@stylusnexus/work-plan 2026.6.9-2 → 2026.6.9-4
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +9 -7
- package/VERSION +1 -1
- package/package.json +1 -1
- package/skills/work-plan/commands/auto_triage.py +14 -1
- package/skills/work-plan/commands/canonicalize.py +48 -11
- package/skills/work-plan/commands/group.py +42 -4
- package/skills/work-plan/commands/init.py +1 -1
- package/skills/work-plan/commands/move.py +131 -0
- package/skills/work-plan/commands/new_track.py +1 -1
- package/skills/work-plan/commands/set_field.py +5 -2
- package/skills/work-plan/commands/where_was_i.py +23 -5
- package/skills/work-plan/lib/export_model.py +54 -1
- package/skills/work-plan/lib/github_state.py +54 -13
- package/skills/work-plan/tests/test_auto_triage.py +27 -0
- package/skills/work-plan/tests/test_export.py +126 -1
- package/skills/work-plan/tests/test_export_command.py +2 -2
- package/skills/work-plan/tests/test_github_state.py +52 -14
- package/skills/work-plan/tests/test_group_apply.py +63 -0
- package/skills/work-plan/tests/test_move.py +240 -0
- package/skills/work-plan/tests/test_new_track.py +4 -4
- package/skills/work-plan/tests/test_where_was_i.py +135 -0
- package/skills/work-plan/work_plan.py +11 -6
package/README.md
CHANGED
|
@@ -62,11 +62,13 @@ A dozen more subcommands cover slotting new issues into tracks, closing tracks (
|
|
|
62
62
|
|
|
63
63
|
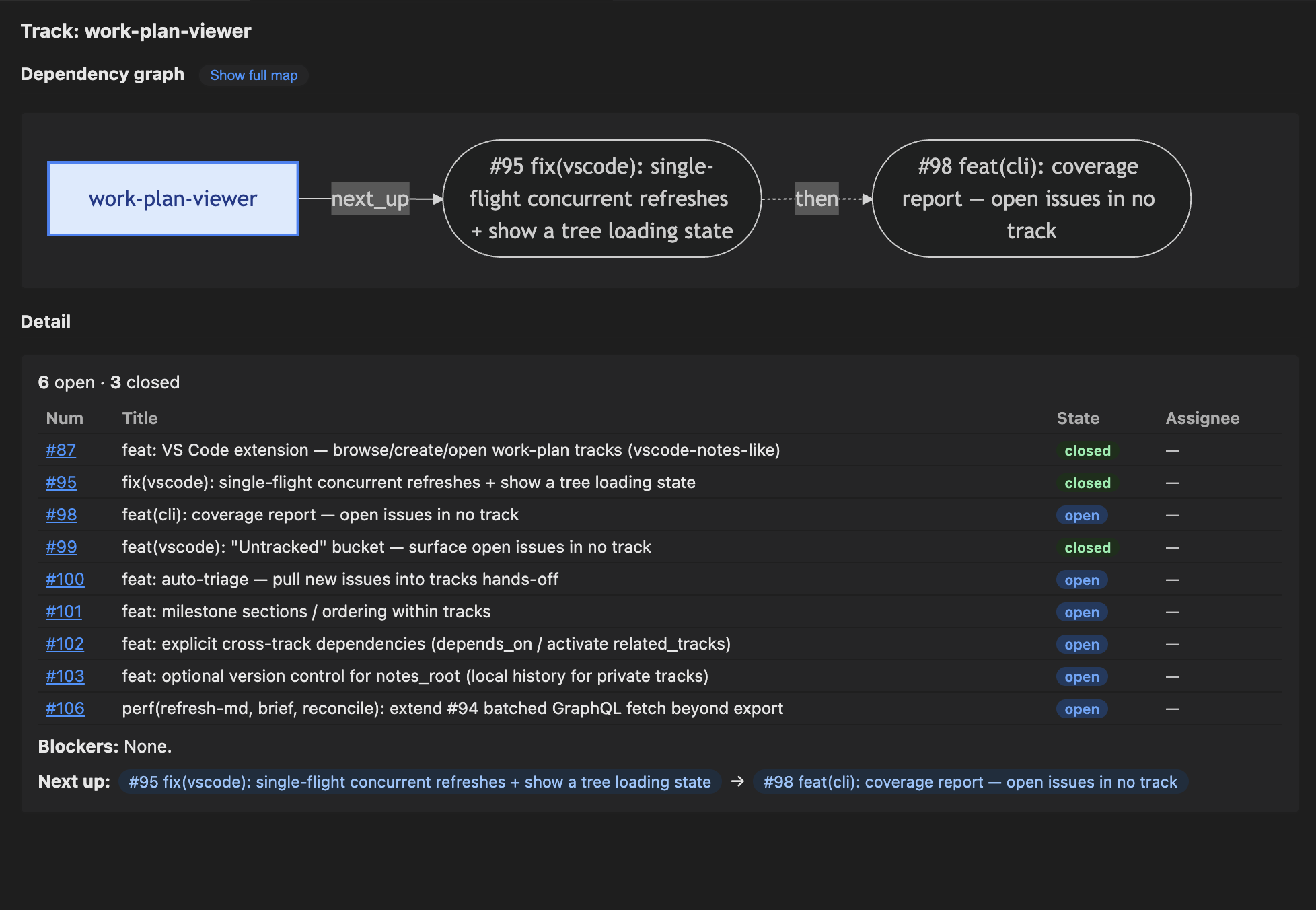
**Coverage + auto-triage** — `coverage --repo=<key>` reports how many open issues fall outside the track model (42% on a real production repo). `auto-triage --repo=<key>` then produces an AI prompt to assign those orphans to existing tracks. Run both periodically to keep the backlog visible.
|
|
64
64
|
|
|
65
|
+
**Cross-track dependencies** — set `depends_on: [<track-slug>]` in a track's frontmatter to declare explicit dependencies between tracks. The VS Code viewer renders these as thick amber `==>` edges in the dependency graph, and the detail panel shows clickable dependency chips that navigate directly to the dependent track. Set via `/work-plan set <track> depends_on=slug1,slug2` or the "Edit Track Fields" right-click menu in VS Code. Complementary to the issue-derived "owns" edges already inferred from blockers.
|
|
66
|
+
|
|
65
67
|
Beyond issue tracking, **`plan-status`** answers a different question — *which of your accumulated plan/spec docs actually shipped, half-shipped, or died*. It correlates each plan's declared file-manifest (`Create:`/`Modify:`/`Test:` paths) against git and the filesystem rather than trusting checkboxes (which are routinely left unchecked even for shipped work). Read-only by default; optionally stamp the verdict into each doc (`--stamp`), get an AI verdict on prose/ambiguous docs (`--llm`), and act on the results behind confirmation gates (`--archive` dead plans, `--issues` for partial ones). See [Plan & doc liveness](#plan--doc-liveness-plan-status).
|
|
66
68
|
|
|
67
69
|
## How it works
|
|
68
70
|
|
|
69
|
-
The toolkit treats GitHub as the canonical source of issue state and never tries to mirror it. Track markdown files are lightweight references — they list issue numbers and a few pieces of derived metadata (priority, milestone, `next_up`, last session timestamp). The CLI re-derives everything else live from `gh`, `git`, and the markdown body.
|
|
71
|
+
The toolkit treats GitHub as the canonical source of issue state and never tries to mirror it. Track markdown files are lightweight references — they list issue numbers and a few pieces of derived metadata (priority, milestone, `next_up`, `depends_on`, last session timestamp). The CLI re-derives everything else live from `gh`, `git`, and the markdown body.
|
|
70
72
|
|
|
71
73
|
```mermaid
|
|
72
74
|
flowchart TB
|
|
@@ -279,7 +281,7 @@ To install for **both** Claude Code AND Codex, run the installer twice with diff
|
|
|
279
281
|
|
|
280
282
|
### VS Code extension
|
|
281
283
|
|
|
282
|
-
The **Work Plan** extension is the visual face of the CLI — a sidebar tree (repos → tracks), a Mermaid dependency graph, the Untracked bucket, and full read/write (slot/close/edit/new-track/…) with a public-repo confirm modal.
|
|
284
|
+
The **Work Plan** extension is the visual face of the CLI — a sidebar tree (repos → tracks), a Mermaid dependency graph (with focus toggle and repo-scoped full map), the Untracked bucket, cross-track dependency chips, per-issue move buttons, and full read/write (slot/close/edit/move/new-track/…) with a public-repo confirm modal.
|
|
283
285
|
|
|
284
286
|
|
|
285
287
|
|
|
@@ -378,9 +380,9 @@ work-plan-toolkit/
|
|
|
378
380
|
│ ├── work-plan/
|
|
379
381
|
│ │ ├── SKILL.md
|
|
380
382
|
│ │ ├── work_plan.py # CLI entry
|
|
381
|
-
│ │ ├── commands/ #
|
|
383
|
+
│ │ ├── commands/ # 24 subcommand modules
|
|
382
384
|
│ │ ├── lib/ # config, frontmatter, gh, git, prompts, …
|
|
383
|
-
│ │ └── tests/ #
|
|
385
|
+
│ │ └── tests/ # 600+ unittest cases
|
|
384
386
|
│ └── repo-activity-summary/
|
|
385
387
|
│ └── SKILL.md # bundled companion skill
|
|
386
388
|
├── commands/
|
|
@@ -497,8 +499,8 @@ See `docs/usage-examples.md` for end-to-end scenarios (morning brief, mid-work h
|
|
|
497
499
|
| `new-track <repo> <slug> [--priority=P0..P3] [--milestone=<m>]` | One-shot, non-interactive: create a new track file under `notes_root` for `<repo>` (a config key **or** an `org/repo` slug) with frontmatter. Unlike `init`, it makes the file for you — the headless creation path the VS Code viewer uses. |
|
|
498
500
|
| `set-notes-root <path>` | Relocate where your private track notes live (updates `notes_root` in config). Does not move existing tracks — it warns if any would be orphaned. |
|
|
499
501
|
| `suggest-priorities --repo=<key>` | Two-step AI label backfill: CLI fetches unlabeled issues, Claude proposes priorities, `--apply` writes labels via `gh`. |
|
|
500
|
-
| `group [--milestone=X] [--label=Y] [--repo=Z] [--private] [--apply]` | AI-cluster GitHub issues into thematic track files. Two-step: CLI prints prompt → you save JSON answer → `--apply` creates the tracks. `--private` routes to `notes_root` instead of `.work-plan/`. |
|
|
501
|
-
| `auto-triage [--repo=<key>] [--apply]` | AI-assign untracked open issues to existing tracks. Two-step (same pattern as `group`). Run `coverage` first to measure the gap. |
|
|
502
|
+
| `group [--milestone=X] [--label=Y] [--repo=Z] [--private] [--apply] [--limit=N]` | AI-cluster GitHub issues into thematic track files. Two-step: CLI prints prompt → you save JSON answer → `--apply` creates the tracks. `--private` routes to `notes_root` instead of `.work-plan/`. `--limit` controls how many issues are shown in the prompt (default 100). |
|
|
503
|
+
| `auto-triage [--repo=<key>] [--apply] [--limit=N]` | AI-assign untracked open issues to existing tracks. Two-step (same pattern as `group`). Run `coverage` first to measure the gap. `--limit` controls how many untracked issues are shown (default 100). |
|
|
502
504
|
| `coverage [--repo=<key>] [--list] [--limit=N]` | Report how many open issues are not in any track. `--list` prints titles. Read-only. |
|
|
503
505
|
| `reconcile <track>` `\|` `--all` `\|` `--repo=<key> [--draft]` | Update track MEMBERSHIP (the `github.issues` list in frontmatter) by syncing against a GitHub label. Read-only on GitHub. Default label is `track/<slug>`; override per-track via `github.labels: [...]` in frontmatter (OR semantics). `--draft` previews ADDs/FLAGs without prompting or writing. `--repo=<key>` scopes the sweep to one repo. NOT for hand-curated tracks (it'll propose dropping curated issues every run) — use `refresh-md` if you only want to update issue state. When >50% of frontmatter issues lack the label, reconcile prints a hint pointing to `refresh-md`. |
|
|
504
506
|
| `duplicates [--repo=<key>]` | Find likely-duplicate issues by title similarity (stdlib `difflib`). Prints `gh issue close` consolidation commands. |
|
|
@@ -543,7 +545,7 @@ cd skills/work-plan
|
|
|
543
545
|
python3 -m unittest discover tests
|
|
544
546
|
```
|
|
545
547
|
|
|
546
|
-
|
|
548
|
+
600+ tests, no external dependencies (mocks `gh`/`git` calls).
|
|
547
549
|
|
|
548
550
|
## License
|
|
549
551
|
|
package/VERSION
CHANGED
|
@@ -1 +1 @@
|
|
|
1
|
-
2026.06.09+
|
|
1
|
+
2026.06.09+f25e6e1
|
package/package.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
{
|
|
2
2
|
"name": "@stylusnexus/work-plan",
|
|
3
|
-
"version": "2026.6.9-
|
|
3
|
+
"version": "2026.6.9-4",
|
|
4
4
|
"description": "Track-aware daily work planning over GitHub issues. Shared tracks (git-synced .work-plan/ in each repo), AI clustering (group/auto-triage), VS Code viewer, Claude Code + Codex plugins. Pure Python stdlib.",
|
|
5
5
|
"bin": {
|
|
6
6
|
"work-plan": "bin/work-plan"
|
|
@@ -61,6 +61,15 @@ def run(args: list[str]) -> int:
|
|
|
61
61
|
apply_mode = "--apply" in args
|
|
62
62
|
repo_arg = next((a for a in args if a.startswith("--repo=")), None)
|
|
63
63
|
|
|
64
|
+
limit = 100
|
|
65
|
+
for a in args:
|
|
66
|
+
if a.startswith("--limit="):
|
|
67
|
+
try:
|
|
68
|
+
limit = int(a.split("=", 1)[1])
|
|
69
|
+
except ValueError:
|
|
70
|
+
print("ERROR: --limit must be an integer.")
|
|
71
|
+
return 2
|
|
72
|
+
|
|
64
73
|
try:
|
|
65
74
|
cfg = load_config()
|
|
66
75
|
except ConfigError as e:
|
|
@@ -139,13 +148,17 @@ def run(args: list[str]) -> int:
|
|
|
139
148
|
|
|
140
149
|
print()
|
|
141
150
|
print("Untracked issues to assign:")
|
|
142
|
-
|
|
151
|
+
shown = untracked[:limit]
|
|
152
|
+
for i in shown:
|
|
143
153
|
num = i.get("number", "?")
|
|
144
154
|
title = i.get("title", "")
|
|
145
155
|
milestone = i.get("milestone") or {}
|
|
146
156
|
m_title = milestone.get("title", "—") if isinstance(milestone, dict) else "—"
|
|
147
157
|
labels = [lb["name"] for lb in (i.get("labels") or [])]
|
|
148
158
|
print(f" #{num} [{m_title}] [{','.join(labels) or 'no-labels'}] {title}")
|
|
159
|
+
remainder = len(untracked) - len(shown)
|
|
160
|
+
if remainder > 0:
|
|
161
|
+
print(f" … and {remainder} more issues (use --limit=N to show more)")
|
|
149
162
|
|
|
150
163
|
print("=" * 60)
|
|
151
164
|
print()
|
|
@@ -77,6 +77,7 @@ def run(args: list[str]) -> int:
|
|
|
77
77
|
|
|
78
78
|
new_body = _insert_canonical_table(
|
|
79
79
|
track.body, issue_nums, issues_by_num, replace=force,
|
|
80
|
+
milestone_alignment=track.meta.get("milestone_alignment"),
|
|
80
81
|
)
|
|
81
82
|
write_file(track.path, track.meta, new_body)
|
|
82
83
|
print(f" ✓ {track.name}: canonical table added/refreshed ({len(issue_nums)} issues)")
|
|
@@ -88,9 +89,10 @@ def run(args: list[str]) -> int:
|
|
|
88
89
|
|
|
89
90
|
|
|
90
91
|
def _insert_canonical_table(body: str, issue_nums: list[int],
|
|
91
|
-
issues_by_num: dict, replace: bool = False
|
|
92
|
+
issues_by_num: dict, replace: bool = False,
|
|
93
|
+
milestone_alignment=None) -> str:
|
|
92
94
|
"""Insert (or replace) a canonical table at the top of the body."""
|
|
93
|
-
table_md = _render_canonical_table(issue_nums, issues_by_num)
|
|
95
|
+
table_md = _render_canonical_table(issue_nums, issues_by_num, milestone_alignment)
|
|
94
96
|
|
|
95
97
|
if replace:
|
|
96
98
|
# Strip existing canonical block (marker + heading + table + separator)
|
|
@@ -102,22 +104,57 @@ def _insert_canonical_table(body: str, issue_nums: list[int],
|
|
|
102
104
|
return leading_whitespace + table_md + "\n---\n\n" + body_stripped
|
|
103
105
|
|
|
104
106
|
|
|
105
|
-
def _render_canonical_table(issue_nums: list[int], issues_by_num: dict
|
|
107
|
+
def _render_canonical_table(issue_nums: list[int], issues_by_num: dict,
|
|
108
|
+
milestone_alignment=None) -> str:
|
|
106
109
|
lines = [
|
|
107
110
|
"## Issues (canonical)",
|
|
108
111
|
"",
|
|
109
112
|
f"{CANONICAL_MARKER} — auto-managed by /work-plan refresh-md. Don't edit by hand. -->",
|
|
110
113
|
"",
|
|
111
|
-
"| # | Title | Assignee | Status |",
|
|
112
|
-
"|---|---|---|---|",
|
|
113
114
|
]
|
|
115
|
+
|
|
116
|
+
# Build a normalized issue list with compact milestone strings.
|
|
117
|
+
from lib.github_state import short_milestone
|
|
118
|
+
norm_issues = []
|
|
114
119
|
for num in sorted(issue_nums):
|
|
115
|
-
|
|
116
|
-
|
|
117
|
-
|
|
118
|
-
|
|
119
|
-
|
|
120
|
-
|
|
120
|
+
gh = issues_by_num.get(num, {})
|
|
121
|
+
ms = short_milestone(gh.get("milestone")) or None
|
|
122
|
+
norm_issues.append({"number": num, "milestone": ms, "_gh": gh})
|
|
123
|
+
|
|
124
|
+
from lib.export_model import group_issues_by_milestone
|
|
125
|
+
groups = group_issues_by_milestone(norm_issues, milestone_alignment)
|
|
126
|
+
|
|
127
|
+
if len(groups) <= 1:
|
|
128
|
+
# Single milestone group (or all null) — render flat, same as before.
|
|
129
|
+
lines.append("| # | Title | Assignee | Status |")
|
|
130
|
+
lines.append("|---|---|---|---|")
|
|
131
|
+
for num in sorted(issue_nums):
|
|
132
|
+
i = issues_by_num.get(num, {})
|
|
133
|
+
lines.append(render_issue_row(
|
|
134
|
+
num, i.get("title", "(not fetched)"),
|
|
135
|
+
format_assignees(i), state_to_status_label(i.get("state")),
|
|
136
|
+
))
|
|
137
|
+
lines.append("")
|
|
138
|
+
return "\n".join(lines)
|
|
139
|
+
|
|
140
|
+
# Multiple milestone groups — render with section headings.
|
|
141
|
+
for label, issues in groups:
|
|
142
|
+
if label:
|
|
143
|
+
heading = f"{label} ({len(issues)})"
|
|
144
|
+
else:
|
|
145
|
+
heading = f"No milestone ({len(issues)})"
|
|
146
|
+
lines.append(f"### {heading}")
|
|
147
|
+
lines.append("")
|
|
148
|
+
lines.append("| # | Title | Assignee | Status |")
|
|
149
|
+
lines.append("|---|---|---|---|")
|
|
150
|
+
for norm in issues:
|
|
151
|
+
num = norm["number"]
|
|
152
|
+
i = norm["_gh"]
|
|
153
|
+
lines.append(render_issue_row(
|
|
154
|
+
num, i.get("title", "(not fetched)"),
|
|
155
|
+
format_assignees(i), state_to_status_label(i.get("state")),
|
|
156
|
+
))
|
|
157
|
+
lines.append("")
|
|
121
158
|
return "\n".join(lines)
|
|
122
159
|
|
|
123
160
|
|
|
@@ -63,6 +63,15 @@ def run(args: list[str]) -> int:
|
|
|
63
63
|
label_arg = next((a for a in args if a.startswith("--label=")), None)
|
|
64
64
|
state_arg = next((a for a in args if a.startswith("--state=")), None)
|
|
65
65
|
|
|
66
|
+
limit = 100
|
|
67
|
+
for a in args:
|
|
68
|
+
if a.startswith("--limit="):
|
|
69
|
+
try:
|
|
70
|
+
limit = int(a.split("=", 1)[1])
|
|
71
|
+
except ValueError:
|
|
72
|
+
print("ERROR: --limit must be an integer.")
|
|
73
|
+
return 2
|
|
74
|
+
|
|
66
75
|
try:
|
|
67
76
|
cfg = load_config()
|
|
68
77
|
except ConfigError as e:
|
|
@@ -123,11 +132,15 @@ def run(args: list[str]) -> int:
|
|
|
123
132
|
print()
|
|
124
133
|
print("=" * 60)
|
|
125
134
|
print(PROMPT_TEMPLATE)
|
|
126
|
-
|
|
135
|
+
shown = issues[:limit]
|
|
136
|
+
for i in shown:
|
|
127
137
|
m = i.get("milestone", {})
|
|
128
138
|
m_title = m.get("title", "—") if m else "—"
|
|
129
139
|
labels = [l["name"] for l in i.get("labels", [])]
|
|
130
140
|
print(f"#{i['number']} [{m_title}] [{','.join(labels) or 'no-labels'}] {i['title']}")
|
|
141
|
+
remainder = len(issues) - len(shown)
|
|
142
|
+
if remainder > 0:
|
|
143
|
+
print(f"… and {remainder} more issues (use --limit=N to show more)")
|
|
131
144
|
print("=" * 60)
|
|
132
145
|
print()
|
|
133
146
|
print(f"After agent returns clusters JSON, save to {_answers_path()}")
|
|
@@ -202,7 +215,9 @@ def _apply(cfg: dict, args: list[str] = None) -> int:
|
|
|
202
215
|
slug = _slugify(cluster["slug"])
|
|
203
216
|
name = cluster.get("name", slug)
|
|
204
217
|
summary = cluster.get("summary", "")
|
|
205
|
-
cluster_issues =
|
|
218
|
+
cluster_issues = _sort_by_milestone(
|
|
219
|
+
sorted(set(cluster.get("issues") or [])), issues_by_num, batch_milestone,
|
|
220
|
+
)
|
|
206
221
|
if not cluster_issues:
|
|
207
222
|
print(f" SKIP {slug}: no issues")
|
|
208
223
|
continue
|
|
@@ -214,7 +229,10 @@ def _apply(cfg: dict, args: list[str] = None) -> int:
|
|
|
214
229
|
print(f" SKIP {slug}: file exists but has no frontmatter; use init first")
|
|
215
230
|
continue
|
|
216
231
|
existing_issues = list(existing_meta.get("github", {}).get("issues") or [])
|
|
217
|
-
merged =
|
|
232
|
+
merged = _sort_by_milestone(
|
|
233
|
+
sorted(set(existing_issues) | set(cluster_issues)), issues_by_num,
|
|
234
|
+
existing_meta.get("milestone_alignment") or batch_milestone,
|
|
235
|
+
)
|
|
218
236
|
existing_meta.setdefault("github", {})["issues"] = merged
|
|
219
237
|
existing_meta["last_touched"] = datetime.now().strftime("%Y-%m-%dT%H:%M")
|
|
220
238
|
write_file(path, existing_meta, existing_body)
|
|
@@ -228,7 +246,7 @@ def _apply(cfg: dict, args: list[str] = None) -> int:
|
|
|
228
246
|
"launch_priority": "P3",
|
|
229
247
|
"milestone_alignment": batch_milestone,
|
|
230
248
|
"github": {"repo": repo, "issues": cluster_issues, "branches": []},
|
|
231
|
-
"
|
|
249
|
+
"depends_on": [],
|
|
232
250
|
"last_touched": now, "last_handoff": now,
|
|
233
251
|
"next_up": [], "blockers": [],
|
|
234
252
|
}
|
|
@@ -246,6 +264,26 @@ def _apply(cfg: dict, args: list[str] = None) -> int:
|
|
|
246
264
|
return 0
|
|
247
265
|
|
|
248
266
|
|
|
267
|
+
def _sort_by_milestone(issue_nums, issues_by_num, milestone_alignment=None):
|
|
268
|
+
"""Return issue_nums sorted by milestone then number.
|
|
269
|
+
|
|
270
|
+
milestone_alignment issues come first, then other non-null milestones
|
|
271
|
+
(grouped by label), then null-milestone issues last. Graceful fallback:
|
|
272
|
+
if no milestone data is available, falls back to pure numeric sort.
|
|
273
|
+
"""
|
|
274
|
+
from lib.export_model import milestone_sort_key
|
|
275
|
+
from lib.github_state import short_milestone
|
|
276
|
+
|
|
277
|
+
norm = []
|
|
278
|
+
for num in issue_nums:
|
|
279
|
+
gh = issues_by_num.get(num, {})
|
|
280
|
+
ms = short_milestone(gh.get("milestone")) or None
|
|
281
|
+
norm.append({"number": num, "milestone": ms})
|
|
282
|
+
|
|
283
|
+
norm.sort(key=lambda i: milestone_sort_key(i, milestone_alignment))
|
|
284
|
+
return [i["number"] for i in norm]
|
|
285
|
+
|
|
286
|
+
|
|
249
287
|
def _slugify(s: str) -> str:
|
|
250
288
|
s = s.strip().lower()
|
|
251
289
|
s = re.sub(r"[^a-z0-9-]+", "-", s)
|
|
@@ -119,7 +119,7 @@ def run(args: list[str]) -> int:
|
|
|
119
119
|
"launch_priority": priority,
|
|
120
120
|
"milestone_alignment": milestone,
|
|
121
121
|
"github": {"repo": repo or "TBD", "issues": issue_nums, "branches": []},
|
|
122
|
-
"
|
|
122
|
+
"depends_on": [],
|
|
123
123
|
"last_touched": now, "last_handoff": now,
|
|
124
124
|
"next_up": [], "blockers": [],
|
|
125
125
|
}
|
|
@@ -0,0 +1,131 @@
|
|
|
1
|
+
"""move subcommand — source-first issue relocation between tracks."""
|
|
2
|
+
import json
|
|
3
|
+
|
|
4
|
+
from lib.config import load_config, ConfigError
|
|
5
|
+
from lib.tracks import discover_tracks, find_track_by_name, parse_track_repo_arg, AmbiguousTrackError
|
|
6
|
+
from lib.frontmatter import write_file
|
|
7
|
+
from lib.write_guard import needs_confirm, make_token, valid_token
|
|
8
|
+
from lib.prompts import parse_flags
|
|
9
|
+
|
|
10
|
+
|
|
11
|
+
def run(args: list[str]) -> int:
|
|
12
|
+
"""move <issue-num> <from-track> <to-track> [--confirm=<token>] [--repo=<key>]
|
|
13
|
+
|
|
14
|
+
Removes <issue-num> from <from-track>'s frontmatter and adds it to
|
|
15
|
+
<to-track>'s frontmatter. Both tracks must be active and in the same
|
|
16
|
+
repo. Public-repo writes gate behind --confirm (same flow as slot/set).
|
|
17
|
+
"""
|
|
18
|
+
flags, positional = parse_flags(args, {"--confirm", "--repo"})
|
|
19
|
+
if len(positional) < 3:
|
|
20
|
+
print("usage: work_plan.py move <issue-num> <from-track> <to-track> [--confirm=<token>] [--repo=<key>]")
|
|
21
|
+
return 2
|
|
22
|
+
|
|
23
|
+
try:
|
|
24
|
+
issue_num = int(positional[0])
|
|
25
|
+
except ValueError:
|
|
26
|
+
print(f"ERROR: '{positional[0]}' is not an issue number.")
|
|
27
|
+
return 2
|
|
28
|
+
|
|
29
|
+
from_arg, to_arg = positional[1], positional[2]
|
|
30
|
+
repo_flag = flags.get("--repo") if flags.get("--repo") is not True else None
|
|
31
|
+
|
|
32
|
+
# Resolve from-track
|
|
33
|
+
from_name = from_arg
|
|
34
|
+
repo_qualifier = repo_flag
|
|
35
|
+
name_from, repo_from = parse_track_repo_arg(from_arg)
|
|
36
|
+
if name_from:
|
|
37
|
+
from_name = name_from
|
|
38
|
+
if repo_from:
|
|
39
|
+
repo_qualifier = repo_from
|
|
40
|
+
|
|
41
|
+
# Resolve to-track (may override repo qualifier)
|
|
42
|
+
to_name = to_arg
|
|
43
|
+
name_to, repo_to = parse_track_repo_arg(to_arg)
|
|
44
|
+
if name_to:
|
|
45
|
+
to_name = name_to
|
|
46
|
+
if repo_to:
|
|
47
|
+
repo_qualifier = repo_to
|
|
48
|
+
|
|
49
|
+
try:
|
|
50
|
+
cfg = load_config()
|
|
51
|
+
except ConfigError as e:
|
|
52
|
+
print(f"ERROR: {e}")
|
|
53
|
+
return 1
|
|
54
|
+
|
|
55
|
+
tracks = discover_tracks(cfg)
|
|
56
|
+
|
|
57
|
+
# Find both tracks (active only)
|
|
58
|
+
try:
|
|
59
|
+
src = find_track_by_name(from_name, tracks, active_only=True, repo=repo_qualifier)
|
|
60
|
+
except AmbiguousTrackError as e:
|
|
61
|
+
print(str(e))
|
|
62
|
+
return 1
|
|
63
|
+
|
|
64
|
+
if not src:
|
|
65
|
+
print(f"No active track matching '{from_name}'.")
|
|
66
|
+
return 1
|
|
67
|
+
|
|
68
|
+
try:
|
|
69
|
+
dst = find_track_by_name(to_name, tracks, active_only=True, repo=repo_qualifier)
|
|
70
|
+
except AmbiguousTrackError as e:
|
|
71
|
+
print(str(e))
|
|
72
|
+
return 1
|
|
73
|
+
|
|
74
|
+
if not dst:
|
|
75
|
+
print(f"No active track matching '{to_name}'.")
|
|
76
|
+
return 1
|
|
77
|
+
|
|
78
|
+
# Same-repo guard
|
|
79
|
+
if src.repo != dst.repo:
|
|
80
|
+
print(f"ERROR: cross-repo moves not supported ({src.repo} ≠ {dst.repo}).")
|
|
81
|
+
return 1
|
|
82
|
+
|
|
83
|
+
# Same-track no-op
|
|
84
|
+
if src.name == dst.name:
|
|
85
|
+
print(f"#{issue_num} already in track '{src.name}'.")
|
|
86
|
+
return 0
|
|
87
|
+
|
|
88
|
+
# Validate issue is in source
|
|
89
|
+
src_issues = list(src.meta.get("github", {}).get("issues") or [])
|
|
90
|
+
if issue_num not in src_issues:
|
|
91
|
+
print(f"ERROR: #{issue_num} is not in track '{src.name}'.")
|
|
92
|
+
return 1
|
|
93
|
+
|
|
94
|
+
# Check if already in destination
|
|
95
|
+
dst_issues = list(dst.meta.get("github", {}).get("issues") or [])
|
|
96
|
+
if issue_num in dst_issues:
|
|
97
|
+
print(f"#{issue_num} already in track '{dst.name}'. Removing from '{src.name}' only.")
|
|
98
|
+
# Still remove from source even if already in dest
|
|
99
|
+
src_issues.remove(issue_num)
|
|
100
|
+
src.meta.setdefault("github", {})["issues"] = src_issues
|
|
101
|
+
write_file(src.path, src.meta, src.body)
|
|
102
|
+
print(f" ✓ Removed #{issue_num} from '{src.name}'.")
|
|
103
|
+
return 0
|
|
104
|
+
|
|
105
|
+
# Public-repo confirm gate (on the destination write)
|
|
106
|
+
confirm = flags.get("--confirm")
|
|
107
|
+
if dst.repo and needs_confirm(dst.repo, cfg) and not (
|
|
108
|
+
isinstance(confirm, str) and valid_token(confirm, dst.repo, dst.name)
|
|
109
|
+
):
|
|
110
|
+
print(json.dumps({
|
|
111
|
+
"needs_confirm": True,
|
|
112
|
+
"reason": (
|
|
113
|
+
f"{dst.repo} is PUBLIC (or visibility unknown); "
|
|
114
|
+
f"moving #{issue_num} will be written there."
|
|
115
|
+
),
|
|
116
|
+
"token": make_token(dst.repo, dst.name),
|
|
117
|
+
}))
|
|
118
|
+
return 0
|
|
119
|
+
|
|
120
|
+
# Execute: remove from source, add to destination
|
|
121
|
+
src_issues.remove(issue_num)
|
|
122
|
+
src.meta.setdefault("github", {})["issues"] = src_issues
|
|
123
|
+
write_file(src.path, src.meta, src.body)
|
|
124
|
+
print(f" ✓ Removed #{issue_num} from '{src.name}'.")
|
|
125
|
+
|
|
126
|
+
dst_issues.append(issue_num)
|
|
127
|
+
dst.meta.setdefault("github", {})["issues"] = sorted(dst_issues)
|
|
128
|
+
write_file(dst.path, dst.meta, dst.body)
|
|
129
|
+
print(f" ✓ Added #{issue_num} to '{dst.name}'.")
|
|
130
|
+
|
|
131
|
+
return 0
|
|
@@ -193,7 +193,7 @@ def run(args: list[str]) -> int:
|
|
|
193
193
|
"launch_priority": priority,
|
|
194
194
|
"milestone_alignment": milestone,
|
|
195
195
|
"github": {"repo": github, "issues": [], "branches": []},
|
|
196
|
-
"
|
|
196
|
+
"depends_on": [],
|
|
197
197
|
"last_touched": now,
|
|
198
198
|
"last_handoff": now,
|
|
199
199
|
"next_up": [],
|
|
@@ -6,7 +6,7 @@ from lib.frontmatter import write_file
|
|
|
6
6
|
from lib.write_guard import needs_confirm, make_token, valid_token
|
|
7
7
|
from lib.prompts import parse_flags
|
|
8
8
|
|
|
9
|
-
ALLOWED = {"status", "launch_priority", "milestone_alignment", "blockers", "next_up"}
|
|
9
|
+
ALLOWED = {"status", "launch_priority", "milestone_alignment", "blockers", "next_up", "depends_on"}
|
|
10
10
|
LIST_FIELDS = {"blockers", "next_up"}
|
|
11
11
|
STATUSES = {"active", "in-progress", "blocked", "parked", "shipped", "abandoned"}
|
|
12
12
|
|
|
@@ -29,7 +29,10 @@ def run(args: list[str]) -> int:
|
|
|
29
29
|
k, v = a.split("=", 1)
|
|
30
30
|
if k not in ALLOWED:
|
|
31
31
|
print(f"ERROR: field {k!r} not settable (allowed: {sorted(ALLOWED)})"); return 2
|
|
32
|
-
if k
|
|
32
|
+
if k == "depends_on":
|
|
33
|
+
# Comma-separated track slugs (strings, not issue numbers).
|
|
34
|
+
parsed[k] = [x.strip() for x in v.split(",") if x.strip()] if v.strip() else []
|
|
35
|
+
elif k in LIST_FIELDS:
|
|
33
36
|
try:
|
|
34
37
|
parsed[k] = [int(x) for x in v.split(",") if x.strip()] if v.strip() else []
|
|
35
38
|
except ValueError:
|
|
@@ -25,7 +25,7 @@ from pathlib import Path
|
|
|
25
25
|
from typing import Optional
|
|
26
26
|
|
|
27
27
|
from lib.config import load_config, ConfigError
|
|
28
|
-
from lib.tracks import discover_tracks, find_track_by_name
|
|
28
|
+
from lib.tracks import discover_tracks, find_track_by_name, parse_track_repo_arg, AmbiguousTrackError
|
|
29
29
|
from lib.prompts import prompt_input, parse_flags
|
|
30
30
|
from lib.github_state import fetch_issues, short_milestone
|
|
31
31
|
from lib.git_state import (
|
|
@@ -40,8 +40,18 @@ RULE_WIDTH = 57
|
|
|
40
40
|
|
|
41
41
|
|
|
42
42
|
def run(args: list[str]) -> int:
|
|
43
|
-
flags, positional = parse_flags(args, {"--pick"})
|
|
44
|
-
|
|
43
|
+
flags, positional = parse_flags(args, {"--pick", "--repo"})
|
|
44
|
+
track_arg = positional[0] if positional else None
|
|
45
|
+
repo_flag = flags.get("--repo") if flags.get("--repo") is not True else None
|
|
46
|
+
|
|
47
|
+
# Resolve track name and repo qualifier from <track>@<repo> syntax
|
|
48
|
+
track_name = track_arg
|
|
49
|
+
repo_qualifier = repo_flag
|
|
50
|
+
if track_arg:
|
|
51
|
+
name_from_arg, repo_from_arg = parse_track_repo_arg(track_arg)
|
|
52
|
+
track_name = name_from_arg
|
|
53
|
+
if repo_from_arg:
|
|
54
|
+
repo_qualifier = repo_from_arg
|
|
45
55
|
|
|
46
56
|
try:
|
|
47
57
|
cfg = load_config()
|
|
@@ -78,12 +88,20 @@ def run(args: list[str]) -> int:
|
|
|
78
88
|
return 1
|
|
79
89
|
track = active[idx]
|
|
80
90
|
else:
|
|
81
|
-
|
|
91
|
+
try:
|
|
92
|
+
track = find_track_by_name(choice, tracks, repo=repo_qualifier)
|
|
93
|
+
except AmbiguousTrackError as e:
|
|
94
|
+
print(str(e))
|
|
95
|
+
return 1
|
|
82
96
|
if not track:
|
|
83
97
|
print(f"No track matching '{choice}'.")
|
|
84
98
|
return 1
|
|
85
99
|
else:
|
|
86
|
-
|
|
100
|
+
try:
|
|
101
|
+
track = find_track_by_name(track_name, tracks, repo=repo_qualifier)
|
|
102
|
+
except AmbiguousTrackError as e:
|
|
103
|
+
print(str(e))
|
|
104
|
+
return 1
|
|
87
105
|
if not track:
|
|
88
106
|
print(f"No track matching '{track_name}'.")
|
|
89
107
|
return 1
|
|
@@ -3,6 +3,55 @@ from lib.github_state import format_assignees, short_milestone
|
|
|
3
3
|
|
|
4
4
|
SCHEMA = 1
|
|
5
5
|
|
|
6
|
+
|
|
7
|
+
def milestone_sort_key(issue: dict, milestone_alignment=None):
|
|
8
|
+
"""Sort key for an issue dict (must have 'number' and 'milestone').
|
|
9
|
+
|
|
10
|
+
Returns (tier, milestone_label, number) so that:
|
|
11
|
+
0. issues matching milestone_alignment come first
|
|
12
|
+
1. issues with other non-null milestones come next, grouped by label
|
|
13
|
+
2. issues with null/empty milestone come last.
|
|
14
|
+
|
|
15
|
+
milestone may be a compact string (as from short_milestone) or None.
|
|
16
|
+
"""
|
|
17
|
+
ms = issue.get("milestone")
|
|
18
|
+
num = issue.get("number", 0) or 0
|
|
19
|
+
if ms is None or ms == "":
|
|
20
|
+
return (2, "", num)
|
|
21
|
+
if ms == milestone_alignment:
|
|
22
|
+
return (0, ms, num)
|
|
23
|
+
return (1, ms, num)
|
|
24
|
+
|
|
25
|
+
|
|
26
|
+
def group_issues_by_milestone(issues, milestone_alignment=None):
|
|
27
|
+
"""Partition sorted issues into [(label, [issue, ...]), ...].
|
|
28
|
+
|
|
29
|
+
label is the compact milestone string; None for the no-milestone group.
|
|
30
|
+
Groups are emitted in milestone_sort_key order. A single-group result
|
|
31
|
+
means all issues share the same milestone (or all lack one) — callers
|
|
32
|
+
can use this to decide whether to render section headings.
|
|
33
|
+
"""
|
|
34
|
+
if not issues:
|
|
35
|
+
return []
|
|
36
|
+
sorted_issues = sorted(issues,
|
|
37
|
+
key=lambda i: milestone_sort_key(i, milestone_alignment))
|
|
38
|
+
groups = []
|
|
39
|
+
current_label = None # sentinel — always differs from the first real label
|
|
40
|
+
current_group = []
|
|
41
|
+
for i in sorted_issues:
|
|
42
|
+
label = i.get("milestone") or None
|
|
43
|
+
if label != current_label:
|
|
44
|
+
if current_group:
|
|
45
|
+
groups.append((current_label, current_group))
|
|
46
|
+
current_label = label
|
|
47
|
+
current_group = [i]
|
|
48
|
+
else:
|
|
49
|
+
current_group.append(i)
|
|
50
|
+
if current_group:
|
|
51
|
+
groups.append((current_label, current_group))
|
|
52
|
+
return groups
|
|
53
|
+
|
|
54
|
+
|
|
6
55
|
def _issue(i: dict) -> dict:
|
|
7
56
|
state = (i.get("state") or "OPEN").lower()
|
|
8
57
|
return {
|
|
@@ -13,11 +62,14 @@ def _issue(i: dict) -> dict:
|
|
|
13
62
|
"milestone": short_milestone(i.get("milestone")) or None,
|
|
14
63
|
}
|
|
15
64
|
|
|
65
|
+
|
|
16
66
|
def build_export(tracks, issues_by_track, visibility, now: str,
|
|
17
67
|
untracked_by_repo=None) -> dict:
|
|
18
68
|
out = {"schema": SCHEMA, "generated_at": now, "tracks": []}
|
|
19
69
|
for t in tracks:
|
|
20
70
|
issues = [_issue(i) for i in issues_by_track.get(t.name, [])]
|
|
71
|
+
milestone_alignment = t.meta.get("milestone_alignment")
|
|
72
|
+
issues.sort(key=lambda i: milestone_sort_key(i, milestone_alignment))
|
|
21
73
|
opened = sum(1 for i in issues if i["state"] == "open")
|
|
22
74
|
closed_nums = {i["number"] for i in issues if i["state"] == "closed"}
|
|
23
75
|
next_up = [n for n in (t.meta.get("next_up") or []) if n not in closed_nums]
|
|
@@ -27,10 +79,11 @@ def build_export(tracks, issues_by_track, visibility, now: str,
|
|
|
27
79
|
"tier": getattr(t, "tier", "private") or "private",
|
|
28
80
|
"status": t.meta.get("status"),
|
|
29
81
|
"launch_priority": t.meta.get("launch_priority"),
|
|
30
|
-
"milestone_alignment":
|
|
82
|
+
"milestone_alignment": milestone_alignment,
|
|
31
83
|
"visibility": visibility.get(t.repo),
|
|
32
84
|
"blockers": list(t.meta.get("blockers") or []),
|
|
33
85
|
"next_up": next_up,
|
|
86
|
+
"depends_on": list(t.meta.get("depends_on") or []),
|
|
34
87
|
"rollup": {"open": opened, "closed": len(issues) - opened},
|
|
35
88
|
"issues": issues,
|
|
36
89
|
})
|