@deventerprisesoftware/scrapi-mcp 0.3.0 → 0.3.2
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/README.md +156 -0
- package/package.json +3 -2
package/README.md
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
1
|
+

|
|
2
|
+
|
|
3
|
+
# ScrAPI MCP Server
|
|
4
|
+
|
|
5
|
+
[](https://opensource.org/licenses/MIT)
|
|
6
|
+
[](https://www.npmjs.com/package/@deventerprisesoftware/scrapi-mcp)
|
|
7
|
+
[](https://hub.docker.com/r/deventerprisesoftware/scrapi-mcp)
|
|
8
|
+
[](https://smithery.ai/server/@DevEnterpriseSoftware/scrapi-mcp)
|
|
9
|
+
|
|
10
|
+
MCP server for using [ScrAPI](https://scrapi.tech) to scrape web pages.
|
|
11
|
+
|
|
12
|
+
ScrAPI is your ultimate web scraping solution, offering powerful, reliable, and easy-to-use features to extract data from any website effortlessly.
|
|
13
|
+
|
|
14
|
+
<a href="https://glama.ai/mcp/servers/@DevEnterpriseSoftware/scrapi-mcp">
|
|
15
|
+
<img width="380" height="200" src="https://glama.ai/mcp/servers/@DevEnterpriseSoftware/scrapi-mcp/badge" alt="ScrAPI Server MCP server" />
|
|
16
|
+
</a>
|
|
17
|
+
|
|
18
|
+
## Tools
|
|
19
|
+
|
|
20
|
+
1. `scrape_url_html`
|
|
21
|
+
- Use a URL to scrape a website using the ScrAPI service and retrieve the result as HTML.
|
|
22
|
+
Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions.
|
|
23
|
+
The result will be in HTML which is preferable if advanced parsing is required.
|
|
24
|
+
- Inputs:
|
|
25
|
+
- `url` (string, required): The URL to scrape
|
|
26
|
+
- `browserCommands` (string, optional): JSON array of browser commands to execute before scraping
|
|
27
|
+
- Returns: HTML content of the URL
|
|
28
|
+
|
|
29
|
+
2. `scrape_url_markdown`
|
|
30
|
+
- Use a URL to scrape a website using the ScrAPI service and retrieve the result as Markdown.
|
|
31
|
+
Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions.
|
|
32
|
+
The result will be in Markdown which is preferable if the text content of the webpage is important and not the structural information of the page.
|
|
33
|
+
- Inputs:
|
|
34
|
+
- `url` (string, required): The URL to scrape
|
|
35
|
+
- `browserCommands` (string, optional): JSON array of browser commands to execute before scraping
|
|
36
|
+
- Returns: Markdown content of the URL
|
|
37
|
+
|
|
38
|
+
## Browser Commands
|
|
39
|
+
|
|
40
|
+
Both tools support optional browser commands that allow you to interact with the page before scraping. This is useful for:
|
|
41
|
+
|
|
42
|
+
- Clicking buttons (e.g., "Accept Cookies", "Load More")
|
|
43
|
+
- Filling out forms
|
|
44
|
+
- Selecting dropdown options
|
|
45
|
+
- Scrolling to load dynamic content
|
|
46
|
+
- Waiting for elements to appear
|
|
47
|
+
- Executing custom JavaScript
|
|
48
|
+
|
|
49
|
+
### Available Commands
|
|
50
|
+
|
|
51
|
+
Commands are provided as a JSON array string. All commands are executed with human-like behavior (random mouse movements, variable typing speed, etc.):
|
|
52
|
+
|
|
53
|
+
| Command | Format | Description |
|
|
54
|
+
| -------------- | ----------------------------------------------- | ------------------------------------------------- |
|
|
55
|
+
| **Click** | `{"click": "#buttonId"}` | Click an element using CSS selector |
|
|
56
|
+
| **Input** | `{"input": {"input[name='email']": "value"}}` | Fill an input field |
|
|
57
|
+
| **Select** | `{"select": {"select[name='country']": "USA"}}` | Select from dropdown (by value or text) |
|
|
58
|
+
| **Scroll** | `{"scroll": 1000}` | Scroll down by pixels (negative values scroll up) |
|
|
59
|
+
| **Wait** | `{"wait": 5000}` | Wait for milliseconds (max 15000) |
|
|
60
|
+
| **WaitFor** | `{"waitfor": "#elementId"}` | Wait for element to appear in DOM |
|
|
61
|
+
| **JavaScript** | `{"javascript": "console.log('test')"}` | Execute custom JavaScript code |
|
|
62
|
+
|
|
63
|
+
### Example Usage
|
|
64
|
+
|
|
65
|
+
```json
|
|
66
|
+
[
|
|
67
|
+
{ "click": "#accept-cookies" },
|
|
68
|
+
{ "wait": 2000 },
|
|
69
|
+
{ "input": { "input[name='search']": "web scraping" } },
|
|
70
|
+
{ "click": "button[type='submit']" },
|
|
71
|
+
{ "waitfor": "#results" },
|
|
72
|
+
{ "scroll": 500 }
|
|
73
|
+
]
|
|
74
|
+
```
|
|
75
|
+
|
|
76
|
+
### Finding CSS Selectors
|
|
77
|
+
|
|
78
|
+
Need help finding CSS selectors? Try the [Rayrun browser extension](https://chromewebstore.google.com/detail/rayrun/olljocejdgeipcaompahmnfebhkfmnma) to easily select elements and generate selectors.
|
|
79
|
+
|
|
80
|
+
For more details, see the [Browser Commands documentation](https://scrapi.tech/docs/api_details/v1_scrape/browser_commands).
|
|
81
|
+
|
|
82
|
+
## Setup
|
|
83
|
+
|
|
84
|
+
### API Key (optional)
|
|
85
|
+
|
|
86
|
+
Optionally get an API key from the [ScrAPI website](https://scrapi.tech).
|
|
87
|
+
|
|
88
|
+
Without an API key you will be limited to one concurrent call and twenty free calls per day with minimal queuing capabilities.
|
|
89
|
+
|
|
90
|
+
### Cloud Server
|
|
91
|
+
|
|
92
|
+
The ScrAPI MCP Server is also available in the cloud over SSE at https://api.scrapi.tech/mcp/sse and streamable HTTP at https://api.scrapi.tech/mcp
|
|
93
|
+
|
|
94
|
+
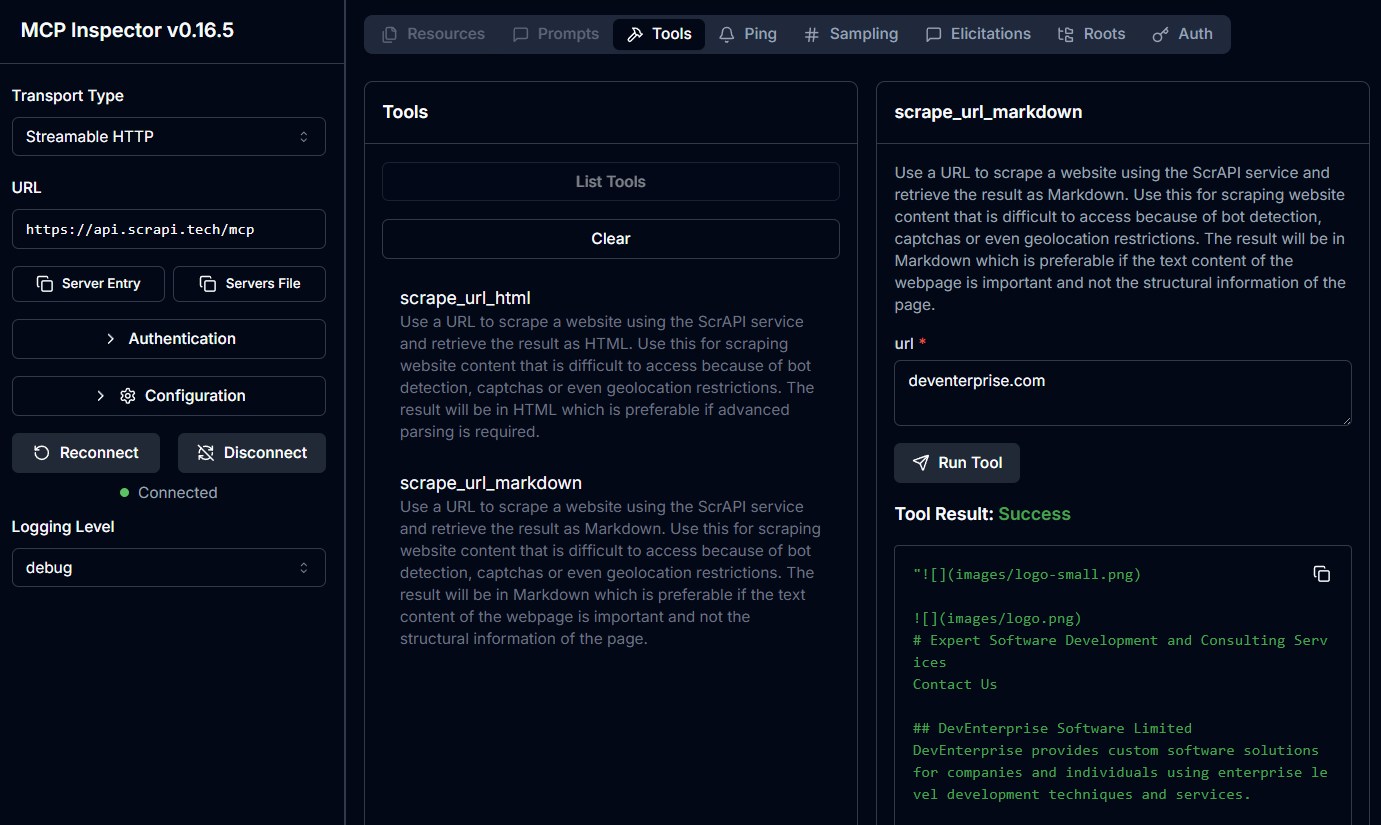
Cloud MCP servers are not widely supported yet but you can access this directly from your own custom clients or use [MCP Inspector](https://github.com/modelcontextprotocol/inspector) to test it. There is currently no facility to pass through your API key when connecting to the cloud MCP server.
|
|
95
|
+
|
|
96
|
+
|
|
97
|
+
|
|
98
|
+
### Usage with Claude Desktop
|
|
99
|
+
|
|
100
|
+
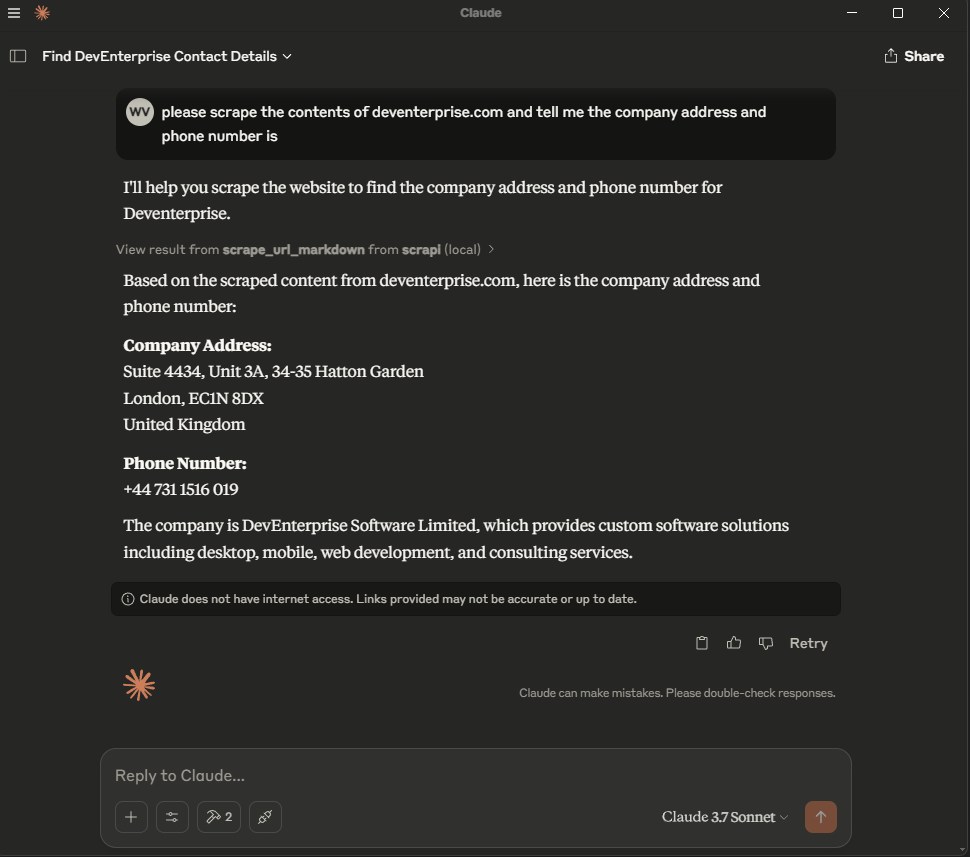
Add the following to your `claude_desktop_config.json`:
|
|
101
|
+
|
|
102
|
+
#### Docker
|
|
103
|
+
|
|
104
|
+
```json
|
|
105
|
+
{
|
|
106
|
+
"mcpServers": {
|
|
107
|
+
"ScrAPI": {
|
|
108
|
+
"command": "docker",
|
|
109
|
+
"args": [
|
|
110
|
+
"run",
|
|
111
|
+
"-i",
|
|
112
|
+
"--rm",
|
|
113
|
+
"-e",
|
|
114
|
+
"SCRAPI_API_KEY",
|
|
115
|
+
"deventerprisesoftware/scrapi-mcp"
|
|
116
|
+
],
|
|
117
|
+
"env": {
|
|
118
|
+
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
|
|
119
|
+
}
|
|
120
|
+
}
|
|
121
|
+
}
|
|
122
|
+
}
|
|
123
|
+
```
|
|
124
|
+
|
|
125
|
+
#### NPX
|
|
126
|
+
|
|
127
|
+
```json
|
|
128
|
+
{
|
|
129
|
+
"mcpServers": {
|
|
130
|
+
"ScrAPI": {
|
|
131
|
+
"command": "npx",
|
|
132
|
+
"args": [
|
|
133
|
+
"-y",
|
|
134
|
+
"@deventerprisesoftware/scrapi-mcp"
|
|
135
|
+
],
|
|
136
|
+
"env": {
|
|
137
|
+
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
|
|
138
|
+
}
|
|
139
|
+
}
|
|
140
|
+
}
|
|
141
|
+
}
|
|
142
|
+
```
|
|
143
|
+
|
|
144
|
+
|
|
145
|
+
|
|
146
|
+
## Build
|
|
147
|
+
|
|
148
|
+
Docker build:
|
|
149
|
+
|
|
150
|
+
```bash
|
|
151
|
+
docker build -t deventerprisesoftware/scrapi-mcp -f Dockerfile .
|
|
152
|
+
```
|
|
153
|
+
|
|
154
|
+
## License
|
|
155
|
+
|
|
156
|
+
This MCP server is licensed under the MIT License. This means you are free to use, modify, and distribute the software, subject to the terms and conditions of the MIT License. For more details, please see the LICENSE file in the project repository.
|
package/package.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
{
|
|
2
2
|
"name": "@deventerprisesoftware/scrapi-mcp",
|
|
3
|
-
"version": "0.3.
|
|
3
|
+
"version": "0.3.2",
|
|
4
4
|
"description": "MCP server for using ScrAPI to scrape web pages.",
|
|
5
5
|
"keywords": [
|
|
6
6
|
"mcp",
|
|
@@ -25,7 +25,8 @@
|
|
|
25
25
|
"scrapi-mcp": "dist/index.js"
|
|
26
26
|
},
|
|
27
27
|
"files": [
|
|
28
|
-
"dist"
|
|
28
|
+
"dist",
|
|
29
|
+
"README.md"
|
|
29
30
|
],
|
|
30
31
|
"scripts": {
|
|
31
32
|
"build": "tsc && shx chmod +x dist/*.js",
|