agentic-api 1.0.2 → 1.0.4
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +55 -17
- package/dist/src/agents/digestor.d.ts +13 -3
- package/dist/src/agents/digestor.js +99 -15
- package/dist/src/agents/digestor.test.d.ts +1 -0
- package/dist/src/agents/digestor.test.js +45 -0
- package/dist/src/execute.js +1 -1
- package/dist/src/types.d.ts +4 -0
- package/package.json +1 -1
package/README.md
CHANGED
|
@@ -1,42 +1,35 @@
|
|
|
1
1
|
# @agentic-api
|
|
2
2
|
|
|
3
|
-
Super simple API for intelligent agent orchestration with automatic sequences and escalations.
|
|
3
|
+
Super simple API for intelligent agent orchestration with automatic sequences and escalations. (inspiré du projet [OpenAI Swarm](https://github.com/openai/openai-realtime-agents))
|
|
4
4
|
|
|
5
5
|
> **Personal Note**:
|
|
6
6
|
> This project is not meant to be better than Vercel or LangChain. It's simply less generic and optimized for a specific set of problems.
|
|
7
7
|
> It focuses on specific features that required too many dependencies with other frameworks.
|
|
8
8
|
|
|
9
|
+
|
|
9
10
|
## 🚀 Key Features
|
|
10
11
|
|
|
11
12
|
- Agent orchestration in predefined sequences
|
|
12
|
-
- Automatic model escalation
|
|
13
|
+
- Automatic model escalation to more intelligent instructions and models.
|
|
13
14
|
- Smart transfer between specialized agents with confidence threshold
|
|
14
|
-
-
|
|
15
|
-
|
|
16
|
-
- Thinking tool for complex reasoning
|
|
17
|
-
- Real-time agent status feedback
|
|
15
|
+
- Prompting models to follow a state machine, for example to accurately collect things like names and phone numbers.
|
|
16
|
+
|
|
18
17
|
|
|
19
18
|
### Key Advantages
|
|
20
19
|
|
|
21
20
|
1. **Simplicity**
|
|
22
21
|
- Minimal configuration
|
|
23
22
|
- Few dependencies
|
|
24
|
-
|
|
25
|
-
2. **Performance**
|
|
26
|
-
- Production-ready
|
|
27
|
-
- Efficient memory management
|
|
28
|
-
- Fast and (relatively) reliable agent transfers
|
|
29
|
-
|
|
30
|
-
3. **Flexibility**
|
|
31
|
-
- Primarily OpenAI support
|
|
32
|
-
- Extensible system
|
|
33
|
-
- Easy agent customization
|
|
23
|
+
- Fast
|
|
34
24
|
|
|
35
25
|
### Recommended Use Cases
|
|
36
26
|
|
|
37
27
|
- Applications requiring specialized agent orchestration
|
|
38
28
|
- Projects needing reliable content extraction
|
|
39
29
|
|
|
30
|
+
|
|
31
|
+
[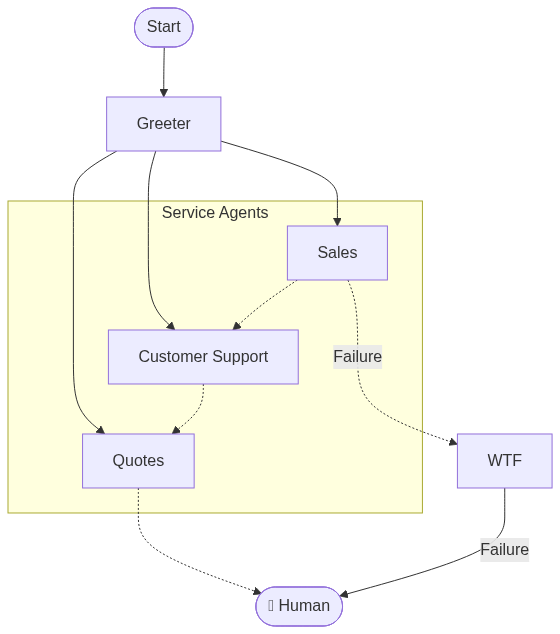](https://mermaid.live/edit#pako:eNpVkcluwjAQhl_FGgmJSoDIQoAcKhEQ7aGXNkiVmqDKTYYkUmJHxu5GeZaq575cH6EmC8sc7PnG_4xn7B1EPEZwYZPztyilQpLVImREmy81dYNqW1_VsVlwIxAlinXNi24Qwt_37w-5VQVlIbTCet2ql0TQMiU-itcswudZgkxuSdAwqbkpdrA4ExjJjDNy93CKekbg0xzPhZ4ZzNVW8gIF8VVZct3k2akV3CsujxnI4pDV7jx4XC3XLVXTkX7_msyaCSvwjAsyL8hqkzsdsuQi0h3QPEsYFnoYknKRfXImaV6LPIP0B2dFPLNhq2Gr5kVbtUn4WtIsVwK_yLxp_HD7KXrUQw_0IxQ0i_U37g6xEGSqmwnB1W6MG6pyGULI9lpKleT-B4vAlUJhDwRXSQruhuZbTaqMqcRFRvW3Fa2kpOyJ8yMm4nBTk60fFsWcKybBHVVScHfwrmFiDgzTGJvToWFY2nrwAe54OBg5pu1Yjj21Dcd29j34rGoPB5OxPT23_T90g8Qf)
|
|
32
|
+
|
|
40
33
|
## 📦 Installation
|
|
41
34
|
|
|
42
35
|
```bash
|
|
@@ -64,7 +57,7 @@ const session: AgenticContext = {
|
|
|
64
57
|
usage: { prompt: 0, completion: 0, total: 0, cost: 0 }
|
|
65
58
|
},
|
|
66
59
|
user: {
|
|
67
|
-
id:
|
|
60
|
+
id: user.id
|
|
68
61
|
}
|
|
69
62
|
};
|
|
70
63
|
|
|
@@ -158,6 +151,51 @@ Agent transfer is automatically managed with:
|
|
|
158
151
|
- Conversation context preservation
|
|
159
152
|
- Automatic system instruction updates
|
|
160
153
|
|
|
154
|
+
## 💾 Pull-based Data Digestion
|
|
155
|
+
|
|
156
|
+
This feature enables agents to process large documents मोहब्बत chunk by chunk. It's designed for scenarios where the entire document cannot fit into the agent's context window.
|
|
157
|
+
|
|
158
|
+
- **Chunked Processing**: The `pullContentDigestor` tool allows an agent to request and process content in manageable chunks.
|
|
159
|
+
- **Stateful Digestion**: The agent receives the current chunk and relevant instructions, including the previous processing results, to maintain context throughout the digestion of the entire document.
|
|
160
|
+
- **Flexible Templates**: Different processing templates (e.g., "facts", "compress", "semantic", "minutes") can be applied to each chunk, guiding the agent on how to digest the information.
|
|
161
|
+
- **EOF Handling**: The tool signals the end of the document with an "EOF" message, allowing the agent to finalize its processing.
|
|
162
|
+
|
|
163
|
+
```typescript
|
|
164
|
+
// Example of how an agent might use the pullContentDigestor tool
|
|
165
|
+
|
|
166
|
+
// Agent receives a call to process a large document
|
|
167
|
+
// Initial call to the tool
|
|
168
|
+
const initialChunkData = await pullContentDigestor({
|
|
169
|
+
path: "path/to/large/document.pdf",
|
|
170
|
+
template: "facts", // or any other relevant template
|
|
171
|
+
position: 0 // Initial position
|
|
172
|
+
});
|
|
173
|
+
|
|
174
|
+
let currentChunk = initialChunkData.content;
|
|
175
|
+
let nextPosition = initialChunkData.nextPosition;
|
|
176
|
+
let accumulatedResults = ""; // Agent will accumulate results here
|
|
177
|
+
|
|
178
|
+
while (!currentChunk.includes("EOF")) {
|
|
179
|
+
// Process the currentChunk based on instructions and template
|
|
180
|
+
// The agent would use its LLM capabilities here,
|
|
181
|
+
// using the provided instructions, previous results, and the new chunk.
|
|
182
|
+
const processingResult = await processMyChunk(currentChunk, initialChunkData.instructions, accumulatedResults);
|
|
183
|
+
accumulatedResults += processingResult; // Append to overall result
|
|
184
|
+
|
|
185
|
+
// Request the next chunk
|
|
186
|
+
const nextChunkData = await pullContentDigestor({
|
|
187
|
+
path: "path/to/large/document.pdf",
|
|
188
|
+
template: "facts",
|
|
189
|
+
position: nextPosition
|
|
190
|
+
});
|
|
191
|
+
currentChunk = nextChunkData.content;
|
|
192
|
+
nextPosition = nextChunkData.nextPosition;
|
|
193
|
+
}
|
|
194
|
+
|
|
195
|
+
// Final processing of accumulatedResults
|
|
196
|
+
const finalDigestedDocument = finalizeProcessing(accumulatedResults);
|
|
197
|
+
```
|
|
198
|
+
|
|
161
199
|
## 🧪 Testing
|
|
162
200
|
|
|
163
201
|
```bash
|
|
@@ -1,7 +1,17 @@
|
|
|
1
|
-
import { AgenticContext, Tool } from "../types";
|
|
1
|
+
import { AgenticCache, AgenticContext, Tool } from "../types";
|
|
2
2
|
export declare const Digestor: {
|
|
3
|
-
createTools: (
|
|
4
|
-
|
|
3
|
+
createTools: (cache: AgenticCache, chunkSize: number, templates: {
|
|
4
|
+
[key: string]: string;
|
|
5
|
+
}) => {
|
|
6
|
+
pullContentDigestor: (args?: any, session?: AgenticContext) => Promise<{
|
|
7
|
+
content: string;
|
|
8
|
+
role?: undefined;
|
|
9
|
+
name?: undefined;
|
|
10
|
+
} | {
|
|
11
|
+
role: string;
|
|
12
|
+
name: string;
|
|
13
|
+
content: string;
|
|
14
|
+
}>;
|
|
5
15
|
toolPullContentDigestor: Tool;
|
|
6
16
|
};
|
|
7
17
|
};
|
|
@@ -1,23 +1,24 @@
|
|
|
1
1
|
"use strict";
|
|
2
2
|
Object.defineProperty(exports, "__esModule", { value: true });
|
|
3
3
|
exports.Digestor = void 0;
|
|
4
|
+
const fs_1 = require("fs");
|
|
4
5
|
const promptPullContentDigestor = `
|
|
5
|
-
This tool allows you to load the content of a large
|
|
6
|
+
This tool allows you to load the content of a large content, chunk by chunk, for progressive processing.
|
|
6
7
|
|
|
7
8
|
# Usage Instructions:
|
|
8
9
|
- On each call, the tool returns the next chunk of the specified file, along with instructions for processing this content.
|
|
9
|
-
- The "position" parameter indicates where to resume reading
|
|
10
|
-
- When all content has been processed, the tool returns "
|
|
10
|
+
- The "position" parameter indicates where to resume reading.
|
|
11
|
+
- When all content has been processed, the tool returns "\nEOF" to signal the end of the file.
|
|
11
12
|
|
|
12
13
|
# Parameters:
|
|
13
|
-
- path (str): Absolute or
|
|
14
|
-
- template (enum): Indicates the type of processing to apply to the chunk (e.g., "facts", "compress", "semantic", "minutes").
|
|
15
|
-
- position (str): Allows you to continue reading from the last known position
|
|
14
|
+
- path (str): Absolute,relative, or inline content.
|
|
15
|
+
- template (enum): Indicates the type of processing to apply to the chunk (e.g., "facts", "compress", "semantic", "minutes", etc).
|
|
16
|
+
- position (str): Allows you to continue reading from the last known position.
|
|
16
17
|
|
|
17
18
|
# Best Practices:
|
|
18
|
-
- Use this tool to process
|
|
19
|
-
- Never skip a chunk: process each piece in order.
|
|
20
|
-
- Stop calling the tool as soon as "EOF" is returned.
|
|
19
|
+
- Use this tool to process contents that are too large to be read in a single pass.
|
|
20
|
+
- Never skip a chunk: process each piece in order and always use the last position parameter.
|
|
21
|
+
- Stop calling the tool as soon as "EOF" (or "\nEOF") is returned.
|
|
21
22
|
`;
|
|
22
23
|
const toolPullContentDigestor = {
|
|
23
24
|
type: "function",
|
|
@@ -30,7 +31,7 @@ const toolPullContentDigestor = {
|
|
|
30
31
|
properties: {
|
|
31
32
|
path: {
|
|
32
33
|
type: "string",
|
|
33
|
-
description: "Absolute or relative path of the file to read."
|
|
34
|
+
description: "Absolute or relative path of the file to read (e.g., 'https:....html', 'file://...', 'https://.../file.pdf')."
|
|
34
35
|
},
|
|
35
36
|
template: {
|
|
36
37
|
type: "string",
|
|
@@ -38,8 +39,8 @@ const toolPullContentDigestor = {
|
|
|
38
39
|
enum: ["facts", "compress", "semantic", "minutes"]
|
|
39
40
|
},
|
|
40
41
|
position: {
|
|
41
|
-
type: "
|
|
42
|
-
description: "
|
|
42
|
+
type: "number",
|
|
43
|
+
description: "position of the last loaded chunk. (0 for the first call)"
|
|
43
44
|
}
|
|
44
45
|
},
|
|
45
46
|
required: ["path", "template", "position"],
|
|
@@ -47,11 +48,94 @@ const toolPullContentDigestor = {
|
|
|
47
48
|
}
|
|
48
49
|
}
|
|
49
50
|
};
|
|
50
|
-
|
|
51
|
+
/**
|
|
52
|
+
* Loads a content chunk from a file or URL.
|
|
53
|
+
*
|
|
54
|
+
* @param {string} path - The path to the content file or URL.
|
|
55
|
+
* @param {number} position - The position in the content to start loading from.
|
|
56
|
+
* @param {number} chunkSize - The size of each content chunk to load.
|
|
57
|
+
* @param {AgenticCache} cache - The cache instance used to store and retrieve content chunks.
|
|
58
|
+
* @param {string} userid - The user ID for caching purposes.
|
|
59
|
+
* @returns {Promise<Content>} A promise that resolves to the content chunk.
|
|
60
|
+
*/
|
|
61
|
+
const loadContentChunk = async (path, position, chunkSize, cache, userid) => {
|
|
62
|
+
//FIXME: multiple users access to the cache with different position!
|
|
63
|
+
const loader = async (path, cache, userid) => {
|
|
64
|
+
const cacheKey = `content:${path}:${userid}`;
|
|
65
|
+
const value = await cache.get(cacheKey);
|
|
66
|
+
if (value) {
|
|
67
|
+
return value;
|
|
68
|
+
}
|
|
69
|
+
if (path.startsWith("file://")) {
|
|
70
|
+
const fileContent = (0, fs_1.readFileSync)(path, "utf8");
|
|
71
|
+
const value = { content: fileContent, position: 0, key: cacheKey };
|
|
72
|
+
await cache.set(cacheKey, value);
|
|
73
|
+
return value;
|
|
74
|
+
}
|
|
75
|
+
if (path.startsWith("http://") || path.startsWith("https://")) {
|
|
76
|
+
const response = await fetch(path);
|
|
77
|
+
const fileContent = await response.text();
|
|
78
|
+
const value = { content: fileContent, position: 0, key: cacheKey };
|
|
79
|
+
await cache.set(cacheKey, value);
|
|
80
|
+
return value;
|
|
81
|
+
}
|
|
82
|
+
//
|
|
83
|
+
// if not a file or url, return the path as content
|
|
84
|
+
return { content: path, position: 0, key: cacheKey };
|
|
85
|
+
};
|
|
86
|
+
//
|
|
87
|
+
// load asset content
|
|
88
|
+
const value = await loader(path, cache, userid);
|
|
89
|
+
const startPos = value.position;
|
|
90
|
+
value.position = startPos + chunkSize;
|
|
91
|
+
await cache.set(value.key, value);
|
|
92
|
+
if (startPos >= value.content.length) {
|
|
93
|
+
return { content: 'EOF', position: startPos };
|
|
94
|
+
}
|
|
95
|
+
if (startPos + chunkSize + 1 > value.content.length) {
|
|
96
|
+
return { content: value.content.slice(startPos) + "\nEOF", position: startPos };
|
|
97
|
+
}
|
|
98
|
+
const endPos = Math.min(startPos + chunkSize, value.content.length);
|
|
99
|
+
return { content: value.content.slice(startPos, endPos), position: endPos };
|
|
100
|
+
};
|
|
101
|
+
/**
|
|
102
|
+
* Creates tools for chunked content loading and processing.
|
|
103
|
+
*
|
|
104
|
+
* @param {AgenticCache} cache - The cache instance used to store and retrieve content chunks.
|
|
105
|
+
* @param {number} chunkSize - The size of each content chunk to load.
|
|
106
|
+
* @param {{[key: string]: string}} templates - An object mapping template names to their instruction strings.
|
|
107
|
+
* @returns {{ pullContentDigestor: Function, toolPullContentDigestor: any }} An object containing the pullContentDigestor function and its tool definition.
|
|
108
|
+
*/
|
|
109
|
+
const createTools = (cache, chunkSize, templates) => {
|
|
51
110
|
const pullContentDigestor = async (args, session) => {
|
|
52
111
|
const { path, template, position } = args;
|
|
53
|
-
|
|
54
|
-
|
|
112
|
+
const userid = session?.user?.id;
|
|
113
|
+
const chunk = await loadContentChunk(path, position, chunkSize, cache, userid);
|
|
114
|
+
if (!chunk || !chunk.content) {
|
|
115
|
+
throw new Error("Load content chunk failed");
|
|
116
|
+
}
|
|
117
|
+
//
|
|
118
|
+
// check template and ask for a valid template name
|
|
119
|
+
if (!templates[template]) {
|
|
120
|
+
return { content: 'Missing template name, recall with a valid template name' };
|
|
121
|
+
}
|
|
122
|
+
//
|
|
123
|
+
// get the prompt for the template
|
|
124
|
+
const promptPullContentDigestorFollowUp = templates[template] || '';
|
|
125
|
+
// Construit le message formaté pour l'agent LLM
|
|
126
|
+
console.log("-- Digest DBG chunk", position, chunk);
|
|
127
|
+
const templateInstructions = !position ? `${promptPullContentDigestorFollowUp}\nTemplate: ${template}\nChunk:\n` : '';
|
|
128
|
+
const content = JSON.stringify({
|
|
129
|
+
instructions: `${templateInstructions}`,
|
|
130
|
+
chunk: `${chunk.content}`,
|
|
131
|
+
nextPosition: chunk.position,
|
|
132
|
+
eof: chunk.content.includes('EOF')
|
|
133
|
+
});
|
|
134
|
+
return {
|
|
135
|
+
role: "assistant",
|
|
136
|
+
name: "pullContentDigestor",
|
|
137
|
+
content
|
|
138
|
+
};
|
|
55
139
|
};
|
|
56
140
|
return { pullContentDigestor, toolPullContentDigestor };
|
|
57
141
|
};
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
export {};
|
|
@@ -0,0 +1,45 @@
|
|
|
1
|
+
"use strict";
|
|
2
|
+
Object.defineProperty(exports, "__esModule", { value: true });
|
|
3
|
+
const execute_1 = require("../execute");
|
|
4
|
+
const digestor_1 = require("./digestor");
|
|
5
|
+
// Implémentation simple du cache pour les tests
|
|
6
|
+
class TestCache {
|
|
7
|
+
constructor() {
|
|
8
|
+
this.cache = new Map();
|
|
9
|
+
}
|
|
10
|
+
async get(key) {
|
|
11
|
+
return this.cache.get(key) || null;
|
|
12
|
+
}
|
|
13
|
+
async set(key, value, ttl) {
|
|
14
|
+
this.cache.set(key, value);
|
|
15
|
+
return value;
|
|
16
|
+
}
|
|
17
|
+
}
|
|
18
|
+
describe("Digestor Agent", () => {
|
|
19
|
+
it("should merge two chunks of 50 characters", async () => {
|
|
20
|
+
// Création d'un contenu de test de 100 caractères
|
|
21
|
+
const testContent = "A".repeat(50) + "B".repeat(50);
|
|
22
|
+
// Configuration de l'agent avec une instruction simple de fusion
|
|
23
|
+
const agentConfig = {
|
|
24
|
+
name: "chunkMerger",
|
|
25
|
+
publicDescription: "Agent that merges chunks of text",
|
|
26
|
+
instructions: `You are a simple agent that merges chunks of text.
|
|
27
|
+
When you receive a chunk, you should:
|
|
28
|
+
1. If it's the first chunk, store it
|
|
29
|
+
2. If it's the second chunk, merge it with the first one
|
|
30
|
+
3. If you receive "EOF", return the final merged result`,
|
|
31
|
+
tools: [digestor_1.Digestor.createTools(new TestCache(), 50).toolPullContentDigestor]
|
|
32
|
+
};
|
|
33
|
+
// Mock du cache pour simuler le contenu
|
|
34
|
+
const cache = new TestCache();
|
|
35
|
+
await cache.set("content:test.txt", testContent);
|
|
36
|
+
// Exécution de l'agent
|
|
37
|
+
const result = await (0, execute_1.executeAgentSet)([agentConfig], {
|
|
38
|
+
messages: [],
|
|
39
|
+
cache,
|
|
40
|
+
user: { id: "test-user" }
|
|
41
|
+
});
|
|
42
|
+
// Vérification du résultat
|
|
43
|
+
expect(result.messages[result.messages.length - 1].content).toBe("A".repeat(50) + "B".repeat(50));
|
|
44
|
+
});
|
|
45
|
+
});
|
package/dist/src/execute.js
CHANGED
|
@@ -58,7 +58,7 @@ function sendFeedback(params) {
|
|
|
58
58
|
usage,
|
|
59
59
|
state
|
|
60
60
|
};
|
|
61
|
-
console.log('--- DBG feedback --:',
|
|
61
|
+
//console.log('--- DBG feedback --:',description);
|
|
62
62
|
//
|
|
63
63
|
// send agent state and description
|
|
64
64
|
stdout.write(`\n<step>${JSON.stringify(feedback)}</step>\n`);
|
package/dist/src/types.d.ts
CHANGED
|
@@ -75,6 +75,10 @@ export interface AgenticMemorySession {
|
|
|
75
75
|
messages: any[];
|
|
76
76
|
usage: Usage;
|
|
77
77
|
}
|
|
78
|
+
export type AgenticCache = {
|
|
79
|
+
get: <T>(key: string) => Promise<T | null>;
|
|
80
|
+
set: <T>(key: string, value: T, ttl?: number) => Promise<T>;
|
|
81
|
+
};
|
|
78
82
|
export interface AgenticContext {
|
|
79
83
|
memory?: AgenticMemorySession;
|
|
80
84
|
user: UserNano;
|
package/package.json
CHANGED