red_amber 0.2.2 → 0.3.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/.rubocop.yml +114 -39
- data/CHANGELOG.md +203 -31
- data/Gemfile +5 -2
- data/README.md +62 -29
- data/benchmark/basic.yml +86 -0
- data/benchmark/combine.yml +62 -0
- data/benchmark/dataframe.yml +62 -0
- data/benchmark/drop_nil.yml +15 -3
- data/benchmark/group.yml +39 -0
- data/benchmark/reshape.yml +31 -0
- data/benchmark/{csv_load_penguins.yml → rover/csv_load_penguins.yml} +3 -3
- data/benchmark/rover/flights.yml +23 -0
- data/benchmark/rover/penguins.yml +23 -0
- data/benchmark/rover/planes.yml +23 -0
- data/benchmark/rover/weather.yml +23 -0
- data/benchmark/vector.yml +60 -0
- data/doc/DataFrame.md +335 -53
- data/doc/Vector.md +91 -0
- data/doc/image/dataframe/join.png +0 -0
- data/doc/image/dataframe/set_and_bind.png +0 -0
- data/doc/image/dataframe_model.png +0 -0
- data/lib/red_amber/data_frame.rb +167 -51
- data/lib/red_amber/data_frame_combinable.rb +486 -0
- data/lib/red_amber/data_frame_displayable.rb +6 -4
- data/lib/red_amber/data_frame_indexable.rb +2 -2
- data/lib/red_amber/data_frame_loadsave.rb +4 -1
- data/lib/red_amber/data_frame_reshaping.rb +35 -10
- data/lib/red_amber/data_frame_selectable.rb +221 -116
- data/lib/red_amber/data_frame_variable_operation.rb +146 -82
- data/lib/red_amber/group.rb +108 -18
- data/lib/red_amber/helper.rb +53 -43
- data/lib/red_amber/refinements.rb +199 -0
- data/lib/red_amber/vector.rb +56 -46
- data/lib/red_amber/vector_functions.rb +23 -83
- data/lib/red_amber/vector_selectable.rb +116 -69
- data/lib/red_amber/vector_updatable.rb +189 -65
- data/lib/red_amber/version.rb +1 -1
- data/lib/red_amber.rb +3 -0
- data/red_amber.gemspec +4 -3
- metadata +24 -10
data/README.md
CHANGED
|
@@ -1,28 +1,31 @@
|
|
|
1
1
|
# RedAmber
|
|
2
2
|
|
|
3
3
|
[](https://badge.fury.io/rb/red_amber)
|
|
4
|
-
[](https://github.com/heronshoes/red_amber/actions/workflows/ci.yml)
|
|
5
|
+
[](https://codeclimate.com/github/heronshoes/red_amber/maintainability)
|
|
6
|
+
[](https://codeclimate.com/github/heronshoes/red_amber/test_coverage)
|
|
7
|
+
[](https://heronshoes.github.io/red_amber/)
|
|
5
8
|
[](https://github.com/heronshoes/red_amber/discussions)
|
|
6
9
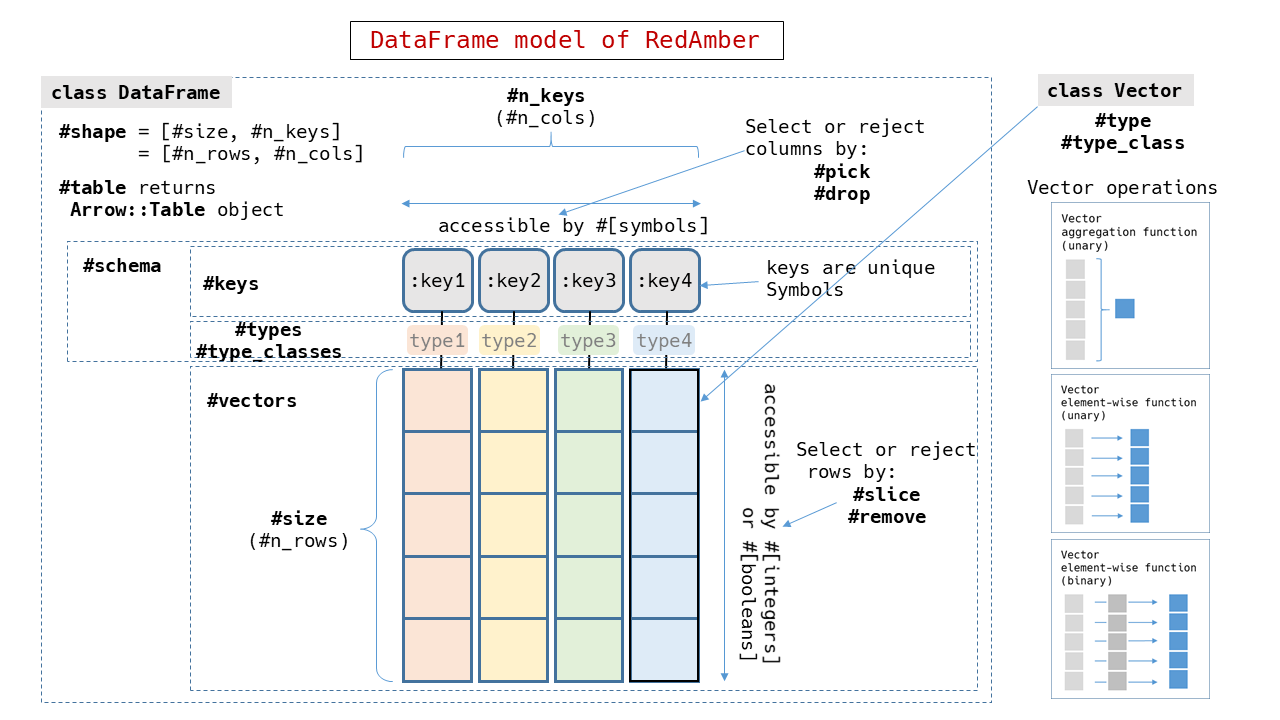
|
|
|
7
10
|
A simple dataframe library for Ruby.
|
|
8
11
|
|
|
9
|
-
- Powered by [Red Arrow](https://github.com/apache/arrow/tree/master/ruby/red-arrow)
|
|
12
|
+
- Powered by [Red Arrow](https://github.com/apache/arrow/tree/master/ruby/red-arrow)
|
|
13
|
+
[](https://gitter.im/red-data-tools/en)
|
|
10
14
|
- Inspired by the dataframe library [Rover-df](https://github.com/ankane/rover)
|
|
11
15
|
|
|
12
|
-

|
|
16
|
+

|
|
13
17
|
|
|
14
18
|
## Requirements
|
|
15
19
|
|
|
16
|
-
Supported Ruby version is >=
|
|
20
|
+
Supported Ruby version is >= 3.0 (since RedAmber 0.3.0).
|
|
17
21
|
|
|
18
|
-
|
|
19
|
-
I recommend Ruby 3 for performance.
|
|
22
|
+
- I decided to remove Ruby 2.7 without waiting for EOL because it cannot solve the problem of simultaneous use of Hash and keyword arguments when implementing DataFrame#join.
|
|
20
23
|
|
|
21
24
|
```ruby
|
|
22
25
|
# Libraries required
|
|
23
|
-
gem 'red-arrow', '
|
|
26
|
+
gem 'red-arrow', '~> 10.0.0' # Requires Apache Arrow (see installation below)
|
|
24
27
|
|
|
25
|
-
gem 'red-parquet', '
|
|
28
|
+
gem 'red-parquet', '~> 10.0.0' # Optional, if you use IO from/to parquet
|
|
26
29
|
gem 'rover-df', '~> 0.3.0' # Optional, if you use IO from/to Rover::DataFrame
|
|
27
30
|
```
|
|
28
31
|
|
|
@@ -30,37 +33,61 @@ gem 'rover-df', '~> 0.3.0' # Optional, if you use IO from/to Rover::DataFrame
|
|
|
30
33
|
|
|
31
34
|
Install requirements before you install Red Amber.
|
|
32
35
|
|
|
33
|
-
- Apache Arrow
|
|
34
|
-
|
|
35
|
-
- Apache Parquet GLib (
|
|
36
|
+
- Apache Arrow (~> 10.0.0)
|
|
37
|
+
- Apache Arrow GLib (~> 10.0.0)
|
|
38
|
+
- Apache Parquet GLib (~> 10.0.0) # If you use IO from/to parquet
|
|
36
39
|
|
|
37
40
|
See [Apache Arrow install document](https://arrow.apache.org/install/).
|
|
38
41
|
|
|
39
|
-
Minimum installation example for the latest Ubuntu
|
|
42
|
+
- Minimum installation example for the latest Ubuntu:
|
|
40
43
|
|
|
41
|
-
|
|
44
|
+
```
|
|
45
|
+
sudo apt update
|
|
46
|
+
sudo apt install -y -V ca-certificates lsb-release wget
|
|
47
|
+
wget https://apache.jfrog.io/artifactory/arrow/$(lsb_release --id --short | tr 'A-Z' 'a-z')/apache-arrow-apt-source-latest-$(lsb_release --codename --short).deb
|
|
48
|
+
sudo apt install -y -V ./apache-arrow-apt-source-latest-$(lsb_release --codename --short).deb
|
|
49
|
+
sudo apt update
|
|
50
|
+
sudo apt install -y -V libarrow-dev
|
|
51
|
+
sudo apt install -y -V libarrow-glib-dev
|
|
52
|
+
```
|
|
42
53
|
|
|
43
|
-
|
|
44
|
-
gem 'red_amber'
|
|
45
|
-
```
|
|
54
|
+
- On Fedora 38 (Rawhide):
|
|
46
55
|
|
|
47
|
-
|
|
56
|
+
```
|
|
57
|
+
sudo dnf update
|
|
58
|
+
sudo dnf -y install gcc-c++ libarrow-devel libarrow-glib-devel ruby-devel
|
|
59
|
+
```
|
|
48
60
|
|
|
49
|
-
|
|
50
|
-
bundle install
|
|
51
|
-
```
|
|
61
|
+
- On macOS, you can install Apache Arrow C++ library using Homebrew:
|
|
52
62
|
|
|
53
|
-
|
|
63
|
+
```
|
|
64
|
+
brew install apache-arrow
|
|
65
|
+
```
|
|
54
66
|
|
|
55
|
-
|
|
56
|
-
|
|
67
|
+
and GLib (C) package with:
|
|
68
|
+
|
|
69
|
+
```
|
|
70
|
+
brew install apache-arrow-glib
|
|
71
|
+
```
|
|
72
|
+
|
|
73
|
+
If you prepared Apache Arrow, add these lines to your Gemfile:
|
|
74
|
+
|
|
75
|
+
```ruby
|
|
76
|
+
gem 'red-arrow', '~> 10.0.0'
|
|
77
|
+
gem 'red_amber'
|
|
78
|
+
gem 'red-parquet', '~> 10.0.0' # Optional, if you use IO from/to parquet
|
|
79
|
+
gem 'rover-df', '~> 0.3.0' # Optional, if you use IO from/to Rover::DataFrame
|
|
80
|
+
gem 'red-datasets-arrow' # Optional, recommended if you use Red Datasets
|
|
81
|
+
gem 'red-arrow-numo-narray' # Optional, recommended if you use inputs from Numo::NArray
|
|
57
82
|
```
|
|
58
83
|
|
|
84
|
+
And then execute `bundle install` or install it yourself as `gem install red_amber`.
|
|
85
|
+
|
|
59
86
|
## Docker image and Jupyter Notebook
|
|
60
87
|
|
|
61
88
|
[RubyData Docker Stacks](https://github.com/RubyData/docker-stacks) is available as a ready-to-run Docker image containing Jupyter and useful data tools as well as RedAmber (Thanks to @mrkn).
|
|
62
89
|
|
|
63
|
-
Also you can try the contents of this README interactively by [Binder](https://mybinder.org/v2/gh/heronshoes/docker-stacks/RedAmber-binder?filepath=
|
|
90
|
+
Also you can try the contents of this README interactively by [Binder](https://mybinder.org/v2/gh/heronshoes/docker-stacks/RedAmber-binder?filepath=red-amber.ipynb).
|
|
64
91
|
[](https://mybinder.org/v2/gh/heronshoes/docker-stacks/RedAmber-binder?filepath=red-amber.ipynb)
|
|
65
92
|
|
|
66
93
|
|
|
@@ -69,9 +96,9 @@ Also you can try the contents of this README interactively by [Binder](https://m
|
|
|
69
96
|
Class `RedAmber::DataFrame` represents a set of data in 2D-shape.
|
|
70
97
|
The entity is a Red Arrow's Table object.
|
|
71
98
|
|
|
72
|
-

|
|
99
|
+
|
|
73
100
|
|
|
74
|
-
|
|
101
|
+
Let's load the library and try some examples.
|
|
75
102
|
|
|
76
103
|
```ruby
|
|
77
104
|
require 'red_amber' # require 'red-amber' is also OK.
|
|
@@ -80,6 +107,11 @@ include RedAmber
|
|
|
80
107
|
|
|
81
108
|
### Example: diamonds dataset
|
|
82
109
|
|
|
110
|
+
First do (if you do not installed) `
|
|
111
|
+
gem install red-datasets-arrow
|
|
112
|
+
`
|
|
113
|
+
then
|
|
114
|
+
|
|
83
115
|
```ruby
|
|
84
116
|
require 'datasets-arrow' # to load sample data
|
|
85
117
|
|
|
@@ -101,7 +133,7 @@ diamonds = DataFrame.new(dataset) # from v0.2.2, should be `dataset.to_arrow` if
|
|
|
101
133
|
53939 0.75 Ideal D SI2 62.2 55.0 2757 5.83 ... 3.64
|
|
102
134
|
```
|
|
103
135
|
|
|
104
|
-
For example, we can compute mean prices per
|
|
136
|
+
For example, we can compute mean prices per cut for the data larger than 1 carat.
|
|
105
137
|
|
|
106
138
|
```ruby
|
|
107
139
|
df = diamonds
|
|
@@ -125,7 +157,7 @@ Arrow data is immutable, so these methods always return new objects.
|
|
|
125
157
|
Next example will rename a column and create a new column by simple calcuration.
|
|
126
158
|
|
|
127
159
|
```ruby
|
|
128
|
-
usdjpy = 110.0
|
|
160
|
+
usdjpy = 110.0 # when the yen was stronger
|
|
129
161
|
|
|
130
162
|
df.rename('mean(price)': :mean_price_USD)
|
|
131
163
|
.assign(:mean_price_JPY) { mean_price_USD * usdjpy }
|
|
@@ -181,7 +213,8 @@ See [Vector.md](doc/Vector.md) for details.
|
|
|
181
213
|
|
|
182
214
|
## Jupyter notebook
|
|
183
215
|
|
|
184
|
-
[
|
|
216
|
+
[89 Examples of Red Amber](https://github.com/heronshoes/docker-stacks/blob/RedAmber-binder/binder/examples_of_red_amber.ipynb)
|
|
217
|
+
([raw file](https://raw.githubusercontent.com/heronshoes/docker-stacks/RedAmber-binder/binder/examples_of_red_amber.ipynb)) shows more examples in jupyter notebook.
|
|
185
218
|
|
|
186
219
|
You can try this notebook on [Binder](https://mybinder.org/v2/gh/heronshoes/docker-stacks/RedAmber-binder?filepath=examples_of_red_amber.ipynb).
|
|
187
220
|
[](https://mybinder.org/v2/gh/heronshoes/docker-stacks/RedAmber-binder?filepath=examples_of_red_amber.ipynb)
|
data/benchmark/basic.yml
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
1
|
+
loop_count: 3
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.3
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.3
|
|
10
|
+
- name: 0.2.0
|
|
11
|
+
gems:
|
|
12
|
+
red_amber: 0.2.0
|
|
13
|
+
- name: 0.1.5
|
|
14
|
+
gems:
|
|
15
|
+
red_amber: 0.1.5
|
|
16
|
+
|
|
17
|
+
prelude: |
|
|
18
|
+
require 'red_amber'
|
|
19
|
+
require 'datasets-arrow'
|
|
20
|
+
|
|
21
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'flights')
|
|
22
|
+
df = RedAmber::DataFrame.new(ds.to_arrow)
|
|
23
|
+
|
|
24
|
+
slicer = df[:distance] > 1000
|
|
25
|
+
distance_km = df[:distance] * 1.852
|
|
26
|
+
|
|
27
|
+
benchmark:
|
|
28
|
+
'B01: Pick([]) by a key name': |
|
|
29
|
+
df[:flight]
|
|
30
|
+
|
|
31
|
+
'B02a: Pick([]) by key names': |
|
|
32
|
+
df[:carrier, :flight]
|
|
33
|
+
|
|
34
|
+
'B03: Pick by key names': |
|
|
35
|
+
df.pick(:carrier, :flight)
|
|
36
|
+
|
|
37
|
+
'B04: Drop by key names': |
|
|
38
|
+
df.drop(:year, :month, :day)
|
|
39
|
+
|
|
40
|
+
'B05: Pick by booleans': |
|
|
41
|
+
df.pick(df.vectors.map(&:string?))
|
|
42
|
+
|
|
43
|
+
'B06: Pick by a block': |
|
|
44
|
+
df.pick { keys.map { |key| key.end_with?('time') } }
|
|
45
|
+
|
|
46
|
+
'B07: Slice([]) by a index': |
|
|
47
|
+
df[877]
|
|
48
|
+
|
|
49
|
+
'B08: Slice by indeces': |
|
|
50
|
+
df.slice(0...5, -5..-1)
|
|
51
|
+
|
|
52
|
+
'B09: Slice([]) by booleans': |
|
|
53
|
+
df[slicer]
|
|
54
|
+
|
|
55
|
+
'B10: Slice by booleans': |
|
|
56
|
+
df.slice(slicer)
|
|
57
|
+
|
|
58
|
+
'B11: Remove by booleans': |
|
|
59
|
+
df.remove(slicer)
|
|
60
|
+
|
|
61
|
+
'B12: Slice by a block': |
|
|
62
|
+
df.slice { slicer }
|
|
63
|
+
|
|
64
|
+
'B13: Rename by Hash': |
|
|
65
|
+
df.rename(distance: :distance_mile)
|
|
66
|
+
|
|
67
|
+
'B14: Assign an existing variable': |
|
|
68
|
+
df.assign(distance: distance_km)
|
|
69
|
+
|
|
70
|
+
'B15: Assign a new variable': |
|
|
71
|
+
df.assign(distance_km: distance_km)
|
|
72
|
+
|
|
73
|
+
'B16: Sort by a key': |
|
|
74
|
+
df.sort(:distance)
|
|
75
|
+
|
|
76
|
+
'B17: Sort by keys': |
|
|
77
|
+
df.sort(:origin, '-distance')
|
|
78
|
+
|
|
79
|
+
'B18: Convert to a Hash': |
|
|
80
|
+
df.to_h
|
|
81
|
+
|
|
82
|
+
'B19: Output in TDR style': |
|
|
83
|
+
df.tdr
|
|
84
|
+
|
|
85
|
+
'B20: Inspect': |
|
|
86
|
+
df.inspect
|
|
@@ -0,0 +1,62 @@
|
|
|
1
|
+
loop_count: 3
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.3
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.3
|
|
10
|
+
|
|
11
|
+
prelude: |
|
|
12
|
+
require 'red_amber'
|
|
13
|
+
include RedAmber
|
|
14
|
+
require 'datasets-arrow'
|
|
15
|
+
|
|
16
|
+
package = 'nycflights13'
|
|
17
|
+
airlines = DataFrame.new(Datasets::Rdatasets.new(package, 'airlines'))
|
|
18
|
+
airports = DataFrame.new(Datasets::Rdatasets.new(package, 'airports'))
|
|
19
|
+
flights = DataFrame.new(Datasets::Rdatasets.new(package, 'flights'))
|
|
20
|
+
.pick(%i[month day carrier flight tailnum origin dest air_time distance])
|
|
21
|
+
planes = DataFrame.new(Datasets::Rdatasets.new(package, 'planes'))
|
|
22
|
+
weather = DataFrame.new(Datasets::Rdatasets.new(package, 'weather'))
|
|
23
|
+
|
|
24
|
+
flights_Q1 = flights.slice { month <= 3 }
|
|
25
|
+
flights_Q2 = flights.slice { month > 3 }
|
|
26
|
+
|
|
27
|
+
flights_1_2 = flights_Q1.slice { month.is_in(1, 2) }
|
|
28
|
+
flights_1_3 = flights_Q1.slice { month.is_in(1, 3) }
|
|
29
|
+
|
|
30
|
+
flights_left = flights_Q1.pick(...5)
|
|
31
|
+
flights_right = flights_Q1.pick(5..)
|
|
32
|
+
|
|
33
|
+
benchmark:
|
|
34
|
+
'C01: Inner join on flights_Q1 by carrier': |
|
|
35
|
+
flights_Q1.inner_join(airlines, :carrier)
|
|
36
|
+
|
|
37
|
+
'C02: Full join on flights_Q1 by planes': |
|
|
38
|
+
flights_Q1.full_join(planes, :tailnum)
|
|
39
|
+
|
|
40
|
+
'C03: Left join on flights_Q1 by planes': |
|
|
41
|
+
flights_Q1.left_join(planes, :tailnum)
|
|
42
|
+
|
|
43
|
+
'C04: Semi join on flights_Q1 by planes': |
|
|
44
|
+
flights_Q1.semi_join(planes, :tailnum)
|
|
45
|
+
|
|
46
|
+
'C05: Anti join on flights_Q1 by planes': |
|
|
47
|
+
flights_Q1.anti_join(planes, :tailnum)
|
|
48
|
+
|
|
49
|
+
'C06: Intersection of flights_1_2 and flights_1_3': |
|
|
50
|
+
flights_1_2.intersect(flights_1_3)
|
|
51
|
+
|
|
52
|
+
'C07: Union of flights_1_2 and flights_1_3': |
|
|
53
|
+
flights_1_2.union(flights_1_3)
|
|
54
|
+
|
|
55
|
+
'C08: Difference between flights_1_2 and flights_1_3': |
|
|
56
|
+
flights_1_2.difference(flights_1_3)
|
|
57
|
+
|
|
58
|
+
'C09: Concatenate flight_Q1 on flight_Q2': |
|
|
59
|
+
flights_Q1.concatenate(flights_Q2)
|
|
60
|
+
|
|
61
|
+
'C10: Merge flights_Q1_right on flights_Q1_left': |
|
|
62
|
+
flights_left.merge(flights_right)
|
|
@@ -0,0 +1,62 @@
|
|
|
1
|
+
loop_count: 3
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.3
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.3
|
|
10
|
+
- name: 0.2.0
|
|
11
|
+
gems:
|
|
12
|
+
red_amber: 0.2.0
|
|
13
|
+
|
|
14
|
+
prelude: |
|
|
15
|
+
require 'red_amber'
|
|
16
|
+
require 'datasets-arrow'
|
|
17
|
+
|
|
18
|
+
diamonds = RedAmber::DataFrame.new(Datasets::Diamonds.new.to_arrow)
|
|
19
|
+
|
|
20
|
+
starwars = RedAmber::DataFrame.new(Datasets::Rdataset.new('dplyr', 'starwars').to_arrow)
|
|
21
|
+
|
|
22
|
+
uri = URI("https://raw.githubusercontent.com/heronshoes/red_amber/master/test/entity/import_cars.tsv")
|
|
23
|
+
import_cars = RedAmber::DataFrame.load(uri)
|
|
24
|
+
|
|
25
|
+
ds = Datasets::Rdataset.new('openintro', 'simpsons_paradox_covid')
|
|
26
|
+
simpsons_paradox_covid = RedAmber::DataFrame.new(ds.to_arrow)
|
|
27
|
+
|
|
28
|
+
benchmark:
|
|
29
|
+
'D01: Diamonds test': |
|
|
30
|
+
diamonds
|
|
31
|
+
.slice { v(:carat) > 1 }
|
|
32
|
+
.pick(:cut, :price)
|
|
33
|
+
.group(:cut)
|
|
34
|
+
.mean
|
|
35
|
+
.sort('-mean(price)')
|
|
36
|
+
.rename('mean(price)': :mean_price_USD)
|
|
37
|
+
.assign { [:mean_price_JPY, v(:mean_price_USD) * 110.0] }
|
|
38
|
+
|
|
39
|
+
'D02: Starwars test': |
|
|
40
|
+
starwars
|
|
41
|
+
.drop { keys.select { |key| key.end_with?('color') } }
|
|
42
|
+
.remove { v(:species) == 'NA' }
|
|
43
|
+
.group(:species) { [count(:species), mean(:height, :mass)] }
|
|
44
|
+
.slice { v(:count) > 1 }
|
|
45
|
+
|
|
46
|
+
'D03: Inport cars test': |
|
|
47
|
+
import_cars
|
|
48
|
+
.to_long(:Year, name: :Manufacturer, value: :Num_of_imported)
|
|
49
|
+
.to_wide(name: :Manufacturer, value: :Num_of_imported)
|
|
50
|
+
.transpose
|
|
51
|
+
|
|
52
|
+
'D04: Simpsons paradox test': |
|
|
53
|
+
simpsons_paradox_covid[simpsons_paradox_covid[:age_group] == 'under 50']
|
|
54
|
+
.group(:vaccine_status, :outcome)
|
|
55
|
+
.count
|
|
56
|
+
.then { |df| df.to_wide(name: :vaccine_status, value: df.keys[-1]) }
|
|
57
|
+
.assign do
|
|
58
|
+
[
|
|
59
|
+
[:'vaccinated_%', (100.0 * v(:vaccinated) / v(:vaccinated).sum)],
|
|
60
|
+
[:'unvaccinated_%', (100.0 * v(:unvaccinated) / v(:unvaccinated).sum)]
|
|
61
|
+
]
|
|
62
|
+
end
|
data/benchmark/drop_nil.yml
CHANGED
|
@@ -1,11 +1,23 @@
|
|
|
1
|
+
contexts:
|
|
2
|
+
- gems:
|
|
3
|
+
red_amber: 0.1.8
|
|
4
|
+
- gems:
|
|
5
|
+
red_amber: 0.2.2
|
|
6
|
+
- name: HEAD
|
|
7
|
+
prelude: |
|
|
8
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
9
|
+
require 'red_amber'
|
|
10
|
+
|
|
1
11
|
prelude: |
|
|
2
12
|
require 'datasets-arrow'
|
|
3
13
|
require 'red_amber'
|
|
4
14
|
|
|
5
15
|
penguins = RedAmber::DataFrame.new(Datasets::Penguins.new.to_arrow)
|
|
6
16
|
|
|
7
|
-
def
|
|
8
|
-
penguins.remove { vectors.map
|
|
17
|
+
def remove_nil(penguins)
|
|
18
|
+
penguins.remove { vectors.map(&:is_nil).reduce(&:|) }
|
|
9
19
|
end
|
|
10
20
|
|
|
11
|
-
benchmark:
|
|
21
|
+
benchmark:
|
|
22
|
+
'Remove and reduce': remove_nil(penguins)
|
|
23
|
+
'remove_nil method': penguins.remove_nil
|
data/benchmark/group.yml
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
1
|
+
loop_count: 3
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.3
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.3
|
|
10
|
+
- name: 0.2.2
|
|
11
|
+
gems:
|
|
12
|
+
red_amber: 0.2.2
|
|
13
|
+
|
|
14
|
+
prelude: |
|
|
15
|
+
require 'red_amber'
|
|
16
|
+
require 'datasets-arrow'
|
|
17
|
+
|
|
18
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'flights')
|
|
19
|
+
df = RedAmber::DataFrame.new(ds.to_arrow)
|
|
20
|
+
.assign(:flight) { flight.map(&:to_s) }
|
|
21
|
+
|
|
22
|
+
slicer = df[:distance] > 1000
|
|
23
|
+
distance_km = df[:distance] * 1.852
|
|
24
|
+
|
|
25
|
+
benchmark:
|
|
26
|
+
'G01: sum distance by destination': |
|
|
27
|
+
df.group(:dest).sum(:distance)
|
|
28
|
+
|
|
29
|
+
'G02: sum arr_delay by month and day': |
|
|
30
|
+
df.group(:month, :day).sum(:arr_delay)
|
|
31
|
+
|
|
32
|
+
'G03: sum arr_delay, mean distance by flight': |
|
|
33
|
+
df.group(:flight) { [sum(:arr_delay), mean(:distance)] }
|
|
34
|
+
|
|
35
|
+
'G04: mean air_time, distance by flight': |
|
|
36
|
+
df.group(:flight).mean(:air_time, :distance)
|
|
37
|
+
|
|
38
|
+
'G05: sum dep_delay, arr_delay by carrer': |
|
|
39
|
+
df.group(:carrier).sum(:dep_delay, :arr_delay)
|
|
@@ -0,0 +1,31 @@
|
|
|
1
|
+
loop_count: 3
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.3
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.3
|
|
10
|
+
- name: 0.2.2
|
|
11
|
+
gems:
|
|
12
|
+
red_amber: 0.2.2
|
|
13
|
+
|
|
14
|
+
prelude: |
|
|
15
|
+
require 'red_amber'
|
|
16
|
+
require 'datasets-arrow'
|
|
17
|
+
|
|
18
|
+
ds = Datasets::Rdatasets.new('tidyr', 'billboard')
|
|
19
|
+
df = RedAmber::DataFrame.new(ds.to_arrow)
|
|
20
|
+
sub_df = df.pick(:track, df.keys.select{ |k| k.start_with? 'wk' })
|
|
21
|
+
long_df = df.to_long(:artist, :track, :'date.entered', name: :week, value: :rank)
|
|
22
|
+
|
|
23
|
+
benchmark:
|
|
24
|
+
'R01: Transpose a DataFrame': |
|
|
25
|
+
sub_df.transpose(name: :week)
|
|
26
|
+
|
|
27
|
+
'R02: Reshape to longer DataFrame': |
|
|
28
|
+
df.to_long(:artist, :track, :'date.entered', name: :week, value: :rank)
|
|
29
|
+
|
|
30
|
+
'R03: Reshape to wider DataFrame': |
|
|
31
|
+
long_df.to_wide(name: :week, value: :rank)
|
|
@@ -2,12 +2,12 @@ prelude: |
|
|
|
2
2
|
require 'rover'
|
|
3
3
|
require 'red_amber'
|
|
4
4
|
|
|
5
|
-
penguins_csv = '
|
|
5
|
+
penguins_csv = 'tmp/penguins.csv'
|
|
6
6
|
|
|
7
7
|
unless File.exist?(penguins_csv)
|
|
8
8
|
require 'datasets-arrow'
|
|
9
|
-
|
|
10
|
-
RedAmber::DataFrame.new(
|
|
9
|
+
ds = Datasets::Penguins.new
|
|
10
|
+
RedAmber::DataFrame.new(ds).save(penguins_csv)
|
|
11
11
|
end
|
|
12
12
|
|
|
13
13
|
benchmark:
|
|
@@ -0,0 +1,23 @@
|
|
|
1
|
+
contexts:
|
|
2
|
+
- gems:
|
|
3
|
+
red_amber: 0.2.2
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
require 'red_amber'
|
|
8
|
+
|
|
9
|
+
prelude: |
|
|
10
|
+
require 'rover'
|
|
11
|
+
require 'datasets-arrow'
|
|
12
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'flights')
|
|
13
|
+
df = RedAmber::DataFrame.new(ds)
|
|
14
|
+
rover = Rover::DataFrame.new(df.to_h)
|
|
15
|
+
group_keys = [:month, :origin]
|
|
16
|
+
summary_key = :air_time
|
|
17
|
+
|
|
18
|
+
benchmark:
|
|
19
|
+
'penguins Group by Rover': |
|
|
20
|
+
rover.group(group_keys).count
|
|
21
|
+
|
|
22
|
+
'penguins Group by RedAmber': |
|
|
23
|
+
df.group(group_keys).count
|
|
@@ -0,0 +1,23 @@
|
|
|
1
|
+
contexts:
|
|
2
|
+
- gems:
|
|
3
|
+
red_amber: 0.2.2
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
require 'red_amber'
|
|
8
|
+
|
|
9
|
+
prelude: |
|
|
10
|
+
require 'rover'
|
|
11
|
+
require 'datasets-arrow'
|
|
12
|
+
ds = Datasets::Penguins.new
|
|
13
|
+
df = RedAmber::DataFrame.new(ds)
|
|
14
|
+
rover = Rover::DataFrame.new(df.to_h)
|
|
15
|
+
group_keys = [:species, :island]
|
|
16
|
+
summary_key = :body_mass_g
|
|
17
|
+
|
|
18
|
+
benchmark:
|
|
19
|
+
'penguins Group by Rover': |
|
|
20
|
+
rover.group(group_keys).mean(summary_key)
|
|
21
|
+
|
|
22
|
+
'penguins Group by RedAmber': |
|
|
23
|
+
df.group(group_keys).mean(summary_key)
|
|
@@ -0,0 +1,23 @@
|
|
|
1
|
+
contexts:
|
|
2
|
+
- gems:
|
|
3
|
+
red_amber: 0.2.2
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
require 'red_amber'
|
|
8
|
+
|
|
9
|
+
prelude: |
|
|
10
|
+
require 'rover'
|
|
11
|
+
require 'datasets-arrow'
|
|
12
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'planes')
|
|
13
|
+
df = RedAmber::DataFrame.new(ds)
|
|
14
|
+
rover = Rover::DataFrame.new(df.to_h)
|
|
15
|
+
group_keys = [:engines, :engine]
|
|
16
|
+
summary_key = :seats
|
|
17
|
+
|
|
18
|
+
benchmark:
|
|
19
|
+
'penguins Group by Rover': |
|
|
20
|
+
rover.group(group_keys).mean(summary_key)
|
|
21
|
+
|
|
22
|
+
'penguins Group by RedAmber': |
|
|
23
|
+
df.group(group_keys).mean(summary_key)
|
|
@@ -0,0 +1,23 @@
|
|
|
1
|
+
contexts:
|
|
2
|
+
- gems:
|
|
3
|
+
red_amber: 0.2.2
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
require 'red_amber'
|
|
8
|
+
|
|
9
|
+
prelude: |
|
|
10
|
+
require 'rover'
|
|
11
|
+
require 'datasets-arrow'
|
|
12
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'weather')
|
|
13
|
+
df = RedAmber::DataFrame.new(ds)
|
|
14
|
+
rover = Rover::DataFrame.new(df.to_h)
|
|
15
|
+
group_keys = [:month, :origin]
|
|
16
|
+
summary_key = :temp
|
|
17
|
+
|
|
18
|
+
benchmark:
|
|
19
|
+
'penguins Group by Rover': |
|
|
20
|
+
rover.group(group_keys).mean(summary_key)
|
|
21
|
+
|
|
22
|
+
'penguins Group by RedAmber': |
|
|
23
|
+
df.group(group_keys).mean(summary_key)
|
|
@@ -0,0 +1,60 @@
|
|
|
1
|
+
loop_count: 10
|
|
2
|
+
|
|
3
|
+
contexts:
|
|
4
|
+
- name: HEAD
|
|
5
|
+
prelude: |
|
|
6
|
+
$LOAD_PATH.unshift(File.expand_path('lib'))
|
|
7
|
+
- name: 0.2.0
|
|
8
|
+
gems:
|
|
9
|
+
red_amber: 0.2.0
|
|
10
|
+
|
|
11
|
+
prelude: |
|
|
12
|
+
require 'red_amber'
|
|
13
|
+
include RedAmber
|
|
14
|
+
require 'datasets-arrow'
|
|
15
|
+
|
|
16
|
+
ds = Datasets::Rdatasets.new('nycflights13', 'flights')
|
|
17
|
+
flights = RedAmber::DataFrame.new(ds.to_arrow)
|
|
18
|
+
df = flights.slice { flights[:month] <= 6 }
|
|
19
|
+
|
|
20
|
+
tailnum_vector = df[:tailnum]
|
|
21
|
+
distance_vector = df[:distance]
|
|
22
|
+
|
|
23
|
+
strings = tailnum_vector.to_a
|
|
24
|
+
arrow_array = tailnum_vector.data
|
|
25
|
+
integers = df[:dep_delay].to_a
|
|
26
|
+
boolean_vector = df[:air_time].is_nil
|
|
27
|
+
index_vector = Vector.new(0...boolean_vector.size).filter(boolean_vector)
|
|
28
|
+
replacer = index_vector.data.map(&:to_s)
|
|
29
|
+
booleans = boolean_vector.to_a
|
|
30
|
+
|
|
31
|
+
benchmark:
|
|
32
|
+
'V01: Vector.new from integer Array': |
|
|
33
|
+
Vector.new(integers)
|
|
34
|
+
|
|
35
|
+
'V02: Vector.new from string Array': |
|
|
36
|
+
Vector.new(strings)
|
|
37
|
+
|
|
38
|
+
'V03: Vector.new from boolean Vector': |
|
|
39
|
+
Vector.new(boolean_vector)
|
|
40
|
+
|
|
41
|
+
'V04: Vector#sum': |
|
|
42
|
+
distance_vector.mean
|
|
43
|
+
|
|
44
|
+
'V05: Vector#*': |
|
|
45
|
+
distance_vector * 1.852
|
|
46
|
+
|
|
47
|
+
'V06: Vector#[booleans]': |
|
|
48
|
+
tailnum_vector[booleans]
|
|
49
|
+
|
|
50
|
+
'V07: Vector#[boolean_vector]': |
|
|
51
|
+
tailnum_vector[boolean_vector]
|
|
52
|
+
|
|
53
|
+
'V08: Vector#[index_vector]': |
|
|
54
|
+
tailnum_vector[index_vector]
|
|
55
|
+
|
|
56
|
+
'V09: Vector#replace': |
|
|
57
|
+
tailnum_vector.replace(booleans, replacer)
|
|
58
|
+
|
|
59
|
+
'V10: Vector#replace with broad casting': |
|
|
60
|
+
tailnum_vector.replace(booleans, 'x')
|