pi-smart-fetch 0.2.22 → 0.2.24
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +60 -197
- package/package.json +1 -1
package/README.md
CHANGED
|
@@ -1,30 +1,33 @@
|
|
|
1
1
|
# pi-smart-fetch
|
|
2
2
|
|
|
3
|
-
`pi-smart-fetch` adds
|
|
3
|
+
`pi-smart-fetch` adds smarter web fetching tools to pi.dev.
|
|
4
4
|
|
|
5
|
-

|
|
6
|
-
|
|
7
|
-
Registers 2 tools:
|
|
8
|
-
- `web_fetch`
|
|
9
|
-
- `batch_web_fetch`
|
|
5
|
+
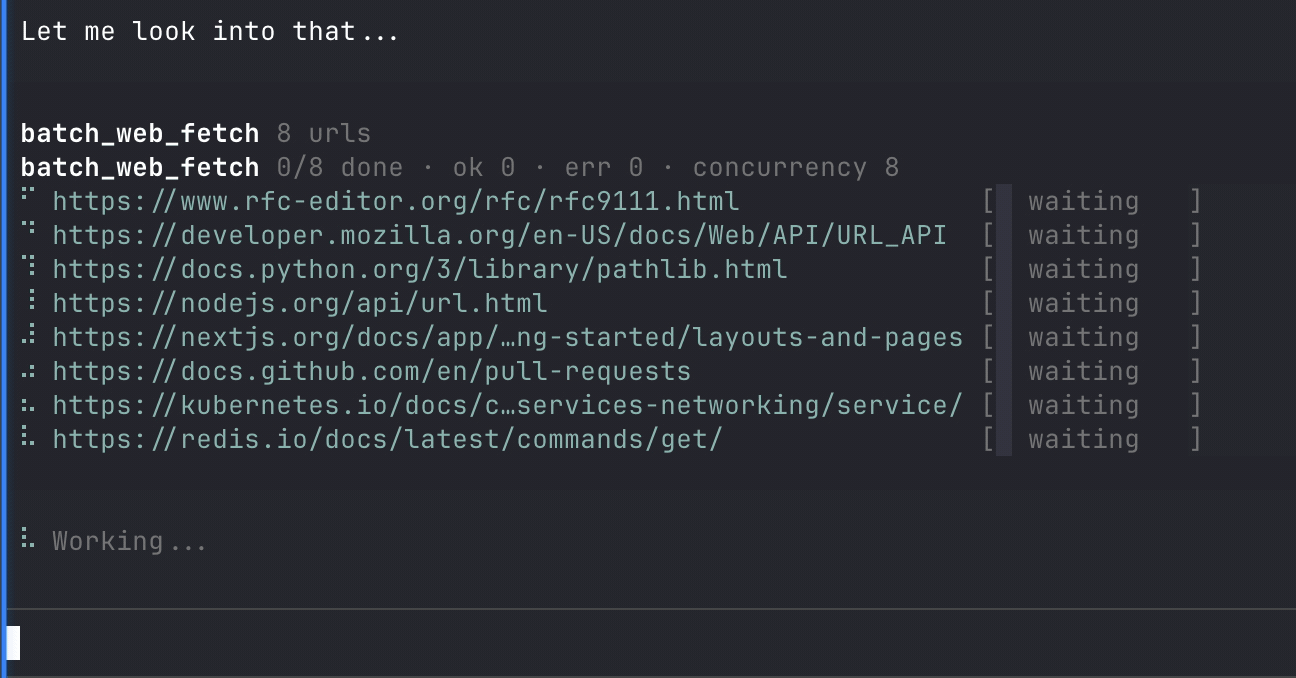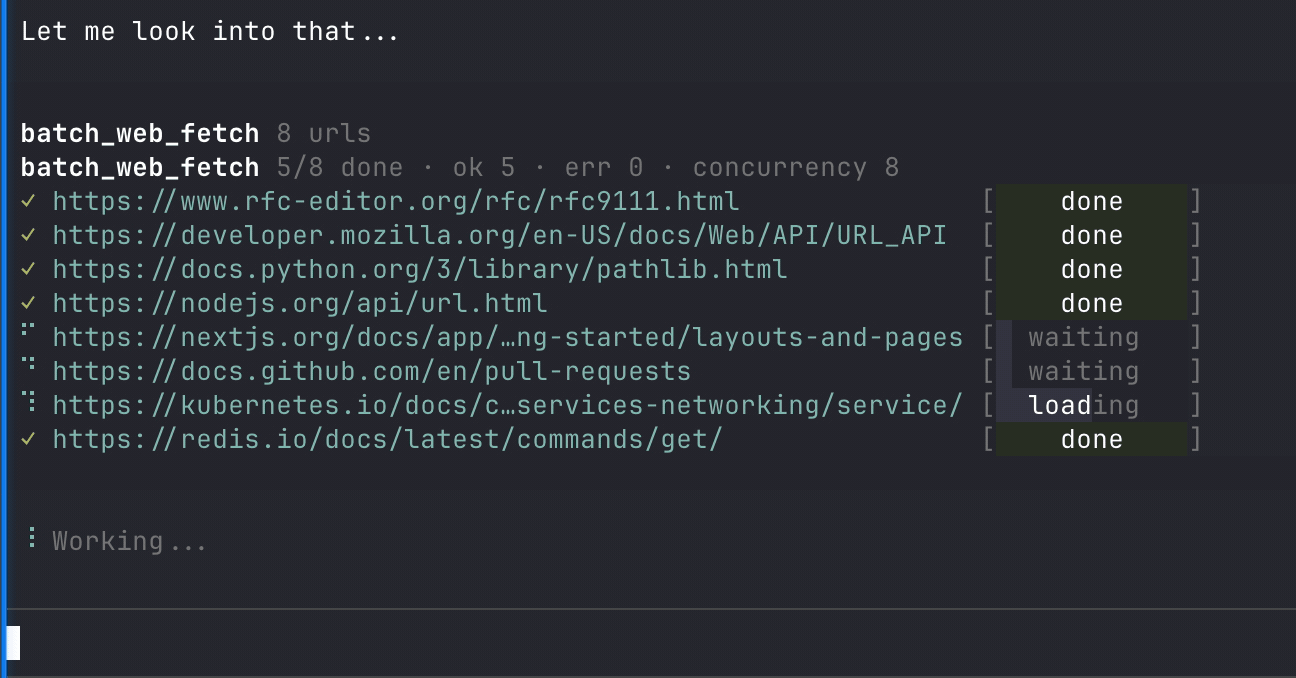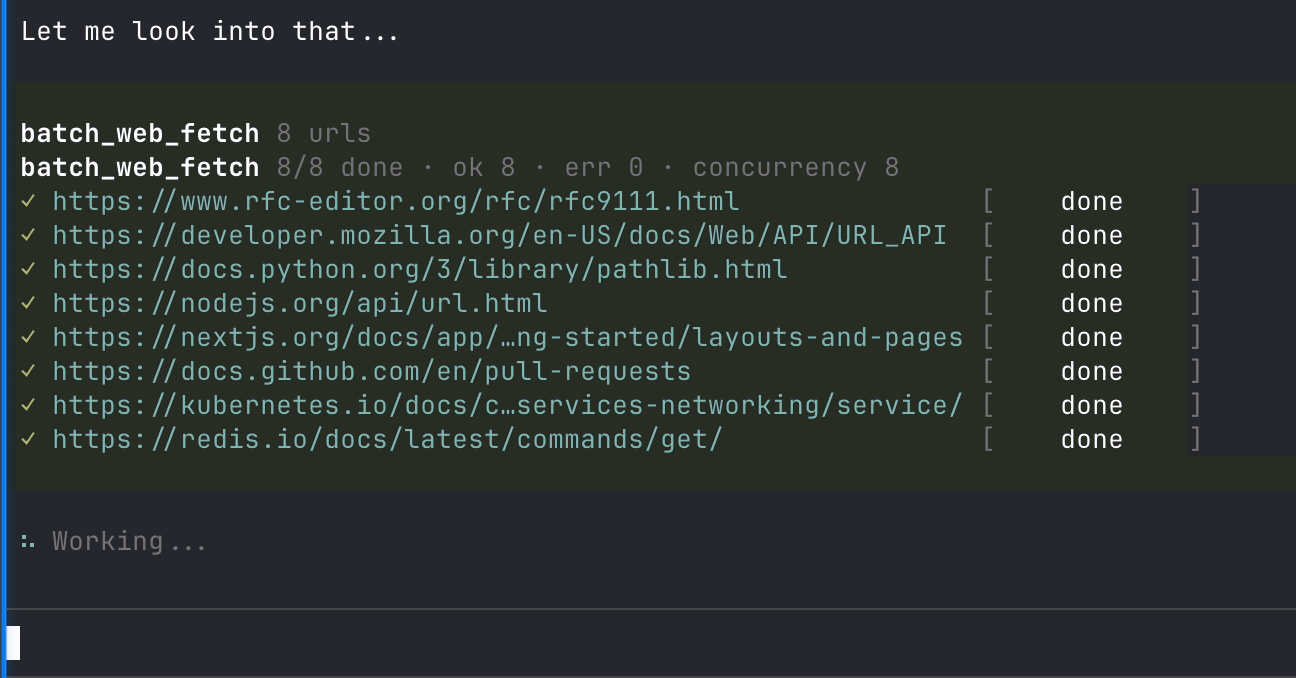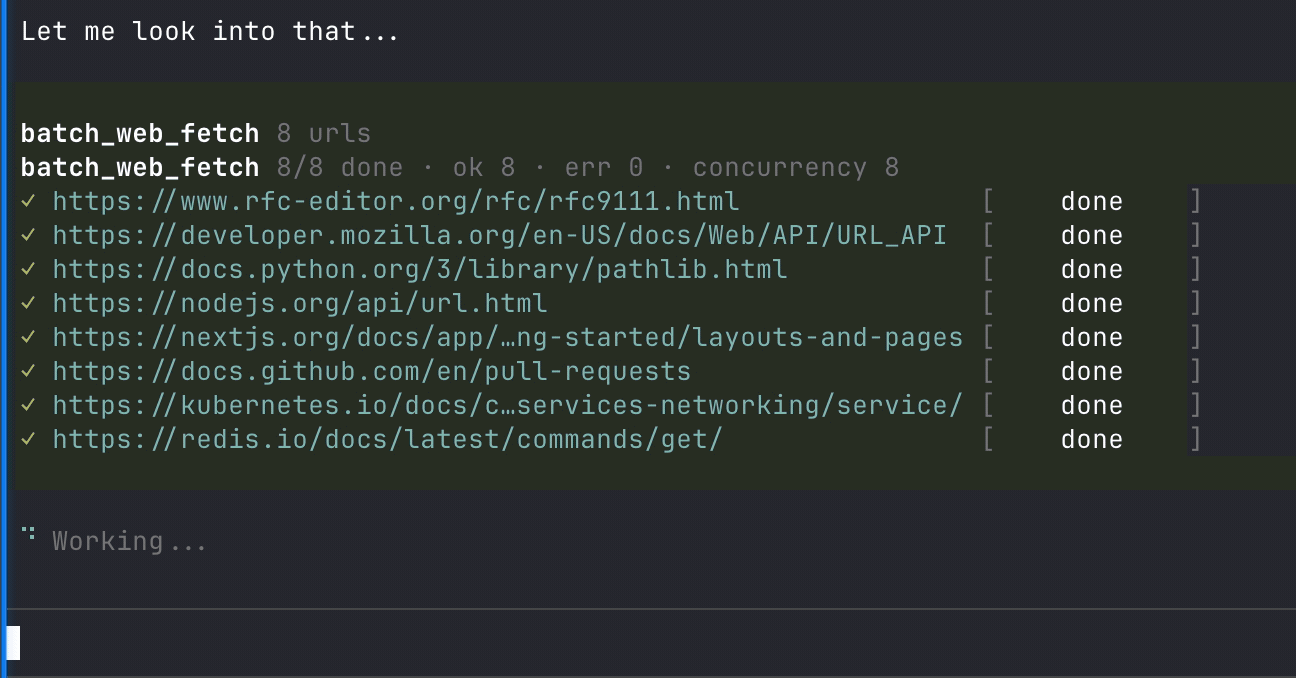
|
|
10
6
|
|
|
11
7
|
## Features
|
|
12
8
|
|
|
13
|
-
|
|
14
|
-
- **
|
|
15
|
-
- **
|
|
16
|
-
- **
|
|
17
|
-
- **
|
|
18
|
-
- **
|
|
19
|
-
|
|
20
|
-
|
|
21
|
-
|
|
22
|
-
|
|
23
|
-
|
|
24
|
-
-
|
|
25
|
-
-
|
|
26
|
-
-
|
|
27
|
-
-
|
|
9
|
+
- 🔐 **Browser-like TLS/SSL + HTTP fingerprints** — better success on bot-defended pages
|
|
10
|
+
- 🧹 **Defuddle extraction** — clean readable content instead of noisy HTML
|
|
11
|
+
- 🧠 **Useful metadata** — title, author, site, language, published date when available
|
|
12
|
+
- 📦 **Downloads + large file support** — stream attachments and binaries to temp files
|
|
13
|
+
- ⚡ **Batch fetch** — fetch many URLs with bounded concurrency
|
|
14
|
+
- 📝 **Multiple output formats** — `markdown`, `html`, `text`, `json`
|
|
15
|
+
|
|
16
|
+
## Site optimisations
|
|
17
|
+
|
|
18
|
+
This package works on general web pages, but some site types benefit especially from Defuddle's extractors and cleanup:
|
|
19
|
+
|
|
20
|
+
- YouTube pages and transcripts
|
|
21
|
+
- Reddit posts and comment threads
|
|
22
|
+
- X / Twitter posts
|
|
23
|
+
- GitHub pages, issues, PRs, and discussions
|
|
24
|
+
- Hacker News threads
|
|
25
|
+
- Substack posts
|
|
26
|
+
- Pages with code blocks, footnotes, math, and callouts
|
|
27
|
+
|
|
28
|
+
Notes:
|
|
29
|
+
- Defuddle is the cleanup layer: it strips common page chrome like nav, sidebars, related links, share widgets, and footers
|
|
30
|
+
- It does **not** execute JavaScript or solve interactive anti-bot/login flows
|
|
28
31
|
|
|
29
32
|
## Install
|
|
30
33
|
|
|
@@ -41,163 +44,38 @@ gh repo clone Thinkscape/agent-smart-fetch
|
|
|
41
44
|
pi install agent-smart-fetch/packages/pi-smart-fetch
|
|
42
45
|
```
|
|
43
46
|
|
|
44
|
-
##
|
|
47
|
+
## Pi tools
|
|
45
48
|
|
|
46
|
-
|
|
47
|
-
-
|
|
48
|
-
-
|
|
49
|
-
- reduce agent token waste on noisy page chrome
|
|
50
|
-
- get author/title/published metadata when available
|
|
51
|
-
- work around pages that reject ordinary server-side fetches
|
|
52
|
-
|
|
53
|
-
Use `batch_web_fetch` when you want to:
|
|
54
|
-
- fetch multiple URLs in one tool call
|
|
55
|
-
- preserve a clear mapping between each input URL and its result
|
|
56
|
-
- let pi show per-item progress while the batch runs
|
|
57
|
-
- collect a mix of successes and failures without losing per-item errors
|
|
49
|
+
Registers:
|
|
50
|
+
- `web_fetch`
|
|
51
|
+
- `batch_web_fetch`
|
|
58
52
|
|
|
59
|
-
|
|
53
|
+
Synopsis:
|
|
60
54
|
|
|
61
55
|
```text
|
|
62
|
-
web_fetch(url, browser?, os?, headers?, maxChars?, format?, removeImages?, includeReplies?, proxy?, verbose?)
|
|
56
|
+
web_fetch(url, browser?, os?, headers?, maxChars?, timeoutMs?, format?, removeImages?, includeReplies?, proxy?, verbose?)
|
|
63
57
|
batch_web_fetch(requests, verbose?)
|
|
64
58
|
```
|
|
65
59
|
|
|
66
|
-
For `batch_web_fetch`, `requests`
|
|
67
|
-
|
|
68
|
-
## Output behavior
|
|
69
|
-
|
|
70
|
-
### `web_fetch`
|
|
71
|
-
|
|
72
|
-
Agent-facing tool output always includes the full non-empty metadata header plus the extracted document body.
|
|
73
|
-
|
|
74
|
-
In the pi TUI backlog/history preview, user-facing metadata is intentionally brief and only shows:
|
|
75
|
-
- Title
|
|
76
|
-
- Published
|
|
77
|
-
|
|
78
|
-
The duplicated `URL:` line is hidden from the preview because the tool call line already shows the URL.
|
|
79
|
-
|
|
80
|
-
The optional `verbose` flag is retained for compatibility, but pi now always returns the full metadata header to the agent.
|
|
81
|
-
|
|
82
|
-
### `batch_web_fetch`
|
|
83
|
-
|
|
84
|
-
Batch output:
|
|
85
|
-
- starts with a batch summary (`Requests`, `Succeeded`, `Failed`, `Concurrency`)
|
|
86
|
-
- keeps results in input order
|
|
87
|
-
- labels each item with its ordinal and URL
|
|
88
|
-
- includes full content for successful items
|
|
89
|
-
- includes a bot-friendly `Error:` line for failed items
|
|
90
|
-
|
|
91
|
-
In the pi TUI, batch mode also streams per-item progress rows showing:
|
|
92
|
-
- a small spinner/check/error glyph
|
|
93
|
-
- a truncated URL
|
|
94
|
-
- a one-word status (`queued`, `fetching`, `extracting`, `done`, `error`)
|
|
95
|
-
- a small progress bar
|
|
96
|
-
|
|
97
|
-
## Example tool outputs
|
|
98
|
-
|
|
99
|
-
### Agent-facing `web_fetch` output
|
|
100
|
-
|
|
101
|
-
```text
|
|
102
|
-
> URL: https://example.com/blog/some-article
|
|
103
|
-
> Title: Some Article
|
|
104
|
-
> Author: Jane Doe
|
|
105
|
-
> Published: 2026-03-12
|
|
106
|
-
> Site: Example Blog
|
|
107
|
-
> Language: en
|
|
108
|
-
> Words: 1284
|
|
109
|
-
> Browser: chrome_145/windows
|
|
110
|
-
|
|
111
|
-
# Some Article
|
|
112
|
-
|
|
113
|
-
This is the cleaned readable content extracted from the page.
|
|
114
|
-
It includes the body plus the full metadata header available to the agent.
|
|
115
|
-
```
|
|
116
|
-
|
|
117
|
-
### pi history/backlog preview for `web_fetch`
|
|
118
|
-
|
|
119
|
-
```text
|
|
120
|
-
web_fetch https://example.com/blog/some-article
|
|
121
|
-
Title: Some Article
|
|
122
|
-
Published: 2026-03-12
|
|
123
|
-
|
|
124
|
-
# Some Article
|
|
125
|
-
|
|
126
|
-
This is the cleaned readable content extracted from the page.
|
|
127
|
-
... (more lines, Ctrl+O to expand)
|
|
128
|
-
```
|
|
129
|
-
|
|
130
|
-
### Attachment/binary `web_fetch` output
|
|
131
|
-
|
|
132
|
-
```text
|
|
133
|
-
> URL: https://example.com/download/report
|
|
134
|
-
> File size: 999999
|
|
135
|
-
> Mime type: application/pdf
|
|
136
|
-
> File path: /absolute/path/to/temp/report.pdf
|
|
137
|
-
```
|
|
138
|
-
|
|
139
|
-
### `batch_web_fetch` output
|
|
140
|
-
|
|
141
|
-
```text
|
|
142
|
-
> Requests: 2
|
|
143
|
-
> Succeeded: 1
|
|
144
|
-
> Failed: 1
|
|
145
|
-
> Concurrency: 8
|
|
146
|
-
|
|
147
|
-
## [1/2] https://example.com/blog/some-article
|
|
148
|
-
> URL: https://example.com/blog/some-article
|
|
149
|
-
> Title: Some Article
|
|
150
|
-
> Author: Jane Doe
|
|
151
|
-
> Published: 2026-03-12
|
|
152
|
-
|
|
153
|
-
# Some Article
|
|
154
|
-
|
|
155
|
-
This is the cleaned readable content extracted from the page.
|
|
156
|
-
|
|
157
|
-
## [2/2] https://blocked.example/post
|
|
158
|
-
> URL: https://blocked.example/post
|
|
159
|
-
> Status: error
|
|
160
|
-
> Error: HTTP 403 Forbidden for https://blocked.example/post
|
|
161
|
-
```
|
|
162
|
-
|
|
163
|
-
### Error output
|
|
164
|
-
|
|
165
|
-
```text
|
|
166
|
-
Error: Invalid URL: not-a-url
|
|
167
|
-
```
|
|
168
|
-
|
|
169
|
-
## Parameters
|
|
170
|
-
|
|
171
|
-
### `web_fetch`
|
|
172
|
-
|
|
173
|
-
| Parameter | Type | Default | Description |
|
|
174
|
-
|-------------------|-------------------------------|-----------------|------------------------------------------------------------------------------|
|
|
175
|
-
| `url` | string | required | URL to fetch |
|
|
176
|
-
| `browser` | string | `chrome_145` | Browser profile used for transport fingerprinting |
|
|
177
|
-
| `os` | string | `windows` | OS profile: `windows`, `macos`, `linux`, `android`, `ios` |
|
|
178
|
-
| `headers` | object | auto | Extra request headers |
|
|
179
|
-
| `maxChars` | number | `50000` | Maximum returned characters. Can be overridden by pi settings |
|
|
180
|
-
| `format` | `markdown` \| `html` \| `text` \| `json` | `markdown` | Output format |
|
|
181
|
-
| `removeImages` | boolean | `false` | Strip image references from output |
|
|
182
|
-
| `includeReplies` | boolean \| `extractors` | `extractors` | Include replies/comments |
|
|
183
|
-
| `proxy` | string | none | Proxy URL |
|
|
184
|
-
| `verbose` | boolean | `false` | Compatibility flag. pi currently returns the full metadata header to the agent regardless; user history preview stays compact |
|
|
60
|
+
For `batch_web_fetch`, each item in `requests` accepts the same parameters as `web_fetch` except `verbose`.
|
|
185
61
|
|
|
186
|
-
|
|
62
|
+
## Output formats
|
|
187
63
|
|
|
188
|
-
|
|
|
189
|
-
|
|
190
|
-
| `
|
|
191
|
-
| `
|
|
64
|
+
| Format | What you get |
|
|
65
|
+
|---|---|
|
|
66
|
+
| `markdown` | Best default for readable page content |
|
|
67
|
+
| `html` | Cleaned HTML output |
|
|
68
|
+
| `text` | Plain text with markdown stripped |
|
|
69
|
+
| `json` | Structured JSON for metadata-heavy workflows |
|
|
192
70
|
|
|
193
|
-
##
|
|
71
|
+
## Global defaults
|
|
194
72
|
|
|
195
|
-
Optional
|
|
73
|
+
Optional settings in `~/.pi/agent/settings.json` or `.pi/settings.json`:
|
|
196
74
|
|
|
197
75
|
```json
|
|
198
76
|
{
|
|
199
77
|
"smartFetchVerboseByDefault": false,
|
|
200
|
-
"smartFetchDefaultMaxChars":
|
|
78
|
+
"smartFetchDefaultMaxChars": 50000,
|
|
201
79
|
"smartFetchDefaultTimeoutMs": 15000,
|
|
202
80
|
"smartFetchDefaultBrowser": "chrome_145",
|
|
203
81
|
"smartFetchDefaultOs": "windows",
|
|
@@ -208,37 +86,22 @@ Optional custom settings in `~/.pi/agent/settings.json` or `.pi/settings.json`:
|
|
|
208
86
|
}
|
|
209
87
|
```
|
|
210
88
|
|
|
211
|
-
|
|
212
|
-
|
|
213
|
-
|
|
214
|
-
|
|
215
|
-
|
|
216
|
-
|
|
217
|
-
|
|
218
|
-
|
|
219
|
-
|
|
220
|
-
|
|
221
|
-
|
|
222
|
-
|
|
223
|
-
|
|
224
|
-
- `
|
|
225
|
-
- `
|
|
226
|
-
|
|
227
|
-
|
|
228
|
-
|
|
229
|
-
|
|
230
|
-
|
|
231
|
-
Do not use these tools when:
|
|
232
|
-
- the site requires JS rendering
|
|
233
|
-
- you need login/session flows
|
|
234
|
-
- you need to click, scroll, or submit forms
|
|
235
|
-
- you need a fully interactive browser session
|
|
236
|
-
|
|
237
|
-
In those cases, switch to browser automation.
|
|
238
|
-
|
|
239
|
-
## Recent feature additions reflected here
|
|
240
|
-
|
|
241
|
-
Recent `feat:` work added:
|
|
242
|
-
- publish-ready TS tooling, tests, and packaging checks
|
|
243
|
-
- timer-driven spinner animation for batch progress in the pi TUI
|
|
244
|
-
- attachment and binary streaming into temp files with sanitized output paths
|
|
89
|
+
| Setting | Default | Description |
|
|
90
|
+
|---|---:|---|
|
|
91
|
+
| `smartFetchVerboseByDefault` | `false` | Stored default for the compatibility `verbose` flag |
|
|
92
|
+
| `smartFetchDefaultMaxChars` | `50000` | Default `maxChars` limit |
|
|
93
|
+
| `smartFetchDefaultTimeoutMs` | `15000` | Default request timeout in milliseconds |
|
|
94
|
+
| `smartFetchDefaultBrowser` | `chrome_145` | Default browser fingerprint profile |
|
|
95
|
+
| `smartFetchDefaultOs` | `windows` | Default OS fingerprint profile |
|
|
96
|
+
| `smartFetchDefaultRemoveImages` | `false` | Strip image references by default |
|
|
97
|
+
| `smartFetchDefaultIncludeReplies` | `extractors` | Include replies/comments only when site extractors support them |
|
|
98
|
+
| `smartFetchDefaultBatchConcurrency` | `8` | Default bounded concurrency for `batch_web_fetch` |
|
|
99
|
+
| `smartFetchTempDir` | OS temp dir | Base directory for attachment and binary downloads |
|
|
100
|
+
|
|
101
|
+
Notes:
|
|
102
|
+
- Project `.pi/settings.json` overrides global `~/.pi/agent/settings.json`
|
|
103
|
+
- Legacy `webFetch*` aliases are still supported
|
|
104
|
+
|
|
105
|
+
## Dev and publishing note
|
|
106
|
+
|
|
107
|
+
This repo uses Bun for local development, tests, and workspace scripts. Package publishing still goes through `npm publish` in CI so npm Trusted Publishing can be used.
|