data-api-client 2.0.0-beta.0 → 2.1.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +639 -146
- package/dist/client.d.ts +3 -0
- package/dist/client.d.ts.map +1 -0
- package/dist/client.js +79 -0
- package/dist/compat/errors.d.ts +28 -0
- package/dist/compat/errors.d.ts.map +1 -0
- package/dist/compat/errors.js +163 -0
- package/dist/compat/index.d.ts +7 -0
- package/dist/compat/index.d.ts.map +1 -0
- package/dist/compat/index.js +12 -0
- package/dist/compat/mysql2.d.ts +86 -0
- package/dist/compat/mysql2.d.ts.map +1 -0
- package/dist/compat/mysql2.js +350 -0
- package/dist/compat/pg.d.ts +142 -0
- package/dist/compat/pg.d.ts.map +1 -0
- package/dist/compat/pg.js +344 -0
- package/dist/index.d.ts +3 -0
- package/dist/index.d.ts.map +1 -0
- package/dist/index.js +3 -0
- package/dist/params.d.ts +19 -0
- package/dist/params.d.ts.map +1 -0
- package/dist/params.js +125 -0
- package/dist/query.d.ts +5 -0
- package/dist/query.d.ts.map +1 -0
- package/dist/query.js +39 -0
- package/dist/results.d.ts +12 -0
- package/dist/results.d.ts.map +1 -0
- package/dist/results.js +93 -0
- package/dist/retry.d.ts +11 -0
- package/dist/retry.d.ts.map +1 -0
- package/dist/retry.js +76 -0
- package/dist/transaction.d.ts +4 -0
- package/dist/transaction.d.ts.map +1 -0
- package/dist/transaction.js +59 -0
- package/dist/types.d.ts +97 -0
- package/dist/types.d.ts.map +1 -0
- package/dist/types.js +2 -0
- package/dist/utils.d.ts +19 -0
- package/dist/utils.d.ts.map +1 -0
- package/dist/utils.js +150 -0
- package/package.json +80 -9
- package/index.js +0 -642
package/README.md
CHANGED
|
@@ -1,25 +1,68 @@
|
|
|
1
1
|

|
|
2
2
|
|
|
3
|
-
[](https://travis-ci.org/jeremydaly/data-api-client)
|
|
4
3
|
[](https://www.npmjs.com/package/data-api-client)
|
|
5
4
|
[](https://www.npmjs.com/package/data-api-client)
|
|
6
5
|
|
|
7
|
-
|
|
6
|
+
> **Note:** Version 2.1.0 introduces mysql2 and pg compatibility layers with full ORM support! We welcome your feedback and bug reports. Please [open an issue](https://github.com/jeremydaly/data-api-client/issues) if you encounter any problems or have suggestions for improvement.
|
|
7
|
+
>
|
|
8
|
+
> **Using v1.x?** See [README_v1.md](README_v1.md) for v1.x documentation.
|
|
8
9
|
|
|
9
|
-
The **Data API Client** is a lightweight wrapper that simplifies working with the Amazon Aurora Serverless Data API by abstracting away the notion of field values. This abstraction annotates native JavaScript types supplied as input parameters, as well as converts annotated response data to native JavaScript types. It's basically a [DocumentClient](https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/DynamoDB/DocumentClient.html) for the Data API. It also
|
|
10
|
+
The **Data API Client** is a lightweight wrapper that simplifies working with the Amazon Aurora Serverless Data API by abstracting away the notion of field values. This abstraction annotates native JavaScript types supplied as input parameters, as well as converts annotated response data to native JavaScript types. It's basically a [DocumentClient](https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/DynamoDB/DocumentClient.html) for the Data API. It also dramatically simplifies **transactions**, provides **automatic retry logic** for scale-to-zero clusters, and includes **compatibility layers** for mysql2 and pg with full **ORM support**.
|
|
11
|
+
|
|
12
|
+
**Version 2.1** adds mysql2 and pg compatibility layers, automatic retry logic for cluster wake-ups, and verified support for Drizzle ORM and Kysely query builder.
|
|
13
|
+
|
|
14
|
+
**Version 2.0** introduced support for the new [RDS Data API for Aurora Serverless v2 and Aurora provisioned database instances](https://aws.amazon.com/about-aws/whats-new/2024/09/amazon-aurora-mysql-rds-data-api/), enhanced [Amazon Aurora PostgreSQL-Compatible Edition](https://aws.amazon.com/about-aws/whats-new/2023/12/amazon-aurora-postgresql-rds-data-api/) support, migration to AWS SDK v3, full TypeScript implementation, and comprehensive PostgreSQL data type coverage including **automatic array handling**.
|
|
10
15
|
|
|
11
16
|
For more information about the Aurora Serverless Data API, you can review the [official documentation](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html) or read [Aurora Serverless Data API: An (updated) First Look](https://www.jeremydaly.com/aurora-serverless-data-api-a-first-look/) for some more insights on performance.
|
|
12
17
|
|
|
18
|
+
## What's New in v2.1
|
|
19
|
+
|
|
20
|
+
- **Automatic Retry Logic**: Built-in retry handling for Aurora Serverless scale-to-zero wake-ups
|
|
21
|
+
- Smart detection of `DatabaseResumingException` with optimized retry delays
|
|
22
|
+
- Automatic handling of connection errors with exponential backoff
|
|
23
|
+
- Configurable and enabled by default
|
|
24
|
+
- **mysql2 Compatibility Layer**: Drop-in replacement for the `mysql2/promise` library
|
|
25
|
+
- Full support for connection pools and transactions
|
|
26
|
+
- Works seamlessly with ORMs like Drizzle and Kysely
|
|
27
|
+
- **pg Compatibility Layer**: Drop-in replacement for the `pg` (node-postgres) library
|
|
28
|
+
- Promise-based and callback-based APIs
|
|
29
|
+
- Compatible with ORMs and query builders
|
|
30
|
+
- **ORM Support**: Tested and verified with popular ORMs:
|
|
31
|
+
- **Drizzle ORM**: Full support for both MySQL and PostgreSQL
|
|
32
|
+
- **Kysely**: Query builder support for both engines
|
|
33
|
+
|
|
34
|
+
## What's New in v2.0
|
|
35
|
+
|
|
36
|
+
- **AWS SDK v3**: Migrated from AWS SDK v2 to v3 for smaller bundle sizes and better tree-shaking
|
|
37
|
+
- **TypeScript**: Full TypeScript implementation with comprehensive type definitions
|
|
38
|
+
- **PostgreSQL Array Support**: Automatic conversion of PostgreSQL arrays to native JavaScript arrays in query results
|
|
39
|
+
- **Comprehensive Data Type Coverage**: Extensive support for PostgreSQL data types including:
|
|
40
|
+
- All numeric types (SMALLINT, INT, BIGINT, DECIMAL, NUMERIC, REAL, DOUBLE PRECISION)
|
|
41
|
+
- String types (CHAR, VARCHAR, TEXT)
|
|
42
|
+
- Boolean, Date/Time types (DATE, TIME, TIMESTAMP, TIMESTAMPTZ)
|
|
43
|
+
- Binary data (BYTEA)
|
|
44
|
+
- JSON and JSONB with nested structures
|
|
45
|
+
- UUID with type casting support
|
|
46
|
+
- Network types (INET, CIDR)
|
|
47
|
+
- Range types (INT4RANGE, NUMRANGE, TSTZRANGE)
|
|
48
|
+
- Arrays of all supported types
|
|
49
|
+
- **Modern Build System**: TypeScript compilation with ES6+ output
|
|
50
|
+
- **Enhanced Type Casting**: Improved support for PostgreSQL type casting with inline (`::type`) and parameter-based casting
|
|
51
|
+
- **Better Error Handling**: More informative error messages and validation
|
|
52
|
+
|
|
13
53
|
## Simple Examples
|
|
14
54
|
|
|
15
|
-
The **Data API Client** makes working with the Aurora Serverless Data API super simple.
|
|
55
|
+
The **Data API Client** makes working with the Aurora Serverless Data API super simple. Import and instantiate the library with basic configuration information, then use the `query()` method to manage your workflows. Below are some examples.
|
|
16
56
|
|
|
17
57
|
```javascript
|
|
18
|
-
//
|
|
19
|
-
|
|
58
|
+
// Import and instantiate data-api-client with secret and cluster
|
|
59
|
+
import dataApiClient from 'data-api-client'
|
|
60
|
+
|
|
61
|
+
const data = dataApiClient({
|
|
20
62
|
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
21
63
|
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name',
|
|
22
|
-
database: 'myDatabase' // default database
|
|
64
|
+
database: 'myDatabase', // default database
|
|
65
|
+
engine: 'pg' // or 'mysql'
|
|
23
66
|
})
|
|
24
67
|
|
|
25
68
|
/*** Assuming we're in an async function ***/
|
|
@@ -35,31 +78,27 @@ let result = await data.query(`SELECT * FROM myTable`)
|
|
|
35
78
|
// }
|
|
36
79
|
|
|
37
80
|
// SELECT with named parameters
|
|
38
|
-
let resultParams = await data.query(`SELECT * FROM myTable WHERE id = :id`, {
|
|
39
|
-
id: 2
|
|
40
|
-
})
|
|
81
|
+
let resultParams = await data.query(`SELECT * FROM myTable WHERE id = :id`, { id: 2 })
|
|
41
82
|
// { records: [ { id: 2, name: 'Mike', age: 52 } ] }
|
|
42
83
|
|
|
43
|
-
// INSERT with named parameters
|
|
44
|
-
let insert = await data.query(`INSERT INTO myTable (name,age,has_curls) VALUES(:name
|
|
84
|
+
// INSERT with named parameters (PostgreSQL with RETURNING)
|
|
85
|
+
let insert = await data.query(`INSERT INTO myTable (name, age, has_curls) VALUES(:name, :age, :curls) RETURNING id`, {
|
|
45
86
|
name: 'Greg',
|
|
46
87
|
age: 18,
|
|
47
88
|
curls: false
|
|
48
89
|
})
|
|
49
90
|
|
|
50
91
|
// BATCH INSERT with named parameters
|
|
51
|
-
let batchInsert = await data.query(`INSERT INTO myTable (name,age,has_curls) VALUES(:name
|
|
92
|
+
let batchInsert = await data.query(`INSERT INTO myTable (name, age, has_curls) VALUES(:name, :age, :curls)`, [
|
|
52
93
|
[{ name: 'Marcia', age: 17, curls: false }],
|
|
53
94
|
[{ name: 'Peter', age: 15, curls: false }],
|
|
54
95
|
[{ name: 'Jan', age: 15, curls: false }],
|
|
55
96
|
[{ name: 'Cindy', age: 12, curls: true }],
|
|
56
97
|
[{ name: 'Bobby', age: 12, curls: false }]
|
|
57
98
|
])
|
|
99
|
+
|
|
58
100
|
// Update with named parameters
|
|
59
|
-
let update = await data.query(`UPDATE myTable SET age = :age WHERE id = :id`, {
|
|
60
|
-
age: 13,
|
|
61
|
-
id: 5
|
|
62
|
-
})
|
|
101
|
+
let update = await data.query(`UPDATE myTable SET age = :age WHERE id = :id`, { age: 13, id: 5 })
|
|
63
102
|
|
|
64
103
|
// Delete with named parameters
|
|
65
104
|
let remove = await data.query(
|
|
@@ -67,64 +106,77 @@ let remove = await data.query(
|
|
|
67
106
|
{ name: 'Jan' } // Sorry Jan :(
|
|
68
107
|
)
|
|
69
108
|
|
|
70
|
-
//
|
|
71
|
-
let
|
|
72
|
-
|
|
73
|
-
|
|
74
|
-
|
|
75
|
-
|
|
76
|
-
|
|
109
|
+
// PostgreSQL with type casting and JSONB
|
|
110
|
+
let pgExample = await data.query(`INSERT INTO users (id, email, metadata) VALUES(:id, :email, :metadata)`, [
|
|
111
|
+
{ name: 'id', value: '550e8400-e29b-41d4-a716-446655440000', cast: 'uuid' },
|
|
112
|
+
{ name: 'email', value: 'user@example.com' },
|
|
113
|
+
{ name: 'metadata', value: JSON.stringify({ role: 'admin' }), cast: 'jsonb' }
|
|
114
|
+
])
|
|
115
|
+
|
|
116
|
+
// PostgreSQL array result (automatically converted to native JavaScript array)
|
|
117
|
+
let arrayResult = await data.query(`SELECT tags FROM products WHERE id = :id`, { id: 123 })
|
|
118
|
+
// { records: [ { tags: ['new', 'featured', 'sale'] } ] }
|
|
77
119
|
```
|
|
78
120
|
|
|
79
121
|
## Why do I need this?
|
|
80
122
|
|
|
81
|
-
The [Data API](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html) requires you to specify data types when passing in parameters. The basic `INSERT` example above would look like this using the native
|
|
123
|
+
The [Data API](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html) requires you to specify data types when passing in parameters. The basic `INSERT` example above would look like this using the native AWS SDK v3:
|
|
82
124
|
|
|
83
125
|
```javascript
|
|
84
|
-
|
|
85
|
-
const client = new RDSDataClient(
|
|
126
|
+
import { RDSDataClient, ExecuteStatementCommand } from '@aws-sdk/client-rds-data'
|
|
127
|
+
const client = new RDSDataClient()
|
|
86
128
|
|
|
87
|
-
|
|
88
|
-
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
89
|
-
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name',
|
|
90
|
-
database: 'myDatabase',
|
|
91
|
-
sql: 'INSERT INTO myTable (name,age,has_curls) VALUES(:name,:age,:curls)',
|
|
92
|
-
parameters: [
|
|
93
|
-
{ name: 'name', value: { stringValue: 'Cousin Oliver' } },
|
|
94
|
-
{ name: 'age', value: { longValue: 10 } },
|
|
95
|
-
{ name: 'curls', value: { booleanValue: false } }
|
|
96
|
-
]
|
|
97
|
-
}
|
|
98
|
-
|
|
99
|
-
const command = new ExecuteStatementCommand(params)
|
|
129
|
+
/*** Assuming we're in an async function ***/
|
|
100
130
|
|
|
101
|
-
//
|
|
102
|
-
|
|
103
|
-
|
|
104
|
-
|
|
105
|
-
|
|
106
|
-
|
|
107
|
-
|
|
131
|
+
// INSERT with named parameters
|
|
132
|
+
let insert = await client.send(
|
|
133
|
+
new ExecuteStatementCommand({
|
|
134
|
+
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
135
|
+
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name',
|
|
136
|
+
database: 'myDatabase',
|
|
137
|
+
sql: 'INSERT INTO myTable (name, age, has_curls) VALUES(:name, :age, :curls)',
|
|
138
|
+
parameters: [
|
|
139
|
+
{ name: 'name', value: { stringValue: 'Cousin Oliver' } },
|
|
140
|
+
{ name: 'age', value: { longValue: 10 } },
|
|
141
|
+
{ name: 'curls', value: { booleanValue: false } }
|
|
142
|
+
]
|
|
143
|
+
})
|
|
144
|
+
)
|
|
108
145
|
```
|
|
109
146
|
|
|
110
|
-
Specifying all of those data types in the parameters
|
|
147
|
+
Specifying all of those data types in the parameters is a bit clunky. In addition to requiring types for parameters, it also returns each field as an object with its value assigned to a key that represents its data type, like this:
|
|
111
148
|
|
|
112
149
|
```javascript
|
|
113
|
-
{
|
|
114
|
-
|
|
150
|
+
{
|
|
151
|
+
// id field
|
|
152
|
+
longValue: 9
|
|
115
153
|
},
|
|
116
|
-
{
|
|
117
|
-
|
|
154
|
+
{
|
|
155
|
+
// name field
|
|
156
|
+
stringValue: 'Cousin Oliver'
|
|
118
157
|
},
|
|
119
|
-
{
|
|
120
|
-
|
|
158
|
+
{
|
|
159
|
+
// age field
|
|
160
|
+
longValue: 10
|
|
121
161
|
},
|
|
122
|
-
{
|
|
123
|
-
|
|
162
|
+
{
|
|
163
|
+
// has_curls field
|
|
164
|
+
booleanValue: false
|
|
124
165
|
}
|
|
125
166
|
```
|
|
126
167
|
|
|
127
|
-
Not only are there no column names, but you have to pull the value from the data type field.
|
|
168
|
+
Not only are there no column names, but you have to pull the value from the data type field. And if you're using PostgreSQL arrays, you get a complex nested structure:
|
|
169
|
+
|
|
170
|
+
```javascript
|
|
171
|
+
{
|
|
172
|
+
// tags field (PostgreSQL array)
|
|
173
|
+
arrayValue: {
|
|
174
|
+
stringValues: ['admin', 'editor', 'viewer']
|
|
175
|
+
}
|
|
176
|
+
}
|
|
177
|
+
```
|
|
178
|
+
|
|
179
|
+
Lots of extra work that the **Data API Client** handles automatically for you, converting arrays to native JavaScript arrays and providing clean, usable data. 😀
|
|
128
180
|
|
|
129
181
|
## Installation and Setup
|
|
130
182
|
|
|
@@ -132,40 +184,88 @@ Not only are there no column names, but you have to pull the value from the data
|
|
|
132
184
|
npm i data-api-client
|
|
133
185
|
```
|
|
134
186
|
|
|
187
|
+
The library has AWS SDK v3's `@aws-sdk/client-rds-data` as an optional peer dependency. In AWS Lambda, the SDK is provided by the runtime. For local development or other environments, install it separately:
|
|
188
|
+
|
|
189
|
+
```
|
|
190
|
+
npm i @aws-sdk/client-rds-data
|
|
191
|
+
```
|
|
192
|
+
|
|
135
193
|
For more information on enabling Data API, see [Enabling Data API](#enabling-data-api).
|
|
136
194
|
|
|
137
195
|
## Configuration Options
|
|
138
196
|
|
|
139
197
|
Below is a table containing all of the possible configuration options for the `data-api-client`. Additional details are provided throughout the documentation.
|
|
140
198
|
|
|
141
|
-
| Property | Type | Description
|
|
142
|
-
| ------------------ | --------------- |
|
|
143
|
-
|
|
|
144
|
-
|
|
|
145
|
-
|
|
|
146
|
-
|
|
|
147
|
-
|
|
|
148
|
-
|
|
|
149
|
-
|
|
|
150
|
-
|
|
|
199
|
+
| Property | Type | Description | Default |
|
|
200
|
+
| ------------------ | --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------ |
|
|
201
|
+
| client | `RDSDataClient` | A custom `@aws-sdk/client-rds-data` instance (for X-Ray tracing, custom config, etc.) | |
|
|
202
|
+
| resourceArn | `string` | The ARN of your Aurora Serverless Cluster. This value is _required_, but can be overridden when querying. | |
|
|
203
|
+
| secretArn | `string` | The ARN of the secret associated with your database credentials. This is _required_, but can be overridden when querying. | |
|
|
204
|
+
| database | `string` | _Optional_ default database to use with queries. Can be overridden when querying. | |
|
|
205
|
+
| engine | `mysql` or `pg` | The type of database engine you're connecting to (MySQL or Postgres). | `pg` |
|
|
206
|
+
| hydrateColumnNames | `boolean` | When `true`, results will be returned as objects with column names as keys. If `false`, results will be returned as an array of values. | `true` |
|
|
207
|
+
| options | `object` | An _optional_ configuration object that is passed directly into the RDSDataClient constructor. See [AWS SDK docs](https://docs.aws.amazon.com/AWSJavaScriptSDK/v3/latest/clients/client-rds-data/classes/rdsdataclient.html) for available options. | `{}` |
|
|
208
|
+
| formatOptions | `object` | Formatting options to auto parse dates and coerce native JavaScript date objects to supported date formats. Valid keys are `deserializeDate` and `treatAsLocalDate`. Both accept boolean values. | `deserializeDate: true, treatAsLocalDate: false` |
|
|
209
|
+
| retryOptions | `object` | Configuration for automatic retry logic. Valid keys are `enabled` (boolean), `maxRetries` (number), and `retryableErrors` (string array). | `enabled: true, maxRetries: 9` |
|
|
210
|
+
|
|
211
|
+
### Automatic Retry Logic
|
|
212
|
+
|
|
213
|
+
Version 2.1 includes built-in retry logic to handle Aurora Serverless scale-to-zero cluster wake-ups automatically. When your cluster is paused and needs to resume, the client will automatically retry your queries with optimized delays.
|
|
214
|
+
|
|
215
|
+
**Features:**
|
|
216
|
+
- **Smart Error Detection**: Automatically detects `DatabaseResumingException` and connection errors
|
|
217
|
+
- **Strategy-Based Retries**: Different retry strategies based on error type:
|
|
218
|
+
- DatabaseResumingException: Up to 10 attempts with progressive delays (0s, 2s, 5s, 10s, 15s, 20s, 25s, 30s, 35s, 40s)
|
|
219
|
+
- Connection errors: 3 quick retries with exponential backoff (0s, 2s, 4s)
|
|
220
|
+
- **Enabled by Default**: Works automatically without any configuration
|
|
221
|
+
- **Configurable**: Customize retry behavior per your needs
|
|
222
|
+
|
|
223
|
+
**Configuration:**
|
|
224
|
+
|
|
225
|
+
```javascript
|
|
226
|
+
const data = dataApiClient({
|
|
227
|
+
secretArn: 'arn:...',
|
|
228
|
+
resourceArn: 'arn:...',
|
|
229
|
+
database: 'myDatabase',
|
|
230
|
+
retryOptions: {
|
|
231
|
+
enabled: true, // Enable/disable retries (default: true)
|
|
232
|
+
maxRetries: 9, // Maximum retry attempts (default: 9 for up to 40s total)
|
|
233
|
+
retryableErrors: [] // Additional error patterns to retry (optional)
|
|
234
|
+
}
|
|
235
|
+
})
|
|
236
|
+
```
|
|
237
|
+
|
|
238
|
+
**Disable retries** (not recommended for scale-to-zero clusters):
|
|
239
|
+
|
|
240
|
+
```javascript
|
|
241
|
+
const data = dataApiClient({
|
|
242
|
+
secretArn: 'arn:...',
|
|
243
|
+
resourceArn: 'arn:...',
|
|
244
|
+
retryOptions: { enabled: false }
|
|
245
|
+
})
|
|
246
|
+
```
|
|
247
|
+
|
|
248
|
+
The retry logic works seamlessly across all operations: queries, transactions, batch operations, and compatibility layer methods.
|
|
151
249
|
|
|
152
250
|
### Connection Reuse
|
|
153
251
|
|
|
154
|
-
It is recommended to enable connection reuse as this dramatically decreases the latency of subsequent calls to the AWS API. This can be done by setting an environment variable
|
|
155
|
-
`AWS_NODEJS_CONNECTION_REUSE_ENABLED=1`. For more information see the [AWS SDK documentation](https://docs.aws.amazon.com/sdk-for-javascript/v2/developer-guide/node-reusing-connections.html).
|
|
252
|
+
It is recommended to enable connection reuse as this dramatically decreases the latency of subsequent calls to the AWS API. This can be done by setting an environment variable `AWS_NODEJS_CONNECTION_REUSE_ENABLED=1`. For more information see the [AWS SDK documentation](https://docs.aws.amazon.com/sdk-for-javascript/v3/developer-guide/node-reusing-connections.html).
|
|
156
253
|
|
|
157
254
|
## How to use this module
|
|
158
255
|
|
|
159
|
-
The **Data API Client** wraps the
|
|
256
|
+
The **Data API Client** wraps the [RDSDataClient Class](https://docs.aws.amazon.com/AWSJavaScriptSDK/v3/latest/clients/client-rds-data/classes/rdsdataclient.html), providing you with a number of convenience features to make your workflow easier. The module also exposes all the standard `RDSDataClient` methods with your default configuration information already merged in. 😉
|
|
160
257
|
|
|
161
|
-
To use the Data API Client,
|
|
258
|
+
To use the Data API Client, import the module and instantiate it with your [Configuration options](#configuration-options). If you are using it with AWS Lambda, require it **OUTSIDE** your main handler function. This will allow you to reuse the initialized module on subsequent invocations.
|
|
162
259
|
|
|
163
260
|
```javascript
|
|
164
|
-
//
|
|
165
|
-
|
|
261
|
+
// Import and instantiate data-api-client with secret and cluster arns
|
|
262
|
+
import dataApiClient from 'data-api-client'
|
|
263
|
+
|
|
264
|
+
const data = dataApiClient({
|
|
166
265
|
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
167
266
|
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name',
|
|
168
|
-
database: 'myDatabase' // set a default database
|
|
267
|
+
database: 'myDatabase', // set a default database
|
|
268
|
+
engine: 'pg' // specify 'pg' for PostgreSQL or 'mysql' for MySQL
|
|
169
269
|
})
|
|
170
270
|
```
|
|
171
271
|
|
|
@@ -187,7 +287,7 @@ By default, this will return your rows as an array of objects with column names
|
|
|
187
287
|
]
|
|
188
288
|
```
|
|
189
289
|
|
|
190
|
-
To query with parameters, you can use named parameters in your SQL, and then
|
|
290
|
+
To query with parameters, you can use named parameters in your SQL, and then provide an object containing your parameters as the second argument to the `query()` method:
|
|
191
291
|
|
|
192
292
|
```javascript
|
|
193
293
|
let result = await data.query(
|
|
@@ -197,14 +297,14 @@ let result = await data.query(
|
|
|
197
297
|
)
|
|
198
298
|
```
|
|
199
299
|
|
|
200
|
-
The Data API Client will automatically convert your parameters into the correct Data API parameter format using native JavaScript types. If you prefer
|
|
300
|
+
The Data API Client will automatically convert your parameters into the correct Data API parameter format using native JavaScript types. If you prefer more control over the data type, you can use the extended parameter format:
|
|
201
301
|
|
|
202
302
|
```javascript
|
|
203
303
|
let result = await data.query(`SELECT * FROM myTable WHERE id = :id AND created > :createDate`, [
|
|
204
304
|
// An array of objects is totally cool, too. We'll merge them for you.
|
|
205
305
|
{ id: 2 },
|
|
206
|
-
//
|
|
207
|
-
{ name: 'createDate', value:
|
|
306
|
+
// Extended format for more control
|
|
307
|
+
{ name: 'createDate', value: '2019-06-01' }
|
|
208
308
|
])
|
|
209
309
|
```
|
|
210
310
|
|
|
@@ -213,17 +313,16 @@ If you want even more control, you can pass in an `object` as the first paramete
|
|
|
213
313
|
```javascript
|
|
214
314
|
let result = await data.query({
|
|
215
315
|
sql: `SELECT * FROM myTable WHERE id = :id`,
|
|
216
|
-
parameters: [
|
|
316
|
+
parameters: [{ id: 2 }], // or just { id: 2 }
|
|
217
317
|
database: 'someOtherDatabase', // override default database
|
|
218
|
-
|
|
219
|
-
|
|
220
|
-
includeResultMetadata: true, // RDSDataClient config option (non-batch only)
|
|
318
|
+
continueAfterTimeout: true, // RDSDataService config option (non-batch only)
|
|
319
|
+
includeResultMetadata: true, // RDSDataService config option (non-batch only)
|
|
221
320
|
hydrateColumnNames: false, // Returns each record as an arrays of values
|
|
222
|
-
transactionId: 'AQC5SRDIm...ZHXP/WORU=' //
|
|
223
|
-
}
|
|
321
|
+
transactionId: 'AQC5SRDIm...ZHXP/WORU=' // RDSDataService config option
|
|
322
|
+
})
|
|
224
323
|
```
|
|
225
324
|
|
|
226
|
-
Sometimes you might want to have _dynamic identifiers_ in your SQL statements. Unfortunately, the
|
|
325
|
+
Sometimes you might want to have _dynamic identifiers_ in your SQL statements. Unfortunately, the native Data API doesn't support this, but the **Data API Client** does! Use a double colon (`::`) prefix to create _named identifiers_ and you can do cool things like this:
|
|
227
326
|
|
|
228
327
|
```javascript
|
|
229
328
|
let result = await data.query(`SELECT ::fields FROM ::table WHERE id > :id`, {
|
|
@@ -233,17 +332,35 @@ let result = await data.query(`SELECT ::fields FROM ::table WHERE id > :id`, {
|
|
|
233
332
|
})
|
|
234
333
|
```
|
|
235
334
|
|
|
236
|
-
Which will produce a query like this:
|
|
335
|
+
Which will produce a query like this for PostgreSQL:
|
|
336
|
+
|
|
337
|
+
```sql
|
|
338
|
+
SELECT "id", "name", "created" FROM "table_123abc" WHERE id > :id
|
|
339
|
+
```
|
|
340
|
+
|
|
341
|
+
Or for MySQL:
|
|
237
342
|
|
|
238
343
|
```sql
|
|
239
|
-
SELECT `id`, `name`, `created` FROM `table_123abc` WHERE id > :id
|
|
344
|
+
SELECT `id`, `name`, `created` FROM `table_123abc` WHERE id > :id
|
|
240
345
|
```
|
|
241
346
|
|
|
242
|
-
You'll notice that we leave the _named parameters_ alone. Anything that Data API and the
|
|
347
|
+
You'll notice that we leave the _named parameters_ alone. Anything that Data API and the native SDK currently handles, we defer to them.
|
|
243
348
|
|
|
244
349
|
### Type-Casting
|
|
245
350
|
|
|
246
|
-
The Aurora Data API can sometimes give you trouble with certain data types, such as uuid, unless you explicitly cast them. While you can certainly do this manually in your SQL string, the Data API Client offers
|
|
351
|
+
The Aurora Data API can sometimes give you trouble with certain data types, such as uuid or jsonb in PostgreSQL, unless you explicitly cast them. While you can certainly do this manually in your SQL string using PostgreSQL's `::` cast syntax, the Data API Client offers an easy way to handle this for you using the parameter `cast` property.
|
|
352
|
+
|
|
353
|
+
**PostgreSQL inline casting** (recommended):
|
|
354
|
+
|
|
355
|
+
```javascript
|
|
356
|
+
const result = await data.query('INSERT INTO users(id, email, metadata) VALUES(:id, :email, :metadata::jsonb)', {
|
|
357
|
+
id: newUserId, // will be cast as string by default
|
|
358
|
+
email: email,
|
|
359
|
+
metadata: JSON.stringify(userMetadata) // cast to jsonb via ::jsonb in SQL
|
|
360
|
+
})
|
|
361
|
+
```
|
|
362
|
+
|
|
363
|
+
**Parameter-based casting** (alternative approach):
|
|
247
364
|
|
|
248
365
|
```javascript
|
|
249
366
|
const result = await data.query(
|
|
@@ -271,9 +388,11 @@ const result = await data.query(
|
|
|
271
388
|
)
|
|
272
389
|
```
|
|
273
390
|
|
|
391
|
+
Both approaches produce the same result, but inline casting is generally cleaner for simple cases.
|
|
392
|
+
|
|
274
393
|
### Batch Queries
|
|
275
394
|
|
|
276
|
-
The
|
|
395
|
+
The Data API provides a `batchExecuteStatement` method that allows you to execute a prepared statement multiple times using different parameter sets. This is only allowed for `INSERT`, `UPDATE` and `DELETE` queries, but is much more efficient than issuing multiple `executeStatement` calls. The Data API Client handles the switching for you based on _how_ you send in your parameters.
|
|
277
396
|
|
|
278
397
|
To issue a batch query, use the `query()` method (either by passing an object or using the two arity form), and provide multiple parameter sets as nested arrays. For example, if you wanted to update multiple records at once, your query might look like this:
|
|
279
398
|
|
|
@@ -292,6 +411,16 @@ Whenever a batch query is executed, it returns an `updateResults` field. Other t
|
|
|
292
411
|
|
|
293
412
|
The Data API returns a `generatedFields` array that contains the value of auto-incrementing primary keys. If this value is returned, the Data API Client will parse this and return it as the `insertId`. This also works for batch queries as well.
|
|
294
413
|
|
|
414
|
+
For PostgreSQL, use the `RETURNING` clause to get generated values:
|
|
415
|
+
|
|
416
|
+
```javascript
|
|
417
|
+
let result = await data.query(`INSERT INTO users (name, email) VALUES (:name, :email) RETURNING id`, {
|
|
418
|
+
name: 'Alice',
|
|
419
|
+
email: 'alice@example.com'
|
|
420
|
+
})
|
|
421
|
+
// result.records[0].id contains the generated ID
|
|
422
|
+
```
|
|
423
|
+
|
|
295
424
|
## Transaction Support
|
|
296
425
|
|
|
297
426
|
Transaction support in the Data API Client has been dramatically simplified. Start a new transaction using the `transaction()` method, and then chain queries using the `query()` method. The `query()` method supports all standard query options. Alternatively, you can specify a function as the only argument in a `query()` method call and return the arguments as an array of values. The function receives two arguments, the result of the last query executed, and an array containing all the previous query results. This is useful if you need values from a previous query as part of your transaction.
|
|
@@ -299,20 +428,23 @@ Transaction support in the Data API Client has been dramatically simplified. Sta
|
|
|
299
428
|
You can specify an optional `rollback()` method in the chain. This will receive the `error` object and the `transactionStatus` object, allowing you to add additional logging or perform some other action. Call the `commit()` method when you are ready to execute the queries.
|
|
300
429
|
|
|
301
430
|
```javascript
|
|
302
|
-
let results = await
|
|
431
|
+
let results = await data
|
|
432
|
+
.transaction()
|
|
303
433
|
.query('INSERT INTO myTable (name) VALUES(:name)', { name: 'Tiger' })
|
|
304
|
-
.query('UPDATE myTable SET age = :age WHERE name = :name' { age: 4, name: 'Tiger' })
|
|
305
|
-
.rollback((e,status) => {
|
|
434
|
+
.query('UPDATE myTable SET age = :age WHERE name = :name', { age: 4, name: 'Tiger' })
|
|
435
|
+
.rollback((e, status) => {
|
|
436
|
+
/* do something with the error */
|
|
437
|
+
}) // optional
|
|
306
438
|
.commit() // execute the queries
|
|
307
439
|
```
|
|
308
440
|
|
|
309
441
|
With a function to get the `insertId` from the previous query:
|
|
310
442
|
|
|
311
443
|
```javascript
|
|
312
|
-
let results = await
|
|
444
|
+
let results = await data
|
|
313
445
|
.transaction()
|
|
314
|
-
.query('INSERT INTO myTable (name) VALUES(:name)', { name: 'Tiger' })
|
|
315
|
-
.query((r) => ['UPDATE myTable SET age = :age WHERE id = :id', { age: 4, id: r.
|
|
446
|
+
.query('INSERT INTO myTable (name) VALUES(:name) RETURNING id', { name: 'Tiger' })
|
|
447
|
+
.query((r) => ['UPDATE myTable SET age = :age WHERE id = :id', { age: 4, id: r.records[0].id }])
|
|
316
448
|
.rollback((e, status) => {
|
|
317
449
|
/* do something with the error */
|
|
318
450
|
}) // optional
|
|
@@ -325,7 +457,7 @@ By default, the `transaction()` method will use the `resourceArn`, `secretArn` a
|
|
|
325
457
|
|
|
326
458
|
### Using native methods directly
|
|
327
459
|
|
|
328
|
-
The Data API Client exposes
|
|
460
|
+
The Data API Client exposes the five RDSDataClient command methods. These are:
|
|
329
461
|
|
|
330
462
|
- `batchExecuteStatement`
|
|
331
463
|
- `beginTransaction`
|
|
@@ -338,87 +470,448 @@ The default configuration information (`resourceArn`, `secretArn`, and `database
|
|
|
338
470
|
```javascript
|
|
339
471
|
let result = await data.executeStatement({
|
|
340
472
|
sql: `SELECT * FROM myTable WHERE id = :id`,
|
|
341
|
-
parameters: [
|
|
342
|
-
{ name: 'id', value: { longValue: 1 } }
|
|
343
|
-
],
|
|
473
|
+
parameters: [{ name: 'id', value: { longValue: 1 } }],
|
|
344
474
|
transactionId: 'AQC5SRDIm...ZHXP/WORU='
|
|
345
|
-
)
|
|
475
|
+
})
|
|
346
476
|
```
|
|
347
477
|
|
|
348
|
-
## Custom SDK
|
|
478
|
+
## Custom AWS SDK Client
|
|
349
479
|
|
|
350
|
-
`data-api-client` allows
|
|
480
|
+
`data-api-client` allows for introducing a custom RDSDataClient instance as a parameter. This parameter is optional. If not present, `data-api-client` will create a default instance.
|
|
351
481
|
|
|
352
482
|
```javascript
|
|
353
|
-
|
|
354
|
-
|
|
483
|
+
import { RDSDataClient } from '@aws-sdk/client-rds-data'
|
|
484
|
+
import dataApiClient from 'data-api-client'
|
|
485
|
+
|
|
486
|
+
// Create a custom client instance
|
|
487
|
+
const rdsClient = new RDSDataClient({
|
|
488
|
+
region: 'us-east-1'
|
|
489
|
+
// other configuration options
|
|
490
|
+
})
|
|
355
491
|
|
|
356
|
-
// Instantiate data-api-client with the
|
|
357
|
-
const data =
|
|
358
|
-
|
|
359
|
-
|
|
492
|
+
// Instantiate data-api-client with the custom client
|
|
493
|
+
const data = dataApiClient({
|
|
494
|
+
client: rdsClient,
|
|
495
|
+
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
496
|
+
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name'
|
|
360
497
|
})
|
|
361
498
|
```
|
|
362
499
|
|
|
363
|
-
|
|
500
|
+
Custom client parameter allows you to introduce X-Ray tracing:
|
|
364
501
|
|
|
365
|
-
|
|
502
|
+
```javascript
|
|
503
|
+
import { RDSDataClient } from '@aws-sdk/client-rds-data'
|
|
504
|
+
import { captureAWSv3Client } from 'aws-xray-sdk-core'
|
|
505
|
+
import dataApiClient from 'data-api-client'
|
|
366
506
|
|
|
367
|
-
|
|
507
|
+
const rdsClient = captureAWSv3Client(new RDSDataClient({ region: 'us-east-1' }))
|
|
368
508
|
|
|
369
|
-
|
|
509
|
+
const data = dataApiClient({
|
|
510
|
+
client: rdsClient,
|
|
511
|
+
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
512
|
+
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster-name'
|
|
513
|
+
})
|
|
514
|
+
```
|
|
515
|
+
|
|
516
|
+
## mysql2 and pg Compatibility Layers
|
|
517
|
+
|
|
518
|
+
Version 2.1 introduces compatibility layers that allow you to use the Data API Client as a drop-in replacement for popular database libraries. This makes it easy to migrate existing applications or use ORMs without modification.
|
|
519
|
+
|
|
520
|
+
### mysql2 Compatibility
|
|
521
|
+
|
|
522
|
+
Use the Data API Client as a replacement for `mysql2/promise`:
|
|
370
523
|
|
|
371
524
|
```javascript
|
|
372
|
-
|
|
525
|
+
import { createMySQLConnection, createMySQLPool } from 'data-api-client/compat/mysql2'
|
|
526
|
+
|
|
527
|
+
// Create a connection
|
|
528
|
+
const connection = createMySQLConnection({
|
|
529
|
+
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster',
|
|
373
530
|
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
374
|
-
|
|
375
|
-
|
|
376
|
-
sql: 'SELECT * FROM myTable WHERE id IN (:ids)',
|
|
377
|
-
parameters: [
|
|
378
|
-
{ name: 'id', value: { blobValue: [1,2,3,4,5] } }
|
|
379
|
-
]
|
|
380
|
-
).promise()
|
|
381
|
-
```
|
|
531
|
+
database: 'myDatabase'
|
|
532
|
+
})
|
|
382
533
|
|
|
383
|
-
|
|
534
|
+
// Use like mysql2/promise
|
|
535
|
+
const [rows, fields] = await connection.query('SELECT * FROM users WHERE id = ?', [123])
|
|
536
|
+
await connection.execute('INSERT INTO users (name, email) VALUES (?, ?)', ['Alice', 'alice@example.com'])
|
|
384
537
|
|
|
385
|
-
|
|
538
|
+
// Note: connection.end() is optional - it's a no-op for Data API (no connection to close)
|
|
386
539
|
|
|
387
|
-
|
|
540
|
+
// Create a pool for connection pooling
|
|
541
|
+
const pool = createMySQLPool({
|
|
542
|
+
resourceArn: 'arn:...',
|
|
543
|
+
secretArn: 'arn:...',
|
|
544
|
+
database: 'myDatabase'
|
|
545
|
+
})
|
|
388
546
|
|
|
389
|
-
|
|
547
|
+
// Get connection from pool
|
|
548
|
+
pool.getConnection((err, connection) => {
|
|
549
|
+
if (err) throw err
|
|
550
|
+
connection.query('SELECT * FROM users', (err, results) => {
|
|
551
|
+
connection.release() // Optional - no-op for Data API
|
|
552
|
+
// Handle results
|
|
553
|
+
})
|
|
554
|
+
})
|
|
555
|
+
|
|
556
|
+
// Or use promises
|
|
557
|
+
const connection = await pool.getConnection()
|
|
558
|
+
const [rows] = await connection.query('SELECT * FROM users')
|
|
559
|
+
connection.release() // Optional - no-op for Data API
|
|
560
|
+
```
|
|
561
|
+
|
|
562
|
+
### pg Compatibility
|
|
390
563
|
|
|
391
|
-
|
|
564
|
+
Use the Data API Client as a replacement for `pg` (node-postgres):
|
|
392
565
|
|
|
393
566
|
```javascript
|
|
394
|
-
|
|
567
|
+
import { createPgClient, createPgPool } from 'data-api-client/compat/pg'
|
|
568
|
+
|
|
569
|
+
// Create a client
|
|
570
|
+
const client = createPgClient({
|
|
571
|
+
resourceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:my-cluster',
|
|
395
572
|
secretArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:mySecret',
|
|
396
|
-
|
|
397
|
-
|
|
398
|
-
|
|
399
|
-
|
|
400
|
-
|
|
401
|
-
|
|
402
|
-
|
|
403
|
-
|
|
404
|
-
|
|
573
|
+
database: 'myDatabase'
|
|
574
|
+
})
|
|
575
|
+
|
|
576
|
+
// Note: client.connect() is optional - it's a no-op for Data API (no connection needed)
|
|
577
|
+
await client.connect() // Optional
|
|
578
|
+
|
|
579
|
+
// Use like pg
|
|
580
|
+
const result = await client.query('SELECT * FROM users WHERE id = $1', [123])
|
|
581
|
+
console.log(result.rows)
|
|
582
|
+
|
|
583
|
+
// With callback style
|
|
584
|
+
client.query('SELECT * FROM users', (err, result) => {
|
|
585
|
+
console.log(result.rows)
|
|
586
|
+
})
|
|
587
|
+
|
|
588
|
+
// Note: client.end() is optional - it's a no-op for Data API (no connection to close)
|
|
589
|
+
await client.end() // Optional
|
|
590
|
+
|
|
591
|
+
// Create a pool
|
|
592
|
+
const pool = createPgPool({
|
|
593
|
+
resourceArn: 'arn:...',
|
|
594
|
+
secretArn: 'arn:...',
|
|
595
|
+
database: 'myDatabase'
|
|
596
|
+
})
|
|
597
|
+
|
|
598
|
+
const result = await pool.query('SELECT * FROM users WHERE id = $1', [123])
|
|
405
599
|
```
|
|
406
600
|
|
|
407
|
-
|
|
601
|
+
### Using with ORMs
|
|
602
|
+
|
|
603
|
+
The compatibility layers work seamlessly with popular ORMs:
|
|
604
|
+
|
|
605
|
+
#### Drizzle ORM
|
|
606
|
+
|
|
607
|
+
**MySQL with Drizzle:**
|
|
608
|
+
|
|
609
|
+
```typescript
|
|
610
|
+
import { drizzle } from 'drizzle-orm/mysql2'
|
|
611
|
+
import { createMySQLPool } from 'data-api-client/compat/mysql2'
|
|
612
|
+
|
|
613
|
+
const pool = createMySQLPool({
|
|
614
|
+
resourceArn: 'arn:...',
|
|
615
|
+
secretArn: 'arn:...',
|
|
616
|
+
database: 'myDatabase'
|
|
617
|
+
})
|
|
618
|
+
|
|
619
|
+
const db = drizzle(pool as any)
|
|
620
|
+
|
|
621
|
+
// Use Drizzle normally
|
|
622
|
+
const users = await db.select().from(usersTable).where(eq(usersTable.id, 123))
|
|
623
|
+
```
|
|
624
|
+
|
|
625
|
+
**PostgreSQL with Drizzle:**
|
|
626
|
+
|
|
627
|
+
```typescript
|
|
628
|
+
import { drizzle } from 'drizzle-orm/node-postgres'
|
|
629
|
+
import { createPgClient } from 'data-api-client/compat/pg'
|
|
630
|
+
|
|
631
|
+
const client = createPgClient({
|
|
632
|
+
resourceArn: 'arn:...',
|
|
633
|
+
secretArn: 'arn:...',
|
|
634
|
+
database: 'myDatabase'
|
|
635
|
+
})
|
|
636
|
+
|
|
637
|
+
// Note: client.connect() is optional (no-op for Data API)
|
|
638
|
+
await client.connect() // Optional - can be omitted
|
|
639
|
+
const db = drizzle(client as any)
|
|
640
|
+
|
|
641
|
+
// Use Drizzle normally
|
|
642
|
+
const users = await db.select().from(usersTable).where(eq(usersTable.id, 123))
|
|
643
|
+
```
|
|
644
|
+
|
|
645
|
+
#### Kysely Query Builder
|
|
646
|
+
|
|
647
|
+
**MySQL with Kysely:**
|
|
648
|
+
|
|
649
|
+
```typescript
|
|
650
|
+
import { Kysely, MysqlDialect } from 'kysely'
|
|
651
|
+
import { createMySQLPool } from 'data-api-client/compat/mysql2'
|
|
652
|
+
|
|
653
|
+
const pool = createMySQLPool({
|
|
654
|
+
resourceArn: 'arn:...',
|
|
655
|
+
secretArn: 'arn:...',
|
|
656
|
+
database: 'myDatabase'
|
|
657
|
+
})
|
|
658
|
+
|
|
659
|
+
const db = new Kysely<Database>({
|
|
660
|
+
dialect: new MysqlDialect({ pool: pool as any })
|
|
661
|
+
})
|
|
662
|
+
|
|
663
|
+
// Use Kysely normally
|
|
664
|
+
const users = await db.selectFrom('users').selectAll().where('id', '=', 123).execute()
|
|
665
|
+
```
|
|
666
|
+
|
|
667
|
+
**PostgreSQL with Kysely:**
|
|
668
|
+
|
|
669
|
+
```typescript
|
|
670
|
+
import { Kysely, PostgresDialect } from 'kysely'
|
|
671
|
+
import { createPgPool } from 'data-api-client/compat/pg'
|
|
672
|
+
|
|
673
|
+
const pool = createPgPool({
|
|
674
|
+
resourceArn: 'arn:...',
|
|
675
|
+
secretArn: 'arn:...',
|
|
676
|
+
database: 'myDatabase'
|
|
677
|
+
})
|
|
678
|
+
|
|
679
|
+
const db = new Kysely<Database>({
|
|
680
|
+
dialect: new PostgresDialect({ pool: pool as any })
|
|
681
|
+
})
|
|
682
|
+
|
|
683
|
+
// Use Kysely normally
|
|
684
|
+
const users = await db.selectFrom('users').selectAll().where('id', '=', 123).execute()
|
|
685
|
+
```
|
|
686
|
+
|
|
687
|
+
**Benefits of Compatibility Layers:**
|
|
688
|
+
- **Zero code changes** when migrating from mysql2 or pg
|
|
689
|
+
- **Full ORM support** (Drizzle, Kysely)
|
|
690
|
+
- **Automatic retry logic** for cluster wake-ups
|
|
691
|
+
- **Connection pooling simulation** (getConnection, release)
|
|
692
|
+
- **Both Promise and callback APIs** supported
|
|
693
|
+
- **No-op connection management**: `connect()`, `end()`, and `release()` are optional since the Data API is connectionless - they're included only for backward compatibility with existing code
|
|
694
|
+
|
|
695
|
+
## PostgreSQL Array Support
|
|
696
|
+
|
|
697
|
+
One of the most powerful features in v2.0 is automatic PostgreSQL array handling. While the Data API has limitations with array _parameters_, array _results_ are fully supported and automatically converted to native JavaScript arrays.
|
|
698
|
+
|
|
699
|
+
### Array Results (Automatic Conversion)
|
|
700
|
+
|
|
701
|
+
When you query PostgreSQL arrays, the Data API Client automatically converts them to native JavaScript arrays:
|
|
702
|
+
|
|
703
|
+
```javascript
|
|
704
|
+
// Query returns PostgreSQL array
|
|
705
|
+
let result = await data.query(`SELECT tags FROM products WHERE id = :id`, { id: 123 })
|
|
706
|
+
|
|
707
|
+
// Automatic conversion to JavaScript array
|
|
708
|
+
// result.records[0].tags = ['new', 'featured', 'sale']
|
|
709
|
+
```
|
|
710
|
+
|
|
711
|
+
**Supported Array Types:**
|
|
712
|
+
|
|
713
|
+
- Integer arrays: `INT[]`, `SMALLINT[]`, `BIGINT[]`
|
|
714
|
+
- Float arrays: `REAL[]`, `DOUBLE PRECISION[]`, `NUMERIC[]`
|
|
715
|
+
- String arrays: `TEXT[]`, `VARCHAR[]`
|
|
716
|
+
- Boolean arrays: `BOOL[]`
|
|
717
|
+
- Date/Time arrays: `DATE[]`, `TIMESTAMP[]`
|
|
718
|
+
- Other types: `UUID[]`, `JSON[]`, `JSONB[]`
|
|
719
|
+
|
|
720
|
+
### Array Parameters (Workarounds Required)
|
|
721
|
+
|
|
722
|
+
The RDS Data API does **not support binding array parameters** directly. You'll need to use one of these workarounds:
|
|
723
|
+
|
|
724
|
+
**1. CSV string with `string_to_array()` (for integer arrays):**
|
|
725
|
+
|
|
726
|
+
```javascript
|
|
727
|
+
await data.query("INSERT INTO products (tags) VALUES (string_to_array(:csv, ',')::int[])", {
|
|
728
|
+
csv: '1,2,3'
|
|
729
|
+
})
|
|
730
|
+
```
|
|
731
|
+
|
|
732
|
+
**2. PostgreSQL array literal syntax:**
|
|
733
|
+
|
|
734
|
+
```javascript
|
|
735
|
+
await data.query('INSERT INTO products (tags) VALUES (:literal::text[])', {
|
|
736
|
+
literal: '{"admin","editor","viewer"}'
|
|
737
|
+
})
|
|
738
|
+
```
|
|
739
|
+
|
|
740
|
+
**3. ARRAY[] constructor with individual parameters:**
|
|
741
|
+
|
|
742
|
+
```javascript
|
|
743
|
+
await data.query('INSERT INTO products (tags) VALUES (ARRAY[:tag1, :tag2, :tag3])', {
|
|
744
|
+
tag1: 'blue',
|
|
745
|
+
tag2: 'sale',
|
|
746
|
+
tag3: 'featured'
|
|
747
|
+
})
|
|
748
|
+
```
|
|
749
|
+
|
|
750
|
+
Despite these input limitations, **all array results are automatically converted to native JavaScript arrays**, making it easy to work with PostgreSQL array data in your application.
|
|
751
|
+
|
|
752
|
+
## PostgreSQL Data Type Support
|
|
753
|
+
|
|
754
|
+
Version 2.0 provides comprehensive support for PostgreSQL data types:
|
|
755
|
+
|
|
756
|
+
### Numeric Types
|
|
757
|
+
|
|
758
|
+
- `SMALLINT`, `INT`, `BIGINT` - Integer types of various sizes
|
|
759
|
+
- `DECIMAL`, `NUMERIC` - Exact numeric types with precision
|
|
760
|
+
- `REAL`, `DOUBLE PRECISION` - Floating-point types
|
|
761
|
+
|
|
762
|
+
```javascript
|
|
763
|
+
await data.query('INSERT INTO products (price, quantity) VALUES (:price, :quantity)', {
|
|
764
|
+
price: 19.99,
|
|
765
|
+
quantity: 100
|
|
766
|
+
})
|
|
767
|
+
```
|
|
768
|
+
|
|
769
|
+
### String Types
|
|
770
|
+
|
|
771
|
+
- `CHAR`, `VARCHAR`, `TEXT` - Character types
|
|
772
|
+
- Full Unicode support
|
|
773
|
+
|
|
774
|
+
```javascript
|
|
775
|
+
await data.query('INSERT INTO posts (title, content) VALUES (:title, :content)', {
|
|
776
|
+
title: 'Hello 世界 🌍',
|
|
777
|
+
content: 'A very long text...'
|
|
778
|
+
})
|
|
779
|
+
```
|
|
780
|
+
|
|
781
|
+
### Boolean Type
|
|
782
|
+
|
|
783
|
+
```javascript
|
|
784
|
+
await data.query('INSERT INTO users (active) VALUES (:active)', { active: true })
|
|
785
|
+
```
|
|
786
|
+
|
|
787
|
+
### Date and Time Types
|
|
788
|
+
|
|
789
|
+
- `DATE` - Calendar date
|
|
790
|
+
- `TIME`, `TIME WITH TIME ZONE` - Time of day
|
|
791
|
+
- `TIMESTAMP`, `TIMESTAMP WITH TIME ZONE` - Date and time
|
|
792
|
+
|
|
793
|
+
```javascript
|
|
794
|
+
await data.query('INSERT INTO events (event_date, event_time) VALUES (:date, :time)', {
|
|
795
|
+
date: '2024-12-25',
|
|
796
|
+
time: new Date()
|
|
797
|
+
})
|
|
798
|
+
```
|
|
799
|
+
|
|
800
|
+
### Binary Data (BYTEA)
|
|
801
|
+
|
|
802
|
+
```javascript
|
|
803
|
+
const binaryData = Buffer.from('Binary content', 'utf-8')
|
|
804
|
+
await data.query('INSERT INTO files (content) VALUES (:content)', { content: binaryData })
|
|
805
|
+
```
|
|
806
|
+
|
|
807
|
+
### JSON and JSONB
|
|
808
|
+
|
|
809
|
+
```javascript
|
|
810
|
+
const metadata = { role: 'admin', permissions: ['read', 'write'] }
|
|
811
|
+
await data.query('INSERT INTO users (metadata) VALUES (:metadata::jsonb)', {
|
|
812
|
+
metadata: JSON.stringify(metadata)
|
|
813
|
+
})
|
|
814
|
+
|
|
815
|
+
// Query result
|
|
816
|
+
let result = await data.query('SELECT metadata FROM users WHERE id = :id', { id: 1 })
|
|
817
|
+
const parsed = JSON.parse(result.records[0].metadata)
|
|
818
|
+
```
|
|
819
|
+
|
|
820
|
+
### UUID
|
|
821
|
+
|
|
822
|
+
```javascript
|
|
823
|
+
await data.query('INSERT INTO sessions (session_id) VALUES (:id::uuid)', {
|
|
824
|
+
id: '550e8400-e29b-41d4-a716-446655440000'
|
|
825
|
+
})
|
|
826
|
+
|
|
827
|
+
// Or with explicit cast parameter
|
|
828
|
+
await data.query('INSERT INTO sessions (session_id) VALUES (:id)', [
|
|
829
|
+
{ name: 'id', value: '550e8400-e29b-41d4-a716-446655440000', cast: 'uuid' }
|
|
830
|
+
])
|
|
831
|
+
```
|
|
832
|
+
|
|
833
|
+
### Network Types
|
|
834
|
+
|
|
835
|
+
- `INET` - IPv4 or IPv6 host address
|
|
836
|
+
- `CIDR` - IPv4 or IPv6 network
|
|
837
|
+
|
|
838
|
+
```javascript
|
|
839
|
+
await data.query('INSERT INTO servers (ip_address, network) VALUES (:ip::inet, :net::cidr)', {
|
|
840
|
+
ip: '192.168.1.1',
|
|
841
|
+
net: '10.0.0.0/8'
|
|
842
|
+
})
|
|
843
|
+
```
|
|
844
|
+
|
|
845
|
+
### Range Types
|
|
846
|
+
|
|
847
|
+
- `INT4RANGE`, `NUMRANGE` - Numeric ranges
|
|
848
|
+
- `TSTZRANGE` - Timestamp ranges
|
|
849
|
+
|
|
850
|
+
```javascript
|
|
851
|
+
await data.query('INSERT INTO bookings (date_range) VALUES (:range::INT4RANGE)', {
|
|
852
|
+
range: '[1,10)'
|
|
853
|
+
})
|
|
854
|
+
```
|
|
855
|
+
|
|
856
|
+
## TypeScript Support
|
|
857
|
+
|
|
858
|
+
Version 2.0 is written in TypeScript and provides comprehensive type definitions:
|
|
859
|
+
|
|
860
|
+
```typescript
|
|
861
|
+
import dataApiClient from 'data-api-client'
|
|
862
|
+
import type { DataAPIClientConfig, QueryResult } from 'data-api-client/types'
|
|
863
|
+
|
|
864
|
+
const config: DataAPIClientConfig = {
|
|
865
|
+
secretArn: 'arn:...',
|
|
866
|
+
resourceArn: 'arn:...',
|
|
867
|
+
database: 'mydb',
|
|
868
|
+
engine: 'pg'
|
|
869
|
+
}
|
|
870
|
+
|
|
871
|
+
const client = dataApiClient(config)
|
|
872
|
+
|
|
873
|
+
interface User {
|
|
874
|
+
id: number
|
|
875
|
+
name: string
|
|
876
|
+
email: string
|
|
877
|
+
tags: string[]
|
|
878
|
+
}
|
|
879
|
+
|
|
880
|
+
const result: QueryResult<User> = await client.query<User>('SELECT * FROM users WHERE id = :id', { id: 123 })
|
|
881
|
+
```
|
|
882
|
+
|
|
883
|
+
## Data API Limitations / Wonkiness
|
|
884
|
+
|
|
885
|
+
While the Data API is powerful, there are some limitations to be aware of:
|
|
886
|
+
|
|
887
|
+
### Array Parameters Not Supported
|
|
888
|
+
|
|
889
|
+
The RDS Data API does **not support binding array parameters** directly. Attempts to use `arrayValue` parameters result in `ValidationException: Array parameters are not supported`. See [PostgreSQL Array Support](#postgresql-array-support) for workarounds.
|
|
890
|
+
|
|
891
|
+
### Array Results ARE Supported
|
|
892
|
+
|
|
893
|
+
Despite parameter limitations, array **results** work great! The Data API Client automatically converts PostgreSQL arrays in query results to native JavaScript arrays.
|
|
894
|
+
|
|
895
|
+
### Some Advanced Types Have Limitations
|
|
896
|
+
|
|
897
|
+
- **MACADDR**: Not supported by the Data API
|
|
898
|
+
- **Multidimensional Arrays**: Limited support for arrays with more than one dimension
|
|
899
|
+
- **NULL values in arrays**: May not work correctly in all cases
|
|
900
|
+
- **Some Range Types**: INT8RANGE, DATERANGE, TSRANGE have casting issues
|
|
408
901
|
|
|
409
|
-
### Batch
|
|
902
|
+
### Batch operations have limited feedback
|
|
410
903
|
|
|
411
|
-
|
|
904
|
+
Batch operations don't return `numberOfRecordsUpdated` for UPDATE/DELETE statements.
|
|
412
905
|
|
|
413
906
|
## Enabling Data API
|
|
414
907
|
|
|
415
|
-
In order to use the Data API, you must enable it on your Aurora Serverless Cluster and create a Secret. You also must grant your execution environment a number of
|
|
908
|
+
In order to use the Data API, you must enable it on your Aurora Serverless Cluster and create a Secret. You also must grant your execution environment a number of permissions as outlined in the following sections.
|
|
416
909
|
|
|
417
|
-
### Enable Data API on your Aurora
|
|
910
|
+
### Enable Data API on your Aurora Cluster
|
|
418
911
|
|
|
419
912
|
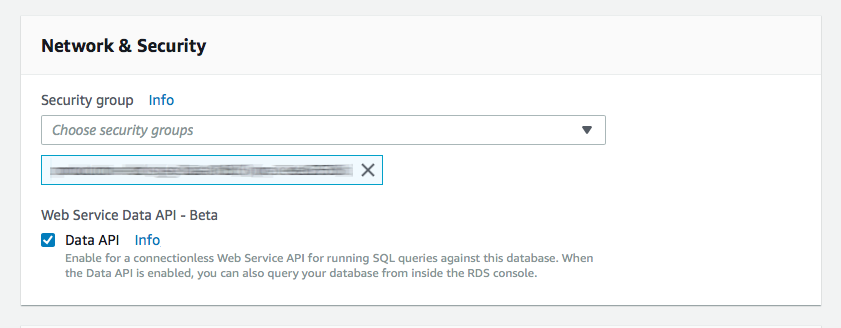
|
|
420
913
|
|
|
421
|
-
You need to modify your Aurora
|
|
914
|
+
You need to modify your Aurora cluster by clicking "ACTIONS" and then "Modify Cluster". Check the Data API box in the _Network & Security_ section and you're good to go. This works for Aurora Serverless v1, Aurora Serverless v2, and Aurora provisioned clusters.
|
|
422
915
|
|
|
423
916
|
### Set up a secret in the Secrets Manager
|
|
424
917
|
|
|
@@ -426,11 +919,11 @@ Next you need to set up a secret in the Secrets Manager. This is actually quite
|
|
|
426
919
|
|
|
427
920
|
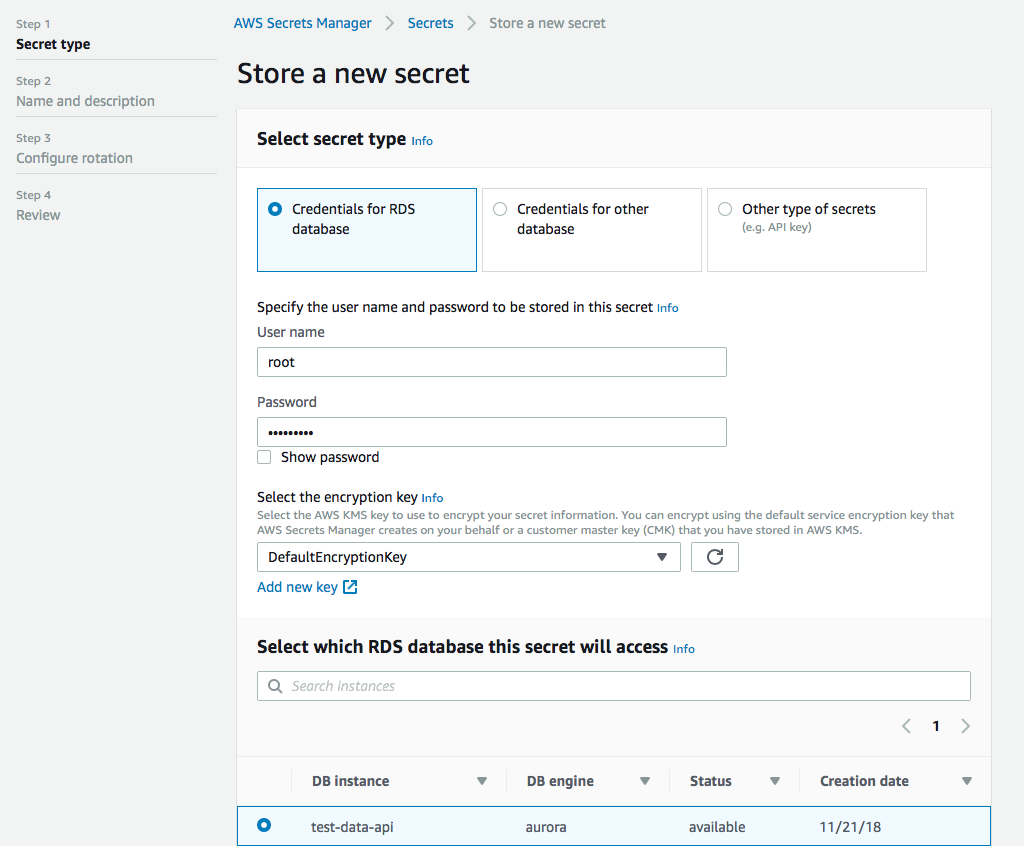
|
|
428
921
|
|
|
429
|
-
Next we give it a name, this is important, because this will be part of the arn when we set up permissions later. You can give it a description as well so you don
|
|
922
|
+
Next we give it a name, this is important, because this will be part of the arn when we set up permissions later. You can give it a description as well so you don't forget what this secret is about when you look at it in a few weeks.
|
|
430
923
|
|
|
431
924
|
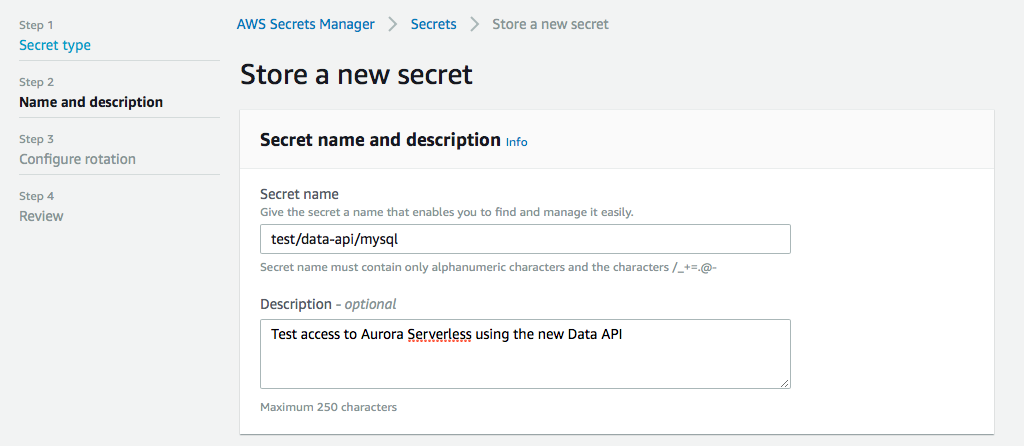
|
|
432
925
|
|
|
433
|
-
You can then configure your rotation settings, if you want, and then you review and create your secret. Then you can click on your newly created secret and grab the arn, we
|
|
926
|
+
You can then configure your rotation settings, if you want, and then you review and create your secret. Then you can click on your newly created secret and grab the arn, we're gonna need that next.
|
|
434
927
|
|
|
435
928
|
|
|
436
929
|
|
|
@@ -483,4 +976,4 @@ Statement:
|
|
|
483
976
|
|
|
484
977
|
## Contributions
|
|
485
978
|
|
|
486
|
-
Contributions, ideas and bug reports are welcome and greatly appreciated. Please add [issues](https://github.com/jeremydaly/data-api-client/issues) for suggestions and bug reports or create a pull request. You can also contact me on
|
|
979
|
+
Contributions, ideas and bug reports are welcome and greatly appreciated. Please add [issues](https://github.com/jeremydaly/data-api-client/issues) for suggestions and bug reports or create a pull request. You can also contact me on X: [@jeremy_daly](https://x.com/jeremy_daly) or LinkedIn: [https://www.linkedin.com/in/jeremydaly/](https://www.linkedin.com/in/jeremydaly/).
|