tiktok-quality 1.0.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- tiktok_quality-1.0.0/.github/workflows/publish.yml +73 -0
- tiktok_quality-1.0.0/.gitignore +26 -0
- tiktok_quality-1.0.0/LICENSE +21 -0
- tiktok_quality-1.0.0/PKG-INFO +172 -0
- tiktok_quality-1.0.0/README.md +147 -0
- tiktok_quality-1.0.0/proof.png +0 -0
- tiktok_quality-1.0.0/pyproject.toml +38 -0
- tiktok_quality-1.0.0/src/tiktok_quality/__init__.py +23 -0
- tiktok_quality-1.0.0/src/tiktok_quality/__main__.py +4 -0
- tiktok_quality-1.0.0/src/tiktok_quality/cli.py +160 -0
- tiktok_quality-1.0.0/src/tiktok_quality/mp4/__init__.py +0 -0
- tiktok_quality-1.0.0/src/tiktok_quality/mp4/builder.py +107 -0
- tiktok_quality-1.0.0/src/tiktok_quality/mp4/parser.py +127 -0
- tiktok_quality-1.0.0/src/tiktok_quality/transform.py +353 -0
- tiktok_quality-1.0.0/tests/test_mp4.py +65 -0
|
@@ -0,0 +1,73 @@
|
|
|
1
|
+
name: CI & Publish
|
|
2
|
+
|
|
3
|
+
on:
|
|
4
|
+
push:
|
|
5
|
+
branches: [main]
|
|
6
|
+
tags: ["v*"]
|
|
7
|
+
pull_request:
|
|
8
|
+
branches: [main]
|
|
9
|
+
|
|
10
|
+
jobs:
|
|
11
|
+
test:
|
|
12
|
+
name: Test Python ${{ matrix.python-version }}
|
|
13
|
+
runs-on: ubuntu-latest
|
|
14
|
+
strategy:
|
|
15
|
+
matrix:
|
|
16
|
+
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
|
17
|
+
|
|
18
|
+
steps:
|
|
19
|
+
- uses: actions/checkout@v4
|
|
20
|
+
|
|
21
|
+
- name: Set up Python ${{ matrix.python-version }}
|
|
22
|
+
uses: actions/setup-python@v5
|
|
23
|
+
with:
|
|
24
|
+
python-version: ${{ matrix.python-version }}
|
|
25
|
+
|
|
26
|
+
- name: Install package + test deps
|
|
27
|
+
run: pip install -e ".[test]"
|
|
28
|
+
|
|
29
|
+
- name: Run tests
|
|
30
|
+
run: pytest tests/ -v
|
|
31
|
+
|
|
32
|
+
build:
|
|
33
|
+
name: Build distribution
|
|
34
|
+
needs: test
|
|
35
|
+
runs-on: ubuntu-latest
|
|
36
|
+
steps:
|
|
37
|
+
- uses: actions/checkout@v4
|
|
38
|
+
|
|
39
|
+
- name: Set up Python
|
|
40
|
+
uses: actions/setup-python@v5
|
|
41
|
+
with:
|
|
42
|
+
python-version: "3.12"
|
|
43
|
+
|
|
44
|
+
- name: Install build
|
|
45
|
+
run: pip install build
|
|
46
|
+
|
|
47
|
+
- name: Build sdist & wheel
|
|
48
|
+
run: python -m build
|
|
49
|
+
|
|
50
|
+
- name: Upload dist artifacts
|
|
51
|
+
uses: actions/upload-artifact@v4
|
|
52
|
+
with:
|
|
53
|
+
name: dist
|
|
54
|
+
path: dist/
|
|
55
|
+
|
|
56
|
+
publish:
|
|
57
|
+
name: Publish to PyPI
|
|
58
|
+
needs: build
|
|
59
|
+
if: startsWith(github.ref, 'refs/tags/v')
|
|
60
|
+
runs-on: ubuntu-latest
|
|
61
|
+
environment: pypi
|
|
62
|
+
permissions:
|
|
63
|
+
id-token: write
|
|
64
|
+
|
|
65
|
+
steps:
|
|
66
|
+
- name: Download dist artifacts
|
|
67
|
+
uses: actions/download-artifact@v4
|
|
68
|
+
with:
|
|
69
|
+
name: dist
|
|
70
|
+
path: dist/
|
|
71
|
+
|
|
72
|
+
- name: Publish to PyPI
|
|
73
|
+
uses: pypa/gh-action-pypi-publish@release/v1
|
|
@@ -0,0 +1,26 @@
|
|
|
1
|
+
__pycache__/
|
|
2
|
+
*.py[cod]
|
|
3
|
+
*.pyo
|
|
4
|
+
*.egg-info/
|
|
5
|
+
*.egg
|
|
6
|
+
dist/
|
|
7
|
+
build/
|
|
8
|
+
*.whl
|
|
9
|
+
|
|
10
|
+
.venv/
|
|
11
|
+
venv/
|
|
12
|
+
env/
|
|
13
|
+
|
|
14
|
+
.vscode/
|
|
15
|
+
.idea/
|
|
16
|
+
*.swp
|
|
17
|
+
*.swo
|
|
18
|
+
|
|
19
|
+
.DS_Store
|
|
20
|
+
Thumbs.db
|
|
21
|
+
|
|
22
|
+
*.mp4
|
|
23
|
+
*.mkv
|
|
24
|
+
*.avi
|
|
25
|
+
*.mov
|
|
26
|
+
test_output/
|
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026 Bastien GIMBERT
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
|
@@ -0,0 +1,172 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: tiktok-quality
|
|
3
|
+
Version: 1.0.0
|
|
4
|
+
Summary: Upload 1080p 60fps on TikTok
|
|
5
|
+
Project-URL: Homepage, https://github.com/BastienGimbert/tiktok-quality
|
|
6
|
+
Author: Bastien GIMBERT
|
|
7
|
+
License-Expression: MIT
|
|
8
|
+
License-File: LICENSE
|
|
9
|
+
Keywords: 1080p,1080p60,60fps,mp4,quality,tiktok,upload,video
|
|
10
|
+
Classifier: Development Status :: 5 - Production/Stable
|
|
11
|
+
Classifier: Environment :: Console
|
|
12
|
+
Classifier: Intended Audience :: Developers
|
|
13
|
+
Classifier: License :: OSI Approved :: MIT License
|
|
14
|
+
Classifier: Programming Language :: Python :: 3
|
|
15
|
+
Classifier: Programming Language :: Python :: 3.10
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
17
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
18
|
+
Classifier: Programming Language :: Python :: 3.13
|
|
19
|
+
Classifier: Topic :: Multimedia :: Video
|
|
20
|
+
Classifier: Topic :: Multimedia :: Video :: Conversion
|
|
21
|
+
Requires-Python: >=3.10
|
|
22
|
+
Provides-Extra: test
|
|
23
|
+
Requires-Dist: pytest>=7.0; extra == 'test'
|
|
24
|
+
Description-Content-Type: text/markdown
|
|
25
|
+
|
|
26
|
+
# Tiktok-Quality
|
|
27
|
+
|
|
28
|
+
## Installation
|
|
29
|
+
|
|
30
|
+
```bash
|
|
31
|
+
pip install tiktok-quality
|
|
32
|
+
```
|
|
33
|
+
|
|
34
|
+
Or from source:
|
|
35
|
+
|
|
36
|
+
```bash
|
|
37
|
+
git clone https://github.com/BastienGimbert/tiktok-quality.git
|
|
38
|
+
cd tiktok-quality
|
|
39
|
+
pip install -e .
|
|
40
|
+
```
|
|
41
|
+
|
|
42
|
+
### Requirements
|
|
43
|
+
|
|
44
|
+
- **Python 3.10+** - zero third-party dependencies
|
|
45
|
+
- **FFmpeg** - optional, for output verification only
|
|
46
|
+
|
|
47
|
+
```bash
|
|
48
|
+
# Check dependencies
|
|
49
|
+
tiktok-quality --check-deps
|
|
50
|
+
|
|
51
|
+
# Install FFmpeg if needed:
|
|
52
|
+
# Windows: winget install Gyan.FFmpeg
|
|
53
|
+
# macOS: brew install ffmpeg
|
|
54
|
+
# Linux: sudo apt install ffmpeg
|
|
55
|
+
```
|
|
56
|
+
|
|
57
|
+
## Usage
|
|
58
|
+
|
|
59
|
+
### CLI
|
|
60
|
+
|
|
61
|
+
```bash
|
|
62
|
+
# Transform a video (10x frame inflation)
|
|
63
|
+
tiktok-quality input.mp4 output.mp4
|
|
64
|
+
|
|
65
|
+
# Custom multiplier
|
|
66
|
+
tiktok-quality input.mp4 output.mp4 -m 15
|
|
67
|
+
|
|
68
|
+
# Custom metadata tag
|
|
69
|
+
tiktok-quality input.mp4 output.mp4 --comment "MyTag123"
|
|
70
|
+
|
|
71
|
+
# Quiet mode
|
|
72
|
+
tiktok-quality input.mp4 output.mp4 -q
|
|
73
|
+
```
|
|
74
|
+
|
|
75
|
+
### Verification
|
|
76
|
+
|
|
77
|
+
```bash
|
|
78
|
+
# Verify output with ffprobe
|
|
79
|
+
tiktok-quality --verify output.mp4
|
|
80
|
+
|
|
81
|
+
# Byte-compare with a reference file
|
|
82
|
+
tiktok-quality --compare output.mp4 reference.mp4
|
|
83
|
+
```
|
|
84
|
+
|
|
85
|
+
### Python API
|
|
86
|
+
|
|
87
|
+
```python
|
|
88
|
+
from tiktok_quality import transform
|
|
89
|
+
|
|
90
|
+
stats = transform("input.mp4", "output.mp4", multiplier=10)
|
|
91
|
+
print(f"Declared frames: {stats['declared_frames']}")
|
|
92
|
+
```
|
|
93
|
+
|
|
94
|
+
## How It Works
|
|
95
|
+
|
|
96
|
+
Manipulates the MP4 container metadata to inflate the declared frame count by adding "ghost frames" - filler NALUs pointing to a single 8-byte padding block.
|
|
97
|
+
|
|
98
|
+
```
|
|
99
|
+
Input: 1920x1080 60fps, 1494 real frames, 50.7 MB
|
|
100
|
+
Output: Same video, 14940 declared frames, 50.8 MB (+107 KB overhead)
|
|
101
|
+
```
|
|
102
|
+
|
|
103
|
+
No pixels are changed. No re-encoding. The video data is byte-for-byte identical but tiktok-quality tricks TikTok into thinking the video has more frames, allowing it to be uploaded at 1080p60.
|
|
104
|
+
|
|
105
|
+
### Transformations Applied
|
|
106
|
+
|
|
107
|
+
| # | What | Detail |
|
|
108
|
+
|---|---|---|
|
|
109
|
+
| 1 | Brand | `mp42` -> `isom` |
|
|
110
|
+
| 2 | Box order | moov moved before mdat (fast-start) |
|
|
111
|
+
| 3 | First frame | SEI NALUs stripped, IDR slice kept |
|
|
112
|
+
| 4 | avcC | High profile extension bytes added |
|
|
113
|
+
| 5 | Video STTS | Ghost frame timing entries appended |
|
|
114
|
+
| 6 | Video STSZ | 8-byte entries for each ghost frame |
|
|
115
|
+
| 7 | Video STSC | New chunk entry for padding region |
|
|
116
|
+
| 8 | Video STCO | Ghost chunks point to single filler NAL |
|
|
117
|
+
| 9 | Padding NAL | 8 bytes appended: `00 00 00 04 00 00 00 00` |
|
|
118
|
+
| 10 | Audio handler | Renamed to "SoundHandler", lang -> `und` |
|
|
119
|
+
| 11 | Audio timing | Last sample trimmed to align with video |
|
|
120
|
+
| 12 | Metadata | iTunes-style comment tag in ilst |
|
|
121
|
+
| 13 | Bitrates | Recalculated for both tracks |
|
|
122
|
+
|
|
123
|
+
### Ghost Frame Mechanism
|
|
124
|
+
|
|
125
|
+
All ghost frames reference a single 8-byte filler NALU at the end of mdat:
|
|
126
|
+
|
|
127
|
+
```
|
|
128
|
+
00 00 00 04 <- NALU length (4 bytes payload)
|
|
129
|
+
00 00 00 00 <- type 0 (filler) + empty content
|
|
130
|
+
```
|
|
131
|
+
|
|
132
|
+
13,446 ghost "frames" share this one block via STCO. Only **8 bytes** of media data added. Metadata tables grow by ~107 KB.
|
|
133
|
+
|
|
134
|
+
## Project Structure
|
|
135
|
+
|
|
136
|
+
```
|
|
137
|
+
tiktok-quality/
|
|
138
|
+
├── pyproject.toml
|
|
139
|
+
├── README.md
|
|
140
|
+
├── LICENSE
|
|
141
|
+
├── proof.png
|
|
142
|
+
├── .github/workflows/publish.yml
|
|
143
|
+
├── src/tiktok_quality/
|
|
144
|
+
│ ├── __init__.py
|
|
145
|
+
│ ├── __main__.py
|
|
146
|
+
│ ├── cli.py
|
|
147
|
+
│ ├── transform.py
|
|
148
|
+
│ └── mp4/
|
|
149
|
+
│ ├── parser.py
|
|
150
|
+
│ └── builder.py
|
|
151
|
+
└── tests/
|
|
152
|
+
└── test_mp4.py
|
|
153
|
+
```
|
|
154
|
+
|
|
155
|
+
## Background
|
|
156
|
+
|
|
157
|
+
Reverse-engineered from the "TikTok Enhancer" Chrome extension (Editing News v2.1.4) which uses a server at `v2.editingnews.com` to apply this container manipulation. The extension:
|
|
158
|
+
|
|
159
|
+
1. Intercepts video file on TikTok upload page
|
|
160
|
+
2. Sends to their server for container manipulation
|
|
161
|
+
3. Server returns "enhanced" file
|
|
162
|
+
4. Extension replaces the file in TikTok's upload form
|
|
163
|
+
|
|
164
|
+
This tool replicates the exact server output - **byte-for-byte identical**.
|
|
165
|
+
|
|
166
|
+
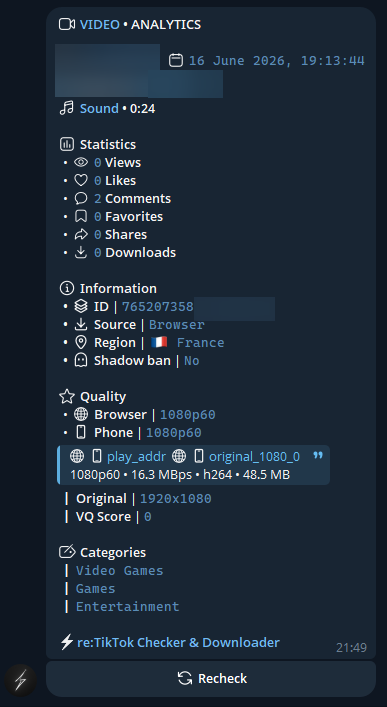
|
|
167
|
+
|
|
168
|
+
**1080p60** upload quality confirmed via re:TikTok Checker & Downloader bot.
|
|
169
|
+
|
|
170
|
+
## License
|
|
171
|
+
|
|
172
|
+
MIT see [LICENSE](LICENSE) file for details.
|
|
@@ -0,0 +1,147 @@
|
|
|
1
|
+
# Tiktok-Quality
|
|
2
|
+
|
|
3
|
+
## Installation
|
|
4
|
+
|
|
5
|
+
```bash
|
|
6
|
+
pip install tiktok-quality
|
|
7
|
+
```
|
|
8
|
+
|
|
9
|
+
Or from source:
|
|
10
|
+
|
|
11
|
+
```bash
|
|
12
|
+
git clone https://github.com/BastienGimbert/tiktok-quality.git
|
|
13
|
+
cd tiktok-quality
|
|
14
|
+
pip install -e .
|
|
15
|
+
```
|
|
16
|
+
|
|
17
|
+
### Requirements
|
|
18
|
+
|
|
19
|
+
- **Python 3.10+** - zero third-party dependencies
|
|
20
|
+
- **FFmpeg** - optional, for output verification only
|
|
21
|
+
|
|
22
|
+
```bash
|
|
23
|
+
# Check dependencies
|
|
24
|
+
tiktok-quality --check-deps
|
|
25
|
+
|
|
26
|
+
# Install FFmpeg if needed:
|
|
27
|
+
# Windows: winget install Gyan.FFmpeg
|
|
28
|
+
# macOS: brew install ffmpeg
|
|
29
|
+
# Linux: sudo apt install ffmpeg
|
|
30
|
+
```
|
|
31
|
+
|
|
32
|
+
## Usage
|
|
33
|
+
|
|
34
|
+
### CLI
|
|
35
|
+
|
|
36
|
+
```bash
|
|
37
|
+
# Transform a video (10x frame inflation)
|
|
38
|
+
tiktok-quality input.mp4 output.mp4
|
|
39
|
+
|
|
40
|
+
# Custom multiplier
|
|
41
|
+
tiktok-quality input.mp4 output.mp4 -m 15
|
|
42
|
+
|
|
43
|
+
# Custom metadata tag
|
|
44
|
+
tiktok-quality input.mp4 output.mp4 --comment "MyTag123"
|
|
45
|
+
|
|
46
|
+
# Quiet mode
|
|
47
|
+
tiktok-quality input.mp4 output.mp4 -q
|
|
48
|
+
```
|
|
49
|
+
|
|
50
|
+
### Verification
|
|
51
|
+
|
|
52
|
+
```bash
|
|
53
|
+
# Verify output with ffprobe
|
|
54
|
+
tiktok-quality --verify output.mp4
|
|
55
|
+
|
|
56
|
+
# Byte-compare with a reference file
|
|
57
|
+
tiktok-quality --compare output.mp4 reference.mp4
|
|
58
|
+
```
|
|
59
|
+
|
|
60
|
+
### Python API
|
|
61
|
+
|
|
62
|
+
```python
|
|
63
|
+
from tiktok_quality import transform
|
|
64
|
+
|
|
65
|
+
stats = transform("input.mp4", "output.mp4", multiplier=10)
|
|
66
|
+
print(f"Declared frames: {stats['declared_frames']}")
|
|
67
|
+
```
|
|
68
|
+
|
|
69
|
+
## How It Works
|
|
70
|
+
|
|
71
|
+
Manipulates the MP4 container metadata to inflate the declared frame count by adding "ghost frames" - filler NALUs pointing to a single 8-byte padding block.
|
|
72
|
+
|
|
73
|
+
```
|
|
74
|
+
Input: 1920x1080 60fps, 1494 real frames, 50.7 MB
|
|
75
|
+
Output: Same video, 14940 declared frames, 50.8 MB (+107 KB overhead)
|
|
76
|
+
```
|
|
77
|
+
|
|
78
|
+
No pixels are changed. No re-encoding. The video data is byte-for-byte identical but tiktok-quality tricks TikTok into thinking the video has more frames, allowing it to be uploaded at 1080p60.
|
|
79
|
+
|
|
80
|
+
### Transformations Applied
|
|
81
|
+
|
|
82
|
+
| # | What | Detail |
|
|
83
|
+
|---|---|---|
|
|
84
|
+
| 1 | Brand | `mp42` -> `isom` |
|
|
85
|
+
| 2 | Box order | moov moved before mdat (fast-start) |
|
|
86
|
+
| 3 | First frame | SEI NALUs stripped, IDR slice kept |
|
|
87
|
+
| 4 | avcC | High profile extension bytes added |
|
|
88
|
+
| 5 | Video STTS | Ghost frame timing entries appended |
|
|
89
|
+
| 6 | Video STSZ | 8-byte entries for each ghost frame |
|
|
90
|
+
| 7 | Video STSC | New chunk entry for padding region |
|
|
91
|
+
| 8 | Video STCO | Ghost chunks point to single filler NAL |
|
|
92
|
+
| 9 | Padding NAL | 8 bytes appended: `00 00 00 04 00 00 00 00` |
|
|
93
|
+
| 10 | Audio handler | Renamed to "SoundHandler", lang -> `und` |
|
|
94
|
+
| 11 | Audio timing | Last sample trimmed to align with video |
|
|
95
|
+
| 12 | Metadata | iTunes-style comment tag in ilst |
|
|
96
|
+
| 13 | Bitrates | Recalculated for both tracks |
|
|
97
|
+
|
|
98
|
+
### Ghost Frame Mechanism
|
|
99
|
+
|
|
100
|
+
All ghost frames reference a single 8-byte filler NALU at the end of mdat:
|
|
101
|
+
|
|
102
|
+
```
|
|
103
|
+
00 00 00 04 <- NALU length (4 bytes payload)
|
|
104
|
+
00 00 00 00 <- type 0 (filler) + empty content
|
|
105
|
+
```
|
|
106
|
+
|
|
107
|
+
13,446 ghost "frames" share this one block via STCO. Only **8 bytes** of media data added. Metadata tables grow by ~107 KB.
|
|
108
|
+
|
|
109
|
+
## Project Structure
|
|
110
|
+
|
|
111
|
+
```
|
|
112
|
+
tiktok-quality/
|
|
113
|
+
├── pyproject.toml
|
|
114
|
+
├── README.md
|
|
115
|
+
├── LICENSE
|
|
116
|
+
├── proof.png
|
|
117
|
+
├── .github/workflows/publish.yml
|
|
118
|
+
├── src/tiktok_quality/
|
|
119
|
+
│ ├── __init__.py
|
|
120
|
+
│ ├── __main__.py
|
|
121
|
+
│ ├── cli.py
|
|
122
|
+
│ ├── transform.py
|
|
123
|
+
│ └── mp4/
|
|
124
|
+
│ ├── parser.py
|
|
125
|
+
│ └── builder.py
|
|
126
|
+
└── tests/
|
|
127
|
+
└── test_mp4.py
|
|
128
|
+
```
|
|
129
|
+
|
|
130
|
+
## Background
|
|
131
|
+
|
|
132
|
+
Reverse-engineered from the "TikTok Enhancer" Chrome extension (Editing News v2.1.4) which uses a server at `v2.editingnews.com` to apply this container manipulation. The extension:
|
|
133
|
+
|
|
134
|
+
1. Intercepts video file on TikTok upload page
|
|
135
|
+
2. Sends to their server for container manipulation
|
|
136
|
+
3. Server returns "enhanced" file
|
|
137
|
+
4. Extension replaces the file in TikTok's upload form
|
|
138
|
+
|
|
139
|
+
This tool replicates the exact server output - **byte-for-byte identical**.
|
|
140
|
+
|
|
141
|
+

|
|
142
|
+
|
|
143
|
+
**1080p60** upload quality confirmed via re:TikTok Checker & Downloader bot.
|
|
144
|
+
|
|
145
|
+
## License
|
|
146
|
+
|
|
147
|
+
MIT see [LICENSE](LICENSE) file for details.
|
|
Binary file
|
|
@@ -0,0 +1,38 @@
|
|
|
1
|
+
[build-system]
|
|
2
|
+
requires = ["hatchling"]
|
|
3
|
+
build-backend = "hatchling.build"
|
|
4
|
+
|
|
5
|
+
[project]
|
|
6
|
+
name = "tiktok-quality"
|
|
7
|
+
version = "1.0.0"
|
|
8
|
+
description = "Upload 1080p 60fps on TikTok"
|
|
9
|
+
readme = "README.md"
|
|
10
|
+
license = "MIT"
|
|
11
|
+
requires-python = ">=3.10"
|
|
12
|
+
authors = [{ name = "Bastien GIMBERT" }]
|
|
13
|
+
keywords = ["tiktok", "mp4", "video", "1080p60", "1080p", "60fps", "upload", "quality"]
|
|
14
|
+
classifiers = [
|
|
15
|
+
"Development Status :: 5 - Production/Stable",
|
|
16
|
+
"Environment :: Console",
|
|
17
|
+
"Intended Audience :: Developers",
|
|
18
|
+
"License :: OSI Approved :: MIT License",
|
|
19
|
+
"Programming Language :: Python :: 3",
|
|
20
|
+
"Programming Language :: Python :: 3.10",
|
|
21
|
+
"Programming Language :: Python :: 3.11",
|
|
22
|
+
"Programming Language :: Python :: 3.12",
|
|
23
|
+
"Programming Language :: Python :: 3.13",
|
|
24
|
+
"Topic :: Multimedia :: Video",
|
|
25
|
+
"Topic :: Multimedia :: Video :: Conversion",
|
|
26
|
+
]
|
|
27
|
+
|
|
28
|
+
[project.scripts]
|
|
29
|
+
tiktok-quality = "tiktok_quality.cli:main"
|
|
30
|
+
|
|
31
|
+
[project.optional-dependencies]
|
|
32
|
+
test = ["pytest>=7.0"]
|
|
33
|
+
|
|
34
|
+
[project.urls]
|
|
35
|
+
Homepage = "https://github.com/BastienGimbert/tiktok-quality"
|
|
36
|
+
|
|
37
|
+
[tool.pytest.ini_options]
|
|
38
|
+
testpaths = ["tests"]
|
|
@@ -0,0 +1,23 @@
|
|
|
1
|
+
"""tiktok-quality
|
|
2
|
+
|
|
3
|
+
Usage::
|
|
4
|
+
|
|
5
|
+
from tiktok_quality import transform
|
|
6
|
+
|
|
7
|
+
# Convert a single file
|
|
8
|
+
stats = transform("input.mp4", "output.mp4", multiplier=10)
|
|
9
|
+
|
|
10
|
+
# Python API with all options
|
|
11
|
+
stats = transform(
|
|
12
|
+
input_path="video.mp4",
|
|
13
|
+
output_path="output.mp4",
|
|
14
|
+
multiplier=10,
|
|
15
|
+
comment="MyTag123",
|
|
16
|
+
)
|
|
17
|
+
"""
|
|
18
|
+
|
|
19
|
+
__version__ = "1.0.0"
|
|
20
|
+
|
|
21
|
+
from .transform import transform
|
|
22
|
+
|
|
23
|
+
__all__ = ["transform"]
|
|
@@ -0,0 +1,160 @@
|
|
|
1
|
+
"""CLI interface for tiktok-quality.
|
|
2
|
+
|
|
3
|
+
Usage:
|
|
4
|
+
tiktok-quality input.mp4 output.mp4 [options]
|
|
5
|
+
python -m tiktok_quality input.mp4 output.mp4 [options]
|
|
6
|
+
"""
|
|
7
|
+
|
|
8
|
+
from __future__ import annotations
|
|
9
|
+
|
|
10
|
+
import argparse
|
|
11
|
+
import json
|
|
12
|
+
import shutil
|
|
13
|
+
import subprocess
|
|
14
|
+
import sys
|
|
15
|
+
from pathlib import Path
|
|
16
|
+
|
|
17
|
+
from . import __version__
|
|
18
|
+
from .transform import transform
|
|
19
|
+
|
|
20
|
+
|
|
21
|
+
def main():
|
|
22
|
+
"""CLI entry point."""
|
|
23
|
+
parser = argparse.ArgumentParser(
|
|
24
|
+
prog='tiktok-quality',
|
|
25
|
+
description='TikTok Quality -- MP4 container manipulation (zero re-encoding)',
|
|
26
|
+
formatter_class=argparse.RawDescriptionHelpFormatter,
|
|
27
|
+
epilog="""
|
|
28
|
+
Examples:
|
|
29
|
+
tiktok-quality video.mp4 output.mp4
|
|
30
|
+
tiktok-quality video.mp4 output.mp4 -m 10
|
|
31
|
+
tiktok-quality video.mp4 output.mp4 --comment "MyTag"
|
|
32
|
+
tiktok-quality --verify output.mp4
|
|
33
|
+
tiktok-quality --check-deps
|
|
34
|
+
"""
|
|
35
|
+
)
|
|
36
|
+
parser.add_argument('input', nargs='?', help='Input MP4 file (H.264/AVC)')
|
|
37
|
+
parser.add_argument('output', nargs='?', help='Output MP4 file path')
|
|
38
|
+
parser.add_argument('-m', '--multiplier', type=int, default=10,
|
|
39
|
+
help='Frame count multiplier (default: 10)')
|
|
40
|
+
parser.add_argument('-c', '--comment', type=str, default='TK8vY5VqBA6hUlo1yuGvNA',
|
|
41
|
+
help='Metadata comment/signature tag')
|
|
42
|
+
parser.add_argument('--verify', metavar='FILE',
|
|
43
|
+
help='Verify a file with ffprobe (no transformation)')
|
|
44
|
+
parser.add_argument('--compare', nargs=2, metavar=('FILE', 'REFERENCE'),
|
|
45
|
+
help='Byte-compare two files')
|
|
46
|
+
parser.add_argument('--check-deps', action='store_true',
|
|
47
|
+
help='Check and install dependencies')
|
|
48
|
+
parser.add_argument('-q', '--quiet', action='store_true',
|
|
49
|
+
help='Suppress progress messages')
|
|
50
|
+
parser.add_argument('-V', '--version', action='version', version=f'%(prog)s {__version__}')
|
|
51
|
+
|
|
52
|
+
args = parser.parse_args()
|
|
53
|
+
|
|
54
|
+
if args.check_deps:
|
|
55
|
+
_check_deps()
|
|
56
|
+
return
|
|
57
|
+
|
|
58
|
+
if args.verify:
|
|
59
|
+
if not Path(args.verify).exists():
|
|
60
|
+
print(f"[!] File not found: {args.verify}", file=sys.stderr)
|
|
61
|
+
sys.exit(1)
|
|
62
|
+
_verify_ffprobe(args.verify)
|
|
63
|
+
return
|
|
64
|
+
|
|
65
|
+
if args.compare:
|
|
66
|
+
f1, f2 = args.compare
|
|
67
|
+
for f in (f1, f2):
|
|
68
|
+
if not Path(f).exists():
|
|
69
|
+
print(f"[!] File not found: {f}", file=sys.stderr)
|
|
70
|
+
sys.exit(1)
|
|
71
|
+
ok = _compare_files(f1, f2)
|
|
72
|
+
sys.exit(0 if ok else 1)
|
|
73
|
+
|
|
74
|
+
if not args.input or not args.output:
|
|
75
|
+
parser.print_help()
|
|
76
|
+
sys.exit(1)
|
|
77
|
+
|
|
78
|
+
if not Path(args.input).exists():
|
|
79
|
+
print(f"[!] File not found: {args.input}", file=sys.stderr)
|
|
80
|
+
sys.exit(1)
|
|
81
|
+
|
|
82
|
+
transform(
|
|
83
|
+
input_path=args.input,
|
|
84
|
+
output_path=args.output,
|
|
85
|
+
multiplier=args.multiplier,
|
|
86
|
+
comment=args.comment,
|
|
87
|
+
verbose=not args.quiet,
|
|
88
|
+
)
|
|
89
|
+
|
|
90
|
+
if not args.quiet:
|
|
91
|
+
_verify_ffprobe(args.output)
|
|
92
|
+
|
|
93
|
+
|
|
94
|
+
def _verify_ffprobe(path: str):
|
|
95
|
+
"""Run ffprobe and print summary."""
|
|
96
|
+
ffprobe = shutil.which('ffprobe')
|
|
97
|
+
if not ffprobe:
|
|
98
|
+
return
|
|
99
|
+
try:
|
|
100
|
+
r = subprocess.run(
|
|
101
|
+
[ffprobe, '-v', 'quiet', '-show_format', '-show_streams', '-print_format', 'json', path],
|
|
102
|
+
capture_output=True, text=True, timeout=30,
|
|
103
|
+
)
|
|
104
|
+
if r.returncode != 0:
|
|
105
|
+
return
|
|
106
|
+
info = json.loads(r.stdout)
|
|
107
|
+
for s in info.get('streams', []):
|
|
108
|
+
if s.get('codec_type') == 'video':
|
|
109
|
+
print(f"[+] Video: {s.get('codec_name')} {s.get('width')}x{s.get('height')}, {s.get('nb_frames')} frames")
|
|
110
|
+
elif s.get('codec_type') == 'audio':
|
|
111
|
+
print(f"[+] Audio: {s.get('codec_name')} @ {s.get('sample_rate')} Hz")
|
|
112
|
+
fmt = info.get('format', {})
|
|
113
|
+
tags = fmt.get('tags', {})
|
|
114
|
+
print(f"[+] Brand: {tags.get('major_brand', '?')}, Comment: {tags.get('comment', '-')}")
|
|
115
|
+
except (FileNotFoundError, subprocess.TimeoutExpired, json.JSONDecodeError):
|
|
116
|
+
pass
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
def _compare_files(path1: str, path2: str) -> bool:
|
|
120
|
+
"""Byte-for-byte comparison."""
|
|
121
|
+
with open(path1, 'rb') as f:
|
|
122
|
+
a = f.read()
|
|
123
|
+
with open(path2, 'rb') as f:
|
|
124
|
+
b = f.read()
|
|
125
|
+
if a == b:
|
|
126
|
+
print("[+] PERFECT MATCH - byte-for-byte identical")
|
|
127
|
+
return True
|
|
128
|
+
print(f"[-] Files differ: {len(a):,} vs {len(b):,} bytes")
|
|
129
|
+
for i in range(min(len(a), len(b))):
|
|
130
|
+
if a[i] != b[i]:
|
|
131
|
+
print(f" First diff @ byte {i}")
|
|
132
|
+
break
|
|
133
|
+
return False
|
|
134
|
+
|
|
135
|
+
|
|
136
|
+
def _check_deps():
|
|
137
|
+
"""Check all dependencies."""
|
|
138
|
+
v = sys.version_info
|
|
139
|
+
print(f"[+] Python {v.major}.{v.minor}.{v.micro}")
|
|
140
|
+
|
|
141
|
+
ffprobe = shutil.which('ffprobe')
|
|
142
|
+
ffmpeg = shutil.which('ffmpeg')
|
|
143
|
+
print(f"[+] ffprobe: {ffprobe or 'NOT FOUND (optional)'}")
|
|
144
|
+
print(f"[+] ffmpeg: {ffmpeg or 'NOT FOUND (optional)'}")
|
|
145
|
+
|
|
146
|
+
if not ffprobe:
|
|
147
|
+
print("\n Install FFmpeg:")
|
|
148
|
+
print(" Windows: winget install Gyan.FFmpeg")
|
|
149
|
+
print(" macOS: brew install ffmpeg")
|
|
150
|
+
print(" Linux: sudo apt install ffmpeg")
|
|
151
|
+
|
|
152
|
+
try:
|
|
153
|
+
import tiktok_quality
|
|
154
|
+
print(f"[+] tiktok-quality v{tiktok_quality.__version__}")
|
|
155
|
+
except ImportError:
|
|
156
|
+
print("[!] Package not installed - run: pip install -e .")
|
|
157
|
+
|
|
158
|
+
|
|
159
|
+
if __name__ == '__main__':
|
|
160
|
+
main()
|
|
File without changes
|
|
@@ -0,0 +1,107 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
import struct
|
|
4
|
+
from typing import List, Tuple
|
|
5
|
+
|
|
6
|
+
|
|
7
|
+
def build_box(box_type: str, content: bytes) -> bytes:
|
|
8
|
+
"""Build a standard MP4 box: [size:4][type:4][content]."""
|
|
9
|
+
return struct.pack('>I', 8 + len(content)) + box_type.encode('latin-1') + content
|
|
10
|
+
|
|
11
|
+
|
|
12
|
+
def build_ftyp(brand: str = 'isom', minor_version: int = 512,
|
|
13
|
+
compatible: str = 'isomiso2avc1mp41') -> bytes:
|
|
14
|
+
"""Build an ftyp box with given brand."""
|
|
15
|
+
content = brand.encode('latin-1') + struct.pack('>I', minor_version) + compatible.encode('latin-1')
|
|
16
|
+
return build_box('ftyp', content)
|
|
17
|
+
|
|
18
|
+
|
|
19
|
+
def build_free() -> bytes:
|
|
20
|
+
"""Build a minimal 8-byte free box."""
|
|
21
|
+
return struct.pack('>I', 8) + b'free'
|
|
22
|
+
|
|
23
|
+
|
|
24
|
+
def build_mvhd(original_content: bytes, duration_ms: int) -> bytes:
|
|
25
|
+
"""Build mvhd box with updated duration (offset 16 in content)."""
|
|
26
|
+
content = bytearray(original_content)
|
|
27
|
+
struct.pack_into('>I', content, 16, duration_ms)
|
|
28
|
+
return build_box('mvhd', bytes(content))
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
def build_mdhd(original_content: bytes, duration: int | None = None, language: int | None = None) -> bytes:
|
|
32
|
+
"""Build mdhd box, optionally patching duration and language."""
|
|
33
|
+
content = bytearray(original_content)
|
|
34
|
+
if duration is not None:
|
|
35
|
+
struct.pack_into('>I', content, 16, duration)
|
|
36
|
+
if language is not None:
|
|
37
|
+
struct.pack_into('>H', content, 20, language)
|
|
38
|
+
return build_box('mdhd', bytes(content))
|
|
39
|
+
|
|
40
|
+
|
|
41
|
+
def build_tkhd(original_data: bytes, duration_ms: int | None = None) -> bytes:
|
|
42
|
+
"""Patch tkhd duration (offset 28). Takes full box bytes."""
|
|
43
|
+
result = bytearray(original_data)
|
|
44
|
+
if duration_ms is not None:
|
|
45
|
+
struct.pack_into('>I', result, 28, duration_ms)
|
|
46
|
+
return bytes(result)
|
|
47
|
+
|
|
48
|
+
|
|
49
|
+
def build_hdlr(handler_type: bytes, name: str) -> bytes:
|
|
50
|
+
"""Build an hdlr box with handler type and name."""
|
|
51
|
+
content = (struct.pack('>II', 0, 0) + handler_type + b'\x00' * 12 +
|
|
52
|
+
name.encode('utf-8') + b'\x00')
|
|
53
|
+
return build_box('hdlr', content)
|
|
54
|
+
|
|
55
|
+
|
|
56
|
+
def build_stts(entries: List[Tuple[int, int]]) -> bytes:
|
|
57
|
+
"""Build stts box from [(sample_count, sample_delta), ...]."""
|
|
58
|
+
body = b''.join(struct.pack('>II', c, d) for c, d in entries)
|
|
59
|
+
return build_box('stts', struct.pack('>II', 0, len(entries)) + body)
|
|
60
|
+
|
|
61
|
+
|
|
62
|
+
def build_stsc(entries: List[Tuple[int, int, int]]) -> bytes:
|
|
63
|
+
"""Build stsc box from [(first_chunk, samples_per_chunk, desc_idx), ...]."""
|
|
64
|
+
body = b''.join(struct.pack('>III', *e) for e in entries)
|
|
65
|
+
return build_box('stsc', struct.pack('>II', 0, len(entries)) + body)
|
|
66
|
+
|
|
67
|
+
|
|
68
|
+
def build_stsz(sample_sizes: List[int]) -> bytes:
|
|
69
|
+
"""Build stsz box with variable per-sample sizes."""
|
|
70
|
+
body = b''.join(struct.pack('>I', s) for s in sample_sizes)
|
|
71
|
+
return build_box('stsz', struct.pack('>III', 0, 0, len(sample_sizes)) + body)
|
|
72
|
+
|
|
73
|
+
|
|
74
|
+
def build_stco(offsets: List[int]) -> bytes:
|
|
75
|
+
"""Build stco box from list of chunk offsets."""
|
|
76
|
+
body = b''.join(struct.pack('>I', o) for o in offsets)
|
|
77
|
+
return build_box('stco', struct.pack('>II', 0, len(offsets)) + body)
|
|
78
|
+
|
|
79
|
+
|
|
80
|
+
def build_stsd_video(fixed_fields: bytes, avcc: bytes, colr: bytes, pasp: bytes, btrt: bytes) -> bytes:
|
|
81
|
+
"""Build video stsd box from sub-components."""
|
|
82
|
+
avc1_content = fixed_fields + avcc + colr + pasp + btrt
|
|
83
|
+
avc1 = struct.pack('>I', 8 + len(avc1_content)) + b'avc1' + avc1_content
|
|
84
|
+
return build_box('stsd', struct.pack('>II', 0, 1) + avc1)
|
|
85
|
+
|
|
86
|
+
|
|
87
|
+
def build_avcc(original_content: bytes, add_high_ext: bool = True) -> bytes:
|
|
88
|
+
"""Build avcC box, optionally adding High profile extension."""
|
|
89
|
+
content = original_content
|
|
90
|
+
if add_high_ext:
|
|
91
|
+
content += b'\xfd\xf8\xf8\x00'
|
|
92
|
+
return build_box('avcC', content)
|
|
93
|
+
|
|
94
|
+
|
|
95
|
+
def build_btrt(buffer_size_db: int, max_bitrate: int, avg_bitrate: int) -> bytes:
|
|
96
|
+
"""Build btrt (bitrate) box."""
|
|
97
|
+
return build_box('btrt', struct.pack('>III', buffer_size_db, max_bitrate, avg_bitrate))
|
|
98
|
+
|
|
99
|
+
|
|
100
|
+
def build_udta_comment(comment: str) -> bytes:
|
|
101
|
+
"""Build udta box with iTunes-style comment metadata."""
|
|
102
|
+
meta_hdlr = build_box('hdlr', struct.pack('>II', 0, 0) + b'mdir' + b'appl' + b'\x00' * 8 + b'\x00')
|
|
103
|
+
data_box = build_box('data', struct.pack('>II', 1, 0) + comment.encode('utf-8'))
|
|
104
|
+
cmt = struct.pack('>I', 8 + len(data_box)) + b'\xa9cmt' + data_box
|
|
105
|
+
ilst = build_box('ilst', cmt)
|
|
106
|
+
meta = build_box('meta', struct.pack('>I', 0) + meta_hdlr + ilst)
|
|
107
|
+
return build_box('udta', meta)
|
|
@@ -0,0 +1,127 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
import struct
|
|
4
|
+
from typing import List, Optional, Tuple
|
|
5
|
+
|
|
6
|
+
|
|
7
|
+
def read_u32(data: bytes, offset: int) -> int:
|
|
8
|
+
return struct.unpack('>I', data[offset:offset + 4])[0]
|
|
9
|
+
|
|
10
|
+
|
|
11
|
+
def read_u16(data: bytes, offset: int) -> int:
|
|
12
|
+
return struct.unpack('>H', data[offset:offset + 2])[0]
|
|
13
|
+
|
|
14
|
+
|
|
15
|
+
def find_box(data: bytes, box_type: str, offset: int = 0, end: int | None = None) -> Tuple[Optional[int], Optional[int]]:
|
|
16
|
+
"""Find a box by type at current level. Returns (position, size) or (None, None)."""
|
|
17
|
+
if end is None:
|
|
18
|
+
end = len(data)
|
|
19
|
+
pos = offset
|
|
20
|
+
while pos + 8 <= end:
|
|
21
|
+
size = read_u32(data, pos)
|
|
22
|
+
btype = data[pos + 4:pos + 8].decode('latin-1')
|
|
23
|
+
if size < 8:
|
|
24
|
+
break
|
|
25
|
+
if btype == box_type:
|
|
26
|
+
return pos, size
|
|
27
|
+
pos += size
|
|
28
|
+
return None, None
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
def find_box_path(data: bytes, path: List[str], offset: int = 0, end: int | None = None) -> Tuple[Optional[int], Optional[int]]:
|
|
32
|
+
"""
|
|
33
|
+
Navigate nested container boxes to find a target.
|
|
34
|
+
Example: find_box_path(data, ['mdia', 'minf', 'stbl'])
|
|
35
|
+
"""
|
|
36
|
+
if end is None:
|
|
37
|
+
end = len(data)
|
|
38
|
+
current_offset = offset
|
|
39
|
+
current_end = end
|
|
40
|
+
|
|
41
|
+
for i, box_type in enumerate(path):
|
|
42
|
+
pos = current_offset
|
|
43
|
+
while pos + 8 <= current_end:
|
|
44
|
+
size = read_u32(data, pos)
|
|
45
|
+
btype = data[pos + 4:pos + 8].decode('latin-1')
|
|
46
|
+
if size < 8:
|
|
47
|
+
break
|
|
48
|
+
if btype == box_type:
|
|
49
|
+
if i == len(path) - 1:
|
|
50
|
+
return pos, size
|
|
51
|
+
current_offset = pos + 8
|
|
52
|
+
current_end = pos + size
|
|
53
|
+
break
|
|
54
|
+
pos += size
|
|
55
|
+
else:
|
|
56
|
+
return None, None
|
|
57
|
+
return None, None
|
|
58
|
+
|
|
59
|
+
|
|
60
|
+
def find_track_by_handler(data: bytes, moov_offset: int, moov_size: int, handler: bytes) -> Tuple[Optional[int], Optional[int]]:
|
|
61
|
+
"""Find a track by handler type (b'vide', b'soun')."""
|
|
62
|
+
pos = moov_offset + 8
|
|
63
|
+
end = moov_offset + moov_size
|
|
64
|
+
while pos + 8 <= end:
|
|
65
|
+
size = read_u32(data, pos)
|
|
66
|
+
btype = data[pos + 4:pos + 8].decode('latin-1')
|
|
67
|
+
if size < 8:
|
|
68
|
+
break
|
|
69
|
+
if btype == 'trak':
|
|
70
|
+
hdlr_pos, _ = find_box_path(data, ['mdia', 'hdlr'], pos + 8, pos + size)
|
|
71
|
+
if hdlr_pos:
|
|
72
|
+
if data[hdlr_pos + 16:hdlr_pos + 20] == handler:
|
|
73
|
+
return pos, size
|
|
74
|
+
pos += size
|
|
75
|
+
return None, None
|
|
76
|
+
|
|
77
|
+
|
|
78
|
+
def parse_stts(data: bytes, offset: int) -> List[Tuple[int, int]]:
|
|
79
|
+
"""Parse time-to-sample box. Returns [(sample_count, sample_delta), ...]."""
|
|
80
|
+
entry_count = read_u32(data, offset + 12)
|
|
81
|
+
return [
|
|
82
|
+
(read_u32(data, offset + 16 + i * 8), read_u32(data, offset + 20 + i * 8))
|
|
83
|
+
for i in range(entry_count)
|
|
84
|
+
]
|
|
85
|
+
|
|
86
|
+
|
|
87
|
+
def parse_stsz(data: bytes, offset: int) -> List[int]:
|
|
88
|
+
"""Parse sample size box. Returns list of per-sample sizes."""
|
|
89
|
+
uniform = read_u32(data, offset + 12)
|
|
90
|
+
count = read_u32(data, offset + 16)
|
|
91
|
+
if uniform != 0:
|
|
92
|
+
return [uniform] * count
|
|
93
|
+
return [read_u32(data, offset + 20 + i * 4) for i in range(count)]
|
|
94
|
+
|
|
95
|
+
|
|
96
|
+
def parse_stsc(data: bytes, offset: int) -> List[Tuple[int, int, int]]:
|
|
97
|
+
"""Parse sample-to-chunk box. Returns [(first_chunk, samples_per_chunk, desc_idx), ...]."""
|
|
98
|
+
entry_count = read_u32(data, offset + 12)
|
|
99
|
+
return [
|
|
100
|
+
(read_u32(data, offset + 16 + i * 12),
|
|
101
|
+
read_u32(data, offset + 20 + i * 12),
|
|
102
|
+
read_u32(data, offset + 24 + i * 12))
|
|
103
|
+
for i in range(entry_count)
|
|
104
|
+
]
|
|
105
|
+
|
|
106
|
+
|
|
107
|
+
def parse_stco(data: bytes, offset: int) -> List[int]:
|
|
108
|
+
"""Parse chunk offset box. Returns list of chunk offsets."""
|
|
109
|
+
entry_count = read_u32(data, offset + 12)
|
|
110
|
+
return [read_u32(data, offset + 16 + i * 4) for i in range(entry_count)]
|
|
111
|
+
|
|
112
|
+
|
|
113
|
+
def parse_nalu_list(sample_data: bytes) -> List[Tuple[int, int, bytes]]:
|
|
114
|
+
"""
|
|
115
|
+
Parse NALUs in an AVC sample (4-byte length-prefixed).
|
|
116
|
+
Returns [(nalu_type, nalu_length, full_nalu_with_prefix), ...].
|
|
117
|
+
"""
|
|
118
|
+
nalus = []
|
|
119
|
+
pos = 0
|
|
120
|
+
while pos + 4 <= len(sample_data):
|
|
121
|
+
nalu_len = read_u32(sample_data, pos)
|
|
122
|
+
if pos + 4 + nalu_len > len(sample_data):
|
|
123
|
+
break
|
|
124
|
+
nalu_type = sample_data[pos + 4] & 0x1F
|
|
125
|
+
nalus.append((nalu_type, nalu_len, sample_data[pos:pos + 4 + nalu_len]))
|
|
126
|
+
pos += 4 + nalu_len
|
|
127
|
+
return nalus
|
|
@@ -0,0 +1,353 @@
|
|
|
1
|
+
from __future__ import annotations
|
|
2
|
+
|
|
3
|
+
import struct
|
|
4
|
+
import sys
|
|
5
|
+
|
|
6
|
+
from .mp4.parser import (
|
|
7
|
+
find_box, find_box_path, find_track_by_handler,
|
|
8
|
+
parse_stco, parse_stsz, parse_stsc, parse_stts, parse_nalu_list,
|
|
9
|
+
read_u32,
|
|
10
|
+
)
|
|
11
|
+
from .mp4.builder import (
|
|
12
|
+
build_box, build_ftyp, build_free, build_mvhd, build_mdhd,
|
|
13
|
+
build_tkhd, build_hdlr, build_stts, build_stsc, build_stsz,
|
|
14
|
+
build_stco, build_stsd_video, build_avcc, build_btrt, build_udta_comment,
|
|
15
|
+
)
|
|
16
|
+
|
|
17
|
+
# 8-byte filler NAL: length=4, type=0 (filler), empty payload
|
|
18
|
+
PADDING_NAL = b'\x00\x00\x00\x04\x00\x00\x00\x00'
|
|
19
|
+
PADDING_SIZE = 8
|
|
20
|
+
|
|
21
|
+
# NALU types to keep in first sample (strip SEI etc.)
|
|
22
|
+
KEEP_NALU_TYPES = {1, 5} # non-IDR slice, IDR slice
|
|
23
|
+
|
|
24
|
+
# ISO 639-2/T packed 'und'
|
|
25
|
+
LANG_UND = 0x55c4
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def transform(input_path: str, output_path: str, multiplier: int = 10,
|
|
29
|
+
comment: str = 'TK8vY5VqBA6hUlo1yuGvNA', verbose: bool = True) -> dict:
|
|
30
|
+
"""
|
|
31
|
+
Apply the TikTok Enhancer transformation pipeline.
|
|
32
|
+
|
|
33
|
+
Args:
|
|
34
|
+
input_path: Path to source MP4 file (H.264/AVC).
|
|
35
|
+
output_path: Path to write the manipulated MP4.
|
|
36
|
+
multiplier: Frame count multiplier (default 10x).
|
|
37
|
+
comment: Metadata comment/signature string.
|
|
38
|
+
verbose: Print progress messages.
|
|
39
|
+
|
|
40
|
+
Returns:
|
|
41
|
+
Dict with stats about the transformation.
|
|
42
|
+
"""
|
|
43
|
+
with open(input_path, 'rb') as f:
|
|
44
|
+
data = f.read()
|
|
45
|
+
|
|
46
|
+
file_size = len(data)
|
|
47
|
+
if verbose:
|
|
48
|
+
print(f"[*] Input: {input_path} ({file_size:,} bytes)")
|
|
49
|
+
|
|
50
|
+
# Parse source
|
|
51
|
+
moov_pos, moov_size = find_box(data, 'moov')
|
|
52
|
+
mdat_pos, mdat_size = find_box(data, 'mdat')
|
|
53
|
+
if moov_pos is None or mdat_pos is None:
|
|
54
|
+
print("[!] ERROR: Missing moov or mdat box", file=sys.stderr)
|
|
55
|
+
sys.exit(1)
|
|
56
|
+
|
|
57
|
+
mdat_data_start = mdat_pos + 8
|
|
58
|
+
|
|
59
|
+
# Video track
|
|
60
|
+
vt_pos, vt_size = find_track_by_handler(data, moov_pos, moov_size, b'vide')
|
|
61
|
+
if vt_pos is None:
|
|
62
|
+
print("[!] ERROR: No video track found", file=sys.stderr)
|
|
63
|
+
sys.exit(1)
|
|
64
|
+
|
|
65
|
+
vt_start, vt_end = vt_pos + 8, vt_pos + vt_size
|
|
66
|
+
stbl_pos, stbl_size = find_box_path(data, ['mdia', 'minf', 'stbl'], vt_start, vt_end)
|
|
67
|
+
sb_start, sb_end = stbl_pos + 8, stbl_pos + stbl_size
|
|
68
|
+
|
|
69
|
+
stco_pos, _ = find_box(data, 'stco', sb_start, sb_end)
|
|
70
|
+
stsz_pos, _ = find_box(data, 'stsz', sb_start, sb_end)
|
|
71
|
+
stsc_pos, _ = find_box(data, 'stsc', sb_start, sb_end)
|
|
72
|
+
stts_pos, _ = find_box(data, 'stts', sb_start, sb_end)
|
|
73
|
+
stsd_pos, stsd_size = find_box(data, 'stsd', sb_start, sb_end)
|
|
74
|
+
stss_pos, stss_size = find_box(data, 'stss', sb_start, sb_end)
|
|
75
|
+
sdtp_pos, sdtp_size = find_box(data, 'sdtp', sb_start, sb_end)
|
|
76
|
+
ctts_pos, ctts_size = find_box(data, 'ctts', sb_start, sb_end)
|
|
77
|
+
|
|
78
|
+
video_chunks = parse_stco(data, stco_pos)
|
|
79
|
+
video_sizes = parse_stsz(data, stsz_pos)
|
|
80
|
+
video_stsc = parse_stsc(data, stsc_pos)
|
|
81
|
+
video_stts = parse_stts(data, stts_pos)
|
|
82
|
+
|
|
83
|
+
orig_frames = len(video_sizes)
|
|
84
|
+
time_delta = video_stts[0][1]
|
|
85
|
+
pad_count = orig_frames * (multiplier - 1)
|
|
86
|
+
total_frames = orig_frames + pad_count
|
|
87
|
+
|
|
88
|
+
v_mdhd_pos, v_mdhd_size = find_box_path(data, ['mdia', 'mdhd'], vt_start, vt_end)
|
|
89
|
+
v_timescale = read_u32(data, v_mdhd_pos + 20)
|
|
90
|
+
v_duration = read_u32(data, v_mdhd_pos + 24)
|
|
91
|
+
v_duration_sec = v_duration / v_timescale
|
|
92
|
+
|
|
93
|
+
if verbose:
|
|
94
|
+
fps = v_timescale / time_delta
|
|
95
|
+
print(f"[*] Video: {orig_frames} frames @ {fps:.0f} fps, {v_duration_sec:.1f}s")
|
|
96
|
+
print(f"[*] Ghost frames: +{pad_count} -> {total_frames} declared")
|
|
97
|
+
|
|
98
|
+
# Strip SEI from first sample
|
|
99
|
+
first_off = video_chunks[0]
|
|
100
|
+
first_size = video_sizes[0]
|
|
101
|
+
first_sample = data[first_off:first_off + first_size]
|
|
102
|
+
|
|
103
|
+
nalus = parse_nalu_list(first_sample)
|
|
104
|
+
kept = [d for t, _, d in nalus if t in KEEP_NALU_TYPES]
|
|
105
|
+
new_first = b''.join(kept) if kept else first_sample
|
|
106
|
+
new_first_size = len(new_first)
|
|
107
|
+
sei_removed = first_size - new_first_size
|
|
108
|
+
|
|
109
|
+
if verbose:
|
|
110
|
+
print(f"[*] First sample: {first_size} -> {new_first_size} bytes (-{sei_removed} SEI)")
|
|
111
|
+
|
|
112
|
+
# Audio track
|
|
113
|
+
at_pos, at_size = find_track_by_handler(data, moov_pos, moov_size, b'soun')
|
|
114
|
+
has_audio = at_pos is not None
|
|
115
|
+
|
|
116
|
+
if has_audio:
|
|
117
|
+
at_start, at_end = at_pos + 8, at_pos + at_size
|
|
118
|
+
a_stbl_pos, _ = find_box_path(data, ['mdia', 'minf', 'stbl'], at_start, at_end)
|
|
119
|
+
a_sb_start, a_sb_end = a_stbl_pos + 8, a_stbl_pos + _
|
|
120
|
+
|
|
121
|
+
a_stco_pos, _ = find_box(data, 'stco', a_sb_start, a_sb_end)
|
|
122
|
+
a_stsz_pos, a_stsz_size = find_box(data, 'stsz', a_sb_start, a_sb_end)
|
|
123
|
+
a_stsc_pos, a_stsc_size = find_box(data, 'stsc', a_sb_start, a_sb_end)
|
|
124
|
+
a_stts_pos, _ = find_box(data, 'stts', a_sb_start, a_sb_end)
|
|
125
|
+
a_stsd_pos, a_stsd_size = find_box(data, 'stsd', a_sb_start, a_sb_end)
|
|
126
|
+
a_sgpd_pos, a_sgpd_size = find_box(data, 'sgpd', a_sb_start, a_sb_end)
|
|
127
|
+
a_sbgp_pos, a_sbgp_size = find_box(data, 'sbgp', a_sb_start, a_sb_end)
|
|
128
|
+
|
|
129
|
+
audio_chunks = parse_stco(data, a_stco_pos)
|
|
130
|
+
audio_sizes = parse_stsz(data, a_stsz_pos)
|
|
131
|
+
audio_stts = parse_stts(data, a_stts_pos)
|
|
132
|
+
|
|
133
|
+
a_mdhd_pos, a_mdhd_size = find_box_path(data, ['mdia', 'mdhd'], at_start, at_end)
|
|
134
|
+
a_timescale = read_u32(data, a_mdhd_pos + 20)
|
|
135
|
+
|
|
136
|
+
# Read audio ELST for timing alignment
|
|
137
|
+
a_elst_pos, _ = find_box_path(data, ['edts', 'elst'], at_start, at_end)
|
|
138
|
+
a_elst_seg_dur = read_u32(data, a_elst_pos + 16) # ms
|
|
139
|
+
a_elst_media_time = read_u32(data, a_elst_pos + 20) # ticks
|
|
140
|
+
|
|
141
|
+
new_audio_dur_ms = a_elst_seg_dur
|
|
142
|
+
new_audio_dur = new_audio_dur_ms * a_timescale // 1000
|
|
143
|
+
|
|
144
|
+
# STTS: align to mdhd + media_time
|
|
145
|
+
a_delta = audio_stts[0][1]
|
|
146
|
+
a_count = len(audio_sizes)
|
|
147
|
+
target_stts = new_audio_dur + a_elst_media_time
|
|
148
|
+
main_n = a_count - 1
|
|
149
|
+
last_delta = target_stts - main_n * a_delta
|
|
150
|
+
|
|
151
|
+
if 0 < last_delta <= a_delta:
|
|
152
|
+
new_a_stts = [(main_n, a_delta), (1, last_delta)]
|
|
153
|
+
else:
|
|
154
|
+
new_a_stts = audio_stts
|
|
155
|
+
new_audio_dur = read_u32(data, a_mdhd_pos + 24)
|
|
156
|
+
new_audio_dur_ms = new_audio_dur * 1000 // a_timescale
|
|
157
|
+
|
|
158
|
+
# Bitrates
|
|
159
|
+
total_a_bytes = sum(audio_sizes)
|
|
160
|
+
old_a_ticks = sum(c * d for c, d in audio_stts)
|
|
161
|
+
new_a_ticks = sum(c * d for c, d in new_a_stts)
|
|
162
|
+
old_a_br = total_a_bytes * 8 * a_timescale // old_a_ticks
|
|
163
|
+
new_a_br = total_a_bytes * 8 * a_timescale // new_a_ticks
|
|
164
|
+
|
|
165
|
+
# Build new mdat
|
|
166
|
+
mdat_before = data[mdat_data_start:first_off]
|
|
167
|
+
mdat_after = data[first_off + first_size:mdat_pos + mdat_size]
|
|
168
|
+
new_mdat_content = mdat_before + new_first + mdat_after + PADDING_NAL
|
|
169
|
+
new_mdat = struct.pack('>I', 8 + len(new_mdat_content)) + b'mdat' + new_mdat_content
|
|
170
|
+
|
|
171
|
+
# Build new moov
|
|
172
|
+
ftyp = build_ftyp()
|
|
173
|
+
free = build_free()
|
|
174
|
+
|
|
175
|
+
# MVHD
|
|
176
|
+
mvhd_pos, mvhd_size = find_box(data, 'mvhd', moov_pos + 8, moov_pos + moov_size)
|
|
177
|
+
mvhd_content = data[mvhd_pos + 8:mvhd_pos + mvhd_size]
|
|
178
|
+
v_tkhd_pos, _ = find_box(data, 'tkhd', vt_start, vt_end)
|
|
179
|
+
v_tkhd_dur_ms = read_u32(data, v_tkhd_pos + 28)
|
|
180
|
+
new_mvhd_dur = max(v_tkhd_dur_ms, new_audio_dur_ms) if has_audio else v_tkhd_dur_ms
|
|
181
|
+
mvhd = build_mvhd(mvhd_content, new_mvhd_dur)
|
|
182
|
+
|
|
183
|
+
# Video track components
|
|
184
|
+
video_tkhd = data[vt_start:vt_start + read_u32(data, vt_start)]
|
|
185
|
+
edts_pos, edts_size = find_box(data, 'edts', vt_start, vt_end)
|
|
186
|
+
video_edts = data[edts_pos:edts_pos + edts_size] if edts_pos else b''
|
|
187
|
+
video_mdhd = data[v_mdhd_pos:v_mdhd_pos + v_mdhd_size]
|
|
188
|
+
v_hdlr_pos, v_hdlr_size = find_box_path(data, ['mdia', 'hdlr'], vt_start, vt_end)
|
|
189
|
+
video_hdlr = data[v_hdlr_pos:v_hdlr_pos + v_hdlr_size]
|
|
190
|
+
vmhd_pos, vmhd_size = find_box_path(data, ['mdia', 'minf', 'vmhd'], vt_start, vt_end)
|
|
191
|
+
video_vmhd = data[vmhd_pos:vmhd_pos + vmhd_size]
|
|
192
|
+
dinf_pos, dinf_size = find_box_path(data, ['mdia', 'minf', 'dinf'], vt_start, vt_end)
|
|
193
|
+
video_dinf = data[dinf_pos:dinf_pos + dinf_size]
|
|
194
|
+
|
|
195
|
+
# Video STSD (avcC + btrt patched)
|
|
196
|
+
stsd_content = data[stsd_pos + 8:stsd_pos + stsd_size]
|
|
197
|
+
avc1_fixed = stsd_content[16:94]
|
|
198
|
+
|
|
199
|
+
avcc_rel = stsd_content.find(b'avcC')
|
|
200
|
+
avcc_start = avcc_rel - 4
|
|
201
|
+
avcc_orig_size = read_u32(stsd_content, avcc_start)
|
|
202
|
+
avcc_new = build_avcc(stsd_content[avcc_start + 8:avcc_start + avcc_orig_size])
|
|
203
|
+
|
|
204
|
+
colr_box = b''
|
|
205
|
+
colr_rel = stsd_content.find(b'colr')
|
|
206
|
+
if colr_rel >= 0:
|
|
207
|
+
cs = colr_rel - 4
|
|
208
|
+
colr_box = stsd_content[cs:cs + read_u32(stsd_content, cs)]
|
|
209
|
+
|
|
210
|
+
pasp_box = b''
|
|
211
|
+
pasp_rel = stsd_content.find(b'pasp')
|
|
212
|
+
if pasp_rel >= 0:
|
|
213
|
+
ps = pasp_rel - 4
|
|
214
|
+
pasp_box = stsd_content[ps:ps + read_u32(stsd_content, ps)]
|
|
215
|
+
|
|
216
|
+
total_v_bytes = sum(video_sizes) - first_size + new_first_size
|
|
217
|
+
new_v_avg_br = int(total_v_bytes * 8 / v_duration_sec)
|
|
218
|
+
btrt_rel = stsd_content.find(b'btrt')
|
|
219
|
+
max_br = read_u32(stsd_content, btrt_rel + 8) if btrt_rel >= 0 else new_v_avg_br
|
|
220
|
+
btrt_new = build_btrt(0, max_br, new_v_avg_br)
|
|
221
|
+
|
|
222
|
+
video_stsd_new = build_stsd_video(avc1_fixed, avcc_new, colr_box, pasp_box, btrt_new)
|
|
223
|
+
|
|
224
|
+
# Video tables
|
|
225
|
+
video_stts_new = build_stts([(orig_frames, time_delta), (pad_count, time_delta)])
|
|
226
|
+
video_stss = data[stss_pos:stss_pos + stss_size] if stss_pos else b''
|
|
227
|
+
video_sdtp = data[sdtp_pos:sdtp_pos + sdtp_size] if sdtp_pos else b''
|
|
228
|
+
video_ctts = data[ctts_pos:ctts_pos + ctts_size] if ctts_pos else b''
|
|
229
|
+
video_stsc_new = build_stsc(list(video_stsc) + [(len(video_chunks) + 1, 1, 1)])
|
|
230
|
+
video_stsz_new = build_stsz([new_first_size] + video_sizes[1:] + [PADDING_SIZE] * pad_count)
|
|
231
|
+
|
|
232
|
+
# STCO placeholder
|
|
233
|
+
total_v_chunks = len(video_chunks) + pad_count
|
|
234
|
+
stco_ph_size = 16 + total_v_chunks * 4
|
|
235
|
+
v_stco_ph = struct.pack('>I', stco_ph_size) + b'stco' + b'\x00' * (stco_ph_size - 8)
|
|
236
|
+
|
|
237
|
+
v_stbl_parts = [video_stsd_new, video_stts_new]
|
|
238
|
+
if video_stss: v_stbl_parts.append(video_stss)
|
|
239
|
+
if video_sdtp: v_stbl_parts.append(video_sdtp)
|
|
240
|
+
if video_ctts: v_stbl_parts.append(video_ctts)
|
|
241
|
+
v_stbl_parts += [video_stsc_new, video_stsz_new, v_stco_ph]
|
|
242
|
+
|
|
243
|
+
video_stbl = build_box('stbl', b''.join(v_stbl_parts))
|
|
244
|
+
video_minf = build_box('minf', video_vmhd + video_dinf + video_stbl)
|
|
245
|
+
video_mdia = build_box('mdia', video_mdhd + video_hdlr + video_minf)
|
|
246
|
+
video_trak = build_box('trak', video_tkhd + video_edts + video_mdia)
|
|
247
|
+
|
|
248
|
+
# Audio track
|
|
249
|
+
if has_audio:
|
|
250
|
+
a_tkhd_pos, a_tkhd_size = find_box(data, 'tkhd', at_start, at_end)
|
|
251
|
+
audio_tkhd = build_tkhd(data[a_tkhd_pos:a_tkhd_pos + a_tkhd_size], new_audio_dur_ms)
|
|
252
|
+
|
|
253
|
+
a_edts_pos, a_edts_size = find_box(data, 'edts', at_start, at_end)
|
|
254
|
+
audio_edts = data[a_edts_pos:a_edts_pos + a_edts_size] if a_edts_pos else b''
|
|
255
|
+
|
|
256
|
+
audio_mdhd = build_mdhd(data[a_mdhd_pos + 8:a_mdhd_pos + a_mdhd_size],
|
|
257
|
+
duration=new_audio_dur, language=LANG_UND)
|
|
258
|
+
audio_hdlr = build_hdlr(b'soun', 'SoundHandler')
|
|
259
|
+
|
|
260
|
+
smhd_pos, smhd_size = find_box_path(data, ['mdia', 'minf', 'smhd'], at_start, at_end)
|
|
261
|
+
audio_smhd = data[smhd_pos:smhd_pos + smhd_size]
|
|
262
|
+
a_dinf_pos, a_dinf_size = find_box_path(data, ['mdia', 'minf', 'dinf'], at_start, at_end)
|
|
263
|
+
audio_dinf = data[a_dinf_pos:a_dinf_pos + a_dinf_size]
|
|
264
|
+
|
|
265
|
+
# Patch audio stsd bitrate
|
|
266
|
+
audio_stsd = bytearray(data[a_stsd_pos:a_stsd_pos + a_stsd_size])
|
|
267
|
+
old_br = struct.pack('>I', old_a_br)
|
|
268
|
+
new_br = struct.pack('>I', new_a_br)
|
|
269
|
+
p = 0
|
|
270
|
+
while (idx := audio_stsd.find(old_br, p)) != -1:
|
|
271
|
+
audio_stsd[idx:idx + 4] = new_br
|
|
272
|
+
p = idx + 4
|
|
273
|
+
audio_stsd = bytes(audio_stsd)
|
|
274
|
+
|
|
275
|
+
audio_stts_new = build_stts(new_a_stts)
|
|
276
|
+
audio_stsc = data[a_stsc_pos:a_stsc_pos + a_stsc_size]
|
|
277
|
+
audio_stsz = data[a_stsz_pos:a_stsz_pos + a_stsz_size]
|
|
278
|
+
|
|
279
|
+
a_stco_ph_size = 16 + len(audio_chunks) * 4
|
|
280
|
+
a_stco_ph = struct.pack('>I', a_stco_ph_size) + b'stco' + b'\x00' * (a_stco_ph_size - 8)
|
|
281
|
+
|
|
282
|
+
a_sgpd = data[a_sgpd_pos:a_sgpd_pos + a_sgpd_size] if a_sgpd_pos else b''
|
|
283
|
+
a_sbgp = data[a_sbgp_pos:a_sbgp_pos + a_sbgp_size] if a_sbgp_pos else b''
|
|
284
|
+
|
|
285
|
+
audio_stbl = build_box('stbl', audio_stsd + audio_stts_new + audio_stsc +
|
|
286
|
+
audio_stsz + a_stco_ph + a_sgpd + a_sbgp)
|
|
287
|
+
audio_minf = build_box('minf', audio_smhd + audio_dinf + audio_stbl)
|
|
288
|
+
audio_mdia = build_box('mdia', audio_mdhd + audio_hdlr + audio_minf)
|
|
289
|
+
audio_trak = build_box('trak', audio_tkhd + audio_edts + audio_mdia)
|
|
290
|
+
else:
|
|
291
|
+
audio_trak = b''
|
|
292
|
+
|
|
293
|
+
udta = build_udta_comment(comment)
|
|
294
|
+
moov = build_box('moov', mvhd + video_trak + audio_trak + udta)
|
|
295
|
+
moov_size_final = len(moov)
|
|
296
|
+
|
|
297
|
+
# Fill STCO offsets
|
|
298
|
+
new_mdat_start = 32 + 8 + moov_size_final + 8
|
|
299
|
+
first_video_rel = first_off - mdat_data_start
|
|
300
|
+
pad_abs = new_mdat_start + len(new_mdat_content) - PADDING_SIZE
|
|
301
|
+
|
|
302
|
+
new_v_offsets = []
|
|
303
|
+
for off in video_chunks:
|
|
304
|
+
rel = off - mdat_data_start
|
|
305
|
+
new_v_offsets.append(new_mdat_start + rel if rel <= first_video_rel
|
|
306
|
+
else new_mdat_start + rel - sei_removed)
|
|
307
|
+
new_v_offsets.extend([pad_abs] * pad_count)
|
|
308
|
+
|
|
309
|
+
new_a_offsets = []
|
|
310
|
+
if has_audio:
|
|
311
|
+
for off in audio_chunks:
|
|
312
|
+
rel = off - mdat_data_start
|
|
313
|
+
new_a_offsets.append(new_mdat_start + rel if rel < first_video_rel
|
|
314
|
+
else new_mdat_start + rel - sei_removed)
|
|
315
|
+
|
|
316
|
+
# Rebuild with final STCOs
|
|
317
|
+
v_stbl_parts[-1] = build_stco(new_v_offsets)
|
|
318
|
+
video_stbl = build_box('stbl', b''.join(v_stbl_parts))
|
|
319
|
+
video_minf = build_box('minf', video_vmhd + video_dinf + video_stbl)
|
|
320
|
+
video_mdia = build_box('mdia', video_mdhd + video_hdlr + video_minf)
|
|
321
|
+
video_trak = build_box('trak', video_tkhd + video_edts + video_mdia)
|
|
322
|
+
|
|
323
|
+
if has_audio:
|
|
324
|
+
audio_stbl = build_box('stbl', audio_stsd + audio_stts_new + audio_stsc +
|
|
325
|
+
audio_stsz + build_stco(new_a_offsets) + a_sgpd + a_sbgp)
|
|
326
|
+
audio_minf = build_box('minf', audio_smhd + audio_dinf + audio_stbl)
|
|
327
|
+
audio_mdia = build_box('mdia', audio_mdhd + audio_hdlr + audio_minf)
|
|
328
|
+
audio_trak = build_box('trak', audio_tkhd + audio_edts + audio_mdia)
|
|
329
|
+
|
|
330
|
+
moov = build_box('moov', mvhd + video_trak + audio_trak + udta)
|
|
331
|
+
assert len(moov) == moov_size_final
|
|
332
|
+
|
|
333
|
+
# Write output
|
|
334
|
+
output = ftyp + free + moov + new_mdat
|
|
335
|
+
with open(output_path, 'wb') as f:
|
|
336
|
+
f.write(output)
|
|
337
|
+
|
|
338
|
+
stats = {
|
|
339
|
+
'input_size': file_size,
|
|
340
|
+
'output_size': len(output),
|
|
341
|
+
'size_delta': len(output) - file_size,
|
|
342
|
+
'original_frames': orig_frames,
|
|
343
|
+
'declared_frames': total_frames,
|
|
344
|
+
'ghost_frames': pad_count,
|
|
345
|
+
'multiplier': multiplier,
|
|
346
|
+
}
|
|
347
|
+
|
|
348
|
+
if verbose:
|
|
349
|
+
print(f"[+] Output: {output_path} ({len(output):,} bytes)")
|
|
350
|
+
print(f"[+] Delta: {stats['size_delta']:+,} bytes")
|
|
351
|
+
print(f"[+] Frames: {orig_frames} -> {total_frames} (x{multiplier})")
|
|
352
|
+
|
|
353
|
+
return stats
|
|
@@ -0,0 +1,65 @@
|
|
|
1
|
+
"""Basic tests for tiktok-quality transform."""
|
|
2
|
+
|
|
3
|
+
from __future__ import annotations
|
|
4
|
+
|
|
5
|
+
import struct
|
|
6
|
+
from tiktok_quality.mp4.parser import find_box, parse_stts, parse_stsz, read_u32
|
|
7
|
+
from tiktok_quality.mp4.builder import build_box, build_ftyp, build_stts, build_stco, build_udta_comment
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
def test_build_box():
|
|
11
|
+
box = build_box('test', b'\x01\x02\x03')
|
|
12
|
+
assert len(box) == 11
|
|
13
|
+
assert struct.unpack('>I', box[:4])[0] == 11
|
|
14
|
+
assert box[4:8] == b'test'
|
|
15
|
+
assert box[8:] == b'\x01\x02\x03'
|
|
16
|
+
|
|
17
|
+
|
|
18
|
+
def test_build_ftyp():
|
|
19
|
+
ftyp = build_ftyp()
|
|
20
|
+
assert len(ftyp) == 32
|
|
21
|
+
assert ftyp[8:12] == b'isom'
|
|
22
|
+
|
|
23
|
+
|
|
24
|
+
def test_build_stts():
|
|
25
|
+
stts = build_stts([(1494, 1500), (13446, 1500)])
|
|
26
|
+
# header(8) + version/flags(4) + count(4) + 2*8 = 32
|
|
27
|
+
assert len(stts) == 32
|
|
28
|
+
assert struct.unpack('>I', stts[:4])[0] == 32
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
def test_build_stco():
|
|
32
|
+
stco = build_stco([100, 200, 300])
|
|
33
|
+
# header(8) + version/flags(4) + count(4) + 3*4 = 28
|
|
34
|
+
assert len(stco) == 28
|
|
35
|
+
|
|
36
|
+
|
|
37
|
+
def test_build_udta_comment():
|
|
38
|
+
udta = build_udta_comment('TestTag123')
|
|
39
|
+
assert b'TestTag123' in udta
|
|
40
|
+
assert b'\xa9cmt' in udta
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
def test_find_box():
|
|
44
|
+
box1 = build_box('aaaa', b'\x00' * 4)
|
|
45
|
+
box2 = build_box('bbbb', b'\x01' * 8)
|
|
46
|
+
data = box1 + box2
|
|
47
|
+
|
|
48
|
+
pos, size = find_box(data, 'bbbb')
|
|
49
|
+
assert pos == len(box1)
|
|
50
|
+
assert size == len(box2)
|
|
51
|
+
|
|
52
|
+
|
|
53
|
+
def test_parse_stts():
|
|
54
|
+
entries = [(1494, 1500), (13446, 1500)]
|
|
55
|
+
stts = build_stts(entries)
|
|
56
|
+
parsed = parse_stts(stts, 0)
|
|
57
|
+
assert parsed == entries
|
|
58
|
+
|
|
59
|
+
|
|
60
|
+
def test_parse_stsz():
|
|
61
|
+
from tiktok_quality.mp4.builder import build_stsz
|
|
62
|
+
sizes = [519, 145, 67, 67, 190]
|
|
63
|
+
stsz = build_stsz(sizes)
|
|
64
|
+
parsed = parse_stsz(stsz, 0)
|
|
65
|
+
assert parsed == sizes
|