langchainrb 0.7.2 → 0.7.5
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/CHANGELOG.md +10 -0
- data/README.md +158 -320
- data/lib/langchain/agent/agents.md +54 -0
- data/lib/langchain/llm/aws_bedrock.rb +216 -0
- data/lib/langchain/llm/openai.rb +26 -9
- data/lib/langchain/llm/response/aws_titan_response.rb +17 -0
- data/lib/langchain/llm/response/base_response.rb +3 -0
- data/lib/langchain/utils/token_length/ai21_validator.rb +1 -0
- data/lib/langchain/utils/token_length/base_validator.rb +6 -2
- data/lib/langchain/utils/token_length/cohere_validator.rb +1 -0
- data/lib/langchain/utils/token_length/google_palm_validator.rb +1 -0
- data/lib/langchain/utils/token_length/openai_validator.rb +20 -0
- data/lib/langchain/vectorsearch/chroma.rb +3 -1
- data/lib/langchain/vectorsearch/milvus.rb +3 -1
- data/lib/langchain/vectorsearch/pgvector.rb +3 -1
- data/lib/langchain/vectorsearch/pinecone.rb +3 -1
- data/lib/langchain/vectorsearch/qdrant.rb +3 -1
- data/lib/langchain/vectorsearch/weaviate.rb +4 -2
- data/lib/langchain/version.rb +1 -1
- metadata +19 -5
- data/lib/langchain/evals/ragas/critique.rb +0 -62
- data/lib/langchain/evals/ragas/prompts/critique.yml +0 -18
- data/lib/langchain/loader_chunkers/html.rb +0 -27
|
@@ -0,0 +1,54 @@
|
|
|
1
|
+
|
|
2
|
+
### Agents 🤖
|
|
3
|
+
Agents are semi-autonomous bots that can respond to user questions and use available to them Tools to provide informed replies. They break down problems into series of steps and define Actions (and Action Inputs) along the way that are executed and fed back to them as additional information. Once an Agent decides that it has the Final Answer it responds with it.
|
|
4
|
+
|
|
5
|
+
#### ReAct Agent
|
|
6
|
+
|
|
7
|
+
Add `gem "ruby-openai"`, `gem "eqn"`, and `gem "google_search_results"` to your Gemfile
|
|
8
|
+
|
|
9
|
+
```ruby
|
|
10
|
+
search_tool = Langchain::Tool::GoogleSearch.new(api_key: ENV["SERPAPI_API_KEY"])
|
|
11
|
+
calculator = Langchain::Tool::Calculator.new
|
|
12
|
+
|
|
13
|
+
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
14
|
+
|
|
15
|
+
agent = Langchain::Agent::ReActAgent.new(
|
|
16
|
+
llm: openai,
|
|
17
|
+
tools: [search_tool, calculator]
|
|
18
|
+
)
|
|
19
|
+
```
|
|
20
|
+
```ruby
|
|
21
|
+
agent.run(question: "How many full soccer fields would be needed to cover the distance between NYC and DC in a straight line?")
|
|
22
|
+
#=> "Approximately 2,945 soccer fields would be needed to cover the distance between NYC and DC in a straight line."
|
|
23
|
+
```
|
|
24
|
+
|
|
25
|
+
#### SQL-Query Agent
|
|
26
|
+
|
|
27
|
+
Add `gem "sequel"` to your Gemfile
|
|
28
|
+
|
|
29
|
+
```ruby
|
|
30
|
+
database = Langchain::Tool::Database.new(connection_string: "postgres://user:password@localhost:5432/db_name")
|
|
31
|
+
|
|
32
|
+
agent = Langchain::Agent::SQLQueryAgent.new(llm: Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"]), db: database)
|
|
33
|
+
```
|
|
34
|
+
```ruby
|
|
35
|
+
agent.run(question: "How many users have a name with length greater than 5 in the users table?")
|
|
36
|
+
#=> "14 users have a name with length greater than 5 in the users table."
|
|
37
|
+
```
|
|
38
|
+
|
|
39
|
+
#### Demo
|
|
40
|
+
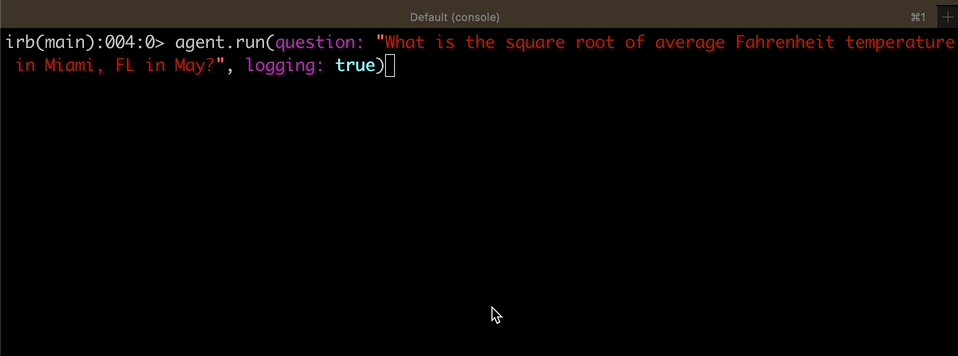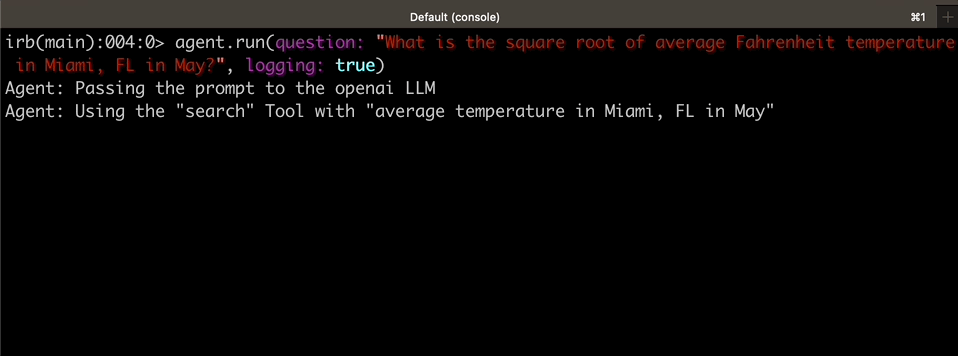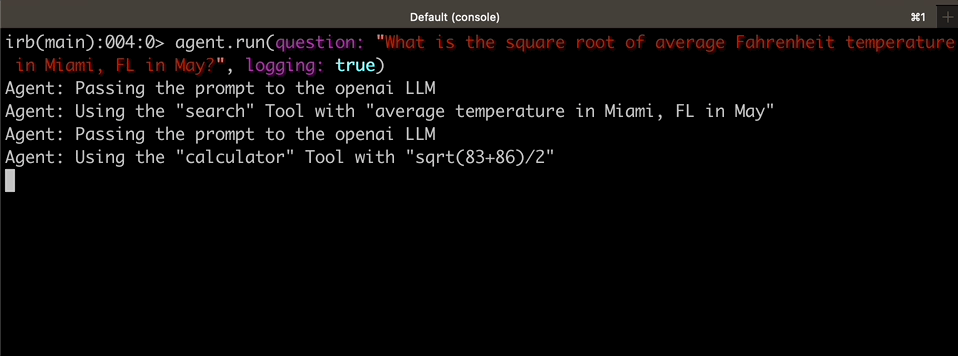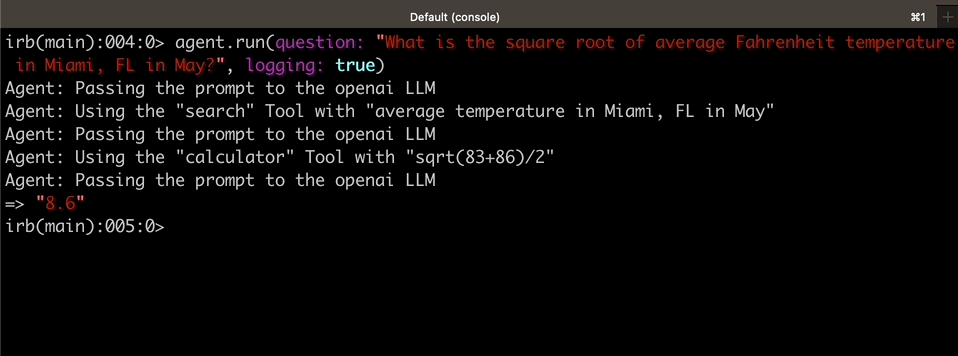
|
|
41
|
+
|
|
42
|
+
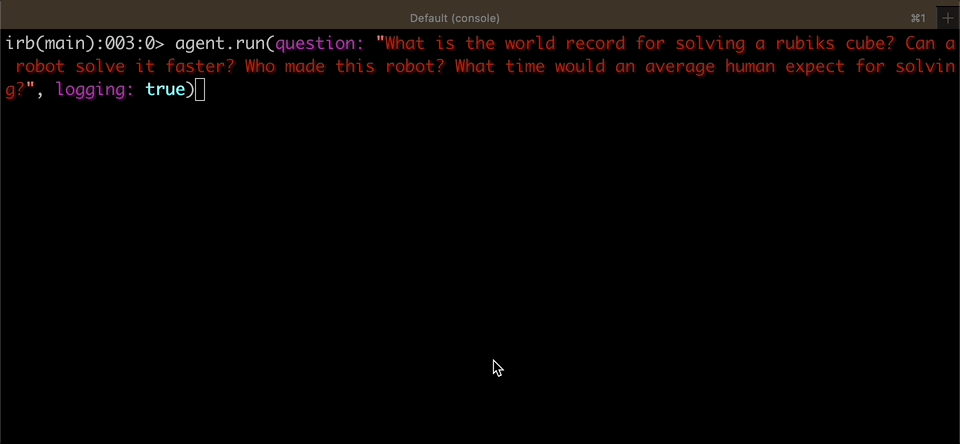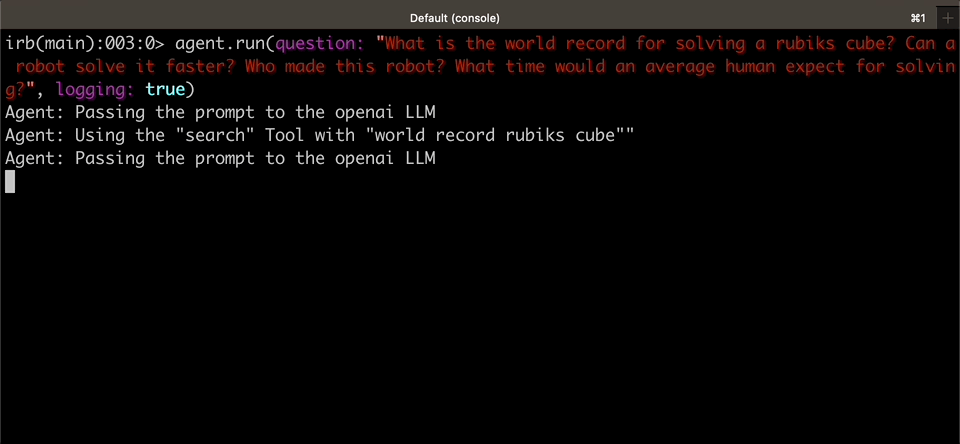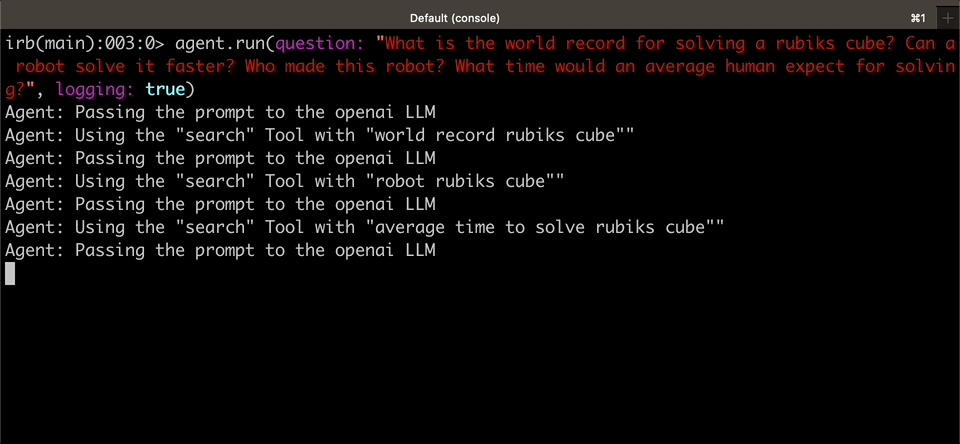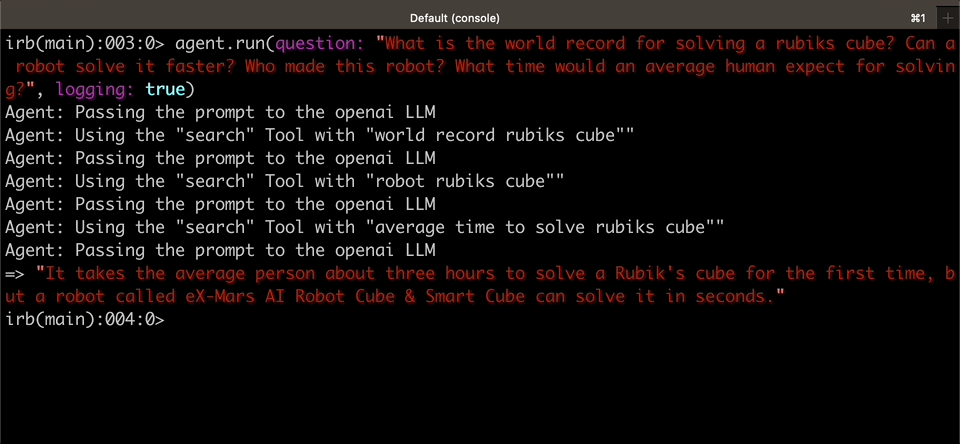
|
|
43
|
+
|
|
44
|
+
#### Available Tools 🛠️
|
|
45
|
+
|
|
46
|
+
| Name | Description | ENV Requirements | Gem Requirements |
|
|
47
|
+
| ------------ | :------------------------------------------------: | :-----------------------------------------------------------: | :---------------------------------------: |
|
|
48
|
+
| "calculator" | Useful for getting the result of a math expression | | `gem "eqn", "~> 1.6.5"` |
|
|
49
|
+
| "database" | Useful for querying a SQL database | | `gem "sequel", "~> 5.68.0"` |
|
|
50
|
+
| "ruby_code_interpreter" | Interprets Ruby expressions | | `gem "safe_ruby", "~> 1.0.4"` |
|
|
51
|
+
| "google_search" | A wrapper around Google Search | `ENV["SERPAPI_API_KEY"]` (https://serpapi.com/manage-api-key) | `gem "google_search_results", "~> 2.0.0"` |
|
|
52
|
+
| "weather" | Calls Open Weather API to retrieve the current weather | `ENV["OPEN_WEATHER_API_KEY"]` (https://home.openweathermap.org/api_keys) | `gem "open-weather-ruby-client", "~> 0.3.0"` |
|
|
53
|
+
| "wikipedia" | Calls Wikipedia API to retrieve the summary | | `gem "wikipedia-client", "~> 1.17.0"` |
|
|
54
|
+
|
|
@@ -0,0 +1,216 @@
|
|
|
1
|
+
# frozen_string_literal: true
|
|
2
|
+
|
|
3
|
+
module Langchain::LLM
|
|
4
|
+
# LLM interface for Aws Bedrock APIs: https://docs.aws.amazon.com/bedrock/
|
|
5
|
+
#
|
|
6
|
+
# Gem requirements:
|
|
7
|
+
# gem 'aws-sdk-bedrockruntime', '~> 1.1'
|
|
8
|
+
#
|
|
9
|
+
# Usage:
|
|
10
|
+
# bedrock = Langchain::LLM::AwsBedrock.new(llm_options: {})
|
|
11
|
+
#
|
|
12
|
+
class AwsBedrock < Base
|
|
13
|
+
DEFAULTS = {
|
|
14
|
+
completion_model_name: "anthropic.claude-v2",
|
|
15
|
+
embedding_model_name: "amazon.titan-embed-text-v1",
|
|
16
|
+
max_tokens_to_sample: 300,
|
|
17
|
+
temperature: 1,
|
|
18
|
+
top_k: 250,
|
|
19
|
+
top_p: 0.999,
|
|
20
|
+
stop_sequences: ["\n\nHuman:"],
|
|
21
|
+
anthropic_version: "bedrock-2023-05-31",
|
|
22
|
+
return_likelihoods: "NONE",
|
|
23
|
+
count_penalty: {
|
|
24
|
+
scale: 0,
|
|
25
|
+
apply_to_whitespaces: false,
|
|
26
|
+
apply_to_punctuations: false,
|
|
27
|
+
apply_to_numbers: false,
|
|
28
|
+
apply_to_stopwords: false,
|
|
29
|
+
apply_to_emojis: false
|
|
30
|
+
},
|
|
31
|
+
presence_penalty: {
|
|
32
|
+
scale: 0,
|
|
33
|
+
apply_to_whitespaces: false,
|
|
34
|
+
apply_to_punctuations: false,
|
|
35
|
+
apply_to_numbers: false,
|
|
36
|
+
apply_to_stopwords: false,
|
|
37
|
+
apply_to_emojis: false
|
|
38
|
+
},
|
|
39
|
+
frequency_penalty: {
|
|
40
|
+
scale: 0,
|
|
41
|
+
apply_to_whitespaces: false,
|
|
42
|
+
apply_to_punctuations: false,
|
|
43
|
+
apply_to_numbers: false,
|
|
44
|
+
apply_to_stopwords: false,
|
|
45
|
+
apply_to_emojis: false
|
|
46
|
+
}
|
|
47
|
+
}.freeze
|
|
48
|
+
|
|
49
|
+
SUPPORTED_COMPLETION_PROVIDERS = %i[anthropic cohere ai21].freeze
|
|
50
|
+
SUPPORTED_EMBEDDING_PROVIDERS = %i[amazon].freeze
|
|
51
|
+
|
|
52
|
+
def initialize(completion_model: DEFAULTS[:completion_model_name], embedding_model: DEFAULTS[:embedding_model_name], aws_client_options: {}, default_options: {})
|
|
53
|
+
depends_on "aws-sdk-bedrockruntime", req: "aws-sdk-bedrockruntime"
|
|
54
|
+
|
|
55
|
+
@client = ::Aws::BedrockRuntime::Client.new(**aws_client_options)
|
|
56
|
+
@defaults = DEFAULTS.merge(default_options)
|
|
57
|
+
.merge(completion_model_name: completion_model)
|
|
58
|
+
.merge(embedding_model_name: embedding_model)
|
|
59
|
+
end
|
|
60
|
+
|
|
61
|
+
#
|
|
62
|
+
# Generate an embedding for a given text
|
|
63
|
+
#
|
|
64
|
+
# @param text [String] The text to generate an embedding for
|
|
65
|
+
# @param params extra parameters passed to Aws::BedrockRuntime::Client#invoke_model
|
|
66
|
+
# @return [Langchain::LLM::AwsTitanResponse] Response object
|
|
67
|
+
#
|
|
68
|
+
def embed(text:, **params)
|
|
69
|
+
raise "Completion provider #{embedding_provider} is not supported." unless SUPPORTED_EMBEDDING_PROVIDERS.include?(embedding_provider)
|
|
70
|
+
|
|
71
|
+
parameters = {inputText: text}
|
|
72
|
+
parameters = parameters.merge(params)
|
|
73
|
+
|
|
74
|
+
response = client.invoke_model({
|
|
75
|
+
model_id: @defaults[:embedding_model_name],
|
|
76
|
+
body: parameters.to_json,
|
|
77
|
+
content_type: "application/json",
|
|
78
|
+
accept: "application/json"
|
|
79
|
+
})
|
|
80
|
+
|
|
81
|
+
Langchain::LLM::AwsTitanResponse.new(JSON.parse(response.body.string))
|
|
82
|
+
end
|
|
83
|
+
|
|
84
|
+
#
|
|
85
|
+
# Generate a completion for a given prompt
|
|
86
|
+
#
|
|
87
|
+
# @param prompt [String] The prompt to generate a completion for
|
|
88
|
+
# @param params extra parameters passed to Aws::BedrockRuntime::Client#invoke_model
|
|
89
|
+
# @return [Langchain::LLM::AnthropicResponse], [Langchain::LLM::CohereResponse] or [Langchain::LLM::AI21Response] Response object
|
|
90
|
+
#
|
|
91
|
+
def complete(prompt:, **params)
|
|
92
|
+
raise "Completion provider #{completion_provider} is not supported." unless SUPPORTED_COMPLETION_PROVIDERS.include?(completion_provider)
|
|
93
|
+
|
|
94
|
+
parameters = compose_parameters params
|
|
95
|
+
|
|
96
|
+
parameters[:prompt] = wrap_prompt prompt
|
|
97
|
+
|
|
98
|
+
response = client.invoke_model({
|
|
99
|
+
model_id: @defaults[:completion_model_name],
|
|
100
|
+
body: parameters.to_json,
|
|
101
|
+
content_type: "application/json",
|
|
102
|
+
accept: "application/json"
|
|
103
|
+
})
|
|
104
|
+
|
|
105
|
+
parse_response response
|
|
106
|
+
end
|
|
107
|
+
|
|
108
|
+
private
|
|
109
|
+
|
|
110
|
+
def completion_provider
|
|
111
|
+
@defaults[:completion_model_name].split(".").first.to_sym
|
|
112
|
+
end
|
|
113
|
+
|
|
114
|
+
def embedding_provider
|
|
115
|
+
@defaults[:embedding_model_name].split(".").first.to_sym
|
|
116
|
+
end
|
|
117
|
+
|
|
118
|
+
def wrap_prompt(prompt)
|
|
119
|
+
if completion_provider == :anthropic
|
|
120
|
+
"\n\nHuman: #{prompt}\n\nAssistant:"
|
|
121
|
+
else
|
|
122
|
+
prompt
|
|
123
|
+
end
|
|
124
|
+
end
|
|
125
|
+
|
|
126
|
+
def max_tokens_key
|
|
127
|
+
if completion_provider == :anthropic
|
|
128
|
+
:max_tokens_to_sample
|
|
129
|
+
elsif completion_provider == :cohere
|
|
130
|
+
:max_tokens
|
|
131
|
+
elsif completion_provider == :ai21
|
|
132
|
+
:maxTokens
|
|
133
|
+
end
|
|
134
|
+
end
|
|
135
|
+
|
|
136
|
+
def compose_parameters(params)
|
|
137
|
+
if completion_provider == :anthropic
|
|
138
|
+
compose_parameters_anthropic params
|
|
139
|
+
elsif completion_provider == :cohere
|
|
140
|
+
compose_parameters_cohere params
|
|
141
|
+
elsif completion_provider == :ai21
|
|
142
|
+
compose_parameters_ai21 params
|
|
143
|
+
end
|
|
144
|
+
end
|
|
145
|
+
|
|
146
|
+
def parse_response(response)
|
|
147
|
+
if completion_provider == :anthropic
|
|
148
|
+
Langchain::LLM::AnthropicResponse.new(JSON.parse(response.body.string))
|
|
149
|
+
elsif completion_provider == :cohere
|
|
150
|
+
Langchain::LLM::CohereResponse.new(JSON.parse(response.body.string))
|
|
151
|
+
elsif completion_provider == :ai21
|
|
152
|
+
Langchain::LLM::AI21Response.new(JSON.parse(response.body.string, symbolize_names: true))
|
|
153
|
+
end
|
|
154
|
+
end
|
|
155
|
+
|
|
156
|
+
def compose_parameters_cohere(params)
|
|
157
|
+
default_params = @defaults.merge(params)
|
|
158
|
+
|
|
159
|
+
{
|
|
160
|
+
max_tokens: default_params[:max_tokens_to_sample],
|
|
161
|
+
temperature: default_params[:temperature],
|
|
162
|
+
p: default_params[:top_p],
|
|
163
|
+
k: default_params[:top_k],
|
|
164
|
+
stop_sequences: default_params[:stop_sequences]
|
|
165
|
+
}
|
|
166
|
+
end
|
|
167
|
+
|
|
168
|
+
def compose_parameters_anthropic(params)
|
|
169
|
+
default_params = @defaults.merge(params)
|
|
170
|
+
|
|
171
|
+
{
|
|
172
|
+
max_tokens_to_sample: default_params[:max_tokens_to_sample],
|
|
173
|
+
temperature: default_params[:temperature],
|
|
174
|
+
top_k: default_params[:top_k],
|
|
175
|
+
top_p: default_params[:top_p],
|
|
176
|
+
stop_sequences: default_params[:stop_sequences],
|
|
177
|
+
anthropic_version: default_params[:anthropic_version]
|
|
178
|
+
}
|
|
179
|
+
end
|
|
180
|
+
|
|
181
|
+
def compose_parameters_ai21(params)
|
|
182
|
+
default_params = @defaults.merge(params)
|
|
183
|
+
|
|
184
|
+
{
|
|
185
|
+
maxTokens: default_params[:max_tokens_to_sample],
|
|
186
|
+
temperature: default_params[:temperature],
|
|
187
|
+
topP: default_params[:top_p],
|
|
188
|
+
stopSequences: default_params[:stop_sequences],
|
|
189
|
+
countPenalty: {
|
|
190
|
+
scale: default_params[:count_penalty][:scale],
|
|
191
|
+
applyToWhitespaces: default_params[:count_penalty][:apply_to_whitespaces],
|
|
192
|
+
applyToPunctuations: default_params[:count_penalty][:apply_to_punctuations],
|
|
193
|
+
applyToNumbers: default_params[:count_penalty][:apply_to_numbers],
|
|
194
|
+
applyToStopwords: default_params[:count_penalty][:apply_to_stopwords],
|
|
195
|
+
applyToEmojis: default_params[:count_penalty][:apply_to_emojis]
|
|
196
|
+
},
|
|
197
|
+
presencePenalty: {
|
|
198
|
+
scale: default_params[:presence_penalty][:scale],
|
|
199
|
+
applyToWhitespaces: default_params[:presence_penalty][:apply_to_whitespaces],
|
|
200
|
+
applyToPunctuations: default_params[:presence_penalty][:apply_to_punctuations],
|
|
201
|
+
applyToNumbers: default_params[:presence_penalty][:apply_to_numbers],
|
|
202
|
+
applyToStopwords: default_params[:presence_penalty][:apply_to_stopwords],
|
|
203
|
+
applyToEmojis: default_params[:presence_penalty][:apply_to_emojis]
|
|
204
|
+
},
|
|
205
|
+
frequencyPenalty: {
|
|
206
|
+
scale: default_params[:frequency_penalty][:scale],
|
|
207
|
+
applyToWhitespaces: default_params[:frequency_penalty][:apply_to_whitespaces],
|
|
208
|
+
applyToPunctuations: default_params[:frequency_penalty][:apply_to_punctuations],
|
|
209
|
+
applyToNumbers: default_params[:frequency_penalty][:apply_to_numbers],
|
|
210
|
+
applyToStopwords: default_params[:frequency_penalty][:apply_to_stopwords],
|
|
211
|
+
applyToEmojis: default_params[:frequency_penalty][:apply_to_emojis]
|
|
212
|
+
}
|
|
213
|
+
}
|
|
214
|
+
end
|
|
215
|
+
end
|
|
216
|
+
end
|
data/lib/langchain/llm/openai.rb
CHANGED
|
@@ -4,7 +4,7 @@ module Langchain::LLM
|
|
|
4
4
|
# LLM interface for OpenAI APIs: https://platform.openai.com/overview
|
|
5
5
|
#
|
|
6
6
|
# Gem requirements:
|
|
7
|
-
# gem "ruby-openai", "~>
|
|
7
|
+
# gem "ruby-openai", "~> 5.2.0"
|
|
8
8
|
#
|
|
9
9
|
# Usage:
|
|
10
10
|
# openai = Langchain::LLM::OpenAI.new(api_key:, llm_options: {})
|
|
@@ -29,6 +29,7 @@ module Langchain::LLM
|
|
|
29
29
|
LENGTH_VALIDATOR = Langchain::Utils::TokenLength::OpenAIValidator
|
|
30
30
|
|
|
31
31
|
attr_accessor :functions
|
|
32
|
+
attr_accessor :response_chunks
|
|
32
33
|
|
|
33
34
|
def initialize(api_key:, llm_options: {}, default_options: {})
|
|
34
35
|
depends_on "ruby-openai", req: "openai"
|
|
@@ -69,7 +70,7 @@ module Langchain::LLM
|
|
|
69
70
|
return legacy_complete(prompt, parameters) if is_legacy_model?(parameters[:model])
|
|
70
71
|
|
|
71
72
|
parameters[:messages] = compose_chat_messages(prompt: prompt)
|
|
72
|
-
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model])
|
|
73
|
+
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model], parameters[:max_tokens])
|
|
73
74
|
|
|
74
75
|
response = with_api_error_handling do
|
|
75
76
|
client.chat(parameters: parameters)
|
|
@@ -131,13 +132,11 @@ module Langchain::LLM
|
|
|
131
132
|
if functions
|
|
132
133
|
parameters[:functions] = functions
|
|
133
134
|
else
|
|
134
|
-
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model])
|
|
135
|
+
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model], parameters[:max_tokens])
|
|
135
136
|
end
|
|
136
137
|
|
|
137
138
|
response = with_api_error_handling { client.chat(parameters: parameters) }
|
|
138
|
-
|
|
139
|
-
return if block
|
|
140
|
-
|
|
139
|
+
response = response_from_chunks if block
|
|
141
140
|
Langchain::LLM::OpenAIResponse.new(response)
|
|
142
141
|
end
|
|
143
142
|
|
|
@@ -181,8 +180,11 @@ module Langchain::LLM
|
|
|
181
180
|
parameters = default_params.merge(params)
|
|
182
181
|
|
|
183
182
|
if block
|
|
183
|
+
@response_chunks = []
|
|
184
184
|
parameters[:stream] = proc do |chunk, _bytesize|
|
|
185
|
-
|
|
185
|
+
chunk_content = chunk.dig("choices", 0)
|
|
186
|
+
@response_chunks << chunk
|
|
187
|
+
yield chunk_content
|
|
186
188
|
end
|
|
187
189
|
end
|
|
188
190
|
|
|
@@ -230,13 +232,28 @@ module Langchain::LLM
|
|
|
230
232
|
response
|
|
231
233
|
end
|
|
232
234
|
|
|
233
|
-
def validate_max_tokens(messages, model)
|
|
234
|
-
LENGTH_VALIDATOR.validate_max_tokens!(messages, model)
|
|
235
|
+
def validate_max_tokens(messages, model, max_tokens = nil)
|
|
236
|
+
LENGTH_VALIDATOR.validate_max_tokens!(messages, model, max_tokens: max_tokens)
|
|
235
237
|
end
|
|
236
238
|
|
|
237
239
|
def extract_response(response)
|
|
238
240
|
results = response.dig("choices").map { |choice| choice.dig("message", "content") }
|
|
239
241
|
(results.size == 1) ? results.first : results
|
|
240
242
|
end
|
|
243
|
+
|
|
244
|
+
def response_from_chunks
|
|
245
|
+
@response_chunks.first&.slice("id", "object", "created", "model")&.merge(
|
|
246
|
+
{
|
|
247
|
+
"choices" => [
|
|
248
|
+
{
|
|
249
|
+
"message" => {
|
|
250
|
+
"role" => "assistant",
|
|
251
|
+
"content" => @response_chunks.map { |chunk| chunk.dig("choices", 0, "delta", "content") }.join
|
|
252
|
+
}
|
|
253
|
+
}
|
|
254
|
+
]
|
|
255
|
+
}
|
|
256
|
+
)
|
|
257
|
+
end
|
|
241
258
|
end
|
|
242
259
|
end
|
|
@@ -0,0 +1,17 @@
|
|
|
1
|
+
# frozen_string_literal: true
|
|
2
|
+
|
|
3
|
+
module Langchain::LLM
|
|
4
|
+
class AwsTitanResponse < BaseResponse
|
|
5
|
+
def embedding
|
|
6
|
+
embeddings&.first
|
|
7
|
+
end
|
|
8
|
+
|
|
9
|
+
def embeddings
|
|
10
|
+
[raw_response.dig("embedding")]
|
|
11
|
+
end
|
|
12
|
+
|
|
13
|
+
def prompt_tokens
|
|
14
|
+
raw_response.dig("inputTextTokenCount")
|
|
15
|
+
end
|
|
16
|
+
end
|
|
17
|
+
end
|
|
@@ -5,6 +5,9 @@ module Langchain
|
|
|
5
5
|
class BaseResponse
|
|
6
6
|
attr_reader :raw_response, :model
|
|
7
7
|
|
|
8
|
+
# Save context in the response when doing RAG workflow vectorsearch#ask()
|
|
9
|
+
attr_accessor :context
|
|
10
|
+
|
|
8
11
|
def initialize(raw_response, model: nil)
|
|
9
12
|
@raw_response = raw_response
|
|
10
13
|
@model = model
|
|
@@ -21,12 +21,16 @@ module Langchain
|
|
|
21
21
|
|
|
22
22
|
leftover_tokens = token_limit(model_name) - text_token_length
|
|
23
23
|
|
|
24
|
+
# Some models have a separate token limit for completions (e.g. GPT-4 Turbo)
|
|
25
|
+
# We want the lower of the two limits
|
|
26
|
+
max_tokens = [leftover_tokens, completion_token_limit(model_name)].min
|
|
27
|
+
|
|
24
28
|
# Raise an error even if whole prompt is equal to the model's token limit (leftover_tokens == 0)
|
|
25
|
-
if
|
|
29
|
+
if max_tokens < 0
|
|
26
30
|
raise limit_exceeded_exception(token_limit(model_name), text_token_length)
|
|
27
31
|
end
|
|
28
32
|
|
|
29
|
-
|
|
33
|
+
max_tokens
|
|
30
34
|
end
|
|
31
35
|
|
|
32
36
|
def self.limit_exceeded_exception(limit, length)
|
|
@@ -10,6 +10,14 @@ module Langchain
|
|
|
10
10
|
# It is used to validate the token length before the API call is made
|
|
11
11
|
#
|
|
12
12
|
class OpenAIValidator < BaseValidator
|
|
13
|
+
COMPLETION_TOKEN_LIMITS = {
|
|
14
|
+
# GPT-4 Turbo has a separate token limit for completion
|
|
15
|
+
# Source:
|
|
16
|
+
# https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo
|
|
17
|
+
"gpt-4-1106-preview" => 4096,
|
|
18
|
+
"gpt-4-vision-preview" => 4096
|
|
19
|
+
}
|
|
20
|
+
|
|
13
21
|
TOKEN_LIMITS = {
|
|
14
22
|
# Source:
|
|
15
23
|
# https://platform.openai.com/docs/api-reference/embeddings
|
|
@@ -29,6 +37,8 @@ module Langchain
|
|
|
29
37
|
"gpt-4-32k" => 32768,
|
|
30
38
|
"gpt-4-32k-0314" => 32768,
|
|
31
39
|
"gpt-4-32k-0613" => 32768,
|
|
40
|
+
"gpt-4-1106-preview" => 128000,
|
|
41
|
+
"gpt-4-vision-preview" => 128000,
|
|
32
42
|
"text-curie-001" => 2049,
|
|
33
43
|
"text-babbage-001" => 2049,
|
|
34
44
|
"text-ada-001" => 2049,
|
|
@@ -53,6 +63,16 @@ module Langchain
|
|
|
53
63
|
def self.token_limit(model_name)
|
|
54
64
|
TOKEN_LIMITS[model_name]
|
|
55
65
|
end
|
|
66
|
+
|
|
67
|
+
def self.completion_token_limit(model_name)
|
|
68
|
+
COMPLETION_TOKEN_LIMITS[model_name] || token_limit(model_name)
|
|
69
|
+
end
|
|
70
|
+
|
|
71
|
+
# If :max_tokens is passed in, take the lower of it and the calculated max_tokens
|
|
72
|
+
def self.validate_max_tokens!(content, model_name, options = {})
|
|
73
|
+
max_tokens = super(content, model_name, options)
|
|
74
|
+
[options[:max_tokens], max_tokens].reject(&:nil?).min
|
|
75
|
+
end
|
|
56
76
|
end
|
|
57
77
|
end
|
|
58
78
|
end
|
|
@@ -126,7 +126,9 @@ module Langchain::Vectorsearch
|
|
|
126
126
|
|
|
127
127
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
128
128
|
|
|
129
|
-
llm.chat(prompt: prompt, &block)
|
|
129
|
+
response = llm.chat(prompt: prompt, &block)
|
|
130
|
+
response.context = context
|
|
131
|
+
response
|
|
130
132
|
end
|
|
131
133
|
|
|
132
134
|
private
|
|
@@ -151,7 +151,9 @@ module Langchain::Vectorsearch
|
|
|
151
151
|
|
|
152
152
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
153
153
|
|
|
154
|
-
llm.chat(prompt: prompt, &block)
|
|
154
|
+
response = llm.chat(prompt: prompt, &block)
|
|
155
|
+
response.context = context
|
|
156
|
+
response
|
|
155
157
|
end
|
|
156
158
|
end
|
|
157
159
|
end
|
|
@@ -148,7 +148,9 @@ module Langchain::Vectorsearch
|
|
|
148
148
|
|
|
149
149
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
150
150
|
|
|
151
|
-
llm.chat(prompt: prompt, &block)
|
|
151
|
+
response = llm.chat(prompt: prompt, &block)
|
|
152
|
+
response.context = context
|
|
153
|
+
response
|
|
152
154
|
end
|
|
153
155
|
end
|
|
154
156
|
end
|
|
@@ -180,7 +180,9 @@ module Langchain::Vectorsearch
|
|
|
180
180
|
|
|
181
181
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
182
182
|
|
|
183
|
-
llm.chat(prompt: prompt, &block)
|
|
183
|
+
response = llm.chat(prompt: prompt, &block)
|
|
184
|
+
response.context = context
|
|
185
|
+
response
|
|
184
186
|
end
|
|
185
187
|
|
|
186
188
|
# Pinecone index
|
|
@@ -137,7 +137,9 @@ module Langchain::Vectorsearch
|
|
|
137
137
|
|
|
138
138
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
139
139
|
|
|
140
|
-
llm.chat(prompt: prompt, &block)
|
|
140
|
+
response = llm.chat(prompt: prompt, &block)
|
|
141
|
+
response.context = context
|
|
142
|
+
response
|
|
141
143
|
end
|
|
142
144
|
end
|
|
143
145
|
end
|
|
@@ -6,7 +6,7 @@ module Langchain::Vectorsearch
|
|
|
6
6
|
# Wrapper around Weaviate
|
|
7
7
|
#
|
|
8
8
|
# Gem requirements:
|
|
9
|
-
# gem "weaviate-ruby", "~> 0.8.
|
|
9
|
+
# gem "weaviate-ruby", "~> 0.8.9"
|
|
10
10
|
#
|
|
11
11
|
# Usage:
|
|
12
12
|
# weaviate = Langchain::Vectorsearch::Weaviate.new(url:, api_key:, index_name:, llm:)
|
|
@@ -137,7 +137,9 @@ module Langchain::Vectorsearch
|
|
|
137
137
|
|
|
138
138
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
139
139
|
|
|
140
|
-
llm.chat(prompt: prompt, &block)
|
|
140
|
+
response = llm.chat(prompt: prompt, &block)
|
|
141
|
+
response.context = context
|
|
142
|
+
response
|
|
141
143
|
end
|
|
142
144
|
|
|
143
145
|
private
|
data/lib/langchain/version.rb
CHANGED
metadata
CHANGED
|
@@ -1,14 +1,14 @@
|
|
|
1
1
|
--- !ruby/object:Gem::Specification
|
|
2
2
|
name: langchainrb
|
|
3
3
|
version: !ruby/object:Gem::Version
|
|
4
|
-
version: 0.7.
|
|
4
|
+
version: 0.7.5
|
|
5
5
|
platform: ruby
|
|
6
6
|
authors:
|
|
7
7
|
- Andrei Bondarev
|
|
8
8
|
autorequire:
|
|
9
9
|
bindir: exe
|
|
10
10
|
cert_chain: []
|
|
11
|
-
date: 2023-11-
|
|
11
|
+
date: 2023-11-13 00:00:00.000000000 Z
|
|
12
12
|
dependencies:
|
|
13
13
|
- !ruby/object:Gem::Dependency
|
|
14
14
|
name: baran
|
|
@@ -206,6 +206,20 @@ dependencies:
|
|
|
206
206
|
- - "~>"
|
|
207
207
|
- !ruby/object:Gem::Version
|
|
208
208
|
version: 0.1.0
|
|
209
|
+
- !ruby/object:Gem::Dependency
|
|
210
|
+
name: aws-sdk-bedrockruntime
|
|
211
|
+
requirement: !ruby/object:Gem::Requirement
|
|
212
|
+
requirements:
|
|
213
|
+
- - "~>"
|
|
214
|
+
- !ruby/object:Gem::Version
|
|
215
|
+
version: '1.1'
|
|
216
|
+
type: :development
|
|
217
|
+
prerelease: false
|
|
218
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
219
|
+
requirements:
|
|
220
|
+
- - "~>"
|
|
221
|
+
- !ruby/object:Gem::Version
|
|
222
|
+
version: '1.1'
|
|
209
223
|
- !ruby/object:Gem::Dependency
|
|
210
224
|
name: chroma-db
|
|
211
225
|
requirement: !ruby/object:Gem::Requirement
|
|
@@ -567,6 +581,7 @@ files:
|
|
|
567
581
|
- LICENSE.txt
|
|
568
582
|
- README.md
|
|
569
583
|
- lib/langchain.rb
|
|
584
|
+
- lib/langchain/agent/agents.md
|
|
570
585
|
- lib/langchain/agent/base.rb
|
|
571
586
|
- lib/langchain/agent/react_agent.rb
|
|
572
587
|
- lib/langchain/agent/react_agent/react_agent_prompt.yaml
|
|
@@ -591,16 +606,15 @@ files:
|
|
|
591
606
|
- lib/langchain/dependency_helper.rb
|
|
592
607
|
- lib/langchain/evals/ragas/answer_relevance.rb
|
|
593
608
|
- lib/langchain/evals/ragas/context_relevance.rb
|
|
594
|
-
- lib/langchain/evals/ragas/critique.rb
|
|
595
609
|
- lib/langchain/evals/ragas/faithfulness.rb
|
|
596
610
|
- lib/langchain/evals/ragas/main.rb
|
|
597
611
|
- lib/langchain/evals/ragas/prompts/answer_relevance.yml
|
|
598
612
|
- lib/langchain/evals/ragas/prompts/context_relevance.yml
|
|
599
|
-
- lib/langchain/evals/ragas/prompts/critique.yml
|
|
600
613
|
- lib/langchain/evals/ragas/prompts/faithfulness_statements_extraction.yml
|
|
601
614
|
- lib/langchain/evals/ragas/prompts/faithfulness_statements_verification.yml
|
|
602
615
|
- lib/langchain/llm/ai21.rb
|
|
603
616
|
- lib/langchain/llm/anthropic.rb
|
|
617
|
+
- lib/langchain/llm/aws_bedrock.rb
|
|
604
618
|
- lib/langchain/llm/azure.rb
|
|
605
619
|
- lib/langchain/llm/base.rb
|
|
606
620
|
- lib/langchain/llm/cohere.rb
|
|
@@ -613,6 +627,7 @@ files:
|
|
|
613
627
|
- lib/langchain/llm/replicate.rb
|
|
614
628
|
- lib/langchain/llm/response/ai21_response.rb
|
|
615
629
|
- lib/langchain/llm/response/anthropic_response.rb
|
|
630
|
+
- lib/langchain/llm/response/aws_titan_response.rb
|
|
616
631
|
- lib/langchain/llm/response/base_response.rb
|
|
617
632
|
- lib/langchain/llm/response/cohere_response.rb
|
|
618
633
|
- lib/langchain/llm/response/google_palm_response.rb
|
|
@@ -621,7 +636,6 @@ files:
|
|
|
621
636
|
- lib/langchain/llm/response/openai_response.rb
|
|
622
637
|
- lib/langchain/llm/response/replicate_response.rb
|
|
623
638
|
- lib/langchain/loader.rb
|
|
624
|
-
- lib/langchain/loader_chunkers/html.rb
|
|
625
639
|
- lib/langchain/output_parsers/base.rb
|
|
626
640
|
- lib/langchain/output_parsers/output_fixing_parser.rb
|
|
627
641
|
- lib/langchain/output_parsers/prompts/naive_fix_prompt.yaml
|