dispatch_policy 0.2.0 → 0.4.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +4 -4
- data/CHANGELOG.md +98 -28
- data/MIT-LICENSE +16 -17
- data/README.md +452 -388
- data/app/assets/images/dispatch_policy/logo-large.svg +9 -0
- data/app/assets/images/dispatch_policy/logo-small.svg +7 -0
- data/app/assets/javascripts/dispatch_policy/turbo.es2017-umd.min.js +35 -0
- data/app/assets/stylesheets/dispatch_policy/application.css +294 -0
- data/app/controllers/dispatch_policy/application_controller.rb +45 -1
- data/app/controllers/dispatch_policy/assets_controller.rb +31 -0
- data/app/controllers/dispatch_policy/dashboard_controller.rb +91 -0
- data/app/controllers/dispatch_policy/partitions_controller.rb +122 -0
- data/app/controllers/dispatch_policy/policies_controller.rb +94 -267
- data/app/controllers/dispatch_policy/staged_jobs_controller.rb +9 -0
- data/app/models/dispatch_policy/adaptive_concurrency_stats.rb +11 -81
- data/app/models/dispatch_policy/inflight_job.rb +12 -0
- data/app/models/dispatch_policy/partition.rb +21 -0
- data/app/models/dispatch_policy/staged_job.rb +4 -97
- data/app/models/dispatch_policy/tick_sample.rb +11 -0
- data/app/views/dispatch_policy/dashboard/index.html.erb +109 -0
- data/app/views/dispatch_policy/partitions/index.html.erb +63 -0
- data/app/views/dispatch_policy/partitions/show.html.erb +106 -0
- data/app/views/dispatch_policy/policies/index.html.erb +15 -37
- data/app/views/dispatch_policy/policies/show.html.erb +139 -223
- data/app/views/dispatch_policy/shared/_capacity.html.erb +67 -0
- data/app/views/dispatch_policy/shared/_hints.html.erb +13 -0
- data/app/views/dispatch_policy/shared/_partition_row.html.erb +12 -0
- data/app/views/dispatch_policy/staged_jobs/show.html.erb +31 -0
- data/app/views/layouts/dispatch_policy/application.html.erb +164 -231
- data/config/routes.rb +21 -2
- data/db/migrate/20260501000001_create_dispatch_policy_tables.rb +103 -0
- data/lib/dispatch_policy/assets.rb +38 -0
- data/lib/dispatch_policy/bypass.rb +23 -0
- data/lib/dispatch_policy/config.rb +85 -0
- data/lib/dispatch_policy/context.rb +50 -0
- data/lib/dispatch_policy/cursor_pagination.rb +121 -0
- data/lib/dispatch_policy/decision.rb +22 -0
- data/lib/dispatch_policy/engine.rb +5 -27
- data/lib/dispatch_policy/forwarder.rb +63 -0
- data/lib/dispatch_policy/gate.rb +10 -38
- data/lib/dispatch_policy/gates/adaptive_concurrency.rb +99 -97
- data/lib/dispatch_policy/gates/concurrency.rb +45 -26
- data/lib/dispatch_policy/gates/throttle.rb +65 -41
- data/lib/dispatch_policy/inflight_tracker.rb +174 -0
- data/lib/dispatch_policy/job_extension.rb +155 -0
- data/lib/dispatch_policy/operator_hints.rb +126 -0
- data/lib/dispatch_policy/pipeline.rb +48 -0
- data/lib/dispatch_policy/policy.rb +61 -59
- data/lib/dispatch_policy/policy_dsl.rb +120 -0
- data/lib/dispatch_policy/railtie.rb +35 -0
- data/lib/dispatch_policy/registry.rb +46 -0
- data/lib/dispatch_policy/repository.rb +723 -0
- data/lib/dispatch_policy/serializer.rb +36 -0
- data/lib/dispatch_policy/tick.rb +260 -256
- data/lib/dispatch_policy/tick_loop.rb +59 -26
- data/lib/dispatch_policy/version.rb +1 -1
- data/lib/dispatch_policy.rb +72 -52
- data/lib/generators/dispatch_policy/install/install_generator.rb +70 -0
- data/lib/generators/dispatch_policy/install/templates/create_dispatch_policy_tables.rb.tt +95 -0
- data/lib/generators/dispatch_policy/install/templates/dispatch_tick_loop_job.rb.tt +53 -0
- data/lib/generators/dispatch_policy/install/templates/initializer.rb.tt +11 -0
- metadata +134 -42
- data/app/models/dispatch_policy/partition_inflight_count.rb +0 -42
- data/app/models/dispatch_policy/partition_observation.rb +0 -76
- data/app/models/dispatch_policy/throttle_bucket.rb +0 -41
- data/db/migrate/20260424000001_create_dispatch_policy_tables.rb +0 -80
- data/db/migrate/20260424000002_create_adaptive_concurrency_stats.rb +0 -22
- data/db/migrate/20260424000003_create_adaptive_concurrency_samples.rb +0 -25
- data/db/migrate/20260424000004_rename_samples_to_partition_observations.rb +0 -32
- data/db/migrate/20260425000001_add_duration_to_partition_observations.rb +0 -8
- data/lib/dispatch_policy/active_job_perform_all_later_patch.rb +0 -32
- data/lib/dispatch_policy/dispatch_context.rb +0 -53
- data/lib/dispatch_policy/dispatchable.rb +0 -123
- data/lib/dispatch_policy/gates/fair_interleave.rb +0 -32
- data/lib/dispatch_policy/gates/global_cap.rb +0 -26
data/README.md
CHANGED
|
@@ -1,550 +1,614 @@
|
|
|
1
|
+
<p align="center">
|
|
2
|
+
<picture>
|
|
3
|
+
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/ceritium/dispatch_policy/master/arts/logo-lockup-dark.svg">
|
|
4
|
+
<img src="https://raw.githubusercontent.com/ceritium/dispatch_policy/master/arts/logo-lockup.svg" alt="dispatch_policy" width="360">
|
|
5
|
+
</picture>
|
|
6
|
+
</p>
|
|
7
|
+
|
|
1
8
|
# DispatchPolicy
|
|
2
9
|
|
|
3
|
-
>
|
|
4
|
-
>
|
|
5
|
-
>
|
|
6
|
-
> what breaks. If you pick it up for your own project, pin the exact
|
|
7
|
-
> version and expect to follow the changelog.
|
|
10
|
+
> **Pre-1.0.** Published on RubyGems but the API, schema, and
|
|
11
|
+
> defaults can still shift between minor versions. See `CHANGELOG.md`
|
|
12
|
+
> before upgrading.
|
|
8
13
|
>
|
|
9
|
-
> **PostgreSQL only
|
|
10
|
-
>
|
|
11
|
-
>
|
|
12
|
-
>
|
|
13
|
-
>
|
|
14
|
-
> (shadow columns for `jsonb`, full indexes instead of partial, a
|
|
15
|
-
> different batch-fetch strategy for fairness). Contributions welcome.
|
|
14
|
+
> **PostgreSQL only.** Staging, admission, and adaptive stats lean on
|
|
15
|
+
> `jsonb`, partial indexes, `FOR UPDATE SKIP LOCKED`, `ON CONFLICT`,
|
|
16
|
+
> and the adapter sharing `ActiveRecord::Base.connection` so the
|
|
17
|
+
> admit + adapter INSERT can join one transaction. Tested against
|
|
18
|
+
> good_job and solid_queue.
|
|
16
19
|
|
|
17
20
|
Per-partition admission control for ActiveJob. Stages `perform_later`
|
|
18
21
|
into a dedicated table, runs a tick loop that admits jobs through
|
|
19
|
-
declared gates (throttle
|
|
20
|
-
|
|
22
|
+
declared gates (`throttle`, `concurrency`, `adaptive_concurrency`),
|
|
23
|
+
then forwards survivors to the real adapter. The admission and the
|
|
24
|
+
adapter INSERT happen inside one Postgres transaction, so a worker
|
|
25
|
+
crash mid-tick can't lose a job.
|
|
21
26
|
|
|
22
27
|
Use it when you need:
|
|
23
28
|
|
|
24
|
-
- **Per-tenant / per-endpoint throttle**
|
|
25
|
-
|
|
26
|
-
- **Per-partition concurrency**
|
|
27
|
-
completion
|
|
29
|
+
- **Per-tenant / per-endpoint throttle** — token bucket per partition,
|
|
30
|
+
refreshed lazily on read.
|
|
31
|
+
- **Per-partition concurrency** — fixed cap on in-flight jobs with a
|
|
32
|
+
release hook on completion and a heartbeat-based reaper for crashes.
|
|
28
33
|
- **Adaptive concurrency** — a cap that shrinks under queue pressure
|
|
29
|
-
and grows back when workers keep up,
|
|
30
|
-
- **
|
|
31
|
-
|
|
32
|
-
tenant's burst can't starve the others
|
|
33
|
-
|
|
34
|
-
|
|
34
|
+
and grows back when workers keep up, no manual tuning per tenant.
|
|
35
|
+
- **In-tick fairness** — within a single tick, partitions are reordered
|
|
36
|
+
by recent activity (EWMA) and an optional global cap is shared
|
|
37
|
+
fairly across them. So one tenant's burst can't starve the others.
|
|
38
|
+
- **Sharding** — split a policy across N queues so independent tick
|
|
39
|
+
workers admit in parallel.
|
|
35
40
|
|
|
36
41
|
## Demo
|
|
37
42
|
|
|
38
|
-
|
|
39
|
-
|
|
40
|
-
|
|
41
|
-
|
|
42
|
-
|
|
43
|
+
The demo lives in `test/dummy/` — a tiny Rails app inside this repo.
|
|
44
|
+
Run it locally to play with every gate and the admin UI:
|
|
45
|
+
|
|
46
|
+
```bash
|
|
47
|
+
bin/dummy setup good_job # creates the DB and migrates
|
|
48
|
+
DUMMY_ADAPTER=good_job bundle exec foreman start
|
|
49
|
+
```
|
|
50
|
+
|
|
51
|
+
Then open:
|
|
52
|
+
|
|
53
|
+
- `http://localhost:3000/` — playground with one card per job and a
|
|
54
|
+
storm form that exercises the adaptive cap and fairness reorder
|
|
55
|
+
across many tenants.
|
|
56
|
+
- `http://localhost:3000/dispatch_policy` — admin UI: live throughput,
|
|
57
|
+
partition state, denial reasons, capacity hints.
|
|
58
|
+
|
|
59
|
+
The dummy ships ten purpose-built jobs covering throttle, concurrency,
|
|
60
|
+
mixed gates, scheduling, retries, stress tests, sharding, fairness, and
|
|
61
|
+
adaptive concurrency. See `test/dummy/app/jobs/`.
|
|
62
|
+
|
|
63
|
+
## Screenshots
|
|
64
|
+
|
|
65
|
+
The admin UI lives at `/dispatch_policy` once the engine is mounted.
|
|
66
|
+
Live throughput, capacity hints, denial reasons, and per-partition
|
|
67
|
+
sparklines:
|
|
68
|
+
|
|
69
|
+
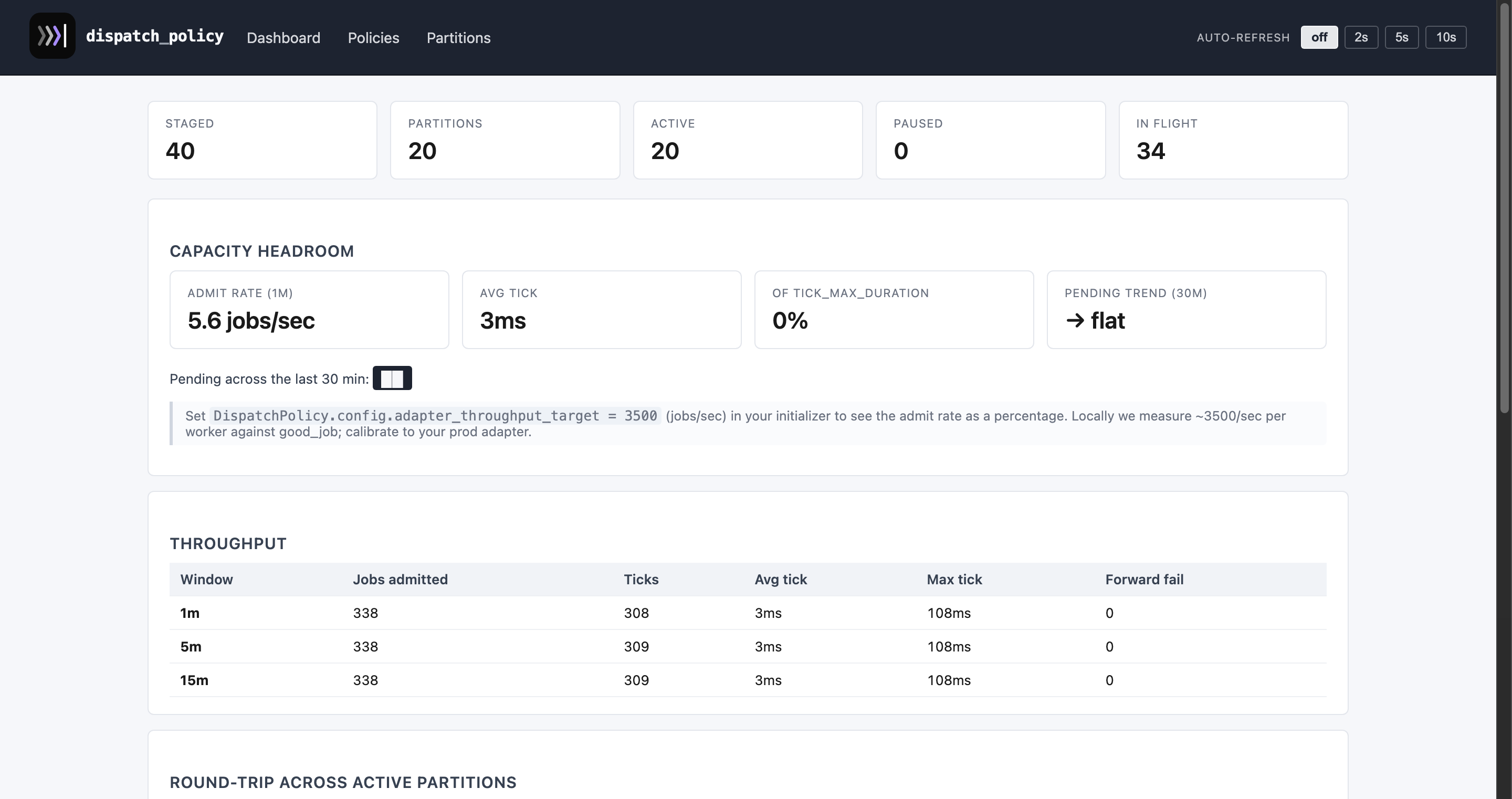
|
|
70
|
+
|
|
71
|
+
A policy detail page — totals, EWMA queue-lag chart, throughput
|
|
72
|
+
window, and a searchable list of all partitions:
|
|
73
|
+
|
|
74
|
+
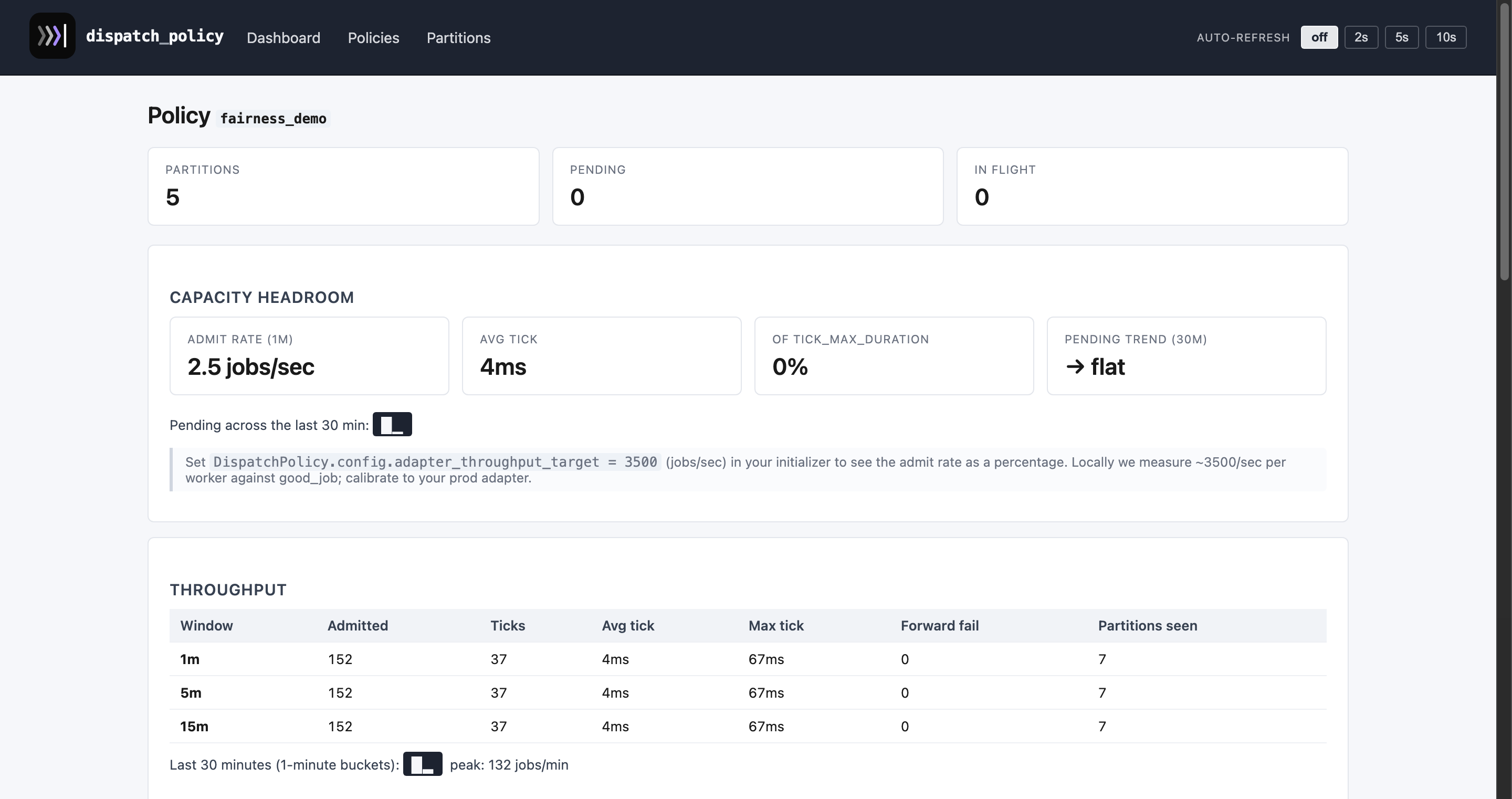
|
|
75
|
+
|
|
76
|
+
Other per-policy pages:
|
|
77
|
+
[adaptive_demo](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/admin-policy-adaptive_demo.png) ·
|
|
78
|
+
[high_throttle](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/admin-policy-high_throttle.png) ·
|
|
79
|
+
[high_concurrency](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/admin-policy-high_concurrency.png) ·
|
|
80
|
+
[mixed](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/admin-policy-mixed.png) ·
|
|
81
|
+
[policies index](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/policies-index.png) ·
|
|
82
|
+
[partitions index](https://raw.githubusercontent.com/ceritium/dispatch_policy/master/screenshots/partitions-index.png).
|
|
83
|
+
|
|
84
|
+
Regenerate everything against the dummy app with:
|
|
85
|
+
|
|
86
|
+
```bash
|
|
87
|
+
bin/screenshots
|
|
88
|
+
```
|
|
89
|
+
|
|
90
|
+
The script seeds realistic state (ticks admit some, GoodJob drains
|
|
91
|
+
inline, then a few fresh jobs are left pending) and drives Capybara
|
|
92
|
+
with headless Chrome through the admin pages. Stop `bin/dummy
|
|
93
|
+
good_job` (or any running tick loop) first so the seeding isn't
|
|
94
|
+
racing a live worker — Selenium Manager auto-downloads chromedriver,
|
|
95
|
+
you only need Chrome installed locally.
|
|
43
96
|
|
|
44
97
|
## Install
|
|
45
98
|
|
|
46
99
|
Add to your `Gemfile`:
|
|
47
100
|
|
|
48
101
|
```ruby
|
|
49
|
-
gem "dispatch_policy"
|
|
102
|
+
gem "dispatch_policy", "~> 0.3"
|
|
50
103
|
```
|
|
51
104
|
|
|
52
|
-
|
|
105
|
+
Generate the install bundle (migration + initializer + tick loop job):
|
|
53
106
|
|
|
54
|
-
```
|
|
55
|
-
|
|
56
|
-
|
|
107
|
+
```bash
|
|
108
|
+
bin/rails generate dispatch_policy:install
|
|
109
|
+
bin/rails db:migrate
|
|
57
110
|
```
|
|
58
111
|
|
|
59
|
-
Mount the admin UI
|
|
112
|
+
Mount the admin UI (optional but recommended):
|
|
60
113
|
|
|
61
114
|
```ruby
|
|
62
|
-
mount DispatchPolicy::Engine
|
|
115
|
+
mount DispatchPolicy::Engine, at: "/dispatch_policy"
|
|
63
116
|
```
|
|
64
117
|
|
|
65
|
-
|
|
118
|
+
Then schedule the tick loop. The generator wrote a
|
|
119
|
+
`DispatchTickLoopJob` in `app/jobs/`; kick it off once and it
|
|
120
|
+
re-enqueues itself:
|
|
66
121
|
|
|
67
122
|
```ruby
|
|
68
|
-
|
|
69
|
-
c.enabled = ENV.fetch("DISPATCH_POLICY_ENABLED", "true") != "false"
|
|
70
|
-
c.lease_duration = 15.minutes
|
|
71
|
-
c.batch_size = 500
|
|
72
|
-
c.round_robin_quantum = 50
|
|
73
|
-
c.tick_sleep = 1 # idle
|
|
74
|
-
c.tick_sleep_busy = 0.05 # after productive ticks
|
|
75
|
-
end
|
|
123
|
+
DispatchTickLoopJob.perform_later
|
|
76
124
|
```
|
|
77
125
|
|
|
78
126
|
## Flow
|
|
79
127
|
|
|
80
128
|
```
|
|
81
129
|
ActiveJob#perform_later
|
|
82
|
-
→
|
|
83
|
-
→
|
|
130
|
+
→ JobExtension.around_enqueue_for
|
|
131
|
+
→ Repository.stage! (INSERT staged + UPSERT partition; ctx refreshed)
|
|
84
132
|
|
|
85
133
|
(tick loop, periodically)
|
|
86
|
-
→
|
|
87
|
-
→
|
|
88
|
-
→
|
|
89
|
-
|
|
134
|
+
→ claim_partitions (FOR UPDATE SKIP LOCKED, ordered by last_checked_at)
|
|
135
|
+
→ reorder by decayed_admits ASC (in-tick fairness)
|
|
136
|
+
→ for each: pipeline.call(ctx, partition, fair_share)
|
|
137
|
+
→ gates evaluate; admit_count = min(allowed)
|
|
138
|
+
→ ONE TX: claim_staged_jobs! + insert_inflight! + Forwarder.dispatch
|
|
139
|
+
(the adapter INSERT shares the TX; rollback if anything raises)
|
|
140
|
+
→ bulk-flush deny-state in one UPDATE ... FROM (VALUES ...)
|
|
90
141
|
|
|
91
142
|
(worker runs perform)
|
|
92
|
-
→
|
|
143
|
+
→ InflightTracker.track (around_perform)
|
|
144
|
+
→ INSERT inflight_jobs ON CONFLICT DO NOTHING
|
|
145
|
+
→ spawn heartbeat thread
|
|
93
146
|
→ block.call
|
|
94
|
-
→
|
|
147
|
+
→ record_observation on adaptive gates (queue_lag → AIMD update)
|
|
148
|
+
→ DELETE inflight_jobs
|
|
95
149
|
```
|
|
96
150
|
|
|
97
151
|
## Declaring a policy
|
|
98
152
|
|
|
99
153
|
```ruby
|
|
100
|
-
class
|
|
101
|
-
|
|
154
|
+
class FetchEndpointJob < ApplicationJob
|
|
155
|
+
dispatch_policy_inflight_tracking # only required if a concurrency gate is used
|
|
102
156
|
|
|
103
|
-
dispatch_policy do
|
|
104
|
-
# Persisted in the staged row so gates can read it without touching AR.
|
|
157
|
+
dispatch_policy :endpoints do
|
|
105
158
|
context ->(args) {
|
|
106
159
|
event = args.first
|
|
107
|
-
{
|
|
160
|
+
{
|
|
161
|
+
endpoint_id: event.endpoint_id,
|
|
162
|
+
rate_limit: event.endpoint.rate_limit,
|
|
163
|
+
max_per_account: event.account.dispatch_concurrency
|
|
164
|
+
}
|
|
108
165
|
}
|
|
109
166
|
|
|
110
|
-
#
|
|
111
|
-
|
|
112
|
-
|
|
113
|
-
# Tenant fairness — see the "Round-robin" section below.
|
|
114
|
-
round_robin_by ->(args) { args.first.account_id }
|
|
167
|
+
# Required: every gate in the policy enforces against this scope.
|
|
168
|
+
partition_by ->(ctx) { ctx[:endpoint_id] }
|
|
115
169
|
|
|
116
170
|
gate :throttle,
|
|
117
|
-
rate:
|
|
118
|
-
per:
|
|
119
|
-
partition_by: ->(ctx) { ctx[:endpoint_id] }
|
|
171
|
+
rate: ->(ctx) { ctx[:rate_limit] },
|
|
172
|
+
per: 1.minute
|
|
120
173
|
|
|
121
|
-
gate :
|
|
174
|
+
gate :concurrency,
|
|
175
|
+
max: ->(ctx) { ctx[:max_per_account] || 5 }
|
|
176
|
+
|
|
177
|
+
retry_strategy :restage # default; alternative: :bypass
|
|
122
178
|
end
|
|
123
179
|
|
|
124
|
-
def perform(event)
|
|
180
|
+
def perform(event)
|
|
181
|
+
# ... call the rate-limited HTTP endpoint
|
|
182
|
+
end
|
|
125
183
|
end
|
|
126
184
|
```
|
|
127
185
|
|
|
128
186
|
`perform_later` stages the job; the tick admits it when its gates pass.
|
|
187
|
+
With multiple gates the actual `admit_count` per tick comes out as
|
|
188
|
+
`min(allowed)` across all of them.
|
|
129
189
|
|
|
130
|
-
|
|
131
|
-
a shared pool) skip ahead to [Recipes](#multi-tenant-webhook-delivery)
|
|
132
|
-
— `round_robin_by weight: :time` plus `:adaptive_concurrency` covers
|
|
133
|
-
it without an explicit throttle.
|
|
134
|
-
|
|
135
|
-
## Gates
|
|
190
|
+
## Choosing the partition scope
|
|
136
191
|
|
|
137
|
-
|
|
138
|
-
|
|
139
|
-
|
|
192
|
+
`partition_by` is the most consequential decision in a policy and the
|
|
193
|
+
only required field. It tells the gem **what counts as one logical
|
|
194
|
+
partition** — what scope each gate enforces against, and what the
|
|
195
|
+
in-tick fairness reorder operates over.
|
|
140
196
|
|
|
141
|
-
|
|
197
|
+
A policy with `partition_by` and **no gates** is also valid: the
|
|
198
|
+
pipeline passes the full budget through, and the Tick caps it via
|
|
199
|
+
`admission_batch_size` (or `tick_admission_budget` if set). Useful
|
|
200
|
+
for "balance N tenants evenly" without rate-limiting any of them.
|
|
142
201
|
|
|
143
|
-
|
|
144
|
-
|
|
145
|
-
|
|
146
|
-
|
|
147
|
-
(worker crashed).
|
|
202
|
+
If you need genuinely different scopes per gate (throttle by endpoint
|
|
203
|
+
AND concurrency by account, each enforced at its own scope), **split
|
|
204
|
+
into two policies** and chain them: the staging policy admits, its
|
|
205
|
+
worker enqueues into the second.
|
|
148
206
|
|
|
149
|
-
|
|
150
|
-
gate :concurrency,
|
|
151
|
-
max: ->(ctx) { ctx[:max_per_account] || 5 },
|
|
152
|
-
partition_by: ->(ctx) { "acct:#{ctx[:account_id]}" }
|
|
153
|
-
```
|
|
207
|
+
## Gates
|
|
154
208
|
|
|
155
|
-
|
|
156
|
-
|
|
157
|
-
|
|
209
|
+
Gates run in declared order; each narrows the survivor count. Every
|
|
210
|
+
option that takes a value can alternatively take a lambda receiving
|
|
211
|
+
the `ctx` hash, so parameters can depend on per-job data.
|
|
158
212
|
|
|
159
213
|
### `:throttle` — token-bucket rate limit per partition
|
|
160
214
|
|
|
161
|
-
Refills `rate` tokens every `per` seconds, capped at `
|
|
162
|
-
|
|
163
|
-
pending for the next tick.
|
|
215
|
+
Refills `rate` tokens every `per` seconds, capped at `rate` (no
|
|
216
|
+
separate burst). Admits jobs while tokens are available; leaves the
|
|
217
|
+
rest pending for the next tick. State is persisted in
|
|
218
|
+
`partitions.gate_state.throttle`.
|
|
164
219
|
|
|
165
220
|
```ruby
|
|
166
221
|
gate :throttle,
|
|
167
|
-
rate:
|
|
168
|
-
per:
|
|
169
|
-
burst: 100, # bucket cap (optional, defaults to rate)
|
|
170
|
-
partition_by: ->(ctx) { "host:#{ctx[:host]}" }
|
|
222
|
+
rate: ->(ctx) { ctx[:rate_limit] },
|
|
223
|
+
per: 1.minute
|
|
171
224
|
```
|
|
172
225
|
|
|
173
|
-
|
|
174
|
-
|
|
226
|
+
Throttle does **not** release tokens on completion — tokens refill
|
|
227
|
+
only with elapsed time.
|
|
228
|
+
|
|
229
|
+
### `:concurrency` — in-flight cap per partition
|
|
230
|
+
|
|
231
|
+
Caps the number of admitted-but-not-yet-completed jobs per partition.
|
|
232
|
+
Counts rows in `dispatch_policy_inflight_jobs` keyed by the policy's
|
|
233
|
+
canonical partition. Decremented by `InflightTracker.track`'s
|
|
234
|
+
`around_perform`; reaped by a periodic sweeper if a worker crashes.
|
|
175
235
|
|
|
176
236
|
```ruby
|
|
177
|
-
gate :
|
|
178
|
-
|
|
179
|
-
per: 1.minute,
|
|
180
|
-
partition_by: ->(ctx) { ctx[:endpoint_id] }
|
|
237
|
+
gate :concurrency,
|
|
238
|
+
max: ->(ctx) { ctx[:max_per_account] || 5 }
|
|
181
239
|
```
|
|
182
240
|
|
|
183
|
-
|
|
184
|
-
|
|
241
|
+
When the cap is full, the gate returns `retry_after = full_backoff`
|
|
242
|
+
(default 1s) so the partition skips the next ticks instead of
|
|
243
|
+
hammering `count(*)` every iteration.
|
|
185
244
|
|
|
186
|
-
### `:
|
|
245
|
+
### `:adaptive_concurrency` — per-partition cap that self-tunes
|
|
187
246
|
|
|
188
|
-
|
|
189
|
-
|
|
190
|
-
|
|
247
|
+
Like `:concurrency` but the cap (`current_max`) shrinks when the
|
|
248
|
+
adapter queue backs up and grows when workers drain it quickly.
|
|
249
|
+
AIMD loop on a per-partition stats row in
|
|
250
|
+
`dispatch_policy_adaptive_concurrency_stats`.
|
|
191
251
|
|
|
192
252
|
```ruby
|
|
193
|
-
gate :
|
|
194
|
-
|
|
253
|
+
gate :adaptive_concurrency,
|
|
254
|
+
initial_max: 3,
|
|
255
|
+
target_lag_ms: 1000, # acceptable queue wait before backoff
|
|
256
|
+
min: 1 # floor; a partition can't lock out
|
|
195
257
|
```
|
|
196
258
|
|
|
197
|
-
|
|
259
|
+
- **Feedback signal**: `admitted_at → perform_start` (queue wait in
|
|
260
|
+
the real adapter). Pure saturation signal — slow performs in the
|
|
261
|
+
downstream service don't punish admissions if workers still drain
|
|
262
|
+
the queue quickly.
|
|
263
|
+
- **Growth**: `current_max += 1` per fast success.
|
|
264
|
+
- **Slow shrink**: `current_max *= 0.95` when EWMA lag > target.
|
|
265
|
+
- **Failure shrink**: `current_max *= 0.5` when `perform` raises.
|
|
266
|
+
- **Safety valve**: when `in_flight == 0` the gate floors `remaining`
|
|
267
|
+
at `initial_max` so a partition that AIMD shrunk to `min` during
|
|
268
|
+
a past burst can re-grow when it idles.
|
|
198
269
|
|
|
199
|
-
|
|
270
|
+
#### Choosing `target_lag_ms`
|
|
200
271
|
|
|
201
|
-
|
|
202
|
-
partition and interleaves, so no single partition can starve others
|
|
203
|
-
even if it has many pending jobs.
|
|
272
|
+
It's the knob that trades latency for throughput. Rough guide:
|
|
204
273
|
|
|
205
|
-
|
|
206
|
-
|
|
207
|
-
|
|
208
|
-
|
|
274
|
+
- **Too low** (10–50 ms): the gate reacts to every tiny bump in
|
|
275
|
+
queue wait and shrinks aggressively. Workers idle while jobs sit
|
|
276
|
+
pending — overshoot.
|
|
277
|
+
- **Too high** (30 s+): the gate barely pushes back; throughput is
|
|
278
|
+
near-max but new admissions wait seconds before a worker picks
|
|
279
|
+
them up.
|
|
280
|
+
- **Reasonable starting point**: `≈ worker_threads × avg_perform_ms`.
|
|
281
|
+
E.g. 5 workers × 200 ms perform = 1000 ms means "queue depth up
|
|
282
|
+
to ~1 s is fine".
|
|
209
283
|
|
|
210
|
-
|
|
211
|
-
off the first partition a row picked up.
|
|
284
|
+
## Fairness within a tick
|
|
212
285
|
|
|
213
|
-
|
|
286
|
+
When several partitions compete for admission inside the same tick,
|
|
287
|
+
the gem reorders them by **least-recently-active first** so a hot
|
|
288
|
+
partition with thousands of pending jobs cannot starve a cold one
|
|
289
|
+
that just woke up.
|
|
214
290
|
|
|
215
|
-
The
|
|
216
|
-
|
|
217
|
-
|
|
218
|
-
per-partition stats row (`dispatch_policy_adaptive_concurrency_stats`).
|
|
291
|
+
The mechanism has two knobs: an EWMA half-life (controls *how* the
|
|
292
|
+
order is decided) and an optional global tick cap (controls *how
|
|
293
|
+
much* each partition is allowed in one tick).
|
|
219
294
|
|
|
220
|
-
|
|
221
|
-
|
|
222
|
-
|
|
223
|
-
|
|
224
|
-
|
|
225
|
-
|
|
226
|
-
|
|
295
|
+
### `fairness half_life:`
|
|
296
|
+
|
|
297
|
+
Each partition keeps `decayed_admits` and `decayed_admits_at`,
|
|
298
|
+
updated atomically inside the admit transaction:
|
|
299
|
+
|
|
300
|
+
```
|
|
301
|
+
decayed_admits := decayed_admits * exp(-Δt / τ) + admitted
|
|
302
|
+
where τ = half_life / ln(2)
|
|
227
303
|
```
|
|
228
304
|
|
|
229
|
-
|
|
230
|
-
|
|
231
|
-
|
|
232
|
-
the queue quickly.
|
|
233
|
-
- **Growth**: +1 per fast success. No hard ceiling; the algorithm
|
|
234
|
-
self-limits via `target_lag_ms`. If the queue builds up, the cap
|
|
235
|
-
shrinks multiplicatively.
|
|
236
|
-
- **Failure**: `current_max *= 0.5` (halve) when `perform` raises.
|
|
237
|
-
- **Slow**: `current_max *= 0.95` when EWMA lag > target.
|
|
305
|
+
After `half_life` seconds without admitting, the value halves. The
|
|
306
|
+
Tick sorts the claimed batch by current `decayed_admits` ASC, so the
|
|
307
|
+
under-admitted go first.
|
|
238
308
|
|
|
239
|
-
|
|
309
|
+
| Value | Behaviour |
|
|
310
|
+
|-----------|------------------------------------------------------------------------------|
|
|
311
|
+
| 5–10 s | Reacts to brief pauses. Bursty workloads where short stalls deserve a head start. |
|
|
312
|
+
| **60 s** (default) | Stable steady-state. Hot partitions stay "hot" through normal latency variation. |
|
|
313
|
+
| 5–15 min | Long memory. Burst on partition A penalises A for many minutes. |
|
|
240
314
|
|
|
241
|
-
|
|
315
|
+
Set `c.fairness_half_life_seconds = nil` to disable the reorder
|
|
316
|
+
entirely — partitions are processed in `claim_partitions` order
|
|
317
|
+
(last-checked-first).
|
|
318
|
+
|
|
319
|
+
### `tick_admission_budget`
|
|
242
320
|
|
|
243
|
-
|
|
244
|
-
|
|
245
|
-
|
|
246
|
-
|
|
247
|
-
|
|
248
|
-
you get near-maximum throughput at the cost of real queue buildup;
|
|
249
|
-
newly admitted jobs may wait seconds before a worker picks them
|
|
250
|
-
up.
|
|
251
|
-
- **Reasonable starting point**: `≈ worker_max_threads × avg_perform_ms`.
|
|
252
|
-
If you run 5 workers at ~200 ms/perform, `target_lag_ms: 1000`
|
|
253
|
-
means "it's OK if the adapter queue stays at most ~1 second
|
|
254
|
-
deep". You'll want to tune from there based on what your
|
|
255
|
-
downstream tolerates and how fast you want bursts to drain.
|
|
256
|
-
|
|
257
|
-
Pair it with `round_robin_by` for multi-tenant systems that want
|
|
258
|
-
automatic backpressure without hand-tuned caps per tenant:
|
|
321
|
+
Without this, each partition admits up to `admission_batch_size`.
|
|
322
|
+
With it set, the per-partition ceiling becomes `fair_share = ceil(cap
|
|
323
|
+
/ claimed_partitions)`. Pass-1 walks the (decay-sorted) partitions
|
|
324
|
+
giving each up to `fair_share`; pass-2 redistributes any leftover to
|
|
325
|
+
those that filled their share.
|
|
259
326
|
|
|
260
327
|
```ruby
|
|
261
|
-
|
|
262
|
-
|
|
263
|
-
|
|
264
|
-
|
|
265
|
-
|
|
328
|
+
DispatchPolicy.configure do |c|
|
|
329
|
+
c.fairness_half_life_seconds = 60
|
|
330
|
+
c.tick_admission_budget = nil # default — no global cap
|
|
331
|
+
end
|
|
332
|
+
|
|
333
|
+
# Per-policy override:
|
|
334
|
+
dispatch_policy :endpoints do
|
|
335
|
+
partition_by ->(c) { c[:endpoint_id] }
|
|
336
|
+
fairness half_life: 30.seconds
|
|
337
|
+
tick_admission_budget 200
|
|
338
|
+
gate :throttle, rate: 100, per: 60
|
|
339
|
+
end
|
|
266
340
|
```
|
|
267
341
|
|
|
268
|
-
|
|
342
|
+
When the cap is hit before all partitions admit, the rest are denied
|
|
343
|
+
with reason `tick_cap_exhausted`. They were still observed
|
|
344
|
+
(`last_checked_at` bumped), so they're at the front of the next
|
|
345
|
+
tick's order.
|
|
269
346
|
|
|
270
|
-
|
|
271
|
-
ActiveJob `queue` and `priority` travel through staging into admission
|
|
272
|
-
and on to the real adapter — workers of each queue pick up their jobs
|
|
273
|
-
normally — but neither affects which staged rows the gates see. All
|
|
274
|
-
enqueues of the same job class share one policy, one throttle bucket,
|
|
275
|
-
one concurrency cap.
|
|
347
|
+
### Anti-stagnation
|
|
276
348
|
|
|
277
|
-
|
|
349
|
+
The decay-based reorder only applies to partitions already claimed.
|
|
350
|
+
Selection (`Repository.claim_partitions`) still orders by
|
|
351
|
+
`last_checked_at NULLS FIRST, id`. Every active partition with
|
|
352
|
+
pending jobs is visited in at most ⌈N / partition_batch_size⌉ ticks
|
|
353
|
+
regardless of how hot or cold it is.
|
|
278
354
|
|
|
279
|
-
|
|
280
|
-
queue priority at admission; they share the policy's gates. If
|
|
281
|
-
urgent work should jump ahead, set a lower ActiveJob `priority`
|
|
282
|
-
(the admission SELECT is `ORDER BY priority, staged_at`) — or split
|
|
283
|
-
into a subclass with its own policy.
|
|
284
|
-
- `dedupe_key` is queue-agnostic: the same key enqueued to
|
|
285
|
-
`:urgent` and `:low` dedupes to one row.
|
|
355
|
+
### Mixing `:adaptive_concurrency` with fairness
|
|
286
356
|
|
|
287
|
-
|
|
357
|
+
Adaptive and fairness operate at different layers and compose
|
|
358
|
+
without sharing state:
|
|
288
359
|
|
|
289
|
-
|
|
290
|
-
|
|
360
|
+
- **Fairness** writes `partitions.decayed_admits` inside the
|
|
361
|
+
per-partition admit TX.
|
|
362
|
+
- **Adaptive** writes `dispatch_policy_adaptive_concurrency_stats`
|
|
363
|
+
from the worker's `around_perform` via `record_observation`.
|
|
364
|
+
|
|
365
|
+
Different tables, different locks. Each tick the actual admit_count
|
|
366
|
+
becomes `min(fair_share, current_max - in_flight)` (with the
|
|
367
|
+
adaptive safety valve when `in_flight == 0`). Fairness picks order +
|
|
368
|
+
budget per tick; adaptive shapes how aggressively each partition
|
|
369
|
+
consumes its share.
|
|
291
370
|
|
|
292
371
|
```ruby
|
|
293
|
-
|
|
294
|
-
|
|
372
|
+
dispatch_policy :tenants do
|
|
373
|
+
partition_by ->(c) { c[:tenant] }
|
|
295
374
|
|
|
296
|
-
|
|
297
|
-
|
|
375
|
+
gate :adaptive_concurrency,
|
|
376
|
+
initial_max: 5,
|
|
377
|
+
target_lag_ms: 1000,
|
|
378
|
+
min: 1
|
|
298
379
|
|
|
299
|
-
|
|
300
|
-
|
|
301
|
-
gate :throttle,
|
|
302
|
-
rate: 100,
|
|
303
|
-
per: 1.minute,
|
|
304
|
-
partition_by: ->(ctx) { "#{ctx[:queue_name]}:#{ctx[:account_id]}" }
|
|
305
|
-
end
|
|
380
|
+
fairness half_life: 30.seconds
|
|
381
|
+
tick_admission_budget 60
|
|
306
382
|
end
|
|
307
|
-
|
|
308
|
-
SendEmailJob.set(queue: :urgent).perform_later(user)
|
|
309
|
-
SendEmailJob.set(queue: :default).perform_later(user)
|
|
310
|
-
# → two partitions, each with its own bucket.
|
|
311
383
|
```
|
|
312
384
|
|
|
313
|
-
|
|
314
|
-
|
|
385
|
+
The dummy `AdaptiveDemoJob` declares both; the storm form drives it
|
|
386
|
+
across many tenants with a triangular weight distribution so you can
|
|
387
|
+
watch the EWMA reorder hot tenants AND the AIMD shrink their cap.
|
|
388
|
+
Integration test: `test/integration/adaptive_with_fairness_test.rb`.
|
|
389
|
+
|
|
390
|
+
## Sharding a policy across worker pools
|
|
391
|
+
|
|
392
|
+
Shards partition the gem horizontally: each tick worker sees only
|
|
393
|
+
the partitions on its own shard, so multiple workers can admit in
|
|
394
|
+
parallel for the same policy. Declare a `shard_by`:
|
|
315
395
|
|
|
316
396
|
```ruby
|
|
317
|
-
|
|
318
|
-
|
|
319
|
-
|
|
320
|
-
|
|
321
|
-
|
|
322
|
-
|
|
397
|
+
dispatch_policy :events do
|
|
398
|
+
context ->(args) { { account_id: args.first[:account_id] } }
|
|
399
|
+
partition_by ->(c) { "acct:#{c[:account_id]}" }
|
|
400
|
+
shard_by ->(c) { "events-shard-#{c[:account_id].hash.abs % 4}" }
|
|
401
|
+
|
|
402
|
+
gate :concurrency, max: 50
|
|
323
403
|
end
|
|
324
404
|
```
|
|
325
405
|
|
|
326
|
-
|
|
406
|
+
Run one `DispatchTickLoopJob` per shard:
|
|
407
|
+
|
|
408
|
+
```ruby
|
|
409
|
+
4.times { |i| DispatchTickLoopJob.perform_later("events", "events-shard-#{i}") }
|
|
410
|
+
```
|
|
411
|
+
|
|
412
|
+
The generated `DispatchTickLoopJob` template uses
|
|
413
|
+
`queue_as { arguments[1] }` so each tick is enqueued on the same
|
|
414
|
+
queue it monitors. Workers listening on `events-shard-*` queues run
|
|
415
|
+
both the tick loops and the admitted jobs from one pool per shard.
|
|
327
416
|
|
|
328
|
-
|
|
329
|
-
`
|
|
417
|
+
The gem's automatic context enrichment puts `:queue_name` into the
|
|
418
|
+
ctx hash so `shard_by` can use it directly without your `context`
|
|
419
|
+
proc having to know about it.
|
|
330
420
|
|
|
331
|
-
|
|
332
|
-
|
|
333
|
-
|
|
334
|
-
- Returning `nil` from the lambda → no dedup for that enqueue.
|
|
421
|
+
**`shard_by` must be ≥ as coarse as the most restrictive throttle's
|
|
422
|
+
scope.** If not, the bucket duplicates across shards and the
|
|
423
|
+
effective rate becomes `rate × N_shards`.
|
|
335
424
|
|
|
336
|
-
|
|
337
|
-
`"event:abc123"`). Keep it stable for the duration of a logical unit
|
|
338
|
-
of work.
|
|
425
|
+
## Atomic admission
|
|
339
426
|
|
|
340
|
-
|
|
427
|
+
`Forwarder.dispatch` runs inside the per-partition admission
|
|
428
|
+
transaction. The adapter (good_job, solid_queue) uses
|
|
429
|
+
`ActiveRecord::Base.connection`, so its `INSERT INTO good_jobs`
|
|
430
|
+
joins the same TX as the `DELETE FROM staged_jobs` and the `INSERT
|
|
431
|
+
INTO inflight_jobs`. Any exception (deserialize, adapter error,
|
|
432
|
+
network) rolls everything back atomically — no window where staged
|
|
433
|
+
is gone but the adapter never received the job.
|
|
341
434
|
|
|
342
|
-
|
|
343
|
-
|
|
344
|
-
|
|
345
|
-
|
|
435
|
+
The trade-off: the gem requires a PG-backed adapter for
|
|
436
|
+
at-least-once. The railtie warns at boot if the adapter doesn't
|
|
437
|
+
look PG-shared (Sidekiq, Resque, async, …) but doesn't hard-fail —
|
|
438
|
+
a custom PG-backed adapter we don't recognise can still work.
|
|
439
|
+
|
|
440
|
+
For Rails multi-DB (e.g. solid_queue on a separate `:queue` role):
|
|
346
441
|
|
|
347
442
|
```ruby
|
|
348
|
-
|
|
349
|
-
|
|
350
|
-
round_robin_by ->(args) { args.first.account_id }
|
|
443
|
+
DispatchPolicy.configure do |c|
|
|
444
|
+
c.database_role = :queue
|
|
351
445
|
end
|
|
352
446
|
```
|
|
353
447
|
|
|
354
|
-
|
|
355
|
-
`
|
|
356
|
-
|
|
357
|
-
|
|
358
|
-
1. **LATERAL join** — distinct keys × per-key `LIMIT round_robin_quantum`.
|
|
359
|
-
Guarantees each active tenant gets at least `quantum` rows per
|
|
360
|
-
tick, so a tenant with 10 pending is served in the same tick as
|
|
361
|
-
a tenant with 50k pending.
|
|
362
|
-
2. **Top-up** — if the fairness floor doesn't fill `batch_size`, the
|
|
363
|
-
remaining slots go to the oldest pending (excluding the ids
|
|
364
|
-
already locked). Keeps single-tenant throughput at full capacity.
|
|
448
|
+
`Repository.with_connection` wraps the admission TX in
|
|
449
|
+
`connected_to(role:)` when set. Staging tables and the adapter's
|
|
450
|
+
table must live in the same DB for atomicity to hold.
|
|
365
451
|
|
|
366
|
-
|
|
367
|
-
admin stays snappy even with thousands of distinct tenants.
|
|
368
|
-
|
|
369
|
-
### Time-weighted variant
|
|
452
|
+
## Running the tick
|
|
370
453
|
|
|
371
|
-
|
|
372
|
-
|
|
373
|
-
|
|
374
|
-
|
|
375
|
-
|
|
454
|
+
`DispatchPolicy::TickLoop.run(policy_name:, shard:, stop_when:)` is
|
|
455
|
+
the entry point. It claims partitions under `FOR UPDATE SKIP
|
|
456
|
+
LOCKED`, evaluates gates, atomically admits, and updates partition
|
|
457
|
+
state. The install generator scaffolds a `DispatchTickLoopJob` you
|
|
458
|
+
schedule like any other ActiveJob:
|
|
376
459
|
|
|
377
460
|
```ruby
|
|
378
|
-
|
|
461
|
+
DispatchTickLoopJob.perform_later # all policies
|
|
462
|
+
DispatchTickLoopJob.perform_later("endpoints") # one policy
|
|
463
|
+
DispatchTickLoopJob.perform_later("endpoints", "shard-2")
|
|
379
464
|
```
|
|
380
465
|
|
|
381
|
-
|
|
382
|
-
|
|
383
|
-
|
|
384
|
-
|
|
385
|
-
|
|
386
|
-
|
|
387
|
-
this tick `fast` claims ~99% of `batch_size` while `slow` gets the
|
|
388
|
-
floor — total compute per minute stays balanced and you don't need a
|
|
389
|
-
throttle on top.
|
|
466
|
+
Each job uses `good_job_control_concurrency_with` (or solid_queue's
|
|
467
|
+
`limits_concurrency`) so only one tick is active per
|
|
468
|
+
(policy, shard) combination at a time. The job re-enqueues itself
|
|
469
|
+
with a 1-second tail wait, so the loop survives normal restarts.
|
|
470
|
+
|
|
471
|
+
## Admin UI
|
|
390
472
|
|
|
391
|
-
|
|
473
|
+
Mount the engine and visit `/dispatch_policy`:
|
|
392
474
|
|
|
393
|
-
|
|
475
|
+
- **Dashboard** — totals, throughput windows, round-trip stats,
|
|
476
|
+
capacity gauges (admit rate vs adapter ceiling, avg tick vs
|
|
477
|
+
`tick_max_duration`), pending trend with up/down arrow, auto-hints
|
|
478
|
+
("avg tick at 88% of tick_max_duration — shard or lower
|
|
479
|
+
admission_batch_size").
|
|
480
|
+
- **Policies** — per-policy throughput, denial reasons breakdown,
|
|
481
|
+
top partitions by lifetime/pending, pause/resume/drain.
|
|
482
|
+
- **Partitions** — searchable list, detail view with gate state,
|
|
483
|
+
decayed_admits + admits/min estimate, recent staged jobs,
|
|
484
|
+
force-admit, drain.
|
|
394
485
|
|
|
395
|
-
|
|
396
|
-
|
|
486
|
+
The UI auto-refreshes via Turbo morph + a controllable picker
|
|
487
|
+
(off / 2s / 5s / 10s) stored in sessionStorage; preserves scroll
|
|
488
|
+
position; and skips a refresh while a previous Turbo visit is in
|
|
489
|
+
flight so a slow page doesn't stack visits.
|
|
397
490
|
|
|
398
|
-
|
|
399
|
-
|
|
400
|
-
|
|
401
|
-
|
|
402
|
-
dispatch_policy do
|
|
403
|
-
context ->(args) { { account_id: args.first[:account_id] } }
|
|
404
|
-
|
|
405
|
-
# Fetch-level fairness by *compute time* (not request count). When
|
|
406
|
-
# several accounts compete, per-tick quanta are sized inverse to
|
|
407
|
-
# their recent perform duration; solo accounts top up to batch_size.
|
|
408
|
-
round_robin_by ->(args) { args.first[:account_id] },
|
|
409
|
-
weight: :time, window: 60
|
|
410
|
-
|
|
411
|
-
# Drip-feed admission per account based on adapter queue lag.
|
|
412
|
-
# Without this, a single account with thousands of pending could
|
|
413
|
-
# dump batch_size jobs into the adapter queue in one tick and lose
|
|
414
|
-
# the ability to react to performance changes mid-burst.
|
|
415
|
-
gate :adaptive_concurrency,
|
|
416
|
-
partition_by: ->(ctx) { ctx[:account_id] },
|
|
417
|
-
initial_max: 3,
|
|
418
|
-
target_lag_ms: 500
|
|
419
|
-
end
|
|
491
|
+
CSRF and forgery protection use the host app's settings. The UI
|
|
492
|
+
ships unauthenticated; wrap the `mount` with a constraint or
|
|
493
|
+
`before_action` for auth in production.
|
|
420
494
|
|
|
421
|
-
|
|
495
|
+
## Configuration
|
|
496
|
+
|
|
497
|
+
```ruby
|
|
498
|
+
# config/initializers/dispatch_policy.rb
|
|
499
|
+
DispatchPolicy.configure do |c|
|
|
500
|
+
c.tick_max_duration = 25 # seconds the tick job stays admitting
|
|
501
|
+
c.partition_batch_size = 50 # partitions claimed per tick iteration
|
|
502
|
+
c.admission_batch_size = 100 # max jobs admitted per partition per iteration
|
|
503
|
+
c.idle_pause = 0.5 # seconds slept when a tick admits nothing
|
|
504
|
+
c.partition_inactive_after = 86_400 # GC partitions idle this long
|
|
505
|
+
c.inflight_stale_after = 300 # GC inflight rows whose worker stopped heartbeating
|
|
506
|
+
c.inflight_heartbeat_interval = 30 # how often the worker bumps heartbeat_at
|
|
507
|
+
c.sweep_every_ticks = 50 # sweeper cadence (in tick iterations)
|
|
508
|
+
c.metrics_retention = 86_400 # tick_samples kept this long
|
|
509
|
+
c.fairness_half_life_seconds = 60 # EWMA half-life for in-tick reorder; nil disables
|
|
510
|
+
c.tick_admission_budget = nil # global cap on admissions per tick; nil = none
|
|
511
|
+
c.adapter_throughput_target = nil # jobs/sec; UI shows admit rate as % of this
|
|
512
|
+
c.database_role = nil # AR role for the admission TX (multi-DB)
|
|
422
513
|
end
|
|
423
514
|
```
|
|
424
515
|
|
|
425
|
-
|
|
426
|
-
|
|
427
|
-
- A solo account runs at whatever throughput its downstream allows;
|
|
428
|
-
`:adaptive_concurrency` grows `current_max` while queue lag stays
|
|
429
|
-
under `target_lag_ms`.
|
|
430
|
-
- A slow account (1 s/perform) and a fast account (100 ms/perform)
|
|
431
|
-
competing → `weight: :time` gives the fast one most of each tick's
|
|
432
|
-
budget; the slow one's adaptive cap shrinks toward `min`. Total
|
|
433
|
-
compute time per minute stays balanced and the adapter queue
|
|
434
|
-
doesn't pile up behind whichever tenant happened to enqueue first.
|
|
435
|
-
- A misbehaving downstream that suddenly goes from 100 ms to 5 s →
|
|
436
|
-
that tenant's `current_max` drops within a few completions and its
|
|
437
|
-
fetch quantum shrinks; the other tenants are unaffected.
|
|
438
|
-
|
|
439
|
-
Tune `target_lag_ms` for the latency budget you can tolerate (see
|
|
440
|
-
[Choosing target_lag_ms](#choosing-target_lag_ms)) and `window` for
|
|
441
|
-
how reactive the time-balancing should be (smaller = noisier, larger
|
|
442
|
-
= more stable).
|
|
516
|
+
You can override `admission_batch_size`, `fairness_half_life_seconds`,
|
|
517
|
+
and `tick_admission_budget` per policy via the DSL.
|
|
443
518
|
|
|
444
|
-
##
|
|
519
|
+
## `partitions.context` is refreshed on every enqueue
|
|
445
520
|
|
|
446
|
-
|
|
447
|
-
|
|
448
|
-
queue-adapter specific (GoodJob's `total_limit`, Sidekiq Enterprise
|
|
449
|
-
uniqueness, etc.), so you write a small job in your app that wraps
|
|
450
|
-
the loop with whatever dedup your adapter provides. Example for
|
|
451
|
-
GoodJob:
|
|
521
|
+
When you call `perform_later`, the gem evaluates your `context` proc
|
|
522
|
+
and upserts the partition row with the resulting hash:
|
|
452
523
|
|
|
453
|
-
```
|
|
454
|
-
|
|
455
|
-
|
|
456
|
-
|
|
457
|
-
|
|
458
|
-
|
|
459
|
-
|
|
460
|
-
)
|
|
461
|
-
|
|
462
|
-
def perform(policy_name = nil)
|
|
463
|
-
deadline = Time.current + DispatchPolicy.config.tick_max_duration
|
|
464
|
-
DispatchPolicy::TickLoop.run(
|
|
465
|
-
policy_name: policy_name,
|
|
466
|
-
stop_when: -> {
|
|
467
|
-
GoodJob.current_thread_shutting_down? || Time.current >= deadline
|
|
468
|
-
}
|
|
469
|
-
)
|
|
470
|
-
# Self-chain so the next run starts immediately; cron below is a safety net.
|
|
471
|
-
DispatchTickLoopJob.set(wait: 1.second).perform_later(policy_name)
|
|
472
|
-
end
|
|
473
|
-
end
|
|
524
|
+
```sql
|
|
525
|
+
INSERT INTO dispatch_policy_partitions (..., context, context_updated_at, ...) VALUES (...)
|
|
526
|
+
ON CONFLICT (policy_name, partition_key) DO UPDATE
|
|
527
|
+
SET context = EXCLUDED.context,
|
|
528
|
+
context_updated_at = EXCLUDED.context_updated_at,
|
|
529
|
+
pending_count = dispatch_policy_partitions.pending_count + 1,
|
|
530
|
+
...
|
|
474
531
|
```
|
|
475
532
|
|
|
476
|
-
|
|
477
|
-
|
|
533
|
+
Gates evaluate against `partition.context`, **not** the per-job
|
|
534
|
+
snapshot in `staged_jobs.context`. So if a tenant bumps their
|
|
535
|
+
`dispatch_concurrency` from 5 to 20 and a new job arrives, the next
|
|
536
|
+
admission uses the new value — no need to drain the partition
|
|
537
|
+
first. If a partition has no new traffic, the context stays at the
|
|
538
|
+
value seen by the last enqueue.
|
|
539
|
+
|
|
540
|
+
## Retry strategies
|
|
541
|
+
|
|
542
|
+
By default a retry produced by `retry_on` re-enters the policy and
|
|
543
|
+
is staged again, so throttle/concurrency apply equally to first
|
|
544
|
+
attempts and retries. Use `retry_strategy :bypass` if you want
|
|
545
|
+
retries to skip the gem and go straight to the adapter:
|
|
478
546
|
|
|
479
547
|
```ruby
|
|
480
|
-
|
|
481
|
-
|
|
482
|
-
|
|
483
|
-
|
|
484
|
-
|
|
485
|
-
}
|
|
486
|
-
}
|
|
548
|
+
dispatch_policy :foo do
|
|
549
|
+
partition_by ->(_c) { "k" }
|
|
550
|
+
gate :throttle, rate: 5, per: 60
|
|
551
|
+
retry_strategy :bypass
|
|
552
|
+
end
|
|
487
553
|
```
|
|
488
554
|
|
|
489
|
-
|
|
490
|
-
yourself (e.g. `pg_try_advisory_lock` inside `perform`) before calling
|
|
491
|
-
`DispatchPolicy::TickLoop.run`.
|
|
492
|
-
|
|
493
|
-
## Admin UI
|
|
555
|
+
## Compatibility
|
|
494
556
|
|
|
495
|
-
|
|
496
|
-
|
|
497
|
-
|
|
498
|
-
-
|
|
499
|
-
|
|
500
|
-
list) showing pending-eligible / pending-scheduled / in-flight /
|
|
501
|
-
completed / adaptive cap / EWMA latency / last enqueue / last
|
|
502
|
-
dispatch per partition.
|
|
503
|
-
- Line chart of avg EWMA queue lag (last hour, per minute) with
|
|
504
|
-
completions-per-minute bars behind it.
|
|
505
|
-
- Per-partition sparkline with the same overlay; click to watch /
|
|
506
|
-
unwatch. Watched set is persisted in `localStorage` and synced into
|
|
507
|
-
the URL so reloading keeps your view.
|
|
508
|
-
- Opt-in auto-refresh (off / 2s / 5s / 15s) stored in `localStorage`.
|
|
509
|
-
Page updates via Turbo morph — scroll position and tooltips survive.
|
|
557
|
+
- Rails 7.1+ (developed against 8.1).
|
|
558
|
+
- PostgreSQL 12+ (uses `FOR UPDATE SKIP LOCKED`, `JSONB`, `ON CONFLICT`).
|
|
559
|
+
- `good_job` ≥ 4.0 or `solid_queue` ≥ 1.0.
|
|
560
|
+
- Sidekiq / Resque are NOT supported — the at-least-once guarantee
|
|
561
|
+
needs the adapter to share Postgres with the gem.
|
|
510
562
|
|
|
511
563
|
## Testing
|
|
512
564
|
|
|
513
|
-
```
|
|
514
|
-
bundle
|
|
515
|
-
bundle exec rake
|
|
565
|
+
```bash
|
|
566
|
+
bundle exec rake test # 124 runs / 284 assertions
|
|
567
|
+
bundle exec rake bench # manual benchmark suite (creates dispatch_policy_bench DB)
|
|
568
|
+
bundle exec rake bench:real # end-to-end against good_job on the dummy DB
|
|
569
|
+
bundle exec rake bench:limits # stretches every path to its breaking point
|
|
516
570
|
```
|
|
517
571
|
|
|
518
|
-
|
|
519
|
-
|
|
520
|
-
`
|
|
521
|
-
`test/dummy/config/database.yml`.
|
|
572
|
+
Integration tests skip when no Postgres is reachable (default DB
|
|
573
|
+
`dispatch_policy_test`; override via `DB_NAME`, `DB_HOST`,
|
|
574
|
+
`DB_USER`, `DB_PASS`).
|
|
522
575
|
|
|
523
576
|
## Releasing
|
|
524
577
|
|
|
525
|
-
|
|
526
|
-
|
|
527
|
-
|
|
528
|
-
|
|
529
|
-
|
|
530
|
-
|
|
531
|
-
|
|
532
|
-
|
|
533
|
-
3.
|
|
534
|
-
|
|
535
|
-
4.
|
|
536
|
-
|
|
537
|
-
|
|
538
|
-
|
|
539
|
-
|
|
540
|
-
|
|
541
|
-
|
|
542
|
-
|
|
543
|
-
|
|
544
|
-
|
|
545
|
-
|
|
546
|
-
|
|
547
|
-
|
|
578
|
+
Cutting a new version is driven by `bin/release`. Steps:
|
|
579
|
+
|
|
580
|
+
1. Bump `DispatchPolicy::VERSION` in
|
|
581
|
+
`lib/dispatch_policy/version.rb`.
|
|
582
|
+
2. Add a `## <VERSION>` section in `CHANGELOG.md` describing the
|
|
583
|
+
release. The script extracts that section verbatim as the
|
|
584
|
+
GitHub release notes, so anything missing here will be missing
|
|
585
|
+
on GitHub.
|
|
586
|
+
3. Commit both on `master` and push so `origin/master` matches
|
|
587
|
+
local.
|
|
588
|
+
4. Run the script from the repo root:
|
|
589
|
+
|
|
590
|
+
```bash
|
|
591
|
+
bin/release
|
|
592
|
+
```
|
|
593
|
+
|
|
594
|
+
The script:
|
|
595
|
+
|
|
596
|
+
- Refuses to run unless you are on `master`, the working tree is
|
|
597
|
+
clean, the local branch matches `origin/master`, and the tag
|
|
598
|
+
`v<VERSION>` does not yet exist.
|
|
599
|
+
- Asks for a `y` confirmation before doing anything.
|
|
600
|
+
- Hands off to `bundle exec rake release` (builds the gem, creates
|
|
601
|
+
the `v<VERSION>` tag, pushes the tag to GitHub, pushes the gem to
|
|
602
|
+
RubyGems.org).
|
|
603
|
+
- Creates a GitHub release for `v<VERSION>` using the matching
|
|
604
|
+
CHANGELOG section as the body. Requires the `gh` CLI; if it is
|
|
605
|
+
missing, the gem ships but you'll need to create the GitHub
|
|
606
|
+
release manually with `gh release create v<VERSION> --notes-file
|
|
607
|
+
CHANGELOG.md`.
|
|
608
|
+
|
|
609
|
+
Prerequisites: a configured `~/.gem/credentials` for RubyGems push
|
|
610
|
+
and `gh auth login` for the GitHub release.
|
|
611
|
+
|
|
548
612
|
|
|
549
613
|
## License
|
|
550
614
|
|