timescaledb 0.2.6 → 0.2.8
Sign up to get free protection for your applications and to get access to all the features.
- checksums.yaml +4 -4
- data/bin/tsdb +30 -29
- data/lib/timescaledb/acts_as_hypertable/core.rb +1 -1
- data/lib/timescaledb/acts_as_hypertable.rb +5 -2
- data/lib/timescaledb/connection.rb +43 -0
- data/lib/timescaledb/connection_handling.rb +16 -0
- data/lib/timescaledb/database/chunk_statements.rb +21 -0
- data/lib/timescaledb/database/hypertable_statements.rb +37 -0
- data/lib/timescaledb/database/quoting.rb +12 -0
- data/lib/timescaledb/database/schema_statements.rb +246 -0
- data/lib/timescaledb/database/types.rb +20 -0
- data/lib/timescaledb/database.rb +15 -0
- data/lib/timescaledb/migration_helpers.rb +36 -8
- data/lib/timescaledb/schema_dumper.rb +40 -12
- data/lib/timescaledb/stats/chunks.rb +41 -0
- data/lib/timescaledb/stats/continuous_aggregates.rb +24 -0
- data/lib/timescaledb/stats/hypertables.rb +102 -0
- data/lib/timescaledb/stats/job_stats.rb +29 -0
- data/lib/timescaledb/stats.rb +22 -0
- data/lib/timescaledb/toolkit/time_vector.rb +21 -17
- data/lib/timescaledb/version.rb +1 -1
- data/lib/timescaledb.rb +3 -0
- metadata +15 -95
- data/.github/workflows/ci.yml +0 -72
- data/.gitignore +0 -12
- data/.rspec +0 -3
- data/.ruby-version +0 -1
- data/.tool-versions +0 -1
- data/.travis.yml +0 -9
- data/CODE_OF_CONDUCT.md +0 -74
- data/Fastfile +0 -17
- data/Gemfile +0 -8
- data/Gemfile.lock +0 -75
- data/Gemfile.scenic +0 -7
- data/Gemfile.scenic.lock +0 -119
- data/README.md +0 -490
- data/Rakefile +0 -21
- data/bin/console +0 -28
- data/bin/setup +0 -13
- data/docs/command_line.md +0 -178
- data/docs/img/lttb_example.png +0 -0
- data/docs/img/lttb_sql_vs_ruby.gif +0 -0
- data/docs/img/lttb_zoom.gif +0 -0
- data/docs/index.md +0 -72
- data/docs/migrations.md +0 -76
- data/docs/models.md +0 -78
- data/docs/toolkit.md +0 -507
- data/docs/toolkit_lttb_tutorial.md +0 -557
- data/docs/toolkit_lttb_zoom.md +0 -357
- data/docs/toolkit_ohlc.md +0 -315
- data/docs/videos.md +0 -16
- data/examples/all_in_one/all_in_one.rb +0 -94
- data/examples/all_in_one/benchmark_comparison.rb +0 -108
- data/examples/all_in_one/caggs.rb +0 -93
- data/examples/all_in_one/query_data.rb +0 -78
- data/examples/ranking/.gitattributes +0 -7
- data/examples/ranking/.gitignore +0 -29
- data/examples/ranking/.ruby-version +0 -1
- data/examples/ranking/Gemfile +0 -33
- data/examples/ranking/Gemfile.lock +0 -189
- data/examples/ranking/README.md +0 -166
- data/examples/ranking/Rakefile +0 -6
- data/examples/ranking/app/controllers/application_controller.rb +0 -2
- data/examples/ranking/app/controllers/concerns/.keep +0 -0
- data/examples/ranking/app/jobs/application_job.rb +0 -7
- data/examples/ranking/app/models/application_record.rb +0 -3
- data/examples/ranking/app/models/concerns/.keep +0 -0
- data/examples/ranking/app/models/game.rb +0 -2
- data/examples/ranking/app/models/play.rb +0 -7
- data/examples/ranking/bin/bundle +0 -114
- data/examples/ranking/bin/rails +0 -4
- data/examples/ranking/bin/rake +0 -4
- data/examples/ranking/bin/setup +0 -33
- data/examples/ranking/config/application.rb +0 -39
- data/examples/ranking/config/boot.rb +0 -4
- data/examples/ranking/config/credentials.yml.enc +0 -1
- data/examples/ranking/config/database.yml +0 -86
- data/examples/ranking/config/environment.rb +0 -5
- data/examples/ranking/config/environments/development.rb +0 -60
- data/examples/ranking/config/environments/production.rb +0 -75
- data/examples/ranking/config/environments/test.rb +0 -53
- data/examples/ranking/config/initializers/cors.rb +0 -16
- data/examples/ranking/config/initializers/filter_parameter_logging.rb +0 -8
- data/examples/ranking/config/initializers/inflections.rb +0 -16
- data/examples/ranking/config/initializers/timescale.rb +0 -2
- data/examples/ranking/config/locales/en.yml +0 -33
- data/examples/ranking/config/puma.rb +0 -43
- data/examples/ranking/config/routes.rb +0 -6
- data/examples/ranking/config/storage.yml +0 -34
- data/examples/ranking/config.ru +0 -6
- data/examples/ranking/db/migrate/20220209120747_create_games.rb +0 -10
- data/examples/ranking/db/migrate/20220209120910_create_plays.rb +0 -19
- data/examples/ranking/db/migrate/20220209143347_create_score_per_hours.rb +0 -5
- data/examples/ranking/db/schema.rb +0 -47
- data/examples/ranking/db/seeds.rb +0 -7
- data/examples/ranking/db/views/score_per_hours_v01.sql +0 -7
- data/examples/ranking/lib/tasks/.keep +0 -0
- data/examples/ranking/log/.keep +0 -0
- data/examples/ranking/public/robots.txt +0 -1
- data/examples/ranking/storage/.keep +0 -0
- data/examples/ranking/tmp/.keep +0 -0
- data/examples/ranking/tmp/pids/.keep +0 -0
- data/examples/ranking/tmp/storage/.keep +0 -0
- data/examples/ranking/vendor/.keep +0 -0
- data/examples/toolkit-demo/compare_volatility.rb +0 -104
- data/examples/toolkit-demo/lttb/README.md +0 -15
- data/examples/toolkit-demo/lttb/lttb.rb +0 -92
- data/examples/toolkit-demo/lttb/lttb_sinatra.rb +0 -139
- data/examples/toolkit-demo/lttb/lttb_test.rb +0 -21
- data/examples/toolkit-demo/lttb/views/index.erb +0 -27
- data/examples/toolkit-demo/lttb-zoom/README.md +0 -13
- data/examples/toolkit-demo/lttb-zoom/lttb_zoomable.rb +0 -90
- data/examples/toolkit-demo/lttb-zoom/views/index.erb +0 -33
- data/examples/toolkit-demo/ohlc.rb +0 -175
- data/mkdocs.yml +0 -34
- data/timescaledb.gemspec +0 -40
data/docs/toolkit_lttb_zoom.md
DELETED
|
@@ -1,357 +0,0 @@
|
|
|
1
|
-
# Downsampling and zooming
|
|
2
|
-
|
|
3
|
-
Less than 2 decades ago, google revolutionised the digital maps system, raising the bar of maps rendering and helping people to navigate in the unknown. Helping tourists and drivers to drammatically speed up the time to analyze a route and get the next step. With time-series dates and numbers, several indicators where created to make data scientists digest things faster like candle sticks and indicators that can easily show insights about relevant moments in the data.
|
|
4
|
-
|
|
5
|
-
In this tutorial, we're going to cover data resolution and how to present data in a reasonable resolution.
|
|
6
|
-
|
|
7
|
-
if you're zooming out years of time-series data, no matter how wide is your monitor, probably you'll not be able to see more than a few thounsand points in your screen.
|
|
8
|
-
|
|
9
|
-
One of the hard challenges we face to plot data is downsampling it in a proper resolution. Generally, when we zoom in, we lose resolution as we focus on a slice of the data points available. With less data points, the distribution of the data points become far from each other and we adopt lines between the points to promote a fake connection between the elements. Often, fetching all the data seems unreasonable and expensive.
|
|
10
|
-
|
|
11
|
-
In this tutorial, you'll see how Timescale can help you to strike a balance between speed and screen resolution. We're going to walk you through a downsampling method that allows you to downsampling milions of records to your screen resolution for a fast rendering process.
|
|
12
|
-
|
|
13
|
-
Establishing a threshold that is reasonable for the screen resolution, every zoom in will fetch new slices of downsampled data.
|
|
14
|
-
|
|
15
|
-
Downsampling in the the front end is pretty common for the plotting libraries, but the process still very expensive while delegating to the back end and make the zooming experience smooth like zooming on digital maps. You still watch the old resolution while fetches nes data and keep narrowing down for a new slice of data that represents the actual period.
|
|
16
|
-
|
|
17
|
-
In this example, we're going to use the [lttb][3] function, that is part of the [functions pipelines][4] that can simplify a lot of your data analysis in the database.
|
|
18
|
-
|
|
19
|
-
If you're not familiar with the LTTB algorithm, feel free to try the [LTTB Tutorial][1] first and then you'll understand completely how the downsampling algorithm is choosing what points to print.
|
|
20
|
-
|
|
21
|
-
The focus of this example is to show how you can build a recursive process to just downsample the data to keep it with a good resolution.
|
|
22
|
-
|
|
23
|
-
The image bellow corresponds to the step by step guide provided here.
|
|
24
|
-
|
|
25
|
-
|
|
26
|
-
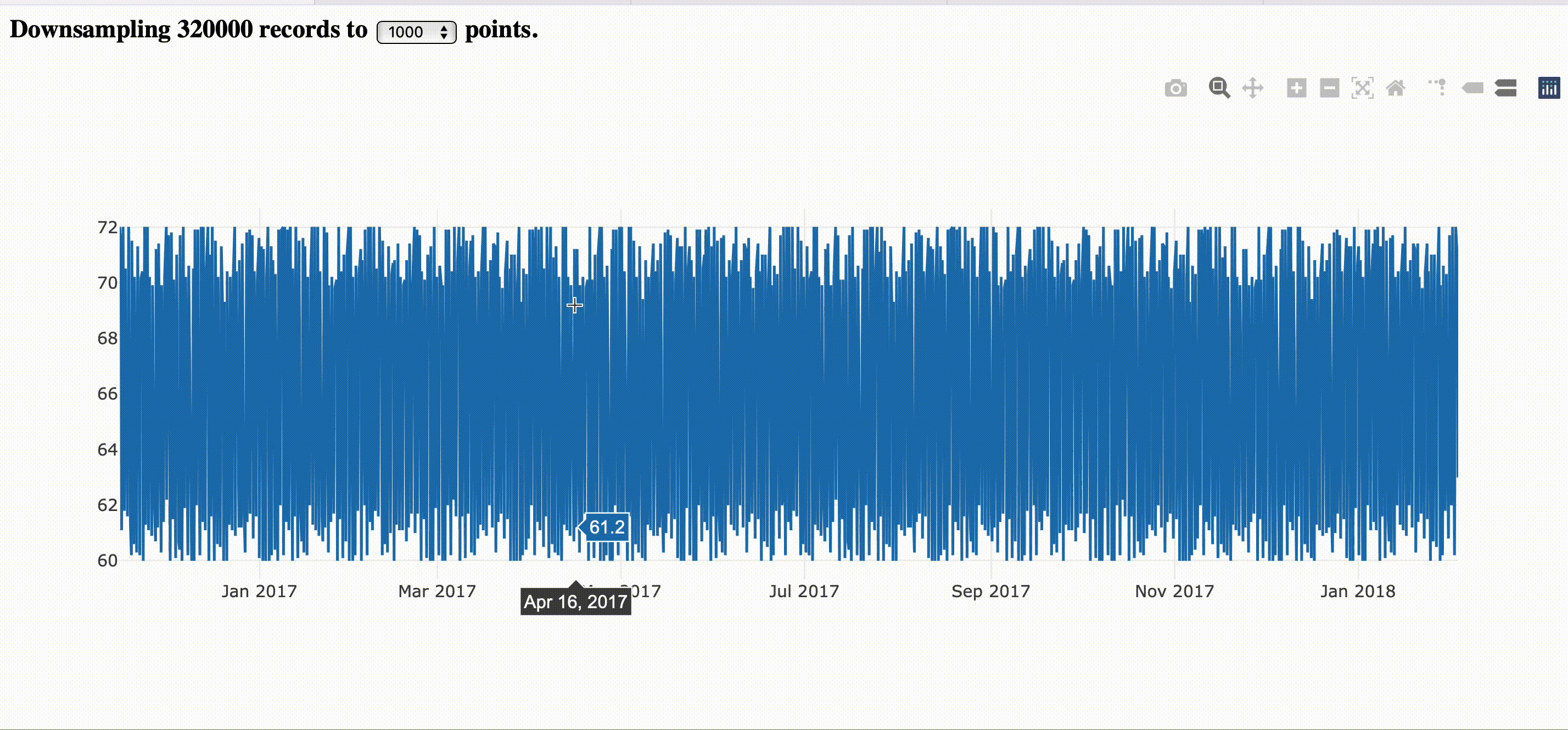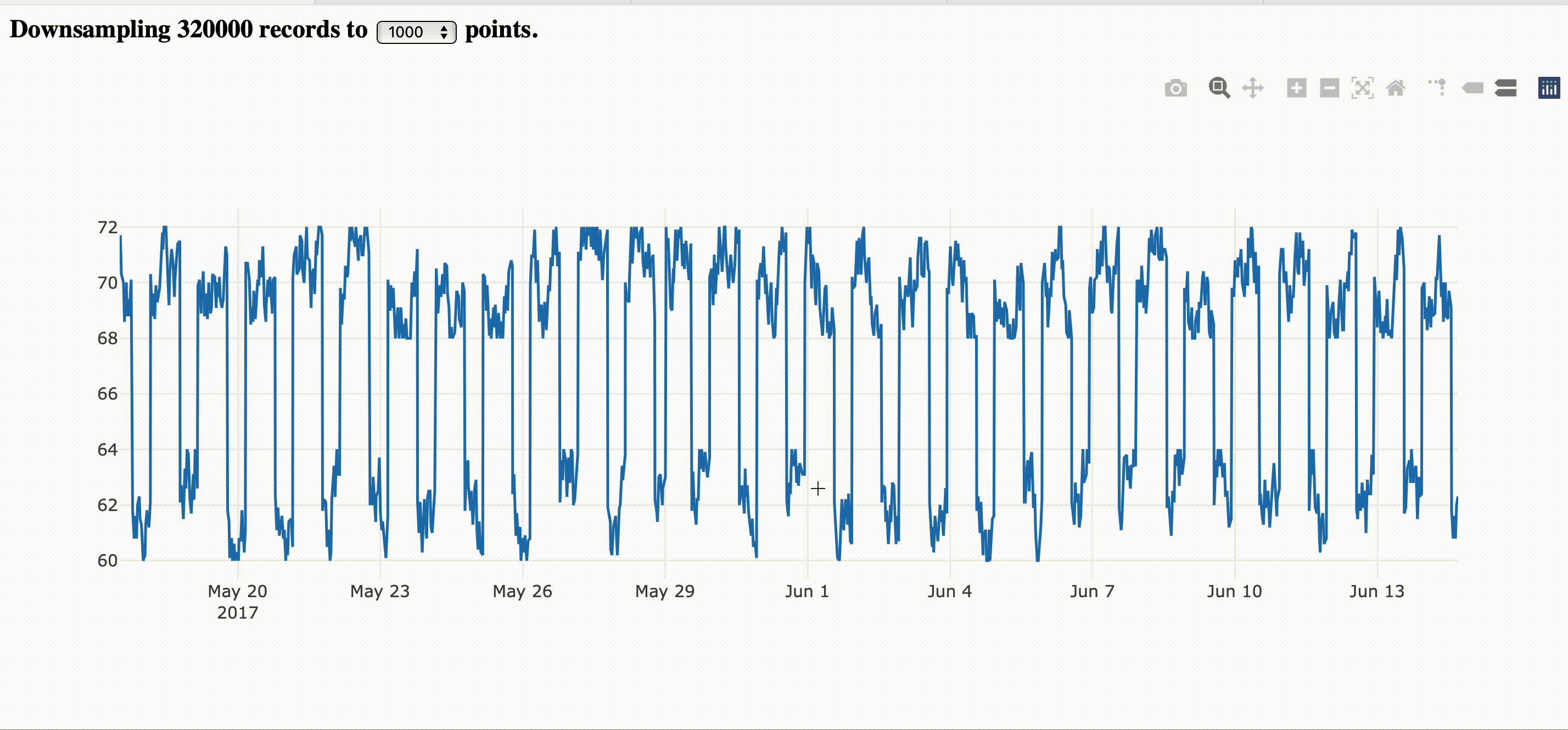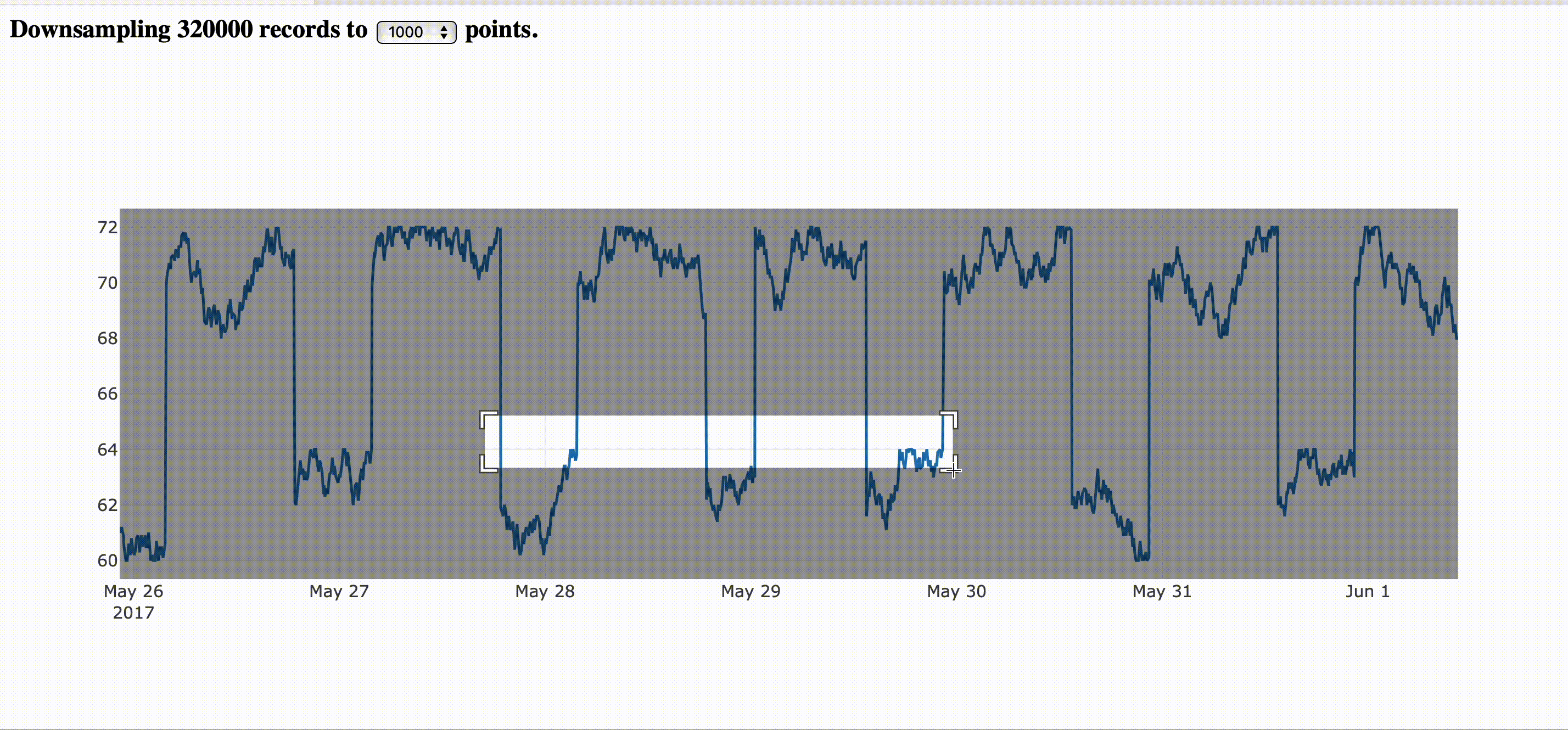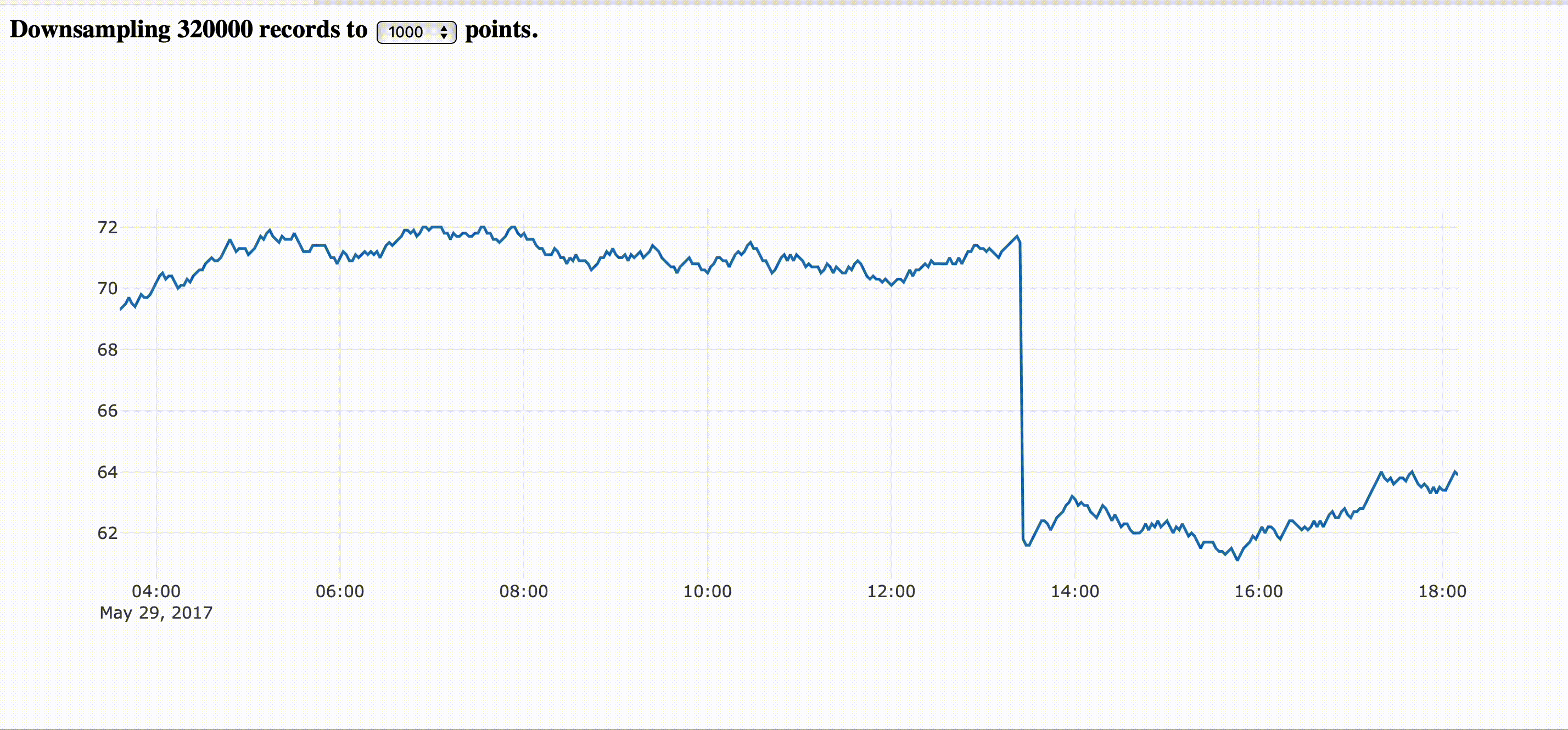
|
|
27
|
-
|
|
28
|
-
|
|
29
|
-
If you want to just go and run it directly, you can fetch the complete example [here][2].
|
|
30
|
-
|
|
31
|
-
Now, we'll split the work in two main sessions: preparing the back-end and front-end.
|
|
32
|
-
|
|
33
|
-
## Preparing the Back end
|
|
34
|
-
|
|
35
|
-
The back-end will be a Ruby script to fetch the dataset and prepare the database in case it's not ready. It will also offer the JSON endpoint with the downsampled data that will be consumed by the front-end.
|
|
36
|
-
|
|
37
|
-
|
|
38
|
-
### Set up dependencies
|
|
39
|
-
|
|
40
|
-
The example is using Bundler inline, as it avoids the creation of the `Gemfile`. It's very handy for prototyping code that you can ship in a single file. You can declare all the gems in the `gemfile` code block, and Bundler will install them dynamically.
|
|
41
|
-
|
|
42
|
-
```ruby
|
|
43
|
-
require 'bundler/inline' #require only what you need
|
|
44
|
-
|
|
45
|
-
gemfile(true) do
|
|
46
|
-
gem 'timescaledb'
|
|
47
|
-
gem 'pry'
|
|
48
|
-
gem 'sinatra', require: false
|
|
49
|
-
gem 'sinatra-reloader'
|
|
50
|
-
gem 'sinatra-cross_origin'
|
|
51
|
-
end
|
|
52
|
-
```
|
|
53
|
-
|
|
54
|
-
The Timescale gem doesn't require the toolkit by default, so you must specify it to use.
|
|
55
|
-
|
|
56
|
-
!!!warning
|
|
57
|
-
Note that we do not require the rest of the libraries because Bundler inline already requires the specified libraries by default which is very convenient for examples in a single file.
|
|
58
|
-
|
|
59
|
-
Let's take a look at what dependencies we have for what purpose:
|
|
60
|
-
|
|
61
|
-
* [timescaledb][4] gem is the ActiveRecord wrapper for TimescaleDB functions.
|
|
62
|
-
* [sinatra][6] is a DSL for quickly creating web applications with minimal effort.
|
|
63
|
-
|
|
64
|
-
Only for development purposes we also have:
|
|
65
|
-
|
|
66
|
-
1. The [pry][5] library is widely adopted to debug any Ruby code. It can facilitate to explore the app and easily troubleshoot any issues you find.
|
|
67
|
-
2. The `sinatra-cross_origin` allow the application to use javascript directly from foreign servers without denying the access.
|
|
68
|
-
3. The `sinatra-reloader` is very convenient to keep updating the code examples without the need to restart the ruby process.
|
|
69
|
-
|
|
70
|
-
```ruby
|
|
71
|
-
require 'sinatra'
|
|
72
|
-
require 'sinatra/json'
|
|
73
|
-
require 'sinatra/contrib'
|
|
74
|
-
require 'timescaledb/toolkit'
|
|
75
|
-
|
|
76
|
-
register Sinatra::Reloader
|
|
77
|
-
register Sinatra::Contrib
|
|
78
|
-
```
|
|
79
|
-
|
|
80
|
-
## Setup database
|
|
81
|
-
|
|
82
|
-
Now, it's time to set up the database for this application. Make sure you have TimescaleDB installed or [learn how to install TimescaleDB here][12].
|
|
83
|
-
|
|
84
|
-
### Establishing the connection
|
|
85
|
-
|
|
86
|
-
The next step is to connect to the database so that we will run this example with the PostgreSQL URI as the last argument of the command line.
|
|
87
|
-
|
|
88
|
-
```ruby
|
|
89
|
-
PG_URI = ARGV.last
|
|
90
|
-
ActiveRecord::Base.establish_connection(PG_URI)
|
|
91
|
-
```
|
|
92
|
-
|
|
93
|
-
If this line works, it means your connection is good.
|
|
94
|
-
|
|
95
|
-
### Downloading the dataset
|
|
96
|
-
|
|
97
|
-
The data comes from a real scenario. The data loaded in the example comes from the [weather dataset][8] and contains several profiles with more or less data and with a reasonable resolution for the actual example.
|
|
98
|
-
|
|
99
|
-
Here is small automation to make it run smoothly with small, medium, and big data sets.
|
|
100
|
-
|
|
101
|
-
```ruby
|
|
102
|
-
VALID_SIZES = %i[small med big]
|
|
103
|
-
def download_weather_dataset size: :small
|
|
104
|
-
unless VALID_SIZES.include?(size)
|
|
105
|
-
fail "Invalid size: #{size}. Valid are #{VALID_SIZES}"
|
|
106
|
-
end
|
|
107
|
-
url = "https://timescaledata.blob.core.windows.net/datasets/weather_#{size}.tar.gz"
|
|
108
|
-
puts "fetching #{size} weather dataset..."
|
|
109
|
-
system "wget \"#{url}\""
|
|
110
|
-
puts "done!"
|
|
111
|
-
end
|
|
112
|
-
```
|
|
113
|
-
|
|
114
|
-
Now, let's create the setup method to verify if the database is created and have the data loaded, and fetch it if necessary.
|
|
115
|
-
|
|
116
|
-
```ruby
|
|
117
|
-
def setup size: :small
|
|
118
|
-
file = "weather_#{size}.tar.gz"
|
|
119
|
-
download_weather_dataset unless File.exists? file
|
|
120
|
-
puts "extracting #{file}"
|
|
121
|
-
system "tar -xvzf #{file} "
|
|
122
|
-
puts "creating data structures"
|
|
123
|
-
system "psql #{PG_URI} < weather.sql"
|
|
124
|
-
system %|psql #{PG_URI} -c "\\COPY locations FROM weather_#{size}_locations.csv CSV"|
|
|
125
|
-
system %|psql #{PG_URI} -c "\\COPY conditions FROM weather_#{size}_conditions.csv CSV"|
|
|
126
|
-
end
|
|
127
|
-
```
|
|
128
|
-
|
|
129
|
-
!!!info
|
|
130
|
-
Maybe you'll need to recreate the database if you want to test with a different dataset.
|
|
131
|
-
|
|
132
|
-
### Declaring the models
|
|
133
|
-
|
|
134
|
-
Now, let's declare the ActiveRecord models. The location is an auxiliary table
|
|
135
|
-
to control the placement of the device.
|
|
136
|
-
|
|
137
|
-
```ruby
|
|
138
|
-
class Location < ActiveRecord::Base
|
|
139
|
-
self.primary_key = "device_id"
|
|
140
|
-
|
|
141
|
-
has_many :conditions, foreign_key: "device_id"
|
|
142
|
-
end
|
|
143
|
-
```
|
|
144
|
-
|
|
145
|
-
Every location emits weather conditions with `temperature` and `humidity` every X minutes.
|
|
146
|
-
|
|
147
|
-
The `conditions` is the time-series data we'll refer to here.
|
|
148
|
-
|
|
149
|
-
```ruby
|
|
150
|
-
class Condition < ActiveRecord::Base
|
|
151
|
-
acts_as_hypertable time_column: "time"
|
|
152
|
-
acts_as_time_vector value_column: "temperature", segment_by: "device_id"
|
|
153
|
-
belongs_to :location, foreign_key: "device_id"
|
|
154
|
-
end
|
|
155
|
-
```
|
|
156
|
-
|
|
157
|
-
### Putting all together
|
|
158
|
-
|
|
159
|
-
Now it's time to call the methods we implemented before. So, let's set up a logger to print the data to the standard output (STDOUT) to confirm the steps and add the toolkit to the search path.
|
|
160
|
-
|
|
161
|
-
Similar to database migration, we need to verify if the table exists, set up the hypertable and load the data if necessary.
|
|
162
|
-
|
|
163
|
-
```ruby
|
|
164
|
-
ActiveRecord::Base.connection.instance_exec do
|
|
165
|
-
ActiveRecord::Base.logger = Logger.new(STDOUT)
|
|
166
|
-
add_toolkit_to_search_path!
|
|
167
|
-
|
|
168
|
-
unless Condition.table_exists?
|
|
169
|
-
setup size: :small
|
|
170
|
-
end
|
|
171
|
-
end
|
|
172
|
-
```
|
|
173
|
-
|
|
174
|
-
The `setup` method also can fetch different datasets and you'll need to manually drop the `conditions` and `locations` tables to reload it.
|
|
175
|
-
|
|
176
|
-
|
|
177
|
-
### Filtering data
|
|
178
|
-
|
|
179
|
-
We'll have two main scenarios to plot the data. When the user is not filtering any data and when the user is filtering during a zoom phase.
|
|
180
|
-
|
|
181
|
-
To simplify the example, we're going to use only the `weather-pro-000001` device_id to make it easier to follow:
|
|
182
|
-
|
|
183
|
-
```ruby
|
|
184
|
-
def filter_by_request_params
|
|
185
|
-
filter= {device_id: "weather-pro-000001"}
|
|
186
|
-
if params[:filter] && params[:filter] != "null"
|
|
187
|
-
from, to = params[:filter].split(",").map(&Time.method(:parse))
|
|
188
|
-
filter[:time] = from..to
|
|
189
|
-
end
|
|
190
|
-
filter
|
|
191
|
-
end
|
|
192
|
-
```
|
|
193
|
-
|
|
194
|
-
The method is just building the proper where clause using the ActiveRecord style to be filtering the conditions we want to use for the example. Now, let's use the previous method defining the scope of the data that will be downsampled from the database.
|
|
195
|
-
|
|
196
|
-
```ruby
|
|
197
|
-
def conditions
|
|
198
|
-
Condition.where(filter_by_request_params).order('time')
|
|
199
|
-
end
|
|
200
|
-
```
|
|
201
|
-
|
|
202
|
-
### Downsampling data
|
|
203
|
-
|
|
204
|
-
The threshold can be defined as a method as it can also be used further in the front-end for rendering the initial template values.
|
|
205
|
-
|
|
206
|
-
```ruby
|
|
207
|
-
def threshold
|
|
208
|
-
params[:threshold]&.to_i || 50
|
|
209
|
-
end
|
|
210
|
-
```
|
|
211
|
-
|
|
212
|
-
Now, the most important method of this example, the call to the [lttb][3] function that is responsible for the downsampling algorithm. It also reuses all previous logic built here.
|
|
213
|
-
|
|
214
|
-
```ruby
|
|
215
|
-
def downsampled
|
|
216
|
-
conditions.lttb(threshold: threshold, segment_by: nil)
|
|
217
|
-
end
|
|
218
|
-
```
|
|
219
|
-
|
|
220
|
-
The `segment_by` keyword explicit `nil` because we have the `segment_by` explicit in the `acts_as_time_vector` macro in the model that is being inherited here. As the filter is specifying a `device_id`, we can skip this option to simplify the data coming from lttb.
|
|
221
|
-
|
|
222
|
-
!!!info "The lttb scope"
|
|
223
|
-
The `lttb` method call in reality is a ActiveRecord scope. It is encapsulating all the logic behind the library. The SQL code is not big, but there's some caveats involved here. So, behind the scenes the following SQL query is executed:
|
|
224
|
-
|
|
225
|
-
```sql
|
|
226
|
-
SELECT time AS time, value AS temperature
|
|
227
|
-
FROM (
|
|
228
|
-
WITH ordered AS
|
|
229
|
-
(SELECT "conditions"."time",
|
|
230
|
-
"conditions"."temperature"
|
|
231
|
-
FROM "conditions"
|
|
232
|
-
WHERE "conditions"."device_id" = 'weather-pro-000001'
|
|
233
|
-
ORDER BY time, "conditions"."time" ASC)
|
|
234
|
-
SELECT (
|
|
235
|
-
lttb( ordered.time, ordered.temperature, 50) ->
|
|
236
|
-
toolkit_experimental.unnest()
|
|
237
|
-
).* FROM ordered
|
|
238
|
-
) AS ordered
|
|
239
|
-
```
|
|
240
|
-
|
|
241
|
-
The `acts_as_time_vector` macro makes the `lttb` scope available in the ActiveRecord scopes allowing to mix conditions in advance and nest the queries in the way that it can process the LTTB and unnest it properly.
|
|
242
|
-
|
|
243
|
-
Also, note that it's using the `->` pipeline operator to unnest the timevector and transform the data in tupples again.
|
|
244
|
-
|
|
245
|
-
|
|
246
|
-
### Exposing endpoints
|
|
247
|
-
|
|
248
|
-
Now, let's start with the web part using the sinatra macros. First, let's
|
|
249
|
-
configure the server to allow cross origin requests and fetch the javascripts
|
|
250
|
-
libraries directly from their official website.
|
|
251
|
-
|
|
252
|
-
```ruby
|
|
253
|
-
configure do
|
|
254
|
-
enable :cross_origin
|
|
255
|
-
end
|
|
256
|
-
```
|
|
257
|
-
Now, let's declare the root endpoint that will render the index template and
|
|
258
|
-
the JSON endpoint that will return the downsampled data.
|
|
259
|
-
|
|
260
|
-
```ruby
|
|
261
|
-
get '/' do
|
|
262
|
-
erb :index
|
|
263
|
-
end
|
|
264
|
-
```
|
|
265
|
-
|
|
266
|
-
Note that the erb template should be on `views/index.erb` and will be covered in
|
|
267
|
-
the front end section soon.
|
|
268
|
-
|
|
269
|
-
```ruby
|
|
270
|
-
get "/lttb_sql" do
|
|
271
|
-
json downsampled
|
|
272
|
-
end
|
|
273
|
-
```
|
|
274
|
-
|
|
275
|
-
## Front end
|
|
276
|
-
|
|
277
|
-
The front-end will be a simple HTML with Javascript to Plot the fetched data and asynchronouysly refresh the data in a new resolution in case of zooming in.
|
|
278
|
-
|
|
279
|
-
The sinatrarb works with a simple "views" folder and by default it renders erb templates that is a mix of Ruby scriptlets and HTML templates.
|
|
280
|
-
|
|
281
|
-
All the following snippets goes to the same file. They're just split into
|
|
282
|
-
separated parts that will make it easier to understand what each part does.
|
|
283
|
-
|
|
284
|
-
Let's start with the header that contains the extra scripts.
|
|
285
|
-
|
|
286
|
-
We're just using two libraries:
|
|
287
|
-
|
|
288
|
-
1. **jQuery** to fetch data async with ajax calls.
|
|
289
|
-
2. [plotly][9] to plot the data.
|
|
290
|
-
|
|
291
|
-
```html
|
|
292
|
-
<head>
|
|
293
|
-
<script src="https://cdn.jsdelivr.net/npm/jquery@3.6.1/dist/jquery.min.js"></script>
|
|
294
|
-
<script src="https://cdn.plot.ly/plotly-latest.min.js"></script>
|
|
295
|
-
</head>
|
|
296
|
-
```
|
|
297
|
-
|
|
298
|
-
Now, let's have a small status showing how many records are present in the
|
|
299
|
-
database and allowing to use a different threshold and test different subset of
|
|
300
|
-
downsampled data.
|
|
301
|
-
|
|
302
|
-
```html
|
|
303
|
-
<h3>Downsampling <%= conditions.count %> records to
|
|
304
|
-
<select value="<%= threshold %>" onchange="location.href=`/?threshold=${this.value}`">
|
|
305
|
-
<option><%= threshold %></option>
|
|
306
|
-
<option value="50">50</option>
|
|
307
|
-
<option value="100">100</option>
|
|
308
|
-
<option value="500">500</option>
|
|
309
|
-
<option value="1000">1000</option>
|
|
310
|
-
<option value="5000">5000</option>
|
|
311
|
-
</select> points.
|
|
312
|
-
</h3>
|
|
313
|
-
```
|
|
314
|
-
|
|
315
|
-
Note that some Ruby scripts are wrapped with `<%= ... %>`in the middle of the HTML instructions to inherit the defaults established in the back-end.
|
|
316
|
-
|
|
317
|
-
Now, it's time to declare the div that will receive the plot component and
|
|
318
|
-
declare the method to fetch data and create the chart.
|
|
319
|
-
|
|
320
|
-
```html
|
|
321
|
-
<div id='container'></div>
|
|
322
|
-
<script>
|
|
323
|
-
let chart = document.getElementById('container');
|
|
324
|
-
function fetch(filter) {
|
|
325
|
-
$.ajax({
|
|
326
|
-
url: `/lttb_sql?threshold=<%= threshold %>&filter=${filter}`,
|
|
327
|
-
success: function(result) {
|
|
328
|
-
let x = result.map((e) => e[0]);
|
|
329
|
-
let y = result.map((e) => parseFloat(e[1]));
|
|
330
|
-
Plotly.newPlot(chart, [{x, y}]);
|
|
331
|
-
chart.on('plotly_relayout',
|
|
332
|
-
function(eventdata){
|
|
333
|
-
fetch([eventdata['xaxis.range[0]'], eventdata['xaxis.range[1]']]);
|
|
334
|
-
});
|
|
335
|
-
}});
|
|
336
|
-
}
|
|
337
|
-
fetch(null);
|
|
338
|
-
</script>
|
|
339
|
-
```
|
|
340
|
-
|
|
341
|
-
That's all for today folks!
|
|
342
|
-
|
|
343
|
-
|
|
344
|
-
[1]: /toolkit_lttb_tutorial
|
|
345
|
-
[2]: https://github.com/jonatas/timescaledb/blob/master/examples/toolkit-demo/lttb_zoom
|
|
346
|
-
[3]: https://docs.timescale.com/api/latest/hyperfunctions/downsample/lttb/
|
|
347
|
-
[4]: https://docs.timescale.com/timescaledb/latest/how-to-guides/hyperfunctions/function-pipelines/
|
|
348
|
-
[5]: https://github.com/jonatas/timescaledb
|
|
349
|
-
[6]: http://pry.github.io
|
|
350
|
-
[7]: http://sinatrarb.com
|
|
351
|
-
[8]: https://docs.timescale.com/timescaledb/latest/tutorials/sample-datasets/#weather-datasets
|
|
352
|
-
[9]: https://plotly.com
|
|
353
|
-
[10]:
|
|
354
|
-
[11]:
|
|
355
|
-
[12]:
|
|
356
|
-
[13]:
|
|
357
|
-
[4]:
|
data/docs/toolkit_ohlc.md
DELETED
|
@@ -1,315 +0,0 @@
|
|
|
1
|
-
# OHLC / Candlesticks
|
|
2
|
-
|
|
3
|
-
Candlesticks are a popular tool in technical analysis, used by traders to determine potential market movements.
|
|
4
|
-
|
|
5
|
-
The toolkit also allows you to compute candlesticks with the [ohlc][1] function.
|
|
6
|
-
|
|
7
|
-
Candlesticks are a type of price chart that displays the high, low, open, and close prices of a security for a specific period. They can be useful because they can provide information about market trends and reversals. For example, if you see that the stock has been trading in a range for a while, it may be worth considering buying or selling when the price moves outside of this range. Additionally, candlesticks can be used in conjunction with other technical indicators to make trading decisions.
|
|
8
|
-
|
|
9
|
-
|
|
10
|
-
Let's start defining a table that stores the trades from financial market data
|
|
11
|
-
and then we can calculate the candlesticks with the Timescaledb Toolkit.
|
|
12
|
-
|
|
13
|
-
## Migration
|
|
14
|
-
|
|
15
|
-
The `ticks` table is a hypertable that will be partitioning the data into one
|
|
16
|
-
week intervl. Compressing them after a month to save storage.
|
|
17
|
-
|
|
18
|
-
```ruby
|
|
19
|
-
hypertable_options = {
|
|
20
|
-
time_column: 'time',
|
|
21
|
-
chunk_time_interval: '1 week',
|
|
22
|
-
compress_segmentby: 'symbol',
|
|
23
|
-
compress_orderby: 'time',
|
|
24
|
-
compression_interval: '1 month'
|
|
25
|
-
}
|
|
26
|
-
create_table :ticks, hypertable: hypertable_options, id: false do |t|
|
|
27
|
-
t.timestampt :time
|
|
28
|
-
t.string :symbol
|
|
29
|
-
t.decimal :price
|
|
30
|
-
t.integer :volume
|
|
31
|
-
end
|
|
32
|
-
```
|
|
33
|
-
|
|
34
|
-
In the previous code block, we assume it goes inside a Rails migration or you
|
|
35
|
-
can embed such code into a `ActiveRecord::Base.connection.instance_exec` block.
|
|
36
|
-
|
|
37
|
-
## Defining the model
|
|
38
|
-
|
|
39
|
-
As we don't need a primary key for the table, let's set it to nil. The
|
|
40
|
-
`acts_as_hypertable` macro will give us several useful scopes that can be
|
|
41
|
-
wrapping some of the TimescaleDB features.
|
|
42
|
-
|
|
43
|
-
The `acts_as_time_vector` will allow us to set what are the default columns used
|
|
44
|
-
to calculate the data.
|
|
45
|
-
|
|
46
|
-
|
|
47
|
-
```ruby
|
|
48
|
-
class Tick < ActiveRecord::Base
|
|
49
|
-
self.primary_key = nil
|
|
50
|
-
acts_as_hypertable time_column: :time
|
|
51
|
-
acts_as_time_vector value_column: price, segment_by: :symbol
|
|
52
|
-
end
|
|
53
|
-
```
|
|
54
|
-
|
|
55
|
-
The candlestick will split the timeframe by the `time_column` and use the `price` as the default value to process the candlestick. It will also segment the candles by `symbol`.
|
|
56
|
-
|
|
57
|
-
If you need to generate some data for your table, please check [this post][2].
|
|
58
|
-
|
|
59
|
-
## The `ohlc` scope
|
|
60
|
-
|
|
61
|
-
When the `acts_as_time_vector` method is used in the model, it will inject
|
|
62
|
-
several scopes from the toolkit to easily have access to functions like the
|
|
63
|
-
ohlc.
|
|
64
|
-
|
|
65
|
-
The `ohlc` scope is available with a few parameters that inherits the
|
|
66
|
-
configuration from the `acts_as_time_vector` declared previously.
|
|
67
|
-
|
|
68
|
-
The simplest query is:
|
|
69
|
-
|
|
70
|
-
```ruby
|
|
71
|
-
Tick.ohlc(timeframe: '1m')
|
|
72
|
-
```
|
|
73
|
-
|
|
74
|
-
It will generate the following SQL:
|
|
75
|
-
|
|
76
|
-
```sql
|
|
77
|
-
SELECT symbol,
|
|
78
|
-
"time",
|
|
79
|
-
toolkit_experimental.open(ohlc),
|
|
80
|
-
toolkit_experimental.high(ohlc),
|
|
81
|
-
toolkit_experimental.low(ohlc),
|
|
82
|
-
toolkit_experimental.close(ohlc),
|
|
83
|
-
toolkit_experimental.open_time(ohlc),
|
|
84
|
-
toolkit_experimental.high_time(ohlc),
|
|
85
|
-
toolkit_experimental.low_time(ohlc),
|
|
86
|
-
toolkit_experimental.close_time(ohlc)
|
|
87
|
-
FROM (
|
|
88
|
-
SELECT time_bucket('1m', time) as time,
|
|
89
|
-
"ticks"."symbol",
|
|
90
|
-
toolkit_experimental.ohlc(time, price)
|
|
91
|
-
FROM "ticks" GROUP BY 1, 2 ORDER BY 1)
|
|
92
|
-
AS ohlc
|
|
93
|
-
```
|
|
94
|
-
|
|
95
|
-
The timeframe argument can also be skipped and the default is `1 hour`.
|
|
96
|
-
|
|
97
|
-
You can also combine other scopes to filter data before you get the data from the candlestick:
|
|
98
|
-
|
|
99
|
-
```ruby
|
|
100
|
-
Tick.yesterday
|
|
101
|
-
.where(symbol: "APPL")
|
|
102
|
-
.ohlc(timeframe: '1m')
|
|
103
|
-
```
|
|
104
|
-
|
|
105
|
-
The `yesterday` scope is automatically included because of the `acts_as_hypertable` macro. And it will be combining with other where clauses.
|
|
106
|
-
|
|
107
|
-
## Continuous aggregates
|
|
108
|
-
|
|
109
|
-
If you would like to continuous aggregate the candlesticks on a materialized
|
|
110
|
-
view you can use continuous aggregates for it.
|
|
111
|
-
|
|
112
|
-
The next examples shows how to create a continuous aggregates of 1 minute
|
|
113
|
-
candlesticks:
|
|
114
|
-
|
|
115
|
-
```ruby
|
|
116
|
-
options = {
|
|
117
|
-
with_data: false,
|
|
118
|
-
refresh_policies: {
|
|
119
|
-
start_offset: "INTERVAL '1 month'",
|
|
120
|
-
end_offset: "INTERVAL '1 minute'",
|
|
121
|
-
schedule_interval: "INTERVAL '1 minute'"
|
|
122
|
-
}
|
|
123
|
-
}
|
|
124
|
-
create_continuous_aggregate('ohlc_1m', Tick.ohlc(timeframe: '1m'), **options)
|
|
125
|
-
```
|
|
126
|
-
|
|
127
|
-
|
|
128
|
-
Note that the `create_continuous_aggregate` calls the `to_sql` method in case
|
|
129
|
-
the second parameter is not a string.
|
|
130
|
-
|
|
131
|
-
## Rollup
|
|
132
|
-
|
|
133
|
-
The rollup allows you to combine ohlc structures from smaller timeframes
|
|
134
|
-
to bigger timeframes without needing to reprocess all the data.
|
|
135
|
-
|
|
136
|
-
With this feature, you can group by the ohcl multiple times saving processing
|
|
137
|
-
from the server and make it easier to manage candlesticks from different time intervals.
|
|
138
|
-
|
|
139
|
-
In the previous example, we used the `.ohlc` function that returns already the
|
|
140
|
-
attributes from the different timeframes. In the SQL command it's calling the
|
|
141
|
-
`open`, `high`, `low`, `close` functions that can access the values behind the
|
|
142
|
-
ohlcsummary type.
|
|
143
|
-
|
|
144
|
-
To merge the ohlc we need to rollup the `ohlcsummary` to a bigger timeframe and
|
|
145
|
-
only access the values as a final resort to see them and access as attributes.
|
|
146
|
-
|
|
147
|
-
Let's rebuild the structure:
|
|
148
|
-
|
|
149
|
-
```ruby
|
|
150
|
-
execute "CREATE VIEW ohlc_1h AS #{ Ohlc1m.rollup(timeframe: '1 hour').to_sql}"
|
|
151
|
-
execute "CREATE VIEW ohlc_1d AS #{ Ohlc1h.rollup(timeframe: '1 day').to_sql}"
|
|
152
|
-
```
|
|
153
|
-
|
|
154
|
-
## Defining models for views
|
|
155
|
-
|
|
156
|
-
Note that the previous code refers to `Ohlc1m` and `Ohlc1h` as two classes that
|
|
157
|
-
are not defined yet. They will basically be ActiveRecord readonly models to
|
|
158
|
-
allow to build scopes from it.
|
|
159
|
-
|
|
160
|
-
Ohlc for one hour:
|
|
161
|
-
```ruby
|
|
162
|
-
class Ohlc1m < ActiveRecord::Base
|
|
163
|
-
self.table_name = 'ohlc_1m'
|
|
164
|
-
include Ohlc
|
|
165
|
-
end
|
|
166
|
-
```
|
|
167
|
-
|
|
168
|
-
Ohlc for one day is pretty much the same:
|
|
169
|
-
```ruby
|
|
170
|
-
class Ohlc1h < ActiveRecord::Base
|
|
171
|
-
self.table_name = 'ohlc_1h'
|
|
172
|
-
include Ohlc
|
|
173
|
-
end
|
|
174
|
-
```
|
|
175
|
-
|
|
176
|
-
We'll also have the `Ohlc` as a shared concern that can help you to reuse
|
|
177
|
-
queries in different views.
|
|
178
|
-
|
|
179
|
-
```ruby
|
|
180
|
-
module Ohlc
|
|
181
|
-
extend ActiveSupport::Concern
|
|
182
|
-
|
|
183
|
-
included do
|
|
184
|
-
scope :rollup, -> (timeframe: '1h') do
|
|
185
|
-
select("symbol, time_bucket('#{timeframe}', time) as time,
|
|
186
|
-
toolkit_experimental.rollup(ohlc) as ohlc")
|
|
187
|
-
.group(1,2)
|
|
188
|
-
end
|
|
189
|
-
|
|
190
|
-
scope :attributes, -> do
|
|
191
|
-
select("symbol, time,
|
|
192
|
-
toolkit_experimental.open(ohlc),
|
|
193
|
-
toolkit_experimental.high(ohlc),
|
|
194
|
-
toolkit_experimental.low(ohlc),
|
|
195
|
-
toolkit_experimental.close(ohlc),
|
|
196
|
-
toolkit_experimental.open_time(ohlc),
|
|
197
|
-
toolkit_experimental.high_time(ohlc),
|
|
198
|
-
toolkit_experimental.low_time(ohlc),
|
|
199
|
-
toolkit_experimental.close_time(ohlc)")
|
|
200
|
-
end
|
|
201
|
-
|
|
202
|
-
# Following the attributes scope, we can define accessors in the
|
|
203
|
-
# model to populate from the previous scope to make it similar
|
|
204
|
-
# to a regular model structure.
|
|
205
|
-
attribute :time, :time
|
|
206
|
-
attribute :symbol, :string
|
|
207
|
-
|
|
208
|
-
%w[open high low close].each do |name|
|
|
209
|
-
attribute name, :decimal
|
|
210
|
-
attribute "#{name}_time", :time
|
|
211
|
-
end
|
|
212
|
-
|
|
213
|
-
def readonly?
|
|
214
|
-
true
|
|
215
|
-
end
|
|
216
|
-
end
|
|
217
|
-
end
|
|
218
|
-
```
|
|
219
|
-
|
|
220
|
-
The `rollup` scope is the one that was used to redefine the data into big timeframes
|
|
221
|
-
and the `attributes` allow to access the attributes from the [OpenHighLowClose][3]
|
|
222
|
-
type.
|
|
223
|
-
|
|
224
|
-
In this way, the views become just shortcuts and complex sql can also be done
|
|
225
|
-
just nesting the model scope. For example, to rollup from a minute to a month,
|
|
226
|
-
you can do:
|
|
227
|
-
|
|
228
|
-
```ruby
|
|
229
|
-
Ohlc1m.attributes.from(
|
|
230
|
-
Ohlc1m.rollup(timeframe: '1 month')
|
|
231
|
-
)
|
|
232
|
-
```
|
|
233
|
-
|
|
234
|
-
Soon the continuous aggregates will [support nested aggregates][4] and you'll be
|
|
235
|
-
abble to define the materialized views with steps like this:
|
|
236
|
-
|
|
237
|
-
|
|
238
|
-
```ruby
|
|
239
|
-
Ohlc1m.attributes.from(
|
|
240
|
-
Ohlc1m.rollup(timeframe: '1 month').from(
|
|
241
|
-
Ohlc1m.rollup(timeframe: '1 week').from(
|
|
242
|
-
Ohlc1m.rollup(timeframe: '1 day').from(
|
|
243
|
-
Ohlc1m.rollup(timeframe: '1 hour')
|
|
244
|
-
)
|
|
245
|
-
)
|
|
246
|
-
)
|
|
247
|
-
)
|
|
248
|
-
```
|
|
249
|
-
|
|
250
|
-
For now composing the subqueries will probably be less efficient and unnecessary.
|
|
251
|
-
But the foundation is already here to help you in future analysis. Just to make
|
|
252
|
-
it clear, here is the SQL generated from the previous code:
|
|
253
|
-
|
|
254
|
-
```sql
|
|
255
|
-
SELECT symbol,
|
|
256
|
-
time,
|
|
257
|
-
toolkit_experimental.open(ohlc),
|
|
258
|
-
toolkit_experimental.high(ohlc),
|
|
259
|
-
toolkit_experimental.low(ohlc),
|
|
260
|
-
toolkit_experimental.close(ohlc),
|
|
261
|
-
toolkit_experimental.open_time(ohlc),
|
|
262
|
-
toolkit_experimental.high_time(ohlc),
|
|
263
|
-
toolkit_experimental.low_time(ohlc),
|
|
264
|
-
toolkit_experimental.close_time(ohlc)
|
|
265
|
-
FROM (
|
|
266
|
-
SELECT symbol,
|
|
267
|
-
time_bucket('1 month', time) as time,
|
|
268
|
-
toolkit_experimental.rollup(ohlc) as ohlc
|
|
269
|
-
FROM (
|
|
270
|
-
SELECT symbol,
|
|
271
|
-
time_bucket('1 week', time) as time,
|
|
272
|
-
toolkit_experimental.rollup(ohlc) as ohlc
|
|
273
|
-
FROM (
|
|
274
|
-
SELECT symbol,
|
|
275
|
-
time_bucket('1 day', time) as time,
|
|
276
|
-
toolkit_experimental.rollup(ohlc) as ohlc
|
|
277
|
-
FROM (
|
|
278
|
-
SELECT symbol,
|
|
279
|
-
time_bucket('1 hour', time) as time,
|
|
280
|
-
toolkit_experimental.rollup(ohlc) as ohlc
|
|
281
|
-
FROM "ohlc_1m"
|
|
282
|
-
GROUP BY 1, 2
|
|
283
|
-
) subquery
|
|
284
|
-
GROUP BY 1, 2
|
|
285
|
-
) subquery
|
|
286
|
-
GROUP BY 1, 2
|
|
287
|
-
) subquery
|
|
288
|
-
GROUP BY 1, 2
|
|
289
|
-
) subquery
|
|
290
|
-
```
|
|
291
|
-
|
|
292
|
-
You can also define more scopes that will be useful depending on what are you
|
|
293
|
-
working on. Example:
|
|
294
|
-
|
|
295
|
-
```ruby
|
|
296
|
-
scope :yesterday, -> { where("DATE(#{time_column}) = ?", Date.yesterday.in_time_zone.to_date) }
|
|
297
|
-
```
|
|
298
|
-
|
|
299
|
-
And then, just combine the scopes:
|
|
300
|
-
|
|
301
|
-
```ruby
|
|
302
|
-
Ohlc1m.yesterday.attributes
|
|
303
|
-
```
|
|
304
|
-
I hope you find this tutorial interesting and you can also check the
|
|
305
|
-
`ohlc.rb` file in the [examples/toolkit-demo][5] folder.
|
|
306
|
-
|
|
307
|
-
If you have any questions or concerns, feel free to reach me ([@jonatasdp][7]) in the [Timescale community][6] or tag timescaledb in your StackOverflow issue.
|
|
308
|
-
|
|
309
|
-
[1]: https://docs.timescale.com/api/latest/hyperfunctions/financial-analysis/ohlc/
|
|
310
|
-
[2]: https://ideia.me/timescale-continuous-aggregates-with-ruby
|
|
311
|
-
[3]: https://github.com/timescale/timescaledb-toolkit/blob/cbbca7b2e69968e585c845924e7ed7aff1cea20a/extension/src/ohlc.rs#L20-L24
|
|
312
|
-
[4]: https://github.com/timescale/timescaledb/pull/4668
|
|
313
|
-
[5]: https://github.com/jonatas/timescaledb/tree/master/examples/toolkit-demo
|
|
314
|
-
[6]: https://timescale.com/community
|
|
315
|
-
[7]: https://twitter.com/jonatasdp
|
data/docs/videos.md
DELETED
|
@@ -1,16 +0,0 @@
|
|
|
1
|
-
# Videos about the TimescaleDB Gem
|
|
2
|
-
|
|
3
|
-
This library was started on [twitch.tv/timescaledb](https://twitch.tv/timescaledb).
|
|
4
|
-
You can watch all episodes here:
|
|
5
|
-
|
|
6
|
-
1. [Wrapping Functions to Ruby Helpers](https://www.youtube.com/watch?v=hGPsUxLFAYk).
|
|
7
|
-
2. [Extending ActiveRecord with Timescale Helpers](https://www.youtube.com/watch?v=IEyJIHk1Clk).
|
|
8
|
-
3. [Setup Hypertables for Rails testing environment](https://www.youtube.com/watch?v=wM6hVrZe7xA).
|
|
9
|
-
4. [Packing the code to this repository](https://www.youtube.com/watch?v=CMdGAl_XlL4).
|
|
10
|
-
4. [the code to this repository](https://www.youtube.com/watch?v=CMdGAl_XlL4).
|
|
11
|
-
5. [Working with Timescale continuous aggregates](https://youtu.be/co4HnBkHzVw).
|
|
12
|
-
6. [Creating the command-line application in Ruby to explore the Timescale API](https://www.youtube.com/watch?v=I3vM_q2m7T0).
|
|
13
|
-
|
|
14
|
-
|
|
15
|
-
If you create any content related to how to use the Timescale Gem, please open a
|
|
16
|
-
[Pull Request](https://github.com/jonatas/timescaledb/pulls).
|