wgit 0.8.0 → 0.10.2
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/.yardopts +1 -1
- data/CHANGELOG.md +68 -2
- data/LICENSE.txt +1 -1
- data/README.md +114 -326
- data/bin/wgit +9 -5
- data/lib/wgit/assertable.rb +3 -3
- data/lib/wgit/base.rb +39 -0
- data/lib/wgit/crawler.rb +206 -76
- data/lib/wgit/database/database.rb +309 -134
- data/lib/wgit/database/model.rb +10 -3
- data/lib/wgit/document.rb +145 -95
- data/lib/wgit/{document_extensions.rb → document_extractors.rb} +11 -11
- data/lib/wgit/dsl.rb +324 -0
- data/lib/wgit/indexer.rb +66 -163
- data/lib/wgit/response.rb +5 -2
- data/lib/wgit/url.rb +177 -63
- data/lib/wgit/utils.rb +32 -20
- data/lib/wgit/version.rb +2 -1
- data/lib/wgit.rb +3 -1
- metadata +34 -19
data/README.md
CHANGED
|
@@ -8,382 +8,184 @@
|
|
|
8
8
|
|
|
9
9
|
---
|
|
10
10
|
|
|
11
|
-
Wgit is a
|
|
11
|
+
Wgit is a HTML web crawler, written in Ruby, that allows you to programmatically extract the data you want from the web.
|
|
12
12
|
|
|
13
|
-
|
|
13
|
+
Wgit was primarily designed to crawl static HTML websites to index and search their content - providing the basis of any search engine; but Wgit is suitable for many application domains including:
|
|
14
14
|
|
|
15
|
-
|
|
15
|
+
- URL parsing
|
|
16
|
+
- Document content extraction (data mining)
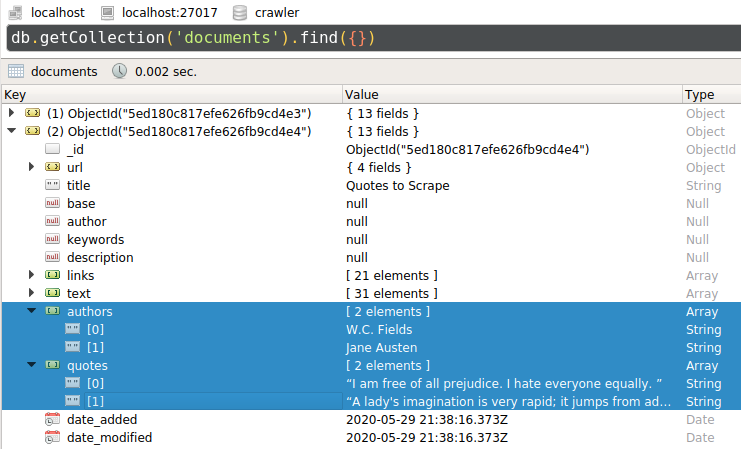
|
|
17
|
+
- Crawling entire websites (statistical analysis)
|
|
16
18
|
|
|
17
|
-
|
|
19
|
+
Wgit provides a high level, easy-to-use API and DSL that you can use in your own applications and scripts.
|
|
18
20
|
|
|
19
|
-
|
|
20
|
-
|
|
21
|
-
1. [Installation](#Installation)
|
|
22
|
-
2. [Basic Usage](#Basic-Usage)
|
|
23
|
-
3. [Documentation](#Documentation)
|
|
24
|
-
4. [Practical Examples](#Practical-Examples)
|
|
25
|
-
5. [Database Example](#Database-Example)
|
|
26
|
-
6. [Extending The API](#Extending-The-API)
|
|
27
|
-
7. [Caveats](#Caveats)
|
|
28
|
-
8. [Executable](#Executable)
|
|
29
|
-
9. [Change Log](#Change-Log)
|
|
30
|
-
10. [License](#License)
|
|
31
|
-
11. [Contributing](#Contributing)
|
|
32
|
-
12. [Development](#Development)
|
|
21
|
+
Check out this [demo search engine](https://search-engine-rb.herokuapp.com) - [built](https://github.com/michaeltelford/search_engine) using Wgit and Sinatra - deployed to [Heroku](https://www.heroku.com/). Heroku's free tier is used so the initial page load may be slow. Try searching for "Matz" or something else that's Ruby related.
|
|
33
22
|
|
|
34
|
-
##
|
|
23
|
+
## Table Of Contents
|
|
35
24
|
|
|
36
|
-
|
|
25
|
+
1. [Usage](#Usage)
|
|
26
|
+
2. [Why Wgit?](#Why-Wgit)
|
|
27
|
+
3. [Why Not Wgit?](#Why-Not-Wgit)
|
|
28
|
+
4. [Installation](#Installation)
|
|
29
|
+
5. [Documentation](#Documentation)
|
|
30
|
+
6. [Executable](#Executable)
|
|
31
|
+
7. [License](#License)
|
|
32
|
+
8. [Contributing](#Contributing)
|
|
33
|
+
9. [Development](#Development)
|
|
37
34
|
|
|
38
|
-
|
|
35
|
+
## Usage
|
|
39
36
|
|
|
40
|
-
|
|
37
|
+
Let's crawl a [quotes website](http://quotes.toscrape.com/) extracting its *quotes* and *authors* using the Wgit DSL:
|
|
41
38
|
|
|
42
39
|
```ruby
|
|
43
|
-
|
|
44
|
-
|
|
40
|
+
require 'wgit'
|
|
41
|
+
require 'json'
|
|
45
42
|
|
|
46
|
-
|
|
43
|
+
include Wgit::DSL
|
|
47
44
|
|
|
48
|
-
|
|
45
|
+
start 'http://quotes.toscrape.com/tag/humor/'
|
|
46
|
+
follow "//li[@class='next']/a/@href"
|
|
49
47
|
|
|
50
|
-
|
|
48
|
+
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
49
|
+
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
51
50
|
|
|
52
|
-
|
|
51
|
+
quotes = []
|
|
53
52
|
|
|
54
|
-
|
|
53
|
+
crawl_site do |doc|
|
|
54
|
+
doc.quotes.zip(doc.authors).each do |arr|
|
|
55
|
+
quotes << {
|
|
56
|
+
quote: arr.first,
|
|
57
|
+
author: arr.last
|
|
58
|
+
}
|
|
59
|
+
end
|
|
60
|
+
end
|
|
55
61
|
|
|
56
|
-
|
|
62
|
+
puts JSON.generate(quotes)
|
|
63
|
+
```
|
|
57
64
|
|
|
58
|
-
|
|
65
|
+
But what if we want to crawl and store the content in a database, so that it can be searched? Wgit makes it easy to index and search HTML using [MongoDB](https://www.mongodb.com/):
|
|
59
66
|
|
|
60
67
|
```ruby
|
|
61
68
|
require 'wgit'
|
|
62
69
|
|
|
63
|
-
|
|
64
|
-
url = Wgit::Url.new 'https://wikileaks.org/What-is-Wikileaks.html'
|
|
65
|
-
|
|
66
|
-
doc = crawler.crawl url # Or use #crawl_site(url) { |doc| ... } etc.
|
|
67
|
-
crawler.last_response.class # => Wgit::Response is a wrapper for Typhoeus::Response.
|
|
68
|
-
|
|
69
|
-
doc.class # => Wgit::Document
|
|
70
|
-
doc.class.public_instance_methods(false).sort # => [
|
|
71
|
-
# :==, :[], :author, :base, :base_url, :content, :css, :description, :doc, :empty?,
|
|
72
|
-
# :external_links, :external_urls, :html, :internal_absolute_links,
|
|
73
|
-
# :internal_absolute_urls,:internal_links, :internal_urls, :keywords, :links, :score,
|
|
74
|
-
# :search, :search!, :size, :statistics, :stats, :text, :title, :to_h, :to_json,
|
|
75
|
-
# :url, :xpath
|
|
76
|
-
# ]
|
|
77
|
-
|
|
78
|
-
doc.url # => "https://wikileaks.org/What-is-Wikileaks.html"
|
|
79
|
-
doc.title # => "WikiLeaks - What is WikiLeaks"
|
|
80
|
-
doc.stats # => {
|
|
81
|
-
# :url=>44, :html=>28133, :title=>17, :keywords=>0,
|
|
82
|
-
# :links=>35, :text=>67, :text_bytes=>13735
|
|
83
|
-
# }
|
|
84
|
-
doc.links # => ["#submit_help_contact", "#submit_help_tor", "#submit_help_tips", ...]
|
|
85
|
-
doc.text # => ["The Courage Foundation is an international organisation that <snip>", ...]
|
|
86
|
-
|
|
87
|
-
results = doc.search 'corruption' # Searches doc.text for the given query.
|
|
88
|
-
results.first # => "ial materials involving war, spying and corruption.
|
|
89
|
-
# It has so far published more"
|
|
90
|
-
```
|
|
91
|
-
|
|
92
|
-
## Documentation
|
|
93
|
-
|
|
94
|
-
100% of Wgit's code is documented using [YARD](https://yardoc.org/), deployed to [rubydoc.info](https://www.rubydoc.info/github/michaeltelford/wgit/master). This greatly benefits developers in using Wgit in their own programs. Another good source of information (as to how the library behaves) are the [tests](https://github.com/michaeltelford/wgit/tree/master/test). Also, see the [Practical Examples](#Practical-Examples) section below for real working examples of Wgit in action.
|
|
95
|
-
|
|
96
|
-
## Practical Examples
|
|
97
|
-
|
|
98
|
-
Below are some practical examples of Wgit in use. You can copy and run the code for yourself (it's all been tested).
|
|
99
|
-
|
|
100
|
-
In addition to the practical examples below, the [wiki](https://github.com/michaeltelford/wgit/wiki) contains a useful 'How To' section with more specific usage of Wgit. You should finish reading this `README` first however.
|
|
101
|
-
|
|
102
|
-
### WWW HTML Indexer
|
|
103
|
-
|
|
104
|
-
See the [`Wgit::Indexer#index_www`](https://www.rubydoc.info/github/michaeltelford/wgit/master/Wgit%2Eindex_www) documentation and source code for an already built example of a WWW HTML indexer. It will crawl any external URL's (in the database) and index their HTML for later use, be it searching or otherwise. It will literally crawl the WWW forever if you let it!
|
|
105
|
-
|
|
106
|
-
See the [Database Example](#Database-Example) for information on how to configure a database for use with Wgit.
|
|
107
|
-
|
|
108
|
-
### Website Downloader
|
|
70
|
+
include Wgit::DSL
|
|
109
71
|
|
|
110
|
-
Wgit
|
|
72
|
+
Wgit.logger.level = Logger::WARN
|
|
111
73
|
|
|
112
|
-
|
|
74
|
+
connection_string 'mongodb://user:password@localhost/crawler'
|
|
113
75
|
|
|
114
|
-
|
|
76
|
+
start 'http://quotes.toscrape.com/tag/humor/'
|
|
77
|
+
follow "//li[@class='next']/a/@href"
|
|
115
78
|
|
|
116
|
-
|
|
79
|
+
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
80
|
+
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
117
81
|
|
|
118
|
-
|
|
119
|
-
|
|
120
|
-
```
|
|
121
|
-
require 'wgit'
|
|
122
|
-
require 'wgit/core_ext' # Provides the String#to_url and Enumerable#to_urls methods.
|
|
123
|
-
|
|
124
|
-
crawler = Wgit::Crawler.new
|
|
125
|
-
url = 'https://www.facebook.com'.to_url
|
|
126
|
-
|
|
127
|
-
doc = crawler.crawl url
|
|
128
|
-
|
|
129
|
-
# Provide your own xpath (or css selector) to search the HTML using Nokogiri underneath.
|
|
130
|
-
hrefs = doc.xpath "//link[@rel='stylesheet']/@href"
|
|
82
|
+
index_site
|
|
83
|
+
search 'prejudice'
|
|
84
|
+
```
|
|
131
85
|
|
|
132
|
-
|
|
133
|
-
href = hrefs.first.value # => "https://static.xx.fbcdn.net/rsrc.php/v3/y1/l/0,cross/NvZ4mNTW3Fd.css"
|
|
86
|
+
The `search` call (on the last line) will return and output the results:
|
|
134
87
|
|
|
135
|
-
|
|
136
|
-
|
|
88
|
+
```text
|
|
89
|
+
Quotes to Scrape
|
|
90
|
+
“I am free of all prejudice. I hate everyone equally. ”
|
|
91
|
+
http://quotes.toscrape.com/tag/humor/page/2/
|
|
137
92
|
```
|
|
138
93
|
|
|
139
|
-
|
|
94
|
+
Using a MongoDB [client](https://robomongo.org/), we can see that the two web pages have been indexed, along with their extracted *quotes* and *authors*:
|
|
95
|
+
|
|
96
|
+
|
|
140
97
|
|
|
141
|
-
The
|
|
98
|
+
The [DSL](https://github.com/michaeltelford/wgit/wiki/How-To-Use-The-DSL) makes it easy to write scripts for experimenting with. Wgit's DSL is simply a wrapper around the underlying classes however. For comparison, here is the above example written using the Wgit API *instead of* the DSL:
|
|
142
99
|
|
|
143
100
|
```ruby
|
|
144
101
|
require 'wgit'
|
|
145
|
-
require '
|
|
146
|
-
|
|
147
|
-
my_pages_keywords = ['Everest', 'mountaineering school', 'adventure']
|
|
148
|
-
my_pages_missing_keywords = []
|
|
149
|
-
|
|
150
|
-
competitor_urls = [
|
|
151
|
-
'http://altitudejunkies.com',
|
|
152
|
-
'http://www.mountainmadness.com',
|
|
153
|
-
'http://www.adventureconsultants.com'
|
|
154
|
-
].to_urls
|
|
102
|
+
require 'json'
|
|
155
103
|
|
|
156
104
|
crawler = Wgit::Crawler.new
|
|
157
|
-
|
|
158
|
-
|
|
159
|
-
|
|
160
|
-
|
|
161
|
-
|
|
162
|
-
|
|
105
|
+
url = Wgit::Url.new('http://quotes.toscrape.com/tag/humor/')
|
|
106
|
+
quotes = []
|
|
107
|
+
|
|
108
|
+
Wgit::Document.define_extractor(:quotes, "//div[@class='quote']/span[@class='text']", singleton: false)
|
|
109
|
+
Wgit::Document.define_extractor(:authors, "//div[@class='quote']/span/small", singleton: false)
|
|
110
|
+
|
|
111
|
+
crawler.crawl_site(url, follow: "//li[@class='next']/a/@href") do |doc|
|
|
112
|
+
doc.quotes.zip(doc.authors).each do |arr|
|
|
113
|
+
quotes << {
|
|
114
|
+
quote: arr.first,
|
|
115
|
+
author: arr.last
|
|
116
|
+
}
|
|
163
117
|
end
|
|
164
118
|
end
|
|
165
119
|
|
|
166
|
-
|
|
167
|
-
puts 'Your pages are missing no keywords, nice one!'
|
|
168
|
-
else
|
|
169
|
-
puts 'Your pages compared to your competitors are missing the following keywords:'
|
|
170
|
-
puts my_pages_missing_keywords.uniq
|
|
171
|
-
end
|
|
172
|
-
```
|
|
173
|
-
|
|
174
|
-
## Database Example
|
|
175
|
-
|
|
176
|
-
The next example requires a configured database instance. The use of a database for Wgit is entirely optional however and isn't required for crawling or URL parsing etc. A database is only needed when indexing (inserting crawled data into the database).
|
|
177
|
-
|
|
178
|
-
Currently the only supported DBMS is MongoDB. See [MongoDB Atlas](https://www.mongodb.com/cloud/atlas) for a (small) free account or provide your own MongoDB instance. Take a look at this [Docker Hub image](https://hub.docker.com/r/michaeltelford/mongo-wgit) for an already built example of a `mongo` image configured for use with Wgit; the source of which can be found in the [`./docker`](https://github.com/michaeltelford/wgit/tree/master/docker) directory of this repository.
|
|
179
|
-
|
|
180
|
-
[`Wgit::Database`](https://www.rubydoc.info/github/michaeltelford/wgit/master/Wgit/Database) provides a light wrapper of logic around the `mongo` gem allowing for simple database interactivity and object serialisation. Using Wgit you can index webpages, store them in a database and then search through all that's been indexed; quickly and easily.
|
|
181
|
-
|
|
182
|
-
### Versioning
|
|
183
|
-
|
|
184
|
-
The following versions of MongoDB are currently supported:
|
|
185
|
-
|
|
186
|
-
| Gem | Database |
|
|
187
|
-
| ------ | -------- |
|
|
188
|
-
| ~> 2.9 | ~> 4.0 |
|
|
189
|
-
|
|
190
|
-
### Data Model
|
|
191
|
-
|
|
192
|
-
The data model for Wgit is deliberately simplistic. The MongoDB collections consist of:
|
|
193
|
-
|
|
194
|
-
| Collection | Purpose |
|
|
195
|
-
| ----------- | ----------------------------------------------- |
|
|
196
|
-
| `urls` | Stores URL's to be crawled at a later date |
|
|
197
|
-
| `documents` | Stores web documents after they've been crawled |
|
|
198
|
-
|
|
199
|
-
Wgit provides respective Ruby classes for each collection object, allowing for serialisation.
|
|
200
|
-
|
|
201
|
-
### Configuring MongoDB
|
|
202
|
-
|
|
203
|
-
Follow the steps below to configure MongoDB for use with Wgit. This is only required if you want to read/write database records using your own (manually configured) instance of Mongo DB.
|
|
204
|
-
|
|
205
|
-
1) Create collections for: `urls` and `documents`.
|
|
206
|
-
2) Add a [*unique index*](https://docs.mongodb.com/manual/core/index-unique/) for the `url` field in **both** collections using:
|
|
207
|
-
|
|
208
|
-
| Collection | Fields | Options |
|
|
209
|
-
| ----------- | ------------------- | ------------------- |
|
|
210
|
-
| `urls` | `{ "url" : 1 }` | `{ unique : true }` |
|
|
211
|
-
| `documents` | `{ "url.url" : 1 }` | `{ unique : true }` |
|
|
212
|
-
|
|
213
|
-
3) Enable `textSearchEnabled` in MongoDB's configuration (if not already so - it's typically enabled by default).
|
|
214
|
-
4) Create a [*text search index*](https://docs.mongodb.com/manual/core/index-text/#index-feature-text) for the `documents` collection using:
|
|
215
|
-
```json
|
|
216
|
-
{
|
|
217
|
-
"text": "text",
|
|
218
|
-
"author": "text",
|
|
219
|
-
"keywords": "text",
|
|
220
|
-
"title": "text"
|
|
221
|
-
}
|
|
120
|
+
puts JSON.generate(quotes)
|
|
222
121
|
```
|
|
223
122
|
|
|
224
|
-
|
|
123
|
+
## Why Wgit?
|
|
225
124
|
|
|
226
|
-
|
|
125
|
+
There are many [other HTML crawlers](https://awesome-ruby.com/#-web-crawling) out there so why use Wgit?
|
|
227
126
|
|
|
228
|
-
|
|
127
|
+
- Wgit has excellent unit testing, 100% documentation coverage and follows [semantic versioning](https://semver.org/) rules.
|
|
128
|
+
- Wgit excels at crawling an entire website's HTML out of the box. Many alternative crawlers require you to provide the `xpath` needed to *follow* the next URLs to crawl. Wgit by default, crawls the entire site by extracting its internal links pointing to the same host.
|
|
129
|
+
- Wgit allows you to define content *extractors* that will fire on every subsequent crawl; be it a single URL or an entire website. This enables you to focus on the content you want.
|
|
130
|
+
- Wgit can index (crawl and store) HTML to a database making it a breeze to build custom search engines. You can also specify which page content gets searched, making the search more meaningful. For example, here's a script that will index the Wgit [wiki](https://github.com/michaeltelford/wgit/wiki) articles:
|
|
229
131
|
|
|
230
132
|
```ruby
|
|
231
133
|
require 'wgit'
|
|
232
134
|
|
|
233
|
-
|
|
234
|
-
|
|
235
|
-
# In the absence of a connection string parameter, ENV['WGIT_CONNECTION_STRING'] will be used.
|
|
236
|
-
db = Wgit::Database.connect '<your_connection_string>'
|
|
135
|
+
ENV['WGIT_CONNECTION_STRING'] = 'mongodb://user:password@localhost/crawler'
|
|
237
136
|
|
|
238
|
-
|
|
137
|
+
wiki = Wgit::Url.new('https://github.com/michaeltelford/wgit/wiki')
|
|
239
138
|
|
|
240
|
-
#
|
|
241
|
-
|
|
242
|
-
|
|
243
|
-
'
|
|
244
|
-
|
|
245
|
-
)
|
|
246
|
-
db.insert doc
|
|
247
|
-
|
|
248
|
-
### SEARCH THE DATABASE ###
|
|
249
|
-
|
|
250
|
-
# Searching the database returns Wgit::Document's which have fields containing the query.
|
|
251
|
-
query = 'cow'
|
|
252
|
-
results = db.search query
|
|
253
|
-
|
|
254
|
-
# By default, the MongoDB ranking applies i.e. results.first has the most hits.
|
|
255
|
-
# Because results is an Array of Wgit::Document's, we can custom sort/rank e.g.
|
|
256
|
-
# `results.sort_by! { |doc| doc.url.crawl_duration }` ranks via page load times with
|
|
257
|
-
# results.first being the fastest. Any Wgit::Document attribute can be used, including
|
|
258
|
-
# those you define yourself by extending the API.
|
|
259
|
-
|
|
260
|
-
top_result = results.first
|
|
261
|
-
top_result.class # => Wgit::Document
|
|
262
|
-
doc.url == top_result.url # => true
|
|
263
|
-
|
|
264
|
-
### PULL OUT THE BITS THAT MATCHED OUR QUERY ###
|
|
265
|
-
|
|
266
|
-
# Searching each result gives the matching text snippets from that Wgit::Document.
|
|
267
|
-
top_result.search(query).first # => "How now brown cow."
|
|
268
|
-
|
|
269
|
-
### SEED URLS TO BE CRAWLED LATER ###
|
|
139
|
+
# Only index the most recent of each wiki article, ignoring the rest of Github.
|
|
140
|
+
opts = {
|
|
141
|
+
allow_paths: 'michaeltelford/wgit/wiki/*',
|
|
142
|
+
disallow_paths: 'michaeltelford/wgit/wiki/*/_history'
|
|
143
|
+
}
|
|
270
144
|
|
|
271
|
-
|
|
272
|
-
|
|
145
|
+
indexer = Wgit::Indexer.new
|
|
146
|
+
indexer.index_site(wiki, **opts)
|
|
273
147
|
```
|
|
274
148
|
|
|
275
|
-
##
|
|
276
|
-
|
|
277
|
-
Document serialising in Wgit is the means of downloading a web page and serialising parts of its content into accessible `Wgit::Document` attributes/methods. For example, `Wgit::Document#author` will return you the webpage's xpath value of `meta[@name='author']`.
|
|
278
|
-
|
|
279
|
-
There are two ways to extend the Document serialising behaviour of Wgit for your own means:
|
|
280
|
-
|
|
281
|
-
1. Add additional **textual** content to `Wgit::Document#text`.
|
|
282
|
-
2. Define `Wgit::Document` instance methods for specific HTML **elements**.
|
|
149
|
+
## Why Not Wgit?
|
|
283
150
|
|
|
284
|
-
|
|
151
|
+
So why might you not use Wgit, I hear you ask?
|
|
285
152
|
|
|
286
|
-
|
|
153
|
+
- Wgit doesn't allow for webpage interaction e.g. signing in as a user. There are better gems out there for that.
|
|
154
|
+
- Wgit can parse a crawled page's Javascript, but it doesn't do so by default. If your crawls are JS heavy then you might best consider a pure browser-based crawler instead.
|
|
155
|
+
- Wgit while fast (using `libcurl` for HTTP etc.), isn't multi-threaded; so each URL gets crawled sequentially. You could hand each crawled document to a worker thread for processing - but if you need concurrent crawling then you should consider something else.
|
|
287
156
|
|
|
288
|
-
|
|
289
|
-
|
|
290
|
-
The below code example shows how to extract additional text from a webpage:
|
|
291
|
-
|
|
292
|
-
```ruby
|
|
293
|
-
require 'wgit'
|
|
294
|
-
|
|
295
|
-
# The default text_elements cover most visible page text but let's say we
|
|
296
|
-
# have a <table> element with text content that we want.
|
|
297
|
-
Wgit::Document.text_elements << :table
|
|
298
|
-
|
|
299
|
-
doc = Wgit::Document.new(
|
|
300
|
-
'http://some_url.com',
|
|
301
|
-
<<~HTML
|
|
302
|
-
<html>
|
|
303
|
-
<p>Hello world!</p>
|
|
304
|
-
<table>My table</table>
|
|
305
|
-
</html>
|
|
306
|
-
HTML
|
|
307
|
-
)
|
|
308
|
-
|
|
309
|
-
# Now every crawled Document#text will include <table> text content.
|
|
310
|
-
doc.text # => ["Hello world!", "My table"]
|
|
311
|
-
doc.search('table') # => ["My table"]
|
|
312
|
-
```
|
|
157
|
+
## Installation
|
|
313
158
|
|
|
314
|
-
|
|
159
|
+
Only MRI Ruby is tested and supported, but Wgit may work with other Ruby implementations.
|
|
315
160
|
|
|
316
|
-
|
|
161
|
+
Currently, the required MRI Ruby version is:
|
|
317
162
|
|
|
318
|
-
|
|
163
|
+
`ruby '>= 2.6', '< 4'`
|
|
319
164
|
|
|
320
|
-
|
|
165
|
+
### Using Bundler
|
|
321
166
|
|
|
322
|
-
|
|
167
|
+
$ bundle add wgit
|
|
323
168
|
|
|
324
|
-
|
|
325
|
-
require 'wgit'
|
|
326
|
-
|
|
327
|
-
# Let's get all the page's <table> elements.
|
|
328
|
-
Wgit::Document.define_extension(
|
|
329
|
-
:tables, # Wgit::Document#tables will return the page's tables.
|
|
330
|
-
'//table', # The xpath to extract the tables.
|
|
331
|
-
singleton: false, # True returns the first table found, false returns all.
|
|
332
|
-
text_content_only: false, # True returns the table text, false returns the Nokogiri object.
|
|
333
|
-
) do |tables|
|
|
334
|
-
# Here we can inspect/manipulate the tables before they're set as Wgit::Document#tables.
|
|
335
|
-
tables
|
|
336
|
-
end
|
|
169
|
+
### Using RubyGems
|
|
337
170
|
|
|
338
|
-
|
|
339
|
-
# is initialised e.g. manually (as below) or via Wgit::Crawler methods etc.
|
|
340
|
-
doc = Wgit::Document.new(
|
|
341
|
-
'http://some_url.com',
|
|
342
|
-
<<~HTML
|
|
343
|
-
<html>
|
|
344
|
-
<p>Hello world! Welcome to my site.</p>
|
|
345
|
-
<table>
|
|
346
|
-
<tr><th>Name</th><th>Age</th></tr>
|
|
347
|
-
<tr><td>Socrates</td><td>101</td></tr>
|
|
348
|
-
<tr><td>Plato</td><td>106</td></tr>
|
|
349
|
-
</table>
|
|
350
|
-
<p>I hope you enjoyed your visit :-)</p>
|
|
351
|
-
</html>
|
|
352
|
-
HTML
|
|
353
|
-
)
|
|
354
|
-
|
|
355
|
-
# Call our newly defined method to obtain the table data we're interested in.
|
|
356
|
-
tables = doc.tables
|
|
357
|
-
|
|
358
|
-
# Both the collection and each table within the collection are plain Nokogiri objects.
|
|
359
|
-
tables.class # => Nokogiri::XML::NodeSet
|
|
360
|
-
tables.first.class # => Nokogiri::XML::Element
|
|
361
|
-
|
|
362
|
-
# Note, the Document's stats now include our 'tables' extension.
|
|
363
|
-
doc.stats # => {
|
|
364
|
-
# :url=>19, :html=>242, :links=>0, :text=>8, :text_bytes=>91, :tables=>1
|
|
365
|
-
# }
|
|
366
|
-
```
|
|
367
|
-
|
|
368
|
-
See the [Wgit::Document.define_extension](https://www.rubydoc.info/github/michaeltelford/wgit/master/Wgit%2FDocument.define_extension) docs for more information.
|
|
171
|
+
$ gem install wgit
|
|
369
172
|
|
|
370
|
-
|
|
173
|
+
### Verify
|
|
371
174
|
|
|
372
|
-
|
|
373
|
-
- A `Wgit::Document` extension (once initialised) will become a Document instance variable, meaning that the value will be inserted into the Database if it's a primitive type e.g. `String`, `Array` etc. Complex types e.g. Ruby objects won't be inserted. It's up to you to ensure the data you want inserted, can be inserted.
|
|
374
|
-
- Once inserted into the Database, you can search a `Wgit::Document`'s extension attributes by updating the Database's *text search index*. See the [Database Example](#Database-Example) for more information.
|
|
175
|
+
$ wgit
|
|
375
176
|
|
|
376
|
-
|
|
177
|
+
Calling the installed executable will start an REPL session.
|
|
377
178
|
|
|
378
|
-
|
|
179
|
+
## Documentation
|
|
379
180
|
|
|
380
|
-
-
|
|
381
|
-
-
|
|
382
|
-
-
|
|
181
|
+
- [Getting Started](https://github.com/michaeltelford/wgit/wiki/Getting-Started)
|
|
182
|
+
- [Wiki](https://github.com/michaeltelford/wgit/wiki)
|
|
183
|
+
- [API Yardocs](https://www.rubydoc.info/gems/wgit)
|
|
184
|
+
- [CHANGELOG](https://github.com/michaeltelford/wgit/blob/master/CHANGELOG.md)
|
|
383
185
|
|
|
384
186
|
## Executable
|
|
385
187
|
|
|
386
|
-
Installing the Wgit gem
|
|
188
|
+
Installing the Wgit gem adds a `wgit` executable to your `$PATH`. The executable launches an interactive REPL session with the Wgit gem already loaded; making it super easy to index and search from the command line without the need for scripts.
|
|
387
189
|
|
|
388
190
|
The `wgit` executable does the following things (in order):
|
|
389
191
|
|
|
@@ -391,21 +193,7 @@ The `wgit` executable does the following things (in order):
|
|
|
391
193
|
2. `eval`'s a `.wgit.rb` file (if one exists in either the local or home directory, which ever is found first)
|
|
392
194
|
3. Starts an interactive shell (using `pry` if it's installed, or `irb` if not)
|
|
393
195
|
|
|
394
|
-
The `.wgit.rb` file can be used to seed fixture data or define helper functions for the session. For example, you could define a function which indexes your website for quick and easy searching everytime you start a new session.
|
|
395
|
-
|
|
396
|
-
## Change Log
|
|
397
|
-
|
|
398
|
-
See the [CHANGELOG.md](https://github.com/michaeltelford/wgit/blob/master/CHANGELOG.md) for differences (including any breaking changes) between releases of Wgit.
|
|
399
|
-
|
|
400
|
-
### Gem Versioning
|
|
401
|
-
|
|
402
|
-
The `wgit` gem follows these versioning rules:
|
|
403
|
-
|
|
404
|
-
- The version format is `MAJOR.MINOR.PATCH` e.g. `0.1.0`.
|
|
405
|
-
- Since the gem hasn't reached `v1.0.0` yet, slightly different semantic versioning rules apply.
|
|
406
|
-
- The `PATCH` represents *non breaking changes* while the `MINOR` represents *breaking changes* e.g. updating from version `0.1.0` to `0.2.0` will likely introduce breaking changes necessitating updates to your codebase.
|
|
407
|
-
- To determine what changes are needed, consult the `CHANGELOG.md`. If you need help, raise an issue.
|
|
408
|
-
- Once `wgit v1.0.0` is released, *normal* [semantic versioning](https://semver.org/) rules will apply e.g. only a `MAJOR` version change should introduce breaking changes.
|
|
196
|
+
The `.wgit.rb` file can be used to seed fixture data or define helper functions for the session. For example, you could define a function which indexes your website for quick and easy searching everytime you start a new session.
|
|
409
197
|
|
|
410
198
|
## License
|
|
411
199
|
|
|
@@ -431,14 +219,14 @@ And you're good to go!
|
|
|
431
219
|
|
|
432
220
|
### Tooling
|
|
433
221
|
|
|
434
|
-
Wgit uses the [`toys`](https://github.com/dazuma/toys) gem (instead of Rake) for task invocation
|
|
222
|
+
Wgit uses the [`toys`](https://github.com/dazuma/toys) gem (instead of Rake) for task invocation. For a full list of available tasks a.k.a. tools, run `toys --tools`. You can search for a tool using `toys -s tool_name`. The most commonly used tools are listed below...
|
|
435
223
|
|
|
436
|
-
Run `toys db` to see a list of database related tools, enabling you to run a Mongo DB instance locally using Docker. Run `toys test` to execute the tests
|
|
224
|
+
Run `toys db` to see a list of database related tools, enabling you to run a Mongo DB instance locally using Docker. Run `toys test` to execute the tests.
|
|
437
225
|
|
|
438
|
-
To generate code documentation run `toys yardoc`. To browse the
|
|
226
|
+
To generate code documentation locally, run `toys yardoc`. To browse the docs in a browser run `toys yardoc --serve`. You can also use the `yri` command line tool e.g. `yri Wgit::Crawler#crawl_site` etc.
|
|
439
227
|
|
|
440
|
-
To install this gem onto your local machine, run `toys install
|
|
228
|
+
To install this gem onto your local machine, run `toys install` and follow the prompt.
|
|
441
229
|
|
|
442
230
|
### Console
|
|
443
231
|
|
|
444
|
-
You can run `toys console` for an interactive shell using the `./bin/wgit` executable. The `toys setup` task will have created
|
|
232
|
+
You can run `toys console` for an interactive shell using the `./bin/wgit` executable. The `toys setup` task will have created an `.env` and `.wgit.rb` file which get loaded by the executable. You can use the contents of this [gist](https://gist.github.com/michaeltelford/b90d5e062da383be503ca2c3a16e9164) to turn the executable into a development console. It defines some useful functions, fixtures and connects to the database etc. Don't forget to set the `WGIT_CONNECTION_STRING` in the `.env` file.
|
data/bin/wgit
CHANGED
|
@@ -2,18 +2,22 @@
|
|
|
2
2
|
|
|
3
3
|
require 'wgit'
|
|
4
4
|
|
|
5
|
-
# Eval .wgit.rb file (if it exists).
|
|
6
|
-
def eval_wgit
|
|
7
|
-
puts 'Searching for .wgit.rb in local and home directories...'
|
|
5
|
+
# Eval .wgit.rb file (if it exists somewhere).
|
|
6
|
+
def eval_wgit(filepath = nil)
|
|
7
|
+
puts 'Searching for .wgit.rb file in local and home directories...'
|
|
8
8
|
|
|
9
|
-
[
|
|
9
|
+
[filepath, Dir.pwd, Dir.home].each do |dir|
|
|
10
10
|
path = "#{dir}/.wgit.rb"
|
|
11
11
|
next unless File.exist?(path)
|
|
12
12
|
|
|
13
|
-
puts "Eval'ing #{path}
|
|
13
|
+
puts "Eval'ing #{path}"
|
|
14
|
+
puts 'Call `eval_wgit` after changes to re-eval the file'
|
|
14
15
|
eval(File.read(path))
|
|
16
|
+
|
|
15
17
|
break
|
|
16
18
|
end
|
|
19
|
+
|
|
20
|
+
nil
|
|
17
21
|
end
|
|
18
22
|
|
|
19
23
|
eval_wgit
|
data/lib/wgit/assertable.rb
CHANGED
|
@@ -6,7 +6,7 @@ module Wgit
|
|
|
6
6
|
# Default type fail message.
|
|
7
7
|
DEFAULT_TYPE_FAIL_MSG = 'Expected: %s, Actual: %s'
|
|
8
8
|
# Wrong method message.
|
|
9
|
-
|
|
9
|
+
NON_ENUMERABLE_MSG = 'Expected an Enumerable responding to #each, not: %s'
|
|
10
10
|
# Default duck fail message.
|
|
11
11
|
DEFAULT_DUCK_FAIL_MSG = "%s doesn't respond_to? %s"
|
|
12
12
|
# Default required keys message.
|
|
@@ -42,7 +42,7 @@ present: %s"
|
|
|
42
42
|
# @raise [StandardError] If the assertion fails.
|
|
43
43
|
# @return [Object] The given arr on successful assertion.
|
|
44
44
|
def assert_arr_types(arr, type_or_types, msg = nil)
|
|
45
|
-
raise
|
|
45
|
+
raise format(NON_ENUMERABLE_MSG, arr.class) unless arr.respond_to?(:each)
|
|
46
46
|
|
|
47
47
|
arr.each { |obj| assert_types(obj, type_or_types, msg) }
|
|
48
48
|
end
|
|
@@ -56,7 +56,7 @@ present: %s"
|
|
|
56
56
|
# @raise [StandardError] If the assertion fails.
|
|
57
57
|
# @return [Object] The given obj_or_objs on successful assertion.
|
|
58
58
|
def assert_respond_to(obj_or_objs, methods, msg = nil)
|
|
59
|
-
methods =
|
|
59
|
+
methods = *methods
|
|
60
60
|
|
|
61
61
|
if obj_or_objs.respond_to?(:each)
|
|
62
62
|
obj_or_objs.each { |obj| _assert_respond_to(obj, methods, msg) }
|
data/lib/wgit/base.rb
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
1
|
+
module Wgit
|
|
2
|
+
# Class to inherit from, as an alternative form of using the `Wgit::DSL`.
|
|
3
|
+
# All subclasses must define a `#parse(doc, &block)` method.
|
|
4
|
+
class Base
|
|
5
|
+
extend Wgit::DSL
|
|
6
|
+
|
|
7
|
+
# Runs once before the crawl/index is run. Override as needed.
|
|
8
|
+
def setup; end
|
|
9
|
+
|
|
10
|
+
# Runs once after the crawl/index is complete. Override as needed.
|
|
11
|
+
def teardown; end
|
|
12
|
+
|
|
13
|
+
# Runs the crawl/index passing each crawled `Wgit::Document` and the given
|
|
14
|
+
# block to the subclass's `#parse` method.
|
|
15
|
+
def self.run(&block)
|
|
16
|
+
crawl_method = @method || :crawl
|
|
17
|
+
obj = new
|
|
18
|
+
|
|
19
|
+
unless obj.respond_to?(:parse)
|
|
20
|
+
raise "#{obj.class} must respond_to? #parse(doc, &block)"
|
|
21
|
+
end
|
|
22
|
+
|
|
23
|
+
obj.setup
|
|
24
|
+
send(crawl_method) { |doc| obj.parse(doc, &block) }
|
|
25
|
+
obj.teardown
|
|
26
|
+
|
|
27
|
+
obj
|
|
28
|
+
end
|
|
29
|
+
|
|
30
|
+
# Sets the crawl/index method to call when `Base.run` is called.
|
|
31
|
+
# The mode method must match one defined in the `Wgit::Crawler` or
|
|
32
|
+
# `Wgit::Indexer` class.
|
|
33
|
+
#
|
|
34
|
+
# @param method [Symbol] The crawl/index method to call.
|
|
35
|
+
def self.mode(method)
|
|
36
|
+
@method = method
|
|
37
|
+
end
|
|
38
|
+
end
|
|
39
|
+
end
|