MeUtils 2025.3.3.18.41.24__py3-none-any.whl → 2025.3.5.19.55.22__py3-none-any.whl
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/METADATA +264 -264
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/RECORD +61 -33
- examples/_openaisdk/open_router.py +2 -1
- examples/_openaisdk/openai_files.py +16 -5
- examples/_openaisdk/openai_images.py +1 -0
- examples/_openaisdk/openai_moon.py +22 -19
- examples/sh/__init__.py +11 -0
- meutils/apis/baidu/bdaitpzs.py +9 -17
- meutils/apis/chatglm/glm_video_api.py +2 -2
- meutils/apis/images/edits.py +7 -2
- meutils/apis/jimeng/common.py +1 -1
- meutils/apis/oneapi/common.py +4 -4
- meutils/apis/proxy/ips.py +2 -0
- meutils/caches/common.py +4 -0
- meutils/data/VERSION +1 -1
- meutils/data/oneapi/NOTICE.html +12 -0
- meutils/data/oneapi/__init__.py +1 -1
- meutils/data/oneapi/index.html +275 -0
- meutils/io/_openai_files.py +31 -0
- meutils/io/openai_files.py +138 -0
- meutils/io/parsers/__init__.py +10 -0
- meutils/io/parsers/fileparser/PDF/346/212/275/345/217/226.py +58 -0
- meutils/io/parsers/fileparser/__init__.py +11 -0
- meutils/io/parsers/fileparser/common.py +91 -0
- meutils/io/parsers/fileparser/demo.py +41 -0
- meutils/io/parsers/fileparser/filetype/__init__.py +10 -0
- meutils/io/parsers/fileparser/filetype/__main__.py +37 -0
- meutils/io/parsers/fileparser/filetype/filetype.py +98 -0
- meutils/io/parsers/fileparser/filetype/helpers.py +140 -0
- meutils/io/parsers/fileparser/filetype/match.py +155 -0
- meutils/io/parsers/fileparser/filetype/types/__init__.py +118 -0
- meutils/io/parsers/fileparser/filetype/types/application.py +22 -0
- meutils/io/parsers/fileparser/filetype/types/archive.py +687 -0
- meutils/io/parsers/fileparser/filetype/types/audio.py +212 -0
- meutils/io/parsers/fileparser/filetype/types/base.py +29 -0
- meutils/io/parsers/fileparser/filetype/types/document.py +256 -0
- meutils/io/parsers/fileparser/filetype/types/font.py +115 -0
- meutils/io/parsers/fileparser/filetype/types/image.py +383 -0
- meutils/io/parsers/fileparser/filetype/types/isobmff.py +33 -0
- meutils/io/parsers/fileparser/filetype/types/video.py +223 -0
- meutils/io/parsers/fileparser/filetype/utils.py +84 -0
- meutils/io/parsers/fileparser/filetype.py +41 -0
- meutils/io/parsers/fileparser/mineru.py +48 -0
- meutils/io/parsers/fileparser/pdf.py +30 -0
- meutils/io/parsers/fileparser//350/241/250/346/240/274/346/212/275/345/217/226.py +118 -0
- meutils/llm/check_utils.py +33 -2
- meutils/llm/clients.py +1 -0
- meutils/llm/completions/chat_gemini.py +72 -0
- meutils/llm/completions/chat_plus.py +78 -0
- meutils/llm/completions/{agents/file.py → chat_spark.py} +46 -26
- meutils/llm/completions/qwenllm.py +57 -16
- meutils/llm/completions/yuanbao.py +29 -3
- meutils/llm/openai_utils/common.py +2 -2
- meutils/schemas/oneapi/common.py +22 -19
- meutils/schemas/openai_types.py +65 -29
- meutils/schemas/yuanbao_types.py +6 -7
- meutils/types.py +2 -0
- meutils/data/oneapi/NOTICE.md +0 -1
- meutils/data/oneapi/_NOTICE.md +0 -140
- meutils/llm/completions/gemini.py +0 -69
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/LICENSE +0 -0
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/WHEEL +0 -0
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/entry_points.txt +0 -0
- {MeUtils-2025.3.3.18.41.24.dist-info → MeUtils-2025.3.5.19.55.22.dist-info}/top_level.txt +0 -0
|
@@ -17,18 +17,19 @@ AttributeError: 'str' object has no attribute 'choices'
|
|
|
17
17
|
from openai import AsyncOpenAI
|
|
18
18
|
|
|
19
19
|
from meutils.pipe import *
|
|
20
|
-
from meutils.io.files_utils import to_bytes
|
|
21
20
|
from meutils.decorators.retry import retrying
|
|
21
|
+
from meutils.io.files_utils import to_bytes, guess_mime_type
|
|
22
|
+
from meutils.caches import rcache
|
|
22
23
|
|
|
23
24
|
from meutils.llm.clients import qwen_client
|
|
24
25
|
from meutils.llm.openai_utils import to_openai_params
|
|
25
26
|
|
|
26
27
|
from meutils.config_utils.lark_utils import get_next_token_for_polling
|
|
27
|
-
from meutils.schemas.openai_types import chat_completion, chat_completion_chunk,
|
|
28
|
+
from meutils.schemas.openai_types import chat_completion, chat_completion_chunk, CompletionRequest, CompletionUsage
|
|
28
29
|
|
|
29
30
|
FEISHU_URL = "https://xchatllm.feishu.cn/sheets/Bmjtst2f6hfMqFttbhLcdfRJnNf?sheet=PP1PGr"
|
|
30
31
|
|
|
31
|
-
base_url = "https://chat.
|
|
32
|
+
base_url = "https://chat.qwen.ai/api"
|
|
32
33
|
|
|
33
34
|
from fake_useragent import UserAgent
|
|
34
35
|
|
|
@@ -36,14 +37,18 @@ ua = UserAgent()
|
|
|
36
37
|
|
|
37
38
|
|
|
38
39
|
@retrying()
|
|
39
|
-
|
|
40
|
-
|
|
41
|
-
|
|
40
|
+
@rcache(ttl=3600, serializer='pickle')
|
|
41
|
+
async def to_file(file):
|
|
42
|
+
filename = Path(file).name if isinstance(file, str) else 'untitled'
|
|
43
|
+
mime_type = guess_mime_type(file)
|
|
44
|
+
file_bytes: bytes = await to_bytes(file)
|
|
45
|
+
file = (filename, file_bytes, mime_type)
|
|
42
46
|
file_object = await qwen_client.files.create(file=file, purpose="file-extract")
|
|
47
|
+
logger.debug(file_object)
|
|
43
48
|
return file_object
|
|
44
49
|
|
|
45
50
|
|
|
46
|
-
async def create(request:
|
|
51
|
+
async def create(request: CompletionRequest, token: Optional[str] = None): # ChatCompletionRequest 重构
|
|
47
52
|
|
|
48
53
|
token = token or await get_next_token_for_polling(feishu_url=FEISHU_URL)
|
|
49
54
|
|
|
@@ -54,11 +59,12 @@ async def create(request: ChatCompletionRequest, token: Optional[str] = None):
|
|
|
54
59
|
)
|
|
55
60
|
|
|
56
61
|
# qwen结构
|
|
57
|
-
|
|
62
|
+
model = request.model.lower()
|
|
63
|
+
if any(i in model for i in ("search",)):
|
|
58
64
|
request.model = "qwen-max-latest"
|
|
59
65
|
request.messages[-1]['chat_type'] = "search"
|
|
60
66
|
|
|
61
|
-
if any(i in
|
|
67
|
+
if any(i in model for i in ("qwq", "think")): # qwq-max-search
|
|
62
68
|
request.model = "qwen-max-latest"
|
|
63
69
|
request.messages[-1]['feature_config'] = {"thinking_enabled": True}
|
|
64
70
|
|
|
@@ -67,6 +73,7 @@ async def create(request: ChatCompletionRequest, token: Optional[str] = None):
|
|
|
67
73
|
# # await to_file
|
|
68
74
|
last_message = request.messages[-1]
|
|
69
75
|
logger.debug(last_message)
|
|
76
|
+
|
|
70
77
|
if last_message.get("role") == "user":
|
|
71
78
|
user_content = last_message.get("content")
|
|
72
79
|
if isinstance(user_content, list):
|
|
@@ -79,10 +86,26 @@ async def create(request: ChatCompletionRequest, token: Optional[str] = None):
|
|
|
79
86
|
|
|
80
87
|
elif content.get("type") == 'image_url':
|
|
81
88
|
url = content.get(content.get("type")).get("url")
|
|
82
|
-
file_object = await to_file(url
|
|
89
|
+
file_object = await to_file(url)
|
|
83
90
|
|
|
84
91
|
user_content[i] = {"type": "image", "image": file_object.id}
|
|
85
92
|
|
|
93
|
+
elif user_content.startswith("http"):
|
|
94
|
+
file_url, user_content = user_content.split(maxsplit=1)
|
|
95
|
+
|
|
96
|
+
user_content = [{"type": "text", "text": user_content}]
|
|
97
|
+
|
|
98
|
+
file_object = await to_file(file_url)
|
|
99
|
+
|
|
100
|
+
content_type = file_object.meta.get("content_type", "")
|
|
101
|
+
if content_type.startswith("image"):
|
|
102
|
+
user_content.append({"type": "image", "image": file_object.id})
|
|
103
|
+
else:
|
|
104
|
+
user_content.append({"type": "file", "file": file_object.id})
|
|
105
|
+
|
|
106
|
+
request.messages[-1]['content'] = user_content
|
|
107
|
+
|
|
108
|
+
logger.debug(request)
|
|
86
109
|
data = to_openai_params(request)
|
|
87
110
|
if request.stream:
|
|
88
111
|
_chunk = ""
|
|
@@ -133,17 +156,19 @@ if __name__ == '__main__':
|
|
|
133
156
|
{
|
|
134
157
|
"type": "file_url",
|
|
135
158
|
"file_url": {
|
|
136
|
-
"url": "https://oss.ffire.cc/files
|
|
159
|
+
"url": "https://oss.ffire.cc/files/AIGC.pdf"
|
|
137
160
|
}
|
|
138
161
|
}
|
|
139
162
|
|
|
140
163
|
]
|
|
141
164
|
|
|
142
|
-
request =
|
|
165
|
+
request = CompletionRequest(
|
|
143
166
|
# model="qwen-turbo-2024-11-01",
|
|
144
|
-
|
|
167
|
+
model="qwen-max-latest",
|
|
145
168
|
# model="qwen-max-latest-search",
|
|
146
|
-
model="qwq-max",
|
|
169
|
+
# model="qwq-max",
|
|
170
|
+
# model="qwq-max-search",
|
|
171
|
+
|
|
147
172
|
# model="qwen2.5-vl-72b-instruct",
|
|
148
173
|
|
|
149
174
|
# model="qwen-plus-latest",
|
|
@@ -152,8 +177,8 @@ if __name__ == '__main__':
|
|
|
152
177
|
{
|
|
153
178
|
'role': 'user',
|
|
154
179
|
# 'content': '今天南京天气',
|
|
155
|
-
'content': "9.8 9.11哪个大",
|
|
156
|
-
|
|
180
|
+
# 'content': "9.8 9.11哪个大",
|
|
181
|
+
'content': 'https://oss.ffire.cc/files/AIGC.pdf 总结下',
|
|
157
182
|
|
|
158
183
|
# "chat_type": "search",
|
|
159
184
|
|
|
@@ -174,6 +199,22 @@ if __name__ == '__main__':
|
|
|
174
199
|
# }
|
|
175
200
|
# ]
|
|
176
201
|
|
|
202
|
+
# "content": [
|
|
203
|
+
# {
|
|
204
|
+
# "type": "text",
|
|
205
|
+
# "text": "总结下",
|
|
206
|
+
# "chat_type": "t2t",
|
|
207
|
+
# "feature_config": {
|
|
208
|
+
# "thinking_enabled": False
|
|
209
|
+
# }
|
|
210
|
+
# },
|
|
211
|
+
# {
|
|
212
|
+
# "type": "file_url",
|
|
213
|
+
# "file_url": {
|
|
214
|
+
# "url": 'xxxxxxx'
|
|
215
|
+
# }
|
|
216
|
+
# }
|
|
217
|
+
# ]
|
|
177
218
|
# "content": [
|
|
178
219
|
# {
|
|
179
220
|
# "type": "text",
|
|
@@ -9,13 +9,14 @@
|
|
|
9
9
|
# @Description :
|
|
10
10
|
import asyncio
|
|
11
11
|
|
|
12
|
+
import pandas as pd
|
|
12
13
|
from aiostream import stream
|
|
13
14
|
|
|
14
15
|
from meutils.pipe import *
|
|
15
16
|
from meutils.io.image import image2nowatermark_image
|
|
16
17
|
|
|
17
18
|
from meutils.llm.utils import oneturn2multiturn
|
|
18
|
-
from meutils.schemas.openai_types import
|
|
19
|
+
from meutils.schemas.openai_types import CompletionRequest
|
|
19
20
|
from meutils.schemas.image_types import HunyuanImageRequest
|
|
20
21
|
|
|
21
22
|
from meutils.schemas.yuanbao_types import FEISHU_URL, SSEData, YUANBAO_BASE_URL, API_CHAT, API_GENERATE_ID, \
|
|
@@ -41,7 +42,7 @@ class Completions(object):
|
|
|
41
42
|
|
|
42
43
|
async def create(
|
|
43
44
|
self,
|
|
44
|
-
request: Optional[
|
|
45
|
+
request: Optional[CompletionRequest] = None,
|
|
45
46
|
image_request: Optional[HunyuanImageRequest] = None,
|
|
46
47
|
token: Optional[str] = None
|
|
47
48
|
):
|
|
@@ -111,6 +112,7 @@ class Completions(object):
|
|
|
111
112
|
logger.debug(response.status_code)
|
|
112
113
|
response.raise_for_status()
|
|
113
114
|
|
|
115
|
+
reasoning = "<think>\n" # </think>
|
|
114
116
|
async for chunk in response.aiter_lines():
|
|
115
117
|
sse = SSEData(chunk=chunk)
|
|
116
118
|
if image_request and sse.image:
|
|
@@ -118,6 +120,24 @@ class Completions(object):
|
|
|
118
120
|
yield sse.image
|
|
119
121
|
|
|
120
122
|
if request:
|
|
123
|
+
if sse.reasoning_content:
|
|
124
|
+
yield reasoning
|
|
125
|
+
yield sse.reasoning_content
|
|
126
|
+
reasoning = ""
|
|
127
|
+
elif sse.content and reasoning == "":
|
|
128
|
+
reasoning = "\n</think>"
|
|
129
|
+
yield reasoning
|
|
130
|
+
|
|
131
|
+
if sse.search_content:
|
|
132
|
+
df = pd.DataFrame(sse.search_content)
|
|
133
|
+
df['title'] = "[" + df['title'] + "](" + df['url'] + ")"
|
|
134
|
+
df['sourceName'] = "![" + df['sourceName'] + "](" + df['icon_url'] + ")"
|
|
135
|
+
df = df[['title', 'web_site_name', 'sourceName', "publish_time"]]
|
|
136
|
+
df.index += 1
|
|
137
|
+
yield '> Search\n'
|
|
138
|
+
yield df.to_markdown()
|
|
139
|
+
yield '\n\n'
|
|
140
|
+
|
|
121
141
|
yield sse.content
|
|
122
142
|
|
|
123
143
|
def generate_id(self, random: bool = True):
|
|
@@ -166,9 +186,15 @@ if __name__ == '__main__':
|
|
|
166
186
|
|
|
167
187
|
# async2sync_generator(Completions(api_key).achat('画条狗')) | xprint
|
|
168
188
|
# request = HunyuanImageRequest(prompt='画条狗', size='16:9')
|
|
189
|
+
# deep_seek deep_seek_v3 hunyuan_t1 hunyuan_gpt_175B_0404
|
|
190
|
+
# model = 'deep_seek_v3-search'
|
|
191
|
+
model = 'deep_seek-search'
|
|
169
192
|
|
|
170
193
|
arun(Completions().create(
|
|
171
|
-
|
|
194
|
+
CompletionRequest(
|
|
195
|
+
model=model,
|
|
196
|
+
messages=[{'role': 'user', 'content': '南京天气如何'}]
|
|
197
|
+
),
|
|
172
198
|
# image_request=request,
|
|
173
199
|
# token=token
|
|
174
200
|
))
|
|
@@ -21,7 +21,7 @@ from meutils.apis.oneapi.user import get_user_money, get_api_key_log
|
|
|
21
21
|
from meutils.apis.oneapi.token import get_api_key_money
|
|
22
22
|
|
|
23
23
|
from meutils.schemas.oneapi import MODEL_PRICE
|
|
24
|
-
from meutils.schemas.openai_types import ChatCompletionRequest, TTSRequest, STTRequest
|
|
24
|
+
from meutils.schemas.openai_types import CompletionRequest, ChatCompletionRequest, TTSRequest, STTRequest
|
|
25
25
|
from meutils.schemas.openai_types import ChatCompletion, ChatCompletionChunk, CompletionUsage
|
|
26
26
|
from meutils.schemas.openai_types import chat_completion, chat_completion_chunk, chat_completion_chunk_stop # todo
|
|
27
27
|
|
|
@@ -37,7 +37,7 @@ AUDIO_TRANSCRIPTIONS_PARAMS = get_function_params(fn=OpenAI(api_key='').audio.tr
|
|
|
37
37
|
|
|
38
38
|
|
|
39
39
|
def to_openai_params(
|
|
40
|
-
request: Union[dict, ChatCompletionRequest, ImageRequest, TTSRequest, STTRequest],
|
|
40
|
+
request: Union[dict, CompletionRequest, ChatCompletionRequest, ImageRequest, TTSRequest, STTRequest],
|
|
41
41
|
redirect_model: Optional[str] = None,
|
|
42
42
|
) -> dict:
|
|
43
43
|
data = copy.deepcopy(request)
|
meutils/schemas/oneapi/common.py
CHANGED
|
@@ -280,28 +280,28 @@ MODEL_PRICE = {
|
|
|
280
280
|
# MJ
|
|
281
281
|
"mj-chat": 0.3,
|
|
282
282
|
|
|
283
|
-
"mj_fast_blend": 0.
|
|
283
|
+
"mj_fast_blend": 0.1,
|
|
284
284
|
"mj_fast_custom_oom": 0,
|
|
285
|
-
"mj_fast_describe": 0.
|
|
286
|
-
"mj_fast_high_variation": 0.
|
|
287
|
-
"mj_fast_imagine": 0.
|
|
285
|
+
"mj_fast_describe": 0.05,
|
|
286
|
+
"mj_fast_high_variation": 0.1,
|
|
287
|
+
"mj_fast_imagine": 0.1,
|
|
288
288
|
"mj_fast_inpaint": 0,
|
|
289
|
-
"mj_fast_low_variation": 0.
|
|
290
|
-
"mj_fast_modal": 0.
|
|
291
|
-
"mj_fast_pan": 0.
|
|
289
|
+
"mj_fast_low_variation": 0.1,
|
|
290
|
+
"mj_fast_modal": 0.1,
|
|
291
|
+
"mj_fast_pan": 0.1,
|
|
292
292
|
"mj_fast_pic_reader": 0,
|
|
293
293
|
"mj_fast_prompt_analyzer": 0,
|
|
294
294
|
"mj_fast_prompt_analyzer_extended": 0,
|
|
295
|
-
"mj_fast_reroll": 0.
|
|
296
|
-
"mj_fast_shorten": 0.
|
|
297
|
-
"mj_fast_upload": 0.
|
|
298
|
-
"mj_fast_upscale": 0.
|
|
299
|
-
"mj_fast_upscale_creative": 0.
|
|
300
|
-
"mj_fast_upscale_subtle": 0.
|
|
301
|
-
"mj_fast_variation": 0.
|
|
302
|
-
"mj_fast_zoom": 0.
|
|
295
|
+
"mj_fast_reroll": 0.1,
|
|
296
|
+
"mj_fast_shorten": 0.1,
|
|
297
|
+
"mj_fast_upload": 0.1,
|
|
298
|
+
"mj_fast_upscale": 0.05,
|
|
299
|
+
"mj_fast_upscale_creative": 0.1,
|
|
300
|
+
"mj_fast_upscale_subtle": 0.1,
|
|
301
|
+
"mj_fast_variation": 0.1,
|
|
302
|
+
"mj_fast_zoom": 0.1,
|
|
303
303
|
|
|
304
|
-
"mj_relax_imagine": 0.
|
|
304
|
+
"mj_relax_imagine": 0.05 * MJ_RELAX,
|
|
305
305
|
|
|
306
306
|
"mj_relax_blend": 0.08,
|
|
307
307
|
"mj_relax_custom_oom": 0,
|
|
@@ -401,12 +401,13 @@ MODEL_RATIO = {
|
|
|
401
401
|
# 阿里千问 https://dashscope.console.aliyun.com/billing
|
|
402
402
|
"qwen-long": 0.25,
|
|
403
403
|
"qwen-turbo": 0.05,
|
|
404
|
-
"qwen-plus":
|
|
404
|
+
"qwen-plus": 0.8,
|
|
405
405
|
"qwen-max": 1.2,
|
|
406
406
|
"qwen-max-longcontext": 20,
|
|
407
407
|
"qwen-turbo-2024-11-01": 0.15,
|
|
408
408
|
"qwen-max-latest": 1.2,
|
|
409
409
|
"qwen2.5-max": 1.2,
|
|
410
|
+
"qwen-max-2025-01-25": 1.2,
|
|
410
411
|
|
|
411
412
|
"qwen-vl-max-latest": 1.5,
|
|
412
413
|
"qwen-vl-plus-latest": 0.75,
|
|
@@ -421,7 +422,6 @@ MODEL_RATIO = {
|
|
|
421
422
|
"qwen/qwq-32b-preview": 1,
|
|
422
423
|
"Qwen/QwQ-32B-Preview": 1,
|
|
423
424
|
|
|
424
|
-
|
|
425
425
|
"qwq-max": 1.2,
|
|
426
426
|
"qwq-max-search": 1.2,
|
|
427
427
|
"qwen-max-search": 1.2,
|
|
@@ -771,7 +771,7 @@ COMPLETION_RATIO = {
|
|
|
771
771
|
"gpt-4-all": 4,
|
|
772
772
|
"gpt-4-gizmo-*": 4,
|
|
773
773
|
"gpt-4o-all": 4,
|
|
774
|
-
"gpt-4.5-preview-2025-02-27":2,
|
|
774
|
+
"gpt-4.5-preview-2025-02-27": 2,
|
|
775
775
|
|
|
776
776
|
"o1-mini": 4,
|
|
777
777
|
"o1-preview": 4,
|
|
@@ -862,6 +862,9 @@ COMPLETION_RATIO = {
|
|
|
862
862
|
"qwen2-vl-72b-instruct": 5,
|
|
863
863
|
"qwen-max-latest": 4,
|
|
864
864
|
"qwen2.5-max": 4,
|
|
865
|
+
"qwen-max-2025-01-25": 4,
|
|
866
|
+
|
|
867
|
+
"qwen-plus": 2.5,
|
|
865
868
|
|
|
866
869
|
"qwq-max": 4,
|
|
867
870
|
"qwq-max-search": 4,
|
meutils/schemas/openai_types.py
CHANGED
|
@@ -117,31 +117,49 @@ class CompletionRequest(BaseModel):
|
|
|
117
117
|
user: Optional[str] = None
|
|
118
118
|
|
|
119
119
|
# 拓展字段
|
|
120
|
-
last_message: Optional[Dict[str, Any]] = None
|
|
121
|
-
|
|
122
|
-
user_content: Optional[Any] = None # str dict
|
|
123
|
-
|
|
124
|
-
system_messages: Optional[list] = None
|
|
125
|
-
last_content: Optional[Any] = None
|
|
126
120
|
|
|
127
121
|
def __init__(self, **kwargs):
|
|
128
122
|
super().__init__(**kwargs)
|
|
129
123
|
|
|
130
|
-
last_message = self.messages[-1] # role content
|
|
131
|
-
if last_message.get("role") == "user":
|
|
132
|
-
user_content = last_message.get("content")
|
|
133
|
-
if isinstance(user_content, list): # todo: 多模态 'image_url','video_url' and 'video' 'file' audio
|
|
134
|
-
for i, c in enumerate(user_content):
|
|
135
|
-
if c.get("type") == "image_url":
|
|
136
|
-
user_content[i]["type"] = "image_url"
|
|
137
|
-
user_content[i]["image_url"] = user_content[i].get("image_url", {}).get("url", "")
|
|
138
|
-
|
|
139
|
-
self.messages = self.messages or [{'role': 'user', 'content': 'hi'}]
|
|
140
|
-
self.system_messages = [m for m in self.messages if m.get("role") == "system"]
|
|
141
|
-
|
|
142
124
|
class Config:
|
|
143
125
|
extra = "allow"
|
|
144
126
|
|
|
127
|
+
@cached_property
|
|
128
|
+
def last_message(self):
|
|
129
|
+
return self.messages and self.messages[-1]
|
|
130
|
+
|
|
131
|
+
@cached_property
|
|
132
|
+
def last_user_content(self) -> str:
|
|
133
|
+
for i, message in enumerate(self.messages[::-1], 1):
|
|
134
|
+
if message.get("role") == "user":
|
|
135
|
+
user_contents = message.get("content")
|
|
136
|
+
if isinstance(user_contents, list):
|
|
137
|
+
for content in user_contents:
|
|
138
|
+
return content.get('text', "")
|
|
139
|
+
else:
|
|
140
|
+
return user_contents
|
|
141
|
+
|
|
142
|
+
@cached_property
|
|
143
|
+
def last_urls(self): # file_url 多轮对话需要 sum(request.last_urls.values(), [])
|
|
144
|
+
content_types = {"image_url", "file", "file_url", "video_url", "audio_url"}
|
|
145
|
+
for i, message in enumerate(self.messages[::-1], 1):
|
|
146
|
+
data = {}
|
|
147
|
+
if message.get("role") == "user": # 每一轮还要处理
|
|
148
|
+
user_contents = message.get("content")
|
|
149
|
+
if isinstance(user_contents, list): # 用户 url
|
|
150
|
+
for content in user_contents:
|
|
151
|
+
content_type = content.get("type")
|
|
152
|
+
if content_type in content_types:
|
|
153
|
+
if _url := content.get(content_type, {}): # {"type": "file", "file": fileid}
|
|
154
|
+
if isinstance(_url, str): # 兼容了spark qwenai
|
|
155
|
+
url = _url
|
|
156
|
+
else:
|
|
157
|
+
url = _url.get("url")
|
|
158
|
+
url and data.setdefault(content_type, []).append(url)
|
|
159
|
+
|
|
160
|
+
if data: return data
|
|
161
|
+
return {}
|
|
162
|
+
|
|
145
163
|
|
|
146
164
|
class ChatCompletionRequest(BaseModel):
|
|
147
165
|
"""
|
|
@@ -408,19 +426,37 @@ if __name__ == '__main__':
|
|
|
408
426
|
#
|
|
409
427
|
#
|
|
410
428
|
# print(A(n=11))
|
|
411
|
-
|
|
412
|
-
|
|
413
|
-
|
|
414
|
-
|
|
415
|
-
|
|
416
|
-
|
|
417
|
-
|
|
418
|
-
|
|
429
|
+
messages = [
|
|
430
|
+
{'role': 'user',
|
|
431
|
+
'content': [{"type": "image_url", "image_url": "https://oss.ffire.cc/files/kling_watermark.png"}]},
|
|
432
|
+
{'role': 'assistant', 'content': [{"type": "image_url", "image_url": "这是个图片链接"}]},
|
|
433
|
+
|
|
434
|
+
{'role': 'assistant', 'content': [{"type": "image_url", "image_url": "这是个图片链接"}]},
|
|
435
|
+
|
|
436
|
+
{'role': 'user', 'content': [
|
|
437
|
+
{"type": "image_url", "image_url": {"url": "这是个图片链接1"}},
|
|
438
|
+
{"type": "file_url", "file_url": {"url": "这是个file_url"}},
|
|
439
|
+
{"type": "file_url", "file_url": {"url": "这是个file_url"}},
|
|
440
|
+
{"type": "file", "file": "这是个fileid"},
|
|
441
|
+
|
|
442
|
+
{"type": "audio_url", "audio_url": {"url": "这是个file_url"}},
|
|
443
|
+
{"type": "video_url", "video_url": {"url": "这是个video_url"}}
|
|
444
|
+
]},
|
|
445
|
+
|
|
446
|
+
{'role': 'assistant', 'content': [{"type": "image_url", "image_url": "这是个图片链接"}]},
|
|
447
|
+
{'role': 'user', 'content': [
|
|
448
|
+
{"type": "text", "text": "这是个文本"},
|
|
449
|
+
{"type": "image_url", "image_url": "这是个图片链接"}
|
|
450
|
+
]},
|
|
451
|
+
]
|
|
419
452
|
#
|
|
420
453
|
# r = ChatCompletionRequest(model="gpt-3.5-turbo", messages=messages)
|
|
421
454
|
# r.messages[-1]['content'] = [{"type": "image_url", "image_url": {"url": r.urls[-1]}}]
|
|
422
455
|
# print(r)
|
|
423
456
|
|
|
424
|
-
print(chat_completion_chunk)
|
|
425
|
-
print(chat_completion)
|
|
426
|
-
print(chat_completion_chunk_stop)
|
|
457
|
+
# print(chat_completion_chunk)
|
|
458
|
+
# print(chat_completion)
|
|
459
|
+
# print(chat_completion_chunk_stop)
|
|
460
|
+
|
|
461
|
+
# print(CompletionRequest(messages=messages).last_urls)
|
|
462
|
+
print(CompletionRequest(messages=messages).last_user_content)
|
meutils/schemas/yuanbao_types.py
CHANGED
|
@@ -7,6 +7,7 @@
|
|
|
7
7
|
# @WeChat : meutils
|
|
8
8
|
# @Software : PyCharm
|
|
9
9
|
# @Description :
|
|
10
|
+
import pandas as pd
|
|
10
11
|
|
|
11
12
|
from meutils.pipe import *
|
|
12
13
|
|
|
@@ -221,6 +222,7 @@ class SSEData(BaseModel):
|
|
|
221
222
|
|
|
222
223
|
content: str = ""
|
|
223
224
|
reasoning_content: str = ""
|
|
225
|
+
search_content: str = ""
|
|
224
226
|
|
|
225
227
|
image: Optional[str] = None
|
|
226
228
|
|
|
@@ -229,10 +231,11 @@ class SSEData(BaseModel):
|
|
|
229
231
|
def __init__(self, **data):
|
|
230
232
|
super().__init__(**data)
|
|
231
233
|
|
|
232
|
-
logger.debug(self.chunk)
|
|
234
|
+
# logger.debug(self.chunk)
|
|
233
235
|
|
|
234
236
|
chunk = self.chunk.lstrip("data:")
|
|
235
237
|
|
|
238
|
+
content = ""
|
|
236
239
|
if '"type":"progress"' in chunk:
|
|
237
240
|
content = json.loads(chunk).get("msg", "")
|
|
238
241
|
|
|
@@ -254,14 +257,10 @@ class SSEData(BaseModel):
|
|
|
254
257
|
# df['image'] = ""
|
|
255
258
|
|
|
256
259
|
elif '{"type":"think"' in chunk: # 思考中...
|
|
257
|
-
|
|
260
|
+
self.reasoning_content = json.loads(chunk).get("content", "")
|
|
258
261
|
|
|
259
262
|
elif '{"type":"searchGuid"' in chunk: # 思考中...
|
|
260
|
-
|
|
261
|
-
|
|
262
|
-
else:
|
|
263
|
-
content = ""
|
|
264
|
-
# chunk.strip() or logger.debug(chunk) # debug
|
|
263
|
+
self.search_content = json.loads(chunk).get("docs", "")
|
|
265
264
|
|
|
266
265
|
self.content = content
|
|
267
266
|
|
meutils/types.py
CHANGED
meutils/data/oneapi/NOTICE.md
DELETED
|
@@ -1 +0,0 @@
|
|
|
1
|
-
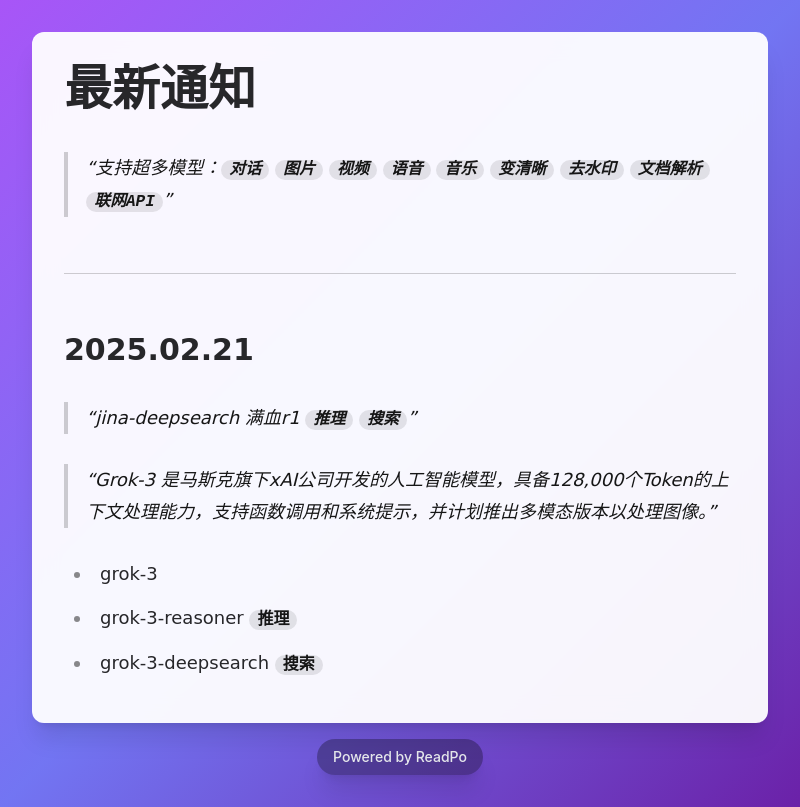
|
meutils/data/oneapi/_NOTICE.md
DELETED
|
@@ -1,140 +0,0 @@
|
|
|
1
|
-
<h1 align = "center">🔥公告🚀</h1>
|
|
2
|
-
|
|
3
|
-
---
|
|
4
|
-
<details markdown="1">
|
|
5
|
-
<summary><b>🔥业务经营范围</b></summary>
|
|
6
|
-
|
|
7
|
-
- api服务(没有的找企微客服增加)
|
|
8
|
-
- 提供主流大模型服务,gpt/claude/gemini/llama/国产大模型等等
|
|
9
|
-
- 提供多模态模型服务,文件解析/图片解析/语音解析/视频解析等等
|
|
10
|
-
- 提供垂类智能体服务,文件问答/联网问答/学术搜索等等
|
|
11
|
-
- 提供语音克隆&语音合成服务,hailuo/fish/chattts等等
|
|
12
|
-
- 提供embedding服务,bge/jina/openai等等
|
|
13
|
-
- 提供图片生成服务,kling/flux/ideogram/recraft/虚拟换衣/换头等等
|
|
14
|
-
- 提供视频生成服务,kling/cogviewx/hailuo/hunyuan/vidu/sora等等
|
|
15
|
-
- 提供图片编辑服务,变清晰、去水印、抠图等等
|
|
16
|
-
- 提供文档智能服务,ocr/pdf-to-markdown/url-to-markdown等等
|
|
17
|
-
- 提供对象存储服务
|
|
18
|
-
|
|
19
|
-
- 账号服务(市面上有的都可以)
|
|
20
|
-
- gpt-plus/claude-pro
|
|
21
|
-
- api-key
|
|
22
|
-
|
|
23
|
-
- 个性化服务
|
|
24
|
-
- 定制同款api聚合站点,一键对接货源
|
|
25
|
-
- 定制企业智能体,类似gpt-4-all/kimi
|
|
26
|
-
- 定制知识库智能问答(RAG)
|
|
27
|
-
- 定制AI类网站/小程序等等
|
|
28
|
-
- 承接数据标注/数据跑批任务
|
|
29
|
-
- 承接大模型微调,定制化大模型(可端到端)
|
|
30
|
-
- 承接其他项目,算法模型等等
|
|
31
|
-
|
|
32
|
-
</details>
|
|
33
|
-
|
|
34
|
-
<details markdown="1">
|
|
35
|
-
<summary><b>大额对公,请联系客服</b></summary>
|
|
36
|
-
</details>
|
|
37
|
-
|
|
38
|
-
## 2025-02-20 新上模型
|
|
39
|
-
- jina-deepsearch 满血r1+搜索
|
|
40
|
-
|
|
41
|
-
|
|
42
|
-
---
|
|
43
|
-
|
|
44
|
-
<details markdown="1">
|
|
45
|
-
<summary><b>历史更新</b></summary>
|
|
46
|
-
|
|
47
|
-
## 2025-01-04
|
|
48
|
-
|
|
49
|
-
- 增加模型配额 gemini-2.0-flash-exp、gemini-2.0-flash-thinking-exp-1219
|
|
50
|
-
|
|
51
|
-
## 2024-12-31
|
|
52
|
-
|
|
53
|
-
- 上线新模型
|
|
54
|
-
- `glm-zero/glm-zero-preview`:GLM-Zero-Preview 专注于增强模型推理能力,擅长处理数理逻辑、代码和需要深度推理的复杂问题。同基座模型相比,GLM-Zero-Preview
|
|
55
|
-
在不显著降低通用任务能力的情况下,在专家任务能力方面表现大幅提升。其在 AIME 2024、MATH500 和 LiveCodeBench 评测中,效果与
|
|
56
|
-
OpenAI-o1-Preview 相当。
|
|
57
|
-
- 兼容SparkAI客户端,文件问答&图片问答:baseurl改为`https://api.chatfire.cn/sparkai/v1`
|
|
58
|
-
|
|
59
|
-
## 2024-12-27
|
|
60
|
-
|
|
61
|
-
- 上线新模型
|
|
62
|
-
- deepseek-v3
|
|
63
|
-
- deepseek-r1:deepseek-v3的思考模型
|
|
64
|
-
- deepseek-search:deepseek-v3的联网模型
|
|
65
|
-
|
|
66
|
-
## 2024-12-24
|
|
67
|
-
|
|
68
|
-
- 上线新模型
|
|
69
|
-
- doubao-pro-256k:相比Doubao-pro-128k/240628,长文任务效果显著提升10%以上,要点提取、字数遵循、多轮对话上文记忆等能力大幅提升
|
|
70
|
-
- [qvq-72b-preview](https://mp.weixin.qq.com/s/WzL7tbFUZOgE2IFMeHT-sQ):Qwen开源视觉推理模型QVQ,更睿智地看世界!
|
|
71
|
-
|
|
72
|
-
- 增加gemini-2.0配额,支持多模型,默认分组可用
|
|
73
|
-
- "gemini-2.0-flash"
|
|
74
|
-
- "gemini-2.0-flash-exp"
|
|
75
|
-
|
|
76
|
-
## 2024-12-20
|
|
77
|
-
|
|
78
|
-
- 修复SunoV4无水印版本
|
|
79
|
-
- [异步任务接口文档](https://api.chatfire.cn/docs/api-246593467)
|
|
80
|
-
- [增加视频解析模型](https://api.chatfire.cn/docs/api-246688638)
|
|
81
|
-
- 增加高并发mj-fast
|
|
82
|
-
|
|
83
|
-
## 2024-12-19
|
|
84
|
-
|
|
85
|
-
- 新增生图模型 SeedEdit(文生图&图生图/图片编辑): 一句话编辑你的世界:字节跳动推出革命性图片编辑工具SeedEdit
|
|
86
|
-
- [Chat模式接口文档](https://api.chatfire.cn/docs/api-214415540)
|
|
87
|
-
- [Images接口文档](https://api.chatfire.cn/docs/api-246137616)
|
|
88
|
-
- [异步任务接口文档](https://api.chatfire.cn/docs/api-246120232)
|
|
89
|
-
- 新增视觉模型
|
|
90
|
-
- deepseek-ai/deepseek-vl2
|
|
91
|
-
- doubao-vision-pro-32k
|
|
92
|
-
- doubao-vision-lite-32k
|
|
93
|
-
- 新增视频模型 Sora
|
|
94
|
-
- Chat模式:`sora-1:1-480p-5s`
|
|
95
|
-
- 异步任务接口在路上
|
|
96
|
-
|
|
97
|
-
## 2024-12-13
|
|
98
|
-
|
|
99
|
-
- 新增模型 混元视频(支持高并发,非逆向可商用,限时特价1毛)[接口文档](https://api.chatfire.cn/docs/api-244309840)
|
|
100
|
-
HunyuanVideo 是腾讯推出的开源视频生成基础模型,拥有超过 130
|
|
101
|
-
亿参数,是目前最大的开源视频生成模型。该模型采用统一的图像和视频生成架构,集成了数据整理、图像-视频联合模型训练和高效基础设施等关键技术。模型使用多模态大语言模型作为文本编码器,通过
|
|
102
|
-
3D VAE 进行空间-时间压缩,并提供提示词重写功能。根据专业人工评估结果,HunyuanVideo 在文本对齐、运动质量和视觉质量等方面的表现优于现有最先进的模型
|
|
103
|
-
|
|
104
|
-
## 2024-12-09
|
|
105
|
-
|
|
106
|
-
- 新增模型
|
|
107
|
-
- meta-llama/Llama-3.3-70B-Instruct: Llama 3.3 是 Llama 系列最先进的多语言开源大型语言模型,以极低成本体验媲美 405B
|
|
108
|
-
模型的性能。基于 Transformer
|
|
109
|
-
结构,并通过监督微调(SFT)和人类反馈强化学习(RLHF)提升有用性和安全性。其指令调优版本专为多语言对话优化,在多项行业基准上表现优于众多开源和封闭聊天模型。知识截止日期为
|
|
110
|
-
2023 年 12 月。
|
|
111
|
-
- jimeng-v2.1:豆包画图,支持即梦超强图像生成能力,兼容chat/dalle-image调用方式。
|
|
112
|
-
- 海螺最新的I2V-01-live图生视频模型:特别针对二次元图生视频效果,进行了优化,动作流畅又生动,让2D二次元角色像复活一样。
|
|
113
|
-
|
|
114
|
-
## 2024-12-06
|
|
115
|
-
|
|
116
|
-
- 新增模型
|
|
117
|
-
- o1-plus: (官网 plus 版本 `逆向工程`,有思考过程显示)o1 是OpenAI针对复杂任务的新推理模型,该任务需要广泛的常识。该模型具有
|
|
118
|
-
200k 上下文,目前全球最强模型,支持图片识别
|
|
119
|
-
- o1-pro: (官网 200刀 plus 版本 `逆向工程`,有思考过程显示)o1-pro 是OpenAI针对复杂任务的新推理模型,该任务需要广泛的常识。该模型具有
|
|
120
|
-
200k 上下文,目前全球最强模型,支持图片识别
|
|
121
|
-
|
|
122
|
-
## 2024-12-05
|
|
123
|
-
|
|
124
|
-
- 新增模型gpt-4-plus/gpt-4o-plus按倍率计算
|
|
125
|
-
> OpenAI-plus会员 逆向工程
|
|
126
|
-
|
|
127
|
-
## 2024-11-29
|
|
128
|
-
|
|
129
|
-
- 新增推理模型
|
|
130
|
-
- Qwen/QwQ-32B-Preview
|
|
131
|
-
> 强大的数学问题解决能力,在AIME、MATH-500数学评测上,超过了OpenAI o1-preview优秀的编码能力,LiveCodeBench接近OpenAI
|
|
132
|
-
o1-preview
|
|
133
|
-
|
|
134
|
-
## 2024-11-25
|
|
135
|
-
|
|
136
|
-
- 新增虚拟换衣接口
|
|
137
|
-
- [可灵官方api格式](https://api.chatfire.cn/docs/api-237182295) 0.8/次
|
|
138
|
-
- [老接口格式](https://api.chatfire.cn/docs/api-226983436) 0.1/次
|
|
139
|
-
|
|
140
|
-
</details>
|