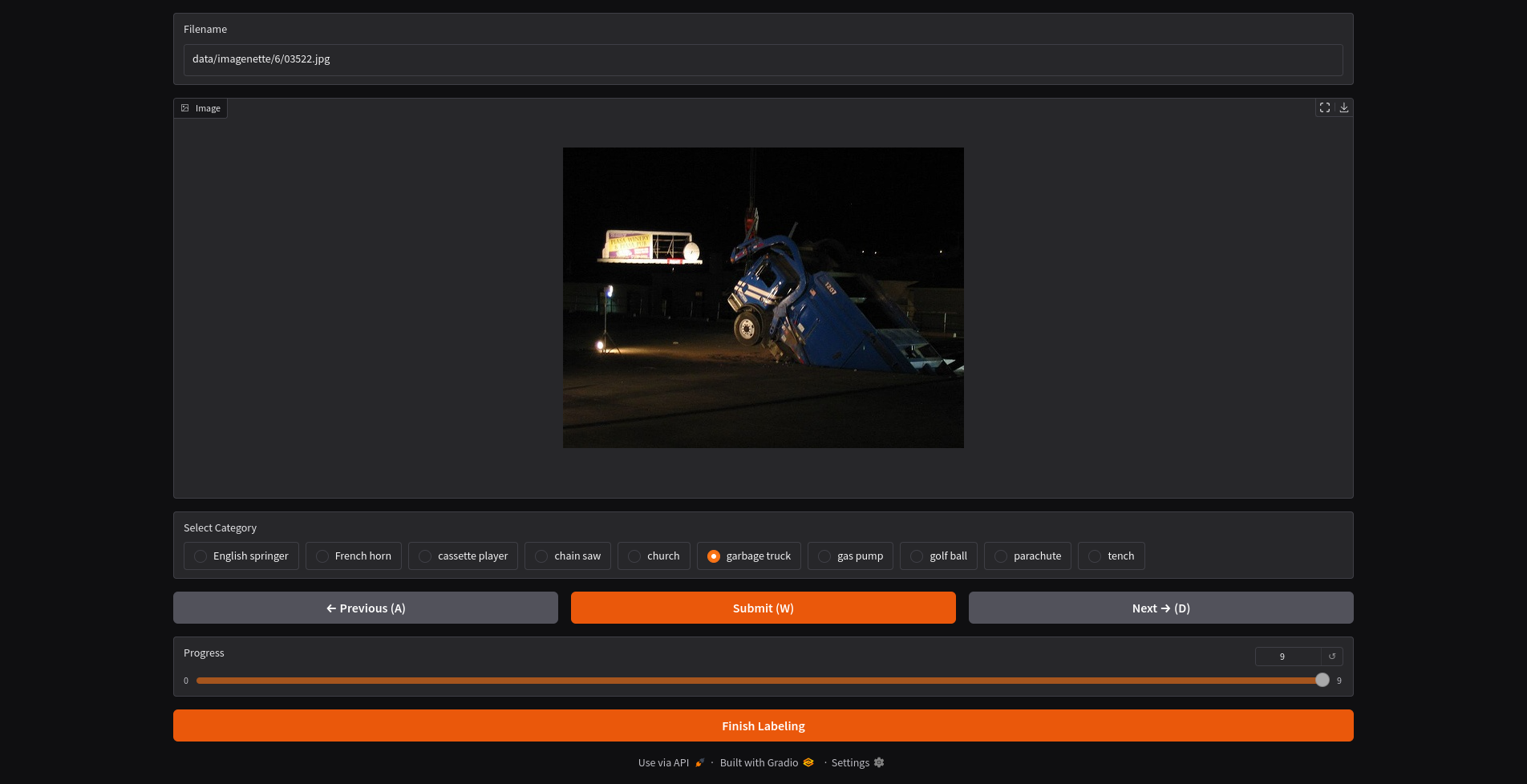
|
|
128
129
|
|
|
130
|
+
In the UI, you can optionally run zero-shot inference on the image. This will use a VLM to predict the label of the image. There are a dozen VLM models as supported in the [x.infer project](https://github.com/dnth/x.infer).
|
|
131
|
+
|
|
132
|
+

|
|
133
|
+
|
|
129
134
|
Once complete, the labeled samples will be save into a new df.
|
|
130
135
|
We can now add the newly labeled data to the training set.
|
|
131
136
|
|
|
@@ -167,15 +172,15 @@ The active learning loop is a iterative process and can keep going until you hit
|
|
|
167
172
|
- You hit a budget.
|
|
168
173
|
- Other criteria.
|
|
169
174
|
|
|
170
|
-
For this dataset,I decided to stop the active learning loop at 275 labeled images because the performance on the evaluation set
|
|
175
|
+
For this dataset, I decided to stop the active learning loop at 275 labeled images because the performance on the evaluation set exceeds the top performing model on the leaderboard.
|
|
171
176
|
|
|
172
177
|
|
|
173
|
-
| #Labeled Images
|
|
174
|
-
|
|
175
|
-
| 9469
|
|
176
|
-
| 9469
|
|
177
|
-
| 275
|
|
178
|
-
| 275
|
|
178
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
179
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------- |
|
|
180
|
+
| 9469 | 94.90% | 80 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
181
|
+
| 9469 | 95.11% | 200 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
182
|
+
| 275 | 99.33% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/05_retrain_larger.ipynb) |
|
|
183
|
+
| 275 | 93.40% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/04_relabel_loop.ipynb) |
|
|
179
184
|
|
|
180
185
|
### Dog Food
|
|
181
186
|
- num classes: 2
|
|
@@ -185,11 +190,11 @@ To start the active learning loop, I labeled 20 images (10 images from each clas
|
|
|
185
190
|
|
|
186
191
|
I decided to stop the active learning loop at 160 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
187
192
|
|
|
188
|
-
| #Labeled Images
|
|
189
|
-
|
|
190
|
-
| 2100
|
|
191
|
-
| 160
|
|
192
|
-
| 160
|
|
193
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
194
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |--------------------------------------------------------------------------------------------- |
|
|
195
|
+
| 2100 | 99.70% | ? | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/abhishek/autotrain-dog-vs-food) |
|
|
196
|
+
| 160 | 100.00% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/02_train.ipynb) |
|
|
197
|
+
| 160 | 97.60% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/01_label.ipynb) |
|
|
193
198
|
|
|
194
199
|
### Oxford-IIIT Pet
|
|
195
200
|
- num classes: 37
|
|
@@ -199,13 +204,27 @@ To start the active learning loop, I labeled 370 images (10 images from each cla
|
|
|
199
204
|
|
|
200
205
|
I decided to stop the active learning loop at 612 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
201
206
|
|
|
202
|
-
| #Labeled Images
|
|
203
|
-
|
|
204
|
-
| 3680
|
|
205
|
-
| 612
|
|
206
|
-
| 612
|
|
207
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
208
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------------------- |
|
|
209
|
+
| 3680 | 95.40% | 5 | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/walterg777/vit-base-oxford-iiit-pets) |
|
|
210
|
+
| 612 | 90.26% | 11 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/02_train.ipynb) |
|
|
211
|
+
| 612 | 91.38% | 11 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/03_train_vit.ipynb) |
|
|
212
|
+
|
|
213
|
+
### Eurosat RGB
|
|
214
|
+
- num classes: 10
|
|
215
|
+
- num images: 16100
|
|
216
|
+
|
|
217
|
+
To start the active learning loop, I labeled 100 images (10 images from each class) and iteratively labeled the most informative images until I hit 1188 labeled images.
|
|
218
|
+
|
|
219
|
+
I decided to stop the active learning loop at 1188 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
207
220
|
|
|
208
221
|
|
|
222
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
223
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |-------------------------------------------------------------------------------------------- |
|
|
224
|
+
| 16100 | 98.55% | 6 | vit-base-patch16-224 | ❌ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/03_train_all.ipynb) |
|
|
225
|
+
| 1188 | 94.59% | 6 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
226
|
+
| 1188 | 96.57% | 13 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
227
|
+
|
|
209
228
|
|
|
210
229
|
## ➿ Workflow
|
|
211
230
|
This section describes a more detailed workflow for active learning. There are two workflows for active learning that we can use depending on the availability of labeled data.
|
|
@@ -273,55 +292,21 @@ graph TD
|
|
|
273
292
|
|
|
274
293
|
|
|
275
294
|
|
|
276
|
-
|
|
277
|
-
To test out the workflows we will use the [imagenette dataset](https://huggingface.co/datasets/frgfm/imagenette). But this will be applicable to any dataset.
|
|
278
|
-
|
|
279
|
-
Imagenette is a subset of the ImageNet dataset with 10 classes. We will use this dataset to test out the workflows. Additionally, Imagenette has an existing leaderboard which we can use to evaluate the performance of the models.
|
|
280
|
-
|
|
281
|
-
### Step 1: Download the dataset
|
|
282
|
-
Download the imagenette dataset. The imagenette dataset has a train and validation split. Since the leaderboard is based on the validation set, we will evalutate the performance of our model on the validation set to make it easier to compare to the leaderboard.
|
|
283
|
-
|
|
284
|
-
We will treat the imagenette train set as a unlabeled set and iteratively sample from it while monitoring the performance on the validation set. Ideally we will be able to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
295
|
+
## 🧱 Sampling Approaches
|
|
285
296
|
|
|
286
|
-
|
|
297
|
+
Recommendation 1:
|
|
298
|
+
- 10% randomly selected from unlabeled items.
|
|
299
|
+
- 80% selected from the lowest confidence items.
|
|
300
|
+
- 10% selected as outliers.
|
|
287
301
|
|
|
288
|
-
|
|
289
|
-
```python
|
|
290
|
-
from datasets import load_dataset
|
|
291
|
-
|
|
292
|
-
unlabeled_dataset = load_dataset("dnth/active-learning-imagenette", "unlabeled")
|
|
293
|
-
eval_dataset = load_dataset("dnth/active-learning-imagenette", "evaluation")
|
|
294
|
-
```
|
|
302
|
+
Recommendation 2:
|
|
295
303
|
|
|
296
|
-
|
|
297
|
-
|
|
304
|
+
- Sample 100 predicted images at 10–20% confidence.
|
|
305
|
+
- Sample 100 predicted images at 20–30% confidence.
|
|
306
|
+
- Sample 100 predicted images at 30–40% confidence, and so on.
|
|
298
307
|
|
|
299
|
-
### Step 3: Training the proxy model
|
|
300
|
-
Train a proxy model on the initial dataset. The proxy model will be a small model that is easy to train and deploy. We will use the fastai framework to train the model. We will use the resnet18 architecture as a starting point. Once training is complete, compute the accuracy of the proxy model on the validation set and compare it to the leaderboard.
|
|
301
308
|
|
|
302
|
-
|
|
303
|
-
> With the initial model we got 91.24% accuracy on the validation set. See the [notebook](./nbs/01_initial_sampling.ipynb) for more details.
|
|
304
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
305
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
306
|
-
> | 10 | 100 | 91.24% | Initial sampling [notebook](./nbs/01_initial_sampling.ipynb) |
|
|
307
|
-
> | 80 | 9469 | 94.90% | fastai |
|
|
308
|
-
> | 200 | 9469 | 95.11% | fastai |
|
|
309
|
+
Uncertainty and diversity sampling are most effective when combined. For instance, you could first sample the most uncertain items using an uncertainty sampling method, then apply a diversity sampling method such as clustering to select a diverse set from the uncertain items.
|
|
309
310
|
|
|
311
|
+
Ultimately, the right ratios can depend on the specific task and dataset.
|
|
310
312
|
|
|
311
|
-
|
|
312
|
-
### Step 4: Inference on the unlabeled dataset
|
|
313
|
-
Run inference on the unlabeled dataset (the remaining imagenette train set) and evaluate the performance of the proxy model.
|
|
314
|
-
|
|
315
|
-
### Step 5: Active learning
|
|
316
|
-
Use active learning to select the most informative images to label from the unlabeled set. Pick the top 10 images from the unlabeled set that the proxy model is least confident about and label them.
|
|
317
|
-
|
|
318
|
-
### Step 6: Repeat
|
|
319
|
-
Repeat step 3 - 5 until the performance on the validation set is close to the leaderboard. Note the number of labeled images vs the performance on the validation set. Ideally we want to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
320
|
-
|
|
321
|
-
|
|
322
|
-
After the first iteration we got 94.57% accuracy on the validation set. See the [notebook](./nbs/03_retrain_model.ipynb) for more details.
|
|
323
|
-
|
|
324
|
-
> [!TIP]
|
|
325
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
326
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
327
|
-
> | 10 | 200 | 94.57% | First relabeling [notebook](./nbs/03_retrain_model.ipynb) | -->
|
|
@@ -0,0 +1,7 @@
|
|
|
1
|
+
active_vision/__init__.py,sha256=SxR6MPyULKlvx-86S3NIk46Tz1xlN-g_vI_aW3LitG4,43
|
|
2
|
+
active_vision/core.py,sha256=4Nl8e3isinIlzcD6bCbG9TTGiuG0PQkKNUIvnAsbaTY,27373
|
|
3
|
+
active_vision-0.2.0.dist-info/LICENSE,sha256=xx0jnfkXJvxRnG63LTGOxlggYnIysveWIZ6H3PNdCrQ,11357
|
|
4
|
+
active_vision-0.2.0.dist-info/METADATA,sha256=3XvDTC1Cnxd3rIUUXyY8MwTgKGcnncN9D2VvKnkw1jQ,15675
|
|
5
|
+
active_vision-0.2.0.dist-info/WHEEL,sha256=In9FTNxeP60KnTkGw7wk6mJPYd_dQSjEZmXdBdMCI-8,91
|
|
6
|
+
active_vision-0.2.0.dist-info/top_level.txt,sha256=7qUQvccN2UU63z5S9vrgJmqK-8sFGrtpf1e9Z86nihE,14
|
|
7
|
+
active_vision-0.2.0.dist-info/RECORD,,
|
|
@@ -1,7 +0,0 @@
|
|
|
1
|
-
active_vision/__init__.py,sha256=dDQijes3C7zAUc_08TyblLSP6Lk0PcPPI8PYgEliKCI,43
|
|
2
|
-
active_vision/core.py,sha256=D_ve-nMv2EWSaQCOBTggleo-1op8JHXchk0QLicGDqg,21715
|
|
3
|
-
active_vision-0.1.0.dist-info/LICENSE,sha256=xx0jnfkXJvxRnG63LTGOxlggYnIysveWIZ6H3PNdCrQ,11357
|
|
4
|
-
active_vision-0.1.0.dist-info/METADATA,sha256=aA793OK3PGKnKVchMQthXl1H14xcBh_kq9tAO9o6jf0,15944
|
|
5
|
-
active_vision-0.1.0.dist-info/WHEEL,sha256=In9FTNxeP60KnTkGw7wk6mJPYd_dQSjEZmXdBdMCI-8,91
|
|
6
|
-
active_vision-0.1.0.dist-info/top_level.txt,sha256=7qUQvccN2UU63z5S9vrgJmqK-8sFGrtpf1e9Z86nihE,14
|
|
7
|
-
active_vision-0.1.0.dist-info/RECORD,,
|
|
File without changes
|
|
File without changes
|
|
File without changes
|