updatesupport 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- updatesupport-0.1.0/LICENSE +21 -0
- updatesupport-0.1.0/PKG-INFO +671 -0
- updatesupport-0.1.0/README.md +635 -0
- updatesupport-0.1.0/pyproject.toml +71 -0
- updatesupport-0.1.0/setup.cfg +4 -0
- updatesupport-0.1.0/tests/test_adapters.py +155 -0
- updatesupport-0.1.0/tests/test_cvxpy_backend.py +351 -0
- updatesupport-0.1.0/tests/test_dataframe.py +111 -0
- updatesupport-0.1.0/tests/test_dowhy.py +134 -0
- updatesupport-0.1.0/tests/test_folktables_example.py +273 -0
- updatesupport-0.1.0/tests/test_q_presets.py +190 -0
- updatesupport-0.1.0/tests/test_report.py +336 -0
- updatesupport-0.1.0/tests/test_updatesupport.py +169 -0
- updatesupport-0.1.0/updatesupport/__init__.py +146 -0
- updatesupport-0.1.0/updatesupport/adapters.py +367 -0
- updatesupport-0.1.0/updatesupport/data.py +262 -0
- updatesupport-0.1.0/updatesupport/dowhy.py +209 -0
- updatesupport-0.1.0/updatesupport/environments.py +1794 -0
- updatesupport-0.1.0/updatesupport/partition.py +215 -0
- updatesupport-0.1.0/updatesupport/presets.py +819 -0
- updatesupport-0.1.0/updatesupport/problem.py +423 -0
- updatesupport-0.1.0/updatesupport/report.py +2287 -0
- updatesupport-0.1.0/updatesupport/results.py +104 -0
- updatesupport-0.1.0/updatesupport.egg-info/PKG-INFO +671 -0
- updatesupport-0.1.0/updatesupport.egg-info/SOURCES.txt +26 -0
- updatesupport-0.1.0/updatesupport.egg-info/dependency_links.txt +1 -0
- updatesupport-0.1.0/updatesupport.egg-info/requires.txt +18 -0
- updatesupport-0.1.0/updatesupport.egg-info/top_level.txt +1 -0
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026 updatesupport contributors
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
|
@@ -0,0 +1,671 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: updatesupport
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: Representation adequacy and transport-stability auditing in Python
|
|
5
|
+
License-Expression: MIT
|
|
6
|
+
Project-URL: Homepage, https://github.com/nahuaque/updatesupport
|
|
7
|
+
Project-URL: Repository, https://github.com/nahuaque/updatesupport
|
|
8
|
+
Project-URL: Issues, https://github.com/nahuaque/updatesupport/issues
|
|
9
|
+
Keywords: causal-inference,partial-identification,representation-adequacy,sensitivity-analysis,transport-stability
|
|
10
|
+
Classifier: Development Status :: 3 - Alpha
|
|
11
|
+
Classifier: Intended Audience :: Science/Research
|
|
12
|
+
Classifier: Programming Language :: Python :: 3
|
|
13
|
+
Classifier: Programming Language :: Python :: 3.10
|
|
14
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
15
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.13
|
|
17
|
+
Classifier: Topic :: Scientific/Engineering :: Information Analysis
|
|
18
|
+
Requires-Python: >=3.10
|
|
19
|
+
Description-Content-Type: text/markdown
|
|
20
|
+
License-File: LICENSE
|
|
21
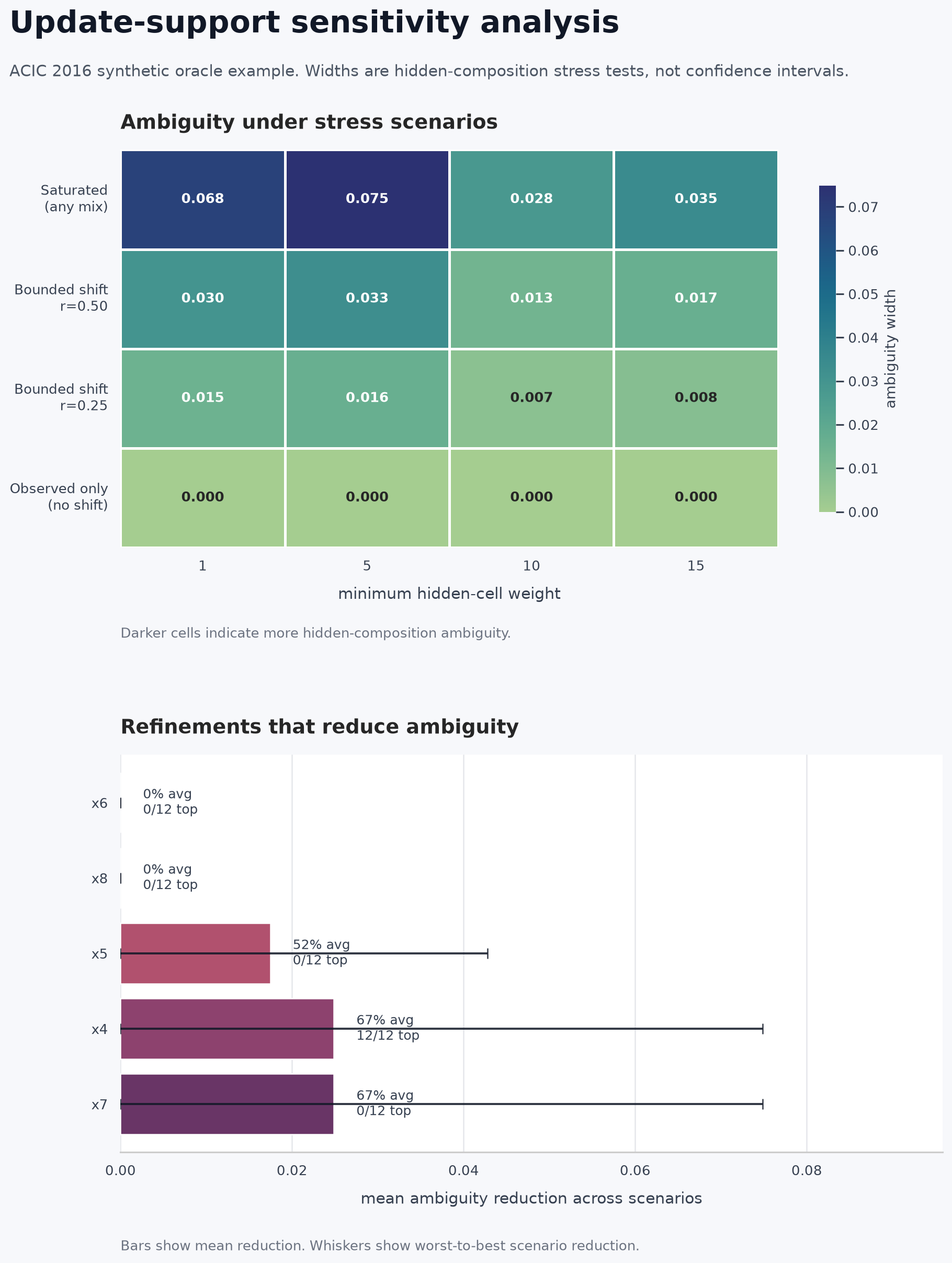
|
+
Requires-Dist: numpy>=2.2.6
|
|
22
|
+
Requires-Dist: scipy>=1.15.3
|
|
23
|
+
Provides-Extra: causal
|
|
24
|
+
Requires-Dist: econml>=0.16; extra == "causal"
|
|
25
|
+
Requires-Dist: numba>=0.61; extra == "causal"
|
|
26
|
+
Provides-Extra: cvxpy
|
|
27
|
+
Requires-Dist: cvxpy>=1.5; extra == "cvxpy"
|
|
28
|
+
Provides-Extra: dowhy
|
|
29
|
+
Requires-Dist: dowhy>=0.13; extra == "dowhy"
|
|
30
|
+
Provides-Extra: examples
|
|
31
|
+
Requires-Dist: folktables>=0.0.12; extra == "examples"
|
|
32
|
+
Requires-Dist: matplotlib>=3.9; extra == "examples"
|
|
33
|
+
Requires-Dist: pandas>=2.0; extra == "examples"
|
|
34
|
+
Requires-Dist: seaborn>=0.13; extra == "examples"
|
|
35
|
+
Dynamic: license-file
|
|
36
|
+
|
|
37
|
+
# updatesupport
|
|
38
|
+
|
|
39
|
+
Are your observed categories good enough for the estimate you are reporting?
|
|
40
|
+
|
|
41
|
+
`updatesupport` is a Python library for representation adequacy and
|
|
42
|
+
transport-stability auditing. It asks whether a coarse public representation,
|
|
43
|
+
such as age band, education band, and sex, is enough to determine an aggregate
|
|
44
|
+
estimate once hidden composition inside those public cells is allowed to vary.
|
|
45
|
+
|
|
46
|
+
The motivating workflow is simple:
|
|
47
|
+
|
|
48
|
+
1. Choose the public categories you would report.
|
|
49
|
+
2. Choose hidden variables that refine those public categories.
|
|
50
|
+
3. Choose the target rate or other linear estimand you care about.
|
|
51
|
+
4. Stress test the estimate while holding the public distribution fixed.
|
|
52
|
+
5. Report how much the answer could move, which public cells drive the movement,
|
|
53
|
+
and which extra variables would reduce the ambiguity.
|
|
54
|
+
|
|
55
|
+
This is useful when a table, dashboard, policy analysis, or model evaluation
|
|
56
|
+
reports aggregates over coarse categories and you want to know whether those
|
|
57
|
+
categories are stable enough for the estimate being reported.
|
|
58
|
+
|
|
59
|
+
## Plain-English Example
|
|
60
|
+
|
|
61
|
+
In the Folktables ACSIncome demo, the public categories are:
|
|
62
|
+
|
|
63
|
+
```text
|
|
64
|
+
AGE_BAND x EDU_BAND x SEX
|
|
65
|
+
```
|
|
66
|
+
|
|
67
|
+
The hidden variables include occupation, class of worker, weekly-hours band,
|
|
68
|
+
race, marital status, birthplace, and relationship status. The observed target
|
|
69
|
+
rate is `12.37%`: the share of sampled people exceeding the ACSIncome income
|
|
70
|
+
threshold.
|
|
71
|
+
|
|
72
|
+
The stress test keeps the public mix fixed but allows hidden composition inside
|
|
73
|
+
each public cell to change. Under that stress test, the target rate could range
|
|
74
|
+
from:
|
|
75
|
+
|
|
76
|
+
```text
|
|
77
|
+
11.79% to 13.44%
|
|
78
|
+
```
|
|
79
|
+
|
|
80
|
+
The width, `1.65` percentage points, is the transport ambiguity. It means that
|
|
81
|
+
hidden composition changes could move the aggregate rate by up to about `1.65`
|
|
82
|
+
percentage points even when the public demographic mix is held fixed.
|
|
83
|
+
|
|
84
|
+
That interval is not a confidence interval. It does not measure sampling error.
|
|
85
|
+
It measures sensitivity to hidden composition under the chosen stress test.
|
|
86
|
+
|
|
87
|
+
See [docs/folktables-acs-income-interpretation.md](docs/folktables-acs-income-interpretation.md)
|
|
88
|
+
for the analyst-facing interpretation of this result.
|
|
89
|
+
|
|
90
|
+
## What This Is
|
|
91
|
+
|
|
92
|
+
`updatesupport` is an audit layer for finite-state reporting representations. It
|
|
93
|
+
helps answer:
|
|
94
|
+
|
|
95
|
+
- Are the public categories adequate for this estimand?
|
|
96
|
+
- If not, how large is the remaining ambiguity?
|
|
97
|
+
- Which public cells contribute most to the ambiguity?
|
|
98
|
+
- Which hidden variables would make the public representation more stable?
|
|
99
|
+
|
|
100
|
+
It is not a causal inference package, a sampling-uncertainty estimator, or a
|
|
101
|
+
replacement for substantive modeling. It can complement those workflows by
|
|
102
|
+
checking whether the categories used to report an estimate are too coarse.
|
|
103
|
+
|
|
104
|
+
For causal workflows, use DoWhy, EconML, CausalML, or DoubleML to estimate or
|
|
105
|
+
validate causal effects, then use `updatesupport` to audit whether the public
|
|
106
|
+
categories used to report those effects are stable to hidden composition changes.
|
|
107
|
+
See [docs/causal-library-integration.md](docs/causal-library-integration.md).
|
|
108
|
+
|
|
109
|
+
```python
|
|
110
|
+
suite = us.causal_reporting_stability(
|
|
111
|
+
df,
|
|
112
|
+
public=["AGE_BAND", "SEX"],
|
|
113
|
+
hidden=["AGE_BAND", "SEX", "OCC_MAJOR", "WKHP_BAND", "RAC1P"],
|
|
114
|
+
effect="tau_hat",
|
|
115
|
+
weight="sample_weight",
|
|
116
|
+
candidate_refinements=["OCC_MAJOR", "WKHP_BAND", "RAC1P"],
|
|
117
|
+
q=us.q_bounded_shift(0.5),
|
|
118
|
+
sensitivity_min_cell_weights=[10, 25],
|
|
119
|
+
sensitivity_q_presets=[
|
|
120
|
+
"saturated",
|
|
121
|
+
us.q_bounded_shift(0.5),
|
|
122
|
+
"observed",
|
|
123
|
+
],
|
|
124
|
+
statistical_estimate=ate_hat,
|
|
125
|
+
statistical_interval=(ci_low, ci_high),
|
|
126
|
+
statistical_method="causal estimator bootstrap",
|
|
127
|
+
)
|
|
128
|
+
|
|
129
|
+
print(suite.to_markdown())
|
|
130
|
+
```
|
|
131
|
+
|
|
132
|
+
## Install Locally
|
|
133
|
+
|
|
134
|
+
```bash
|
|
135
|
+
uv sync
|
|
136
|
+
uv run python -m unittest
|
|
137
|
+
```
|
|
138
|
+
|
|
139
|
+
For the Folktables examples:
|
|
140
|
+
|
|
141
|
+
```bash
|
|
142
|
+
uv sync --extra examples
|
|
143
|
+
```
|
|
144
|
+
|
|
145
|
+
For the EconML causal example:
|
|
146
|
+
|
|
147
|
+
```bash
|
|
148
|
+
uv sync --extra causal
|
|
149
|
+
```
|
|
150
|
+
|
|
151
|
+
For convex Q presets and custom CVXPY environments:
|
|
152
|
+
|
|
153
|
+
```bash
|
|
154
|
+
uv sync --extra cvxpy
|
|
155
|
+
```
|
|
156
|
+
|
|
157
|
+
For the reproducible benchmark gallery:
|
|
158
|
+
|
|
159
|
+
```bash
|
|
160
|
+
uv sync --extra examples --extra causal
|
|
161
|
+
```
|
|
162
|
+
|
|
163
|
+
For DoWhy `CausalRefutation` conversion:
|
|
164
|
+
|
|
165
|
+
```bash
|
|
166
|
+
uv sync --extra dowhy
|
|
167
|
+
```
|
|
168
|
+
|
|
169
|
+
## Core Model
|
|
170
|
+
|
|
171
|
+
The library implements a finite-state computational version of the
|
|
172
|
+
update-relevant support machinery from
|
|
173
|
+
[Update-Relevant Support: Hume's Missing Descent](https://philpapers.org/go.pl?id=BRUUSH&proxyId=&u=https%3A%2F%2Fphilpapers.org%2Farchive%2FBRUUSH.pdf).
|
|
174
|
+
It models:
|
|
175
|
+
|
|
176
|
+
- a finite hidden state space `D`
|
|
177
|
+
- a public projection `pi: D -> O`
|
|
178
|
+
- a linear estimand `psi(q) = <h, q>`
|
|
179
|
+
- an admissible environment class `Q`, which may be saturated, finite-linear,
|
|
180
|
+
or convex
|
|
181
|
+
|
|
182
|
+
The library then checks whether a public or refined support is adequate and
|
|
183
|
+
quantifies the remaining ambiguity among admissible environments that share the
|
|
184
|
+
same public law. Simple finite-linear classes use closed-form or linear-program
|
|
185
|
+
backends; TV, chi-square, KL, Wasserstein, and custom convex restrictions use
|
|
186
|
+
CVXPY.
|
|
187
|
+
|
|
188
|
+
## Tabular Compiler
|
|
189
|
+
|
|
190
|
+
Use `from_dataframe(...)` to compile a pandas-like dataframe or iterable of row
|
|
191
|
+
mappings into a finite problem:
|
|
192
|
+
|
|
193
|
+
```python
|
|
194
|
+
import updatesupport as us
|
|
195
|
+
|
|
196
|
+
grouped = us.from_dataframe(
|
|
197
|
+
rows_or_frame,
|
|
198
|
+
public=["AGE_BAND", "EDU_BAND", "SEX"],
|
|
199
|
+
hidden=["AGE_BAND", "EDU_BAND", "SEX", "OCC_MAJOR", "WKHP_BAND"],
|
|
200
|
+
target="__target__",
|
|
201
|
+
weight="PWGTP",
|
|
202
|
+
min_cell_weight=25,
|
|
203
|
+
q="saturated",
|
|
204
|
+
)
|
|
205
|
+
|
|
206
|
+
interval = grouped.problem.global_transport_modulus()
|
|
207
|
+
|
|
208
|
+
print(grouped.public_law)
|
|
209
|
+
print(interval.lower, interval.upper, interval.diameter)
|
|
210
|
+
```
|
|
211
|
+
|
|
212
|
+
Each retained hidden cell becomes one finite state. The estimand value for that
|
|
213
|
+
state is the weighted empirical target mean inside the cell. The chosen `Q`
|
|
214
|
+
preset fixes the observed public law and then defines which hidden-composition
|
|
215
|
+
shifts are admissible: saturated reweighting, bounded linear shifts, or convex
|
|
216
|
+
divergence/transport budgets.
|
|
217
|
+
|
|
218
|
+
## Q Presets
|
|
219
|
+
|
|
220
|
+
`Q` is the admissible environment class used for the hidden-composition stress
|
|
221
|
+
test. The built-in presets are:
|
|
222
|
+
|
|
223
|
+
- `q="saturated"` or `us.q_saturated()`: fix the observed public law and allow
|
|
224
|
+
arbitrary reweighting among retained hidden cells inside each public cell.
|
|
225
|
+
- `q=us.q_bounded_shift(radius)`: fix the observed public law and constrain each
|
|
226
|
+
hidden-cell mass to stay within `(1 +/- radius)` times its observed mass.
|
|
227
|
+
- `q=us.q_tv_budget(radius)`: fix the observed public law and constrain total
|
|
228
|
+
variation distance from the observed hidden distribution. This uses CVXPY.
|
|
229
|
+
- `q=us.q_chi_square_budget(radius)`: fix the observed public law and constrain
|
|
230
|
+
Pearson chi-square divergence from the observed hidden distribution. This uses
|
|
231
|
+
CVXPY.
|
|
232
|
+
- `q=us.q_kl_budget(radius)`: fix the observed public law and constrain KL
|
|
233
|
+
divergence from the observed hidden distribution. This uses CVXPY.
|
|
234
|
+
- `q=us.q_wasserstein(cost, radius)`: fix the observed public law and constrain
|
|
235
|
+
Wasserstein distance from the observed hidden distribution using an explicit
|
|
236
|
+
hidden-cell cost matrix. This uses CVXPY.
|
|
237
|
+
- `q="observed"` or `us.q_observed()`: use only the observed hidden distribution,
|
|
238
|
+
giving zero hidden-composition ambiguity.
|
|
239
|
+
|
|
240
|
+
Install the CVXPY extra before using TV, chi-square, KL, Wasserstein, custom
|
|
241
|
+
convex environments, or parameterized CVXPY radius sweeps:
|
|
242
|
+
|
|
243
|
+
```bash
|
|
244
|
+
uv sync --extra cvxpy
|
|
245
|
+
```
|
|
246
|
+
|
|
247
|
+
See [docs/transport-presets.md](docs/transport-presets.md) for guidance on
|
|
248
|
+
which preset to use, how to choose radii, and how to interpret sensitivity
|
|
249
|
+
tables.
|
|
250
|
+
|
|
251
|
+
## Public Descent Report
|
|
252
|
+
|
|
253
|
+
Use `public_descent_report(...)` to produce a structured report and render it as
|
|
254
|
+
Markdown:
|
|
255
|
+
|
|
256
|
+
```python
|
|
257
|
+
report = us.public_descent_report(
|
|
258
|
+
rows_or_frame,
|
|
259
|
+
public=["AGE_BAND", "EDU_BAND", "SEX"],
|
|
260
|
+
hidden=["AGE_BAND", "EDU_BAND", "SEX", "OCC_MAJOR", "WKHP_BAND"],
|
|
261
|
+
target="__target__",
|
|
262
|
+
weight="PWGTP",
|
|
263
|
+
candidate_refinements=["OCC_MAJOR", "WKHP_BAND"],
|
|
264
|
+
min_cell_weight=25,
|
|
265
|
+
q="saturated",
|
|
266
|
+
title="ACSIncome Representation Adequacy Report",
|
|
267
|
+
)
|
|
268
|
+
|
|
269
|
+
print(report.to_markdown())
|
|
270
|
+
```
|
|
271
|
+
|
|
272
|
+
The report includes the observed value, stress interval, transport ambiguity,
|
|
273
|
+
public adequacy flag, worst public fibers, and one-column refinement candidates
|
|
274
|
+
with before ambiguity, after ambiguity, absolute reduction, and percentage
|
|
275
|
+
reduction.
|
|
276
|
+
|
|
277
|
+
## Sensitivity Checks
|
|
278
|
+
|
|
279
|
+
Use `sensitivity_report(...)` to rerun the audit across Q presets,
|
|
280
|
+
`min_cell_weight` thresholds, and alternative hidden-column sets:
|
|
281
|
+
|
|
282
|
+
|
|
283
|
+
|
|
284
|
+
Regenerate the README figure with:
|
|
285
|
+
|
|
286
|
+
```bash
|
|
287
|
+
uv run --extra examples python examples/sensitivity_plots.py
|
|
288
|
+
```
|
|
289
|
+
|
|
290
|
+
```python
|
|
291
|
+
sensitivity = us.sensitivity_report(
|
|
292
|
+
rows_or_frame,
|
|
293
|
+
public=["AGE_BAND", "EDU_BAND", "SEX"],
|
|
294
|
+
hidden=["AGE_BAND", "EDU_BAND", "SEX", "OCC_MAJOR", "WKHP_BAND"],
|
|
295
|
+
target="__target__",
|
|
296
|
+
weight="PWGTP",
|
|
297
|
+
min_cell_weights=[1, 10, 25],
|
|
298
|
+
q_presets=["saturated", us.q_bounded_shift(0.5), "observed"],
|
|
299
|
+
)
|
|
300
|
+
|
|
301
|
+
print(sensitivity.to_markdown())
|
|
302
|
+
```
|
|
303
|
+
|
|
304
|
+
This is the recommended way to check whether the headline ambiguity is sensitive
|
|
305
|
+
to sparse hidden cells or to the chosen admissible-environment preset. The
|
|
306
|
+
Markdown output starts with a scenario summary, highlights the lowest- and
|
|
307
|
+
highest-ambiguity scenarios, flags mixed public-adequacy conclusions, and then
|
|
308
|
+
renders the full scenario table.
|
|
309
|
+
|
|
310
|
+
When the grid contains repeated TV, chi-square, KL, or Wasserstein presets that
|
|
311
|
+
differ only by radius, the sensitivity routines automatically route those rows
|
|
312
|
+
through the parameterized CVXPY backend and reuse the compiled problem for the
|
|
313
|
+
fixed hidden state space.
|
|
314
|
+
|
|
315
|
+
Use `recommend_refinements_sensitivity(...)` to rank candidate public
|
|
316
|
+
refinements across the same kind of grid:
|
|
317
|
+
|
|
318
|
+
```python
|
|
319
|
+
refinements = us.recommend_refinements_sensitivity(
|
|
320
|
+
rows_or_frame,
|
|
321
|
+
public=["AGE_BAND", "EDU_BAND", "SEX"],
|
|
322
|
+
hidden=["AGE_BAND", "EDU_BAND", "SEX", "OCC_MAJOR", "WKHP_BAND", "RAC1P"],
|
|
323
|
+
target="__target__",
|
|
324
|
+
weight="PWGTP",
|
|
325
|
+
candidate_refinements=["OCC_MAJOR", "WKHP_BAND", "RAC1P"],
|
|
326
|
+
min_cell_weights=[1, 10, 25],
|
|
327
|
+
q_presets=["saturated", us.q_bounded_shift(0.5), "observed"],
|
|
328
|
+
)
|
|
329
|
+
|
|
330
|
+
print(refinements.to_markdown())
|
|
331
|
+
```
|
|
332
|
+
|
|
333
|
+
The aggregate ranking reports mean reduction, worst-case reduction, rank
|
|
334
|
+
stability, and the number of scenarios where each refinement ranked first.
|
|
335
|
+
|
|
336
|
+
## Public-Fiber-Saturated Example
|
|
337
|
+
|
|
338
|
+
When all reweightings inside public fibers are admissible, the transport
|
|
339
|
+
modulus has the closed form:
|
|
340
|
+
|
|
341
|
+
```text
|
|
342
|
+
Omega(p; psi) = sum_o p(o) * (max_{u in pi^-1(o)} h(u) - min_{u in pi^-1(o)} h(u))
|
|
343
|
+
```
|
|
344
|
+
|
|
345
|
+
```python
|
|
346
|
+
import updatesupport as us
|
|
347
|
+
|
|
348
|
+
problem = us.FiniteProblem(
|
|
349
|
+
states=["a", "b", "c", "d"],
|
|
350
|
+
public={"a": "x", "b": "x", "c": "y", "d": "y"},
|
|
351
|
+
estimand={"a": 0.0, "b": 1.0, "c": 0.0, "d": 3.0},
|
|
352
|
+
environments=us.PublicFiberSaturated(),
|
|
353
|
+
)
|
|
354
|
+
|
|
355
|
+
print(problem.is_public_adequate())
|
|
356
|
+
# False
|
|
357
|
+
|
|
358
|
+
print(problem.fiber_ranges())
|
|
359
|
+
# {"x": 1.0, "y": 3.0}
|
|
360
|
+
|
|
361
|
+
print(problem.global_transport_modulus().diameter)
|
|
362
|
+
# 3.0
|
|
363
|
+
|
|
364
|
+
print(problem.local_transport_modulus({"x": 0.25, "y": 0.75}).diameter)
|
|
365
|
+
# 2.5
|
|
366
|
+
```
|
|
367
|
+
|
|
368
|
+
## How To Read A Report
|
|
369
|
+
|
|
370
|
+
A typical report should separate four ideas:
|
|
371
|
+
|
|
372
|
+
- **Observed value**: the estimate under the observed hidden composition.
|
|
373
|
+
- **Stress interval**: the possible estimate range after hidden composition is
|
|
374
|
+
varied within the chosen environment class `Q`.
|
|
375
|
+
- **Transport ambiguity**: the width of that interval.
|
|
376
|
+
- **Refinement value**: how much ambiguity would shrink if another hidden
|
|
377
|
+
variable were added to the public representation.
|
|
378
|
+
|
|
379
|
+
The stress interval is a partial-identification or stability interval, not a
|
|
380
|
+
statistical confidence interval. If the interval is wide, the public categories
|
|
381
|
+
do not determine the estimate very tightly under the chosen stress test. If the
|
|
382
|
+
interval is narrow, the estimate is comparatively stable to the modeled hidden
|
|
383
|
+
composition changes.
|
|
384
|
+
|
|
385
|
+
## Folktables ACS Worked Example
|
|
386
|
+
|
|
387
|
+
The Folktables example turns ACSIncome or ACSEmployment into an update-support
|
|
388
|
+
stress test:
|
|
389
|
+
|
|
390
|
+
- public cells are coarse observed categories such as age band, education band,
|
|
391
|
+
and sex
|
|
392
|
+
- hidden cells refine those categories with occupation, race, work hours, and
|
|
393
|
+
other task-specific ACS fields
|
|
394
|
+
- the estimand is the observed label rate in each hidden cell
|
|
395
|
+
- the environment class allows arbitrary reweighting inside the observed public
|
|
396
|
+
cells while preserving the observed public law
|
|
397
|
+
|
|
398
|
+
Run the real Folktables ACSIncome example:
|
|
399
|
+
|
|
400
|
+
```bash
|
|
401
|
+
uv run --extra examples python examples/folktables_acs.py \
|
|
402
|
+
--task income \
|
|
403
|
+
--states CA \
|
|
404
|
+
--year 2018 \
|
|
405
|
+
--sample 50000 \
|
|
406
|
+
--min-cell-weight 25
|
|
407
|
+
```
|
|
408
|
+
|
|
409
|
+
Run ACSEmployment instead:
|
|
410
|
+
|
|
411
|
+
```bash
|
|
412
|
+
uv run --extra examples python examples/folktables_acs.py \
|
|
413
|
+
--task employment \
|
|
414
|
+
--states CA TX \
|
|
415
|
+
--year 2018
|
|
416
|
+
```
|
|
417
|
+
|
|
418
|
+
The script prints:
|
|
419
|
+
|
|
420
|
+
- the observed target rate
|
|
421
|
+
- the partial-identification interval under hidden reweighting
|
|
422
|
+
- the observed-law transport ambiguity
|
|
423
|
+
- a statistical interpretation of the interval and ambiguity
|
|
424
|
+
- worst public fibers by ambiguity contribution
|
|
425
|
+
- one-column refinements ranked by ambiguity reduction, including before/after
|
|
426
|
+
ambiguity and percentage reduction
|
|
427
|
+
|
|
428
|
+
There is also a no-download smoke demo:
|
|
429
|
+
|
|
430
|
+
```bash
|
|
431
|
+
uv run python examples/folktables_acs.py --synthetic
|
|
432
|
+
```
|
|
433
|
+
|
|
434
|
+
There is also a causal-effect reporting example. It fits an EconML CATE
|
|
435
|
+
estimator, computes `tau_hat = estimator.effect(X)`, then audits whether that
|
|
436
|
+
effect is stable when reported by coarse public categories:
|
|
437
|
+
|
|
438
|
+
```bash
|
|
439
|
+
uv run --extra examples --extra causal python examples/folktables_acs_causal.py \
|
|
440
|
+
--task income \
|
|
441
|
+
--states CA \
|
|
442
|
+
--year 2018 \
|
|
443
|
+
--sample 50000
|
|
444
|
+
```
|
|
445
|
+
|
|
446
|
+
The no-download version is:
|
|
447
|
+
|
|
448
|
+
```bash
|
|
449
|
+
uv run --extra causal python examples/folktables_acs_causal.py --synthetic
|
|
450
|
+
```
|
|
451
|
+
|
|
452
|
+
The built-in first stage uses EconML `CausalForestDML`. In a real causal
|
|
453
|
+
workflow, swap in the DoWhy, EconML, CausalML, or DoubleML estimator that fits
|
|
454
|
+
your identification strategy and produces a `tau_hat` effect target; the
|
|
455
|
+
`updatesupport` stage is the same.
|
|
456
|
+
|
|
457
|
+
## Benchmark Gallery
|
|
458
|
+
|
|
459
|
+
The benchmark gallery regenerates saved Markdown reports under gitignored
|
|
460
|
+
`data/benchmark_gallery/`:
|
|
461
|
+
|
|
462
|
+
```bash
|
|
463
|
+
uv run --extra examples --extra causal python examples/benchmark_gallery.py
|
|
464
|
+
```
|
|
465
|
+
|
|
466
|
+
It includes no-download Folktables reports plus ACIC 2016 oracle and
|
|
467
|
+
EconML-estimated effect reports when `data/acic_2016_p1_s1.csv` is present. It
|
|
468
|
+
also attempts a real Folktables ACS sample from cached data; pass
|
|
469
|
+
`--folktables-download` to fetch the ACS data. See
|
|
470
|
+
[docs/benchmark-gallery.md](docs/benchmark-gallery.md).
|
|
471
|
+
|
|
472
|
+
## ACIC 2016 Causal Benchmark Example
|
|
473
|
+
|
|
474
|
+
The ACIC 2016 example uses the same causal handoff on benchmark-style rows. It
|
|
475
|
+
defaults to an oracle effect when potential-outcome columns such as `y0`/`y1` or
|
|
476
|
+
`mu0`/`mu1` are present, and otherwise can fit EconML from observed `y` and `z`.
|
|
477
|
+
The update-support audit defaults to the treated rows, matching the SATT focus
|
|
478
|
+
of the 2016 competition. The official assets live in the
|
|
479
|
+
[vdorie/aciccomp 2016 R package](https://github.com/vdorie/aciccomp/tree/master/2016).
|
|
480
|
+
|
|
481
|
+
Run the no-download smoke demo:
|
|
482
|
+
|
|
483
|
+
```bash
|
|
484
|
+
uv run --extra examples python examples/acic_2016.py --synthetic
|
|
485
|
+
```
|
|
486
|
+
|
|
487
|
+
Run against a CSV exported from the official ACIC 2016 R package:
|
|
488
|
+
|
|
489
|
+
```bash
|
|
490
|
+
uv run --extra examples --extra causal python examples/acic_2016.py \
|
|
491
|
+
--input-csv data/acic_2016_p1_s1.csv \
|
|
492
|
+
--effect-source econml \
|
|
493
|
+
--sample 5000
|
|
494
|
+
```
|
|
495
|
+
|
|
496
|
+
If your exported CSV includes potential outcomes, use `--effect-source oracle`
|
|
497
|
+
and optionally pass `--y0-column` / `--y1-column`.
|
|
498
|
+
|
|
499
|
+
For DoWhy workflows, use `audit_dowhy_effects(...)` to package the
|
|
500
|
+
representation audit with the DoWhy estimate, then call `audit.to_refutation()`
|
|
501
|
+
to produce a DoWhy `CausalRefutation` object when the optional DoWhy dependency
|
|
502
|
+
is installed.
|
|
503
|
+
|
|
504
|
+
## Current Python Surface
|
|
505
|
+
|
|
506
|
+
Implemented now:
|
|
507
|
+
|
|
508
|
+
- `FiniteProblem`
|
|
509
|
+
- `Partition`
|
|
510
|
+
- `PublicFiberSaturated`
|
|
511
|
+
- `FiniteEnvironments`
|
|
512
|
+
- `LineSegment`
|
|
513
|
+
- `PolytopeEnvironments` via SciPy `linprog`
|
|
514
|
+
- `CvxpyEnvironments` for convex finite-state environment restrictions
|
|
515
|
+
- `ParameterizedCvxpyEnvironments` for cached CVXPY radius sweeps
|
|
516
|
+
- `from_dataframe(...)` for compiling grouped tabular data into a finite problem
|
|
517
|
+
- Q presets: `saturated`, `observed`, `bounded_shift`, `tv_budget`,
|
|
518
|
+
`chi_square_budget`, `kl_budget`, and `wasserstein`
|
|
519
|
+
- `PublicDescentReport` with Markdown output
|
|
520
|
+
- `public_descent_report(...)` for analyst-facing report objects
|
|
521
|
+
- `audit_effects(...)` for causal/uplift effect-reporting stability audits
|
|
522
|
+
- `causal_reporting_stability(...)` for packaging causal estimate,
|
|
523
|
+
statistical uncertainty metadata, hidden-composition ambiguity, sensitivity
|
|
524
|
+
grids, and public refinement recommendations
|
|
525
|
+
- estimator adapters: `adapt_dataframe_effects(...)`,
|
|
526
|
+
`adapt_econml_effects(...)`, `adapt_dowhy_effects(...)`, and
|
|
527
|
+
`adapt_doubleml_effects(...)`
|
|
528
|
+
- `audit_dowhy_effects(...)` and `dowhy_refutation_from_report(...)` for DoWhy
|
|
529
|
+
workflows
|
|
530
|
+
- `recommend_refinements(...)` for ranking candidate hidden variables
|
|
531
|
+
- `recommend_refinements_sensitivity(...)` for aggregating refinement value
|
|
532
|
+
across Q, hidden-set, and sparsity scenarios
|
|
533
|
+
- `sensitivity_report(...)` for robustness grids over Q, hidden sets, and
|
|
534
|
+
`min_cell_weight`
|
|
535
|
+
- `examples/benchmark_gallery.py` for regenerating saved Folktables and ACIC
|
|
536
|
+
benchmark reports under gitignored `data/benchmark_gallery/`
|
|
537
|
+
- adequacy checks with witnesses
|
|
538
|
+
- adequate, minimal, and least support enumeration for small finite problems
|
|
539
|
+
- local and global transport moduli
|
|
540
|
+
- partial-identification intervals
|
|
541
|
+
- cardinal gaps when a least support exists
|
|
542
|
+
- simple Markdown reports
|
|
543
|
+
|
|
544
|
+
Planned next slices:
|
|
545
|
+
|
|
546
|
+
- experimental transport types such as Gromov-Wasserstein once the comparison
|
|
547
|
+
object is a pair of relational hidden-state geometries rather than one fixed
|
|
548
|
+
hidden-cell cost matrix
|
|
549
|
+
|
|
550
|
+
## Finite-Linear Backend
|
|
551
|
+
|
|
552
|
+
`PolytopeEnvironments` uses `scipy.optimize.linprog` for finite-state
|
|
553
|
+
environment classes described by linear equality and inequality constraints:
|
|
554
|
+
|
|
555
|
+
```python
|
|
556
|
+
problem = us.FiniteProblem(
|
|
557
|
+
states=["a", "b"],
|
|
558
|
+
public={"a": "o", "b": "o"},
|
|
559
|
+
estimand={"a": 0.0, "b": 4.0},
|
|
560
|
+
environments=us.PolytopeEnvironments(
|
|
561
|
+
constraints=[
|
|
562
|
+
us.geq({"a": 1.0}, 0.25),
|
|
563
|
+
us.geq({"b": 1.0}, 0.25),
|
|
564
|
+
]
|
|
565
|
+
),
|
|
566
|
+
)
|
|
567
|
+
|
|
568
|
+
result = problem.global_transport_modulus()
|
|
569
|
+
|
|
570
|
+
print(result.lower, result.upper, result.diameter)
|
|
571
|
+
# 1.0 3.0 2.0
|
|
572
|
+
```
|
|
573
|
+
|
|
574
|
+
The simplex constraints are implicit. Additional constraints can be supplied
|
|
575
|
+
with `us.leq(...)`, `us.geq(...)`, `us.eq(...)`, or `us.linear_constraint(...)`.
|
|
576
|
+
|
|
577
|
+
## Convex CVXPY Backend
|
|
578
|
+
|
|
579
|
+
`CvxpyEnvironments` supports the same finite-state simplex and linear
|
|
580
|
+
constraints, plus custom convex constraints over the state-probability vector:
|
|
581
|
+
|
|
582
|
+
```python
|
|
583
|
+
def cap_b(_cp, q, _states, state_index):
|
|
584
|
+
return (q[state_index["b"]] <= 0.75,)
|
|
585
|
+
|
|
586
|
+
problem = us.FiniteProblem(
|
|
587
|
+
states=["a", "b"],
|
|
588
|
+
public={"a": "o", "b": "o"},
|
|
589
|
+
estimand={"a": 0.0, "b": 1.0},
|
|
590
|
+
environments=us.CvxpyEnvironments(
|
|
591
|
+
fixed_public_law={"o": 1.0},
|
|
592
|
+
constraint_builders=(cap_b,),
|
|
593
|
+
),
|
|
594
|
+
)
|
|
595
|
+
```
|
|
596
|
+
|
|
597
|
+
The TV, chi-square, KL, and Wasserstein Q presets are wrappers around this
|
|
598
|
+
backend. Use CVXPY when admissible hidden shifts are convex but not just
|
|
599
|
+
finite-linear constraints.
|
|
600
|
+
|
|
601
|
+
Solved CVXPY transport intervals expose dual diagnostics:
|
|
602
|
+
|
|
603
|
+
```python
|
|
604
|
+
interval = grouped.problem.global_transport_modulus()
|
|
605
|
+
for row in interval.dual_summary(top=5):
|
|
606
|
+
print(row.solve, row.name, row.kind, row.magnitude)
|
|
607
|
+
```
|
|
608
|
+
|
|
609
|
+
These rows are CVXPY/KKT sensitivity diagnostics. Large multipliers identify
|
|
610
|
+
constraints that are locally influential for the solved interval, such as
|
|
611
|
+
public-law equalities, Q-budget constraints, or active state lower bounds. Custom
|
|
612
|
+
constraint builders can return `us.cvxpy_constraint(...)` to attach a readable
|
|
613
|
+
name and kind to their dual rows.
|
|
614
|
+
|
|
615
|
+
For repeated radius sweeps on the same compiled finite problem, use the
|
|
616
|
+
parameterized backend:
|
|
617
|
+
|
|
618
|
+
```python
|
|
619
|
+
grouped = us.from_dataframe(
|
|
620
|
+
rows_or_frame,
|
|
621
|
+
public=["AGE_BAND", "SEX"],
|
|
622
|
+
hidden=["AGE_BAND", "SEX", "OCC_MAJOR"],
|
|
623
|
+
target="__target__",
|
|
624
|
+
q=us.q_tv_budget(0.10, backend="parameterized_cvxpy"),
|
|
625
|
+
)
|
|
626
|
+
|
|
627
|
+
first = grouped.problem.global_transport_modulus()
|
|
628
|
+
grouped.problem.environments.set_parameter("radius", 0.20)
|
|
629
|
+
second = grouped.problem.global_transport_modulus()
|
|
630
|
+
```
|
|
631
|
+
|
|
632
|
+
`ParameterizedCvxpyEnvironments` caches the CVXPY problem and updates CVXPY
|
|
633
|
+
parameters for the objective, public law, and preset radius. It is useful when
|
|
634
|
+
you are sweeping radii for TV, chi-square, KL, or Wasserstein budgets on a fixed
|
|
635
|
+
state space.
|
|
636
|
+
|
|
637
|
+
## Theory Example: No Least Support
|
|
638
|
+
|
|
639
|
+
The finite poset of adequate supports need not have a least element.
|
|
640
|
+
|
|
641
|
+
```python
|
|
642
|
+
problem = us.FiniteProblem(
|
|
643
|
+
states=["a", "b", "c"],
|
|
644
|
+
public={"a": "o", "b": "o", "c": "o"},
|
|
645
|
+
estimand={"a": 0.0, "b": 1.0, "c": 2.0},
|
|
646
|
+
environments=us.LineSegment(
|
|
647
|
+
center={"a": 1 / 3, "b": 1 / 3, "c": 1 / 3},
|
|
648
|
+
direction={"a": 0.0, "b": 1.0, "c": -1.0},
|
|
649
|
+
radius=1 / 3,
|
|
650
|
+
),
|
|
651
|
+
)
|
|
652
|
+
|
|
653
|
+
least = problem.least_support()
|
|
654
|
+
|
|
655
|
+
print(least.exists)
|
|
656
|
+
# False
|
|
657
|
+
|
|
658
|
+
for support in least.minimal_supports:
|
|
659
|
+
print(support.format())
|
|
660
|
+
# {{a, c}, {b}}
|
|
661
|
+
# {{a, b}, {c}}
|
|
662
|
+
```
|
|
663
|
+
|
|
664
|
+
## More Documentation
|
|
665
|
+
|
|
666
|
+
- [Representation adequacy guide](docs/representation-adequacy.md)
|
|
667
|
+
- [Benchmark gallery](docs/benchmark-gallery.md)
|
|
668
|
+
- [Transport preset guide](docs/transport-presets.md)
|
|
669
|
+
- [Using `updatesupport` with causal inference libraries](docs/causal-library-integration.md)
|
|
670
|
+
- [Folktables ACSIncome result interpretation](docs/folktables-acs-income-interpretation.md)
|
|
671
|
+
- [Update-Relevant Support: Hume's Missing Descent](https://philpapers.org/go.pl?id=BRUUSH&proxyId=&u=https%3A%2F%2Fphilpapers.org%2Farchive%2FBRUUSH.pdf)
|