@huggingface/tasks 0.0.1
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/assets/audio-classification/audio.wav +0 -0
- package/assets/audio-to-audio/input.wav +0 -0
- package/assets/audio-to-audio/label-0.wav +0 -0
- package/assets/audio-to-audio/label-1.wav +0 -0
- package/assets/automatic-speech-recognition/input.flac +0 -0
- package/assets/automatic-speech-recognition/wav2vec2.png +0 -0
- package/assets/contribution-guide/anatomy.png +0 -0
- package/assets/contribution-guide/libraries.png +0 -0
- package/assets/depth-estimation/depth-estimation-input.jpg +0 -0
- package/assets/depth-estimation/depth-estimation-output.png +0 -0
- package/assets/document-question-answering/document-question-answering-input.png +0 -0
- package/assets/image-classification/image-classification-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-input.jpeg +0 -0
- package/assets/image-segmentation/image-segmentation-output.png +0 -0
- package/assets/image-to-image/image-to-image-input.jpeg +0 -0
- package/assets/image-to-image/image-to-image-output.png +0 -0
- package/assets/image-to-image/pix2pix_examples.jpg +0 -0
- package/assets/image-to-text/savanna.jpg +0 -0
- package/assets/object-detection/object-detection-input.jpg +0 -0
- package/assets/object-detection/object-detection-output.jpg +0 -0
- package/assets/table-question-answering/tableQA.jpg +0 -0
- package/assets/text-to-image/image.jpeg +0 -0
- package/assets/text-to-speech/audio.wav +0 -0
- package/assets/text-to-video/text-to-video-output.gif +0 -0
- package/assets/unconditional-image-generation/unconditional-image-generation-output.jpeg +0 -0
- package/assets/video-classification/video-classification-input.gif +0 -0
- package/assets/visual-question-answering/elephant.jpeg +0 -0
- package/assets/zero-shot-image-classification/image-classification-input.jpeg +0 -0
- package/dist/index.cjs +3105 -0
- package/dist/index.d.cts +145 -0
- package/dist/index.d.ts +145 -0
- package/dist/index.js +3079 -0
- package/package.json +35 -0
- package/src/Types.ts +58 -0
- package/src/audio-classification/about.md +85 -0
- package/src/audio-classification/data.ts +77 -0
- package/src/audio-to-audio/about.md +55 -0
- package/src/audio-to-audio/data.ts +63 -0
- package/src/automatic-speech-recognition/about.md +86 -0
- package/src/automatic-speech-recognition/data.ts +77 -0
- package/src/const.ts +51 -0
- package/src/conversational/about.md +50 -0
- package/src/conversational/data.ts +62 -0
- package/src/depth-estimation/about.md +38 -0
- package/src/depth-estimation/data.ts +52 -0
- package/src/document-question-answering/about.md +54 -0
- package/src/document-question-answering/data.ts +67 -0
- package/src/feature-extraction/about.md +35 -0
- package/src/feature-extraction/data.ts +57 -0
- package/src/fill-mask/about.md +51 -0
- package/src/fill-mask/data.ts +77 -0
- package/src/image-classification/about.md +48 -0
- package/src/image-classification/data.ts +88 -0
- package/src/image-segmentation/about.md +63 -0
- package/src/image-segmentation/data.ts +96 -0
- package/src/image-to-image/about.md +81 -0
- package/src/image-to-image/data.ts +97 -0
- package/src/image-to-text/about.md +58 -0
- package/src/image-to-text/data.ts +87 -0
- package/src/index.ts +2 -0
- package/src/object-detection/about.md +36 -0
- package/src/object-detection/data.ts +73 -0
- package/src/placeholder/about.md +15 -0
- package/src/placeholder/data.ts +18 -0
- package/src/question-answering/about.md +56 -0
- package/src/question-answering/data.ts +69 -0
- package/src/reinforcement-learning/about.md +176 -0
- package/src/reinforcement-learning/data.ts +78 -0
- package/src/sentence-similarity/about.md +97 -0
- package/src/sentence-similarity/data.ts +100 -0
- package/src/summarization/about.md +57 -0
- package/src/summarization/data.ts +72 -0
- package/src/table-question-answering/about.md +43 -0
- package/src/table-question-answering/data.ts +63 -0
- package/src/tabular-classification/about.md +67 -0
- package/src/tabular-classification/data.ts +69 -0
- package/src/tabular-regression/about.md +91 -0
- package/src/tabular-regression/data.ts +58 -0
- package/src/tasksData.ts +104 -0
- package/src/text-classification/about.md +171 -0
- package/src/text-classification/data.ts +90 -0
- package/src/text-generation/about.md +128 -0
- package/src/text-generation/data.ts +124 -0
- package/src/text-to-image/about.md +65 -0
- package/src/text-to-image/data.ts +88 -0
- package/src/text-to-speech/about.md +63 -0
- package/src/text-to-speech/data.ts +70 -0
- package/src/text-to-video/about.md +36 -0
- package/src/text-to-video/data.ts +97 -0
- package/src/token-classification/about.md +78 -0
- package/src/token-classification/data.ts +83 -0
- package/src/translation/about.md +65 -0
- package/src/translation/data.ts +68 -0
- package/src/unconditional-image-generation/about.md +45 -0
- package/src/unconditional-image-generation/data.ts +66 -0
- package/src/video-classification/about.md +53 -0
- package/src/video-classification/data.ts +84 -0
- package/src/visual-question-answering/about.md +43 -0
- package/src/visual-question-answering/data.ts +90 -0
- package/src/zero-shot-classification/about.md +39 -0
- package/src/zero-shot-classification/data.ts +66 -0
- package/src/zero-shot-image-classification/about.md +68 -0
- package/src/zero-shot-image-classification/data.ts +79 -0
|
@@ -0,0 +1,171 @@
|
|
|
1
|
+
## Use Cases
|
|
2
|
+
|
|
3
|
+
### Sentiment Analysis on Customer Reviews
|
|
4
|
+
|
|
5
|
+
You can track the sentiments of your customers from the product reviews using sentiment analysis models. This can help understand churn and retention by grouping reviews by sentiment, to later analyze the text and make strategic decisions based on this knowledge.
|
|
6
|
+
|
|
7
|
+
## Task Variants
|
|
8
|
+
|
|
9
|
+
### Natural Language Inference (NLI)
|
|
10
|
+
|
|
11
|
+
In NLI the model determines the relationship between two given texts. Concretely, the model takes a premise and a hypothesis and returns a class that can either be:
|
|
12
|
+
|
|
13
|
+
- **entailment**, which means the hypothesis is true.
|
|
14
|
+
- **contraction**, which means the hypothesis is false.
|
|
15
|
+
- **neutral**, which means there's no relation between the hypothesis and the premise.
|
|
16
|
+
|
|
17
|
+
The benchmark dataset for this task is GLUE (General Language Understanding Evaluation). NLI models have different variants, such as Multi-Genre NLI, Question NLI and Winograd NLI.
|
|
18
|
+
|
|
19
|
+
### Multi-Genre NLI (MNLI)
|
|
20
|
+
|
|
21
|
+
MNLI is used for general NLI. Here are som examples:
|
|
22
|
+
|
|
23
|
+
```
|
|
24
|
+
Example 1:
|
|
25
|
+
Premise: A man inspects the uniform of a figure in some East Asian country.
|
|
26
|
+
Hypothesis: The man is sleeping.
|
|
27
|
+
Label: Contradiction
|
|
28
|
+
|
|
29
|
+
Example 2:
|
|
30
|
+
Premise: Soccer game with multiple males playing.
|
|
31
|
+
Hypothesis: Some men are playing a sport.
|
|
32
|
+
Label: Entailment
|
|
33
|
+
```
|
|
34
|
+
|
|
35
|
+
#### Inference
|
|
36
|
+
|
|
37
|
+
You can use the 🤗 Transformers library `text-classification` pipeline to infer with NLI models.
|
|
38
|
+
|
|
39
|
+
```python
|
|
40
|
+
from transformers import pipeline
|
|
41
|
+
|
|
42
|
+
classifier = pipeline("text-classification", model = "roberta-large-mnli")
|
|
43
|
+
classifier("A soccer game with multiple males playing. Some men are playing a sport.")
|
|
44
|
+
## [{'label': 'ENTAILMENT', 'score': 0.98}]
|
|
45
|
+
```
|
|
46
|
+
|
|
47
|
+
### Question Natural Language Inference (QNLI)
|
|
48
|
+
|
|
49
|
+
QNLI is the task of determining if the answer to a certain question can be found in a given document. If the answer can be found the label is “entailment”. If the answer cannot be found the label is “not entailment".
|
|
50
|
+
|
|
51
|
+
```
|
|
52
|
+
Question: What percentage of marine life died during the extinction?
|
|
53
|
+
Sentence: It is also known as the “Great Dying” because it is considered the largest mass extinction in the Earth’s history.
|
|
54
|
+
Label: not entailment
|
|
55
|
+
|
|
56
|
+
Question: Who was the London Weekend Television’s Managing Director?
|
|
57
|
+
Sentence: The managing director of London Weekend Television (LWT), Greg Dyke, met with the representatives of the "big five" football clubs in England in 1990.
|
|
58
|
+
Label: entailment
|
|
59
|
+
```
|
|
60
|
+
|
|
61
|
+
#### Inference
|
|
62
|
+
|
|
63
|
+
You can use the 🤗 Transformers library `text-classification` pipeline to infer with QNLI models. The model returns the label and the confidence.
|
|
64
|
+
|
|
65
|
+
```python
|
|
66
|
+
from transformers import pipeline
|
|
67
|
+
|
|
68
|
+
classifier = pipeline("text-classification", model = "cross-encoder/qnli-electra-base")
|
|
69
|
+
classifier("Where is the capital of France?, Paris is the capital of France.")
|
|
70
|
+
## [{'label': 'entailment', 'score': 0.997}]
|
|
71
|
+
```
|
|
72
|
+
|
|
73
|
+
### Sentiment Analysis
|
|
74
|
+
|
|
75
|
+
In Sentiment Analysis, the classes can be polarities like positive, negative, neutral, or sentiments such as happiness or anger.
|
|
76
|
+
|
|
77
|
+
#### Inference
|
|
78
|
+
|
|
79
|
+
You can use the 🤗 Transformers library with the `sentiment-analysis` pipeline to infer with Sentiment Analysis models. The model returns the label with the score.
|
|
80
|
+
|
|
81
|
+
```python
|
|
82
|
+
from transformers import pipeline
|
|
83
|
+
|
|
84
|
+
classifier = pipeline("sentiment-analysis")
|
|
85
|
+
classifier("I loved Star Wars so much!")
|
|
86
|
+
## [{'label': 'POSITIVE', 'score': 0.99}
|
|
87
|
+
```
|
|
88
|
+
|
|
89
|
+
### Quora Question Pairs
|
|
90
|
+
|
|
91
|
+
Quora Question Pairs models assess whether two provided questions are paraphrases of each other. The model takes two questions and returns a binary value, with 0 being mapped to “not paraphrase” and 1 to “paraphrase". The benchmark dataset is [Quora Question Pairs](https://huggingface.co/datasets/glue/viewer/qqp/test) inside the [GLUE benchmark](https://huggingface.co/datasets/glue). The dataset consists of question pairs and their labels.
|
|
92
|
+
|
|
93
|
+
```
|
|
94
|
+
Question1: “How can I increase the speed of my internet connection while using a VPN?”
|
|
95
|
+
Question2: How can Internet speed be increased by hacking through DNS?
|
|
96
|
+
Label: Not paraphrase
|
|
97
|
+
|
|
98
|
+
Question1: “What can make Physics easy to learn?”
|
|
99
|
+
Question2: “How can you make physics easy to learn?”
|
|
100
|
+
Label: Paraphrase
|
|
101
|
+
```
|
|
102
|
+
|
|
103
|
+
#### Inference
|
|
104
|
+
|
|
105
|
+
You can use the 🤗 Transformers library `text-classification` pipeline to infer with QQPI models.
|
|
106
|
+
|
|
107
|
+
```python
|
|
108
|
+
from transformers import pipeline
|
|
109
|
+
|
|
110
|
+
classifier = pipeline("text-classification", model = "textattack/bert-base-uncased-QQP")
|
|
111
|
+
classifier("Which city is the capital of France?, Where is the capital of France?")
|
|
112
|
+
## [{'label': 'paraphrase', 'score': 0.998}]
|
|
113
|
+
```
|
|
114
|
+
|
|
115
|
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer text classification models on Hugging Face Hub.
|
|
116
|
+
|
|
117
|
+
```javascript
|
|
118
|
+
import { HfInference } from "@huggingface/inference";
|
|
119
|
+
|
|
120
|
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
|
121
|
+
await inference.conversational({
|
|
122
|
+
model: 'distilbert-base-uncased-finetuned-sst-2-english',
|
|
123
|
+
inputs: "I love this movie!"
|
|
124
|
+
})
|
|
125
|
+
```
|
|
126
|
+
### Grammatical Correctness
|
|
127
|
+
|
|
128
|
+
Linguistic Acceptability is the task of assessing the grammatical acceptability of a sentence. The classes in this task are “acceptable” and “unacceptable”. The benchmark dataset used for this task is [Corpus of Linguistic Acceptability (CoLA)](https://huggingface.co/datasets/glue/viewer/cola/test). The dataset consists of texts and their labels.
|
|
129
|
+
|
|
130
|
+
```
|
|
131
|
+
Example: Books were sent to each other by the students.
|
|
132
|
+
Label: Unacceptable
|
|
133
|
+
|
|
134
|
+
Example: She voted for herself.
|
|
135
|
+
Label: Acceptable.
|
|
136
|
+
```
|
|
137
|
+
|
|
138
|
+
#### Inference
|
|
139
|
+
|
|
140
|
+
```python
|
|
141
|
+
from transformers import pipeline
|
|
142
|
+
|
|
143
|
+
classifier = pipeline("text-classification", model = "textattack/distilbert-base-uncased-CoLA")
|
|
144
|
+
classifier("I will walk to home when I went through the bus.")
|
|
145
|
+
## [{'label': 'unacceptable', 'score': 0.95}]
|
|
146
|
+
```
|
|
147
|
+
|
|
148
|
+
## Useful Resources
|
|
149
|
+
|
|
150
|
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
|
|
151
|
+
|
|
152
|
+
- [Course Chapter on Fine-tuning a Text Classification Model](https://huggingface.co/course/chapter3/1?fw=pt)
|
|
153
|
+
- [Getting Started with Sentiment Analysis using Python](https://huggingface.co/blog/sentiment-analysis-python)
|
|
154
|
+
- [Sentiment Analysis on Encrypted Data with Homomorphic Encryption](https://huggingface.co/blog/sentiment-analysis-fhe)
|
|
155
|
+
- [Leveraging Hugging Face for complex text classification use cases](https://huggingface.co/blog/classification-use-cases)
|
|
156
|
+
|
|
157
|
+
### Notebooks
|
|
158
|
+
|
|
159
|
+
- [PyTorch](https://github.com/huggingface/notebooks/blob/master/examples/text_classification.ipynb)
|
|
160
|
+
- [TensorFlow](https://github.com/huggingface/notebooks/blob/master/examples/text_classification-tf.ipynb)
|
|
161
|
+
- [Flax](https://github.com/huggingface/notebooks/blob/master/examples/text_classification_flax.ipynb)
|
|
162
|
+
|
|
163
|
+
### Scripts for training
|
|
164
|
+
|
|
165
|
+
- [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification)
|
|
166
|
+
- [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification)
|
|
167
|
+
- [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification)
|
|
168
|
+
|
|
169
|
+
### Documentation
|
|
170
|
+
|
|
171
|
+
- [Text classification task guide](https://huggingface.co/docs/transformers/tasks/sequence_classification)
|
|
@@ -0,0 +1,90 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../Types";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "A widely used dataset used to benchmark multiple variants of text classification.",
|
|
7
|
+
id: "glue",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "A text classification dataset used to benchmark natural language inference models",
|
|
11
|
+
id: "snli",
|
|
12
|
+
},
|
|
13
|
+
],
|
|
14
|
+
demo: {
|
|
15
|
+
inputs: [
|
|
16
|
+
{
|
|
17
|
+
label: "Input",
|
|
18
|
+
content: "I love Hugging Face!",
|
|
19
|
+
type: "text",
|
|
20
|
+
},
|
|
21
|
+
|
|
22
|
+
],
|
|
23
|
+
outputs: [
|
|
24
|
+
{
|
|
25
|
+
type: "chart",
|
|
26
|
+
data: [
|
|
27
|
+
{
|
|
28
|
+
label: "POSITIVE",
|
|
29
|
+
score: 0.90,
|
|
30
|
+
},
|
|
31
|
+
{
|
|
32
|
+
label: "NEUTRAL",
|
|
33
|
+
score: 0.10,
|
|
34
|
+
},
|
|
35
|
+
{
|
|
36
|
+
label: "NEGATIVE",
|
|
37
|
+
score: 0.00,
|
|
38
|
+
},
|
|
39
|
+
],
|
|
40
|
+
},
|
|
41
|
+
],
|
|
42
|
+
},
|
|
43
|
+
metrics: [
|
|
44
|
+
{
|
|
45
|
+
description: "",
|
|
46
|
+
id: "accuracy",
|
|
47
|
+
},
|
|
48
|
+
{
|
|
49
|
+
description: "",
|
|
50
|
+
id: "recall",
|
|
51
|
+
},
|
|
52
|
+
{
|
|
53
|
+
description: "",
|
|
54
|
+
id: "precision",
|
|
55
|
+
},
|
|
56
|
+
{
|
|
57
|
+
description: "The F1 metric is the harmonic mean of the precision and recall. It can be calculated as: F1 = 2 * (precision * recall) / (precision + recall)",
|
|
58
|
+
id: "f1",
|
|
59
|
+
},
|
|
60
|
+
],
|
|
61
|
+
models: [
|
|
62
|
+
{
|
|
63
|
+
description: "A robust model trained for sentiment analysis.",
|
|
64
|
+
id: "distilbert-base-uncased-finetuned-sst-2-english",
|
|
65
|
+
},
|
|
66
|
+
{
|
|
67
|
+
description: "Multi-genre natural language inference model.",
|
|
68
|
+
id: "roberta-large-mnli",
|
|
69
|
+
},
|
|
70
|
+
],
|
|
71
|
+
spaces: [
|
|
72
|
+
{
|
|
73
|
+
description: "An application that can classify financial sentiment.",
|
|
74
|
+
id: "IoannisTr/Tech_Stocks_Trading_Assistant",
|
|
75
|
+
},
|
|
76
|
+
{
|
|
77
|
+
description: "A dashboard that contains various text classification tasks.",
|
|
78
|
+
id: "miesnerjacob/Multi-task-NLP",
|
|
79
|
+
},
|
|
80
|
+
{
|
|
81
|
+
description: "An application that analyzes user reviews in healthcare.",
|
|
82
|
+
id: "spacy/healthsea-demo",
|
|
83
|
+
},
|
|
84
|
+
],
|
|
85
|
+
summary: "Text Classification is the task of assigning a label or class to a given text. Some use cases are sentiment analysis, natural language inference, and assessing grammatical correctness.",
|
|
86
|
+
widgetModels: ["distilbert-base-uncased-finetuned-sst-2-english"],
|
|
87
|
+
youtubeId: "leNG9fN9FQU",
|
|
88
|
+
};
|
|
89
|
+
|
|
90
|
+
export default taskData;
|
|
@@ -0,0 +1,128 @@
|
|
|
1
|
+
This task covers guides on both [text-generation](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads) and [text-to-text generation](https://huggingface.co/models?pipeline_tag=text2text-generation&sort=downloads) models. Popular large language models that are used for chats or following instructions are also covered in this task. You can find the list of selected open-source large language models [here](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), ranked by their performance scores.
|
|
2
|
+
|
|
3
|
+
## Use Cases
|
|
4
|
+
|
|
5
|
+
### Instruction Models
|
|
6
|
+
|
|
7
|
+
A model trained for text generation can be later adapted to follow instructions. One of the most used open-source models for instruction is OpenAssistant, which you can try [at Hugging Chat](https://huggingface.co/chat).
|
|
8
|
+
|
|
9
|
+
### Code Generation
|
|
10
|
+
|
|
11
|
+
A Text Generation model, also known as a causal language model, can be trained on code from scratch to help the programmers in their repetitive coding tasks. One of the most popular open-source models for code generation is StarCoder, which can generate code in 80+ languages. You can try it [here](https://huggingface.co/spaces/bigcode/bigcode-playground).
|
|
12
|
+
|
|
13
|
+
### Stories Generation
|
|
14
|
+
|
|
15
|
+
A story generation model can receive an input like "Once upon a time" and proceed to create a story-like text based on those first words. You can try [this application](https://huggingface.co/spaces/mosaicml/mpt-7b-storywriter) which contains a model trained on story generation, by MosaicML.
|
|
16
|
+
|
|
17
|
+
If your generative model training data is different than your use case, you can train a causal language model from scratch. Learn how to do it in the free transformers [course](https://huggingface.co/course/chapter7/6?fw=pt)!
|
|
18
|
+
|
|
19
|
+
## Task Variants
|
|
20
|
+
|
|
21
|
+
### Completion Generation Models
|
|
22
|
+
|
|
23
|
+
A popular variant of Text Generation models predicts the next word given a bunch of words. Word by word a longer text is formed that results in for example:
|
|
24
|
+
|
|
25
|
+
- Given an incomplete sentence, complete it.
|
|
26
|
+
- Continue a story given the first sentences.
|
|
27
|
+
- Provided a code description, generate the code.
|
|
28
|
+
|
|
29
|
+
The most popular models for this task are GPT-based models or [Llama series](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf). These models are trained on data that has no labels, so you just need plain text to train your own model. You can train text generation models to generate a wide variety of documents, from code to stories.
|
|
30
|
+
|
|
31
|
+
### Text-to-Text Generation Models
|
|
32
|
+
|
|
33
|
+
These models are trained to learn the mapping between a pair of texts (e.g. translation from one language to another). The most popular variants of these models are [FLAN-T5](https://huggingface.co/google/flan-t5-xxl), and [BART](https://huggingface.co/docs/transformers/model_doc/bart). Text-to-Text models are trained with multi-tasking capabilities, they can accomplish a wide range of tasks, including summarization, translation, and text classification.
|
|
34
|
+
|
|
35
|
+
## Inference
|
|
36
|
+
|
|
37
|
+
You can use the 🤗 Transformers library `text-generation` pipeline to do inference with Text Generation models. It takes an incomplete text and returns multiple outputs with which the text can be completed.
|
|
38
|
+
|
|
39
|
+
```python
|
|
40
|
+
from transformers import pipeline
|
|
41
|
+
generator = pipeline('text-generation', model = 'gpt2')
|
|
42
|
+
generator("Hello, I'm a language model", max_length = 30, num_return_sequences=3)
|
|
43
|
+
## [{'generated_text': "Hello, I'm a language modeler. So while writing this, when I went out to meet my wife or come home she told me that my"},
|
|
44
|
+
## {'generated_text': "Hello, I'm a language modeler. I write and maintain software in Python. I love to code, and that includes coding things that require writing"}, ...
|
|
45
|
+
```
|
|
46
|
+
|
|
47
|
+
|
|
48
|
+
[Text-to-Text generation models](https://huggingface.co/models?pipeline_tag=text2text-generation&sort=downloads) have a separate pipeline called `text2text-generation`. This pipeline takes an input containing the sentence including the task and returns the output of the accomplished task.
|
|
49
|
+
|
|
50
|
+
```python
|
|
51
|
+
from transformers import pipeline
|
|
52
|
+
|
|
53
|
+
text2text_generator = pipeline("text2text-generation")
|
|
54
|
+
text2text_generator("question: What is 42 ? context: 42 is the answer to life, the universe and everything")
|
|
55
|
+
[{'generated_text': 'the answer to life, the universe and everything'}]
|
|
56
|
+
|
|
57
|
+
text2text_generator("translate from English to French: I'm very happy")
|
|
58
|
+
[{'generated_text': 'Je suis très heureux'}]
|
|
59
|
+
```
|
|
60
|
+
|
|
61
|
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer text classification models on Hugging Face Hub.
|
|
62
|
+
|
|
63
|
+
```javascript
|
|
64
|
+
import { HfInference } from "@huggingface/inference";
|
|
65
|
+
|
|
66
|
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
|
67
|
+
await inference.conversational({
|
|
68
|
+
model: 'distilbert-base-uncased-finetuned-sst-2-english',
|
|
69
|
+
inputs: "I love this movie!"
|
|
70
|
+
})
|
|
71
|
+
```
|
|
72
|
+
|
|
73
|
+
## Text Generation Inference
|
|
74
|
+
|
|
75
|
+
[Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is an open-source toolkit for serving LLMs tackling challenges such as response time. TGI powers inference solutions like [Inference Endpoints](https://huggingface.co/inference-endpoints) and [Hugging Chat](https://huggingface.co/chat/), as well as multiple community projects. You can use it to deploy any supported open-source large language model of your choice.
|
|
76
|
+
|
|
77
|
+
## ChatUI Spaces
|
|
78
|
+
|
|
79
|
+
Hugging Face Spaces includes templates to easily deploy your own instance of a specific application. [ChatUI](https://github.com/huggingface/chat-ui) is an open-source interface that enables serving conversational interface for large language models and can be deployed with few clicks at Spaces. TGI powers these Spaces under the hood for faster inference. Thanks to the template, you can deploy your own instance based on a large language model with only a few clicks and customize it. Learn more about it [here](https://huggingface.co/docs/hub/spaces-sdks-docker-chatui) and create your large language model instance [here](https://huggingface.co/new-space?template=huggingchat/chat-ui-template).
|
|
80
|
+
|
|
81
|
+
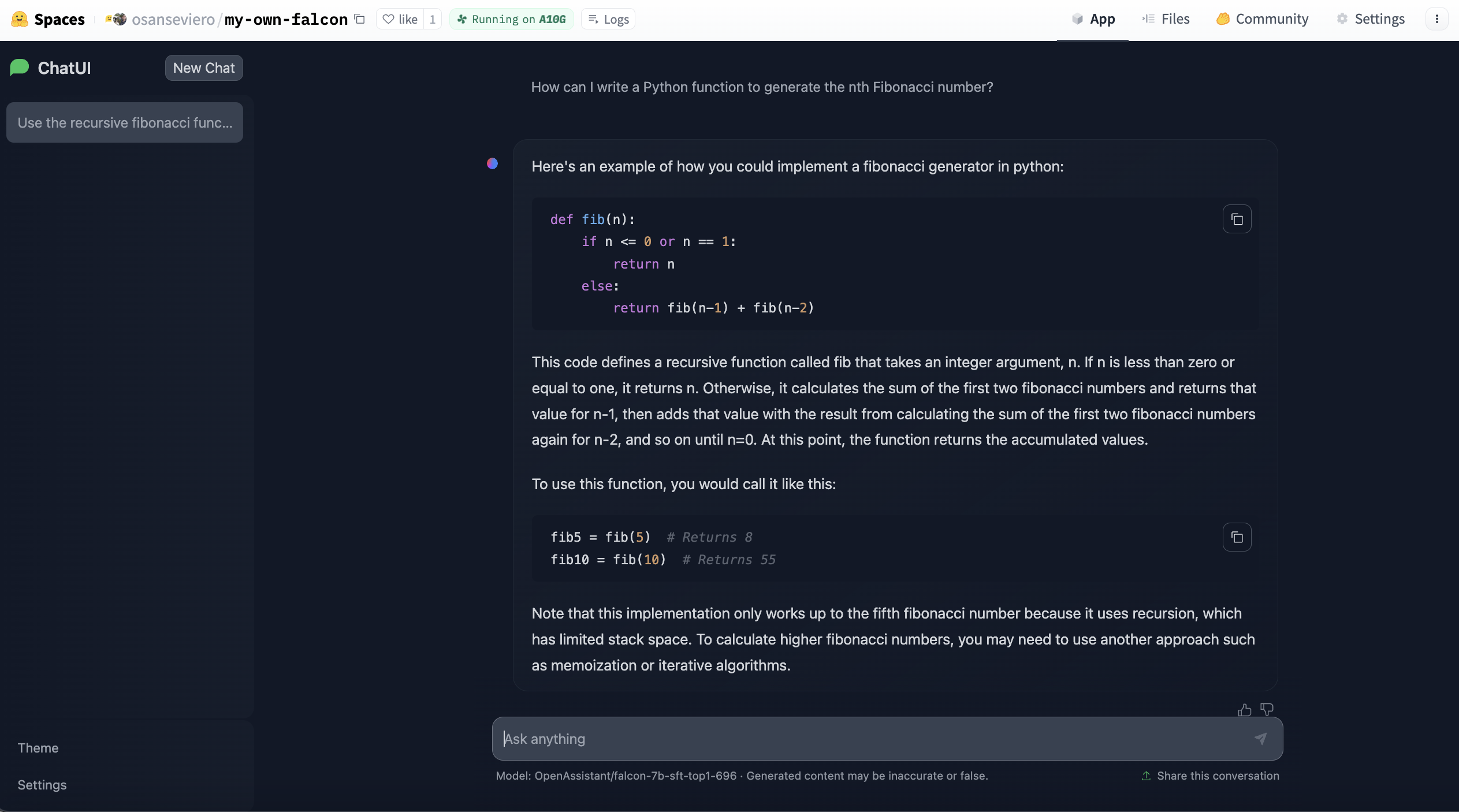
|
|
82
|
+
|
|
83
|
+
|
|
84
|
+
## Useful Resources
|
|
85
|
+
|
|
86
|
+
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
|
|
87
|
+
|
|
88
|
+
### Tools within Hugging Face Ecosystem
|
|
89
|
+
- You can use [PEFT](https://github.com/huggingface/peft) to adapt large language models in efficient way.
|
|
90
|
+
- [ChatUI](https://github.com/huggingface/chat-ui) is the open-source interface to conversate with Large Language Models.
|
|
91
|
+
- [text-generation-inferface](https://github.com/huggingface/text-generation-inference)
|
|
92
|
+
- [HuggingChat](https://huggingface.co/chat/) is a chat interface powered by Hugging Face to chat with powerful models like Llama 2 70B.
|
|
93
|
+
|
|
94
|
+
### Documentation
|
|
95
|
+
- [PEFT documentation](https://huggingface.co/docs/peft/index)
|
|
96
|
+
- [ChatUI Docker Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker-chatui)
|
|
97
|
+
- [Causal language modeling task guide](https://huggingface.co/docs/transformers/tasks/language_modeling)
|
|
98
|
+
- [Text generation strategies](https://huggingface.co/docs/transformers/generation_strategies)
|
|
99
|
+
|
|
100
|
+
### Course and Blogs
|
|
101
|
+
- [Course Chapter on Training a causal language model from scratch](https://huggingface.co/course/chapter7/6?fw=pt)
|
|
102
|
+
- [TO Discussion with Victor Sanh](https://www.youtube.com/watch?v=Oy49SCW_Xpw&ab_channel=HuggingFace)
|
|
103
|
+
- [Hugging Face Course Workshops: Pretraining Language Models & CodeParrot](https://www.youtube.com/watch?v=ExUR7w6xe94&ab_channel=HuggingFace)
|
|
104
|
+
- [Training CodeParrot 🦜 from Scratch](https://huggingface.co/blog/codeparrot)
|
|
105
|
+
- [How to generate text: using different decoding methods for language generation with Transformers](https://huggingface.co/blog/how-to-generate)
|
|
106
|
+
- [Guiding Text Generation with Constrained Beam Search in 🤗 Transformers](https://huggingface.co/blog/constrained-beam-search)
|
|
107
|
+
- [Code generation with Hugging Face](https://huggingface.co/spaces/codeparrot/code-generation-models)
|
|
108
|
+
- [🌸 Introducing The World's Largest Open Multilingual Language Model: BLOOM 🌸](https://huggingface.co/blog/bloom)
|
|
109
|
+
- [The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed)
|
|
110
|
+
- [Faster Text Generation with TensorFlow and XLA](https://huggingface.co/blog/tf-xla-generate)
|
|
111
|
+
- [Assisted Generation: a new direction toward low-latency text generation](https://huggingface.co/blog/assisted-generation)
|
|
112
|
+
- [Introducing RWKV - An RNN with the advantages of a transformer](https://huggingface.co/blog/rwkv)
|
|
113
|
+
- [Creating a Coding Assistant with StarCoder](https://huggingface.co/blog/starchat-alpha)
|
|
114
|
+
- [StarCoder: A State-of-the-Art LLM for Code](https://huggingface.co/blog/starcoder)
|
|
115
|
+
- [Open-Source Text Generation & LLM Ecosystem at Hugging Face](https://huggingface.co/blog/os-llms)
|
|
116
|
+
- [Llama 2 is at Hugging Face](https://huggingface.co/blog/llama2)
|
|
117
|
+
|
|
118
|
+
### Notebooks
|
|
119
|
+
|
|
120
|
+
- [Training a CLM in Flax](https://github.com/huggingface/notebooks/blob/master/examples/causal_language_modeling_flax.ipynb)
|
|
121
|
+
- [Training a CLM in TensorFlow](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling_from_scratch-tf.ipynb)
|
|
122
|
+
- [Training a CLM in PyTorch](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling_from_scratch.ipynb)
|
|
123
|
+
|
|
124
|
+
### Scripts for training
|
|
125
|
+
|
|
126
|
+
- [Training a CLM in PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling)
|
|
127
|
+
- [Training a CLM in TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling)
|
|
128
|
+
- [Text Generation in PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation)
|
|
@@ -0,0 +1,124 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../Types";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "A large multilingual dataset of text crawled from the web.",
|
|
7
|
+
id: "mc4",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "Diverse open-source data consisting of 22 smaller high-quality datasets. It was used to train GPT-Neo.",
|
|
11
|
+
id: "the_pile",
|
|
12
|
+
},
|
|
13
|
+
{
|
|
14
|
+
description: "A crowd-sourced instruction dataset to develop an AI assistant.",
|
|
15
|
+
id: "OpenAssistant/oasst1",
|
|
16
|
+
},
|
|
17
|
+
{
|
|
18
|
+
description: "A crowd-sourced instruction dataset created by Databricks employees.",
|
|
19
|
+
id: "databricks/databricks-dolly-15k",
|
|
20
|
+
},
|
|
21
|
+
],
|
|
22
|
+
demo: {
|
|
23
|
+
inputs: [
|
|
24
|
+
{
|
|
25
|
+
label: "Input",
|
|
26
|
+
content:
|
|
27
|
+
"Once upon a time,",
|
|
28
|
+
type: "text",
|
|
29
|
+
},
|
|
30
|
+
|
|
31
|
+
],
|
|
32
|
+
outputs: [
|
|
33
|
+
{
|
|
34
|
+
label: "Output",
|
|
35
|
+
content:
|
|
36
|
+
"Once upon a time, we knew that our ancestors were on the verge of extinction. The great explorers and poets of the Old World, from Alexander the Great to Chaucer, are dead and gone. A good many of our ancient explorers and poets have",
|
|
37
|
+
type: "text",
|
|
38
|
+
},
|
|
39
|
+
],
|
|
40
|
+
},
|
|
41
|
+
metrics: [
|
|
42
|
+
{
|
|
43
|
+
description: "Cross Entropy is a metric that calculates the difference between two probability distributions. Each probability distribution is the distribution of predicted words",
|
|
44
|
+
id: "Cross Entropy",
|
|
45
|
+
},
|
|
46
|
+
{
|
|
47
|
+
description: "The Perplexity metric is the exponential of the cross-entropy loss. It evaluates the probabilities assigned to the next word by the model. Lower perplexity indicates better performance",
|
|
48
|
+
id: "Perplexity",
|
|
49
|
+
},
|
|
50
|
+
],
|
|
51
|
+
models: [
|
|
52
|
+
{
|
|
53
|
+
description: "A large language model trained for text generation.",
|
|
54
|
+
id: "bigscience/bloom-560m",
|
|
55
|
+
},
|
|
56
|
+
{
|
|
57
|
+
description: "A large code generation model that can generate code in 80+ languages.",
|
|
58
|
+
id: "bigcode/starcoder",
|
|
59
|
+
},
|
|
60
|
+
{
|
|
61
|
+
description: "A model trained to follow instructions, uses Pythia-12b as base model.",
|
|
62
|
+
id: "databricks/dolly-v2-12b",
|
|
63
|
+
},
|
|
64
|
+
{
|
|
65
|
+
description: "A model trained to follow instructions curated by community, uses Pythia-12b as base model.",
|
|
66
|
+
id: "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
|
|
67
|
+
},
|
|
68
|
+
{
|
|
69
|
+
description: "A large language model trained to generate text in English.",
|
|
70
|
+
id: "stabilityai/stablelm-tuned-alpha-7b",
|
|
71
|
+
},
|
|
72
|
+
{
|
|
73
|
+
description: "A model trained to follow instructions, based on mosaicml/mpt-7b.",
|
|
74
|
+
id: "mosaicml/mpt-7b-instruct",
|
|
75
|
+
},
|
|
76
|
+
{
|
|
77
|
+
description: "A large language model trained to generate text in English.",
|
|
78
|
+
id: "EleutherAI/pythia-12b",
|
|
79
|
+
},
|
|
80
|
+
{
|
|
81
|
+
description: "A large text-to-text model trained to follow instructions.",
|
|
82
|
+
id: "google/flan-ul2",
|
|
83
|
+
},
|
|
84
|
+
{
|
|
85
|
+
description: "A large and powerful text generation model.",
|
|
86
|
+
id: "tiiuae/falcon-40b",
|
|
87
|
+
},
|
|
88
|
+
{
|
|
89
|
+
description: "State-of-the-art open-source large language model.",
|
|
90
|
+
id: "meta-llama/Llama-2-70b-hf",
|
|
91
|
+
},
|
|
92
|
+
],
|
|
93
|
+
spaces: [
|
|
94
|
+
{
|
|
95
|
+
description: "A robust text generation model that can perform various tasks through natural language prompting.",
|
|
96
|
+
id: "huggingface/bloom_demo",
|
|
97
|
+
},
|
|
98
|
+
{
|
|
99
|
+
description: "An text generation based application that can write code for 80+ languages.",
|
|
100
|
+
id: "bigcode/bigcode-playground",
|
|
101
|
+
},
|
|
102
|
+
{
|
|
103
|
+
description: "An text generation based application for conversations.",
|
|
104
|
+
id: "h2oai/h2ogpt-chatbot",
|
|
105
|
+
},
|
|
106
|
+
{
|
|
107
|
+
description: "An text generation application that combines OpenAI and Hugging Face models.",
|
|
108
|
+
id: "microsoft/HuggingGPT",
|
|
109
|
+
},
|
|
110
|
+
{
|
|
111
|
+
description: "An text generation application that uses StableLM-tuned-alpha-7b.",
|
|
112
|
+
id: "stabilityai/stablelm-tuned-alpha-chat",
|
|
113
|
+
},
|
|
114
|
+
{
|
|
115
|
+
description: "An UI that uses StableLM-tuned-alpha-7b.",
|
|
116
|
+
id: "togethercomputer/OpenChatKit",
|
|
117
|
+
},
|
|
118
|
+
],
|
|
119
|
+
summary: "Generating text is the task of producing new text. These models can, for example, fill in incomplete text or paraphrase.",
|
|
120
|
+
widgetModels: ["tiiuae/falcon-7b-instruct"],
|
|
121
|
+
youtubeId: "Vpjb1lu0MDk",
|
|
122
|
+
};
|
|
123
|
+
|
|
124
|
+
export default taskData;
|
|
@@ -0,0 +1,65 @@
|
|
|
1
|
+
## Use Cases
|
|
2
|
+
### Data Generation
|
|
3
|
+
|
|
4
|
+
Businesses can generate data for their their use cases by inputting text and getting image outputs.
|
|
5
|
+
|
|
6
|
+
### Immersive Conversational Chatbots
|
|
7
|
+
|
|
8
|
+
Chatbots can be made more immersive if they provide contextual images based on the input provided by the user.
|
|
9
|
+
|
|
10
|
+
### Creative Ideas for Fashion Industry
|
|
11
|
+
|
|
12
|
+
Different patterns can be generated to obtain unique pieces of fashion. Text-to-image models make creations easier for designers to conceptualize their design before actually implementing it.
|
|
13
|
+
|
|
14
|
+
### Architecture Industry
|
|
15
|
+
|
|
16
|
+
Architects can utilise the models to construct an environment based out on the requirements of the floor plan. This can also include the furniture that has to be placed in that environment.
|
|
17
|
+
|
|
18
|
+
## Task Variants
|
|
19
|
+
|
|
20
|
+
You can contribute variants of this task [here](https://github.com/huggingface/hub-docs/blob/main/tasks/src/text-to-image/about.md).
|
|
21
|
+
|
|
22
|
+
|
|
23
|
+
## Inference
|
|
24
|
+
|
|
25
|
+
You can use diffusers pipelines to infer with `text-to-image` models.
|
|
26
|
+
```python
|
|
27
|
+
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
|
|
28
|
+
|
|
29
|
+
model_id = "stabilityai/stable-diffusion-2"
|
|
30
|
+
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
|
|
31
|
+
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
|
|
32
|
+
pipe = pipe.to("cuda")
|
|
33
|
+
|
|
34
|
+
prompt = "a photo of an astronaut riding a horse on mars"
|
|
35
|
+
image = pipe(prompt).images[0]
|
|
36
|
+
```
|
|
37
|
+
|
|
38
|
+
You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer text-to-image models on Hugging Face Hub.
|
|
39
|
+
|
|
40
|
+
```javascript
|
|
41
|
+
import { HfInference } from "@huggingface/inference";
|
|
42
|
+
|
|
43
|
+
const inference = new HfInference(HF_ACCESS_TOKEN);
|
|
44
|
+
await inference.textToImage({
|
|
45
|
+
model: 'stabilityai/stable-diffusion-2',
|
|
46
|
+
inputs: 'award winning high resolution photo of a giant tortoise/((ladybird)) hybrid, [trending on artstation]',
|
|
47
|
+
parameters: {
|
|
48
|
+
negative_prompt: 'blurry',
|
|
49
|
+
}
|
|
50
|
+
})
|
|
51
|
+
```
|
|
52
|
+
|
|
53
|
+
## Useful Resources
|
|
54
|
+
- [Hugging Face Diffusion Models Course](https://github.com/huggingface/diffusion-models-class)
|
|
55
|
+
- [Getting Started with Diffusers](https://huggingface.co/docs/diffusers/index)
|
|
56
|
+
- [Text-to-Image Generation](https://huggingface.co/docs/diffusers/using-diffusers/conditional_image_generation)
|
|
57
|
+
- [MinImagen - Build Your Own Imagen Text-to-Image Model](https://www.assemblyai.com/blog/minimagen-build-your-own-imagen-text-to-image-model/)
|
|
58
|
+
- [Using LoRA for Efficient Stable Diffusion Fine-Tuning](https://huggingface.co/blog/lora)
|
|
59
|
+
- [Using Stable Diffusion with Core ML on Apple Silicon](https://huggingface.co/blog/diffusers-coreml)
|
|
60
|
+
- [A guide on Vector Quantized Diffusion](https://huggingface.co/blog/vq-diffusion)
|
|
61
|
+
- [🧨 Stable Diffusion in JAX/Flax](https://huggingface.co/blog/stable_diffusion_jax)
|
|
62
|
+
- [Running IF with 🧨 diffusers on a Free Tier Google Colab](https://huggingface.co/blog/if)
|
|
63
|
+
|
|
64
|
+
|
|
65
|
+
This page was made possible thanks to the efforts of [Ishan Dutta](https://huggingface.co/ishandutta), [Enrique Elias Ubaldo](https://huggingface.co/herrius) and [Oğuz Akif](https://huggingface.co/oguzakif).
|
|
@@ -0,0 +1,88 @@
|
|
|
1
|
+
import type { TaskDataCustom } from "../Types";
|
|
2
|
+
|
|
3
|
+
const taskData: TaskDataCustom = {
|
|
4
|
+
datasets: [
|
|
5
|
+
{
|
|
6
|
+
description: "RedCaps is a large-scale dataset of 12M image-text pairs collected from Reddit.",
|
|
7
|
+
id: "red_caps",
|
|
8
|
+
},
|
|
9
|
+
{
|
|
10
|
+
description: "Conceptual Captions is a dataset consisting of ~3.3M images annotated with captions.",
|
|
11
|
+
id: "conceptual_captions",
|
|
12
|
+
},
|
|
13
|
+
],
|
|
14
|
+
demo: {
|
|
15
|
+
inputs: [
|
|
16
|
+
{
|
|
17
|
+
label: "Input",
|
|
18
|
+
content: "A city above clouds, pastel colors, Victorian style",
|
|
19
|
+
type: "text",
|
|
20
|
+
},
|
|
21
|
+
],
|
|
22
|
+
outputs: [
|
|
23
|
+
{
|
|
24
|
+
filename: "image.jpeg",
|
|
25
|
+
type: "img",
|
|
26
|
+
},
|
|
27
|
+
],
|
|
28
|
+
},
|
|
29
|
+
metrics: [
|
|
30
|
+
{
|
|
31
|
+
description: "The Inception Score (IS) measure assesses diversity and meaningfulness. It uses a generated image sample to predict its label. A higher score signifies more diverse and meaningful images.",
|
|
32
|
+
id: "IS",
|
|
33
|
+
},
|
|
34
|
+
{
|
|
35
|
+
description: "The Fréchet Inception Distance (FID) calculates the distance between distributions between synthetic and real samples. A lower FID score indicates better similarity between the distributions of real and generated images.",
|
|
36
|
+
id: "FID",
|
|
37
|
+
},
|
|
38
|
+
{
|
|
39
|
+
description: "R-precision assesses how the generated image aligns with the provided text description. It uses the generated images as queries to retrieve relevant text descriptions. The top 'r' relevant descriptions are selected and used to calculate R-precision as r/R, where 'R' is the number of ground truth descriptions associated with the generated images. A higher R-precision value indicates a better model.",
|
|
40
|
+
id: "R-Precision",
|
|
41
|
+
},
|
|
42
|
+
],
|
|
43
|
+
models: [
|
|
44
|
+
{
|
|
45
|
+
description: "A latent text-to-image diffusion model capable of generating photo-realistic images given any text input.",
|
|
46
|
+
id: "CompVis/stable-diffusion-v1-4",
|
|
47
|
+
},
|
|
48
|
+
{
|
|
49
|
+
description: "A model that can be used to generate images based on text prompts. The DALL·E Mega model is the largest version of DALLE Mini.",
|
|
50
|
+
id: "dalle-mini/dalle-mega",
|
|
51
|
+
},
|
|
52
|
+
{
|
|
53
|
+
description: "A text-to-image model that can generate coherent text inside image.",
|
|
54
|
+
id: "DeepFloyd/IF-I-XL-v1.0",
|
|
55
|
+
},
|
|
56
|
+
{
|
|
57
|
+
description: "A powerful text-to-image model.",
|
|
58
|
+
id: "kakaobrain/karlo-v1-alpha",
|
|
59
|
+
},
|
|
60
|
+
],
|
|
61
|
+
spaces: [
|
|
62
|
+
{
|
|
63
|
+
description: "A powerful text-to-image application.",
|
|
64
|
+
id: "stabilityai/stable-diffusion",
|
|
65
|
+
},
|
|
66
|
+
{
|
|
67
|
+
description: "An text-to-image application that can generate coherent text inside the image.",
|
|
68
|
+
id: "DeepFloyd/IF",
|
|
69
|
+
},
|
|
70
|
+
{
|
|
71
|
+
description: "An powerful text-to-image application that can generate images.",
|
|
72
|
+
id: "kakaobrain/karlo",
|
|
73
|
+
},
|
|
74
|
+
{
|
|
75
|
+
description: "An powerful text-to-image application that can generates 3D representations.",
|
|
76
|
+
id: "hysts/Shap-E",
|
|
77
|
+
},
|
|
78
|
+
{
|
|
79
|
+
description: "A strong application for `text-to-image`, `image-to-image` and image inpainting.",
|
|
80
|
+
id: "ArtGAN/Stable-Diffusion-ControlNet-WebUI",
|
|
81
|
+
},
|
|
82
|
+
],
|
|
83
|
+
summary: "Generates images from input text. These models can be used to generate and modify images based on text prompts.",
|
|
84
|
+
widgetModels: ["CompVis/stable-diffusion-v1-4"],
|
|
85
|
+
youtubeId: "",
|
|
86
|
+
};
|
|
87
|
+
|
|
88
|
+
export default taskData;
|