tamil-romanizer 1.0.0 → 1.0.2
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +98 -38
- package/data/exceptions.json +40 -2
- package/package.json +14 -3
- package/src/contextAnalyzer.js +13 -6
- package/src/romanizer.js +34 -11
- package/src/sanitizer.js +5 -2
- package/src/schemeResolver.js +2 -1
- package/src/schemes/practical.js +3 -3
- package/src/specialTokens.js +3 -8
- package/src/tokenizer.js +18 -2
package/README.md
CHANGED
|
@@ -1,16 +1,33 @@
|
|
|
1
|
-
#
|
|
1
|
+
# tamil-romanizer
|
|
2
2
|
|
|
3
|
-
A
|
|
3
|
+
A completely context-aware, highly accurate Tamil-to-English romanization library for Node.js and the browser.
|
|
4
4
|
|
|
5
|
-
|
|
5
|
+
Unlike naive character-replacement scripts that turn `"சிங்கம்"` into `cinkam`, `tamil-romanizer` understands Tamil phonology. It natively handles intervocalic softening, post-nasal voicing, and word-boundaries to produce natural, readable Tanglish (e.g., `"singam"`).
|
|
6
6
|
|
|
7
|
-
|
|
7
|
+
It is fast, rigorously tested (100% ISO compliance), and built for real-world text.
|
|
8
8
|
|
|
9
|
-
|
|
10
|
-
|
|
11
|
-
|
|
12
|
-
|
|
13
|
-
|
|
9
|
+
---
|
|
10
|
+
|
|
11
|
+
## Live Demo
|
|
12
|
+
|
|
13
|
+
Try the engine instantly in your browser: [**Tamil Romanizer Live Demo**](https://haroldalan.github.io/tamil-romanizer/)
|
|
14
|
+
|
|
15
|
+
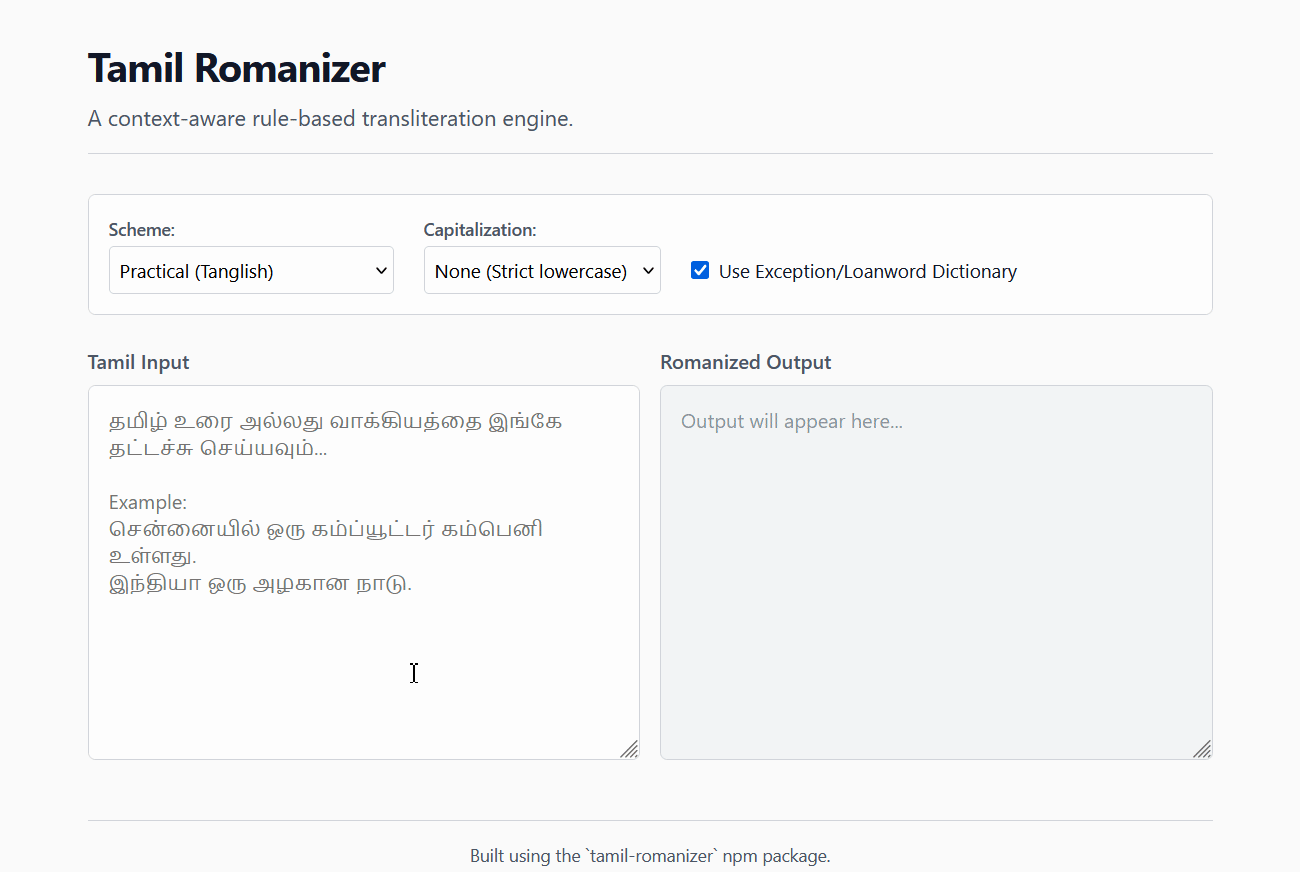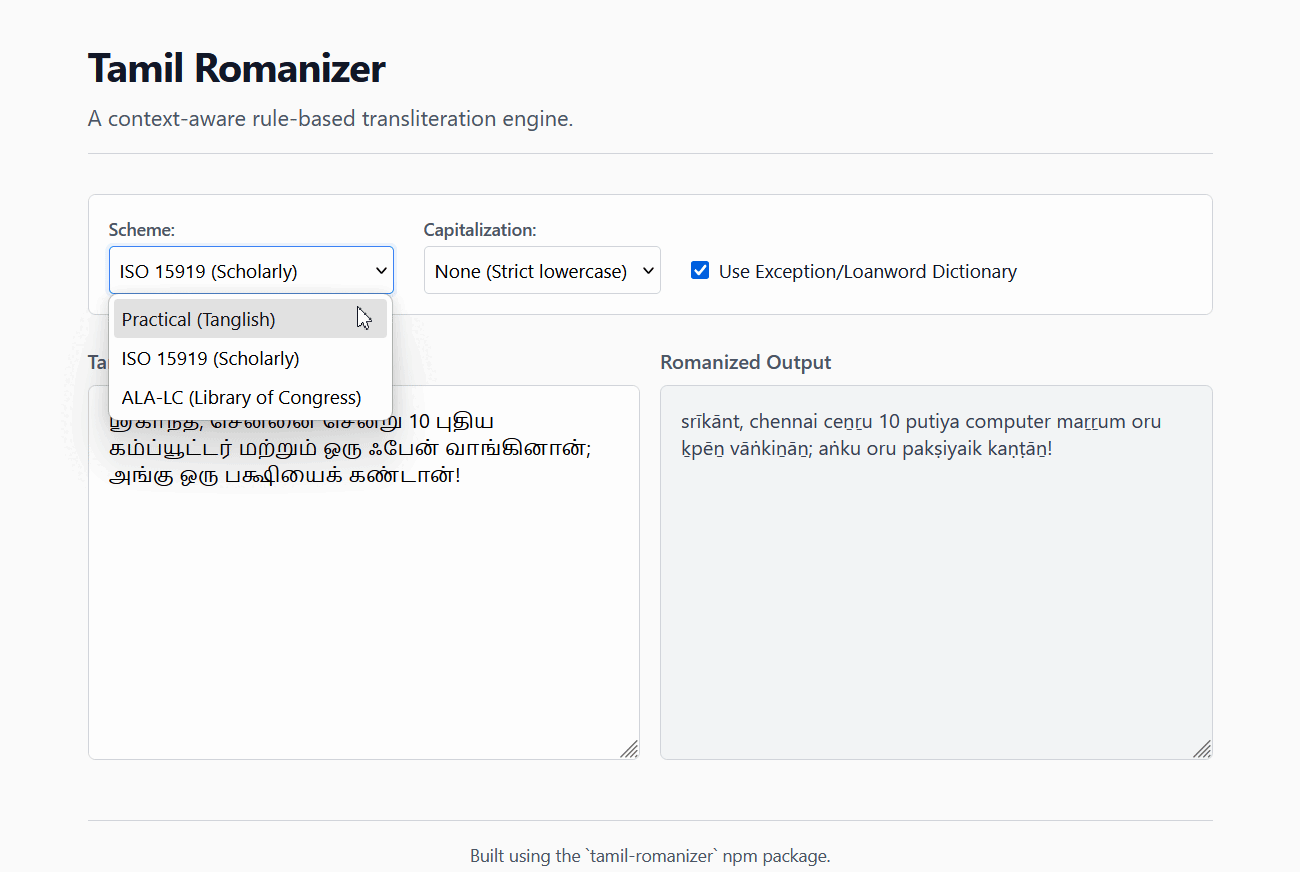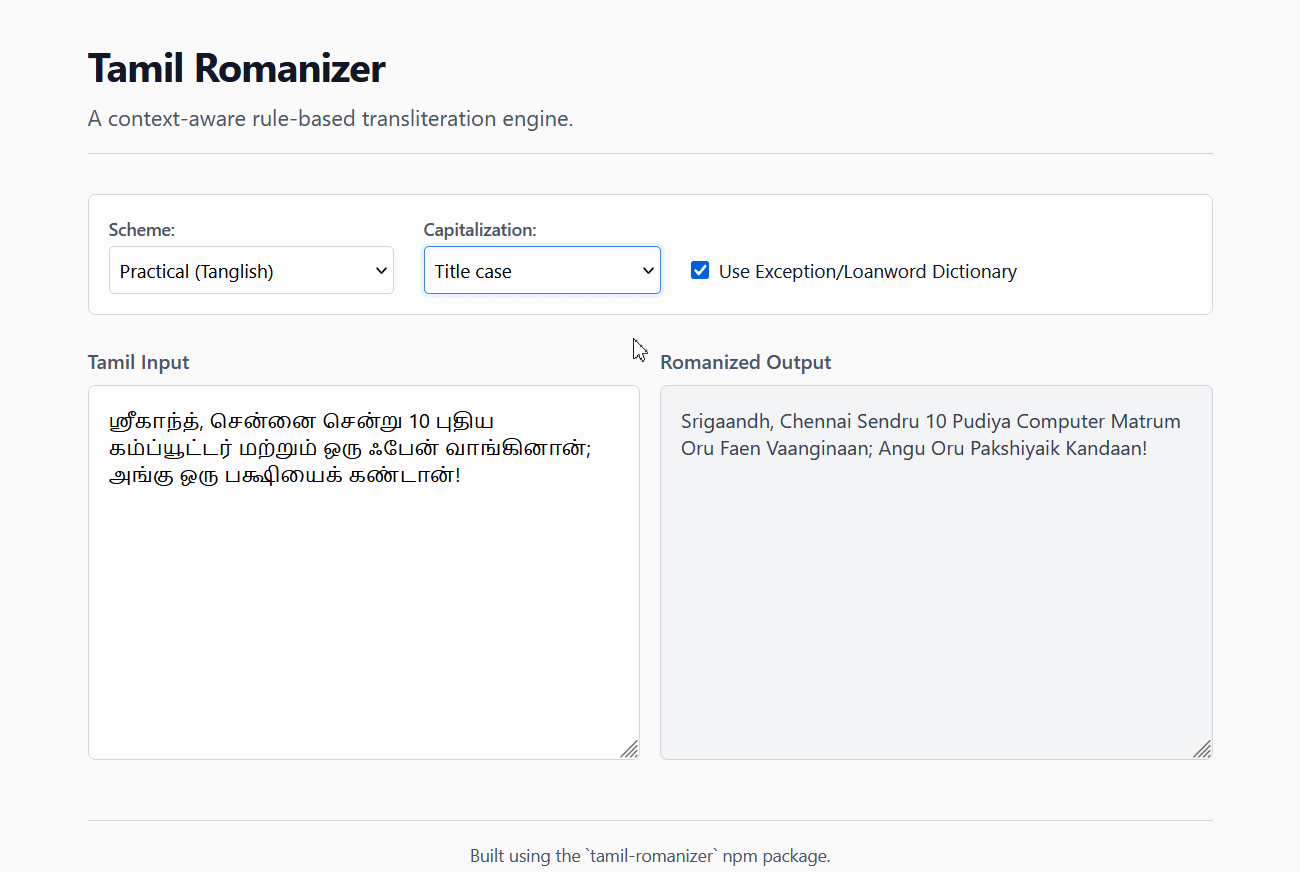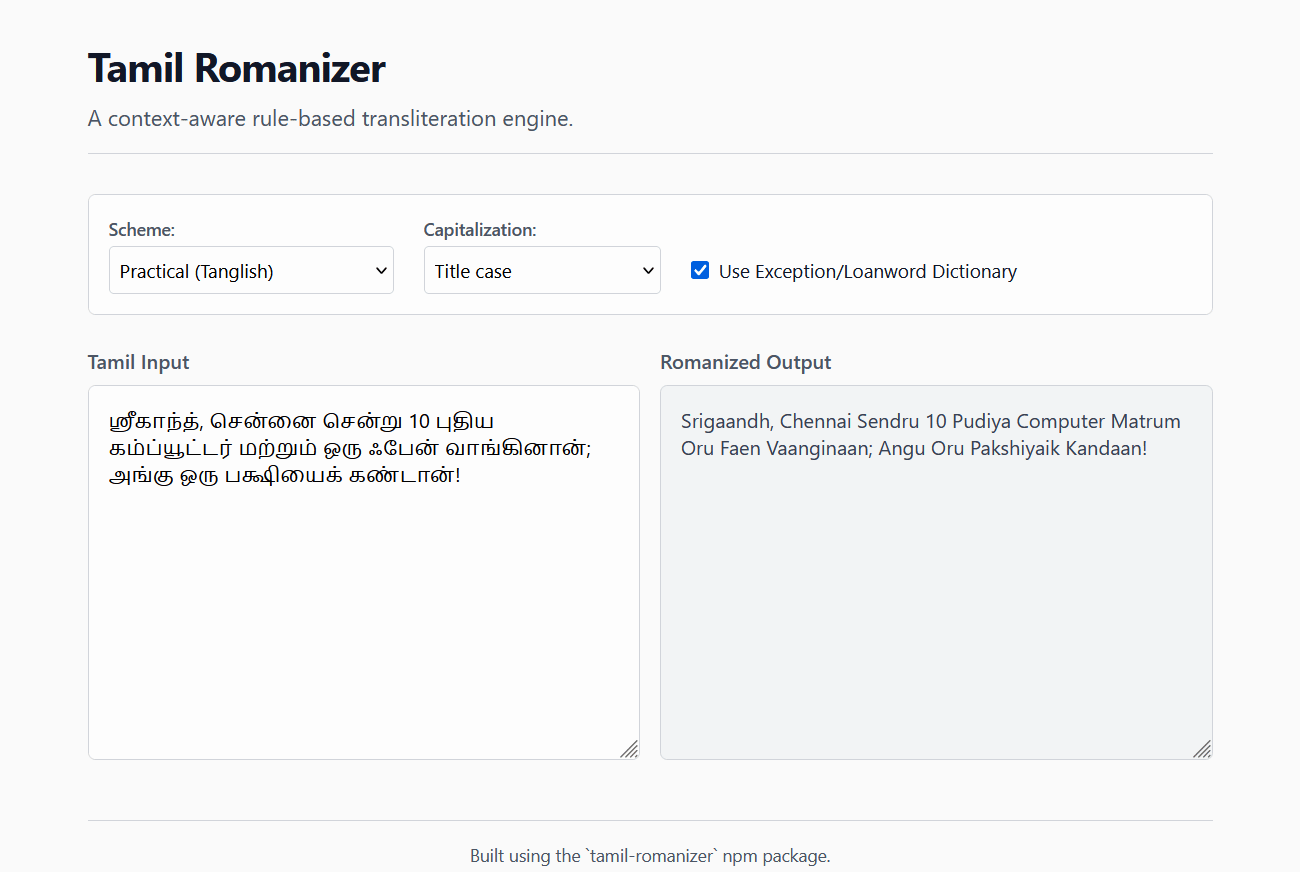
|
|
16
|
+
|
|
17
|
+
---
|
|
18
|
+
|
|
19
|
+
## Why this library?
|
|
20
|
+
|
|
21
|
+
Most Tamil transliteration tools fail because they treat the language as a 1-to-1 character map. Tamil doesn't work that way. `tamil-romanizer` analyzes the context of every letter:
|
|
22
|
+
|
|
23
|
+
| Tamil Input | Naive approach | `tamil-romanizer` | Why? |
|
|
24
|
+
|-------------|----------------|-------------------|------|
|
|
25
|
+
| **ப**ம்பரம் | **p**am**p**aram | **p**am**b**aram | Identifies word-initial `p` vs post-nasal `b` |
|
|
26
|
+
| ச**ட்ட**ம் | sa**t**am | sa**tt**am | Detects geminate (double) consonant clusters |
|
|
27
|
+
| **ஞா**னம் | **ny**anam | **gn**anam | Uses practical Tanglish conventions for word-initials |
|
|
28
|
+
| **ஃ**பேன் | **ak**paen | **f**an | Analyzes Aytham lookaheads and cross-references an internal proper-noun dictionary |
|
|
29
|
+
|
|
30
|
+
---
|
|
14
31
|
|
|
15
32
|
## Installation
|
|
16
33
|
|
|
@@ -18,46 +35,89 @@ Vastly outperforming naive character-replacement scripts, this library implement
|
|
|
18
35
|
npm install tamil-romanizer
|
|
19
36
|
```
|
|
20
37
|
|
|
21
|
-
|
|
38
|
+
---
|
|
22
39
|
|
|
40
|
+
## Quick Start
|
|
23
41
|
```javascript
|
|
24
42
|
import { romanize } from 'tamil-romanizer';
|
|
25
43
|
|
|
26
|
-
// Basic
|
|
27
|
-
|
|
44
|
+
// 1. Basic usage maps to highly accurate practical phonetics
|
|
45
|
+
const text = romanize("தமிழ்நாடு");
|
|
46
|
+
console.log(text); // "tamilnadu" (detected via built-in dictionary)
|
|
47
|
+
|
|
48
|
+
const text2 = romanize("பம்பரம்");
|
|
49
|
+
console.log(text2); // "pambaram" (context-aware mapping)
|
|
50
|
+
```
|
|
51
|
+
|
|
52
|
+
## Advanced Options
|
|
53
|
+
|
|
54
|
+
Provide an `options` object as the second argument to control the output format, scheme, or dictionary usage.
|
|
55
|
+
|
|
56
|
+
### 1. Capitalization Formatting
|
|
57
|
+
|
|
58
|
+
Romanize targets English letters (which have case), while Tamil does not. You can enforce casing rules natively:
|
|
59
|
+
|
|
60
|
+
```javascript
|
|
61
|
+
const sentence = "சென்னை ஒரு அழகான நகரம்";
|
|
62
|
+
|
|
63
|
+
console.log(romanize(sentence));
|
|
64
|
+
// "chennai oru azhagana nagaram" (Default: 'none' - strict lowercase)
|
|
65
|
+
|
|
66
|
+
console.log(romanize(sentence, { capitalize: 'sentence' }));
|
|
67
|
+
// "Chennai oru azhagana nagaram"
|
|
68
|
+
|
|
69
|
+
console.log(romanize(sentence, { capitalize: 'words' }));
|
|
70
|
+
// "Chennai Oru Azhagana Nagaram"
|
|
71
|
+
```
|
|
72
|
+
|
|
73
|
+
### 2. Scholarly Translating (ISO 15919)
|
|
74
|
+
|
|
75
|
+
If you are building an academic tool or require strict, lossless character-level transliteration, use the `iso15919` scheme.
|
|
76
|
+
|
|
77
|
+
```javascript
|
|
78
|
+
// ISO 15919 enforces direct diacritic mapping without contextual softening
|
|
79
|
+
const text = romanize("பம்பரம்", { scheme: 'iso15919', exceptions: false });
|
|
80
|
+
console.log(text); // "pamparam"
|
|
81
|
+
|
|
82
|
+
const strict = romanize("தமிழ்", { scheme: 'iso15919' });
|
|
83
|
+
console.log(strict); // "tamiḻ"
|
|
84
|
+
```
|
|
85
|
+
*(Also supports `ala-lc` schema via `{ scheme: 'ala-lc' }`)*
|
|
86
|
+
|
|
87
|
+
### 3. Turning off the Exception Dictionary
|
|
88
|
+
|
|
89
|
+
The library ships with a fast exception trie that automatically corrects common loan words and proper nouns (e.g. `பஸ்` -> `bus`, `சென்னை` -> `Chennai`).
|
|
28
90
|
|
|
29
|
-
|
|
30
|
-
console.log(romanize("பம்பரம்")); // "pambaram" (Initial P, Post-Nasal B)
|
|
31
|
-
console.log(romanize("சிங்கம்")); // "singam"
|
|
91
|
+
If you want the raw, algorithmic output of the underlying state machine, disable the `exceptions` flag:
|
|
32
92
|
|
|
33
|
-
|
|
34
|
-
|
|
93
|
+
```javascript
|
|
94
|
+
// With dictionary (Default)
|
|
95
|
+
romanize("பஸ்"); // "bus"
|
|
35
96
|
|
|
36
|
-
//
|
|
37
|
-
|
|
97
|
+
// Algorithmic output
|
|
98
|
+
romanize("பஸ்", { exceptions: false }); // "bas"
|
|
38
99
|
```
|
|
39
100
|
|
|
40
|
-
##
|
|
41
|
-
|
|
101
|
+
## Mixed-language Safe
|
|
102
|
+
|
|
103
|
+
Don't worry about sanitizing your inputs. If you pass a string containing English, numbers, emojis, or punctuation, `tamil-romanizer` surgically transliterates *only* the Tamil characters and leaves everything else perfectly intact.
|
|
42
104
|
|
|
43
|
-
|
|
44
|
-
|
|
45
|
-
|
|
105
|
+
```javascript
|
|
106
|
+
const mixed = "The ticket price is ௫௦௦ rupees (ரூபாய்) 🤯!";
|
|
107
|
+
console.log(romanize(mixed));
|
|
108
|
+
// "The ticket price is 500 rupees (roobaay) 🤯!"
|
|
109
|
+
```
|
|
110
|
+
*(Notice how it also safely converts native Tamil numerals natively!)*
|
|
46
111
|
|
|
47
|
-
##
|
|
112
|
+
## API Reference
|
|
48
113
|
|
|
49
|
-
|
|
50
|
-
2. **Cluster Tokenizer:** Uses `Intl.Segmenter` to split graphemes accurately.
|
|
51
|
-
3. **Decomposer:** Maps bases and vowel modifiers distinctively.
|
|
52
|
-
4. **Context Analyzer:** Positional tagging (Word Initial, Intervocalic, Geminate, Post-Nasal).
|
|
53
|
-
5. **Scheme Resolver:** Base lookup to targeted transliteration schema (`iso15919`, `practical`, `ala-lc`).
|
|
54
|
-
6. **Special Token Handler:** Cross-cluster constraints (Aytham lookaheads, Grantha sequence transformations).
|
|
55
|
-
7. **Exception Trie:** Fast dictionary overrides.
|
|
114
|
+
`romanize(text: string, options?: Object) => string`
|
|
56
115
|
|
|
57
|
-
|
|
58
|
-
|
|
59
|
-
|
|
60
|
-
|
|
61
|
-
|
|
62
|
-
2. Run `node test/stress/evaluate.js`
|
|
116
|
+
| Option | Type | Default | Description |
|
|
117
|
+
|---|---|---|---|
|
|
118
|
+
| `scheme` | `'practical' \| 'iso15919' \| 'ala-lc'` | `'practical'` | Determines the transliteration ruleset. |
|
|
119
|
+
| `exceptions` | `boolean` | `true` | Enables/disables the internal dictionary for loan words. |
|
|
120
|
+
| `capitalize` | `'none' \| 'sentence' \| 'words'` | `'none'` | Controls the casing of the returned string. |
|
|
63
121
|
|
|
122
|
+
---
|
|
123
|
+
*Built for Tamil by Harold Alan.*
|
package/data/exceptions.json
CHANGED
|
@@ -1,9 +1,47 @@
|
|
|
1
1
|
{
|
|
2
2
|
"சென்னை": "Chennai",
|
|
3
|
-
"தமிழ்நாடு": "
|
|
3
|
+
"தமிழ்நாடு": "Tamilnadu",
|
|
4
4
|
"கோயம்புத்தூர்": "Coimbatore",
|
|
5
5
|
"மதுரை": "Madurai",
|
|
6
|
+
"தஞ்சாவூர்": "Thanjavur",
|
|
7
|
+
"திருச்சி": "Trichy",
|
|
8
|
+
"திருச்சிராப்பள்ளி": "Tiruchirappalli",
|
|
9
|
+
"சேலம்": "Salem",
|
|
10
|
+
"திருப்பூர்": "Tiruppur",
|
|
11
|
+
"நெல்லை": "Nellai",
|
|
12
|
+
"திருநெல்வேலி": "Tirunelveli",
|
|
13
|
+
"கன்னியாகுமரி": "Kanyakumari",
|
|
14
|
+
"பெங்களூர்": "Bangalore",
|
|
15
|
+
"கேரளா": "Kerala",
|
|
16
|
+
"மும்பை": "Mumbai",
|
|
17
|
+
"டெல்லி": "Delhi",
|
|
18
|
+
"கல்கத்தா": "Kolkata",
|
|
19
|
+
"இந்தியா": "India",
|
|
20
|
+
"அமெரிக்கா": "America",
|
|
21
|
+
"லண்டன்": "London",
|
|
6
22
|
"பஸ்": "bus",
|
|
23
|
+
"கார்": "car",
|
|
24
|
+
"லாரி": "lorry",
|
|
25
|
+
"ரயில்": "rail",
|
|
26
|
+
"பிளைட்": "flight",
|
|
7
27
|
"டீ": "tea",
|
|
8
|
-
"
|
|
28
|
+
"காபி": "coffee",
|
|
29
|
+
"டிபன்": "tiffin",
|
|
30
|
+
"ஹோட்டல்": "hotel",
|
|
31
|
+
"டாக்டர்": "doctor",
|
|
32
|
+
"போலீஸ்": "police",
|
|
33
|
+
"ஸ்டேஷன்": "station",
|
|
34
|
+
"கம்ப்யூட்டர்": "computer",
|
|
35
|
+
"இன்டர்நெட்": "internet",
|
|
36
|
+
"வாட்ஸ்அப்": "whatsapp",
|
|
37
|
+
"பேஸ்புக்": "facebook",
|
|
38
|
+
"யூடியூப்": "youtube",
|
|
39
|
+
"சினிமா": "cinema",
|
|
40
|
+
"டிக்கெட்": "ticket",
|
|
41
|
+
"ஹீரோ": "hero",
|
|
42
|
+
"டிவி": "TV",
|
|
43
|
+
"பேங்க்": "bank",
|
|
44
|
+
"போன்": "phone",
|
|
45
|
+
"ஃபேக்டரி": "factory",
|
|
46
|
+
"ஆபீஸ்": "office"
|
|
9
47
|
}
|
package/package.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
{
|
|
2
2
|
"name": "tamil-romanizer",
|
|
3
|
-
"version": "1.0.
|
|
4
|
-
"description": "Tamil
|
|
3
|
+
"version": "1.0.2",
|
|
4
|
+
"description": "A robust, context-aware rule-based Tamil-to-English romanization library",
|
|
5
5
|
"main": "index.js",
|
|
6
6
|
"type": "module",
|
|
7
7
|
"scripts": {
|
|
@@ -9,9 +9,20 @@
|
|
|
9
9
|
},
|
|
10
10
|
"keywords": [
|
|
11
11
|
"tamil",
|
|
12
|
+
"tamil_extended",
|
|
13
|
+
"tamil_superscripted",
|
|
14
|
+
"phonetic",
|
|
12
15
|
"romanizer",
|
|
13
|
-
"
|
|
16
|
+
"romanization",
|
|
17
|
+
"transliteration",
|
|
18
|
+
"indic-scripts",
|
|
19
|
+
"nlp",
|
|
20
|
+
"unicode",
|
|
21
|
+
"iso15919",
|
|
22
|
+
"ala-lc",
|
|
23
|
+
"practical"
|
|
14
24
|
],
|
|
25
|
+
"repository": "github:haroldalan/tamil-romanizer",
|
|
15
26
|
"author": "Harold Alan",
|
|
16
27
|
"license": "ISC",
|
|
17
28
|
"files": [
|
package/src/contextAnalyzer.js
CHANGED
|
@@ -6,6 +6,7 @@ export const contextTags = {
|
|
|
6
6
|
GEMINATE: 'GEMINATE',
|
|
7
7
|
POST_NASAL: 'POST_NASAL',
|
|
8
8
|
INTERVOCALIC: 'INTERVOCALIC',
|
|
9
|
+
FRICATIVE_MUTATED: 'FRICATIVE_MUTATED',
|
|
9
10
|
WORD_FINAL: 'WORD_FINAL',
|
|
10
11
|
DEFAULT: 'DEFAULT'
|
|
11
12
|
};
|
|
@@ -48,10 +49,12 @@ export function analyzeContext(tokens) {
|
|
|
48
49
|
|
|
49
50
|
// Determine word boundaries.
|
|
50
51
|
// A token is word initial if it's the very first token in the string,
|
|
51
|
-
// OR if the previous token was a space/punctuation
|
|
52
|
-
const isWordInitial = index === 0 ||
|
|
52
|
+
// OR if the previous token was a space/punctuation
|
|
53
|
+
const isWordInitial = index === 0 ||
|
|
54
|
+
(prevToken && (prevToken.type === tokenTypes.WHITESPACE || prevToken.type === tokenTypes.PUNCTUATION || prevToken.type === tokenTypes.OTHER));
|
|
53
55
|
|
|
54
|
-
const isWordFinal = index === tokens.length - 1 ||
|
|
56
|
+
const isWordFinal = index === tokens.length - 1 ||
|
|
57
|
+
(nextToken && (nextToken.type === tokenTypes.WHITESPACE || nextToken.type === tokenTypes.PUNCTUATION || nextToken.type === tokenTypes.OTHER));
|
|
55
58
|
|
|
56
59
|
if (isWordInitial) {
|
|
57
60
|
tag = contextTags.WORD_INITIAL;
|
|
@@ -69,11 +72,15 @@ export function analyzeContext(tokens) {
|
|
|
69
72
|
else if (prevToken && prevToken.modifierType === modifierTypes.VIRAMA && nasals.includes(prevToken.base)) {
|
|
70
73
|
tag = contextTags.POST_NASAL;
|
|
71
74
|
}
|
|
72
|
-
// 3.
|
|
73
|
-
else if (
|
|
75
|
+
// 3. FRICATIVE_MUTATED: Immediately preceded by an AYTHAM token (ஃ) AND current base is ப or ஜ
|
|
76
|
+
else if (prevToken && prevToken.type === tokenTypes.AYTHAM && (token.base === 'ப' || token.base === 'ஜ')) {
|
|
77
|
+
tag = contextTags.FRICATIVE_MUTATED;
|
|
78
|
+
}
|
|
79
|
+
// 4. INTERVOCALIC: Preceding cluster holds a vowel AND current cluster's modifier is not VIRAMA
|
|
80
|
+
else if (carriesVowel(prevToken) && token.modifierType !== modifierTypes.VIRAMA) {
|
|
74
81
|
tag = contextTags.INTERVOCALIC;
|
|
75
82
|
}
|
|
76
|
-
//
|
|
83
|
+
// 5. WORD_FINAL: Last cluster in a word
|
|
77
84
|
else if (isWordFinal) {
|
|
78
85
|
tag = contextTags.WORD_FINAL;
|
|
79
86
|
}
|
package/src/romanizer.js
CHANGED
|
@@ -46,28 +46,51 @@ export function romanize(text, options = {}) {
|
|
|
46
46
|
const cleanText = sanitize(text);
|
|
47
47
|
if (!cleanText) return '';
|
|
48
48
|
|
|
49
|
+
// Tokenize the ENTIRE string first. This fixes punctuation and spaces breaking the Trie.
|
|
50
|
+
const allTokens = tokenize(cleanText);
|
|
51
|
+
|
|
52
|
+
// We group tokens into "words" bounded by whitespace and punctuation.
|
|
53
|
+
// E.g., "சென்னை," -> word chunk: "சென்னை", punctuation chunk: ","
|
|
54
|
+
const chunks = [];
|
|
55
|
+
let currentChunk = [];
|
|
56
|
+
|
|
57
|
+
for (const token of allTokens) {
|
|
58
|
+
if (token.type === 'whitespace' || token.type === 'punctuation' || token.type === 'other') {
|
|
59
|
+
if (currentChunk.length > 0) {
|
|
60
|
+
chunks.push({ type: 'word', tokens: currentChunk });
|
|
61
|
+
currentChunk = [];
|
|
62
|
+
}
|
|
63
|
+
chunks.push({ type: 'separator', tokens: [token] });
|
|
64
|
+
} else {
|
|
65
|
+
currentChunk.push(token);
|
|
66
|
+
}
|
|
67
|
+
}
|
|
68
|
+
if (currentChunk.length > 0) {
|
|
69
|
+
chunks.push({ type: 'word', tokens: currentChunk });
|
|
70
|
+
}
|
|
71
|
+
|
|
49
72
|
let outputWords = [];
|
|
50
|
-
// Tokenize by spaces to apply whole-word Exception Trie natively
|
|
51
|
-
const words = cleanText.split(/(\s+)/);
|
|
52
73
|
|
|
53
|
-
for (const
|
|
54
|
-
if (
|
|
55
|
-
outputWords.push({ text:
|
|
74
|
+
for (const chunk of chunks) {
|
|
75
|
+
if (chunk.type === 'separator') {
|
|
76
|
+
outputWords.push({ text: chunk.tokens[0].text, isException: false });
|
|
56
77
|
continue;
|
|
57
78
|
}
|
|
58
79
|
|
|
59
|
-
//
|
|
80
|
+
// Reconstruct the raw text of the Tamil word for Trie lookup
|
|
81
|
+
const wordText = chunk.tokens.map(t => t.text).join('');
|
|
82
|
+
|
|
83
|
+
// Step 2. Exception Trie Intercept (Right after Layer 1 chunking)
|
|
60
84
|
if (exceptions) {
|
|
61
|
-
const hardMatch = exceptionDictionary.lookup(
|
|
85
|
+
const hardMatch = exceptionDictionary.lookup(wordText);
|
|
62
86
|
if (hardMatch) {
|
|
63
87
|
outputWords.push({ text: hardMatch, isException: true });
|
|
64
|
-
continue;
|
|
88
|
+
continue; // Bypass Layers 2-5 for this chunk completely
|
|
65
89
|
}
|
|
66
90
|
}
|
|
67
91
|
|
|
68
|
-
// Pipeline Execution
|
|
69
|
-
const
|
|
70
|
-
const decomposed = decompose(tokens);
|
|
92
|
+
// Pipeline Execution for non-exception clusters
|
|
93
|
+
const decomposed = decompose(chunk.tokens);
|
|
71
94
|
const analyzed = analyzeContext(decomposed);
|
|
72
95
|
const resolved = resolveScheme(analyzed, scheme, table);
|
|
73
96
|
const finalizedWord = handleSpecialTokens(resolved, scheme);
|
package/src/sanitizer.js
CHANGED
|
@@ -10,8 +10,11 @@ export function sanitize(text) {
|
|
|
10
10
|
if (typeof text !== 'string') return '';
|
|
11
11
|
|
|
12
12
|
return text
|
|
13
|
-
// 1. ZWJ (U+200D) / ZWNJ (U+200C) removal
|
|
14
|
-
|
|
13
|
+
// 1. ZWJ (U+200D) / ZWNJ (U+200C) removal ONLY when adjacent to Tamil text
|
|
14
|
+
// We match any Tamil character (U+0B80-U+0BFF) followed optionally by ZWJ/ZWNJ repeatedly
|
|
15
|
+
// to strictly scope the removal and prevent corrupting Malayalam text.
|
|
16
|
+
.replace(/([\u0B80-\u0BFF])[\u200C\u200D]+/g, '$1')
|
|
17
|
+
.replace(/[\u200C\u200D]+([\u0B80-\u0BFF])/g, '$1')
|
|
15
18
|
|
|
16
19
|
// 2. ஸ்ரீ (Sri) canonicalization
|
|
17
20
|
// Normalize variant `ஶ்ரீ` (U+0BB6) to canonical `ஸ்ரீ` (U+0BB8)
|
package/src/schemeResolver.js
CHANGED
package/src/schemes/practical.js
CHANGED
|
@@ -8,8 +8,8 @@ export default {
|
|
|
8
8
|
'க': { DEFAULT: 'k', INTERVOCALIC: 'g', POST_NASAL: 'g', GEMINATE: 'kk' },
|
|
9
9
|
'ச': { DEFAULT: 's', WORD_INITIAL: 's', INTERVOCALIC: 's', POST_NASAL: 'j', GEMINATE: 'chch' },
|
|
10
10
|
'ட': { DEFAULT: 't', INTERVOCALIC: 'd', POST_NASAL: 'd', GEMINATE: 'tt' },
|
|
11
|
-
'த': { DEFAULT: 'th', INTERVOCALIC: 'd', POST_NASAL: '
|
|
12
|
-
'ப': { DEFAULT: 'p', INTERVOCALIC: 'b', POST_NASAL: 'b', GEMINATE: 'pp' },
|
|
11
|
+
'த': { DEFAULT: 'th', INTERVOCALIC: 'd', POST_NASAL: 'dh', GEMINATE: 'tth' },
|
|
12
|
+
'ப': { DEFAULT: 'p', INTERVOCALIC: 'b', POST_NASAL: 'b', GEMINATE: 'pp', FRICATIVE_MUTATED: 'f' },
|
|
13
13
|
'ற': { DEFAULT: 'r', INTERVOCALIC: 'r', POST_NASAL: 'dr', GEMINATE: 'tr' },
|
|
14
14
|
// Nasals and other consonants that change based on context or position
|
|
15
15
|
'ங': { DEFAULT: 'n', WORD_INITIAL: 'ng' },
|
|
@@ -26,7 +26,7 @@ export default {
|
|
|
26
26
|
'ர': { DEFAULT: 'r' },
|
|
27
27
|
'வ': { DEFAULT: 'v' },
|
|
28
28
|
// Grantha mappings standard for practical
|
|
29
|
-
'ஜ': { DEFAULT: 'j' },
|
|
29
|
+
'ஜ': { DEFAULT: 'j', FRICATIVE_MUTATED: 'z' },
|
|
30
30
|
'ஷ': { DEFAULT: 'sh' },
|
|
31
31
|
'ஸ': { DEFAULT: 's' },
|
|
32
32
|
'ஹ': { DEFAULT: 'h' }
|
package/src/specialTokens.js
CHANGED
|
@@ -22,14 +22,9 @@ export function handleSpecialTokens(resolvedTokens, schemeName = 'practical') {
|
|
|
22
22
|
const nextToken = resolvedTokens[i + 1];
|
|
23
23
|
|
|
24
24
|
if (isPractical) {
|
|
25
|
-
|
|
26
|
-
|
|
27
|
-
|
|
28
|
-
} else if (nextToken && nextToken.base === 'ஜ') {
|
|
29
|
-
// Replace 'j' with 'z' in the next token's romanization
|
|
30
|
-
nextToken.romanized = nextToken.romanized.replace(/^j/i, 'z');
|
|
31
|
-
}
|
|
32
|
-
// For other cases or standalone 'ஃ', it's omitted in practical scheme, so nothing is added to outputString here.
|
|
25
|
+
// In practical scheme, the Āytham token itself is dropped silently.
|
|
26
|
+
// The subsequent base ('ப' or 'ஜ') has already been mutated by Layer 3 + Layer 4 to 'f' or 'z'.
|
|
27
|
+
// So we do nothing to outputString here.
|
|
33
28
|
} else {
|
|
34
29
|
// ISO 15919
|
|
35
30
|
outputString += 'ḵ';
|
package/src/tokenizer.js
CHANGED
|
@@ -5,7 +5,11 @@ export const tokenTypes = {
|
|
|
5
5
|
CONSONANT_VIRAMA: 'consonant_virama',
|
|
6
6
|
CONSONANT_VOWEL_SIGN: 'consonant_vowel_sign',
|
|
7
7
|
CONSONANT_BARE: 'consonant_bare',
|
|
8
|
-
|
|
8
|
+
AYTHAM: 'aytham',
|
|
9
|
+
WHITESPACE: 'whitespace',
|
|
10
|
+
NUMERAL: 'numeral',
|
|
11
|
+
PUNCTUATION: 'punctuation',
|
|
12
|
+
OTHER: 'other' // non-tamil
|
|
9
13
|
};
|
|
10
14
|
|
|
11
15
|
// Vowels (அ to ஔ) U+0B85 to U+0B94
|
|
@@ -29,6 +33,10 @@ const isVowelSign = (char) => {
|
|
|
29
33
|
return code >= 0x0BBE && code <= 0x0BCD && code !== 0x0BCD; // Exclude virama explicitly
|
|
30
34
|
};
|
|
31
35
|
|
|
36
|
+
const isWhitespace = (str) => /^\s+$/.test(str);
|
|
37
|
+
const isNumeral = (str) => /^\d+$/.test(str) || /^[\u0BE6-\u0BEF]+$/.test(str); // matches 0-9 and tamil numerals
|
|
38
|
+
const isPunctuation = (str) => /^[.,/#!$%^&*;:{}=\-_`~()""'']+$/.test(str);
|
|
39
|
+
|
|
32
40
|
/**
|
|
33
41
|
* Tokenizes a sanitized Tamil string into grapheme clusters.
|
|
34
42
|
*
|
|
@@ -43,7 +51,15 @@ export function tokenize(text) {
|
|
|
43
51
|
let type = tokenTypes.OTHER;
|
|
44
52
|
|
|
45
53
|
// Check classification based on first character and any modifiers
|
|
46
|
-
if (segment
|
|
54
|
+
if (segment === 'ஃ') {
|
|
55
|
+
type = tokenTypes.AYTHAM;
|
|
56
|
+
} else if (isWhitespace(segment)) {
|
|
57
|
+
type = tokenTypes.WHITESPACE;
|
|
58
|
+
} else if (isNumeral(segment)) {
|
|
59
|
+
type = tokenTypes.NUMERAL;
|
|
60
|
+
} else if (isPunctuation(segment)) {
|
|
61
|
+
type = tokenTypes.PUNCTUATION;
|
|
62
|
+
} else if (segment.length === 1) {
|
|
47
63
|
if (isVowel(segment)) {
|
|
48
64
|
type = tokenTypes.VOWEL;
|
|
49
65
|
} else if (isConsonant(segment)) {
|