wgit 0.9.0 → 0.10.3
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/CHANGELOG.md +38 -2
- data/README.md +36 -43
- data/lib/wgit/base.rb +10 -1
- data/lib/wgit/database/database.rb +7 -9
- data/lib/wgit/document.rb +7 -0
- data/lib/wgit/indexer.rb +4 -4
- data/lib/wgit/url.rb +51 -39
- data/lib/wgit/version.rb +1 -1
- metadata +11 -8
checksums.yaml
CHANGED
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
---
|
|
2
2
|
SHA256:
|
|
3
|
-
metadata.gz:
|
|
4
|
-
data.tar.gz:
|
|
3
|
+
metadata.gz: 720cf6b84698fbd54c109319f05557ee2e29bdbda59ec23278422dc5ddc77f2f
|
|
4
|
+
data.tar.gz: d4304bce849b404b9d2d7faa4d9a3f7969784f649a83152605b51b2e0bd21ac4
|
|
5
5
|
SHA512:
|
|
6
|
-
metadata.gz:
|
|
7
|
-
data.tar.gz:
|
|
6
|
+
metadata.gz: a8743ec17b3caaa9b6c5dd5c9b9b18902561927dfd992003f25db88334cc2b4364a4c6ce2dea34629f801d5d7dbe9761b15e7f2f034e00ba526db36ce828dcaf
|
|
7
|
+
data.tar.gz: 00cf954a86c8b0d96f2e694359c1c75e3193e0e6d146ffba19b3857bef4c15ca93d25f1310ebebf815de8da93ede1b97e325dc54aade699219b9ab35f2976e49
|
data/CHANGELOG.md
CHANGED
|
@@ -9,6 +9,42 @@
|
|
|
9
9
|
- ...
|
|
10
10
|
---
|
|
11
11
|
|
|
12
|
+
## v0.10.3
|
|
13
|
+
### Added
|
|
14
|
+
- ...
|
|
15
|
+
### Changed/Removed
|
|
16
|
+
- Changed `Database#create_collections` and `#create_unique_indexes` by removing `rescue nil` from their database operations. Now any underlying errors with the database client are not masked.
|
|
17
|
+
### Fixed
|
|
18
|
+
- ...
|
|
19
|
+
---
|
|
20
|
+
|
|
21
|
+
## v0.10.2
|
|
22
|
+
### Added
|
|
23
|
+
- `Wgit::Base#setup` and `#teardown` methods (lifecycle hooks) that can be overridden by subclasses.
|
|
24
|
+
### Changed/Removed
|
|
25
|
+
- ...
|
|
26
|
+
### Fixed
|
|
27
|
+
- ...
|
|
28
|
+
---
|
|
29
|
+
|
|
30
|
+
## v0.10.1
|
|
31
|
+
### Added
|
|
32
|
+
- Support for Ruby 3.
|
|
33
|
+
### Changed/Removed
|
|
34
|
+
- Removed support for Ruby 2.5 (as it's too old).
|
|
35
|
+
### Fixed
|
|
36
|
+
- ...
|
|
37
|
+
---
|
|
38
|
+
|
|
39
|
+
## v0.10.0
|
|
40
|
+
### Added
|
|
41
|
+
- `Wgit::Url#scheme_relative?` method.
|
|
42
|
+
### Changed/Removed
|
|
43
|
+
- Breaking change: Changed method signature of `Wgit::Url#prefix_scheme` by making the previously named parameter a defaulted positional parameter. Remove the `protocol` named parameter for the old behaviour.
|
|
44
|
+
### Fixed
|
|
45
|
+
- [Scheme-relative bug](https://github.com/michaeltelford/wgit/issues/10) by adding support for scheme-relative URL's.
|
|
46
|
+
---
|
|
47
|
+
|
|
12
48
|
## v0.9.0
|
|
13
49
|
This release is a big one with the introduction of a `Wgit::DSL` and Javascript parse support. The `README` has been revamped as a result with new usage examples. And all of the wiki articles have been updated to reflect the latest code base.
|
|
14
50
|
### Added
|
|
@@ -112,7 +148,7 @@ This release is a big one with the introduction of a `Wgit::DSL` and Javascript
|
|
|
112
148
|
- `Wgit::Response` class containing adapter agnostic HTTP response logic.
|
|
113
149
|
### Changed/Removed
|
|
114
150
|
- Breaking changes: Removed `Wgit::Document#date_crawled` and `#crawl_duration` because both of these methods exist on the `Wgit::Document#url`. Instead, use `doc.url.date_crawled` etc.
|
|
115
|
-
- Breaking changes: Added to and moved `Document.define_extension` block params, it's now `|value, source, type|`. The `source` is not what it used to be; it's now `type` - of either `:document` or `:object`. Confused? See the [docs](https://www.rubydoc.info/
|
|
151
|
+
- Breaking changes: Added to and moved `Document.define_extension` block params, it's now `|value, source, type|`. The `source` is not what it used to be; it's now `type` - of either `:document` or `:object`. Confused? See the [docs](https://www.rubydoc.info/gems/wgit).
|
|
116
152
|
- Breaking changes: Changed `Wgit::Url#prefix_protocol` so that it no longer modifies the receiver.
|
|
117
153
|
- Breaking changes: Updated `Wgit::Url#to_anchor` and `#to_query` logic to align with that of `Addressable::URI` e.g. the anchor value no longer contains `#` prefix; and the query value no longer contains `?` prefix.
|
|
118
154
|
- Breaking changes: Renamed `Wgit::Url` methods containing `anchor` to now be named `fragment` e.g. `to_anchor` is now called `to_fragment` and `without_anchor` is `without_fragment` etc.
|
|
@@ -160,7 +196,7 @@ This release is a big one with the introduction of a `Wgit::DSL` and Javascript
|
|
|
160
196
|
---
|
|
161
197
|
|
|
162
198
|
## v0.2.0
|
|
163
|
-
This version of Wgit see's a major refactor of the code base involving multiple changes to method names and their signatures (optional parameters turned into named parameters in most cases). A list of the breaking changes are below including how to fix any breakages; but if you're having issues with the upgrade see the documentation at: https://www.rubydoc.info/
|
|
199
|
+
This version of Wgit see's a major refactor of the code base involving multiple changes to method names and their signatures (optional parameters turned into named parameters in most cases). A list of the breaking changes are below including how to fix any breakages; but if you're having issues with the upgrade see the documentation at: https://www.rubydoc.info/gems/wgit
|
|
164
200
|
### Added
|
|
165
201
|
- `Wgit::Url#absolute?` method.
|
|
166
202
|
- `Wgit::Url#relative? base: url` support.
|
data/README.md
CHANGED
|
@@ -10,7 +10,7 @@
|
|
|
10
10
|
|
|
11
11
|
Wgit is a HTML web crawler, written in Ruby, that allows you to programmatically extract the data you want from the web.
|
|
12
12
|
|
|
13
|
-
Wgit was primarily designed to crawl static HTML websites to index and
|
|
13
|
+
Wgit was primarily designed to crawl static HTML websites to index and search their content - providing the basis of any search engine; but Wgit is suitable for many application domains including:
|
|
14
14
|
|
|
15
15
|
- URL parsing
|
|
16
16
|
- Document content extraction (data mining)
|
|
@@ -62,31 +62,6 @@ end
|
|
|
62
62
|
puts JSON.generate(quotes)
|
|
63
63
|
```
|
|
64
64
|
|
|
65
|
-
The [DSL](https://github.com/michaeltelford/wgit/wiki/How-To-Use-The-DSL) makes it easy to write scripts for experimenting with. Wgit's DSL is simply a wrapper around the underlying classes however. For comparison, here is the above example written using the Wgit API *instead of* the DSL:
|
|
66
|
-
|
|
67
|
-
```ruby
|
|
68
|
-
require 'wgit'
|
|
69
|
-
require 'json'
|
|
70
|
-
|
|
71
|
-
crawler = Wgit::Crawler.new
|
|
72
|
-
url = Wgit::Url.new('http://quotes.toscrape.com/tag/humor/')
|
|
73
|
-
quotes = []
|
|
74
|
-
|
|
75
|
-
Wgit::Document.define_extractor(:quotes, "//div[@class='quote']/span[@class='text']", singleton: false)
|
|
76
|
-
Wgit::Document.define_extractor(:authors, "//div[@class='quote']/span/small", singleton: false)
|
|
77
|
-
|
|
78
|
-
crawler.crawl_site(url, follow: "//li[@class='next']/a/@href") do |doc|
|
|
79
|
-
doc.quotes.zip(doc.authors).each do |arr|
|
|
80
|
-
quotes << {
|
|
81
|
-
quote: arr.first,
|
|
82
|
-
author: arr.last
|
|
83
|
-
}
|
|
84
|
-
end
|
|
85
|
-
end
|
|
86
|
-
|
|
87
|
-
puts JSON.generate(quotes)
|
|
88
|
-
```
|
|
89
|
-
|
|
90
65
|
But what if we want to crawl and store the content in a database, so that it can be searched? Wgit makes it easy to index and search HTML using [MongoDB](https://www.mongodb.com/):
|
|
91
66
|
|
|
92
67
|
```ruby
|
|
@@ -97,14 +72,13 @@ include Wgit::DSL
|
|
|
97
72
|
Wgit.logger.level = Logger::WARN
|
|
98
73
|
|
|
99
74
|
connection_string 'mongodb://user:password@localhost/crawler'
|
|
100
|
-
clear_db!
|
|
101
|
-
|
|
102
|
-
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
103
|
-
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
104
75
|
|
|
105
76
|
start 'http://quotes.toscrape.com/tag/humor/'
|
|
106
77
|
follow "//li[@class='next']/a/@href"
|
|
107
78
|
|
|
79
|
+
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
80
|
+
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
81
|
+
|
|
108
82
|
index_site
|
|
109
83
|
search 'prejudice'
|
|
110
84
|
```
|
|
@@ -117,10 +91,35 @@ Quotes to Scrape
|
|
|
117
91
|
http://quotes.toscrape.com/tag/humor/page/2/
|
|
118
92
|
```
|
|
119
93
|
|
|
120
|
-
Using a
|
|
94
|
+
Using a MongoDB [client](https://robomongo.org/), we can see that the two web pages have been indexed, along with their extracted *quotes* and *authors*:
|
|
121
95
|
|
|
122
96
|
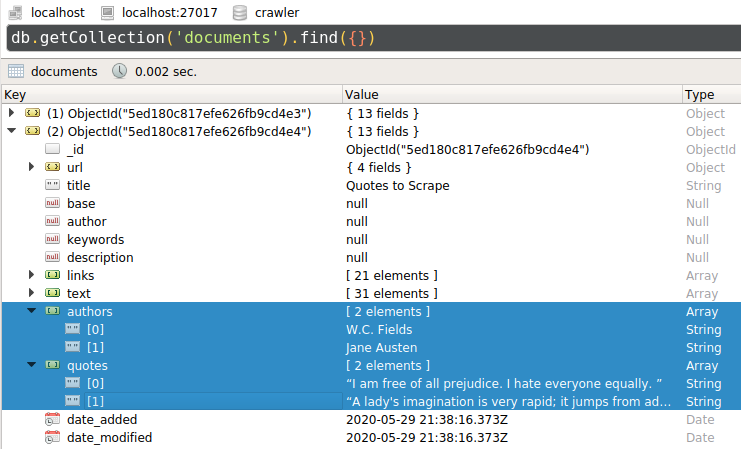
|
|
123
97
|
|
|
98
|
+
The [DSL](https://github.com/michaeltelford/wgit/wiki/How-To-Use-The-DSL) makes it easy to write scripts for experimenting with. Wgit's DSL is simply a wrapper around the underlying classes however. For comparison, here is the above example written using the Wgit API *instead of* the DSL:
|
|
99
|
+
|
|
100
|
+
```ruby
|
|
101
|
+
require 'wgit'
|
|
102
|
+
require 'json'
|
|
103
|
+
|
|
104
|
+
crawler = Wgit::Crawler.new
|
|
105
|
+
url = Wgit::Url.new('http://quotes.toscrape.com/tag/humor/')
|
|
106
|
+
quotes = []
|
|
107
|
+
|
|
108
|
+
Wgit::Document.define_extractor(:quotes, "//div[@class='quote']/span[@class='text']", singleton: false)
|
|
109
|
+
Wgit::Document.define_extractor(:authors, "//div[@class='quote']/span/small", singleton: false)
|
|
110
|
+
|
|
111
|
+
crawler.crawl_site(url, follow: "//li[@class='next']/a/@href") do |doc|
|
|
112
|
+
doc.quotes.zip(doc.authors).each do |arr|
|
|
113
|
+
quotes << {
|
|
114
|
+
quote: arr.first,
|
|
115
|
+
author: arr.last
|
|
116
|
+
}
|
|
117
|
+
end
|
|
118
|
+
end
|
|
119
|
+
|
|
120
|
+
puts JSON.generate(quotes)
|
|
121
|
+
```
|
|
122
|
+
|
|
124
123
|
## Why Wgit?
|
|
125
124
|
|
|
126
125
|
There are many [other HTML crawlers](https://awesome-ruby.com/#-web-crawling) out there so why use Wgit?
|
|
@@ -161,33 +160,27 @@ Only MRI Ruby is tested and supported, but Wgit may work with other Ruby impleme
|
|
|
161
160
|
|
|
162
161
|
Currently, the required MRI Ruby version is:
|
|
163
162
|
|
|
164
|
-
|
|
163
|
+
`ruby '>= 2.6', '< 4'`
|
|
165
164
|
|
|
166
165
|
### Using Bundler
|
|
167
166
|
|
|
168
|
-
|
|
169
|
-
|
|
170
|
-
```ruby
|
|
171
|
-
gem 'wgit'
|
|
172
|
-
```
|
|
173
|
-
|
|
174
|
-
And then execute:
|
|
175
|
-
|
|
176
|
-
$ bundle
|
|
167
|
+
$ bundle add wgit
|
|
177
168
|
|
|
178
169
|
### Using RubyGems
|
|
179
170
|
|
|
180
171
|
$ gem install wgit
|
|
181
172
|
|
|
182
|
-
Verify
|
|
173
|
+
### Verify
|
|
183
174
|
|
|
184
175
|
$ wgit
|
|
185
176
|
|
|
177
|
+
Calling the installed executable will start an REPL session.
|
|
178
|
+
|
|
186
179
|
## Documentation
|
|
187
180
|
|
|
188
181
|
- [Getting Started](https://github.com/michaeltelford/wgit/wiki/Getting-Started)
|
|
189
182
|
- [Wiki](https://github.com/michaeltelford/wgit/wiki)
|
|
190
|
-
- [Yardocs](https://www.rubydoc.info/
|
|
183
|
+
- [API Yardocs](https://www.rubydoc.info/gems/wgit)
|
|
191
184
|
- [CHANGELOG](https://github.com/michaeltelford/wgit/blob/master/CHANGELOG.md)
|
|
192
185
|
|
|
193
186
|
## Executable
|
data/lib/wgit/base.rb
CHANGED
|
@@ -4,16 +4,25 @@ module Wgit
|
|
|
4
4
|
class Base
|
|
5
5
|
extend Wgit::DSL
|
|
6
6
|
|
|
7
|
+
# Runs once before the crawl/index is run. Override as needed.
|
|
8
|
+
def setup; end
|
|
9
|
+
|
|
10
|
+
# Runs once after the crawl/index is complete. Override as needed.
|
|
11
|
+
def teardown; end
|
|
12
|
+
|
|
7
13
|
# Runs the crawl/index passing each crawled `Wgit::Document` and the given
|
|
8
14
|
# block to the subclass's `#parse` method.
|
|
9
15
|
def self.run(&block)
|
|
16
|
+
crawl_method = @method || :crawl
|
|
10
17
|
obj = new
|
|
18
|
+
|
|
11
19
|
unless obj.respond_to?(:parse)
|
|
12
20
|
raise "#{obj.class} must respond_to? #parse(doc, &block)"
|
|
13
21
|
end
|
|
14
22
|
|
|
15
|
-
|
|
23
|
+
obj.setup
|
|
16
24
|
send(crawl_method) { |doc| obj.parse(doc, &block) }
|
|
25
|
+
obj.teardown
|
|
17
26
|
|
|
18
27
|
obj
|
|
19
28
|
end
|
|
@@ -91,29 +91,27 @@ module Wgit
|
|
|
91
91
|
|
|
92
92
|
### DDL ###
|
|
93
93
|
|
|
94
|
-
# Creates the urls and documents collections
|
|
95
|
-
# This method is therefore idempotent.
|
|
94
|
+
# Creates the 'urls' and 'documents' collections.
|
|
96
95
|
#
|
|
97
96
|
# @return [nil] Always returns nil.
|
|
98
97
|
def create_collections
|
|
99
|
-
|
|
100
|
-
|
|
98
|
+
@client[URLS_COLLECTION].create
|
|
99
|
+
@client[DOCUMENTS_COLLECTION].create
|
|
101
100
|
|
|
102
101
|
nil
|
|
103
102
|
end
|
|
104
103
|
|
|
105
|
-
# Creates the urls and documents unique 'url' indexes
|
|
106
|
-
# exist. This method is therefore idempotent.
|
|
104
|
+
# Creates the urls and documents unique 'url' indexes.
|
|
107
105
|
#
|
|
108
106
|
# @return [nil] Always returns nil.
|
|
109
107
|
def create_unique_indexes
|
|
110
108
|
@client[URLS_COLLECTION].indexes.create_one(
|
|
111
109
|
{ url: 1 }, name: UNIQUE_INDEX, unique: true
|
|
112
|
-
)
|
|
110
|
+
)
|
|
113
111
|
|
|
114
112
|
@client[DOCUMENTS_COLLECTION].indexes.create_one(
|
|
115
113
|
{ 'url.url' => 1 }, name: UNIQUE_INDEX, unique: true
|
|
116
|
-
)
|
|
114
|
+
)
|
|
117
115
|
|
|
118
116
|
nil
|
|
119
117
|
end
|
|
@@ -186,7 +184,7 @@ module Wgit
|
|
|
186
184
|
data_hash = model.merge(Wgit::Model.common_update_data)
|
|
187
185
|
result = @client[collection].replace_one(query, data_hash, upsert: true)
|
|
188
186
|
|
|
189
|
-
result.matched_count
|
|
187
|
+
result.matched_count.zero?
|
|
190
188
|
end
|
|
191
189
|
|
|
192
190
|
### Retrieve Data ###
|
data/lib/wgit/document.rb
CHANGED
|
@@ -413,6 +413,13 @@ be relative"
|
|
|
413
413
|
return [] if @links.empty?
|
|
414
414
|
|
|
415
415
|
links = @links
|
|
416
|
+
.map do |link|
|
|
417
|
+
if link.scheme_relative?
|
|
418
|
+
link.prefix_scheme(@url.to_scheme.to_sym)
|
|
419
|
+
else
|
|
420
|
+
link
|
|
421
|
+
end
|
|
422
|
+
end
|
|
416
423
|
.reject { |link| link.relative?(host: @url.to_origin) }
|
|
417
424
|
.map(&:omit_trailing_slash)
|
|
418
425
|
|
data/lib/wgit/indexer.rb
CHANGED
|
@@ -80,8 +80,8 @@ database capacity, exiting.")
|
|
|
80
80
|
urls_count += write_urls_to_db(ext_links)
|
|
81
81
|
end
|
|
82
82
|
|
|
83
|
-
Wgit.logger.info("Crawled and indexed
|
|
84
|
-
overall for this iteration.")
|
|
83
|
+
Wgit.logger.info("Crawled and indexed documents for #{docs_count} \
|
|
84
|
+
url(s) overall for this iteration.")
|
|
85
85
|
Wgit.logger.info("Found and saved #{urls_count} external url(s) for \
|
|
86
86
|
the next iteration.")
|
|
87
87
|
|
|
@@ -136,8 +136,8 @@ the next iteration.")
|
|
|
136
136
|
Wgit.logger.info("Found and saved #{num_inserted_urls} external url(s)")
|
|
137
137
|
end
|
|
138
138
|
|
|
139
|
-
Wgit.logger.info("Crawled and indexed #{total_pages_indexed}
|
|
140
|
-
the site: #{url}")
|
|
139
|
+
Wgit.logger.info("Crawled and indexed #{total_pages_indexed} documents \
|
|
140
|
+
for the site: #{url}")
|
|
141
141
|
|
|
142
142
|
total_pages_indexed
|
|
143
143
|
end
|
data/lib/wgit/url.rb
CHANGED
|
@@ -162,6 +162,7 @@ Addressable::URI::InvalidURIError")
|
|
|
162
162
|
opts = defaults.merge(opts)
|
|
163
163
|
raise 'Url (self) cannot be empty' if empty?
|
|
164
164
|
|
|
165
|
+
return false if scheme_relative?
|
|
165
166
|
return true if @uri.relative?
|
|
166
167
|
|
|
167
168
|
# Self is absolute but may be relative to the opts param e.g. host.
|
|
@@ -266,26 +267,28 @@ protocol scheme and domain (e.g. http://example.com): #{url}"
|
|
|
266
267
|
# @return [Wgit::Url] Self in absolute form.
|
|
267
268
|
def make_absolute(doc)
|
|
268
269
|
assert_type(doc, Wgit::Document)
|
|
270
|
+
raise 'Cannot make absolute when Document @url is not valid' \
|
|
271
|
+
unless doc.url.valid?
|
|
272
|
+
|
|
273
|
+
return prefix_scheme(doc.url.to_scheme&.to_sym) if scheme_relative?
|
|
269
274
|
|
|
270
275
|
absolute? ? self : doc.base_url(link: self).concat(self)
|
|
271
276
|
end
|
|
272
277
|
|
|
273
|
-
# Returns self having prefixed a protocol
|
|
278
|
+
# Returns self having prefixed a scheme/protocol. Doesn't modify receiver.
|
|
274
279
|
# Returns self even if absolute (with scheme); therefore is idempotent.
|
|
275
280
|
#
|
|
276
|
-
# @param
|
|
277
|
-
# @return [Wgit::Url] Self with a
|
|
278
|
-
def prefix_scheme(
|
|
279
|
-
|
|
280
|
-
|
|
281
|
-
case protocol
|
|
282
|
-
when :http
|
|
283
|
-
Wgit::Url.new("http://#{url}")
|
|
284
|
-
when :https
|
|
285
|
-
Wgit::Url.new("https://#{url}")
|
|
286
|
-
else
|
|
287
|
-
raise "protocol must be :http or :https, not :#{protocol}"
|
|
281
|
+
# @param scheme [Symbol] Either :http or :https.
|
|
282
|
+
# @return [Wgit::Url] Self with a scheme prefix.
|
|
283
|
+
def prefix_scheme(scheme = :http)
|
|
284
|
+
unless %i[http https].include?(scheme)
|
|
285
|
+
raise "scheme must be :http or :https, not :#{scheme}"
|
|
288
286
|
end
|
|
287
|
+
|
|
288
|
+
return self if absolute? && !scheme_relative?
|
|
289
|
+
|
|
290
|
+
separator = scheme_relative? ? '' : '//'
|
|
291
|
+
Wgit::Url.new("#{scheme}:#{separator}#{self}")
|
|
289
292
|
end
|
|
290
293
|
|
|
291
294
|
# Returns a Hash containing this Url's instance vars excluding @uri.
|
|
@@ -624,31 +627,40 @@ protocol scheme and domain (e.g. http://example.com): #{url}"
|
|
|
624
627
|
self == '/'
|
|
625
628
|
end
|
|
626
629
|
|
|
627
|
-
|
|
628
|
-
|
|
629
|
-
|
|
630
|
-
|
|
631
|
-
|
|
632
|
-
|
|
633
|
-
|
|
634
|
-
|
|
635
|
-
alias
|
|
636
|
-
alias
|
|
637
|
-
alias
|
|
638
|
-
alias
|
|
639
|
-
alias
|
|
640
|
-
alias
|
|
641
|
-
alias
|
|
642
|
-
alias
|
|
643
|
-
alias
|
|
644
|
-
alias
|
|
645
|
-
alias
|
|
646
|
-
alias
|
|
647
|
-
alias
|
|
648
|
-
alias
|
|
649
|
-
alias
|
|
650
|
-
alias
|
|
651
|
-
alias
|
|
652
|
-
alias
|
|
630
|
+
# Returns true if self starts with '//' a.k.a a scheme/protocol relative
|
|
631
|
+
# path.
|
|
632
|
+
#
|
|
633
|
+
# @return [Boolean] True if self starts with '//', false otherwise.
|
|
634
|
+
def scheme_relative?
|
|
635
|
+
start_with?('//')
|
|
636
|
+
end
|
|
637
|
+
|
|
638
|
+
alias + concat
|
|
639
|
+
alias crawled? crawled
|
|
640
|
+
alias is_relative? relative?
|
|
641
|
+
alias is_absolute? absolute?
|
|
642
|
+
alias is_valid? valid?
|
|
643
|
+
alias is_query? query?
|
|
644
|
+
alias is_fragment? fragment?
|
|
645
|
+
alias is_index? index?
|
|
646
|
+
alias is_scheme_relative? scheme_relative?
|
|
647
|
+
alias uri to_uri
|
|
648
|
+
alias url to_url
|
|
649
|
+
alias scheme to_scheme
|
|
650
|
+
alias host to_host
|
|
651
|
+
alias port to_port
|
|
652
|
+
alias domain to_domain
|
|
653
|
+
alias brand to_brand
|
|
654
|
+
alias base to_base
|
|
655
|
+
alias origin to_origin
|
|
656
|
+
alias path to_path
|
|
657
|
+
alias endpoint to_endpoint
|
|
658
|
+
alias query to_query
|
|
659
|
+
alias query_hash to_query_hash
|
|
660
|
+
alias fragment to_fragment
|
|
661
|
+
alias extension to_extension
|
|
662
|
+
alias user to_user
|
|
663
|
+
alias password to_password
|
|
664
|
+
alias sub_domain to_sub_domain
|
|
653
665
|
end
|
|
654
666
|
end
|
data/lib/wgit/version.rb
CHANGED
metadata
CHANGED
|
@@ -1,14 +1,14 @@
|
|
|
1
1
|
--- !ruby/object:Gem::Specification
|
|
2
2
|
name: wgit
|
|
3
3
|
version: !ruby/object:Gem::Version
|
|
4
|
-
version: 0.
|
|
4
|
+
version: 0.10.3
|
|
5
5
|
platform: ruby
|
|
6
6
|
authors:
|
|
7
7
|
- Michael Telford
|
|
8
|
-
autorequire:
|
|
8
|
+
autorequire:
|
|
9
9
|
bindir: bin
|
|
10
10
|
cert_chain: []
|
|
11
|
-
date:
|
|
11
|
+
date: 2021-11-25 00:00:00.000000000 Z
|
|
12
12
|
dependencies:
|
|
13
13
|
- !ruby/object:Gem::Dependency
|
|
14
14
|
name: addressable
|
|
@@ -241,7 +241,7 @@ metadata:
|
|
|
241
241
|
source_code_uri: https://github.com/michaeltelford/wgit
|
|
242
242
|
changelog_uri: https://github.com/michaeltelford/wgit/blob/master/CHANGELOG.md
|
|
243
243
|
bug_tracker_uri: https://github.com/michaeltelford/wgit/issues
|
|
244
|
-
documentation_uri: https://www.rubydoc.info/
|
|
244
|
+
documentation_uri: https://www.rubydoc.info/gems/wgit
|
|
245
245
|
allowed_push_host: https://rubygems.org
|
|
246
246
|
post_install_message: Added the 'wgit' executable to $PATH
|
|
247
247
|
rdoc_options: []
|
|
@@ -249,17 +249,20 @@ require_paths:
|
|
|
249
249
|
- lib
|
|
250
250
|
required_ruby_version: !ruby/object:Gem::Requirement
|
|
251
251
|
requirements:
|
|
252
|
-
- - "
|
|
252
|
+
- - ">="
|
|
253
|
+
- !ruby/object:Gem::Version
|
|
254
|
+
version: '2.6'
|
|
255
|
+
- - "<"
|
|
253
256
|
- !ruby/object:Gem::Version
|
|
254
|
-
version: '
|
|
257
|
+
version: '4'
|
|
255
258
|
required_rubygems_version: !ruby/object:Gem::Requirement
|
|
256
259
|
requirements:
|
|
257
260
|
- - ">="
|
|
258
261
|
- !ruby/object:Gem::Version
|
|
259
262
|
version: '0'
|
|
260
263
|
requirements: []
|
|
261
|
-
rubygems_version: 3.
|
|
262
|
-
signing_key:
|
|
264
|
+
rubygems_version: 3.2.22
|
|
265
|
+
signing_key:
|
|
263
266
|
specification_version: 4
|
|
264
267
|
summary: Wgit is a HTML web crawler, written in Ruby, that allows you to programmatically
|
|
265
268
|
extract the data you want from the web.
|