wgit 0.5.1 → 0.10.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/.yardopts +7 -0
- data/CHANGELOG.md +249 -0
- data/CODE_OF_CONDUCT.md +76 -0
- data/CONTRIBUTING.md +21 -0
- data/LICENSE.txt +21 -0
- data/README.md +232 -0
- data/bin/wgit +39 -0
- data/lib/wgit.rb +3 -1
- data/lib/wgit/assertable.rb +3 -3
- data/lib/wgit/base.rb +30 -0
- data/lib/wgit/core_ext.rb +1 -1
- data/lib/wgit/crawler.rb +304 -148
- data/lib/wgit/database/database.rb +310 -135
- data/lib/wgit/database/model.rb +10 -3
- data/lib/wgit/document.rb +241 -169
- data/lib/wgit/{document_extensions.rb → document_extractors.rb} +20 -10
- data/lib/wgit/dsl.rb +324 -0
- data/lib/wgit/indexer.rb +68 -156
- data/lib/wgit/response.rb +17 -14
- data/lib/wgit/url.rb +213 -73
- data/lib/wgit/utils.rb +32 -20
- data/lib/wgit/version.rb +3 -2
- metadata +38 -19
checksums.yaml
CHANGED
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
---
|
|
2
2
|
SHA256:
|
|
3
|
-
metadata.gz:
|
|
4
|
-
data.tar.gz:
|
|
3
|
+
metadata.gz: b6719bb2015379133ef2c9b417cada1826deab254f6fa1adaa093314f8fece99
|
|
4
|
+
data.tar.gz: 5ced648c0dff501bf0191aebfc0188d535f4ee657a072e1dbccd68ebbc6ac881
|
|
5
5
|
SHA512:
|
|
6
|
-
metadata.gz:
|
|
7
|
-
data.tar.gz:
|
|
6
|
+
metadata.gz: 4a7782b4ccf6fa69fad9bb63d7d421fa548603ad5a35304db554bdcdf6deafe305395aba1ac9f35bcd095bc6cf4049ce70e56645faf1457e2e1313d48d1eb7f8
|
|
7
|
+
data.tar.gz: 8b8bb1454a131201e262eda060c6ae8490266a7675910026a0dd6ae0b2b55f2accf140d473edf135078f68cbe1048c4bb86f2dc5a6d4cf08a006f8fc20ac49b5
|
data/.yardopts
ADDED
data/CHANGELOG.md
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
1
|
+
# Wgit Change Log
|
|
2
|
+
|
|
3
|
+
## v0.0.0 (TEMPLATE - DO NOT EDIT)
|
|
4
|
+
### Added
|
|
5
|
+
- ...
|
|
6
|
+
### Changed/Removed
|
|
7
|
+
- ...
|
|
8
|
+
### Fixed
|
|
9
|
+
- ...
|
|
10
|
+
---
|
|
11
|
+
|
|
12
|
+
## v0.10.0
|
|
13
|
+
### Added
|
|
14
|
+
- `Wgit::Url#scheme_relative?` method.
|
|
15
|
+
### Changed/Removed
|
|
16
|
+
- Breaking change: Changed method signature of `Wgit::Url#prefix_scheme` by making the previously named parameter a defaulted positional parameter. Remove the `protocol` named parameter for the old behaviour.
|
|
17
|
+
### Fixed
|
|
18
|
+
- [Scheme-relative bug](https://github.com/michaeltelford/wgit/issues/10) by adding support for scheme-relative URL's.
|
|
19
|
+
---
|
|
20
|
+
|
|
21
|
+
## v0.9.0
|
|
22
|
+
This release is a big one with the introduction of a `Wgit::DSL` and Javascript parse support. The `README` has been revamped as a result with new usage examples. And all of the wiki articles have been updated to reflect the latest code base.
|
|
23
|
+
### Added
|
|
24
|
+
- `Wgit::DSL` module providing a wrapper around the underlying classes and methods. Check out the `README` for example usage.
|
|
25
|
+
- `Wgit::Crawler#parse_javascript` which when set to `true` uses Chrome to parse a page's Javascript before returning the fully rendered HTML. This feature is disabled by default.
|
|
26
|
+
- `Wgit::Base` class to inherit from, acting as an alternative form of using the DSL.
|
|
27
|
+
- `Wgit::Utils.sanitize` which calls `.sanitize_*` underneath.
|
|
28
|
+
- `Wgit::Crawler#crawl_site` now has a `follow:` named param - if set, it's xpath value is used to retrieve the next urls to crawl. Otherwise the `:default` is used (as it was before). Use this to override how the site is crawled.
|
|
29
|
+
- `Wgit::Database` methods: `#clear_urls`, `#clear_docs`, `#clear_db`, `#text_index`, `#text_index=`, `#create_collections`, `#create_unique_indexes`, `#docs`, `#get`, `#exists?`, `#delete`, `#upsert`.
|
|
30
|
+
- `Wgit::Database#clear_db!` alias.
|
|
31
|
+
- `Wgit::Document` methods: `#at_xpath`, `#at_css` - which call nokogiri underneath.
|
|
32
|
+
- `Wgit::Document#extract` method to perform one off content extractions.
|
|
33
|
+
- `Wgit::Indexer#index_urls` method which can index several urls in one call.
|
|
34
|
+
- `Wgit::Url` methods: `#to_user`, `#to_password`, `#to_sub_domain`, `#to_port`, `#omit_origin`, `#index?`.
|
|
35
|
+
### Changed/Removed
|
|
36
|
+
- Breaking change: Moved all `Wgit.index*` convienence methods into `Wgit::DSL`.
|
|
37
|
+
- Breaking change: Removed `Wgit::Url#normalise`, use `#normalize` instead.
|
|
38
|
+
- Breaking change: Removed `Wgit::Database#num_documents`, use `#num_docs` instead.
|
|
39
|
+
- Breaking change: Removed `Wgit::Database#length` and `#count`, use `#size` instead.
|
|
40
|
+
- Breaking change: Removed `Wgit::Database#document?`, use `#doc?` instead.
|
|
41
|
+
- Breaking change: Renamed `Wgit::Indexer#index_page` to `#index_url`.
|
|
42
|
+
- Breaking change: Renamed `Wgit::Url.parse_or_nil` to be `.parse?`.
|
|
43
|
+
- Breaking change: Renamed `Wgit::Utils.process_*` to be `.sanitize_*`.
|
|
44
|
+
- Breaking change: Renamed `Wgit::Utils.remove_non_bson_types` to be `Wgit::Model.select_bson_types`.
|
|
45
|
+
- Breaking change: Changed `Wgit::Indexer.index*` named param default from `insert_externals: true` to `false`. Explicitly set it to `true` for the old behaviour.
|
|
46
|
+
- Breaking change: Renamed `Wgit::Document.define_extension` to `define_extractor`. Same goes for `remove_extension -> remove_extractor` and `extensions -> extractors`. See the docs for more information.
|
|
47
|
+
- Breaking change: Renamed `Wgit::Document#doc` to `#parser`.
|
|
48
|
+
- Breaking change: Renamed `Wgit::Crawler#time_out` to `#timeout`. Same goes for the named param passed to `Wgit::Crawler.initialize`.
|
|
49
|
+
- Breaking change: Refactored `Wgit::Url#relative?` now takes `:origin` instead of `:base` which takes the port into account. This has a knock on effect for some other methods too - check the docs if you're getting parameter errors.
|
|
50
|
+
- Breaking change: Renamed `Wgit::Url#prefix_base` to `#make_absolute`.
|
|
51
|
+
- Updated `Utils.printf_search_results` to return the number of results.
|
|
52
|
+
- Updated `Wgit::Indexer.new` which can now be called without parameters - the first param (for a database) now defaults to `Wgit::Database.new` which works if `ENV['WGIT_CONNECTION_STRING']` is set.
|
|
53
|
+
- Updated `Wgit::Document.define_extractor` to define a setter method (as well as the usual getter method).
|
|
54
|
+
- Updated `Wgit::Document#search` to support a `Regexp` query (in addition to a String).
|
|
55
|
+
### Fixed
|
|
56
|
+
- [Re-indexing bug](https://github.com/michaeltelford/wgit/issues/8) so that indexing content a 2nd time will update it in the database - before it simply disgarded the document.
|
|
57
|
+
- `Wgit::Crawler#crawl_site` params `allow/disallow_paths` values can now start with a `/`.
|
|
58
|
+
---
|
|
59
|
+
|
|
60
|
+
## v0.8.0
|
|
61
|
+
### Added
|
|
62
|
+
- To the range of `Wgit::Document.text_elements`. Now (only and) all visible page text should be extracted into `Wgit::Document#text` successfully.
|
|
63
|
+
- `Wgit::Document#description` default extension.
|
|
64
|
+
- `Wgit::Url.parse_or_nil` method.
|
|
65
|
+
### Changed/Removed
|
|
66
|
+
- Breaking change: Renamed `Document#stats[:text_snippets]` to be `:text`.
|
|
67
|
+
- Breaking change: `Wgit::Document.define_extension`'s block return value now becomes the `var` value, even when `nil` is returned. This allows `var` to be set to `nil`.
|
|
68
|
+
- Potential breaking change: Renamed `Wgit::Response#crawl_time` (alias) to be `#crawl_duration`.
|
|
69
|
+
- Updated `Wgit::Crawler::SUPPORTED_FILE_EXTENSIONS` to be `Wgit::Crawler.supported_file_extensions`, making it configurable. Now you can add your own URL extensions if needed.
|
|
70
|
+
- Updated the Wgit core extension `String#to_url` to use `Wgit::Url.parse` allowing instances of `Wgit::Url` to returned as is. This also affects `Enumerable#to_urls` in the same way.
|
|
71
|
+
### Fixed
|
|
72
|
+
- An issue where too much `Wgit::Document#text` was being extracted from the HTML. This was fixed by reverting the recent commit: "Document.text_elements_xpath is now `//*/text()`".
|
|
73
|
+
---
|
|
74
|
+
|
|
75
|
+
## v0.7.0
|
|
76
|
+
### Added
|
|
77
|
+
- `Wgit::Indexer.new` optional `crawler:` named param.
|
|
78
|
+
- `bin/wgit` executable; available after `gem install wgit`. Just type `wgit` at the command line for an interactive shell session with the Wgit gem already loaded.
|
|
79
|
+
- `Document.extensions` returning a Set of all defined extensions.
|
|
80
|
+
### Changed/Removed
|
|
81
|
+
- Potential breaking changes: Updated the default search param from `whole_sentence: false` to `true` across all search methods e.g. `Wgit::Database#search`, `Wgit::Document#search` `Wgit.indexed_search` etc. This brings back more relevant search results by default.
|
|
82
|
+
- Updated the Docker image to now include index names; making it easier to identify them.
|
|
83
|
+
### Fixed
|
|
84
|
+
- ...
|
|
85
|
+
---
|
|
86
|
+
|
|
87
|
+
## v0.6.0
|
|
88
|
+
### Added
|
|
89
|
+
- Added `Wgit::Utils.proces_arr encode:` param.
|
|
90
|
+
### Changed/Removed
|
|
91
|
+
- Breaking changes: Updated `Wgit::Response#success?` and `#failure?` logic.
|
|
92
|
+
- Breaking changes: Updated `Wgit::Crawler` redirect logic. See the [docs](https://www.rubydoc.info/github/michaeltelford/wgit/Wgit/Crawler#crawl_url-instance_method) for more info.
|
|
93
|
+
- Breaking changes: Updated `Wgit::Crawler#crawl_site` path params logic to support globs e.g. `allow_paths: 'wiki/*'`. See the [docs](https://www.rubydoc.info/github/michaeltelford/wgit/Wgit/Crawler#crawl_site-instance_method) for more info.
|
|
94
|
+
- Breaking changes: Refactored references of `encode_html:` to `encode:` in the `Wgit::Document` and `Wgit::Crawler` classes.
|
|
95
|
+
- Breaking changes: `Wgit::Document.text_elements_xpath` is now `//*/text()`. This means that more text is extracted from each page and you can no longer be selective of the text elements on a page.
|
|
96
|
+
- Improved `Wgit::Url#valid?` and `#relative?`.
|
|
97
|
+
### Fixed
|
|
98
|
+
- Bug fix in `Wgit::Crawler#crawl_site` where `*.php` URLs weren't being crawled. The fix was to implement `Wgit::Crawler::SUPPORTED_FILE_EXTENSIONS`.
|
|
99
|
+
- Bug fix in `Wgit::Document#search`.
|
|
100
|
+
---
|
|
101
|
+
|
|
102
|
+
## v0.5.1
|
|
103
|
+
### Added
|
|
104
|
+
- `Wgit.version_str` method.
|
|
105
|
+
### Changed/Removed
|
|
106
|
+
- Switched to optimistic dependency versioning.
|
|
107
|
+
### Fixed
|
|
108
|
+
- Bug in `Wgit::Url#concat`.
|
|
109
|
+
---
|
|
110
|
+
|
|
111
|
+
## v0.5.0
|
|
112
|
+
### Added
|
|
113
|
+
- A Wgit Wiki! [https://github.com/michaeltelford/wgit/wiki](https://github.com/michaeltelford/wgit/wiki)
|
|
114
|
+
- `Wgit::Document#content` alias for `#html`.
|
|
115
|
+
- `Wgit::Url#prefix_base` method.
|
|
116
|
+
- `Wgit::Url#to_addressable_uri` method.
|
|
117
|
+
- Support for partially crawling a site using `Wgit::Crawler#crawl_site(allow_paths: [])` or `disallow_paths:`.
|
|
118
|
+
- `Wgit::Url#+` as alias for `#concat`.
|
|
119
|
+
- `Wgit::Url#invalid?` method.
|
|
120
|
+
- `Wgit.version` method.
|
|
121
|
+
- `Wgit::Response` class containing adapter agnostic HTTP response logic.
|
|
122
|
+
### Changed/Removed
|
|
123
|
+
- Breaking changes: Removed `Wgit::Document#date_crawled` and `#crawl_duration` because both of these methods exist on the `Wgit::Document#url`. Instead, use `doc.url.date_crawled` etc.
|
|
124
|
+
- Breaking changes: Added to and moved `Document.define_extension` block params, it's now `|value, source, type|`. The `source` is not what it used to be; it's now `type` - of either `:document` or `:object`. Confused? See the [docs](https://www.rubydoc.info/gems/wgit).
|
|
125
|
+
- Breaking changes: Changed `Wgit::Url#prefix_protocol` so that it no longer modifies the receiver.
|
|
126
|
+
- Breaking changes: Updated `Wgit::Url#to_anchor` and `#to_query` logic to align with that of `Addressable::URI` e.g. the anchor value no longer contains `#` prefix; and the query value no longer contains `?` prefix.
|
|
127
|
+
- Breaking changes: Renamed `Wgit::Url` methods containing `anchor` to now be named `fragment` e.g. `to_anchor` is now called `to_fragment` and `without_anchor` is `without_fragment` etc.
|
|
128
|
+
- Breaking changes: Renamed `Wgit::Url#prefix_protocol` to `#prefix_scheme`. The `protocol:` param name remains unchanged.
|
|
129
|
+
- Breaking changes: Renamed all `Wgit::Url` methods starting with `without_*` to `omit_*`.
|
|
130
|
+
- Breaking changes: `Wgit::Indexer` no longer inserts invalid external URL's (to be crawled at a later date).
|
|
131
|
+
- Breaking changes: `Wgit::Crawler#last_response` is now of type `Wgit::Response`. You can access the underlying `Typhoeus::Response` object with `crawler.last_response.adapter_response`.
|
|
132
|
+
### Fixed
|
|
133
|
+
- Bug in `Wgit::Document#base_url` around the handling of invalid base URL scenarios.
|
|
134
|
+
- Several bugs in `Wgit::Database` class caused by the recent changes to the data model (in version 0.3.0).
|
|
135
|
+
---
|
|
136
|
+
|
|
137
|
+
## v0.4.1
|
|
138
|
+
### Added
|
|
139
|
+
- ...
|
|
140
|
+
### Changed/Removed
|
|
141
|
+
- ...
|
|
142
|
+
### Fixed
|
|
143
|
+
- A crawl bug that resulted in some servers dropping requests due to the use of Typhoeus's default `User-Agent` header. This has now been changed.
|
|
144
|
+
---
|
|
145
|
+
|
|
146
|
+
## v0.4.0
|
|
147
|
+
### Added
|
|
148
|
+
- `Wgit::Document#stats` alias `#statistics`.
|
|
149
|
+
- `Wgit::Crawler#time_out` logic for long crawls. Can also be set via `initialize`.
|
|
150
|
+
- `Wgit::Crawler#last_response#redirect_count` method logic.
|
|
151
|
+
- `Wgit::Crawler#last_response#total_time` method logic.
|
|
152
|
+
- `Wgit::Utils.fetch(hash, key, default = nil)` method which tries multiple key formats before giving up e.g. `:foo, 'foo', 'FOO'` etc.
|
|
153
|
+
### Changed/Removed
|
|
154
|
+
- Breaking changes: Updated `Wgit::Crawler` crawl logic to use `typhoeus` instead of `Net:HTTP`. Users should see a significant improvement in crawl speed as a result. This means that `Wgit::Crawler#last_response` is now of type `Typhoeus::Response`. See https://rubydoc.info/gems/typhoeus/Typhoeus/Response for more info.
|
|
155
|
+
### Fixed
|
|
156
|
+
- ...
|
|
157
|
+
---
|
|
158
|
+
|
|
159
|
+
## v0.3.0
|
|
160
|
+
### Added
|
|
161
|
+
- `Url#crawl_duration` method.
|
|
162
|
+
- `Document#crawl_duration` method.
|
|
163
|
+
- `Benchmark.measure` to Crawler logic to set `Url#crawl_duration`.
|
|
164
|
+
### Changed/Removed
|
|
165
|
+
- Breaking changes: Updated data model to embed the full `url` object inside the documents object.
|
|
166
|
+
- Breaking changes: Updated data model by removing documents `score` attribute.
|
|
167
|
+
### Fixed
|
|
168
|
+
- ...
|
|
169
|
+
---
|
|
170
|
+
|
|
171
|
+
## v0.2.0
|
|
172
|
+
This version of Wgit see's a major refactor of the code base involving multiple changes to method names and their signatures (optional parameters turned into named parameters in most cases). A list of the breaking changes are below including how to fix any breakages; but if you're having issues with the upgrade see the documentation at: https://www.rubydoc.info/gems/wgit
|
|
173
|
+
### Added
|
|
174
|
+
- `Wgit::Url#absolute?` method.
|
|
175
|
+
- `Wgit::Url#relative? base: url` support.
|
|
176
|
+
- `Wgit::Database.connect` method (alias for `Wgit::Database.new`).
|
|
177
|
+
- `Wgit::Database#search` and `Wgit::Document#search` methods now support `case_sensitive:` and `whole_sentence:` named parameters.
|
|
178
|
+
### Changed/Removed
|
|
179
|
+
- Breaking changes: Renamed the following `Wgit` and `Wgit::Indexer` methods: `Wgit.index_the_web` to `Wgit.index_www`, `Wgit::Indexer.index_the_web` to `Wgit::Indexer.index_www`, `Wgit.index_this_site` to `Wgit.index_site`, `Wgit::Indexer.index_this_site` to `Wgit::Indexer.index_site`, `Wgit.index_this_page` to `Wgit.index_page`, `Wgit::Indexer.index_this_page` to `Wgit::Indexer.index_page`.
|
|
180
|
+
- Breaking changes: All `Wgit::Indexer` methods now take named parameters.
|
|
181
|
+
- Breaking changes: The following `Wgit::Url` method signatures have changed: `initialize` aka `new`,
|
|
182
|
+
- Breaking changes: The following `Wgit::Url` class methods have been removed: `.validate`, `.valid?`, `.prefix_protocol`, `.concat` in favour of instance methods by the same names.
|
|
183
|
+
- Breaking changes: The following `Wgit::Url` instance methods/aliases have been changed/removed: `#to_protocol` (now `#to_scheme`), `#to_query_string` and `#query_string` (now `#to_query`), `#relative_link?` (now `#relative?`), `#without_query_string` (now `#without_query`), `#is_query_string?` (now `#query?`).
|
|
184
|
+
- Breaking changes: The database connection string is now passed directly to `Wgit::Database.new`; or in its absence, obtained from `ENV['WGIT_CONNECTION_STRING']`. See the `README.md` section entitled: `Practical Database Example` for an example.
|
|
185
|
+
- Breaking changes: The following `Wgit::Database` instance methods now take named parameters: `#urls`, `#crawled_urls`, `#uncrawled_urls`, `#search`.
|
|
186
|
+
- Breaking changes: The following `Wgit::Document` instance methods now take named parameters: `#to_h`, `#to_json`, `#search`, `#search!`.
|
|
187
|
+
- Breaking changes: The following `Wgit::Document` instance methods/aliases have been changed/removed: `#internal_full_links` (now `#internal_absolute_links`).
|
|
188
|
+
- Breaking changes: Any `Wgit::Document` method alias for returning links containing the word `relative` has been removed for clarity. Use `#internal_links`, `#internal_absolute_links` or `#external_links` instead.
|
|
189
|
+
- Breaking changes: `Wgit::Crawler` instance vars `@docs` and `@urls` have been removed causing the following instance methods to also be removed: `#urls=`, `#[]`, `#<<`. Also, `.new` aka `#initialize` now requires no params.
|
|
190
|
+
- Breaking changes: `Wgit::Crawler.new` now takes an optional `redirect_limit:` parameter. This is now the only way of customising the redirect crawl behavior. `Wgit::Crawler.redirect_limit` no longer exists.
|
|
191
|
+
- Breaking changes: The following `Wgit::Crawler` instance methods signatures have changed: `#crawl_site` and `#crawl_url` now require a `url` param (which no longer defaults), `#crawl_urls` now requires one or more `*urls` (which no longer defaults).
|
|
192
|
+
- Breaking changes: The following `Wgit::Assertable` method aliases have been removed: `.type`, `.types` (use `.assert_types` instead) and `.arr_type`, `.arr_types` (use `.assert_arr_types` instead).
|
|
193
|
+
- Breaking changes: The following `Wgit::Utils` methods now take named parameters: `.to_h` and `.printf_search_results`.
|
|
194
|
+
- Breaking changes: `Wgit::Utils.printf_search_results`'s method signature has changed; the search parameters have been removed. Before calling this method you must call `doc.search!` on each of the `results`. See the docs for the full details.
|
|
195
|
+
- `Wgit::Document` instances can now be instantiated with `String` Url's (previously only `Wgit::Url`'s).
|
|
196
|
+
### Fixed
|
|
197
|
+
- ...
|
|
198
|
+
---
|
|
199
|
+
|
|
200
|
+
## v0.0.18
|
|
201
|
+
### Added
|
|
202
|
+
- `Wgit::Url#to_brand` method and updated `Wgit::Url#is_relative?` to support it.
|
|
203
|
+
### Changed/Removed
|
|
204
|
+
- Updated certain classes by changing some `private` methods to `protected`.
|
|
205
|
+
### Fixed
|
|
206
|
+
- ...
|
|
207
|
+
---
|
|
208
|
+
|
|
209
|
+
## v0.0.17
|
|
210
|
+
### Added
|
|
211
|
+
- Support for `<base>` element in `Wgit::Document`'s.
|
|
212
|
+
- New `Wgit::Url` methods: `without_query_string`, `is_query_string?`, `is_anchor?`, `replace` (override of `String#replace`).
|
|
213
|
+
### Changed/Removed
|
|
214
|
+
- Breaking changes: Removed `Wgit::Document#internal_links_without_anchors` method.
|
|
215
|
+
- Breaking changes (potentially): `Wgit::Url`'s are now replaced with the redirected to Url during a crawl.
|
|
216
|
+
- Updated `Wgit::Document#base_url` to support an optional `link:` named parameter.
|
|
217
|
+
- Updated `Wgit::Crawler#crawl_site` to allow the initial url to redirect to another host.
|
|
218
|
+
- Updated `Wgit::Url#is_relative?` to support an optional `domain:` named parameter.
|
|
219
|
+
### Fixed
|
|
220
|
+
- Bug in `Wgit::Document#internal_full_links` affecting anchor and query string links including those used during `Wgit::Crawler#crawl_site`.
|
|
221
|
+
- Bug causing an 'Invalid URL' error for `Wgit::Crawler#crawl_site`.
|
|
222
|
+
---
|
|
223
|
+
|
|
224
|
+
## v0.0.16
|
|
225
|
+
### Added
|
|
226
|
+
- Added `Wgit::Url.parse` class method as alias for `Wgit::Url.new`.
|
|
227
|
+
### Changed/Removed
|
|
228
|
+
- Breaking changes: Removed `Wgit::Url.relative_link?` (class method). Use `Wgit::Url#is_relative?` (instance method) instead e.g. `Wgit::Url.new('/blah').is_relative?`.
|
|
229
|
+
### Fixed
|
|
230
|
+
- Several URI related bugs in `Wgit::Url` affecting crawls.
|
|
231
|
+
---
|
|
232
|
+
|
|
233
|
+
## v0.0.15
|
|
234
|
+
### Added
|
|
235
|
+
- Support for IRI's (non ASCII based URL's).
|
|
236
|
+
### Changed/Removed
|
|
237
|
+
- Breaking changes: Removed `Document` and `Url#to_hash` aliases. Call `to_h` instead.
|
|
238
|
+
### Fixed
|
|
239
|
+
- Bug in `Crawler#crawl_site` where an internal redirect to an external site's page was being followed.
|
|
240
|
+
---
|
|
241
|
+
|
|
242
|
+
## v0.0.14
|
|
243
|
+
### Added
|
|
244
|
+
- `Indexer#index_this_page` method.
|
|
245
|
+
### Changed/Removed
|
|
246
|
+
- Breaking Changes: `Wgit::CONNECTION_DETAILS` now only requires `DB_CONNECTION_STRING`.
|
|
247
|
+
### Fixed
|
|
248
|
+
- Found and fixed a bug in `Document#new`.
|
|
249
|
+
---
|
data/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
1
|
+
# Contributor Covenant Code of Conduct
|
|
2
|
+
|
|
3
|
+
## Our Pledge
|
|
4
|
+
|
|
5
|
+
In the interest of fostering an open and welcoming environment, we as
|
|
6
|
+
contributors and maintainers pledge to making participation in our project and
|
|
7
|
+
our community a harassment-free experience for everyone, regardless of age, body
|
|
8
|
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
|
9
|
+
level of experience, education, socio-economic status, nationality, personal
|
|
10
|
+
appearance, race, religion, or sexual identity and orientation.
|
|
11
|
+
|
|
12
|
+
## Our Standards
|
|
13
|
+
|
|
14
|
+
Examples of behavior that contributes to creating a positive environment
|
|
15
|
+
include:
|
|
16
|
+
|
|
17
|
+
* Using welcoming and inclusive language
|
|
18
|
+
* Being respectful of differing viewpoints and experiences
|
|
19
|
+
* Gracefully accepting constructive criticism
|
|
20
|
+
* Focusing on what is best for the community
|
|
21
|
+
* Showing empathy towards other community members
|
|
22
|
+
|
|
23
|
+
Examples of unacceptable behavior by participants include:
|
|
24
|
+
|
|
25
|
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
|
26
|
+
advances
|
|
27
|
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
|
28
|
+
* Public or private harassment
|
|
29
|
+
* Publishing others' private information, such as a physical or electronic
|
|
30
|
+
address, without explicit permission
|
|
31
|
+
* Other conduct which could reasonably be considered inappropriate in a
|
|
32
|
+
professional setting
|
|
33
|
+
|
|
34
|
+
## Our Responsibilities
|
|
35
|
+
|
|
36
|
+
Project maintainers are responsible for clarifying the standards of acceptable
|
|
37
|
+
behavior and are expected to take appropriate and fair corrective action in
|
|
38
|
+
response to any instances of unacceptable behavior.
|
|
39
|
+
|
|
40
|
+
Project maintainers have the right and responsibility to remove, edit, or
|
|
41
|
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
|
42
|
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
|
43
|
+
permanently any contributor for other behaviors that they deem inappropriate,
|
|
44
|
+
threatening, offensive, or harmful.
|
|
45
|
+
|
|
46
|
+
## Scope
|
|
47
|
+
|
|
48
|
+
This Code of Conduct applies both within project spaces and in public spaces
|
|
49
|
+
when an individual is representing the project or its community. Examples of
|
|
50
|
+
representing a project or community include using an official project e-mail
|
|
51
|
+
address, posting via an official social media account, or acting as an appointed
|
|
52
|
+
representative at an online or offline event. Representation of a project may be
|
|
53
|
+
further defined and clarified by project maintainers.
|
|
54
|
+
|
|
55
|
+
## Enforcement
|
|
56
|
+
|
|
57
|
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
|
58
|
+
reported by contacting the project team at michael.telford@live.com. All
|
|
59
|
+
complaints will be reviewed and investigated and will result in a response that
|
|
60
|
+
is deemed necessary and appropriate to the circumstances. The project team is
|
|
61
|
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
|
62
|
+
Further details of specific enforcement policies may be posted separately.
|
|
63
|
+
|
|
64
|
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
|
65
|
+
faith may face temporary or permanent repercussions as determined by other
|
|
66
|
+
members of the project's leadership.
|
|
67
|
+
|
|
68
|
+
## Attribution
|
|
69
|
+
|
|
70
|
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
|
71
|
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
|
72
|
+
|
|
73
|
+
[homepage]: https://www.contributor-covenant.org
|
|
74
|
+
|
|
75
|
+
For answers to common questions about this code of conduct, see
|
|
76
|
+
https://www.contributor-covenant.org/faq
|
data/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
# Contributing
|
|
2
|
+
|
|
3
|
+
## Consult
|
|
4
|
+
|
|
5
|
+
Before you make a contribution, reach out to michael.telford@live.com about what changes need made. Otherwise, your time spent might be wasted. Once you're clear on what needs done follow the technical steps below.
|
|
6
|
+
|
|
7
|
+
## Technical Steps
|
|
8
|
+
|
|
9
|
+
- Fork the repository
|
|
10
|
+
- Create a branch
|
|
11
|
+
- Write some tests (which fail)
|
|
12
|
+
- Write some code
|
|
13
|
+
- Re-run the tests (which now hopefully pass)
|
|
14
|
+
- Push your branch to your `origin` remote
|
|
15
|
+
- Open a GitHub Pull Request (with the target branch being wgit's `origin/master`)
|
|
16
|
+
- Apply any requested changes
|
|
17
|
+
- Wait for your PR to be merged
|
|
18
|
+
|
|
19
|
+
## Thanks
|
|
20
|
+
|
|
21
|
+
Thanks in advance for your contribution.
|
data/LICENSE.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
The MIT License (MIT)
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2016 - 2020 Michael Telford
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in
|
|
13
|
+
all copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
|
21
|
+
THE SOFTWARE.
|
data/README.md
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
1
|
+
# Wgit
|
|
2
|
+
|
|
3
|
+
[](https://rubygems.org/gems/wgit)
|
|
4
|
+
[](https://rubygems.org/gems/wgit)
|
|
5
|
+
[](https://travis-ci.org/michaeltelford/wgit)
|
|
6
|
+
[](http://inch-ci.org/github/michaeltelford/wgit)
|
|
7
|
+
[](https://www.codacy.com/app/michaeltelford/wgit?utm_source=github.com&utm_medium=referral&utm_content=michaeltelford/wgit&utm_campaign=Badge_Grade)
|
|
8
|
+
|
|
9
|
+
---
|
|
10
|
+
|
|
11
|
+
Wgit is a HTML web crawler, written in Ruby, that allows you to programmatically extract the data you want from the web.
|
|
12
|
+
|
|
13
|
+
Wgit was primarily designed to crawl static HTML websites to index and search their content - providing the basis of any search engine; but Wgit is suitable for many application domains including:
|
|
14
|
+
|
|
15
|
+
- URL parsing
|
|
16
|
+
- Document content extraction (data mining)
|
|
17
|
+
- Crawling entire websites (statistical analysis)
|
|
18
|
+
|
|
19
|
+
Wgit provides a high level, easy-to-use API and DSL that you can use in your own applications and scripts.
|
|
20
|
+
|
|
21
|
+
Check out this [demo search engine](https://search-engine-rb.herokuapp.com) - [built](https://github.com/michaeltelford/search_engine) using Wgit and Sinatra - deployed to [Heroku](https://www.heroku.com/). Heroku's free tier is used so the initial page load may be slow. Try searching for "Matz" or something else that's Ruby related.
|
|
22
|
+
|
|
23
|
+
## Table Of Contents
|
|
24
|
+
|
|
25
|
+
1. [Usage](#Usage)
|
|
26
|
+
2. [Why Wgit?](#Why-Wgit)
|
|
27
|
+
3. [Why Not Wgit?](#Why-Not-Wgit)
|
|
28
|
+
4. [Installation](#Installation)
|
|
29
|
+
5. [Documentation](#Documentation)
|
|
30
|
+
6. [Executable](#Executable)
|
|
31
|
+
7. [License](#License)
|
|
32
|
+
8. [Contributing](#Contributing)
|
|
33
|
+
9. [Development](#Development)
|
|
34
|
+
|
|
35
|
+
## Usage
|
|
36
|
+
|
|
37
|
+
Let's crawl a [quotes website](http://quotes.toscrape.com/) extracting its *quotes* and *authors* using the Wgit DSL:
|
|
38
|
+
|
|
39
|
+
```ruby
|
|
40
|
+
require 'wgit'
|
|
41
|
+
require 'json'
|
|
42
|
+
|
|
43
|
+
include Wgit::DSL
|
|
44
|
+
|
|
45
|
+
start 'http://quotes.toscrape.com/tag/humor/'
|
|
46
|
+
follow "//li[@class='next']/a/@href"
|
|
47
|
+
|
|
48
|
+
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
49
|
+
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
50
|
+
|
|
51
|
+
quotes = []
|
|
52
|
+
|
|
53
|
+
crawl_site do |doc|
|
|
54
|
+
doc.quotes.zip(doc.authors).each do |arr|
|
|
55
|
+
quotes << {
|
|
56
|
+
quote: arr.first,
|
|
57
|
+
author: arr.last
|
|
58
|
+
}
|
|
59
|
+
end
|
|
60
|
+
end
|
|
61
|
+
|
|
62
|
+
puts JSON.generate(quotes)
|
|
63
|
+
```
|
|
64
|
+
|
|
65
|
+
But what if we want to crawl and store the content in a database, so that it can be searched? Wgit makes it easy to index and search HTML using [MongoDB](https://www.mongodb.com/):
|
|
66
|
+
|
|
67
|
+
```ruby
|
|
68
|
+
require 'wgit'
|
|
69
|
+
|
|
70
|
+
include Wgit::DSL
|
|
71
|
+
|
|
72
|
+
Wgit.logger.level = Logger::WARN
|
|
73
|
+
|
|
74
|
+
connection_string 'mongodb://user:password@localhost/crawler'
|
|
75
|
+
|
|
76
|
+
start 'http://quotes.toscrape.com/tag/humor/'
|
|
77
|
+
follow "//li[@class='next']/a/@href"
|
|
78
|
+
|
|
79
|
+
extract :quotes, "//div[@class='quote']/span[@class='text']", singleton: false
|
|
80
|
+
extract :authors, "//div[@class='quote']/span/small", singleton: false
|
|
81
|
+
|
|
82
|
+
index_site
|
|
83
|
+
search 'prejudice'
|
|
84
|
+
```
|
|
85
|
+
|
|
86
|
+
The `search` call (on the last line) will return and output the results:
|
|
87
|
+
|
|
88
|
+
```text
|
|
89
|
+
Quotes to Scrape
|
|
90
|
+
“I am free of all prejudice. I hate everyone equally. ”
|
|
91
|
+
http://quotes.toscrape.com/tag/humor/page/2/
|
|
92
|
+
```
|
|
93
|
+
|
|
94
|
+
Using a MongoDB [client](https://robomongo.org/), we can see that the two web pages have been indexed, along with their extracted *quotes* and *authors*:
|
|
95
|
+
|
|
96
|
+
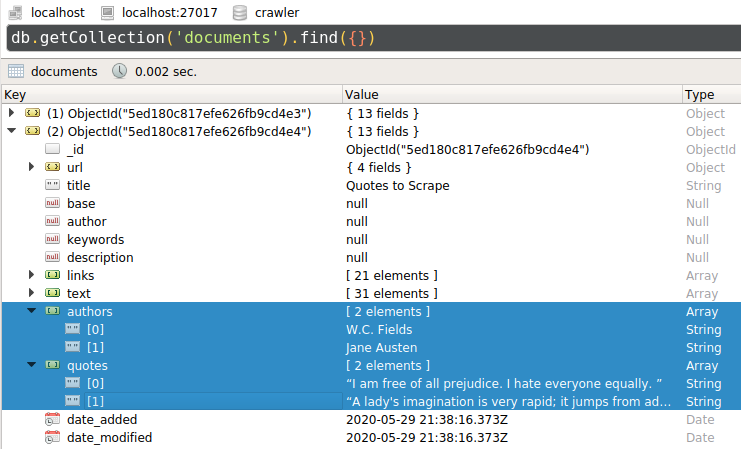
|
|
97
|
+
|
|
98
|
+
The [DSL](https://github.com/michaeltelford/wgit/wiki/How-To-Use-The-DSL) makes it easy to write scripts for experimenting with. Wgit's DSL is simply a wrapper around the underlying classes however. For comparison, here is the above example written using the Wgit API *instead of* the DSL:
|
|
99
|
+
|
|
100
|
+
```ruby
|
|
101
|
+
require 'wgit'
|
|
102
|
+
require 'json'
|
|
103
|
+
|
|
104
|
+
crawler = Wgit::Crawler.new
|
|
105
|
+
url = Wgit::Url.new('http://quotes.toscrape.com/tag/humor/')
|
|
106
|
+
quotes = []
|
|
107
|
+
|
|
108
|
+
Wgit::Document.define_extractor(:quotes, "//div[@class='quote']/span[@class='text']", singleton: false)
|
|
109
|
+
Wgit::Document.define_extractor(:authors, "//div[@class='quote']/span/small", singleton: false)
|
|
110
|
+
|
|
111
|
+
crawler.crawl_site(url, follow: "//li[@class='next']/a/@href") do |doc|
|
|
112
|
+
doc.quotes.zip(doc.authors).each do |arr|
|
|
113
|
+
quotes << {
|
|
114
|
+
quote: arr.first,
|
|
115
|
+
author: arr.last
|
|
116
|
+
}
|
|
117
|
+
end
|
|
118
|
+
end
|
|
119
|
+
|
|
120
|
+
puts JSON.generate(quotes)
|
|
121
|
+
```
|
|
122
|
+
|
|
123
|
+
## Why Wgit?
|
|
124
|
+
|
|
125
|
+
There are many [other HTML crawlers](https://awesome-ruby.com/#-web-crawling) out there so why use Wgit?
|
|
126
|
+
|
|
127
|
+
- Wgit has excellent unit testing, 100% documentation coverage and follows [semantic versioning](https://semver.org/) rules.
|
|
128
|
+
- Wgit excels at crawling an entire website's HTML out of the box. Many alternative crawlers require you to provide the `xpath` needed to *follow* the next URLs to crawl. Wgit by default, crawls the entire site by extracting its internal links pointing to the same host.
|
|
129
|
+
- Wgit allows you to define content *extractors* that will fire on every subsequent crawl; be it a single URL or an entire website. This enables you to focus on the content you want.
|
|
130
|
+
- Wgit can index (crawl and store) HTML to a database making it a breeze to build custom search engines. You can also specify which page content gets searched, making the search more meaningful. For example, here's a script that will index the Wgit [wiki](https://github.com/michaeltelford/wgit/wiki) articles:
|
|
131
|
+
|
|
132
|
+
```ruby
|
|
133
|
+
require 'wgit'
|
|
134
|
+
|
|
135
|
+
ENV['WGIT_CONNECTION_STRING'] = 'mongodb://user:password@localhost/crawler'
|
|
136
|
+
|
|
137
|
+
wiki = Wgit::Url.new('https://github.com/michaeltelford/wgit/wiki')
|
|
138
|
+
|
|
139
|
+
# Only index the most recent of each wiki article, ignoring the rest of Github.
|
|
140
|
+
opts = {
|
|
141
|
+
allow_paths: 'michaeltelford/wgit/wiki/*',
|
|
142
|
+
disallow_paths: 'michaeltelford/wgit/wiki/*/_history'
|
|
143
|
+
}
|
|
144
|
+
|
|
145
|
+
indexer = Wgit::Indexer.new
|
|
146
|
+
indexer.index_site(wiki, **opts)
|
|
147
|
+
```
|
|
148
|
+
|
|
149
|
+
## Why Not Wgit?
|
|
150
|
+
|
|
151
|
+
So why might you not use Wgit, I hear you ask?
|
|
152
|
+
|
|
153
|
+
- Wgit doesn't allow for webpage interaction e.g. signing in as a user. There are better gems out there for that.
|
|
154
|
+
- Wgit can parse a crawled page's Javascript, but it doesn't do so by default. If your crawls are JS heavy then you might best consider a pure browser-based crawler instead.
|
|
155
|
+
- Wgit while fast (using `libcurl` for HTTP etc.), isn't multi-threaded; so each URL gets crawled sequentially. You could hand each crawled document to a worker thread for processing - but if you need concurrent crawling then you should consider something else.
|
|
156
|
+
|
|
157
|
+
## Installation
|
|
158
|
+
|
|
159
|
+
Only MRI Ruby is tested and supported, but Wgit may work with other Ruby implementations.
|
|
160
|
+
|
|
161
|
+
Currently, the required MRI Ruby version is:
|
|
162
|
+
|
|
163
|
+
`~> 2.5` (a.k.a.) `>= 2.5 && < 3`
|
|
164
|
+
|
|
165
|
+
### Using Bundler
|
|
166
|
+
|
|
167
|
+
$ bundle add wgit
|
|
168
|
+
|
|
169
|
+
### Using RubyGems
|
|
170
|
+
|
|
171
|
+
$ gem install wgit
|
|
172
|
+
|
|
173
|
+
### Verify
|
|
174
|
+
|
|
175
|
+
$ wgit
|
|
176
|
+
|
|
177
|
+
Calling the installed executable will start an REPL session.
|
|
178
|
+
|
|
179
|
+
## Documentation
|
|
180
|
+
|
|
181
|
+
- [Getting Started](https://github.com/michaeltelford/wgit/wiki/Getting-Started)
|
|
182
|
+
- [Wiki](https://github.com/michaeltelford/wgit/wiki)
|
|
183
|
+
- [API Yardocs](https://www.rubydoc.info/gems/wgit)
|
|
184
|
+
- [CHANGELOG](https://github.com/michaeltelford/wgit/blob/master/CHANGELOG.md)
|
|
185
|
+
|
|
186
|
+
## Executable
|
|
187
|
+
|
|
188
|
+
Installing the Wgit gem adds a `wgit` executable to your `$PATH`. The executable launches an interactive REPL session with the Wgit gem already loaded; making it super easy to index and search from the command line without the need for scripts.
|
|
189
|
+
|
|
190
|
+
The `wgit` executable does the following things (in order):
|
|
191
|
+
|
|
192
|
+
1. `require wgit`
|
|
193
|
+
2. `eval`'s a `.wgit.rb` file (if one exists in either the local or home directory, which ever is found first)
|
|
194
|
+
3. Starts an interactive shell (using `pry` if it's installed, or `irb` if not)
|
|
195
|
+
|
|
196
|
+
The `.wgit.rb` file can be used to seed fixture data or define helper functions for the session. For example, you could define a function which indexes your website for quick and easy searching everytime you start a new session.
|
|
197
|
+
|
|
198
|
+
## License
|
|
199
|
+
|
|
200
|
+
The gem is available as open source under the terms of the MIT License. See [LICENSE.txt](https://github.com/michaeltelford/wgit/blob/master/LICENSE.txt) for more details.
|
|
201
|
+
|
|
202
|
+
## Contributing
|
|
203
|
+
|
|
204
|
+
Bug reports and feature requests are welcome on [GitHub](https://github.com/michaeltelford/wgit/issues). Just raise an issue, checking it doesn't already exist.
|
|
205
|
+
|
|
206
|
+
The current road map is rudimentally listed in the [Road Map](https://github.com/michaeltelford/wgit/wiki/Road-Map) wiki page. Maybe your feature request is already there?
|
|
207
|
+
|
|
208
|
+
Before you consider making a contribution, check out [CONTRIBUTING.md](https://github.com/michaeltelford/wgit/blob/master/CONTRIBUTING.md).
|
|
209
|
+
|
|
210
|
+
## Development
|
|
211
|
+
|
|
212
|
+
After checking out the repo, run the following commands:
|
|
213
|
+
|
|
214
|
+
1. `gem install bundler toys`
|
|
215
|
+
2. `bundle install --jobs=3`
|
|
216
|
+
3. `toys setup`
|
|
217
|
+
|
|
218
|
+
And you're good to go!
|
|
219
|
+
|
|
220
|
+
### Tooling
|
|
221
|
+
|
|
222
|
+
Wgit uses the [`toys`](https://github.com/dazuma/toys) gem (instead of Rake) for task invocation. For a full list of available tasks a.k.a. tools, run `toys --tools`. You can search for a tool using `toys -s tool_name`. The most commonly used tools are listed below...
|
|
223
|
+
|
|
224
|
+
Run `toys db` to see a list of database related tools, enabling you to run a Mongo DB instance locally using Docker. Run `toys test` to execute the tests.
|
|
225
|
+
|
|
226
|
+
To generate code documentation locally, run `toys yardoc`. To browse the docs in a browser run `toys yardoc --serve`. You can also use the `yri` command line tool e.g. `yri Wgit::Crawler#crawl_site` etc.
|
|
227
|
+
|
|
228
|
+
To install this gem onto your local machine, run `toys install` and follow the prompt.
|
|
229
|
+
|
|
230
|
+
### Console
|
|
231
|
+
|
|
232
|
+
You can run `toys console` for an interactive shell using the `./bin/wgit` executable. The `toys setup` task will have created an `.env` and `.wgit.rb` file which get loaded by the executable. You can use the contents of this [gist](https://gist.github.com/michaeltelford/b90d5e062da383be503ca2c3a16e9164) to turn the executable into a development console. It defines some useful functions, fixtures and connects to the database etc. Don't forget to set the `WGIT_CONNECTION_STRING` in the `.env` file.
|