tictacsync 0.1a10__tar.gz → 0.1a12__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of tictacsync might be problematic. Click here for more details.
- tictacsync-0.1a12/PKG-INFO +87 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/setup.py +8 -4
- tictacsync-0.1a12/tictacsync/LTCcheck.py +394 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync/device_scanner.py +67 -121
- tictacsync-0.1a12/tictacsync/entry.py +258 -0
- tictacsync-0.1a12/tictacsync/multi2polywav.py +194 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync/timeline.py +121 -200
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync/yaltc.py +254 -166
- tictacsync-0.1a12/tictacsync.egg-info/PKG-INFO +87 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync.egg-info/SOURCES.txt +2 -0
- tictacsync-0.1a12/tictacsync.egg-info/entry_points.txt +4 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync.egg-info/requires.txt +1 -1
- tictacsync-0.1a10/PKG-INFO +0 -87
- tictacsync-0.1a10/tictacsync/entry.py +0 -229
- tictacsync-0.1a10/tictacsync.egg-info/PKG-INFO +0 -87
- tictacsync-0.1a10/tictacsync.egg-info/entry_points.txt +0 -3
- {tictacsync-0.1a10 → tictacsync-0.1a12}/LICENSE +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/README.md +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/setup.cfg +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync/__init__.py +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync.egg-info/dependency_links.txt +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync.egg-info/not-zip-safe +0 -0
- {tictacsync-0.1a10 → tictacsync-0.1a12}/tictacsync.egg-info/top_level.txt +0 -0
|
@@ -0,0 +1,87 @@
|
|
|
1
|
+
Metadata-Version: 2.1
|
|
2
|
+
Name: tictacsync
|
|
3
|
+
Version: 0.1a12
|
|
4
|
+
Summary: command for syncing audio video recordings
|
|
5
|
+
Home-page: https://sr.ht/~proflutz/TicTacSync/
|
|
6
|
+
Author: Raymond Lutz
|
|
7
|
+
Author-email: lutzrayblog@mac.com
|
|
8
|
+
Classifier: Development Status :: 2 - Pre-Alpha
|
|
9
|
+
Classifier: Environment :: Console
|
|
10
|
+
Classifier: Intended Audience :: End Users/Desktop
|
|
11
|
+
Classifier: License :: OSI Approved :: MIT License
|
|
12
|
+
Classifier: Operating System :: MacOS
|
|
13
|
+
Classifier: Operating System :: Microsoft :: Windows
|
|
14
|
+
Classifier: Operating System :: POSIX
|
|
15
|
+
Classifier: Programming Language :: Python :: 3
|
|
16
|
+
Classifier: Topic :: Multimedia :: Sound/Audio
|
|
17
|
+
Classifier: Topic :: Utilities
|
|
18
|
+
Classifier: Topic :: Multimedia :: Sound/Audio :: Capture/Recording
|
|
19
|
+
Classifier: Topic :: Multimedia :: Video :: Non-Linear Editor
|
|
20
|
+
Requires-Python: >=3.10
|
|
21
|
+
Description-Content-Type: text/markdown
|
|
22
|
+
License-File: LICENSE
|
|
23
|
+
|
|
24
|
+
# tictacsync
|
|
25
|
+
|
|
26
|
+
## Warning: this is at pre-alpha stage
|
|
27
|
+
|
|
28
|
+
Unfinished sloppy code ahead, but should run without errors. Some functionalities are still missing. Don't run the code without parental supervision. Suggestions and enquiries are welcome via the [lists hosted on sourcehut](https://sr.ht/~proflutz/TicTacSync/lists).
|
|
29
|
+
|
|
30
|
+
## Description
|
|
31
|
+
|
|
32
|
+
`tictacsync` is a python script to sync audio and video files shot
|
|
33
|
+
with [dual system sound](https://www.learnlightandsound.com/blog/2017/2/23/how-to-record-sound-for-video-dual-systemsync-sound) using a specific hardware timecode generator
|
|
34
|
+
called [Tic Tac Sync](https://tictacsync.org). The timecode is named YaLTC for *yet
|
|
35
|
+
another longitudinal time code* and should be recorded on a scratch
|
|
36
|
+
track on each device for the syncing to be performed, later in _postprod_ before editing.
|
|
37
|
+
|
|
38
|
+
## Status
|
|
39
|
+
|
|
40
|
+
`tictacsync` scans for audio video files and displays their starting time and then merges overlapping audio and video recordings. Multicam syncing with one stereo audio recorder has been tested (spring 2023, [see demo](https://youtu.be/pklTSTi7cqs)). Multi audio recorders coming soon...
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
## Installation
|
|
44
|
+
|
|
45
|
+
This uses the [python interpreter](https://www.python.org/downloads/) and multiple packages (so you need python 3 + pip). Also, you need to install two non-python command line executables: [ffmpeg](https://windowsloop.com/install-ffmpeg-windows-10/) and [sox](https://sourceforge.net/projects/sox/files/). Make sure those are _accessible through your `PATH` system environment variable_.
|
|
46
|
+
Then pip install the syncing program:
|
|
47
|
+
|
|
48
|
+
|
|
49
|
+
pip install tictacsync
|
|
50
|
+
|
|
51
|
+
|
|
52
|
+
This should install python dependencies _and_ the `tictacsync` command.
|
|
53
|
+
## Usage
|
|
54
|
+
|
|
55
|
+
Download some sample files [here](https://tictacsync.org/sampleFiles.zip), unzip and run
|
|
56
|
+
|
|
57
|
+
tictacsync sampleFiles
|
|
58
|
+
The resulting synced videos will be in a subfolder named `tictacsynced`. For a very verbose output add the `-v` flag:
|
|
59
|
+
|
|
60
|
+
tictacsync -v sampleFiles
|
|
61
|
+
|
|
62
|
+
When the argument is an unique media file (not a directory), no syncing will occur but the decoded starting time will be printed to stdout:
|
|
63
|
+
|
|
64
|
+
tictacsync sampleFiles/canon24fps01.MOV
|
|
65
|
+
|
|
66
|
+
Recording started at 2023-04-23 01:09:08.1605 UTC
|
|
67
|
+
true sample rate: 48000.545 Hz
|
|
68
|
+
first sync at 37414 samples
|
|
69
|
+
N.B.: all results are precise to the displayed digits!
|
|
70
|
+
|
|
71
|
+
|
|
72
|
+
When called with the `-p` flag, zoomable plots will be produced for diagnostic purpose (close the plotting window for the 2nd one) and the decoded starting time will be output to stdin:
|
|
73
|
+
|
|
74
|
+
tictacsync -p sampleFiles/canon24fps01.MOV
|
|
75
|
+
|
|
76
|
+
Typical first plot produced :
|
|
77
|
+
|
|
78
|
+
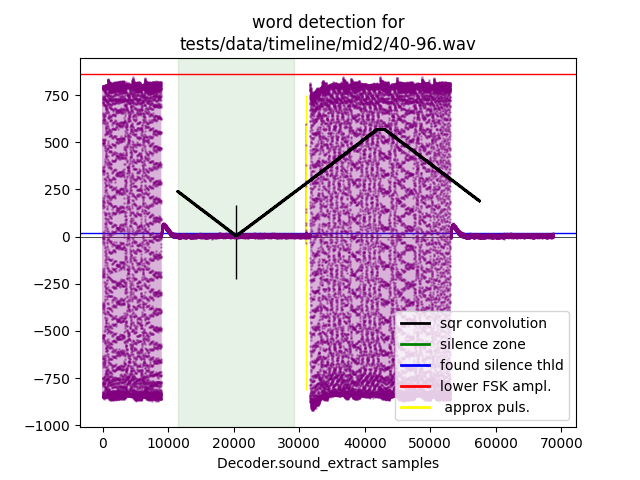
|
|
79
|
+
|
|
80
|
+
Typical second plot produced (note the 34 [FSK](https://en.wikipedia.org/wiki/Frequency-shift_keying) encoded bits `0010111101001111100110000110010000`):
|
|
81
|
+
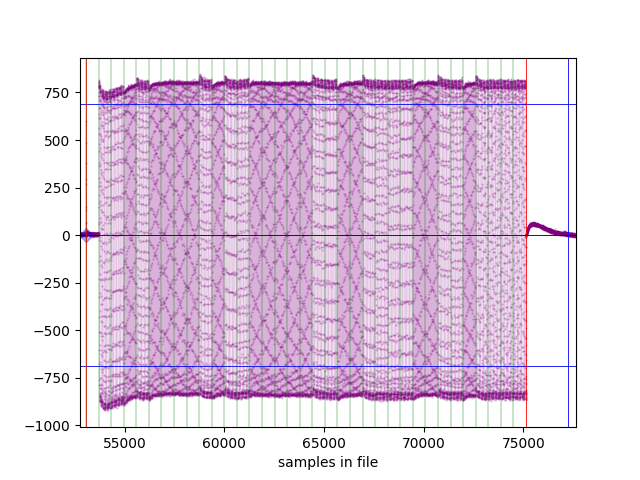
|
|
82
|
+
|
|
83
|
+
|
|
84
|
+
<!-- To run some tests, from top level `git cloned` dir:
|
|
85
|
+
|
|
86
|
+
cd tictacsync ; python -m pytest
|
|
87
|
+
Yes, the coverage is low. -->
|
|
@@ -20,14 +20,18 @@ setup(
|
|
|
20
20
|
'matplotlib>=3.7.1',
|
|
21
21
|
'numpy>=1.24.3',
|
|
22
22
|
'rich>=10.12.0',
|
|
23
|
-
'lmfit
|
|
23
|
+
'lmfit',
|
|
24
24
|
'scipy>=1.10.1',
|
|
25
25
|
'scikit-learn==1.2.2'],
|
|
26
|
-
python_requires='>=3.
|
|
26
|
+
python_requires='>=3.10',
|
|
27
27
|
entry_points = {
|
|
28
|
-
"console_scripts": [
|
|
28
|
+
"console_scripts": [
|
|
29
|
+
'tictacsync = tictacsync.entry:main',
|
|
30
|
+
'LTCcheck = tictacsync.LTCcheck:main',
|
|
31
|
+
'multi2polywav = tictacsync.multi2polywav:main',
|
|
32
|
+
]
|
|
29
33
|
},
|
|
30
|
-
version = '0.
|
|
34
|
+
version = '0.1a12',
|
|
31
35
|
description = "command for syncing audio video recordings",
|
|
32
36
|
long_description_content_type='text/markdown',
|
|
33
37
|
long_description = long_descr,
|
|
@@ -0,0 +1,394 @@
|
|
|
1
|
+
print('Loading modules')
|
|
2
|
+
import subprocess, io
|
|
3
|
+
import argparse, os, sys, ffmpeg
|
|
4
|
+
from loguru import logger
|
|
5
|
+
from pathlib import Path
|
|
6
|
+
from scipy.io import wavfile
|
|
7
|
+
import numpy as np
|
|
8
|
+
import matplotlib.pyplot as plt
|
|
9
|
+
from rich.progress import track, Progress
|
|
10
|
+
from pprint import pprint
|
|
11
|
+
from collections import deque
|
|
12
|
+
import wave
|
|
13
|
+
try:
|
|
14
|
+
from . import yaltc
|
|
15
|
+
except:
|
|
16
|
+
import yaltc
|
|
17
|
+
try:
|
|
18
|
+
from . import device_scanner
|
|
19
|
+
except:
|
|
20
|
+
import device_scanner
|
|
21
|
+
|
|
22
|
+
# LEVELMODE = 'over_noise_silence'
|
|
23
|
+
LEVELMODE = 'mean_silence_AFSK'
|
|
24
|
+
|
|
25
|
+
OFFSET_NXT_PULSE = 50 # samples
|
|
26
|
+
LENGTH_EXTRACT = int(14e-3 * 96000) # samples max freq
|
|
27
|
+
|
|
28
|
+
logger.level("DEBUG", color="<yellow>")
|
|
29
|
+
logger.remove()
|
|
30
|
+
# logger.add(sys.stdout, filter="tictacsync.LTCcheck")
|
|
31
|
+
# logger.add(sys.stdout, filter="tictacsync.yaltc")
|
|
32
|
+
|
|
33
|
+
def ppm(a,b):
|
|
34
|
+
return 1e6*(max(a,b)/min(a,b)-1)
|
|
35
|
+
|
|
36
|
+
class TCframe:
|
|
37
|
+
def __init__(self, string, max_FF):
|
|
38
|
+
# string is 'HH:MM:SS:FF' or ;|,|.
|
|
39
|
+
# max_FF is int for max frame number (hence fps-1)
|
|
40
|
+
string = string.replace('.',':').replace(';',':').replace(',',':')
|
|
41
|
+
ints = [int(e) for e in string.split(':')]
|
|
42
|
+
self.HH = ints[0]
|
|
43
|
+
self.MM = ints[1]
|
|
44
|
+
self.SS = ints[2]
|
|
45
|
+
self.FF = ints[3]
|
|
46
|
+
self.MAXFF = max_FF
|
|
47
|
+
|
|
48
|
+
def __repr__(self):
|
|
49
|
+
# return '%s-%s-%s-%s/%i'%(*self.ints(), self.MAXFF)
|
|
50
|
+
return '%02i-%02i-%02i-%02i'%self.ints()
|
|
51
|
+
|
|
52
|
+
def ints(self):
|
|
53
|
+
return (self.HH,self.MM,self.SS,self.FF)
|
|
54
|
+
|
|
55
|
+
def __eq__(self, other):
|
|
56
|
+
a,b,c,d = self.ints()
|
|
57
|
+
h,m,s,f = other.ints()
|
|
58
|
+
return a==h and b==m and c==s and d==f
|
|
59
|
+
|
|
60
|
+
def __sub__(self, tcf2):
|
|
61
|
+
# H1, M1, S1, F1 = self.ints()
|
|
62
|
+
# H2, M2, S2, F2 = tcf2.ints()
|
|
63
|
+
f1 = np.array(self.ints())
|
|
64
|
+
f2 = np.array(tcf2.ints())
|
|
65
|
+
HR, MR, SR, FR = f1 - f2
|
|
66
|
+
if FR < 0:
|
|
67
|
+
FR += self.MAXFF + 1
|
|
68
|
+
SR -= 1 # borrow
|
|
69
|
+
if SR < 0:
|
|
70
|
+
SR += 60
|
|
71
|
+
MR -= 1 # borrow
|
|
72
|
+
if MR < 0:
|
|
73
|
+
MR += 60
|
|
74
|
+
HR -= 1 # borrow
|
|
75
|
+
if HR < 0:
|
|
76
|
+
HR += 24 # underflow?
|
|
77
|
+
# logger.debug('%s %s'%(self.ints(), tcf2.ints()))
|
|
78
|
+
return TCframe('%02i:%02i:%02i:%02i'%(HR,MR,SR,FR), self.MAXFF)
|
|
79
|
+
|
|
80
|
+
def read_whole_audio_data(path):
|
|
81
|
+
dryrun = (ffmpeg
|
|
82
|
+
.input(str(path))
|
|
83
|
+
.output('pipe:', format='s16le', acodec='pcm_s16le')
|
|
84
|
+
.get_args())
|
|
85
|
+
dryrun = ' '.join(dryrun)
|
|
86
|
+
logger.debug('using ffmpeg-python built args to pipe wav file into numpy array:\nffmpeg %s'%dryrun)
|
|
87
|
+
try:
|
|
88
|
+
out, _ = (ffmpeg
|
|
89
|
+
.input(str(path))
|
|
90
|
+
.output('pipe:', format='s16le', acodec='pcm_s16le')
|
|
91
|
+
.global_args("-loglevel", "quiet")
|
|
92
|
+
.global_args("-nostats")
|
|
93
|
+
.global_args("-hide_banner")
|
|
94
|
+
.run(capture_stdout=True))
|
|
95
|
+
data = np.frombuffer(out, np.int16)
|
|
96
|
+
except ffmpeg.Error as e:
|
|
97
|
+
print('error',e.stderr)
|
|
98
|
+
with wave.open(path, 'rb') as f:
|
|
99
|
+
samplerate = f.getframerate()
|
|
100
|
+
n_chan = f.getnchannels()
|
|
101
|
+
all_channels_data = data.reshape(int(len(data)/n_chan),n_chan).T
|
|
102
|
+
return all_channels_data
|
|
103
|
+
|
|
104
|
+
def find_nearest_fps(value):
|
|
105
|
+
array = np.asarray([24, 25, 30])
|
|
106
|
+
idx = (np.abs(array - value)).argmin()
|
|
107
|
+
return array[idx]
|
|
108
|
+
|
|
109
|
+
def fps_rel_to_audio(frame_pos, samplerate):
|
|
110
|
+
_, first_frame_pos = frame_pos[0]
|
|
111
|
+
_, scnd_last_frame_pos = frame_pos[-2]
|
|
112
|
+
frame_duration = (scnd_last_frame_pos - first_frame_pos)/len(frame_pos[:-2]) # in audio samples
|
|
113
|
+
fps = float(samplerate) / frame_duration
|
|
114
|
+
return fps
|
|
115
|
+
|
|
116
|
+
# def HHMMSSFF_from_line(line):
|
|
117
|
+
# line = line.replace('.',':')
|
|
118
|
+
# line = line.replace(';',':')
|
|
119
|
+
# ll = line.split()[1].split(':')
|
|
120
|
+
# return [int(e) for e in ll]
|
|
121
|
+
|
|
122
|
+
def check_continuity_and_DF(LTC_frames_and_pos):
|
|
123
|
+
errors = []
|
|
124
|
+
DF_flag = False
|
|
125
|
+
oneframe = TCframe('00:00:00:01',None)
|
|
126
|
+
threeframes = TCframe('00:00:00:03',None)
|
|
127
|
+
last_two_TC = deque([], maxlen=2)
|
|
128
|
+
last_two_TC.append(LTC_frames_and_pos[0][0])
|
|
129
|
+
last_two_TC.append(LTC_frames_and_pos[1][0])
|
|
130
|
+
for frame, pos in track(LTC_frames_and_pos[2:],
|
|
131
|
+
description="Checking each frame increment"):
|
|
132
|
+
last_two_TC.append(frame)
|
|
133
|
+
past, now = last_two_TC
|
|
134
|
+
diff = now - past
|
|
135
|
+
if diff not in [oneframe, threeframes]:
|
|
136
|
+
errors.append((frame, pos))
|
|
137
|
+
continue
|
|
138
|
+
if diff == oneframe:
|
|
139
|
+
continue
|
|
140
|
+
if diff == threeframes:
|
|
141
|
+
# DF? check if it is 59:xx and minutes are not mult. of tens
|
|
142
|
+
if past.SS != 59 or now.MM%10 == 0:
|
|
143
|
+
errors.append((frame, pos))
|
|
144
|
+
DF_flag = True
|
|
145
|
+
return errors, DF_flag
|
|
146
|
+
|
|
147
|
+
def ltcdump_and_check(file, channel):
|
|
148
|
+
# returns list of anormal frames, a bool if TC is DF, fps and
|
|
149
|
+
# a list of tuples (frame => str, sample position in file => int) as
|
|
150
|
+
# determined by external util ltcdump https://github.com/x42/ltc-tools
|
|
151
|
+
process_list = ["ltcdump","-c %i"%channel, file]
|
|
152
|
+
logger.debug('process %s'%process_list)
|
|
153
|
+
proc = subprocess.Popen(process_list, stdout=subprocess.PIPE)
|
|
154
|
+
LTC_frames_and_pos = []
|
|
155
|
+
iter_io = io.TextIOWrapper(proc.stdout, encoding="utf-8")
|
|
156
|
+
next(iter_io) # ltcdump 1st line: User bits Timecode | Pos. (samples)
|
|
157
|
+
print()
|
|
158
|
+
try:
|
|
159
|
+
next(iter_io) # ltcdump 2nd line: #DISCONTINUITY
|
|
160
|
+
except StopIteration:
|
|
161
|
+
print('ltcdump has no output, is channel #%i really LTC?'%channel)
|
|
162
|
+
quit()
|
|
163
|
+
old = 0
|
|
164
|
+
for line in track(iter_io,
|
|
165
|
+
description=' Parsing ltcdump output'): # next ones
|
|
166
|
+
# print(line)
|
|
167
|
+
if line == '#DISCONTINUITY\n':
|
|
168
|
+
# print('#DISCONTINUITY!')
|
|
169
|
+
continue
|
|
170
|
+
user_bits, HHMMSSFF_str, _, start_sample, end_sample =\
|
|
171
|
+
line.split()
|
|
172
|
+
audio_position = int(end_sample)
|
|
173
|
+
# print(audio_position - old, end=' ')
|
|
174
|
+
# old = audio_position
|
|
175
|
+
# audio_position = int(start_sample)
|
|
176
|
+
tc = HHMMSSFF_str
|
|
177
|
+
LTC_frames_and_pos.append((tc, audio_position))
|
|
178
|
+
with wave.open(file, 'rb') as f:
|
|
179
|
+
samplerate = f.getframerate()
|
|
180
|
+
fps = fps_rel_to_audio(LTC_frames_and_pos, samplerate)
|
|
181
|
+
rounded_fps = round(fps)
|
|
182
|
+
LTC_frames_and_pos = [(TCframe(tc, rounded_fps-1), pos) for tc, pos in LTC_frames_and_pos]
|
|
183
|
+
errors, DF_flag = check_continuity_and_DF(LTC_frames_and_pos)
|
|
184
|
+
return errors, DF_flag, fps, LTC_frames_and_pos
|
|
185
|
+
|
|
186
|
+
def find_pulses(TTC_data, recording):
|
|
187
|
+
samplerate = recording.true_samplerate
|
|
188
|
+
i_samplerate = round(samplerate)
|
|
189
|
+
pulse_position = recording.sync_position
|
|
190
|
+
logger.debug('first detected pulse %i'%pulse_position)
|
|
191
|
+
# first_pulse_nbr_of_seconds = int(pulse_position/samplerate)
|
|
192
|
+
# if first_pulse_nbr_of_seconds > 1:
|
|
193
|
+
# pulse_position = pulse_position%i_samplerate # very first pulse in file
|
|
194
|
+
# print('0 %i'%pulse_position)
|
|
195
|
+
pulse_position = pulse_position%i_samplerate
|
|
196
|
+
logger.debug('starting at %i'%pulse_position)
|
|
197
|
+
second = 0
|
|
198
|
+
duration = int(recording.get_duration())
|
|
199
|
+
decoder = recording.decoder
|
|
200
|
+
pulse_detection_level = decoder._get_pulse_detection_level()
|
|
201
|
+
logger.debug(' detection level %f'%pulse_detection_level)
|
|
202
|
+
pulses = []
|
|
203
|
+
approx_next_pulse = pulse_position
|
|
204
|
+
skipped_printed = False
|
|
205
|
+
while second < duration - 1:
|
|
206
|
+
second += 1
|
|
207
|
+
approx_next_pulse -= OFFSET_NXT_PULSE
|
|
208
|
+
start_of_extract = approx_next_pulse
|
|
209
|
+
sound_extract = TTC_data[start_of_extract:start_of_extract + LENGTH_EXTRACT]
|
|
210
|
+
abs_signal = abs(sound_extract)
|
|
211
|
+
detected_point = \
|
|
212
|
+
np.argmax(abs_signal > pulse_detection_level)
|
|
213
|
+
old_pulse_position = pulse_position
|
|
214
|
+
pulse_position = detected_point + start_of_extract
|
|
215
|
+
diff = pulse_position - old_pulse_position
|
|
216
|
+
logger.debug('pulse_position %f old_pulse_position %f diff %f'%(pulse_position,
|
|
217
|
+
old_pulse_position, diff))
|
|
218
|
+
if not np.isclose(diff, samplerate, rtol=1e-4):
|
|
219
|
+
if not skipped_printed:
|
|
220
|
+
print('\nSkipped: ', end='')
|
|
221
|
+
skipped_printed = True
|
|
222
|
+
print('%i, '%(pulse_position), end='')
|
|
223
|
+
# if diff < samplerate:
|
|
224
|
+
# else:
|
|
225
|
+
# print('skipped: samples %i and %i are too far'%(pulse_position, old_pulse_position))
|
|
226
|
+
else:
|
|
227
|
+
pulses.append((second, pulse_position))
|
|
228
|
+
approx_next_pulse = pulse_position + i_samplerate
|
|
229
|
+
if skipped_printed:
|
|
230
|
+
print('\n')
|
|
231
|
+
return pulses
|
|
232
|
+
|
|
233
|
+
def main():
|
|
234
|
+
print('in main()')
|
|
235
|
+
parser = argparse.ArgumentParser()
|
|
236
|
+
parser.add_argument(
|
|
237
|
+
"LTC_chan",
|
|
238
|
+
type=int,
|
|
239
|
+
# nargs=2,
|
|
240
|
+
help="LTC channel number"
|
|
241
|
+
)
|
|
242
|
+
parser.add_argument(
|
|
243
|
+
"file_argument",
|
|
244
|
+
type=str,
|
|
245
|
+
nargs=1,
|
|
246
|
+
help="media file"
|
|
247
|
+
)
|
|
248
|
+
args = parser.parse_args()
|
|
249
|
+
# print(args.channels)
|
|
250
|
+
LTC_chan = args.LTC_chan
|
|
251
|
+
file_argument = args.file_argument[0]
|
|
252
|
+
logger.info('args.file_argument: %s'%file_argument)
|
|
253
|
+
if os.path.isdir(file_argument):
|
|
254
|
+
print('argument shoud be a media file, not a directory. Bye...')
|
|
255
|
+
quit()
|
|
256
|
+
# print(file_argument)
|
|
257
|
+
if not os.path.exists(file_argument):
|
|
258
|
+
print('%s does not exist, bye'%file_argument)
|
|
259
|
+
quit()
|
|
260
|
+
errors, DF_flag, fps_rel_to_audio, LTC_frames_and_pos = ltcdump_and_check(file_argument, LTC_chan)
|
|
261
|
+
if errors:
|
|
262
|
+
print('errors! %s'%errors)
|
|
263
|
+
print('Some errors in those %i but detected FPS rel to audio is %0.3f%s'%(len(LTC_frames_and_pos),
|
|
264
|
+
fps_rel_to_audio, 'DF' if DF_flag else 'NDF'))
|
|
265
|
+
else:
|
|
266
|
+
print('\nAll %i frames are sequential and detected FPS rel to audio is %0.3f%s\n'%(len(LTC_frames_and_pos),
|
|
267
|
+
fps_rel_to_audio, 'DF' if DF_flag else 'NDF'))
|
|
268
|
+
# print('trying to decode TTC...')
|
|
269
|
+
with Progress(transient=True) as progress:
|
|
270
|
+
task = progress.add_task("trying to decode TTC...")
|
|
271
|
+
progress.start()
|
|
272
|
+
m = device_scanner.media_dict_from_path(Path(file_argument))
|
|
273
|
+
logger.debug('media_dict_from_path %s'%m)
|
|
274
|
+
recording = yaltc.Recording(m, )
|
|
275
|
+
logger.debug('Rec %s'%recording)
|
|
276
|
+
time = recording.get_start_time(progress=progress, task=task)
|
|
277
|
+
if time == None:
|
|
278
|
+
print('Start time couldnt be determined')
|
|
279
|
+
else:
|
|
280
|
+
audio_samplerate_gps_corrected = recording.true_samplerate
|
|
281
|
+
audio_error = audio_samplerate_gps_corrected/recording.get_samplerate()
|
|
282
|
+
gps_corrected_framerate = fps_rel_to_audio*audio_error
|
|
283
|
+
print('gps_corrected_framerate',gps_corrected_framerate,audio_error)
|
|
284
|
+
frac_time = int(time.microsecond / 1e2)
|
|
285
|
+
d = '%s.%s'%(time.strftime("%Y-%m-%d %H:%M:%S"),frac_time)
|
|
286
|
+
base = os.path.basename(file_argument)
|
|
287
|
+
print('%s UTC:%s pulse: %i on chan %i'%(base, d,
|
|
288
|
+
recording.sync_position,
|
|
289
|
+
recording.YaLTC_channel))
|
|
290
|
+
print('audio samplerate (gps)', audio_samplerate_gps_corrected)
|
|
291
|
+
all_channels_data = read_whole_audio_data(file_argument)
|
|
292
|
+
TTC_data = all_channels_data[recording.YaLTC_channel]
|
|
293
|
+
sec_and_pulses = find_pulses(TTC_data, recording)
|
|
294
|
+
secs, pulses = list(zip(*sec_and_pulses))
|
|
295
|
+
pulses = list(pulses)
|
|
296
|
+
logger.debug('pulses %s'%pulses)
|
|
297
|
+
samples_between_UTC_pulses = []
|
|
298
|
+
for n1, n2 in zip(pulses[1:], pulses):
|
|
299
|
+
delta = n1 - n2
|
|
300
|
+
if np.isclose(delta, audio_samplerate_gps_corrected, rtol=1e-3):
|
|
301
|
+
samples_between_UTC_pulses.append(delta - audio_samplerate_gps_corrected)
|
|
302
|
+
samples_between_UTC_pulses = np.array(samples_between_UTC_pulses)
|
|
303
|
+
pulse_length_std = samples_between_UTC_pulses.std()
|
|
304
|
+
max_min_over_2 = abs(samples_between_UTC_pulses.max() - samples_between_UTC_pulses.min())/2
|
|
305
|
+
# print(samples_between_UTC_pulses)
|
|
306
|
+
# print('time is measured with a precision of %f audio samples'%(pulse_length_std))
|
|
307
|
+
precision = 1e6*max_min_over_2/audio_samplerate_gps_corrected
|
|
308
|
+
print('Time is measured with a precision of %0.1f audio samples (%0.1f μs)'%(max_min_over_2, precision))
|
|
309
|
+
frame_duration = 1/fps_rel_to_audio
|
|
310
|
+
rel_min_error = 100*1e-6*precision/frame_duration
|
|
311
|
+
print('so LTC syncword jitter less than %0.1f %% wont be detected'%(rel_min_error))
|
|
312
|
+
# fig, ax = plt.subplots()
|
|
313
|
+
# n, bins, patches = ax.hist(samples_between_UTC_pulses)
|
|
314
|
+
# plt.show()
|
|
315
|
+
# x = range(len(pulses))
|
|
316
|
+
a, b = np.polyfit(pulses, secs, 1)
|
|
317
|
+
logger.debug('slope, b = %f %f'%(a,b))
|
|
318
|
+
# sr_slope = 1/a
|
|
319
|
+
# print(sr_slope/recording.true_samplerate)
|
|
320
|
+
coherent_sr = np.isclose(a*audio_samplerate_gps_corrected, 1, rtol=1e-7)
|
|
321
|
+
logger.debug('samplerates (slope VS rec) are close: %s ratio %f'%(coherent_sr,
|
|
322
|
+
a*audio_samplerate_gps_corrected))
|
|
323
|
+
if not coherent_sr:
|
|
324
|
+
print('warning, wav samplerate are incoherent (Rec + Decode VS slope)')
|
|
325
|
+
def make_sample2time(a, b):
|
|
326
|
+
return lambda n : a*n + b
|
|
327
|
+
sample2time = make_sample2time(a, b)
|
|
328
|
+
logger.debug('sample2time fct: %s'%sample2time)
|
|
329
|
+
LTC_samples = [N for _, N in LTC_frames_and_pos]
|
|
330
|
+
LTC_times = [sample2time(N) for N in LTC_samples]
|
|
331
|
+
slope_fps, _ = np.polyfit(LTC_times, range(len(LTC_times)), 1)
|
|
332
|
+
print('slope_fps l329', ppm(slope_fps,24))
|
|
333
|
+
print('diff slope, ppm',ppm(gps_corrected_framerate, slope_fps))
|
|
334
|
+
LTC_frame_durations_samples = [a - b for a, b in zip(LTC_samples[1:], LTC_samples)]
|
|
335
|
+
# print(LTC_frame_durations_samples)
|
|
336
|
+
frame_duration = 1/fps_rel_to_audio
|
|
337
|
+
errors_useconds = [1e6*(frame_duration -(a - b)) for a, b in zip(LTC_times[1:], LTC_times)]
|
|
338
|
+
# print(errors_useconds)
|
|
339
|
+
errors_useconds = np.array(errors_useconds)
|
|
340
|
+
LTC_std = abs(errors_useconds).std()
|
|
341
|
+
LTC_max_min = abs(errors_useconds.max() - errors_useconds.min())/2
|
|
342
|
+
# print('Mean frame duration is %i audio samples'%)
|
|
343
|
+
print('\nhere LTC frame duration varies by %f μs ('%LTC_max_min, end='')
|
|
344
|
+
print('%0.3fFPS nominal frame duration is %0.0f μs)\n'%(fps_rel_to_audio, 1e6/fps_rel_to_audio))
|
|
345
|
+
# print(errors_useconds[:200])
|
|
346
|
+
# audio_sampling_period = 1/samplerate
|
|
347
|
+
# print(audio_sampling_period)
|
|
348
|
+
# errors_in_audiosamples = [int(e/audio_sampling_period) for e in errors_seconds]
|
|
349
|
+
# print(delta_milliseconds)
|
|
350
|
+
# plt.plot(LTC_times, marker='.', markersize='1',
|
|
351
|
+
# linestyle='None', color='black')
|
|
352
|
+
# plt.show()
|
|
353
|
+
# print(LTC_times)
|
|
354
|
+
# fig, ax = plt.subplots()
|
|
355
|
+
|
|
356
|
+
# the histogram of the data
|
|
357
|
+
# print(errors_in_audiosamples)
|
|
358
|
+
fig, ax = plt.subplots()
|
|
359
|
+
n, bins, patches = ax.hist(errors_useconds, bins=40)
|
|
360
|
+
plt.show()
|
|
361
|
+
quit()
|
|
362
|
+
|
|
363
|
+
if __name__ == '__main__':
|
|
364
|
+
main()
|
|
365
|
+
|
|
366
|
+
# import matplotlib.pyplot as plt
|
|
367
|
+
# import numpy as np
|
|
368
|
+
|
|
369
|
+
# rng = np.random.default_rng(19680801)
|
|
370
|
+
|
|
371
|
+
# # example data
|
|
372
|
+
# mu = 106 # mean of distribution
|
|
373
|
+
# sigma = 17 # standard deviation of distribution
|
|
374
|
+
# x = rng.normal(loc=mu, scale=sigma, size=420)
|
|
375
|
+
|
|
376
|
+
# num_bins = 42
|
|
377
|
+
|
|
378
|
+
# fig, ax = plt.subplots()
|
|
379
|
+
|
|
380
|
+
# # the histogram of the data
|
|
381
|
+
# n, bins, patches = ax.hist(x, num_bins, density=True)
|
|
382
|
+
|
|
383
|
+
# # add a 'best fit' line
|
|
384
|
+
# y = ((1 / (np.sqrt(2 * np.pi) * sigma)) *
|
|
385
|
+
# np.exp(-0.5 * (1 / sigma * (bins - mu))**2))
|
|
386
|
+
# ax.plot(bins, y, '--')
|
|
387
|
+
# ax.set_xlabel('Value')
|
|
388
|
+
# ax.set_ylabel('Probability density')
|
|
389
|
+
# ax.set_title('Histogram of normal distribution sample: '
|
|
390
|
+
# fr'$\mu={mu:.0f}$, $\sigma={sigma:.0f}$')
|
|
391
|
+
|
|
392
|
+
# # Tweak spacing to prevent clipping of ylabel
|
|
393
|
+
# fig.tight_layout()
|
|
394
|
+
# plt.show()
|