pico_http_parser 0.0.1
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +7 -0
- data/.gitignore +17 -0
- data/.gitmodules +3 -0
- data/.rspec +2 -0
- data/Gemfile +5 -0
- data/LICENSE.txt +378 -0
- data/README.md +68 -0
- data/Rakefile +19 -0
- data/benchmark/bench_helper.rb +5 -0
- data/benchmark/benchmark.pl +35 -0
- data/ext/pico_http_parser/extconf.rb +2 -0
- data/ext/pico_http_parser/pico_http_parser.c +167 -0
- data/ext/pico_http_parser/picohttpparser/.gitattributes +1 -0
- data/ext/pico_http_parser/picohttpparser/.gitmodules +3 -0
- data/ext/pico_http_parser/picohttpparser/.travis.yml +6 -0
- data/ext/pico_http_parser/picohttpparser/Makefile +39 -0
- data/ext/pico_http_parser/picohttpparser/README.md +24 -0
- data/ext/pico_http_parser/picohttpparser/bench.c +52 -0
- data/ext/pico_http_parser/picohttpparser/picohttpparser.c +377 -0
- data/ext/pico_http_parser/picohttpparser/picohttpparser.h +62 -0
- data/ext/pico_http_parser/picohttpparser/test.c +241 -0
- data/lib/pico_http_parser.rb +5 -0
- data/lib/pico_http_parser/version.rb +3 -0
- data/pico_http_parser.gemspec +50 -0
- data/spec/01_simple_spec.rb +170 -0
- data/spec/02_too_much_spec.rb +50 -0
- data/spec/spec_helper.rb +2 -0
- metadata +116 -0
data/Rakefile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
1
|
+
require "bundler/gem_tasks"
|
|
2
|
+
require "rake/extensiontask"
|
|
3
|
+
|
|
4
|
+
Rake::ExtensionTask.new "pico_http_parser" do |ext|
|
|
5
|
+
ext.lib_dir = "lib/pico_http_parser"
|
|
6
|
+
end
|
|
7
|
+
|
|
8
|
+
require 'rspec/core/rake_task'
|
|
9
|
+
RSpec::Core::RakeTask.new(:spec) do |spec|
|
|
10
|
+
spec.pattern = 'spec/*_spec.rb'
|
|
11
|
+
# spec.rspec_opts = ['-cfs']
|
|
12
|
+
end
|
|
13
|
+
|
|
14
|
+
task :test do
|
|
15
|
+
Rake::Task["clobber"].invoke
|
|
16
|
+
Rake::Task["compile"].invoke
|
|
17
|
+
Rake::Task["spec"].invoke
|
|
18
|
+
end
|
|
19
|
+
|
|
@@ -0,0 +1,35 @@
|
|
|
1
|
+
require File.expand_path(File.dirname(__FILE__) + '/bench_helper')
|
|
2
|
+
|
|
3
|
+
require 'pico_http_parser'
|
|
4
|
+
|
|
5
|
+
request_body = <<REQ
|
|
6
|
+
GET /blakjsdfkas HTTP/1.1\r
|
|
7
|
+
Host: blooperblorp\r
|
|
8
|
+
Cookie: blah=woop\r
|
|
9
|
+
\r
|
|
10
|
+
REQ
|
|
11
|
+
loop = 300000
|
|
12
|
+
|
|
13
|
+
#File.read(File.expand_path(File.dirname(__FILE__) + '/sample_request.http'))
|
|
14
|
+
|
|
15
|
+
Benchmark.bmbm(20) do |bm|
|
|
16
|
+
bm.report("PicoHTTPParser") do
|
|
17
|
+
0.upto(loop) do
|
|
18
|
+
env = {}
|
|
19
|
+
PicoHTTPParser.parse_http_request(request_body,env)
|
|
20
|
+
end
|
|
21
|
+
end
|
|
22
|
+
begin
|
|
23
|
+
require 'unicorn'
|
|
24
|
+
include Unicorn
|
|
25
|
+
bm.report("HttpParser") do
|
|
26
|
+
0.upto(loop) do
|
|
27
|
+
parser = HttpParser.new
|
|
28
|
+
parser.buf << request_body
|
|
29
|
+
parser.parse
|
|
30
|
+
end
|
|
31
|
+
end
|
|
32
|
+
rescue LoadError
|
|
33
|
+
puts("Can't benchmark unicorn as it couldn't be loaded.")
|
|
34
|
+
end
|
|
35
|
+
end
|
|
@@ -0,0 +1,167 @@
|
|
|
1
|
+
#include <ruby.h>
|
|
2
|
+
#include <ctype.h>
|
|
3
|
+
#include "picohttpparser/picohttpparser.c"
|
|
4
|
+
|
|
5
|
+
#define MAX_HEADER_NAME_LEN 1024
|
|
6
|
+
#define MAX_HEADERS 128
|
|
7
|
+
#define TOU(ch) (('a' <= ch && ch <= 'z') ? ch - ('a' - 'A') : ch)
|
|
8
|
+
|
|
9
|
+
VALUE cPicoHTTPParser;
|
|
10
|
+
|
|
11
|
+
static
|
|
12
|
+
size_t find_ch(const char* s, size_t len, char ch)
|
|
13
|
+
{
|
|
14
|
+
size_t i;
|
|
15
|
+
for (i = 0; i != len; ++i, ++s)
|
|
16
|
+
if (*s == ch)
|
|
17
|
+
break;
|
|
18
|
+
return i;
|
|
19
|
+
}
|
|
20
|
+
|
|
21
|
+
static
|
|
22
|
+
int header_is(const struct phr_header* header, const char* name,
|
|
23
|
+
size_t len)
|
|
24
|
+
{
|
|
25
|
+
const char* x, * y;
|
|
26
|
+
if (header->name_len != len)
|
|
27
|
+
return 0;
|
|
28
|
+
for (x = header->name, y = name; len != 0; --len, ++x, ++y)
|
|
29
|
+
if (TOU(*x) != *y)
|
|
30
|
+
return 0;
|
|
31
|
+
return 1;
|
|
32
|
+
}
|
|
33
|
+
|
|
34
|
+
|
|
35
|
+
static
|
|
36
|
+
int store_path_info(VALUE envref, const char* src, size_t src_len) {
|
|
37
|
+
size_t dlen = 0, i = 0;
|
|
38
|
+
char *d;
|
|
39
|
+
char s2, s3;
|
|
40
|
+
|
|
41
|
+
d = (char*)malloc(src_len * 3 + 1);
|
|
42
|
+
for (i = 0; i < src_len; i++ ) {
|
|
43
|
+
if ( src[i] == '%' ) {
|
|
44
|
+
if ( !isxdigit(src[i+1]) || !isxdigit(src[i+2]) ) {
|
|
45
|
+
free(d);
|
|
46
|
+
return -1;
|
|
47
|
+
}
|
|
48
|
+
s2 = src[i+1];
|
|
49
|
+
s3 = src[i+2];
|
|
50
|
+
s2 -= s2 <= '9' ? '0'
|
|
51
|
+
: s2 <= 'F' ? 'A' - 10
|
|
52
|
+
: 'a' - 10;
|
|
53
|
+
s3 -= s3 <= '9' ? '0'
|
|
54
|
+
: s3 <= 'F' ? 'A' - 10
|
|
55
|
+
: 'a' - 10;
|
|
56
|
+
d[dlen++] = s2 * 16 + s3;
|
|
57
|
+
i += 2;
|
|
58
|
+
}
|
|
59
|
+
else {
|
|
60
|
+
d[dlen++] = src[i];
|
|
61
|
+
}
|
|
62
|
+
}
|
|
63
|
+
d[dlen]='0';
|
|
64
|
+
rb_hash_aset(envref, rb_str_new2("PATH_INFO"), rb_str_new(d, dlen));
|
|
65
|
+
free(d);
|
|
66
|
+
return dlen;
|
|
67
|
+
}
|
|
68
|
+
|
|
69
|
+
|
|
70
|
+
static
|
|
71
|
+
VALUE phr_parse_http_request(VALUE self, VALUE buf, VALUE envref)
|
|
72
|
+
{
|
|
73
|
+
const char* buf_str;
|
|
74
|
+
size_t buf_len;
|
|
75
|
+
const char* method;
|
|
76
|
+
size_t method_len;
|
|
77
|
+
const char* path;
|
|
78
|
+
size_t path_len;
|
|
79
|
+
size_t o_path_len;
|
|
80
|
+
int minor_version;
|
|
81
|
+
struct phr_header headers[MAX_HEADERS];
|
|
82
|
+
size_t num_headers, question_at;
|
|
83
|
+
size_t i;
|
|
84
|
+
int ret;
|
|
85
|
+
char tmp[MAX_HEADER_NAME_LEN + sizeof("HTTP_") - 1];
|
|
86
|
+
VALUE last_value;
|
|
87
|
+
|
|
88
|
+
buf_str = StringValuePtr(buf);
|
|
89
|
+
buf_len = strlen(buf_str);
|
|
90
|
+
num_headers = MAX_HEADERS;
|
|
91
|
+
ret = phr_parse_request(buf_str, buf_len, &method, &method_len, &path,
|
|
92
|
+
&path_len, &minor_version, headers, &num_headers, 0);
|
|
93
|
+
if (ret < 0)
|
|
94
|
+
goto done;
|
|
95
|
+
|
|
96
|
+
rb_hash_aset(envref, rb_str_new2("REQUEST_METHOD"), rb_str_new(method,method_len));
|
|
97
|
+
rb_hash_aset(envref, rb_str_new2("REQUEST_URI"), rb_str_new(path, path_len));
|
|
98
|
+
rb_hash_aset(envref, rb_str_new2("SCRIPT_NAME"), rb_str_new2(""));
|
|
99
|
+
i = sprintf(tmp,"HTTP/1.%d",minor_version);
|
|
100
|
+
rb_hash_aset(envref, rb_str_new2("SERVER_PROTOCOL"), rb_str_new(tmp, i));
|
|
101
|
+
|
|
102
|
+
/* PATH_INFO QUERY_STRING */
|
|
103
|
+
path_len = find_ch(path, path_len, '#'); /* strip off all text after # after storing request_uri */
|
|
104
|
+
question_at = find_ch(path, path_len, '?');
|
|
105
|
+
if ( store_path_info(envref, path, question_at) < 0 ) {
|
|
106
|
+
rb_hash_clear(envref);
|
|
107
|
+
ret = -1;
|
|
108
|
+
goto done;
|
|
109
|
+
}
|
|
110
|
+
if (question_at != path_len) ++question_at;
|
|
111
|
+
rb_hash_aset(envref, rb_str_new2("QUERY_STRING"), rb_str_new(path + question_at, path_len - question_at));
|
|
112
|
+
|
|
113
|
+
last_value = Qnil;
|
|
114
|
+
for (i = 0; i < num_headers; ++i) {
|
|
115
|
+
if (headers[i].name != NULL) {
|
|
116
|
+
const char* name;
|
|
117
|
+
size_t name_len;
|
|
118
|
+
VALUE slot;
|
|
119
|
+
if (header_is(headers + i, "CONTENT-TYPE", sizeof("CONTENT-TYPE") - 1)) {
|
|
120
|
+
name = "CONTENT_TYPE";
|
|
121
|
+
name_len = sizeof("CONTENT_TYPE") - 1;
|
|
122
|
+
} else if (header_is(headers + i, "CONTENT-LENGTH", sizeof("CONTENT-LENGTH") - 1)) {
|
|
123
|
+
name = "CONTENT_LENGTH";
|
|
124
|
+
name_len = sizeof("CONTENT_LENGTH") - 1;
|
|
125
|
+
} else {
|
|
126
|
+
const char* s;
|
|
127
|
+
char* d;
|
|
128
|
+
size_t n;
|
|
129
|
+
if (sizeof(tmp) - 5 < headers[i].name_len) {
|
|
130
|
+
rb_hash_clear(envref);
|
|
131
|
+
ret = -1;
|
|
132
|
+
goto done;
|
|
133
|
+
}
|
|
134
|
+
strcpy(tmp, "HTTP_");
|
|
135
|
+
for (s = headers[i].name, n = headers[i].name_len, d = tmp + 5;
|
|
136
|
+
n != 0;
|
|
137
|
+
s++, --n, d++) {
|
|
138
|
+
*d = *s == '-' ? '_' : TOU(*s);
|
|
139
|
+
name = tmp;
|
|
140
|
+
name_len = headers[i].name_len + 5;
|
|
141
|
+
}
|
|
142
|
+
}
|
|
143
|
+
slot = rb_hash_aref(envref, rb_str_new(name, name_len));
|
|
144
|
+
if ( slot != Qnil ) {
|
|
145
|
+
rb_str_cat2(slot, ", ");
|
|
146
|
+
rb_str_cat(slot, headers[i].value, headers[i].value_len);
|
|
147
|
+
} else {
|
|
148
|
+
slot = rb_str_new(headers[i].value, headers[i].value_len);
|
|
149
|
+
rb_hash_aset(envref, rb_str_new(name, name_len), slot);
|
|
150
|
+
last_value = slot;
|
|
151
|
+
}
|
|
152
|
+
} else {
|
|
153
|
+
/* continuing lines of a mulitiline header */
|
|
154
|
+
rb_str_cat(last_value, headers[i].value, headers[i].value_len);
|
|
155
|
+
}
|
|
156
|
+
}
|
|
157
|
+
|
|
158
|
+
done:
|
|
159
|
+
return rb_int_new(ret);
|
|
160
|
+
}
|
|
161
|
+
|
|
162
|
+
void Init_pico_http_parser()
|
|
163
|
+
{
|
|
164
|
+
|
|
165
|
+
cPicoHTTPParser = rb_const_get(rb_cObject, rb_intern("PicoHTTPParser"));
|
|
166
|
+
rb_define_module_function(cPicoHTTPParser, "parse_http_request", phr_parse_http_request, 2);
|
|
167
|
+
}
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
picohttpparser.* ident
|
|
@@ -0,0 +1,39 @@
|
|
|
1
|
+
#
|
|
2
|
+
# Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase
|
|
3
|
+
#
|
|
4
|
+
# The software is licensed under either the MIT License (below) or the Perl
|
|
5
|
+
# license.
|
|
6
|
+
#
|
|
7
|
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
8
|
+
# of this software and associated documentation files (the "Software"), to
|
|
9
|
+
# deal in the Software without restriction, including without limitation the
|
|
10
|
+
# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
|
11
|
+
# sell copies of the Software, and to permit persons to whom the Software is
|
|
12
|
+
# furnished to do so, subject to the following conditions:
|
|
13
|
+
#
|
|
14
|
+
# The above copyright notice and this permission notice shall be included in
|
|
15
|
+
# all copies or substantial portions of the Software.
|
|
16
|
+
#
|
|
17
|
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
18
|
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
19
|
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
20
|
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
21
|
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
|
22
|
+
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
|
23
|
+
# IN THE SOFTWARE.
|
|
24
|
+
|
|
25
|
+
CC?=gcc
|
|
26
|
+
PROVE?=prove
|
|
27
|
+
|
|
28
|
+
all:
|
|
29
|
+
|
|
30
|
+
test: test-bin
|
|
31
|
+
$(PROVE) -v ./test-bin
|
|
32
|
+
|
|
33
|
+
test-bin: picohttpparser.c picotest/picotest.c test.c
|
|
34
|
+
$(CC) -Wall $(CFLAGS) $(LDFLAGS) -o $@ $^
|
|
35
|
+
|
|
36
|
+
clean:
|
|
37
|
+
rm -f test-bin
|
|
38
|
+
|
|
39
|
+
.PHONY: test
|
|
@@ -0,0 +1,24 @@
|
|
|
1
|
+
PicoHTTPParser
|
|
2
|
+
=============
|
|
3
|
+
|
|
4
|
+
Copyright (c) 2009-2014 [Kazuho Oku](https://github.com/kazuho), [Tokuhiro Matsuno](https://github.com/tokuhirom), [Daisuke Murase](https://github.com/typester)
|
|
5
|
+
|
|
6
|
+
PicoHTTPParser is a tiny, primitive, fast HTTP request/response parser.
|
|
7
|
+
|
|
8
|
+
Unlike most parsers, it is stateless and does not allocate memory by itself.
|
|
9
|
+
All it does is accept pointer to buffer and the output structure, and setups the pointers in the latter to point at the necessary portions of the buffer.
|
|
10
|
+
|
|
11
|
+
The code is widely deployed within Perl applications through popular modules that use it, including [Plack](https://metacpan.org/pod/Plack), [Starman](https://metacpan.org/pod/Starman), [Starlet](https://metacpan.org/pod/Starlet), [Furl](https://metacpan.org/pod/Furl). It is also the HTTP/1 parser of [H2O](https://github.com/h2o/h2o).
|
|
12
|
+
|
|
13
|
+
Check out [test.c] to find out how to use the parser.
|
|
14
|
+
|
|
15
|
+
The software is dual-licensed under the Perl License or the MIT License.
|
|
16
|
+
|
|
17
|
+
Benchmark
|
|
18
|
+
---------
|
|
19
|
+
|
|
20
|
+
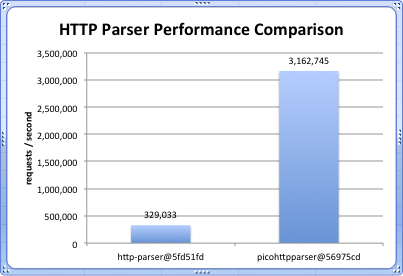
|
|
21
|
+
|
|
22
|
+
The benchmark code is from [fukamachi/fast-http](https://github.com/fukamachi/fast-http/).
|
|
23
|
+
|
|
24
|
+
The internals of picohttpparser has been described to some extent in [my blog entry]( http://blog.kazuhooku.com/2014/11/the-internals-h2o-or-how-to-write-fast.html).
|
|
@@ -0,0 +1,52 @@
|
|
|
1
|
+
/*
|
|
2
|
+
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase
|
|
3
|
+
*
|
|
4
|
+
* The software is licensed under either the MIT License (below) or the Perl
|
|
5
|
+
* license.
|
|
6
|
+
*
|
|
7
|
+
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
8
|
+
* of this software and associated documentation files (the "Software"), to
|
|
9
|
+
* deal in the Software without restriction, including without limitation the
|
|
10
|
+
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
|
11
|
+
* sell copies of the Software, and to permit persons to whom the Software is
|
|
12
|
+
* furnished to do so, subject to the following conditions:
|
|
13
|
+
*
|
|
14
|
+
* The above copyright notice and this permission notice shall be included in
|
|
15
|
+
* all copies or substantial portions of the Software.
|
|
16
|
+
*
|
|
17
|
+
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
18
|
+
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
19
|
+
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
20
|
+
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
21
|
+
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
|
22
|
+
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
|
23
|
+
* IN THE SOFTWARE.
|
|
24
|
+
*/
|
|
25
|
+
|
|
26
|
+
#include <assert.h>
|
|
27
|
+
#include <stdio.h>
|
|
28
|
+
#include "picohttpparser.h"
|
|
29
|
+
|
|
30
|
+
#define REQ "GET /wp-content/uploads/2010/03/hello-kitty-darth-vader-pink.jpg HTTP/1.1\r\nHost: www.kittyhell.com\r\nUser-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.6; ja-JP-mac; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3 Pathtraq/0.9\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nAccept-Language: ja,en-us;q=0.7,en;q=0.3\r\nAccept-Encoding: gzip,deflate\r\nAccept-Charset: Shift_JIS,utf-8;q=0.7,*;q=0.7\r\nKeep-Alive: 115\r\nConnection: keep-alive\r\nCookie: wp_ozh_wsa_visits=2; wp_ozh_wsa_visit_lasttime=xxxxxxxxxx; __utma=xxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.x; __utmz=xxxxxxxxx.xxxxxxxxxx.x.x.utmccn=(referral)|utmcsr=reader.livedoor.com|utmcct=/reader/|utmcmd=referral\r\n\r\n"
|
|
31
|
+
|
|
32
|
+
int main(void)
|
|
33
|
+
{
|
|
34
|
+
const char* method;
|
|
35
|
+
size_t method_len;
|
|
36
|
+
const char* path;
|
|
37
|
+
size_t path_len;
|
|
38
|
+
int minor_version;
|
|
39
|
+
struct phr_header headers[32];
|
|
40
|
+
size_t num_headers;
|
|
41
|
+
int i, ret;
|
|
42
|
+
|
|
43
|
+
for (i = 0; i < 1000000; i++) {
|
|
44
|
+
num_headers = sizeof(headers) / sizeof(headers[0]);
|
|
45
|
+
ret = phr_parse_request(REQ, sizeof(REQ) - 1, &method, &method_len, &path,
|
|
46
|
+
&path_len, &minor_version, headers, &num_headers,
|
|
47
|
+
0);
|
|
48
|
+
assert(ret == sizeof(REQ) - 1);
|
|
49
|
+
}
|
|
50
|
+
|
|
51
|
+
return 0;
|
|
52
|
+
}
|
|
@@ -0,0 +1,377 @@
|
|
|
1
|
+
/*
|
|
2
|
+
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase
|
|
3
|
+
*
|
|
4
|
+
* The software is licensed under either the MIT License (below) or the Perl
|
|
5
|
+
* license.
|
|
6
|
+
*
|
|
7
|
+
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
8
|
+
* of this software and associated documentation files (the "Software"), to
|
|
9
|
+
* deal in the Software without restriction, including without limitation the
|
|
10
|
+
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
|
11
|
+
* sell copies of the Software, and to permit persons to whom the Software is
|
|
12
|
+
* furnished to do so, subject to the following conditions:
|
|
13
|
+
*
|
|
14
|
+
* The above copyright notice and this permission notice shall be included in
|
|
15
|
+
* all copies or substantial portions of the Software.
|
|
16
|
+
*
|
|
17
|
+
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
18
|
+
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
19
|
+
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
20
|
+
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
21
|
+
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
|
22
|
+
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
|
23
|
+
* IN THE SOFTWARE.
|
|
24
|
+
*/
|
|
25
|
+
|
|
26
|
+
#include <stddef.h>
|
|
27
|
+
#include "picohttpparser.h"
|
|
28
|
+
|
|
29
|
+
/* $Id$ */
|
|
30
|
+
|
|
31
|
+
#if __GNUC__ >= 3
|
|
32
|
+
# define likely(x) __builtin_expect(!!(x), 1)
|
|
33
|
+
# define unlikely(x) __builtin_expect(!!(x), 0)
|
|
34
|
+
#else
|
|
35
|
+
# define likely(x) (x)
|
|
36
|
+
# define unlikely(x) (x)
|
|
37
|
+
#endif
|
|
38
|
+
|
|
39
|
+
#define IS_PRINTABLE_ASCII(c) ((unsigned char)(c) - 040u < 0137u)
|
|
40
|
+
|
|
41
|
+
#define CHECK_EOF() \
|
|
42
|
+
if (buf == buf_end) { \
|
|
43
|
+
*ret = -2; \
|
|
44
|
+
return NULL; \
|
|
45
|
+
}
|
|
46
|
+
|
|
47
|
+
#define EXPECT_CHAR(ch) \
|
|
48
|
+
CHECK_EOF(); \
|
|
49
|
+
if (*buf++ != ch) { \
|
|
50
|
+
*ret = -1; \
|
|
51
|
+
return NULL; \
|
|
52
|
+
}
|
|
53
|
+
|
|
54
|
+
#define ADVANCE_TOKEN(tok, toklen) do { \
|
|
55
|
+
const char* tok_start = buf; \
|
|
56
|
+
for (; ; ++buf) { \
|
|
57
|
+
CHECK_EOF(); \
|
|
58
|
+
if (*buf == ' ') { \
|
|
59
|
+
break; \
|
|
60
|
+
} else if (unlikely(! IS_PRINTABLE_ASCII(*buf))) { \
|
|
61
|
+
if ((unsigned char)*buf < '\040' || *buf == '\177') { \
|
|
62
|
+
*ret = -1; \
|
|
63
|
+
return NULL; \
|
|
64
|
+
} \
|
|
65
|
+
} \
|
|
66
|
+
} \
|
|
67
|
+
tok = tok_start; \
|
|
68
|
+
toklen = buf - tok_start; \
|
|
69
|
+
} while (0)
|
|
70
|
+
|
|
71
|
+
static const char* token_char_map =
|
|
72
|
+
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
|
73
|
+
"\0\1\1\1\1\1\1\1\0\0\1\1\0\1\1\0\1\1\1\1\1\1\1\1\1\1\0\0\0\0\0\0"
|
|
74
|
+
"\0\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\0\0\1\1"
|
|
75
|
+
"\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\1\0\1\0"
|
|
76
|
+
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
|
77
|
+
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
|
78
|
+
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
|
79
|
+
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";
|
|
80
|
+
|
|
81
|
+
static const char* get_token_to_eol(const char* buf, const char* buf_end,
|
|
82
|
+
const char** token, size_t* token_len,
|
|
83
|
+
int* ret)
|
|
84
|
+
{
|
|
85
|
+
const char* token_start = buf;
|
|
86
|
+
|
|
87
|
+
/* find non-printable char within the next 8 bytes, this is the hottest code; manually inlined */
|
|
88
|
+
while (likely(buf_end - buf >= 8)) {
|
|
89
|
+
#define DOIT() if (unlikely(! IS_PRINTABLE_ASCII(*buf))) goto NonPrintable; ++buf
|
|
90
|
+
DOIT(); DOIT(); DOIT(); DOIT();
|
|
91
|
+
DOIT(); DOIT(); DOIT(); DOIT();
|
|
92
|
+
#undef DOIT
|
|
93
|
+
continue;
|
|
94
|
+
NonPrintable:
|
|
95
|
+
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
|
96
|
+
goto FOUND_CTL;
|
|
97
|
+
}
|
|
98
|
+
++buf;
|
|
99
|
+
}
|
|
100
|
+
for (; ; ++buf) {
|
|
101
|
+
CHECK_EOF();
|
|
102
|
+
if (unlikely(! IS_PRINTABLE_ASCII(*buf))) {
|
|
103
|
+
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
|
104
|
+
goto FOUND_CTL;
|
|
105
|
+
}
|
|
106
|
+
}
|
|
107
|
+
}
|
|
108
|
+
FOUND_CTL:
|
|
109
|
+
if (likely(*buf == '\015')) {
|
|
110
|
+
++buf;
|
|
111
|
+
EXPECT_CHAR('\012');
|
|
112
|
+
*token_len = buf - 2 - token_start;
|
|
113
|
+
} else if (*buf == '\012') {
|
|
114
|
+
*token_len = buf - token_start;
|
|
115
|
+
++buf;
|
|
116
|
+
} else {
|
|
117
|
+
*ret = -1;
|
|
118
|
+
return NULL;
|
|
119
|
+
}
|
|
120
|
+
*token = token_start;
|
|
121
|
+
|
|
122
|
+
return buf;
|
|
123
|
+
}
|
|
124
|
+
|
|
125
|
+
static const char* is_complete(const char* buf, const char* buf_end,
|
|
126
|
+
size_t last_len, int* ret)
|
|
127
|
+
{
|
|
128
|
+
int ret_cnt = 0;
|
|
129
|
+
buf = last_len < 3 ? buf : buf + last_len - 3;
|
|
130
|
+
|
|
131
|
+
while (1) {
|
|
132
|
+
CHECK_EOF();
|
|
133
|
+
if (*buf == '\015') {
|
|
134
|
+
++buf;
|
|
135
|
+
CHECK_EOF();
|
|
136
|
+
EXPECT_CHAR('\012');
|
|
137
|
+
++ret_cnt;
|
|
138
|
+
} else if (*buf == '\012') {
|
|
139
|
+
++buf;
|
|
140
|
+
++ret_cnt;
|
|
141
|
+
} else {
|
|
142
|
+
++buf;
|
|
143
|
+
ret_cnt = 0;
|
|
144
|
+
}
|
|
145
|
+
if (ret_cnt == 2) {
|
|
146
|
+
return buf;
|
|
147
|
+
}
|
|
148
|
+
}
|
|
149
|
+
|
|
150
|
+
*ret = -2;
|
|
151
|
+
return NULL;
|
|
152
|
+
}
|
|
153
|
+
|
|
154
|
+
/* *_buf is always within [buf, buf_end) upon success */
|
|
155
|
+
static const char* parse_int(const char* buf, const char* buf_end, int* value,
|
|
156
|
+
int* ret)
|
|
157
|
+
{
|
|
158
|
+
int v;
|
|
159
|
+
CHECK_EOF();
|
|
160
|
+
if (! ('0' <= *buf && *buf <= '9')) {
|
|
161
|
+
*ret = -1;
|
|
162
|
+
return NULL;
|
|
163
|
+
}
|
|
164
|
+
v = 0;
|
|
165
|
+
for (; ; ++buf) {
|
|
166
|
+
CHECK_EOF();
|
|
167
|
+
if ('0' <= *buf && *buf <= '9') {
|
|
168
|
+
v = v * 10 + *buf - '0';
|
|
169
|
+
} else {
|
|
170
|
+
break;
|
|
171
|
+
}
|
|
172
|
+
}
|
|
173
|
+
|
|
174
|
+
*value = v;
|
|
175
|
+
return buf;
|
|
176
|
+
}
|
|
177
|
+
|
|
178
|
+
/* returned pointer is always within [buf, buf_end), or null */
|
|
179
|
+
static const char* parse_http_version(const char* buf, const char* buf_end,
|
|
180
|
+
int* minor_version, int* ret)
|
|
181
|
+
{
|
|
182
|
+
EXPECT_CHAR('H'); EXPECT_CHAR('T'); EXPECT_CHAR('T'); EXPECT_CHAR('P');
|
|
183
|
+
EXPECT_CHAR('/'); EXPECT_CHAR('1'); EXPECT_CHAR('.');
|
|
184
|
+
return parse_int(buf, buf_end, minor_version, ret);
|
|
185
|
+
}
|
|
186
|
+
|
|
187
|
+
static const char* parse_headers(const char* buf, const char* buf_end,
|
|
188
|
+
struct phr_header* headers,
|
|
189
|
+
size_t* num_headers, size_t max_headers,
|
|
190
|
+
int* ret)
|
|
191
|
+
{
|
|
192
|
+
for (; ; ++*num_headers) {
|
|
193
|
+
CHECK_EOF();
|
|
194
|
+
if (*buf == '\015') {
|
|
195
|
+
++buf;
|
|
196
|
+
EXPECT_CHAR('\012');
|
|
197
|
+
break;
|
|
198
|
+
} else if (*buf == '\012') {
|
|
199
|
+
++buf;
|
|
200
|
+
break;
|
|
201
|
+
}
|
|
202
|
+
if (*num_headers == max_headers) {
|
|
203
|
+
*ret = -1;
|
|
204
|
+
return NULL;
|
|
205
|
+
}
|
|
206
|
+
if (! (*num_headers != 0 && (*buf == ' ' || *buf == '\t'))) {
|
|
207
|
+
if (! token_char_map[(unsigned char)*buf]) {
|
|
208
|
+
*ret = -1;
|
|
209
|
+
return NULL;
|
|
210
|
+
}
|
|
211
|
+
/* parsing name, but do not discard SP before colon, see
|
|
212
|
+
* http://www.mozilla.org/security/announce/2006/mfsa2006-33.html */
|
|
213
|
+
headers[*num_headers].name = buf;
|
|
214
|
+
for (; ; ++buf) {
|
|
215
|
+
CHECK_EOF();
|
|
216
|
+
if (*buf == ':') {
|
|
217
|
+
break;
|
|
218
|
+
} else if (*buf < ' ') {
|
|
219
|
+
*ret = -1;
|
|
220
|
+
return NULL;
|
|
221
|
+
}
|
|
222
|
+
}
|
|
223
|
+
headers[*num_headers].name_len = buf - headers[*num_headers].name;
|
|
224
|
+
++buf;
|
|
225
|
+
for (; ; ++buf) {
|
|
226
|
+
CHECK_EOF();
|
|
227
|
+
if (! (*buf == ' ' || *buf == '\t')) {
|
|
228
|
+
break;
|
|
229
|
+
}
|
|
230
|
+
}
|
|
231
|
+
} else {
|
|
232
|
+
headers[*num_headers].name = NULL;
|
|
233
|
+
headers[*num_headers].name_len = 0;
|
|
234
|
+
}
|
|
235
|
+
if ((buf = get_token_to_eol(buf, buf_end, &headers[*num_headers].value,
|
|
236
|
+
&headers[*num_headers].value_len, ret))
|
|
237
|
+
== NULL) {
|
|
238
|
+
return NULL;
|
|
239
|
+
}
|
|
240
|
+
}
|
|
241
|
+
return buf;
|
|
242
|
+
}
|
|
243
|
+
|
|
244
|
+
const char* parse_request(const char* buf, const char* buf_end,
|
|
245
|
+
const char** method, size_t* method_len,
|
|
246
|
+
const char** path, size_t* path_len,
|
|
247
|
+
int* minor_version, struct phr_header* headers,
|
|
248
|
+
size_t* num_headers, size_t max_headers, int* ret)
|
|
249
|
+
{
|
|
250
|
+
/* skip first empty line (some clients add CRLF after POST content) */
|
|
251
|
+
CHECK_EOF();
|
|
252
|
+
if (*buf == '\015') {
|
|
253
|
+
++buf;
|
|
254
|
+
EXPECT_CHAR('\012');
|
|
255
|
+
} else if (*buf == '\012') {
|
|
256
|
+
++buf;
|
|
257
|
+
}
|
|
258
|
+
|
|
259
|
+
/* parse request line */
|
|
260
|
+
ADVANCE_TOKEN(*method, *method_len);
|
|
261
|
+
++buf;
|
|
262
|
+
ADVANCE_TOKEN(*path, *path_len);
|
|
263
|
+
++buf;
|
|
264
|
+
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
|
265
|
+
return NULL;
|
|
266
|
+
}
|
|
267
|
+
if (*buf == '\015') {
|
|
268
|
+
++buf;
|
|
269
|
+
EXPECT_CHAR('\012');
|
|
270
|
+
} else if (*buf == '\012') {
|
|
271
|
+
++buf;
|
|
272
|
+
} else {
|
|
273
|
+
*ret = -1;
|
|
274
|
+
return NULL;
|
|
275
|
+
}
|
|
276
|
+
|
|
277
|
+
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
|
278
|
+
}
|
|
279
|
+
|
|
280
|
+
int phr_parse_request(const char* buf_start, size_t len, const char** method,
|
|
281
|
+
size_t* method_len, const char** path, size_t* path_len,
|
|
282
|
+
int* minor_version, struct phr_header* headers,
|
|
283
|
+
size_t* num_headers, size_t last_len)
|
|
284
|
+
{
|
|
285
|
+
const char * buf = buf_start, * buf_end = buf_start + len;
|
|
286
|
+
size_t max_headers = *num_headers;
|
|
287
|
+
int r;
|
|
288
|
+
|
|
289
|
+
*method = NULL;
|
|
290
|
+
*method_len = 0;
|
|
291
|
+
*path = NULL;
|
|
292
|
+
*path_len = 0;
|
|
293
|
+
*minor_version = -1;
|
|
294
|
+
*num_headers = 0;
|
|
295
|
+
|
|
296
|
+
/* if last_len != 0, check if the request is complete (a fast countermeasure
|
|
297
|
+
againt slowloris */
|
|
298
|
+
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
|
299
|
+
return r;
|
|
300
|
+
}
|
|
301
|
+
|
|
302
|
+
if ((buf = parse_request(buf, buf_end, method, method_len, path, path_len,
|
|
303
|
+
minor_version, headers, num_headers, max_headers,
|
|
304
|
+
&r))
|
|
305
|
+
== NULL) {
|
|
306
|
+
return r;
|
|
307
|
+
}
|
|
308
|
+
|
|
309
|
+
return (int)(buf - buf_start);
|
|
310
|
+
}
|
|
311
|
+
|
|
312
|
+
static const char* parse_response(const char* buf, const char* buf_end,
|
|
313
|
+
int* minor_version, int* status,
|
|
314
|
+
const char** msg, size_t* msg_len,
|
|
315
|
+
struct phr_header* headers,
|
|
316
|
+
size_t* num_headers, size_t max_headers,
|
|
317
|
+
int* ret)
|
|
318
|
+
{
|
|
319
|
+
/* parse "HTTP/1.x" */
|
|
320
|
+
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
|
321
|
+
return NULL;
|
|
322
|
+
}
|
|
323
|
+
/* skip space */
|
|
324
|
+
if (*buf++ != ' ') {
|
|
325
|
+
*ret = -1;
|
|
326
|
+
return NULL;
|
|
327
|
+
}
|
|
328
|
+
/* parse status code */
|
|
329
|
+
if ((buf = parse_int(buf, buf_end, status, ret)) == NULL) {
|
|
330
|
+
return NULL;
|
|
331
|
+
}
|
|
332
|
+
/* skip space */
|
|
333
|
+
if (*buf++ != ' ') {
|
|
334
|
+
*ret = -1;
|
|
335
|
+
return NULL;
|
|
336
|
+
}
|
|
337
|
+
/* get message */
|
|
338
|
+
if ((buf = get_token_to_eol(buf, buf_end, msg, msg_len, ret)) == NULL) {
|
|
339
|
+
return NULL;
|
|
340
|
+
}
|
|
341
|
+
|
|
342
|
+
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
|
343
|
+
}
|
|
344
|
+
|
|
345
|
+
int phr_parse_response(const char* buf_start, size_t len, int* minor_version,
|
|
346
|
+
int* status, const char** msg, size_t* msg_len,
|
|
347
|
+
struct phr_header* headers, size_t* num_headers,
|
|
348
|
+
size_t last_len)
|
|
349
|
+
{
|
|
350
|
+
const char * buf = buf_start, * buf_end = buf + len;
|
|
351
|
+
size_t max_headers = *num_headers;
|
|
352
|
+
int r;
|
|
353
|
+
|
|
354
|
+
*minor_version = -1;
|
|
355
|
+
*status = 0;
|
|
356
|
+
*msg = NULL;
|
|
357
|
+
*msg_len = 0;
|
|
358
|
+
*num_headers = 0;
|
|
359
|
+
|
|
360
|
+
/* if last_len != 0, check if the response is complete (a fast countermeasure
|
|
361
|
+
against slowloris */
|
|
362
|
+
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
|
363
|
+
return r;
|
|
364
|
+
}
|
|
365
|
+
|
|
366
|
+
if ((buf = parse_response(buf, buf_end, minor_version, status, msg, msg_len,
|
|
367
|
+
headers, num_headers, max_headers, &r))
|
|
368
|
+
== NULL) {
|
|
369
|
+
return r;
|
|
370
|
+
}
|
|
371
|
+
|
|
372
|
+
return (int)(buf - buf_start);
|
|
373
|
+
}
|
|
374
|
+
|
|
375
|
+
#undef CHECK_EOF
|
|
376
|
+
#undef EXPECT_CHAR
|
|
377
|
+
#undef ADVANCE_TOKEN
|