activeadmin_pagedown 0.0.1
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- data/.gitignore +17 -0
- data/Gemfile +3 -0
- data/Gemfile.lock +141 -0
- data/README.md +45 -0
- data/Rakefile +1 -0
- data/active_admin_pagedown.gemspec +22 -0
- data/app/assets/images/active_admin_pagedown/wmd-buttons.png +0 -0
- data/app/assets/javascripts/active_admin_pagedown/Markdown.Converter.js +1332 -0
- data/app/assets/javascripts/active_admin_pagedown/Markdown.Editor.js +2212 -0
- data/app/assets/javascripts/active_admin_pagedown/Markdown.Sanitizer.js +108 -0
- data/app/assets/javascripts/active_admin_pagedown/base.js +3 -0
- data/app/assets/javascripts/active_admin_pagedown/default.js +5 -0
- data/app/assets/stylesheets/active_admin_pagedown/base.css.scss +98 -0
- data/app/inputs/pagedown_text_input.rb +24 -0
- data/lib/active_admin_pagedown.rb +5 -0
- data/lib/active_admin_pagedown/version.rb +3 -0
- data/lib/activeadmin_pagedown.rb +1 -0
- data/pagedown.png +0 -0
- metadata +80 -0
data/.gitignore
ADDED
data/Gemfile
ADDED
data/Gemfile.lock
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
1
|
+
PATH
|
|
2
|
+
remote: .
|
|
3
|
+
specs:
|
|
4
|
+
activeadmin_pagedown (0.0.1)
|
|
5
|
+
activeadmin (>= 0.5.0)
|
|
6
|
+
|
|
7
|
+
GEM
|
|
8
|
+
remote: http://rubygems.org/
|
|
9
|
+
specs:
|
|
10
|
+
actionmailer (3.2.11)
|
|
11
|
+
actionpack (= 3.2.11)
|
|
12
|
+
mail (~> 2.4.4)
|
|
13
|
+
actionpack (3.2.11)
|
|
14
|
+
activemodel (= 3.2.11)
|
|
15
|
+
activesupport (= 3.2.11)
|
|
16
|
+
builder (~> 3.0.0)
|
|
17
|
+
erubis (~> 2.7.0)
|
|
18
|
+
journey (~> 1.0.4)
|
|
19
|
+
rack (~> 1.4.0)
|
|
20
|
+
rack-cache (~> 1.2)
|
|
21
|
+
rack-test (~> 0.6.1)
|
|
22
|
+
sprockets (~> 2.2.1)
|
|
23
|
+
activeadmin (0.5.1)
|
|
24
|
+
arbre (>= 1.0.1)
|
|
25
|
+
bourbon (>= 1.0.0)
|
|
26
|
+
devise (>= 1.1.2)
|
|
27
|
+
fastercsv
|
|
28
|
+
formtastic (>= 2.0.0)
|
|
29
|
+
inherited_resources (>= 1.3.1)
|
|
30
|
+
jquery-rails (>= 1.0.0)
|
|
31
|
+
kaminari (>= 0.13.0)
|
|
32
|
+
meta_search (>= 0.9.2)
|
|
33
|
+
rails (>= 3.0.0)
|
|
34
|
+
sass (>= 3.1.0)
|
|
35
|
+
activemodel (3.2.11)
|
|
36
|
+
activesupport (= 3.2.11)
|
|
37
|
+
builder (~> 3.0.0)
|
|
38
|
+
activerecord (3.2.11)
|
|
39
|
+
activemodel (= 3.2.11)
|
|
40
|
+
activesupport (= 3.2.11)
|
|
41
|
+
arel (~> 3.0.2)
|
|
42
|
+
tzinfo (~> 0.3.29)
|
|
43
|
+
activeresource (3.2.11)
|
|
44
|
+
activemodel (= 3.2.11)
|
|
45
|
+
activesupport (= 3.2.11)
|
|
46
|
+
activesupport (3.2.11)
|
|
47
|
+
i18n (~> 0.6)
|
|
48
|
+
multi_json (~> 1.0)
|
|
49
|
+
arbre (1.0.1)
|
|
50
|
+
activesupport (>= 3.0.0)
|
|
51
|
+
arel (3.0.2)
|
|
52
|
+
bcrypt-ruby (3.0.1)
|
|
53
|
+
bourbon (3.0.1)
|
|
54
|
+
sass (>= 3.2.0)
|
|
55
|
+
thor
|
|
56
|
+
builder (3.0.4)
|
|
57
|
+
devise (2.2.1)
|
|
58
|
+
bcrypt-ruby (~> 3.0)
|
|
59
|
+
orm_adapter (~> 0.1)
|
|
60
|
+
railties (~> 3.1)
|
|
61
|
+
warden (~> 1.2.1)
|
|
62
|
+
erubis (2.7.0)
|
|
63
|
+
fastercsv (1.5.5)
|
|
64
|
+
formtastic (2.2.1)
|
|
65
|
+
actionpack (>= 3.0)
|
|
66
|
+
has_scope (0.5.1)
|
|
67
|
+
hike (1.2.1)
|
|
68
|
+
i18n (0.6.1)
|
|
69
|
+
inherited_resources (1.3.1)
|
|
70
|
+
has_scope (~> 0.5.0)
|
|
71
|
+
responders (~> 0.6)
|
|
72
|
+
journey (1.0.4)
|
|
73
|
+
jquery-rails (2.1.4)
|
|
74
|
+
railties (>= 3.0, < 5.0)
|
|
75
|
+
thor (>= 0.14, < 2.0)
|
|
76
|
+
json (1.7.6)
|
|
77
|
+
kaminari (0.14.1)
|
|
78
|
+
actionpack (>= 3.0.0)
|
|
79
|
+
activesupport (>= 3.0.0)
|
|
80
|
+
mail (2.4.4)
|
|
81
|
+
i18n (>= 0.4.0)
|
|
82
|
+
mime-types (~> 1.16)
|
|
83
|
+
treetop (~> 1.4.8)
|
|
84
|
+
meta_search (1.1.3)
|
|
85
|
+
actionpack (~> 3.1)
|
|
86
|
+
activerecord (~> 3.1)
|
|
87
|
+
activesupport (~> 3.1)
|
|
88
|
+
polyamorous (~> 0.5.0)
|
|
89
|
+
mime-types (1.19)
|
|
90
|
+
multi_json (1.5.0)
|
|
91
|
+
orm_adapter (0.4.0)
|
|
92
|
+
polyamorous (0.5.0)
|
|
93
|
+
activerecord (~> 3.0)
|
|
94
|
+
polyglot (0.3.3)
|
|
95
|
+
rack (1.4.3)
|
|
96
|
+
rack-cache (1.2)
|
|
97
|
+
rack (>= 0.4)
|
|
98
|
+
rack-ssl (1.3.2)
|
|
99
|
+
rack
|
|
100
|
+
rack-test (0.6.2)
|
|
101
|
+
rack (>= 1.0)
|
|
102
|
+
rails (3.2.11)
|
|
103
|
+
actionmailer (= 3.2.11)
|
|
104
|
+
actionpack (= 3.2.11)
|
|
105
|
+
activerecord (= 3.2.11)
|
|
106
|
+
activeresource (= 3.2.11)
|
|
107
|
+
activesupport (= 3.2.11)
|
|
108
|
+
bundler (~> 1.0)
|
|
109
|
+
railties (= 3.2.11)
|
|
110
|
+
railties (3.2.11)
|
|
111
|
+
actionpack (= 3.2.11)
|
|
112
|
+
activesupport (= 3.2.11)
|
|
113
|
+
rack-ssl (~> 1.3.2)
|
|
114
|
+
rake (>= 0.8.7)
|
|
115
|
+
rdoc (~> 3.4)
|
|
116
|
+
thor (>= 0.14.6, < 2.0)
|
|
117
|
+
rake (10.0.3)
|
|
118
|
+
rdoc (3.12)
|
|
119
|
+
json (~> 1.4)
|
|
120
|
+
responders (0.9.3)
|
|
121
|
+
railties (~> 3.1)
|
|
122
|
+
sass (3.2.5)
|
|
123
|
+
sprockets (2.2.2)
|
|
124
|
+
hike (~> 1.2)
|
|
125
|
+
multi_json (~> 1.0)
|
|
126
|
+
rack (~> 1.0)
|
|
127
|
+
tilt (~> 1.1, != 1.3.0)
|
|
128
|
+
thor (0.16.0)
|
|
129
|
+
tilt (1.3.3)
|
|
130
|
+
treetop (1.4.12)
|
|
131
|
+
polyglot
|
|
132
|
+
polyglot (>= 0.3.1)
|
|
133
|
+
tzinfo (0.3.35)
|
|
134
|
+
warden (1.2.1)
|
|
135
|
+
rack (>= 1.0)
|
|
136
|
+
|
|
137
|
+
PLATFORMS
|
|
138
|
+
ruby
|
|
139
|
+
|
|
140
|
+
DEPENDENCIES
|
|
141
|
+
activeadmin_pagedown!
|
data/README.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
1
|
+
# ActiveAdmin Pagedown
|
|
2
|
+
|
|
3
|
+
Formtastic Input to add the [Pagedown](http://code.google.com/p/pagedown/) Markdown editor for Active Admin.
|
|
4
|
+
|
|
5
|
+
https://github.com/mguymon/active_admin_pagedown
|
|
6
|
+
|
|
7
|
+
## Install
|
|
8
|
+
|
|
9
|
+
### Bundle the Gem
|
|
10
|
+
|
|
11
|
+
gem 'activeadmin_pagedown'
|
|
12
|
+
|
|
13
|
+
### The Stylesheets
|
|
14
|
+
|
|
15
|
+
Add the import to active_admin.css.scss:
|
|
16
|
+
|
|
17
|
+
@import "active_admin_pagedown/base"
|
|
18
|
+
|
|
19
|
+
### The Javascript
|
|
20
|
+
|
|
21
|
+
Add the following to active_admin.js.coffee to load the Pagedown javascript:
|
|
22
|
+
|
|
23
|
+
//= require active_admin_pagedown/base
|
|
24
|
+
|
|
25
|
+
If you want to use the simple default intializer for Pagedown, add the following as well:
|
|
26
|
+
|
|
27
|
+
## Usage
|
|
28
|
+
|
|
29
|
+
Now you can use the `pagedown_text` input via the `:as` option:
|
|
30
|
+
|
|
31
|
+
form do |f|
|
|
32
|
+
f.inputs do
|
|
33
|
+
f.input :body, :as => :pagedown_text
|
|
34
|
+
f.actions
|
|
35
|
+
end
|
|
36
|
+
end
|
|
37
|
+
|
|
38
|
+
Then you should see in your ActiveAdmin form:
|
|
39
|
+
|
|
40
|
+
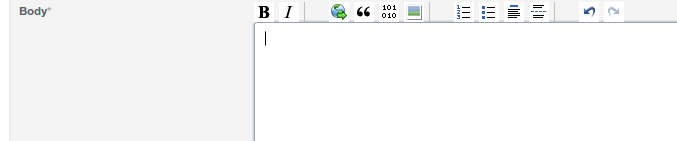
|
|
41
|
+
|
|
42
|
+
## Caveats
|
|
43
|
+
|
|
44
|
+
* Only will work with 1 field per page at the moment. The Pagedown JS looks for specific dom ids, which is hard coded in the input right now.
|
|
45
|
+
* There is no image uploader. Pagedown on its own does not provide one, but it should be possible to add hooks to support it
|
data/Rakefile
ADDED
|
@@ -0,0 +1 @@
|
|
|
1
|
+
require 'bundler/gem_tasks'
|
|
@@ -0,0 +1,22 @@
|
|
|
1
|
+
# -*- encoding: utf-8 -*-
|
|
2
|
+
$:.push File.expand_path("../lib", __FILE__)
|
|
3
|
+
require "active_admin_pagedown/version"
|
|
4
|
+
|
|
5
|
+
Gem::Specification.new do |s|
|
|
6
|
+
s.name = %q{activeadmin_pagedown}
|
|
7
|
+
s.license = "MIT"
|
|
8
|
+
s.version = ActiveAdminPagedown::VERSION
|
|
9
|
+
s.platform = Gem::Platform::RUBY
|
|
10
|
+
s.homepage = %q{https://github.com/mguymon/active_admin_pagedown}
|
|
11
|
+
s.authors = ["Michael Guymon"]
|
|
12
|
+
s.email = ["mguymon@tobedevoured.com"]
|
|
13
|
+
s.description = %q{Pagedown widget for ActiveAdmin.}
|
|
14
|
+
s.summary = %q{Pagedown widget for ActiveAdmin.}
|
|
15
|
+
|
|
16
|
+
s.files = `git ls-files`.split("\n").sort
|
|
17
|
+
s.test_files = `git ls-files -- {test,spec,features}/*`.split("\n")
|
|
18
|
+
s.executables = `git ls-files -- bin/*`.split("\n").map{ |f| File.basename(f) }
|
|
19
|
+
s.require_paths = ["lib"]
|
|
20
|
+
|
|
21
|
+
s.add_dependency("activeadmin", ">= 0.5.0")
|
|
22
|
+
end
|
|
Binary file
|
|
@@ -0,0 +1,1332 @@
|
|
|
1
|
+
var Markdown;
|
|
2
|
+
|
|
3
|
+
if (typeof exports === "object" && typeof require === "function") // we're in a CommonJS (e.g. Node.js) module
|
|
4
|
+
Markdown = exports;
|
|
5
|
+
else
|
|
6
|
+
Markdown = {};
|
|
7
|
+
|
|
8
|
+
// The following text is included for historical reasons, but should
|
|
9
|
+
// be taken with a pinch of salt; it's not all true anymore.
|
|
10
|
+
|
|
11
|
+
//
|
|
12
|
+
// Wherever possible, Showdown is a straight, line-by-line port
|
|
13
|
+
// of the Perl version of Markdown.
|
|
14
|
+
//
|
|
15
|
+
// This is not a normal parser design; it's basically just a
|
|
16
|
+
// series of string substitutions. It's hard to read and
|
|
17
|
+
// maintain this way, but keeping Showdown close to the original
|
|
18
|
+
// design makes it easier to port new features.
|
|
19
|
+
//
|
|
20
|
+
// More importantly, Showdown behaves like markdown.pl in most
|
|
21
|
+
// edge cases. So web applications can do client-side preview
|
|
22
|
+
// in Javascript, and then build identical HTML on the server.
|
|
23
|
+
//
|
|
24
|
+
// This port needs the new RegExp functionality of ECMA 262,
|
|
25
|
+
// 3rd Edition (i.e. Javascript 1.5). Most modern web browsers
|
|
26
|
+
// should do fine. Even with the new regular expression features,
|
|
27
|
+
// We do a lot of work to emulate Perl's regex functionality.
|
|
28
|
+
// The tricky changes in this file mostly have the "attacklab:"
|
|
29
|
+
// label. Major or self-explanatory changes don't.
|
|
30
|
+
//
|
|
31
|
+
// Smart diff tools like Araxis Merge will be able to match up
|
|
32
|
+
// this file with markdown.pl in a useful way. A little tweaking
|
|
33
|
+
// helps: in a copy of markdown.pl, replace "#" with "//" and
|
|
34
|
+
// replace "$text" with "text". Be sure to ignore whitespace
|
|
35
|
+
// and line endings.
|
|
36
|
+
//
|
|
37
|
+
|
|
38
|
+
|
|
39
|
+
//
|
|
40
|
+
// Usage:
|
|
41
|
+
//
|
|
42
|
+
// var text = "Markdown *rocks*.";
|
|
43
|
+
//
|
|
44
|
+
// var converter = new Markdown.Converter();
|
|
45
|
+
// var html = converter.makeHtml(text);
|
|
46
|
+
//
|
|
47
|
+
// alert(html);
|
|
48
|
+
//
|
|
49
|
+
// Note: move the sample code to the bottom of this
|
|
50
|
+
// file before uncommenting it.
|
|
51
|
+
//
|
|
52
|
+
|
|
53
|
+
(function () {
|
|
54
|
+
|
|
55
|
+
function identity(x) { return x; }
|
|
56
|
+
function returnFalse(x) { return false; }
|
|
57
|
+
|
|
58
|
+
function HookCollection() { }
|
|
59
|
+
|
|
60
|
+
HookCollection.prototype = {
|
|
61
|
+
|
|
62
|
+
chain: function (hookname, func) {
|
|
63
|
+
var original = this[hookname];
|
|
64
|
+
if (!original)
|
|
65
|
+
throw new Error("unknown hook " + hookname);
|
|
66
|
+
|
|
67
|
+
if (original === identity)
|
|
68
|
+
this[hookname] = func;
|
|
69
|
+
else
|
|
70
|
+
this[hookname] = function (x) { return func(original(x)); }
|
|
71
|
+
},
|
|
72
|
+
set: function (hookname, func) {
|
|
73
|
+
if (!this[hookname])
|
|
74
|
+
throw new Error("unknown hook " + hookname);
|
|
75
|
+
this[hookname] = func;
|
|
76
|
+
},
|
|
77
|
+
addNoop: function (hookname) {
|
|
78
|
+
this[hookname] = identity;
|
|
79
|
+
},
|
|
80
|
+
addFalse: function (hookname) {
|
|
81
|
+
this[hookname] = returnFalse;
|
|
82
|
+
}
|
|
83
|
+
};
|
|
84
|
+
|
|
85
|
+
Markdown.HookCollection = HookCollection;
|
|
86
|
+
|
|
87
|
+
// g_urls and g_titles allow arbitrary user-entered strings as keys. This
|
|
88
|
+
// caused an exception (and hence stopped the rendering) when the user entered
|
|
89
|
+
// e.g. [push] or [__proto__]. Adding a prefix to the actual key prevents this
|
|
90
|
+
// (since no builtin property starts with "s_"). See
|
|
91
|
+
// http://meta.stackoverflow.com/questions/64655/strange-wmd-bug
|
|
92
|
+
// (granted, switching from Array() to Object() alone would have left only __proto__
|
|
93
|
+
// to be a problem)
|
|
94
|
+
function SaveHash() { }
|
|
95
|
+
SaveHash.prototype = {
|
|
96
|
+
set: function (key, value) {
|
|
97
|
+
this["s_" + key] = value;
|
|
98
|
+
},
|
|
99
|
+
get: function (key) {
|
|
100
|
+
return this["s_" + key];
|
|
101
|
+
}
|
|
102
|
+
};
|
|
103
|
+
|
|
104
|
+
Markdown.Converter = function () {
|
|
105
|
+
var pluginHooks = this.hooks = new HookCollection();
|
|
106
|
+
pluginHooks.addNoop("plainLinkText"); // given a URL that was encountered by itself (without markup), should return the link text that's to be given to this link
|
|
107
|
+
pluginHooks.addNoop("preConversion"); // called with the orignal text as given to makeHtml. The result of this plugin hook is the actual markdown source that will be cooked
|
|
108
|
+
pluginHooks.addNoop("postConversion"); // called with the final cooked HTML code. The result of this plugin hook is the actual output of makeHtml
|
|
109
|
+
|
|
110
|
+
//
|
|
111
|
+
// Private state of the converter instance:
|
|
112
|
+
//
|
|
113
|
+
|
|
114
|
+
// Global hashes, used by various utility routines
|
|
115
|
+
var g_urls;
|
|
116
|
+
var g_titles;
|
|
117
|
+
var g_html_blocks;
|
|
118
|
+
|
|
119
|
+
// Used to track when we're inside an ordered or unordered list
|
|
120
|
+
// (see _ProcessListItems() for details):
|
|
121
|
+
var g_list_level;
|
|
122
|
+
|
|
123
|
+
this.makeHtml = function (text) {
|
|
124
|
+
|
|
125
|
+
//
|
|
126
|
+
// Main function. The order in which other subs are called here is
|
|
127
|
+
// essential. Link and image substitutions need to happen before
|
|
128
|
+
// _EscapeSpecialCharsWithinTagAttributes(), so that any *'s or _'s in the <a>
|
|
129
|
+
// and <img> tags get encoded.
|
|
130
|
+
//
|
|
131
|
+
|
|
132
|
+
// This will only happen if makeHtml on the same converter instance is called from a plugin hook.
|
|
133
|
+
// Don't do that.
|
|
134
|
+
if (g_urls)
|
|
135
|
+
throw new Error("Recursive call to converter.makeHtml");
|
|
136
|
+
|
|
137
|
+
// Create the private state objects.
|
|
138
|
+
g_urls = new SaveHash();
|
|
139
|
+
g_titles = new SaveHash();
|
|
140
|
+
g_html_blocks = [];
|
|
141
|
+
g_list_level = 0;
|
|
142
|
+
|
|
143
|
+
text = pluginHooks.preConversion(text);
|
|
144
|
+
|
|
145
|
+
// attacklab: Replace ~ with ~T
|
|
146
|
+
// This lets us use tilde as an escape char to avoid md5 hashes
|
|
147
|
+
// The choice of character is arbitray; anything that isn't
|
|
148
|
+
// magic in Markdown will work.
|
|
149
|
+
text = text.replace(/~/g, "~T");
|
|
150
|
+
|
|
151
|
+
// attacklab: Replace $ with ~D
|
|
152
|
+
// RegExp interprets $ as a special character
|
|
153
|
+
// when it's in a replacement string
|
|
154
|
+
text = text.replace(/\$/g, "~D");
|
|
155
|
+
|
|
156
|
+
// Standardize line endings
|
|
157
|
+
text = text.replace(/\r\n/g, "\n"); // DOS to Unix
|
|
158
|
+
text = text.replace(/\r/g, "\n"); // Mac to Unix
|
|
159
|
+
|
|
160
|
+
// Make sure text begins and ends with a couple of newlines:
|
|
161
|
+
text = "\n\n" + text + "\n\n";
|
|
162
|
+
|
|
163
|
+
// Convert all tabs to spaces.
|
|
164
|
+
text = _Detab(text);
|
|
165
|
+
|
|
166
|
+
// Strip any lines consisting only of spaces and tabs.
|
|
167
|
+
// This makes subsequent regexen easier to write, because we can
|
|
168
|
+
// match consecutive blank lines with /\n+/ instead of something
|
|
169
|
+
// contorted like /[ \t]*\n+/ .
|
|
170
|
+
text = text.replace(/^[ \t]+$/mg, "");
|
|
171
|
+
|
|
172
|
+
// Turn block-level HTML blocks into hash entries
|
|
173
|
+
text = _HashHTMLBlocks(text);
|
|
174
|
+
|
|
175
|
+
// Strip link definitions, store in hashes.
|
|
176
|
+
text = _StripLinkDefinitions(text);
|
|
177
|
+
|
|
178
|
+
text = _RunBlockGamut(text);
|
|
179
|
+
|
|
180
|
+
text = _UnescapeSpecialChars(text);
|
|
181
|
+
|
|
182
|
+
// attacklab: Restore dollar signs
|
|
183
|
+
text = text.replace(/~D/g, "$$");
|
|
184
|
+
|
|
185
|
+
// attacklab: Restore tildes
|
|
186
|
+
text = text.replace(/~T/g, "~");
|
|
187
|
+
|
|
188
|
+
text = pluginHooks.postConversion(text);
|
|
189
|
+
|
|
190
|
+
g_html_blocks = g_titles = g_urls = null;
|
|
191
|
+
|
|
192
|
+
return text;
|
|
193
|
+
};
|
|
194
|
+
|
|
195
|
+
function _StripLinkDefinitions(text) {
|
|
196
|
+
//
|
|
197
|
+
// Strips link definitions from text, stores the URLs and titles in
|
|
198
|
+
// hash references.
|
|
199
|
+
//
|
|
200
|
+
|
|
201
|
+
// Link defs are in the form: ^[id]: url "optional title"
|
|
202
|
+
|
|
203
|
+
/*
|
|
204
|
+
text = text.replace(/
|
|
205
|
+
^[ ]{0,3}\[(.+)\]: // id = $1 attacklab: g_tab_width - 1
|
|
206
|
+
[ \t]*
|
|
207
|
+
\n? // maybe *one* newline
|
|
208
|
+
[ \t]*
|
|
209
|
+
<?(\S+?)>? // url = $2
|
|
210
|
+
(?=\s|$) // lookahead for whitespace instead of the lookbehind removed below
|
|
211
|
+
[ \t]*
|
|
212
|
+
\n? // maybe one newline
|
|
213
|
+
[ \t]*
|
|
214
|
+
( // (potential) title = $3
|
|
215
|
+
(\n*) // any lines skipped = $4 attacklab: lookbehind removed
|
|
216
|
+
[ \t]+
|
|
217
|
+
["(]
|
|
218
|
+
(.+?) // title = $5
|
|
219
|
+
[")]
|
|
220
|
+
[ \t]*
|
|
221
|
+
)? // title is optional
|
|
222
|
+
(?:\n+|$)
|
|
223
|
+
/gm, function(){...});
|
|
224
|
+
*/
|
|
225
|
+
|
|
226
|
+
text = text.replace(/^[ ]{0,3}\[(.+)\]:[ \t]*\n?[ \t]*<?(\S+?)>?(?=\s|$)[ \t]*\n?[ \t]*((\n*)["(](.+?)[")][ \t]*)?(?:\n+)/gm,
|
|
227
|
+
function (wholeMatch, m1, m2, m3, m4, m5) {
|
|
228
|
+
m1 = m1.toLowerCase();
|
|
229
|
+
g_urls.set(m1, _EncodeAmpsAndAngles(m2)); // Link IDs are case-insensitive
|
|
230
|
+
if (m4) {
|
|
231
|
+
// Oops, found blank lines, so it's not a title.
|
|
232
|
+
// Put back the parenthetical statement we stole.
|
|
233
|
+
return m3;
|
|
234
|
+
} else if (m5) {
|
|
235
|
+
g_titles.set(m1, m5.replace(/"/g, """));
|
|
236
|
+
}
|
|
237
|
+
|
|
238
|
+
// Completely remove the definition from the text
|
|
239
|
+
return "";
|
|
240
|
+
}
|
|
241
|
+
);
|
|
242
|
+
|
|
243
|
+
return text;
|
|
244
|
+
}
|
|
245
|
+
|
|
246
|
+
function _HashHTMLBlocks(text) {
|
|
247
|
+
|
|
248
|
+
// Hashify HTML blocks:
|
|
249
|
+
// We only want to do this for block-level HTML tags, such as headers,
|
|
250
|
+
// lists, and tables. That's because we still want to wrap <p>s around
|
|
251
|
+
// "paragraphs" that are wrapped in non-block-level tags, such as anchors,
|
|
252
|
+
// phrase emphasis, and spans. The list of tags we're looking for is
|
|
253
|
+
// hard-coded:
|
|
254
|
+
var block_tags_a = "p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|ins|del"
|
|
255
|
+
var block_tags_b = "p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math"
|
|
256
|
+
|
|
257
|
+
// First, look for nested blocks, e.g.:
|
|
258
|
+
// <div>
|
|
259
|
+
// <div>
|
|
260
|
+
// tags for inner block must be indented.
|
|
261
|
+
// </div>
|
|
262
|
+
// </div>
|
|
263
|
+
//
|
|
264
|
+
// The outermost tags must start at the left margin for this to match, and
|
|
265
|
+
// the inner nested divs must be indented.
|
|
266
|
+
// We need to do this before the next, more liberal match, because the next
|
|
267
|
+
// match will start at the first `<div>` and stop at the first `</div>`.
|
|
268
|
+
|
|
269
|
+
// attacklab: This regex can be expensive when it fails.
|
|
270
|
+
|
|
271
|
+
/*
|
|
272
|
+
text = text.replace(/
|
|
273
|
+
( // save in $1
|
|
274
|
+
^ // start of line (with /m)
|
|
275
|
+
<($block_tags_a) // start tag = $2
|
|
276
|
+
\b // word break
|
|
277
|
+
// attacklab: hack around khtml/pcre bug...
|
|
278
|
+
[^\r]*?\n // any number of lines, minimally matching
|
|
279
|
+
</\2> // the matching end tag
|
|
280
|
+
[ \t]* // trailing spaces/tabs
|
|
281
|
+
(?=\n+) // followed by a newline
|
|
282
|
+
) // attacklab: there are sentinel newlines at end of document
|
|
283
|
+
/gm,function(){...}};
|
|
284
|
+
*/
|
|
285
|
+
text = text.replace(/^(<(p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|ins|del)\b[^\r]*?\n<\/\2>[ \t]*(?=\n+))/gm, hashElement);
|
|
286
|
+
|
|
287
|
+
//
|
|
288
|
+
// Now match more liberally, simply from `\n<tag>` to `</tag>\n`
|
|
289
|
+
//
|
|
290
|
+
|
|
291
|
+
/*
|
|
292
|
+
text = text.replace(/
|
|
293
|
+
( // save in $1
|
|
294
|
+
^ // start of line (with /m)
|
|
295
|
+
<($block_tags_b) // start tag = $2
|
|
296
|
+
\b // word break
|
|
297
|
+
// attacklab: hack around khtml/pcre bug...
|
|
298
|
+
[^\r]*? // any number of lines, minimally matching
|
|
299
|
+
.*</\2> // the matching end tag
|
|
300
|
+
[ \t]* // trailing spaces/tabs
|
|
301
|
+
(?=\n+) // followed by a newline
|
|
302
|
+
) // attacklab: there are sentinel newlines at end of document
|
|
303
|
+
/gm,function(){...}};
|
|
304
|
+
*/
|
|
305
|
+
text = text.replace(/^(<(p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math)\b[^\r]*?.*<\/\2>[ \t]*(?=\n+)\n)/gm, hashElement);
|
|
306
|
+
|
|
307
|
+
// Special case just for <hr />. It was easier to make a special case than
|
|
308
|
+
// to make the other regex more complicated.
|
|
309
|
+
|
|
310
|
+
/*
|
|
311
|
+
text = text.replace(/
|
|
312
|
+
\n // Starting after a blank line
|
|
313
|
+
[ ]{0,3}
|
|
314
|
+
( // save in $1
|
|
315
|
+
(<(hr) // start tag = $2
|
|
316
|
+
\b // word break
|
|
317
|
+
([^<>])*?
|
|
318
|
+
\/?>) // the matching end tag
|
|
319
|
+
[ \t]*
|
|
320
|
+
(?=\n{2,}) // followed by a blank line
|
|
321
|
+
)
|
|
322
|
+
/g,hashElement);
|
|
323
|
+
*/
|
|
324
|
+
text = text.replace(/\n[ ]{0,3}((<(hr)\b([^<>])*?\/?>)[ \t]*(?=\n{2,}))/g, hashElement);
|
|
325
|
+
|
|
326
|
+
// Special case for standalone HTML comments:
|
|
327
|
+
|
|
328
|
+
/*
|
|
329
|
+
text = text.replace(/
|
|
330
|
+
\n\n // Starting after a blank line
|
|
331
|
+
[ ]{0,3} // attacklab: g_tab_width - 1
|
|
332
|
+
( // save in $1
|
|
333
|
+
<!
|
|
334
|
+
(--(?:|(?:[^>-]|-[^>])(?:[^-]|-[^-])*)--) // see http://www.w3.org/TR/html-markup/syntax.html#comments and http://meta.stackoverflow.com/q/95256
|
|
335
|
+
>
|
|
336
|
+
[ \t]*
|
|
337
|
+
(?=\n{2,}) // followed by a blank line
|
|
338
|
+
)
|
|
339
|
+
/g,hashElement);
|
|
340
|
+
*/
|
|
341
|
+
text = text.replace(/\n\n[ ]{0,3}(<!(--(?:|(?:[^>-]|-[^>])(?:[^-]|-[^-])*)--)>[ \t]*(?=\n{2,}))/g, hashElement);
|
|
342
|
+
|
|
343
|
+
// PHP and ASP-style processor instructions (<?...?> and <%...%>)
|
|
344
|
+
|
|
345
|
+
/*
|
|
346
|
+
text = text.replace(/
|
|
347
|
+
(?:
|
|
348
|
+
\n\n // Starting after a blank line
|
|
349
|
+
)
|
|
350
|
+
( // save in $1
|
|
351
|
+
[ ]{0,3} // attacklab: g_tab_width - 1
|
|
352
|
+
(?:
|
|
353
|
+
<([?%]) // $2
|
|
354
|
+
[^\r]*?
|
|
355
|
+
\2>
|
|
356
|
+
)
|
|
357
|
+
[ \t]*
|
|
358
|
+
(?=\n{2,}) // followed by a blank line
|
|
359
|
+
)
|
|
360
|
+
/g,hashElement);
|
|
361
|
+
*/
|
|
362
|
+
text = text.replace(/(?:\n\n)([ ]{0,3}(?:<([?%])[^\r]*?\2>)[ \t]*(?=\n{2,}))/g, hashElement);
|
|
363
|
+
|
|
364
|
+
return text;
|
|
365
|
+
}
|
|
366
|
+
|
|
367
|
+
function hashElement(wholeMatch, m1) {
|
|
368
|
+
var blockText = m1;
|
|
369
|
+
|
|
370
|
+
// Undo double lines
|
|
371
|
+
blockText = blockText.replace(/^\n+/, "");
|
|
372
|
+
|
|
373
|
+
// strip trailing blank lines
|
|
374
|
+
blockText = blockText.replace(/\n+$/g, "");
|
|
375
|
+
|
|
376
|
+
// Replace the element text with a marker ("~KxK" where x is its key)
|
|
377
|
+
blockText = "\n\n~K" + (g_html_blocks.push(blockText) - 1) + "K\n\n";
|
|
378
|
+
|
|
379
|
+
return blockText;
|
|
380
|
+
}
|
|
381
|
+
|
|
382
|
+
function _RunBlockGamut(text, doNotUnhash) {
|
|
383
|
+
//
|
|
384
|
+
// These are all the transformations that form block-level
|
|
385
|
+
// tags like paragraphs, headers, and list items.
|
|
386
|
+
//
|
|
387
|
+
text = _DoHeaders(text);
|
|
388
|
+
|
|
389
|
+
// Do Horizontal Rules:
|
|
390
|
+
var replacement = "<hr />\n";
|
|
391
|
+
text = text.replace(/^[ ]{0,2}([ ]?\*[ ]?){3,}[ \t]*$/gm, replacement);
|
|
392
|
+
text = text.replace(/^[ ]{0,2}([ ]?-[ ]?){3,}[ \t]*$/gm, replacement);
|
|
393
|
+
text = text.replace(/^[ ]{0,2}([ ]?_[ ]?){3,}[ \t]*$/gm, replacement);
|
|
394
|
+
|
|
395
|
+
text = _DoLists(text);
|
|
396
|
+
text = _DoCodeBlocks(text);
|
|
397
|
+
text = _DoBlockQuotes(text);
|
|
398
|
+
|
|
399
|
+
// We already ran _HashHTMLBlocks() before, in Markdown(), but that
|
|
400
|
+
// was to escape raw HTML in the original Markdown source. This time,
|
|
401
|
+
// we're escaping the markup we've just created, so that we don't wrap
|
|
402
|
+
// <p> tags around block-level tags.
|
|
403
|
+
text = _HashHTMLBlocks(text);
|
|
404
|
+
text = _FormParagraphs(text, doNotUnhash);
|
|
405
|
+
|
|
406
|
+
return text;
|
|
407
|
+
}
|
|
408
|
+
|
|
409
|
+
function _RunSpanGamut(text) {
|
|
410
|
+
//
|
|
411
|
+
// These are all the transformations that occur *within* block-level
|
|
412
|
+
// tags like paragraphs, headers, and list items.
|
|
413
|
+
//
|
|
414
|
+
|
|
415
|
+
text = _DoCodeSpans(text);
|
|
416
|
+
text = _EscapeSpecialCharsWithinTagAttributes(text);
|
|
417
|
+
text = _EncodeBackslashEscapes(text);
|
|
418
|
+
|
|
419
|
+
// Process anchor and image tags. Images must come first,
|
|
420
|
+
// because ![foo][f] looks like an anchor.
|
|
421
|
+
text = _DoImages(text);
|
|
422
|
+
text = _DoAnchors(text);
|
|
423
|
+
|
|
424
|
+
// Make links out of things like `<http://example.com/>`
|
|
425
|
+
// Must come after _DoAnchors(), because you can use < and >
|
|
426
|
+
// delimiters in inline links like [this](<url>).
|
|
427
|
+
text = _DoAutoLinks(text);
|
|
428
|
+
|
|
429
|
+
text = text.replace(/~P/g, "://"); // put in place to prevent autolinking; reset now
|
|
430
|
+
|
|
431
|
+
text = _EncodeAmpsAndAngles(text);
|
|
432
|
+
text = _DoItalicsAndBold(text);
|
|
433
|
+
|
|
434
|
+
// Do hard breaks:
|
|
435
|
+
text = text.replace(/ +\n/g, " <br>\n");
|
|
436
|
+
|
|
437
|
+
return text;
|
|
438
|
+
}
|
|
439
|
+
|
|
440
|
+
function _EscapeSpecialCharsWithinTagAttributes(text) {
|
|
441
|
+
//
|
|
442
|
+
// Within tags -- meaning between < and > -- encode [\ ` * _] so they
|
|
443
|
+
// don't conflict with their use in Markdown for code, italics and strong.
|
|
444
|
+
//
|
|
445
|
+
|
|
446
|
+
// Build a regex to find HTML tags and comments. See Friedl's
|
|
447
|
+
// "Mastering Regular Expressions", 2nd Ed., pp. 200-201.
|
|
448
|
+
|
|
449
|
+
// SE: changed the comment part of the regex
|
|
450
|
+
|
|
451
|
+
var regex = /(<[a-z\/!$]("[^"]*"|'[^']*'|[^'">])*>|<!(--(?:|(?:[^>-]|-[^>])(?:[^-]|-[^-])*)--)>)/gi;
|
|
452
|
+
|
|
453
|
+
text = text.replace(regex, function (wholeMatch) {
|
|
454
|
+
var tag = wholeMatch.replace(/(.)<\/?code>(?=.)/g, "$1`");
|
|
455
|
+
tag = escapeCharacters(tag, wholeMatch.charAt(1) == "!" ? "\\`*_/" : "\\`*_"); // also escape slashes in comments to prevent autolinking there -- http://meta.stackoverflow.com/questions/95987
|
|
456
|
+
return tag;
|
|
457
|
+
});
|
|
458
|
+
|
|
459
|
+
return text;
|
|
460
|
+
}
|
|
461
|
+
|
|
462
|
+
function _DoAnchors(text) {
|
|
463
|
+
//
|
|
464
|
+
// Turn Markdown link shortcuts into XHTML <a> tags.
|
|
465
|
+
//
|
|
466
|
+
//
|
|
467
|
+
// First, handle reference-style links: [link text] [id]
|
|
468
|
+
//
|
|
469
|
+
|
|
470
|
+
/*
|
|
471
|
+
text = text.replace(/
|
|
472
|
+
( // wrap whole match in $1
|
|
473
|
+
\[
|
|
474
|
+
(
|
|
475
|
+
(?:
|
|
476
|
+
\[[^\]]*\] // allow brackets nested one level
|
|
477
|
+
|
|
|
478
|
+
[^\[] // or anything else
|
|
479
|
+
)*
|
|
480
|
+
)
|
|
481
|
+
\]
|
|
482
|
+
|
|
483
|
+
[ ]? // one optional space
|
|
484
|
+
(?:\n[ ]*)? // one optional newline followed by spaces
|
|
485
|
+
|
|
486
|
+
\[
|
|
487
|
+
(.*?) // id = $3
|
|
488
|
+
\]
|
|
489
|
+
)
|
|
490
|
+
()()()() // pad remaining backreferences
|
|
491
|
+
/g, writeAnchorTag);
|
|
492
|
+
*/
|
|
493
|
+
text = text.replace(/(\[((?:\[[^\]]*\]|[^\[\]])*)\][ ]?(?:\n[ ]*)?\[(.*?)\])()()()()/g, writeAnchorTag);
|
|
494
|
+
|
|
495
|
+
//
|
|
496
|
+
// Next, inline-style links: [link text](url "optional title")
|
|
497
|
+
//
|
|
498
|
+
|
|
499
|
+
/*
|
|
500
|
+
text = text.replace(/
|
|
501
|
+
( // wrap whole match in $1
|
|
502
|
+
\[
|
|
503
|
+
(
|
|
504
|
+
(?:
|
|
505
|
+
\[[^\]]*\] // allow brackets nested one level
|
|
506
|
+
|
|
|
507
|
+
[^\[\]] // or anything else
|
|
508
|
+
)*
|
|
509
|
+
)
|
|
510
|
+
\]
|
|
511
|
+
\( // literal paren
|
|
512
|
+
[ \t]*
|
|
513
|
+
() // no id, so leave $3 empty
|
|
514
|
+
<?( // href = $4
|
|
515
|
+
(?:
|
|
516
|
+
\([^)]*\) // allow one level of (correctly nested) parens (think MSDN)
|
|
517
|
+
|
|
|
518
|
+
[^()\s]
|
|
519
|
+
)*?
|
|
520
|
+
)>?
|
|
521
|
+
[ \t]*
|
|
522
|
+
( // $5
|
|
523
|
+
(['"]) // quote char = $6
|
|
524
|
+
(.*?) // Title = $7
|
|
525
|
+
\6 // matching quote
|
|
526
|
+
[ \t]* // ignore any spaces/tabs between closing quote and )
|
|
527
|
+
)? // title is optional
|
|
528
|
+
\)
|
|
529
|
+
)
|
|
530
|
+
/g, writeAnchorTag);
|
|
531
|
+
*/
|
|
532
|
+
|
|
533
|
+
text = text.replace(/(\[((?:\[[^\]]*\]|[^\[\]])*)\]\([ \t]*()<?((?:\([^)]*\)|[^()\s])*?)>?[ \t]*((['"])(.*?)\6[ \t]*)?\))/g, writeAnchorTag);
|
|
534
|
+
|
|
535
|
+
//
|
|
536
|
+
// Last, handle reference-style shortcuts: [link text]
|
|
537
|
+
// These must come last in case you've also got [link test][1]
|
|
538
|
+
// or [link test](/foo)
|
|
539
|
+
//
|
|
540
|
+
|
|
541
|
+
/*
|
|
542
|
+
text = text.replace(/
|
|
543
|
+
( // wrap whole match in $1
|
|
544
|
+
\[
|
|
545
|
+
([^\[\]]+) // link text = $2; can't contain '[' or ']'
|
|
546
|
+
\]
|
|
547
|
+
)
|
|
548
|
+
()()()()() // pad rest of backreferences
|
|
549
|
+
/g, writeAnchorTag);
|
|
550
|
+
*/
|
|
551
|
+
text = text.replace(/(\[([^\[\]]+)\])()()()()()/g, writeAnchorTag);
|
|
552
|
+
|
|
553
|
+
return text;
|
|
554
|
+
}
|
|
555
|
+
|
|
556
|
+
function writeAnchorTag(wholeMatch, m1, m2, m3, m4, m5, m6, m7) {
|
|
557
|
+
if (m7 == undefined) m7 = "";
|
|
558
|
+
var whole_match = m1;
|
|
559
|
+
var link_text = m2.replace(/:\/\//g, "~P"); // to prevent auto-linking withing the link. will be converted back after the auto-linker runs
|
|
560
|
+
var link_id = m3.toLowerCase();
|
|
561
|
+
var url = m4;
|
|
562
|
+
var title = m7;
|
|
563
|
+
|
|
564
|
+
if (url == "") {
|
|
565
|
+
if (link_id == "") {
|
|
566
|
+
// lower-case and turn embedded newlines into spaces
|
|
567
|
+
link_id = link_text.toLowerCase().replace(/ ?\n/g, " ");
|
|
568
|
+
}
|
|
569
|
+
url = "#" + link_id;
|
|
570
|
+
|
|
571
|
+
if (g_urls.get(link_id) != undefined) {
|
|
572
|
+
url = g_urls.get(link_id);
|
|
573
|
+
if (g_titles.get(link_id) != undefined) {
|
|
574
|
+
title = g_titles.get(link_id);
|
|
575
|
+
}
|
|
576
|
+
}
|
|
577
|
+
else {
|
|
578
|
+
if (whole_match.search(/\(\s*\)$/m) > -1) {
|
|
579
|
+
// Special case for explicit empty url
|
|
580
|
+
url = "";
|
|
581
|
+
} else {
|
|
582
|
+
return whole_match;
|
|
583
|
+
}
|
|
584
|
+
}
|
|
585
|
+
}
|
|
586
|
+
url = encodeProblemUrlChars(url);
|
|
587
|
+
url = escapeCharacters(url, "*_");
|
|
588
|
+
var result = "<a href=\"" + url + "\"";
|
|
589
|
+
|
|
590
|
+
if (title != "") {
|
|
591
|
+
title = attributeEncode(title);
|
|
592
|
+
title = escapeCharacters(title, "*_");
|
|
593
|
+
result += " title=\"" + title + "\"";
|
|
594
|
+
}
|
|
595
|
+
|
|
596
|
+
result += ">" + link_text + "</a>";
|
|
597
|
+
|
|
598
|
+
return result;
|
|
599
|
+
}
|
|
600
|
+
|
|
601
|
+
function _DoImages(text) {
|
|
602
|
+
//
|
|
603
|
+
// Turn Markdown image shortcuts into <img> tags.
|
|
604
|
+
//
|
|
605
|
+
|
|
606
|
+
//
|
|
607
|
+
// First, handle reference-style labeled images: ![alt text][id]
|
|
608
|
+
//
|
|
609
|
+
|
|
610
|
+
/*
|
|
611
|
+
text = text.replace(/
|
|
612
|
+
( // wrap whole match in $1
|
|
613
|
+
!\[
|
|
614
|
+
(.*?) // alt text = $2
|
|
615
|
+
\]
|
|
616
|
+
|
|
617
|
+
[ ]? // one optional space
|
|
618
|
+
(?:\n[ ]*)? // one optional newline followed by spaces
|
|
619
|
+
|
|
620
|
+
\[
|
|
621
|
+
(.*?) // id = $3
|
|
622
|
+
\]
|
|
623
|
+
)
|
|
624
|
+
()()()() // pad rest of backreferences
|
|
625
|
+
/g, writeImageTag);
|
|
626
|
+
*/
|
|
627
|
+
text = text.replace(/(!\[(.*?)\][ ]?(?:\n[ ]*)?\[(.*?)\])()()()()/g, writeImageTag);
|
|
628
|
+
|
|
629
|
+
//
|
|
630
|
+
// Next, handle inline images: 
|
|
631
|
+
// Don't forget: encode * and _
|
|
632
|
+
|
|
633
|
+
/*
|
|
634
|
+
text = text.replace(/
|
|
635
|
+
( // wrap whole match in $1
|
|
636
|
+
!\[
|
|
637
|
+
(.*?) // alt text = $2
|
|
638
|
+
\]
|
|
639
|
+
\s? // One optional whitespace character
|
|
640
|
+
\( // literal paren
|
|
641
|
+
[ \t]*
|
|
642
|
+
() // no id, so leave $3 empty
|
|
643
|
+
<?(\S+?)>? // src url = $4
|
|
644
|
+
[ \t]*
|
|
645
|
+
( // $5
|
|
646
|
+
(['"]) // quote char = $6
|
|
647
|
+
(.*?) // title = $7
|
|
648
|
+
\6 // matching quote
|
|
649
|
+
[ \t]*
|
|
650
|
+
)? // title is optional
|
|
651
|
+
\)
|
|
652
|
+
)
|
|
653
|
+
/g, writeImageTag);
|
|
654
|
+
*/
|
|
655
|
+
text = text.replace(/(!\[(.*?)\]\s?\([ \t]*()<?(\S+?)>?[ \t]*((['"])(.*?)\6[ \t]*)?\))/g, writeImageTag);
|
|
656
|
+
|
|
657
|
+
return text;
|
|
658
|
+
}
|
|
659
|
+
|
|
660
|
+
function attributeEncode(text) {
|
|
661
|
+
// unconditionally replace angle brackets here -- what ends up in an attribute (e.g. alt or title)
|
|
662
|
+
// never makes sense to have verbatim HTML in it (and the sanitizer would totally break it)
|
|
663
|
+
return text.replace(/>/g, ">").replace(/</g, "<").replace(/"/g, """);
|
|
664
|
+
}
|
|
665
|
+
|
|
666
|
+
function writeImageTag(wholeMatch, m1, m2, m3, m4, m5, m6, m7) {
|
|
667
|
+
var whole_match = m1;
|
|
668
|
+
var alt_text = m2;
|
|
669
|
+
var link_id = m3.toLowerCase();
|
|
670
|
+
var url = m4;
|
|
671
|
+
var title = m7;
|
|
672
|
+
|
|
673
|
+
if (!title) title = "";
|
|
674
|
+
|
|
675
|
+
if (url == "") {
|
|
676
|
+
if (link_id == "") {
|
|
677
|
+
// lower-case and turn embedded newlines into spaces
|
|
678
|
+
link_id = alt_text.toLowerCase().replace(/ ?\n/g, " ");
|
|
679
|
+
}
|
|
680
|
+
url = "#" + link_id;
|
|
681
|
+
|
|
682
|
+
if (g_urls.get(link_id) != undefined) {
|
|
683
|
+
url = g_urls.get(link_id);
|
|
684
|
+
if (g_titles.get(link_id) != undefined) {
|
|
685
|
+
title = g_titles.get(link_id);
|
|
686
|
+
}
|
|
687
|
+
}
|
|
688
|
+
else {
|
|
689
|
+
return whole_match;
|
|
690
|
+
}
|
|
691
|
+
}
|
|
692
|
+
|
|
693
|
+
alt_text = escapeCharacters(attributeEncode(alt_text), "*_[]()");
|
|
694
|
+
url = escapeCharacters(url, "*_");
|
|
695
|
+
var result = "<img src=\"" + url + "\" alt=\"" + alt_text + "\"";
|
|
696
|
+
|
|
697
|
+
// attacklab: Markdown.pl adds empty title attributes to images.
|
|
698
|
+
// Replicate this bug.
|
|
699
|
+
|
|
700
|
+
//if (title != "") {
|
|
701
|
+
title = attributeEncode(title);
|
|
702
|
+
title = escapeCharacters(title, "*_");
|
|
703
|
+
result += " title=\"" + title + "\"";
|
|
704
|
+
//}
|
|
705
|
+
|
|
706
|
+
result += " />";
|
|
707
|
+
|
|
708
|
+
return result;
|
|
709
|
+
}
|
|
710
|
+
|
|
711
|
+
function _DoHeaders(text) {
|
|
712
|
+
|
|
713
|
+
// Setext-style headers:
|
|
714
|
+
// Header 1
|
|
715
|
+
// ========
|
|
716
|
+
//
|
|
717
|
+
// Header 2
|
|
718
|
+
// --------
|
|
719
|
+
//
|
|
720
|
+
text = text.replace(/^(.+)[ \t]*\n=+[ \t]*\n+/gm,
|
|
721
|
+
function (wholeMatch, m1) { return "<h1>" + _RunSpanGamut(m1) + "</h1>\n\n"; }
|
|
722
|
+
);
|
|
723
|
+
|
|
724
|
+
text = text.replace(/^(.+)[ \t]*\n-+[ \t]*\n+/gm,
|
|
725
|
+
function (matchFound, m1) { return "<h2>" + _RunSpanGamut(m1) + "</h2>\n\n"; }
|
|
726
|
+
);
|
|
727
|
+
|
|
728
|
+
// atx-style headers:
|
|
729
|
+
// # Header 1
|
|
730
|
+
// ## Header 2
|
|
731
|
+
// ## Header 2 with closing hashes ##
|
|
732
|
+
// ...
|
|
733
|
+
// ###### Header 6
|
|
734
|
+
//
|
|
735
|
+
|
|
736
|
+
/*
|
|
737
|
+
text = text.replace(/
|
|
738
|
+
^(\#{1,6}) // $1 = string of #'s
|
|
739
|
+
[ \t]*
|
|
740
|
+
(.+?) // $2 = Header text
|
|
741
|
+
[ \t]*
|
|
742
|
+
\#* // optional closing #'s (not counted)
|
|
743
|
+
\n+
|
|
744
|
+
/gm, function() {...});
|
|
745
|
+
*/
|
|
746
|
+
|
|
747
|
+
text = text.replace(/^(\#{1,6})[ \t]*(.+?)[ \t]*\#*\n+/gm,
|
|
748
|
+
function (wholeMatch, m1, m2) {
|
|
749
|
+
var h_level = m1.length;
|
|
750
|
+
return "<h" + h_level + ">" + _RunSpanGamut(m2) + "</h" + h_level + ">\n\n";
|
|
751
|
+
}
|
|
752
|
+
);
|
|
753
|
+
|
|
754
|
+
return text;
|
|
755
|
+
}
|
|
756
|
+
|
|
757
|
+
function _DoLists(text) {
|
|
758
|
+
//
|
|
759
|
+
// Form HTML ordered (numbered) and unordered (bulleted) lists.
|
|
760
|
+
//
|
|
761
|
+
|
|
762
|
+
// attacklab: add sentinel to hack around khtml/safari bug:
|
|
763
|
+
// http://bugs.webkit.org/show_bug.cgi?id=11231
|
|
764
|
+
text += "~0";
|
|
765
|
+
|
|
766
|
+
// Re-usable pattern to match any entirel ul or ol list:
|
|
767
|
+
|
|
768
|
+
/*
|
|
769
|
+
var whole_list = /
|
|
770
|
+
( // $1 = whole list
|
|
771
|
+
( // $2
|
|
772
|
+
[ ]{0,3} // attacklab: g_tab_width - 1
|
|
773
|
+
([*+-]|\d+[.]) // $3 = first list item marker
|
|
774
|
+
[ \t]+
|
|
775
|
+
)
|
|
776
|
+
[^\r]+?
|
|
777
|
+
( // $4
|
|
778
|
+
~0 // sentinel for workaround; should be $
|
|
779
|
+
|
|
|
780
|
+
\n{2,}
|
|
781
|
+
(?=\S)
|
|
782
|
+
(?! // Negative lookahead for another list item marker
|
|
783
|
+
[ \t]*
|
|
784
|
+
(?:[*+-]|\d+[.])[ \t]+
|
|
785
|
+
)
|
|
786
|
+
)
|
|
787
|
+
)
|
|
788
|
+
/g
|
|
789
|
+
*/
|
|
790
|
+
var whole_list = /^(([ ]{0,3}([*+-]|\d+[.])[ \t]+)[^\r]+?(~0|\n{2,}(?=\S)(?![ \t]*(?:[*+-]|\d+[.])[ \t]+)))/gm;
|
|
791
|
+
|
|
792
|
+
if (g_list_level) {
|
|
793
|
+
text = text.replace(whole_list, function (wholeMatch, m1, m2) {
|
|
794
|
+
var list = m1;
|
|
795
|
+
var list_type = (m2.search(/[*+-]/g) > -1) ? "ul" : "ol";
|
|
796
|
+
|
|
797
|
+
var result = _ProcessListItems(list, list_type);
|
|
798
|
+
|
|
799
|
+
// Trim any trailing whitespace, to put the closing `</$list_type>`
|
|
800
|
+
// up on the preceding line, to get it past the current stupid
|
|
801
|
+
// HTML block parser. This is a hack to work around the terrible
|
|
802
|
+
// hack that is the HTML block parser.
|
|
803
|
+
result = result.replace(/\s+$/, "");
|
|
804
|
+
result = "<" + list_type + ">" + result + "</" + list_type + ">\n";
|
|
805
|
+
return result;
|
|
806
|
+
});
|
|
807
|
+
} else {
|
|
808
|
+
whole_list = /(\n\n|^\n?)(([ ]{0,3}([*+-]|\d+[.])[ \t]+)[^\r]+?(~0|\n{2,}(?=\S)(?![ \t]*(?:[*+-]|\d+[.])[ \t]+)))/g;
|
|
809
|
+
text = text.replace(whole_list, function (wholeMatch, m1, m2, m3) {
|
|
810
|
+
var runup = m1;
|
|
811
|
+
var list = m2;
|
|
812
|
+
|
|
813
|
+
var list_type = (m3.search(/[*+-]/g) > -1) ? "ul" : "ol";
|
|
814
|
+
var result = _ProcessListItems(list, list_type);
|
|
815
|
+
result = runup + "<" + list_type + ">\n" + result + "</" + list_type + ">\n";
|
|
816
|
+
return result;
|
|
817
|
+
});
|
|
818
|
+
}
|
|
819
|
+
|
|
820
|
+
// attacklab: strip sentinel
|
|
821
|
+
text = text.replace(/~0/, "");
|
|
822
|
+
|
|
823
|
+
return text;
|
|
824
|
+
}
|
|
825
|
+
|
|
826
|
+
var _listItemMarkers = { ol: "\\d+[.]", ul: "[*+-]" };
|
|
827
|
+
|
|
828
|
+
function _ProcessListItems(list_str, list_type) {
|
|
829
|
+
//
|
|
830
|
+
// Process the contents of a single ordered or unordered list, splitting it
|
|
831
|
+
// into individual list items.
|
|
832
|
+
//
|
|
833
|
+
// list_type is either "ul" or "ol".
|
|
834
|
+
|
|
835
|
+
// The $g_list_level global keeps track of when we're inside a list.
|
|
836
|
+
// Each time we enter a list, we increment it; when we leave a list,
|
|
837
|
+
// we decrement. If it's zero, we're not in a list anymore.
|
|
838
|
+
//
|
|
839
|
+
// We do this because when we're not inside a list, we want to treat
|
|
840
|
+
// something like this:
|
|
841
|
+
//
|
|
842
|
+
// I recommend upgrading to version
|
|
843
|
+
// 8. Oops, now this line is treated
|
|
844
|
+
// as a sub-list.
|
|
845
|
+
//
|
|
846
|
+
// As a single paragraph, despite the fact that the second line starts
|
|
847
|
+
// with a digit-period-space sequence.
|
|
848
|
+
//
|
|
849
|
+
// Whereas when we're inside a list (or sub-list), that line will be
|
|
850
|
+
// treated as the start of a sub-list. What a kludge, huh? This is
|
|
851
|
+
// an aspect of Markdown's syntax that's hard to parse perfectly
|
|
852
|
+
// without resorting to mind-reading. Perhaps the solution is to
|
|
853
|
+
// change the syntax rules such that sub-lists must start with a
|
|
854
|
+
// starting cardinal number; e.g. "1." or "a.".
|
|
855
|
+
|
|
856
|
+
g_list_level++;
|
|
857
|
+
|
|
858
|
+
// trim trailing blank lines:
|
|
859
|
+
list_str = list_str.replace(/\n{2,}$/, "\n");
|
|
860
|
+
|
|
861
|
+
// attacklab: add sentinel to emulate \z
|
|
862
|
+
list_str += "~0";
|
|
863
|
+
|
|
864
|
+
// In the original attacklab showdown, list_type was not given to this function, and anything
|
|
865
|
+
// that matched /[*+-]|\d+[.]/ would just create the next <li>, causing this mismatch:
|
|
866
|
+
//
|
|
867
|
+
// Markdown rendered by WMD rendered by MarkdownSharp
|
|
868
|
+
// ------------------------------------------------------------------
|
|
869
|
+
// 1. first 1. first 1. first
|
|
870
|
+
// 2. second 2. second 2. second
|
|
871
|
+
// - third 3. third * third
|
|
872
|
+
//
|
|
873
|
+
// We changed this to behave identical to MarkdownSharp. This is the constructed RegEx,
|
|
874
|
+
// with {MARKER} being one of \d+[.] or [*+-], depending on list_type:
|
|
875
|
+
|
|
876
|
+
/*
|
|
877
|
+
list_str = list_str.replace(/
|
|
878
|
+
(^[ \t]*) // leading whitespace = $1
|
|
879
|
+
({MARKER}) [ \t]+ // list marker = $2
|
|
880
|
+
([^\r]+? // list item text = $3
|
|
881
|
+
(\n+)
|
|
882
|
+
)
|
|
883
|
+
(?=
|
|
884
|
+
(~0 | \2 ({MARKER}) [ \t]+)
|
|
885
|
+
)
|
|
886
|
+
/gm, function(){...});
|
|
887
|
+
*/
|
|
888
|
+
|
|
889
|
+
var marker = _listItemMarkers[list_type];
|
|
890
|
+
var re = new RegExp("(^[ \\t]*)(" + marker + ")[ \\t]+([^\\r]+?(\\n+))(?=(~0|\\1(" + marker + ")[ \\t]+))", "gm");
|
|
891
|
+
var last_item_had_a_double_newline = false;
|
|
892
|
+
list_str = list_str.replace(re,
|
|
893
|
+
function (wholeMatch, m1, m2, m3) {
|
|
894
|
+
var item = m3;
|
|
895
|
+
var leading_space = m1;
|
|
896
|
+
var ends_with_double_newline = /\n\n$/.test(item);
|
|
897
|
+
var contains_double_newline = ends_with_double_newline || item.search(/\n{2,}/) > -1;
|
|
898
|
+
|
|
899
|
+
if (contains_double_newline || last_item_had_a_double_newline) {
|
|
900
|
+
item = _RunBlockGamut(_Outdent(item), /* doNotUnhash = */true);
|
|
901
|
+
}
|
|
902
|
+
else {
|
|
903
|
+
// Recursion for sub-lists:
|
|
904
|
+
item = _DoLists(_Outdent(item));
|
|
905
|
+
item = item.replace(/\n$/, ""); // chomp(item)
|
|
906
|
+
item = _RunSpanGamut(item);
|
|
907
|
+
}
|
|
908
|
+
last_item_had_a_double_newline = ends_with_double_newline;
|
|
909
|
+
return "<li>" + item + "</li>\n";
|
|
910
|
+
}
|
|
911
|
+
);
|
|
912
|
+
|
|
913
|
+
// attacklab: strip sentinel
|
|
914
|
+
list_str = list_str.replace(/~0/g, "");
|
|
915
|
+
|
|
916
|
+
g_list_level--;
|
|
917
|
+
return list_str;
|
|
918
|
+
}
|
|
919
|
+
|
|
920
|
+
function _DoCodeBlocks(text) {
|
|
921
|
+
//
|
|
922
|
+
// Process Markdown `<pre><code>` blocks.
|
|
923
|
+
//
|
|
924
|
+
|
|
925
|
+
/*
|
|
926
|
+
text = text.replace(/
|
|
927
|
+
(?:\n\n|^)
|
|
928
|
+
( // $1 = the code block -- one or more lines, starting with a space/tab
|
|
929
|
+
(?:
|
|
930
|
+
(?:[ ]{4}|\t) // Lines must start with a tab or a tab-width of spaces - attacklab: g_tab_width
|
|
931
|
+
.*\n+
|
|
932
|
+
)+
|
|
933
|
+
)
|
|
934
|
+
(\n*[ ]{0,3}[^ \t\n]|(?=~0)) // attacklab: g_tab_width
|
|
935
|
+
/g ,function(){...});
|
|
936
|
+
*/
|
|
937
|
+
|
|
938
|
+
// attacklab: sentinel workarounds for lack of \A and \Z, safari\khtml bug
|
|
939
|
+
text += "~0";
|
|
940
|
+
|
|
941
|
+
text = text.replace(/(?:\n\n|^)((?:(?:[ ]{4}|\t).*\n+)+)(\n*[ ]{0,3}[^ \t\n]|(?=~0))/g,
|
|
942
|
+
function (wholeMatch, m1, m2) {
|
|
943
|
+
var codeblock = m1;
|
|
944
|
+
var nextChar = m2;
|
|
945
|
+
|
|
946
|
+
codeblock = _EncodeCode(_Outdent(codeblock));
|
|
947
|
+
codeblock = _Detab(codeblock);
|
|
948
|
+
codeblock = codeblock.replace(/^\n+/g, ""); // trim leading newlines
|
|
949
|
+
codeblock = codeblock.replace(/\n+$/g, ""); // trim trailing whitespace
|
|
950
|
+
|
|
951
|
+
codeblock = "<pre><code>" + codeblock + "\n</code></pre>";
|
|
952
|
+
|
|
953
|
+
return "\n\n" + codeblock + "\n\n" + nextChar;
|
|
954
|
+
}
|
|
955
|
+
);
|
|
956
|
+
|
|
957
|
+
// attacklab: strip sentinel
|
|
958
|
+
text = text.replace(/~0/, "");
|
|
959
|
+
|
|
960
|
+
return text;
|
|
961
|
+
}
|
|
962
|
+
|
|
963
|
+
function hashBlock(text) {
|
|
964
|
+
text = text.replace(/(^\n+|\n+$)/g, "");
|
|
965
|
+
return "\n\n~K" + (g_html_blocks.push(text) - 1) + "K\n\n";
|
|
966
|
+
}
|
|
967
|
+
|
|
968
|
+
function _DoCodeSpans(text) {
|
|
969
|
+
//
|
|
970
|
+
// * Backtick quotes are used for <code></code> spans.
|
|
971
|
+
//
|
|
972
|
+
// * You can use multiple backticks as the delimiters if you want to
|
|
973
|
+
// include literal backticks in the code span. So, this input:
|
|
974
|
+
//
|
|
975
|
+
// Just type ``foo `bar` baz`` at the prompt.
|
|
976
|
+
//
|
|
977
|
+
// Will translate to:
|
|
978
|
+
//
|
|
979
|
+
// <p>Just type <code>foo `bar` baz</code> at the prompt.</p>
|
|
980
|
+
//
|
|
981
|
+
// There's no arbitrary limit to the number of backticks you
|
|
982
|
+
// can use as delimters. If you need three consecutive backticks
|
|
983
|
+
// in your code, use four for delimiters, etc.
|
|
984
|
+
//
|
|
985
|
+
// * You can use spaces to get literal backticks at the edges:
|
|
986
|
+
//
|
|
987
|
+
// ... type `` `bar` `` ...
|
|
988
|
+
//
|
|
989
|
+
// Turns to:
|
|
990
|
+
//
|
|
991
|
+
// ... type <code>`bar`</code> ...
|
|
992
|
+
//
|
|
993
|
+
|
|
994
|
+
/*
|
|
995
|
+
text = text.replace(/
|
|
996
|
+
(^|[^\\]) // Character before opening ` can't be a backslash
|
|
997
|
+
(`+) // $2 = Opening run of `
|
|
998
|
+
( // $3 = The code block
|
|
999
|
+
[^\r]*?
|
|
1000
|
+
[^`] // attacklab: work around lack of lookbehind
|
|
1001
|
+
)
|
|
1002
|
+
\2 // Matching closer
|
|
1003
|
+
(?!`)
|
|
1004
|
+
/gm, function(){...});
|
|
1005
|
+
*/
|
|
1006
|
+
|
|
1007
|
+
text = text.replace(/(^|[^\\])(`+)([^\r]*?[^`])\2(?!`)/gm,
|
|
1008
|
+
function (wholeMatch, m1, m2, m3, m4) {
|
|
1009
|
+
var c = m3;
|
|
1010
|
+
c = c.replace(/^([ \t]*)/g, ""); // leading whitespace
|
|
1011
|
+
c = c.replace(/[ \t]*$/g, ""); // trailing whitespace
|
|
1012
|
+
c = _EncodeCode(c);
|
|
1013
|
+
c = c.replace(/:\/\//g, "~P"); // to prevent auto-linking. Not necessary in code *blocks*, but in code spans. Will be converted back after the auto-linker runs.
|
|
1014
|
+
return m1 + "<code>" + c + "</code>";
|
|
1015
|
+
}
|
|
1016
|
+
);
|
|
1017
|
+
|
|
1018
|
+
return text;
|
|
1019
|
+
}
|
|
1020
|
+
|
|
1021
|
+
function _EncodeCode(text) {
|
|
1022
|
+
//
|
|
1023
|
+
// Encode/escape certain characters inside Markdown code runs.
|
|
1024
|
+
// The point is that in code, these characters are literals,
|
|
1025
|
+
// and lose their special Markdown meanings.
|
|
1026
|
+
//
|
|
1027
|
+
// Encode all ampersands; HTML entities are not
|
|
1028
|
+
// entities within a Markdown code span.
|
|
1029
|
+
text = text.replace(/&/g, "&");
|
|
1030
|
+
|
|
1031
|
+
// Do the angle bracket song and dance:
|
|
1032
|
+
text = text.replace(/</g, "<");
|
|
1033
|
+
text = text.replace(/>/g, ">");
|
|
1034
|
+
|
|
1035
|
+
// Now, escape characters that are magic in Markdown:
|
|
1036
|
+
text = escapeCharacters(text, "\*_{}[]\\", false);
|
|
1037
|
+
|
|
1038
|
+
// jj the line above breaks this:
|
|
1039
|
+
//---
|
|
1040
|
+
|
|
1041
|
+
//* Item
|
|
1042
|
+
|
|
1043
|
+
// 1. Subitem
|
|
1044
|
+
|
|
1045
|
+
// special char: *
|
|
1046
|
+
//---
|
|
1047
|
+
|
|
1048
|
+
return text;
|
|
1049
|
+
}
|
|
1050
|
+
|
|
1051
|
+
function _DoItalicsAndBold(text) {
|
|
1052
|
+
|
|
1053
|
+
// <strong> must go first:
|
|
1054
|
+
text = text.replace(/([\W_]|^)(\*\*|__)(?=\S)([^\r]*?\S[\*_]*)\2([\W_]|$)/g,
|
|
1055
|
+
"$1<strong>$3</strong>$4");
|
|
1056
|
+
|
|
1057
|
+
text = text.replace(/([\W_]|^)(\*|_)(?=\S)([^\r\*_]*?\S)\2([\W_]|$)/g,
|
|
1058
|
+
"$1<em>$3</em>$4");
|
|
1059
|
+
|
|
1060
|
+
return text;
|
|
1061
|
+
}
|
|
1062
|
+
|
|
1063
|
+
function _DoBlockQuotes(text) {
|
|
1064
|
+
|
|
1065
|
+
/*
|
|
1066
|
+
text = text.replace(/
|
|
1067
|
+
( // Wrap whole match in $1
|
|
1068
|
+
(
|
|
1069
|
+
^[ \t]*>[ \t]? // '>' at the start of a line
|
|
1070
|
+
.+\n // rest of the first line
|
|
1071
|
+
(.+\n)* // subsequent consecutive lines
|
|
1072
|
+
\n* // blanks
|
|
1073
|
+
)+
|
|
1074
|
+
)
|
|
1075
|
+
/gm, function(){...});
|
|
1076
|
+
*/
|
|
1077
|
+
|
|
1078
|
+
text = text.replace(/((^[ \t]*>[ \t]?.+\n(.+\n)*\n*)+)/gm,
|
|
1079
|
+
function (wholeMatch, m1) {
|
|
1080
|
+
var bq = m1;
|
|
1081
|
+
|
|
1082
|
+
// attacklab: hack around Konqueror 3.5.4 bug:
|
|
1083
|
+
// "----------bug".replace(/^-/g,"") == "bug"
|
|
1084
|
+
|
|
1085
|
+
bq = bq.replace(/^[ \t]*>[ \t]?/gm, "~0"); // trim one level of quoting
|
|
1086
|
+
|
|
1087
|
+
// attacklab: clean up hack
|
|
1088
|
+
bq = bq.replace(/~0/g, "");
|
|
1089
|
+
|
|
1090
|
+
bq = bq.replace(/^[ \t]+$/gm, ""); // trim whitespace-only lines
|
|
1091
|
+
bq = _RunBlockGamut(bq); // recurse
|
|
1092
|
+
|
|
1093
|
+
bq = bq.replace(/(^|\n)/g, "$1 ");
|
|
1094
|
+
// These leading spaces screw with <pre> content, so we need to fix that:
|
|
1095
|
+
bq = bq.replace(
|
|
1096
|
+
/(\s*<pre>[^\r]+?<\/pre>)/gm,
|
|
1097
|
+
function (wholeMatch, m1) {
|
|
1098
|
+
var pre = m1;
|
|
1099
|
+
// attacklab: hack around Konqueror 3.5.4 bug:
|
|
1100
|
+
pre = pre.replace(/^ /mg, "~0");
|
|
1101
|
+
pre = pre.replace(/~0/g, "");
|
|
1102
|
+
return pre;
|
|
1103
|
+
});
|
|
1104
|
+
|
|
1105
|
+
return hashBlock("<blockquote>\n" + bq + "\n</blockquote>");
|
|
1106
|
+
}
|
|
1107
|
+
);
|
|
1108
|
+
return text;
|
|
1109
|
+
}
|
|
1110
|
+
|
|
1111
|
+
function _FormParagraphs(text, doNotUnhash) {
|
|
1112
|
+
//
|
|
1113
|
+
// Params:
|
|
1114
|
+
// $text - string to process with html <p> tags
|
|
1115
|
+
//
|
|
1116
|
+
|
|
1117
|
+
// Strip leading and trailing lines:
|
|
1118
|
+
text = text.replace(/^\n+/g, "");
|
|
1119
|
+
text = text.replace(/\n+$/g, "");
|
|
1120
|
+
|
|
1121
|
+
var grafs = text.split(/\n{2,}/g);
|
|
1122
|
+
var grafsOut = [];
|
|
1123
|
+
|
|
1124
|
+
var markerRe = /~K(\d+)K/;
|
|
1125
|
+
|
|
1126
|
+
//
|
|
1127
|
+
// Wrap <p> tags.
|
|
1128
|
+
//
|
|
1129
|
+
var end = grafs.length;
|
|
1130
|
+
for (var i = 0; i < end; i++) {
|
|
1131
|
+
var str = grafs[i];
|
|
1132
|
+
|
|
1133
|
+
// if this is an HTML marker, copy it
|
|
1134
|
+
if (markerRe.test(str)) {
|
|
1135
|
+
grafsOut.push(str);
|
|
1136
|
+
}
|
|
1137
|
+
else if (/\S/.test(str)) {
|
|
1138
|
+
str = _RunSpanGamut(str);
|
|
1139
|
+
str = str.replace(/^([ \t]*)/g, "<p>");
|
|
1140
|
+
str += "</p>"
|
|
1141
|
+
grafsOut.push(str);
|
|
1142
|
+
}
|
|
1143
|
+
|
|
1144
|
+
}
|
|
1145
|
+
//
|
|
1146
|
+
// Unhashify HTML blocks
|
|
1147
|
+
//
|
|
1148
|
+
if (!doNotUnhash) {
|
|
1149
|
+
end = grafsOut.length;
|
|
1150
|
+
for (var i = 0; i < end; i++) {
|
|
1151
|
+
var foundAny = true;
|
|
1152
|
+
while (foundAny) { // we may need several runs, since the data may be nested
|
|
1153
|
+
foundAny = false;
|
|
1154
|
+
grafsOut[i] = grafsOut[i].replace(/~K(\d+)K/g, function (wholeMatch, id) {
|
|
1155
|
+
foundAny = true;
|
|
1156
|
+
return g_html_blocks[id];
|
|
1157
|
+
});
|
|
1158
|
+
}
|
|
1159
|
+
}
|
|
1160
|
+
}
|
|
1161
|
+
return grafsOut.join("\n\n");
|
|
1162
|
+
}
|
|
1163
|
+
|
|
1164
|
+
function _EncodeAmpsAndAngles(text) {
|
|
1165
|
+
// Smart processing for ampersands and angle brackets that need to be encoded.
|
|
1166
|
+
|
|
1167
|
+
// Ampersand-encoding based entirely on Nat Irons's Amputator MT plugin:
|
|
1168
|
+
// http://bumppo.net/projects/amputator/
|
|
1169
|
+
text = text.replace(/&(?!#?[xX]?(?:[0-9a-fA-F]+|\w+);)/g, "&");
|
|
1170
|
+
|
|
1171
|
+
// Encode naked <'s
|
|
1172
|
+
text = text.replace(/<(?![a-z\/?!]|~D)/gi, "<");
|
|
1173
|
+
|
|
1174
|
+
return text;
|
|
1175
|
+
}
|
|
1176
|
+
|
|
1177
|
+
function _EncodeBackslashEscapes(text) {
|
|
1178
|
+
//
|
|
1179
|
+
// Parameter: String.
|
|
1180
|
+
// Returns: The string, with after processing the following backslash
|
|
1181
|
+
// escape sequences.
|
|
1182
|
+
//
|
|
1183
|
+
|
|
1184
|
+
// attacklab: The polite way to do this is with the new
|
|
1185
|
+
// escapeCharacters() function:
|
|
1186
|
+
//
|
|
1187
|
+
// text = escapeCharacters(text,"\\",true);
|
|
1188
|
+
// text = escapeCharacters(text,"`*_{}[]()>#+-.!",true);
|
|
1189
|
+
//
|
|
1190
|
+
// ...but we're sidestepping its use of the (slow) RegExp constructor
|
|
1191
|
+
// as an optimization for Firefox. This function gets called a LOT.
|
|
1192
|
+
|
|
1193
|
+
text = text.replace(/\\(\\)/g, escapeCharacters_callback);
|
|
1194
|
+
text = text.replace(/\\([`*_{}\[\]()>#+-.!])/g, escapeCharacters_callback);
|
|
1195
|
+
return text;
|
|
1196
|
+
}
|
|
1197
|
+
|
|
1198
|
+
function _DoAutoLinks(text) {
|
|
1199
|
+
|
|
1200
|
+
// note that at this point, all other URL in the text are already hyperlinked as <a href=""></a>
|
|
1201
|
+
// *except* for the <http://www.foo.com> case
|
|
1202
|
+
|
|
1203
|
+
// automatically add < and > around unadorned raw hyperlinks
|
|
1204
|
+
// must be preceded by space/BOF and followed by non-word/EOF character
|
|
1205
|
+
text = text.replace(/(^|\s)(https?|ftp)(:\/\/[-A-Z0-9+&@#\/%?=~_|\[\]\(\)!:,\.;]*[-A-Z0-9+&@#\/%=~_|\[\]])($|\W)/gi, "$1<$2$3>$4");
|
|
1206
|
+
|
|
1207
|
+
// autolink anything like <http://example.com>
|
|
1208
|
+
|
|
1209
|
+
var replacer = function (wholematch, m1) { return "<a href=\"" + m1 + "\">" + pluginHooks.plainLinkText(m1) + "</a>"; }
|
|
1210
|
+
text = text.replace(/<((https?|ftp):[^'">\s]+)>/gi, replacer);
|
|
1211
|
+
|
|
1212
|
+
// Email addresses: <address@domain.foo>
|
|
1213
|
+
/*
|
|
1214
|
+
text = text.replace(/
|
|
1215
|
+
<
|
|
1216
|
+
(?:mailto:)?
|
|
1217
|
+
(
|
|
1218
|
+
[-.\w]+
|
|
1219
|
+
\@
|
|
1220
|
+
[-a-z0-9]+(\.[-a-z0-9]+)*\.[a-z]+
|
|
1221
|
+
)
|
|
1222
|
+
>
|
|
1223
|
+
/gi, _DoAutoLinks_callback());
|
|
1224
|
+
*/
|
|
1225
|
+
|
|
1226
|
+
/* disabling email autolinking, since we don't do that on the server, either
|
|
1227
|
+
text = text.replace(/<(?:mailto:)?([-.\w]+\@[-a-z0-9]+(\.[-a-z0-9]+)*\.[a-z]+)>/gi,
|
|
1228
|
+
function(wholeMatch,m1) {
|
|
1229
|
+
return _EncodeEmailAddress( _UnescapeSpecialChars(m1) );
|
|
1230
|
+
}
|
|
1231
|
+
);
|
|
1232
|
+
*/
|
|
1233
|
+
return text;
|
|
1234
|
+
}
|
|
1235
|
+
|
|
1236
|
+
function _UnescapeSpecialChars(text) {
|
|
1237
|
+
//
|
|
1238
|
+
// Swap back in all the special characters we've hidden.
|
|
1239
|
+
//
|
|
1240
|
+
text = text.replace(/~E(\d+)E/g,
|
|
1241
|
+
function (wholeMatch, m1) {
|
|
1242
|
+
var charCodeToReplace = parseInt(m1);
|
|
1243
|
+
return String.fromCharCode(charCodeToReplace);
|
|
1244
|
+
}
|
|
1245
|
+
);
|
|
1246
|
+
return text;
|
|
1247
|
+
}
|
|
1248
|
+
|
|
1249
|
+
function _Outdent(text) {
|
|
1250
|
+
//
|
|
1251
|
+
// Remove one level of line-leading tabs or spaces
|
|
1252
|
+
//
|
|
1253
|
+
|
|
1254
|
+
// attacklab: hack around Konqueror 3.5.4 bug:
|
|
1255
|
+
// "----------bug".replace(/^-/g,"") == "bug"
|
|
1256
|
+
|
|
1257
|
+
text = text.replace(/^(\t|[ ]{1,4})/gm, "~0"); // attacklab: g_tab_width
|
|
1258
|
+
|
|
1259
|
+
// attacklab: clean up hack
|
|
1260
|
+
text = text.replace(/~0/g, "")
|
|
1261
|
+
|
|
1262
|
+
return text;
|
|
1263
|
+
}
|
|
1264
|
+
|
|
1265
|
+
function _Detab(text) {
|
|
1266
|
+
if (!/\t/.test(text))
|
|
1267
|
+
return text;
|
|
1268
|
+
|
|
1269
|
+
var spaces = [" ", " ", " ", " "],
|
|
1270
|
+
skew = 0,
|
|
1271
|
+
v;
|
|
1272
|
+
|
|
1273
|
+
return text.replace(/[\n\t]/g, function (match, offset) {
|
|
1274
|
+
if (match === "\n") {
|
|
1275
|
+
skew = offset + 1;
|
|
1276
|
+
return match;
|
|
1277
|
+
}
|
|
1278
|
+
v = (offset - skew) % 4;
|
|
1279
|
+
skew = offset + 1;
|
|
1280
|
+
return spaces[v];
|
|
1281
|
+
});
|
|
1282
|
+
}
|
|
1283
|
+
|
|
1284
|
+
//
|
|
1285
|
+
// attacklab: Utility functions
|
|
1286
|
+
//
|
|
1287
|
+
|
|
1288
|
+
var _problemUrlChars = /(?:["'*()[\]:]|~D)/g;
|
|
1289
|
+
|
|
1290
|
+
// hex-encodes some unusual "problem" chars in URLs to avoid URL detection problems
|
|
1291
|
+
function encodeProblemUrlChars(url) {
|
|
1292
|
+
if (!url)
|
|
1293
|
+
return "";
|
|
1294
|
+
|
|
1295
|
+
var len = url.length;
|
|
1296
|
+
|
|
1297
|
+
return url.replace(_problemUrlChars, function (match, offset) {
|
|
1298
|
+
if (match == "~D") // escape for dollar
|
|
1299
|
+
return "%24";
|
|
1300
|
+
if (match == ":") {
|
|
1301
|
+
if (offset == len - 1 || /[0-9\/]/.test(url.charAt(offset + 1)))
|
|
1302
|
+
return ":"
|
|
1303
|
+
}
|
|
1304
|
+
return "%" + match.charCodeAt(0).toString(16);
|
|
1305
|
+
});
|
|
1306
|
+
}
|
|
1307
|
+
|
|
1308
|
+
|
|
1309
|
+
function escapeCharacters(text, charsToEscape, afterBackslash) {
|
|
1310
|
+
// First we have to escape the escape characters so that
|
|
1311
|
+
// we can build a character class out of them
|
|
1312
|
+
var regexString = "([" + charsToEscape.replace(/([\[\]\\])/g, "\\$1") + "])";
|
|
1313
|
+
|
|
1314
|
+
if (afterBackslash) {
|
|
1315
|
+
regexString = "\\\\" + regexString;
|
|
1316
|
+
}
|
|
1317
|
+
|
|
1318
|
+
var regex = new RegExp(regexString, "g");
|
|
1319
|
+
text = text.replace(regex, escapeCharacters_callback);
|
|
1320
|
+
|
|
1321
|
+
return text;
|
|
1322
|
+
}
|
|
1323
|
+
|
|
1324
|
+
|
|
1325
|
+
function escapeCharacters_callback(wholeMatch, m1) {
|
|
1326
|
+
var charCodeToEscape = m1.charCodeAt(0);
|
|
1327
|
+
return "~E" + charCodeToEscape + "E";
|
|
1328
|
+
}
|
|
1329
|
+
|
|
1330
|
+
}; // end of the Markdown.Converter constructor
|
|
1331
|
+
|
|
1332
|
+
})();
|