statslibx 0.2.4__tar.gz → 0.2.6__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- statslibx-0.2.6/PKG-INFO +125 -0
- statslibx-0.2.6/README.md +90 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/pyproject.toml +8 -4
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/__init__.py +12 -5
- statslibx-0.2.6/statslibx/cli.py +241 -0
- statslibx-0.2.6/statslibx/computational.py +1059 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/__init__.py +2 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/preprocessing/__init__.py +3 -34
- statslibx-0.2.6/statslibx/viewx/__init__.py +14 -0
- statslibx-0.2.6/statslibx.egg-info/PKG-INFO +125 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx.egg-info/SOURCES.txt +5 -2
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx.egg-info/requires.txt +1 -1
- statslibx-0.2.6/tests/test2.py +39 -0
- statslibx-0.2.6/tests/test3.py +1 -0
- statslibx-0.2.4/PKG-INFO +0 -86
- statslibx-0.2.4/README.md +0 -53
- statslibx-0.2.4/statslibx/cli.py +0 -48
- statslibx-0.2.4/statslibx/computacional.py +0 -37
- statslibx-0.2.4/statslibx.egg-info/PKG-INFO +0 -86
- {statslibx-0.2.4 → statslibx-0.2.6}/MANIFEST.in +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/setup.cfg +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/Cocoa_Bubbles_Investment_Nigeria_Ghana_1980_2023.xlsx +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/course_completion.csv +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/iris.csv +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/penguins.csv +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/sp500_companies.csv +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/datasets/titanic.csv +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/descriptive.py +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/inferential.py +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx/utils.py +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx.egg-info/dependency_links.txt +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx.egg-info/entry_points.txt +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/statslibx.egg-info/top_level.txt +0 -0
- {statslibx-0.2.4 → statslibx-0.2.6}/tests/test1.py +0 -0
statslibx-0.2.6/PKG-INFO
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: statslibx
|
|
3
|
+
Version: 0.2.6
|
|
4
|
+
Summary: StatsLibx - Librería de estadística descriptiva, inferencial y computacional
|
|
5
|
+
Author-email: Emmanuel Ascendra Perez <ascendraemmanuel@gmail.com>
|
|
6
|
+
License: MIT
|
|
7
|
+
Project-URL: Documentation, https://ghostanalyst30.github.io/StatsLibX/Documentation_Page/index.html
|
|
8
|
+
Project-URL: Repository, https://ghostanalyst30.github.io/StatsLibX
|
|
9
|
+
Classifier: Development Status :: 3 - Alpha
|
|
10
|
+
Classifier: Intended Audience :: Science/Research
|
|
11
|
+
Classifier: Topic :: Scientific/Engineering :: Mathematics
|
|
12
|
+
Classifier: License :: OSI Approved :: MIT License
|
|
13
|
+
Classifier: Programming Language :: Python :: 3
|
|
14
|
+
Classifier: Programming Language :: Python :: 3.9
|
|
15
|
+
Classifier: Programming Language :: Python :: 3.10
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
17
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
18
|
+
Requires-Python: >=3.8
|
|
19
|
+
Description-Content-Type: text/markdown
|
|
20
|
+
Requires-Dist: pandas>=1.5
|
|
21
|
+
Requires-Dist: matplotlib>=3.5
|
|
22
|
+
Requires-Dist: numpy>=1.23
|
|
23
|
+
Requires-Dist: scipy>=1.9
|
|
24
|
+
Requires-Dist: scikit-learn>=1.0
|
|
25
|
+
Requires-Dist: statsmodels>=0.13
|
|
26
|
+
Requires-Dist: seaborn>=0.11
|
|
27
|
+
Requires-Dist: plotly>=5.0
|
|
28
|
+
Requires-Dist: viewx>=2.1
|
|
29
|
+
Provides-Extra: viz
|
|
30
|
+
Requires-Dist: seaborn>=0.11; extra == "viz"
|
|
31
|
+
Requires-Dist: plotly>=5.0; extra == "viz"
|
|
32
|
+
Provides-Extra: advanced
|
|
33
|
+
Requires-Dist: scikit-learn>=1.0; extra == "advanced"
|
|
34
|
+
Requires-Dist: statsmodels>=0.13; extra == "advanced"
|
|
35
|
+
|
|
36
|
+
# StatsLibX v2.6
|
|
37
|
+
|
|
38
|
+

|
|
39
|
+
|
|
40
|
+
StatsLibX es un paquete de Python diseñado para proporcionar una solución sencilla, eficiente y flexible para manejar volumenes de datos.
|
|
41
|
+
|
|
42
|
+
Este proyecto surge con la idea de ofrecer una alternativa moderna, intuitiva y ligera que permita a desarrolladores y entusiastas integrar la **estadistica descriptiva, inferencial y computacional** sin complicaciones, con multiples funcionalidades y utilidades pensadas para el futuro.
|
|
43
|
+
|
|
44
|
+
|
|
45
|
+
| **Documentacion:** | **GitHub del Proyecto:** |
|
|
46
|
+
|-------------------|--------------------------|
|
|
47
|
+
[Documentacion StatsLibX](https://ghostanalyst30.github.io/StatsLibX/Documentation_Page/index.html) | [Github/StatsLibX](https://github.com/GhostAnalyst30/StatsLibX)
|
|
48
|
+
|**Version:** 0.2.6 | **Autor:** Emmanuel Ascendra |
|
|
49
|
+
|
|
50
|
+
|
|
51
|
+
## Características principales
|
|
52
|
+
|
|
53
|
+
- Rápido y eficiente: optimizado para ofrecer un rendimiento suave incluso en tareas exigentes.
|
|
54
|
+
|
|
55
|
+
- Fácil de usar: una API limpia para que empieces en segundos.
|
|
56
|
+
|
|
57
|
+
- Altamente extensible: personalízalo según tus necesidades.
|
|
58
|
+
|
|
59
|
+
- Documentación clara: ejemplos simples y prácticos.
|
|
60
|
+
|
|
61
|
+
- Diseñado con visión a futuro: construido para escalar y adaptarse.
|
|
62
|
+
|
|
63
|
+
## Ejemplo rápido
|
|
64
|
+
```python
|
|
65
|
+
from statslibx import DescriptiveStats, InferentialStats, ComputationalStats, UtilsStats
|
|
66
|
+
from statslibx.datasets import load_iris()
|
|
67
|
+
|
|
68
|
+
data = load_iris()
|
|
69
|
+
|
|
70
|
+
stats = DescriptiveStats(data)
|
|
71
|
+
# InferentialStats(data), ComputationalStats(data), UtilsStats()
|
|
72
|
+
|
|
73
|
+
stats.summary()
|
|
74
|
+
```
|
|
75
|
+
Para ver mas funciones: [StatslibX](https://github.com/GhostAnalyst30/StatsLibX/blob/main/how_use_statslibx.ipynb)
|
|
76
|
+
|
|
77
|
+
## Instalación
|
|
78
|
+
```bash
|
|
79
|
+
pip install statslibx
|
|
80
|
+
```
|
|
81
|
+
|
|
82
|
+
## Implementacion con ViewX
|
|
83
|
+
|
|
84
|
+
```python
|
|
85
|
+
from statslibx.viewx import HTML, Slides, Report, DataMatrix
|
|
86
|
+
```
|
|
87
|
+
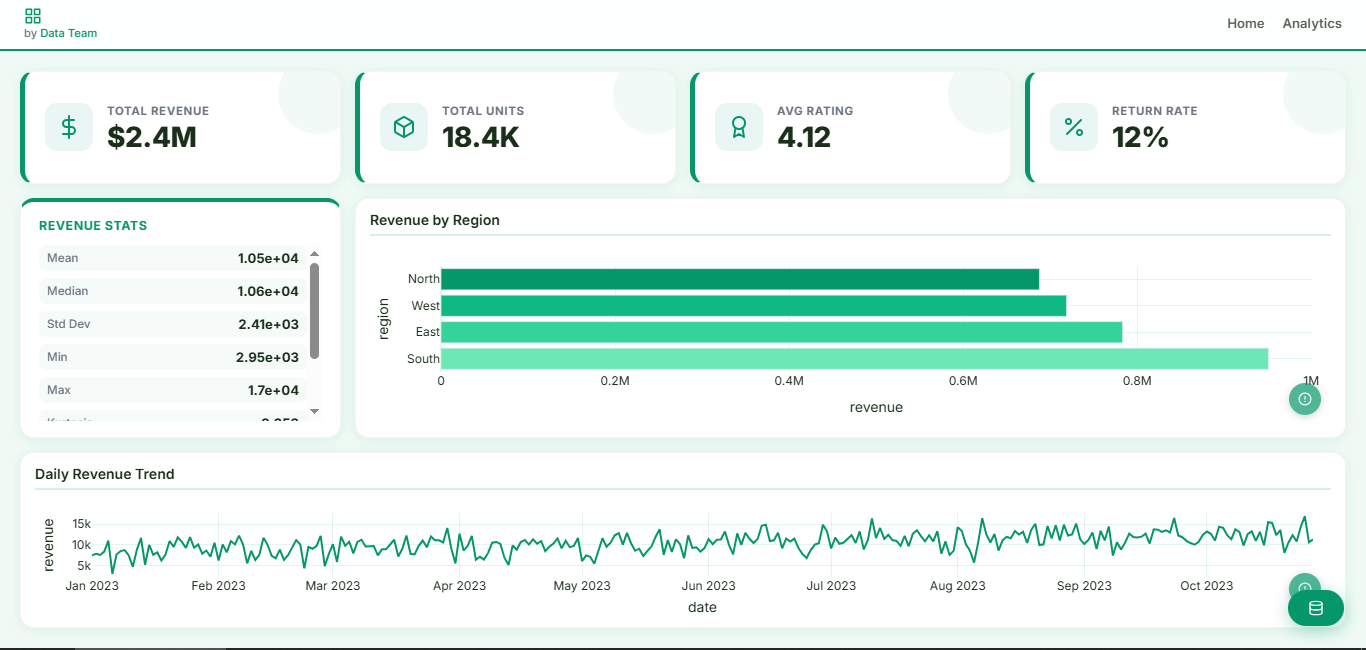
|
|
88
|
+
|
|
89
|
+
Para saber mas: [ViewX](https://ghostanalyst30.github.io/ViewX/Documentation_Page/index.html)
|
|
90
|
+
|
|
91
|
+
## ¡Usalo en la terminal!
|
|
92
|
+
```bash
|
|
93
|
+
# Data
|
|
94
|
+
statslibx data iris.csv
|
|
95
|
+
|
|
96
|
+
statslibx data mi_archivo.csv --summary --types --missing
|
|
97
|
+
|
|
98
|
+
# Info
|
|
99
|
+
statslibx info iris.csv
|
|
100
|
+
|
|
101
|
+
statslibx info iris.csv --detailed
|
|
102
|
+
|
|
103
|
+
# Describe
|
|
104
|
+
statslibx describe iris.csv --numeric
|
|
105
|
+
|
|
106
|
+
statslibx describe iris.csv --categorical
|
|
107
|
+
|
|
108
|
+
statslibx describe iris.csv
|
|
109
|
+
|
|
110
|
+
# Quality
|
|
111
|
+
statslibx quality iris.csv
|
|
112
|
+
|
|
113
|
+
statslibx quality iris.csv --verbose
|
|
114
|
+
|
|
115
|
+
# Preview
|
|
116
|
+
statslibx preview iris.csv -n 10
|
|
117
|
+
|
|
118
|
+
statslibx preview iris.csv -n 5 --sample
|
|
119
|
+
```
|
|
120
|
+
|
|
121
|
+
## Contribuciones
|
|
122
|
+
|
|
123
|
+
¡Todas las mejoras e ideas son bienvenidas!
|
|
124
|
+
|
|
125
|
+
E-mail: ascendraemmanuel@gmail.com
|
|
@@ -0,0 +1,90 @@
|
|
|
1
|
+
# StatsLibX v2.6
|
|
2
|
+
|
|
3
|
+

|
|
4
|
+
|
|
5
|
+
StatsLibX es un paquete de Python diseñado para proporcionar una solución sencilla, eficiente y flexible para manejar volumenes de datos.
|
|
6
|
+
|
|
7
|
+
Este proyecto surge con la idea de ofrecer una alternativa moderna, intuitiva y ligera que permita a desarrolladores y entusiastas integrar la **estadistica descriptiva, inferencial y computacional** sin complicaciones, con multiples funcionalidades y utilidades pensadas para el futuro.
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
| **Documentacion:** | **GitHub del Proyecto:** |
|
|
11
|
+
|-------------------|--------------------------|
|
|
12
|
+
[Documentacion StatsLibX](https://ghostanalyst30.github.io/StatsLibX/Documentation_Page/index.html) | [Github/StatsLibX](https://github.com/GhostAnalyst30/StatsLibX)
|
|
13
|
+
|**Version:** 0.2.6 | **Autor:** Emmanuel Ascendra |
|
|
14
|
+
|
|
15
|
+
|
|
16
|
+
## Características principales
|
|
17
|
+
|
|
18
|
+
- Rápido y eficiente: optimizado para ofrecer un rendimiento suave incluso en tareas exigentes.
|
|
19
|
+
|
|
20
|
+
- Fácil de usar: una API limpia para que empieces en segundos.
|
|
21
|
+
|
|
22
|
+
- Altamente extensible: personalízalo según tus necesidades.
|
|
23
|
+
|
|
24
|
+
- Documentación clara: ejemplos simples y prácticos.
|
|
25
|
+
|
|
26
|
+
- Diseñado con visión a futuro: construido para escalar y adaptarse.
|
|
27
|
+
|
|
28
|
+
## Ejemplo rápido
|
|
29
|
+
```python
|
|
30
|
+
from statslibx import DescriptiveStats, InferentialStats, ComputationalStats, UtilsStats
|
|
31
|
+
from statslibx.datasets import load_iris()
|
|
32
|
+
|
|
33
|
+
data = load_iris()
|
|
34
|
+
|
|
35
|
+
stats = DescriptiveStats(data)
|
|
36
|
+
# InferentialStats(data), ComputationalStats(data), UtilsStats()
|
|
37
|
+
|
|
38
|
+
stats.summary()
|
|
39
|
+
```
|
|
40
|
+
Para ver mas funciones: [StatslibX](https://github.com/GhostAnalyst30/StatsLibX/blob/main/how_use_statslibx.ipynb)
|
|
41
|
+
|
|
42
|
+
## Instalación
|
|
43
|
+
```bash
|
|
44
|
+
pip install statslibx
|
|
45
|
+
```
|
|
46
|
+
|
|
47
|
+
## Implementacion con ViewX
|
|
48
|
+
|
|
49
|
+
```python
|
|
50
|
+
from statslibx.viewx import HTML, Slides, Report, DataMatrix
|
|
51
|
+
```
|
|
52
|
+

|
|
53
|
+
|
|
54
|
+
Para saber mas: [ViewX](https://ghostanalyst30.github.io/ViewX/Documentation_Page/index.html)
|
|
55
|
+
|
|
56
|
+
## ¡Usalo en la terminal!
|
|
57
|
+
```bash
|
|
58
|
+
# Data
|
|
59
|
+
statslibx data iris.csv
|
|
60
|
+
|
|
61
|
+
statslibx data mi_archivo.csv --summary --types --missing
|
|
62
|
+
|
|
63
|
+
# Info
|
|
64
|
+
statslibx info iris.csv
|
|
65
|
+
|
|
66
|
+
statslibx info iris.csv --detailed
|
|
67
|
+
|
|
68
|
+
# Describe
|
|
69
|
+
statslibx describe iris.csv --numeric
|
|
70
|
+
|
|
71
|
+
statslibx describe iris.csv --categorical
|
|
72
|
+
|
|
73
|
+
statslibx describe iris.csv
|
|
74
|
+
|
|
75
|
+
# Quality
|
|
76
|
+
statslibx quality iris.csv
|
|
77
|
+
|
|
78
|
+
statslibx quality iris.csv --verbose
|
|
79
|
+
|
|
80
|
+
# Preview
|
|
81
|
+
statslibx preview iris.csv -n 10
|
|
82
|
+
|
|
83
|
+
statslibx preview iris.csv -n 5 --sample
|
|
84
|
+
```
|
|
85
|
+
|
|
86
|
+
## Contribuciones
|
|
87
|
+
|
|
88
|
+
¡Todas las mejoras e ideas son bienvenidas!
|
|
89
|
+
|
|
90
|
+
E-mail: ascendraemmanuel@gmail.com
|
|
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
|
|
4
4
|
|
|
5
5
|
[project]
|
|
6
6
|
name = "statslibx"
|
|
7
|
-
version = "0.2.
|
|
7
|
+
version = "0.2.6"
|
|
8
8
|
description = "StatsLibx - Librería de estadística descriptiva, inferencial y computacional"
|
|
9
9
|
readme = "README.md"
|
|
10
10
|
requires-python = ">=3.8"
|
|
@@ -31,11 +31,11 @@ dependencies = [
|
|
|
31
31
|
"matplotlib>=3.5",
|
|
32
32
|
"numpy>=1.23",
|
|
33
33
|
"scipy>=1.9",
|
|
34
|
-
"polars>=0.16",
|
|
35
34
|
"scikit-learn>=1.0",
|
|
36
35
|
"statsmodels>=0.13",
|
|
37
36
|
"seaborn>=0.11",
|
|
38
|
-
"plotly>=5.0"
|
|
37
|
+
"plotly>=5.0",
|
|
38
|
+
"viewx>=2.1"
|
|
39
39
|
]
|
|
40
40
|
|
|
41
41
|
[project.optional-dependencies]
|
|
@@ -46,7 +46,11 @@ advanced = ["scikit-learn>=1.0", "statsmodels>=0.13"]
|
|
|
46
46
|
statslibx = "statslibx.cli:main"
|
|
47
47
|
|
|
48
48
|
[tool.setuptools.package-data]
|
|
49
|
-
|
|
49
|
+
statslibx = ["datasets/*.csv", "datasets/*.xlsx"]
|
|
50
50
|
|
|
51
51
|
[tool.setuptools.packages.find]
|
|
52
52
|
where = ["."]
|
|
53
|
+
|
|
54
|
+
[project.urls]
|
|
55
|
+
Documentation = "https://ghostanalyst30.github.io/StatsLibX/Documentation_Page/index.html"
|
|
56
|
+
Repository = "https://ghostanalyst30.github.io/StatsLibX"
|
|
@@ -1,19 +1,20 @@
|
|
|
1
1
|
"""
|
|
2
2
|
StatsLibx - Librería de Estadística para Python
|
|
3
3
|
Autor: Emmanuel Ascendra
|
|
4
|
-
Versión: 0.2.
|
|
4
|
+
Versión: 0.2.5
|
|
5
5
|
"""
|
|
6
6
|
|
|
7
|
-
__version__ = "0.2.
|
|
7
|
+
__version__ = "0.2.5"
|
|
8
8
|
__author__ = "Emmanuel Ascendra"
|
|
9
9
|
|
|
10
10
|
# Importar las clases principales
|
|
11
11
|
from .descriptive import DescriptiveStats, DescriptiveSummary
|
|
12
12
|
from .inferential import InferentialStats, TestResult
|
|
13
|
-
from .
|
|
13
|
+
from .computational import ComputationalStats
|
|
14
14
|
from .utils import UtilsStats
|
|
15
15
|
from .preprocessing import Preprocessing
|
|
16
16
|
from .datasets import load_dataset, generate_dataset
|
|
17
|
+
from .viewx import HTML, Slides, Report, DataMatrix
|
|
17
18
|
|
|
18
19
|
# Definir qué se expone cuando se hace: from statslib import *
|
|
19
20
|
__all__ = [
|
|
@@ -25,7 +26,13 @@ __all__ = [
|
|
|
25
26
|
'UtilsStats',
|
|
26
27
|
'Preprocessing',
|
|
27
28
|
'load_dataset',
|
|
28
|
-
'generate_dataset'
|
|
29
|
+
'generate_dataset',
|
|
30
|
+
|
|
31
|
+
# Viewx
|
|
32
|
+
'HTML',
|
|
33
|
+
'Slides',
|
|
34
|
+
'Report',
|
|
35
|
+
'DataMatrix'
|
|
29
36
|
]
|
|
30
37
|
|
|
31
38
|
# Mensaje de bienvenida (opcional)
|
|
@@ -37,7 +44,7 @@ def welcome():
|
|
|
37
44
|
print(f"\nClases disponibles:")
|
|
38
45
|
print(f" - DescriptiveStats: Estadística descriptiva")
|
|
39
46
|
print(f" - InferentialStats: Estadística inferencial")
|
|
40
|
-
print(f" - ComputacionalStats:
|
|
47
|
+
print(f" - ComputacionalStats: Estadística computacional")
|
|
41
48
|
print(f" - UtilsStats: Utilidades Extras")
|
|
42
49
|
print(f"\nMódulos disponibles:")
|
|
43
50
|
print(f" - Datasets: Carga de Datasets")
|
|
@@ -0,0 +1,241 @@
|
|
|
1
|
+
import argparse
|
|
2
|
+
import statslibx as slx
|
|
3
|
+
from statslibx.datasets import load_dataset
|
|
4
|
+
from statslibx.preprocessing import Preprocessing
|
|
5
|
+
import pandas as pd
|
|
6
|
+
|
|
7
|
+
|
|
8
|
+
def main():
|
|
9
|
+
parser = argparse.ArgumentParser(
|
|
10
|
+
prog="statslibx",
|
|
11
|
+
description="Statslibx - Data analysis from terminal"
|
|
12
|
+
)
|
|
13
|
+
|
|
14
|
+
subparsers = parser.add_subparsers(dest="command", help="Comandos disponibles")
|
|
15
|
+
|
|
16
|
+
# describe - Estadísticas descriptivas completas
|
|
17
|
+
describe = subparsers.add_parser("describe", help="Estadísticas descriptivas")
|
|
18
|
+
describe.add_argument("file", help="Ruta del archivo o nombre del dataset (ej: iris, titanic)")
|
|
19
|
+
describe.add_argument("-n", "--numeric", action="store_true", help="Solo columnas numéricas")
|
|
20
|
+
describe.add_argument("-c", "--categorical", action="store_true", help="Solo columnas categóricas")
|
|
21
|
+
|
|
22
|
+
# quality - Calidad de datos
|
|
23
|
+
quality = subparsers.add_parser("quality", help="Reporte de calidad de datos")
|
|
24
|
+
quality.add_argument("file", help="Ruta del archivo o nombre del dataset")
|
|
25
|
+
quality.add_argument("-v", "--verbose", action="store_true", help="Mostrar detalles")
|
|
26
|
+
|
|
27
|
+
# preview - Vista previa
|
|
28
|
+
preview = subparsers.add_parser("preview", help="Vista previa de los datos")
|
|
29
|
+
preview.add_argument("file", help="Ruta del archivo o nombre del dataset")
|
|
30
|
+
preview.add_argument("-n", "--rows", type=int, default=5, help="Número de filas (default: 5)")
|
|
31
|
+
preview.add_argument("-s", "--sample", action="store_true", help="Muestra aleatoria")
|
|
32
|
+
|
|
33
|
+
# info - Información completa del dataset (NUEVO)
|
|
34
|
+
info = subparsers.add_parser("info", help="Información completa del dataset")
|
|
35
|
+
info.add_argument("file", help="Ruta del archivo o nombre del dataset")
|
|
36
|
+
info.add_argument("-d", "--detailed", action="store_true", help="Información detallada (tipos, nulos, memoria)")
|
|
37
|
+
|
|
38
|
+
# data - Comando específico que pediste
|
|
39
|
+
data = subparsers.add_parser("data", help="Resumen del dataset (filas, columnas, tipos)")
|
|
40
|
+
data.add_argument("file", help="Ruta del archivo o nombre del dataset (ej: iris, titanic, o archivo.csv)")
|
|
41
|
+
data.add_argument("-s", "--summary", action="store_true", help="Mostrar resumen estadístico básico")
|
|
42
|
+
data.add_argument("-t", "--types", action="store_true", help="Mostrar tipos de datos")
|
|
43
|
+
data.add_argument("-m", "--missing", action="store_true", help="Mostrar valores faltantes")
|
|
44
|
+
|
|
45
|
+
args = parser.parse_args()
|
|
46
|
+
|
|
47
|
+
if not args.command:
|
|
48
|
+
print(slx.welcome())
|
|
49
|
+
return
|
|
50
|
+
|
|
51
|
+
# Cargar datos (soporta datasets internos y archivos externos)
|
|
52
|
+
df = load_dataset(args.file)
|
|
53
|
+
|
|
54
|
+
# Verificar si los datos se cargaron correctamente
|
|
55
|
+
if df is None or df.empty:
|
|
56
|
+
print(f"❌ Error: No se pudieron cargar los datos desde '{args.file}'")
|
|
57
|
+
return
|
|
58
|
+
|
|
59
|
+
pp = Preprocessing(df)
|
|
60
|
+
|
|
61
|
+
# Comando: describe
|
|
62
|
+
if args.command == "describe":
|
|
63
|
+
print("\n" + "="*80)
|
|
64
|
+
print(f"📊 ESTADÍSTICAS DESCRIPTIVAS - {args.file.upper()}")
|
|
65
|
+
print("="*80)
|
|
66
|
+
|
|
67
|
+
if args.numeric:
|
|
68
|
+
print(pp.describe_numeric())
|
|
69
|
+
elif args.categorical:
|
|
70
|
+
print(pp.describe_categorical() if hasattr(pp, 'describe_categorical') else df.describe(include=['object', 'category']))
|
|
71
|
+
else:
|
|
72
|
+
# Mostrar ambas
|
|
73
|
+
print("\n📈 Variables Numéricas:")
|
|
74
|
+
print(pp.describe_numeric())
|
|
75
|
+
print("\n📝 Variables Categóricas:")
|
|
76
|
+
if hasattr(pp, 'describe_categorical'):
|
|
77
|
+
print(pp.describe_categorical())
|
|
78
|
+
else:
|
|
79
|
+
print(df.describe(include=['object', 'category']))
|
|
80
|
+
|
|
81
|
+
# Comando: quality
|
|
82
|
+
elif args.command == "quality":
|
|
83
|
+
print("\n" + "="*80)
|
|
84
|
+
print(f"🔍 CALIDAD DE DATOS - {args.file.upper()}")
|
|
85
|
+
print("="*80)
|
|
86
|
+
quality_report = pp.data_quality()
|
|
87
|
+
print(quality_report)
|
|
88
|
+
|
|
89
|
+
if args.verbose and hasattr(pp, 'missing_details'):
|
|
90
|
+
print("\n📋 Detalle de valores faltantes:")
|
|
91
|
+
print(pp.missing_details())
|
|
92
|
+
|
|
93
|
+
# Comando: preview
|
|
94
|
+
elif args.command == "preview":
|
|
95
|
+
print("\n" + "="*80)
|
|
96
|
+
print(f"👁️ VISTA PREVIA - {args.file.upper()}")
|
|
97
|
+
print("="*80)
|
|
98
|
+
|
|
99
|
+
if args.sample:
|
|
100
|
+
print(f"\n🎲 Muestra aleatoria de {args.rows} filas:")
|
|
101
|
+
print(df.sample(min(args.rows, len(df))))
|
|
102
|
+
else:
|
|
103
|
+
print(f"\n📄 Primeras {args.rows} filas:")
|
|
104
|
+
print(pp.preview_data(args.rows))
|
|
105
|
+
|
|
106
|
+
# Comando: info (nuevo - información completa)
|
|
107
|
+
elif args.command == "info":
|
|
108
|
+
print("\n" + "="*80)
|
|
109
|
+
print(f"ℹ️ INFORMACIÓN DEL DATASET - {args.file.upper()}")
|
|
110
|
+
print("="*80)
|
|
111
|
+
|
|
112
|
+
# Información básica
|
|
113
|
+
print(f"\n📏 Dimensiones: {df.shape[0]} filas × {df.shape[1]} columnas")
|
|
114
|
+
print(f"💾 Memoria: {df.memory_usage(deep=True).sum() / 1024:.2f} KB")
|
|
115
|
+
|
|
116
|
+
print(f"\n📋 Columnas ({len(df.columns)}):")
|
|
117
|
+
for i, col in enumerate(df.columns, 1):
|
|
118
|
+
print(f" {i:3d}. {col}")
|
|
119
|
+
|
|
120
|
+
if args.detailed:
|
|
121
|
+
print("\n🔧 Tipos de datos:")
|
|
122
|
+
print(df.dtypes)
|
|
123
|
+
|
|
124
|
+
print("\n⚠️ Valores nulos:")
|
|
125
|
+
nulls = df.isnull().sum()
|
|
126
|
+
null_pct = (nulls / len(df)) * 100
|
|
127
|
+
null_df = pd.DataFrame({
|
|
128
|
+
'Nulos': nulls,
|
|
129
|
+
'Porcentaje': null_pct
|
|
130
|
+
})
|
|
131
|
+
print(null_df[null_df['Nulos'] > 0] if (nulls > 0).any() else "✅ No hay valores nulos")
|
|
132
|
+
|
|
133
|
+
print("\n🔄 Valores únicos por columna:")
|
|
134
|
+
for col in df.columns:
|
|
135
|
+
unique_count = df[col].nunique()
|
|
136
|
+
print(f" {col}: {unique_count:,} únicos")
|
|
137
|
+
|
|
138
|
+
# Comando: data (el que pediste específicamente)
|
|
139
|
+
elif args.command == "data":
|
|
140
|
+
print("\n" + "="*80)
|
|
141
|
+
print(f"📊 RESUMEN DEL DATASET - {args.file.upper()}")
|
|
142
|
+
print("="*80)
|
|
143
|
+
|
|
144
|
+
# Información básica siempre visible
|
|
145
|
+
print(f"\n📏 Dimensiones:")
|
|
146
|
+
print(f" • Filas: {df.shape[0]:,}")
|
|
147
|
+
print(f" • Columnas: {df.shape[1]:,}")
|
|
148
|
+
|
|
149
|
+
print(f"\n📋 Columnas:")
|
|
150
|
+
for i, col in enumerate(df.columns, 1):
|
|
151
|
+
dtype = df[col].dtype
|
|
152
|
+
nulls = df[col].isnull().sum()
|
|
153
|
+
unique = df[col].nunique()
|
|
154
|
+
print(f" {i:2d}. {col:20s} | Tipo: {str(dtype):12s} | Nulos: {nulls:4d} | Únicos: {unique:,}")
|
|
155
|
+
|
|
156
|
+
if args.types:
|
|
157
|
+
print(f"\n🔧 Tipos de datos detallados:")
|
|
158
|
+
print(df.dtypes.to_string())
|
|
159
|
+
|
|
160
|
+
if args.missing:
|
|
161
|
+
missing = df.isnull().sum()
|
|
162
|
+
missing_pct = (missing / len(df)) * 100
|
|
163
|
+
missing_data = missing[missing > 0]
|
|
164
|
+
if len(missing_data) > 0:
|
|
165
|
+
print(f"\n⚠️ Valores faltantes:")
|
|
166
|
+
for col, nulos in missing_data.items():
|
|
167
|
+
print(f" • {col}: {nulos:,} ({missing_pct[col]:.1f}%)")
|
|
168
|
+
else:
|
|
169
|
+
print(f"\n✅ No hay valores faltantes")
|
|
170
|
+
|
|
171
|
+
if args.summary:
|
|
172
|
+
print(f"\n📈 Resumen estadístico rápido:")
|
|
173
|
+
numeric_cols = df.select_dtypes(include=['number']).columns
|
|
174
|
+
if len(numeric_cols) > 0:
|
|
175
|
+
print(f"\n Variables numéricas ({len(numeric_cols)}):")
|
|
176
|
+
for col in numeric_cols[:5]: # Mostrar primeras 5 numéricas
|
|
177
|
+
print(f" • {col}:")
|
|
178
|
+
print(f" Mín: {df[col].min():.2f} | Máx: {df[col].max():.2f}")
|
|
179
|
+
print(f" Media: {df[col].mean():.2f} | Mediana: {df[col].median():.2f}")
|
|
180
|
+
if len(numeric_cols) > 5:
|
|
181
|
+
print(f" ... y {len(numeric_cols)-5} columnas numéricas más")
|
|
182
|
+
else:
|
|
183
|
+
print(" No hay variables numéricas")
|
|
184
|
+
|
|
185
|
+
categorical_cols = df.select_dtypes(include=['object', 'category']).columns
|
|
186
|
+
if len(categorical_cols) > 0:
|
|
187
|
+
print(f"\n Variables categóricas ({len(categorical_cols)}):")
|
|
188
|
+
for col in categorical_cols[:3]:
|
|
189
|
+
top_value = df[col].mode().iloc[0] if not df[col].mode().empty else "N/A"
|
|
190
|
+
print(f" • {col}: {df[col].nunique():,} categorías (Moda: {top_value})")
|
|
191
|
+
if len(categorical_cols) > 3:
|
|
192
|
+
print(f" ... y {len(categorical_cols)-3} columnas categóricas más")
|
|
193
|
+
|
|
194
|
+
else:
|
|
195
|
+
print(f"❌ Comando desconocido: {args.command}")
|
|
196
|
+
|
|
197
|
+
"""
|
|
198
|
+
# Básico - muestra dimensiones y columnas
|
|
199
|
+
statslibx data iris.csv
|
|
200
|
+
|
|
201
|
+
# Con resumen estadístico
|
|
202
|
+
statslibx data iris.csv --summary
|
|
203
|
+
|
|
204
|
+
# Con tipos de datos
|
|
205
|
+
statslibx data iris.csv --types
|
|
206
|
+
|
|
207
|
+
# Con valores faltantes
|
|
208
|
+
statslibx data iris.csv --missing
|
|
209
|
+
|
|
210
|
+
statslibx data mi_archivo.csv --summary --types --missing
|
|
211
|
+
|
|
212
|
+
# Información completa
|
|
213
|
+
statslibx info iris.csv
|
|
214
|
+
|
|
215
|
+
# Con detalles avanzados
|
|
216
|
+
statslibx info iris.csv --detailed
|
|
217
|
+
|
|
218
|
+
# Solo numéricas
|
|
219
|
+
statslibx describe iris.csv --numeric
|
|
220
|
+
|
|
221
|
+
# Solo categóricas
|
|
222
|
+
statslibx describe iris.csv --categorical
|
|
223
|
+
|
|
224
|
+
statslibx describe iris.csv
|
|
225
|
+
|
|
226
|
+
# Reporte básico
|
|
227
|
+
statslibx quality iris.csv
|
|
228
|
+
|
|
229
|
+
# Con verbose
|
|
230
|
+
statslibx quality iris.csv --verbose
|
|
231
|
+
|
|
232
|
+
# Primeras filas
|
|
233
|
+
statslibx preview iris.csv -n 10
|
|
234
|
+
|
|
235
|
+
# Muestra aleatoria
|
|
236
|
+
statslibx preview iris.csv -n 5 --sample
|
|
237
|
+
"""
|
|
238
|
+
|
|
239
|
+
|
|
240
|
+
if __name__ == "__main__":
|
|
241
|
+
main()
|