schema-search 0.1.4__tar.gz → 0.1.6__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of schema-search might be problematic. Click here for more details.
- {schema_search-0.1.4/schema_search.egg-info → schema_search-0.1.6}/PKG-INFO +9 -10
- {schema_search-0.1.4 → schema_search-0.1.6}/README.md +3 -3
- {schema_search-0.1.4 → schema_search-0.1.6/schema_search.egg-info}/PKG-INFO +9 -10
- {schema_search-0.1.4 → schema_search-0.1.6}/setup.py +5 -7
- {schema_search-0.1.4 → schema_search-0.1.6}/LICENSE +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/MANIFEST.in +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/config.yml +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/chunkers/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/chunkers/base.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/chunkers/factory.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/chunkers/llm.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/chunkers/markdown.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/embedding_cache/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/embedding_cache/base.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/embedding_cache/bm25.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/embedding_cache/factory.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/embedding_cache/inmemory.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/graph_builder.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/mcp_server.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/metrics.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/rankers/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/rankers/base.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/rankers/cross_encoder.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/rankers/factory.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/schema_extractor.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/schema_search.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/base.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/bm25.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/factory.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/fuzzy.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/hybrid.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/search/semantic.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search/types.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search.egg-info/SOURCES.txt +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search.egg-info/dependency_links.txt +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search.egg-info/entry_points.txt +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search.egg-info/requires.txt +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/schema_search.egg-info/top_level.txt +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/setup.cfg +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/tests/__init__.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/tests/test_integration.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/tests/test_llm_sql_generation.py +0 -0
- {schema_search-0.1.4 → schema_search-0.1.6}/tests/test_spider_eval.py +0 -0
|
@@ -1,18 +1,16 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: schema-search
|
|
3
|
-
Version: 0.1.
|
|
4
|
-
Summary: Natural language
|
|
5
|
-
Home-page: https://
|
|
6
|
-
Author:
|
|
3
|
+
Version: 0.1.6
|
|
4
|
+
Summary: Natural language database schema search with graph-aware semantic retrieval
|
|
5
|
+
Home-page: https://adibhasan.com/blog/schema-search/
|
|
6
|
+
Author: Adib Hasan
|
|
7
7
|
Classifier: Development Status :: 3 - Alpha
|
|
8
8
|
Classifier: Intended Audience :: Developers
|
|
9
9
|
Classifier: License :: OSI Approved :: MIT License
|
|
10
10
|
Classifier: Programming Language :: Python :: 3
|
|
11
|
-
Classifier: Programming Language :: Python :: 3.8
|
|
12
|
-
Classifier: Programming Language :: Python :: 3.9
|
|
13
11
|
Classifier: Programming Language :: Python :: 3.10
|
|
14
12
|
Classifier: Programming Language :: Python :: 3.11
|
|
15
|
-
Requires-Python: >=3.
|
|
13
|
+
Requires-Python: >=3.10
|
|
16
14
|
Description-Content-Type: text/markdown
|
|
17
15
|
License-File: LICENSE
|
|
18
16
|
Requires-Dist: sqlalchemy>=1.4.0
|
|
@@ -40,6 +38,7 @@ Requires-Dist: snowflake-sqlalchemy>=1.4.0; extra == "snowflake"
|
|
|
40
38
|
Requires-Dist: snowflake-connector-python>=3.0.0; extra == "snowflake"
|
|
41
39
|
Provides-Extra: bigquery
|
|
42
40
|
Requires-Dist: sqlalchemy-bigquery>=1.6.0; extra == "bigquery"
|
|
41
|
+
Dynamic: author
|
|
43
42
|
Dynamic: classifier
|
|
44
43
|
Dynamic: description
|
|
45
44
|
Dynamic: description-content-type
|
|
@@ -211,14 +210,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
211
210
|
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
212
211
|
|
|
213
212
|
### Without Reranker (`reranker.model: null`)
|
|
214
|
-

|
|
213
|
+
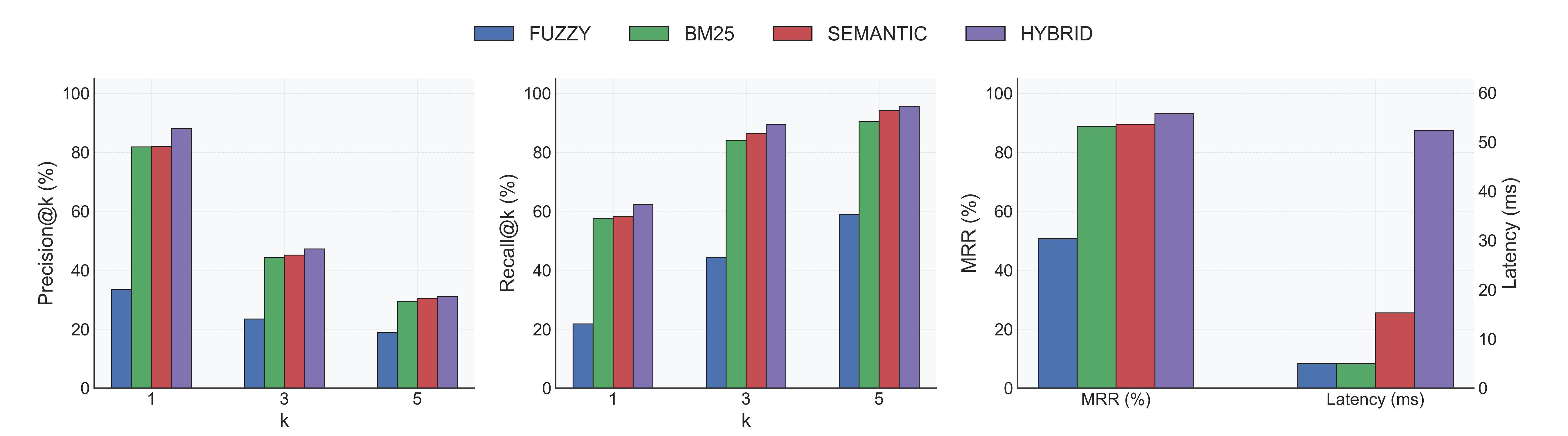
|
|
215
214
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
216
215
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
217
216
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
218
217
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
219
218
|
|
|
220
219
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
221
|
-

|
|
220
|
+
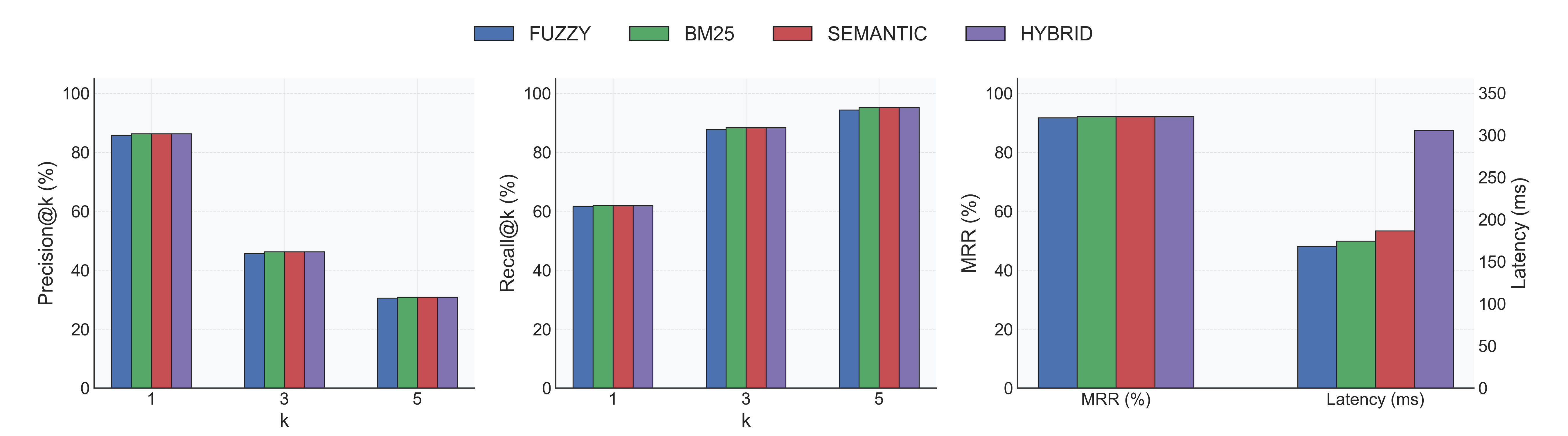
|
|
222
221
|
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
223
222
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
224
223
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -268,7 +267,7 @@ search = SchemaSearch(
|
|
|
268
267
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
269
268
|
6. Return top tables with full schema and relationships
|
|
270
269
|
|
|
271
|
-
Cache stored in
|
|
270
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
272
271
|
|
|
273
272
|
## License
|
|
274
273
|
|
|
@@ -159,14 +159,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
159
159
|
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
160
160
|
|
|
161
161
|
### Without Reranker (`reranker.model: null`)
|
|
162
|
-

|
|
162
|
+

|
|
163
163
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
164
164
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
165
165
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
166
166
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
167
167
|
|
|
168
168
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
169
|
-

|
|
169
|
+

|
|
170
170
|
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
171
171
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
172
172
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -216,7 +216,7 @@ search = SchemaSearch(
|
|
|
216
216
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
217
217
|
6. Return top tables with full schema and relationships
|
|
218
218
|
|
|
219
|
-
Cache stored in
|
|
219
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
220
220
|
|
|
221
221
|
## License
|
|
222
222
|
|
|
@@ -1,18 +1,16 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: schema-search
|
|
3
|
-
Version: 0.1.
|
|
4
|
-
Summary: Natural language
|
|
5
|
-
Home-page: https://
|
|
6
|
-
Author:
|
|
3
|
+
Version: 0.1.6
|
|
4
|
+
Summary: Natural language database schema search with graph-aware semantic retrieval
|
|
5
|
+
Home-page: https://adibhasan.com/blog/schema-search/
|
|
6
|
+
Author: Adib Hasan
|
|
7
7
|
Classifier: Development Status :: 3 - Alpha
|
|
8
8
|
Classifier: Intended Audience :: Developers
|
|
9
9
|
Classifier: License :: OSI Approved :: MIT License
|
|
10
10
|
Classifier: Programming Language :: Python :: 3
|
|
11
|
-
Classifier: Programming Language :: Python :: 3.8
|
|
12
|
-
Classifier: Programming Language :: Python :: 3.9
|
|
13
11
|
Classifier: Programming Language :: Python :: 3.10
|
|
14
12
|
Classifier: Programming Language :: Python :: 3.11
|
|
15
|
-
Requires-Python: >=3.
|
|
13
|
+
Requires-Python: >=3.10
|
|
16
14
|
Description-Content-Type: text/markdown
|
|
17
15
|
License-File: LICENSE
|
|
18
16
|
Requires-Dist: sqlalchemy>=1.4.0
|
|
@@ -40,6 +38,7 @@ Requires-Dist: snowflake-sqlalchemy>=1.4.0; extra == "snowflake"
|
|
|
40
38
|
Requires-Dist: snowflake-connector-python>=3.0.0; extra == "snowflake"
|
|
41
39
|
Provides-Extra: bigquery
|
|
42
40
|
Requires-Dist: sqlalchemy-bigquery>=1.6.0; extra == "bigquery"
|
|
41
|
+
Dynamic: author
|
|
43
42
|
Dynamic: classifier
|
|
44
43
|
Dynamic: description
|
|
45
44
|
Dynamic: description-content-type
|
|
@@ -211,14 +210,14 @@ We [benchmarked](/tests/test_spider_eval.py) on the Spider dataset (1,234 train
|
|
|
211
210
|
**Memory:** The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
|
|
212
211
|
|
|
213
212
|
### Without Reranker (`reranker.model: null`)
|
|
214
|
-

|
|
213
|
+

|
|
215
214
|
- **Indexing:** 0.22s ± 0.08s per database (18 total).
|
|
216
215
|
- **Accuracy:** Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
|
|
217
216
|
- **Latency:** BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
|
|
218
217
|
- **Fuzzy baseline:** Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
|
|
219
218
|
|
|
220
219
|
### With Reranker (`Alibaba-NLP/gte-reranker-modernbert-base`)
|
|
221
|
-

|
|
220
|
+

|
|
222
221
|
- **Indexing:** 0.25s ± 0.05s per database (same 18 DBs).
|
|
223
222
|
- **Accuracy:** All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
|
|
224
223
|
- **Latency trade-off:** Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
|
|
@@ -268,7 +267,7 @@ search = SchemaSearch(
|
|
|
268
267
|
5. **Optional reranking** with CrossEncoder to refine results
|
|
269
268
|
6. Return top tables with full schema and relationships
|
|
270
269
|
|
|
271
|
-
Cache stored in
|
|
270
|
+
Cache stored in `/tmp/.schema_search_cache/` (configurable in `config.yml`)
|
|
272
271
|
|
|
273
272
|
## License
|
|
274
273
|
|
|
@@ -2,12 +2,12 @@ from setuptools import setup, find_packages
|
|
|
2
2
|
|
|
3
3
|
setup(
|
|
4
4
|
name="schema-search",
|
|
5
|
-
version="0.1.
|
|
6
|
-
description="Natural language
|
|
7
|
-
author="",
|
|
5
|
+
version="0.1.6",
|
|
6
|
+
description="Natural language database schema search with graph-aware semantic retrieval",
|
|
7
|
+
author="Adib Hasan",
|
|
8
8
|
long_description=open("README.md").read(),
|
|
9
9
|
long_description_content_type="text/markdown",
|
|
10
|
-
url="https://
|
|
10
|
+
url="https://adibhasan.com/blog/schema-search/",
|
|
11
11
|
packages=find_packages(),
|
|
12
12
|
install_requires=[
|
|
13
13
|
"sqlalchemy>=1.4.0",
|
|
@@ -49,14 +49,12 @@ setup(
|
|
|
49
49
|
"schema-search=schema_search.mcp_server:main",
|
|
50
50
|
],
|
|
51
51
|
},
|
|
52
|
-
python_requires=">=3.
|
|
52
|
+
python_requires=">=3.10",
|
|
53
53
|
classifiers=[
|
|
54
54
|
"Development Status :: 3 - Alpha",
|
|
55
55
|
"Intended Audience :: Developers",
|
|
56
56
|
"License :: OSI Approved :: MIT License",
|
|
57
57
|
"Programming Language :: Python :: 3",
|
|
58
|
-
"Programming Language :: Python :: 3.8",
|
|
59
|
-
"Programming Language :: Python :: 3.9",
|
|
60
58
|
"Programming Language :: Python :: 3.10",
|
|
61
59
|
"Programming Language :: Python :: 3.11",
|
|
62
60
|
],
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|