@huggingface/tasks 0.0.3 → 0.0.5
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/LICENSE +21 -0
- package/README.md +20 -0
- package/dist/index.d.ts +368 -46
- package/dist/index.js +117 -41
- package/dist/{index.cjs → index.mjs} +84 -67
- package/package.json +43 -33
- package/src/Types.ts +49 -43
- package/src/audio-classification/about.md +5 -5
- package/src/audio-classification/data.ts +11 -11
- package/src/audio-to-audio/about.md +4 -3
- package/src/audio-to-audio/data.ts +18 -15
- package/src/automatic-speech-recognition/about.md +5 -4
- package/src/automatic-speech-recognition/data.ts +18 -17
- package/src/const.ts +52 -44
- package/src/conversational/about.md +9 -9
- package/src/conversational/data.ts +22 -18
- package/src/depth-estimation/about.md +1 -3
- package/src/depth-estimation/data.ts +11 -11
- package/src/document-question-answering/about.md +1 -2
- package/src/document-question-answering/data.ts +22 -19
- package/src/feature-extraction/about.md +2 -3
- package/src/feature-extraction/data.ts +12 -15
- package/src/fill-mask/about.md +1 -1
- package/src/fill-mask/data.ts +16 -14
- package/src/image-classification/about.md +5 -3
- package/src/image-classification/data.ts +15 -15
- package/src/image-segmentation/about.md +4 -4
- package/src/image-segmentation/data.ts +26 -23
- package/src/image-to-image/about.md +10 -12
- package/src/image-to-image/data.ts +31 -27
- package/src/image-to-text/about.md +13 -6
- package/src/image-to-text/data.ts +20 -21
- package/src/index.ts +11 -0
- package/src/modelLibraries.ts +43 -0
- package/src/object-detection/about.md +2 -1
- package/src/object-detection/data.ts +20 -17
- package/src/pipelines.ts +619 -0
- package/src/placeholder/about.md +3 -3
- package/src/placeholder/data.ts +8 -8
- package/src/question-answering/about.md +1 -1
- package/src/question-answering/data.ts +21 -19
- package/src/reinforcement-learning/about.md +167 -176
- package/src/reinforcement-learning/data.ts +75 -78
- package/src/sentence-similarity/data.ts +29 -28
- package/src/summarization/about.md +6 -5
- package/src/summarization/data.ts +23 -20
- package/src/table-question-answering/about.md +5 -5
- package/src/table-question-answering/data.ts +35 -39
- package/src/tabular-classification/about.md +4 -6
- package/src/tabular-classification/data.ts +11 -12
- package/src/tabular-regression/about.md +14 -18
- package/src/tabular-regression/data.ts +10 -11
- package/src/tasksData.ts +47 -50
- package/src/text-classification/about.md +5 -4
- package/src/text-classification/data.ts +21 -20
- package/src/text-generation/about.md +7 -6
- package/src/text-generation/data.ts +36 -34
- package/src/text-to-image/about.md +19 -18
- package/src/text-to-image/data.ts +32 -26
- package/src/text-to-speech/about.md +4 -5
- package/src/text-to-speech/data.ts +16 -17
- package/src/text-to-video/about.md +41 -36
- package/src/text-to-video/data.ts +43 -38
- package/src/token-classification/about.md +1 -3
- package/src/token-classification/data.ts +26 -25
- package/src/translation/about.md +4 -4
- package/src/translation/data.ts +21 -21
- package/src/unconditional-image-generation/about.md +10 -5
- package/src/unconditional-image-generation/data.ts +26 -20
- package/src/video-classification/about.md +5 -1
- package/src/video-classification/data.ts +14 -14
- package/src/visual-question-answering/about.md +8 -3
- package/src/visual-question-answering/data.ts +22 -19
- package/src/zero-shot-classification/about.md +5 -4
- package/src/zero-shot-classification/data.ts +20 -20
- package/src/zero-shot-image-classification/about.md +17 -9
- package/src/zero-shot-image-classification/data.ts +12 -14
- package/tsconfig.json +18 -0
- package/assets/audio-classification/audio.wav +0 -0
- package/assets/audio-to-audio/input.wav +0 -0
- package/assets/audio-to-audio/label-0.wav +0 -0
- package/assets/audio-to-audio/label-1.wav +0 -0
- package/assets/automatic-speech-recognition/input.flac +0 -0
- package/assets/automatic-speech-recognition/wav2vec2.png +0 -0
- package/assets/contribution-guide/anatomy.png +0 -0
- package/assets/contribution-guide/libraries.png +0 -0
- package/assets/depth-estimation/depth-estimation-input.jpg +0 -0
- package/assets/depth-estimation/depth-estimation-output.png +0 -0
- package/assets/document-question-answering/document-question-answering-input.png +0 -0
- package/assets/image-classification/image-classification-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-output.png +0 -0
- package/assets/image-to-image/image-to-image-input.jpeg +0 -0
- package/assets/image-to-image/image-to-image-output.png +0 -0
- package/assets/image-to-image/pix2pix_examples.jpg +0 -0
- package/assets/image-to-text/savanna.jpg +0 -0
- package/assets/object-detection/object-detection-input.jpg +0 -0
- package/assets/object-detection/object-detection-output.jpg +0 -0
- package/assets/table-question-answering/tableQA.jpg +0 -0
- package/assets/text-to-image/image.jpeg +0 -0
- package/assets/text-to-speech/audio.wav +0 -0
- package/assets/text-to-video/text-to-video-output.gif +0 -0
- package/assets/unconditional-image-generation/unconditional-image-generation-output.jpeg +0 -0
- package/assets/video-classification/video-classification-input.gif +0 -0
- package/assets/visual-question-answering/elephant.jpeg +0 -0
- package/assets/zero-shot-image-classification/image-classification-input.jpeg +0 -0
- package/dist/index.d.cts +0 -145
|
@@ -4,93 +4,96 @@ const taskData: TaskDataCustom = {
|
|
|
4
4
|
datasets: [
|
|
5
5
|
{
|
|
6
6
|
description: "Scene segmentation dataset.",
|
|
7
|
-
id:
|
|
7
|
+
id: "scene_parse_150",
|
|
8
8
|
},
|
|
9
9
|
],
|
|
10
10
|
demo: {
|
|
11
11
|
inputs: [
|
|
12
12
|
{
|
|
13
13
|
filename: "image-segmentation-input.jpeg",
|
|
14
|
-
type:
|
|
14
|
+
type: "img",
|
|
15
15
|
},
|
|
16
16
|
],
|
|
17
17
|
outputs: [
|
|
18
18
|
{
|
|
19
19
|
filename: "image-segmentation-output.png",
|
|
20
|
-
type:
|
|
20
|
+
type: "img",
|
|
21
21
|
},
|
|
22
22
|
],
|
|
23
23
|
},
|
|
24
24
|
metrics: [
|
|
25
25
|
{
|
|
26
|
-
description:
|
|
27
|
-
|
|
26
|
+
description:
|
|
27
|
+
"Average Precision (AP) is the Area Under the PR Curve (AUC-PR). It is calculated for each semantic class separately",
|
|
28
|
+
id: "Average Precision",
|
|
28
29
|
},
|
|
29
30
|
{
|
|
30
31
|
description: "Mean Average Precision (mAP) is the overall average of the AP values",
|
|
31
|
-
id:
|
|
32
|
+
id: "Mean Average Precision",
|
|
32
33
|
},
|
|
33
34
|
{
|
|
34
|
-
description:
|
|
35
|
-
|
|
35
|
+
description:
|
|
36
|
+
"Intersection over Union (IoU) is the overlap of segmentation masks. Mean IoU is the average of the IoU of all semantic classes",
|
|
37
|
+
id: "Mean Intersection over Union",
|
|
36
38
|
},
|
|
37
39
|
{
|
|
38
40
|
description: "APα is the Average Precision at the IoU threshold of a α value, for example, AP50 and AP75",
|
|
39
|
-
id:
|
|
41
|
+
id: "APα",
|
|
40
42
|
},
|
|
41
43
|
],
|
|
42
44
|
models: [
|
|
43
45
|
{
|
|
44
46
|
// TO DO: write description
|
|
45
47
|
description: "Solid panoptic segmentation model trained on the COCO 2017 benchmark dataset.",
|
|
46
|
-
id:
|
|
48
|
+
id: "facebook/detr-resnet-50-panoptic",
|
|
47
49
|
},
|
|
48
50
|
{
|
|
49
51
|
description: "Semantic segmentation model trained on ADE20k benchmark dataset.",
|
|
50
|
-
id:
|
|
52
|
+
id: "microsoft/beit-large-finetuned-ade-640-640",
|
|
51
53
|
},
|
|
52
54
|
{
|
|
53
55
|
description: "Semantic segmentation model trained on ADE20k benchmark dataset with 512x512 resolution.",
|
|
54
|
-
id:
|
|
56
|
+
id: "nvidia/segformer-b0-finetuned-ade-512-512",
|
|
55
57
|
},
|
|
56
58
|
{
|
|
57
59
|
description: "Semantic segmentation model trained Cityscapes dataset.",
|
|
58
|
-
id:
|
|
60
|
+
id: "facebook/mask2former-swin-large-cityscapes-semantic",
|
|
59
61
|
},
|
|
60
62
|
{
|
|
61
63
|
description: "Panoptic segmentation model trained COCO (common objects) dataset.",
|
|
62
|
-
id:
|
|
64
|
+
id: "facebook/mask2former-swin-large-coco-panoptic",
|
|
63
65
|
},
|
|
64
66
|
],
|
|
65
|
-
spaces:
|
|
67
|
+
spaces: [
|
|
66
68
|
{
|
|
67
69
|
description: "A semantic segmentation application that can predict unseen instances out of the box.",
|
|
68
|
-
id:
|
|
70
|
+
id: "facebook/ov-seg",
|
|
69
71
|
},
|
|
70
72
|
{
|
|
71
73
|
description: "One of the strongest segmentation applications.",
|
|
72
|
-
id:
|
|
74
|
+
id: "jbrinkma/segment-anything",
|
|
73
75
|
},
|
|
74
76
|
{
|
|
75
77
|
description: "A semantic segmentation application that predicts human silhouettes.",
|
|
76
|
-
id:
|
|
78
|
+
id: "keras-io/Human-Part-Segmentation",
|
|
77
79
|
},
|
|
78
80
|
{
|
|
79
81
|
description: "An instance segmentation application to predict neuronal cell types from microscopy images.",
|
|
80
|
-
id:
|
|
82
|
+
id: "rashmi/sartorius-cell-instance-segmentation",
|
|
81
83
|
},
|
|
82
84
|
{
|
|
83
85
|
description: "An application that segments videos.",
|
|
84
|
-
id:
|
|
86
|
+
id: "ArtGAN/Segment-Anything-Video",
|
|
85
87
|
},
|
|
86
88
|
{
|
|
87
89
|
description: "An panoptic segmentation application built for outdoor environments.",
|
|
88
|
-
id:
|
|
90
|
+
id: "segments/panoptic-segment-anything",
|
|
89
91
|
},
|
|
90
92
|
],
|
|
91
|
-
summary:
|
|
93
|
+
summary:
|
|
94
|
+
"Image Segmentation divides an image into segments where each pixel in the image is mapped to an object. This task has multiple variants such as instance segmentation, panoptic segmentation and semantic segmentation.",
|
|
92
95
|
widgetModels: ["facebook/detr-resnet-50-panoptic"],
|
|
93
|
-
youtubeId:
|
|
96
|
+
youtubeId: "dKE8SIt9C-w",
|
|
94
97
|
};
|
|
95
98
|
|
|
96
99
|
export default taskData;
|
|
@@ -45,36 +45,34 @@ import { HfInference } from "@huggingface/inference";
|
|
|
45
45
|
|
|
46
46
|
const inference = new HfInference(HF_ACCESS_TOKEN);
|
|
47
47
|
await inference.imageToImage({
|
|
48
|
-
|
|
49
|
-
|
|
50
|
-
|
|
51
|
-
|
|
52
|
-
|
|
53
|
-
})
|
|
48
|
+
data: await (await fetch("image")).blob(),
|
|
49
|
+
model: "timbrooks/instruct-pix2pix",
|
|
50
|
+
parameters: {
|
|
51
|
+
prompt: "Deblur this image",
|
|
52
|
+
},
|
|
53
|
+
});
|
|
54
54
|
```
|
|
55
55
|
|
|
56
56
|
## ControlNet
|
|
57
57
|
|
|
58
58
|
Controlling outputs of diffusion models only with a text prompt is a challenging problem. ControlNet is a neural network type that provides an image based control to diffusion models. These controls can be edges or landmarks in an image.
|
|
59
59
|
|
|
60
|
-
Many ControlNet models were trained in our community event, JAX Diffusers sprint. You can see the full list of the ControlNet models available [here](https://huggingface.co/spaces/jax-diffusers-event/leaderboard).
|
|
60
|
+
Many ControlNet models were trained in our community event, JAX Diffusers sprint. You can see the full list of the ControlNet models available [here](https://huggingface.co/spaces/jax-diffusers-event/leaderboard).
|
|
61
61
|
|
|
62
62
|
## Most Used Model for the Task
|
|
63
63
|
|
|
64
64
|
Pix2Pix is a popular model used for image to image translation tasks. It is based on a conditional-GAN (generative adversarial network) where instead of a noise vector a 2D image is given as input. More information about Pix2Pix can be retrieved from this [link](https://phillipi.github.io/pix2pix/) where the associated paper and the GitHub repository can be found.
|
|
65
65
|
|
|
66
|
-
|
|
67
66
|
Below images show some of the examples shared in the paper that can be obtained using Pix2Pix. There are various cases this model can be applied on. It is capable of relatively simpler things, e.g. converting a grayscale image to its colored version. But more importantly, it can generate realistic pictures from rough sketches (can be seen in the purse example) or from painting-like images (can be seen in the street and facade examples below).
|
|
68
67
|
|
|
69
|
-
|
|
70
|
-
|
|
68
|
+
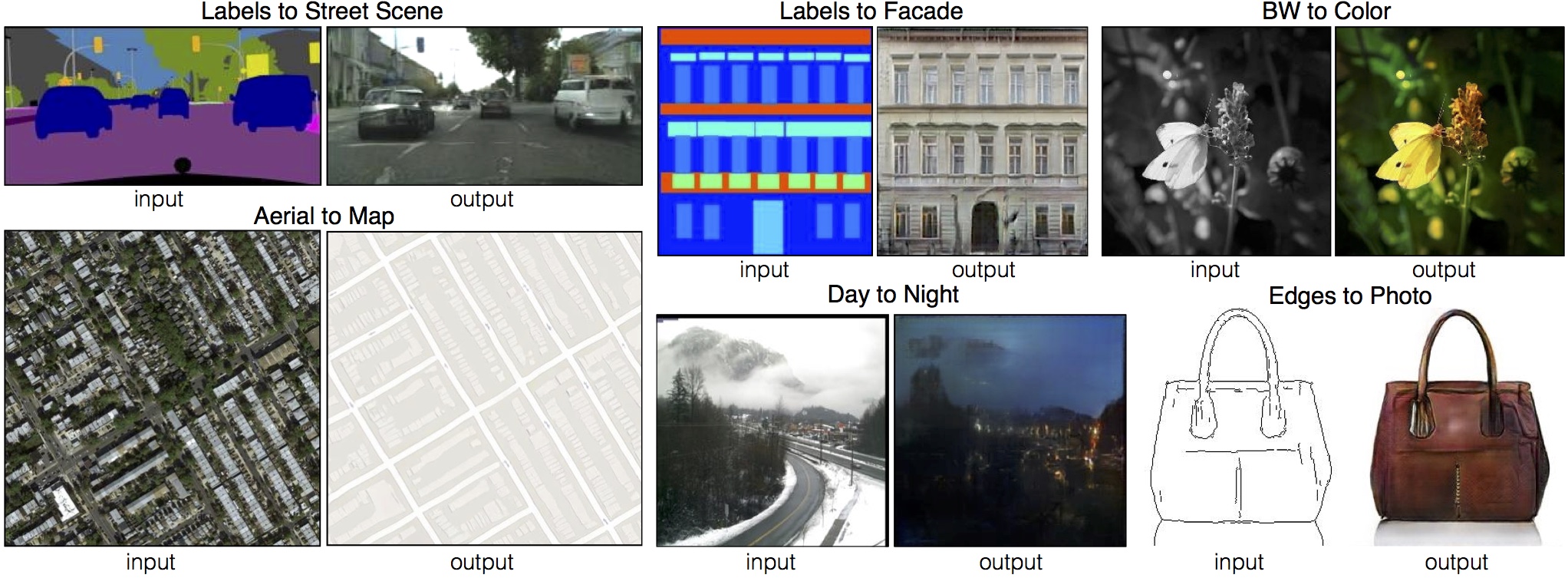
|
|
71
69
|
|
|
72
|
-
##
|
|
70
|
+
## Useful Resources
|
|
73
71
|
|
|
74
72
|
- [Train your ControlNet with diffusers 🧨](https://huggingface.co/blog/train-your-controlnet)
|
|
75
73
|
- [Ultra fast ControlNet with 🧨 Diffusers](https://huggingface.co/blog/controlnet)
|
|
76
74
|
|
|
77
|
-
## References
|
|
75
|
+
## References
|
|
78
76
|
|
|
79
77
|
[1] P. Isola, J. -Y. Zhu, T. Zhou and A. A. Efros, "Image-to-Image Translation with Conditional Adversarial Networks," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5967-5976, doi: 10.1109/CVPR.2017.632.
|
|
80
78
|
|
|
@@ -4,94 +4,98 @@ const taskData: TaskDataCustom = {
|
|
|
4
4
|
datasets: [
|
|
5
5
|
{
|
|
6
6
|
description: "Synthetic dataset, for image relighting",
|
|
7
|
-
id:
|
|
7
|
+
id: "VIDIT",
|
|
8
8
|
},
|
|
9
9
|
{
|
|
10
10
|
description: "Multiple images of celebrities, used for facial expression translation",
|
|
11
|
-
id:
|
|
11
|
+
id: "huggan/CelebA-faces",
|
|
12
12
|
},
|
|
13
13
|
],
|
|
14
14
|
demo: {
|
|
15
15
|
inputs: [
|
|
16
16
|
{
|
|
17
17
|
filename: "image-to-image-input.jpeg",
|
|
18
|
-
type:
|
|
18
|
+
type: "img",
|
|
19
19
|
},
|
|
20
20
|
],
|
|
21
21
|
outputs: [
|
|
22
22
|
{
|
|
23
23
|
filename: "image-to-image-output.png",
|
|
24
|
-
type:
|
|
24
|
+
type: "img",
|
|
25
25
|
},
|
|
26
26
|
],
|
|
27
27
|
},
|
|
28
28
|
isPlaceholder: false,
|
|
29
|
-
metrics:
|
|
29
|
+
metrics: [
|
|
30
30
|
{
|
|
31
|
-
description:
|
|
32
|
-
|
|
31
|
+
description:
|
|
32
|
+
"Peak Signal to Noise Ratio (PSNR) is an approximation of the human perception, considering the ratio of the absolute intensity with respect to the variations. Measured in dB, a high value indicates a high fidelity.",
|
|
33
|
+
id: "PSNR",
|
|
33
34
|
},
|
|
34
35
|
{
|
|
35
|
-
description:
|
|
36
|
-
|
|
36
|
+
description:
|
|
37
|
+
"Structural Similarity Index (SSIM) is a perceptual metric which compares the luminance, contrast and structure of two images. The values of SSIM range between -1 and 1, and higher values indicate closer resemblance to the original image.",
|
|
38
|
+
id: "SSIM",
|
|
37
39
|
},
|
|
38
40
|
{
|
|
39
|
-
description:
|
|
40
|
-
|
|
41
|
+
description:
|
|
42
|
+
"Inception Score (IS) is an analysis of the labels predicted by an image classification model when presented with a sample of the generated images.",
|
|
43
|
+
id: "IS",
|
|
41
44
|
},
|
|
42
45
|
],
|
|
43
46
|
models: [
|
|
44
47
|
{
|
|
45
48
|
description: "A model that enhances images captured in low light conditions.",
|
|
46
|
-
id:
|
|
49
|
+
id: "keras-io/low-light-image-enhancement",
|
|
47
50
|
},
|
|
48
51
|
{
|
|
49
52
|
description: "A model that increases the resolution of an image.",
|
|
50
|
-
id:
|
|
53
|
+
id: "keras-io/super-resolution",
|
|
51
54
|
},
|
|
52
55
|
{
|
|
53
|
-
description:
|
|
54
|
-
|
|
56
|
+
description:
|
|
57
|
+
"A model that creates a set of variations of the input image in the style of DALL-E using Stable Diffusion.",
|
|
58
|
+
id: "lambdalabs/sd-image-variations-diffusers",
|
|
55
59
|
},
|
|
56
60
|
{
|
|
57
61
|
description: "A model that generates images based on segments in the input image and the text prompt.",
|
|
58
|
-
id:
|
|
62
|
+
id: "mfidabel/controlnet-segment-anything",
|
|
59
63
|
},
|
|
60
64
|
{
|
|
61
65
|
description: "A model that takes an image and an instruction to edit the image.",
|
|
62
|
-
id:
|
|
66
|
+
id: "timbrooks/instruct-pix2pix",
|
|
63
67
|
},
|
|
64
68
|
],
|
|
65
|
-
spaces:
|
|
69
|
+
spaces: [
|
|
66
70
|
{
|
|
67
71
|
description: "Image enhancer application for low light.",
|
|
68
|
-
id:
|
|
72
|
+
id: "keras-io/low-light-image-enhancement",
|
|
69
73
|
},
|
|
70
74
|
{
|
|
71
75
|
description: "Style transfer application.",
|
|
72
|
-
id:
|
|
76
|
+
id: "keras-io/neural-style-transfer",
|
|
73
77
|
},
|
|
74
78
|
{
|
|
75
79
|
description: "An application that generates images based on segment control.",
|
|
76
|
-
id:
|
|
80
|
+
id: "mfidabel/controlnet-segment-anything",
|
|
77
81
|
},
|
|
78
82
|
{
|
|
79
83
|
description: "Image generation application that takes image control and text prompt.",
|
|
80
|
-
id:
|
|
84
|
+
id: "hysts/ControlNet",
|
|
81
85
|
},
|
|
82
86
|
{
|
|
83
87
|
description: "Colorize any image using this app.",
|
|
84
|
-
id:
|
|
88
|
+
id: "ioclab/brightness-controlnet",
|
|
85
89
|
},
|
|
86
90
|
{
|
|
87
91
|
description: "Edit images with instructions.",
|
|
88
|
-
id:
|
|
92
|
+
id: "timbrooks/instruct-pix2pix",
|
|
89
93
|
},
|
|
90
|
-
|
|
91
94
|
],
|
|
92
|
-
summary:
|
|
95
|
+
summary:
|
|
96
|
+
"Image-to-image is the task of transforming a source image to match the characteristics of a target image or a target image domain. Any image manipulation and enhancement is possible with image to image models.",
|
|
93
97
|
widgetModels: ["lllyasviel/sd-controlnet-canny"],
|
|
94
|
-
youtubeId:
|
|
98
|
+
youtubeId: "",
|
|
95
99
|
};
|
|
96
100
|
|
|
97
101
|
export default taskData;
|
|
@@ -1,20 +1,24 @@
|
|
|
1
1
|
## Use Cases
|
|
2
|
+
|
|
2
3
|
### Image Captioning
|
|
3
|
-
|
|
4
|
+
|
|
5
|
+
Image Captioning is the process of generating textual description of an image.
|
|
4
6
|
This can help the visually impaired people to understand what's happening in their surroundings.
|
|
5
7
|
|
|
6
8
|
### Optical Character Recognition (OCR)
|
|
7
|
-
OCR models convert the text present in an image, e.g. a scanned document, to text.
|
|
8
|
-
|
|
9
9
|
|
|
10
|
+
OCR models convert the text present in an image, e.g. a scanned document, to text.
|
|
10
11
|
|
|
11
12
|
## Pix2Struct
|
|
12
13
|
|
|
13
14
|
Pix2Struct is a state-of-the-art model built and released by Google AI. The model itself has to be trained on a downstream task to be used. These tasks include, captioning UI components, images including text, visual questioning infographics, charts, scientific diagrams and more. You can find these models on recommended models of this page.
|
|
14
15
|
|
|
15
16
|
## Inference
|
|
17
|
+
|
|
16
18
|
### Image Captioning
|
|
19
|
+
|
|
17
20
|
You can use the 🤗 Transformers library's `image-to-text` pipeline to generate caption for the Image input.
|
|
21
|
+
|
|
18
22
|
```python
|
|
19
23
|
from transformers import pipeline
|
|
20
24
|
|
|
@@ -24,7 +28,9 @@ captioner("https://huggingface.co/datasets/Narsil/image_dummy/resolve/main/parro
|
|
|
24
28
|
```
|
|
25
29
|
|
|
26
30
|
### OCR
|
|
31
|
+
|
|
27
32
|
This code snippet uses Microsoft’s TrOCR, an encoder-decoder model consisting of an image Transformer encoder and a text Transformer decoder for state-of-the-art optical character recognition (OCR) on single-text line images.
|
|
33
|
+
|
|
28
34
|
```python
|
|
29
35
|
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
|
|
30
36
|
|
|
@@ -44,12 +50,13 @@ import { HfInference } from "@huggingface/inference";
|
|
|
44
50
|
|
|
45
51
|
const inference = new HfInference(HF_ACCESS_TOKEN);
|
|
46
52
|
await inference.imageToText({
|
|
47
|
-
|
|
48
|
-
|
|
49
|
-
})
|
|
53
|
+
data: await (await fetch("https://picsum.photos/300/300")).blob(),
|
|
54
|
+
model: "Salesforce/blip-image-captioning-base",
|
|
55
|
+
});
|
|
50
56
|
```
|
|
51
57
|
|
|
52
58
|
## Useful Resources
|
|
59
|
+
|
|
53
60
|
- [Image Captioning](https://huggingface.co/docs/transformers/main/en/tasks/image_captioning)
|
|
54
61
|
- [Image captioning use case](https://blog.google/outreach-initiatives/accessibility/get-image-descriptions/)
|
|
55
62
|
- [Train Image Captioning model on your dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb)
|
|
@@ -5,27 +5,26 @@ const taskData: TaskDataCustom = {
|
|
|
5
5
|
{
|
|
6
6
|
// TODO write proper description
|
|
7
7
|
description: "Dataset from 12M image-text of Reddit",
|
|
8
|
-
id:
|
|
8
|
+
id: "red_caps",
|
|
9
9
|
},
|
|
10
10
|
{
|
|
11
11
|
// TODO write proper description
|
|
12
12
|
description: "Dataset from 3.3M images of Google",
|
|
13
|
-
id:
|
|
13
|
+
id: "datasets/conceptual_captions",
|
|
14
14
|
},
|
|
15
|
-
|
|
16
15
|
],
|
|
17
16
|
demo: {
|
|
18
17
|
inputs: [
|
|
19
18
|
{
|
|
20
19
|
filename: "savanna.jpg",
|
|
21
|
-
type:
|
|
20
|
+
type: "img",
|
|
22
21
|
},
|
|
23
22
|
],
|
|
24
23
|
outputs: [
|
|
25
24
|
{
|
|
26
|
-
label:
|
|
25
|
+
label: "Detailed description",
|
|
27
26
|
content: "a herd of giraffes and zebras grazing in a field",
|
|
28
|
-
type:
|
|
27
|
+
type: "text",
|
|
29
28
|
},
|
|
30
29
|
],
|
|
31
30
|
},
|
|
@@ -33,55 +32,55 @@ const taskData: TaskDataCustom = {
|
|
|
33
32
|
models: [
|
|
34
33
|
{
|
|
35
34
|
description: "A robust image captioning model.",
|
|
36
|
-
id:
|
|
35
|
+
id: "Salesforce/blip-image-captioning-large",
|
|
37
36
|
},
|
|
38
37
|
{
|
|
39
38
|
description: "A strong image captioning model.",
|
|
40
|
-
id:
|
|
39
|
+
id: "nlpconnect/vit-gpt2-image-captioning",
|
|
41
40
|
},
|
|
42
41
|
{
|
|
43
42
|
description: "A strong optical character recognition model.",
|
|
44
|
-
id:
|
|
43
|
+
id: "microsoft/trocr-base-printed",
|
|
45
44
|
},
|
|
46
45
|
{
|
|
47
46
|
description: "A strong visual question answering model for scientific diagrams.",
|
|
48
|
-
id:
|
|
47
|
+
id: "google/pix2struct-ai2d-base",
|
|
49
48
|
},
|
|
50
49
|
{
|
|
51
50
|
description: "A strong captioning model for UI components.",
|
|
52
|
-
id:
|
|
51
|
+
id: "google/pix2struct-widget-captioning-base",
|
|
53
52
|
},
|
|
54
53
|
{
|
|
55
54
|
description: "A captioning model for images that contain text.",
|
|
56
|
-
id:
|
|
55
|
+
id: "google/pix2struct-textcaps-base",
|
|
57
56
|
},
|
|
58
57
|
],
|
|
59
|
-
spaces:
|
|
58
|
+
spaces: [
|
|
60
59
|
{
|
|
61
60
|
description: "A robust image captioning application.",
|
|
62
|
-
id:
|
|
61
|
+
id: "flax-community/image-captioning",
|
|
63
62
|
},
|
|
64
63
|
{
|
|
65
64
|
description: "An application that transcribes handwritings into text.",
|
|
66
|
-
id:
|
|
65
|
+
id: "nielsr/TrOCR-handwritten",
|
|
67
66
|
},
|
|
68
67
|
{
|
|
69
68
|
description: "An application that can caption images and answer questions about a given image.",
|
|
70
|
-
id:
|
|
69
|
+
id: "Salesforce/BLIP",
|
|
71
70
|
},
|
|
72
71
|
{
|
|
73
72
|
description: "An application that can caption images and answer questions with a conversational agent.",
|
|
74
|
-
id:
|
|
73
|
+
id: "Salesforce/BLIP2",
|
|
75
74
|
},
|
|
76
75
|
{
|
|
77
76
|
description: "An image captioning application that demonstrates the effect of noise on captions.",
|
|
78
|
-
id:
|
|
77
|
+
id: "johko/capdec-image-captioning",
|
|
79
78
|
},
|
|
80
79
|
],
|
|
81
|
-
summary:
|
|
80
|
+
summary:
|
|
81
|
+
"Image to text models output a text from a given image. Image captioning or optical character recognition can be considered as the most common applications of image to text.",
|
|
82
82
|
widgetModels: ["Salesforce/blip-image-captioning-base"],
|
|
83
|
-
youtubeId:
|
|
83
|
+
youtubeId: "",
|
|
84
84
|
};
|
|
85
85
|
|
|
86
|
-
|
|
87
86
|
export default taskData;
|
package/src/index.ts
CHANGED
|
@@ -1,2 +1,13 @@
|
|
|
1
1
|
export type { TaskData, TaskDemo, TaskDemoEntry, ExampleRepo } from "./Types";
|
|
2
2
|
export { TASKS_DATA } from "./tasksData";
|
|
3
|
+
export {
|
|
4
|
+
PIPELINE_DATA,
|
|
5
|
+
PIPELINE_TYPES,
|
|
6
|
+
type PipelineType,
|
|
7
|
+
type PipelineData,
|
|
8
|
+
type Modality,
|
|
9
|
+
MODALITIES,
|
|
10
|
+
MODALITY_LABELS,
|
|
11
|
+
} from "./pipelines";
|
|
12
|
+
export { ModelLibrary } from "./modelLibraries";
|
|
13
|
+
export type { ModelLibraryKey } from "./modelLibraries";
|
|
@@ -0,0 +1,43 @@
|
|
|
1
|
+
/**
|
|
2
|
+
* Add your new library here.
|
|
3
|
+
*
|
|
4
|
+
* This is for modeling (= architectures) libraries, not for file formats (like ONNX, etc).
|
|
5
|
+
* File formats live in an enum inside the internal codebase.
|
|
6
|
+
*/
|
|
7
|
+
export enum ModelLibrary {
|
|
8
|
+
"adapter-transformers" = "Adapter Transformers",
|
|
9
|
+
"allennlp" = "allenNLP",
|
|
10
|
+
"asteroid" = "Asteroid",
|
|
11
|
+
"bertopic" = "BERTopic",
|
|
12
|
+
"diffusers" = "Diffusers",
|
|
13
|
+
"doctr" = "docTR",
|
|
14
|
+
"espnet" = "ESPnet",
|
|
15
|
+
"fairseq" = "Fairseq",
|
|
16
|
+
"flair" = "Flair",
|
|
17
|
+
"keras" = "Keras",
|
|
18
|
+
"k2" = "K2",
|
|
19
|
+
"nemo" = "NeMo",
|
|
20
|
+
"open_clip" = "OpenCLIP",
|
|
21
|
+
"paddlenlp" = "PaddleNLP",
|
|
22
|
+
"peft" = "PEFT",
|
|
23
|
+
"pyannote-audio" = "pyannote.audio",
|
|
24
|
+
"sample-factory" = "Sample Factory",
|
|
25
|
+
"sentence-transformers" = "Sentence Transformers",
|
|
26
|
+
"sklearn" = "Scikit-learn",
|
|
27
|
+
"spacy" = "spaCy",
|
|
28
|
+
"span-marker" = "SpanMarker",
|
|
29
|
+
"speechbrain" = "speechbrain",
|
|
30
|
+
"tensorflowtts" = "TensorFlowTTS",
|
|
31
|
+
"timm" = "Timm",
|
|
32
|
+
"fastai" = "fastai",
|
|
33
|
+
"transformers" = "Transformers",
|
|
34
|
+
"transformers.js" = "Transformers.js",
|
|
35
|
+
"stanza" = "Stanza",
|
|
36
|
+
"fasttext" = "fastText",
|
|
37
|
+
"stable-baselines3" = "Stable-Baselines3",
|
|
38
|
+
"ml-agents" = "ML-Agents",
|
|
39
|
+
"pythae" = "Pythae",
|
|
40
|
+
"mindspore" = "MindSpore",
|
|
41
|
+
}
|
|
42
|
+
|
|
43
|
+
export type ModelLibraryKey = keyof typeof ModelLibrary;
|
|
@@ -32,5 +32,6 @@ model("path_to_cat_image")
|
|
|
32
32
|
```
|
|
33
33
|
|
|
34
34
|
# Useful Resources
|
|
35
|
+
|
|
35
36
|
- [Walkthrough of Computer Vision Ecosystem in Hugging Face - CV Study Group](https://www.youtube.com/watch?v=oL-xmufhZM8)
|
|
36
|
-
- [Object detection task guide](https://huggingface.co/docs/transformers/tasks/object_detection)
|
|
37
|
+
- [Object detection task guide](https://huggingface.co/docs/transformers/tasks/object_detection)
|
|
@@ -5,69 +5,72 @@ const taskData: TaskDataCustom = {
|
|
|
5
5
|
{
|
|
6
6
|
// TODO write proper description
|
|
7
7
|
description: "Widely used benchmark dataset for multiple Vision tasks.",
|
|
8
|
-
id:
|
|
8
|
+
id: "merve/coco2017",
|
|
9
9
|
},
|
|
10
10
|
],
|
|
11
11
|
demo: {
|
|
12
12
|
inputs: [
|
|
13
13
|
{
|
|
14
14
|
filename: "object-detection-input.jpg",
|
|
15
|
-
type:
|
|
15
|
+
type: "img",
|
|
16
16
|
},
|
|
17
17
|
],
|
|
18
18
|
outputs: [
|
|
19
19
|
{
|
|
20
20
|
filename: "object-detection-output.jpg",
|
|
21
|
-
type:
|
|
21
|
+
type: "img",
|
|
22
22
|
},
|
|
23
23
|
],
|
|
24
24
|
},
|
|
25
25
|
metrics: [
|
|
26
26
|
{
|
|
27
|
-
description:
|
|
28
|
-
|
|
27
|
+
description:
|
|
28
|
+
"The Average Precision (AP) metric is the Area Under the PR Curve (AUC-PR). It is calculated for each class separately",
|
|
29
|
+
id: "Average Precision",
|
|
29
30
|
},
|
|
30
31
|
{
|
|
31
32
|
description: "The Mean Average Precision (mAP) metric is the overall average of the AP values",
|
|
32
|
-
id:
|
|
33
|
+
id: "Mean Average Precision",
|
|
33
34
|
},
|
|
34
35
|
{
|
|
35
|
-
description:
|
|
36
|
-
|
|
36
|
+
description:
|
|
37
|
+
"The APα metric is the Average Precision at the IoU threshold of a α value, for example, AP50 and AP75",
|
|
38
|
+
id: "APα",
|
|
37
39
|
},
|
|
38
40
|
],
|
|
39
41
|
models: [
|
|
40
42
|
{
|
|
41
43
|
// TO DO: write description
|
|
42
44
|
description: "Solid object detection model trained on the benchmark dataset COCO 2017.",
|
|
43
|
-
id:
|
|
45
|
+
id: "facebook/detr-resnet-50",
|
|
44
46
|
},
|
|
45
47
|
{
|
|
46
48
|
description: "Strong object detection model trained on ImageNet-21k dataset.",
|
|
47
|
-
id:
|
|
49
|
+
id: "microsoft/beit-base-patch16-224-pt22k-ft22k",
|
|
48
50
|
},
|
|
49
51
|
],
|
|
50
|
-
spaces:
|
|
52
|
+
spaces: [
|
|
51
53
|
{
|
|
52
54
|
description: "An object detection application that can detect unseen objects out of the box.",
|
|
53
|
-
id:
|
|
55
|
+
id: "adirik/OWL-ViT",
|
|
54
56
|
},
|
|
55
57
|
{
|
|
56
58
|
description: "An application that contains various object detection models to try from.",
|
|
57
|
-
id:
|
|
59
|
+
id: "Gradio-Blocks/Object-Detection-With-DETR-and-YOLOS",
|
|
58
60
|
},
|
|
59
61
|
{
|
|
60
62
|
description: "An application that shows multiple cutting edge techniques for object detection and tracking.",
|
|
61
|
-
id:
|
|
63
|
+
id: "kadirnar/torchyolo",
|
|
62
64
|
},
|
|
63
65
|
{
|
|
64
66
|
description: "An object tracking, segmentation and inpainting application.",
|
|
65
|
-
id:
|
|
67
|
+
id: "VIPLab/Track-Anything",
|
|
66
68
|
},
|
|
67
69
|
],
|
|
68
|
-
summary:
|
|
70
|
+
summary:
|
|
71
|
+
"Object Detection models allow users to identify objects of certain defined classes. Object detection models receive an image as input and output the images with bounding boxes and labels on detected objects.",
|
|
69
72
|
widgetModels: ["facebook/detr-resnet-50"],
|
|
70
|
-
youtubeId:
|
|
73
|
+
youtubeId: "WdAeKSOpxhw",
|
|
71
74
|
};
|
|
72
75
|
|
|
73
76
|
export default taskData;
|