pandata 0.3.4 → 2.0.0
Sign up to get free protection for your applications and to get access to all the features.
- checksums.yaml +4 -4
- data/README.md +35 -17
- data/lib/pandata.rb +1 -10
- data/lib/pandata/argv_parser.rb +2 -27
- data/lib/pandata/cli.rb +5 -8
- data/lib/pandata/data_urls.rb +0 -5
- data/lib/pandata/parser.rb +2 -74
- data/lib/pandata/scraper.rb +0 -35
- data/lib/pandata/version.rb +10 -0
- metadata +36 -36
checksums.yaml
CHANGED
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
---
|
|
2
2
|
SHA1:
|
|
3
|
-
metadata.gz:
|
|
4
|
-
data.tar.gz:
|
|
3
|
+
metadata.gz: 94c921582f5d5d1d8c56d82894b49a2903383082
|
|
4
|
+
data.tar.gz: bfca95f7246ed9a403a4127ccdb5cd40af1214c5
|
|
5
5
|
SHA512:
|
|
6
|
-
metadata.gz:
|
|
7
|
-
data.tar.gz:
|
|
6
|
+
metadata.gz: 1700ebfca8412057890d4e4aa6ce68024260aad32412bf005e8b1313d19d768864db7b8726b1b0ee28d2ad899eb20d0c17e2f377a41c7cd620b2359b8c388c4e
|
|
7
|
+
data.tar.gz: 1ec60d0df1026059df3b97f04114c038c34be1647e81bf2e83fcfdae24fa09fc76e13533dafcf87030fe0cbd624d7ed225facb273262b6b9df6969241abfdef1
|
data/README.md
CHANGED
|
@@ -1,19 +1,16 @@
|
|
|
1
|
-
# Pandata
|
|
1
|
+
# Pandata [](https://travis-ci.org/ustasb/pandata)
|
|
2
2
|
|
|
3
3
|
Pandata is a Ruby 1.9+ library for downloading a user's Pandora.com data. This data includes:
|
|
4
4
|
|
|
5
|
-
- Playing Station *
|
|
6
|
-
- Recent Activity *
|
|
7
|
-
- Stations *
|
|
8
|
-
- Bookmarks (artists, tracks) *
|
|
9
5
|
- Likes (albums, artists, stations, tracks)
|
|
10
6
|
- Followers
|
|
11
7
|
- Following
|
|
12
8
|
|
|
13
|
-
Where possible, Pandora [feeds][1] are used (indicated by an * above).
|
|
14
|
-
|
|
15
9
|
**Pandata can only access public Pandora profiles.** This option can be changed in Pandora's settings.
|
|
16
10
|
|
|
11
|
+
**Note:** Scraping is a fragile task and Pandora can (and has) easily break this
|
|
12
|
+
gem. Version 2 of this gem represents the removal of Pandora's [feeds][1] feature.
|
|
13
|
+
|
|
17
14
|
## Installing
|
|
18
15
|
|
|
19
16
|
Pandata is a Ruby gem. To install, execute:
|
|
@@ -38,7 +35,7 @@ pandora.com/profile/\<my_webname\>
|
|
|
38
35
|
First, create a new Pandata scraper for a user:
|
|
39
36
|
|
|
40
37
|
require 'pandata'
|
|
41
|
-
|
|
38
|
+
|
|
42
39
|
# Scraper.get takes either an email or a webname.
|
|
43
40
|
# Returns an array of similar webnames if no match is found.
|
|
44
41
|
johns_scraper = Pandata::Scraper.get('john@example.com')
|
|
@@ -48,12 +45,6 @@ Next, start scraping!
|
|
|
48
45
|
# Get only liked tracks
|
|
49
46
|
likes = johns_scraper.likes(:tracks)
|
|
50
47
|
|
|
51
|
-
# Get all bookmarks (artists and tracks)
|
|
52
|
-
bookmarks = johns_scraper.bookmarks
|
|
53
|
-
|
|
54
|
-
# Get all stations
|
|
55
|
-
stations = johns_scraper.stations
|
|
56
|
-
|
|
57
48
|
# Get all followers
|
|
58
49
|
followers = johns_scraper.followers
|
|
59
50
|
|
|
@@ -75,11 +66,38 @@ For an up-to-date list, check out:
|
|
|
75
66
|
|
|
76
67
|
pandata john@example.com --liked_tracks
|
|
77
68
|
|
|
78
|
-
# Get liked tracks, artists
|
|
79
|
-
pandata my_webname -
|
|
69
|
+
# Get liked tracks, artists + output as JSON.
|
|
70
|
+
pandata my_webname -lL --json
|
|
80
71
|
|
|
81
72
|
# Get all data and output to a file.
|
|
82
73
|
pandata my_webname --all -o my_pandora_data.txt
|
|
83
74
|
|
|
84
|
-
|
|
75
|
+
### FAQ
|
|
76
|
+
|
|
77
|
+
#### Q: Pandata is not grabbing all my liked tracks on Pandora. What's up with that?!
|
|
78
|
+
|
|
79
|
+
First, for those coming from [pandify.com](http://pandify.com), Pandata is the
|
|
80
|
+
tool that actually grabs your Pandora data.
|
|
81
|
+
|
|
82
|
+
So, Pandora doesn't make it easy to retrieve users' data. This gem scrapes
|
|
83
|
+
public Pandora profiles by going through a few fake proxy accounts. These fake
|
|
84
|
+
accounts are shared between all Pandata users and it seems that Pandora now
|
|
85
|
+
prevents those accounts from seeing some data on the website:
|
|
86
|
+
|
|
87
|
+
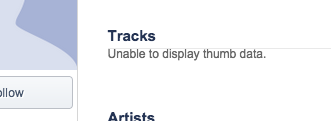
|
|
88
|
+
|
|
89
|
+
As a workaround, I tried using the same fake accounts via the mobile endpoints.
|
|
90
|
+
Pandora hasn't flagged the fake proxy accounts yet via this method. However, I've
|
|
91
|
+
noticed that if you try to scroll through some user's liked tracks on Pandora's
|
|
92
|
+
mobile app, the app will get stuck randomly and fail to load the next tracks.
|
|
93
|
+
The loading spinner will never stop:
|
|
94
|
+
|
|
95
|
+
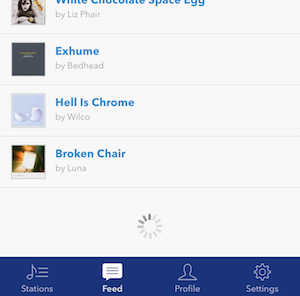
|
|
96
|
+
|
|
97
|
+
*The above is Tom Conrad's liked tracks mobile feed. He has 1200+ but the feed stops at around 185.*
|
|
98
|
+
|
|
99
|
+
Again, this only happens for some users and I can't do anything about it. If it
|
|
100
|
+
affects you, I'm sorry :(
|
|
101
|
+
|
|
102
|
+
[1]: http://blog.pandora.com/2006/02/02/pandora_21_rss
|
|
85
103
|
[2]: http://rubydoc.info/gems/pandata/frames
|
data/lib/pandata.rb
CHANGED
|
@@ -4,17 +4,8 @@ require_relative 'pandata/data_urls'
|
|
|
4
4
|
require_relative 'pandata/downloader'
|
|
5
5
|
require_relative 'pandata/parser'
|
|
6
6
|
require_relative 'pandata/scraper'
|
|
7
|
+
require_relative 'pandata/version'
|
|
7
8
|
|
|
8
9
|
module Pandata
|
|
9
10
|
class PandataError < StandardError; end
|
|
10
|
-
|
|
11
|
-
module Version
|
|
12
|
-
MAJOR = 0
|
|
13
|
-
MINOR = 3
|
|
14
|
-
PATCH = 4
|
|
15
|
-
BUILD = nil
|
|
16
|
-
|
|
17
|
-
STRING = [MAJOR, MINOR, PATCH, BUILD].compact.join('.')
|
|
18
|
-
end
|
|
19
11
|
end
|
|
20
|
-
|
data/lib/pandata/argv_parser.rb
CHANGED
|
@@ -23,14 +23,14 @@ module Pandata
|
|
|
23
23
|
get_all_data = false
|
|
24
24
|
|
|
25
25
|
options[:opts] = OptionParser.new do |opts|
|
|
26
|
-
opts.banner = 'Pandata: A tool for downloading Pandora.com data
|
|
26
|
+
opts.banner = 'Pandata: A tool for downloading Pandora.com data'
|
|
27
27
|
opts.define_head 'Usage: pandata <email|webname> [options]'
|
|
28
28
|
opts.separator <<-END
|
|
29
29
|
|
|
30
30
|
Examples:
|
|
31
31
|
pandata john@example.com --liked_tracks
|
|
32
32
|
pandata my_webname --all -o my_pandora_data.txt
|
|
33
|
-
pandata my_webname -
|
|
33
|
+
pandata my_webname -lL --json
|
|
34
34
|
|
|
35
35
|
Options:
|
|
36
36
|
END
|
|
@@ -39,18 +39,6 @@ Options:
|
|
|
39
39
|
get_all_data = true
|
|
40
40
|
end
|
|
41
41
|
|
|
42
|
-
opts.on('-a', '--recent_activity', 'Get recent activity') do
|
|
43
|
-
options[:data_to_get] << :recent_activity
|
|
44
|
-
end
|
|
45
|
-
|
|
46
|
-
opts.on('-B', '--bookmarked_artists', 'Get all bookmarked artists') do
|
|
47
|
-
options[:data_to_get] << :bookmarked_artists
|
|
48
|
-
end
|
|
49
|
-
|
|
50
|
-
opts.on('-b', '--bookmarked_tracks', 'Get all bookmarked tracks') do
|
|
51
|
-
options[:data_to_get] << :bookmarked_tracks
|
|
52
|
-
end
|
|
53
|
-
|
|
54
42
|
opts.on('-F', '--followers', "Get all user's followers") do
|
|
55
43
|
options[:data_to_get] << :followers
|
|
56
44
|
end
|
|
@@ -83,14 +71,6 @@ Options:
|
|
|
83
71
|
options[:output_file] = path
|
|
84
72
|
end
|
|
85
73
|
|
|
86
|
-
opts.on('-S', '--playing_station', 'Get currently playing station') do
|
|
87
|
-
options[:data_to_get] << :playing_station
|
|
88
|
-
end
|
|
89
|
-
|
|
90
|
-
opts.on('-s', '--stations', 'Get all stations') do
|
|
91
|
-
options[:data_to_get] << :stations
|
|
92
|
-
end
|
|
93
|
-
|
|
94
74
|
opts.on_tail("-h", "--help", "Show this message") do
|
|
95
75
|
options[:help] = true
|
|
96
76
|
end
|
|
@@ -107,11 +87,6 @@ Options:
|
|
|
107
87
|
|
|
108
88
|
if get_all_data
|
|
109
89
|
options[:data_to_get] = [
|
|
110
|
-
:recent_activity,
|
|
111
|
-
:playing_station,
|
|
112
|
-
:stations,
|
|
113
|
-
:bookmarked_tracks,
|
|
114
|
-
:bookmarked_artists,
|
|
115
90
|
:liked_tracks,
|
|
116
91
|
:liked_artists,
|
|
117
92
|
:liked_albums,
|
data/lib/pandata/cli.rb
CHANGED
|
@@ -85,11 +85,9 @@ module Pandata
|
|
|
85
85
|
" ** No Data **\n"
|
|
86
86
|
else
|
|
87
87
|
case category
|
|
88
|
-
when /
|
|
89
|
-
formatter.list(cat_data)
|
|
90
|
-
when /liked_tracks|bookmarked_tracks/
|
|
88
|
+
when /liked_tracks/
|
|
91
89
|
formatter.tracks(cat_data)
|
|
92
|
-
when /liked_artists|
|
|
90
|
+
when /liked_artists|liked_stations/
|
|
93
91
|
formatter.sort_list(cat_data)
|
|
94
92
|
when :liked_albums
|
|
95
93
|
formatter.albums(cat_data)
|
|
@@ -109,10 +107,9 @@ module Pandata
|
|
|
109
107
|
scraper_data = {}
|
|
110
108
|
|
|
111
109
|
@data_to_get.each do |data_category|
|
|
112
|
-
if /(
|
|
113
|
-
|
|
114
|
-
|
|
115
|
-
scraper_data[data_category] = @scraper.public_send(method, argument)
|
|
110
|
+
if /liked_(.*)/ =~ data_category
|
|
111
|
+
argument = $1.to_sym # :tracks, :artists, :stations or :albums
|
|
112
|
+
scraper_data[data_category] = @scraper.public_send(:likes, argument)
|
|
116
113
|
else
|
|
117
114
|
scraper_data[data_category] = @scraper.public_send(data_category)
|
|
118
115
|
end
|
data/lib/pandata/data_urls.rb
CHANGED
|
@@ -5,11 +5,6 @@ module Pandata
|
|
|
5
5
|
# URLs to Pandora's data!
|
|
6
6
|
DATA_FEED_URLS = {
|
|
7
7
|
user_search: 'http://www.pandora.com/content/connect?searchString=%{searchString}',
|
|
8
|
-
recent_activity: 'http://feeds.pandora.com/feeds/people/%{webname}/recentactivity.xml',
|
|
9
|
-
playing_station: 'http://feeds.pandora.com/feeds/people/%{webname}/nowplaying.xml',
|
|
10
|
-
stations: "http://feeds.pandora.com/feeds/people/%{webname}/stations.xml?max=#{MAX_RESULTS}",
|
|
11
|
-
bookmarked_tracks: "http://feeds.pandora.com/feeds/people/%{webname}/favorites.xml?max=#{MAX_RESULTS}",
|
|
12
|
-
bookmarked_artists: "http://feeds.pandora.com/feeds/people/%{webname}/favoriteartists.xml?max=#{MAX_RESULTS}",
|
|
13
8
|
liked_tracks: 'http://www.pandora.com/content/mobile/profile_likes_track.vm?likeStartIndex=%{nextLikeStartIndex}&thumbStartIndex=%{nextThumbStartIndex}&webname=%{webname}&pat=%{pat}',
|
|
14
9
|
liked_artists: 'http://www.pandora.com/content/artistlikes?artistStartIndex=%{nextStartIndex}&webname=%{webname}',
|
|
15
10
|
liked_stations: 'http://www.pandora.com/content/stationlikes?stationStartIndex=%{nextStartIndex}&webname=%{webname}',
|
data/lib/pandata/parser.rb
CHANGED
|
@@ -40,68 +40,6 @@ module Pandata
|
|
|
40
40
|
end
|
|
41
41
|
end
|
|
42
42
|
|
|
43
|
-
# @param xml [String]
|
|
44
|
-
# Returns an array of recent activity names.
|
|
45
|
-
def get_recent_activity(xml)
|
|
46
|
-
activity_names = []
|
|
47
|
-
|
|
48
|
-
xml_each_item(xml) do |title|
|
|
49
|
-
activity_names << title
|
|
50
|
-
end
|
|
51
|
-
|
|
52
|
-
activity_names
|
|
53
|
-
end
|
|
54
|
-
|
|
55
|
-
# @param xml [String]
|
|
56
|
-
# Returns an array of station names.
|
|
57
|
-
def get_stations(xml)
|
|
58
|
-
stations = []
|
|
59
|
-
|
|
60
|
-
xml_each_item(xml) do |title|
|
|
61
|
-
stations << title
|
|
62
|
-
end
|
|
63
|
-
|
|
64
|
-
stations
|
|
65
|
-
end
|
|
66
|
-
|
|
67
|
-
# @param xml [String]
|
|
68
|
-
# @return [String]
|
|
69
|
-
def get_playing_station(xml)
|
|
70
|
-
station = ''
|
|
71
|
-
|
|
72
|
-
xml_each_item(xml) do |title|
|
|
73
|
-
station = title # First title is the station name.
|
|
74
|
-
break
|
|
75
|
-
end
|
|
76
|
-
|
|
77
|
-
station
|
|
78
|
-
end
|
|
79
|
-
|
|
80
|
-
# @param xml [String]
|
|
81
|
-
# Returns an array of hashes with :artist and :track keys.
|
|
82
|
-
def get_bookmarked_tracks(xml)
|
|
83
|
-
tracks = []
|
|
84
|
-
|
|
85
|
-
xml_each_item(xml) do |title|
|
|
86
|
-
track, artist = title.split(' by ')
|
|
87
|
-
tracks << { artist: artist, track: track }
|
|
88
|
-
end
|
|
89
|
-
|
|
90
|
-
tracks
|
|
91
|
-
end
|
|
92
|
-
|
|
93
|
-
# @param xml [String]
|
|
94
|
-
# Returns an array of artist names.
|
|
95
|
-
def get_bookmarked_artists(xml)
|
|
96
|
-
artists = []
|
|
97
|
-
|
|
98
|
-
xml_each_item(xml) do |title|
|
|
99
|
-
artists << title
|
|
100
|
-
end
|
|
101
|
-
|
|
102
|
-
artists
|
|
103
|
-
end
|
|
104
|
-
|
|
105
43
|
# @param html [String]
|
|
106
44
|
# Returns an array of hashes with :artist and :track keys.
|
|
107
45
|
def get_liked_tracks(html)
|
|
@@ -153,16 +91,6 @@ module Pandata
|
|
|
153
91
|
|
|
154
92
|
private
|
|
155
93
|
|
|
156
|
-
# Loops over each 'item' tag and yields the title and description.
|
|
157
|
-
# @param xml [String]
|
|
158
|
-
def xml_each_item(xml)
|
|
159
|
-
Nokogiri::XML(xml).css('item').each do |item|
|
|
160
|
-
title = item.at_css('title').text
|
|
161
|
-
desc = item.at_css('description').text
|
|
162
|
-
yield(title, desc)
|
|
163
|
-
end
|
|
164
|
-
end
|
|
165
|
-
|
|
166
94
|
# Loops over each .infobox container and yields the title and subtitle.
|
|
167
95
|
# @param html [String]
|
|
168
96
|
def infobox_each_link(html)
|
|
@@ -182,8 +110,8 @@ module Pandata
|
|
|
182
110
|
# @param html [String]
|
|
183
111
|
def doublelink_each_link(html)
|
|
184
112
|
Nokogiri::HTML(html).css('.double-link').each do |doublelink|
|
|
185
|
-
title_link = doublelink.css('
|
|
186
|
-
subtitle_link = doublelink.css('.
|
|
113
|
+
title_link = doublelink.css('.media__bd__header').text.strip
|
|
114
|
+
subtitle_link = doublelink.css('.media__bd__subheader').text.strip
|
|
187
115
|
|
|
188
116
|
yield(title_link, subtitle_link)
|
|
189
117
|
end
|
data/lib/pandata/scraper.rb
CHANGED
|
@@ -41,41 +41,6 @@ module Pandata
|
|
|
41
41
|
@webname = webname
|
|
42
42
|
end
|
|
43
43
|
|
|
44
|
-
# Get the user's recent activity.
|
|
45
|
-
# @return [Array] array of activity names
|
|
46
|
-
def recent_activity
|
|
47
|
-
scrape_for(:recent_activity, :get_recent_activity)
|
|
48
|
-
end
|
|
49
|
-
|
|
50
|
-
# Get the user's playing station.
|
|
51
|
-
# @return [String]
|
|
52
|
-
def playing_station
|
|
53
|
-
scrape_for(:playing_station, :get_playing_station).first
|
|
54
|
-
end
|
|
55
|
-
|
|
56
|
-
# Get the user's stations.
|
|
57
|
-
# @return [Array] array of station names
|
|
58
|
-
def stations
|
|
59
|
-
scrape_for(:stations, :get_stations)
|
|
60
|
-
end
|
|
61
|
-
|
|
62
|
-
# Get the user's bookmarked data.
|
|
63
|
-
# @param bookmark_type [Symbol]
|
|
64
|
-
# - :artists - returns an array of artist names
|
|
65
|
-
# - :tracks - returns an array of hashes with :artist and :track keys
|
|
66
|
-
# - :all - returns a hash with all bookmarked data
|
|
67
|
-
def bookmarks(bookmark_type = :all)
|
|
68
|
-
case bookmark_type
|
|
69
|
-
when :tracks
|
|
70
|
-
scrape_for(:bookmarked_tracks, :get_bookmarked_tracks)
|
|
71
|
-
when :artists
|
|
72
|
-
scrape_for(:bookmarked_artists, :get_bookmarked_artists)
|
|
73
|
-
when :all
|
|
74
|
-
{ artists: bookmarks(:artists),
|
|
75
|
-
tracks: bookmarks(:tracks) }
|
|
76
|
-
end
|
|
77
|
-
end
|
|
78
|
-
|
|
79
44
|
# Get the user's liked data. (The results from giving a 'thumbs up.')
|
|
80
45
|
# @param like_type [Symbol]
|
|
81
46
|
# - :artists - returns an array of artist names
|
metadata
CHANGED
|
@@ -1,101 +1,100 @@
|
|
|
1
1
|
--- !ruby/object:Gem::Specification
|
|
2
2
|
name: pandata
|
|
3
3
|
version: !ruby/object:Gem::Version
|
|
4
|
-
version: 0.
|
|
4
|
+
version: 2.0.0
|
|
5
5
|
platform: ruby
|
|
6
6
|
authors:
|
|
7
7
|
- Brian Ustas
|
|
8
8
|
autorequire:
|
|
9
9
|
bindir: bin
|
|
10
10
|
cert_chain: []
|
|
11
|
-
date:
|
|
11
|
+
date: 2016-01-27 00:00:00.000000000 Z
|
|
12
12
|
dependencies:
|
|
13
13
|
- !ruby/object:Gem::Dependency
|
|
14
14
|
name: nokogiri
|
|
15
15
|
requirement: !ruby/object:Gem::Requirement
|
|
16
16
|
requirements:
|
|
17
|
-
- -
|
|
17
|
+
- - ~>
|
|
18
18
|
- !ruby/object:Gem::Version
|
|
19
|
-
version: 1.6.
|
|
19
|
+
version: 1.6.7
|
|
20
20
|
type: :runtime
|
|
21
21
|
prerelease: false
|
|
22
22
|
version_requirements: !ruby/object:Gem::Requirement
|
|
23
23
|
requirements:
|
|
24
|
-
- -
|
|
24
|
+
- - ~>
|
|
25
25
|
- !ruby/object:Gem::Version
|
|
26
|
-
version: 1.6.
|
|
26
|
+
version: 1.6.7
|
|
27
27
|
- !ruby/object:Gem::Dependency
|
|
28
28
|
name: ruby-progressbar
|
|
29
29
|
requirement: !ruby/object:Gem::Requirement
|
|
30
30
|
requirements:
|
|
31
|
-
- -
|
|
31
|
+
- - ~>
|
|
32
32
|
- !ruby/object:Gem::Version
|
|
33
|
-
version: 1.
|
|
33
|
+
version: 1.5.1
|
|
34
34
|
type: :runtime
|
|
35
35
|
prerelease: false
|
|
36
36
|
version_requirements: !ruby/object:Gem::Requirement
|
|
37
37
|
requirements:
|
|
38
|
-
- -
|
|
38
|
+
- - ~>
|
|
39
39
|
- !ruby/object:Gem::Version
|
|
40
|
-
version: 1.
|
|
40
|
+
version: 1.5.1
|
|
41
41
|
- !ruby/object:Gem::Dependency
|
|
42
42
|
name: rspec
|
|
43
43
|
requirement: !ruby/object:Gem::Requirement
|
|
44
44
|
requirements:
|
|
45
|
-
- -
|
|
45
|
+
- - ~>
|
|
46
46
|
- !ruby/object:Gem::Version
|
|
47
|
-
version:
|
|
47
|
+
version: 3.4.0
|
|
48
48
|
type: :development
|
|
49
49
|
prerelease: false
|
|
50
50
|
version_requirements: !ruby/object:Gem::Requirement
|
|
51
51
|
requirements:
|
|
52
|
-
- -
|
|
52
|
+
- - ~>
|
|
53
53
|
- !ruby/object:Gem::Version
|
|
54
|
-
version:
|
|
54
|
+
version: 3.4.0
|
|
55
55
|
- !ruby/object:Gem::Dependency
|
|
56
56
|
name: vcr
|
|
57
57
|
requirement: !ruby/object:Gem::Requirement
|
|
58
58
|
requirements:
|
|
59
|
-
- -
|
|
59
|
+
- - ~>
|
|
60
60
|
- !ruby/object:Gem::Version
|
|
61
|
-
version:
|
|
61
|
+
version: 3.0.1
|
|
62
62
|
type: :development
|
|
63
63
|
prerelease: false
|
|
64
64
|
version_requirements: !ruby/object:Gem::Requirement
|
|
65
65
|
requirements:
|
|
66
|
-
- -
|
|
66
|
+
- - ~>
|
|
67
67
|
- !ruby/object:Gem::Version
|
|
68
|
-
version:
|
|
68
|
+
version: 3.0.1
|
|
69
69
|
- !ruby/object:Gem::Dependency
|
|
70
70
|
name: webmock
|
|
71
71
|
requirement: !ruby/object:Gem::Requirement
|
|
72
72
|
requirements:
|
|
73
|
-
- -
|
|
73
|
+
- - ~>
|
|
74
74
|
- !ruby/object:Gem::Version
|
|
75
|
-
version: 1.
|
|
75
|
+
version: 1.22.6
|
|
76
76
|
type: :development
|
|
77
77
|
prerelease: false
|
|
78
78
|
version_requirements: !ruby/object:Gem::Requirement
|
|
79
79
|
requirements:
|
|
80
|
-
- -
|
|
80
|
+
- - ~>
|
|
81
81
|
- !ruby/object:Gem::Version
|
|
82
|
-
version: 1.
|
|
82
|
+
version: 1.22.6
|
|
83
83
|
- !ruby/object:Gem::Dependency
|
|
84
84
|
name: yard
|
|
85
85
|
requirement: !ruby/object:Gem::Requirement
|
|
86
86
|
requirements:
|
|
87
|
-
- -
|
|
87
|
+
- - ~>
|
|
88
88
|
- !ruby/object:Gem::Version
|
|
89
|
-
version: 0.8.
|
|
89
|
+
version: 0.8.7.6
|
|
90
90
|
type: :development
|
|
91
91
|
prerelease: false
|
|
92
92
|
version_requirements: !ruby/object:Gem::Requirement
|
|
93
93
|
requirements:
|
|
94
|
-
- -
|
|
94
|
+
- - ~>
|
|
95
95
|
- !ruby/object:Gem::Version
|
|
96
|
-
version: 0.8.
|
|
97
|
-
description: A library and tool for downloading Pandora.com data
|
|
98
|
-
stations, etc.)
|
|
96
|
+
version: 0.8.7.6
|
|
97
|
+
description: A library and tool for downloading Pandora.com data.
|
|
99
98
|
email: brianustas@gmail.com
|
|
100
99
|
executables:
|
|
101
100
|
- pandata
|
|
@@ -104,10 +103,6 @@ extra_rdoc_files:
|
|
|
104
103
|
- LICENSE
|
|
105
104
|
- README.md
|
|
106
105
|
files:
|
|
107
|
-
- LICENSE
|
|
108
|
-
- README.md
|
|
109
|
-
- bin/pandata
|
|
110
|
-
- lib/pandata.rb
|
|
111
106
|
- lib/pandata/argv_parser.rb
|
|
112
107
|
- lib/pandata/cli.rb
|
|
113
108
|
- lib/pandata/data_formatter.rb
|
|
@@ -115,6 +110,11 @@ files:
|
|
|
115
110
|
- lib/pandata/downloader.rb
|
|
116
111
|
- lib/pandata/parser.rb
|
|
117
112
|
- lib/pandata/scraper.rb
|
|
113
|
+
- lib/pandata/version.rb
|
|
114
|
+
- lib/pandata.rb
|
|
115
|
+
- LICENSE
|
|
116
|
+
- README.md
|
|
117
|
+
- bin/pandata
|
|
118
118
|
homepage: https://github.com/ustasb/pandata
|
|
119
119
|
licenses:
|
|
120
120
|
- MIT
|
|
@@ -125,17 +125,17 @@ require_paths:
|
|
|
125
125
|
- lib
|
|
126
126
|
required_ruby_version: !ruby/object:Gem::Requirement
|
|
127
127
|
requirements:
|
|
128
|
-
- -
|
|
128
|
+
- - '>='
|
|
129
129
|
- !ruby/object:Gem::Version
|
|
130
|
-
version: 1.9.
|
|
130
|
+
version: 1.9.3
|
|
131
131
|
required_rubygems_version: !ruby/object:Gem::Requirement
|
|
132
132
|
requirements:
|
|
133
|
-
- -
|
|
133
|
+
- - '>='
|
|
134
134
|
- !ruby/object:Gem::Version
|
|
135
135
|
version: '0'
|
|
136
136
|
requirements: []
|
|
137
137
|
rubyforge_project:
|
|
138
|
-
rubygems_version: 2.
|
|
138
|
+
rubygems_version: 2.0.0
|
|
139
139
|
signing_key:
|
|
140
140
|
specification_version: 4
|
|
141
141
|
summary: A Pandora.com web scraper
|