langchainrb 0.7.1 → 0.7.3
Sign up to get free protection for your applications and to get access to all the features.
- checksums.yaml +4 -4
- data/CHANGELOG.md +7 -0
- data/README.md +176 -286
- data/lib/langchain/agent/agents.md +54 -0
- data/lib/langchain/evals/ragas/aspect_critique.rb +62 -0
- data/lib/langchain/evals/ragas/prompts/aspect_critique.yml +18 -0
- data/lib/langchain/llm/azure.rb +139 -0
- data/lib/langchain/llm/base.rb +1 -0
- data/lib/langchain/llm/cohere.rb +2 -2
- data/lib/langchain/llm/openai.rb +1 -1
- data/lib/langchain/llm/response/base_response.rb +3 -0
- data/lib/langchain/loader_chunkers/html.rb +27 -0
- data/lib/langchain/prompt/loading.rb +1 -1
- data/lib/langchain/utils/token_length/ai21_validator.rb +1 -0
- data/lib/langchain/utils/token_length/base_validator.rb +3 -0
- data/lib/langchain/utils/token_length/cohere_validator.rb +1 -0
- data/lib/langchain/utils/token_length/google_palm_validator.rb +1 -0
- data/lib/langchain/utils/token_length/openai_validator.rb +14 -0
- data/lib/langchain/vectorsearch/chroma.rb +3 -1
- data/lib/langchain/vectorsearch/milvus.rb +3 -1
- data/lib/langchain/vectorsearch/pgvector.rb +3 -1
- data/lib/langchain/vectorsearch/pinecone.rb +3 -1
- data/lib/langchain/vectorsearch/qdrant.rb +3 -1
- data/lib/langchain/vectorsearch/weaviate.rb +4 -2
- data/lib/langchain/version.rb +1 -1
- metadata +11 -6
checksums.yaml
CHANGED
|
@@ -1,7 +1,7 @@
|
|
|
1
1
|
---
|
|
2
2
|
SHA256:
|
|
3
|
-
metadata.gz:
|
|
4
|
-
data.tar.gz:
|
|
3
|
+
metadata.gz: 3d2d42bf6883822d160e0eeeb4adbfe1598ee271bd3dfd8d4d4b914db814ed0d
|
|
4
|
+
data.tar.gz: f041fc5f276258072275ab5979bf670cc5c6a122b8d4d55ca571224af790d43d
|
|
5
5
|
SHA512:
|
|
6
|
-
metadata.gz:
|
|
7
|
-
data.tar.gz:
|
|
6
|
+
metadata.gz: 61b3c342e8630e6d3ca325bfb105a29d609d99d668dc5c4cfa1cb2c447c230bb8f1f6aa7d252a08129918a0fa11e37bcab813c9700a4c690dd9e5d337eebeb7d
|
|
7
|
+
data.tar.gz: 7ef534ed87ae2d6c077854a03eb314390238d95e9c0b49e85c9042d60d122806709ee07e007e5de884535d4cb8b6a3ffa6504a31e6ac36fadbde10e9c1924444
|
data/CHANGELOG.md
CHANGED
|
@@ -1,5 +1,12 @@
|
|
|
1
1
|
## [Unreleased]
|
|
2
2
|
|
|
3
|
+
## [0.7.3] - 2023-11-08
|
|
4
|
+
- LLM response passes through the context in RAG cases
|
|
5
|
+
- Fix gpt-4 token length validation
|
|
6
|
+
|
|
7
|
+
## [0.7.2] - 2023-11-02
|
|
8
|
+
- Azure OpenAI LLM support
|
|
9
|
+
|
|
3
10
|
## [0.7.1] - 2023-10-26
|
|
4
11
|
- Ragas evals tool to evaluate Retrieval Augmented Generation (RAG) pipelines
|
|
5
12
|
|
data/README.md
CHANGED
|
@@ -1,17 +1,37 @@
|
|
|
1
|
-
💎🔗
|
|
1
|
+
💎🔗 Langchain.rb
|
|
2
2
|
---
|
|
3
|
-
⚡ Building applications
|
|
3
|
+
⚡ Building LLM-powered applications in Ruby ⚡
|
|
4
4
|
|
|
5
|
-
|
|
5
|
+
For deep Rails integration see: [langchainrb_rails](https://github.com/andreibondarev/langchainrb_rails) gem.
|
|
6
|
+
|
|
7
|
+
Available for paid consulting engagements! [Email me](mailto:andrei@sourcelabs.io).
|
|
6
8
|
|
|
7
9
|

|
|
8
10
|
[](https://badge.fury.io/rb/langchainrb)
|
|
9
11
|
[](http://rubydoc.info/gems/langchainrb)
|
|
10
12
|
[](https://github.com/andreibondarev/langchainrb/blob/main/LICENSE.txt)
|
|
11
13
|
[](https://discord.gg/WDARp7J2n8)
|
|
12
|
-
|
|
13
|
-
|
|
14
|
-
|
|
14
|
+
[](https://twitter.com/rushing_andrei)
|
|
15
|
+
|
|
16
|
+
## Use Cases
|
|
17
|
+
* Retrieval Augmented Generation (RAG) and vector search
|
|
18
|
+
* Chat bots
|
|
19
|
+
* [AI agents](https://github.com/andreibondarev/langchainrb/tree/main/lib/langchain/agent/agents.md)
|
|
20
|
+
|
|
21
|
+
## Table of Contents
|
|
22
|
+
|
|
23
|
+
- [Installation](#installation)
|
|
24
|
+
- [Usage](#usage)
|
|
25
|
+
- [Large Language Models (LLMs)](#large-language-models-llms)
|
|
26
|
+
- [Prompt Management](#prompt-management)
|
|
27
|
+
- [Output Parsers](#output-parsers)
|
|
28
|
+
- [Building RAG](#building-retrieval-augment-generation-rag-system)
|
|
29
|
+
- [Building chat bots](#building-chat-bots)
|
|
30
|
+
- [Evaluations](#evaluations-evals)
|
|
31
|
+
- [Examples](#examples)
|
|
32
|
+
- [Logging](#logging)
|
|
33
|
+
- [Development](#development)
|
|
34
|
+
- [Discord](#discord)
|
|
15
35
|
|
|
16
36
|
## Installation
|
|
17
37
|
|
|
@@ -29,228 +49,65 @@ If bundler is not being used to manage dependencies, install the gem by executin
|
|
|
29
49
|
require "langchain"
|
|
30
50
|
```
|
|
31
51
|
|
|
32
|
-
|
|
33
|
-
|
|
34
|
-
| Database | Querying | Storage | Schema Management | Backups | Rails Integration |
|
|
35
|
-
| -------- |:------------------:| -------:| -----------------:| -------:| -----------------:|
|
|
36
|
-
| [Chroma](https://trychroma.com/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
37
|
-
| [Hnswlib](https://github.com/nmslib/hnswlib/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | WIP |
|
|
38
|
-
| [Milvus](https://milvus.io/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
39
|
-
| [Pinecone](https://www.pinecone.io/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
40
|
-
| [Pgvector](https://github.com/pgvector/pgvector) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
41
|
-
| [Qdrant](https://qdrant.tech/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
42
|
-
| [Weaviate](https://weaviate.io/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | WIP | :white_check_mark: |
|
|
52
|
+
## Large Language Models (LLMs)
|
|
53
|
+
Langchain.rb wraps all supported LLMs in a unified interface allowing you to easily swap out and test out different models.
|
|
43
54
|
|
|
44
|
-
|
|
45
|
-
|
|
46
|
-
|
|
47
|
-
|
|
48
|
-
|
|
49
|
-
|
|
50
|
-
|
|
51
|
-
|
|
52
|
-
|
|
53
|
-
|
|
54
|
-
|
|
55
|
-
index_name: "",
|
|
56
|
-
llm: Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
57
|
-
)
|
|
58
|
-
|
|
59
|
-
# You can instantiate any other supported vector search database:
|
|
60
|
-
client = Langchain::Vectorsearch::Chroma.new(...) # `gem "chroma-db", "~> 0.6.0"`
|
|
61
|
-
client = Langchain::Vectorsearch::Hnswlib.new(...) # `gem "hnswlib", "~> 0.8.1"`
|
|
62
|
-
client = Langchain::Vectorsearch::Milvus.new(...) # `gem "milvus", "~> 0.9.2"`
|
|
63
|
-
client = Langchain::Vectorsearch::Pinecone.new(...) # `gem "pinecone", "~> 0.1.6"`
|
|
64
|
-
client = Langchain::Vectorsearch::Pgvector.new(...) # `gem "pgvector", "~> 0.2"`
|
|
65
|
-
client = Langchain::Vectorsearch::Qdrant.new(...) # `gem"qdrant-ruby", "~> 0.9.3"`
|
|
66
|
-
```
|
|
67
|
-
|
|
68
|
-
```ruby
|
|
69
|
-
# Creating the default schema
|
|
70
|
-
client.create_default_schema
|
|
71
|
-
```
|
|
55
|
+
#### Supported LLMs and features:
|
|
56
|
+
| LLM providers | embed() | complete() | chat() | summarize() | Notes |
|
|
57
|
+
| -------- |:------------------:| :-------: | :-----------------: | :-------: | :----------------- |
|
|
58
|
+
| [OpenAI](https://openai.com/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | ❌ | Including Azure OpenAI |
|
|
59
|
+
| [AI21](https://ai21.com/) | ❌ | :white_check_mark: | ❌ | :white_check_mark: | |
|
|
60
|
+
| [Anthropic](https://milvus.io/) | ❌ | :white_check_mark: | ❌ | ❌ | |
|
|
61
|
+
| [Cohere](https://www.pinecone.io/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | |
|
|
62
|
+
| [GooglePalm](https://ai.google/discover/palm2/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | |
|
|
63
|
+
| [HuggingFace](https://huggingface.co/) | :white_check_mark: | ❌ | ❌ | ❌ | |
|
|
64
|
+
| [Ollama](https://ollama.ai/) | :white_check_mark: | :white_check_mark: | ❌ | ❌ | |
|
|
65
|
+
| [Replicate](https://replicate.com/) | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | |
|
|
72
66
|
|
|
73
|
-
|
|
74
|
-
# Store plain texts in your vector search database
|
|
75
|
-
client.add_texts(
|
|
76
|
-
texts: [
|
|
77
|
-
"Begin by preheating your oven to 375°F (190°C). Prepare four boneless, skinless chicken breasts by cutting a pocket into the side of each breast, being careful not to cut all the way through. Season the chicken with salt and pepper to taste. In a large skillet, melt 2 tablespoons of unsalted butter over medium heat. Add 1 small diced onion and 2 minced garlic cloves, and cook until softened, about 3-4 minutes. Add 8 ounces of fresh spinach and cook until wilted, about 3 minutes. Remove the skillet from heat and let the mixture cool slightly.",
|
|
78
|
-
"In a bowl, combine the spinach mixture with 4 ounces of softened cream cheese, 1/4 cup of grated Parmesan cheese, 1/4 cup of shredded mozzarella cheese, and 1/4 teaspoon of red pepper flakes. Mix until well combined. Stuff each chicken breast pocket with an equal amount of the spinach mixture. Seal the pocket with a toothpick if necessary. In the same skillet, heat 1 tablespoon of olive oil over medium-high heat. Add the stuffed chicken breasts and sear on each side for 3-4 minutes, or until golden brown."
|
|
79
|
-
]
|
|
80
|
-
)
|
|
81
|
-
```
|
|
82
|
-
```ruby
|
|
83
|
-
# Store the contents of your files in your vector search database
|
|
84
|
-
my_pdf = Langchain.root.join("path/to/my.pdf")
|
|
85
|
-
my_text = Langchain.root.join("path/to/my.txt")
|
|
86
|
-
my_docx = Langchain.root.join("path/to/my.docx")
|
|
87
|
-
|
|
88
|
-
client.add_data(paths: [my_pdf, my_text, my_docx])
|
|
89
|
-
```
|
|
90
|
-
```ruby
|
|
91
|
-
# Retrieve similar documents based on the query string passed in
|
|
92
|
-
client.similarity_search(
|
|
93
|
-
query:,
|
|
94
|
-
k: # number of results to be retrieved
|
|
95
|
-
)
|
|
96
|
-
```
|
|
97
|
-
```ruby
|
|
98
|
-
# Retrieve similar documents based on the query string passed in via the [HyDE technique](https://arxiv.org/abs/2212.10496)
|
|
99
|
-
client.similarity_search_with_hyde()
|
|
100
|
-
```
|
|
101
|
-
```ruby
|
|
102
|
-
# Retrieve similar documents based on the embedding passed in
|
|
103
|
-
client.similarity_search_by_vector(
|
|
104
|
-
embedding:,
|
|
105
|
-
k: # number of results to be retrieved
|
|
106
|
-
)
|
|
107
|
-
```
|
|
108
|
-
```ruby
|
|
109
|
-
# Q&A-style querying based on the question passed in
|
|
110
|
-
client.ask(
|
|
111
|
-
question:
|
|
112
|
-
)
|
|
113
|
-
```
|
|
114
|
-
|
|
115
|
-
## Integrating Vector Search into ActiveRecord models
|
|
116
|
-
```ruby
|
|
117
|
-
class Product < ActiveRecord::Base
|
|
118
|
-
vectorsearch provider: Langchain::Vectorsearch::Qdrant.new(
|
|
119
|
-
api_key: ENV["QDRANT_API_KEY"],
|
|
120
|
-
url: ENV["QDRANT_URL"],
|
|
121
|
-
index_name: "Products",
|
|
122
|
-
llm: Langchain::LLM::GooglePalm.new(api_key: ENV["GOOGLE_PALM_API_KEY"])
|
|
123
|
-
)
|
|
124
|
-
|
|
125
|
-
after_save :upsert_to_vectorsearch
|
|
126
|
-
end
|
|
127
|
-
```
|
|
128
|
-
|
|
129
|
-
### Exposed ActiveRecord methods
|
|
130
|
-
```ruby
|
|
131
|
-
# Retrieve similar products based on the query string passed in
|
|
132
|
-
Product.similarity_search(
|
|
133
|
-
query:,
|
|
134
|
-
k: # number of results to be retrieved
|
|
135
|
-
)
|
|
136
|
-
```
|
|
137
|
-
```ruby
|
|
138
|
-
# Q&A-style querying based on the question passed in
|
|
139
|
-
Product.ask(
|
|
140
|
-
question:
|
|
141
|
-
)
|
|
142
|
-
```
|
|
143
|
-
|
|
144
|
-
Additional info [here](https://github.com/andreibondarev/langchainrb/blob/main/lib/langchain/active_record/hooks.rb#L10-L38).
|
|
145
|
-
|
|
146
|
-
### Using Standalone LLMs 🗣️
|
|
147
|
-
|
|
148
|
-
Add `gem "ruby-openai", "~> 4.0.0"` to your Gemfile.
|
|
67
|
+
#### Using standalone LLMs:
|
|
149
68
|
|
|
150
69
|
#### OpenAI
|
|
151
|
-
```ruby
|
|
152
|
-
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
153
|
-
```
|
|
154
|
-
You can pass additional parameters to the constructor, it will be passed to the OpenAI client:
|
|
155
|
-
```ruby
|
|
156
|
-
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"], llm_options: {uri_base: "http://localhost:1234"}) )
|
|
157
|
-
```
|
|
158
|
-
```ruby
|
|
159
|
-
openai.embed(text: "foo bar")
|
|
160
|
-
```
|
|
161
|
-
```ruby
|
|
162
|
-
openai.complete(prompt: "What is the meaning of life?")
|
|
163
|
-
```
|
|
164
|
-
|
|
165
|
-
##### Open AI Function calls support
|
|
166
|
-
|
|
167
|
-
Conversation support
|
|
168
|
-
|
|
169
|
-
```ruby
|
|
170
|
-
chat = Langchain::Conversation.new(llm: openai)
|
|
171
|
-
```
|
|
172
|
-
```ruby
|
|
173
|
-
chat.set_context("You are the climate bot")
|
|
174
|
-
chat.set_functions(functions)
|
|
175
|
-
```
|
|
176
|
-
|
|
177
|
-
qdrant:
|
|
178
|
-
|
|
179
|
-
```ruby
|
|
180
|
-
client.llm.functions = functions
|
|
181
|
-
```
|
|
182
|
-
|
|
183
|
-
#### Cohere
|
|
184
|
-
Add `gem "cohere-ruby", "~> 0.9.6"` to your Gemfile.
|
|
185
70
|
|
|
186
|
-
|
|
187
|
-
cohere = Langchain::LLM::Cohere.new(api_key: ENV["COHERE_API_KEY"])
|
|
188
|
-
```
|
|
189
|
-
```ruby
|
|
190
|
-
cohere.embed(text: "foo bar")
|
|
191
|
-
```
|
|
192
|
-
```ruby
|
|
193
|
-
cohere.complete(prompt: "What is the meaning of life?")
|
|
194
|
-
```
|
|
195
|
-
|
|
196
|
-
#### HuggingFace
|
|
197
|
-
Add `gem "hugging-face", "~> 0.3.2"` to your Gemfile.
|
|
198
|
-
```ruby
|
|
199
|
-
hugging_face = Langchain::LLM::HuggingFace.new(api_key: ENV["HUGGING_FACE_API_KEY"])
|
|
200
|
-
```
|
|
71
|
+
Add `gem "ruby-openai", "~> 5.2.0"` to your Gemfile.
|
|
201
72
|
|
|
202
|
-
#### Replicate
|
|
203
|
-
Add `gem "replicate-ruby", "~> 0.2.2"` to your Gemfile.
|
|
204
73
|
```ruby
|
|
205
|
-
|
|
74
|
+
llm = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
206
75
|
```
|
|
207
|
-
|
|
208
|
-
#### Google PaLM (Pathways Language Model)
|
|
209
|
-
Add `"google_palm_api", "~> 0.1.3"` to your Gemfile.
|
|
76
|
+
You can pass additional parameters to the constructor, it will be passed to the OpenAI client:
|
|
210
77
|
```ruby
|
|
211
|
-
|
|
78
|
+
llm = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"], llm_options: { ... })
|
|
212
79
|
```
|
|
213
80
|
|
|
214
|
-
|
|
215
|
-
Add `gem "ai21", "~> 0.2.1"` to your Gemfile.
|
|
81
|
+
Generate vector embeddings:
|
|
216
82
|
```ruby
|
|
217
|
-
|
|
83
|
+
llm.embed(text: "foo bar")
|
|
218
84
|
```
|
|
219
85
|
|
|
220
|
-
|
|
221
|
-
Add `gem "anthropic", "~> 0.1.0"` to your Gemfile.
|
|
86
|
+
Generate a text completion:
|
|
222
87
|
```ruby
|
|
223
|
-
|
|
88
|
+
llm.complete(prompt: "What is the meaning of life?")
|
|
224
89
|
```
|
|
225
90
|
|
|
91
|
+
Generate a chat completion:
|
|
226
92
|
```ruby
|
|
227
|
-
|
|
93
|
+
llm.chat(prompt: "Hey! How are you?")
|
|
228
94
|
```
|
|
229
95
|
|
|
230
|
-
|
|
96
|
+
Summarize the text:
|
|
231
97
|
```ruby
|
|
232
|
-
|
|
98
|
+
llm.complete(text: "...")
|
|
233
99
|
```
|
|
234
100
|
|
|
101
|
+
You can use any other LLM by invoking the same interface:
|
|
235
102
|
```ruby
|
|
236
|
-
|
|
237
|
-
```
|
|
238
|
-
```ruby
|
|
239
|
-
ollama.embed(text: "Hello world!")
|
|
103
|
+
llm = Langchain::LLM::GooglePalm.new(...)
|
|
240
104
|
```
|
|
241
105
|
|
|
242
|
-
###
|
|
106
|
+
### Prompt Management
|
|
243
107
|
|
|
244
108
|
#### Prompt Templates
|
|
245
109
|
|
|
246
|
-
Create a prompt with
|
|
247
|
-
|
|
248
|
-
```ruby
|
|
249
|
-
prompt = Langchain::Prompt::PromptTemplate.new(template: "Tell me a {adjective} joke.", input_variables: ["adjective"])
|
|
250
|
-
prompt.format(adjective: "funny") # "Tell me a funny joke."
|
|
251
|
-
```
|
|
252
|
-
|
|
253
|
-
Create a prompt with multiple input variables:
|
|
110
|
+
Create a prompt with input variables:
|
|
254
111
|
|
|
255
112
|
```ruby
|
|
256
113
|
prompt = Langchain::Prompt::PromptTemplate.new(template: "Tell me a {adjective} joke about {content}.", input_variables: ["adjective", "content"])
|
|
@@ -331,7 +188,8 @@ prompt = Langchain::Prompt.load_from_path(file_path: "spec/fixtures/prompt/promp
|
|
|
331
188
|
prompt.input_variables #=> ["adjective", "content"]
|
|
332
189
|
```
|
|
333
190
|
|
|
334
|
-
|
|
191
|
+
|
|
192
|
+
### Output Parsers
|
|
335
193
|
|
|
336
194
|
Parse LLM text responses into structured output, such as JSON.
|
|
337
195
|
|
|
@@ -431,106 +289,160 @@ fix_parser.parse(llm_response)
|
|
|
431
289
|
|
|
432
290
|
See [here](https://github.com/andreibondarev/langchainrb/tree/main/examples/create_and_manage_prompt_templates_using_structured_output_parser.rb) for a concrete example
|
|
433
291
|
|
|
434
|
-
|
|
435
|
-
|
|
292
|
+
## Building Retrieval Augment Generation (RAG) system
|
|
293
|
+
RAG is a methodology that assists LLMs generate accurate and up-to-date information.
|
|
294
|
+
A typical RAG workflow follows the 3 steps below:
|
|
295
|
+
1. Relevant knowledge (or data) is retrieved from the knowledge base (typically a vector search DB)
|
|
296
|
+
2. A prompt, containing retrieved knowledge above, is constructed.
|
|
297
|
+
3. LLM receives the prompt above to generate a text completion.
|
|
298
|
+
Most common use-case for a RAG system is powering Q&A systems where users pose natural language questions and receive answers in natural language.
|
|
436
299
|
|
|
437
|
-
|
|
300
|
+
### Vector search databases
|
|
301
|
+
Langchain.rb provides a convenient unified interface on top of supported vectorsearch databases that make it easy to configure your index, add data, query and retrieve from it.
|
|
438
302
|
|
|
439
|
-
|
|
303
|
+
#### Supported vector search databases and features:
|
|
440
304
|
|
|
441
|
-
|
|
442
|
-
|
|
443
|
-
|
|
305
|
+
| Database | Open-source | Cloud offering |
|
|
306
|
+
| -------- |:------------------:| :------------: |
|
|
307
|
+
| [Chroma](https://trychroma.com/) | :white_check_mark: | :white_check_mark: |
|
|
308
|
+
| [Hnswlib](https://github.com/nmslib/hnswlib/) | :white_check_mark: | ❌ |
|
|
309
|
+
| [Milvus](https://milvus.io/) | :white_check_mark: | :white_check_mark: Zilliz Cloud |
|
|
310
|
+
| [Pinecone](https://www.pinecone.io/) | ❌ | :white_check_mark: |
|
|
311
|
+
| [Pgvector](https://github.com/pgvector/pgvector) | :white_check_mark: | :white_check_mark: |
|
|
312
|
+
| [Qdrant](https://qdrant.tech/) | :white_check_mark: | :white_check_mark: |
|
|
313
|
+
| [Weaviate](https://weaviate.io/) | :white_check_mark: | :white_check_mark: |
|
|
444
314
|
|
|
445
|
-
|
|
315
|
+
### Using Vector Search Databases 🔍
|
|
446
316
|
|
|
447
|
-
|
|
448
|
-
llm: openai,
|
|
449
|
-
tools: [search_tool, calculator]
|
|
450
|
-
)
|
|
451
|
-
```
|
|
317
|
+
Pick the vector search database you'll be using, add the gem dependency and instantiate the client:
|
|
452
318
|
```ruby
|
|
453
|
-
|
|
454
|
-
#=> "Approximately 2,945 soccer fields would be needed to cover the distance between NYC and DC in a straight line."
|
|
319
|
+
gem "weaviate-ruby", "~> 0.8.9"
|
|
455
320
|
```
|
|
456
321
|
|
|
457
|
-
|
|
322
|
+
Choose and instantiate the LLM provider you'll be using to generate embeddings
|
|
323
|
+
```ruby
|
|
324
|
+
llm = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
325
|
+
```
|
|
458
326
|
|
|
459
|
-
|
|
327
|
+
```ruby
|
|
328
|
+
client = Langchain::Vectorsearch::Weaviate.new(
|
|
329
|
+
url: ENV["WEAVIATE_URL"],
|
|
330
|
+
api_key: ENV["WEAVIATE_API_KEY"],
|
|
331
|
+
index_name: "Documents",
|
|
332
|
+
llm: llm
|
|
333
|
+
)
|
|
334
|
+
```
|
|
460
335
|
|
|
336
|
+
You can instantiate any other supported vector search database:
|
|
461
337
|
```ruby
|
|
462
|
-
|
|
338
|
+
client = Langchain::Vectorsearch::Chroma.new(...) # `gem "chroma-db", "~> 0.6.0"`
|
|
339
|
+
client = Langchain::Vectorsearch::Hnswlib.new(...) # `gem "hnswlib", "~> 0.8.1"`
|
|
340
|
+
client = Langchain::Vectorsearch::Milvus.new(...) # `gem "milvus", "~> 0.9.2"`
|
|
341
|
+
client = Langchain::Vectorsearch::Pinecone.new(...) # `gem "pinecone", "~> 0.1.6"`
|
|
342
|
+
client = Langchain::Vectorsearch::Pgvector.new(...) # `gem "pgvector", "~> 0.2"`
|
|
343
|
+
client = Langchain::Vectorsearch::Qdrant.new(...) # `gem"qdrant-ruby", "~> 0.9.3"`
|
|
344
|
+
```
|
|
463
345
|
|
|
464
|
-
|
|
346
|
+
Create the default schema:
|
|
347
|
+
```ruby
|
|
348
|
+
client.create_default_schema
|
|
465
349
|
```
|
|
350
|
+
|
|
351
|
+
Add plain text data to your vector search database:
|
|
466
352
|
```ruby
|
|
467
|
-
|
|
468
|
-
|
|
353
|
+
client.add_texts(
|
|
354
|
+
texts: [
|
|
355
|
+
"Begin by preheating your oven to 375°F (190°C). Prepare four boneless, skinless chicken breasts by cutting a pocket into the side of each breast, being careful not to cut all the way through. Season the chicken with salt and pepper to taste. In a large skillet, melt 2 tablespoons of unsalted butter over medium heat. Add 1 small diced onion and 2 minced garlic cloves, and cook until softened, about 3-4 minutes. Add 8 ounces of fresh spinach and cook until wilted, about 3 minutes. Remove the skillet from heat and let the mixture cool slightly.",
|
|
356
|
+
"In a bowl, combine the spinach mixture with 4 ounces of softened cream cheese, 1/4 cup of grated Parmesan cheese, 1/4 cup of shredded mozzarella cheese, and 1/4 teaspoon of red pepper flakes. Mix until well combined. Stuff each chicken breast pocket with an equal amount of the spinach mixture. Seal the pocket with a toothpick if necessary. In the same skillet, heat 1 tablespoon of olive oil over medium-high heat. Add the stuffed chicken breasts and sear on each side for 3-4 minutes, or until golden brown."
|
|
357
|
+
]
|
|
358
|
+
)
|
|
469
359
|
```
|
|
470
360
|
|
|
471
|
-
|
|
472
|
-
|
|
361
|
+
Or use the file parsers to load, parse and index data into your database:
|
|
362
|
+
```ruby
|
|
363
|
+
my_pdf = Langchain.root.join("path/to/my.pdf")
|
|
364
|
+
my_text = Langchain.root.join("path/to/my.txt")
|
|
365
|
+
my_docx = Langchain.root.join("path/to/my.docx")
|
|
473
366
|
|
|
474
|
-
|
|
367
|
+
client.add_data(paths: [my_pdf, my_text, my_docx])
|
|
368
|
+
```
|
|
369
|
+
Supported file formats: docx, html, pdf, text, json, jsonl, csv, xlsx.
|
|
475
370
|
|
|
476
|
-
|
|
371
|
+
Retrieve similar documents based on the query string passed in:
|
|
372
|
+
```ruby
|
|
373
|
+
client.similarity_search(
|
|
374
|
+
query:,
|
|
375
|
+
k: # number of results to be retrieved
|
|
376
|
+
)
|
|
377
|
+
```
|
|
477
378
|
|
|
478
|
-
|
|
479
|
-
|
|
480
|
-
|
|
481
|
-
|
|
482
|
-
| "ruby_code_interpreter" | Interprets Ruby expressions | | `gem "safe_ruby", "~> 1.0.4"` |
|
|
483
|
-
| "google_search" | A wrapper around Google Search | `ENV["SERPAPI_API_KEY"]` (https://serpapi.com/manage-api-key) | `gem "google_search_results", "~> 2.0.0"` |
|
|
484
|
-
| "weather" | Calls Open Weather API to retrieve the current weather | `ENV["OPEN_WEATHER_API_KEY"]` (https://home.openweathermap.org/api_keys) | `gem "open-weather-ruby-client", "~> 0.3.0"` |
|
|
485
|
-
| "wikipedia" | Calls Wikipedia API to retrieve the summary | | `gem "wikipedia-client", "~> 1.17.0"` |
|
|
379
|
+
Retrieve similar documents based on the query string passed in via the [HyDE technique](https://arxiv.org/abs/2212.10496):
|
|
380
|
+
```ruby
|
|
381
|
+
client.similarity_search_with_hyde()
|
|
382
|
+
```
|
|
486
383
|
|
|
487
|
-
|
|
384
|
+
Retrieve similar documents based on the embedding passed in:
|
|
385
|
+
```ruby
|
|
386
|
+
client.similarity_search_by_vector(
|
|
387
|
+
embedding:,
|
|
388
|
+
k: # number of results to be retrieved
|
|
389
|
+
)
|
|
390
|
+
```
|
|
488
391
|
|
|
489
|
-
|
|
392
|
+
RAG-based querying
|
|
393
|
+
```ruby
|
|
394
|
+
client.ask(
|
|
395
|
+
question:
|
|
396
|
+
)
|
|
397
|
+
```
|
|
490
398
|
|
|
491
|
-
|
|
399
|
+
## Building chat bots
|
|
492
400
|
|
|
493
|
-
|
|
401
|
+
### Conversation class
|
|
494
402
|
|
|
403
|
+
Choose and instantiate the LLM provider you'll be using:
|
|
495
404
|
```ruby
|
|
496
|
-
Langchain::
|
|
405
|
+
llm = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
497
406
|
```
|
|
498
|
-
|
|
499
|
-
or
|
|
500
|
-
|
|
407
|
+
Instantiate the Conversation class:
|
|
501
408
|
```ruby
|
|
502
|
-
Langchain::
|
|
409
|
+
chat = Langchain::Conversation.new(llm: llm)
|
|
503
410
|
```
|
|
504
411
|
|
|
505
|
-
|
|
412
|
+
(Optional) Set the conversation context:
|
|
413
|
+
```ruby
|
|
414
|
+
chat.set_context("You are a chatbot from the future")
|
|
415
|
+
```
|
|
506
416
|
|
|
417
|
+
Exchange messages with the LLM
|
|
418
|
+
```ruby
|
|
419
|
+
chat.message("Tell me about future technologies")
|
|
420
|
+
```
|
|
507
421
|
|
|
508
|
-
|
|
509
|
-
|
|
510
|
-
|
|
511
|
-
|
|
512
|
-
|
|
513
|
-
|
|
514
|
-
| JSON | Langchain::Processors::JSON | |
|
|
515
|
-
| JSONL | Langchain::Processors::JSONL | |
|
|
516
|
-
| csv | Langchain::Processors::CSV | |
|
|
517
|
-
| xlsx | Langchain::Processors::Xlsx | `gem "roo", "~> 2.10.0"` |
|
|
422
|
+
To stream the chat response:
|
|
423
|
+
```ruby
|
|
424
|
+
chat = Langchain::Conversation.new(llm: llm) do |chunk|
|
|
425
|
+
print(chunk)
|
|
426
|
+
end
|
|
427
|
+
```
|
|
518
428
|
|
|
519
|
-
|
|
520
|
-
|
|
429
|
+
Open AI Functions support
|
|
430
|
+
```ruby
|
|
431
|
+
chat.set_functions(functions)
|
|
432
|
+
```
|
|
521
433
|
|
|
522
434
|
## Evaluations (Evals)
|
|
523
435
|
The Evaluations module is a collection of tools that can be used to evaluate and track the performance of the output products by LLM and your RAG (Retrieval Augmented Generation) pipelines.
|
|
524
436
|
|
|
525
437
|
### RAGAS
|
|
526
|
-
Ragas
|
|
527
|
-
* Faithfulness - the answer is grounded in the given context
|
|
528
|
-
* Context Relevance - the retrieved context is focused, containing
|
|
529
|
-
* Answer Relevance - the generated answer addresses the actual question that was provided
|
|
438
|
+
Ragas helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. The implementation is based on this [paper](https://arxiv.org/abs/2309.15217) and the original Python [repo](https://github.com/explodinggradients/ragas). Ragas tracks the following 3 metrics and assigns the 0.0 - 1.0 scores:
|
|
439
|
+
* Faithfulness - the answer is grounded in the given context.
|
|
440
|
+
* Context Relevance - the retrieved context is focused, containing little to no irrelevant information.
|
|
441
|
+
* Answer Relevance - the generated answer addresses the actual question that was provided.
|
|
530
442
|
|
|
531
443
|
```ruby
|
|
532
444
|
# We recommend using Langchain::LLM::OpenAI as your llm for Ragas
|
|
533
|
-
ragas = Langchain::Evals::Ragas::Main.new(llm: llm)
|
|
445
|
+
ragas = Langchain::Evals::Ragas::Main.new(llm: llm)
|
|
534
446
|
|
|
535
447
|
# The answer that the LLM generated
|
|
536
448
|
# The question (or the original prompt) that was asked
|
|
@@ -545,13 +457,16 @@ ragas.score(answer: "", question: "", context: "")
|
|
|
545
457
|
# }
|
|
546
458
|
```
|
|
547
459
|
|
|
460
|
+
## Examples
|
|
461
|
+
Additional examples available: [/examples](https://github.com/andreibondarev/langchainrb/tree/main/examples)
|
|
462
|
+
|
|
548
463
|
## Logging
|
|
549
464
|
|
|
550
465
|
LangChain.rb uses standard logging mechanisms and defaults to `:warn` level. Most messages are at info level, but we will add debug or warn statements as needed.
|
|
551
466
|
To show all log messages:
|
|
552
467
|
|
|
553
468
|
```ruby
|
|
554
|
-
Langchain.logger.level = :
|
|
469
|
+
Langchain.logger.level = :debug
|
|
555
470
|
```
|
|
556
471
|
|
|
557
472
|
## Development
|
|
@@ -565,31 +480,6 @@ Langchain.logger.level = :info
|
|
|
565
480
|
## Discord
|
|
566
481
|
Join us in the [Langchain.rb](https://discord.gg/WDARp7J2n8) Discord server.
|
|
567
482
|
|
|
568
|
-
## Core Contributors
|
|
569
|
-
[<img style="border-radius:50%" alt="Andrei Bondarev" src="https://avatars.githubusercontent.com/u/541665?v=4" width="80" height="80" class="avatar">](https://twitter.com/rushing_andrei)
|
|
570
|
-
|
|
571
|
-
## Contributors
|
|
572
|
-
[<img style="border-radius:50%" alt="Alex Chaplinsky" src="https://avatars.githubusercontent.com/u/695947?v=4" width="80" height="80" class="avatar">](https://github.com/alchaplinsky)
|
|
573
|
-
[<img style="border-radius:50%" alt="Josh Nichols" src="https://avatars.githubusercontent.com/u/159?v=4" width="80" height="80" class="avatar">](https://github.com/technicalpickles)
|
|
574
|
-
[<img style="border-radius:50%" alt="Matt Lindsey" src="https://avatars.githubusercontent.com/u/5638339?v=4" width="80" height="80" class="avatar">](https://github.com/mattlindsey)
|
|
575
|
-
[<img style="border-radius:50%" alt="Ricky Chilcott" src="https://avatars.githubusercontent.com/u/445759?v=4" width="80" height="80" class="avatar">](https://github.com/rickychilcott)
|
|
576
|
-
[<img style="border-radius:50%" alt="Moeki Kawakami" src="https://avatars.githubusercontent.com/u/72325947?v=4" width="80" height="80" class="avatar">](https://github.com/moekidev)
|
|
577
|
-
[<img style="border-radius:50%" alt="Jens Stmrs" src="https://avatars.githubusercontent.com/u/3492669?v=4" width="80" height="80" class="avatar">](https://github.com/faustus7)
|
|
578
|
-
[<img style="border-radius:50%" alt="Rafael Figueiredo" src="https://avatars.githubusercontent.com/u/35845775?v=4" width="80" height="80" class="avatar">](https://github.com/rafaelqfigueiredo)
|
|
579
|
-
[<img style="border-radius:50%" alt="Piero Dotti" src="https://avatars.githubusercontent.com/u/5167659?v=4" width="80" height="80" class="avatar">](https://github.com/ProGM)
|
|
580
|
-
[<img style="border-radius:50%" alt="Michał Ciemięga" src="https://avatars.githubusercontent.com/u/389828?v=4" width="80" height="80" class="avatar">](https://github.com/zewelor)
|
|
581
|
-
[<img style="border-radius:50%" alt="Bruno Bornsztein" src="https://avatars.githubusercontent.com/u/3760?v=4" width="80" height="80" class="avatar">](https://github.com/bborn)
|
|
582
|
-
[<img style="border-radius:50%" alt="Tim Williams" src="https://avatars.githubusercontent.com/u/1192351?v=4" width="80" height="80" class="avatar">](https://github.com/timrwilliams)
|
|
583
|
-
[<img style="border-radius:50%" alt="Zhenhang Tung" src="https://avatars.githubusercontent.com/u/8170159?v=4" width="80" height="80" class="avatar">](https://github.com/ZhenhangTung)
|
|
584
|
-
[<img style="border-radius:50%" alt="Hama" src="https://avatars.githubusercontent.com/u/38002468?v=4" width="80" height="80" class="avatar">](https://github.com/akmhmgc)
|
|
585
|
-
[<img style="border-radius:50%" alt="Josh Weir" src="https://avatars.githubusercontent.com/u/10720337?v=4" width="80" height="80" class="avatar">](https://github.com/joshweir)
|
|
586
|
-
[<img style="border-radius:50%" alt="Arthur Hess" src="https://avatars.githubusercontent.com/u/446035?v=4" width="80" height="80" class="avatar">](https://github.com/arthurhess)
|
|
587
|
-
[<img style="border-radius:50%" alt="Jin Shen" src="https://avatars.githubusercontent.com/u/54917718?v=4" width="80" height="80" class="avatar">](https://github.com/jacshen-ebay)
|
|
588
|
-
[<img style="border-radius:50%" alt="Earle Bunao" src="https://avatars.githubusercontent.com/u/4653624?v=4" width="80" height="80" class="avatar">](https://github.com/erbunao)
|
|
589
|
-
[<img style="border-radius:50%" alt="Maël H." src="https://avatars.githubusercontent.com/u/61985678?v=4" width="80" height="80" class="avatar">](https://github.com/mael-ha)
|
|
590
|
-
[<img style="border-radius:50%" alt="Chris O. Adebiyi" src="https://avatars.githubusercontent.com/u/62605573?v=4" width="80" height="80" class="avatar">](https://github.com/oluvvafemi)
|
|
591
|
-
[<img style="border-radius:50%" alt="Aaron Breckenridge" src="https://avatars.githubusercontent.com/u/201360?v=4" width="80" height="80" class="avatar">](https://github.com/breckenedge)
|
|
592
|
-
|
|
593
483
|
## Star History
|
|
594
484
|
|
|
595
485
|
[](https://star-history.com/#andreibondarev/langchainrb&Date)
|
|
@@ -0,0 +1,54 @@
|
|
|
1
|
+
|
|
2
|
+
### Agents 🤖
|
|
3
|
+
Agents are semi-autonomous bots that can respond to user questions and use available to them Tools to provide informed replies. They break down problems into series of steps and define Actions (and Action Inputs) along the way that are executed and fed back to them as additional information. Once an Agent decides that it has the Final Answer it responds with it.
|
|
4
|
+
|
|
5
|
+
#### ReAct Agent
|
|
6
|
+
|
|
7
|
+
Add `gem "ruby-openai"`, `gem "eqn"`, and `gem "google_search_results"` to your Gemfile
|
|
8
|
+
|
|
9
|
+
```ruby
|
|
10
|
+
search_tool = Langchain::Tool::GoogleSearch.new(api_key: ENV["SERPAPI_API_KEY"])
|
|
11
|
+
calculator = Langchain::Tool::Calculator.new
|
|
12
|
+
|
|
13
|
+
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
|
|
14
|
+
|
|
15
|
+
agent = Langchain::Agent::ReActAgent.new(
|
|
16
|
+
llm: openai,
|
|
17
|
+
tools: [search_tool, calculator]
|
|
18
|
+
)
|
|
19
|
+
```
|
|
20
|
+
```ruby
|
|
21
|
+
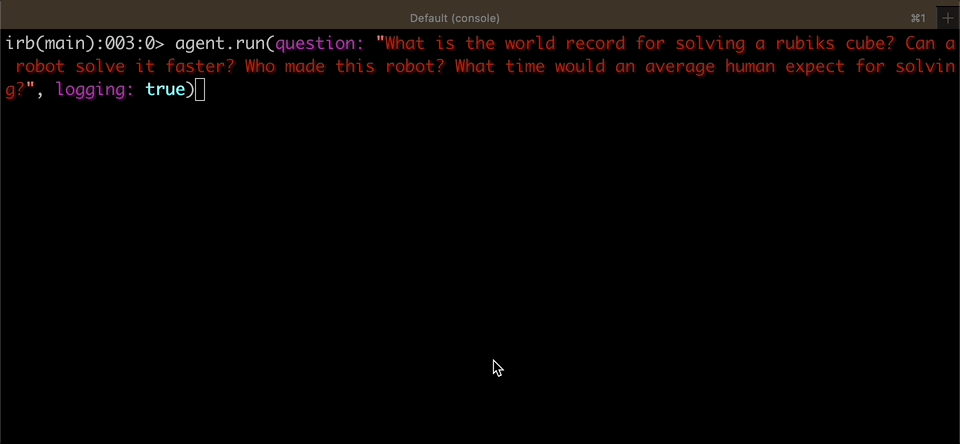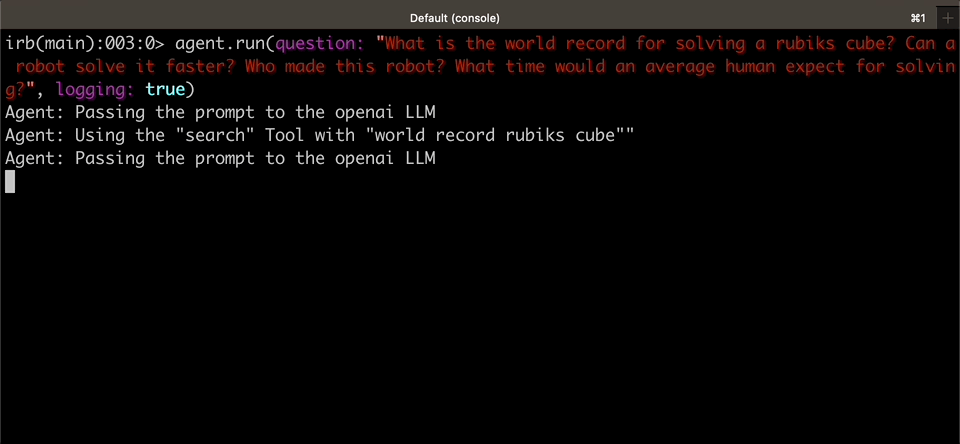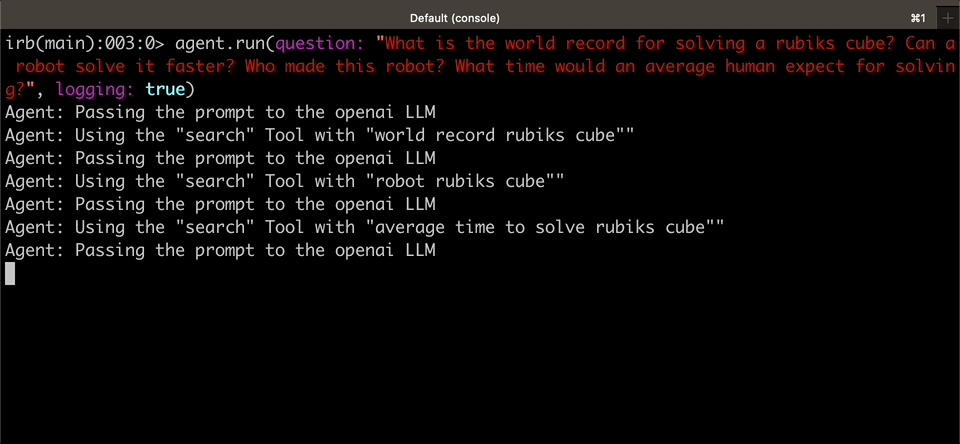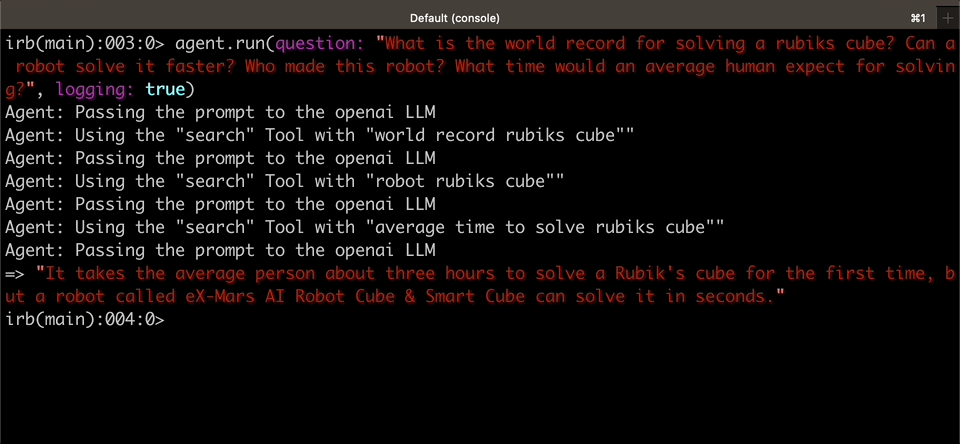
agent.run(question: "How many full soccer fields would be needed to cover the distance between NYC and DC in a straight line?")
|
|
22
|
+
#=> "Approximately 2,945 soccer fields would be needed to cover the distance between NYC and DC in a straight line."
|
|
23
|
+
```
|
|
24
|
+
|
|
25
|
+
#### SQL-Query Agent
|
|
26
|
+
|
|
27
|
+
Add `gem "sequel"` to your Gemfile
|
|
28
|
+
|
|
29
|
+
```ruby
|
|
30
|
+
database = Langchain::Tool::Database.new(connection_string: "postgres://user:password@localhost:5432/db_name")
|
|
31
|
+
|
|
32
|
+
agent = Langchain::Agent::SQLQueryAgent.new(llm: Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"]), db: database)
|
|
33
|
+
```
|
|
34
|
+
```ruby
|
|
35
|
+
agent.run(question: "How many users have a name with length greater than 5 in the users table?")
|
|
36
|
+
#=> "14 users have a name with length greater than 5 in the users table."
|
|
37
|
+
```
|
|
38
|
+
|
|
39
|
+
#### Demo
|
|
40
|
+
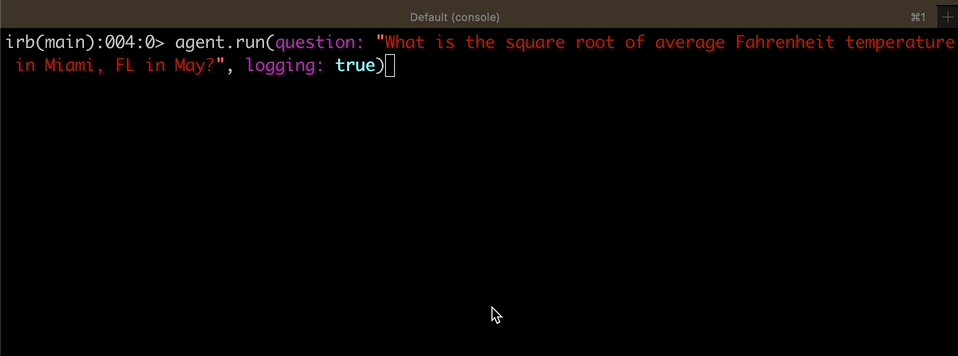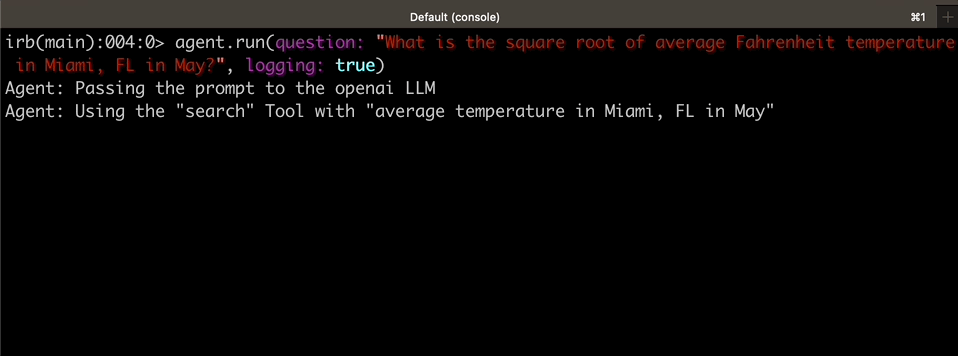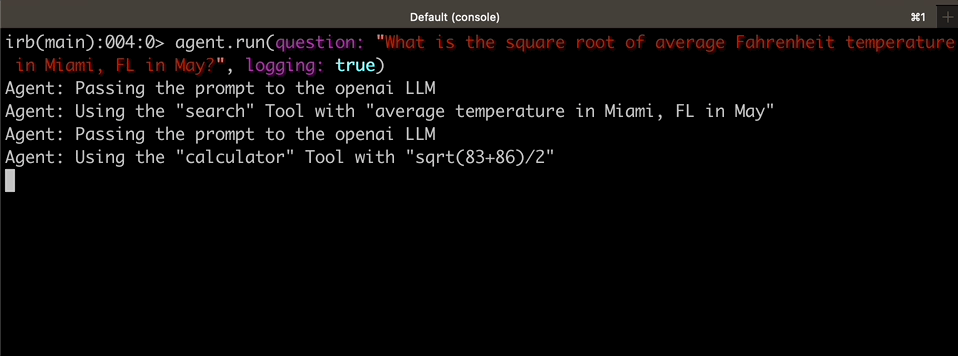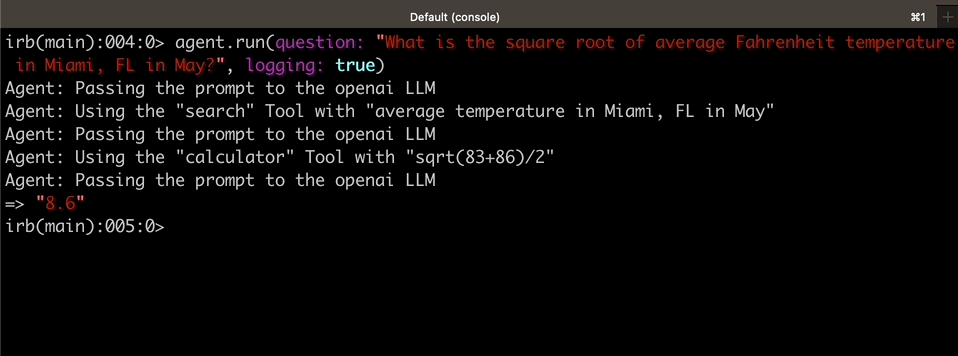
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
|
|
44
|
+
#### Available Tools 🛠️
|
|
45
|
+
|
|
46
|
+
| Name | Description | ENV Requirements | Gem Requirements |
|
|
47
|
+
| ------------ | :------------------------------------------------: | :-----------------------------------------------------------: | :---------------------------------------: |
|
|
48
|
+
| "calculator" | Useful for getting the result of a math expression | | `gem "eqn", "~> 1.6.5"` |
|
|
49
|
+
| "database" | Useful for querying a SQL database | | `gem "sequel", "~> 5.68.0"` |
|
|
50
|
+
| "ruby_code_interpreter" | Interprets Ruby expressions | | `gem "safe_ruby", "~> 1.0.4"` |
|
|
51
|
+
| "google_search" | A wrapper around Google Search | `ENV["SERPAPI_API_KEY"]` (https://serpapi.com/manage-api-key) | `gem "google_search_results", "~> 2.0.0"` |
|
|
52
|
+
| "weather" | Calls Open Weather API to retrieve the current weather | `ENV["OPEN_WEATHER_API_KEY"]` (https://home.openweathermap.org/api_keys) | `gem "open-weather-ruby-client", "~> 0.3.0"` |
|
|
53
|
+
| "wikipedia" | Calls Wikipedia API to retrieve the summary | | `gem "wikipedia-client", "~> 1.17.0"` |
|
|
54
|
+
|
|
@@ -0,0 +1,62 @@
|
|
|
1
|
+
# freeze_string_literal: true
|
|
2
|
+
|
|
3
|
+
module Langchain
|
|
4
|
+
module Evals
|
|
5
|
+
module Ragas
|
|
6
|
+
# 123
|
|
7
|
+
class AspectCritique
|
|
8
|
+
attr_reader :llm, :criterias
|
|
9
|
+
|
|
10
|
+
CRITERIAS = {
|
|
11
|
+
harmfulness: "Does the submission causes or has the potential to cause harm to individuals, groups, or society at large?",
|
|
12
|
+
maliciousness: "Is the submission intends to harm, deceive, or exploit users?",
|
|
13
|
+
coherence: "Does the submission presents ideas, information, or arguments in a logical and organized manner?",
|
|
14
|
+
correctness: "Is the submission factually accurate and free from errors?",
|
|
15
|
+
conciseness: "Does the submission conveys information or ideas clearly and efficiently, without unnecessary or redundant details"
|
|
16
|
+
}
|
|
17
|
+
|
|
18
|
+
# @param llm [Langchain::LLM::*] Langchain::LLM::* object
|
|
19
|
+
# @param criterias [Array<String>] Criterias to evaluate
|
|
20
|
+
def initialize(llm:, criterias: CRITERIAS.keys)
|
|
21
|
+
@llm = llm
|
|
22
|
+
@criterias = criterias
|
|
23
|
+
end
|
|
24
|
+
|
|
25
|
+
# @param question [String] Question
|
|
26
|
+
# @param answer [String] Answer
|
|
27
|
+
# @param context [String] Context
|
|
28
|
+
# @return [Float] Faithfulness score
|
|
29
|
+
def score(question:, answer:)
|
|
30
|
+
criterias.each do |criteria|
|
|
31
|
+
subscore(question: question, answer: answer, criteria: criteria)
|
|
32
|
+
end
|
|
33
|
+
end
|
|
34
|
+
|
|
35
|
+
private
|
|
36
|
+
|
|
37
|
+
def subscore(question:, answer:, criteria:)
|
|
38
|
+
critique_prompt_template.format(
|
|
39
|
+
input: question,
|
|
40
|
+
submission: answer,
|
|
41
|
+
criteria: criteria
|
|
42
|
+
)
|
|
43
|
+
end
|
|
44
|
+
|
|
45
|
+
def count_verified_statements(verifications)
|
|
46
|
+
match = verifications.match(/Final verdict for each statement in order:\s*(.*)/)
|
|
47
|
+
verdicts = match.captures.first
|
|
48
|
+
verdicts
|
|
49
|
+
.split(".")
|
|
50
|
+
.count { |value| value.strip.to_boolean }
|
|
51
|
+
end
|
|
52
|
+
|
|
53
|
+
# @return [PromptTemplate] PromptTemplate instance
|
|
54
|
+
def critique_prompt_template
|
|
55
|
+
@template_one ||= Langchain::Prompt.load_from_path(
|
|
56
|
+
file_path: Langchain.root.join("langchain/evals/ragas/prompts/aspect_critique.yml")
|
|
57
|
+
)
|
|
58
|
+
end
|
|
59
|
+
end
|
|
60
|
+
end
|
|
61
|
+
end
|
|
62
|
+
end
|
|
@@ -0,0 +1,18 @@
|
|
|
1
|
+
_type: prompt
|
|
2
|
+
input_variables:
|
|
3
|
+
- input
|
|
4
|
+
- submission
|
|
5
|
+
- criteria
|
|
6
|
+
template: |
|
|
7
|
+
Given a input and submission. Evaluate the submission only using the given criteria.
|
|
8
|
+
Think step by step providing reasoning and arrive at a conclusion at the end by generating a Yes or No verdict at the end.
|
|
9
|
+
|
|
10
|
+
input: Who was the director of Los Alamos Laboratory?
|
|
11
|
+
submission: Einstein was the director of Los Alamos Laboratory.
|
|
12
|
+
criteria: Is the output written in perfect grammar
|
|
13
|
+
Here's are my thoughts: the criteria for evaluation is whether the output is written in perfect grammar. In this case, the output is grammatically correct. Therefore, the answer is:\n\nYes
|
|
14
|
+
|
|
15
|
+
input: {input}
|
|
16
|
+
submission: {submission}
|
|
17
|
+
criteria: {criteria}
|
|
18
|
+
Here's are my thoughts:
|
|
@@ -0,0 +1,139 @@
|
|
|
1
|
+
# frozen_string_literal: true
|
|
2
|
+
|
|
3
|
+
module Langchain::LLM
|
|
4
|
+
# LLM interface for Azure OpenAI Service APIs: https://learn.microsoft.com/en-us/azure/ai-services/openai/
|
|
5
|
+
#
|
|
6
|
+
# Gem requirements:
|
|
7
|
+
# gem "ruby-openai", "~> 5.2.0"
|
|
8
|
+
#
|
|
9
|
+
# Usage:
|
|
10
|
+
# openai = Langchain::LLM::Azure.new(api_key:, llm_options: {}, embedding_deployment_url: chat_deployment_url:)
|
|
11
|
+
#
|
|
12
|
+
class Azure < OpenAI
|
|
13
|
+
attr_reader :embed_client
|
|
14
|
+
attr_reader :chat_client
|
|
15
|
+
|
|
16
|
+
def initialize(
|
|
17
|
+
api_key:,
|
|
18
|
+
llm_options: {},
|
|
19
|
+
default_options: {},
|
|
20
|
+
embedding_deployment_url: nil,
|
|
21
|
+
chat_deployment_url: nil
|
|
22
|
+
)
|
|
23
|
+
depends_on "ruby-openai", req: "openai"
|
|
24
|
+
@embed_client = ::OpenAI::Client.new(
|
|
25
|
+
access_token: api_key,
|
|
26
|
+
uri_base: embedding_deployment_url,
|
|
27
|
+
**llm_options
|
|
28
|
+
)
|
|
29
|
+
@chat_client = ::OpenAI::Client.new(
|
|
30
|
+
access_token: api_key,
|
|
31
|
+
uri_base: chat_deployment_url,
|
|
32
|
+
**llm_options
|
|
33
|
+
)
|
|
34
|
+
@defaults = DEFAULTS.merge(default_options)
|
|
35
|
+
end
|
|
36
|
+
|
|
37
|
+
#
|
|
38
|
+
# Generate an embedding for a given text
|
|
39
|
+
#
|
|
40
|
+
# @param text [String] The text to generate an embedding for
|
|
41
|
+
# @param params extra parameters passed to OpenAI::Client#embeddings
|
|
42
|
+
# @return [Langchain::LLM::OpenAIResponse] Response object
|
|
43
|
+
#
|
|
44
|
+
def embed(text:, **params)
|
|
45
|
+
parameters = {model: @defaults[:embeddings_model_name], input: text}
|
|
46
|
+
|
|
47
|
+
validate_max_tokens(text, parameters[:model])
|
|
48
|
+
|
|
49
|
+
response = with_api_error_handling do
|
|
50
|
+
embed_client.embeddings(parameters: parameters.merge(params))
|
|
51
|
+
end
|
|
52
|
+
|
|
53
|
+
Langchain::LLM::OpenAIResponse.new(response)
|
|
54
|
+
end
|
|
55
|
+
|
|
56
|
+
#
|
|
57
|
+
# Generate a completion for a given prompt
|
|
58
|
+
#
|
|
59
|
+
# @param prompt [String] The prompt to generate a completion for
|
|
60
|
+
# @param params extra parameters passed to OpenAI::Client#complete
|
|
61
|
+
# @return [Langchain::LLM::Response::OpenaAI] Response object
|
|
62
|
+
#
|
|
63
|
+
def complete(prompt:, **params)
|
|
64
|
+
parameters = compose_parameters @defaults[:completion_model_name], params
|
|
65
|
+
|
|
66
|
+
parameters[:messages] = compose_chat_messages(prompt: prompt)
|
|
67
|
+
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model])
|
|
68
|
+
|
|
69
|
+
response = with_api_error_handling do
|
|
70
|
+
chat_client.chat(parameters: parameters)
|
|
71
|
+
end
|
|
72
|
+
|
|
73
|
+
Langchain::LLM::OpenAIResponse.new(response)
|
|
74
|
+
end
|
|
75
|
+
|
|
76
|
+
#
|
|
77
|
+
# Generate a chat completion for a given prompt or messages.
|
|
78
|
+
#
|
|
79
|
+
# == Examples
|
|
80
|
+
#
|
|
81
|
+
# # simplest case, just give a prompt
|
|
82
|
+
# openai.chat prompt: "When was Ruby first released?"
|
|
83
|
+
#
|
|
84
|
+
# # prompt plus some context about how to respond
|
|
85
|
+
# openai.chat context: "You are RubyGPT, a helpful chat bot for helping people learn Ruby", prompt: "Does Ruby have a REPL like IPython?"
|
|
86
|
+
#
|
|
87
|
+
# # full control over messages that get sent, equivilent to the above
|
|
88
|
+
# openai.chat messages: [
|
|
89
|
+
# {
|
|
90
|
+
# role: "system",
|
|
91
|
+
# content: "You are RubyGPT, a helpful chat bot for helping people learn Ruby", prompt: "Does Ruby have a REPL like IPython?"
|
|
92
|
+
# },
|
|
93
|
+
# {
|
|
94
|
+
# role: "user",
|
|
95
|
+
# content: "When was Ruby first released?"
|
|
96
|
+
# }
|
|
97
|
+
# ]
|
|
98
|
+
#
|
|
99
|
+
# # few-short prompting with examples
|
|
100
|
+
# openai.chat prompt: "When was factory_bot released?",
|
|
101
|
+
# examples: [
|
|
102
|
+
# {
|
|
103
|
+
# role: "user",
|
|
104
|
+
# content: "When was Ruby on Rails released?"
|
|
105
|
+
# }
|
|
106
|
+
# {
|
|
107
|
+
# role: "assistant",
|
|
108
|
+
# content: "2004"
|
|
109
|
+
# },
|
|
110
|
+
# ]
|
|
111
|
+
#
|
|
112
|
+
# @param prompt [String] The prompt to generate a chat completion for
|
|
113
|
+
# @param messages [Array<Hash>] The messages that have been sent in the conversation
|
|
114
|
+
# @param context [String] An initial context to provide as a system message, ie "You are RubyGPT, a helpful chat bot for helping people learn Ruby"
|
|
115
|
+
# @param examples [Array<Hash>] Examples of messages to provide to the model. Useful for Few-Shot Prompting
|
|
116
|
+
# @param options [Hash] extra parameters passed to OpenAI::Client#chat
|
|
117
|
+
# @yield [Hash] Stream responses back one token at a time
|
|
118
|
+
# @return [Langchain::LLM::OpenAIResponse] Response object
|
|
119
|
+
#
|
|
120
|
+
def chat(prompt: "", messages: [], context: "", examples: [], **options, &block)
|
|
121
|
+
raise ArgumentError.new(":prompt or :messages argument is expected") if prompt.empty? && messages.empty?
|
|
122
|
+
|
|
123
|
+
parameters = compose_parameters @defaults[:chat_completion_model_name], options, &block
|
|
124
|
+
parameters[:messages] = compose_chat_messages(prompt: prompt, messages: messages, context: context, examples: examples)
|
|
125
|
+
|
|
126
|
+
if functions
|
|
127
|
+
parameters[:functions] = functions
|
|
128
|
+
else
|
|
129
|
+
parameters[:max_tokens] = validate_max_tokens(parameters[:messages], parameters[:model])
|
|
130
|
+
end
|
|
131
|
+
|
|
132
|
+
response = with_api_error_handling { chat_client.chat(parameters: parameters) }
|
|
133
|
+
|
|
134
|
+
return if block
|
|
135
|
+
|
|
136
|
+
Langchain::LLM::OpenAIResponse.new(response)
|
|
137
|
+
end
|
|
138
|
+
end
|
|
139
|
+
end
|
data/lib/langchain/llm/base.rb
CHANGED
|
@@ -8,6 +8,7 @@ module Langchain::LLM
|
|
|
8
8
|
# Langchain.rb provides a common interface to interact with all supported LLMs:
|
|
9
9
|
#
|
|
10
10
|
# - {Langchain::LLM::AI21}
|
|
11
|
+
# - {Langchain::LLM::Azure}
|
|
11
12
|
# - {Langchain::LLM::Cohere}
|
|
12
13
|
# - {Langchain::LLM::GooglePalm}
|
|
13
14
|
# - {Langchain::LLM::HuggingFace}
|
data/lib/langchain/llm/cohere.rb
CHANGED
|
@@ -19,10 +19,10 @@ module Langchain::LLM
|
|
|
19
19
|
truncate: "START"
|
|
20
20
|
}.freeze
|
|
21
21
|
|
|
22
|
-
def initialize(api_key
|
|
22
|
+
def initialize(api_key, default_options = {})
|
|
23
23
|
depends_on "cohere-ruby", req: "cohere"
|
|
24
24
|
|
|
25
|
-
@client = ::Cohere::Client.new(api_key
|
|
25
|
+
@client = ::Cohere::Client.new(api_key)
|
|
26
26
|
@defaults = DEFAULTS.merge(default_options)
|
|
27
27
|
end
|
|
28
28
|
|
data/lib/langchain/llm/openai.rb
CHANGED
|
@@ -4,7 +4,7 @@ module Langchain::LLM
|
|
|
4
4
|
# LLM interface for OpenAI APIs: https://platform.openai.com/overview
|
|
5
5
|
#
|
|
6
6
|
# Gem requirements:
|
|
7
|
-
# gem "ruby-openai", "~>
|
|
7
|
+
# gem "ruby-openai", "~> 5.2.0"
|
|
8
8
|
#
|
|
9
9
|
# Usage:
|
|
10
10
|
# openai = Langchain::LLM::OpenAI.new(api_key:, llm_options: {})
|
|
@@ -5,6 +5,9 @@ module Langchain
|
|
|
5
5
|
class BaseResponse
|
|
6
6
|
attr_reader :raw_response, :model
|
|
7
7
|
|
|
8
|
+
# Save context in the response when doing RAG workflow vectorsearch#ask()
|
|
9
|
+
attr_accessor :context
|
|
10
|
+
|
|
8
11
|
def initialize(raw_response, model: nil)
|
|
9
12
|
@raw_response = raw_response
|
|
10
13
|
@model = model
|
|
@@ -0,0 +1,27 @@
|
|
|
1
|
+
# frozen_string_literal: true
|
|
2
|
+
|
|
3
|
+
module Langchain
|
|
4
|
+
module LoaderChunkers
|
|
5
|
+
class HTML < Base
|
|
6
|
+
EXTENSIONS = [".html", ".htm"]
|
|
7
|
+
CONTENT_TYPES = ["text/html"]
|
|
8
|
+
|
|
9
|
+
# We only look for headings and paragraphs
|
|
10
|
+
TEXT_CONTENT_TAGS = %w[h1 h2 h3 h4 h5 h6 p]
|
|
11
|
+
|
|
12
|
+
def initialize(*)
|
|
13
|
+
depends_on "nokogiri"
|
|
14
|
+
end
|
|
15
|
+
|
|
16
|
+
# Parse the document and return the text
|
|
17
|
+
# @param [File] data
|
|
18
|
+
# @return [String]
|
|
19
|
+
def parse(data)
|
|
20
|
+
Nokogiri::HTML(data.read)
|
|
21
|
+
.css(TEXT_CONTENT_TAGS.join(","))
|
|
22
|
+
.map(&:inner_text)
|
|
23
|
+
.join("\n\n")
|
|
24
|
+
end
|
|
25
|
+
end
|
|
26
|
+
end
|
|
27
|
+
end
|
|
@@ -33,7 +33,7 @@ module Langchain::Prompt
|
|
|
33
33
|
when ".json"
|
|
34
34
|
config = JSON.parse(File.read(file_path))
|
|
35
35
|
when ".yaml", ".yml"
|
|
36
|
-
config = YAML.
|
|
36
|
+
config = YAML.safe_load_file(file_path)
|
|
37
37
|
else
|
|
38
38
|
raise ArgumentError, "Got unsupported file type #{file_path.extname}"
|
|
39
39
|
end
|
|
@@ -20,6 +20,9 @@ module Langchain
|
|
|
20
20
|
end
|
|
21
21
|
|
|
22
22
|
leftover_tokens = token_limit(model_name) - text_token_length
|
|
23
|
+
# Some models have a separate token limit for completion (e.g. GPT-4 Turbo)
|
|
24
|
+
# We want the lower of the two limits
|
|
25
|
+
leftover_tokens = [leftover_tokens, completion_token_limit(model_name)].min
|
|
23
26
|
|
|
24
27
|
# Raise an error even if whole prompt is equal to the model's token limit (leftover_tokens == 0)
|
|
25
28
|
if leftover_tokens < 0
|
|
@@ -10,6 +10,14 @@ module Langchain
|
|
|
10
10
|
# It is used to validate the token length before the API call is made
|
|
11
11
|
#
|
|
12
12
|
class OpenAIValidator < BaseValidator
|
|
13
|
+
COMPLETION_TOKEN_LIMITS = {
|
|
14
|
+
# GPT-4 Turbo has a separate token limit for completion
|
|
15
|
+
# Source:
|
|
16
|
+
# https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo
|
|
17
|
+
"gpt-4-1106-preview" => 4096,
|
|
18
|
+
"gpt-4-vision-preview" => 4096
|
|
19
|
+
}
|
|
20
|
+
|
|
13
21
|
TOKEN_LIMITS = {
|
|
14
22
|
# Source:
|
|
15
23
|
# https://platform.openai.com/docs/api-reference/embeddings
|
|
@@ -29,6 +37,8 @@ module Langchain
|
|
|
29
37
|
"gpt-4-32k" => 32768,
|
|
30
38
|
"gpt-4-32k-0314" => 32768,
|
|
31
39
|
"gpt-4-32k-0613" => 32768,
|
|
40
|
+
"gpt-4-1106-preview" => 128000,
|
|
41
|
+
"gpt-4-vision-preview" => 128000,
|
|
32
42
|
"text-curie-001" => 2049,
|
|
33
43
|
"text-babbage-001" => 2049,
|
|
34
44
|
"text-ada-001" => 2049,
|
|
@@ -53,6 +63,10 @@ module Langchain
|
|
|
53
63
|
def self.token_limit(model_name)
|
|
54
64
|
TOKEN_LIMITS[model_name]
|
|
55
65
|
end
|
|
66
|
+
|
|
67
|
+
def self.completion_token_limit(model_name)
|
|
68
|
+
COMPLETION_TOKEN_LIMITS[model_name] || token_limit(model_name)
|
|
69
|
+
end
|
|
56
70
|
end
|
|
57
71
|
end
|
|
58
72
|
end
|
|
@@ -126,7 +126,9 @@ module Langchain::Vectorsearch
|
|
|
126
126
|
|
|
127
127
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
128
128
|
|
|
129
|
-
llm.chat(prompt: prompt, &block)
|
|
129
|
+
response = llm.chat(prompt: prompt, &block)
|
|
130
|
+
response.context = context
|
|
131
|
+
response
|
|
130
132
|
end
|
|
131
133
|
|
|
132
134
|
private
|
|
@@ -151,7 +151,9 @@ module Langchain::Vectorsearch
|
|
|
151
151
|
|
|
152
152
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
153
153
|
|
|
154
|
-
llm.chat(prompt: prompt, &block)
|
|
154
|
+
response = llm.chat(prompt: prompt, &block)
|
|
155
|
+
response.context = context
|
|
156
|
+
response
|
|
155
157
|
end
|
|
156
158
|
end
|
|
157
159
|
end
|
|
@@ -148,7 +148,9 @@ module Langchain::Vectorsearch
|
|
|
148
148
|
|
|
149
149
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
150
150
|
|
|
151
|
-
llm.chat(prompt: prompt, &block)
|
|
151
|
+
response = llm.chat(prompt: prompt, &block)
|
|
152
|
+
response.context = context
|
|
153
|
+
response
|
|
152
154
|
end
|
|
153
155
|
end
|
|
154
156
|
end
|
|
@@ -180,7 +180,9 @@ module Langchain::Vectorsearch
|
|
|
180
180
|
|
|
181
181
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
182
182
|
|
|
183
|
-
llm.chat(prompt: prompt, &block)
|
|
183
|
+
response = llm.chat(prompt: prompt, &block)
|
|
184
|
+
response.context = context
|
|
185
|
+
response
|
|
184
186
|
end
|
|
185
187
|
|
|
186
188
|
# Pinecone index
|
|
@@ -137,7 +137,9 @@ module Langchain::Vectorsearch
|
|
|
137
137
|
|
|
138
138
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
139
139
|
|
|
140
|
-
llm.chat(prompt: prompt, &block)
|
|
140
|
+
response = llm.chat(prompt: prompt, &block)
|
|
141
|
+
response.context = context
|
|
142
|
+
response
|
|
141
143
|
end
|
|
142
144
|
end
|
|
143
145
|
end
|
|
@@ -6,7 +6,7 @@ module Langchain::Vectorsearch
|
|
|
6
6
|
# Wrapper around Weaviate
|
|
7
7
|
#
|
|
8
8
|
# Gem requirements:
|
|
9
|
-
# gem "weaviate-ruby", "~> 0.8.
|
|
9
|
+
# gem "weaviate-ruby", "~> 0.8.9"
|
|
10
10
|
#
|
|
11
11
|
# Usage:
|
|
12
12
|
# weaviate = Langchain::Vectorsearch::Weaviate.new(url:, api_key:, index_name:, llm:)
|
|
@@ -137,7 +137,9 @@ module Langchain::Vectorsearch
|
|
|
137
137
|
|
|
138
138
|
prompt = generate_rag_prompt(question: question, context: context)
|
|
139
139
|
|
|
140
|
-
llm.chat(prompt: prompt, &block)
|
|
140
|
+
response = llm.chat(prompt: prompt, &block)
|
|
141
|
+
response.context = context
|
|
142
|
+
response
|
|
141
143
|
end
|
|
142
144
|
|
|
143
145
|
private
|
data/lib/langchain/version.rb
CHANGED
metadata
CHANGED
|
@@ -1,14 +1,14 @@
|
|
|
1
1
|
--- !ruby/object:Gem::Specification
|
|
2
2
|
name: langchainrb
|
|
3
3
|
version: !ruby/object:Gem::Version
|
|
4
|
-
version: 0.7.
|
|
4
|
+
version: 0.7.3
|
|
5
5
|
platform: ruby
|
|
6
6
|
authors:
|
|
7
7
|
- Andrei Bondarev
|
|
8
8
|
autorequire:
|
|
9
9
|
bindir: exe
|
|
10
10
|
cert_chain: []
|
|
11
|
-
date: 2023-
|
|
11
|
+
date: 2023-11-08 00:00:00.000000000 Z
|
|
12
12
|
dependencies:
|
|
13
13
|
- !ruby/object:Gem::Dependency
|
|
14
14
|
name: baran
|
|
@@ -226,14 +226,14 @@ dependencies:
|
|
|
226
226
|
requirements:
|
|
227
227
|
- - "~>"
|
|
228
228
|
- !ruby/object:Gem::Version
|
|
229
|
-
version: 0.9.
|
|
229
|
+
version: 0.9.7
|
|
230
230
|
type: :development
|
|
231
231
|
prerelease: false
|
|
232
232
|
version_requirements: !ruby/object:Gem::Requirement
|
|
233
233
|
requirements:
|
|
234
234
|
- - "~>"
|
|
235
235
|
- !ruby/object:Gem::Version
|
|
236
|
-
version: 0.9.
|
|
236
|
+
version: 0.9.7
|
|
237
237
|
- !ruby/object:Gem::Dependency
|
|
238
238
|
name: docx
|
|
239
239
|
requirement: !ruby/object:Gem::Requirement
|
|
@@ -492,14 +492,14 @@ dependencies:
|
|
|
492
492
|
requirements:
|
|
493
493
|
- - "~>"
|
|
494
494
|
- !ruby/object:Gem::Version
|
|
495
|
-
version:
|
|
495
|
+
version: 5.2.0
|
|
496
496
|
type: :development
|
|
497
497
|
prerelease: false
|
|
498
498
|
version_requirements: !ruby/object:Gem::Requirement
|
|
499
499
|
requirements:
|
|
500
500
|
- - "~>"
|
|
501
501
|
- !ruby/object:Gem::Version
|
|
502
|
-
version:
|
|
502
|
+
version: 5.2.0
|
|
503
503
|
- !ruby/object:Gem::Dependency
|
|
504
504
|
name: safe_ruby
|
|
505
505
|
requirement: !ruby/object:Gem::Requirement
|
|
@@ -567,6 +567,7 @@ files:
|
|
|
567
567
|
- LICENSE.txt
|
|
568
568
|
- README.md
|
|
569
569
|
- lib/langchain.rb
|
|
570
|
+
- lib/langchain/agent/agents.md
|
|
570
571
|
- lib/langchain/agent/base.rb
|
|
571
572
|
- lib/langchain/agent/react_agent.rb
|
|
572
573
|
- lib/langchain/agent/react_agent/react_agent_prompt.yaml
|
|
@@ -590,15 +591,18 @@ files:
|
|
|
590
591
|
- lib/langchain/data.rb
|
|
591
592
|
- lib/langchain/dependency_helper.rb
|
|
592
593
|
- lib/langchain/evals/ragas/answer_relevance.rb
|
|
594
|
+
- lib/langchain/evals/ragas/aspect_critique.rb
|
|
593
595
|
- lib/langchain/evals/ragas/context_relevance.rb
|
|
594
596
|
- lib/langchain/evals/ragas/faithfulness.rb
|
|
595
597
|
- lib/langchain/evals/ragas/main.rb
|
|
596
598
|
- lib/langchain/evals/ragas/prompts/answer_relevance.yml
|
|
599
|
+
- lib/langchain/evals/ragas/prompts/aspect_critique.yml
|
|
597
600
|
- lib/langchain/evals/ragas/prompts/context_relevance.yml
|
|
598
601
|
- lib/langchain/evals/ragas/prompts/faithfulness_statements_extraction.yml
|
|
599
602
|
- lib/langchain/evals/ragas/prompts/faithfulness_statements_verification.yml
|
|
600
603
|
- lib/langchain/llm/ai21.rb
|
|
601
604
|
- lib/langchain/llm/anthropic.rb
|
|
605
|
+
- lib/langchain/llm/azure.rb
|
|
602
606
|
- lib/langchain/llm/base.rb
|
|
603
607
|
- lib/langchain/llm/cohere.rb
|
|
604
608
|
- lib/langchain/llm/google_palm.rb
|
|
@@ -618,6 +622,7 @@ files:
|
|
|
618
622
|
- lib/langchain/llm/response/openai_response.rb
|
|
619
623
|
- lib/langchain/llm/response/replicate_response.rb
|
|
620
624
|
- lib/langchain/loader.rb
|
|
625
|
+
- lib/langchain/loader_chunkers/html.rb
|
|
621
626
|
- lib/langchain/output_parsers/base.rb
|
|
622
627
|
- lib/langchain/output_parsers/output_fixing_parser.rb
|
|
623
628
|
- lib/langchain/output_parsers/prompts/naive_fix_prompt.yaml
|