stream-dataset 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- stream_dataset-0.1.0/.git +1 -0
- stream_dataset-0.1.0/.gitignore +177 -0
- stream_dataset-0.1.0/LICENSE +21 -0
- stream_dataset-0.1.0/PKG-INFO +302 -0
- stream_dataset-0.1.0/README.md +271 -0
- stream_dataset-0.1.0/images/adding_problem.png +0 -0
- stream_dataset-0.1.0/images/bracket_matching.png +0 -0
- stream_dataset-0.1.0/images/chaotic_forecasting.png +0 -0
- stream_dataset-0.1.0/images/continuous_pattern_completion.png +0 -0
- stream_dataset-0.1.0/images/continuous_postcasting.png +0 -0
- stream_dataset-0.1.0/images/discrete_pattern_completion.png +0 -0
- stream_dataset-0.1.0/images/discrete_postcasting.png +0 -0
- stream_dataset-0.1.0/images/selective_copy.png +0 -0
- stream_dataset-0.1.0/images/sequential_mnist.png +0 -0
- stream_dataset-0.1.0/images/simple_copy.png +0 -0
- stream_dataset-0.1.0/images/sinus_forecasting.png +0 -0
- stream_dataset-0.1.0/images/sorting_problem.png +0 -0
- stream_dataset-0.1.0/pyproject.toml +17 -0
- stream_dataset-0.1.0/requirements.txt +1 -0
- stream_dataset-0.1.0/stream_dataset/__init__.py +98 -0
- stream_dataset-0.1.0/stream_dataset/evals.py +206 -0
- stream_dataset-0.1.0/stream_dataset/libs/CSL.py +342 -0
- stream_dataset-0.1.0/stream_dataset/tasks.py +679 -0
- stream_dataset-0.1.0/test.ipynb +0 -0
|
@@ -0,0 +1 @@
|
|
|
1
|
+
gitdir: ../../.git/modules/code/STREAM-Dataset
|
|
@@ -0,0 +1,177 @@
|
|
|
1
|
+
data/
|
|
2
|
+
stream_venv/
|
|
3
|
+
|
|
4
|
+
# Byte-compiled / optimized / DLL files
|
|
5
|
+
__pycache__/
|
|
6
|
+
*.py[cod]
|
|
7
|
+
*$py.class
|
|
8
|
+
|
|
9
|
+
# C extensions
|
|
10
|
+
*.so
|
|
11
|
+
|
|
12
|
+
# Distribution / packaging
|
|
13
|
+
.Python
|
|
14
|
+
build/
|
|
15
|
+
develop-eggs/
|
|
16
|
+
dist/
|
|
17
|
+
downloads/
|
|
18
|
+
eggs/
|
|
19
|
+
.eggs/
|
|
20
|
+
lib/
|
|
21
|
+
lib64/
|
|
22
|
+
parts/
|
|
23
|
+
sdist/
|
|
24
|
+
var/
|
|
25
|
+
wheels/
|
|
26
|
+
share/python-wheels/
|
|
27
|
+
*.egg-info/
|
|
28
|
+
.installed.cfg
|
|
29
|
+
*.egg
|
|
30
|
+
MANIFEST
|
|
31
|
+
|
|
32
|
+
# PyInstaller
|
|
33
|
+
# Usually these files are written by a python script from a template
|
|
34
|
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
|
35
|
+
*.manifest
|
|
36
|
+
*.spec
|
|
37
|
+
|
|
38
|
+
# Installer logs
|
|
39
|
+
pip-log.txt
|
|
40
|
+
pip-delete-this-directory.txt
|
|
41
|
+
|
|
42
|
+
# Unit test / coverage reports
|
|
43
|
+
htmlcov/
|
|
44
|
+
.tox/
|
|
45
|
+
.nox/
|
|
46
|
+
.coverage
|
|
47
|
+
.coverage.*
|
|
48
|
+
.cache
|
|
49
|
+
nosetests.xml
|
|
50
|
+
coverage.xml
|
|
51
|
+
*.cover
|
|
52
|
+
*.py,cover
|
|
53
|
+
.hypothesis/
|
|
54
|
+
.pytest_cache/
|
|
55
|
+
cover/
|
|
56
|
+
|
|
57
|
+
# Translations
|
|
58
|
+
*.mo
|
|
59
|
+
*.pot
|
|
60
|
+
|
|
61
|
+
# Django stuff:
|
|
62
|
+
*.log
|
|
63
|
+
local_settings.py
|
|
64
|
+
db.sqlite3
|
|
65
|
+
db.sqlite3-journal
|
|
66
|
+
|
|
67
|
+
# Flask stuff:
|
|
68
|
+
instance/
|
|
69
|
+
.webassets-cache
|
|
70
|
+
|
|
71
|
+
# Scrapy stuff:
|
|
72
|
+
.scrapy
|
|
73
|
+
|
|
74
|
+
# Sphinx documentation
|
|
75
|
+
docs/_build/
|
|
76
|
+
|
|
77
|
+
# PyBuilder
|
|
78
|
+
.pybuilder/
|
|
79
|
+
target/
|
|
80
|
+
|
|
81
|
+
# Jupyter Notebook
|
|
82
|
+
.ipynb_checkpoints
|
|
83
|
+
|
|
84
|
+
# IPython
|
|
85
|
+
profile_default/
|
|
86
|
+
ipython_config.py
|
|
87
|
+
|
|
88
|
+
# pyenv
|
|
89
|
+
# For a library or package, you might want to ignore these files since the code is
|
|
90
|
+
# intended to run in multiple environments; otherwise, check them in:
|
|
91
|
+
# .python-version
|
|
92
|
+
|
|
93
|
+
# pipenv
|
|
94
|
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
|
95
|
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
|
96
|
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
|
97
|
+
# install all needed dependencies.
|
|
98
|
+
#Pipfile.lock
|
|
99
|
+
|
|
100
|
+
# UV
|
|
101
|
+
# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
|
|
102
|
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
|
103
|
+
# commonly ignored for libraries.
|
|
104
|
+
#uv.lock
|
|
105
|
+
|
|
106
|
+
# poetry
|
|
107
|
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
|
108
|
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
|
109
|
+
# commonly ignored for libraries.
|
|
110
|
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
|
111
|
+
#poetry.lock
|
|
112
|
+
|
|
113
|
+
# pdm
|
|
114
|
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
|
115
|
+
#pdm.lock
|
|
116
|
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
|
117
|
+
# in version control.
|
|
118
|
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
|
119
|
+
.pdm.toml
|
|
120
|
+
.pdm-python
|
|
121
|
+
.pdm-build/
|
|
122
|
+
|
|
123
|
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
|
124
|
+
__pypackages__/
|
|
125
|
+
|
|
126
|
+
# Celery stuff
|
|
127
|
+
celerybeat-schedule
|
|
128
|
+
celerybeat.pid
|
|
129
|
+
|
|
130
|
+
# SageMath parsed files
|
|
131
|
+
*.sage.py
|
|
132
|
+
|
|
133
|
+
# Environments
|
|
134
|
+
.env
|
|
135
|
+
.venv
|
|
136
|
+
env/
|
|
137
|
+
venv/
|
|
138
|
+
ENV/
|
|
139
|
+
env.bak/
|
|
140
|
+
venv.bak/
|
|
141
|
+
|
|
142
|
+
# Spyder project settings
|
|
143
|
+
.spyderproject
|
|
144
|
+
.spyproject
|
|
145
|
+
|
|
146
|
+
# Rope project settings
|
|
147
|
+
.ropeproject
|
|
148
|
+
|
|
149
|
+
# mkdocs documentation
|
|
150
|
+
/site
|
|
151
|
+
|
|
152
|
+
# mypy
|
|
153
|
+
.mypy_cache/
|
|
154
|
+
.dmypy.json
|
|
155
|
+
dmypy.json
|
|
156
|
+
|
|
157
|
+
# Pyre type checker
|
|
158
|
+
.pyre/
|
|
159
|
+
|
|
160
|
+
# pytype static type analyzer
|
|
161
|
+
.pytype/
|
|
162
|
+
|
|
163
|
+
# Cython debug symbols
|
|
164
|
+
cython_debug/
|
|
165
|
+
|
|
166
|
+
# PyCharm
|
|
167
|
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
|
168
|
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
|
169
|
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
|
170
|
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
|
171
|
+
#.idea/
|
|
172
|
+
|
|
173
|
+
# Ruff stuff:
|
|
174
|
+
.ruff_cache/
|
|
175
|
+
|
|
176
|
+
# PyPI configuration file
|
|
177
|
+
.pypirc
|
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2025 Yannis Bendi-Ouis
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
|
@@ -0,0 +1,302 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: stream-dataset
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: STREAM (Sequential Tasks Review to Evaluate Artificial Memory) is a dataset of 12 diverse sequential tasks to assess neural networks’ memory. Scalable in complexity and sequence length, it covers pattern completion, copy tasks, forecasting, bracket matching, and sorting—ideal for comparing architectures on memory retention and sequential reasoning.
|
|
5
|
+
Author-email: Yannis Bendi-Ouis <yannis.bendiouis@gmail.com>
|
|
6
|
+
License: MIT License
|
|
7
|
+
|
|
8
|
+
Copyright (c) 2025 Yannis Bendi-Ouis
|
|
9
|
+
|
|
10
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
11
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
12
|
+
in the Software without restriction, including without limitation the rights
|
|
13
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
14
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
15
|
+
furnished to do so, subject to the following conditions:
|
|
16
|
+
|
|
17
|
+
The above copyright notice and this permission notice shall be included in all
|
|
18
|
+
copies or substantial portions of the Software.
|
|
19
|
+
|
|
20
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
21
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
22
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
23
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
24
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
25
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
26
|
+
SOFTWARE.
|
|
27
|
+
License-File: LICENSE
|
|
28
|
+
Requires-Python: >=3.8
|
|
29
|
+
Requires-Dist: numpy
|
|
30
|
+
Description-Content-Type: text/markdown
|
|
31
|
+
|
|
32
|
+
# Stream Dataset
|
|
33
|
+
|
|
34
|
+
A comprehensive dataset suite for evaluating sequence modeling capabilities of neural networks, particularly focusing on memory, long-term dependencies, and temporal reasoning tasks.
|
|
35
|
+
|
|
36
|
+
## 🚀 Features
|
|
37
|
+
|
|
38
|
+
- **12 Diverse Tasks**: From simple memory tests to complex pattern recognition
|
|
39
|
+
- **Multiple Difficulty Levels**: Small, medium and large configurations. Advice : if you're building an architecture, you should begin with small.
|
|
40
|
+
- **Unified Interface**: Consistent API across all tasks with standardized evaluation metrics
|
|
41
|
+
- **Ready-to-Use**: Pre-configured datasets with train/validation/test splits
|
|
42
|
+
- **Flexible**: Support for both classification and regression tasks
|
|
43
|
+
|
|
44
|
+
## 📦 Installation
|
|
45
|
+
|
|
46
|
+
```bash
|
|
47
|
+
pip install stream-dataset
|
|
48
|
+
```
|
|
49
|
+
|
|
50
|
+
Or install from source:
|
|
51
|
+
|
|
52
|
+
```bash
|
|
53
|
+
git clone https://github.com/Naowak/stream-dataset.git
|
|
54
|
+
cd stream-dataset
|
|
55
|
+
pip install -e .
|
|
56
|
+
```
|
|
57
|
+
|
|
58
|
+
## 🎯 Quick Start
|
|
59
|
+
|
|
60
|
+
```python
|
|
61
|
+
import stream_dataset as sd
|
|
62
|
+
|
|
63
|
+
# Build a task
|
|
64
|
+
task_data = sd.build_task('simple_copy', difficulty='small', seed=0)
|
|
65
|
+
|
|
66
|
+
# Access the data
|
|
67
|
+
X_train = task_data['X_train'] # Training inputs
|
|
68
|
+
Y_train = task_data['Y_train'] # Training targets
|
|
69
|
+
T_train = task_data['T_train'] # Prediction timesteps
|
|
70
|
+
|
|
71
|
+
# Train your model (example with dummy predictions)
|
|
72
|
+
Y_pred = your_model.predict(X_train)
|
|
73
|
+
|
|
74
|
+
# Evaluate performance
|
|
75
|
+
score = sd.compute_score(
|
|
76
|
+
Y=Y_train,
|
|
77
|
+
Y_hat=Y_pred,
|
|
78
|
+
prediction_timesteps=T_train,
|
|
79
|
+
classification=task_data['classification']
|
|
80
|
+
)
|
|
81
|
+
print(f"Score: {score}")
|
|
82
|
+
```
|
|
83
|
+
|
|
84
|
+
## 📚 Available Tasks
|
|
85
|
+
|
|
86
|
+
### Memory Tests
|
|
87
|
+
### Postcasting Tasks
|
|
88
|
+
- **`discrete_postcasting`**: Copy discrete sequences after a delay
|
|
89
|
+
|
|
90
|
+
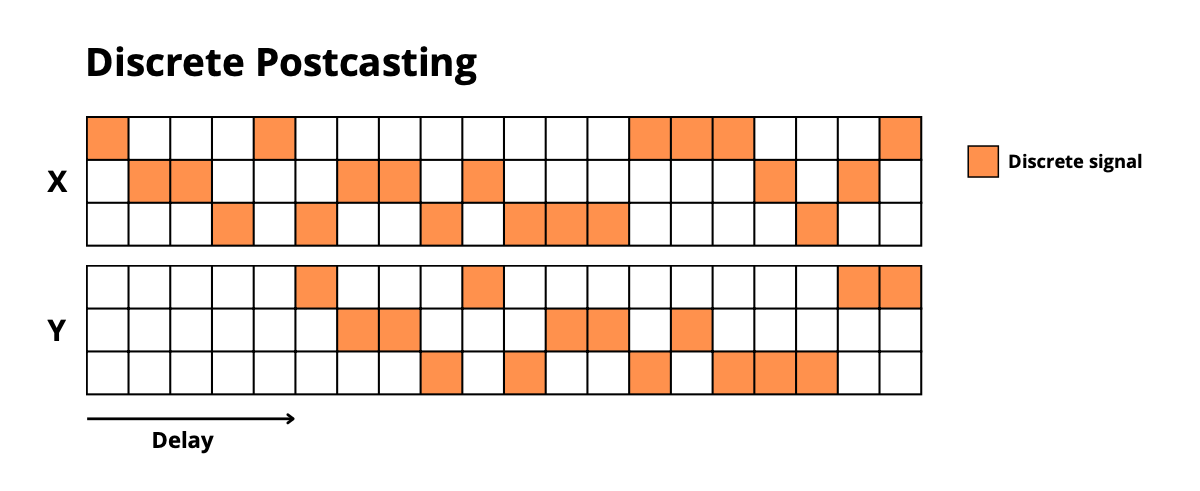
|
|
91
|
+
|
|
92
|
+
- **`continuous_postcasting`**: Copy continuous sequences after a delay
|
|
93
|
+
|
|
94
|
+
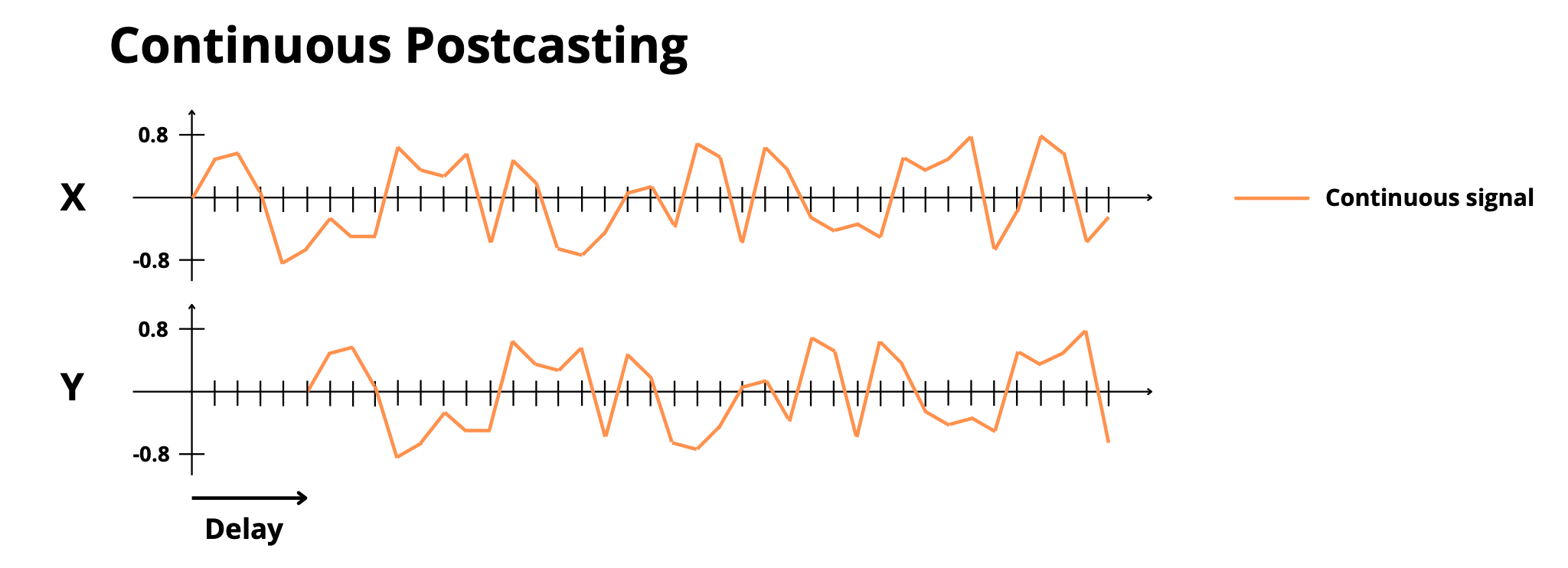
|
|
95
|
+
|
|
96
|
+
### Signal Processing
|
|
97
|
+
- **`sinus_forecasting`**: Predict frequency-modulated sinusoidal signals
|
|
98
|
+
|
|
99
|
+
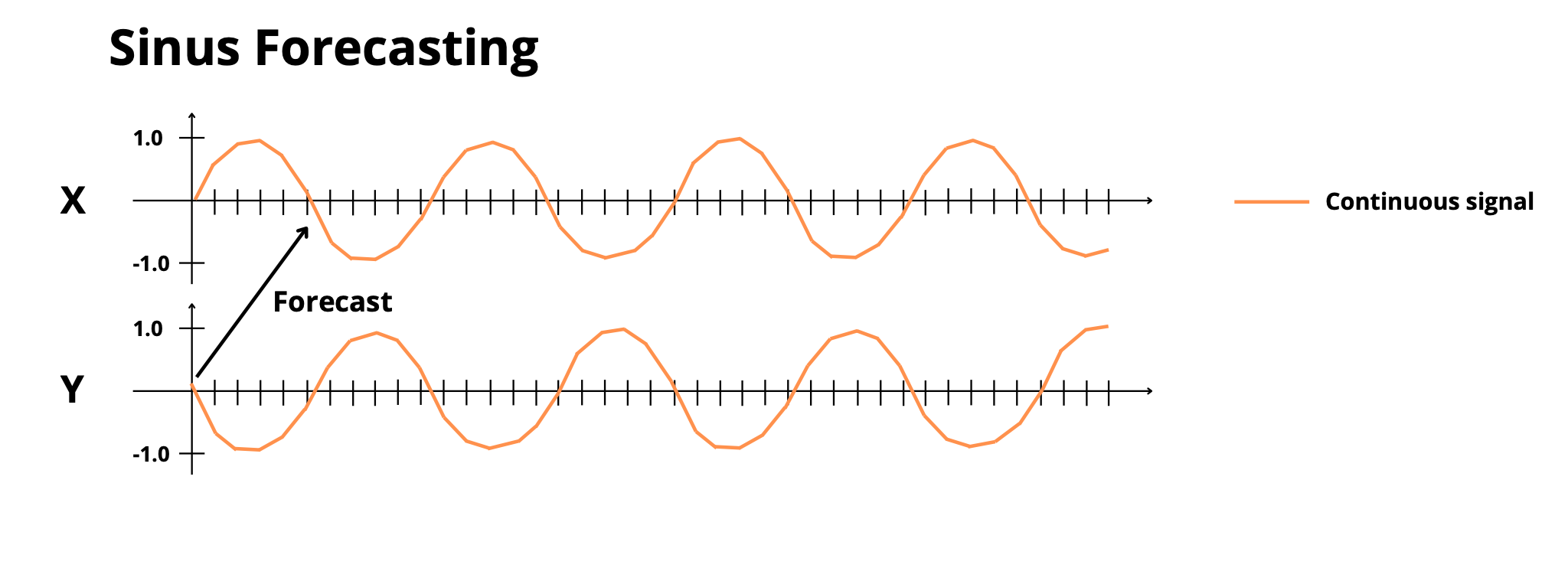
|
|
100
|
+
|
|
101
|
+
- **`chaotic_forecasting`**: Forecast Lorenz system dynamics
|
|
102
|
+
|
|
103
|
+
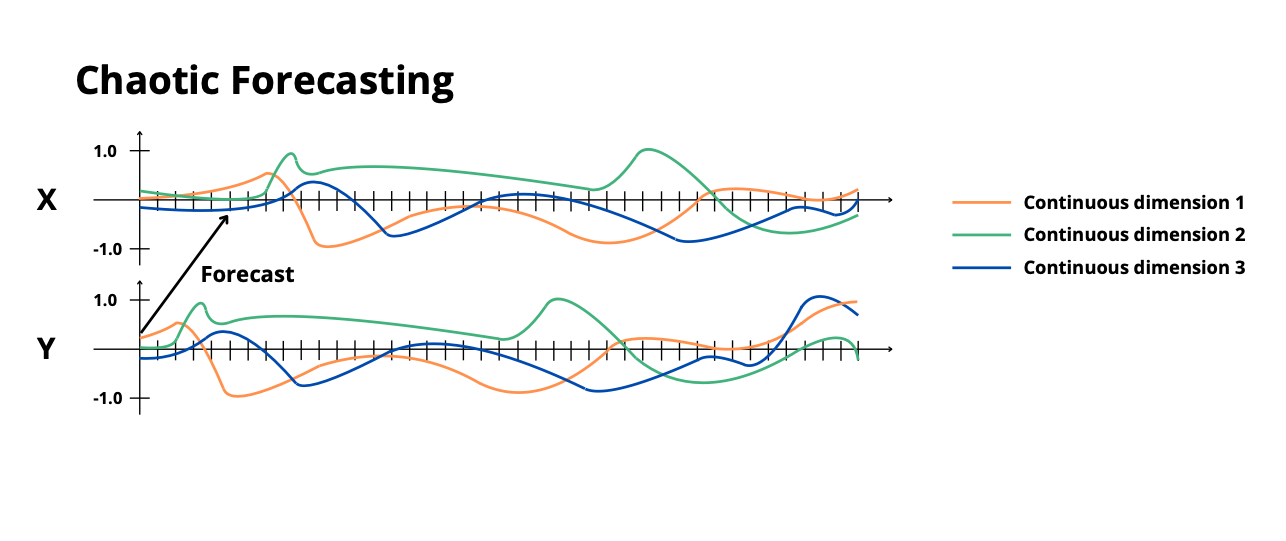
|
|
104
|
+
|
|
105
|
+
|
|
106
|
+
### Long-term Dependencies
|
|
107
|
+
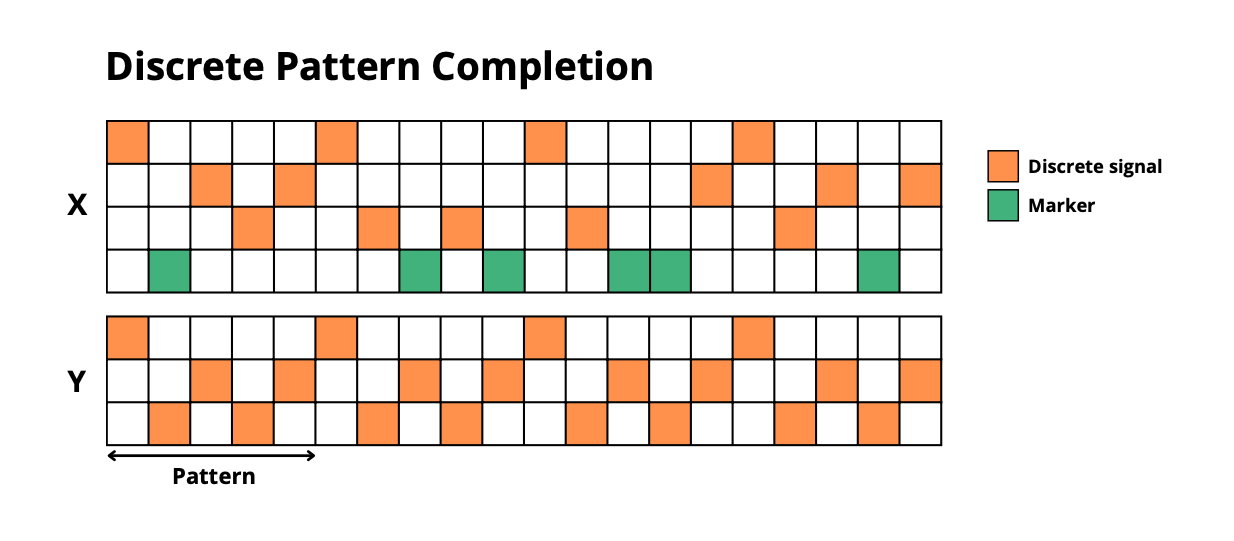
- **`discrete_pattern_completion`**: Complete masked repetitive patterns (discrete)
|
|
108
|
+
|
|
109
|
+
|
|
110
|
+
|
|
111
|
+
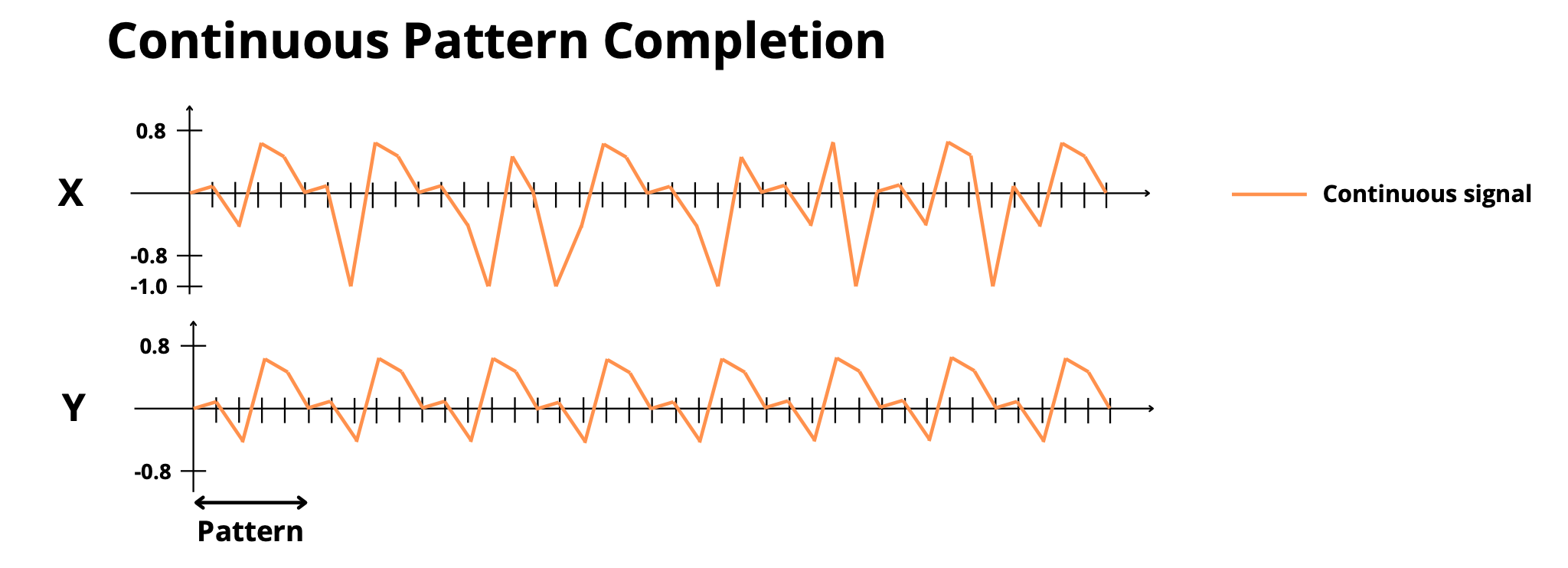
- **`continuous_pattern_completion`**: Complete masked repetitive patterns (continuous)
|
|
112
|
+
|
|
113
|
+
|
|
114
|
+
|
|
115
|
+
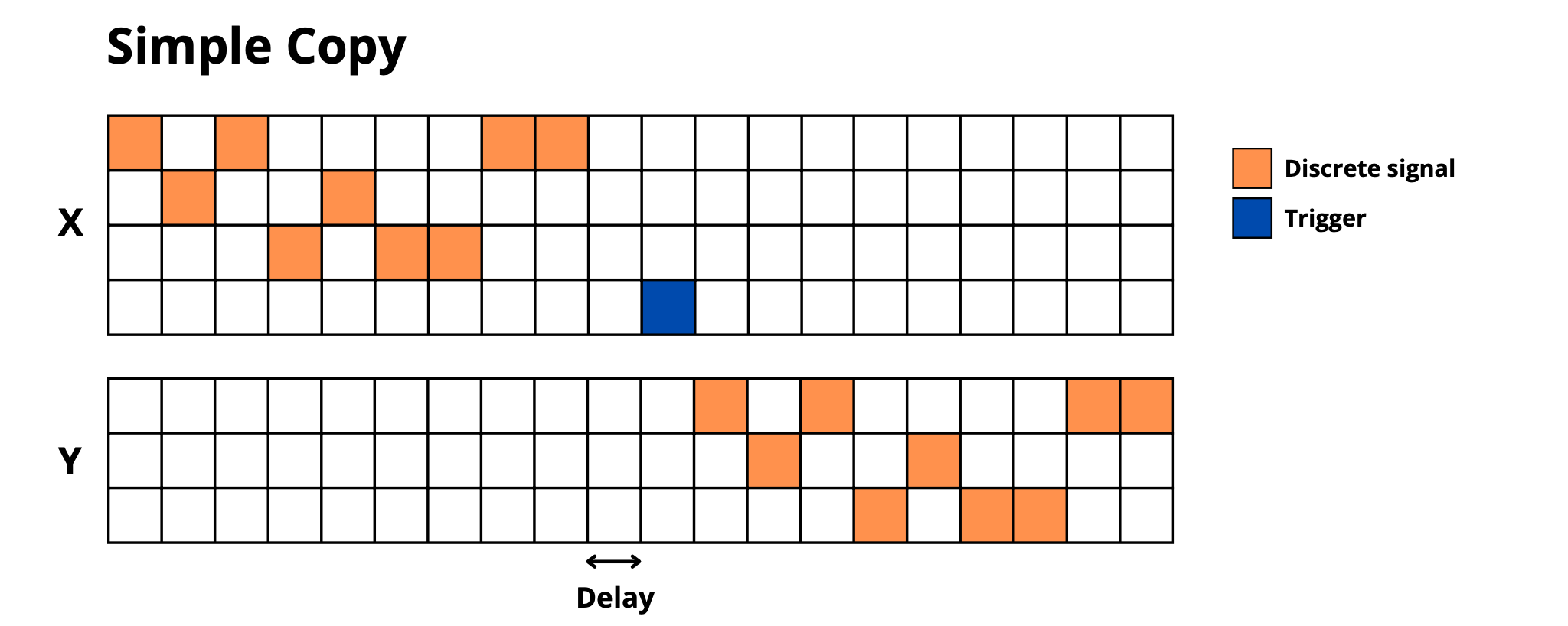
- **`simple_copy`**: Memorize and reproduce sequences after delay + trigger
|
|
116
|
+
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
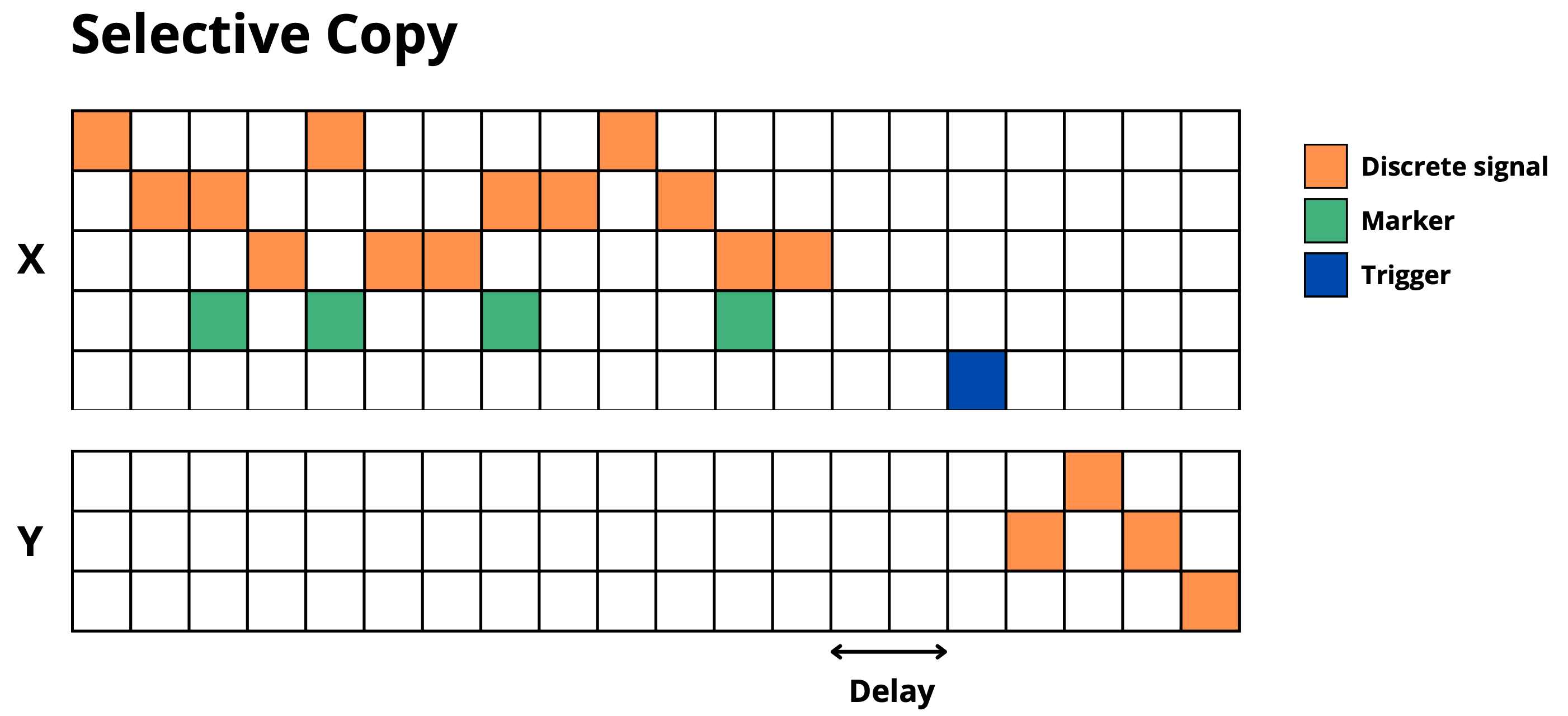
- **`selective_copy`**: Memorize only marked elements and reproduce them
|
|
120
|
+
|
|
121
|
+
|
|
122
|
+
|
|
123
|
+
|
|
124
|
+
### Information Manipulation
|
|
125
|
+
- **`adding_problem`**: Add numbers at marked positions
|
|
126
|
+
|
|
127
|
+
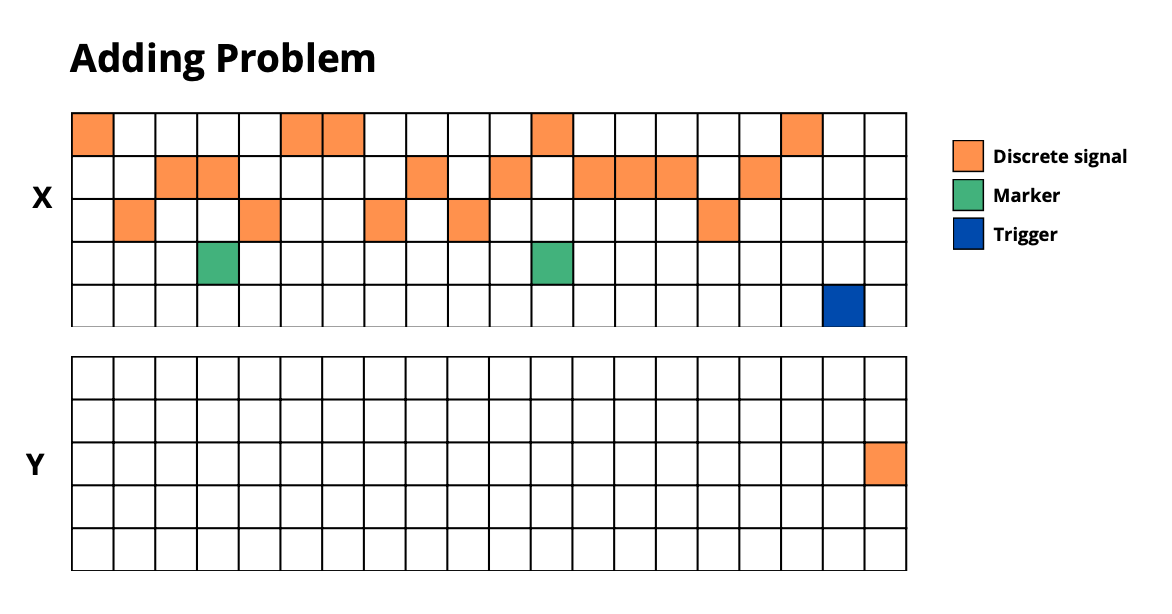
|
|
128
|
+
|
|
129
|
+
- **`sorting_problem`**: Sort sequences according to given positions
|
|
130
|
+
|
|
131
|
+
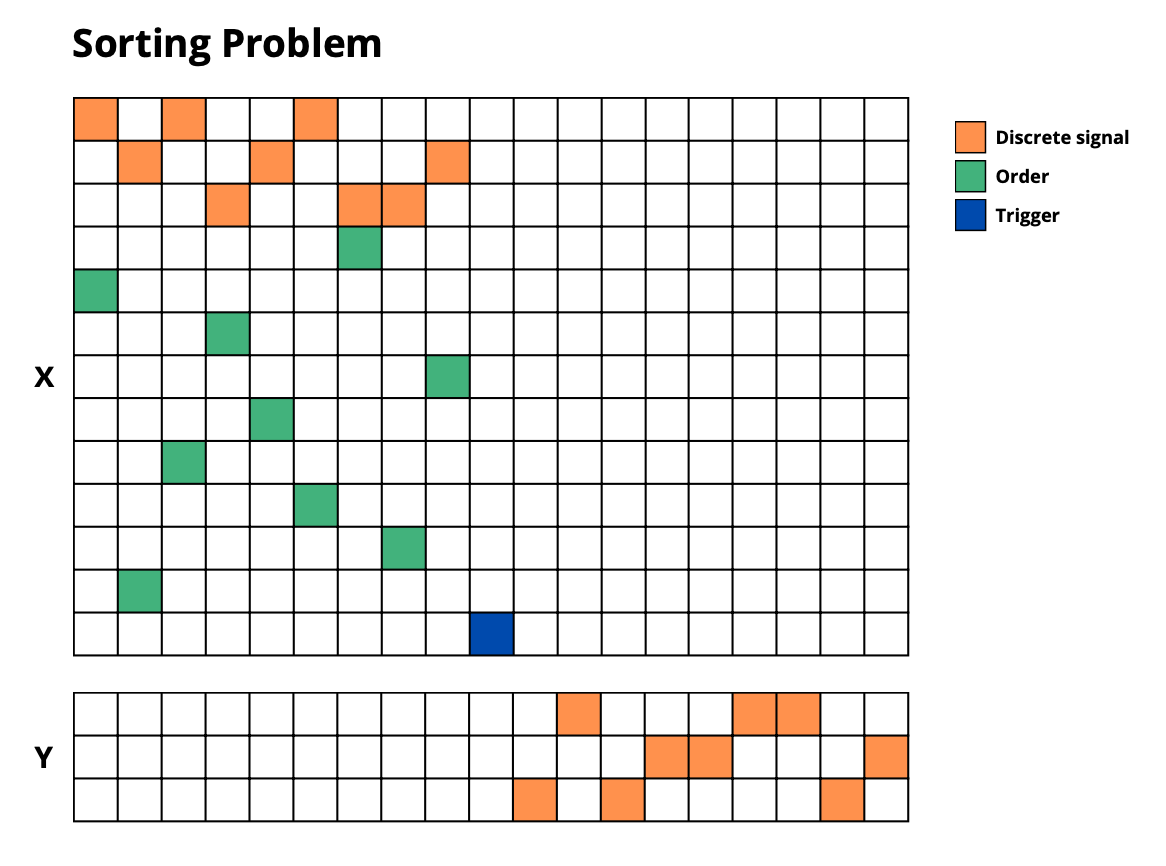
|
|
132
|
+
|
|
133
|
+
- **`bracket_matching`**: Validate parentheses sequences
|
|
134
|
+
|
|
135
|
+
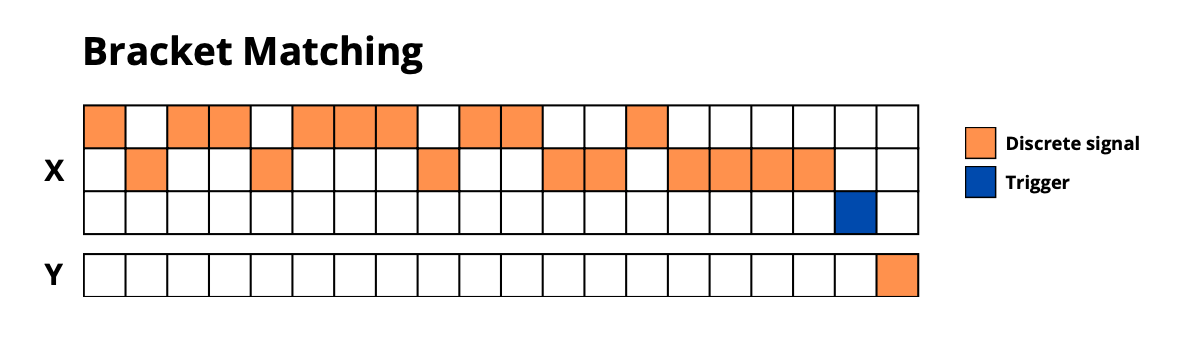
|
|
136
|
+
|
|
137
|
+
- **`sequential_mnist`**: Classify MNIST digits read column by column
|
|
138
|
+
|
|
139
|
+

|
|
140
|
+
|
|
141
|
+
|
|
142
|
+
## 🔧 Task Configuration
|
|
143
|
+
|
|
144
|
+
Each task supports three difficulty levels (the following numbers may vary in function of the task):
|
|
145
|
+
|
|
146
|
+
### Small
|
|
147
|
+
- Reduced sequence lengths and sample counts
|
|
148
|
+
- Suitable for quick experiments and debugging
|
|
149
|
+
- Example: 100 training samples, sequences of ~50-100 timesteps
|
|
150
|
+
|
|
151
|
+
### Medium
|
|
152
|
+
- Realistic problem sizes
|
|
153
|
+
- Suitable for thorough model evaluation
|
|
154
|
+
- Example: 1,000 training samples, sequences of ~100-200 timesteps
|
|
155
|
+
|
|
156
|
+
### Large
|
|
157
|
+
- Big Data configurations
|
|
158
|
+
- Suitable for high-performance models
|
|
159
|
+
- Example: 10,000 training samples, sequences of ~200-500 timesteps
|
|
160
|
+
|
|
161
|
+
For the tasks that allow it, the difficulty is also adjusted by the dimensions of input & output.
|
|
162
|
+
|
|
163
|
+
```python
|
|
164
|
+
# Small configuration (fast)
|
|
165
|
+
task_small = sd.build_task('bracket_matching', difficulty='small', seed=0)
|
|
166
|
+
|
|
167
|
+
# Medium configuration (thorough)
|
|
168
|
+
task_medium = sd.build_task('bracket_matching', difficulty='medium', seed=0)
|
|
169
|
+
|
|
170
|
+
# Large configuration (comprehensive)
|
|
171
|
+
task_large = sd.build_task('bracket_matching', difficulty='large', seed=0)
|
|
172
|
+
```
|
|
173
|
+
|
|
174
|
+
## 📊 Data Format
|
|
175
|
+
|
|
176
|
+
All tasks return a standardized dictionary:
|
|
177
|
+
|
|
178
|
+
```python
|
|
179
|
+
{
|
|
180
|
+
'X_train': np.ndarray, # Training inputs [batch, time, features]
|
|
181
|
+
'Y_train': np.ndarray, # Training targets [batch, time, outputs]
|
|
182
|
+
'T_train': np.ndarray, # Training prediction timesteps [batch, n_predictions]
|
|
183
|
+
'X_valid': np.ndarray, # Validation inputs
|
|
184
|
+
'Y_valid': np.ndarray, # Validation targets
|
|
185
|
+
'T_valid': np.ndarray, # Validation prediction timesteps
|
|
186
|
+
'X_test': np.ndarray, # Test inputs
|
|
187
|
+
'Y_test': np.ndarray, # Test targets
|
|
188
|
+
'T_test': np.ndarray, # Test prediction timesteps
|
|
189
|
+
'classification': bool # True for classification, False for regression : used to select the correspongind loss
|
|
190
|
+
}
|
|
191
|
+
```
|
|
192
|
+
|
|
193
|
+
## 🎨 Example: Complete Evaluation Pipeline
|
|
194
|
+
|
|
195
|
+
```python
|
|
196
|
+
import stream_dataset as sd
|
|
197
|
+
import numpy as np
|
|
198
|
+
from MyModel import MyModel
|
|
199
|
+
|
|
200
|
+
def evaluate_model_on_all_tasks(model, difficulty='small'):
|
|
201
|
+
"""Evaluate a model on all available tasks."""
|
|
202
|
+
|
|
203
|
+
results = {}
|
|
204
|
+
task_names = [
|
|
205
|
+
'simple_copy', 'selective_copy', 'adding_problem',
|
|
206
|
+
'discrete_postcasting', 'continuous_postcasting',
|
|
207
|
+
'discrete_pattern_completion', 'continuous_pattern_completion',
|
|
208
|
+
'bracket_matching', 'sorting_problem', 'sequential_mnist',
|
|
209
|
+
'sinus_forecasting', 'chaotic_forecasting'
|
|
210
|
+
]
|
|
211
|
+
|
|
212
|
+
for task_name in task_names:
|
|
213
|
+
print(f"Evaluating on {task_name}...")
|
|
214
|
+
|
|
215
|
+
# Load task
|
|
216
|
+
task_data = sd.build_task(task_name, difficulty=difficulty)
|
|
217
|
+
|
|
218
|
+
# Train model (simplified)
|
|
219
|
+
model = MyModel(...)
|
|
220
|
+
model.train(task_data['X_train'], task_data['Y_train'], task_data['T_train'])
|
|
221
|
+
# If you want your model to learn all timesteps, including the ones that are not evaluated :
|
|
222
|
+
# Comment the previous line and uncomment the following one
|
|
223
|
+
# model.train(task_data['X_train'], task_data['Y_train'])
|
|
224
|
+
|
|
225
|
+
# Predict on test set
|
|
226
|
+
Y_pred = model.predict(task_data['X_test'])
|
|
227
|
+
|
|
228
|
+
# Compute score
|
|
229
|
+
score = sd.compute_score(
|
|
230
|
+
Y=task_data['Y_test'],
|
|
231
|
+
Y_hat=Y_pred,
|
|
232
|
+
prediction_timesteps=task_data['T_test'],
|
|
233
|
+
classification=task_data['classification']
|
|
234
|
+
)
|
|
235
|
+
|
|
236
|
+
results[task_name] = score
|
|
237
|
+
print(f" Score: {score:.4f}")
|
|
238
|
+
|
|
239
|
+
return results
|
|
240
|
+
|
|
241
|
+
# Usage
|
|
242
|
+
# results = evaluate_model_on_all_tasks(your_model, difficulty='medium')
|
|
243
|
+
```
|
|
244
|
+
|
|
245
|
+
## 🧪 Task Details
|
|
246
|
+
|
|
247
|
+
### Memory and Copy Tasks
|
|
248
|
+
Test the model's ability to store and retrieve information over time.
|
|
249
|
+
|
|
250
|
+
### Pattern Recognition Tasks
|
|
251
|
+
Evaluate pattern detection and completion capabilities with both discrete and continuous sequences.
|
|
252
|
+
|
|
253
|
+
### Algorithmic Reasoning Tasks
|
|
254
|
+
Assess the model's ability to perform computations on stored information (adding, sorting).
|
|
255
|
+
|
|
256
|
+
### Real-world Sequence Tasks
|
|
257
|
+
Include practical applications like MNIST digit classification and signal forecasting.
|
|
258
|
+
|
|
259
|
+
## 📈 Evaluation Metrics
|
|
260
|
+
|
|
261
|
+
- **Classification tasks**: Error rate (1 - accuracy)
|
|
262
|
+
- **Regression tasks**: Mean Squared Error (MSE)
|
|
263
|
+
|
|
264
|
+
Lower scores indicate better performance for both metrics.
|
|
265
|
+
|
|
266
|
+
## 🤝 Contributing
|
|
267
|
+
|
|
268
|
+
We welcome contributions! Please see our [Contributing Guidelines](CONTRIBUTING.md) for details.
|
|
269
|
+
|
|
270
|
+
## 📄 License
|
|
271
|
+
|
|
272
|
+
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
|
|
273
|
+
|
|
274
|
+
## 📚 Citation
|
|
275
|
+
|
|
276
|
+
If you use Stream Dataset in your research, please cite:
|
|
277
|
+
|
|
278
|
+
(paper in progress...)
|
|
279
|
+
|
|
280
|
+
```bibtex
|
|
281
|
+
@software{stream_dataset,
|
|
282
|
+
title={Stream Dataset: Sequential Task Review to Evaluate Artificial Memory},
|
|
283
|
+
author={Yannis Bendi-Ouis, Xavier Hinaut},
|
|
284
|
+
year={2025},
|
|
285
|
+
url={https://github.com/Naowak/stream-dataset}
|
|
286
|
+
}
|
|
287
|
+
```
|
|
288
|
+
|
|
289
|
+
## 🙏 Acknowledgments
|
|
290
|
+
|
|
291
|
+
- Inspired by classic sequence modeling datasets
|
|
292
|
+
- Built with NumPy and Hugging Face Datasets
|
|
293
|
+
- MNIST task uses the official MNIST dataset
|
|
294
|
+
|
|
295
|
+
## 📞 Support
|
|
296
|
+
|
|
297
|
+
- 🐛 Issues: [GitHub Issues](https://github.com/Naowak/stream-dataset/issues)
|
|
298
|
+
- 💬 Discussions: [GitHub Discussions](https://github.com/Naowak/stream-dataset/discussions)
|
|
299
|
+
|
|
300
|
+
---
|
|
301
|
+
|
|
302
|
+
*Stream Dataset - Advancing sequence modeling evaluation, one task at a time.*
|