sbol-torch 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- sbol_torch-0.1.0/.flake8 +11 -0
- sbol_torch-0.1.0/.gitignore +20 -0
- sbol_torch-0.1.0/.pre-commit-config.yaml +25 -0
- sbol_torch-0.1.0/LICENSE +21 -0
- sbol_torch-0.1.0/PKG-INFO +135 -0
- sbol_torch-0.1.0/README.md +103 -0
- sbol_torch-0.1.0/docs/architecture.md +88 -0
- sbol_torch-0.1.0/docs/backbones.md +47 -0
- sbol_torch-0.1.0/docs/capabilities.md +90 -0
- sbol_torch-0.1.0/docs/configuration.md +152 -0
- sbol_torch-0.1.0/docs/data.md +90 -0
- sbol_torch-0.1.0/docs/extending.md +91 -0
- sbol_torch-0.1.0/docs/images/wandb_structure_aware.png +0 -0
- sbol_torch-0.1.0/docs/images/wandb_train_graph.png +0 -0
- sbol_torch-0.1.0/examples/README.md +52 -0
- sbol_torch-0.1.0/examples/configs/finetune_expression.yaml +46 -0
- sbol_torch-0.1.0/examples/configs/finetune_structure_aware.yaml +59 -0
- sbol_torch-0.1.0/examples/configs/pretrain_mlm.yaml +51 -0
- sbol_torch-0.1.0/examples/configs/train_graph.yaml +50 -0
- sbol_torch-0.1.0/examples/quickstart.py +31 -0
- sbol_torch-0.1.0/examples/run_wandb_examples.py +50 -0
- sbol_torch-0.1.0/pyproject.toml +64 -0
- sbol_torch-0.1.0/src/sboltorch/__init__.py +32 -0
- sbol_torch-0.1.0/src/sboltorch/cli.py +53 -0
- sbol_torch-0.1.0/src/sboltorch/config.py +181 -0
- sbol_torch-0.1.0/src/sboltorch/data/__init__.py +21 -0
- sbol_torch-0.1.0/src/sboltorch/data/corpus.py +36 -0
- sbol_torch-0.1.0/src/sboltorch/data/local.py +150 -0
- sbol_torch-0.1.0/src/sboltorch/data/materialize.py +166 -0
- sbol_torch-0.1.0/src/sboltorch/data/sbol_db.py +226 -0
- sbol_torch-0.1.0/src/sboltorch/data/synthetic.py +195 -0
- sbol_torch-0.1.0/src/sboltorch/datasets/__init__.py +8 -0
- sbol_torch-0.1.0/src/sboltorch/datasets/dataset.py +62 -0
- sbol_torch-0.1.0/src/sboltorch/datasets/mlm_collator.py +57 -0
- sbol_torch-0.1.0/src/sboltorch/datasets/splits.py +87 -0
- sbol_torch-0.1.0/src/sboltorch/encoders/__init__.py +19 -0
- sbol_torch-0.1.0/src/sboltorch/encoders/base.py +76 -0
- sbol_torch-0.1.0/src/sboltorch/encoders/graph.py +111 -0
- sbol_torch-0.1.0/src/sboltorch/encoders/sequence.py +34 -0
- sbol_torch-0.1.0/src/sboltorch/encoders/structure.py +113 -0
- sbol_torch-0.1.0/src/sboltorch/engine/__init__.py +20 -0
- sbol_torch-0.1.0/src/sboltorch/engine/batch.py +51 -0
- sbol_torch-0.1.0/src/sboltorch/engine/callbacks.py +185 -0
- sbol_torch-0.1.0/src/sboltorch/engine/trainer.py +179 -0
- sbol_torch-0.1.0/src/sboltorch/exceptions.py +27 -0
- sbol_torch-0.1.0/src/sboltorch/models/__init__.py +55 -0
- sbol_torch-0.1.0/src/sboltorch/models/backbone.py +41 -0
- sbol_torch-0.1.0/src/sboltorch/models/graph.py +73 -0
- sbol_torch-0.1.0/src/sboltorch/models/heads.py +26 -0
- sbol_torch-0.1.0/src/sboltorch/models/mlm.py +53 -0
- sbol_torch-0.1.0/src/sboltorch/models/sequence_model.py +39 -0
- sbol_torch-0.1.0/src/sboltorch/pipeline.py +157 -0
- sbol_torch-0.1.0/src/sboltorch/reproducibility.py +17 -0
- sbol_torch-0.1.0/src/sboltorch/tasks/__init__.py +8 -0
- sbol_torch-0.1.0/src/sboltorch/tasks/base.py +49 -0
- sbol_torch-0.1.0/src/sboltorch/tasks/mlm.py +39 -0
- sbol_torch-0.1.0/src/sboltorch/tasks/supervised.py +63 -0
- sbol_torch-0.1.0/src/sboltorch/tokenize/__init__.py +17 -0
- sbol_torch-0.1.0/src/sboltorch/tokenize/base.py +65 -0
- sbol_torch-0.1.0/src/sboltorch/tokenize/char.py +45 -0
- sbol_torch-0.1.0/src/sboltorch/tokenize/hf.py +59 -0
- sbol_torch-0.1.0/src/sboltorch/tokenize/kmer.py +61 -0
- sbol_torch-0.1.0/src/sboltorch/types.py +225 -0
- sbol_torch-0.1.0/tests/conftest.py +73 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/COMMIT_SHA.txt +1 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/PROVENANCE.md +22 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/sbol2/pICH44179.xml +160 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/sbol3/BBa_F2620_PoPSReceiver.ttl +354 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/sbol3/toggle_switch.nt +371 -0
- sbol_torch-0.1.0/tests/fixtures/sbol/sbol3/toggle_switch.ttl +464 -0
- sbol_torch-0.1.0/tests/test_config.py +56 -0
- sbol_torch-0.1.0/tests/test_engine.py +108 -0
- sbol_torch-0.1.0/tests/test_fixtures_sbol.py +49 -0
- sbol_torch-0.1.0/tests/test_graph.py +70 -0
- sbol_torch-0.1.0/tests/test_learning.py +156 -0
- sbol_torch-0.1.0/tests/test_local_corpus.py +33 -0
- sbol_torch-0.1.0/tests/test_materialize.py +53 -0
- sbol_torch-0.1.0/tests/test_mlm.py +114 -0
- sbol_torch-0.1.0/tests/test_sbol_db_client.py +64 -0
- sbol_torch-0.1.0/tests/test_splits.py +33 -0
- sbol_torch-0.1.0/tests/test_structure.py +86 -0
- sbol_torch-0.1.0/tests/test_synthetic.py +70 -0
- sbol_torch-0.1.0/tests/test_tokenize.py +47 -0
- sbol_torch-0.1.0/tests/test_types.py +29 -0
- sbol_torch-0.1.0/tests/test_wandb.py +270 -0
- sbol_torch-0.1.0/uv.lock +2629 -0
sbol_torch-0.1.0/.flake8
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
1
|
+
__pycache__/
|
|
2
|
+
*.py[cod]
|
|
3
|
+
.venv/
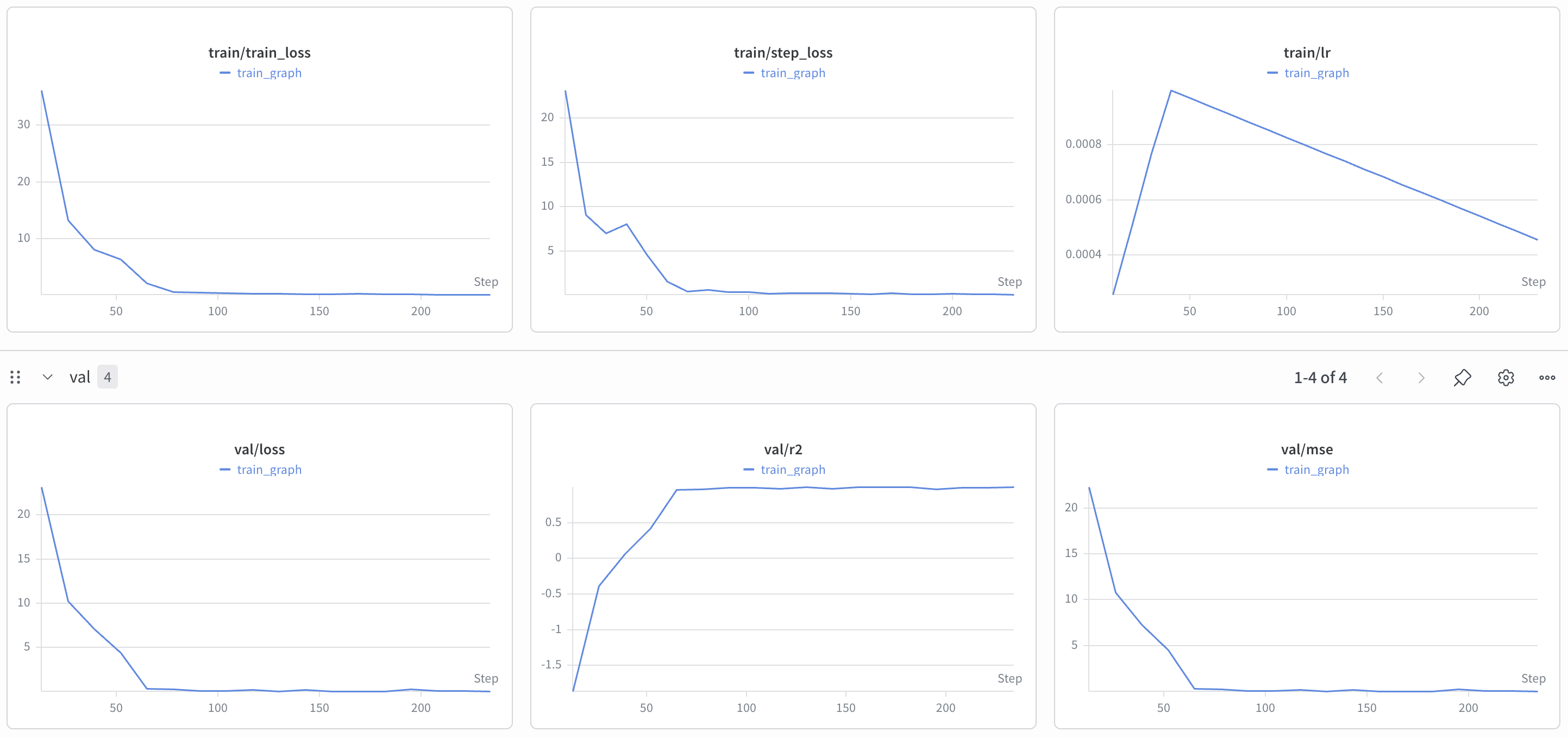
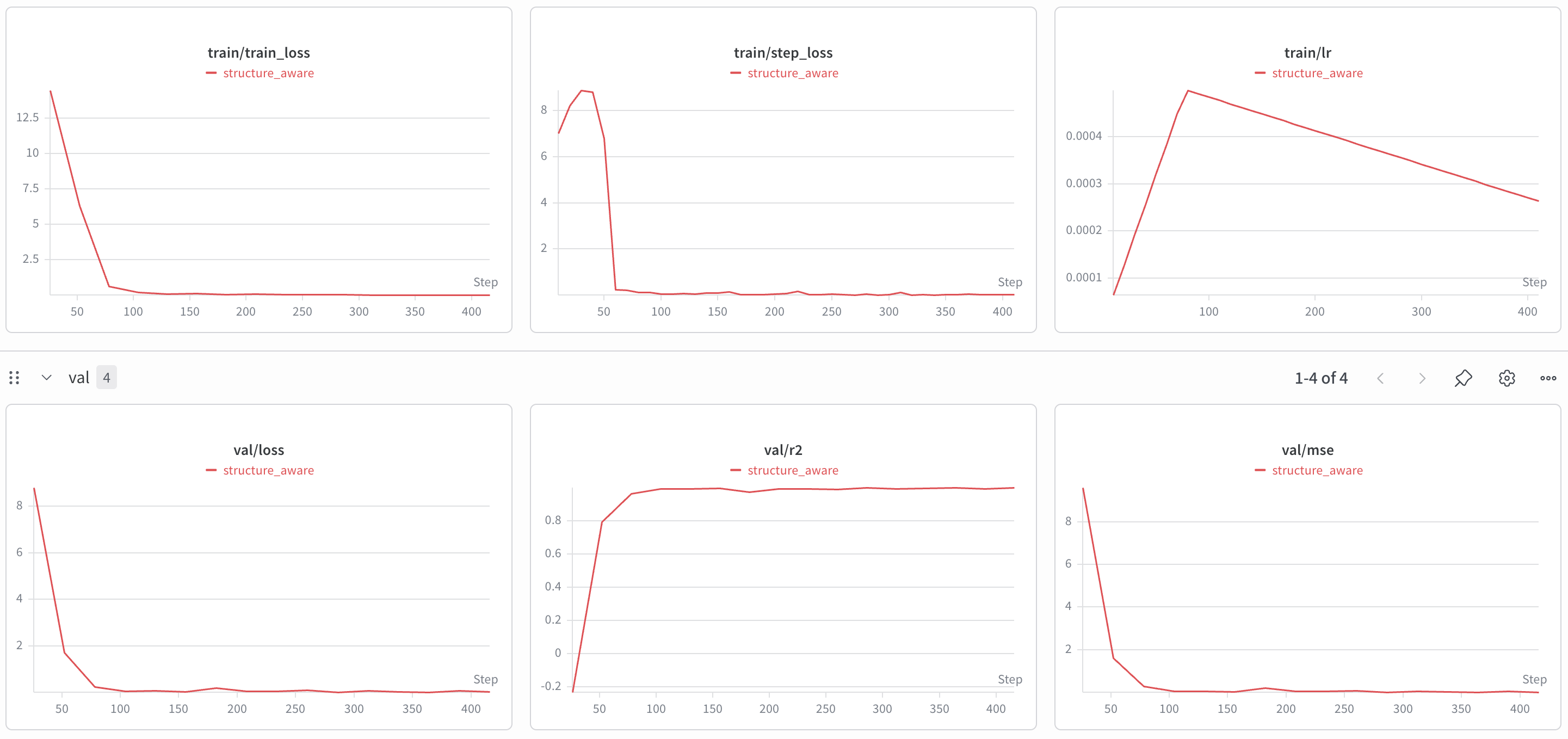
|
|
4
|
+
venv/
|
|
5
|
+
*.egg-info/
|
|
6
|
+
build/
|
|
7
|
+
dist/
|
|
8
|
+
.mypy_cache/
|
|
9
|
+
.pytest_cache/
|
|
10
|
+
.ruff_cache/
|
|
11
|
+
|
|
12
|
+
# Local materialized corpora and run outputs
|
|
13
|
+
.sboltorch_cache/
|
|
14
|
+
runs/
|
|
15
|
+
*.parquet
|
|
16
|
+
wandb/
|
|
17
|
+
|
|
18
|
+
# Environment
|
|
19
|
+
.env
|
|
20
|
+
.env.*
|
|
@@ -0,0 +1,25 @@
|
|
|
1
|
+
repos:
|
|
2
|
+
- repo: https://github.com/pycqa/isort
|
|
3
|
+
rev: 5.13.2
|
|
4
|
+
hooks:
|
|
5
|
+
- id: isort
|
|
6
|
+
- repo: https://github.com/psf/black
|
|
7
|
+
rev: 24.3.0
|
|
8
|
+
hooks:
|
|
9
|
+
- id: black
|
|
10
|
+
- repo: https://github.com/pycqa/flake8
|
|
11
|
+
rev: 7.0.0
|
|
12
|
+
hooks:
|
|
13
|
+
- id: flake8
|
|
14
|
+
# Run mypy in the project environment so it type-checks against the real
|
|
15
|
+
# dependencies (torch, transformers, wandb). An isolated env would treat them
|
|
16
|
+
# as Any and miss real type errors.
|
|
17
|
+
- repo: local
|
|
18
|
+
hooks:
|
|
19
|
+
- id: mypy
|
|
20
|
+
name: mypy
|
|
21
|
+
entry: uv run mypy
|
|
22
|
+
language: system
|
|
23
|
+
types: [python]
|
|
24
|
+
pass_filenames: false
|
|
25
|
+
args: [--config-file=pyproject.toml]
|
sbol_torch-0.1.0/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026 Mike Arpaia
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
|
@@ -0,0 +1,135 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: sbol-torch
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: A PyTorch library for synthetic biology and biodesign automation
|
|
5
|
+
Author-email: Mike Arpaia <mike@arpaia.co>
|
|
6
|
+
License: MIT
|
|
7
|
+
License-File: LICENSE
|
|
8
|
+
Requires-Python: >=3.11
|
|
9
|
+
Requires-Dist: einops>=0.7
|
|
10
|
+
Requires-Dist: httpx>=0.27
|
|
11
|
+
Requires-Dist: numpy>=1.26
|
|
12
|
+
Requires-Dist: pyarrow>=15
|
|
13
|
+
Requires-Dist: pydantic>=2.6
|
|
14
|
+
Requires-Dist: pyyaml>=6
|
|
15
|
+
Requires-Dist: rdflib>=7
|
|
16
|
+
Requires-Dist: tokenizers>=0.19
|
|
17
|
+
Requires-Dist: torch-geometric>=2.5
|
|
18
|
+
Requires-Dist: torch>=2.2
|
|
19
|
+
Requires-Dist: transformers<5,>=4.40
|
|
20
|
+
Requires-Dist: wandb>=0.17
|
|
21
|
+
Provides-Extra: dev
|
|
22
|
+
Requires-Dist: black>=24.3; extra == 'dev'
|
|
23
|
+
Requires-Dist: flake8>=7; extra == 'dev'
|
|
24
|
+
Requires-Dist: isort>=5.13; extra == 'dev'
|
|
25
|
+
Requires-Dist: mypy>=1.9; extra == 'dev'
|
|
26
|
+
Requires-Dist: pre-commit>=3.7; extra == 'dev'
|
|
27
|
+
Requires-Dist: pytest-mock>=3.12; extra == 'dev'
|
|
28
|
+
Requires-Dist: pytest>=8; extra == 'dev'
|
|
29
|
+
Requires-Dist: respx>=0.21; extra == 'dev'
|
|
30
|
+
Requires-Dist: types-pyyaml; extra == 'dev'
|
|
31
|
+
Description-Content-Type: text/markdown
|
|
32
|
+
|
|
33
|
+
# sbol-torch
|
|
34
|
+
|
|
35
|
+
A PyTorch library for synthetic biology and biodesign automation.
|
|
36
|
+
|
|
37
|
+
Installed as `sbol-torch`, imported as `sboltorch` (commonly `import sboltorch as st`).
|
|
38
|
+
|
|
39
|
+
sbol-torch pulls designs from a running [sbol-db](https://github.com/marpaia/sbol-db)
|
|
40
|
+
instance (or local SBOL/FASTA files), normalizes them into a single record type,
|
|
41
|
+
and trains transformer models against them. The input modality, tokenizer, and
|
|
42
|
+
training objective are all set in configuration, so trying a new combination
|
|
43
|
+
never means forking the pipeline.
|
|
44
|
+
|
|
45
|
+
## Capabilities
|
|
46
|
+
|
|
47
|
+
| Axis | Options |
|
|
48
|
+
|------|---------|
|
|
49
|
+
| **Data sources** | sbol-db REST API, local SBOL/FASTA files, or a synthetic generator |
|
|
50
|
+
| **Tokenizers** | pretrained HuggingFace (`hf`), overlapping k-mer, or IUPAC character |
|
|
51
|
+
| **Modalities** | `sequence`, `structure_aware` (feature boundaries), `graph` (PyG composition transformer) |
|
|
52
|
+
| **Objectives** | `supervised` fine-tuning, `frozen`-backbone head, `mlm` pretraining (from-scratch and continued) |
|
|
53
|
+
| **Engine** | raw-PyTorch loop, early stopping, checkpointing, AMP, LR schedule, gradient accumulation |
|
|
54
|
+
| **Tracking** | per-epoch `metrics.jsonl`, optional [Weights & Biases](https://docs.wandb.ai/) (scalars, config, lineage, model artifact) |
|
|
55
|
+
| **Reproducibility** | one validated config per run, seeded splits, content-fingerprinted Parquet cache |
|
|
56
|
+
|
|
57
|
+
## Install
|
|
58
|
+
|
|
59
|
+
```bash
|
|
60
|
+
pip install sbol-torch
|
|
61
|
+
```
|
|
62
|
+
|
|
63
|
+
For development:
|
|
64
|
+
|
|
65
|
+
```bash
|
|
66
|
+
uv venv
|
|
67
|
+
uv pip install -e '.[dev]'
|
|
68
|
+
```
|
|
69
|
+
|
|
70
|
+
## Quickstart
|
|
71
|
+
|
|
72
|
+
A run is fully specified by one YAML config. From the command line:
|
|
73
|
+
|
|
74
|
+
```bash
|
|
75
|
+
# Materialize a corpus to the local Parquet cache (offline, reproducible).
|
|
76
|
+
sboltorch ingest examples/configs/finetune_expression.yaml
|
|
77
|
+
|
|
78
|
+
# Train. Resolved config, per-epoch metrics.jsonl, and best.pt land in output_dir.
|
|
79
|
+
sboltorch train examples/configs/finetune_expression.yaml
|
|
80
|
+
```
|
|
81
|
+
|
|
82
|
+
Or from Python:
|
|
83
|
+
|
|
84
|
+
```python
|
|
85
|
+
import sboltorch as st
|
|
86
|
+
|
|
87
|
+
config = st.RunConfig.from_yaml("examples/configs/train_graph.yaml")
|
|
88
|
+
metrics = st.run_training(config)
|
|
89
|
+
```
|
|
90
|
+
|
|
91
|
+
### Example configs
|
|
92
|
+
|
|
93
|
+
| Config | What it does |
|
|
94
|
+
|--------|--------------|
|
|
95
|
+
| [`finetune_expression.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_expression.yaml) | Frozen DNABERT-2 backbone feeding a regression head. |
|
|
96
|
+
| [`pretrain_mlm.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/pretrain_mlm.yaml) | From-scratch masked-LM pretraining; writes a reusable backbone. |
|
|
97
|
+
| [`finetune_structure_aware.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_structure_aware.yaml) | Sequence + feature-boundary markers. |
|
|
98
|
+
| [`train_graph.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/train_graph.yaml) | Graph transformer over the composition graph. |
|
|
99
|
+
|
|
100
|
+
## Experiment tracking
|
|
101
|
+
|
|
102
|
+
The two synthetic-data configs ([`train_graph.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/train_graph.yaml)
|
|
103
|
+
and [`finetune_structure_aware.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_structure_aware.yaml))
|
|
104
|
+
ship with [Weights & Biases](https://docs.wandb.ai/) enabled. Set `WANDB_API_KEY`
|
|
105
|
+
in a `.env` at the repo root and run both:
|
|
106
|
+
|
|
107
|
+
```bash
|
|
108
|
+
python examples/run_wandb_examples.py
|
|
109
|
+
```
|
|
110
|
+
|
|
111
|
+
Each run logs per-step loss and learning rate, per-epoch train/val metrics, the
|
|
112
|
+
resolved config, the corpus fingerprint and split sizes as lineage, and the best
|
|
113
|
+
checkpoint as a model artifact.
|
|
114
|
+
|
|
115
|
+
| Graph transformer | Structure-aware sequence |
|
|
116
|
+
|-------------------|--------------------------|
|
|
117
|
+
|  |  |
|
|
118
|
+
|
|
119
|
+
## Documentation
|
|
120
|
+
|
|
121
|
+
| Doc | Contents |
|
|
122
|
+
|-----|----------|
|
|
123
|
+
| [architecture.md](https://github.com/marpaia/sbol-torch/blob/master/docs/architecture.md) | How the system is built — record type, plug points, engine, data flow. |
|
|
124
|
+
| [capabilities.md](https://github.com/marpaia/sbol-torch/blob/master/docs/capabilities.md) | Modalities, objectives, tokenizers, metrics. |
|
|
125
|
+
| [configuration.md](https://github.com/marpaia/sbol-torch/blob/master/docs/configuration.md) | Complete `RunConfig` reference. |
|
|
126
|
+
| [data.md](https://github.com/marpaia/sbol-torch/blob/master/docs/data.md) | Data sources, the sbol-db client, materialization, fixtures. |
|
|
127
|
+
| [backbones.md](https://github.com/marpaia/sbol-torch/blob/master/docs/backbones.md) | Choosing/loading backbones and environment constraints. |
|
|
128
|
+
| [extending.md](https://github.com/marpaia/sbol-torch/blob/master/docs/extending.md) | Adding a tokenizer, encoder, task, callback, or data source. |
|
|
129
|
+
|
|
130
|
+
## Develop
|
|
131
|
+
|
|
132
|
+
```bash
|
|
133
|
+
uv run pytest
|
|
134
|
+
pre-commit run --all-files
|
|
135
|
+
```
|
|
@@ -0,0 +1,103 @@
|
|
|
1
|
+
# sbol-torch
|
|
2
|
+
|
|
3
|
+
A PyTorch library for synthetic biology and biodesign automation.
|
|
4
|
+
|
|
5
|
+
Installed as `sbol-torch`, imported as `sboltorch` (commonly `import sboltorch as st`).
|
|
6
|
+
|
|
7
|
+
sbol-torch pulls designs from a running [sbol-db](https://github.com/marpaia/sbol-db)
|
|
8
|
+
instance (or local SBOL/FASTA files), normalizes them into a single record type,
|
|
9
|
+
and trains transformer models against them. The input modality, tokenizer, and
|
|
10
|
+
training objective are all set in configuration, so trying a new combination
|
|
11
|
+
never means forking the pipeline.
|
|
12
|
+
|
|
13
|
+
## Capabilities
|
|
14
|
+
|
|
15
|
+
| Axis | Options |
|
|
16
|
+
|------|---------|
|
|
17
|
+
| **Data sources** | sbol-db REST API, local SBOL/FASTA files, or a synthetic generator |
|
|
18
|
+
| **Tokenizers** | pretrained HuggingFace (`hf`), overlapping k-mer, or IUPAC character |
|
|
19
|
+
| **Modalities** | `sequence`, `structure_aware` (feature boundaries), `graph` (PyG composition transformer) |
|
|
20
|
+
| **Objectives** | `supervised` fine-tuning, `frozen`-backbone head, `mlm` pretraining (from-scratch and continued) |
|
|
21
|
+
| **Engine** | raw-PyTorch loop, early stopping, checkpointing, AMP, LR schedule, gradient accumulation |
|
|
22
|
+
| **Tracking** | per-epoch `metrics.jsonl`, optional [Weights & Biases](https://docs.wandb.ai/) (scalars, config, lineage, model artifact) |
|
|
23
|
+
| **Reproducibility** | one validated config per run, seeded splits, content-fingerprinted Parquet cache |
|
|
24
|
+
|
|
25
|
+
## Install
|
|
26
|
+
|
|
27
|
+
```bash
|
|
28
|
+
pip install sbol-torch
|
|
29
|
+
```
|
|
30
|
+
|
|
31
|
+
For development:
|
|
32
|
+
|
|
33
|
+
```bash
|
|
34
|
+
uv venv
|
|
35
|
+
uv pip install -e '.[dev]'
|
|
36
|
+
```
|
|
37
|
+
|
|
38
|
+
## Quickstart
|
|
39
|
+
|
|
40
|
+
A run is fully specified by one YAML config. From the command line:
|
|
41
|
+
|
|
42
|
+
```bash
|
|
43
|
+
# Materialize a corpus to the local Parquet cache (offline, reproducible).
|
|
44
|
+
sboltorch ingest examples/configs/finetune_expression.yaml
|
|
45
|
+
|
|
46
|
+
# Train. Resolved config, per-epoch metrics.jsonl, and best.pt land in output_dir.
|
|
47
|
+
sboltorch train examples/configs/finetune_expression.yaml
|
|
48
|
+
```
|
|
49
|
+
|
|
50
|
+
Or from Python:
|
|
51
|
+
|
|
52
|
+
```python
|
|
53
|
+
import sboltorch as st
|
|
54
|
+
|
|
55
|
+
config = st.RunConfig.from_yaml("examples/configs/train_graph.yaml")
|
|
56
|
+
metrics = st.run_training(config)
|
|
57
|
+
```
|
|
58
|
+
|
|
59
|
+
### Example configs
|
|
60
|
+
|
|
61
|
+
| Config | What it does |
|
|
62
|
+
|--------|--------------|
|
|
63
|
+
| [`finetune_expression.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_expression.yaml) | Frozen DNABERT-2 backbone feeding a regression head. |
|
|
64
|
+
| [`pretrain_mlm.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/pretrain_mlm.yaml) | From-scratch masked-LM pretraining; writes a reusable backbone. |
|
|
65
|
+
| [`finetune_structure_aware.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_structure_aware.yaml) | Sequence + feature-boundary markers. |
|
|
66
|
+
| [`train_graph.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/train_graph.yaml) | Graph transformer over the composition graph. |
|
|
67
|
+
|
|
68
|
+
## Experiment tracking
|
|
69
|
+
|
|
70
|
+
The two synthetic-data configs ([`train_graph.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/train_graph.yaml)
|
|
71
|
+
and [`finetune_structure_aware.yaml`](https://github.com/marpaia/sbol-torch/blob/master/examples/configs/finetune_structure_aware.yaml))
|
|
72
|
+
ship with [Weights & Biases](https://docs.wandb.ai/) enabled. Set `WANDB_API_KEY`
|
|
73
|
+
in a `.env` at the repo root and run both:
|
|
74
|
+
|
|
75
|
+
```bash
|
|
76
|
+
python examples/run_wandb_examples.py
|
|
77
|
+
```
|
|
78
|
+
|
|
79
|
+
Each run logs per-step loss and learning rate, per-epoch train/val metrics, the
|
|
80
|
+
resolved config, the corpus fingerprint and split sizes as lineage, and the best
|
|
81
|
+
checkpoint as a model artifact.
|
|
82
|
+
|
|
83
|
+
| Graph transformer | Structure-aware sequence |
|
|
84
|
+
|-------------------|--------------------------|
|
|
85
|
+
|  |  |
|
|
86
|
+
|
|
87
|
+
## Documentation
|
|
88
|
+
|
|
89
|
+
| Doc | Contents |
|
|
90
|
+
|-----|----------|
|
|
91
|
+
| [architecture.md](https://github.com/marpaia/sbol-torch/blob/master/docs/architecture.md) | How the system is built — record type, plug points, engine, data flow. |
|
|
92
|
+
| [capabilities.md](https://github.com/marpaia/sbol-torch/blob/master/docs/capabilities.md) | Modalities, objectives, tokenizers, metrics. |
|
|
93
|
+
| [configuration.md](https://github.com/marpaia/sbol-torch/blob/master/docs/configuration.md) | Complete `RunConfig` reference. |
|
|
94
|
+
| [data.md](https://github.com/marpaia/sbol-torch/blob/master/docs/data.md) | Data sources, the sbol-db client, materialization, fixtures. |
|
|
95
|
+
| [backbones.md](https://github.com/marpaia/sbol-torch/blob/master/docs/backbones.md) | Choosing/loading backbones and environment constraints. |
|
|
96
|
+
| [extending.md](https://github.com/marpaia/sbol-torch/blob/master/docs/extending.md) | Adding a tokenizer, encoder, task, callback, or data source. |
|
|
97
|
+
|
|
98
|
+
## Develop
|
|
99
|
+
|
|
100
|
+
```bash
|
|
101
|
+
uv run pytest
|
|
102
|
+
pre-commit run --all-files
|
|
103
|
+
```
|
|
@@ -0,0 +1,88 @@
|
|
|
1
|
+
# Architecture
|
|
2
|
+
|
|
3
|
+
sbol-torch turns SBOL designs into trained transformer models. Three ideas shape
|
|
4
|
+
it: every source normalizes to one record type, the parts that vary plug in
|
|
5
|
+
behind protocols, and the training engine stays small and explicit.
|
|
6
|
+
|
|
7
|
+
## One record type
|
|
8
|
+
|
|
9
|
+
Every data source — the sbol-db REST API, local SBOL/FASTA files, or the synthetic
|
|
10
|
+
generator — is normalized into `SbolObject` (`sboltorch.types`):
|
|
11
|
+
|
|
12
|
+
```
|
|
13
|
+
SbolObject(iri, sbol_class, roles, types, sequence, features, neighbors, label, raw)
|
|
14
|
+
```
|
|
15
|
+
|
|
16
|
+
Training code consumes only `SbolObject`s and never branches on provenance. A
|
|
17
|
+
source is anything satisfying the `Corpus` protocol (`__iter__` yielding
|
|
18
|
+
`SbolObject`s, plus a `fingerprint()` for caching).
|
|
19
|
+
|
|
20
|
+
## Swappable plug points
|
|
21
|
+
|
|
22
|
+
Three independent axes are each a `Protocol` with interchangeable implementations,
|
|
23
|
+
selected by configuration:
|
|
24
|
+
|
|
25
|
+
- **Tokenizer** — how a sequence becomes tokens (`hf`, `kmer`, `char`).
|
|
26
|
+
- **Encoder** — the input modality, turning an `SbolObject` into model input
|
|
27
|
+
(`sequence`, `structure_aware`, `graph`).
|
|
28
|
+
- **Task** — the training objective, owning loss and metrics (`supervised`,
|
|
29
|
+
`frozen`, `mlm`).
|
|
30
|
+
|
|
31
|
+
Adding an implementation and registering it in the matching `build_*` factory
|
|
32
|
+
extends a capability without touching the engine. See [extending.md](extending.md).
|
|
33
|
+
|
|
34
|
+
## The training engine
|
|
35
|
+
|
|
36
|
+
The training loop (`sboltorch.engine`) is plain PyTorch: AMP, gradient
|
|
37
|
+
accumulation and clipping, a linear warmup/decay schedule, and a list of
|
|
38
|
+
callbacks (`EarlyStopping`, `ModelCheckpoint`, `MetricLogger`). It learns the
|
|
39
|
+
batch shape only through a `BatchAdapter`, so the same loop trains a sequence
|
|
40
|
+
model (tensor-dict batches) or a graph model (PyG `Batch` objects).
|
|
41
|
+
|
|
42
|
+
## Data flow
|
|
43
|
+
|
|
44
|
+
A `RunConfig` drives the whole pipeline. The configured `Corpus` source is
|
|
45
|
+
materialized to Parquet and split into train/val/test (seeded). The `Encoder`
|
|
46
|
+
turns each `SbolObject` into model input for its modality, using the `Tokenizer`,
|
|
47
|
+
and a `DataLoader` batches the result through a collator. The `Trainer` then runs
|
|
48
|
+
the loop under the `Task` and `BatchAdapter`, writing a checkpoint and metrics.
|
|
49
|
+
|
|
50
|
+
## Layers
|
|
51
|
+
|
|
52
|
+
| Layer | Module | Responsibility |
|
|
53
|
+
|-------|--------|----------------|
|
|
54
|
+
| Config | `sboltorch.config` | One Pydantic `RunConfig` per run; validated, serialized. |
|
|
55
|
+
| Data | `sboltorch.data` | Corpus sources (`SbolDbClient`, `LocalFileCorpus`, synthetic) and Parquet materialization. |
|
|
56
|
+
| Tokenize | `sboltorch.tokenize` | `hf` / `kmer` / `char` behind one protocol. |
|
|
57
|
+
| Encoders | `sboltorch.encoders` | Turn an `SbolObject` into model input, per modality. |
|
|
58
|
+
| Datasets | `sboltorch.datasets` | Torch `Dataset`, padding collator, MLM collator, seeded splits. |
|
|
59
|
+
| Models | `sboltorch.models` | Backbone (pretrained or from-scratch) + pooling + head; MLM and graph models. |
|
|
60
|
+
| Tasks | `sboltorch.tasks` | Loss, metrics, label dtype, target transform. |
|
|
61
|
+
| Engine | `sboltorch.engine` | Training loop, callbacks, batch adapters. |
|
|
62
|
+
| Pipeline | `sboltorch.pipeline` | Wires the layers from a `RunConfig`. |
|
|
63
|
+
|
|
64
|
+
## Key protocols
|
|
65
|
+
|
|
66
|
+
- `Corpus`: `__iter__() -> Iterator[SbolObject]`, `fingerprint() -> str`.
|
|
67
|
+
- `Tokenizer`: `encode`, `tokenize_content`, `vocab_size`, `pad_token_id`,
|
|
68
|
+
`mask_token_id`, `special_token_ids`, `max_length`.
|
|
69
|
+
- `Encoder`: `encode(SbolObject) -> ModelInput`, `output_spec -> EncoderSpec`.
|
|
70
|
+
- `Task`: `loss`, `predict`, `epoch_metrics`, `primary_metric`, `label_dtype`.
|
|
71
|
+
- `BatchAdapter`: `to_device`, `forward(model, batch)`, `labels(batch)`.
|
|
72
|
+
- `Callback`: `on_train_start`, `on_epoch_end`, `on_train_end`.
|
|
73
|
+
|
|
74
|
+
## Reproducibility
|
|
75
|
+
|
|
76
|
+
- A run is fully specified by its `RunConfig`; the resolved config is written to
|
|
77
|
+
`<output_dir>/config.resolved.yaml`.
|
|
78
|
+
- `seed` seeds Python, NumPy, and torch, and the train/val/test split is a pure
|
|
79
|
+
function of `(n, ratios, seed, strategy)`.
|
|
80
|
+
- Corpora are materialized to content-fingerprinted Parquet, so a run is offline
|
|
81
|
+
and byte-for-byte comparable across executions. See [data.md](data.md).
|
|
82
|
+
|
|
83
|
+
## Consuming sbol-db
|
|
84
|
+
|
|
85
|
+
`SbolDbClient` reads designs over the sbol-db REST API: keyset-paginated object
|
|
86
|
+
listing, single/bulk IRI resolution, bounded neighborhood traversal, sequence
|
|
87
|
+
search, and ontology descendant expansion. Sequence elements are read from each
|
|
88
|
+
object's JSON-LD slice by predicate local-name. Details in [data.md](data.md).
|
|
@@ -0,0 +1,47 @@
|
|
|
1
|
+
# Backbones & environment
|
|
2
|
+
|
|
3
|
+
The backbone is any HuggingFace encoder, or one built from scratch. The `hf`
|
|
4
|
+
tokenizer is a generic `AutoTokenizer` adapter, so any model that accepts a raw
|
|
5
|
+
sequence string works by pointing `model.backbone` and `tokenizer.model_name` at
|
|
6
|
+
the same id.
|
|
7
|
+
|
|
8
|
+
## Choosing a backbone
|
|
9
|
+
|
|
10
|
+
| Goal | `model` config |
|
|
11
|
+
|------|----------------|
|
|
12
|
+
| Fine-tune a pretrained DNA model | `backbone: <hub-id>`, `from_scratch: false` |
|
|
13
|
+
| Train a head over a frozen backbone | as above, with `task.kind: frozen` |
|
|
14
|
+
| Pretrain / train from scratch | `from_scratch: true` + `model.arch` (sized to the tokenizer vocab) |
|
|
15
|
+
| Reuse a model you pretrained | `backbone: <output_dir>/backbone` (a local path) |
|
|
16
|
+
|
|
17
|
+
`model.backbone` accepts either a hub id or a local directory. A masked-LM run
|
|
18
|
+
writes its encoder to `<output_dir>/backbone/`, which a later supervised run loads
|
|
19
|
+
directly.
|
|
20
|
+
|
|
21
|
+
## transformers version
|
|
22
|
+
|
|
23
|
+
sbol-torch pins `transformers` to the 4.x line. The 5.x line changes the ESM and
|
|
24
|
+
custom modeling code that the pretrained DNA backbones rely on, so it is not
|
|
25
|
+
compatible with them.
|
|
26
|
+
|
|
27
|
+
## Known backbone constraints
|
|
28
|
+
|
|
29
|
+
- **DNABERT-2 (`zhihan1996/DNABERT-2-117M`)** — its remote modeling code requires
|
|
30
|
+
`triton`, which has no macOS wheels, so DNABERT-2 runs on Linux/GPU only.
|
|
31
|
+
`einops` (also required by that code) is a declared dependency. The DNABERT-2
|
|
32
|
+
tokenizer loads on any platform; only the model weights need Linux/GPU.
|
|
33
|
+
- **Nucleotide Transformer v2** — the tokenizer loads everywhere; the checkpoint
|
|
34
|
+
needs a transformers version whose ESM implementation matches its gated-MLP
|
|
35
|
+
shapes. Verify the pairing before relying on it.
|
|
36
|
+
|
|
37
|
+
For local development on CPU/macOS, use a `from_scratch` model with the `kmer` or
|
|
38
|
+
`char` tokenizer, or a small standard encoder; run bio-specific backbones like
|
|
39
|
+
DNABERT-2 on a Linux/GPU host.
|
|
40
|
+
|
|
41
|
+
## Structure-aware backbones
|
|
42
|
+
|
|
43
|
+
The structure-aware encoder adds feature-boundary markers to the vocabulary, so
|
|
44
|
+
its `output_spec.vocab_size` exceeds a base tokenizer's. A `from_scratch` model is
|
|
45
|
+
sized to that vocabulary automatically. To use a pretrained backbone with the
|
|
46
|
+
structure-aware encoder, resize its token embeddings to the encoder's vocab size
|
|
47
|
+
first.
|
|
@@ -0,0 +1,90 @@
|
|
|
1
|
+
# Capabilities
|
|
2
|
+
|
|
3
|
+
sbol-torch trains transformer models on SBOL data. The input modality, training
|
|
4
|
+
objective, data source, and tokenizer are independent axes, each picked in
|
|
5
|
+
configuration. Changing one reuses the same code path rather than branching it.
|
|
6
|
+
|
|
7
|
+
## Input modalities (`encoder.kind`)
|
|
8
|
+
|
|
9
|
+
| Modality | Consumes | Model | Config |
|
|
10
|
+
|----------|----------|-------|--------|
|
|
11
|
+
| `sequence` | raw sequence elements | pretrained or from-scratch encoder + pooling + head | [finetune_expression.yaml](../examples/configs/finetune_expression.yaml) |
|
|
12
|
+
| `structure_aware` | sequence + feature boundaries (role, orientation) | same, over an extended vocabulary | [finetune_structure_aware.yaml](../examples/configs/finetune_structure_aware.yaml) |
|
|
13
|
+
| `graph` | the SBOL composition graph | PyG graph transformer (`TransformerConv`) | [train_graph.yaml](../examples/configs/train_graph.yaml) |
|
|
14
|
+
|
|
15
|
+
- **Sequence** tokenizes the object's elements directly.
|
|
16
|
+
- **Structure-aware** wraps each annotated feature span with role-keyed boundary
|
|
17
|
+
markers (e.g. `[promoter] … [/promoter]`) and a reverse-complement marker,
|
|
18
|
+
injected inline as tokens. The markers extend the base tokenizer's vocabulary,
|
|
19
|
+
so the model sees SBOL structure alongside sequence. Use it with a
|
|
20
|
+
`from_scratch` model, or a pretrained backbone whose embeddings you've resized.
|
|
21
|
+
- **Graph** turns each object's neighborhood into a graph: nodes carry a
|
|
22
|
+
`(sbol_class, role, identity)` feature triple, edges carry a predicate type,
|
|
23
|
+
edges are bidirectional, and a global mean pool feeds the task head.
|
|
24
|
+
|
|
25
|
+
All three produce batches consumed by one training engine through a
|
|
26
|
+
`BatchAdapter`, so the loop is modality-agnostic (see [extending.md](extending.md)).
|
|
27
|
+
|
|
28
|
+
## Objectives (`task.kind`)
|
|
29
|
+
|
|
30
|
+
| Objective | Head / loss | Metrics | Label |
|
|
31
|
+
|-----------|-------------|---------|-------|
|
|
32
|
+
| `frozen` | regression or classification head; backbone frozen | `val_mae`/`val_mse`/`val_r2` or `val_accuracy` | required |
|
|
33
|
+
| `supervised` | same, fine-tuned end to end | same | required |
|
|
34
|
+
| `mlm` | tied LM head; masked cross-entropy | `val_loss` (= masked CE), `val_masked_accuracy` | none (self-supervised) |
|
|
35
|
+
|
|
36
|
+
- **Supervised regression** supports `target_transform: log1p` for expression/
|
|
37
|
+
fitness-style targets; metrics are reported back in the original space.
|
|
38
|
+
- **Classification** requires `task.num_classes`.
|
|
39
|
+
- **MLM** masks ~`mlm_probability` of content tokens (80% `<mask>`, 10% random,
|
|
40
|
+
10% unchanged), never masking special tokens.
|
|
41
|
+
|
|
42
|
+
## Pretrain, then fine-tune
|
|
43
|
+
|
|
44
|
+
An `mlm` run writes its trained encoder to `<output_dir>/backbone/` in
|
|
45
|
+
HuggingFace format. A later `supervised`/`frozen` run loads it by setting
|
|
46
|
+
`model.backbone` to that directory — the masked-LM pretraining and the
|
|
47
|
+
downstream task share one backbone.
|
|
48
|
+
|
|
49
|
+
MLM supports two modes via `model.from_scratch`:
|
|
50
|
+
|
|
51
|
+
- `true` — build a fresh architecture from `model.arch` + the tokenizer vocab
|
|
52
|
+
(pretrain a DNA LM on the SBOL corpus with the k-mer/char tokenizer).
|
|
53
|
+
- `false` — continued pretraining of a pretrained `model.backbone`.
|
|
54
|
+
|
|
55
|
+
## Tokenizers (`tokenizer.kind`)
|
|
56
|
+
|
|
57
|
+
| Tokenizer | Description |
|
|
58
|
+
|-----------|-------------|
|
|
59
|
+
| `hf` | Any pretrained HuggingFace `AutoTokenizer` (DNABERT-2, Nucleotide Transformer, …), wrapped behind the library's tokenizer protocol. |
|
|
60
|
+
| `kmer` | Overlapping k-mers over `{A,C,G,T}`; ambiguous bases map to `<unk>`. |
|
|
61
|
+
| `char` | IUPAC character-level. |
|
|
62
|
+
|
|
63
|
+
All expose the same protocol (`vocab_size`, `pad_token_id`, `mask_token_id`,
|
|
64
|
+
`special_token_ids`, `tokenize_content`, `encode`), so tokenizers, encoders, and
|
|
65
|
+
objectives mix freely.
|
|
66
|
+
|
|
67
|
+
## Metrics
|
|
68
|
+
|
|
69
|
+
- Regression: MAE, MSE, R² (`val_mae`, `val_mse`, `val_r2`).
|
|
70
|
+
- Classification: accuracy (`val_accuracy`).
|
|
71
|
+
- MLM: masked cross-entropy as `val_loss` (perplexity is `exp(val_loss)`) and
|
|
72
|
+
`val_masked_accuracy`.
|
|
73
|
+
|
|
74
|
+
Per-epoch metrics are printed and appended to `<output_dir>/metrics.jsonl`; the
|
|
75
|
+
best checkpoint (by the task's primary metric) is saved to `best.pt`.
|
|
76
|
+
|
|
77
|
+
## What the test suite verifies
|
|
78
|
+
|
|
79
|
+
`tests/test_learning.py` trains each capability on a learnable signal and asserts
|
|
80
|
+
that the loss drops and the model generalizes, not just that the code runs:
|
|
81
|
+
|
|
82
|
+
| Capability | Asserted |
|
|
83
|
+
|------------|----------|
|
|
84
|
+
| Supervised sequence (from scratch) | val_loss falls, `val_r2 > 0.5` |
|
|
85
|
+
| MLM (from scratch) | val_loss falls, masked accuracy rises |
|
|
86
|
+
| Structure-aware | val_loss falls, `val_r2 > 0.5` |
|
|
87
|
+
| Graph transformer | val_loss falls, `val_r2 > 0.5` |
|
|
88
|
+
|
|
89
|
+
Continued pretraining and pretrained-backbone loading are exercised against a
|
|
90
|
+
real hub model in the data/model tests.
|