@huggingface/tasks 0.0.3 → 0.0.4
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/LICENSE +21 -0
- package/README.md +20 -0
- package/dist/index.d.ts +358 -46
- package/dist/index.js +103 -41
- package/dist/{index.cjs → index.mjs} +73 -68
- package/package.json +43 -33
- package/src/Types.ts +49 -43
- package/src/audio-classification/about.md +5 -5
- package/src/audio-classification/data.ts +11 -11
- package/src/audio-to-audio/about.md +4 -3
- package/src/audio-to-audio/data.ts +18 -15
- package/src/automatic-speech-recognition/about.md +5 -4
- package/src/automatic-speech-recognition/data.ts +18 -17
- package/src/const.ts +52 -44
- package/src/conversational/about.md +9 -9
- package/src/conversational/data.ts +22 -18
- package/src/depth-estimation/about.md +1 -3
- package/src/depth-estimation/data.ts +11 -11
- package/src/document-question-answering/about.md +1 -2
- package/src/document-question-answering/data.ts +22 -19
- package/src/feature-extraction/about.md +2 -3
- package/src/feature-extraction/data.ts +12 -15
- package/src/fill-mask/about.md +1 -1
- package/src/fill-mask/data.ts +16 -14
- package/src/image-classification/about.md +5 -3
- package/src/image-classification/data.ts +15 -15
- package/src/image-segmentation/about.md +4 -4
- package/src/image-segmentation/data.ts +26 -23
- package/src/image-to-image/about.md +8 -10
- package/src/image-to-image/data.ts +31 -27
- package/src/image-to-text/about.md +13 -6
- package/src/image-to-text/data.ts +20 -21
- package/src/index.ts +2 -0
- package/src/modelLibraries.ts +43 -0
- package/src/object-detection/about.md +2 -1
- package/src/object-detection/data.ts +20 -17
- package/src/pipelines.ts +608 -0
- package/src/placeholder/about.md +3 -3
- package/src/placeholder/data.ts +8 -8
- package/src/question-answering/about.md +1 -1
- package/src/question-answering/data.ts +21 -19
- package/src/reinforcement-learning/about.md +167 -176
- package/src/reinforcement-learning/data.ts +75 -78
- package/src/sentence-similarity/data.ts +29 -28
- package/src/summarization/about.md +6 -5
- package/src/summarization/data.ts +23 -20
- package/src/table-question-answering/about.md +5 -5
- package/src/table-question-answering/data.ts +35 -39
- package/src/tabular-classification/about.md +4 -6
- package/src/tabular-classification/data.ts +11 -12
- package/src/tabular-regression/about.md +14 -18
- package/src/tabular-regression/data.ts +10 -11
- package/src/tasksData.ts +47 -50
- package/src/text-classification/about.md +5 -4
- package/src/text-classification/data.ts +21 -20
- package/src/text-generation/about.md +7 -6
- package/src/text-generation/data.ts +36 -34
- package/src/text-to-image/about.md +19 -18
- package/src/text-to-image/data.ts +32 -26
- package/src/text-to-speech/about.md +4 -5
- package/src/text-to-speech/data.ts +16 -17
- package/src/text-to-video/about.md +41 -36
- package/src/text-to-video/data.ts +43 -38
- package/src/token-classification/about.md +1 -3
- package/src/token-classification/data.ts +26 -25
- package/src/translation/about.md +4 -4
- package/src/translation/data.ts +21 -21
- package/src/unconditional-image-generation/about.md +10 -5
- package/src/unconditional-image-generation/data.ts +26 -20
- package/src/video-classification/about.md +5 -1
- package/src/video-classification/data.ts +14 -14
- package/src/visual-question-answering/about.md +8 -3
- package/src/visual-question-answering/data.ts +22 -19
- package/src/zero-shot-classification/about.md +5 -4
- package/src/zero-shot-classification/data.ts +20 -20
- package/src/zero-shot-image-classification/about.md +17 -9
- package/src/zero-shot-image-classification/data.ts +12 -14
- package/tsconfig.json +18 -0
- package/assets/audio-classification/audio.wav +0 -0
- package/assets/audio-to-audio/input.wav +0 -0
- package/assets/audio-to-audio/label-0.wav +0 -0
- package/assets/audio-to-audio/label-1.wav +0 -0
- package/assets/automatic-speech-recognition/input.flac +0 -0
- package/assets/automatic-speech-recognition/wav2vec2.png +0 -0
- package/assets/contribution-guide/anatomy.png +0 -0
- package/assets/contribution-guide/libraries.png +0 -0
- package/assets/depth-estimation/depth-estimation-input.jpg +0 -0
- package/assets/depth-estimation/depth-estimation-output.png +0 -0
- package/assets/document-question-answering/document-question-answering-input.png +0 -0
- package/assets/image-classification/image-classification-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-output.png +0 -0
- package/assets/image-to-image/image-to-image-input.jpeg +0 -0
- package/assets/image-to-image/image-to-image-output.png +0 -0
- package/assets/image-to-image/pix2pix_examples.jpg +0 -0
- package/assets/image-to-text/savanna.jpg +0 -0
- package/assets/object-detection/object-detection-input.jpg +0 -0
- package/assets/object-detection/object-detection-output.jpg +0 -0
- package/assets/table-question-answering/tableQA.jpg +0 -0
- package/assets/text-to-image/image.jpeg +0 -0
- package/assets/text-to-speech/audio.wav +0 -0
- package/assets/text-to-video/text-to-video-output.gif +0 -0
- package/assets/unconditional-image-generation/unconditional-image-generation-output.jpeg +0 -0
- package/assets/video-classification/video-classification-input.gif +0 -0
- package/assets/visual-question-answering/elephant.jpeg +0 -0
- package/assets/zero-shot-image-classification/image-classification-input.jpeg +0 -0
- package/dist/index.d.cts +0 -145
package/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2023 Hugging Face
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
package/README.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
1
|
+
# Tasks
|
|
2
|
+
|
|
3
|
+
This package contains data used for https://huggingface.co/tasks.
|
|
4
|
+
|
|
5
|
+
## Philosophy behind Tasks
|
|
6
|
+
|
|
7
|
+
The Task pages are made to lower the barrier of entry to understand a task that can be solved with machine learning and use or train a model to accomplish it. It's a collaborative documentation effort made to help out software developers, social scientists, or anyone with no background in machine learning that is interested in understanding how machine learning models can be used to solve a problem.
|
|
8
|
+
|
|
9
|
+
The task pages avoid jargon to let everyone understand the documentation, and if specific terminology is needed, it is explained on the most basic level possible. This is important to understand before contributing to Tasks: at the end of every task page, the user is expected to be able to find and pull a model from the Hub and use it on their data and see if it works for their use case to come up with a proof of concept.
|
|
10
|
+
|
|
11
|
+
## How to Contribute
|
|
12
|
+
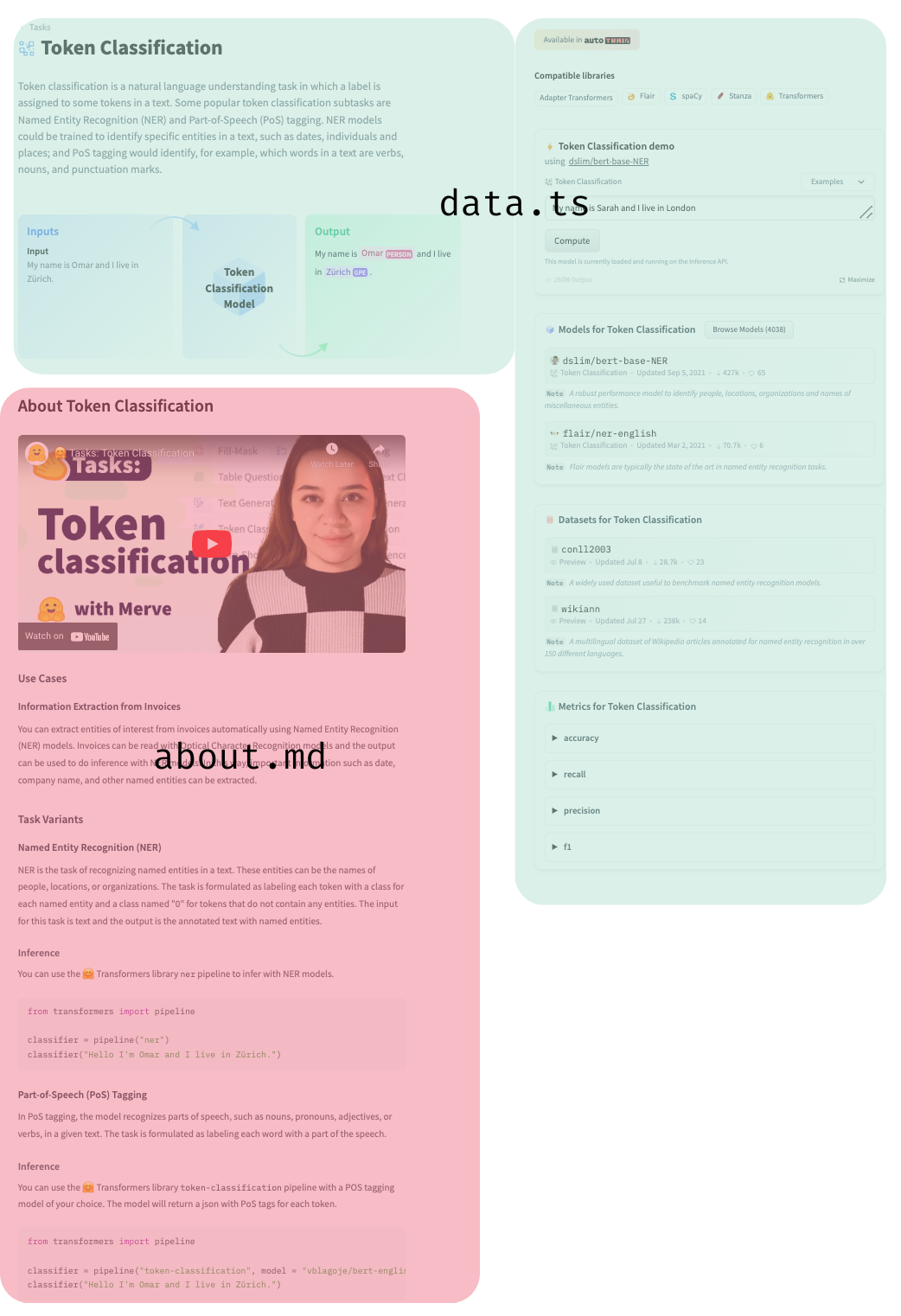
You can open a pull request to contribute a new documentation about a new task. Under `src` we have a folder for every task that contains two files, `about.md` and `data.ts`. `about.md` contains the markdown part of the page, use cases, resources and minimal code block to infer a model that belongs to the task. `data.ts` contains redirections to canonical models and datasets, metrics, the schema of the task and the information the inference widget needs.
|
|
13
|
+
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
We have a [`dataset`](https://huggingface.co/datasets/huggingfacejs/tasks) that contains data used in the inference widget. The last file is `const.ts`, which has the task to library mapping (e.g. spacy to token-classification) where you can add a library. They will look in the top right corner like below.
|
|
17
|
+
|
|
18
|
+

|
|
19
|
+
|
|
20
|
+
This might seem overwhelming, but you don't necessarily need to add all of these in one pull request or on your own, you can simply contribute one section. Feel free to ask for help whenever you need.
|
package/dist/index.d.ts
CHANGED
|
@@ -1,5 +1,48 @@
|
|
|
1
|
+
/**
|
|
2
|
+
* Add your new library here.
|
|
3
|
+
*
|
|
4
|
+
* This is for modeling (= architectures) libraries, not for file formats (like ONNX, etc).
|
|
5
|
+
* File formats live in an enum inside the internal codebase.
|
|
6
|
+
*/
|
|
7
|
+
declare enum ModelLibrary {
|
|
8
|
+
"adapter-transformers" = "Adapter Transformers",
|
|
9
|
+
"allennlp" = "allenNLP",
|
|
10
|
+
"asteroid" = "Asteroid",
|
|
11
|
+
"bertopic" = "BERTopic",
|
|
12
|
+
"diffusers" = "Diffusers",
|
|
13
|
+
"doctr" = "docTR",
|
|
14
|
+
"espnet" = "ESPnet",
|
|
15
|
+
"fairseq" = "Fairseq",
|
|
16
|
+
"flair" = "Flair",
|
|
17
|
+
"keras" = "Keras",
|
|
18
|
+
"k2" = "K2",
|
|
19
|
+
"nemo" = "NeMo",
|
|
20
|
+
"open_clip" = "OpenCLIP",
|
|
21
|
+
"paddlenlp" = "PaddleNLP",
|
|
22
|
+
"peft" = "PEFT",
|
|
23
|
+
"pyannote-audio" = "pyannote.audio",
|
|
24
|
+
"sample-factory" = "Sample Factory",
|
|
25
|
+
"sentence-transformers" = "Sentence Transformers",
|
|
26
|
+
"sklearn" = "Scikit-learn",
|
|
27
|
+
"spacy" = "spaCy",
|
|
28
|
+
"span-marker" = "SpanMarker",
|
|
29
|
+
"speechbrain" = "speechbrain",
|
|
30
|
+
"tensorflowtts" = "TensorFlowTTS",
|
|
31
|
+
"timm" = "Timm",
|
|
32
|
+
"fastai" = "fastai",
|
|
33
|
+
"transformers" = "Transformers",
|
|
34
|
+
"transformers.js" = "Transformers.js",
|
|
35
|
+
"stanza" = "Stanza",
|
|
36
|
+
"fasttext" = "fastText",
|
|
37
|
+
"stable-baselines3" = "Stable-Baselines3",
|
|
38
|
+
"ml-agents" = "ML-Agents",
|
|
39
|
+
"pythae" = "Pythae",
|
|
40
|
+
"mindspore" = "MindSpore"
|
|
41
|
+
}
|
|
42
|
+
type ModelLibraryKey = keyof typeof ModelLibrary;
|
|
43
|
+
|
|
1
44
|
declare const MODALITIES: readonly ["cv", "nlp", "audio", "tabular", "multimodal", "rl", "other"];
|
|
2
|
-
type Modality = typeof MODALITIES[number];
|
|
45
|
+
type Modality = (typeof MODALITIES)[number];
|
|
3
46
|
/**
|
|
4
47
|
* Public interface for a sub task.
|
|
5
48
|
*
|
|
@@ -43,52 +86,321 @@ interface PipelineData {
|
|
|
43
86
|
*/
|
|
44
87
|
hideInDatasets?: boolean;
|
|
45
88
|
}
|
|
46
|
-
declare const PIPELINE_DATA:
|
|
89
|
+
declare const PIPELINE_DATA: {
|
|
90
|
+
"text-classification": {
|
|
91
|
+
name: string;
|
|
92
|
+
subtasks: {
|
|
93
|
+
type: string;
|
|
94
|
+
name: string;
|
|
95
|
+
}[];
|
|
96
|
+
modality: "nlp";
|
|
97
|
+
color: "orange";
|
|
98
|
+
};
|
|
99
|
+
"token-classification": {
|
|
100
|
+
name: string;
|
|
101
|
+
subtasks: {
|
|
102
|
+
type: string;
|
|
103
|
+
name: string;
|
|
104
|
+
}[];
|
|
105
|
+
modality: "nlp";
|
|
106
|
+
color: "blue";
|
|
107
|
+
};
|
|
108
|
+
"table-question-answering": {
|
|
109
|
+
name: string;
|
|
110
|
+
modality: "nlp";
|
|
111
|
+
color: "green";
|
|
112
|
+
};
|
|
113
|
+
"question-answering": {
|
|
114
|
+
name: string;
|
|
115
|
+
subtasks: {
|
|
116
|
+
type: string;
|
|
117
|
+
name: string;
|
|
118
|
+
}[];
|
|
119
|
+
modality: "nlp";
|
|
120
|
+
color: "blue";
|
|
121
|
+
};
|
|
122
|
+
"zero-shot-classification": {
|
|
123
|
+
name: string;
|
|
124
|
+
modality: "nlp";
|
|
125
|
+
color: "yellow";
|
|
126
|
+
};
|
|
127
|
+
translation: {
|
|
128
|
+
name: string;
|
|
129
|
+
modality: "nlp";
|
|
130
|
+
color: "green";
|
|
131
|
+
};
|
|
132
|
+
summarization: {
|
|
133
|
+
name: string;
|
|
134
|
+
subtasks: {
|
|
135
|
+
type: string;
|
|
136
|
+
name: string;
|
|
137
|
+
}[];
|
|
138
|
+
modality: "nlp";
|
|
139
|
+
color: "indigo";
|
|
140
|
+
};
|
|
141
|
+
conversational: {
|
|
142
|
+
name: string;
|
|
143
|
+
subtasks: {
|
|
144
|
+
type: string;
|
|
145
|
+
name: string;
|
|
146
|
+
}[];
|
|
147
|
+
modality: "nlp";
|
|
148
|
+
color: "green";
|
|
149
|
+
};
|
|
150
|
+
"feature-extraction": {
|
|
151
|
+
name: string;
|
|
152
|
+
modality: "multimodal";
|
|
153
|
+
color: "red";
|
|
154
|
+
};
|
|
155
|
+
"text-generation": {
|
|
156
|
+
name: string;
|
|
157
|
+
subtasks: {
|
|
158
|
+
type: string;
|
|
159
|
+
name: string;
|
|
160
|
+
}[];
|
|
161
|
+
modality: "nlp";
|
|
162
|
+
color: "indigo";
|
|
163
|
+
};
|
|
164
|
+
"text2text-generation": {
|
|
165
|
+
name: string;
|
|
166
|
+
subtasks: {
|
|
167
|
+
type: string;
|
|
168
|
+
name: string;
|
|
169
|
+
}[];
|
|
170
|
+
modality: "nlp";
|
|
171
|
+
color: "indigo";
|
|
172
|
+
};
|
|
173
|
+
"fill-mask": {
|
|
174
|
+
name: string;
|
|
175
|
+
subtasks: {
|
|
176
|
+
type: string;
|
|
177
|
+
name: string;
|
|
178
|
+
}[];
|
|
179
|
+
modality: "nlp";
|
|
180
|
+
color: "red";
|
|
181
|
+
};
|
|
182
|
+
"sentence-similarity": {
|
|
183
|
+
name: string;
|
|
184
|
+
modality: "nlp";
|
|
185
|
+
color: "yellow";
|
|
186
|
+
};
|
|
187
|
+
"text-to-speech": {
|
|
188
|
+
name: string;
|
|
189
|
+
modality: "audio";
|
|
190
|
+
color: "yellow";
|
|
191
|
+
};
|
|
192
|
+
"text-to-audio": {
|
|
193
|
+
name: string;
|
|
194
|
+
modality: "audio";
|
|
195
|
+
color: "yellow";
|
|
196
|
+
};
|
|
197
|
+
"automatic-speech-recognition": {
|
|
198
|
+
name: string;
|
|
199
|
+
modality: "audio";
|
|
200
|
+
color: "yellow";
|
|
201
|
+
};
|
|
202
|
+
"audio-to-audio": {
|
|
203
|
+
name: string;
|
|
204
|
+
modality: "audio";
|
|
205
|
+
color: "blue";
|
|
206
|
+
};
|
|
207
|
+
"audio-classification": {
|
|
208
|
+
name: string;
|
|
209
|
+
subtasks: {
|
|
210
|
+
type: string;
|
|
211
|
+
name: string;
|
|
212
|
+
}[];
|
|
213
|
+
modality: "audio";
|
|
214
|
+
color: "green";
|
|
215
|
+
};
|
|
216
|
+
"voice-activity-detection": {
|
|
217
|
+
name: string;
|
|
218
|
+
modality: "audio";
|
|
219
|
+
color: "red";
|
|
220
|
+
};
|
|
221
|
+
"depth-estimation": {
|
|
222
|
+
name: string;
|
|
223
|
+
modality: "cv";
|
|
224
|
+
color: "yellow";
|
|
225
|
+
};
|
|
226
|
+
"image-classification": {
|
|
227
|
+
name: string;
|
|
228
|
+
subtasks: {
|
|
229
|
+
type: string;
|
|
230
|
+
name: string;
|
|
231
|
+
}[];
|
|
232
|
+
modality: "cv";
|
|
233
|
+
color: "blue";
|
|
234
|
+
};
|
|
235
|
+
"object-detection": {
|
|
236
|
+
name: string;
|
|
237
|
+
subtasks: {
|
|
238
|
+
type: string;
|
|
239
|
+
name: string;
|
|
240
|
+
}[];
|
|
241
|
+
modality: "cv";
|
|
242
|
+
color: "yellow";
|
|
243
|
+
};
|
|
244
|
+
"image-segmentation": {
|
|
245
|
+
name: string;
|
|
246
|
+
subtasks: {
|
|
247
|
+
type: string;
|
|
248
|
+
name: string;
|
|
249
|
+
}[];
|
|
250
|
+
modality: "cv";
|
|
251
|
+
color: "green";
|
|
252
|
+
};
|
|
253
|
+
"text-to-image": {
|
|
254
|
+
name: string;
|
|
255
|
+
modality: "multimodal";
|
|
256
|
+
color: "yellow";
|
|
257
|
+
};
|
|
258
|
+
"image-to-text": {
|
|
259
|
+
name: string;
|
|
260
|
+
subtasks: {
|
|
261
|
+
type: string;
|
|
262
|
+
name: string;
|
|
263
|
+
}[];
|
|
264
|
+
modality: "multimodal";
|
|
265
|
+
color: "red";
|
|
266
|
+
};
|
|
267
|
+
"image-to-image": {
|
|
268
|
+
name: string;
|
|
269
|
+
modality: "cv";
|
|
270
|
+
color: "indigo";
|
|
271
|
+
};
|
|
272
|
+
"unconditional-image-generation": {
|
|
273
|
+
name: string;
|
|
274
|
+
modality: "cv";
|
|
275
|
+
color: "green";
|
|
276
|
+
};
|
|
277
|
+
"video-classification": {
|
|
278
|
+
name: string;
|
|
279
|
+
modality: "cv";
|
|
280
|
+
color: "blue";
|
|
281
|
+
};
|
|
282
|
+
"reinforcement-learning": {
|
|
283
|
+
name: string;
|
|
284
|
+
modality: "rl";
|
|
285
|
+
color: "red";
|
|
286
|
+
};
|
|
287
|
+
robotics: {
|
|
288
|
+
name: string;
|
|
289
|
+
modality: "rl";
|
|
290
|
+
subtasks: {
|
|
291
|
+
type: string;
|
|
292
|
+
name: string;
|
|
293
|
+
}[];
|
|
294
|
+
color: "blue";
|
|
295
|
+
};
|
|
296
|
+
"tabular-classification": {
|
|
297
|
+
name: string;
|
|
298
|
+
modality: "tabular";
|
|
299
|
+
subtasks: {
|
|
300
|
+
type: string;
|
|
301
|
+
name: string;
|
|
302
|
+
}[];
|
|
303
|
+
color: "blue";
|
|
304
|
+
};
|
|
305
|
+
"tabular-regression": {
|
|
306
|
+
name: string;
|
|
307
|
+
modality: "tabular";
|
|
308
|
+
subtasks: {
|
|
309
|
+
type: string;
|
|
310
|
+
name: string;
|
|
311
|
+
}[];
|
|
312
|
+
color: "blue";
|
|
313
|
+
};
|
|
314
|
+
"tabular-to-text": {
|
|
315
|
+
name: string;
|
|
316
|
+
modality: "tabular";
|
|
317
|
+
subtasks: {
|
|
318
|
+
type: string;
|
|
319
|
+
name: string;
|
|
320
|
+
}[];
|
|
321
|
+
color: "blue";
|
|
322
|
+
hideInModels: true;
|
|
323
|
+
};
|
|
324
|
+
"table-to-text": {
|
|
325
|
+
name: string;
|
|
326
|
+
modality: "nlp";
|
|
327
|
+
color: "blue";
|
|
328
|
+
hideInModels: true;
|
|
329
|
+
};
|
|
330
|
+
"multiple-choice": {
|
|
331
|
+
name: string;
|
|
332
|
+
subtasks: {
|
|
333
|
+
type: string;
|
|
334
|
+
name: string;
|
|
335
|
+
}[];
|
|
336
|
+
modality: "nlp";
|
|
337
|
+
color: "blue";
|
|
338
|
+
hideInModels: true;
|
|
339
|
+
};
|
|
340
|
+
"text-retrieval": {
|
|
341
|
+
name: string;
|
|
342
|
+
subtasks: {
|
|
343
|
+
type: string;
|
|
344
|
+
name: string;
|
|
345
|
+
}[];
|
|
346
|
+
modality: "nlp";
|
|
347
|
+
color: "indigo";
|
|
348
|
+
hideInModels: true;
|
|
349
|
+
};
|
|
350
|
+
"time-series-forecasting": {
|
|
351
|
+
name: string;
|
|
352
|
+
modality: "tabular";
|
|
353
|
+
subtasks: {
|
|
354
|
+
type: string;
|
|
355
|
+
name: string;
|
|
356
|
+
}[];
|
|
357
|
+
color: "blue";
|
|
358
|
+
hideInModels: true;
|
|
359
|
+
};
|
|
360
|
+
"text-to-video": {
|
|
361
|
+
name: string;
|
|
362
|
+
modality: "multimodal";
|
|
363
|
+
color: "green";
|
|
364
|
+
};
|
|
365
|
+
"visual-question-answering": {
|
|
366
|
+
name: string;
|
|
367
|
+
subtasks: {
|
|
368
|
+
type: string;
|
|
369
|
+
name: string;
|
|
370
|
+
}[];
|
|
371
|
+
modality: "multimodal";
|
|
372
|
+
color: "red";
|
|
373
|
+
};
|
|
374
|
+
"document-question-answering": {
|
|
375
|
+
name: string;
|
|
376
|
+
subtasks: {
|
|
377
|
+
type: string;
|
|
378
|
+
name: string;
|
|
379
|
+
}[];
|
|
380
|
+
modality: "multimodal";
|
|
381
|
+
color: "blue";
|
|
382
|
+
hideInDatasets: true;
|
|
383
|
+
};
|
|
384
|
+
"zero-shot-image-classification": {
|
|
385
|
+
name: string;
|
|
386
|
+
modality: "cv";
|
|
387
|
+
color: "yellow";
|
|
388
|
+
};
|
|
389
|
+
"graph-ml": {
|
|
390
|
+
name: string;
|
|
391
|
+
modality: "multimodal";
|
|
392
|
+
color: "green";
|
|
393
|
+
};
|
|
394
|
+
other: {
|
|
395
|
+
name: string;
|
|
396
|
+
modality: "other";
|
|
397
|
+
color: "blue";
|
|
398
|
+
hideInModels: true;
|
|
399
|
+
hideInDatasets: true;
|
|
400
|
+
};
|
|
401
|
+
};
|
|
47
402
|
type PipelineType = keyof typeof PIPELINE_DATA;
|
|
48
403
|
|
|
49
|
-
/**
|
|
50
|
-
* Add your new library here.
|
|
51
|
-
*
|
|
52
|
-
* This is for modeling (= architectures) libraries, not for file formats (like ONNX, etc).
|
|
53
|
-
* File formats live in an enum inside the internal codebase.
|
|
54
|
-
*/
|
|
55
|
-
declare enum ModelLibrary {
|
|
56
|
-
"adapter-transformers" = "Adapter Transformers",
|
|
57
|
-
"allennlp" = "allenNLP",
|
|
58
|
-
"asteroid" = "Asteroid",
|
|
59
|
-
"bertopic" = "BERTopic",
|
|
60
|
-
"diffusers" = "Diffusers",
|
|
61
|
-
"doctr" = "docTR",
|
|
62
|
-
"espnet" = "ESPnet",
|
|
63
|
-
"fairseq" = "Fairseq",
|
|
64
|
-
"flair" = "Flair",
|
|
65
|
-
"keras" = "Keras",
|
|
66
|
-
"k2" = "K2",
|
|
67
|
-
"nemo" = "NeMo",
|
|
68
|
-
"open_clip" = "OpenCLIP",
|
|
69
|
-
"paddlenlp" = "PaddleNLP",
|
|
70
|
-
"peft" = "PEFT",
|
|
71
|
-
"pyannote-audio" = "pyannote.audio",
|
|
72
|
-
"sample-factory" = "Sample Factory",
|
|
73
|
-
"sentence-transformers" = "Sentence Transformers",
|
|
74
|
-
"sklearn" = "Scikit-learn",
|
|
75
|
-
"spacy" = "spaCy",
|
|
76
|
-
"span-marker" = "SpanMarker",
|
|
77
|
-
"speechbrain" = "speechbrain",
|
|
78
|
-
"tensorflowtts" = "TensorFlowTTS",
|
|
79
|
-
"timm" = "Timm",
|
|
80
|
-
"fastai" = "fastai",
|
|
81
|
-
"transformers" = "Transformers",
|
|
82
|
-
"transformers.js" = "Transformers.js",
|
|
83
|
-
"stanza" = "Stanza",
|
|
84
|
-
"fasttext" = "fastText",
|
|
85
|
-
"stable-baselines3" = "Stable-Baselines3",
|
|
86
|
-
"ml-agents" = "ML-Agents",
|
|
87
|
-
"pythae" = "Pythae",
|
|
88
|
-
"mindspore" = "MindSpore"
|
|
89
|
-
}
|
|
90
|
-
type ModelLibraryKey = keyof typeof ModelLibrary;
|
|
91
|
-
|
|
92
404
|
interface ExampleRepo {
|
|
93
405
|
description: string;
|
|
94
406
|
id: string;
|
|
@@ -142,4 +454,4 @@ interface TaskData {
|
|
|
142
454
|
|
|
143
455
|
declare const TASKS_DATA: Record<PipelineType, TaskData | undefined>;
|
|
144
456
|
|
|
145
|
-
export {
|
|
457
|
+
export { ExampleRepo, MODALITIES, Modality, ModelLibrary, PIPELINE_DATA, PipelineData, PipelineType, TASKS_DATA, TaskData, TaskDemo, TaskDemoEntry };
|