schema-search 0.1.5__tar.gz → 0.1.7__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of schema-search might be problematic. Click here for more details.
- {schema_search-0.1.5/schema_search.egg-info → schema_search-0.1.7}/PKG-INFO +67 -53
- {schema_search-0.1.5 → schema_search-0.1.7}/README.md +62 -49
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/mcp_server.py +4 -5
- {schema_search-0.1.5 → schema_search-0.1.7/schema_search.egg-info}/PKG-INFO +67 -53
- {schema_search-0.1.5 → schema_search-0.1.7}/setup.py +4 -4
- {schema_search-0.1.5 → schema_search-0.1.7}/LICENSE +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/MANIFEST.in +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/config.yml +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/chunkers/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/chunkers/base.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/chunkers/factory.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/chunkers/llm.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/chunkers/markdown.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/embedding_cache/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/embedding_cache/base.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/embedding_cache/bm25.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/embedding_cache/factory.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/embedding_cache/inmemory.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/graph_builder.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/metrics.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/rankers/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/rankers/base.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/rankers/cross_encoder.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/rankers/factory.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/schema_extractor.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/schema_search.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/base.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/bm25.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/factory.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/fuzzy.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/hybrid.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/search/semantic.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search/types.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search.egg-info/SOURCES.txt +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search.egg-info/dependency_links.txt +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search.egg-info/entry_points.txt +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search.egg-info/requires.txt +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/schema_search.egg-info/top_level.txt +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/setup.cfg +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/tests/__init__.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/tests/test_integration.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/tests/test_llm_sql_generation.py +0 -0
- {schema_search-0.1.5 → schema_search-0.1.7}/tests/test_spider_eval.py +0 -0
|
@@ -1,9 +1,9 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: schema-search
|
|
3
|
-
Version: 0.1.
|
|
4
|
-
Summary: Natural language
|
|
5
|
-
Home-page: https://
|
|
6
|
-
Author:
|
|
3
|
+
Version: 0.1.7
|
|
4
|
+
Summary: Natural language database schema search with graph-aware semantic retrieval
|
|
5
|
+
Home-page: https://adibhasan.com/blog/schema-search/
|
|
6
|
+
Author: Adib Hasan
|
|
7
7
|
Classifier: Development Status :: 3 - Alpha
|
|
8
8
|
Classifier: Intended Audience :: Developers
|
|
9
9
|
Classifier: License :: OSI Approved :: MIT License
|
|
@@ -38,6 +38,7 @@ Requires-Dist: snowflake-sqlalchemy>=1.4.0; extra == "snowflake"
|
|
|
38
38
|
Requires-Dist: snowflake-connector-python>=3.0.0; extra == "snowflake"
|
|
39
39
|
Provides-Extra: bigquery
|
|
40
40
|
Requires-Dist: sqlalchemy-bigquery>=1.6.0; extra == "bigquery"
|
|
41
|
+
Dynamic: author
|
|
41
42
|
Dynamic: classifier
|
|
42
43
|
Dynamic: description
|
|
43
44
|
Dynamic: description-content-type
|
|
@@ -82,6 +83,48 @@ uv pip install "schema-search[snowflake,mcp]" # Snowflake
|
|
|
82
83
|
uv pip install "schema-search[bigquery,mcp]" # BigQuery
|
|
83
84
|
```
|
|
84
85
|
|
|
86
|
+
## Configuration
|
|
87
|
+
|
|
88
|
+
Edit [`config.yml`](https://github.com/Neehan/schema-search/blob/main/config.yml):
|
|
89
|
+
|
|
90
|
+
```yaml
|
|
91
|
+
logging:
|
|
92
|
+
level: "WARNING"
|
|
93
|
+
|
|
94
|
+
embedding:
|
|
95
|
+
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
96
|
+
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
97
|
+
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
98
|
+
batch_size: 32
|
|
99
|
+
show_progress: false
|
|
100
|
+
cache_dir: "/tmp/.schema_search_cache"
|
|
101
|
+
|
|
102
|
+
chunking:
|
|
103
|
+
strategy: "raw" # Options: "raw", "llm"
|
|
104
|
+
max_tokens: 256
|
|
105
|
+
overlap_tokens: 50
|
|
106
|
+
model: "gpt-4o-mini"
|
|
107
|
+
|
|
108
|
+
search:
|
|
109
|
+
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
110
|
+
strategy: "hybrid"
|
|
111
|
+
initial_top_k: 20
|
|
112
|
+
rerank_top_k: 5
|
|
113
|
+
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
114
|
+
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
115
|
+
|
|
116
|
+
reranker:
|
|
117
|
+
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
118
|
+
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
119
|
+
|
|
120
|
+
schema:
|
|
121
|
+
include_columns: true
|
|
122
|
+
include_indices: true
|
|
123
|
+
include_foreign_keys: true
|
|
124
|
+
include_constraints: true
|
|
125
|
+
```
|
|
126
|
+
|
|
127
|
+
|
|
85
128
|
## MCP Server
|
|
86
129
|
|
|
87
130
|
Integrate with Claude Desktop or any MCP client.
|
|
@@ -96,7 +139,13 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
96
139
|
"mcpServers": {
|
|
97
140
|
"schema-search": {
|
|
98
141
|
"command": "uvx",
|
|
99
|
-
"args": [
|
|
142
|
+
"args": [
|
|
143
|
+
"schema-search[postgres,mcp]",
|
|
144
|
+
"postgresql://user:pass@localhost/db",
|
|
145
|
+
"optional/path/to/config.yml",
|
|
146
|
+
"optional llm_api_key",
|
|
147
|
+
"optional llm_base_url"
|
|
148
|
+
]
|
|
100
149
|
}
|
|
101
150
|
}
|
|
102
151
|
}
|
|
@@ -107,8 +156,14 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
107
156
|
{
|
|
108
157
|
"mcpServers": {
|
|
109
158
|
"schema-search": {
|
|
110
|
-
|
|
111
|
-
"
|
|
159
|
+
// conda: /Users/<username>/opt/miniconda3/envs/<your env>/bin/schema-search",
|
|
160
|
+
"command": "path/to/schema-search",
|
|
161
|
+
"args": [
|
|
162
|
+
"postgresql://user:pass@localhost/db",
|
|
163
|
+
"optional/path/to/config.yml",
|
|
164
|
+
"optional llm_api_key",
|
|
165
|
+
"optional llm_base_url"
|
|
166
|
+
]
|
|
112
167
|
}
|
|
113
168
|
}
|
|
114
169
|
}
|
|
@@ -120,7 +175,7 @@ The LLM API key and base url are only required if you use LLM-generated schema s
|
|
|
120
175
|
### CLI Usage
|
|
121
176
|
|
|
122
177
|
```bash
|
|
123
|
-
schema-search "postgresql://user:pass@localhost/db"
|
|
178
|
+
schema-search "postgresql://user:pass@localhost/db" "optional/path/to/config.yml"
|
|
124
179
|
```
|
|
125
180
|
|
|
126
181
|
Optional args: `[config_path] [llm_api_key] [llm_base_url]`
|
|
@@ -151,47 +206,6 @@ results = search.search("user_table", hops=0, limit=5, search_type="semantic")
|
|
|
151
206
|
|
|
152
207
|
`SchemaSearch.index()` automatically detects schema changes and refreshes cached metadata, so you rarely need to force a reindex manually.
|
|
153
208
|
|
|
154
|
-
## Configuration
|
|
155
|
-
|
|
156
|
-
Edit `[config.yml](config.yml)`:
|
|
157
|
-
|
|
158
|
-
```yaml
|
|
159
|
-
logging:
|
|
160
|
-
level: "WARNING"
|
|
161
|
-
|
|
162
|
-
embedding:
|
|
163
|
-
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
164
|
-
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
165
|
-
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
166
|
-
batch_size: 32
|
|
167
|
-
show_progress: false
|
|
168
|
-
cache_dir: "/tmp/.schema_search_cache"
|
|
169
|
-
|
|
170
|
-
chunking:
|
|
171
|
-
strategy: "raw" # Options: "raw", "llm"
|
|
172
|
-
max_tokens: 256
|
|
173
|
-
overlap_tokens: 50
|
|
174
|
-
model: "gpt-4o-mini"
|
|
175
|
-
|
|
176
|
-
search:
|
|
177
|
-
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
178
|
-
strategy: "hybrid"
|
|
179
|
-
initial_top_k: 20
|
|
180
|
-
rerank_top_k: 5
|
|
181
|
-
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
182
|
-
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
183
|
-
|
|
184
|
-
reranker:
|
|
185
|
-
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
186
|
-
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
187
|
-
|
|
188
|
-
schema:
|
|
189
|
-
include_columns: true
|
|
190
|
-
include_indices: true
|
|
191
|
-
include_foreign_keys: true
|
|
192
|
-
include_constraints: true
|
|
193
|
-
```
|
|
194
|
-
|
|
195
209
|
## Search Strategies
|
|
196
210
|
|
|
197
211
|
Schema Search supports four search strategies:
|
|
@@ -199,7 +213,7 @@ Schema Search supports four search strategies:
|
|
|
199
213
|
- **semantic**: Embedding-based similarity search using sentence transformers
|
|
200
214
|
- **bm25**: Lexical search using BM25 ranking algorithm
|
|
201
215
|
- **fuzzy**: String matching on table/column names using fuzzy matching
|
|
202
|
-
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33%
|
|
216
|
+
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33% bm25)
|
|
203
217
|
|
|
204
218
|
Each strategy performs its own initial ranking, then optionally applies CrossEncoder reranking if `reranker.model` is configured. Set `reranker.model` to `null` to disable reranking.
|
|
205
219
|
|
|
@@ -209,14 +223,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
209
223
|
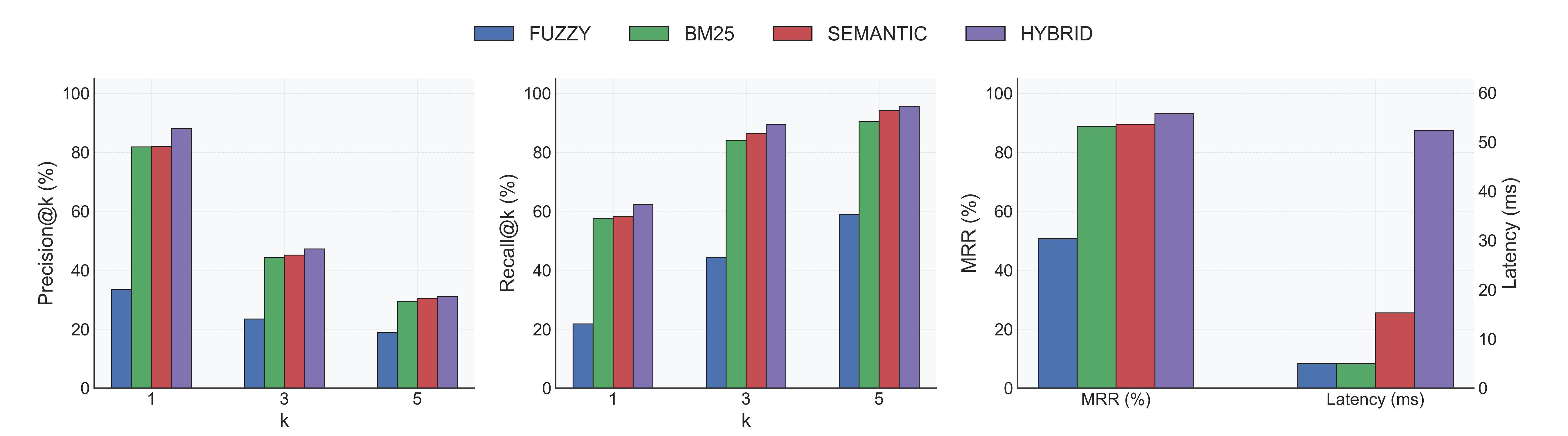
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
210
224
|
|
|
211
225
|
### Without Reranker (`reranker.model: null`)
|
|
212
|
-

|
|
226
|
+
|
|
213
227
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
214
228
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
215
229
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
216
230
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
217
231
|
|
|
218
232
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
219
|
-

|
|
233
|
+
|
|
220
234
|
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
221
235
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
222
236
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -266,7 +280,7 @@ search = SchemaSearch(
|
|
|
266
280
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
267
281
|
6. Return top tables with full schema and relationships
|
|
268
282
|
|
|
269
|
-
Cache stored in
|
|
283
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
270
284
|
|
|
271
285
|
## License
|
|
272
286
|
|
|
@@ -32,6 +32,48 @@ uv pip install "schema-search[snowflake,mcp]" # Snowflake
|
|
|
32
32
|
uv pip install "schema-search[bigquery,mcp]" # BigQuery
|
|
33
33
|
```
|
|
34
34
|
|
|
35
|
+
## Configuration
|
|
36
|
+
|
|
37
|
+
Edit [`config.yml`](https://github.com/Neehan/schema-search/blob/main/config.yml):
|
|
38
|
+
|
|
39
|
+
```yaml
|
|
40
|
+
logging:
|
|
41
|
+
level: "WARNING"
|
|
42
|
+
|
|
43
|
+
embedding:
|
|
44
|
+
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
45
|
+
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
46
|
+
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
47
|
+
batch_size: 32
|
|
48
|
+
show_progress: false
|
|
49
|
+
cache_dir: "/tmp/.schema_search_cache"
|
|
50
|
+
|
|
51
|
+
chunking:
|
|
52
|
+
strategy: "raw" # Options: "raw", "llm"
|
|
53
|
+
max_tokens: 256
|
|
54
|
+
overlap_tokens: 50
|
|
55
|
+
model: "gpt-4o-mini"
|
|
56
|
+
|
|
57
|
+
search:
|
|
58
|
+
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
59
|
+
strategy: "hybrid"
|
|
60
|
+
initial_top_k: 20
|
|
61
|
+
rerank_top_k: 5
|
|
62
|
+
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
63
|
+
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
64
|
+
|
|
65
|
+
reranker:
|
|
66
|
+
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
67
|
+
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
68
|
+
|
|
69
|
+
schema:
|
|
70
|
+
include_columns: true
|
|
71
|
+
include_indices: true
|
|
72
|
+
include_foreign_keys: true
|
|
73
|
+
include_constraints: true
|
|
74
|
+
```
|
|
75
|
+
|
|
76
|
+
|
|
35
77
|
## MCP Server
|
|
36
78
|
|
|
37
79
|
Integrate with Claude Desktop or any MCP client.
|
|
@@ -46,7 +88,13 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
46
88
|
"mcpServers": {
|
|
47
89
|
"schema-search": {
|
|
48
90
|
"command": "uvx",
|
|
49
|
-
"args": [
|
|
91
|
+
"args": [
|
|
92
|
+
"schema-search[postgres,mcp]",
|
|
93
|
+
"postgresql://user:pass@localhost/db",
|
|
94
|
+
"optional/path/to/config.yml",
|
|
95
|
+
"optional llm_api_key",
|
|
96
|
+
"optional llm_base_url"
|
|
97
|
+
]
|
|
50
98
|
}
|
|
51
99
|
}
|
|
52
100
|
}
|
|
@@ -57,8 +105,14 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
57
105
|
{
|
|
58
106
|
"mcpServers": {
|
|
59
107
|
"schema-search": {
|
|
60
|
-
|
|
61
|
-
"
|
|
108
|
+
// conda: /Users/<username>/opt/miniconda3/envs/<your env>/bin/schema-search",
|
|
109
|
+
"command": "path/to/schema-search",
|
|
110
|
+
"args": [
|
|
111
|
+
"postgresql://user:pass@localhost/db",
|
|
112
|
+
"optional/path/to/config.yml",
|
|
113
|
+
"optional llm_api_key",
|
|
114
|
+
"optional llm_base_url"
|
|
115
|
+
]
|
|
62
116
|
}
|
|
63
117
|
}
|
|
64
118
|
}
|
|
@@ -70,7 +124,7 @@ The LLM API key and base url are only required if you use LLM-generated schema s
|
|
|
70
124
|
### CLI Usage
|
|
71
125
|
|
|
72
126
|
```bash
|
|
73
|
-
schema-search "postgresql://user:pass@localhost/db"
|
|
127
|
+
schema-search "postgresql://user:pass@localhost/db" "optional/path/to/config.yml"
|
|
74
128
|
```
|
|
75
129
|
|
|
76
130
|
Optional args: `[config_path] [llm_api_key] [llm_base_url]`
|
|
@@ -101,47 +155,6 @@ results = search.search("user_table", hops=0, limit=5, search_type="semantic")
|
|
|
101
155
|
|
|
102
156
|
`SchemaSearch.index()` automatically detects schema changes and refreshes cached metadata, so you rarely need to force a reindex manually.
|
|
103
157
|
|
|
104
|
-
## Configuration
|
|
105
|
-
|
|
106
|
-
Edit `[config.yml](config.yml)`:
|
|
107
|
-
|
|
108
|
-
```yaml
|
|
109
|
-
logging:
|
|
110
|
-
level: "WARNING"
|
|
111
|
-
|
|
112
|
-
embedding:
|
|
113
|
-
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
114
|
-
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
115
|
-
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
116
|
-
batch_size: 32
|
|
117
|
-
show_progress: false
|
|
118
|
-
cache_dir: "/tmp/.schema_search_cache"
|
|
119
|
-
|
|
120
|
-
chunking:
|
|
121
|
-
strategy: "raw" # Options: "raw", "llm"
|
|
122
|
-
max_tokens: 256
|
|
123
|
-
overlap_tokens: 50
|
|
124
|
-
model: "gpt-4o-mini"
|
|
125
|
-
|
|
126
|
-
search:
|
|
127
|
-
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
128
|
-
strategy: "hybrid"
|
|
129
|
-
initial_top_k: 20
|
|
130
|
-
rerank_top_k: 5
|
|
131
|
-
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
132
|
-
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
133
|
-
|
|
134
|
-
reranker:
|
|
135
|
-
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
136
|
-
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
137
|
-
|
|
138
|
-
schema:
|
|
139
|
-
include_columns: true
|
|
140
|
-
include_indices: true
|
|
141
|
-
include_foreign_keys: true
|
|
142
|
-
include_constraints: true
|
|
143
|
-
```
|
|
144
|
-
|
|
145
158
|
## Search Strategies
|
|
146
159
|
|
|
147
160
|
Schema Search supports four search strategies:
|
|
@@ -149,7 +162,7 @@ Schema Search supports four search strategies:
|
|
|
149
162
|
- **semantic**: Embedding-based similarity search using sentence transformers
|
|
150
163
|
- **bm25**: Lexical search using BM25 ranking algorithm
|
|
151
164
|
- **fuzzy**: String matching on table/column names using fuzzy matching
|
|
152
|
-
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33%
|
|
165
|
+
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33% bm25)
|
|
153
166
|
|
|
154
167
|
Each strategy performs its own initial ranking, then optionally applies CrossEncoder reranking if `reranker.model` is configured. Set `reranker.model` to `null` to disable reranking.
|
|
155
168
|
|
|
@@ -159,14 +172,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
159
172
|
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
160
173
|
|
|
161
174
|
### Without Reranker (`reranker.model: null`)
|
|
162
|
-

|
|
175
|
+

|
|
163
176
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
164
177
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
165
178
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
166
179
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
167
180
|
|
|
168
181
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
169
|
-

|
|
182
|
+

|
|
170
183
|
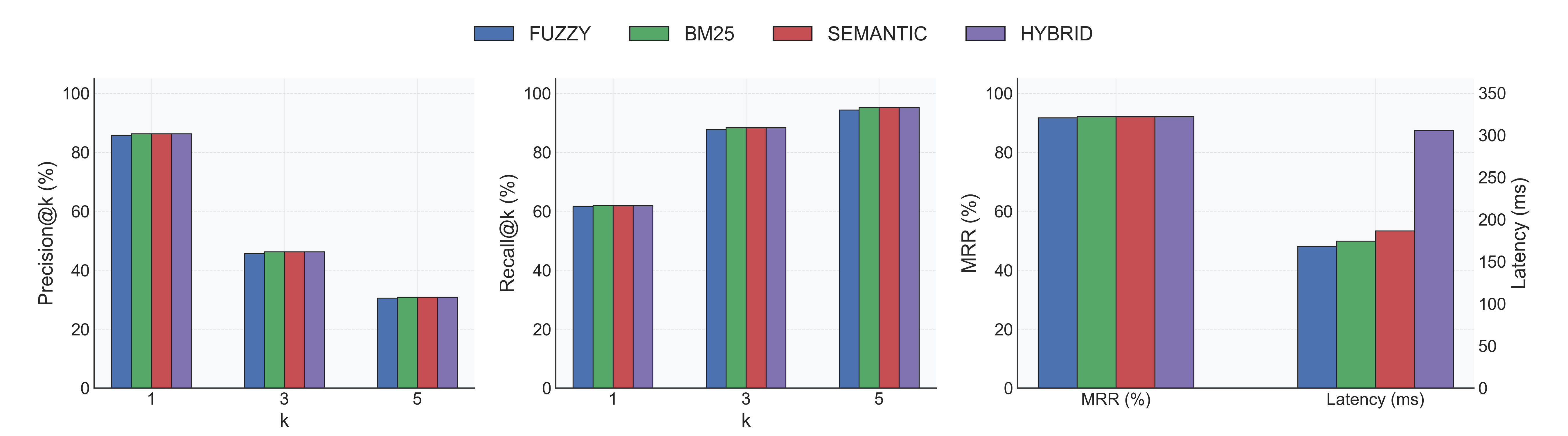
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
171
184
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
172
185
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -216,7 +229,7 @@ search = SchemaSearch(
|
|
|
216
229
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
217
230
|
6. Return top tables with full schema and relationships
|
|
218
231
|
|
|
219
|
-
Cache stored in
|
|
232
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
220
233
|
|
|
221
234
|
## License
|
|
222
235
|
|
|
@@ -16,7 +16,6 @@ mcp = FastMCP("schema-search")
|
|
|
16
16
|
@mcp.tool()
|
|
17
17
|
def schema_search(
|
|
18
18
|
query: str,
|
|
19
|
-
hops: Optional[int] = None,
|
|
20
19
|
limit: int = 5,
|
|
21
20
|
) -> dict:
|
|
22
21
|
"""Search database schema using natural language.
|
|
@@ -25,14 +24,14 @@ def schema_search(
|
|
|
25
24
|
using semantic similarity. Expands results by traversing foreign key relationships.
|
|
26
25
|
|
|
27
26
|
Args:
|
|
28
|
-
query: Natural language question about database schema (e.g., '
|
|
29
|
-
|
|
30
|
-
limit: Maximum number of table schemas to return in results. Default: 5
|
|
27
|
+
query: Natural language question about database schema (e.g., 'tables related to payments')
|
|
28
|
+
limit: Maximum number of table schemas to return in results. Default: 5; Max: 10.
|
|
31
29
|
|
|
32
30
|
Returns:
|
|
33
31
|
Dictionary with 'results' (list of table schemas with columns, types, constraints, and relationships) and 'latency_sec' (query execution time)
|
|
34
32
|
"""
|
|
35
|
-
|
|
33
|
+
limit = min(limit, 10)
|
|
34
|
+
search_result = mcp.search_engine.search(query, limit=limit) # type: ignore
|
|
36
35
|
return {
|
|
37
36
|
"results": search_result["results"],
|
|
38
37
|
"latency_sec": search_result["latency_sec"],
|
|
@@ -1,9 +1,9 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: schema-search
|
|
3
|
-
Version: 0.1.
|
|
4
|
-
Summary: Natural language
|
|
5
|
-
Home-page: https://
|
|
6
|
-
Author:
|
|
3
|
+
Version: 0.1.7
|
|
4
|
+
Summary: Natural language database schema search with graph-aware semantic retrieval
|
|
5
|
+
Home-page: https://adibhasan.com/blog/schema-search/
|
|
6
|
+
Author: Adib Hasan
|
|
7
7
|
Classifier: Development Status :: 3 - Alpha
|
|
8
8
|
Classifier: Intended Audience :: Developers
|
|
9
9
|
Classifier: License :: OSI Approved :: MIT License
|
|
@@ -38,6 +38,7 @@ Requires-Dist: snowflake-sqlalchemy>=1.4.0; extra == "snowflake"
|
|
|
38
38
|
Requires-Dist: snowflake-connector-python>=3.0.0; extra == "snowflake"
|
|
39
39
|
Provides-Extra: bigquery
|
|
40
40
|
Requires-Dist: sqlalchemy-bigquery>=1.6.0; extra == "bigquery"
|
|
41
|
+
Dynamic: author
|
|
41
42
|
Dynamic: classifier
|
|
42
43
|
Dynamic: description
|
|
43
44
|
Dynamic: description-content-type
|
|
@@ -82,6 +83,48 @@ uv pip install "schema-search[snowflake,mcp]" # Snowflake
|
|
|
82
83
|
uv pip install "schema-search[bigquery,mcp]" # BigQuery
|
|
83
84
|
```
|
|
84
85
|
|
|
86
|
+
## Configuration
|
|
87
|
+
|
|
88
|
+
Edit [`config.yml`](https://github.com/Neehan/schema-search/blob/main/config.yml):
|
|
89
|
+
|
|
90
|
+
```yaml
|
|
91
|
+
logging:
|
|
92
|
+
level: "WARNING"
|
|
93
|
+
|
|
94
|
+
embedding:
|
|
95
|
+
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
96
|
+
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
97
|
+
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
98
|
+
batch_size: 32
|
|
99
|
+
show_progress: false
|
|
100
|
+
cache_dir: "/tmp/.schema_search_cache"
|
|
101
|
+
|
|
102
|
+
chunking:
|
|
103
|
+
strategy: "raw" # Options: "raw", "llm"
|
|
104
|
+
max_tokens: 256
|
|
105
|
+
overlap_tokens: 50
|
|
106
|
+
model: "gpt-4o-mini"
|
|
107
|
+
|
|
108
|
+
search:
|
|
109
|
+
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
110
|
+
strategy: "hybrid"
|
|
111
|
+
initial_top_k: 20
|
|
112
|
+
rerank_top_k: 5
|
|
113
|
+
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
114
|
+
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
115
|
+
|
|
116
|
+
reranker:
|
|
117
|
+
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
118
|
+
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
119
|
+
|
|
120
|
+
schema:
|
|
121
|
+
include_columns: true
|
|
122
|
+
include_indices: true
|
|
123
|
+
include_foreign_keys: true
|
|
124
|
+
include_constraints: true
|
|
125
|
+
```
|
|
126
|
+
|
|
127
|
+
|
|
85
128
|
## MCP Server
|
|
86
129
|
|
|
87
130
|
Integrate with Claude Desktop or any MCP client.
|
|
@@ -96,7 +139,13 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
96
139
|
"mcpServers": {
|
|
97
140
|
"schema-search": {
|
|
98
141
|
"command": "uvx",
|
|
99
|
-
"args": [
|
|
142
|
+
"args": [
|
|
143
|
+
"schema-search[postgres,mcp]",
|
|
144
|
+
"postgresql://user:pass@localhost/db",
|
|
145
|
+
"optional/path/to/config.yml",
|
|
146
|
+
"optional llm_api_key",
|
|
147
|
+
"optional llm_base_url"
|
|
148
|
+
]
|
|
100
149
|
}
|
|
101
150
|
}
|
|
102
151
|
}
|
|
@@ -107,8 +156,14 @@ Add to your MCP config (e.g., `~/.cursor/mcp.json` or Claude Desktop config):
|
|
|
107
156
|
{
|
|
108
157
|
"mcpServers": {
|
|
109
158
|
"schema-search": {
|
|
110
|
-
|
|
111
|
-
"
|
|
159
|
+
// conda: /Users/<username>/opt/miniconda3/envs/<your env>/bin/schema-search",
|
|
160
|
+
"command": "path/to/schema-search",
|
|
161
|
+
"args": [
|
|
162
|
+
"postgresql://user:pass@localhost/db",
|
|
163
|
+
"optional/path/to/config.yml",
|
|
164
|
+
"optional llm_api_key",
|
|
165
|
+
"optional llm_base_url"
|
|
166
|
+
]
|
|
112
167
|
}
|
|
113
168
|
}
|
|
114
169
|
}
|
|
@@ -120,7 +175,7 @@ The LLM API key and base url are only required if you use LLM-generated schema s
|
|
|
120
175
|
### CLI Usage
|
|
121
176
|
|
|
122
177
|
```bash
|
|
123
|
-
schema-search "postgresql://user:pass@localhost/db"
|
|
178
|
+
schema-search "postgresql://user:pass@localhost/db" "optional/path/to/config.yml"
|
|
124
179
|
```
|
|
125
180
|
|
|
126
181
|
Optional args: `[config_path] [llm_api_key] [llm_base_url]`
|
|
@@ -151,47 +206,6 @@ results = search.search("user_table", hops=0, limit=5, search_type="semantic")
|
|
|
151
206
|
|
|
152
207
|
`SchemaSearch.index()` automatically detects schema changes and refreshes cached metadata, so you rarely need to force a reindex manually.
|
|
153
208
|
|
|
154
|
-
## Configuration
|
|
155
|
-
|
|
156
|
-
Edit `[config.yml](config.yml)`:
|
|
157
|
-
|
|
158
|
-
```yaml
|
|
159
|
-
logging:
|
|
160
|
-
level: "WARNING"
|
|
161
|
-
|
|
162
|
-
embedding:
|
|
163
|
-
location: "memory" # Options: "memory", "vectordb" (coming soon)
|
|
164
|
-
model: "multi-qa-MiniLM-L6-cos-v1"
|
|
165
|
-
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
|
|
166
|
-
batch_size: 32
|
|
167
|
-
show_progress: false
|
|
168
|
-
cache_dir: "/tmp/.schema_search_cache"
|
|
169
|
-
|
|
170
|
-
chunking:
|
|
171
|
-
strategy: "raw" # Options: "raw", "llm"
|
|
172
|
-
max_tokens: 256
|
|
173
|
-
overlap_tokens: 50
|
|
174
|
-
model: "gpt-4o-mini"
|
|
175
|
-
|
|
176
|
-
search:
|
|
177
|
-
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
|
|
178
|
-
strategy: "hybrid"
|
|
179
|
-
initial_top_k: 20
|
|
180
|
-
rerank_top_k: 5
|
|
181
|
-
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
|
|
182
|
-
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
|
|
183
|
-
|
|
184
|
-
reranker:
|
|
185
|
-
# CrossEncoder model for reranking. Set to null to disable reranking
|
|
186
|
-
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
|
|
187
|
-
|
|
188
|
-
schema:
|
|
189
|
-
include_columns: true
|
|
190
|
-
include_indices: true
|
|
191
|
-
include_foreign_keys: true
|
|
192
|
-
include_constraints: true
|
|
193
|
-
```
|
|
194
|
-
|
|
195
209
|
## Search Strategies
|
|
196
210
|
|
|
197
211
|
Schema Search supports four search strategies:
|
|
@@ -199,7 +213,7 @@ Schema Search supports four search strategies:
|
|
|
199
213
|
- **semantic**: Embedding-based similarity search using sentence transformers
|
|
200
214
|
- **bm25**: Lexical search using BM25 ranking algorithm
|
|
201
215
|
- **fuzzy**: String matching on table/column names using fuzzy matching
|
|
202
|
-
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33%
|
|
216
|
+
- **hybrid**: Combines semantic and bm25 scores (default: 67% semantic, 33% bm25)
|
|
203
217
|
|
|
204
218
|
Each strategy performs its own initial ranking, then optionally applies CrossEncoder reranking if `reranker.model` is configured. Set `reranker.model` to `null` to disable reranking.
|
|
205
219
|
|
|
@@ -209,14 +223,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
209
223
|
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
210
224
|
|
|
211
225
|
### Without Reranker (`reranker.model: null`)
|
|
212
|
-

|
|
226
|
+

|
|
213
227
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
214
228
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
215
229
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
216
230
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
217
231
|
|
|
218
232
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
219
|
-

|
|
233
|
+

|
|
220
234
|
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
221
235
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
222
236
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -266,7 +280,7 @@ search = SchemaSearch(
|
|
|
266
280
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
267
281
|
6. Return top tables with full schema and relationships
|
|
268
282
|
|
|
269
|
-
Cache stored in
|
|
283
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
270
284
|
|
|
271
285
|
## License
|
|
272
286
|
|
|
@@ -2,12 +2,12 @@ from setuptools import setup, find_packages
|
|
|
2
2
|
|
|
3
3
|
setup(
|
|
4
4
|
name="schema-search",
|
|
5
|
-
version="0.1.
|
|
6
|
-
description="Natural language
|
|
7
|
-
author="",
|
|
5
|
+
version="0.1.7",
|
|
6
|
+
description="Natural language database schema search with graph-aware semantic retrieval",
|
|
7
|
+
author="Adib Hasan",
|
|
8
8
|
long_description=open("README.md").read(),
|
|
9
9
|
long_description_content_type="text/markdown",
|
|
10
|
-
url="https://
|
|
10
|
+
url="https://adibhasan.com/blog/schema-search/",
|
|
11
11
|
packages=find_packages(),
|
|
12
12
|
install_requires=[
|
|
13
13
|
"sqlalchemy>=1.4.0",
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|