@autobe/agent 0.30.4-dev.20260324 → 0.30.4
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- package/LICENSE +661 -661
- package/lib/orchestrate/interface/utils/AutoBeJsonSchemaValidator.js +283 -283
- package/package.json +5 -5
- package/src/AutoBeMockAgent.ts +283 -283
- package/src/orchestrate/interface/orchestrateInterfaceSchemaRefine.ts +291 -291
- package/src/orchestrate/interface/orchestrateInterfaceSchemaReview.ts +309 -309
- package/src/orchestrate/interface/utils/AutoBeJsonSchemaValidator.ts +763 -763
- package/src/orchestrate/test/experimental/orchestrateTestCorrect.ast +237 -237
- package/src/orchestrate/test/experimental/orchestrateTestWrite.ast +322 -322
- package/src/orchestrate/test/experimental/transformTestCorrectHistories.ast +52 -52
- package/src/structures/IAutoBeVendor.ts +127 -127
- package/README.md +0 -261
|
@@ -1,52 +1,52 @@
|
|
|
1
|
-
import { IAgenticaHistoryJson } from "@agentica/core";
|
|
2
|
-
import { IAutoBeTypeScriptCompileResult } from "@autobe/interface";
|
|
3
|
-
import { v7 } from "uuid";
|
|
4
|
-
|
|
5
|
-
import { AutoBeSystemPromptConstant } from "../../constants/AutoBeSystemPromptConstant";
|
|
6
|
-
import { IAutoBeTestWriteResult } from "./structures/IAutoBeTestWriteResult";
|
|
7
|
-
|
|
8
|
-
export const transformTestCorrectHistories = (
|
|
9
|
-
// ctx: AutoBeContext<Model>,
|
|
10
|
-
written: IAutoBeTestWriteResult,
|
|
11
|
-
failure: IAutoBeTypeScriptCompileResult.IFailure,
|
|
12
|
-
): Array<
|
|
13
|
-
IAgenticaHistoryJson.IAssistantMessage | IAgenticaHistoryJson.ISystemMessage
|
|
14
|
-
> => {
|
|
15
|
-
return [
|
|
16
|
-
{
|
|
17
|
-
id: v7(),
|
|
18
|
-
created_at: new Date().toISOString(),
|
|
19
|
-
type: "systemMessage",
|
|
20
|
-
text: AutoBeSystemPromptConstant.TEST_WRITE,
|
|
21
|
-
},
|
|
22
|
-
{
|
|
23
|
-
id: v7(),
|
|
24
|
-
created_at: new Date().toISOString(),
|
|
25
|
-
type: "assistantMessage",
|
|
26
|
-
text: [
|
|
27
|
-
"## Original Code",
|
|
28
|
-
"## `AutoBeTest.IFunction` data",
|
|
29
|
-
"```json",
|
|
30
|
-
JSON.stringify(written.file.function),
|
|
31
|
-
"```",
|
|
32
|
-
"## Generated TypeScript Code",
|
|
33
|
-
"```typescript",
|
|
34
|
-
written.file.content,
|
|
35
|
-
"```",
|
|
36
|
-
"",
|
|
37
|
-
"## Compile Errors",
|
|
38
|
-
"Fix the compilation error in the provided code.",
|
|
39
|
-
"",
|
|
40
|
-
"```json",
|
|
41
|
-
JSON.stringify(failure.diagnostics),
|
|
42
|
-
"```",
|
|
43
|
-
].join("\n"),
|
|
44
|
-
},
|
|
45
|
-
{
|
|
46
|
-
id: v7(),
|
|
47
|
-
created_at: new Date().toISOString(),
|
|
48
|
-
type: "systemMessage",
|
|
49
|
-
text: AutoBeSystemPromptConstant.TEST_CORRECT,
|
|
50
|
-
},
|
|
51
|
-
];
|
|
52
|
-
};
|
|
1
|
+
import { IAgenticaHistoryJson } from "@agentica/core";
|
|
2
|
+
import { IAutoBeTypeScriptCompileResult } from "@autobe/interface";
|
|
3
|
+
import { v7 } from "uuid";
|
|
4
|
+
|
|
5
|
+
import { AutoBeSystemPromptConstant } from "../../constants/AutoBeSystemPromptConstant";
|
|
6
|
+
import { IAutoBeTestWriteResult } from "./structures/IAutoBeTestWriteResult";
|
|
7
|
+
|
|
8
|
+
export const transformTestCorrectHistories = (
|
|
9
|
+
// ctx: AutoBeContext<Model>,
|
|
10
|
+
written: IAutoBeTestWriteResult,
|
|
11
|
+
failure: IAutoBeTypeScriptCompileResult.IFailure,
|
|
12
|
+
): Array<
|
|
13
|
+
IAgenticaHistoryJson.IAssistantMessage | IAgenticaHistoryJson.ISystemMessage
|
|
14
|
+
> => {
|
|
15
|
+
return [
|
|
16
|
+
{
|
|
17
|
+
id: v7(),
|
|
18
|
+
created_at: new Date().toISOString(),
|
|
19
|
+
type: "systemMessage",
|
|
20
|
+
text: AutoBeSystemPromptConstant.TEST_WRITE,
|
|
21
|
+
},
|
|
22
|
+
{
|
|
23
|
+
id: v7(),
|
|
24
|
+
created_at: new Date().toISOString(),
|
|
25
|
+
type: "assistantMessage",
|
|
26
|
+
text: [
|
|
27
|
+
"## Original Code",
|
|
28
|
+
"## `AutoBeTest.IFunction` data",
|
|
29
|
+
"```json",
|
|
30
|
+
JSON.stringify(written.file.function),
|
|
31
|
+
"```",
|
|
32
|
+
"## Generated TypeScript Code",
|
|
33
|
+
"```typescript",
|
|
34
|
+
written.file.content,
|
|
35
|
+
"```",
|
|
36
|
+
"",
|
|
37
|
+
"## Compile Errors",
|
|
38
|
+
"Fix the compilation error in the provided code.",
|
|
39
|
+
"",
|
|
40
|
+
"```json",
|
|
41
|
+
JSON.stringify(failure.diagnostics),
|
|
42
|
+
"```",
|
|
43
|
+
].join("\n"),
|
|
44
|
+
},
|
|
45
|
+
{
|
|
46
|
+
id: v7(),
|
|
47
|
+
created_at: new Date().toISOString(),
|
|
48
|
+
type: "systemMessage",
|
|
49
|
+
text: AutoBeSystemPromptConstant.TEST_CORRECT,
|
|
50
|
+
},
|
|
51
|
+
];
|
|
52
|
+
};
|
|
@@ -1,127 +1,127 @@
|
|
|
1
|
-
import OpenAI from "openai";
|
|
2
|
-
|
|
3
|
-
/**
|
|
4
|
-
* Interface representing AI vendor configuration for the AutoBeAgent.
|
|
5
|
-
*
|
|
6
|
-
* Defines the connection parameters and settings required to integrate with AI
|
|
7
|
-
* service providers that power the vibe coding pipeline. While utilizing the
|
|
8
|
-
* OpenAI SDK as the connection interface, this configuration supports various
|
|
9
|
-
* LLM vendors beyond OpenAI through flexible endpoint and authentication
|
|
10
|
-
* configuration, enabling integration with Claude, DeepSeek, Meta Llama, and
|
|
11
|
-
* other providers that follow OpenAI-compatible API patterns.
|
|
12
|
-
*
|
|
13
|
-
* The vendor configuration determines the AI capabilities available throughout
|
|
14
|
-
* the entire automated development workflow, from requirements analysis and
|
|
15
|
-
* database design through API specification, testing, and final implementation.
|
|
16
|
-
* Different vendors may offer varying performance characteristics, cost
|
|
17
|
-
* structures, and feature support that can be optimized for specific vibe
|
|
18
|
-
* coding needs.
|
|
19
|
-
*
|
|
20
|
-
* Concurrent request management is built-in to prevent API rate limiting and
|
|
21
|
-
* optimize resource utilization across multiple development phases and parallel
|
|
22
|
-
* operations within the vibe coding pipeline.
|
|
23
|
-
*
|
|
24
|
-
* @author Samchon
|
|
25
|
-
*/
|
|
26
|
-
export interface IAutoBeVendor {
|
|
27
|
-
/**
|
|
28
|
-
* OpenAI SDK instance configured for the target AI vendor.
|
|
29
|
-
*
|
|
30
|
-
* Provides the API connection interface used by the AutoBeAgent to
|
|
31
|
-
* communicate with AI services. While this uses the OpenAI SDK, it can be
|
|
32
|
-
* configured to connect with various LLM providers by setting the appropriate
|
|
33
|
-
* `baseURL` and authentication credentials. The SDK serves as a universal
|
|
34
|
-
* connector that abstracts the underlying API communication protocols.
|
|
35
|
-
*
|
|
36
|
-
* For non-OpenAI vendors, configure the SDK with the vendor's API endpoint
|
|
37
|
-
* and authentication requirements to enable seamless integration with the
|
|
38
|
-
* vibe coding system.
|
|
39
|
-
*/
|
|
40
|
-
api: OpenAI;
|
|
41
|
-
|
|
42
|
-
/**
|
|
43
|
-
* Specific model identifier to use for AI operations.
|
|
44
|
-
*
|
|
45
|
-
* Specifies the exact model name or identifier that should be used for vibe
|
|
46
|
-
* coding tasks. Supports both official OpenAI chat models and custom model
|
|
47
|
-
* identifiers for third-party hosting services, cloud providers, or
|
|
48
|
-
* alternative LLM vendors. The model choice significantly impacts the
|
|
49
|
-
* quality, performance, and cost of the automated development process.
|
|
50
|
-
*
|
|
51
|
-
* Examples include "gpt-4", "gpt-3.5-turbo" for OpenAI, or vendor-specific
|
|
52
|
-
* identifiers like "claude-3-sonnet", "deepseek-chat-v3", "llama3.3-70b" when
|
|
53
|
-
* using alternative providers through compatible APIs.
|
|
54
|
-
*/
|
|
55
|
-
model: OpenAI.ChatModel | ({} & string);
|
|
56
|
-
|
|
57
|
-
/**
|
|
58
|
-
* Optional human-readable label for this vendor/model configuration.
|
|
59
|
-
*
|
|
60
|
-
* This is a display or grouping name that is distinct from the underlying
|
|
61
|
-
* `model` identifier, and is intended for use in logs, UIs, selection menus,
|
|
62
|
-
* or archive views where a more descriptive name is helpful (for example,
|
|
63
|
-
* "Primary GPT-4", "Fast Drafting Model", or "Internal Llama Cluster").
|
|
64
|
-
*
|
|
65
|
-
* When omitted, callers should fall back to displaying or logging the `model`
|
|
66
|
-
* value itself, or another sensible default derived from the model
|
|
67
|
-
* identifier.
|
|
68
|
-
*/
|
|
69
|
-
label?: string | undefined;
|
|
70
|
-
|
|
71
|
-
/**
|
|
72
|
-
* Optional request configuration for API calls.
|
|
73
|
-
*
|
|
74
|
-
* Additional request options that will be applied to all API calls made
|
|
75
|
-
* through the OpenAI SDK. This can include custom headers, timeouts, retry
|
|
76
|
-
* policies, or other HTTP client configuration that may be required for
|
|
77
|
-
* specific vendor integrations or enterprise environments.
|
|
78
|
-
*
|
|
79
|
-
* These options provide fine-grained control over the API communication
|
|
80
|
-
* behavior and can be used to optimize performance or meet specific
|
|
81
|
-
* infrastructure requirements.
|
|
82
|
-
*/
|
|
83
|
-
options?: OpenAI.RequestOptions | undefined;
|
|
84
|
-
|
|
85
|
-
/**
|
|
86
|
-
* Maximum number of concurrent API requests allowed.
|
|
87
|
-
*
|
|
88
|
-
* Controls the concurrency level for AI API calls to prevent rate limiting,
|
|
89
|
-
* manage resource consumption, and optimize system performance. The vibe
|
|
90
|
-
* coding pipeline may make multiple parallel requests during development
|
|
91
|
-
* phases, and this setting ensures controlled resource utilization.
|
|
92
|
-
*
|
|
93
|
-
* A reasonable default provides balanced performance while respecting typical
|
|
94
|
-
* API rate limits. Lower values reduce resource consumption but may slow
|
|
95
|
-
* development progress, while higher values can improve performance but risk
|
|
96
|
-
* hitting rate limits or overwhelming the AI service.
|
|
97
|
-
*
|
|
98
|
-
* Set to undefined to disable concurrency limiting, allowing unlimited
|
|
99
|
-
* parallel requests (use with caution based on your API limits and
|
|
100
|
-
* infrastructure capacity).
|
|
101
|
-
*
|
|
102
|
-
* @default 16
|
|
103
|
-
*/
|
|
104
|
-
semaphore?: number | undefined;
|
|
105
|
-
|
|
106
|
-
/**
|
|
107
|
-
* Indicates whether this vendor/model supports explicit tool choice control.
|
|
108
|
-
*
|
|
109
|
-
* When set to `true`, the agent may pass the `tool_choice` parameter with a
|
|
110
|
-
* value of `"required"` (or other explicit values) for models that implement
|
|
111
|
-
* OpenAI-style tool calling. This allows the agent to force the model to call
|
|
112
|
-
* one of the provided tools when appropriate.
|
|
113
|
-
*
|
|
114
|
-
* When set to `false`, the agent will avoid sending `tool_choice` in a way
|
|
115
|
-
* that forces tool invocation, and will instead rely on the model's default
|
|
116
|
-
* behavior or omit tool-choice configuration entirely. This should be used
|
|
117
|
-
* for vendors or models that do not understand, partially implement, or are
|
|
118
|
-
* unstable with the `tool_choice` parameter.
|
|
119
|
-
*
|
|
120
|
-
* This flag is necessary so that a single agent implementation can work
|
|
121
|
-
* across multiple vendors and models with differing levels of tool-calling
|
|
122
|
-
* support, without causing API errors or unexpected behavior.
|
|
123
|
-
*
|
|
124
|
-
* @default true
|
|
125
|
-
*/
|
|
126
|
-
useToolChoice?: boolean;
|
|
127
|
-
}
|
|
1
|
+
import OpenAI from "openai";
|
|
2
|
+
|
|
3
|
+
/**
|
|
4
|
+
* Interface representing AI vendor configuration for the AutoBeAgent.
|
|
5
|
+
*
|
|
6
|
+
* Defines the connection parameters and settings required to integrate with AI
|
|
7
|
+
* service providers that power the vibe coding pipeline. While utilizing the
|
|
8
|
+
* OpenAI SDK as the connection interface, this configuration supports various
|
|
9
|
+
* LLM vendors beyond OpenAI through flexible endpoint and authentication
|
|
10
|
+
* configuration, enabling integration with Claude, DeepSeek, Meta Llama, and
|
|
11
|
+
* other providers that follow OpenAI-compatible API patterns.
|
|
12
|
+
*
|
|
13
|
+
* The vendor configuration determines the AI capabilities available throughout
|
|
14
|
+
* the entire automated development workflow, from requirements analysis and
|
|
15
|
+
* database design through API specification, testing, and final implementation.
|
|
16
|
+
* Different vendors may offer varying performance characteristics, cost
|
|
17
|
+
* structures, and feature support that can be optimized for specific vibe
|
|
18
|
+
* coding needs.
|
|
19
|
+
*
|
|
20
|
+
* Concurrent request management is built-in to prevent API rate limiting and
|
|
21
|
+
* optimize resource utilization across multiple development phases and parallel
|
|
22
|
+
* operations within the vibe coding pipeline.
|
|
23
|
+
*
|
|
24
|
+
* @author Samchon
|
|
25
|
+
*/
|
|
26
|
+
export interface IAutoBeVendor {
|
|
27
|
+
/**
|
|
28
|
+
* OpenAI SDK instance configured for the target AI vendor.
|
|
29
|
+
*
|
|
30
|
+
* Provides the API connection interface used by the AutoBeAgent to
|
|
31
|
+
* communicate with AI services. While this uses the OpenAI SDK, it can be
|
|
32
|
+
* configured to connect with various LLM providers by setting the appropriate
|
|
33
|
+
* `baseURL` and authentication credentials. The SDK serves as a universal
|
|
34
|
+
* connector that abstracts the underlying API communication protocols.
|
|
35
|
+
*
|
|
36
|
+
* For non-OpenAI vendors, configure the SDK with the vendor's API endpoint
|
|
37
|
+
* and authentication requirements to enable seamless integration with the
|
|
38
|
+
* vibe coding system.
|
|
39
|
+
*/
|
|
40
|
+
api: OpenAI;
|
|
41
|
+
|
|
42
|
+
/**
|
|
43
|
+
* Specific model identifier to use for AI operations.
|
|
44
|
+
*
|
|
45
|
+
* Specifies the exact model name or identifier that should be used for vibe
|
|
46
|
+
* coding tasks. Supports both official OpenAI chat models and custom model
|
|
47
|
+
* identifiers for third-party hosting services, cloud providers, or
|
|
48
|
+
* alternative LLM vendors. The model choice significantly impacts the
|
|
49
|
+
* quality, performance, and cost of the automated development process.
|
|
50
|
+
*
|
|
51
|
+
* Examples include "gpt-4", "gpt-3.5-turbo" for OpenAI, or vendor-specific
|
|
52
|
+
* identifiers like "claude-3-sonnet", "deepseek-chat-v3", "llama3.3-70b" when
|
|
53
|
+
* using alternative providers through compatible APIs.
|
|
54
|
+
*/
|
|
55
|
+
model: OpenAI.ChatModel | ({} & string);
|
|
56
|
+
|
|
57
|
+
/**
|
|
58
|
+
* Optional human-readable label for this vendor/model configuration.
|
|
59
|
+
*
|
|
60
|
+
* This is a display or grouping name that is distinct from the underlying
|
|
61
|
+
* `model` identifier, and is intended for use in logs, UIs, selection menus,
|
|
62
|
+
* or archive views where a more descriptive name is helpful (for example,
|
|
63
|
+
* "Primary GPT-4", "Fast Drafting Model", or "Internal Llama Cluster").
|
|
64
|
+
*
|
|
65
|
+
* When omitted, callers should fall back to displaying or logging the `model`
|
|
66
|
+
* value itself, or another sensible default derived from the model
|
|
67
|
+
* identifier.
|
|
68
|
+
*/
|
|
69
|
+
label?: string | undefined;
|
|
70
|
+
|
|
71
|
+
/**
|
|
72
|
+
* Optional request configuration for API calls.
|
|
73
|
+
*
|
|
74
|
+
* Additional request options that will be applied to all API calls made
|
|
75
|
+
* through the OpenAI SDK. This can include custom headers, timeouts, retry
|
|
76
|
+
* policies, or other HTTP client configuration that may be required for
|
|
77
|
+
* specific vendor integrations or enterprise environments.
|
|
78
|
+
*
|
|
79
|
+
* These options provide fine-grained control over the API communication
|
|
80
|
+
* behavior and can be used to optimize performance or meet specific
|
|
81
|
+
* infrastructure requirements.
|
|
82
|
+
*/
|
|
83
|
+
options?: OpenAI.RequestOptions | undefined;
|
|
84
|
+
|
|
85
|
+
/**
|
|
86
|
+
* Maximum number of concurrent API requests allowed.
|
|
87
|
+
*
|
|
88
|
+
* Controls the concurrency level for AI API calls to prevent rate limiting,
|
|
89
|
+
* manage resource consumption, and optimize system performance. The vibe
|
|
90
|
+
* coding pipeline may make multiple parallel requests during development
|
|
91
|
+
* phases, and this setting ensures controlled resource utilization.
|
|
92
|
+
*
|
|
93
|
+
* A reasonable default provides balanced performance while respecting typical
|
|
94
|
+
* API rate limits. Lower values reduce resource consumption but may slow
|
|
95
|
+
* development progress, while higher values can improve performance but risk
|
|
96
|
+
* hitting rate limits or overwhelming the AI service.
|
|
97
|
+
*
|
|
98
|
+
* Set to undefined to disable concurrency limiting, allowing unlimited
|
|
99
|
+
* parallel requests (use with caution based on your API limits and
|
|
100
|
+
* infrastructure capacity).
|
|
101
|
+
*
|
|
102
|
+
* @default 16
|
|
103
|
+
*/
|
|
104
|
+
semaphore?: number | undefined;
|
|
105
|
+
|
|
106
|
+
/**
|
|
107
|
+
* Indicates whether this vendor/model supports explicit tool choice control.
|
|
108
|
+
*
|
|
109
|
+
* When set to `true`, the agent may pass the `tool_choice` parameter with a
|
|
110
|
+
* value of `"required"` (or other explicit values) for models that implement
|
|
111
|
+
* OpenAI-style tool calling. This allows the agent to force the model to call
|
|
112
|
+
* one of the provided tools when appropriate.
|
|
113
|
+
*
|
|
114
|
+
* When set to `false`, the agent will avoid sending `tool_choice` in a way
|
|
115
|
+
* that forces tool invocation, and will instead rely on the model's default
|
|
116
|
+
* behavior or omit tool-choice configuration entirely. This should be used
|
|
117
|
+
* for vendors or models that do not understand, partially implement, or are
|
|
118
|
+
* unstable with the `tool_choice` parameter.
|
|
119
|
+
*
|
|
120
|
+
* This flag is necessary so that a single agent implementation can work
|
|
121
|
+
* across multiple vendors and models with differing levels of tool-calling
|
|
122
|
+
* support, without causing API errors or unexpected behavior.
|
|
123
|
+
*
|
|
124
|
+
* @default true
|
|
125
|
+
*/
|
|
126
|
+
useToolChoice?: boolean;
|
|
127
|
+
}
|
package/README.md
DELETED
|
@@ -1,261 +0,0 @@
|
|
|
1
|
-
# AutoBE - AI backend builder for prototype to production
|
|
2
|
-
|
|
3
|
-
[](https://github.com/wrtnlabs/autobe/blob/master/LICENSE)
|
|
4
|
-
[](https://www.npmjs.com/package/@autobe/agent)
|
|
5
|
-
[](https://www.npmjs.com/package/@autobe/agent)
|
|
6
|
-
[](https://github.com/wrtnlabs/autobe/actions?query=workflow%3Abuild)
|
|
7
|
-
[](https://autobe.dev/docs/)
|
|
8
|
-
[](https://discord.gg/aMhRmzkqCx)
|
|
9
|
-
|
|
10
|
-
Describe your backend requirements in natural language through AutoBE's chat interface.
|
|
11
|
-
|
|
12
|
-
AutoBE will analyze your requirements and build the backend application for you. The generated backend application is designed to be 100% buildable by AI-friendly compilers and ensures stability through powerful e2e test functions.
|
|
13
|
-
|
|
14
|
-
With such AutoBE, build your first backend application quickly, then maintain and extend it with AI code assistants like Claude Code for enhanced productivity and stability.
|
|
15
|
-
|
|
16
|
-
AutoBE will generate complete specifications, detailed database and API documentation, comprehensive test coverage for stability, and clean implementation logic that serves as a learning foundation for juniors while significantly improving senior developer productivity.
|
|
17
|
-
|
|
18
|
-
Check out these complete backend application examples generated by AutoBE:
|
|
19
|
-
|
|
20
|
-
https://github.com/user-attachments/assets/b995dd2a-23bd-43c9-96cb-96d5c805f19f
|
|
21
|
-
|
|
22
|
-
1. **To Do List**: [`todo`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/todo)
|
|
23
|
-
2. **Discussion Board**: [`bbs`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs)
|
|
24
|
-
3. **Reddit Community**: [`reddit](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/reddit)
|
|
25
|
-
4. **E-Commerce**: [`shopping`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping)
|
|
26
|
-
- Requirements Analysis: [Report](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/docs/analysis)
|
|
27
|
-
- Database Design: [Entity Relationship Diagram](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/docs/ERD.md) / [Prisma Schema](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/prisma/schema)
|
|
28
|
-
- API Design: [API Controllers](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/src/controllers) / [DTO Structures](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/src/api/structures)
|
|
29
|
-
- E2E Test Functions: [`test/features/api`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/test/features/api)
|
|
30
|
-
- API Implementations: [`src/providers`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/shopping/src/providers)
|
|
31
|
-
|
|
32
|
-
## Getting Started
|
|
33
|
-
|
|
34
|
-
```bash
|
|
35
|
-
git clone https://github.com/wrtnlabs/autobe --depth=1
|
|
36
|
-
cd autobe
|
|
37
|
-
pnpm install
|
|
38
|
-
pnpm run playground
|
|
39
|
-
```
|
|
40
|
-
|
|
41
|
-
To use AutoBE, clone the repository and run the playground application locally. This allows you to chat with AutoBE's AI agents, manage multiple sessions, and use various LLM providers including local models like `qwen3-next-80b-a3b-instruct`.
|
|
42
|
-
|
|
43
|
-
After installation, the playground will be available at http://localhost:5713. You can interact with AutoBE through a chat interface - simply describe what you want to build, and AutoBE will generate the backend application for you.
|
|
44
|
-
|
|
45
|
-
Here's an example conversation script that guides AutoBE to create an "Economic/Political Discussion Board":
|
|
46
|
-
|
|
47
|
-
1. **Requirements Analysis**: "I want to create an economic/political discussion board. Since I'm not familiar with programming, please write a requirements analysis report as you see fit."
|
|
48
|
-
2. **Database Design**: "Design the database schema."
|
|
49
|
-
3. **API Specification**: "Create the API interface specification."
|
|
50
|
-
4. **Testing**: "Make the e2e test functions."
|
|
51
|
-
5. **Implementation**: "Implement API functions."
|
|
52
|
-
|
|
53
|
-
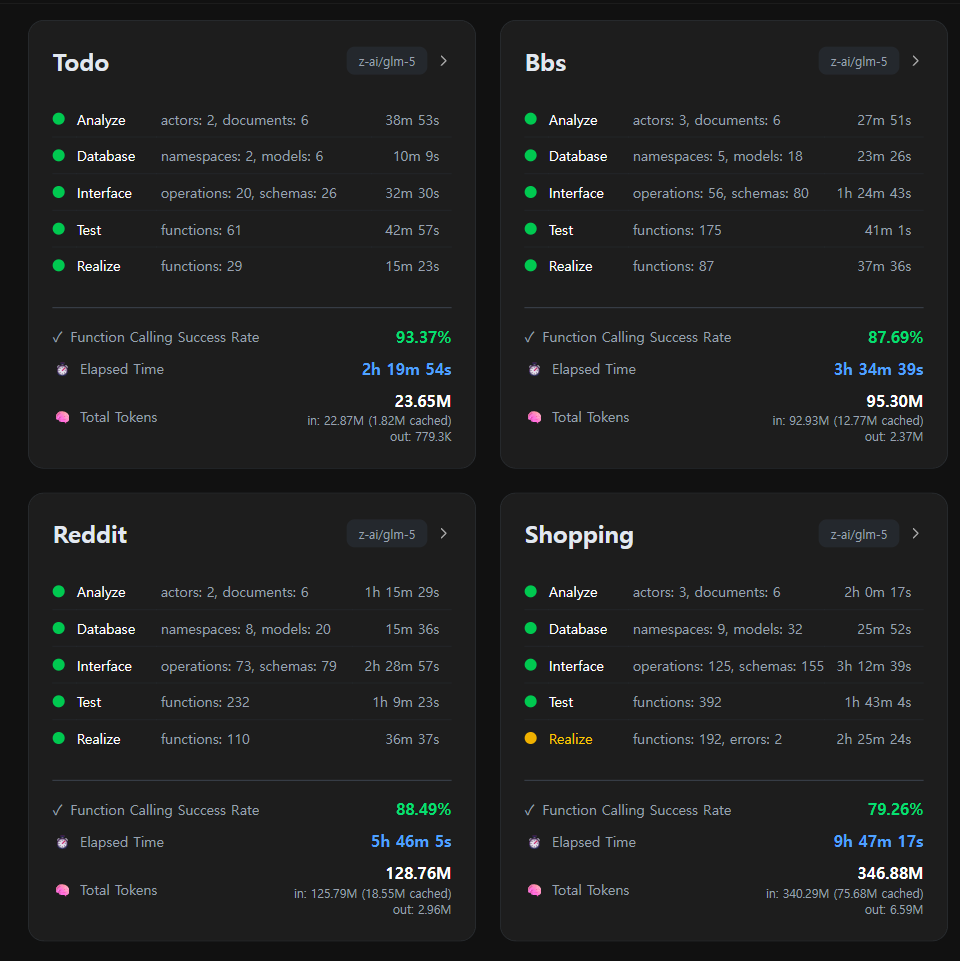
|
|
54
|
-
|
|
55
|
-
> The playground includes a replay feature at http://localhost:5713/replay/index.html where you can view chat sessions from the AutoBE development team's testing and benchmarks.
|
|
56
|
-
|
|
57
|
-
## Documentation Resources
|
|
58
|
-
|
|
59
|
-
Find comprehensive resources at our [official website](https://autobe.dev).
|
|
60
|
-
|
|
61
|
-
### 🏠 Home
|
|
62
|
-
|
|
63
|
-
- 🙋🏻♂️ [Introduction](https://autobe.dev/docs)
|
|
64
|
-
- 📦 [Setup](https://autobe.dev/docs/setup)
|
|
65
|
-
- 🔍 Concepts
|
|
66
|
-
- [Waterfall Model](https://autobe.dev/docs/concepts/waterfall)
|
|
67
|
-
- [Compiler Strategy](https://autobe.dev/docs/concepts/compiler)
|
|
68
|
-
- [AI Function Calling](https://autobe.dev/docs/concepts/function-calling)
|
|
69
|
-
|
|
70
|
-
### 📖 Features
|
|
71
|
-
|
|
72
|
-
- 🤖 Agent Library
|
|
73
|
-
- [Facade Controller](https://autobe.dev/docs/agent/facade)
|
|
74
|
-
- [Configuration](https://autobe.dev/docs/agent/config)
|
|
75
|
-
- [Event Handling](https://autobe.dev/docs/agent/event)
|
|
76
|
-
- [Prompt Histories](https://autobe.dev/docs/agent/history)
|
|
77
|
-
- 📡 WebSocket Protocol
|
|
78
|
-
- [Remote Procedure Call](https://autobe.dev/docs/websocket/rpc)
|
|
79
|
-
- [NestJS Server](https://autobe.dev/docs/websocket/nestjs)
|
|
80
|
-
- [NodeJS Server](https://autobe.dev/docs/websocket/nodejs)
|
|
81
|
-
- [Client Application](https://autobe.dev/docs/websocket/client)
|
|
82
|
-
- 🛠️ Backend Stack
|
|
83
|
-
- [TypeScript](https://autobe.dev/docs/stack/typescript)
|
|
84
|
-
- [Prisma ORM](https://autobe.dev/docs/stack/prisma)
|
|
85
|
-
- [NestJS Framework](https://autobe.dev/docs/stack/nestjs)
|
|
86
|
-
|
|
87
|
-
### 🔗 Appendix
|
|
88
|
-
|
|
89
|
-
- 🌐 [No-Code Ecosystem](https://autobe.dev/docs/ecosystem)
|
|
90
|
-
- 📅 Roadmap
|
|
91
|
-
- [Alpha Release (done)](https://autobe.dev/docs/roadmap/alpha)
|
|
92
|
-
- [Beta Release (done)](https://autobe.dev/docs/roadmap/beta)
|
|
93
|
-
- [Gamma Release (done)](https://autobe.dev/docs/roadmap/gamma)
|
|
94
|
-
- [Delta Release (active)](https://autobe.dev/docs/roadmap/delta)
|
|
95
|
-
- 🔧 [API Documentation](https://autobe.dev/api)
|
|
96
|
-
|
|
97
|
-
## How AutoBE Works
|
|
98
|
-
|
|
99
|
-
```mermaid
|
|
100
|
-
flowchart
|
|
101
|
-
subgraph "Backend Coding Agent"
|
|
102
|
-
coder("Facade Controller")
|
|
103
|
-
end
|
|
104
|
-
subgraph "Functional Agents"
|
|
105
|
-
coder --"Requirements Analysis"--> analyze("Analyze")
|
|
106
|
-
coder --"ERD"--> database("Database")
|
|
107
|
-
coder --"API Design"--> interface("Interface")
|
|
108
|
-
coder --"Test Codes" --> test("Test")
|
|
109
|
-
coder --"Main Program" --> realize("Realize")
|
|
110
|
-
end
|
|
111
|
-
subgraph "Compiler Feedback"
|
|
112
|
-
database --"validates" --> prismaCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/database/AutoBeDatabase.ts" target="_blank">Prisma Compiler</a>")
|
|
113
|
-
interface --"generates" --> openapiCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/openapi/AutoBeOpenApi.ts" target="_blank">OpenAPI Compiler</a>")
|
|
114
|
-
test --"analyzes" --> testCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/test/AutoBeTest.ts" target="_blank">Test Compiler</a>")
|
|
115
|
-
realize --"compiles" --> realizeCompiler("TypeScript Compiler")
|
|
116
|
-
end
|
|
117
|
-
```
|
|
118
|
-
|
|
119
|
-
AutoBE follows a waterfall methodology to generate backend applications, with 40+ specialized agents handling each phase. The agents work in coordinated teams throughout the development process.
|
|
120
|
-
|
|
121
|
-
Each waterfall stage includes AI-friendly compilers that guarantee type safety of the generated code. Rather than generating code directly, AutoBE's agents first construct language-neutral Abstract Syntax Trees using predefined schemas. Each AST node undergoes validation against type rules before any code generation occurs, catching structural errors at the conceptual level rather than during compilation.
|
|
122
|
-
|
|
123
|
-
This approach is designed to ensure that the final generated TypeScript and Prisma code is 100% buildable. Based on our testing with multiple example projects including e-commerce platforms, discussion boards, and task management systems, AutoBE maintains this compilation guarantee across diverse application types.
|
|
124
|
-
|
|
125
|
-
To illustrate this process, here are the phase outputs from our "Economic/Political Discussion Board" example:
|
|
126
|
-
|
|
127
|
-
1. **Requirements Analysis**: [Report](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/docs/analysis)
|
|
128
|
-
2. **Database Design**: [Entity Relationship Diagram](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/docs/ERD.md) / [Prisma Schema](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/prisma/schema)
|
|
129
|
-
3. **API Specification**: [API Controllers](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/src/controllers) / [DTO Structures](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/src/api/structures)
|
|
130
|
-
4. **E2E Test Functions**: [`test/features/api`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/test/features/api)
|
|
131
|
-
5. **API Implementations**: [`src/providers`](https://github.com/wrtnlabs/autobe-examples/tree/main/openai/gpt-4.1/bbs/src/providers)
|
|
132
|
-
|
|
133
|
-
Also, you don't need to use all phases - stop at any stage that fits your needs. Whether you want just requirements analysis, database design, API specification, or e2e testing, AutoBE adapts to your workflow.
|
|
134
|
-
|
|
135
|
-
Additionally, if you're skipping the full pipeline because of language preference rather than workflow needs, this capability is in development - AutoBE's language-neutral AST structure will soon support additional programming languages beyond TypeScript.
|
|
136
|
-
|
|
137
|
-
## Type-Safe Client SDK
|
|
138
|
-
|
|
139
|
-
Every AutoBE-generated backend automatically includes a type-safe client SDK, making frontend integration seamless and error-free. This SDK provides:
|
|
140
|
-
|
|
141
|
-
- **Zero Configuration**: SDK is auto-generated alongside your backend - no manual setup required
|
|
142
|
-
- **100% Type Safety**: Full TypeScript support with autocomplete and compile-time validation
|
|
143
|
-
- **Framework Agnostic**: Works with React, Vue, Angular, or any TypeScript/JavaScript project
|
|
144
|
-
- **E2E Test Integration**: Powers AI-generated test suites for comprehensive backend testing
|
|
145
|
-
|
|
146
|
-
```typescript
|
|
147
|
-
import api, { IPost } from "autobe-generated-sdk";
|
|
148
|
-
|
|
149
|
-
// Type-safe API calls with full autocomplete
|
|
150
|
-
const connection: api.IConnection = {
|
|
151
|
-
host: "http://localhost:1234",
|
|
152
|
-
};
|
|
153
|
-
await api.functional.users.login(connection, {
|
|
154
|
-
body: {
|
|
155
|
-
email: "user@example.com",
|
|
156
|
-
password: "secure-password",
|
|
157
|
-
},
|
|
158
|
-
});
|
|
159
|
-
|
|
160
|
-
// TypeScript catches errors at compile time
|
|
161
|
-
const post: IPost = await api.functional.posts.create(connection, {
|
|
162
|
-
body: {
|
|
163
|
-
title: "Hello World",
|
|
164
|
-
content: "My first post",
|
|
165
|
-
// authorId: "123" <- TypeScript error if this field is missing!
|
|
166
|
-
},
|
|
167
|
-
});
|
|
168
|
-
```
|
|
169
|
-
|
|
170
|
-
This SDK eliminates the traditional pain points of API integration - no more manual type definitions, no more runtime surprises, and no more API documentation lookups. Your frontend developers can focus on building features, not wrestling with API contracts.
|
|
171
|
-
|
|
172
|
-
**Beyond Frontend Integration**: The SDK powers both frontend development and E2E test generation. AutoBE uses the same type-safe SDK internally to generate comprehensive test suites, ensuring every API endpoint is thoroughly tested. This creates a robust feedback loop that enhances backend stability - AI writes tests using the SDK, the SDK ensures type safety, and your backend becomes more reliable with every generated test.
|
|
173
|
-
|
|
174
|
-
## Roadmap Schedule
|
|
175
|
-
|
|
176
|
-
```mermaid
|
|
177
|
-
gantt
|
|
178
|
-
dateFormat YYYY-MM-DD
|
|
179
|
-
title AutoBE Delta Roadmap Timeline (2026 Q1)
|
|
180
|
-
|
|
181
|
-
section Local LLM Benchmark
|
|
182
|
-
Qwen3 Database Phase : done, 2026-01-01, 31d
|
|
183
|
-
Qwen3 Interface Phase : done, 2026-01-16, 31d
|
|
184
|
-
Qwen3 Test Phase : done, 2026-02-01, 21d
|
|
185
|
-
Qwen3 Realize Phase : done, 2026-02-01, 59d
|
|
186
|
-
|
|
187
|
-
section Validation Logic Enhancement
|
|
188
|
-
Dynamic Function Calling Schema : done, 2026-01-01, 7d
|
|
189
|
-
Validation Feedback Stringify : done, 2026-01-08, 12d
|
|
190
|
-
JSON Schema Validator : done, 2026-01-08, 12d
|
|
191
|
-
Schema Review Validation Logic : done, 2026-01-20, 35d
|
|
192
|
-
Test Mapping Plan Enhancement : done, 2026-02-05, 24d
|
|
193
|
-
Realize Mapping Plan Enhancement : done, 2026-02-15, 45d
|
|
194
|
-
|
|
195
|
-
section RAG Optimization
|
|
196
|
-
Hybrid Search (Vector + BM25) : done, 2026-01-01, 14d
|
|
197
|
-
Dynamic K Retrieval : done, 2026-01-15, 14d
|
|
198
|
-
RAG Preliminary Prompting : done, 2026-01-15, 28d
|
|
199
|
-
RAG Benchmark & Tuning : done, 2026-02-01, 28d
|
|
200
|
-
Analyze Agent Restructuring : done, 2026-02-01, 28d
|
|
201
|
-
|
|
202
|
-
section Design Integrity
|
|
203
|
-
DB Coverage Agent : done, 2026-01-15, 28d
|
|
204
|
-
API Endpoint Coverage Agent : done, 2026-01-22, 28d
|
|
205
|
-
Schema Relation Agent : done, 2026-02-01, 28d
|
|
206
|
-
Schema Structure Agent : done, 2026-02-01, 28d
|
|
207
|
-
Schema Content Agent : done, 2026-03-01, 28d
|
|
208
|
-
|
|
209
|
-
section Multi-lingual Support
|
|
210
|
-
Java Compiler PoC : done, 2026-01-01, 30d
|
|
211
|
-
Java Database : done, 2026-01-01, 14d
|
|
212
|
-
Java Interface : done, 2026-01-15, 21d
|
|
213
|
-
Java Test : active, 2026-02-05, 28d
|
|
214
|
-
Java Realize : active, 2026-03-01, 31d
|
|
215
|
-
|
|
216
|
-
section Human Modification Support
|
|
217
|
-
Database Schema Parser : active, 2026-02-15, 28d
|
|
218
|
-
Interface Schema Parser : active, 2026-02-22, 28d
|
|
219
|
-
Requirements Sync Agent : planned, 2026-03-08, 24d
|
|
220
|
-
|
|
221
|
-
section Miscellaneous
|
|
222
|
-
System Prompt Simplification : done, 2026-02-01, 28d
|
|
223
|
-
Estimation Agent : done, 2026-02-01, 28d
|
|
224
|
-
Playground Service Enhancement : active, 2026-02-15, 28d
|
|
225
|
-
PR Articles Writing : active, 2026-02-15, 30d
|
|
226
|
-
```
|
|
227
|
-
|
|
228
|
-
AutoBE has successfully completed Alpha, Beta, and Gamma development phases, establishing a solid foundation with **100% compilation success rate**. The current **Delta Release** focuses on transitioning from horizontal expansion to vertical deepening.
|
|
229
|
-
|
|
230
|
-
**Strategic Shift**: In Gamma, we rapidly implemented features like RAG, Modularization, and Complementation under a "just ship it" philosophy. Delta fills the stability gaps that remained by systematically discovering and fixing hidden defects through Local LLM benchmarks.
|
|
231
|
-
|
|
232
|
-
**Key Focus Areas**:
|
|
233
|
-
|
|
234
|
-
- **Local LLM Benchmark**: Using open-source models like Qwen3 as a touchstone to discover hidden defects that commercial models mask, ensuring more robust operation across all model types
|
|
235
|
-
- **Validation Logic Enhancement**: Strengthening schemas and validation logic through dynamic function calling schemas, JSON Schema validators, and progressive validation pipelines
|
|
236
|
-
- **RAG Optimization**: Completing the Hybrid Search system (Vector + BM25) with dynamic K retrieval and comprehensive benchmark tuning
|
|
237
|
-
- **Design Integrity**: Building mechanisms to verify and ensure design consistency between Database and Interface phases through coverage and schema review agents
|
|
238
|
-
- **Multi-lingual Support**: Launching Java/Spring code generation alongside TypeScript/NestJS, with language-neutral AST structures enabling future language additions
|
|
239
|
-
- **Human Modification Support**: Enabling maintenance continuity by parsing user-modified code back into AutoBE's internal AST representation, ensuring AutoBE remains useful beyond initial generation
|
|
240
|
-
|
|
241
|
-
This roadmap prioritizes stability and depth over feature breadth, informed by real-world production experience from Gamma.
|
|
242
|
-
|
|
243
|
-
## Current Limitations
|
|
244
|
-
|
|
245
|
-
While AutoBE achieves 100% compilation success, please note these current limitations:
|
|
246
|
-
|
|
247
|
-
**Runtime Behavior**: Generated applications compile successfully, but runtime behavior may require testing and refinement. Unexpected runtime errors can occur during server execution, such as database connection issues, API endpoint failures, or business logic exceptions that weren't caught during compilation. We strongly recommend thorough testing in development environments before deploying to production. Our v1.0 release targets 100% runtime success to address these issues.
|
|
248
|
-
|
|
249
|
-
**Design Interpretation**: AutoBE's database and API designs may differ from your expectations. We recommend thoroughly reviewing generated specifications before proceeding with implementation, especially before production deployment.
|
|
250
|
-
|
|
251
|
-
**Token Consumption**: AutoBE requires significant AI token usage for complex projects. Based on our testing, projects typically consume 30M-250M+ tokens depending on complexity (simple todo apps use ~4M tokens, while complex e-commerce platforms may require 250M+ tokens). We are working on RAG optimization to reduce this overhead in future releases.
|
|
252
|
-
|
|
253
|
-
**Maintenance**: AutoBE focuses on initial generation and does not provide ongoing maintenance capabilities. Once your backend is generated, you'll need to handle bug fixes, feature additions, performance optimizations, and security updates manually. We recommend establishing a development workflow that combines the generated codebase with AI coding assistants like Claude Code for efficient ongoing development and maintenance tasks.
|
|
254
|
-
|
|
255
|
-
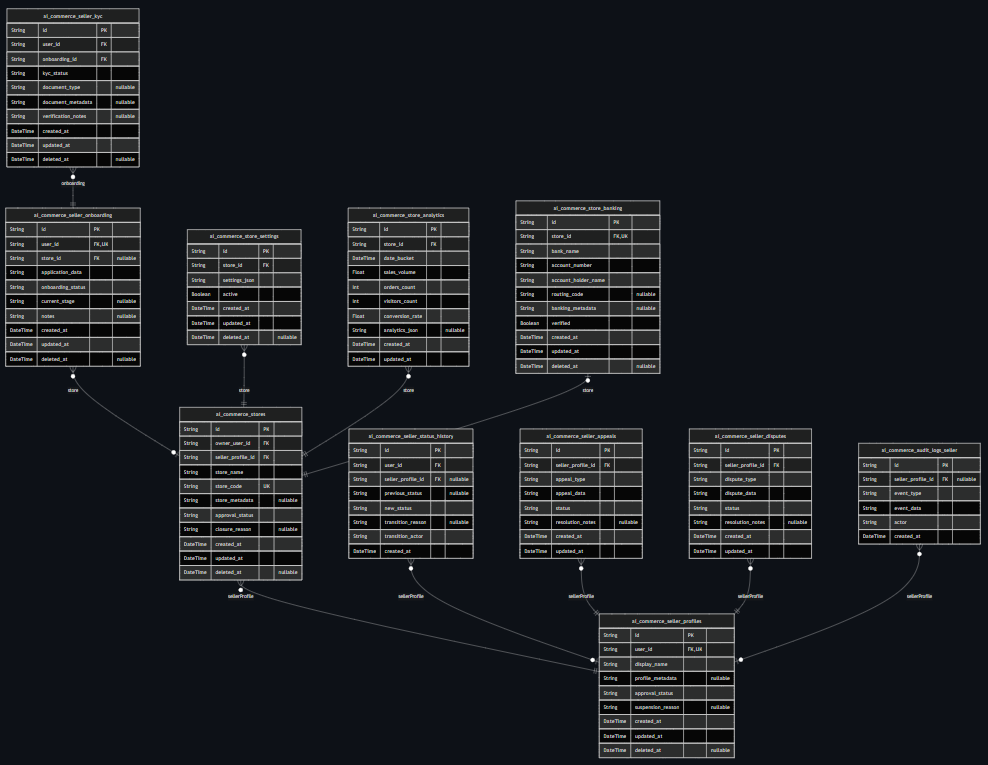
|
|
256
|
-
|
|
257
|
-
## License
|
|
258
|
-
|
|
259
|
-
AutoBE is licensed under the [GNU Affero General Public License v3.0 (AGPL-3.0)](LICENSE). If you modify AutoBE itself or offer it as a network service, you must make your source code available under the same license.
|
|
260
|
-
|
|
261
|
-
However, backend applications generated by AutoBE can be relicensed under any license you choose, such as MIT. This means you can freely use AutoBE-generated code in commercial projects without open source obligations, similar to how other code generation tools work.
|